
Abstract
While intensifiers are primarily associated with informal spoken registers, they serve important interpersonal functions also in more formal registers like academic prose. The use of intensifiers in scientific writing has accordingly been explored in Present-Day English, and previous studies have also investigated diachronic changes in this register in Middle and Early Modern English. However, the Late Modern English period remains largely unexplored, despite the fact that at least in medical writing it represents an important transition period both intellectually and textually. To follow up on the trends and developments established in previous work, this paper explores the patterns of intensification in eighteenth century medical writing using Late Modern English Medical Texts (LMEMT; Taavitsainen et al. 2019), which contains a large collection of texts representing different areas of medicine. While the intensifiers that are selected for study are ubiquitous in the data, their frequency varies considerably between individual texts, and this variation is often linked to the characteristics of individual sub-registers. At the same time, the use of intensifiers in this period is characterized by stability rather than dramatic change, despite ongoing changes in the sociocultural context of medicine. Along with providing a detailed investigation of the frequency of the main intensifiers in different categories of medical writing of the period, the analysis describes their co-selection patterns with particular adjectives.
1. Introduction
Register has been shown to be an important determinant of variation in the use of intensifiers (Biber, Johansson, Leech, Conrad & Finegan 1999:564-566). Although generally seen as part of informal language use (Lorenz 2002), intensifiers—degree adverbs scaling upwards or downwards the meaning of the item they modify (Quirk, Greenbaum, Leech & Svartvik 1985:589-590)—also occur in more formal registers like academic prose where they serve important interpersonal functions. Some studies have accordingly shown that intensifiers are linked to rhetorical concerns and audience accommodation in Present-Day English scientific writing (Swales & Burke 2003; Pahta 2006b), but specific patterns of register and sub-register variation in the context of formal writing remain relatively uncharted overall.
This is also true of individual historical periods: while scientific and medical writing in Middle and Early Modern English have received attention (Pahta 2006a; Méndez-Naya & Pahta 2010; Hiltunen 2012), the Late Modern English period remains largely unexplored. Yet this specific period is particularly interesting from the perspective of sub-register variation, representing an important transition period both intellectually and textually (Taavitsainen et al. 2014). As changes in the communicative contexts were manifested in increasing diversification of sub-registers (Hiltunen & Taavitsainen 2019), it could be expected that this would have influenced the use of intensifiers. From a broader societal perspective, however, the eighteenth century is characterized by internal stability in England after the upheavals of the previous century (Görlach 2001:1; Hickey 2010:2), and major changes in the grammar of English had likewise taken place already before 1700 (Denison 1999). Against this background, changes in this specific area of grammar are likely to be linked to pragmatic factors and discursive concerns, rather than grammatical change per se. On the other hand, intensifiers have also been identified as a domain where changes can happen quickly when language users experiment with innovative and creative usage (Bolinger 1972; Peters 1993; Tagliamonte 2016).
The aim of this paper is thus to follow up on the trends and developments established in previous work by exploring the patterns of intensification in eighteenth century medical writing, using Late Modern English Medical Texts (LMEMT; Taavitsainen et al. 2019), which contains a large collection of texts representing different areas of medicine. Methodologically, the chosen approach is motivated by two specific ideas from recent historical corpus research: that specific sub-register differences are crucial in studying historical language use (Biber & Gray 2013), and that intensifiers are often intricately linked to the lexical items they modify and should therefore not be studied separately from them (Wagner 2017).
Focusing on three major grammaticalized amplifiers—so, very, and too—the analysis shows that while they are ubiquitous in the data, their frequency varies considerably between texts, and that this variation is linked to the characteristics of the register of medical writing and its more specialized sub-registers. Overall, the use of amplifiers in this period is characterized by stability rather than dramatic change, despite changes in the sociocultural context of medicine. The corpus-pragmatic analysis (Rühlemann & Aijmer 2015) offers insights into both how intensifiers are used in eighteenth century medical writing and how they contribute to the expressions of specific textual functions like physical description and evaluation in this register.
2. Background
The research on intensification in English is broad, including both synchronic and diachronic studies representing various perspectives (e.g., Bolinger 1972; Partington 1993; Lorenz 1999; Ito & Tagliamonte 2003; Tagliamonte & Roberts 2005; Méndez-Naya 2008; Zeschel 2012; Breban & Davidse 2016; Tagliamonte 2016; Wagner 2017; Schweinberger 2020). Of these studies, the most relevant to the present study are those focusing on variation and change in intensification constructions. Such studies adopting a historical perspective have described the processes by which individual intensifiers have developed, often in competition with other items (Méndez-Naya 2008, 2017). Peters (1993) analyzes the source domain of “boosters” and investigates their frequency in Early Modern English letters, showing how concrete lexical meanings of adverbs have developed into more abstract ones. Partington (1993) uses collocational evidence obtained from the OED database to describe the development of two groups of words, the terribly and the highly group, showing how the development of the intensifying function goes hand in hand with the widening of the collocational range (but see Zeschel 2012:50). For Lorenz (2002), individual intensifiers represent different degrees of delexicalization, and they can be classified according to the semantic domains of origin (scalar, semantic feature copying, evaluative, comparative, and modal). Attention has also been paid to compound adverbs and co-occurrence with other intensifiers (e.g., very much, very extremely; see González-Dı́az 2008; Méndez-Naya 2017). In synchronic variationist studies, the focus has been on the emergence of new and creative intensifiers (Tagliamonte & Roberts 2005), and linking them to sociolinguistic factors and questions of identity (Tagliamonte 2016).
The register of medical writing has been the focus of some historical studies. Pahta (2006a) studied texts representing Late Middle English, finding that full is the main intensifier followed by right, so, all, and well, and the study by Méndez-Naya and Pahta (2010:194) documented the dramatic rise of very towards the beginning of the Early Modern English period and the concomitant decline of the main intensifiers in the Middle English period.
Despite the volume of previous work, the perspective of register variation has not been fully explored either in synchronic or diachronic studies, despite the importance of register as an explanatory factor. This is noted by Fuchs and Gut (2016:187-188), who identify the main focus areas of previous research as being the semantic properties of individual intensifiers as well as their syntactic and collocational preferences (see also Schweinberger 2020:227). Yet there are good reasons for placing register at the center of studies on variation in intensifier usage, because different situational contexts give rise to the use of different linguistic features that are considered appropriate. For example, Biber, Johansson, Leech, Conrad, and Finegan (1999:564-566), also mentioned by Fuchs and Gut (2016), draw attention to the different behavior of intensifiers particularly across conversation and academic prose in Present-Day English: the former register exhibiting a higher incidence of amplifiers overall, and the latter favoring intensifiers like highly which are nearly exclusively used in that register. Swales and Burke (2003) and Pahta (2006b) have further observed and described variation within the register of scientific and medical writing.
In addition, Biber and Gray (2013) have argued that it is often necessary to look not only at registers but also at more specialized sub-registers to capture the parameters that determine variation in diachronic studies. Following this line of thinking, the present study incorporates into the research design different sub-registers of eighteenth century medical writing, which also reflect the increasing specialization of contemporaneous medical science and practice. Thus, the hypothesis empirically explored in this study is that since these individual sub-registers—operationalized as text categories in LMEMT, as described in section 3—vary in their situational and contextual parameters, these differences are reflected in the frequencies and co-occurrence patterns and are thus observable in corpus data.
Another contribution of the present study is the focus on the interrelationship between intensifiers and specific adjectives that they modify. While surprisingly little attention has been paid to the effect of the lexical adjective as driving the use of intensifiers (Tagliamonte 2011:144), recent studies by Wagner (2017) and Schweinberger (2020) demonstrate that specific intensifier bigrams behave differently, and collocational differences are therefore key to understanding changes in this category. To account for these, the present analysis explores the co-occurrence preferences of three high-frequency amplifiers in the pre-adjectival slot, using Schmid’s (2000) notions “attraction” and “reliance.”
3. Material and Methods
3.1. Data
The data for this study comes from the Late Modern English Medical Writing corpus (LMEMT, Taavitsainen et al. 2019). The corpus is divided into seven text categories, which enable the study of sub-register differences within medical writing. The categories, which are defined based on text-external factors (Hiltunen & Taavitsainen 2019), are:
General treatises and textbooks (GEN)
Specific treatises (SPEC) (includes four sub-categories)
Medical recipe collections (RECIP)
Regimens and health guides (REG)
Surgical and anatomical texts (SUR)
Public health (PUB)
Scientific periodicals (PER) (includes two sub-categories)
The Gentleman’s Magazine
General treatises and textbooks contain extracts from medical treatises and textbooks which cover, or claim to cover, the whole field of medicine. 1 The difference between this category and Specific treatises is that the latter category has a narrower scope, focusing on specific illnesses and methods of treatment, but in many ways these two categories are similar in terms of their textual characteristics. 2 More radical differences in communicative purpose can be observed in the remaining categories. Medical recipe collections focus on the preparation and administration of remedies, Regimens and health guides discuss the preservation of health, and Surgical and anatomical texts provide instructions on how to perform surgical operations. Public health texts contain texts anticipating the public health movement of the nineteenth century. The final category represents the genre of scientific periodicals, a category which had emerged in the previous century with the establishment of the Philosophical Transactions of the Royal Society (PT); along with the PT, the LMEMT covers the Edinburgh Medical Journal and The Gentleman’s Magazine. More detailed descriptions of the text categories are provided in the relevant sections of Taavitsainen and Hiltunen (2019). The material examined for this study comprises 404 texts and 1.6 million words.
The distribution of texts and their word counts are shown in Figure 1. As can be seen, the word counts of individual texts vary somewhat, due to the fact that short texts were included in their entirety whereas longer texts are represented by roughly 10,000-word samples. As far as text length is concerned, the figure also highlights the fact that journal articles are different from the majority of texts in the other categories in being considerably shorter. 3 While this difference does not preclude cross-category comparisons, it might be a cause of some of the differences observed in the data. The other categories included in the study do not display major differences in the mean text length.
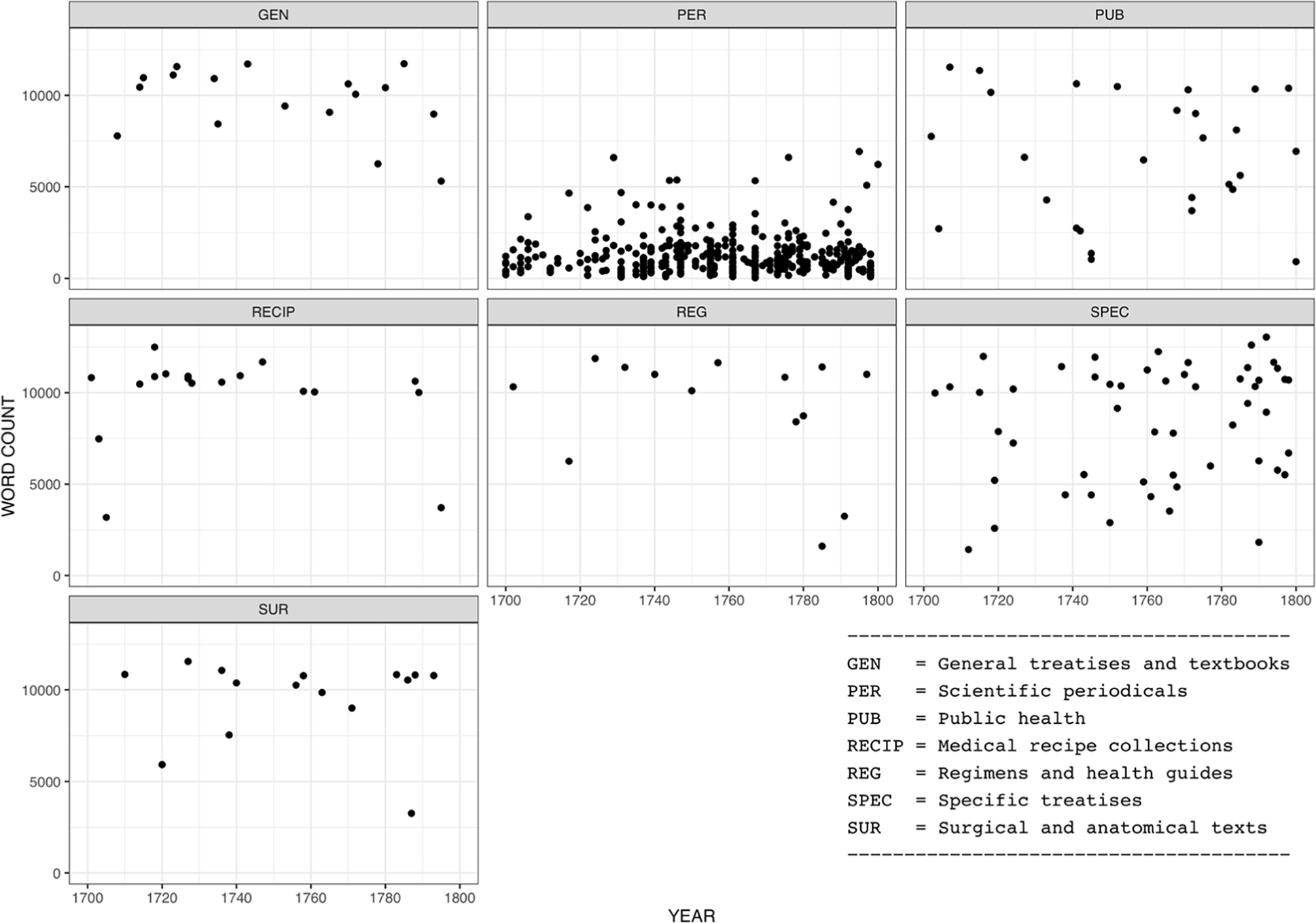
Text Categories and Wordcounts of Individual Texts in the LMEMT Corpus
The corpus was POS-tagged for this study using CLAWS (Garside & Smith 1997).
3.2. Method of Analysis
The main focus of this study is the use of “amplifiers,” the class of items which scale the degree of a gradable head word upward from some norm (see Quirk, Greenbaum, Leech & Svartvik 1985:589). 4 As they represent an open class of items, the repertoire attested in the corpus is large, as can be expected; this is illustrated in Table 1, where the twenty most frequently occurring items are listed. 5
Most Frequently Occurring Amplifiers in LMEMT

An exploratory survey of amplifiers in LMEMT based on concordance data indicates that the vast majority of them occur pre-adjectivally or pre-adverbially, and some of them, like very and too, are effectively restricted to these positions (cf. Huddleston & Pullum 2002:532). Also worth noting is the fact that three top items in Table 1—very, so, and too—far outnumber the other amplifiers in the material. In other words, despite the apparent lexical diversity in Table 1, the majority of items in fact occur infrequently, with the vast majority of tokens being made up of only three high-frequency amplifiers. This study concentrates on these three intensifiers because their frequent occurrence in the data (over 9000 tokens) enables us to gauge their co-occurrence preferences across different categories of eighteenth century medical writing, which would not be possible for low-frequency intensifiers. Moreover, because these three intensifiers account for a considerable proportion of all tokens in the data, the analysis of very, so, and too can be expected to offer a good representation of the category of amplifiers as a whole.
That said, while the use of these high-frequency amplifiers has been analyzed in conjunction in previous studies (e.g., Fuchs & Gut 2016:203-204; Wagner 2017), 6 they are not fully equivalent semantically and therefore cannot be treated as different ways of saying the same thing in all contexts. In particular, whereas so and very occupy a largely similar semantic space and are often in direct competition with each other (e.g., Schweinberger 2020:232), the meanings expressed by too-constructions are different, as illustrated below. This being the case, the aim of this study is not to explore the three amplifiers from a fully variationist perspective, but to explore their frequencies and co-occurrence preferences to establish what the main patterns of usage are and link them to typical discourse functions and meaning configurations expressed in different categories of medical texts from this period.
Syntactically, this study is restricted to two types of “intensity expressions” (Zeschel 2012:44): expressions where the three amplifiers in focus pre-modify adjectival heads (very
(1) This is a very
(2) In these fits, she becomes insensible, her legs, her arms, and many of the muscles of the trunk of her body, are so
While very is in many ways a prototypical degree word, and unrivalled in terms of frequency since the Early Modern period (Méndez-Naya 2017:256), the usage of too and so is somewhat different. Too indicates a degree which is higher relative to some baseline, which is typically expressed in a complement (Huddleston & Pullum 2002:585). To illustrate, in (3), the infinitival complement (underlined) indicates a potential situation which is not actualized; it can thus be inferred from the sentence that the person was impatient and did not wait until the swelling had subsided. So +
(3) Years ago I remember having seen his son, who rents a considerable farm from me, with an enormous scrophulous swelling on his neck, he was too impatient
(4) All my Difficulty was to remove it; I try’d my Probe, I endeavour’d with my Fingers, but all was in vain; it was so slippery
The analysis follows a corpus-pragmatic approach, which integrates “vertical” reading associated with concordances and frequency data, and “horizontal” reading associated with qualitative pragmatic analysis of individual examples in context (Rühlemann & Aijmer 2015). Vertical reading captures the main trends in the material and allows generalizations to be made, while horizontal reading enables the investigation into how individual surface forms are linked to specific contextual configurations and textual meaning expressed in medical texts from this period.
The instances of these three amplifiers were exhaustively retrieved from the corpus. Next, occurrences that were not instances of the grammatical patterns in focus were removed (e.g., so used as a linking adverb or very modifying a nominal or prepositional head; the latter were very infrequent in the data). The resulting data set (so: N = 3510; very: N = 4263; too: N = 1331)
8
was coded for the variables:
The analysis of frequency utilizes the so-called Type B design (Biber & Jones 2009:1298) where each text file is treated as an observation, which makes it possible to determine mean frequencies and quantify the amount of dispersion, as well as to use inferential statistics to determine whether the observed differences are statistically significant. The frequencies are normalized to 1000 words of running text, which, although not ideal for determining opportunity of use (Wallis, Bowie & Aarts 2012), is deemed sufficiently accurate for the present purposes. 9
The analysis of co-occurrence preferences of words and grammatical constructions, commonly referred to as “colligations” or “collostructions” (Stefanowitsch & Gries 2003; Wiechmann 2008), makes use of the Type A design, where each occurrence of the word is treated as an observation (Biber & Jones 2009:1296). The analysis itself is carried out with the help of two measures, attraction and reliance
In Schmid’s (2000) terminology, attraction refers to the degree to which the intensifier attracts a specific adjective, and it is calculated by dividing the frequency of the adjective modified by the amplifier by the total frequency of the
To illustrate these concepts, let us consider one such adjective, namely hard. Hard occurs in the corpus a total of 501 times, of which eighteen are instances of so hard. For hard, we thus obtain the value 0.93 for attraction and 3.6 for reliance. If we repeat this procedure for all the adjectives and adverbs for the three amplifiers, it is possible to compare their lexical preferences, and relate this information to the frequency information discussed in 3.1.
4. Results
4.1. Frequency in Different Categories of Medical Writing
Figure 2 shows the mean frequencies of the three intensifiers—so (panel a.), very (panel b.), and too (panel c.)—across the seven categories of medical writing. The error bars represent a 95 percent confidence interval around the mean value.
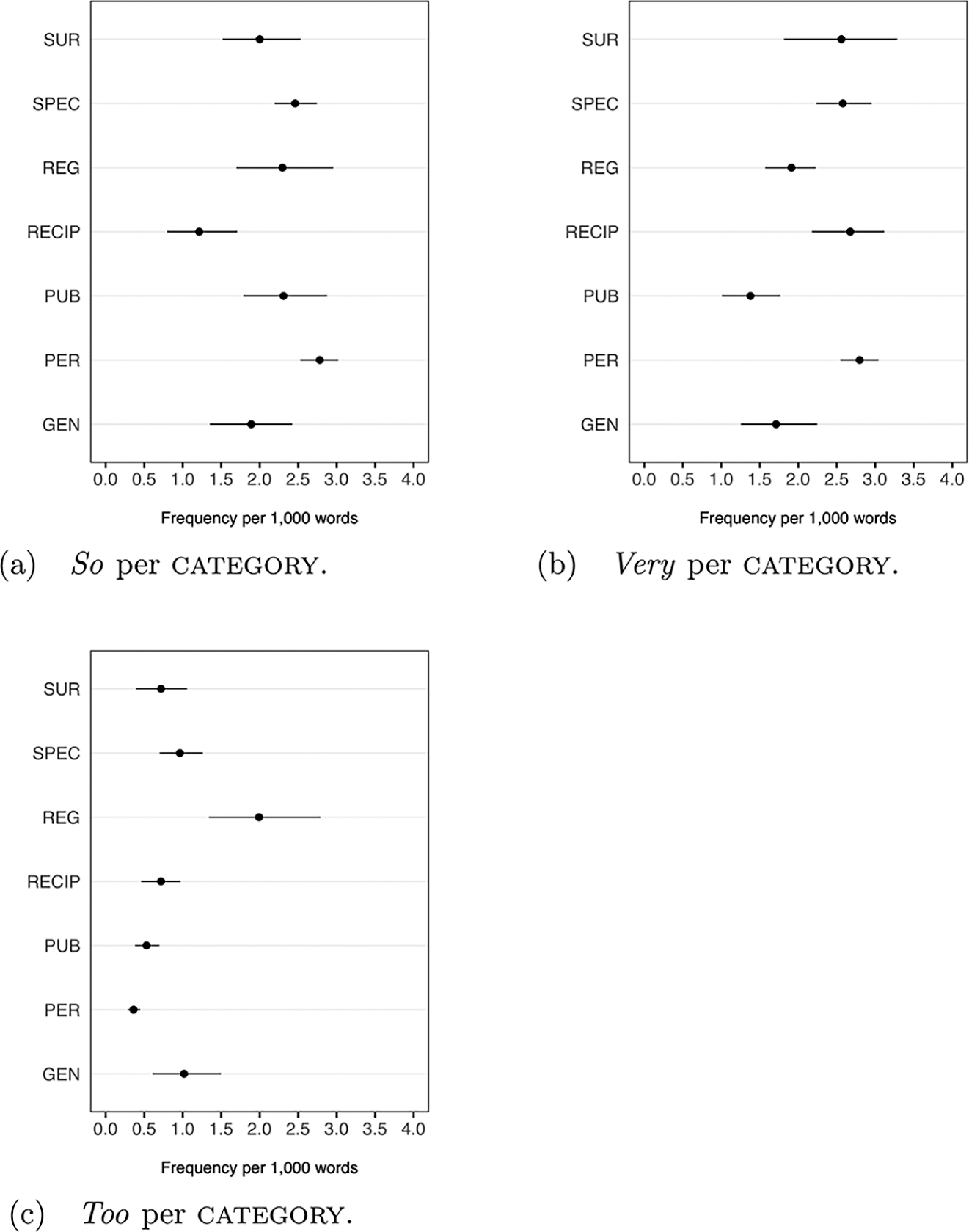
Mean Frequencies of So, Very, and Too across Different Text Categories of Medical Writing
Given that text categories represent different sub-registers of medical writing, the data presented in Figure 2 can be used to explore whether and to what extent particular intensifiers are associated with specific sub-registers of eighteenth century medical discourse. As can be seen, all three intensifiers are used in all seven categories, but we can also observe differences in their usage. Starting with so, its frequency of occurrence is largely similar in all the categories, except Recipes, where the frequency is lower. Very, by contrast, displays a different pattern of usage: the normalized frequencies are comparatively high precisely in Recipes, together with Specialized treatises, Surgical treatises, and Scientific periodicals. The third intensifier, too, exhibits yet another type of frequency profile: its incidence is highest in the category Regimens and health guides, closely followed by General treatises. Taken together, this data thus provides initial support for the idea that the use of these amplifiers is influenced by the characteristics of medical writing at the level of sub-register. In this case, the frequency differences across categories are likely due to environmental differences between “textual habitats” (cf. Szmrecsanyi 2016): texts belonging to the same category typically express similar meanings, which gives rise to specific contexts and grammatical constructions where the three words in focus—very, so, and too—can occur, and these are not necessarily shared by other categories.
To explore the reasons for the observed tendencies, it is necessary to complement the frequency data with qualitative analysis of instances of specific intensifiers in their textual context to determine their discourse functions, as these may explain why they are more frequently used in some medical texts than in others. Starting from so +
(5) Yes; Thomas Fiens about 125 Years ago, proposed a Palliative Cure for such Patients, where a radicative Cure could not be expected; an Operation which may be performed with safety on the most Ancient; the Wound is so
(6) [. . .] we had just Reason to apprehend our Patient would soon sink under so
We can thus observe in the data a clear link between relative frequency of this pattern and the communicative purpose of the sub-registers of medicine. While the descriptions illustrated in (5) and (6) are common in most categories of medical writing, they are less common in Recipes, whose communicative purpose is to describe how specific medicines are prepared and administered to the patients. Due to the relative paucity of physiological and anatomical descriptions in Recipes, the category thus offers fewer opportunities for using adjectives premodified by so.
A discourse-pragmatic analysis based on close reading likewise helps us explain why the amplifier very is frequent in Recipes: it is associated with promotional discourse, praising the virtues of the remedy that is described. This function is illustrated in (7) and (8), which describe the qualities of and effects of medicines and medical substances in favorable terms.
(7) The soluble tartar is a very
(8) I have known very
Reasons for the comparatively high frequency of too in Regimens and health guides are less clear. A partial explanation can be found by looking at the numerous cautionary descriptions of bad diet and lack of exercise, which give rise to the use of too-constructions with adjectives and adverbs, illustrated in (9) and (10).
(9) As the Lungs are the chief Organ of Sanguification, crude and viscous Chyle, viscous Aliment, Spices, but especially spirituous Liquors, may occasion this Inflammation, too
(10) Whether the losing of blood in the spring, be necessary for the preservation of the health [. . .] it is benefical [sic], to prevent such dangers as a too
4.2. Diachronic Change
Like the analysis presented in section 4.1, this part relies on text-based frequencies but adds a variable, namely,
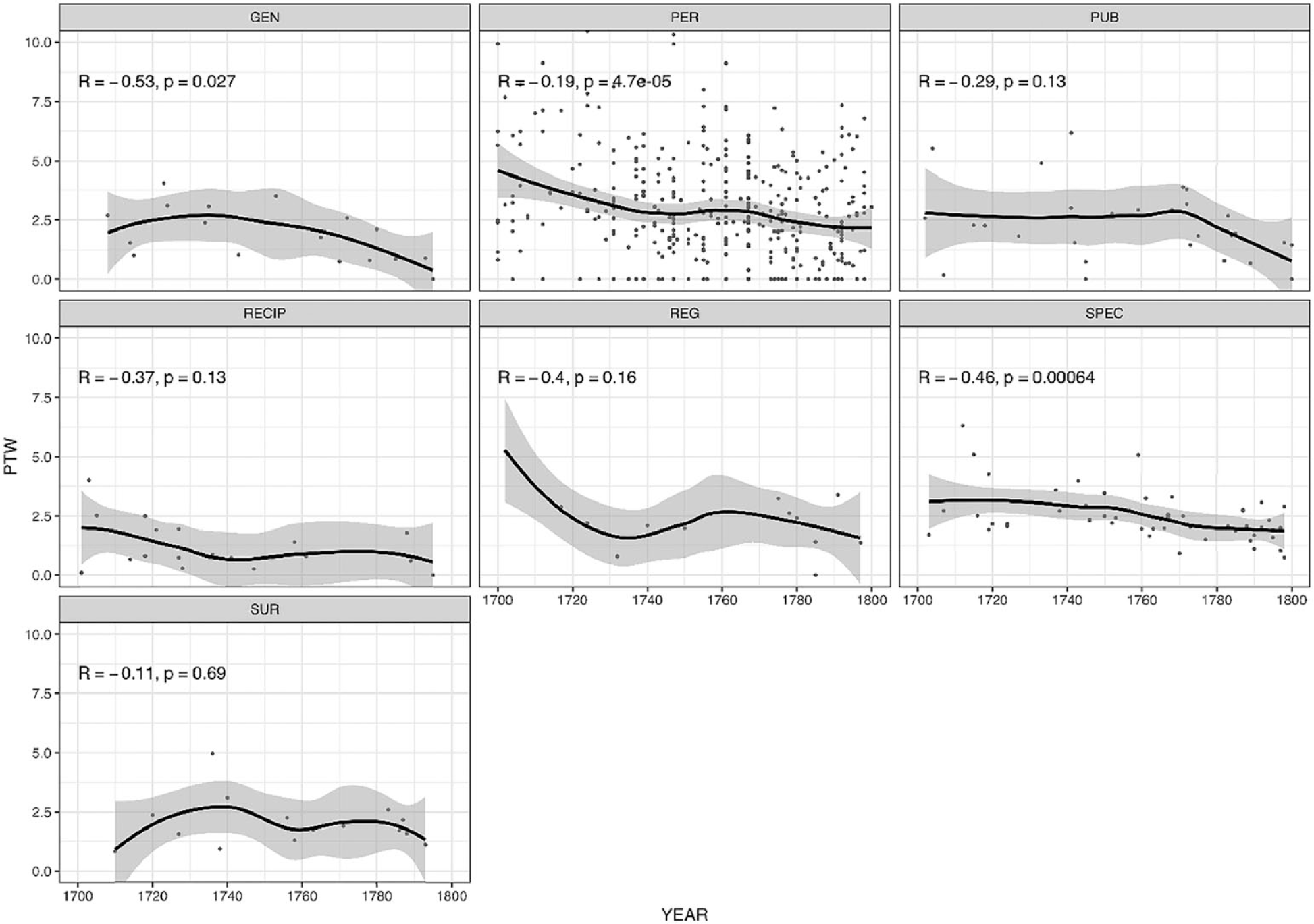
Diachronic Development of Frequencies of So
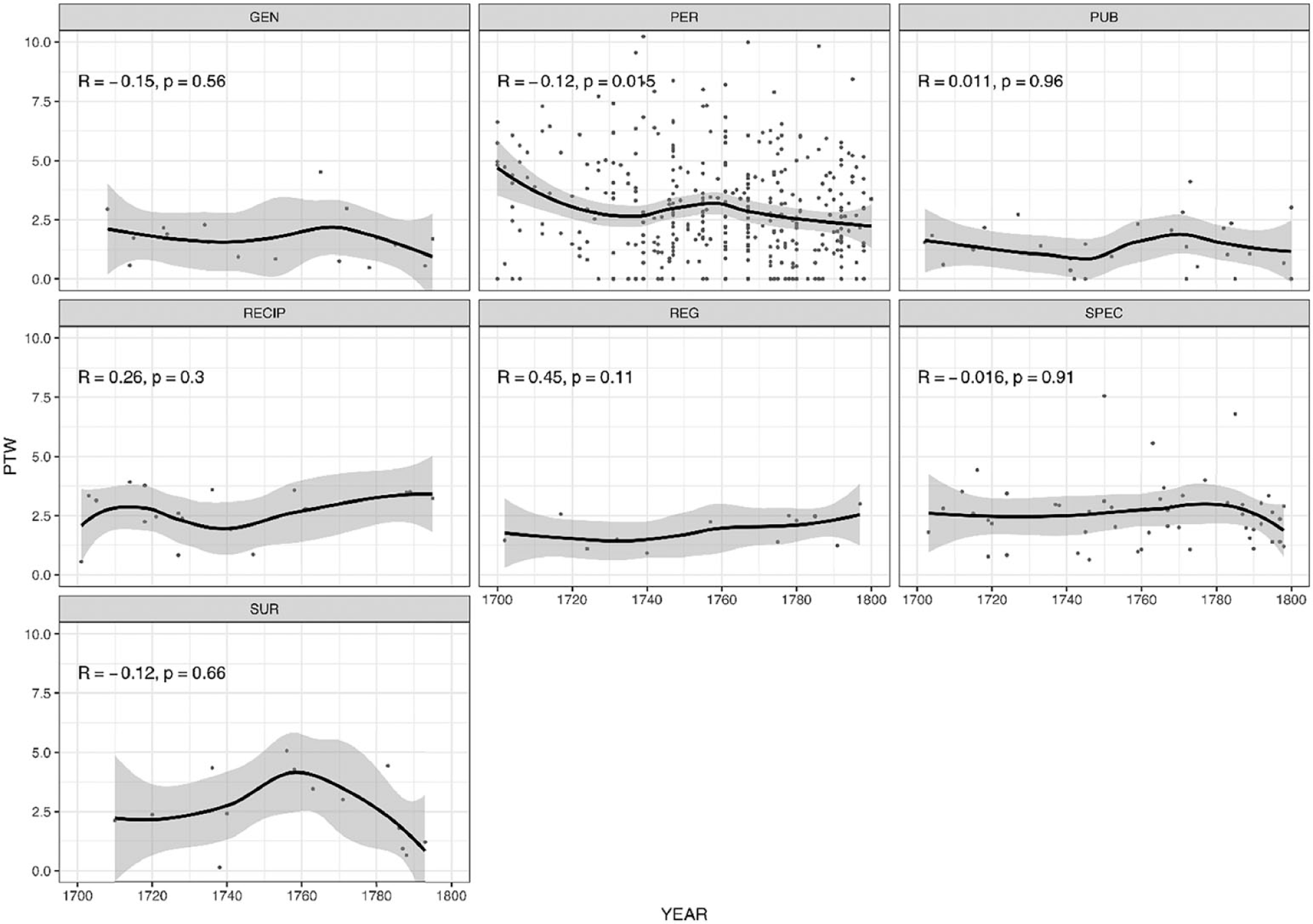
Diachronic Development of Frequencies of Very
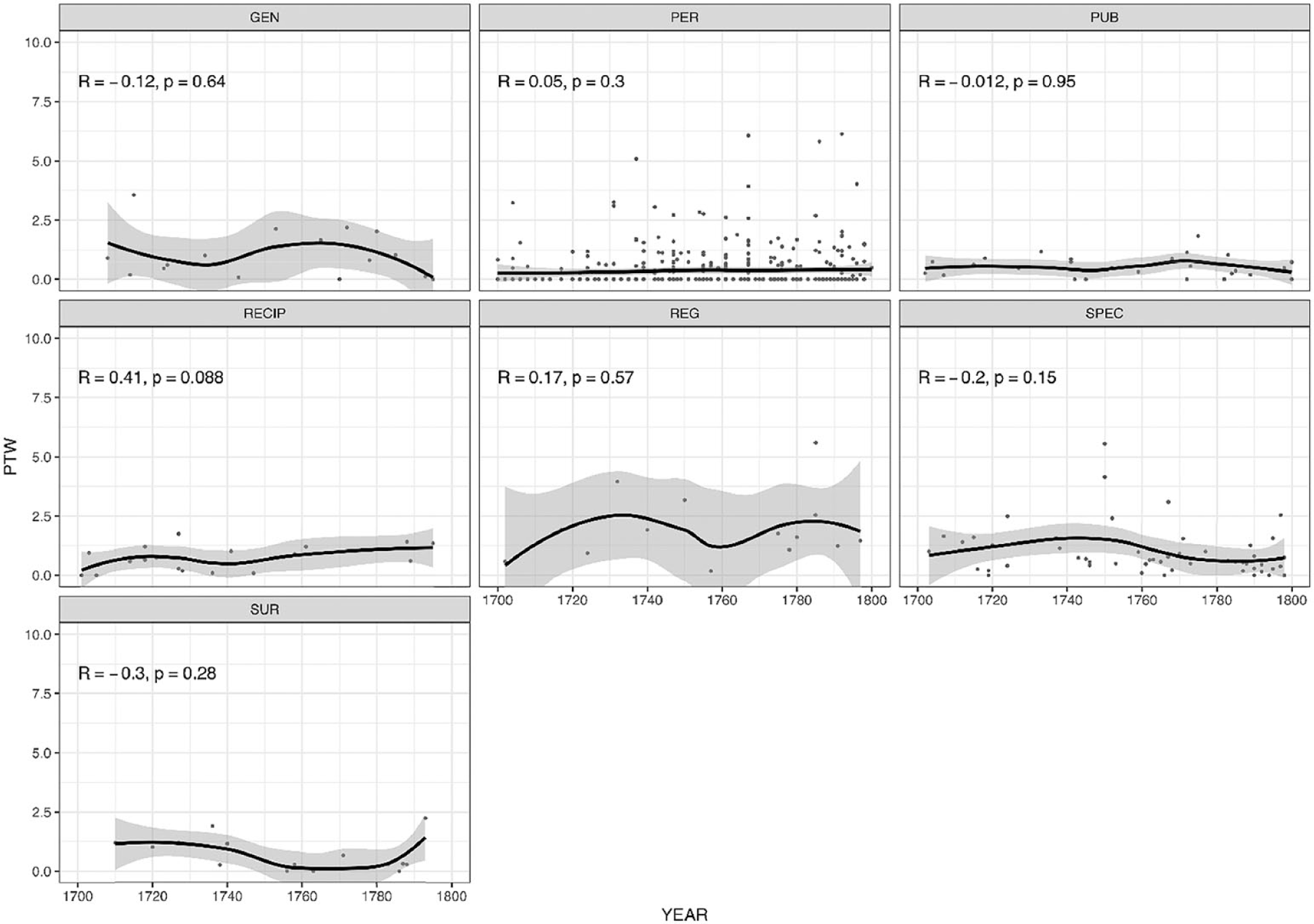
Diachronic Development of Frequencies of Too
Based on the figures, the eighteenth century clearly represents a period of continuing stability, as can be seen from the fact that most smoother curves record only minor shifts on the vertical axis. We can only observe a small but statistically significant (p < 0.05) decline in frequency for so and very in Periodicals, as well as for so in General and Specific treatises; for the other panels the test yields a nonsignificant p-value. Such stability is particularly remarkable when contrasted with data from previous centuries investigated in Méndez-Naya and Pahta (2010): their study of medical writing from the late Middle English period to 1700 tracked many changes taking place in the English intensifier system in general, including the remarkable rise of very and the decline of right, full, and well. By contrast, even though we can observe several rhetorical and discourse-pragmatic changes in medical writing in the eighteenth century as a response to major ideological changes and disciplinary advances (Taavitsainen et al. 2014), these changes are not reflected in the use of amplifiers very, so, and too in the data.
In sum, by looking at frequencies synchronically and diachronically and exploring cross-category differences, it is possible to offer initial hypotheses for the observed differences in frequency. However, this approach clearly offers only part of the explanation, as by focusing on normalized frequencies, it is implicitly assumed that each word could potentially be substituted with any of the amplifiers in focus. Such a model is clearly unrealistic, although it does serve as a rough-and-ready indication of differences in discourse function, especially since determining the true rate of variation is difficult and laborious (see e.g., the discussion in Wallis, Bowie & Aarts 2012). Given that simple frequency analysis has these shortcomings, it is useful to complement it with the analysis of co-occurrence preferences, as doing so enables us to determine to what extent the frequency of intensifier is driven by specific lexical items that co-occur with particular intensifiers (Wagner 2017; Schweinberger 2020). This approach is explored in the following section.
4.3. Co-occurrence Preferences
The final section of the analysis investigates what lexical items tend to co-occur with the three intensifiers in focus, and in particular determines how such lexical associations are linked to the function of the intensifier patterns. To this end, the attraction and reliance values were determined for so, very, and too co-occurring with adjectives, the prototypical function of intensification (Lorenz 2002:144). 10 These are plotted in Figures 6-8. 11 Adjectives shared by all three amplifiers are shown in italics, and those that occur only with one of them are shown in bold.
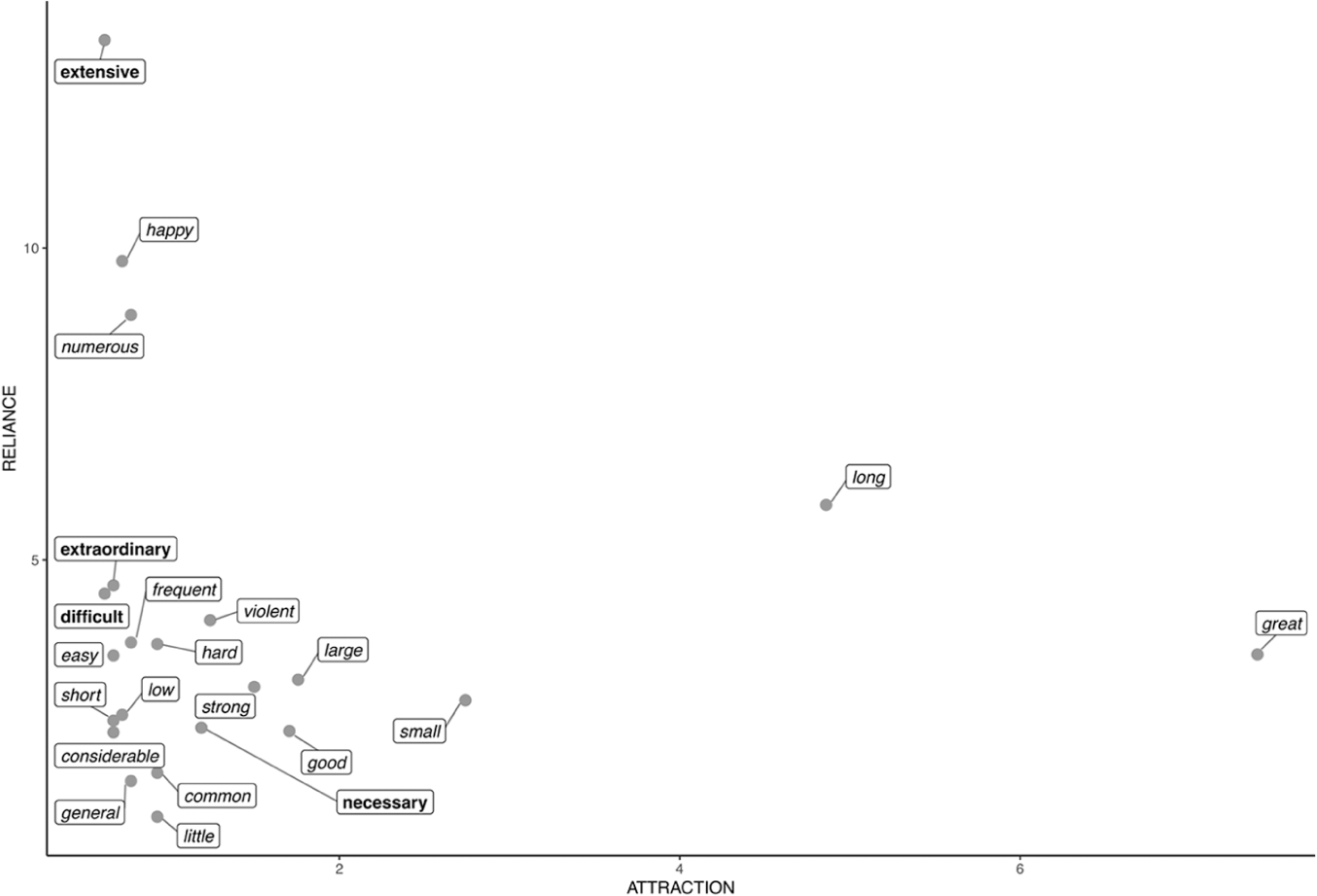
Attraction and Reliance for So +
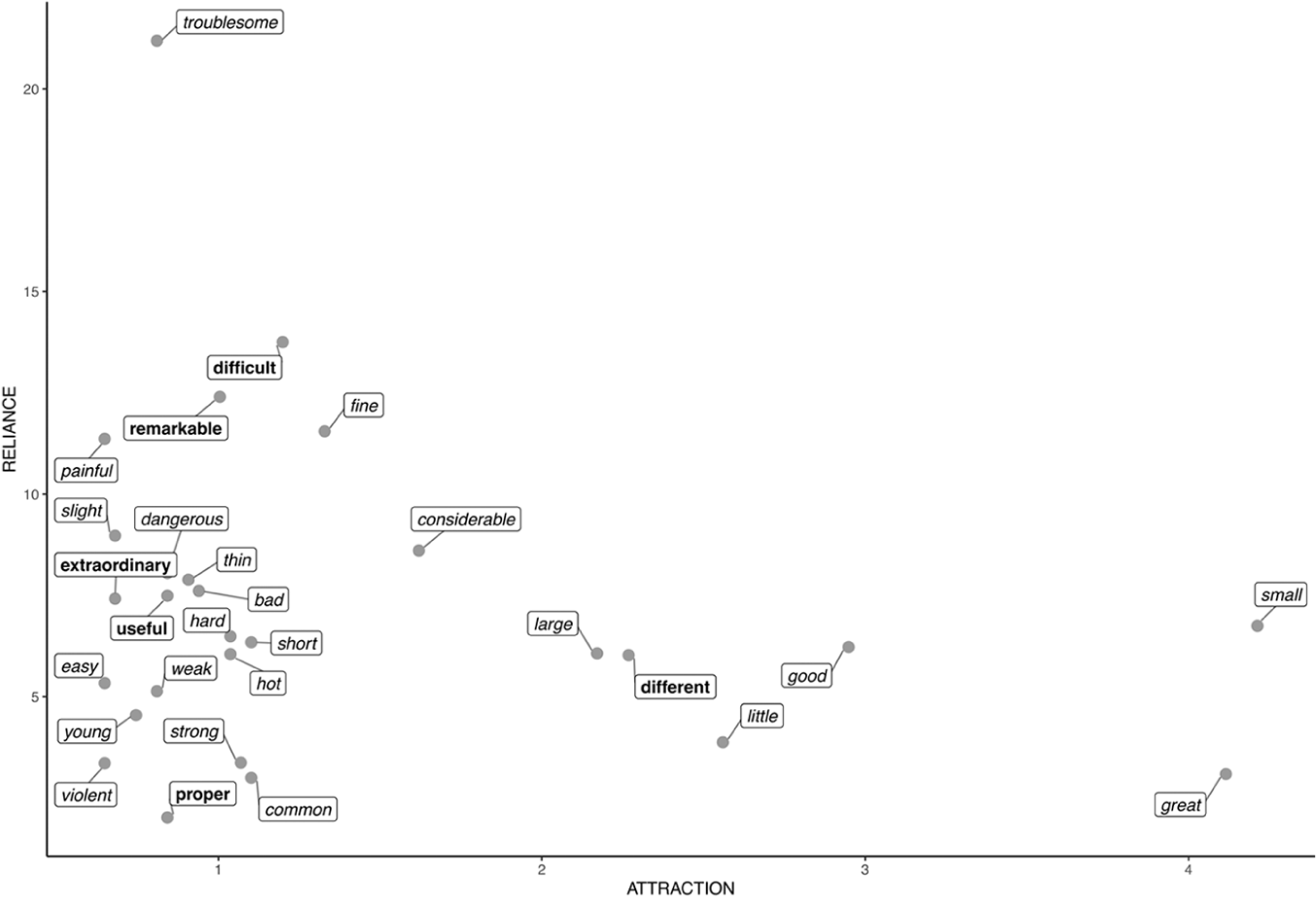
Attraction and Reliance for Very +
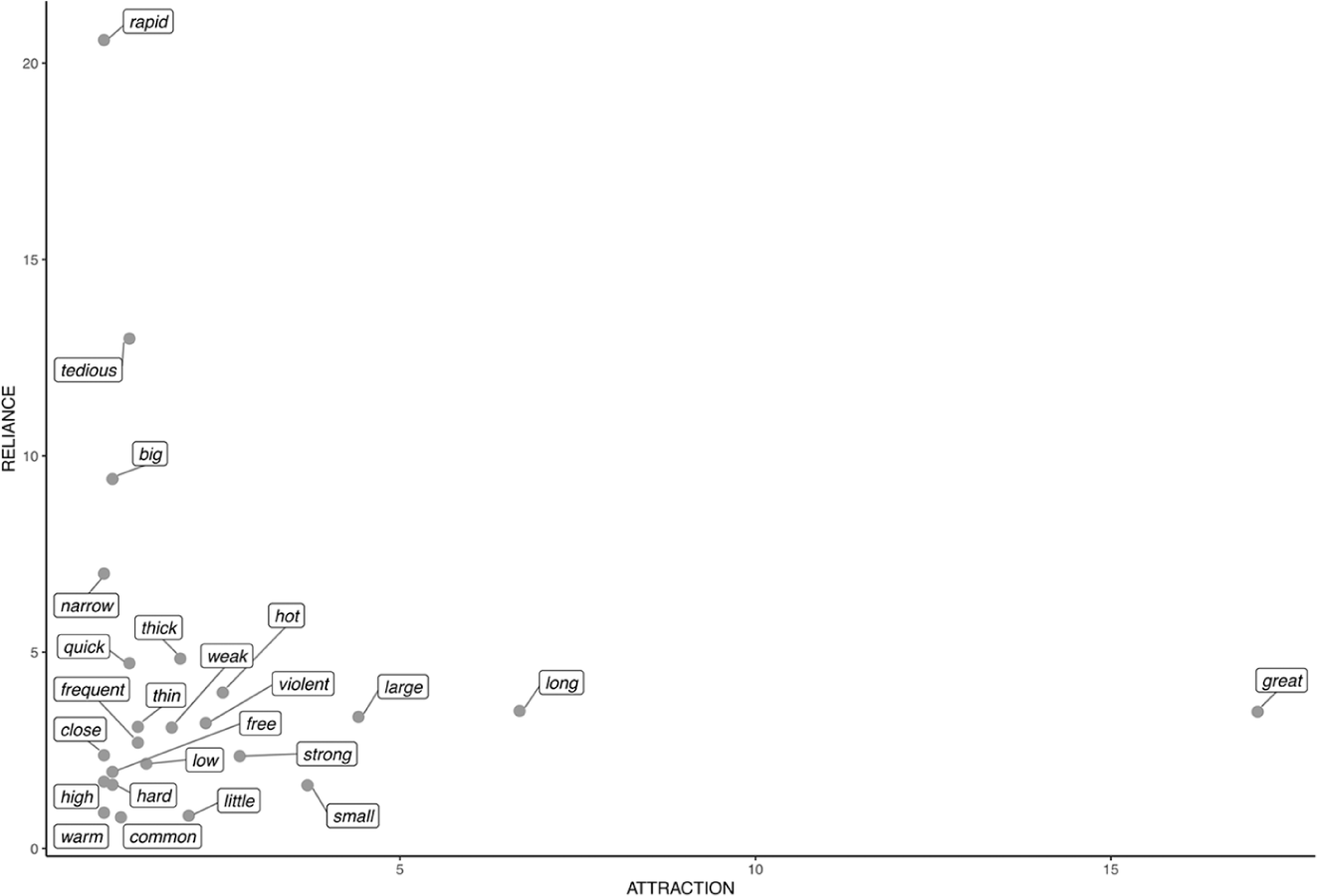
Attraction and Reliance for Too +
These two measures provided a visual representation of the differences in the use of individual adjectives together with the three amplifiers in focus. “Attraction” on the horizontal axis shows the token frequencies relative to the total number of
As can be seen, despite the differences of meaning and grammatical patterning between the three amplifiers, they in fact share many of the frequently co-occurring (italicized) adjectives. A case in point is great: despite being the adjective with the highest value of attraction across the board, its occurrence is not particularly dependent on any one of the three amplifiers, as shown by the comparatively low value for reliance in all three plots.
A useful way to systematically approach the meanings of adjectives modified by amplifiers is Dixon’s (2005) meaning-oriented grammar, where the grammatical description of words relies heavily on the meanings they express. He classifies English adjectives into “semantic types” Dimension, Physical property, Speed, Age, Color, Value, Difficulty, Volition, Quantification, and Human propensity (Dixon 2005:84-85), which can be applied to the adjectives shown in Figures 6-8. Adjectives representing the types Dimension and Physical property are also common in all three plots, as shown by their high value for attraction (horizontal axis); the former group includes small, large, long, and little, while thin, thick, hard, hot, strong, and weak belong to the latter. In addition, adjectives expressing Value (e.g., good, bad, useful, remarkable, and necessary) are common in the data, but they are rarely used with too (with the exception of tedious in semi-fixed phrases like too tedious to mention).
Along with observing similarities, the figures also allow us to identify differences between the colligational profiles of the three amplifiers. These are particularly visible in the lists of adjectives with a high value for reliance (vertical axis). For so (Figure 6), we can identify an association with one specific group: adjectives indicating the frequency and wide distribution of some object or phenomenon: common, frequent, general, and numerous (as in 11 and 12).
(11) No one who believes this will be surprised, on a view of the female world, to find diseases and death so
(12) Bardana, Burdock [. . .] Venereal Disease, because it contains Oils: For this Reason it is, we give it in the Leprosy: First, because by its Salts it volatilises the acid Salts in that Disease, and then by its oily Parts it relieves the Itching so
So is also associated with the adjective happy, which is interesting, because adjectives denoting emotional responses are overall relatively infrequent among the collocates. This finding also underlines the importance of sub-register differences in the analysis of data, as these instances are the by-product of the epistolary format, which is frequently found in early scientific periodicals, as illustrated in (13). 12
(13) Your kind Communication of Dr. Hales’s judicious Remarks and Improvement on my Discovery does me great Honour and Pleasure; and the more so, as I was so
By contrast, adjectives which most rely on very for their occurrence include troublesome, painful, and slight (as in 14 and 15). These occur in descriptions of patients’ symptoms and the degrees of discomfort. The frequency of slight is increased by the fact that it also regularly occurs in another context, namely in descriptions involving a high degree of precision. In this sense it behaves in a similar way to fine, which is also frequently modified by very in the data (as in 16).
(14) With regard to contents, if it is omentum only, and has been gradually formed, it seldom produces any bad symptoms, though its weight may become very
(15) The tendon with its sheath being now laid bare, a very
(16) The scarf, or outward skin, is a very
Finally, too displays a colligational profile that is distinct from the other two amplifiers, which is motivated by its semantic and pragmatic characteristics described above: specifically, the entailment that the situation being described did not actualize (see 3). Due to this, too +
(17) The canula, which I left in the wound, was of the common sort, and therefore too
(18) [. . .] then he made Incision upon the furrow’d Staffe on the Convex part of it, putting a hollow Tent-Pipe or Cannula into the Wound, for the Urine to run through, going no further that time, but leaving the Stone in the Bladder, except it appear’d in the Wound, which then he took out, either with a pair of Forceps or the Hamulus, but if the Stone appear’d not in the Wound, or if it was too
More than the two other amplifiers, too also patterns with adjectives denoting Speed (quick, rapid). This finding is linked to passages describing symptoms (as in 19 and 20). 13
(19) If the pulse is too
(20) Many of their diseases were also too violent in their symptoms, and too
In sum, the analysis of attraction and reliance highlights usage patterns shared by the three amplifiers, but at the same time draws attention to colligational differences, which are motivated by the semantics of the intensifiers and their functional associations with particular textual functions. Such associations are often rather intricate and can only be discovered through qualitative analysis, which stresses the importance of “horizontal reading” (Rühlemann & Aijmer 2015:3) in the discourse-pragmatic analysis of corpus data.
5. Conclusion
The analyses presented here provide new evidence about the use of intensifiers in eighteenth century medical writing, considering both frequency data across seven sub-registers and statistical evidence of co-occurrence preferences of three major amplifiers (so, very, and too) using Schmid’s (2000) measures of attraction and reliance. The study thus presents a specific application of a corpus-pragmatic method, incorporating both vertical reading associated with corpus studies and qualitative analyses of “contextual embeddedness of communication” (Rühlemann & Aijmer 2015:3).
By integrating these perspectives, the results shed light on different aspects of the use of the amplifiers in focus. Frequency analysis, which explored the differences across categories in terms of the rates of occurrence, points to clear associations between specific sub-registers—i.e., categories of eighteenth century medical writing—and their preference for particular intensifiers. This in turn provides support for the idea that, as in Present-Day English, the use of intensifiers in eighteenth century medical writing is linked to situational characteristics and communicative purposes of the sub-registers, which give rise to specific
Diachronic analysis of frequencies across categories points to stability rather than dramatic change. While this finding is perhaps not entirely unsurprising given the stability of the time period both societally and linguistically, it is nonetheless notable that the major disciplinary and institutional changes in medicine (see Taavitsainen et al. 2014) do not seem to have a major impact on this aspect of language use in medical texts. It is of course possible that this conclusion only applies to the three major grammaticalized intensifiers investigated in this study and that by including more intensifier types, and looking specifically into whether any of them emerge as new additions to the repertoire, we would be able to detect changes. On the other hand, since most such types have a much lower token frequency in LMEMT (including highly, which is a frequent amplifier in present-day academic prose), it is uncertain whether including them in the analysis of frequency would actually have a major impact on the general trends. Nonetheless, this is clearly one of the main aspects that would complement the present findings and could be explored in future studies, along with extending the timeline to cover medical texts from later periods and adding further layers of annotation to indicate textual functions within the seven sub-registers in focus.
Footnotes
Acknowledgements
I wish to thank the anonymous reviewers as well as Merja Kytö, Claudia Claridge, Alexandra D’Arcy, and Peter Grund for their comments on an earlier version of this article.
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.