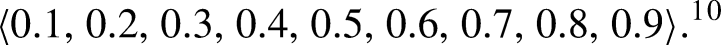In this paper, we investigate the conditions under which data imbalances, a common data characteristic that occurs when factor values are unevenly distributed, are problematic for the performance of Coincidence Analysis (CNA). We further examine how such imbalances relate to fragmentation and noise in data. We show that even extreme data imbalances, when not combined with fragmentation or noise, do not negatively affect CNA’s performance. However, an extended series of simulation experiments on fuzzy-set data reveals that, when mixed with fragmentation or noise, data imbalances may substantially impair CNA’s performance. Furthermore, we find that the performance impairment is higher when endogenous factors are imbalanced than when exogenous factors are concerned. Our results allow us to quantify these impacts and demarcate degrees at which data imbalances should be considered as problematic. Thus, applied researchers can use our demarcation guidelines to enhance the validity of their studies.
Coincidence Analysis (CNA; Baumgartner and Ambühl, 2020) is a novel method of causal learning that belongs to the family of configurational comparative methods (CCMs; Rihoux and Ragin, 2009). Unlike most methods of data analysis, CNA can handle complex causal structures involving conjunctivity (when multiple factors interact to produce an outcome) and disjunctivity (when alternative pathways produce the same outcome independently of one another), which do not necessarily exhibit pairwise dependencies between a cause and its effect. CNA accomplishes this by fitting complex Boolean functions as a whole to the data, and it is the only method of its kind capable of detecting links between multiple outcomes (sequentiality), which are characteristic for causal chains.
As such, CNA has been increasingly applied in a wide range of fields, including political science (e.g., Haesebrouck, 2023), environmental studies (e.g., Edianto, Trencher, and Matsubae, 2022), public health (e.g., Yakovchenko et al., 2020), medical informatics (e.g., Womack et al., 2022), sociology (e.g., Epple and Schief, 2016), and organizational behavior (e.g., Swiatczak, 2021). In parallel, methodological research has substantially improved the quality of CNA’s data analysis approach (e.g., Parkkinen and Baumgartner, 2023). However, data distribution requirements have not yet been investigated for CNA. This is all the more striking as, for example, within the framework of statistical methods, assessing data distributions is a crucial pre-analytical step for selecting appropriate methods and determining the expected accuracy of analyses. Accordingly, various data distribution characteristics have been widely shown to create issues for these methods (e.g., von Hippel, 2013; Yuan, Bentler, and Zhang, 2005).
This study examines how the performance of CNA is affected by a common data distribution characteristic: data imbalances (also referred to as skewness), which occur if factors have value distributions that partition the cases in the data into sets of notably unequal sizes. Such imbalances are often encountered in CCM applications. For instance, the vast majority of countries are classified as not wealthy based on the world bank GDP classification system (Goertz, 2020), decisions against the termination of pregnancy after a prenatal diagnosis of Down syndrome are very rare (Britt et al., 2000), educational poverty is a marginal occurrence in developed countries (Glaesser, 2022), and employees prevailingly consider themselves competent (Swiatczak, 2021).
Skewness has received some attention in the methodological literature on Qualitative Comparative Analysis (QCA; Ragin, 2009), another method from the family of CCMs (e.g., Oana, Schneider, and Thomann, 2021; Schneider and Wagemann, 2012). However, on the one hand, those discussions have so far focused on particular data examples, which do not yield quantitative performance assessments or generalizable conclusions. On the other hand, findings on QCA cannot be transferred to CNA because of substantive algorithmic differences between the two methods (Swiatczak, 2022). As a consequence, thus far, applied CNA researchers lack a means to determine whether their data are imbalanced to such an extent that countermeasures should be taken or reliable results can be expected.
The aim of this study is to remedy this situation by systematically investigating to what extent data imbalances affect the quality of CNA’s output. First, we demonstrate that, contrary to previous discussions on skewness, no general claims can be made about the effect of data imbalances in isolation of other aspects of data quality. More precisely, data imbalances do not affect CNA’s performance if the data are completely free from noise and fragmentation. By contrast, it is far from clear how imbalances interact with noise and fragmentation. Do they affect CNA’s performance solely by exacerbating noise and fragmentation or do they have their own impact on performance that is independent of other data deficiencies? Second, to answer these questions, we present the results of a series of simulation experiments benchmarking CNA’s performance under varying degrees of distributional imbalances while controlling for other data deficiencies. Our experiments are designed as inverse search trials, meaning that we randomly draw data-generating causal structures from which we simulate data with varying imbalances and different combinations of other data deficiencies, consecutively analyze these data with CNA, and measure how frequently the original causal structures (or proper parts thereof) are contained in CNA’s output.
Overall, we find that increasing imbalances while keeping noise and fragmentation constant results in impaired performance, which our results allow to quantify. In other words, imbalances not only exacerbate other data deficiencies but also have a negative impact of their own. This impact is higher for imbalances in endogenous factors than in exogenous ones. Our study identifies degrees at which distributional imbalances should be considered problematic and proposes approaches to address them.
Data Imbalances in CNA
CNA Preliminaries
To infer causal structures featuring conjunctivity, disjunctivity, and sequentiality from data, CNA draws on the so-called (M)INUS theory of causation (Baumgartner and Falk, 2023; Mackie, 1974),1 which is specifically designed for the analysis of such structures as it defines causation via complex Boolean dependencies. Factors are the basic modeling devices of the MINUS theory and of CNA. They are analogous to variables, meaning they are functions from (measured) properties into a range of values (typically integers). CNA can process data comprising crisp- and fuzzy-set or multi-value factors (Baumgartner and Ambühl, 2020). For reasons of space, the ensuing discussion will, however, focus on crisp- and fuzzy-set factors only.
Values of a crisp- and fuzzy-set factor can be interpreted as membership scores in the set of cases exhibiting the property represented by . That is, a case of type is a full member of that set, a case of type is a full non-member, and a case of type , where , is a member to degree . A case is considered a member if its membership score is above the 0.5-anchor, that is, , and it is a non-member if . In the process of calibration, the meanings of full membership, full non-membership, and cross-over at the 0.5-anchor are defined for each set and then used to transform raw data into crisp or fuzzy membership scores (see e.g., Thiem and Duşa, 2013; Oana et al., 2021 on calibration methods and algorithms).
As the explicit “Factorvalue” notation yields convoluted syntactic expressions, we will use the following shorthand notation, which is conventional in Boolean algebra: “” signifies membership in the set of cases exhibiting the property represented by and “” signifies non-membership in that set. Italicization thus carries meaning: “” designates the factor and “” membership in the set of cases with values of above . Moreover, we write “” for the Boolean operation of conjunction “and”, “” for the disjunction “or”, “” for the implication “ifthen”, and “” for the equivalence “if, and only if,”. For crisp-set factors, the Boolean operations are given a rendering in classical logic (e.g., Lemmon, 1965), and for fuzzy-set factors, these operations are rendered in fuzzy logic (e.g., Baumgartner and Ambühl, 2020).2 The implication operator is used to define the notions of sufficiency and necessity, which are the two Boolean dependencies exploited by the MINUS theory and CNA: is sufficient for if, and only if, ; and is necessary for if, and only if, .
To reflect causation, sufficiency and necessity relations need to be rigorously freed of redundancies, which is accomplished if sufficient and necessary conditions are minimal, meaning they do not have proper parts that are, respectively, sufficient and necessary on their own (Baumgartner and Falk, 2023). In sum, using techniques from Boolean algebra, set theory, and fuzzy logic, CNA infers minimally necessary disjunctions of minimally sufficient conditions of scrutinized outcomes (in disjunctive normal form), so-called MINUS-formulas, from data. The following is an example:
When causally interpreted, (1) entails that each of , , , and is a cause of outcome and that and conjunctively cause on one path while and operate on another path.
In view of its embedding in the MINUS theory, CNA—unlike most other methods—does not infer its output from associations (e.g., effect sizes) in the data as a whole; rather, it exploits difference-making evidence on the level of individual factor configurations instantiated by cases in the data. For example, if two configurations and coincide in all measured factors except for and , such that features and and features and , this is evidence—assuming the homogeneity of the unmeasured causal background (for details, see Baumgartner and Ambühl, 2020)—that makes a difference to in the causal background of and .3 It follows that must be part of some conjunction causally relevant for . Correspondingly, a pair of configurations as and is called a difference-making pair for the causal relevance of to (Baumgartner and Falk, 2023).
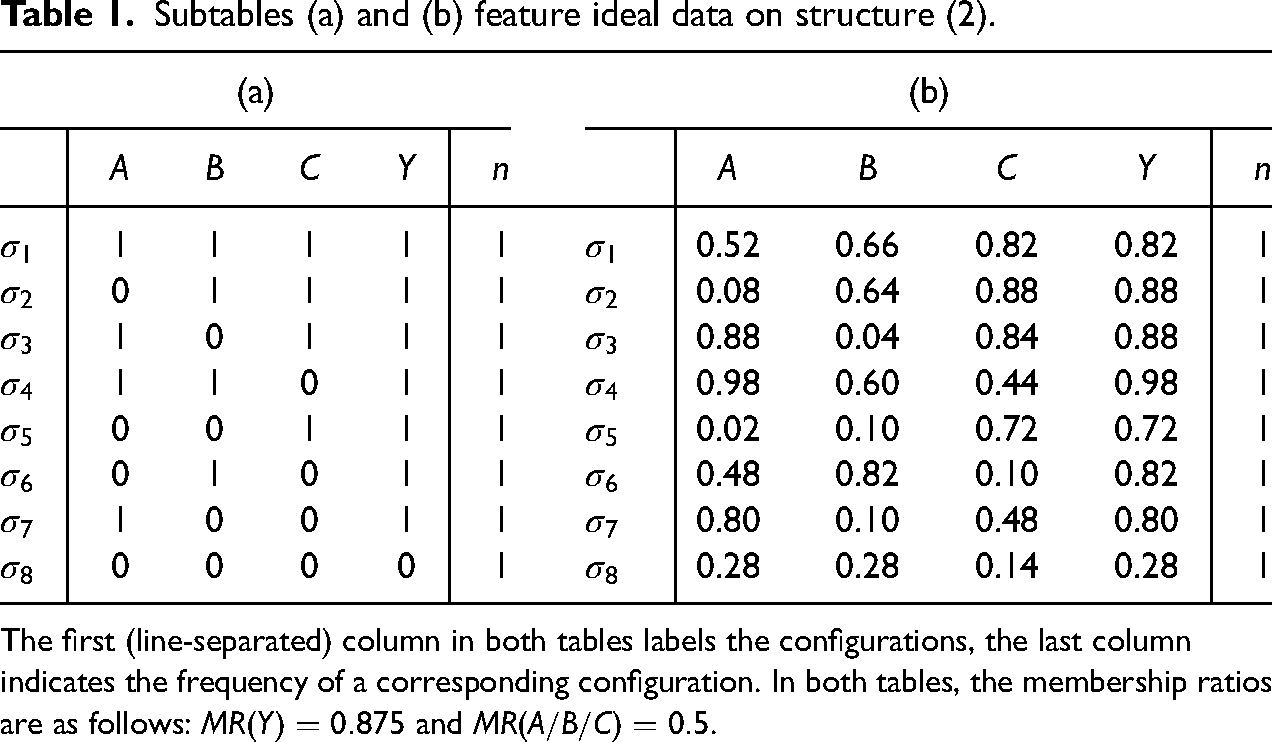
Subtables (a) and (b) feature ideal data on structure (2).
(a)
(b)
1
1
1
1
0.52
0.66
0.82
0.82
0
1
1
1
0.08
0.64
0.88
0.88
1
0
1
1
0.88
0.04
0.84
0.88
1
1
0
1
0.98
0.60
0.44
0.98
0
0
1
1
0.02
0.10
0.72
0.72
0
1
0
1
0.48
0.82
0.10
0.82
1
0
0
1
0.80
0.10
0.48
0.80
0
0
0
0
0.28
0.28
0.14
0.28
The first (line-separated) column in both tables labels the configurations, the last column indicates the frequency of a corresponding configuration. In both tables, the membership ratios are as follows: and .
The Problem of Imbalanced Data
As difference-making pairs are the main drivers of CNA’s inference to causation, the value distributions of factors above and below the 0.5-anchor may affect CNA’s performance. Notably in extreme scenarios, where all values of or are above or below the 0.5-anchor, the data do not contain any difference-making pairs whatsoever, for the simple reason that all cases are uniformly in or out of and . Without differences in set memberships, no difference-making pairs and, thus, no difference-making evidence. In order for data to contain reliably exploitable difference-making evidence, the value distributions of analyzed factors must be balanced so that an appropriate number of cases fall above and below the 0.5-anchor. Of course, the exact meaning of “appropriate” requires specification—which is the very topic of this paper.
Based on Oana et al. (2021), we define the membership ratio () in a crisp or fuzzy set to be the ratio of cases in data with X to all cases in .4 For example, means that takes a value in 80% of the cases in and a value in 20% of the cases. Whenever the value distributions of a factor do not partition the cases in the data into sets of roughly equal size, we speak of an imbalanced (or skewed) factor distribution. Imbalanced distributions come in degrees and are the higher the farther away membership ratios are from . However, data imbalances are the norm in applied research and most of them are unproblematic because they do not impair CNA’s performance. For to contain an appropriate amount of difference-making evidence, it suffices that membership ratios lie in some interval centered around 0.5. A factor only counts as problematically imbalanced if the membership ratio in is outside of this moderate interval. Problematic imbalances are those imbalances that our subsequent investigation shows to significantly weaken CNA’s performance, on average.
For QCA, Oana et al. (2021) propose that “as a rule of thumb” (p. 48) ratios outside of the interval are problematic. But they do not provide an argument for why this, rather than, say, is the relevant interval and they stress themselves that these are not fixed thresholds. Moreover, as there are many algorithmic differences between CNA and QCA (Swiatczak, 2022), the question as to the interval outside of which membership ratios should be considered problematic is entirely open for CNA at this point. Note that the CCM literature typically discusses data imbalances under the label of skewness (e.g., Schneider and Wagemann, 2012; Oana et al., 2021; Thomann and Maggetti, 2020), which must not be confused with skewness in statistics, where it is a measure for the asymmetry of the distribution of a variable around its mean (e.g., Tabachnick and Fidell, 2019). What matters for difference-making evidence in CCMs, however, are neither distributional symmetries nor mean factor values, but only the ratios of cases above and below the 0.5-anchor.5 For that reason, we prefer to speak of data imbalances or imbalanced distributions. Even so, we acknowledge that the term skewness has an established usage in CCMs and, occasionally, also speak of skewness or skewed distributions.6
The Case of Ideal Data
Before turning to the problem of demarcating the interval of problematic membership ratios, the special case of ideal data requires separate treatment. The reason is that, in ideal data, membership ratios can be extreme without any negative consequences for the performance of CNA. To see this, we first have to specify when data are ideal in configurational causal modeling. This is best accomplished by example. Thus, assume that the behavior of the factors in the set is regulated by the causal structure corresponding to this simple MINUS-formula, which we will refer to as the ground truth:
(2) entails that , , and are three alternative causes of . If we take the factors in to be crisp-set and hold additional causes of not contained in constant, it follows that the factors in can be combined in exactly the eight configurations listed in Table 1a. To generalize for the fuzzy-set case, Table 1b contains fuzzy-set data corresponding to the crisp-set configurations in Table 1a. As the factors in take a value above the 0.5-anchor in one of these tables exactly if they take such a value in the other one, both tables feature the same configurations.
There are logically possible ways of combining values above and below the 0.5-anchor of the 3 exogenous factors in (2), all of which are contained in Tables 1a and 1b. Moreover, these tables do not contain any configurations incompatible with (2), that is, (2) is true in all configurations of both tables.7 It follows that Tables 1a and 1b feature neither fragmentation nor noise.8 Fragmentation of a data set generated by a ground truth over a factor set is defined as the ratio of configurations of the factors in compatible with that are missing from . By contrast, data feature noise when some configurations in are incompatible with , which obtains if the left-hand and right-hand sides of the ’’ in the MINUS-formula corresponding to , and , are non-identical (e.g., due to measurement error or confounding). The higher the mean differences between and in , the higher ’s noise level. Accordingly, noise can be measured in terms of the mean absolute difference between and in the cases of :
Data with zero fragmentation and zero noise are ideal data. Thus, Tables 1a and 1b contain ideal data on ground truth (2) with each configuration realized by exactly one case. While the distributions of the exogenous factors are balanced in both tables, Y takes a value above in 7 of 8 cases, yielding . That is, even though Tables 1a and 1b contain ideal data, they feature an endogenous factor that is imbalanced to a degree that counts as problematic for QCA subject to Oana et al.’s (2021) rule of thumb. Clearly though, this extreme imbalance is all but problematic. Rather, it is induced by the form of the ground truth (2) itself. If case frequencies are kept constant, that is, if we ensure that all configurations are realized by an equal amount of cases, ideal data on structure (2) will always have very high membership ratios in Y. Despite the extreme imbalance of Y, CNA easily infers the MINUS-formula (2) from Tables 1a and 1b. Factor Y is imbalanced because, subject to the ground truth (2), there are three independent paths to produce , each of which is activated by simply instantiating one cause. That means the overwhelming majority of all logically possible configurations of the exogenous factors produce , which, correspondingly, occurs frequently in ideal data with constant case frequencies.
Plainly, not only high but also low membership ratios can be induced by the structure of the ground truth. Assume that, instead of (2), the following is the ground truth:
If the three causes of are not disjunctively concatenated as in (2) but conjunctively as in (4), three factors must jointly take values above 0.5 for to occur, which only happens in one of eight configurations in the ideal data on (4) in Tables 2a and 2b, where the membership ratio in is , while , , and are again perfectly balanced at . Just as in case of Table 1, CNA straightforwardly infers (4) from Tables 2a and 2b.
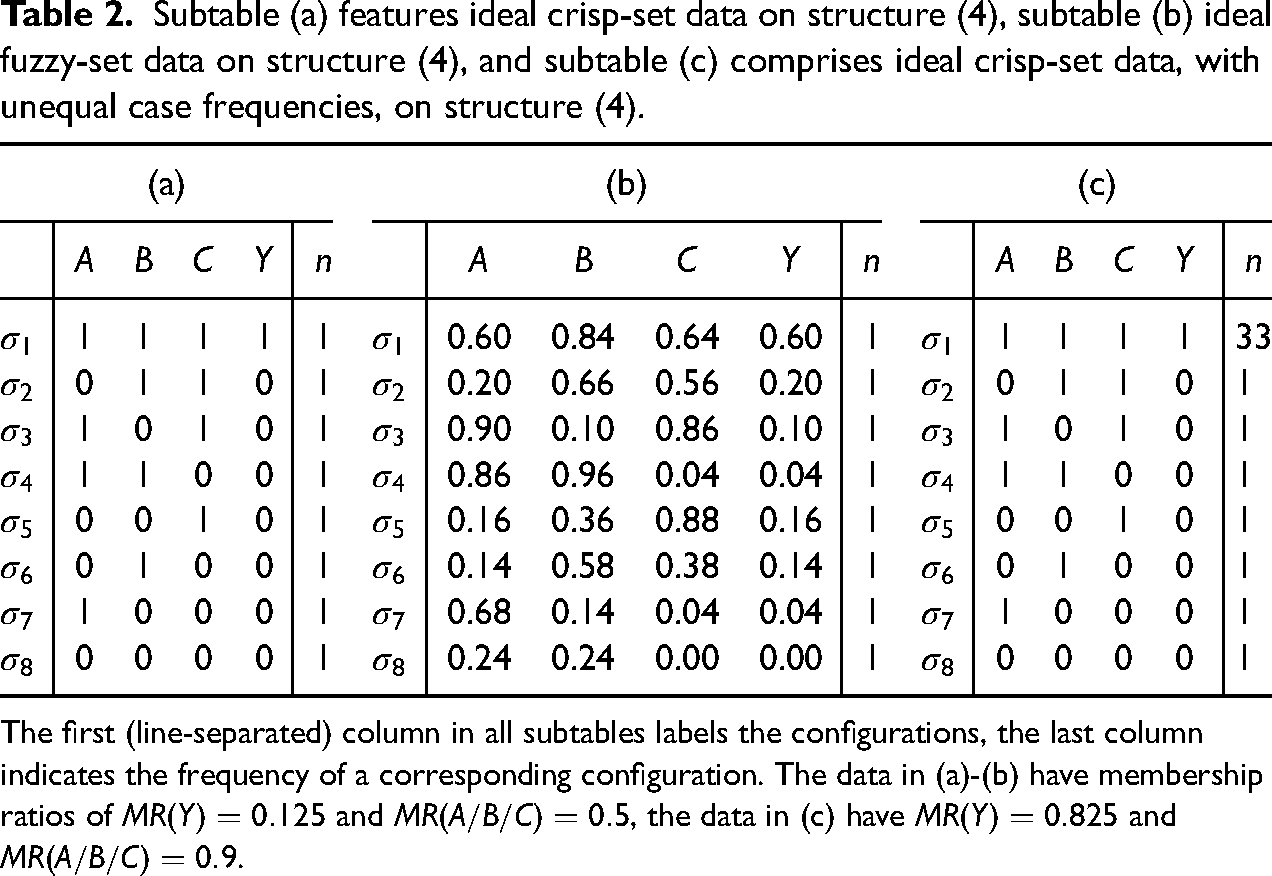
Subtable (a) features ideal crisp-set data on structure (4), subtable (b) ideal fuzzy-set data on structure (4), and subtable (c) comprises ideal crisp-set data, with unequal case frequencies, on structure (4).
(a)
(b)
(c)
1
1
1
1
0.60
0.84
0.64
0.60
1
1
1
1
0
1
1
0
0.20
0.66
0.56
0.20
0
1
1
0
1
0
1
0
0.90
0.10
0.86
0.10
1
0
1
0
1
1
0
0
0.86
0.96
0.04
0.04
1
1
0
0
0
0
1
0
0.16
0.36
0.88
0.16
0
0
1
0
0
1
0
0
0.14
0.58
0.38
0.14
0
1
0
0
1
0
0
0
0.68
0.14
0.04
0.04
1
0
0
0
0
0
0
0
0.24
0.24
0.00
0.00
0
0
0
0
The first (line-separated) column in all subtables labels the configurations, the last column indicates the frequency of a corresponding configuration. The data in (a)-(b) have membership ratios of and , the data in (c) have and .
In general, membership ratios in outcomes in ideal data with constant case frequencies depend on the structural properties of the ground truth in the following manner: Given a fixed number of conjuncts in , the more disjuncts has, the higher the membership ratio in the outcome in , as the outcome can be produced more easily (via more paths), that is, more frequently. Conversely, given a fixed number of disjuncts in , the more conjuncts has, the lower the membership ratio in the outcome in , as more conditions must be satisfied to produce the outcome, which is more difficult to accomplish and, correspondingly, occurs less frequently. We refer to imbalances that are induced by the properties of the ground truth as structure-induced. Note that, in ideal data with constant case frequencies, exogenous factors are always perfectly balanced, even when endogenous factors are affected by structure-induced imbalances.
However, ideal data are not required to have constant case frequencies. Some configurations may be realized by more cases than others in ideal data. To illustrate, consider Table 2c, which, like Table 2a, contains ideal crisp-set data on structure (4). But while all configurations in Tables 2a and 2b are realized by exactly one case, in Table 2c, configuration is realized much more frequently than all others (i.e., by 33 cases). This mismatch in case frequencies is not due to structural properties of (4), rather, cases realizing configuration just happen to be more frequent than cases realizing the other configurations. The frequency mismatch in Table 2c yields that all membership ratios are high: and . Plainly, if configuration instead of was realized more frequently, the result would not be high but low membership ratios. We refer to imbalances that are not induced by the properties of the ground truth as frequency-induced. As the example in Table 2c demonstrates, both exogenous and endogenous factors can be affected by frequency-induced imbalances in ideal data. But importantly, what we showed for CNA’s analysis of Tables 1a, 1b, 2a, and 2b also holds for Table 2c: The MINUS-formula inferred by CNA corresponds to the ground truth.
Overall, extreme imbalances, whether structure- or frequency-induced, do not impair CNA’s performance provided that the data are free of fragmentation and noise, that is, ideal. As indicated in the last section, difference-making pairs of configurations constitute the main inferential lever of CNA. Ideal data contain exactly those difference-making pairs that are characteristic for the underlying ground truth. How often factors take values above the 0.5-anchor or how frequently configurations are realized by cases is irrelevant for the difference-making evidence contained in ideal data and, correspondingly, for CNA’s analysis of such data. If the data contain all and only the difference-making pairs compatible with a ground truth, the latter will always be recovered by CNA. A demonstration of this is provided in an R-script contained in the paper’s supplemental online materials.
The same cannot be expected for fragmented or noisy data. CNA has to fit its models to non-ideal data by lowering the thresholds on its fit measures of consistency and coverage (Baumgartner and Ambühl, 2020), and these measures are sensitive to distributional imbalances generated by case frequencies. Frequency-induced imbalances may push consistency and coverage scores up or down in non-ideal data, thereby distort the signal in the data, and make it difficult to distinguish signal from noise. In the following simulation experiments we determine how data imbalances affect CNA’s performance when analyzing non-ideal data.
Simulation Experiments
We run a series of simulation experiments benchmarking the performance of CNA with noisy or fragmented data featuring varying degrees of distributional imbalances. The experiments are designed as inverse search trials. That is, we first randomly draw ground truths, second, simulate data from these ground truths featuring systematically varied membership ratios in all possible combinations with noise or fragmentation—which we hold constant in most of the trials—, third, analyze the data with CNA, and fourth, measure how frequently the ground truths (or proper parts thereof) are contained in CNA’s output. We use the implementation of CNA in the R-libraries cna and frscore (Ambühl and Baumgartner, 2023; Parkkinen, Baumgartner, and Ambühl, 2021). The code of the test series is available in the paper’s supplemental online materials.
Test Setup and Data Simulation
The series consists of four experiments, which differ in the investigated data characteristics. The data analyzed in all experiments are simulated from a stock of 1,000 ground truths to , randomly drawn from the factor set . As the execution time of the CNA algorithm increases, on average, with the complexity of the models to be built and as we process a total of over 100,000 data sets in the whole series, we have to restrict the maximal complexity of the ground truths . Hence, our have one outcome only and a maximum of three alternative paths (i.e., disjuncts), with a maximum of three causes on each path (i.e., conjuncts), producing the outcome. While many real-life CNA applications actually target causal structures within that complexity range, it must also be emphasized that this restriction has consequences for our experiments. Ground truths drawn within that complexity range tend to have endogenous factors with slightly structure-induced imbalances. More precisely, the average membership ratio in the outcome in ground truths satisfying our complexity restriction is about 0.4. How this affects our findings will be discussed in the results section. Finally, to test how frequently data imbalances induce CNA to erroneously include causally irrelevant factor values (i.e., non-causes) in its models, we ensure that, in all , there is at least one element of missing, values of which, thus, are causally irrelevant.
The first step of the data simulation process then is the same in all four experiments: For every , we generate ideal fuzzy-set data on the factors in , with a sample size of 50 cases each, yielding 1,000 ideal data sets to . For every it holds that the left- and right-hand sides of the MINUS-formula corresponding to have identical membership scores in each row of and that all configurations compatible with are represented by at least one case in . In the second and third step, we add noise or fragmentation to (see Table 3). In experiment 1, we add fragmentation but no noise, in experiment 2, we add noise but no fragmentation, and in experiments 3 and 4 we add both fragmentation and noise. Contrary to experiments 1, 2, and 3, where fragmentation is kept constant at the expense of varying sample sizes, we keep sample sizes constant in experiment 4 and allow fragmentation to vary.
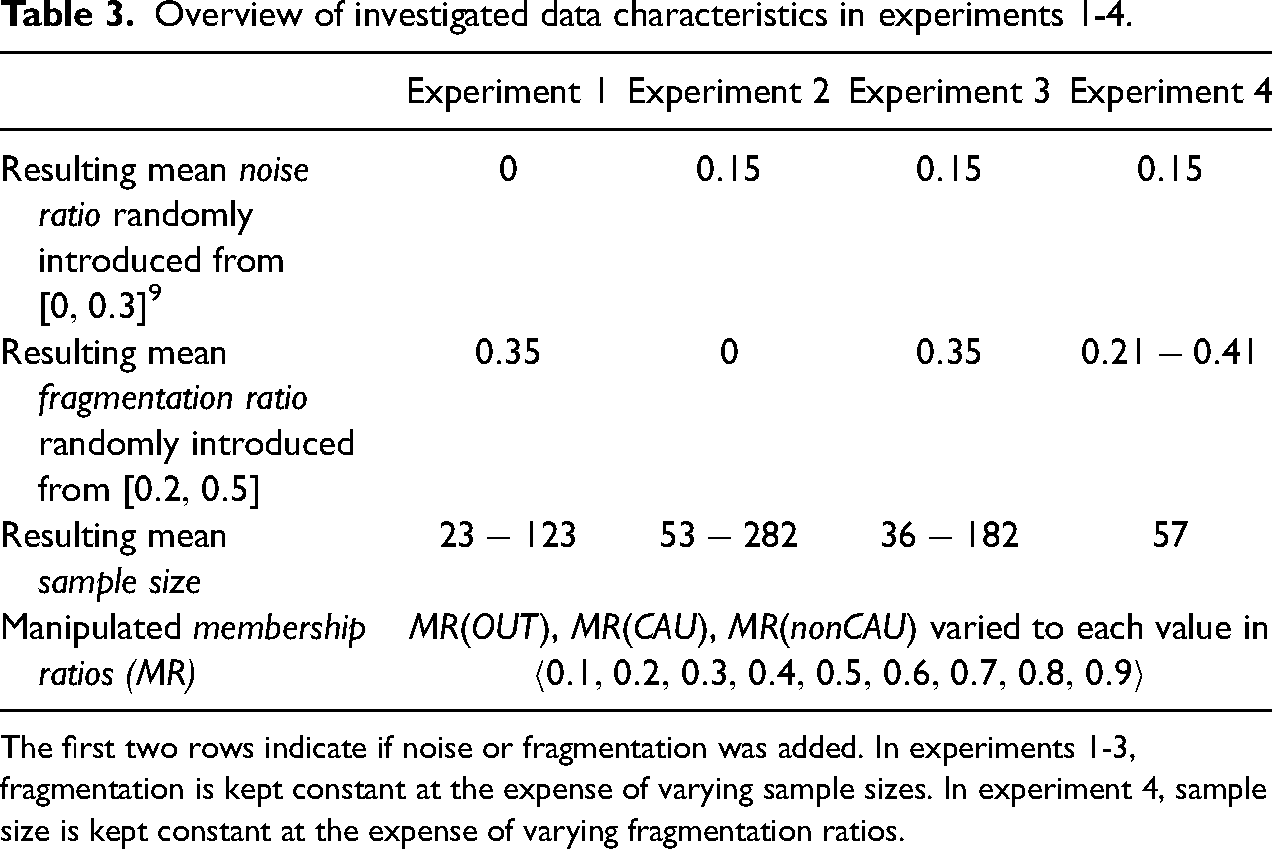
Overview of investigated data characteristics in experiments 1-4.
Experiment 1
Experiment 2
Experiment 3
Experiment 4
Resulting mean noiseratio randomly
introduced from
9
0
Resulting mean
fragmentation ratio
randomly introduced
from
0
Resulting mean
sample size
57
Manipulated membership
ratios (MR)
, , varied to each value in
The first two rows indicate if noise or fragmentation was added. In experiments 1-3, fragmentation is kept constant at the expense of varying sample sizes. In experiment 4, sample size is kept constant at the expense of varying fragmentation ratios.
Whenever noise or fragmentation are introduced, this is done at random. To randomly introduce noise into , we first draw a number from the interval . Second, we draw a sequence of normally distributed random errors from the interval with a length equal to the number of rows of such that, over all rows of , the mean absolute difference between the scores of and is equal to . Third, we replace the outcome value in every row of by the sum of that outcome value and the element of . The resulting data have a noise ratio equal to , meaning anywhere between and . To randomly fragment a data set , we draw a ratio from the interval and sample that ratio of configurations from (without replacement). The resulting data have a fragmentation ratio anywhere between and . The upshot of introducing noise or fragmentation into each in accordance with the requirements of the different experiments are non-ideal base data sets of type , where refers to the experiment and numbers the data set. For example, designates the base data for experiment 2.
In these base data sets, we then, in the fourth step, systematically manipulate case frequencies in order to modify selected membership ratios such that these ratios are transformed to each value in the following variation sequence:
This is done in three different legs of each experiment. In the first leg, case frequencies in are manipulated such that the membership ratio in the outcome (OUT) is transformed to each value of the variation sequence. In the second leg, a cause (CAU) is randomly selected in each and frequencies in manipulated such that the membership ratio in that cause assumes all values in the variation sequence. In the third leg, a non-cause (nonCAU) is selected in each and its membership ratio correspondingly transformed. That is, in every leg of an experiment, 9 (length of the variation sequence) frequency-manipulated data sets are built from every base set . As there are three legs in each of the four experiments, we end up with test data sets for the whole series. We will refer to them by , where indicates the experiment, the targeted membership ratio, the leg of the experiment, and numbers the data. For example, designates the 34 data set in the 3 leg of experiment 2, in which the membership ratio in a non-cause is transformed to .
As these data transformations are done by changing case frequencies in the base data, all resulting membership ratios are frequency-induced. In experiments 1–3, case frequencies are modified by suitably selecting cases from the base in such a way that the fragmentation and noise ratios of are retained (as closely as possible) in the transformed data . Depending on what the initial membership ratio is in , this selection process may cause to have a much larger sample size than . Also, the sample sizes of the test data vary greatly within each leg of an experiment. On average, test sets at the lower and upper ends of the variation sequence have much larger sample sizes than test sets targeting membership ratios around .
As sample sizes may influence the performance of CNA, experiment 4 varies membership ratios in such a way that, apart from noise ratios, also sample sizes are held constant across all data transformations. Selecting cases from the base set in such a way that noise and sample size stay the same can only be accomplished at the expense of varying fragmentation. That is, the test data may have much higher fragmentation than the corresponding base and fragmentation also varies within each leg of an experiment. Test sets targeting membership ratios around tend to have lower fragmentation than sets aiming for extreme ratios. Table 3 summarizes the settings for the four experiments.
Data Analysis and Benchmark Criteria
The 108,000 test data sets are analyzed by CNA using the robustness analysis protocol developed by Parkkinen and Baumgartner (2023). That means that each is not only analyzed at one designated tuning setting of consistency and coverage thresholds but re-analyzed at all settings in a whole sequence of consistency and coverage thresholds. For our analysis we choose the sequence . All MINUS-formulas CNA recovers in that re-analysis series are collected and their robustness and overall model fit measured and scored. For every , we then return the th percentile of top-performing MINUS-formulas as CNA’s output set for that data.
The elements of such a set, which contains between 1 and 6 models in our test series, are indistinguishable on the basis of the evidence contained in by current model selection standards used in CNA. Accordingly, if comprises more than one MINUS-formula, CNA cannot determine which of those formulas truthfully represents the ground truth ; all that can be said is that at least one of them is true of . It follows that a set featuring, say, three MINUS-formulas , , and is to be causally interpreted disjunctively: OROR is true of .11 If CNA returns multiple models in a real-life discovery context, an analyst has to rely on data-external sources of information as theoretical background knowledge to select among the candidates.12 As such a data-external background is not available for simulated data, we take the set inferred from to be CNA’s final output for these data. All in all, analyzing the data of our entire test series yields 108,000 output sets .
According to that criterion, what CNA infers from counts as correct if, and only if, that inference is true of the underlying ground truth . As we have seen above, that is the case if, and only if, at least one MINUS-formula in is true of , which, in turn, holds if, and only if, all factor values contained in are in fact causes of the outcome of and all conjunctive and disjunctive groupings in are in agreement with . In other words, is correct if, and only if, it entails no false positives.13 For example, if formula (1) from our previous example, i.e. , is the ground truth, models as or are correct because all factor values contained in these models are in fact causes of and all conjunctive and disjunctive groupings are true of (1). By contrast, a model as is incorrect because is not in fact a cause of , or is incorrect because and are conjunctively and not disjunctively grouped in (1). If CNA does not infer anything from and, thus, is empty—say, because consistency or coverage thresholds cannot be met— does not pass the correctness benchmark.
The second benchmark is a completeness criterion that quantifies the informativeness of correct MINUS-formulas. Making only true claims about , as is required to pass the correctness benchmark, can be easily accomplished by models that make only very few causal claims. Also, of two correct MINUS-formulas one can be more complex than the other and, hence, reveal more completely. As more informative models are preferable, the completeness benchmark measures the degree to which the correct MINUS-formulas in exhaustively reveal . More specifically, completeness amounts to the ratio of the complexity of the most complex correct MINUS-formula in to the complexity of , where complexity of a MINUS-formula is understood as the number of factor values in . That is, contrary to correctness, which can only be either satisfied or not, the second benchmark can be passed by degree. For example, if (1) is the ground truth, models as or score on completeness, as they recover two of the four factor values contained in the ground truth. When is either empty or does not contain a correct MINUS-formula, completeness is 0 by default.
As a supplement, we measure a third auxiliary criterion, error-freeness, that is also qualitative and counts as passed if, and only if, as a whole is not false. Contrary to correctness and completeness, error-freeness is non-zero both if contains a MINUS-formula that does not entail a false positive and if is empty. As an empty output set is uninformative and thus suboptimal, error-freeness is not a benchmark on a par with correctness and completeness, and our subsequent discussion will mainly focus on the latter two benchmarks. Nonetheless, error-freeness deserves some attention because an empty output is still preferable over a false one.
Results
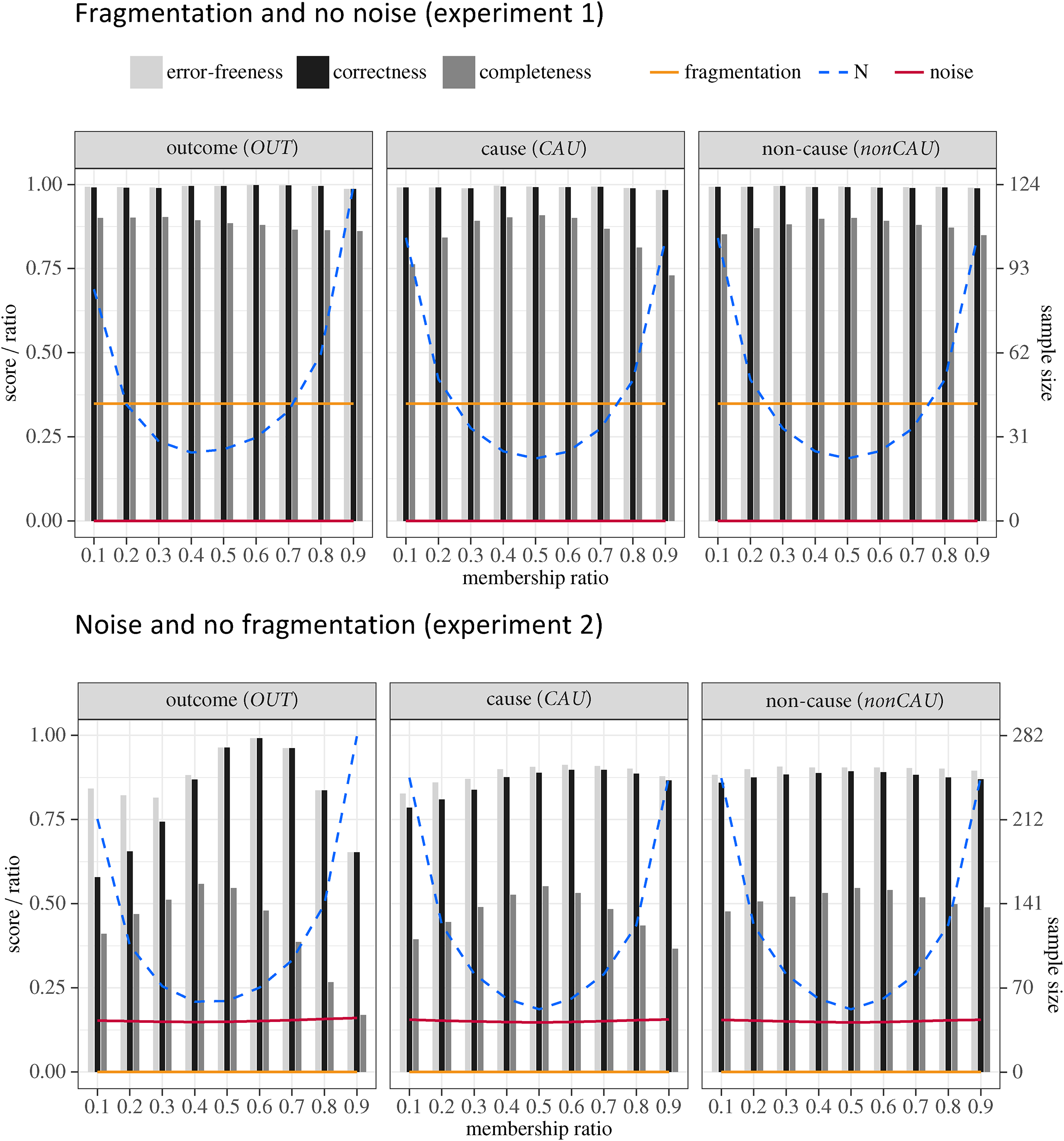
The results of experiments 1 and 2 are plotted in the bar-charts in Figure 1, Figure 2 shows the results of experiments 3 and 4. Black bars represent correctness scores, dark gray bars completeness scores, and light gray bars depict error-freeness scores. The effects of varying membership ratios in an outcome, a cause, and a non-cause are presented in separate panels. The exact values of all scores can be found in the score tables in the paper’s supplemental online materials. Apart from the benchmark scores, the plots also display fragmentation and noise ratios as well as sample sizes. All values are means over 1,000 CNA analyses of 1,000 test data . For example, the correctness score of 0.99 depicted by the first (black) bar in the leftmost panel in the plot of experiment 1 in Figure 1 means that CNA found a correct MINUS-formula for 99% of the 1,000 test data of type . The fragmentation score of 0.35 superimposed over that bar means that, on average, 35% of rows compatible with the corresponding ground truths are missing from the 1,000 .14
Results of experiments 1 and 2, subdivided by their three legs. Membership ratios are plotted on the -axis, benchmark scores (black and shades of gray), noise (red), and fragmentation ratios (orange) are on the left -axis, sample sizes (blue) on the right -axis. All values are means over 1,000 CNA runs.
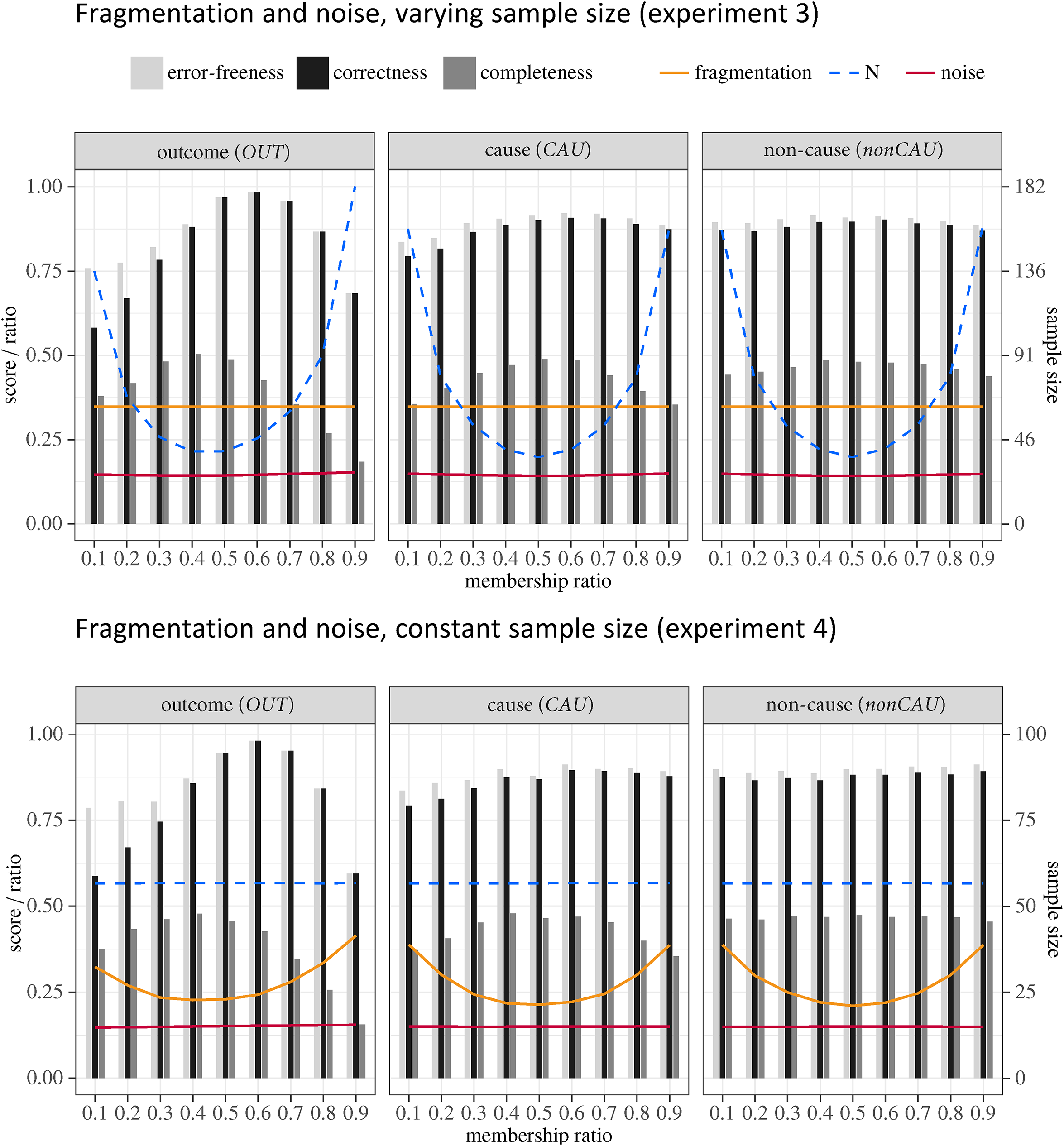
Results of experiments 3 and 4, subdivided by their three legs. Membership ratios are plotted on the -axis, benchmark scores (black and shades of gray), noise (red), and fragmentation ratios (orange) are on the left -axis, sample sizes (blue) on the right -axis. All values are means over 1,000 CNA runs.
First and foremost, our results demonstrate, that increasing distributional imbalances may be associated with decreasing performance even when fragmentation, noise, or sample size are kept constant. This, in turn, shows that data imbalances do not only exacerbate the negative effects of other data deficiencies but also have an independent negative effect. In what follows, we break this main finding down in more detail.
Fragmentation vs. Noise
Data imbalances have weaker effects when paired only with fragmentation than when paired with noise. In all three legs of experiment 1, where fragmented but noise-free data are processed, correctness scores remain almost maximal (between 0.98 and 1). Maximal completeness, however, cannot be achieved because of the fragmentation, which amounts to missing empirical information about ground truths . In legs 1 and 3, varying membership ratios only barely affect completeness scores (which remain between 0.85 and 0.90) beyond the impact of fragmentation. In leg 2, distributional imbalances drag completeness down noticeably. If is set to or , the cause is so rare that it is no longer needed to cover the outcome and thus is not built into the models. By contrast, in the trials with , the cause is so frequent that it covers the outcome even without other causes, which therefore become redundant and are not built into the models. In both scenarios, some causes are missing from CNA’s models in addition to those that are missing due to fragmentation alone.
In experiments 2–4, where data feature noise, both correctness and completeness scores drop significantly compared to experiment 1 because CNA cannot persistently avoid false positives in the presence of noise, which, after all, amounts to incorrect information about . Moreover, in trials when all models in make false claims about , both correctness and completeness are 0. Completeness drops more than correctness because CNA is designed to keep false positives to a minimum, meaning that the method abstains from including a factor value in a model, if its causal relevance is not sufficiently corroborated by the data. The more cautiously a method operates, the less causal inferences it draws, the lower the chances that false positives are committed, yet the less completely is recovered.
Owing to its cautiousness, CNA frequently abstains from drawing any inferences when the outcome is very rare in experiments 2–4. The result are empty output sets in up to 25% of the trials, which can be read off the large difference in correctness and error-freeness scores at the lower end of the variation sequence. Error-free trials that do not pass correctness are trials with empty outputs. In consequence, error-freeness scores remain above 0.75 in all experiments even when the outcome is very rare. By contrast, when , there are no longer any empty outputs, to the effect that error-freeness and correctness coincide and drop well below 0.75. The reason is overfitting. Due to the noise, conjunctions of only one or two factor values are not consistently sufficient for the outcome, such that CNA builds rather complex minimally sufficient conditions, on average. And in order to cover a very frequent outcome with complex conditions, large disjunctions of many of these conditions are needed. In 35%–40% of the trials on noisy data at , CNA’s output sets contain only overfitted models.
Performance Peaks
Another feature of the results obtained in the first leg of experiments 2–4 is that, across all variations of , CNA scores highest on completeness at and highest on correctness at . Why are these performance peaks off-centered? To answer this question recall from the test setup that outcomes have an average structure-induced membership ratio of roughly in the ground truths to , which, in turn, stems from the complexity restriction imposed on them. Deviations from structure-induced membership ratios in our experiments are due to biased case frequencies and hence tend not to be faithful to the structural properties of . The more we increase that frequency bias as we move through the variation sequence, the higher the chances that CNA builds elements into its models that fail to have counterparts in . The complex models contained in output sets have the highest chances of being true of in trials at because, in these trials, case frequencies are manipulated the least, on average, meaning that membership ratios are most faithful to the structural properties of . The higher the chances that complex CNA models in are true, the higher CNA’s completeness scores.
But then, why are the correctness scores, even though they are good at (i.e., between 0.85 and 0.88), not the highest in those trials as well? To understand that, recall that we analyze each data set at a whole range of threshold combinations, going down to consistency and coverage set to . The lower these thresholds, the less accurately models are required to account for the outcome, the higher the chances that very sparse models pass the thresholds. And the sparser a MINUS-formula , the less causal claims it makes, which, in return, increases the probability that does not make any false claims and, thus, is true of . The sparsest possible MINUS-formulas are one-cause formulas of type . In our test series, CNA’s output sets contain the most one-cause formulas at . The fact that the MINUS-formulas with the highest a priori probability of being true are the most frequent in the trials at pushes CNA’s correctness score even higher than it is at (i.e., to scores between 0.98 and 0.99).
Outcome vs. Causes vs. Non-Causes
Finally, our results show that extreme membership ratios have varying performance impacts depending on whether they affect the outcome, a cause, or a non-cause. In all experiments, extreme membership ratios in non-causes have no significant effect on performance beyond fragmentation and noise. That means they do not induce CNA to erroneously include non-causes in models more frequently than they are included because of other data deficiencies. In contrast, extreme membership ratios in causes have sizeable effects on completeness scores in all experiments. The same mechanism as in experiment 1 accounts for this finding in all other experiments. That is, rare causes are often not included in models and frequent causes tend to render other causes redundant, which then are not included. In addition, extreme membership ratios in causes, when combined with noise (i.e., in experiments 2–4), induce a noticeable drop in correctness. Still, correctness scores do not fall below 0.79 and correctness drops are counterbalanced by error-freeness scores well above 0.8, meaning that CNA repeatedly issues no models at all.
In general, when data feature noise (i.e., in experiments 2–4) the performance impact is much higher if the endogenous factors are imbalanced than if exogenous factors are concerned. The reason is that while every has only one outcome, most have several causes, yet only the frequency of one of these is manipulated in our experiments. Thus, whereas frequency distortion in one cause can be counterbalanced by correctly inferred causal claims on other causes, this is not possible with frequency distortion in the outcome which then tends to hinder the correct recovery of the whole .
Discussion
We set out to answer the question whether data imbalances have their own impact on CNA’s performance. In the case of ideal data, even extreme imbalances have no such impact. However, we have seen that in case of non-ideal data, which are common in real-life research settings, extreme membership ratios affect CNA’s performance. It remains to be determined, first, which membership ratios should count as problematic for CNA, second, what counter-measures can be taken to resolve problematic distributional imbalances, and, third, what our study’s limitations are.
Demarcating Problematic Membership Ratios
In light of our results, the answer to the first question depends on an array of conditions such as the quality of the data at hand, the type of factor(s) with extreme imbalances, whether the analysts are primarily interested in correct or complete models, and how willing they are to take a risk. Accordingly, there does not exist a general and objective demarcation between problematic and unproblematic membership ratios. In what follows, we determine whether a performance drop in a particular benchmark measure within a leg of an experiment is problematic by comparing it to the best benchmark score in that leg. In order for a drop to count as problematic we require the difference to the best performance to be higher than 20%. Readers with a different assessment of what counts as problematic have to correspondingly adjust our subsequent demarcations.
If it can be plausibly assumed that the data are collected against a homogeneous background, such that noise is negligible and the only serious data deficiency is fragmentation, distributional imbalances tend not to affect performance beyond fragmentation. The only exception, as the second leg of experiment 1 shows, is that causes with extreme membership ratios noticeably reduce the completeness of CNA’s models. At , CNA recovers 91% of the ground truths, on average, whereas this percentage drops to 76% at and to 73% at , which amount to performance drops of 16.5% and 19.8%, respectively. Although the latter drop borders on the problem zone identified above, the fact that the overall completeness scores remain high throughout the second leg of experiment 1 lets us confidently conclude that these completeness drops, though sizeable, are not to be considered problematic.
This changes when the data are noisy. In the second leg of experiment 2, the best completeness score is 0.55 at ; it drops by more than 20% at and , and similarly in the second legs of experiments 3 and 4. Hence, in the presence of noise, membership ratios of causes outside of the interval drag down completeness to a problematic extent. It follows that somebody with an interest in learning as much as possible about the ground truth should consider countermeasures.
The same does not hold if analysts are primarily interested in correct models, that is, in reliably finding parts of the data-generating structure. While has no effect on correctness at all, correctness drops from a solid score of 0.9 at by about 12% to 0.79 at when the data are noisy. But at the same time, error-freeness remains between 0.83 and 0.85, meaning that the loss in correctness is to a substantive degree due to empty outputs. That is, there is a slightly increased risk of inferring something false at , but that increase is not severe enough to call for countermeasures against distributional imbalances; if an error risk of 15% is considered too high, taking measures against the noise in the data would be more effective.
The most problematic impact extreme membership ratios have on the correctness of CNA’s output occurs when endogenous factors are imbalanced in noisy data. In experiments 2–4, correctness and error-freeness collapse at . While correctness and error-freeness are between 0.84 and 0.87 at in the experiments with noise, these scores drop to values between 0.6 and 0.65 at . Compared to the best correctness scores at , that is a performance drop of almost 40%, down to a level where, in 2 out of 5 CNA runs, all resulting models are fallacious. That is unquestionably an instance of a problematic distributional imbalance.
The situation is not so clear in case of low membership ratios in outcomes. At , CNA only recovers a true model in 58%–67% of the trials, but these low correctness scores are largely due to the fact that CNA often abstains from inferring any models at all. When conditionalized on the trials that produce non-empty outputs, correctness does not fall below 0.75 at in any of our experiments. If a fallacy risk of 25%—in contexts where up to 30% of the observations are distorted by noise—is acceptable to the analyst, even an extremely rare outcome hence does not call for immediate countermeasures. Instead, CNA could be run to see if an output is produced. If that is not the case, the low membership ratio in the outcome is the likely source of the problem, making it an instance of a problematic imbalance after all.
Finally, at the completeness of the output CNA infers from noisy data is reduced by about 25%, which is deep within the problem zone. Similarly, high outcome membership ratios are very consequential for the completeness of CNA’s output in the presence of noise. At completeness drops between 25% and 30% compared to the optimal membership ratio; at completeness is cut in half, and at two thirds of the information CNA recovers at the optimal membership ratio are lost, on average. Hence, if maximal informativeness is a research objective and the data cannot plausibly be assumed to be noise-free, membership ratios in the outcome outside of the interval should be considered problematic.
In sum, based on our convention that performance drops need to be larger than 20% to count as problematic, we propose the following demarcation lines for problematic data imbalances, assuming a typical real-life research with the following two characteristics: First, neither fragmentation nor noise can plausibly be excluded, and second, only outcomes and candidate causes can be distinguished, but the latter cannot be grouped into causes and non-causes. If the analyst is primarily interested in finding a correct model, only is problematic. Yet, if the research context requires learning as much as possible about the data-generating structure, membership ratios in outcomes outside of the interval or membership ratios in candidate causes outside of the interval are problematic.
Resolving Problematic Distributional Imbalances
When it comes to taking countermeasures, problematic distributional imbalances affecting the correctness of CNA’s output must be distinguished from problematic imbalances affecting completeness. The former type requires countermeasures before CNA is applied to the data, whereas the latter type may be addressed after initial applications of CNA are found not to deliver satisfactory results. If an outcome is imbalanced at , CNA’s output cannot be trusted in non-ideal discovery circumstances, making it imperative to take immediate action. By contrast, if the data are imbalanced in a way that does not create problems for correctness but only for completeness, say, an outcome has a membership ratio of 0.2 or 0.1, the analyst may well run an analysis and inspect the results before any action is taken. Our simulations indicate that the likelihood of not receiving any model are high. But if a non-empty output is produced under such circumstances, it may be given consideration. In fact, we have seen that such outputs are correct in 80% of the trials. Thus, if these outputs are informative enough for the research question at hand and analysts are ready to accept a fallacy risk of 20%, they can take such outputs seriously without addressing distributional imbalances. Yet, if it turns out that CNA does not return any models or that returned models are not informative enough, resolving distributional imbalances will be a promising path forward.
There are three main approaches to resolve distributional imbalances: (1) adding or removing cases, (2) adjusting membership scores via recalibration, and (3) negating values of imbalanced factors. We take them in turn. Approach (1) consists in suitably changing the sample of cases in the data. To resolve a problematically high membership ratio in , cases can be added to the data in which the factor takes values below 0.5 or cases can be removed in which takes values above . Analogously, if is problematically low, cases with membership scores above can be added or cases with membership scores below removed. Both adding and removing cases require to reassess the case selection decisions in the study design. For instance, complementing the data in a study analyzing employees from a particular industry by cases featuring employees from another (comparable) industry shifts the study’s analytical focus to employees in the union of both industries. Or, cases can be removed from that study by shifting the level of analysis from all employees in an industry to a particular group of employees from that industry, say, employees without leadership positions. Plainly, such case selection adjustments should not only be assessed based on their capacity to resolve problematic distributional imbalances but, in the first place, they must be theoretically meaningful and in line with the research interests at hand. Avoiding problematic imbalances is only one constraint among many to be taken into account when selecting cases. Moreover, note that after cases have been added or removed in order to resolve the problematic imbalance of some factor , the distributions of all factors must be reassessed, not just of . The reason is that changing the data basis might resolve the distributional problem for but create it for another factor.
Moreover, other constraints must be kept in mind when adding and removing cases to and from the data. First, added cases should have homogenous causal backgrounds and they should be comparable to the cases already contained in the data. For example, if a study affected by problematic imbalances is concerned with Western democracies, adding cases from the set of Asian autocracies will, in all likelihood, induce homogeneity violations and, thereby, render the resulting models uninterpretable. Second, removing cases should, if possible, not increase fragmentation, that is, it should not reduce the number of configurations instantiated in the data and thus reduce the amount of difference-making evidence. In other words, cases should primarily be removed that instantiate configurations which have various other cases instantiating them in the data.
By contrast, when membership ratios are modified by recalibration in the vein of approach (2), the imbalance of one factor can be tackled without affecting the distribution of the other factors. To this end, the number of ’s values above and below the 0.5-anchor is changed by moving the cross-over calibration threshold defining the 0.5-anchor. If is too frequent, that threshold is moved up such that less cases are calibrated to instantiate , whereas if is too rare, the cross-over threshold is moved down such that more cases instantiate .
Note that recalibration also requires changes to the study design, as shifting calibration thresholds changes the subject matter of the analysis; it moves the analytical interest from a problematically imbalanced factor to a different, non-problematic one. Such adjustments must, of course, also be theoretically justified and in line with the study’s research goals. To illustrate, shifting the subject matter via recalibration can be an option when the imbalanced factor represents a concept for which a bias towards higher or lower values that is not induced by the causal structure under investigation can be observed. A concept as self-perceived competence (or self-efficacy) is an example for which many studies observe a general positivity bias resulting in high membership ratios (e.g., Swiatczak, 2021; Gabriel et al., 2018; Schnell, Höge, and Pollet, 2013). If the aim of the study is not to investigate the causal structure underlying overly positive competence assessments, the bias can be counterbalanced by changing the subject matter of the analysis from, say, “competent employees” to “highly competent employees”. In addition, it is clear that such recalibrations should also follow general calibration guidelines (e.g., Oana et al., 2021). Unproblematic distributions are merely one constraint among many to be considered in the calibration process.
Finally, while it can happen that approaches (1) and (2) are inapplicable because there may not be justifiable ways of changing the data basis or the calibration thresholds, approach (3) is always applicable. It amounts to simply replacing an with a problematic membership ratio by its negation , that is, . To illustrate, consider a scenario where is an outcome with a membership ratio of and an initial CNA analysis produces a model that is not informative enough. According to our findings, ’s membership ratio counts as problematic in that scenario. If is now replaced by , the previously problematic membership ratio becomes a ratio of (i.e., ), which our results show not to count as problematic. In fact, we have found that an outcome membership ratio of is almost optimal for completeness maximization in the presence of fragmentation and noise.
Not only is approach (3) always applicable, it also does not require intricate considerations on changing the data basis or the calibration. On the downside, however, it is not always possible to resolve problematic imbalances by simple negation. In particular, when both and fall into ranges of problematic membership ratios, which, according to our findings, holds if is an exogenous factor, approach (3) does not solve the problem. Also, while the adjustments of the study design induced by approaches (1) and (2) may be small, negating outcomes or causes amounts to reversing the subject matter of the study entirely. It shifts the focus from investigating the presence of factors to their absence.
Limitations
Our study’s limitations originate from design decisions we had to take when simulating data. For reasons of computational feasibility, we had to restrict the complexity of the assumed ground truths to structures with one outcome and a complexity range of one to three disjuncts, each consisting of one to three conjuncts. Ground truths were randomly drawn from that complexity range to the effect that resulting ground truth complexities are normally distributed in that range. As pointed out before, the outcomes in those ground truths have mean structure-induced membership ratios of about , which, ultimately, off-centered the demarcation lines we found for problematic imbalances.
While we are confident that the (unknown) ground truths in a majority of actual CNA applications fall into our complexity range, causal structures analyzed by CNA may, of course, have higher complexities, which moreover may not be normally distributed. We suspect that the intervals demarcating problematic distributional imbalances will be more centered, on average, if more complex grounds truths are taken into account, but our study provides no basis for making such a determination. And it is an open question what membership ratio intervals should count as problematic if the complexities of real-life causal structures are not normally distributed. At the same time, as ground truth complexities do not influence the distributions of mutually independent exogenous factors, we have every reason to expect that our findings on causes and non-causes can be generalized to single-outcome ground truths with higher complexities—even if the latter are not normally distributed.
The same does not hold for ground truths with multiple outcomes. Although its capacity to analyze data stemming from multi-outcome structures is one of CNA’s distinctive qualities, we could not integrate that additional layer of complexity into this study. Investigating problematic membership ratios for such structures, hence, remains an important open question.
Furthermore, again for reasons of computational feasibility, we could not systematically vary fragmentation and noise in a controlled manner, even though it is very likely that demarcation lines for problematic data imbalances change with varying levels of fragmentation and noise. Also, fragmentation and noise may be biased in real-life research contexts, to the effect that imbalances affect CNA’s performance in ways unforeseen by our analysis. Finally, when manipulating distributions of exogenous factors we did so for only one exogenous factor in each trial. But, of course, in real-life settings multiple exogenous factors may be imbalanced to varying degrees. It is to be expected that extreme imbalances in more than one such factor interact and negatively impact on performance much beyond the impact we found in our experiments. But quantifying that impact has to await another occasion.
Finally, the reader shall be reminded that our criterion for demarcating problematic from unproblematic performance drops is negotiable. A reader with a different view of what counts as a problematic drop in performance is invited to correspondingly adjust the membership ratio intervals that call for measures against imbalances.
Outlook
This is the first study investigating how data imbalances affect the performance of CNA, in particular, and the first study quantifying that impact for a CCM, in general. Even though CCMs, contrary to many other methods, do not infer causation from distributional properties of the data but from difference-making pairs contained therein, our results show that extreme imbalances can affect both the correctness and the completeness of CNA’s output. The reason, in a nutshell, is that extreme distributional imbalances induce CNA to mistake noise for signal. That mechanism remains underinvestigated despite our study. Further analyses are needed to determine how varying membership ratios impact on performance under the discovery circumstances we had to bracket for reasons of computational feasibility. And we submit that similar studies aiming at quantifying the performance impact are needed for other CCMs, such as QCA.
Another avenue for future research derives from the fact that even extreme distributional imbalances do not negatively affect CNA’s performance when applied to ideal data. We envisage that the closer analyzed data are to ideal data, the lower the negative impact of such imbalances. It follows that a technique estimating the closeness of the data to ideality would likewise provide an estimate for the severity of the performance impact to be expected from problematic distributional imbalances. Such a technique is lacking at the moment.
In sum, our study shows that the problems posed by data imbalances are to be taken seriously—more seriously than they currently are—by both methodologists and applied researchers. The former need to address the many remaining questions surrounding distributional imbalances and CNA (or CCMs, more generally). The latter should learn to take analytical decisions, from the study design to the interpretation of the results, with an eye on distributional imbalances.
Footnotes
Acknowledgments
We thank the audiences at the 9th International QCA Expert Workshop in Zürich and the 1st International Conference on Current Issues in Coincidence Analysis in Bergen, where earlier versions of this article were presented, for valuable exchanges. We also thank Judith Glaesser, Reiping Huang, and Sebastian Klein, as well as two anonymous reviewers for helpful comments and suggestions.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
We gratefully acknowledge the support by the Toppforsk program of the University of Bergen, co-financed by the Trond Mohn Foundation under grant number 811886.
ORCID iDs
Martyna D. Swiatczak
Michael Baumgartner
Data Availability Statement
The datasets generated during this study are available or can be replicated via the replication materials in the OSF repository (Swiatczak and Baumgartner, 2024).
Supplemental Material
Supplemental and replication materials for this article are available in the OSF repository (Swiatczak and Baumgartner, 2024).
Notes
Author Biographies
Martyna Daria Swiatczak is a postdoctoral research fellow at the Department of Philosophy of the University of Bergen. She applies the configurational method of Coincidence Analysis (CNA) in her field of expertise, organizational behavior, and methodologically develops CNA. Her methodological research focuses on topics related to the algorithmic foundations of configurational comparative methods and to the systematic understanding of data preparation processes for such methods.
Michael Baumgartner is a full professor at the Department of Philosophy of the University of Bergen, with a specialization in the philosophy of science and logic. He developed the configurational method Coincidence Analysis (CNA) and has numerous publications on causation, causal reasoning, and data analysis with different methods. Moreover, he has worked on mechanistic constitution, cognition, interventionism, determinism, and logical formalization; and he is a co-developer of the CNA software libraries for the R environment for statistical computing.
BaumgartnerMichaelFalkChristoph. 2023. “Boolean Difference-Making: A Modern Regularity Theory of Causation.” The British Journal for the Philosophy of Science74 (1): 171–197.
6.
BaumgartnerMichaelAmbühlMathias. 2020. “Causal Modeling with Multi-Value and Fuzzy-Set Coincidence Analysis.” Political Science Research and Methods8: 526–542.
7.
BrittDavid W.RisingerSamantha T.MillerVirginiaMansMary K.KrivcheniaEric L.EvansMark I.. 2000. “Determinants of Parental Decisions After the Prenatal Diagnosis of Down Syndrome: Bringing in Context.” American Journal of Medical Genetics93 (5): 410–416.
8.
ChawlaNitesh V. 2010. “Data Mining for Imbalanced Datasets: An Overview.” Pp. 875-886 in Data Mining and Knowledge Discovery Handbook, edited by Oded Maimon and Lior Rokach. New York: Springer.
9.
EdiantoAchmedTrencherGregoryMatsubaeKazuyo. 2022. “Why Do Some Countries Receive More International Financing for Coal-fired Power Plants Than Renewables? Influencing Factors in 23 Countries.” Energy for Sustainable Development66: 177–188.
10.
EppleRuediSchiefSebastian. 2016. “Fighting (For) Gender Equality: The Roles of Social Movements and Power Resources.” Interface8 (2): 394–432.
11.
GabrielAllison S.CampbellJoanna TochmanDjurdjevicEmilijaJohnsonRussell E.RosenChristopher C.. 2018. “Fuzzy Profiles: Comparing and Contrasting Latent Profile Analysis and Fuzzy Set Qualitative Comparative Analysis for Person-Centered Research.” Organizational Research Methods21 (4): 877–904.
GoertzGary. 2020. Social Science Concepts and Measurement: New and Completely Revised Edition. Princeton: Princeton University Press.
14.
HaesebrouckTim. 2023. “The Populist Radical Right and Military Intervention: A Coincidence Analysis of Military Deployment Votes.” International Interactions49 (3): 345–371.
15.
LemmonE. J. 1965. Beginning Logic. London: Chapman & Hall.
16.
MackieJohn L. 1974. The Cement of the Universe. A Study of Causation. Oxford: Clarendon Press.
17.
OanaIoana-ElenaSchneiderCarsten Q.ThomannEva. 2021. Qualitative Comparative Analysis (QCA) Using R: A Beginner’s Guide. Cambridge: Cambridge University Press.
18.
ParkkinenVeli-PekkaBaumgartnerMichael. 2023. “Robustness and Model Selection in Configurational Causal Modeling.” Sociological Methods & Research52 (1): 176–208.
19.
ParkkinenVeli-PekkaBaumgartnerMichaelAmbühlMathias. 2021. frscore: Functions for Calculating Fit-Robustness of CNA-Solutions. R Package Version 0.1.1.https://cran.r-project.org/package=frscore.
20.
RaginCharles C.2009. Redesigning Social Inquiry: Fuzzy Sets and Beyond. Chicago: University of Chicago Press.
21.
RihouxBenoîtRagin,Charles C. ed. 2009. Configurational Comparative Methods: Qualitative Comparative Analysis (QCA) and Related Techniques. London: Sage Publications.
22.
SchneiderCarsten Q.WagemannClaudius. 2012. Set-Theoretic Methods For the Social Sciences: A Guide to Qualitative Comparative Analysis. Cambridge: Cambridge University Press.
23.
SchnellTatjanaHögeThomasPolletEdith. 2013. “Predicting Meaning in Work: Theory, Data, Implications.” Journal of Positive Psychology8 (6): 543–554.
24.
SpirtesPeterGlymourClarkScheinesRichard. 2000. Causation, Prediction, and Search. 2 ed. Cambridge: MIT Press.
25.
SwiatczakMartyna D. 2021. “Towards a Neo-configurational Theory of Intrinsic Motivation.” Motivation and Emotion45 (6): 769–789.
26.
SwiatczakMartyna D. 2022. “Different Algorithms, Different Models.” Quality & Quantity56: 1913–1937.
27.
SwiatczakMartyna D.BaumgartnerMichael. 2024. “Replication Material for ‘Data Imbalances in Coincidence Analysis: A Simulation Study.’” OSF. osf.io/9nc68/
ThiemAlrikDuşaAdrian. 2013. Qualitative Comparative Analysis with R: A User’s Guide. New York, NY: Springer.
30.
ThomannEvaMaggettiMartino. 2020. “Designing Research With Qualitative Comparative Analysis (QCA): Approaches, Challenges, and Tools.” Sociological Methods & Research49 (2): 356–386.
31.
von HippelPaul T. 2013. “Should a Normal Imputation Model be Modified to Impute Skewed Variables?” Sociological Methods & Research42 (1): 105–138.
32.
WomackDana M.MiechEdward J.FoxNicholas J.SilveyLinus C.SomervilleAnna M.EldredgeDeborah H.SteegeLinsey M.. 2022. “Coincidence Analysis: A Novel Approach to Modeling Nurses’ Workplace Experience.” Applied Clinical Informatics13 (4): 794–802.
33.
YakovchenkoVeraMiechEdward J.ChinmanMatthew J.ChartierMaggieGonzalezRachelKirchnerJoAnn E.MorganTimothy R.ParkAngelaPowellByron J.ProctorEnola K.RossDavidWaltzThomas J.RogalShari S.. 2020. “Strategy Configurations Directly Linked to Higher Hepatitis C Virus Treatment Starts: An Applied Use of Configurational Comparative Methods.” Medical Care58 (5): e31–e38.
34.
YuanKe-HaiBentlerPeter M.ZhangWei. 2005. “The Effect of Skewness and Kurtosis on Mean and Covariance Structure Analysis: The Univariate Case and Its Multivariate Implication.” Sociological Methods & Research34 (2): 240–258.