
Abstract
Aims:
This study investigated the impact of the native language (L1) writing system and Chinese proficiency on Chinese character recognition among second-language (L2) Chinese learners. We focused on L2 learners’ perception of and reliance on orthographic, phonological, and semantic information conveyed by radicals in character recognition.
Methodology:
Two hundred and fourteen L2 Chinese learners using L1-alphabetic, Japanese, and Korean writing systems, classified at intermediate and advanced levels of Chinese proficiency through a cloze test, participated in a picture-pseudo-character matching task.
Data and analysis:
Participants’ scores on pseudo-characters were analyzed using mixed-design analyses of variance (ANOVAs) and compared across learners’ L1 writing systems and Chinese proficiency.
Findings:
L2 Chinese learners’ L1 writing system and Chinese proficiency significantly affect their perception and reliance on radicals during character recognition. Alphabetic learners rely more on phonetic radicals than semantic radicals in character recognition, while Japanese learners rely more on semantic radicals than phonetic radicals, regardless of the radicals’ positions. Korean learners demonstrate an equal reliance on semantic and phonetic radicals when radicals are in conventional positions, but they prefer semantic radicals in unconventional positions. Intermediate and advanced learners of the same L1 exhibit similar patterns of radical reliance. In addition, advanced learners are more sensitive to radicals’ conventional positions than intermediate learners.
Originality:
This study extends previous research on sublexical processing of L2 Chinese characters by employing an optimized experimental design and participant categorization.
Significance/implications:
This study contributes to bilingual visual word recognition research by exploring L2 Chinese character recognition patterns by L2 learners with different L1 writing systems and Chinese proficiency. The findings provide valuable insights into L2 Chinese teaching.
Keywords
Introduction
The cross-linguistic effect on L2 word recognition has long been a central topic in linguistic research (Dijkstra & Van Heuven, 2002; Koda, 1996; Perfetti et al., 2007). Extensive studies have examined L2 English word recognition among learners from both alphabetic and non-alphabetic language backgrounds (for review, see Chen et al., 2020). It has been shown that learners’ L1 writing system significantly impacts L2 word recognition, influenced by the orthographic distance between the two writing systems and the extent of L2 input experience (Koda & Zehler, 2008). However, L2 Chinese character recognition by learners with different L1 writing systems and Chinese proficiency levels has received comparatively less focus.
Learning Chinese characters poses significant challenges for L2 Chinese learners, attributed to the unique and visually complex writing system of Chinese (Lin & Collins, 2012; Loh et al., 2018). According to Cook and Bassetti (2005), writing systems can be meaning-based and sound-based. Chinese represents a prototypical example of the meaning-based writing system, where each character’s grapheme represents a morpheme and corresponds to a syllable. Conversely, alphabetic languages like English and Russian use the sound-based writing system, linking graphemes with phonemes. Japanese and Korean incorporate dual writing systems, unlike languages with a single writing system. Japanese uses sound-based Kana and meaning-based Kanji, with Kanji constituting a significant portion of the Japanese writing system (Joyce & Masuda, 2018). Korean uses a sound-based writing system, Hangul, and a meaning-based writing system, Hanja. However, Hanja comprises only a minor part of contemporary usage, such as in station and city names. The dominant Korean script, Hangul, exhibits regular correspondence between graphemes and phonemes (Pae, 2018). Apart from the grapheme-phoneme-morpheme correspondence, the scripts used in Chinese, Japanese, Korean, and alphabetic languages exhibit varying degrees of differences. Japanese and Korean scripts, square-shaped like Chinese, show a closer resemblance to Chinese characters than the linear-structured alphabetic scripts. Some Japanese Kanji and Korean Hanja are identical to their Chinese counterparts (e.g., woman “女”). From the perspective of L1-L2 orthographic distance proposed by Koda (1996), alphabetic writing systems exhibit the most remote orthographic distance from Chinese, Korean is relatively closer, and Japanese is the closest. Given the differences among Chinese, alphabetic, Japanese, and Korean writing systems, it is essential to investigate whether and how learners with different L1 writing systems process L2 Chinese characters differently.
To fill the gap, we investigate Chinese character recognition among learners using alphabetic, Japanese, and Korean L1 writing systems, focusing on how L1-L2 orthographic distance affects their recognition of Chinese characters. We also consider learners’ Chinese proficiency and investigate potential interactions between learners’ L1 writing systems and Chinese proficiency. The study focuses on sublexical processing of Chinese characters, exploring how learners with different L1 and Chinese proficiency backgrounds process the orthographic, phonological, and semantic information conveyed by radicals during Chinese character recognition.
Literature review
Chinese writing system
Chinese characters, as the quintessential representative of the meaning-based writing system, demonstrate strong connections between graphemes and morphemes (Cook & Bassetti, 2005). Although Chinese characters do not follow the grapheme-phoneme correspondence rules characteristic of alphabetic languages, their sublexical units, known as radicals, provide semantic and phonetic information essential for character recognition. Approximately 90% of Chinese characters are phonograms composed of a semantic radical that delivers semantic information and a phonetic radical that offers phonetic cues (Shu & Anderson, 1997). For instance, the character “晴” (qíng, sunny) includes a semantic radical “日” (sun), indicating an association with the sun or weather, and a phonetic radical “青” (qīng), providing a pronunciation clue.
The positions of semantic and phonetic radicals add complexity to the orthography of Chinese characters (Loh et al., 2018). Phonograms exhibit three main structures: left-right (e.g., “晴”), top-bottom (e.g., “草”), and surrounding (e.g., “园”). The same radicals in different positions represent different characters, such as “呆” (dāi, stay) and “杏” (xìng, plum), highlighting the importance of radicals’ position. According to Hsiao and Shillcock (2006), among the 3,027 most frequently used phonograms, 72% are of a left-right structure. Approximately 90% of the left-right phonograms have semantic radicals placed on the left and phonetic radicals placed on the right, and the remaining 10% position the semantic radical on the right and the phonetic radical on the left (e.g., “期” qī, date). Therefore, this study focuses on phonogram recognition, considering left-positioned semantic radicals and right-positioned phonetic radicals as conventional positions.
Given the radicals’ crucial role in conveying orthographic, phonological, and semantic information, the question of whether readers rely more on the orthography-semantics connection conveyed by semantic radicals or the orthography-phonology connection conveyed by phonetic radicals during character recognition has received considerable attention. The relevant studies are grounded in the dual-route theoretical framework, as reviewed in the next section.
Dual-route theory and evidence from L1 Chinese character recognition
The concept of dual-route processing in reading has been developed through various models for alphabetic languages, including the Dual-Route Cascaded Model (Coltheart et al., 2001) and the Triangle Model (Harm & Seidenberg, 2004; Seidenberg & McClelland, 1989). These models propose multiple routes for word recognition: lexical orthography-phonology, orthography-semantics, and sublexical grapheme-phoneme conversion routes. When adapted for Chinese, models such as the Triangle Model (Yang et al., 2009) and the Lexical Constituency Model (Perfetti et al., 2005) propose that Chinese character recognition predominantly involves dual routes: orthography-semantics-phonology and orthography-phonology-semantics, which may operate simultaneously. In these models, radicals function as important sublexical units, providing semantic and phonological information for character recognition.
Considerable studies have investigated lexical and sublexical processing routes for character recognition by Chinese speakers. At the lexical level, studies have predominantly investigated the time course of orthographic, phonological, and semantic activation (Liu et al., 2022; Wang et al., 2016). Regarding the sublexical level, research has mainly focused on the role of radicals. Experiments involving pseudo-characters are commonly employed to manipulate semantic and phonetic radical combinations, thereby revealing readers’ radical reliance. Evidence demonstrates that native Chinese speakers activate and use both semantic and phonetic information conveyed by radicals during character recognition, supporting the dual-route framework (Hsu et al., 2021; Hu, 2010). However, the predominance of one route over the other remains controversial and can be influenced by several factors, including readers’ reading skills and experimental methodology. For instance, more skilled readers, such as adults compared to lower-grade children, rely more on semantic than phonetic radicals for decoding pseudo-characters, indicating increased engagement of the orthography-semantics route during character recognition (Tong et al., 2017; Williams & Bever, 2010).
Previous studies on Chinese character recognition by L2 Chinese learners
Previous studies on L2 Chinese character learning have demonstrated that learners use semantic and phonetic radicals to aid the memorization of character meanings and pronunciations following teacher instructions (Liu et al., 2020; Xu et al., 2014; Zhang et al., 2016). However, debate persists on whether learners exhibit varying degrees of radical perception and reliance during character recognition, influenced by their L1 writing systems and Chinese proficiency. Research on sublexical processing of L2 Chinese characters often employs pseudo-character tasks with diverse designs and participant backgrounds, leading to inconsistent conclusions. We will review several studies exploring these issues and their limitations.
Chen et al. (2015) conducted a pseudo-character selection task with 21 alphabetic learners across different proficiency levels. Participants chose pseudo-characters matching objects in each test trial, with radicals manipulated for semantic and phonetic relatedness. For example, the participants were presented with a picture of the object (e.g., a tree), a description of the object (e.g., “a tree named ‘fen’”), and three pseudo-characters (e.g., 木止, 方分, 方止). They were required to choose one pseudo-character that most matched the description of the tree. The pseudo-characters were designed by manipulating the relatedness of radicals to the object. The radical “木” is semantically related to the tree, “分” is phonologically related to the name of the tree, while “方” and “止” are unrelated to this object. Learners relied equally on semantic and phonetic radicals, with increased perception of radical functions as proficiency improved, evidenced by reduced selection of pseudo-characters with unrelated radicals.
Tong and Yip (2015) and Tong et al. (2016) adapted Chen et al.’s experimental task, using objects with existing Chinese character representations such as “桥” (bridge). They manipulated the characters’ radical positions (e.g., 木合, 讠乔, 合木, 乔讠, 日圭) and cue conditions (no cue, semantic, or phonetic cue). The participants were from various L1 backgrounds. Tong and Yip’s study indicated that learners generally relied more on semantic radicals, with or without cues, than on phonetic radicals. However, with phonetic cues, they favored phonetic radicals. Tong et al. (2016) specifically found that English learners relied more on semantic radicals, while Japanese and Korean learners used both equally without cues. Semantic cues increased reliance for all, especially Japanese learners, while phonetic cues boosted reliance for all, particularly Korean learners. However, using real objects with existing characters raises concerns about measuring radical reliance due to prior knowledge.
Williams and Uchima (2020) studied 113 learners with alphabetic, Japanese, and Korean L1s and categorized alphabetic learners by L1 transparency. Participants selected pseudo-characters based on audio descriptions of novel objects. Findings showed alphabetic learners relied more on phonetic radicals at pre-intermediate levels, Korean learners consistently preferred phonetic radicals, and Japanese learners shifted from semantic to phonetic reliance from elementary to intermediate levels. Despite addressing proficiency effects, the study’s small sample size and audio-only design posed challenges, particularly for Japanese and Korean learners with limited English comprehension. Learners might primarily focus on the pronunciation in the audio, thereby selecting pseudo-characters containing corresponding phonetic radicals. Our study refined this by providing audio in learners’ L1s and visual aids, as described in the Materials section.
Overall, radical reliance in L2 Chinese character processing remains unclear due to limited research across L1 backgrounds, L2 proficiency levels, and differing experimental designs. In existing studies, methodological limitations and inadequate proficiency assessment result in insufficient evidence on how proficiency influences character recognition. To fill the gap, we examine how learners’ L1 writing systems and Chinese proficiency affect sublexical processing of Chinese characters through the following research questions:
Can L2 Chinese learners perceive the orthographic, phonological, and semantic information that radicals convey in character recognition?
Is there any difference between alphabetic, Japanese, and Korean learners’ reliance on semantic and phonetic radicals? If yes, what is the difference?
Is there any difference between intermediate and advanced learners’ reliance on semantic and phonetic radicals? If yes, what is the difference?
Is there any interactive effect of L2 Chinese learners’ L1 writing system and Chinese proficiency on their radical reliance? If yes, what is the effect?
The present study
Participants
Participants were recruited online from universities in mainland China between October 2022 and March 2023. A total of 258 L2 Chinese learners who fulfilled the following criteria were invited to participate in the present study: (1) they were not heritage speakers of Chinese; (2) their native language was Japanese, Korean, or an alphabetic language, such as English, Russian, or French; (3) they had passed HSK (an official Chinese proficiency test for non-native Chinese learners) level 3 or were taking/had taken intermediate or advanced Chinese courses. 1
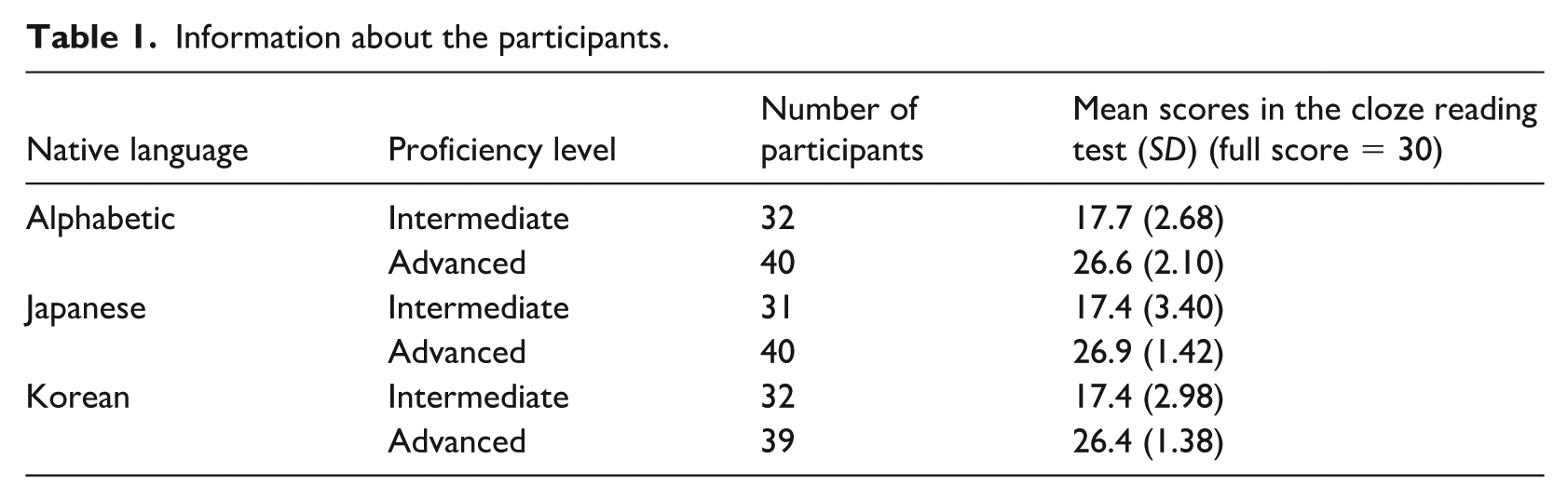
The learners were divided into intermediate and advanced proficiency groups based on their scores from a cloze test (described below), which provides a more up-to-date evaluation of participants’ Chinese proficiency than the reported HSK level. Those who scored 10 or below were excluded from the study. The average score on the cloze test was 23 out of 30. To clearly distinguish learners’ proficiency levels, we used thresholds of below 22 and above 24 to assign participants to the intermediate (scored 11–21) and advanced (scored 25–30) groups, respectively. Participants scoring between 22 and 24 were excluded from the data analysis to ensure clear separation between the intermediate and advanced groups, reducing potential noise from borderline cases. The final dataset comprised 214 participants. The participants’ information is presented in Table 1. There are no significant differences in scores across the same proficiency levels among the three L1 groups (p > .05).
Information about the participants.
This study was conducted following research ethics and received approval from the College Human Subject Ethics Sub-Committee. Participants consented to participate in this study and were ensured that their response data were kept confidential.
Materials
In this study, we administered a cloze test designed by Feng et al. (2020) and a picture–pseudo-character matching task adapted from Tong et al. (2016).
Cloze test
We employed the cloze test to assess the participants’ Chinese proficiency. They were instructed to read a short text containing 30 blanks and to fill each blank with one Chinese character to make the text coherent and meaningful. Each blank correctly filled was given one score, culminating in 30 scores.
Picture-pseudo-character matching task
The picture-pseudo-character matching task comprised 19 trials, including 3 practice and 16 test trials. For each trial, we created an object with (1) a picture of this object, (2) an audio description, and (3) five pseudo-characters representing possible written symbols.
The audio description was designed to convey the pronunciation of the object’s name and a brief description of the object. We created two versions of the audio description for the 19 task trials. The first version followed a meaning-first and pronunciation-second structure, as in “This is a tree, called ‘qì.’” The second version used a pronunciation-first and meaning-second structure, exemplified by “This is called ‘qì’. It is a tree.” These two versions were alternated across the 19 trials to minimize the potential influence of the order of the phonetic and semantic information provided in the audio description on participants’ ratings of the pseudo-characters.
In the design of the written symbols, pseudo-characters were crafted to be orthographically regular, featuring a left-right structure composed of a semantic radical and a phonetic radical. We manipulated the radicals’ positions and their semantic or phonetic relatedness to the object being designed. For example, Figure 1 depicts five pseudo-characters as written symbols for an object, which is a tree called “qì.”

Five pseudo-characters in a sample trial.
Symbol (1) coded as S+P- is a pseudo-character consisting of a semantic radical “木” (mù, wood) related to the object and an unrelated phonetic radical “中” (zhōng, middle) in conventional positions. Symbol (2), coded as S-P+, integrates an unrelated semantic radical “日” (rì, sun) and a related phonetic radical “气” (qì, air) 2 in conventional positions. Symbol (3), coded as P-S+, and symbol (4), coded as P+S-, share the same radicals as (1) and (2), respectively, but the two radicals are in unconventional positions. Symbol (5) coded as S-P- is a controlled pseudo-character with unrelated semantic and phonetic radicals in conventional positions. The presentation order of the five symbols was randomized across trials.
All target semantic and phonetic radicals were selected from levels 1-3 of the New Chinese Proficiency Grading Standards for International Chinese Language Education (State Language Commission, 2021). The participants who passed HSK 3 and learned characters in Chinese courses should be familiar with the selected radicals, both as sublexical elements in compound characters and as standalone characters. For instance, they know “木” means wood as a single Chinese character and signifies wood-related concepts as a semantic radical in compound characters, such as “树” (tree). The stroke numbers and levels of the selected semantic and phonetic radicals across symbol types showed no significant differences, and radical frequencies were balanced according to the Beijing Language and Culture University Corpus Center (Xun et al., 2016). All pseudo-characters and the corresponding English descriptions used in the experiment are presented in Appendix.
The task instructions and audio descriptions were provided in four language versions: Japanese, Korean, English, and Chinese. The participants could select their preferred language to complete the task.
Procedure
L2 Chinese learners interested in participating in this study were required to complete a registration form to provide information about their L1 background, HSK level, and Chinese learning experience. Those learners who met the criteria in the Participants section were subsequently invited to complete the cloze test and the picture-pseudo-character matching task.
The picture-pseudo-character matching task was administered online through the Gorilla Experimental Builder platform. The participants were required to read the instructions and complete three practice trials. The test trials commenced after the participants confirmed their understanding of the task requirements and verified the recordings' audibility. In each trial, the participants were presented with a picture, an audio description, and five symbols (pseudo-characters) of the object. They were asked to rate each of the five pseudo-characters from one score to five based on how well it matched the object, with one indicating the least match and five the most. The same score cannot be assigned to more than one pseudo-character. The task took approximately 20 minutes to complete.
Results
To examine learners’ radical perception and reliance across different L1 writing systems and L2 proficiency levels, we employed a three-way mixed-design analysis of variance (ANOVA), consistent with previous studies. Initially, we constructed a linear mixed-effects model with symbol type, L1 writing system, and Chinese proficiency as fixed effects and participants and trials as random effects. As the random-effects variance approached zero, indicating that participant variability was already captured by the fixed effects and that trial effects were consistent, we used ANOVA for data analysis. Learners’ L1 writing system and L2 proficiency were between-subject variables, and symbol type was a within-subject variable. Results reveal non-significant main effects of learners’ L1 (F (2.0, 208) = 0.86, p > .05) and L2 proficiency (F (1.0, 208) = 0.061, p > .05), indicating that the overall scores for pseudo-characters did not vary significantly across learners with different L1 writing systems or proficiency levels. The main effect of symbol type was significant (F (3.1, 644) = 175.75, p < .001, η²p = .45), demonstrating learners’ sensitivity to the differences between the five types of pseudo-characters. Significant interaction effects were observed for L1 * symbol type (F (6.2, 644) = 11.06, p < .001, η²p = .10) and L2 proficiency * symbol type (F (3.1, 644) = 3.37, p < .05, η²p = .02) on the scoring of pseudo-characters, indicating that learners’ radical reliance varied across their L1 writing systems and proficiency levels. However, the interactive effect of L1 writing system * L2 proficiency * symbol type on the scoring of pseudo-characters was insignificant (F (6.2, 644) = 0.86, p > .05), suggesting that the interaction between learners’ L1 and proficiency level did not affect their radical perception and reliance. In the subsequent analysis, we first examine the general perception of radicals among L2 learners and then explore their reliance on radicals, separately considering learners using different L1 writing systems and at different proficiency levels.
Overview of L2 Chinese learners’ perception of radicals’ orthographic, phonological, and semantic information
We conducted a post hoc Tukey test to investigate participants’ sensitivity to the orthographic, phonological, and semantic information of radicals. Results reveal significant differences in scores between S+P- and P-S+ (p < .001), as well as between the S-P+ and P+S- (p < .001). The participants assigned significantly higher scores to pseudo-characters with radicals in conventional positions than to those in unconventional positions, supporting their sensitivity to radicals’ conventional positions. Furthermore, the scores for S-P- were significantly lower than those for the other four types (p < .001), indicating that participants were aware of radicals’ semantic and phonetic information.
Mean scores for pseudo-characters given by learners of different L1 writing systems
The means of scores given on each type of pseudo-characters by alphabetic, Japanese, and Korean learners are illustrated in Figure 2.
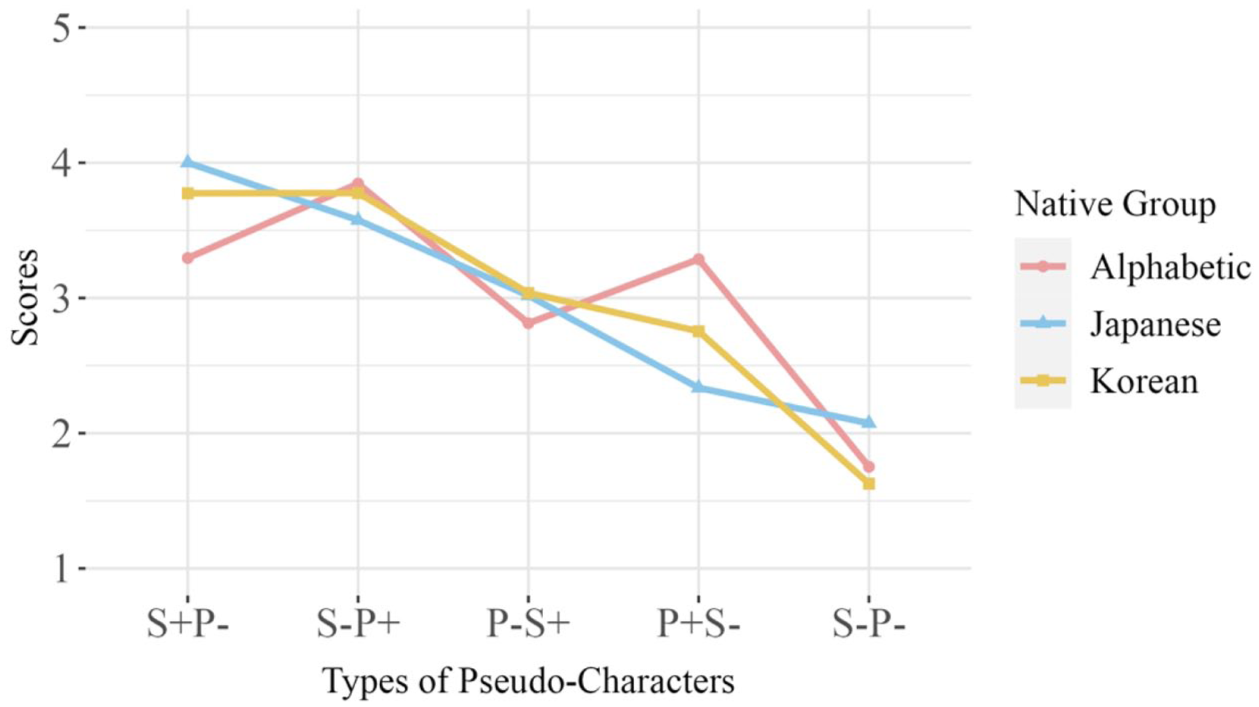
The means of the scoring of five types of pseudo-characters by alphabetic, Japanese, and Korean learners.
Three one-way ANOVAs were conducted to examine the patterns of radical reliance among three L1 groups. The results indicate that symbol types significantly influenced the scoring of pseudo-characters among alphabetic (F (2.65, 188) = 59.5, p < .001, η²p = .46), Japanese (F (3.06, 214) = 58.8, p < .001, η²p = .46), and Korean (F (3.16, 221) = 87.3, p < .001, η²p = .55) learners. Subsequent Bonferroni-adjusted pairwise t-tests reveal differences in scores across pseudo-character types by different L1 groups. Alphabetic learners gave significantly higher scores to S-P+ than to S+P- (p < .001) and to P+S- than to P-S+ (p < .001), exhibiting a greater reliance on phonetic radicals. Conversely, Japanese learners exhibited a preference for semantic radicals, scoring S+P- higher than S-P+ (p < .001) and P-S+ higher than P+S- (p < .001). Regarding Korean learners, no significant difference was found between scores for S+P- and S-P+ (p > .05), suggesting that they relied equally on semantic and phonetic radicals when radicals were in conventional positions. When radicals were in unconventional positions, P-S+ scored significantly higher than P+S- (p < .05), displaying a more substantial reliance on semantic than phonetic radicals.
In addition, we conducted one-way ANOVAs for each symbol type to examine differences between learners’ L1 groups. Significant differences were found among the mean scores of alphabetic, Japanese, and Korean learners on S+P- (F (2, 211) = 17.0, p < .001, η²p = .14), P+S- (F (2, 211) = 23.7, p < .001, η²p = .18), and S-P- (F (2, 211) = 7.63, p < .001, η²p = .07). Post hoc tests reveal that alphabetic learners assigned significantly lower scores to S+P- (p < .001) and higher scores to P+S- (p > .001) than Japanese and Korean learners. It reveals that alphabetic learners emphasized phonological information more than Japanese and Korean learners. Japanese learners rated S-P- significantly higher than their alphabetic and Korean counterparts (p < .05), suggesting a greater sensitivity to radicals’ conventional positions.
Mean scores for pseudo-characters given by learners of different Chinese proficiency levels
Figure 3 illustrates the mean scores assigned to each type of pseudo-character by intermediate and advanced learners.
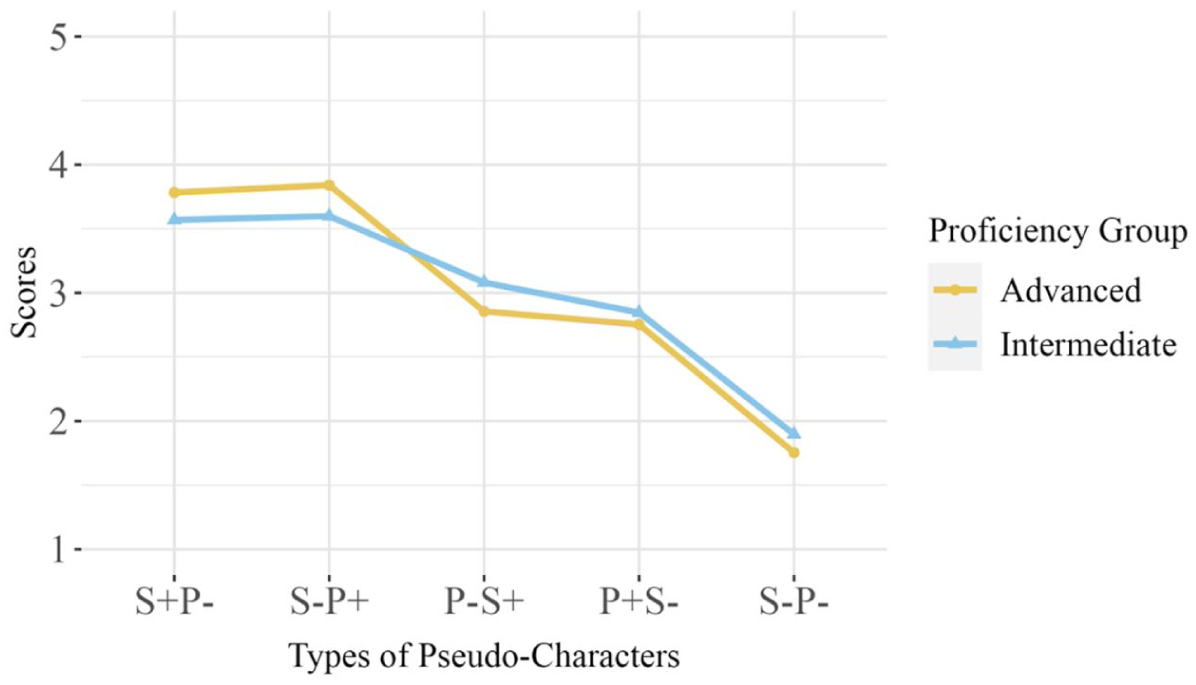
The means of the scoring of five types of pseudo-characters by intermediate and advanced learners.
To examine how intermediate and advanced learners differ in their radical reliance, we conducted a one-way ANOVA for each proficiency group. The results reveal significant symbol type effects on scores of both intermediate (F (2.9, 272) = 56.3, p < .001, η²p = .37) and advanced (F (2.9, 343) = 114, p < .001, η²p = .49) learners. Bonferroni-adjusted pairwise comparisons between symbol types for each proficiency group showed no significant differences between S+P- and S-P+ (p > .05), as well as between P-S+ and P+S- (p > .05). The findings suggest that both intermediate and advanced learners demonstrated equal reliance on semantic and phonetic radicals in character recognition.
Then, we conducted a one-way ANOVA for each symbol type to investigate the differences in the scoring of pseudo-characters between the two proficiency groups. Significant differences were found in the scoring of S+P- (F (1, 212) = 3.91, p < .05, η²p = .02), S-P+ (F (1, 212) = 4.32, p < .05, η²p = .02), and P-S+ (F (1, 212) = 5.76, p < .05, η²p = .03) between intermediate and advanced learners. The findings suggest that advanced learners were more sensitive to radicals’ conventional position than intermediate learners, as evidenced by their higher scores on S+P- and S-P+.
Discussion
The present study investigated alphabetic, Japanese, and Korean learners’ perception and reliance on the orthographic, phonological, and semantic information conveyed by characters’ phonetic and semantic radicals through a picture-pseudo-character matching task.
The findings address the four research questions, indicating that (1) L2 Chinese learners were sensitive to radicals’ orthographic, phonological, and semantic information, recognizing that semantic radicals typically appear on the left and phonetic radicals on the right. Their perception of radicals’ conventional positions was affected by their L1 writing system and L2 proficiency; (2) alphabetic, Japanese, and Korean learners demonstrated different radical reliance patterns in character recognition. Alphabetic learners relied more on phonetic than semantic radicals, while Japanese learners relied more on semantic than phonetic radicals, regardless of the radicals’ positions. Korean learners exhibited a preference for semantic radicals primarily when the radicals were positioned unconventionally; (3) intermediate and advanced learners displayed a similar radical reliance pattern in character recognition, relying equally on semantic and phonetic radicals; (4) learners’ L1 writing system and L2 proficiency had no interactive effect on their radical reliance in character recognition.
Perception of radicals’ information by L2 Chinese learners
The finding on learners’ radical perception is consistent with the reviewed studies. L2 Chinese learners were sensitive to the positional, phonological, and semantic functions of radicals.
Learners’ sensitivity to radicals’ conventional positions was affected by their L1 writing system and L2 proficiency. Japanese learners showed greater sensitivity to characters’ orthographic information than alphabetic and Korean learners, as indicated by their significantly higher scores on pseudo-characters with unrelated radicals in conventional positions. This finding is intuitive due to the close orthographic distance between Japanese Kanji and Chinese characters (Koda, 1996). Since the Japanese use Kanji, which resembles Chinese characters and includes phonograms (Joyce & Masuda, 2018), their orthographic awareness surpasses that of alphabetic and Korean learners. The enhanced orthographic awareness enables Japanese learners to perceive the visual form of Chinese characters more holistically. Therefore, even when presented with pseudo-characters lacking related radicals, Japanese learners still perceived them as resembling real characters as long as the radicals were conventionally positioned.
Regarding learners’ L2 proficiency, advanced learners demonstrated greater sensitivity to the conventional position of radicals than intermediate learners. This finding can be attributed to advanced learners’ longer periods of Chinese study, which result in greater exposure to Chinese characters and more instruction from CFL teachers than intermediate learners. Such prolonged engagement with Chinese characters enables advanced learners to be more familiar with the orthographic pattern of Chinese characters.
Considering learners’ sensitivity to radicals’ information and the unique properties of Chinese characters, we recommend that CFL teachers cultivate learners’ orthographic awareness from the beginning stages, emphasizing the positional functions of radicals. The semantic and phonetic functions should also be introduced to elementary learners, while highlighting the complexity of radicals in conveying irregular and non-transparent semantic and phonological information.
Radical reliance by alphabetic, Japanese, and Korean learners
The present study reveals that alphabetic, Japanese, and Korean learners exhibited different patterns of reliance on semantic and phonetic radicals in character recognition. The findings align with previous studies indicating that learners’ L1 affects their L2 word recognition (Koda, 1996; Tong et al., 2016).
Using the sound-based writing system, alphabetic learners are accustomed to immediately activating pronunciation upon encountering the visual form of a word in their L1 (Leinenger, 2014). They might transfer their L1 mapping rules to L2 word recognition, showing a tendency to seek out pronunciation cues in the audio description and phonological information embedded in the pseudo-characters. Consequently, regardless of the radicals’ positions, they preferred phonetic over semantic radicals, following the orthography-phonology route for sublexical processing of Chinese characters.
Japanese learners’ radical reliance contrasts with their alphabetic counterparts. Japanese learners predominantly relied on semantic radicals, regardless of their position. This result is attributed to the predominant use of Kanji in the Japanese writing system, which enables Japanese learners to become familiar with the grapheme-morpheme mapping rules. According to Igarashi (2007), approximately 60.72% of words in Japanese magazines, newspapers, and TV commercials are Kanji, with the remaining 40% comprising Kana words, alphabetic symbols, and numbers.
Furthermore, the presence of polyphonic characters in Japanese enhances their familiarity with grapheme-morpheme processing strategies. As Cook and Bassetti (2005) noted, many Japanese Kanji have multiple pronunciations per grapheme, which depend on context. For instance, the Japanese Kanji “生” has two pronunciations depending on its meaning. It is pronounced as /nama/ when referring to something raw and as /seː/ when its meaning is related to life (Tamaoka & Makioka, 2004). Consequently, Japanese learners are inevitably skilled at prioritizing semantic content, using the meaning of a Kanji to infer its pronunciation. When learning Chinese characters similar to their L1 Kanji, Japanese learners assimilated the grapheme-morpheme mapping rules from their L1 Kanji recognition to L2 Chinese character recognition. This resulted in their reliance on the orthography-semantics route in character recognition.
Korean learners exhibited a more complex character-recognition pattern, distinct from alphabetic and Japanese learners. Korean learners relied equally on semantic and phonetic radicals when radicals were in conventional positions. However, a significant preference for semantic radicals was found when radicals were in unconventional positions. Since Koreans use meaning-based Hanja and sound-based Hangul, they can simultaneously activate semantic and phonetic information through orthography, leading to equal reliance on dual processing routes.
However, considering that both Japanese and Korean use two writing systems, it raises the question of why Japanese learners consistently relied more on semantic radicals, regardless of the radicals’ positions, while Korean learners did not demonstrate the same pattern. Their differences in character recognition patterns may be attributed to the varying proportions of meaning-based scripts used in Japanese and Korean. Japanese Kanji is the dominant writing script, whereas Korean Hanja is rarely used. Hence, Korean learners are less sensitive to grapheme-morpheme mapping rules than Japanese learners and may not possess the same level of control over the activation of grapheme-phoneme mapping rules as Japanese learners, leading to the activation of both grapheme-phoneme and grapheme-morpheme processing routes in character recognition.
The next question concerns why Korean learners did not consistently rely equally on semantic and phonetic radicals but relied more on semantic radicals when radicals were in unconventional positions. As described in the Introduction section, the orthographic distance between the Korean and Chinese writing systems is relatively close, which constitutes their sensitivity to character orthography. This sensitivity may have made them aware that radicals in unconventional positions occur less frequently than those in conventional positions, and thus led them to consider such characters less familiar. They may find it easier to ascertain an unfamiliar character’s meaning than to determine its pronunciation because semantic radicals provide more reliable cues about a character’s meaning than phonetic radicals about a character’s pronunciation. As Shu et al. (2003) calculated, approximately 65% of phonograms have related meanings to their semantic radicals, while only 43% of phonograms have phonetic radicals providing identical and regular information about character pronunciation. Hence, Korean learners likely cautiously adopt phonetic information as cues for processing unfamiliar Chinese characters. This leads them to consciously activate the grapheme-morpheme mapping rules, predominantly relying on semantic radicals to recognize characters with unconventionally positioned radicals. Future research should also employ qualitative methods, such as interviews, to further investigate Korean learners’ sublexical processing in character recognition.
Radical reliance by intermediate and advanced learners
While learners’ L1 significantly influenced their radical reliance on character recognition, their L2 proficiency did not play a role. We did not observe clear preferences for semantic or phonetic radicals in character recognition among intermediate and advanced learners. Moreover, intermediate and advanced learners of the same L1 exhibited similar character-recognition patterns, as evidenced by the lack of interaction between learners’ L1 writing systems and L2 proficiency in their reliance on radicals.
The findings suggest that learners’ L2 proficiency may not directly correlate with the cognitive processes involved in Chinese character recognition. Our participants, intermediate and advanced learners, had already achieved a certain level of proficiency in Chinese. During the elementary stage, they may have developed stable cognitive patterns of radical reliance in Chinese character recognition under the influence of their L1, even after subsequent improvements in L2 proficiency, such as enhanced reading ability or grammatical knowledge. This finding further supports the predominant role of learners’ L1 in Chinese character recognition and underscores the importance of developing L1-tailored radical instruction, awareness, and effective use of radicals in early Chinese character learning.
Conclusion
This study explored the impact of learners’ L1 writing system and L2 proficiency on Chinese character recognition. Focusing on the sublexical level, we employed a picture-pseudo-character matching task to investigate L2 Chinese learners’ perception of and reliance on orthographic, phonological, and semantic information conveyed by semantic and phonetic radicals in Chinese character recognition. The findings reveal that L2 Chinese learners were aware of the orthographic, phonological, and semantic information associated with radicals during character recognition. Learners’ sensitivity to radicals’ conventional positions was influenced by their L1 writing system and L2 proficiency, whereas their reliance on semantic and phonological information was primarily shaped by their L1 writing system. Intermediate and advanced learners using the same L1 exhibited similar radical reliance patterns in character recognition. Our findings highlight the significant impact of learners’ L1 writing system on sublexical processing of orthographic, phonological, and semantic information during L2 Chinese character recognition, contributing to research on bilingual word recognition.
This study has several limitations. First, we grouped learners by L1 alphabetic writing system, without considering L1 phonetic transparency. Although previous research has not identified differences in radical reliance between learners of transparent and opaque languages, future studies could investigate the effects of phonological transparency on Chinese character recognition using larger samples. Second, this study excluded elementary learners, as their limited radical knowledge constrained our ability to design a sufficient number of pseudo-characters using real radicals. Further investigation should include L2 learners at elementary to advanced levels to enable a more comprehensive exploration of sublexical processing of characters across learners of different proficiency levels. Future research could examine both real characters and pseudo-characters in experiments to explore potential differences in processing.
Footnotes
Appendix
Task stimuli.

| Practice trials | ||
| 1. | “This is a car called /bái/.” | |
| 2. | “This is a bowl made of stone called /xiàng/.” | |
| 3 | “This is called /fēn/, it is a boat.” | |
| Test trials | ||
| 1. | “This is a tree called /qi/.” | |
| 2. | “This is called /mén/, it is a huge mouth.” | |
| 3. | “This is called /yōng/, it is a ground.” | |
| 4. | “This is a sunny weather called /mén/.” | |
| 5. | “This is a special eye called /fāng/.” | |
| 6. | “This is a tool made of stone called /jiāo/.” | |
| 7. | “This is a fire called /qīng/.” | |
| 8. | “This is a pretty mouth called /bái/.” | |
| 9. | “This is a girl called /zhōng/.” | |
| 10. | “This is a vast land called /yóu/.” | |
| 11. | “This is called /liàng/, it is a woman.” | |
| 12. | “This is called /lì/, it is a sunny weather.” | |
| 13. | “This is called /chéng/, it is a pair of mysterious eyes.” | |
| 14. | “This is called /xiàng/, it is a toy made of wood.” | |
| 15. | “This is called /bāo/, it is a car.” | |
| 16. | “This is called /qi/, it is a fire.” | |
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.