
Abstract
Recent evidence from production studies and meta-linguistic commentary suggests that the Northern Cities Shift (NCS) is rising above the level of consciousness to become negatively evaluated, thus prompting its reversal in apparent time. This study probes Chicago-area adolescents’ social evaluations of salient NCS-implicated vowels via a matched guise task. Since the social meanings of linguistic features are determined through their co-occurrence with other features in styles, NCS vowels are examined in combination with (dh)-stopping, itself a cue to lower socioeconomic status. Results suggest that adolescents are aware of the community-level distribution of these variables, reflecting the class- and age-linked patterning of NCS reversal in Chicago, and that the social meanings of this change in progress are evaluated in the context of broader styles.
Keywords
1. Introduction
Speakers draw upon pre-existing socially meaningful linguistic elements in the construction of styles, which are used to position the self in the social landscape (Eckert 2012). It is through the construction of styles that individuals are able to align with or distance themselves from particular social types or personae (Coupland 2007). Consequently, attitudes and ideologies about the social meanings of linguistic features and styles can guide speakers’ engagement with them. Recent reversals of regional vowel shifts in the United States have been attributed to speakers’ orientations away from the place- and class-linked social meanings associated with them. For example, speakers in Raleigh, North Carolina who negatively evaluate the social meanings associated with the Southern Vowel Shift are leading an apparent time change away from it (Dodsworth & Kohn 2012) and economic changes in parts of the Inland North leading individuals to search for employment outside the region have led younger speakers in Michigan and upstate New York to produce less Northern Cities-shifted vowel spaces (King 2018; Nesbitt 2021).
Throughout the Inland North region of the United States, a sound change in progress involving the reversal of the Northern Cities Vowel Shift (NCS) pattern for the
This paper provides corroborating evidence for the ideological connection between NCS vowels and lower socioeconomic status, based on a matched guise task (Lambert, Hodgson, Gardner & Fillenbaum 1960) completed by adolescents from the Chicago area. Adolescents are often the drivers of linguistic change as they draw upon socially meaningful features to position themselves within their social environments (Eckert 2000; Labov 2001; Tagliamonte & D’Arcy 2009). They are also particularly interesting for explorations of the social meanings of class-linked linguistic features, as they have not yet completed their educations, are generally not employed full-time, and do not have the same control over material capital as adults. As such, it is difficult to assign adolescents to class categories using traditional measures. However, adolescents are nevertheless engaged in processes of identity work related to their future class positions. For example, Eckert’s (1989, 2000) classic “jocks and burnouts” study found that high school students’ social group affiliations and corresponding NCS productions were related to their anticipated status as working class (burnouts) versus middle class (jocks). Given that NCS features have been argued to have taken on class-based social meanings, it is worth considering whether adolescents exhibit this indexical (Eckert 2008) association in their social evaluations of the NCS.
A full understanding of the ongoing apparent time sound change in progress necessitates an understanding of the social meanings that speakers attribute to these features. In order to better understand why young people might be orienting away from NCS
2. The Northern Cities Vowel Shift and (dh)-Stopping in Chicago
Recently, the Northern Cities Vowel Shift (NCS) has been observed to be reversing in apparent time throughout the Inland North region of the United States, including Chicago, the largest city in the dialect region (McCarthy 2011; Driscoll & Lape 2015; D’Onofrio & Benheim 2020; Thiel & Dinkin 2020). The NCS is a chain shift involving the low and mid vowels, as depicted in Figure 1 (reproduced from D’Onofrio & Benheim 2020). The NCS has historically been described as typical of white speakers in the Inland North, including Chicago (Herndobler 1977; Labov, Ash & Boberg 2006; McCarthy 2011; inter alia).

The Northern Cities Shift
Over the course of the twentieth century, the NCS advanced among white speakers in the Inland North (Labov, Ash & Boberg 2006; Labov 2010). Today, ideologies prevalent in metalinguistic commentary (Benheim & D’Onofrio 2024, Benheim 2026) and performances (e.g., Hallett & Hallett 2014) in Chicago suggest that NCS features—especially raised/fronted
Given the class-based associations of NCS features in meta-linguistic commentary and production patterns (McCarthy 2011; Wagner, Mason, Nesbitt, Pevan & Savage 2016; Nesbitt 2021), the present study involves the manipulation of two sets of features:
Based on these shared associations, as well as the partial overlap in the distribution of these features, this study tests adolescents’ social evaluations of NCS vowels and (dh)-stopping. It is worth considering what social meanings these frequently discussed features of the “Chicago accent” hold for younger listeners, the age group most likely to advance linguistic changes in progress and on the precipice of attaining their own socioeconomic statuses in adulthood.
3. Social Evaluations in Linguistic Perception
While production patterns can point to the overall demographic or attitudinal factors that might condition the use of a given linguistic feature, a full understanding of the factors motivating NCS reversal—that is, why younger speakers might be orienting away from Northern Cities-shifted
MGTs are useful for probing slightly more subconscious associations between linguistic features and social meanings. Though the MGT is a relatively introspective task, as listeners are explicitly reflecting on social evaluations of voices, these evaluations can differ from the meta-linguistic commentary that might arise in interview contexts, as they don’t require the ability to explicitly discuss specific linguistic features. This is especially useful for the NCS, for which some individuals are unable to provide meta-linguistic commentary (such as speakers who claim there is “no Chicago accent”). For example, in a matched guise task in Michigan, Savage, Mason, Nesbitt, Pevan, and Wagner (2015) observed that Northern Cities-shifted
Importantly, however, the social meanings of linguistic features are evaluated in the context of co-occurring stylistic resources. Through bricolage (Eckert 2012), speakers draw upon pre-existing socially meaningful linguistic elements to construct styles (Coupland 2007; Eckert 2016). While these styles may be used to index new social meanings, they are constructed by drawing on linguistic features which have pre-existing social meanings in the community (Zhang 2008; Eckert 2016). In the context of sound change, then, it is important to consider not just how the linguistic features are undergoing change, but also how these features may be used in combination with others.
Features and styles can become enregistered (Agha 2003) with certain social types or personae. As a result, individuals can use or avoid certain styles in order to align or distance themselves from these social types. This process can then lead to sound change, as speakers orient differently toward or away from social meanings over time (Coupland 2007; Eckert 2016). Crucially, social evaluations of a linguistic feature can depend on the surrounding style in which it is embedded, or the other features that co-occur with it. For example, in a matched guise task, Campbell-Kibler (2009) found that the interpretation of alveolar and velar variants of (ING) depended on a speaker’s perceived regional (Southern versus non-Southern) and social class (working class versus non-working class) background: while alveolar [ɪn] is generally associated with lower ratings on perceived education/intelligence, speakers with Southern accents were universally rated lower on this scale, regardless of the (ING) variant they produced. The social meaning associations of (ING) variants emerged only for non-Southern speakers who were perceived as non-working class.
Similar results have also been found among adolescents: in Copenhagen high schools, Pharao, Maegaard, Møller, and Kristiansen (2014) found that a male speaker was more likely to be perceived as sounding “gay” or “feminine” when producing a fronted (versus alveolar) /s/, but only when this was combined with “modern Copenhagen” prosody. Meanwhile, when the same variants of /s/ were combined with “street language” prosody, fronted /s/ was more likely to be perceived as sounding “gangster,” while the opposite effect (fronted /s/ rated as less “gangster”) was found in the “modern” prosody guises. Such studies demonstrate how listeners are sensitive to the stylistic contexts in which variants occur, which may condition the social meanings associated with them. Additionally, individual variants may contribute different social meanings when incorporated into different styles.
Research on features undergoing change over time has found that listeners of different ages might vary in their evaluations of the social meanings of these features. In Michigan, for instance, Savage, Mason, Nesbitt, Pevan, and Wagner (2015) observed that fronted (NCS)
4. Methods
4.1. Stimuli
A matched guise task tested listener responses to two sets of features, alone and in combination: (1) NCS-implicated
Each speaker was recorded reading a 2-3 sentence passage constructed to contain three tokens each of Sample passage: “I was trying to bake a cake for
Following Tamminga (2017), who found that matched guise effects are similar across read and spontaneous speech styles for at least some linguistic features, read speech was determined to be appropriate for this task and used due to the level of control that this allows for the researcher in creating the stimuli. Four guises were created from each critical passage (4 guises × 4 passages = 16 total stimuli), for each of the possible combinations of
To create the guises, each speaker’s natural productions of
Mean Vowel Midpoint Measurements by Formant, Guise, and Voice
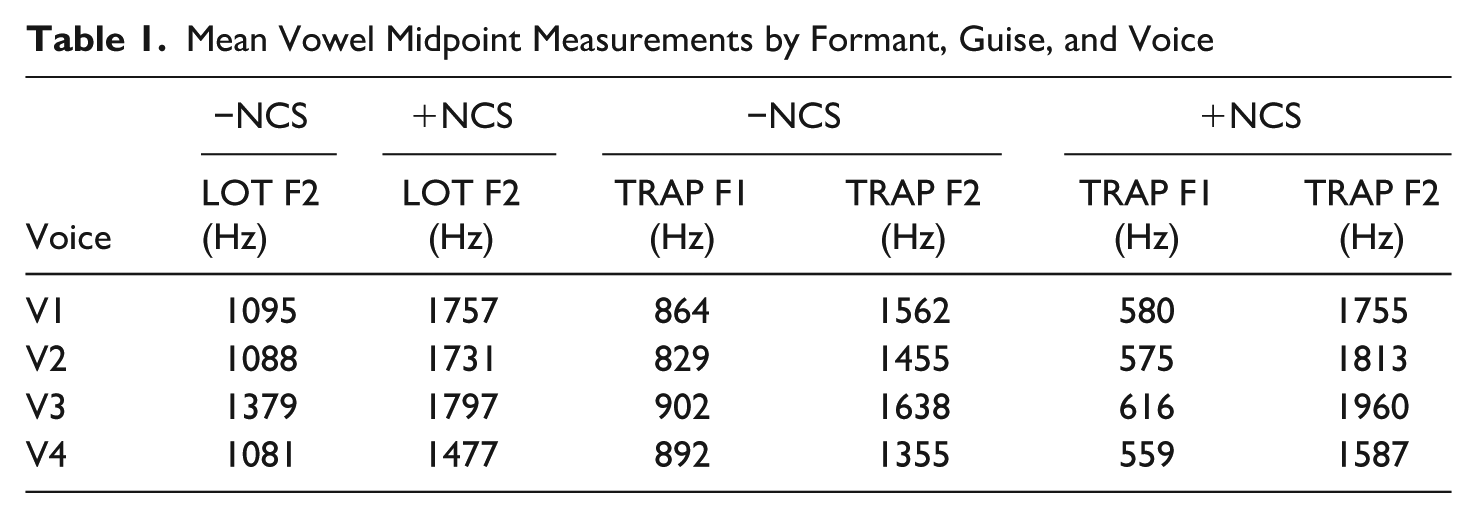
For tokens of (dh), each speaker recorded both stopped and fricative versions of the passage. To produce the stopped guises, the stop and following release burst were spliced onto each speaker’s natural production (with fricatives). In instances where the result sounded unnatural due to durational differences in the following vowel caused by the short lag voice onset time of some of the stops, the following vowel was also spliced. Since each speaker recorded multiple versions of each stimulus, fricative guises were created by splicing the fricative segments from a different recording onto the recording being used to create stimuli (following Campbell-Kibler 2007); in this way, all guises contained spliced (dh) tokens to limit the influence of potentially audible digital manipulation on evaluations.
In order to ensure that each guise sounded equivalently natural given the digital manipulation, a naturalness rating task was conducted over Prolific in which one hundred listeners (native English-speaking United States residents) were randomly assigned one guise per voice and rated each on a 10 point rating scale ranging from “(1) sounds like a human talking” to “(10) sounds like a computer-manipulated voice.” No significant differences were found for ratings between guises within each voice. Though most responses were not at one, indicating that listeners could perceive at least some manipulation in the recordings, they were concentrated toward the “sounds like a human talking” end of the scale: mean ratings by voice equaled ranged from 2.71 (Voice 4) to 3.93 (Voice 3), with an overall mean of 3.18 across all stimuli. An additional twenty-five Prolific participants were presented with the unmanipulated versions of each voice (i.e., each speaker’s natural production of the reading passage) and asked to rate the speaker’s perceived gender (universally rated as male) and racial/ethnic background in a multiple choice task with categories drawn from the US Census (American Indian or Alaska Native, Asian, Black or African American, Hispanic or Latino/a/e, Native Hawaiian or Pacific Islander, and White); participants had the option to select multiple categories, though only three respondents did so. All speakers were perceived as white (alone) by at least 80 percent of listeners ranging from 80 percent (Voice 4) to 96 percent (Voice 1). Other categories receiving more than one response for any voice included Asian, Hispanic or Latino/a/e, and Black or African American.
In the main task, each participant was presented with one instance of each possible combination of features (vowels and (dh)-stopping). Comparing four voices allowed each participant to respond to each possible combination of features, though the specific guise-voice pairings varied across conditions in a Latin Square Design. An additional three filler stimuli (recorded by female speakers in their twenties: a white woman from the Inland North, a Hispanic woman from the South, and a white woman from the Mid-Atlantic) were also recorded, but not manipulated. These fillers were included to mask the purpose of the task and include a relatively even gender balance across stimuli (three women: four men), while minimizing the total duration of the task.
4.2. Procedure
All participants were from the Chicago area (either the city or surrounding suburbs), native English speakers, and in the high school classes of 2020-2024 (age 15-19 at the time of data collection in 2020-2022). Participants were recruited via social media outreach to their parents and snowball sampling. Upon expressing interest in participating, participants over 18 and parents of minor participants were emailed a link to complete an “online listening survey” via Qualtrics. Participants were compensated with a $5 digital gift card upon completing the experiment.
Participants were informed that the researcher was interested in learning what information people can learn about a person based on hearing them talk. Each participant heard all seven stimuli (four critical, three filler) three times across three blocks, responding to more specific questions about the speaker within each successive block, following Becker (2014). The order of presentation of critical and filler stimuli was randomized within each block (i.e., participants could hear the seven stimuli in any order). Participants answered the same question(s) for each stimulus within a block before proceeding to the next block of questions.
In the first block, listeners heard each passage and answered an open-response question about their overall impression of each speaker. In the second block, listeners responded to several open-response questions about the speaker’s macro-social demographic background (perceived race/ethnicity, gender, region, and occupation) and rating scales about each speaker’s perceived age (ranging from 0 to 100) and class (5-point scale with the endpoints labeled “working class” and “wealthy” and the middle point labeled “middle class.” The labels “working class” and “middle class” are drawn from Labov 1972), though Labov’s label for the highest socioeconomic group, “upper middle class,” was replaced with “wealthy” to account for how these terms are used colloquially in the Chicago area. These measures were chosen because the features under study are associated in meta-linguistic commentary with these macro-social categories (e.g., NCS
Finally, in the third block, listeners rated the speaker on several rating scales related to the speaker’s affective, personality, and other demographic traits, drawn from traits associated in previous work with NCS vowels (McCarthy 2011; Savage, Mason, Nesbitt, Pevan & Wagner 2015; D’Onofrio & Benheim 2020) and/or (dh)-stopping (e.g., Rose 2006; Mendoza-Denton 2008): “educated,” “intelligent,” “hardworking,” “annoying,” “masculine,” and “tough.” I additionally tested evaluations along the scales of “friendly,” “kind,” “professional,” and “formal,” measures which listeners often associate with specific linguistic features. “Professional” and “formal” in particular were chosen given the class-based associations both NCS vowels and (dh)-stopping hold in production studies. The ends of the scales were categorical measures to reflect unidirectional measures: to assess masculinity, for instance, participants rated the speaker on a 7-point scale from “not masculine” to “masculine,” and for education, participants rated the speaker from “not educated” to “educated.” In this final block, participants also rated how likely the speaker was to be from Chicago (rating scale) and if so, whether there were certain areas of the city that they were most likely to be from (open-response). Following these three blocks, participants completed a demographic questionnaire.
4.3. Participants
Eighty-one participants completed the matched guise task, though data from nine were excluded for failing to meet the inclusion criteria (either because they were too old and/or not from the Chicago area) or technical issues with completing the survey, resulting in seventy-two total respondents. All participants were age 15-19 at the time of the survey. In an open response question, forty-one participants listed their gender as “female,” twenty-seven as “male,” one as “nonbinary,” and three participants declined to report gender. Demographic information about participants’ racial/ethnic backgrounds was also solicited through an open response question (note that the following numbers total over 72, as participants who listed multiple racial/ethnic categories are included under multiple groups); forty-eight participants reported being white (specific labels provided by participants were: “white,” “Caucasian,” “German and Greek,” “Polish,” “Ashkenazi Jewish,” “Armenian” “I’m white but I’m half Indian and half Jewish,” “Irish,” “German”), sixteen as Latinx (“Hispanic,” “Mexican,” “Mexican American,” “Latina”), six as Black (“Black,” “African American,” “Black American”), seven as Asian (“Asian,” “Indian,” “Pakistani,” “Chinese American,” “Asian American”), and one as Native American (“Native American—Mayan”). Two participants did not report race/ethnicity, and one listed race/ethnicity as “American.”
4.3.1. Quantitative Analysis
Linear mixed effects regression models were fit to responses for each rating scale. The fixed effects of interest included the two sets of features which were manipulated across guises,
Since responses were collapsed across all four voices in order to maximize statistical power and ensure that each participant responded to each possible combination of vowels and (dh), Voice was included as a control fixed effect. Voice often emerged as a significant main effect, indicating that listeners had baseline differences in their evaluations of these voices. Since each passage was recorded by a unique speaker (one voice per passage), these different evaluations may reflect reactions to the voice, the content of the passage, or a combination of both. Past work has found that different voices may impact social evaluations of NCS features, even where passage content is identical (Thiel 2019). In the present data, however, Voice was never found to significantly interact with vowels or (dh), indicating that responses to these particular variables can be generalized across the different voices. Finally, participant was included in all models as a random intercept.
5. Results
Table 2 depicts the estimates for the rating scales for participants evaluations of each feature of interest.
Estimates for Linear Mixed Effects Regression Models

Note: Significance marked with asterisks (*p < .05; **p < .01; ***p < .001).
There were no significant results for the “friendly,” “intelligent,” “hardworking,” “annoying,” “professional,” “masculine,” “tough,” or “kind” scales, nor for ratings of the speaker’s “likelihood of being from Chicago.” Significant effects are discussed in turn below. In each figure, the y-axis is oriented such that higher ratings along the given dimension are placed higher on the graph (e.g., for education, higher values = “more educated”). For each boxplot, the guises are labeled as follows: vowels are specified as either Northern Cities-shifted (“NCS”) or “reversed” and (dh) is specified as containing either “fricative” or “stop” tokens of this segment. These terms are then crossed in the guise labels to reflect the 2 × 2 stimulus design.
On the 5-point rating scale assessing the speakers’ class backgrounds, the endpoints were labeled “working class” (point 1 in Figure 2) and “wealthy” (point 5), while the midpoint (point 3) was labeled “middle class.” A significant main effect of vowels emerged, such that guises containing NCS vowels were evaluated as sounding lower in class than the corresponding reversed guises. In particular, responses for NCS guises were concentrated toward the middle of the scale, whereas those for Reversed guises were generally concentrated toward the top half of the scale. Additionally, guises containing (dh)-stopping were evaluated as sounding significantly lower in class than those containing fricatives. This trend is observable among the Reversed guises, where the median for the Reversed Fricative guise is 4 compared to 3 for the Reversed Stop guise.

Class Ratings by Guise
For age, responses were predominantly clustered between the twenties and mid-thirties, which is consistent with the speakers’ actual ages (all were in their mid-to-late twenties). A significant main effect of vowels emerged, such that NCS vowels were rated as sounding older than more reversed vowels, consistent with the apparent time sound change in progress in which NCS vowels are reversing among younger speakers. Additionally, there is a main effect of (dh)-stopping, such that (dh)-stopping is rated as sounding younger than the fricative guises, perhaps due to ideological associations between “nonstandard” variants and adolescence or young adulthood observable in age-grading patterns (e.g., Labov 1972; Wagner 2008). This finding is interesting given that meta-linguistic commentary suggests that Chicagoans—at least in discussing stereotypes—associate (dh)-stopping primarily with older speakers (this is exemplified by a Chicago Magazine article on Chicago English which alleges that (dh)-stopping is “mainly heard in speakers over 50, as younger people are consciously rejecting such distinctive markers of geography and class,” McClelland 2018). However, a number of participants in the sample occasionally produced stopped tokens of (dh) in sociolinguistic interviews discussed in other work (Benheim 2023), indicating that listeners in the MGT task may be exposed to (dh)-stopping as produced by other adolescents. This is consistent with findings in other locales in the United States where (dh)-stopping among white speakers originated as a substrate effect among an immigrant generation but is maintained by at least some native English-speaking members of younger generations (e.g., Dubois & Horvath 1998). As Figure 3 shows, however, the main effect of (dh)-stopping on age evaluations is driven by responses to the two NCS guises. When the speaker produced reversed vowels, evaluations of speaker age were similar.
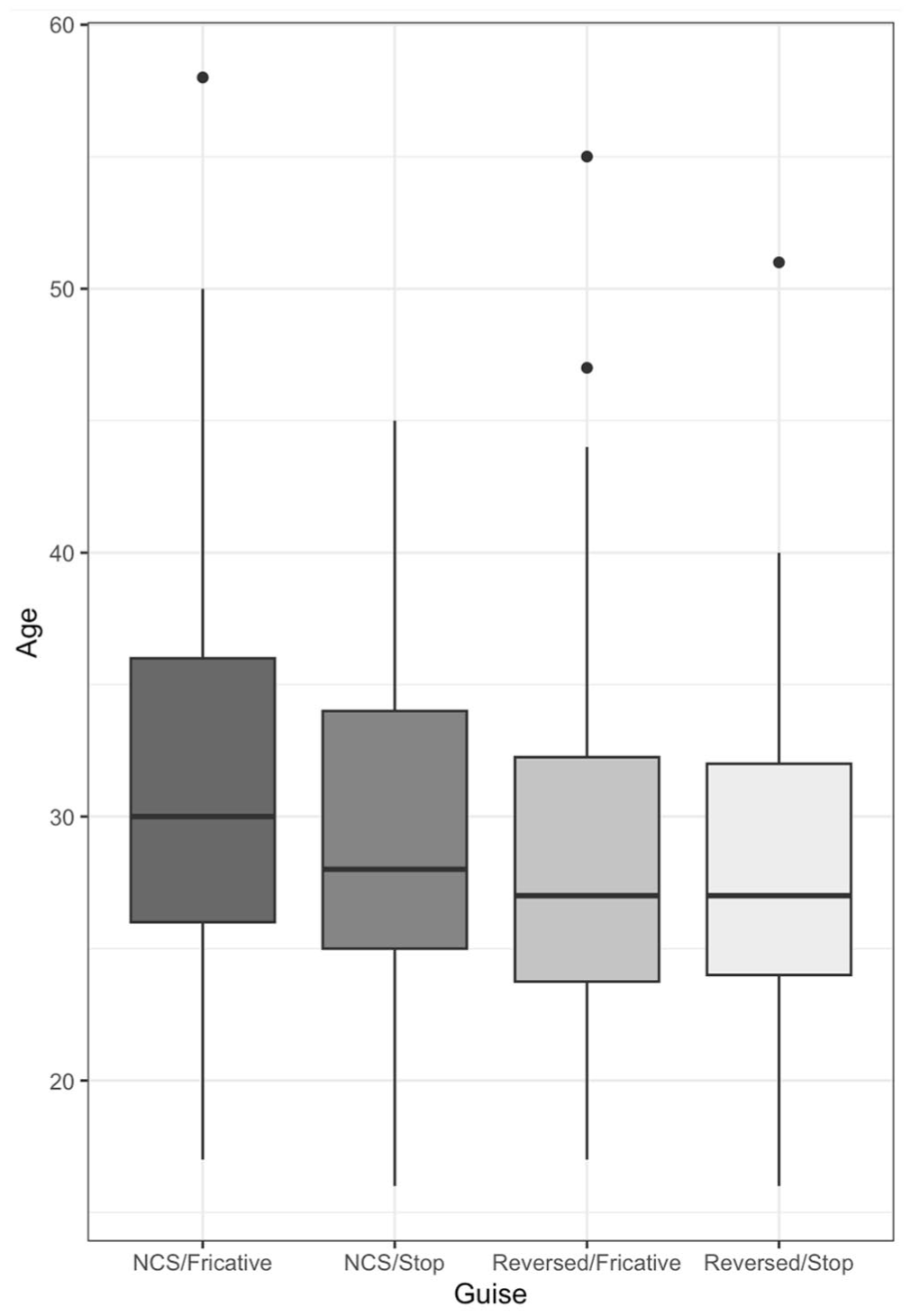
Age Ratings by Guise
This is due to a significant interaction between vowels and (dh)-stopping. Producing Northern Cities-shifted vowels leads a speaker to be perceived as sounding older. However, this effect is attenuated by the presence of (dh)-stopping: speakers producing both NCS vowels and (dh)-stopping are perceived as younger compared to a Northern Cities-shifted speaker who produces fricative tokens of (dh). Notably, this effect of (dh)-stopping only impacts Northern Cities-shifted speakers. For speakers who produce non-NCS (“reversed”) vowels, there is no impact of (dh)-stopping on perceptions of speaker age. While listeners’ evaluations generally pattern according to the apparent time change in progress, with NCS vowels more likely to be attributed to an older speaker, listeners are sensitive to style and co-occurring features in their social evaluations of NCS vowels.
For education, I find significant a significant main effect of (dh)-stopping such that guises containing (dh)-stopping were rated as sounding less educated than guises containing fricative (dh) tokens, consistent with previous work linking (dh)-stopping to lower education levels (e.g., Labov 1966; Newlin-Łukowicz 2013). As evidenced by Figure 4, this effect is primarily driven by responses to the Reversed/Fricative guise, which were evaluated as sounding more educated than the other guises, though neither vowels nor the interaction between vowels and (dh)-stopping emerged as significant.

Educated Ratings by Guise
For perceived formality, a significant main effect emerged for (dh), such that guises containing (dh)-stopping were evaluated as sounding less formal than the fricative guises (Figure 5). Again, this is expected given previous work on the social associations of (dh)-stopping (Labov 1972; Mendoza-Denton 2008; Newlin-Łukowicz 2013).

Formal Ratings by Guise
5.1. Summary of Results
Northern Cities-shifted
Interestingly, there were no significant effects of either vowels or (dh) for a number of the affective traits that were tested. This stands in contrast to findings by Savage, Mason, Nesbitt, Pevan, and Wagner (2015) in Michigan who found that fronted
6. Discussion
6.1. Class and Education in Sociolinguistics
In production and meta-linguistic commentary among adults (and some but not all adolescents; Benheim 2023), both Northern Cities-shifted
The difficulties in defining social class have been frequently discussed in both linguistics (Rickford 1986; Mallinson 2007; Dodsworth 2009; Baranowski & Turton 2018) and sociology (Reeves, Guyot & Krause 2018; inter alia). While some studies have assessed participant social class through index scales measuring multiple factors, including income, educational attainment, and occupation (e.g., Labov 1966, 1972; Becker 2010), others rely on educational attainment (e.g., McCarthy 2011) or occupation (e.g., Turton & Baranowski 2020) alone, often binarily divided into whether or not the participant has received a college degree or is employed in a white versus blue collar occupation, respectively. Labov (2001) observed that a composite scale outperformed individual measures of socioeconomic status in predicting sociolinguistic variation in Philadelphia. However, among the components of the composite scale, occupation was a better predictor of variation for three variables than speakers’ educational attainment or home values. In line with the findings of the present study, this suggests that, while education and class are sometimes assumed to create similar social divisions, in social practice speakers may use particular linguistic variables to index different aspects of what researchers might consider a unified “socioeconomic status” in a composite scale.
There is growing evidence from sociological research that traditional markers of socioeconomic status are shifting, both in demographic patterns as well as in how individuals understand their own positions in class hierarchies. Shifts in “working class” occupations due to decreases in the availability of manufacturing and other traditional “blue collar” jobs and growth in the service sector, coupled with increasing levels of educational attainment, have changed the relationship between education and socioeconomic status (Nesbitt 2021). At the same time, college matriculation has been steadily rising among younger Americans, and a college degree on its own is no longer as predictive of future upper-middle class socioeconomic status as it was several decades ago (Reeves, Guyot & Krause 2018; Fry 2021). Rather, future earnings are predicted by the type of university an individual attends (for the linguistic ramifications of this, see Prichard 2016), and students with college-educated parents remain overrepresented at prestigious universities despite overall increases in college enrollments across the board (Fry 2021).
The participants in this sample, a majority of whom additionally participated in sociolinguistic interviews discussed in other work (Benheim 2026), came from families occupying a broad range of income and parental occupation/education levels. Reflecting the demographic shifts discussed above, all but one participant who was interviewed anticipated attending a four-year university after high school, regardless of their parents’ own educational attainment. These participants also discussed class-stratified future career plans ranging from preschool teachers and retail workers to doctors, lawyers, and politicians, further pointing to a decoupling of college attendance and middle or upper-middle class status. The use of generalized scales to assess socioeconomic status in sociolinguistic research has been critiqued by advocates of more grounded approaches of class. Such approaches are intended to account for locally-relevant indicators of class and include linguistic markets (Sankoff & Laberge 1978), communities of practice (Eckert 2000), social network models (Milroy & Milroy 1992), and relational models of class (Mallinson 2007). Advocates of these more localized understandings of class argue that language, as a symbolic resource, is primarily utilized to index social positions which are locally meaningful within a given community. Therefore, accounts of linguistic variation must utilize models of class that factor in these localized understandings of class (Mallinson 2007; Dodsworth 2009). For participants in the present study, then, for whom educational attainment and class status are not straightforwardly connected, it is unsurprising that evaluations differ across these varying metrics, and that a speaker’s degree of vowel shifting indexes something about their class status while their use of (dh)-stopping indexes both class and educational attainment.
6.2. Place Evaluations and Regional Stereotypes
As noted above, the
That said, some participants did specifically point to NCS vowels in relation to place-linked social meanings. In their meta-linguistic commentary in response to open-ended questions about the speaker, for example, one participant wrote: “The way he says ‘pockets’ suggests that he might be from the southside [of Chicago],” potentially indicating the fronted LOT vowel as salient. Other participants linked the
Work on the NCS has suggested that it was below the level of consciousness for much of the twentieth century (Preston 1998; Gordon 2000; Labov 2010), but has recently begun to feature in metalinguistic commentary and show style-shifting effects (Driscoll & Lape 2015; Thiel & Dinkin 2020). While these participants’ ability to reference specific NCS vowels points to increasing metalinguistic awareness of them, it is possible that some participants are not aware of their place-based social meanings. That said, given the sound change in progress, Chicago-area adolescents are exposed to speakers who are from Chicago but produce relatively reversed vowels (e.g., McCarthy 2011; D’Onofrio & Benheim 2020), and this null result is consistent with a situation in which local speakers may produce either variant.
6.3. Style and Social Meanings of the NCS
In meta-linguistic commentary and parodic performances (Hallett & Hallett 2014; McClelland 2018; D’Onofrio & Benheim 2020), NCS vowels and (dh)-stopping co-create an enregistered, white Chicago working class style. However, the apparent time change in
The interaction between (dh)-stopping and vowels on evaluations of the speakers’ age in the results of this study suggest that in social evaluations, the overall age-based associations of NCS vowels (more Northern Cities-shifted vowels indexing older age) might be mitigated by co-occurring (dh)-stopping, which leads a Northern Cities-shifted speaker to be perceived as younger compared to a Northern Cities-shifted speaker whose (dh) tokens are fricatives. Despite on-going reversal, then, younger community members who also produce other features associated with the white working-class Chicagoan persona may be expected to maintain Northern Cities-shifted vowels. In particular, (dh)-stopping is associated with lower ratings for class, education, and formality, whereas NCS vowels are rated lower only for class. That Northern Cities-shifted
The Northern Cities Shift was long considered to be below the level of consciousness (Preston 1998; Gordon 2000; Labov 2010). Recently, however, it has taken on class-based associations in Chicago and elsewhere in the Inland North (King 2018; Nesbitt 2021). For younger listeners, NCS vowels are perceived as lower in class. But beyond these class-based associations, they also make a speaker sound older, due to the ongoing apparent time change toward more reversed vowels. For a younger speaker, then, producing NCS vowels alongside a feature like (dh)-stopping can be a way of producing a style that activates the class-based social meanings of NCS vowels while simultaneously blocking or attenuating their age-related associations. Since reversed vowels may signal younger age on their own, it is possible that (dh)-stopping does not index additional age-related information about the speaker, and therefore listeners do not perceive an age-related distinction based on the production of (dh)-stopping alone. In this way, bricolage (Eckert 2008) enables the stylistic co-occurrence of sociolinguistic variants to inform how their joint social meanings are interpreted.
These style effects thus point to potential class discrepancies in how these features are produced, as adolescents align themselves with particular classed identities. Different features may carry different social meanings, but work together in creating the social meanings of styles as a whole (Coupland 2007; Eckert 2008, 2016). While listeners are sensitive to the overall age-related production patterns for Northern Cities vowels, they are also sensitive to how these features are produced in styles to index certain kinds of social meanings which may, in turn, influence their own production patterns as the apparent time sound change continues.
Footnotes
Appendix
Other passages used as critical stimuli in the matched guise task (
Acknowledgements
Thank you to Annette D’Onofrio, Ann Bradlow, Shalini Shankar, members of Northwestern’s SocioGroup, and the audience at NWAV 49 for valuable feedback on earlier stages of this work. I am additionally grateful to the speakers who recorded these stimuli and, of course, to the participants for their time and effort.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by funding from the National Science Foundation [DDRIG #BCS-2116957] and the Northwestern-SSRC Dissertation Proposal Development Program.
Ethical Approval
The Institutional Review Board at Northwestern University approved this study (approval #STU00213011-MOD0003).
Informed Consent
Participants over 18 gave informed consent and those who were minors gave assent with parent permission by clicking a checkbox before beginning the experiment.
Data Availability Statement
The datasets generated during and analyzed during the current study are available from the corresponding author on reasonable request.*