
Abstract
N-is constructions combine a variable article and a shell noun such as thing, fact, or problem with copula be. As discourse markers at the left periphery, they focalize information that follows. Using data from a large online newspaper corpus, this study is the first to investigate the variable syntactic integration (bare versus that-clause) of focalizers across a broad range of World Englishes. Variability in syntactic integration reflects the relative recent emergence of this discourse marker. It is also relevant for World Englishes research because it is at the level of semi-idiomatic constructions that nativization in post-colonial varieties is likely to occur. Corpus data show that syntactic integration in N-is focalizers is predicted most strongly by linguistic variables, with regional variety being a much weaker predictor. While no clear-cut regional or variety-type patterns emerge from the data, qualitative analysis reveals some low-frequency patterns as candidates for structural nativization.
Keywords
1. Introduction
In English, so-called “shell” or “signaling” nouns like thing, fact, or problem are regularly used in the left periphery of the sentence with a (variable) definite article and copula be. In these semi-fixed N-is constructions, the noun no longer has referential meaning (e.g., Miller & Weinert 1998; Schmid 1998; Flowerdew & Forest 2015). Instead, N-is constructions have developed a pragmatic function: they are used as discourse markers (DMs) to launch utterances and to focalize the following information. In (1), for instance, having medical insurance is not literally a thing but rather a fact, and, in (2), the DM function of the N-is construction can easily be demonstrated by substituting a pragmatic particle like apparently.
(1) “The thing is all our guys have their own medical insurance, which is a really good system, so they’re not going to be a drain on the New Zealand taxpayer.” (NOW, NZ, February 9, 2016)
(2) Word is they need a lift to get to their house. (NOW, NZ, October 18, 2016)
N-is focalizers are only semi-fixed constructions according to a number of criteria. In addition to variable article use (as in 1 versus 2) and different shell nouns, syntactic integration varies between overt subordination with that and bare subordination: compare (3) with (1) and (2). Moreover, N-is focalizers can be separated by punctuation (as in 4) or not (all other examples). Finally, the shell noun allows for optional pre-modification (see 5 and 6, where sadly could replace the N-is construction as a DM).
(3) Word is
(4) The fact is
(5)
(6) The
Constructional variability can, on the one hand, be argued to be an aspect of (ongoing) constructionalization, i.e., the change from a formerly free clause to a DM. This variability is also highly relevant to discussions about nativization in World Englishes (WEs) because ongoing constructionalization can be found to intersect with processes of structural nativization.
The aim of the present paper is twofold: namely, to investigate the degree to which different N-is focalizers have developed towards DMs, and to investigate potential patterns of regional variation in this ongoing process. It uses corpus evidence from a large online corpus of English newspapers and probabilistic modeling (section 3) to study variation in degree of syntactic integration for six shell nouns across eleven varieties of English. Section 4 presents the results of the probabilistic modeling. Beyond the statistically significant distributions, the corpus data provide intriguing evidence of low-frequency patterns that are suggestive of regional differences in constructionalization, explored in section 5. The discussion (section 6) focuses, for the most part, on the question of variation across WEs, particularly the lack of clear patterns with respect to either region or variety type (e.g., by first or institutionalized second-language).
2. Background
2.1. Constructionalization and the Emergence of Semi-fixed Form-Meaning Pairings
Constructions on Different Levels of Abstraction and Idiomaticity
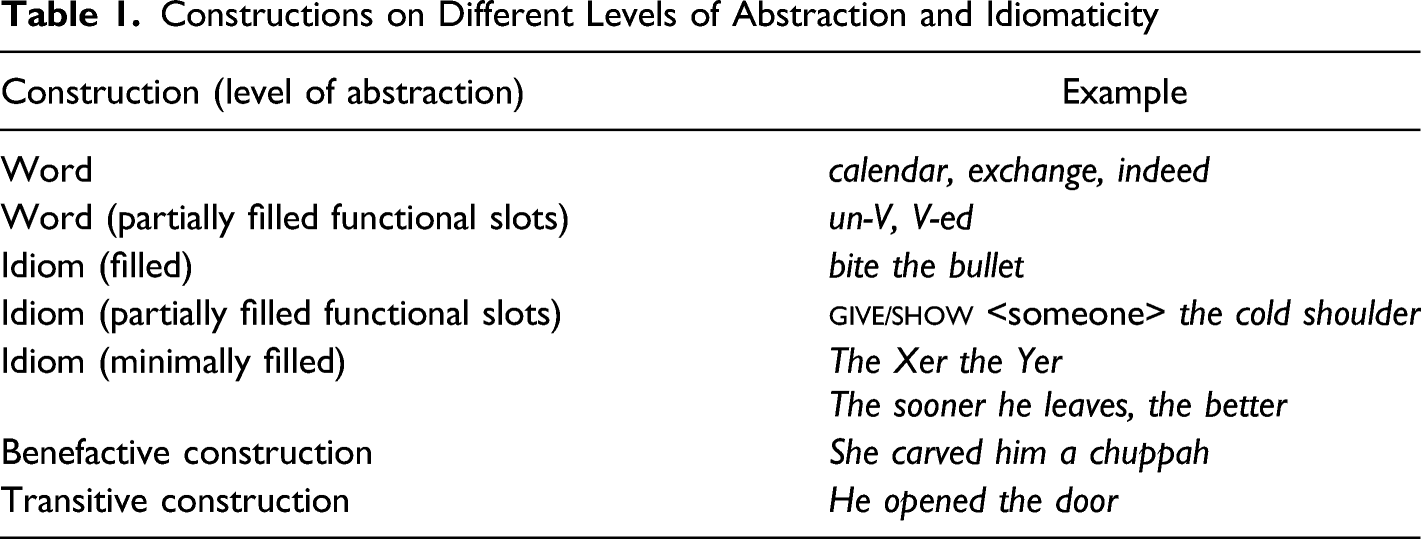
Constructions thus also include DMs such as indeed or the focalizer constructions that are the focus of the present paper. Both are the result of “constructionalization.” Traugott (1995) traces the development of indeed from a combination of a preposition and a lexical noun (in dede) via its use as an adverbial phrase and sentential adverb to DM function. The study thus outlines the change from a lexical construction to a DM, which fits the definition of constructionalization that Traugott and Trousdale (2013:22) put forward: Constructionalisation is the creation of formnew-meaningnew (combinations of) signs. It forms new type nodes, which have new syntax or morphology and new coded meaning, in the linguistic network of a population of speakers. It is accompanied by changes in degree of schematicity, productivity, and compositionality. The constructionalization of schemas always results from a succession of micro-steps and is therefore gradual.
Hundt (2022) uses qualitative evidence from the Oxford English Dictionary and Early English Books online to establish the pathway of development for N-is focalizer for a set of five shell nouns, tracing the development from full main clause with overt subordination to a DM at the left periphery. The study shows that constructionalization started with truth is around the middle of the sixteenth century, with other shell nouns (such as fact, thing, and problem) occurring much later. The data show that constructionalization involves the loss of the subordinator, the addition of a premodifier, and the possibility to omit the definite article (in this order). On this rationale, the most constructionalized variants would be those without an article or that, and (in writing) with comma-separation, as illustrated in (5). Once the constructional template is established, novel shell nouns can enter the construction (e.g., problem is, a recent innovation from the 1940s), allowing the full range of variability from the very beginning (Hundt 2022). Hundt’s (2022) data for the nineteenth and twentieth centuries show that punctuation becomes the most important predictor in written data for bare complementation across time (i.e., it marks a further step along the development towards the left periphery), whereas article omission remains a rare (but salient) characteristic of N-is focalizers.
Previous accounts of N-is constructions differ in their views on whether to treat them as transparent syntactic structures consisting of a main and a subordinate clause (see Brenier & Michaelis 2005; Delahunty 2012) or as semi-fixed patterns (e.g., Biber, Johansson, Leech, Conrad & Finegan 1999; Carter & McCarthy 2006; Aijmer 2007; Keizer 2013, 2016). The development of a pragmatic function presents an argument in favor of the latter interpretation. That these constructions have developed into DMs, which are, moreover, predominantly used in the left periphery of the sentence, is also evidenced by the different terms that are used for them: they are referred to as “introductory constructions” (Curzan 2012), “overtures” (Biber, Johansson, Leech, Conrad & Finegan 1999), “projector/projecting constructions” (Günthner 2008; Curzan 2012; Shibasaki 2014, 2015), “scope operators” (Fiehler, Barden, Elstermann & Kraft 2004), “stance complement” constructions (Quirk, Greenbaum, Leech & Svartvik 1985), “utterance launchers” (Schmid 2000), or “focus formulas (with shell nouns)” (Tuggy 1996; Tárnyiková 2018). The term “focalizer” is the one introduced by Aijmer (2007). Keizer (2013:235) even claims that they are “positionally constrained, always appearing in initial position.” Example (7) is a serendipitous find from my own reading, which indicates that they are also possible at the right periphery (see also Traugott 2015).
(7) “We do good working together, truth is.” (Cornwell 2014:12)
N-is focalizers have been studied from various perspectives. They are often examined in the context of spoken syntax (e.g., Schmid 2001; Miller & Weinert 1998; Flowerdew & Forest 2015). In speech, DMs at the left periphery are typically separated from the main clause by a pause or “comma intonation” (Brinton 2008:8; but see Traugott 2015:13). As far as punctuation in writing is concerned, previous research reveals it as variably present with N-is focalizers, both historically (Hundt 2022) and in current usage. It is not a defining criterion in writing, but we can expect N-is focalizers without overt subordination to also favor orthographic separation from the proposition (i.e., maximum separation at the left periphery).
N-is constructions have a variant form with a double copula, which is typical of spoken discourse, as the instance in (8) from the Corpus of Contemporary American English (COCA) shows.
(8) But the point
This variant has been treated separately in a series of previous papers (Bolinger 1987; McConvell 1988; Tuggy 1996; Massam 1999; Brenier & Michaelis 2005; Curzan 2012) but is too infrequent in writing to be included in the present study (see section 3.2).
Earlier corpus-based research is often restricted to one shell noun (e.g., Delahunty 2012; Shibasaki 2014, 2015; Keizer 2013, 2016). However, the synchronic data used in Hundt and Oppliger (2022) reveal that individual shell nouns vary significantly with respect to the type of proposition (bare versus that-clause) that they focalize. Similarly, article omission varies across individual nouns. It is therefore important to include a range of shell nouns in a study of constructional variation. Aijmer (2007:33) suggests that use of the complementizer that makes the article obligatory. While example (3) shows that N-is focalizers without that are attested with a zero article, we can expect article omission as well as the individual shell noun to be factors in the attested degree of syntactic integration (bare versus that-clause).
2.2. Constructional Variation and Nativization in World Englishes
As English was spread across the world, new varieties developed in countries where it was the majority language but also where it came to be an institutionalized second-language variety. The emergence of new Englishes is characterized by patterns of structural nativization, which can either be distributional, i.e., represent local uses of patterns available in the feature pool of global English (e.g., Hundt 1998; Schneider 2007; Szmrecsanyi, Grafmiller, Heller & Röthlisberger 2016) or constitute innovations, either due to prolonged separation from the input variety or due to language contact in large-scale adult second-language acquisition. The latter may involve various processes, such as transfer from a substrate language (e.g., the kena passive in Singapore English; Bao 2010), analogical extension (e.g., new ditransitives in Indian English; Mukherjee & Hoffmann 2006), or simplification (e.g., article omission or a more general reduction in complexity in the noun phrase in Kenyan and Singaporean English; Brunner 2014). However, language contact may also lead to more overt marking of grammatical categories as a result of what Mesthrie (2017:187) refers to as the “cognitive principle of hyperclarity,” which avoids ambiguity and is the flip-side of the “principle of economy.” Strictly speaking, hyperclarity refers to patterns where Post-Colonial Englishes use redundant marking (e.g., a combination of although and but in the same clause), but Mesthrie (2017:187) also provides an example of a pattern that is simply more transparent than the one used in the target language (i.e., an aspectual adverbial with a verb phrase that marks aspectual meaning). It is in this latter sense of transparency that the term hyperclarity is adopted here (i.e., more in the sense of Rohdenburg’s [1996] notion of “explicitness” than Schneider’s [2012] concept of “redundancy”). With respect to N-is focalizers, speakers of Post-Colonial Englishes might favor dropping the article (and thus be economical) while at the same time preferring to keep the overt subordination (thus avoiding ambiguity). It is important to bear in mind that structural nativization does not necessarily result in statistically significant patterns of usage (see Hundt 2021). Low-frequency idiosyncrasies can nevertheless be highly salient.
Feature Ratings From eWAVE on Article Omission

Note: (A = feature is pervasive or obligatory; B = feature is neither pervasive nor extremely rare; D = attested absence of feature).
Importantly, structural nativization – as defined here – may affect both first- and second-language varieties of English. The various processes may affect the different slots in the N-is focalizer construction differently, however, and may intersect with constructional variation as part of ongoing constructionalization.
Based on the findings of previous research presented here, we can make the following hypothesis for ongoing constructionalization and for N-is focalizers more generally:
(H1) N-is focalizers followed by a bare proposition without complementizer that are less integrated with the proposition and will favor punctuation, i.e., be more likely to be clearly marked as belonging to the left periphery (see Brinton 2008; Keizer 2013; Hundt 2022).
Ongoing constructionalization can intersect with the tendencies outlined in section 2.1, leading us to the following additional hypotheses:
(H2) Individual shell nouns will vary significantly with respect to their preference for bare propositions (Hundt & Oppliger 2022); it is likely that this will result in differences across WEs.
(H3) Varieties that have emerged from large-scale adult second-language acquisition will have an overall higher incidence of propositions with a that complementizer following N-is focalizers (principle of hyperclarity/transparency).
(H4) Differences in the propensity of speakers to omit the article in N-is constructions might lead to regionalization (Asian and African varieties versus others or according to matrilects, i.e., BrE-related versus AmE-related).
3. Material and Methodology
3.1. Material
Ideally, the data for a comparative study of N-is focalizers in WEs would come from carefully compiled corpora representing different registers of both spoken and written language use in a broad range of Englishes. Such corpora are available from the International Corpus of English (ICE) project. However, even for thing, a moderately frequent shell noun in focalizer constructions, the British component of ICE yields fewer than fifty instances; less common shell nouns are attested in ICE-GB with a frequency of just over ten (trouble is) or not at all (word is). Indeed, even a mega corpus such as the Global Web-based English Corpus (GloWbE), at 1.9 million words, does not provide enough evidence on some shell nouns for all varieties under investigation here. Another limiting factor of ICE as a source of data for this study is that ICE-US is still lacking the spoken component.
Varieties Included in the Present Study
With respect to register, the texts in NOW stem from digital news outlets and are not limited to news reports, opinion pieces, and reviews, but also include more diverse types of texts, among them those that are similar to advice columns and letters to the editor (i.e., commentary from readers). Unlike smaller reference corpora, the NOW corpus puts greater emphasis on size than on careful checking of the material that is sampled. It is therefore possible that texts which do not actually originate in the country to which they are assigned in the corpus get included. And, as with other newspaper corpora, it is possible that the materials included were written by people who are speakers of a different variety of English. Great care therefore has to be taken here in manually post-editing and removing instances from material that is problematic (see section 3.2 for details).
3.2. Extracting Data from NOW and Manual Post-editing
Data extraction was based on six shell nouns (fact, problem, thing, truth, trouble, and word) that were attested with a text frequency of at least ten instances in the press section of COCA (see Hundt & Oppliger 2022). The retrieval algorithm made use of the shell noun directly followed by the copula in the present tense. The resulting concordance files were randomized and manually post-edited to exclude false positives.
As indicated above, only the variants with a present tense is were retrieved. Instances with a past tense copula are attested, but they are a lot less frequent than the default option with a present tense form of be. For example, for the thing is/was in the US part of NOW, with an overt article, the ratio of present to past was 2961:260 (retrieval date: June 25, 2018) (see also Tárnyiková 2018:212). Variants with article omission and a past tense copula are even rarer; in the US part of NOW, thing was was attested just eighteen times, nine with premodification and nine without premodification (retrieval date: June 26, 2018). Similarly, NOW yields evidence of the variant with a double copula (as in 9 and 10), but since these were rare (at just over 100 instances in a corpus of almost 10 billion words) and not a variant for all WEs included in the study, they were excluded from the concordances as well. 3
(9) I’m only speaking as a mother, I think, often the problem is is that people don’t really understand what those labels are. (NOW, US, August 13, 2020)
(10) The good thing is is that it’s in our hands. (NOW, GB, December 15, 2017)
In order to keep the amount of data to be manually coded for additional predictors within manageable bounds, a total of fifty relevant hits per shell noun and variety were sampled from randomized sets of the shell noun followed by is. For trouble and word, the total numbers for some varieties did not amount to fifty; the total number of hits therefore is 3438 rather than the expected 3600 (see the legend to Figure 1 for total raw frequency per variety). In sampling the material, great care was taken to exclude non-regional material, such as hits from the Tokyo Reporter in the original Singapore concordance. One general strategy in sampling the data was to give preference to regional news outlets (e.g., the Daily Post, a Laos-based Nigerian newspaper) rather than those that cater to a wider audience (e.g., The News Guru, which—while based in Laos—self-advertises as “Africa’s number one news portal”). The two types of online publication are generally distinguished by a domain name which is regional and one that ends in .com. This is not to say that there is no local news copy produced for an outlet such as Nirametrics.com.
The definition of the variable context used to select the target of fifty tokens per shell noun excludes instances with a determiner other than the definite article, such as (11). Also not relevant to the present study are uses where be is not a copula, as in (12); here it is an auxiliary forming a present progressive.
(11) One vital fact is that it’s the fees that separate Holly from many of its peers. (NOW, US, May 24, 2017)
(12) Word is
Negation of be is also not possible in focalizer constructions because the noun in these contexts has referential meaning, as illustrated in (13).
(13) The problem isn’t that the title doesn’t describe what’s in the book. (NOW, US, September 11, 2013)
Finally, instances with non-finite clauses, as in (14), or phrases, as in (15), following N-is were also excluded, as they are complements of the verb phrase.
(14) The important thing is
(15) Truth is however
The 3438 concordance entries were annotated for the dependent variable
3.3. Predictors
Table 4 gives an overview of the predictors and their levels. Punctuation could theoretically be viewed as an aspect of syntactic integration, i.e., the dependent variable. However, seeing that both instances with that-clause and bare variants can be variably punctuated or not (compare 16 and 17 with 18 and 19),
(16) The trouble is
(17) Fact is
(18) Word is that if the water becomes too warm, bacteria can develop. (NOW, AU, May 26, 2016)
Predictors and Their Levels

(20) But the
Finally, N-is focalizers can be preceded by other pragmatic markers, a conjunction, a phrase, or another clause. These were subsumed under the variable label
(21)
(22)
(23) […]
(24)
(25) The truth is that,
(26) The trouble is
3.4. Statistical Modeling
The approach used here follows previous studies such as Tagliamonte and Baayen (2012) in combining random forest analyses with conditional inference trees (ctrees). Random forests are a type of permutation testing which does not assume normal distribution of the data but instead builds the distribution by resampling the observed dataset. The algorithm fits many regression trees to random subsets of the data and estimates the importance of predictors on the combined result of these trees, i.e., the random forest. Unlike traditional regression analysis, random forest analysis can cope even with highly correlated predictors and avoids overfitting (Strobl, Malley & Tutz 2009; Tagliamonte & Baayen 2012). Additionally, while empty cells or categorical responses for individual predictors pose problems for traditional regression modeling, they do not pose a problem for random forests. R’s party package (Strobl, Hothorn & Zeileis 2009) was used to fit the random forest model, with the number of trees set to 500 (mtry = 2; the default value, i.e., the root value of the number of predictors, in this case rounded down). Somers2 was used to test for model fit. According to Tagliamonte and Baayen (2012:156), a C-value > 0.8 represents a good model fit.
While random forests provide a robust approach to modeling variable importance of non-normally distributed data, they do not provide easily accessible information on possible interaction among predictors. For this purpose, single conditional inference trees can be used. Like random forests, single ctrees make use of recursive partitioning, predicting outcomes on binary splits of the data (the nodes in the tree) and sorting them into maximally homogenous “bins” (the “leaves”). 5 Conditional inference trees have been implemented in R’s partykit package (Strobl, Malley & Tutz 2009; available through R Development Core Team [2011]), with the maximum number of splits between the “root” and the “leaves” of the tree set to four and the significance level for the splits to p < 0.5.
4. Results
In the following, the distribution of the variable (syntactic integration) in N-is focalizer constructions is shown by
4.1. Summary Statistics
As far as syntactic integration is concerned, there is no obvious grouping into varieties spoken primarily as a first language and those where English is (mostly) acquired as an institutional second-language variety, as seen in Figure 1. Among the varieties with bare integration as the dominant variant, we find the two North American and the two southern hemisphere varieties as well as the two Asian varieties SingE and PhilE. BrE and IrE are the first-language varieties with overt that-integration at just over 50 percent, whereas overt integration is clearly the dominant variant in IndE and the two African Englishes. There is thus no clear regional pattern (e.g., Asian versus African varieties). However, there is a difference between conservative first-language varieties (BrE and IrE) with respect to focalizer use and more advanced first-language ones (AmE, CanE, AusE, NZE). Overt Versus Bare Integration Following N-is Focalizers Across Varieties in NOW. (AmE, BrE, IrE, CanE, AusE, NZE, IndE: N = 300; SingE = 277; PhilE = 269; GhE = 227, NigE = 272, KenE = 287)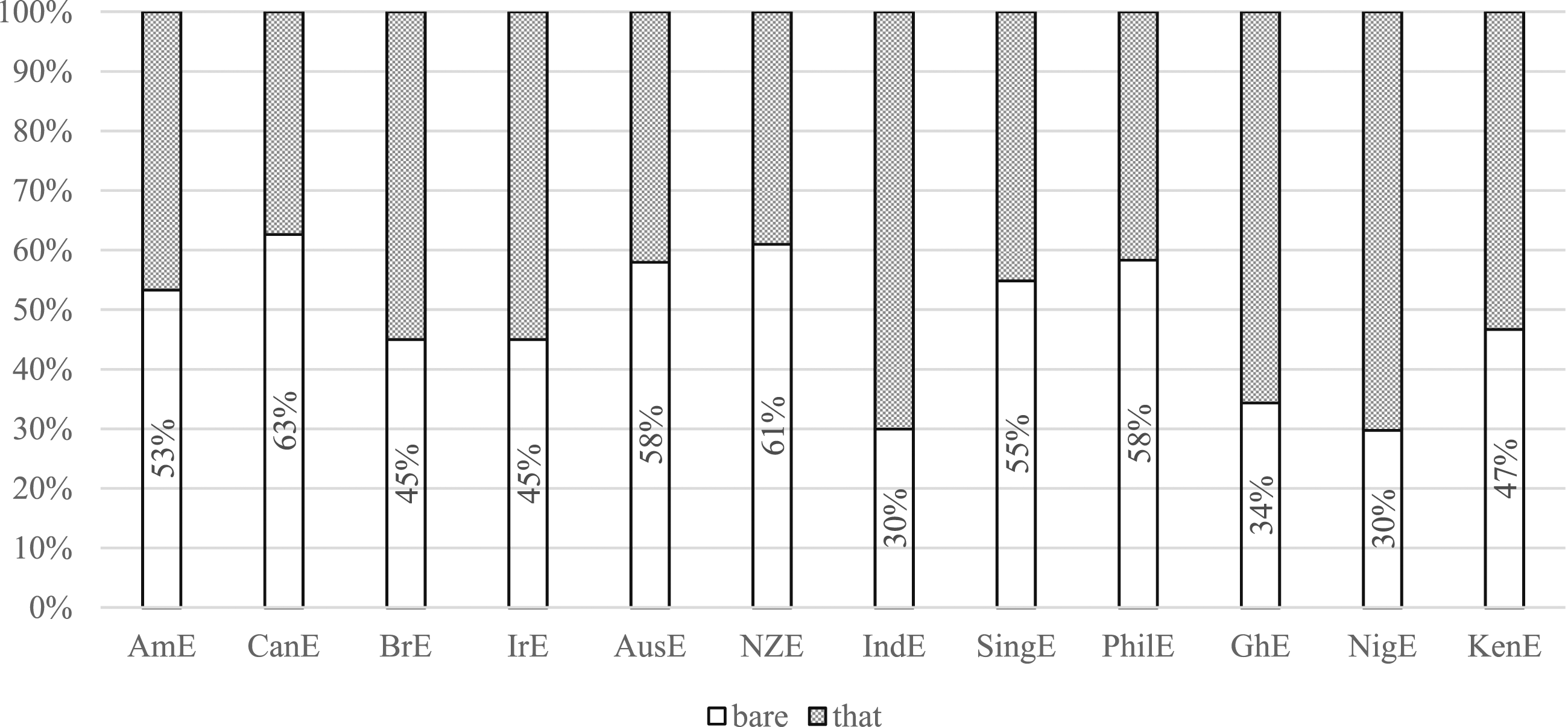
As seen in Figure 2, of the six shell nouns, trouble has the highest proportion of bare integration (65.9 percent), followed by fact, thing, and truth, with rates of around 50 percent. Focalizers with problem and word favor a more syntactically integrated proposition at a little below 40 percent. Overt Versus Bare Integration Following N-is Focalizers Across Shell Nouns in NOW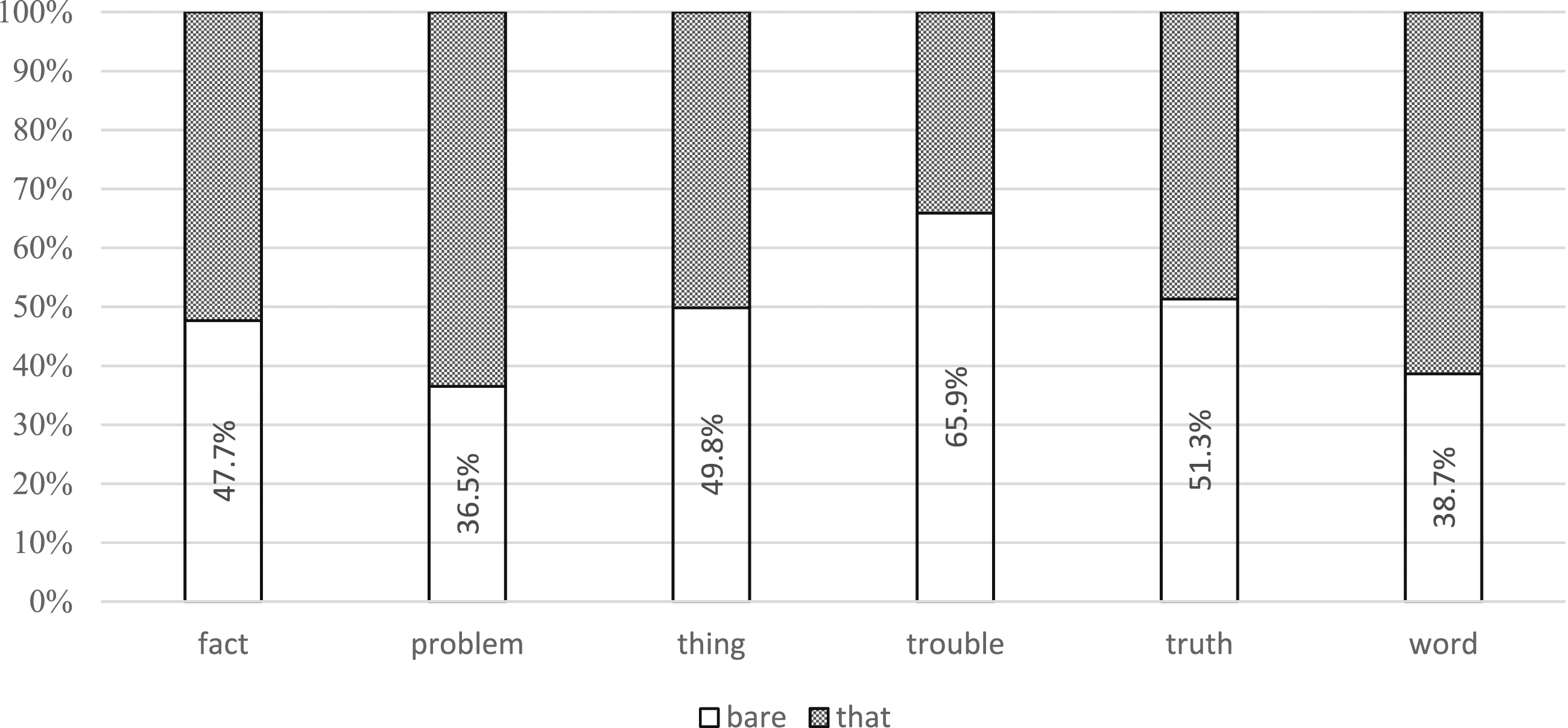
Finally, with respect to integration and punctuation, focalizers followed by a proposition that is not syntactically integrated are relatively equally divided in terms of punctuation (51.5 percent without it versus 48.5 percent with it), whereas punctuation of syntactically integrated propositions (i.e., with that) is extremely rare, at 0.9 percent overall. The NOW data thus confirm the findings of Hundt (2022) that the more constructionalized variants are more likely to be separated by punctuation. Aijmer (2007:33) claims that articles cannot be omitted if the focalizer is followed by a that-clause. Example (3) shows a counter-example from written language. Such forms occur in NOW as well, where the proportion of article omission with that-clauses is much lower (12 percent) than in focalizers followed by a bare proposition (26 percent).
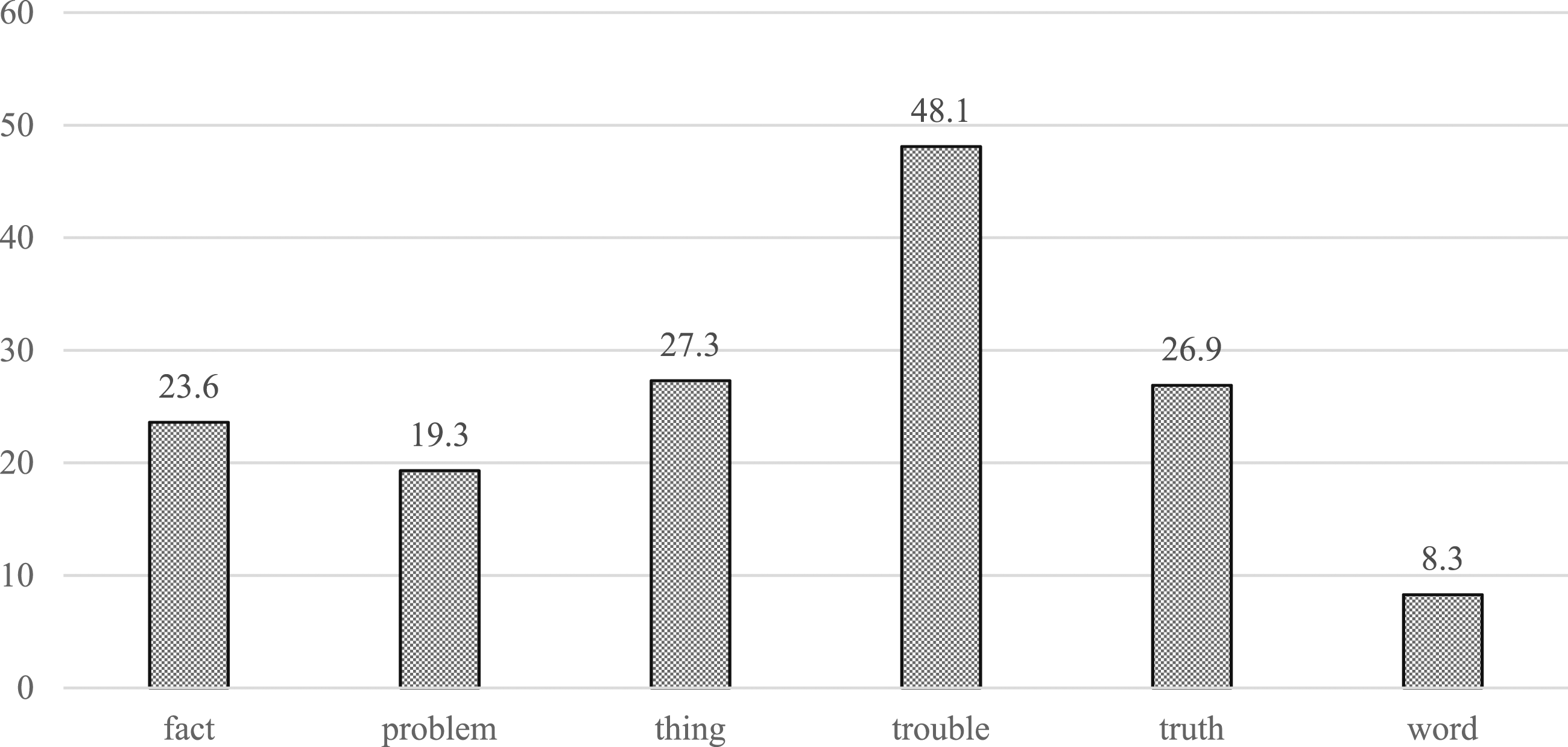
Finally, it is interesting to consider the combinations that are the most idiomatic and clearly separated from the proposition, i.e., the proportion of bare integration by shell noun combined with zero article (Figure 3) and combined with punctuation (Figure 4). When we look at Figure 3, the question arises whether omitting both article and complementizer is indeed a matter of increased constructionalization. If this were the case, we would expect the shell nouns that are attested most frequently in focalizer constructions (i.e., fact and truth, according to Hundt & Oppliger [2022]) to show the highest proportion of the maximally reduced variant (i.e., omission of both the article and the complementizer that). This is clearly not the case. Instead, we find the two shell nouns with the lowest token frequency in the construction showing the highest proportion of the maximally reduced variant. This suggests that a different factor than (ongoing) constructionalization is likely behind the omission of the article and complementizer. I return to this discussion in Section 5. With respect to separation by punctuation of bare complementation, Figure 4 shows that trouble is again the shell noun with the highest proportion of this highly constructionalized variant. Surprisingly, word shows a low proportion of focalizer use with a bare proposition that is separated by punctuation. Taken together, these results suggest that the predictors Proportion of Ø N-is + Bare Proposition Across Shell Nouns in NOW Proportion of Punctuation-Separated N-is + Bare Proposition Across Shell Nouns in NOW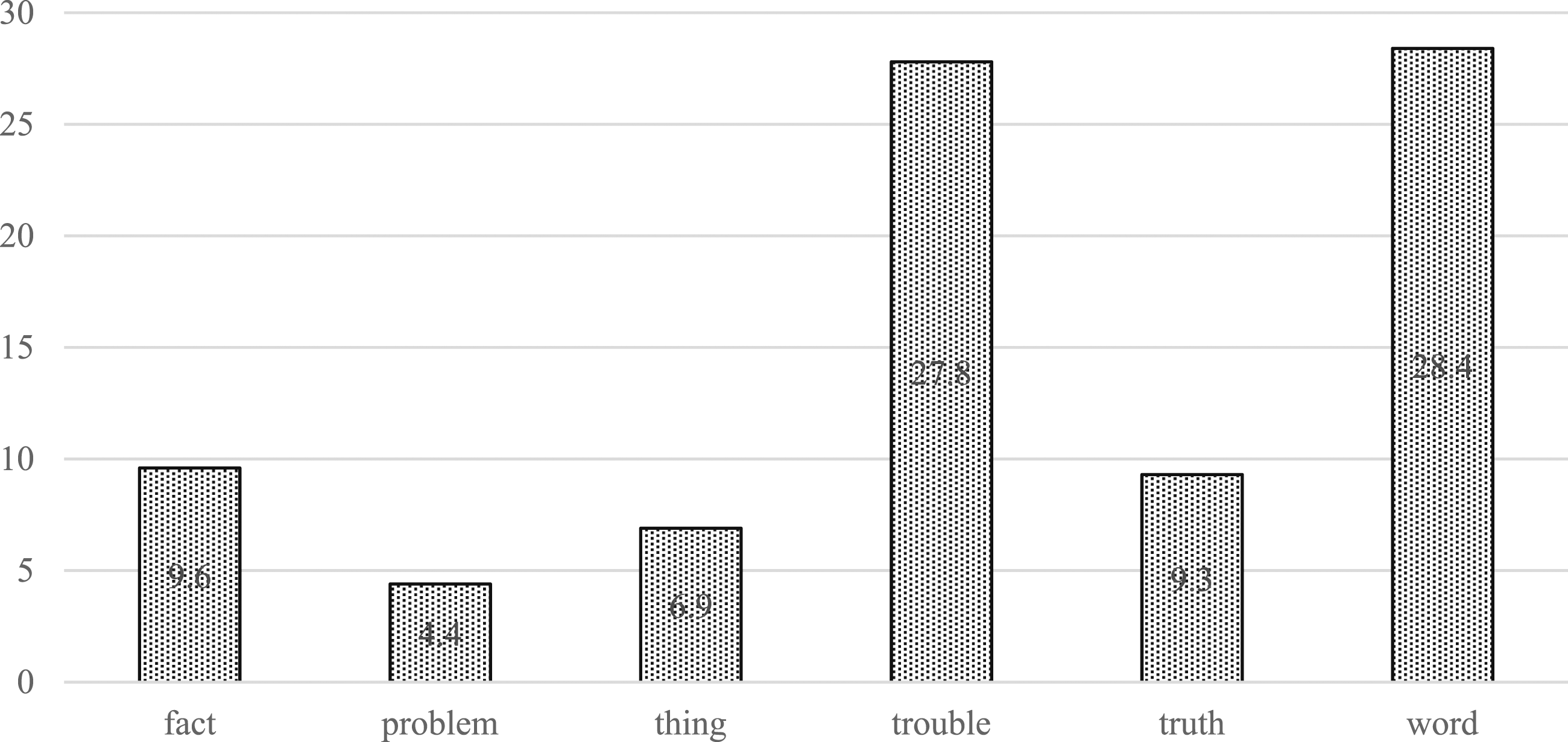
4.2. Modeling Syntactic Integration
The outcome of the random forest analysis for syntactic integration (i.e., that-clause versus bare) is given in Figure 5. Testing for model accuracy with Somers2 Dxy returns a prediction accuracy of 0.677 (above the 0.5 threshold) and a C-index value of 0.838, i.e., a good model fit. Variable Importance Predicting Syntactic Integration in N-is Focalizers in NOW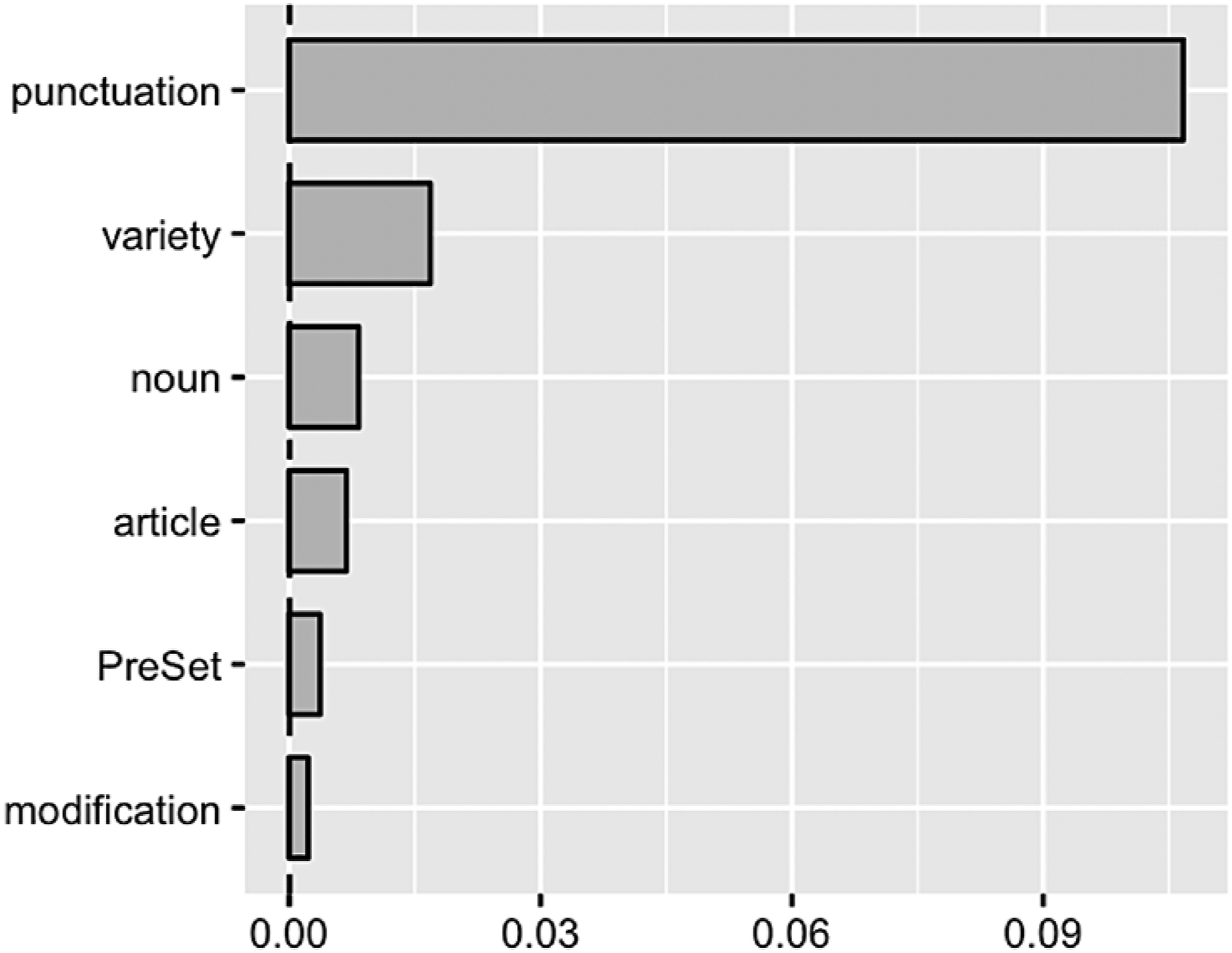
Figure 5 shows that
Figure 6 shows how these predictors interact and in which direction they impact the choice between bare proposition and that-clause. Somers2 for the ctree returns slightly lower values at 0.524 (prediction accuracy) and C = 0.762, which still provide a good model fit. The following comments are limited to those instances where p < 0.001. ctree Analysis Showing Factor Interaction for Syntactic Integration in N-is Focalizers in NOW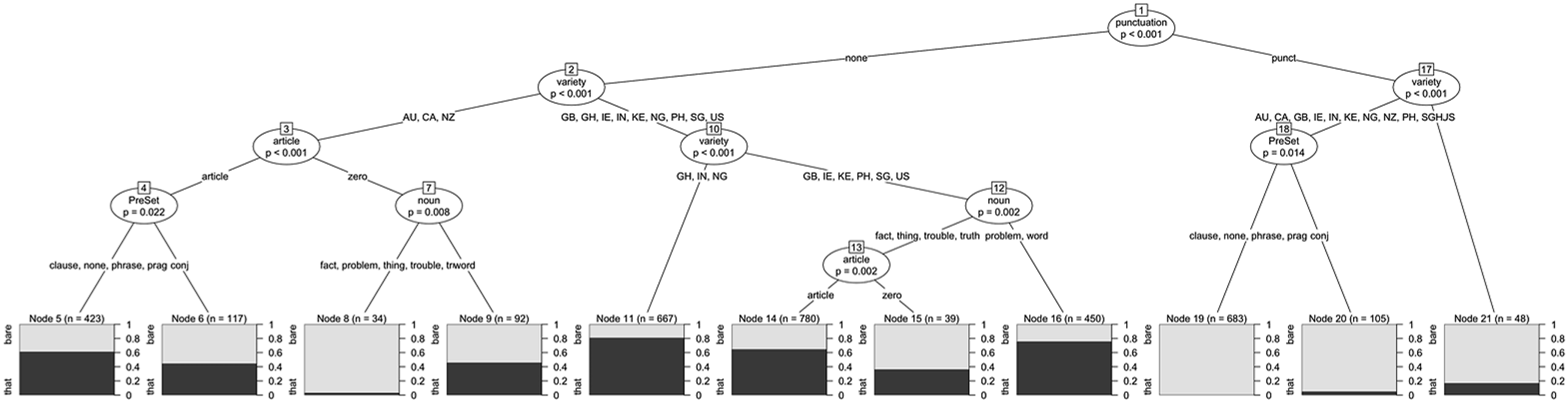
Figure 6 illustrates that N-is focalizers are particularly likely to occur without a that complementizer if they are separated off by punctuation (node 17). What is difficult to see from the ctree is the detailed interaction of
Figure 6 also reveals an interaction between
(27) Fact is owner-occupiers tend to be far more careful when it comes to maintaining the building […] (NOW, AU, November 14, 2013)
(28) Problem is those solutions can be costly and take decades to have a positive impact. (NOW, CA, September 15, 2017)
(29) Thing is just about all of the things people are railing against would actually be fine. (NOW, NZ, February 26, 2017)
(30) Truth is the statistics haven’t changed much in the past ten years […] (NOW, NZ, June 28, 2016)
Second, there is a split between varieties that show a strong tendency towards that-complementizer with no punctuation (GhE, IndE, NigE) and those that show further interaction with other predictors (node 10). Intriguingly, GhE, IndE, and NigE are the varieties that have the overall lowest incidence of bare complementation (Figure 1). For the remaining varieties, there is some interaction (albeit at lower p-values) for
5. Qualitative Analyses
With respect to those instances where the N-is focalizer is separated from the proposition, a closer look at the data reveals some relevant qualitative differences. In (31) and (32), from India and New Zealand, the comma occurs where we would expect it, i.e., between the N-is focalizer and the complementizer.
(31) But the alarming truth is, that the might of the Goa government and police are not able to evict them from our land (NOW Corpus, IN, June 3, 2016)
(32) “The trouble is, that these elections are just so damned important.” (NOW Corpus, NZ, October 10, 2016)
In (33)-(38), from Ghana, Nigeria, and Kenya, however, the complementizer is included in the N-is focalizer and separated from the proposition by the comma, suggesting that it may be part of focalizer constructions in these varieties of English. In other words, reanalysis (as part of the constructionalization process) would have been different in these varieties.
(33) The problem is that
(34) […] but the truth is that
(35) But the unfortunate thing is that
(36) The fact is that
(37) But the worst thing is that
(38) […] and the word is that
Since data collection had to be limited to a manageable amount of instances per shell noun, not all instances with punctuation following the complementizer were retrieved in the initial concordances. A more systematic search for similar instances in the NOW corpus yields further evidence that constructionalization in African Englishes has resulted in a variant that includes that as part of the focalizer. In particular, examples from Nigeria and Ghana with a proposition clause that cannot be introduced by that but where the focalizer includes this (former) complementizer, support this view. 7 Examples are given in (39) to (42).
(39) This notwithstanding, Mr. Dzakpasu reminded that “the important thing is that, let us as a country and stakeholders focus on how best we can get it right […]” (NOW, GH, May 12, 2016)
(40) So, the best thing is that, let me go and try it. (NOW, NG, June 16, 2017)
(41) The next thing is that, where did they come from? (NOW, NG, January 31, 2017)
(42) The real thing is that, make a brand new classification and put all MSMEs in the same basket. (NOW, NG, June 15, 2020)
Interestingly, NigE and GhE are the varieties that, overall, have high overall frequencies of that following N-is focalizers (see Figure 1). IndE has similarly high instances of N-is followed by that (around 30 percent), and a search for instances of punctuation that separate the focalizer after that can also be found in the IndE part of NOW (see 43-45), with (45) being an example where the proposition cannot be introduced by that.
(43) The good thing is that, systemically it doesn’t matter. (NOW, IN, October 7, 2018)
(44) In my opinion, the truth is that, I consider Hollywood and Bollywood completely different industries, […] (NOW, IN, August 18, 2011)
(45) Very surprising thing is that, how can Chavan file the charge sheet once he was transferred […] (NOW, IN, October 31, 2019)
The NOW corpus also provides occasional evidence of the same kind of reanalysis from other regions, including Canada and Great Britain, i.e., countries where English is the first language of the majority of the population, as (46)-(48) illustrate.
(46) The trouble is that, employee discipline issues have also increased. (NOW, PH, November 29, 2018)
(47) I said this is too bad […] but the truth is that, it stopped immediately, it was amazing, and then it became really sunny. (NOW, CA, February 24, 2017)
(48) The fundamental thing is that, it would have been better that they left a long time earlier (NOW, GB, August 8, 2018)
The present study takes its data from newspaper writing. In speech, segmentation of focalizer and proposition might be different in varieties of English as a first language. Indeed, there is an example from the spoken part of the BNC that supports the existence of the N-is that chunk as a variant of the focalizer in BrE; this is shown in (49).
(49) And the tremendous thing is that, Nicodemus may not really have been too sure of what his needs were. (BNC1, KN9 58)
Little is known so far, however, what the precise relationship is between punctuation of focalizers in writing and comma intonation. More specifically, it is difficult to verify whether what linguists have referred to as comma intonation is also reliably transcribed by punctuation in spoken corpora.
Qualitative evidence from mega-corpora like NOW do, however, allow us to verify whether N-is constructions are positionally as constrained as previous research suggests. Keizer (2013:235) claimed that they always occur in initial position, yet examples such as (7) suggest that N-is constructions may also occur at the right periphery. A systematic search for N-is in sentence final position (comma-separated) returned the instances in (50) and (51), where truth is could be similar in function to comment clauses such as I think.
(50) Hate is not a very honorable characteristic, truth is. (NOW, US, December 3, 2019)
(51) J L Austin reminded us, importance is not important, truth is. (NOW, IN, July 13, 2018)
However, these are the only examples in a corpus of a little under 12 billion words, and unlike (7), they lend themselves more easily to a contrastive reading (e.g., while importance is unimportant, truth is not) and would best be separated by a semicolon rather than a comma. In other words, N-is constructions remain firmly rooted in the left periphery in the function of focalizers and do not appear to have spread to the right periphery, yet.
6. Discussion and Conclusion
Research that combines a Construction Grammar approach to syntactic variation and change with a WEs perspective is still relatively rare (cf. Hoffmann 2014, 2020). The present study’s aim was to bring the two strands of research together in order to (i) test whether WEs data would add relevant detail to a case study on ongoing constructionalization and (ii) verify whether patterns of regional variation or nativization could be found. The review of previous research into constructionalization, N-is focalizers, and WEs gave rise to a set of hypotheses that were tested against corpus data from a large, web-based monitor corpus. In this section I discuss the results of the quantitative and qualitative analyses with respect to the hypotheses and consider the contribution that these make to the intersection of constructionalization and WEs research. The present study is able to answer some of the initial questions but also opens up avenues for further research.
With respect to syntactic integration (H1), the data from NOW have shown that
With respect to constructional variation across WEs, the single ctree (Figure 6) shows that across all varieties, that-clauses are strongly disfavored when punctuation marks are present, thus lending further support to H1. All other predictors turn out to be far less important in the random forest (Figure 5). Moreover, while
While the core grammar of N-is focalizers is largely shared across the WEs investigated here, the qualitative analysis of the data turns out to be interesting from the point of view of nativization. A closer look at the data reveals an intriguing difference in the use of punctuation with N-is focalizers followed by that, i.e., evidence of punctuated focalizers with that. This candidate for structural nativization emerged from further qualitative analysis rather than directly from the ctree. From a Construction Grammar perspective, moreover, punctuated focalizers with that are relevant because they do not occur at the more concrete level of the constructional hierarchy, i.e., with the different lexical fillers that enter a constructional slot, but at a more abstract level that reanalyzes the former subordinating conjunction as being part of focalizer constructions. If that in these variants of the N-is focalizer receives stress in speech, it is likely to have been reanalyzed as a demonstrative pronoun, which would tally well with the pragmatic function of the N-is constructions as utterance launchers at the left periphery of the sentence. In fact, it would make the focalizer function even clearer in these varieties and would thus lend itself to an explanation in terms of hyperclarity/transparency which, in turn, would be a factor in constructionalization in the second-language varieties. In other words, while (H3) is not supported by the quantitative analysis it does find support at the qualitative level of analysis.
Further research is needed to substantiate the hypothesis that this variant is particularly frequent in African varieties, and whether there might be a difference in constructionalization of N-is focalizers between West- and East-African varieties: only the former yield a number of examples where the proposition takes the form of a clause that could not be introduced by that, i.e., where reanalysis of that as part of the N-is focalizer must have occurred. This would mean that in the two West-African varieties, a more explicit variant of the N-is focalizer construction is emerging. Future research could verify the hypothesis that the variant including that in the construction is more frequent/entrenched in African varieties by devising an online questionnaire making use of forced choice tasks involving punctuation. Such an approach could more directly target the aspect that emerged as interesting from this study for both a Construction Grammar and a WEs perspective. What this case study has already shown is that it is a fruitful endeavor to bring evidence from a broad range of WEs to bear on studies of constructional variation and (ongoing) constructional change. The NOW corpus, though not an ideal source of data in terms of representativeness, has proven a useful tool to identify a candidate for nativization in second-language varieties of English. Finally, in order to fully understand the connection between what is referred to in the literature as comma intonation and constructionalization in N-is focalizers, it will be necessary to return to spoken evidence and/or combine corpus evidence with data from controlled experimentation (Hundt & Dellwo forthcoming).
Footnotes
Acknowledgments
The author gratefully acknowledges help with the initial extraction of the data set provided by Carlos Hartmann. The audience at the ISLE 5 conference in London, where an initial draft was presented, the anonymous reviewers, and the editors of the journal provided very helpful and constructive criticism, which greatly improved the original paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.