
Abstract
The Kitagawa–Oaxaca–Blinder decomposition approach has been widely used to attribute group-level differences in an outcome to differences in endowment, coefficients, and their interactions. The method has been implemented for Stata in the popular
These decompositions of levels and changes over time can be implemented using the
1 Introduction
The decomposition of group differences in means (Kitagawa 1955; Oaxaca 1973; Blinder 1973) is a popular tool when researchers seek to attribute such differences to differences in the groups’ characteristics and an unexplained part. As such, scholars have applied such decompositions to a variety of topics such as gender income inequality (Blau and Kahn 2017), happiness (Arrosa and Gandelman 2016), or obesity (Taber et al. 2016). This approach has also seen numerous extensions over the last decades to suit researchers’ needs, such as its application to distributional parameters other than the mean (Freeman 1980, 1984), to nonlinear models (Fairlie 2005; Bauer and Sinning 2008), to quantile regression (Machado and Mata 2005), to selection models (Neuman and Oaxaca 2003), and to other topics (for an overview, see Fortin, Lemieux, and Firpo [2011]). In large parts of the applied literature, these kinds of decompositions are known as Oaxaca–Blinder decompositions, after two of the three scholars who pioneered these approaches (Oaxaca 1973; Blinder 1973). We refer to this way of decomposing group mean differences as the Kitagawa–Oaxaca–Blinder (KOB) approach to reference the earliest and often overlooked contribution to this literature as well (Kitagawa 1955).
As researchers became increasingly interested in research questions involving developments over time, further extensions were developed to decompose the changes in mean group differences between two points in time (Smith and Welch 1989; Wellington 1993; Makepeace et al. 1999; DeLeire 2000; Kim 2010). These decomposition techniques are based on principles similar to those in the original KOB decomposition and have been primarily used in repeated cross-sectional studies on income gaps. None of those approaches mentioned above have been coherently implemented in Stata. We therefore propose the
The command enables a user-friendly implementation of five existing decomposition methods for change (Smith and Welch 1989; Wellington 1993; Makepeace et al. 1999; DeLeire 2000; Kim 2010) and retains the possibility of applying it to panel data instead of only repeated cross-sectional regression models. It provides a generalization of the existing
The purpose of this article is to introduce both the
2 Decomposition of levels and change
Generally speaking, there are two ways in which we can use mean decomposition techniques with longitudinal data.
The first way of exploiting longitudinal data examines the contribution of past changes or events to levels of outcome differences between two groups A and B at a single time tu . The second way is the decomposition of group differences in change in an outcome between two groups A and B between times s and t. We address both approaches in turn but highlight the importance of the latter.
Using longitudinal data to determine the contribution of past changes, we ask a typical research question:
1. How much of the difference in an outcome Y between groups A and B at time t is due to the differences in the incidence of a past event X, its different effects, or its different cumulative effects over the last n years?
This type of question utilizes longitudinal data by accounting for individuals’ past experiences. For instance, we may ask to what extent differences in past unemployment spells and their cumulative impact affect the gender wage gap at time t. In figure 1, this would translate into the decomposition of the outcome difference at tu , ΔYt . It would account for the different incidences and effects of events at r and u to explain the level difference ΔYt . Analytically, this type of question is still cross-sectional in nature, and we can examine it using the traditional KOB decomposition. 1
In the following, we denote the repeated decomposition of group differences over time as the longitudinal decomposition of levels over time. Decomposing levels is a distinct approach from the second way of using longitudinal data for decomposition, the decomposition of change.

Decomposition of changes over time
If we seek to decompose the change in mean group differences over time, we compare the mean group differences between groups A and B between two points in time, s and t, and ask what factors narrowed or widened the outcome difference over time. For example, the wage gap between men and women may have decreased over the last 10 years. A researcher might ask whether this occurred because of compositional changes (differential changes in endowments of the groups) or changes in the contribution of coefficients of the two groups. Thus, the second kind of longitudinal question can be expressed as follows:
2. How much of the change in differences in an outcome Y between groups A and B and between times t and s is due to changes in the groups’ composition or the effects of the explanatory variables?
In figure 1, this amounts to decomposing the change in group differences between time s and t, ΔY B − ΔY A .
As has been shown (Smith and Welch 1989; Wellington 1993; Makepeace et al. 1999; DeLeire 2000; Kim 2010), this type of question can be answered with repeated cross-sectional data. In this article, we demonstrate that these existing approaches to the decomposition of change can be easily generalized to the use of panel regression models as well. We argue, however, that the existing approaches are not always easy to interpret when asking a set of research questions that falls under what we call the interventionist perspective. Therefore, we argue that they can be usefully complemented by a new approach to the decomposition of change, which we lay out in detail in section 5.
3 Decomposition of levels
3.1 The KOB decomposition for cross-sectional data
Before we review the existing approaches to the decomposition of change, it is useful to recapitulate what the original KOB decomposition does using cross-sectional data (Kitagawa 1955; Oaxaca 1973; Blinder 1973). We will also introduce the notation we will use throughout the article. We start with a basic linear regression model for an outcome Y and two groups A and B:


and given that
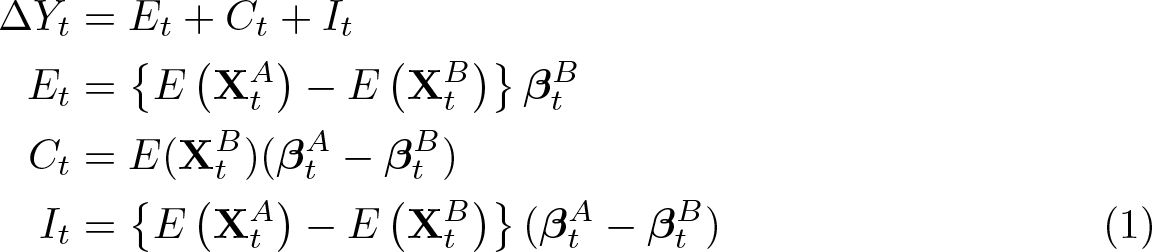
Et is defined as the part of the difference that is due to differences in the groups’ characteristics at time t (endowments effect). Ct is the part of the difference that is due to differences in the coefficients at time t. It , finally, is the part of the difference at time t that is due to the interaction of the groups’ different characteristics and coefficients.
The presented decomposition in (1) is a threefold decomposition from the viewpoint of group B, meaning that Et is weighted by B’s coefficients and that Ct is weighted by B’s characteristics. While this suffices to represent the basic principle of the KOB decomposition, other decompositions such as a twofold decomposition or a decomposition from the viewpoint of group A are possible (compare with Jann [2008] and Fortin, Lemieux, and Firpo [2011]).
From the viewpoint of group A, we would weight the differences in characteristics and coefficients with the characteristics and coefficients of group A instead of group B:
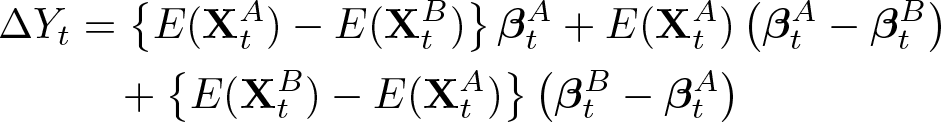
For the twofold decomposition, which is the one originally devised by Oaxaca and Blinder, the outcome difference (with group A as the reference) is decomposed by

This is also implemented in
3.2 Normalization of categorical variables
As has been noted in the literature (Jann 2008; Kim 2010; Yun 2005), there is an identification problem when categorical variables are used for decomposition. A widely used solution is to normalize the coefficients of categorical variables by subtracting the variable-specific mean of the coefficient from each category of the variable-specific coefficients and adding all subtracted means to the intercept for decomposition purposes. This yields a new set of coefficients for the decomposition defined as

In this notation, j indicates the jth categorical variable and c the cth category within the jth categorical variable, with βt,j, 1 constrained to zero for identification in the original model. The time-specific intercept is then defined as

As can be seen, the basic principle of the original KOB decomposition is to get counterfactual estimates for the outcome, for example, group B, assuming it had the same endowments or coefficients as group A. This reasoning is retained in the decomposition of levels and change over time as well.
3.3 Longitudinal data using nonpanel regression models
The use of the KOB decomposition with nonpanel regression models is unproblematic with longitudinal data as long as time is measured discretely. Discretely in this context means that observations are categorized together to have been observed at the same undifferentiated time point, for example, in waves of a cohort of panel study. In this case, the analysis is identical to a repeated cross-sectional approach. However, the assumption can also be that the time variable is (quasi)continuous. In this case, we have to define a bandwidth (b) around the time points to allow for an estimation of the endowments part. The wider the bandwidth is, the more reliable the estimate is because more data points fall into the bandwidth around the time point (and the smaller the standard errors become). Broadening the bandwidth comes at the price of losing sensitivity to time-dependent changes in the endowment. For nonparametric modeling, this is similar to the tradeoff that has to be made between bias and variance (Härdle et al. 2004, 28). We estimate

The subscript t − b refers to the lower bound and t + b refers to the upper bound of the interval on the time variable that is used to estimate the mean of the variables. In the case of the continuous-time variable, the decomposition components become a function of the chosen bandwidth b.
This raises the question of whether the coefficients, like the endowment, can also become dependent on the chosen bandwidth. This has to be decided in line with the choice of the functional form of the time variable in the regression models used for the decomposition. Even when a bandwidth of some kind is used for the endowments, a parametric form can be chosen for the coefficients over time. However, the time variable can be constructed to reflect the bandwidth around prespecified points in time. In such a case, the coefficients can be estimated nonparametrically for each of these time intervals separately, and the decomposition can be done for each of these time intervals. Under these circumstances, coefficients and endowments would be treated analogously.
For simplicity’s sake, we leave out the bandwidth in the index for the remainder of the article, but note that it is theoretically necessary and practically possible to set the bandwidth in cases in which time is assumed to be continuous.
3.4 Longitudinal data using panel regression models
Using panel data, we can also estimate β from a panel regression model. Because panel regressions model time-constant individual error terms, a decomposition using panel regression models must account for empirical group differences in these time-constant, unobserved variables. Thereby, the time-constant individual error terms

Accounting for the time-constant error terms adds the differences in the expectation of
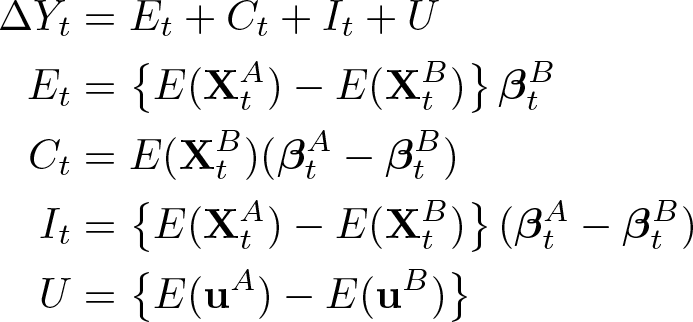
Accordingly, a decomposition using panel regression models attributes parts of the differences between groups to unobserved factors that do not change within the period of observation.
3.5 Model assumptions
Selection and causal identification
Note that any results produced by decompositions of levels or change rely on the assumptions made in the original regression models. This pertains especially to the causal interpretation of the results. Following a counterfactual interpretation of causality in the social sciences (Morgan and Winship 2015), the estimators for the explanatory variables would need to be unbiased. Only then could the results of any of the decomposition approaches presented here (including the original KOB decomposition) be given interpretations like “how much would the gap between group A and group B be reduced if group A had the same endowments as group B?” Panel regression models offer some advantages when it comes to arguing that the assumptions for causal interpretation are fulfilled but still rest on certain assumptions that are often not realistic in applied research (Firebaugh, Warner, and Massoglia 2013).
For example, from a more technical perspective, note that in a standard randomeffects model (which includes the grouping variable
Panel dropout
With longitudinal data, panel dropout is a serious issue that may affect the estimation of coefficients (Oaxaca and Choe 2016) as well as the estimation of the time-specific endowment component. If the results are to be interpreted causally, endogeneity problems resulting from panel dropout have to be solved when designing the panel regression models before the decomposition is applied.
It is possible for dropout rates to differ between the groups under study. This can also affect the estimation of the endowments in (3). To avoid biased endowment estimators, one must construct weights that account for the effects of differential panel dropout and applied them in the estimation of the endowments. How these are constructed is beyond the scope of this article; however, we recommend standard procedures from the literature on survey research (Kalton and Flores-Cervantes 2003; Deming and Stephan 1940; Kim and Kim 2007), which can be implemented in Stata using
Functional form of the time variable
In the modeling process, one can either specify time nonparametrically, estimating an interaction of each time point with the group variable and each decomposition variable, or assume a certain functional form like linear growth. The decomposition will rely on these assumptions made in the modeling process. If the functional form is chosen incorrectly, this will also affect the decomposition, and the results will consequently be biased. This is important not only for the overall growth of the dependent variable but also for the change in the effect of the decomposition variables over time. A nonparametric approach is less statistically efficient but has much weaker assumptions than any parametric function and might therefore be preferred if researchers are uncertain in this regard.
3.6 Decomposition in a multilevel framework
Because all panel models can be understood as a special case of multilevel models (with time points nested within units), we believe that
The interpretation of the decomposition of levels over different clusters does not deviate from repeated cross-sectional KOB decompositions, and so using
4 Decomposition of change
Regardless of whether we have repeated cross-sectional or panel data, given two groups A and B for which we have data for at least two points in time, t and s with t > s, the change in the outcome difference between the two groups and between the two points in time is given by

Alternatively, changes in outcome differences between two groups and two points in time can be expressed as the difference of group differences over time:

Essentially, changes over time can therefore be expressed as the difference between two KOB decompositions at different time points.
Several approaches for the decomposition of change in group differences over time exist. We cover the five most prominent examples. 4 These decompositions of change have been applied to both points using repeated cross-sectional data. The generalization of the decomposition of levels to continuous time and panel data introduced in the previous section applies in the same way to the decomposition of change as it does to the decomposition of levels.
4.1 Simple subtraction method (SSM)
The simplest decomposition of change is a simple subtraction of the decomposition components of the original KOB decomposition at time s from the components at time t and is defined in our notation as SSM:

This method is straightforward to calculate, applied for example in DeLeire (2000). The endowment part can be interpreted as the part in the change in the gap that is due to changes in the endowments given changes in the evaluation (coefficient) in the reference group over time. The coefficient part is the part in the change in the gap that is due to changes in the coefficients given changes in the evaluation (endowment) in the reference group over time. The interaction part is the difference in the interactions of group differences in coefficients and endowments. Similarly to the original KOB, this component is difficult to interpret and might often be treated as the substantively unexplained part.
The approach has also attracted criticism because it does not estimate the unique contribution of coefficient changes and changes in the variable distributions over time (Kim 2010). As Kim (2010) shows, the coefficient differences at each time point are weighted by the mean distribution of the endowments at their respective time and, because the endowments likely change over time, the coefficient effect captures these changes. Similarly, the endowment effect contains interactions between the coefficient and endowment changes. This kind of criticism applies differently for all the decompositions presented here, except for the one by Kim (2010).
4.2 Smith and Welch (1989)
Smith and Welch (1989) propose a fourfold decomposition of change that is defined in our notation as SW (Smith and Welch 1989, 529):
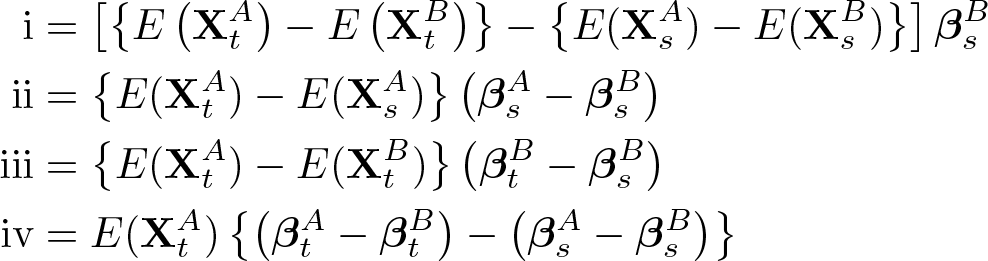
The components can be given the following interpretation: 5
i. Main effect: The component estimates the predicted change in the outcome between the two groups that can be attributed to the two groups are changing in the endowments (valued at base time s) between time t and s. ii. Group interaction: The second component describes the part of change in the endowment of the group that is valued differently at time s. Therefore, a secular rise in endowments gives a higher benefit to the group with the higher return to this endowment at time s. iii. Time interaction: This component takes the endowment differences at the second time point and attributes change to the change in the coefficient of group B. This would mean that higher returns to an endowment benefit the group with higher endowments at time point t. iv. Group-time interaction: The last component attributes change to a change in the differences in the coefficients (returns to endowments) given the initial level of group A. If group A were the disadvantaged group, reduction in the differences to the return to their endowments would close the overall gap between the groups.
4.3 Wellington (1993)
Wellington (1993) proposes a simple twofold decomposition of change in differences in labor market returns. Her decomposition is defined in our notation as WL (Wellington 1993, 393):

Wellington (1993, 393–394) gives the following description of the two components:
WL1. The portion of the change in the gap that can be accounted for by changes in the means if the returns to the independent variables were constant at t (not at baseline s).
WL2. The portion of the change in the gap that can be explained by changes in the coefficients (including the constant term) over the period, evaluated at the groups’ baseline (s) means.
This approach is the one that is closest to our own addition (see next subsection) to the set of possible decomposition approaches, but there is a slight but significant difference, as we discuss in section 5.
4.4 A threefold extension of WL (interventionist)
There is another useful way in which the change in gaps can be decomposed. This is an extension of the WL decomposition, which takes the form of a threefold decomposition.
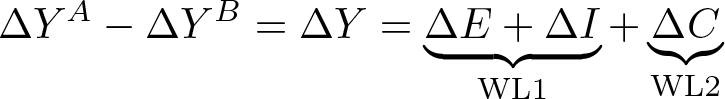
The three components are named analogously to the original KOB decomposition. To obtain the endowments effect, we allow only the groups’ composition to vary over time and hold the coefficients constant at their initial group-specific levels at time s.

As can be seen in (5), we obtain the endowments component by subtracting the groups’ compositional changes over time weighted by their initial coefficients. The endowments component then answers the following question: Given the initial differences in coefficients, how much does the gap between groups change because of the changes in the endowments between both points (if the coefficients do not change)?
Similar to the endowments effect, the component attributable to a change in coefficients is obtained by fixing the groups’ endowments so that

which denotes the change of the difference due to a change in coefficients (including the constant) over time between the groups given the groups’ initial differences in endowments at s. The coefficient component answers this question: Given the initial differences in endowments, how much does the gap between groups change because of changes in the coefficients (if the endowments do not change)?
The interaction between the change in endowments and coefficients is the last component of the decomposition:

As with the original KOB decomposition, it is difficult to give this component a straightforward interpretation on its own. Additionally, note that the subcomponent of ΔC that is attributable to a change in the intercept is usually also a kind of residual, unexplained by the (change in)
We can show that our suggested approach is a direct extension of Wellington (1993). First, our ΔC component is exactly the same as WL2 of the Wellington decomposition.
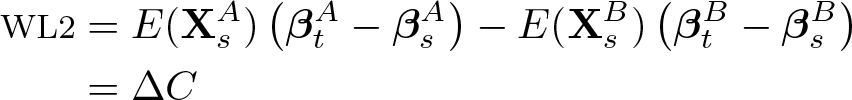
In addition, if we add up the endowment and interaction term of the interventionist decomposition, we get the first part of the Wellington decomposition.

4.5 Makepeace et al. (1999)
Another well-known approach aims at partially mirroring the twofold cross-sectional KOB decomposition into explained and unexplained in the decomposition of change. The authors further divide the explained and unexplained components into a component related to change in endowments (pure) and one aspect related to change in coefficients (price) (Makepeace et al. 1999, 539). Their decomposition is defined in our notation as MPJD:

4.6 Kim (2010)
While many decomposition approaches were developed with particular research questions in mind, Kim (2010) develops the most analytical approach. It yields five components, of which two can be attributed purely to the change in endowments and coefficients. He argues that all methods discussed so far in this article confuse or at least conflate the pure change in endowment and the pure change in the coefficients with interactions of such changes with initial (or current) level differences in coefficients and endowments. We agree with the analysis but argue in section 5 that for the sake of interpretability, this might be a desirable property of a decomposition.
To better understand how the KIM decomposition (Kim 2010, 629) decomposes group differences over time, we need to take the intercepts apart from the rest of the coefficients in this subsection. So far, decompositions have used the standard matrix notation of multiple regression. This means that the time-specific intercepts
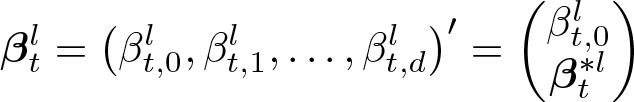
with d being the number of decomposition variables used in the model. Accordingly, the means matrices so far have contained a unity vector that is multiplied with the intercepts:

Kim (2010) uses a different approach by explicitly distinguishing between intercepts and covariates. Therefore, the notation for the coefficients uses

with j being the number of categorical variables, c indexing the categories of each categorical variable,
With the definition of normalization in section 3.2 and

Taking these definitions into account, we define the five-part KIM decomposition in our notation as follows:

Following Kim (2010), we can give the following descriptions of the five components:
D1 Intercept effect: This is purely the difference in differences between group and overall intercepts.
D2 Pure coefficient effect: This component measures how much the gap between groups changes because of changes in the coefficients if there were no differences in the endowments at all, neither between groups nor over time.
D3 Coefficient interaction effect: This component measures how much the gap between groups changes because of the average change in endowment combined with the difference in the averaged coefficient. It is supposed to capture the aspect of initial level differences in coefficients, which affect the change in the gap in interaction with changes in endowments.
D4 Pure endowment effect: This component is the analog to D2 for endowments. It measures how much the gap between groups changes because of changes in the endowments if there were no differences in the coefficients at all, neither between groups nor over time.
D5 Endowment interaction effect: This component is the analog to D3 but reverses the role of endowment and coefficients. It measures how much the gap between groups changes because of the average change in coefficients combined with the difference in the averaged endowments. It is supposed to capture the aspect of initial level differences in endowments, which affect the gap in interaction with changes in coefficients.
4.7 Panel models and time-constant error terms
As mentioned in section 3.4, decompositions can also attribute parts of group differences in levels of the outcome to factors that are time constant within the period of observation. The same can be done for change over time (ΔU). However, this makes sense only if we have an unbalanced panel. If the panel is balanced, the expectations of the time-constant error terms cannot change over time and cannot contribute anything to the decomposition of change between groups.
If we see substantial contributions of the time-constant error terms, the data suffer from group-specific panel attrition, which contributes to a change in the group differences in the outcome. In this case, we can add a component ΔU to all the previous five decompositions as well as to the interventionist decomposition method introduced in the next section.

4.8 The relationship between the different types of decompositions
Because all decomposition approaches decompose the same differences in change over time, each decomposition can be expanded and transformed into any other of the existing decompositions. Nevertheless, there are some direct relationships that are worth mentioning and that are also depicted in figure 2. 6

Relationship among decomposition approaches. note: SSM = simple subtraction method (section 4.1), WL = Wellington (1993) (section 4.3), MPJD = Makepeace et al. (1999) (section 4.5), SW = Smith and Welch (1989) (section 4.2), KIM = Kim (2010) (section 4.6)
The six decomposition methods can be divided into a heuristic based on a combination of two characteristics. The first one is simply the number of components used. Here we see between two and five components. The second characteristic divides the methods into those that conduct decompositions groupwise across time and those that conduct decompositions timewise across groups. Timewise across groups means that the differences between groups at one time point are subtracted from the differences between groups from another time point. In contrast, groupwise across time means that the differences between time points within one group are subtracted from the differences between time points within the other group.
WL, KIM, and the interventionist approach fall clearly into the groupwise-across-time category, while SSM is a timewise-across-group approach. For MPJD and SW, not all components of their decomposition follow this logic. For MPJD, the pure components are groupwise across time, and for SW the components i and iv are timewise across group.
In section 4.4, we have already shown that WL can be further divided to yield a threefold decomposition that we label interventionist and that we argue has a certain desirable property in contrast with all other approaches, which we elaborate on in section 5.
The simple subtraction method does timewise subtractions across groups of the components of endowments, coefficients, and interactions. If we were to exchange time points with groups, we would end up with a groupwise subtraction across time. This is exactly what is done in the interventionist perspective. So if we were to substitute t = A and s = A, the equations would be

These are the same components as in the interventionist perspective, and after changing groups with time points, the SSM could also be reduced to the twofold decomposition of Wellington (1993).
Note that each decomposition retains its substantively different interpretation even if each can be transformed into a different decomposition. When one interprets the results, the decompositions should therefore not be treated as 1:1 substitutes for each other.
5 An interventionist perspective on the decomposition of change
While all the decomposition approaches that we discussed in the previous section have their uses, we argue that the interventionist approach is best suited to address a certain kind of research question that regularly arises in applied social science research and similar fields like epidemiology or public health (see section 4.4). The premise of this approach is that we take the initial differences in levels between the groups at the reference time point s as given. We then ask how the difference between the groups could have changed if either the change in endowments or the change in coefficients had been different. This reflects real-world applications in which either an intervention is designed or a (natural) experiment or policy change occurs between s and t and is evaluated at time point t. The initial differences in both coefficients and endowments at time point s are seen as inextricably linked to an explanation of change because any change is built on the existing levels at s. These initial levels are assumed to be beyond intervention and are therefore not subject to counterfactual predictions within the decomposition approach.
There are two combinable types of counterfactual predictions about endowments and coefficients at time s: 1. across groups and 2. across time (and a combination of both). The former would make statements such as “if group A had the same endowment as group B at time point s,” while the latter would make statements such as “if group A already had the coefficients of time t at time point s.”
From these two types of counterfactual statements, we can derive two formal requirements for a decomposition approach to conform to the assumptions of our interventionist perspective. First, no component should contain a term that takes group differences at s (which constitutes a counterfactual prediction at time s across groups). Instead, only differences of within-group change 7 should be used for the decomposition. Second, changes within groups should be multiplied (valued) only at the initial levels (s) or at change (t − s) but not at the levels at t (or any function of the levels, endowments, or coefficients at t). If we value at levels of t, we make a counterfactual prediction at time s across time.
Except for the interventionist approach, all other decompositions described in section 4 violate these assumptions. They are therefore not applicable under an interventionist perspective. 8 In such a research scenario, it is therefore desirable to use a decomposition that can attribute changes in the gaps to changes in endowments and coefficients given the initial differences in levels in the outcome between groups. We designed the interventionist approach to fill exactly this lack of a decomposition approach to the mean-based decompositions of change in linear models.
Thus, using this decomposition, we seek to answer questions such as how group differences in an outcome would have developed over time had both groups’ characteristics or coefficients changed in the same way. These are counterfactual statements about changes that might have been the result of an intervention, policy change, natural experiment, or any other process or event that occurs between two time points s and t. To this end, we need to find a decomposition that does not violate our two interventionist assumptions. This can be achieved by setting the endowments and coefficients at which within-group changes are valued to their groups’ initial values. 9
6 The xtoaxaca command
The
The exception to this rule is interactions among decomposition variables. These must be created as handmade interaction terms (possibly using dummy variables) and interacted using factor-variable syntax with time and grouping variables. The example in section 7.5 shows how this can be achieved.
The maximum length of variable names for decomposition variables that is supported by
A longitudinal decomposition using
1. Fit a (growth curve) model. This model should condition on the variables that are used as decomposition variables to explain the gap over time between the groups. 2.

6.1 Syntax
The general syntax is
varlist contains all decomposition variables and should include all variables interacted with the variable specified in
6.2 Options
in a results dataset that can be used for further presentation of results in tables or graphs.
6.3 Stored results
When one uses the
Overview of stored results after

note: X stands for the different components within one method.
The
Overview of additional results stored after

7 Example: Increasing household income inequality and composition effects
7.1 Example 1—Decomposition of changes in household income between East and West Germany
To demonstrate the capabilities of the
First, we fit the panel regression model and store its results. Because we are interested in the effects of changing household compositions over time, the model includes a threefold interaction term that includes time, the group variable
After fitting the model, we run the
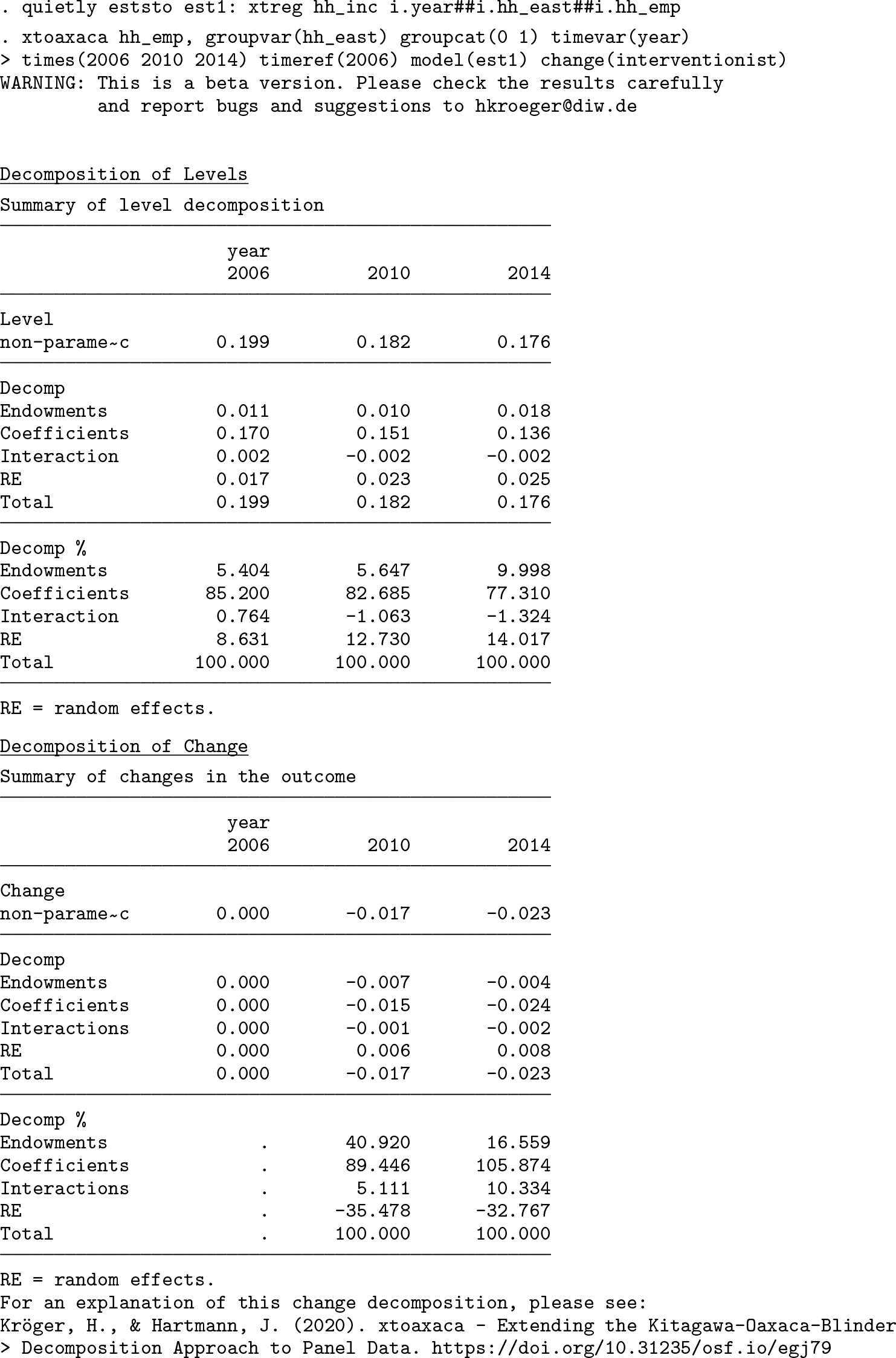
By default,
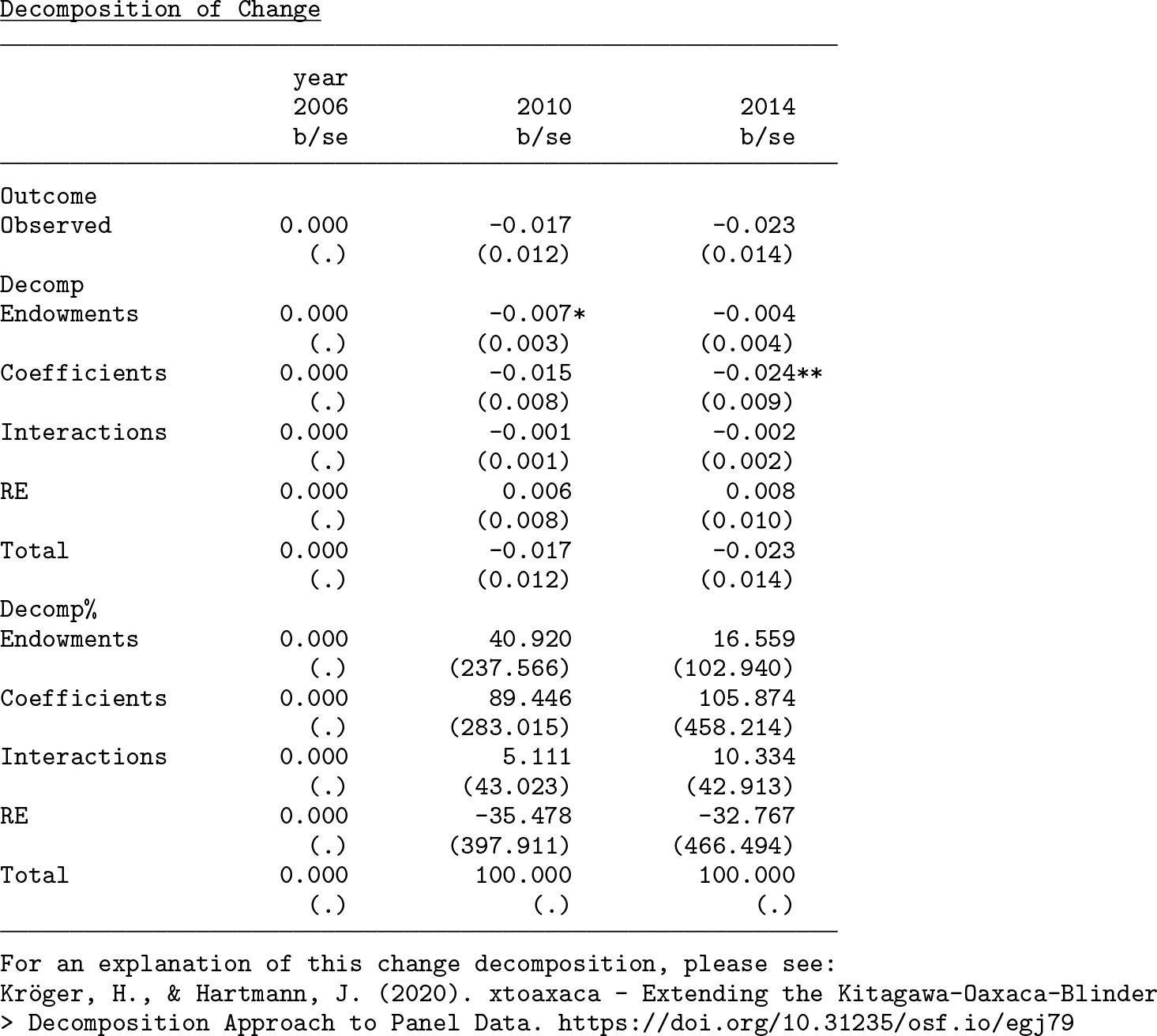
The second table displays the results of the decomposition of change. We see the change in the income gap in comparison with the reference year 2006 in the second and third column. For the observed data, the gap decreased between 2006 and 2014 by 0.023 log incomes. We can now examine the role of changing endowments and coefficients over time. As we can see, the changing household composition decreased the gap by 0.004 log incomes, and the changing coefficients contributed 0.024 log incomes to the narrowing gap between 2006 and 2014. The part that is due to differences between groups in the time-constant error term increased the gap by 0.008 log incomes. While this part is rather small, it still indicates that group-specific panel dropout has a small effect on the results.
7.2 Bootstrapping for standard errors
So far, we have decomposed the changes in household incomes between 2006 and 2014 in Germany and have the estimates but no standard errors. The
Below, we see the same example as above with bootstrap standard errors. The point estimates of the decomposition components are by design identical to the previous example. However, we now get a standard error below the point estimate and can now be more confident that the households’ composition contributes about 5.4% to the income gap in 2006 and almost 10% in 2014, because the components are statistically significant. However, the size of the component of households’ changing composition is small in size and is not statistically significant.

7.3 Blocks of variables
One can also combine two or more variables to blocks and get the standard error via bootstrapping for their combined contribution to the decomposition of both levels and change. The relevant option is


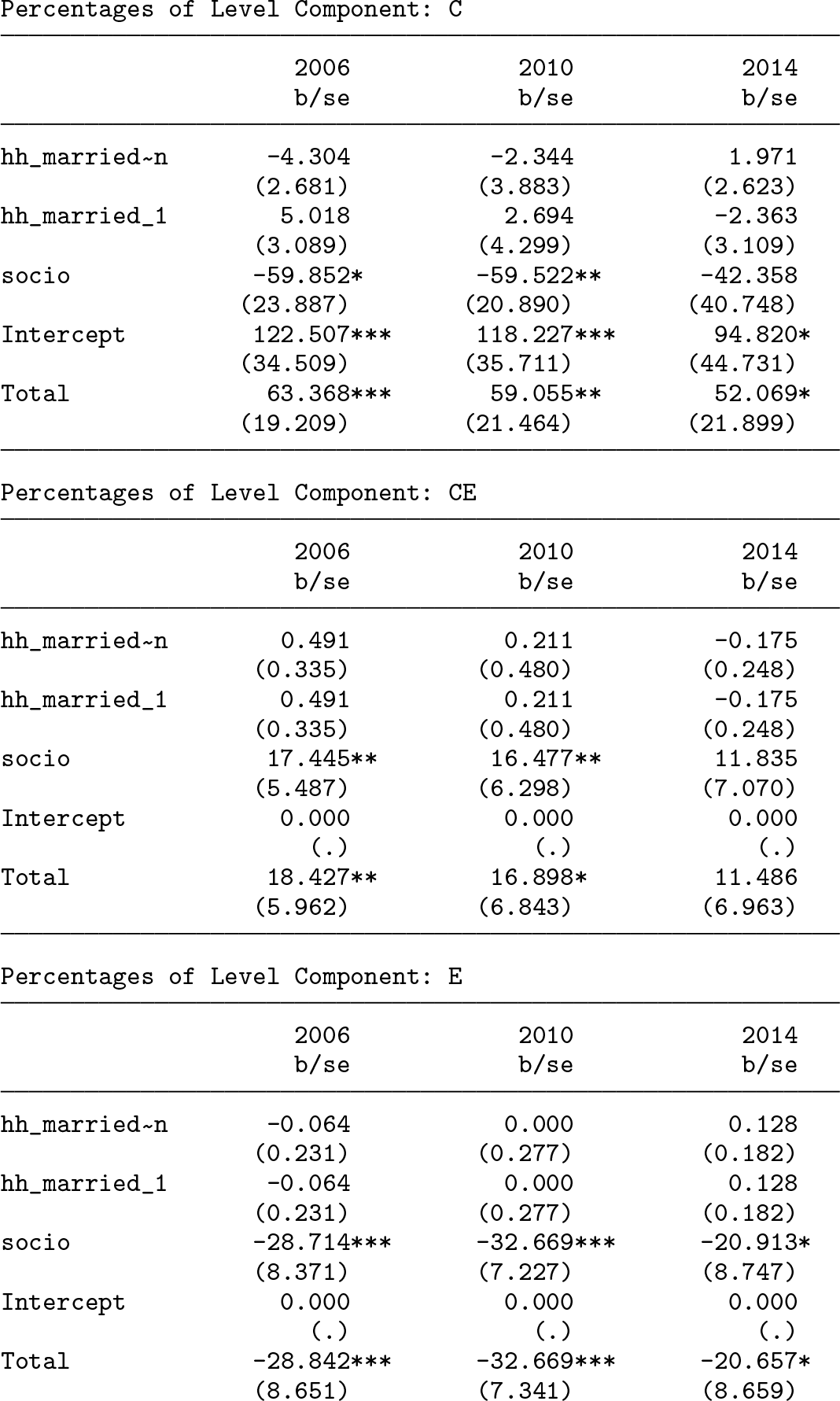
7.4 Example 2—An intervention
As a further example, we simulate a dataset with a group variable (
As with the previous example, the first step involves fitting the model, which now includes two interaction terms: the interaction of the group variable with time and the first decomposition variable and the interaction of the group variable with time and the second decomposition variable. These two interaction terms are included so that the

As can be seen from the output, the changing endowments cause the gap to decrease by 4.5% over time, while the changing coefficients increase the gap by 105%. Thus, we conclude that the increasing gap between the groups over time is not caused by their changing endowments. On the contrary, they decrease the gap over time, while all the increase in the gap can be attributed to changing coefficients. If the role of the changing return to the decomposition variables is to be investigated, results using the
7.5 Example 3—Interaction of decomposition variables
In the last example, we showed how a regression model has to be set up if interactions of decomposition variables are to be used in
Categorical-categorical interactions
For these kinds of interactions, we recommend generating a new variable that contains all combinations of the two categorical variables.
Then, we can use this new variable (
Continuous-continuous interactions
For these kinds of interactions, the key is to create interaction terms by hand and then combine them with the standard Stata factor-variable notation of the group and time variable.





The first difference from the previous examples is the additional output that is generated by using the
The second difference is that this example shows interactions of two continuous decomposition variables. If interactions of decomposition variables are used, note that the individual contribution of each interacted variable is now conditional on the value of the other variable. This means that in our example, we interacted experience with itself to get a squared term in the regression equation. The contribution of labor market experience (
For this particular example, we could state that the difference in change between groups A and B and time points 4 and 2 is explained about 20% by the difference in change in coefficients in the experience variable at the 15 years of experience in the sample (value of 0). If labor market experience is not centered at a meaningful value, this might not be a particular useful result.
Categorical-continuous interactions
The strategy described in section 7.5 for continuous-continuous interactions technically also works for categorical-continuous interactions. There are two limitations, however. First, normalization (3.2) for the categorical variable is not possible. This also implies that we cannot interpret the results for the decomposition by Kim (2010) as originally intended, because this decomposition relies on normalization. Second, we believe that it is overall very difficult to interpret the detailed output for such a decomposition. Users might consider performing the decomposition separately for the categorical variable they wish to interact with the continuous variable to ease interpretation.
8 Limitations
We focus on continuous outcomes and linear models but believe that the general approach can be generalized to nonlinear models as well, as it has been for the crosssectional KOB decomposition (Bauer and Sinning 2008; Jann 2008). Furthermore, applying regression with recentered influence functions in the modeling step might also be a way to circumvent the current restrictions to linear models of
Our decomposition approach is further limited to mean decompositions. Longitudinal decompositions of or using other distributional statistics (for example, percentiles, variances) might also be useful as user-friendly programs (Fortin, Lemieux, and Firpo 2011; Blau and Kahn 1992; Juhn, Murphy, and Pierce 1993).
9 Conclusion
We provided a systematic extension of the KOB decomposition to longitudinal (and multilevel) data. We reviewed five central approaches to the decomposition of change. We noted that none of them are directly useful for the evaluation of an intervention, policy changes, or natural experiments. We proposed an extension of the Wellington (1993) decomposition of change over time from an interventionist perspective. We introduced the
11 Programs and supplemental materials
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025800 - Extending the Kitagawa–Oaxaca–Blinder decomposition approach to panel data
Supplemental Material, sj-zip-1-stj-10.1177_1536867X211025800 for Extending the Kitagawa–Oaxaca–Blinder decomposition approach to panel data by Hannes Kröger and Jörg Hartmann in The Stata Journal
Footnotes
10 Acknowledgments
We would like to thank Benita Combet and Christoph Halbmeier for helpful feedback on earlier versions of this article. We would also like to extend our special thanks to Benita Combet for extensive testing of earlier versions of
Hannes Kröger was funded by the Deutsche Forschungsgemeinschaft (DFG, German Science Foundation) 415809395, 427279591, 40965412 and the German Federal Ministry of Education and Research (BMBF, grants: 01UJ1911BY; 01NV1601B).
11 Programs and supplemental materials
To install a snapshot of the corresponding software files as they existed at the time of publication of this article, type
To install the current version of the software files, type
Notes
A Appendix
B Relations between change decompositions and KOB
In this section are the proofs that all decompositions of change presented in section 4 are derivatives of the difference between two KOB decomposition at two time points. 10
Together, the four components fully decompose changes in group differences over time.
Proof.
As can be shown, WL1 and WL2 fully decompose changes in group differences over time.
Proof.
B.3 Interventionist
Finally, we can show that the three components added up to give the total difference in change between the two groups:
Proof.
Together, the components fully decompose the change in group differences over time.
Proof.
We can show that the KIM decomposition fully decomposes changes in group differences over time.
Proof.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.