
Abstract
Multilevel models are often used to account for the hierarchical structure of social data and the inherent dependencies to produce estimates of regression coefficients, variance components associated with each level, and accurate standard errors. Social network analysis is another important approach to analysing complex data that incoproate the social relationships between a number of individuals. Extended linear regression models, such as network autoregressive models, have been proposed that include the social network information to account for the dependencies between persons. In this article, we propose three types of models that account for both the multilevel structure and the social network structure together, leading to network autoregressive multilevel models. We investigate theoretically and empirically, using simulated data and a data set from the Dutch Social Behavior study, the effect of omitting the levels and the social network on the estimates of the regression coefficients, variance components, network autocorrelation parameter, and standard errors.
Keywords
Introduction
In the quantitative analysis of social data it is increasingly recognized that people are not independent of each other and any analysis should account for their social contexts and connections. Multilevel analysis is carried out routinely to take into account group dependencies arising from people being members of groups such as households, geographical groups such as neighborhoods and organizational groups such as hospitals or schools.
Another source of dependencies for individuals, which may cross the other groups to which they belong, is their social network. While social network analysis (SNA) has recently received much attention in the social sciences, SNA researchers often ignore other aspects of the multilevel population structure. Moreover, most multilevel modelers consider group dependencies (e.g., students in schools), but tend to ignore social network dependencies in their analysis (e.g., students’ friendship networks). In this article, we develop a new class of models called network autoregressive multilevel models (NAMLMs), which include both social network effects and multilevel effects that account for group dependencies when undertaking a regression analysis of a response variable on a set of explanatory variables. It is common to include only some of these effects in an analysis, either because they are not considered or because of data limitations. Our aim is to assess the effects of omitting the social network or group dependencies, both theoretical and empirically.
If groups, such as households, local areas, or networks, are present in a population, two people within the same group tend to be more similar than two people, each from a different group. Multilevel models (MLMs) allow for modeling this similarity. These models often focus on hierarchical groups, although through cross-classified models non-hierachical groupings can be included (Goldstein 2011). MLMs are usually specified that assume the group effect is the same for all individuals in a particular group, although more complex models can be used. An example of three inter-connected groupings of individuals is people within households, neighborhoods and networks. Another example is students within classes and schools and friendship networks.
Failure to account for dependencies in a population usually leads to incorrect estimation of standard errors (SEs), leading to incorrect inferences (Berkhof and Kampen 2004; Moerbeek 2004). In some circumstances, such as in non-linear models, it may also lead to bias in the estimates of regression coefficients. Non-independence of observations was initially seen as a nuisance by statisticians, who developed methods to account for the structure of the data, such as complex survey analysis methods, see Chambers and Skinner (2003). However, the dependencies between people are often of direct substantive interest. MLMs and network autoregressive models (NAMs) provide information about these dependencies through the estimates of the parameters in these models that reflect the correlations between people, these being the variance of the group-level random effects and the associated intra-group correlations that they explain in an MLM, and the autocorrelation parameter in a network model.
In Section “Models for Multilevel Data and Social Networks,” we describe regression models that include several levels, such as households and neighborhoods or classes and schools. In Section “Models for Social Network Dependencies,” we consider popular regression models that account for dependencies induced by a social network. In Section “Extended Models That Include Social Network and Group Dependencies: Network Autoregressive Multilevel Models,” we propose three regression models that take into account the levels and a social network, and outline maximum likelihood estimation. In Section “Theoretical Impact of Omitting Some Part of the Population Structure in the Analysis,” we consider theoretically the likely impact of omitting some part of the population structure, such as levels or a network, in the analysis. A simulation study is conducted in Section “Simulation Study.” Then in Section “Example With School Data,” the models are applied to the Dutch Social Behavior Study modeling delinquent behavior of school students. This article finishes with a summary and conclusions.
Models for Multilevel Data and Social Networks
Households and Neighborhoods
A key feature of social structure is the household. Sample designs often involve the household. It is common to select one person, or all people per selected household, although other options are available (Clark and Steel 2002). Analysis of data from surveys in which all people or more than one person is selected from a household may ignore the household, which will lead to incorrect variance estimates. In some cases, both individual and household-level estimates or effects may be of interest. MLMs have also been applied in a limited way to consider the household level for phenomena such as voting behavior (Johnston et al. 2005).
Sometimes the household is ignored in analysis because a household identifier is not available, or because one person per selected household has been sampled; in this case, the household and person-level effects cannot be separated in the analysis.
Consider individual

Individuals can be grouped into geographical areas. Statistics are produced for geographical areas, such as local authorities, post-codes, or census output areas. Geographical areas may be used in the selection of the sample for a survey, through the use of cluster or multistage sampling. Multilevel modeling has been used for individuals grouped in areas, possibly incorporating contextual variables such as area level means of explanatory variables (Goldstein 2011), with respect to health, see, for example, Subramanian, Jones, and Duncan (2003), for unemployment, see Fieldhouse and Tranmer (2001), and other social outcomes. Standard MLMs assume constant within area correlations between individuals and no correlations across areas, although the latter assumption can be loosened.
A random effect can be added to (1) for areas, where the individual is indexed by
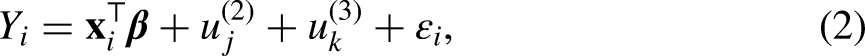
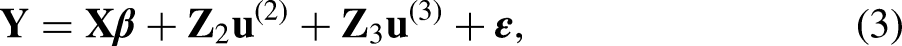
Setting

Classes and Schools
For educational data on students, the information on the classes and schools is incorporated into the MLM, as students are nested within classes and classes within schools. The MLM has students as level 1 units, classes as level 2 units, and schools as level 3 units (Berkhof and Kampen 2004). The residual errors,
Models for Social Network Dependencies
People can also be grouped by their social network, and there is growing interest in SNA following the publications of the books by Wasserman and Faust (1994), Carrington, Scott, and Wasserman (2005) and Scott (2012). Considerable work has been carried out to develop models for networks, such as exponential random graph (p*) models (Snijders et al. 2006). Reviews of statistical models for social networks were also given by Snijders (2011) and Amati, Lomi, and Mira (2018). The importance of social networks with respect to health is discussed by Kawachi and Berkman (2000, 2003), Haines, Beggs, and Hurlbert (2011) and Lusher, Koskinen, and Robins (2013).
Network Effects and Network Disturbance Models
Our interest is not in the modeling of the social network itself, but in accounting for the dependencies induced by the social network when modeling a response variable. We consider two models that allow for the effects of social network dependencies on a response variable and allow for covariates in the model. These are generally described as network autocorrelation models (NAMs) in the social network literature (Leenders 2002).
A network effects model allows for autocorrelation directly in the response variable (Leenders 2002). For a population of N individuals, one way of incorporating social network dependencies, but not other group dependencies, is via the network effects model:

A network disturbance model allows for autocorrelation in the error term, see Leenders (2002) for a review. Here

In the geographical literature, (5) and (6) are both examples of spatial autoregressive regression models (Lesage and Pace 2009), where the connection matrices represent geographical connections such as contiguity, or some other type of geographical link, rather than social network dependencies. In this literature, model (5) is often described as a spatially lagged dependent variable model, and model (6) as a spatial error model (Ward and Gleditsch 2008). As noted by Leenders (2002), this model can also be labeled as a spatial moving average model, see Muir (1999). Model (5) is a simultaneous autoregressive model. An alternative approach in the spatial statistics literature is a conditional autoregressive model; see Cressie (1993: section 6.3) for a discussion of these two different approaches. For this article, we generally use the terminology from the social network literature.
In the geographical literature, Ward and Gleditsch (2008:70) argue, from a social science perspective, that “if we expect to see, or are interested in, feedback, then the spatially lagged/network effects model seems most appropriate, and that the spatial error/network disturbance model is appropriate primarily when researchers believe that there is some spatial (or more generally dependence) pattern that will be reflected in the error term, but the researchers are unwilling or unable to make assumptions about the origin of the error.”
The models specified by (5) and (6) differ according to whether the network dependence is in the regression or error terms part of the model. Model (5) accounts for autocorrelation directly in the response variable, after allowing for the covariates, and would be useful when we suspect such effects exist and are substantively interested in them. In model (6), the autocorrelation is in the individual-level error terms and any apparent autocorrelation in the response variable is due to this.
The theoretical and practical similarities and differences in these two models can be clarified by considering the variance and mean structure that they imply. Set
Multiple Membership (MM) Models
Tranmer, Steel, and Browne (2014) and Tranmer and Lazega (2016) consider an alternative to NAMs using a particular linear mixed model, the MM model, to model the dependencies arising from the network. The MM model is:
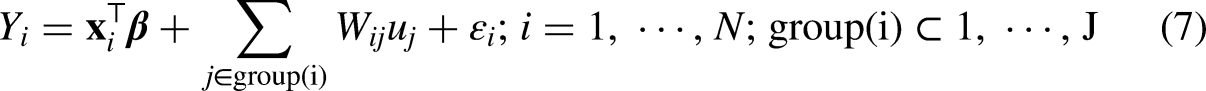
The MM model can be written in matrix form as:

Extended Models That Include Social Network and Group Dependencies: Network Autoregressive Multilevel Models
Bringing together the ideas of statistical models in social network analysis and MLMs, we can consider how the multiple dependencies associated with households, social networks, and geographical groups, for example, can be considered in the same analysis and the consequences of omitting one or more of them in an analysis. In general, we have an individual-level outcome,
Within household/class connections. Connections due to proximity, which may be approximated by geographical groups with a particular scale and boundary, or connections to the same school. Connections via social networks.
We can add random effects for households and neighborhoods, or for classes and schools, in the two social network models considered inSection “Network Effects and Network Disturbance Models.” As in Section “Network Effects and Network Disturbance Models,” the social network dependence may act directly on the response variable, giving a network effects MLM. Alternatively, the network dependence may apply to the error terms, leading to a network disturbance MLM. Once random effects for the higher levels are included in the model, the network dependence may affect both the individual level and higher level random effects or just the individual level error term, leading to two versions of the network disturbance MLM. The three resulting models are described in more detail below. All these extended models combine NAMs with MLMs to produce NAMLMs.
Model I: Network Effects MLM. In this model, the social network dependence acts on the response variable:
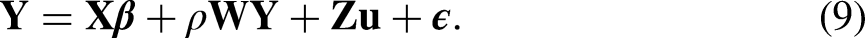
In the network disturbance model, the random effects may or may not be affected by the social network, leading to two types of models.
Model II: Type I Network Disturbance MLM. In this model, the network dependence affects both the individual level and higher level random effects:

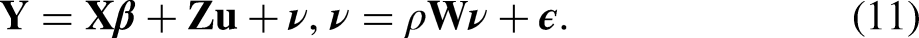
Maximum likelihood estimation of the parameters
Which of these models is appropriate in a particular situation depends on theoretical and empirical considerations that are similar to those expressed in Section “Network Effects and Network Disturbance Models.” If there are substantive reasons or empirical evidence from considering diagnostics involving the network contextual variable
We have considered the common situation where the groups are hierarchal. More general relationships between individuals and non-nested groups can be incorporated in a multilevel framework using MM and multiple classification (MMMC) models (see Browne, Goldstein, and Rasbash 2001). Cross-classified MLMs can be used to analyze data in which individuals belong to two or more types of groups that are not nested, for example, schools and neighborhood. The MM model can be used to allow an individual to be a member of several different groups at the one level and weights can be applied to reflect the importance of each of these groups to the individual, for example, a student attending two schools in a time period. These MMMC models can be analyzed using standard multilevel modeling software, such as MLwiN. The random effects in NAMLMs can also be extended to incorporate MMMC population structures.
As mentioned in Section “Multiple MMs,” Tranmer, Steel, and Browne (2014) and Tranmer and Lazega (2016) show how MM models provide an alternative to NAMs. They also consider NAMs, but only include group effects as fixed effects, which limits the number of levels and the number of groups at each level that it is feasible to include. The NAMLMs developed here fully combine the autoregressive and multilevel structures and allow for the complexity of multilevel effects.
Lazega and Snijders (2016), and the chapters in it, consider a range of issues associated with multilevel network analysis. The focus is on multilevel network analysis, where there are networks within groups, and also analysis of multilevel networks that may involve modeling links across levels. In these situations, the aim is modeling the network structure, so the network is the dependent variable. The focus in this article is in modeling the attributes of actors, that is, individuals and how those may be affected by network and group effects. The chapter by Snijders (2016) also reviews multivariate models used in modeling attributes of actors, and mentions NAMs as an alternative approach, and the chapter by Tranmer and Lazega (2016) considers the use of MM models, as described in Section “Multiple MMs.” The NAMLMs developed here combine the multilevel and autoregressive approaches in one model and can be considered a standard approach to combine existing NAMs and MLMs.
Theoretical Impact of Omitting Some Part of the Population Structure in the Analysis
Regardless of whether the dependencies between individuals are of substantive interest, or are regarded as a nuisance that needs to be recognized in the analysis, an MLM-based approach can be applied. However, the social networks of individuals have not commonly been considered in such analyses; largely a reflection of data availability, but also because the importance of social networks is still to be fully realized. If an important level or grouping is ignored then the model is misspecified. However, the effect on the variation in the outcome variable due to the omitted level does not disappear, rather it affects the estimates of variation for the levels that are included in the analysis, see Tranmer and Steel (2001).
If the impact of both social networks and random effects are of direct interest, we should attempt to include them in the model underpinning our analysis, for example, using one of the NAMLMs in Section Extended Models That Include Social Network and Group Dependencies: Network Autoregressive Multilevel Models.” However, this is not always feasible.
Ignoring the effect of important groupings or social networks can lead to biases in estimates of the regression parameters that reflect the impact of different variables on social and health outcomes, alter variances on estimates of key parameters and result in incorrect inferences. Omitting a component of the variance structure can also lead to biases in the estimates of components that are included. We consider the consequences of omitting levels and social networks in the more complex NAMLMs.
These issues can lead to incorrect social analysis and models and incorrect, ineffective, or counterproductive social policies. For example, in a study of obesity, an analysis of individuals that does not take into account the influence of other people in the household, characteristics of the neighborhood in which a person lives, and the influence of their social network may miss or overstate the impact of important factors that affect obesity, and exaggerate the impact of purely person-level attributes.
It is important to explicitly recognize the potential simultaneous roles of households, neighborhoods, and social networks, for example, but in practice, we may omit one or more of these components. Hence, understanding the impact of omitting a component is important.
Mathematically, omitting an effect will involve the estimation being based on a model that does not include the omitted effect. So, for example, omitting the network effect would mean estimation is based on a standard MLM, which would usually be done using software, such as MLwiN. Omitting the effects for each level would involve an analysis based on a pure NAM, using appropriate software, such as the
Results From Standard MLMs
Firstly, we summarize the results that have been established for standard MLMs (Tranmer and Steel 2001; Berkhof and Kampen 2004; Moerbeek 2004; Van Landeghem, De Fraine, and Van Damme 2005).
For random intercept-only models and balanced data, the effects of omitting a level are relatively easy to describe and can be derived algebraically. For unbalanced data, the effects are more difficult to summarize, but are similar to the balanced case. The following general rules apply. The variance estimate
Re-expressing the Covariance Matrix of NAMLMs
The covariance matrix for Models I and II is
The true covariance matrix for Models I and II is:
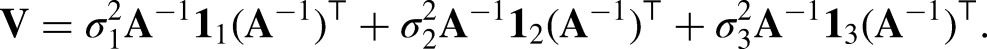
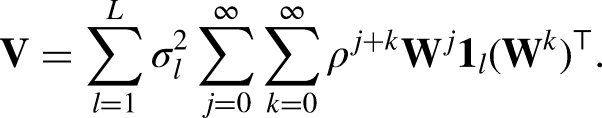
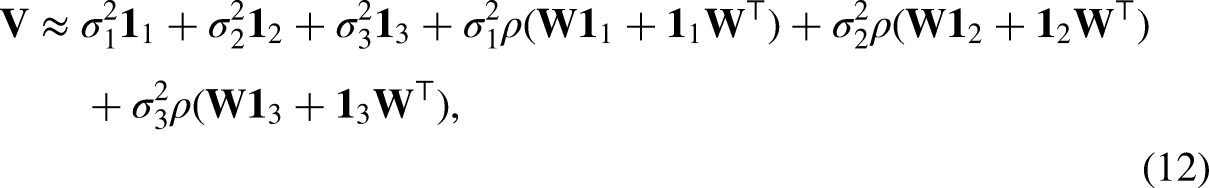
Similarly, for Model III, the first-order approximation is:
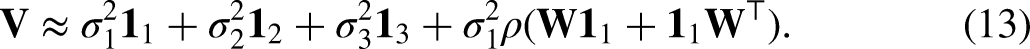
Impact of Omitting Network Dependencies
Fixed effects
The impact of omitting the network dependencies on the estimates of the regression parameters differs for the different NAMLMs described in Section “Extended Models That Include Social Network and Group Dependencies: Network Autoregressive Multilevel Models.” For the network effects MLM given by (9), the expectation of the vector of response variables depends on the network dependencies through
For the network disturbance Models II and III, the network dependencies do not affect the expectation of the vector of response variables, and so omitting them does not introduce bias into the estimation of the regression coefficients.
Random effects
The covariance matrix for Models I and II can also be re-expressed as
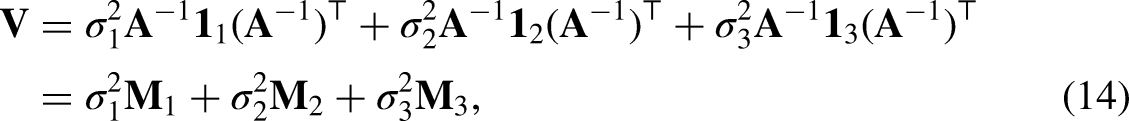
Comparing the true covariance matrix with the one omitting network dependencies, we find that (some of) the estimates of the variance components of the MLM will be overstated, when
The online Appendix C provides some details of this argument. Generally, an analysis that does not account for the network gives estimates of the variance components that are too large, when
When using the arguments of Section “Re-expressing the Covariance Matrix of NAMLMs,” the additional terms refer to a certain level or levels. Ignoring a network should lead to different variance estimate at the affected level and at adjacent levels and likewise for SEs. For example, when the omitted network is above the highest level (level 3), then the level 3 variance estimate component should change. Since the fixed intercept can be considered as a level 4 predictor, then the SE of the fixed intercept should also be affected. However, due to the joint dependence of
For Model III, similar results can be obtained by noting that for this model:
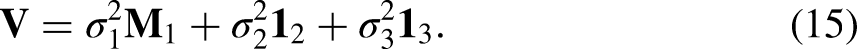
Impact of Omitting Multilevel Dependencies
To assess the impact of omitting a level in the NAMLMs the method of moments is applied, following Berkhof and Kampen (2004). First let us assume the network parameter can be estimated consistently, which may not always hold, but the simulation study (Section “Example With School Data”) indicates that the estimates of the network parameters are roughly the same regardless of the number of levels used in the model. For Model II, the residuals are
However, as we have seen in Section “Re-expressing the Covariance Matrix of NAMLMs” by re-expressing the covariance (12), adding the network to a standard MLM is equivalent to adding other terms related to existing or higher level(s) and the coefficients of these terms are functions of
Simulation Study
Setup of Simulation Study
In this section, we consider a situation involving people within households, which are located within areas and are involved in a social network. To assess the impact of omitting one of the components (network, household, and area) of the model, we conduct a simulation study.
For Models I, II and III, we randomly generate 200 areas, and each area has 10 households. The size for each of the 10 households is randomly chosen using the probabilities 0.294, 0.332, 0.136, 0.146, 0.063, 0.020, 0.006, and 0.002 for household sizes 1,2,3, …, 8. Those probabilities are taken from the Household, Income and Labor Dynamics in Australia (HILDA) survey using the observed frequencies from wave 8 (2008) (Summerfield et al. 2015). The simulations take the number of households in an area as fixed, which is often the case in social surveys. The theoretical results do not assume groups of equal size, nor does the analysis of real data in Section “Example With School Data.”
The data are generated under Models I, II, and III to assess the effect of omitting any combination of the three components. The variance parameters are set to
The covariates were all generated from the standard normal distribution, that is,
In practice, the SEs of the regression coefficients will be estimated for a model or sub-model using the available data. The SE estimates may be biased and not estimate the true SEs well when the network or one or more levels are omitted, which can affect statistical inferences. The effect of omitting the network or levels on statistical inference for the regression coefficients was evaluated in the simulations by examining the relative bias of the SE estimates and coverage of the associated nominal 95 percent confidence intervals (i.e., proportion of times the true regression parameter is included). SEs were estimated in a standard way, using the inverse of the Fisher information matrix (see the online Appendix B.2) and confidence intervals constructed by adding and subtracting 1.96 times the estimated SE to the estimated regression coefficient. A negative bias will lead to underestimation of the true SEs and overstate the statistical significance (i.e., p-value too small) and reduced coverage of the true regression coefficients by the associated 95 percent confidence intervals.
For each of Models I, II, and III, results were generated for the full model and for all submodels, that is, for any combination of the components referring to the household and area level and the network. That means in total
The network comprising all individuals was generated by an ERGM (Snijders et al. 2006) with a GWESP (geometrically weighted edgewise shared partner) statistic, or sometimes called distribution, and an edge statistic with the parameters set to
Results of Simulation Study
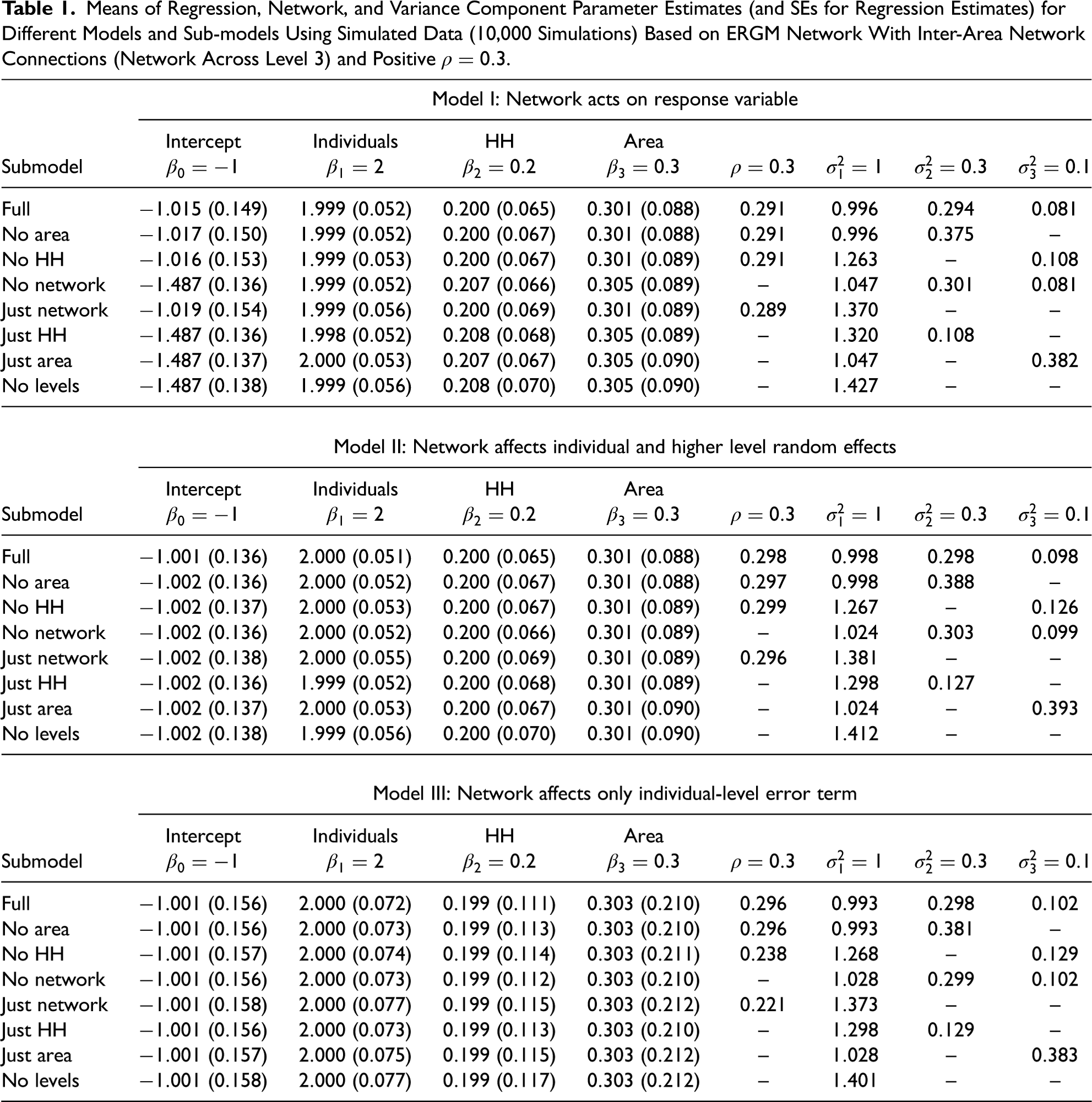
Table 1 shows the results for the three models with
Means of Regression, Network, and Variance Component Parameter Estimates (and SEs for Regression Estimates) for Different Models and Sub-models Using Simulated Data (10,000 Simulations) Based on ERGM Network With Inter-Area Network Connections (Network Across Level 3) and Positive
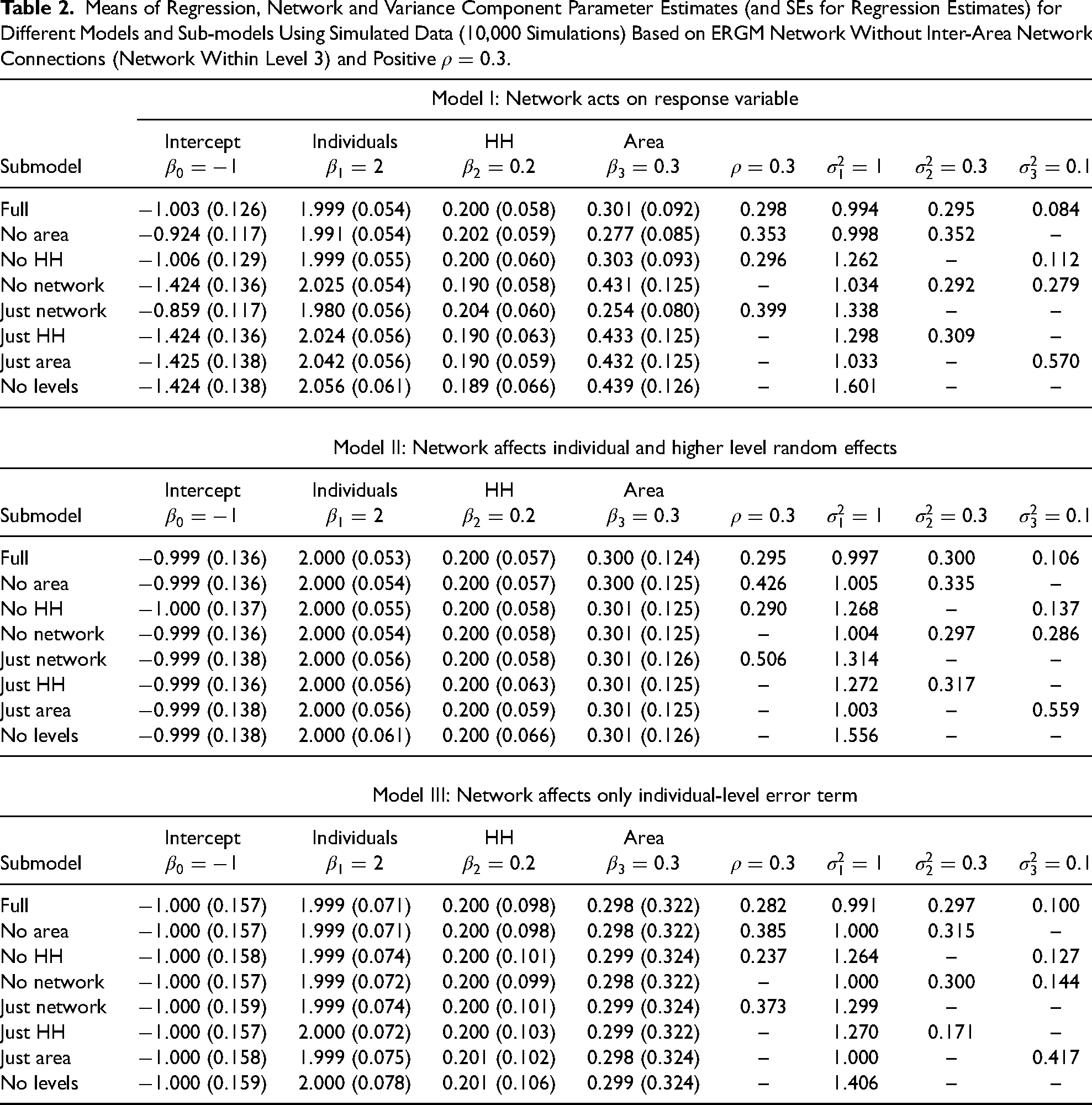
Means of Regression, Network and Variance Component Parameter Estimates (and SEs for Regression Estimates) for Different Models and Sub-models Using Simulated Data (10,000 Simulations) Based on ERGM Network Without Inter-Area Network Connections (Network Within Level 3) and Positive
Effect of omitting levels on estimates of variance components and network parameter
The results in Table 1 show that when the social network is included, omitting one or more levels has a very similar effect on the estimates of the remaining variance components as in a standard MLM described in Section “Re-expressing the Covariance Matrix of NAMLMs.” There is no appreciable effect on the estimation of the network parameter,
Effect of omitting network dependencies on estimates of variance components
When no network is included, there is no appreciable effect on the estimates of the variance components when all are included. However, the omission of the area level component decreases the household level and increases the individual-level variance components considerably. When the household level is omitted, the area-level variance component increases considerably. This does not happen when the network is included, suggesting that it plays a role in the effects of omitting a level.
Effect of omitting network dependencies or levels on estimates of regression parameters
The mean of the estimates of the regression parameters is not affected at all by omitting the social network or levels in Models II and III. Even in Model I, where an effect might be expected when the network is omitted, there is no impact on the individual-level regression parameter and very small effects for the regression parameters of household and area level covariates, although the estimation of the intercept is affected.
Effect on SEs and inferences for regression coefficients
The SEs of the regression coefficients estimates shown in Table 1 reflect the loss of efficiency as levels or the social network are omitted from the variance structure, V(Y), used in estimating these coefficients. For a particular submodel, the loss of efficiency is the ratio of the square of the SE to that of the full model (i.e., ratio of variances). When only the network is omitted, so a standard MLM is fitted, the SEs are essentially the same as for the full model and there is no loss of efficiency. The SEs are the highest when all levels and the network are omitted, resulting in the efficiency losses ranging between 3 percent and 21 percent. These SEs are close to the case when only the network is included. In general, provided at least one of the household or area level is included any efficiency loss is small. An exception to these results is the intercept in Model I, where omitting the network leads to smaller SEs. In all cases, the SEs for the regression coefficients obtained using Model III are appreciably larger than for Models I and II, which are similar to each other.
The relative biases of the SE estimates and the coverage of the associated 95 percent confidence intervals are given in Table 3 for the simulations allowing network dependencies between individuals in different areas, corresponding to Table 1. Poor coverage can arise due to underestimation of the SE and/or bias in the estimate of the regression coefficients. For the individual-level regression coefficients, the relative bias of the SE estimates is very small and the coverage is always close to the nominal 95 percent (i.e., 5 percent significance level) for all models or submodels used, including the submodel omitting the network and levels. For the household and area-level regression coefficients the omission of the network has a little or no effect on coverage provided the levels are included. Including only the network leads to appreciable negative relative biases in the SE estimates and poor coverage. Omitting only the household (area) leads to negative biases in the SE estimates and poor coverage of the household (area)-level regression coefficient. When the network is omitted, omitting the household (area) leads to a poor coverage for the area (household) regression coefficient. For the intercept in Models II and III, there is a large negative relative bias in the estimated SEs leading to a poor coverage, except for the full model or where the household is omitted. For Model I, even worse coverages are obtained because of the bias in the estimation of the intercept when there is no network already shown in Table 1, combined with underestimation of the SEs. We see that the expectation of the estimates of the regression coefficients and inferences about the individual-level regression coefficient are generally not affected by the omission of the network or levels. However, the inferences about the household and area-level regression coefficients and the intercept can be affected due to the underestimation of the SEs, which leads to overstating the statistical significance and poor coverage.
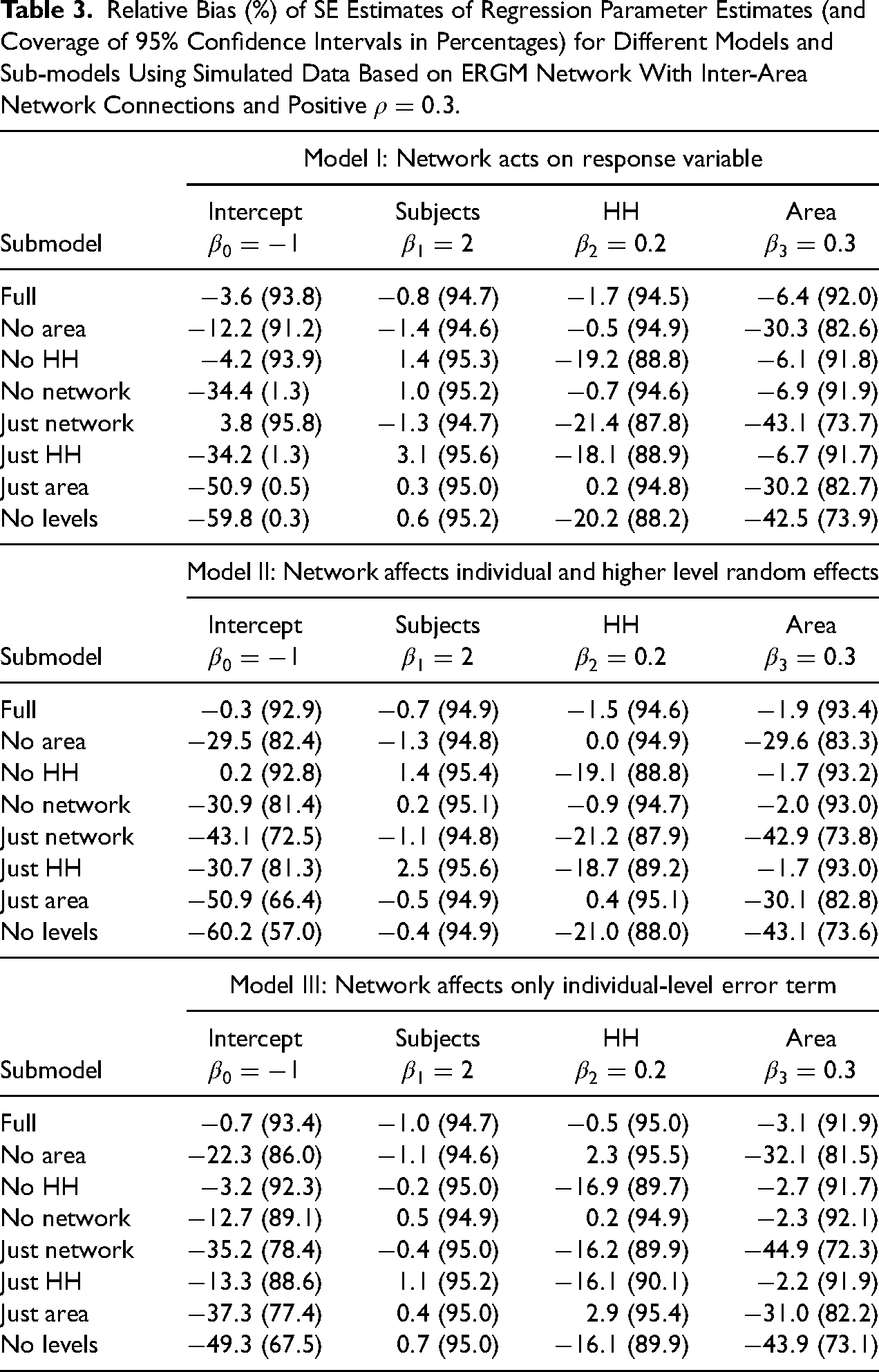
Relative Bias (%) of SE Estimates of Regression Parameter Estimates (and Coverage of 95% Confidence Intervals in Percentages) for Different Models and Sub-models Using Simulated Data Based on ERGM Network With Inter-Area Network Connections and Positive
Results when social network contained within areas
The results in Table 2 correspond to the case when the social network is contained within the area level, but can still connect different households. Many of the observations made for Table 1 apply, however, there are some noteworthy differences associated with the interplay between the network and the area-level effect. When the area level is omitted, the estimate of
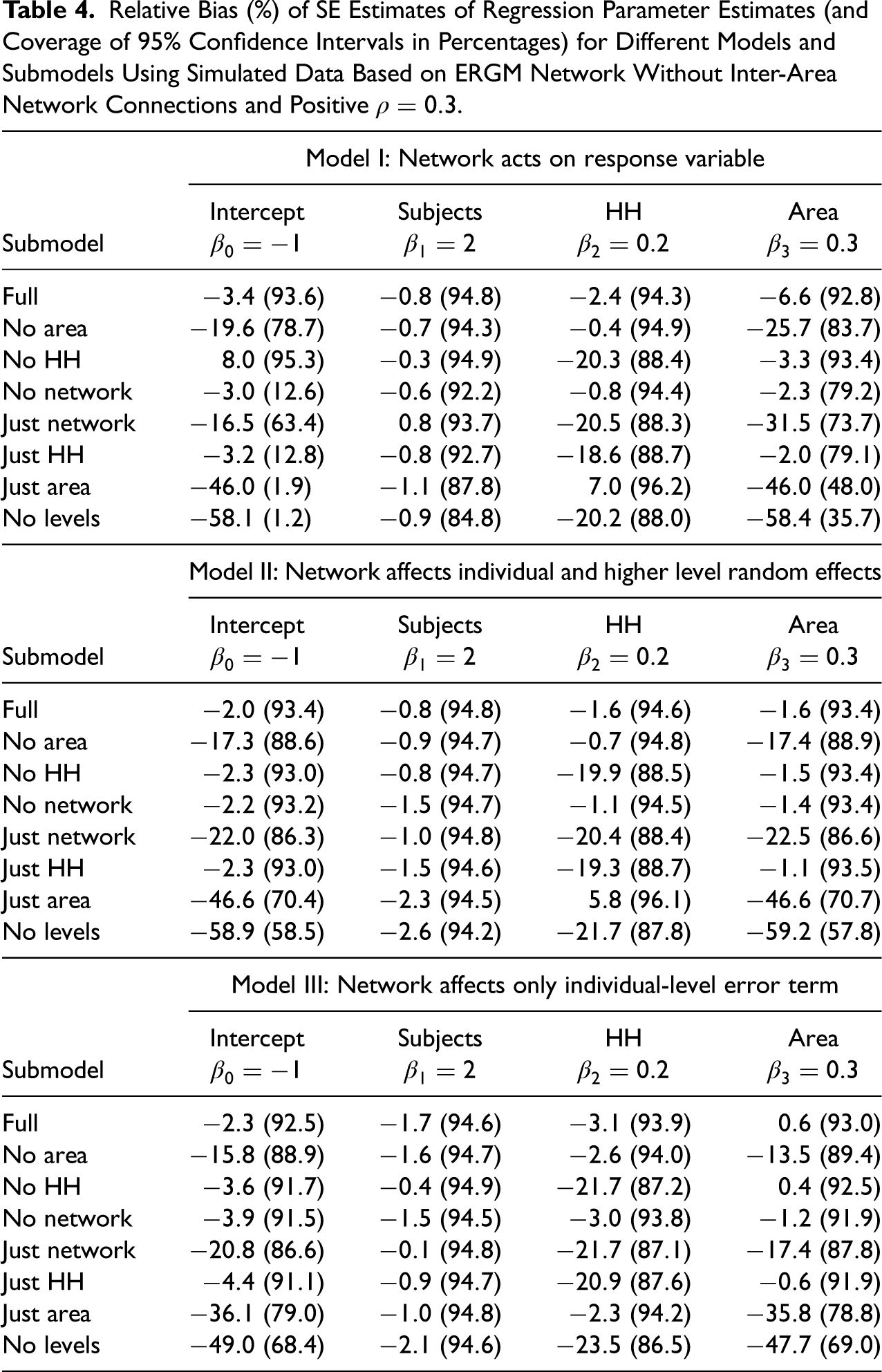
Relative Bias (%) of SE Estimates of Regression Parameter Estimates (and Coverage of 95% Confidence Intervals in Percentages) for Different Models and Submodels Using Simulated Data Based on ERGM Network Without Inter-Area Network Connections and Positive
Results with negative
In Supplemental Table S1, where
When
or
We have not shown simulation study results for
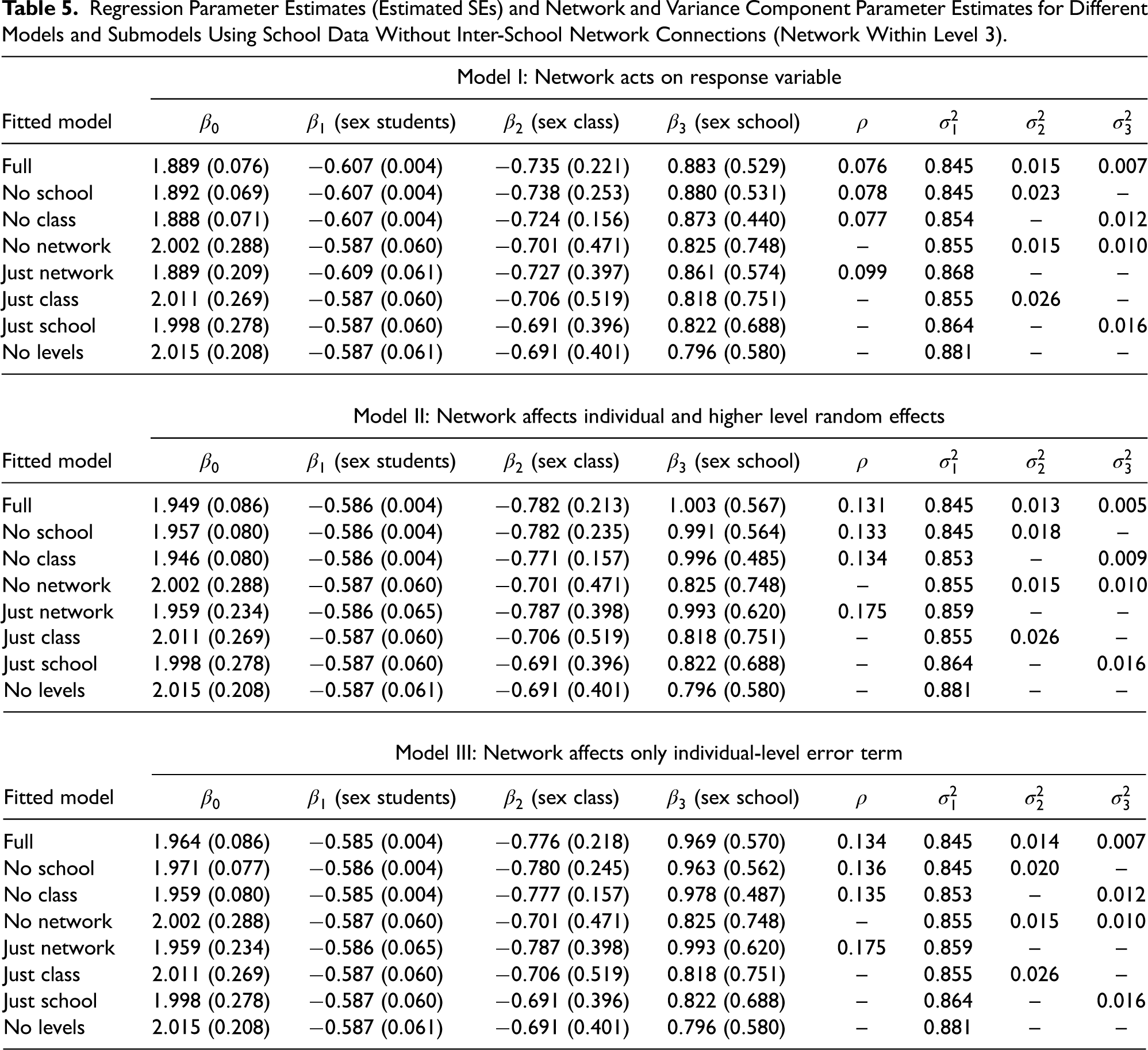
Regression Parameter Estimates (Estimated SEs) and Network and Variance Component Parameter Estimates for Different Models and Submodels Using School Data Without Inter-School Network Connections (Network Within Level 3).
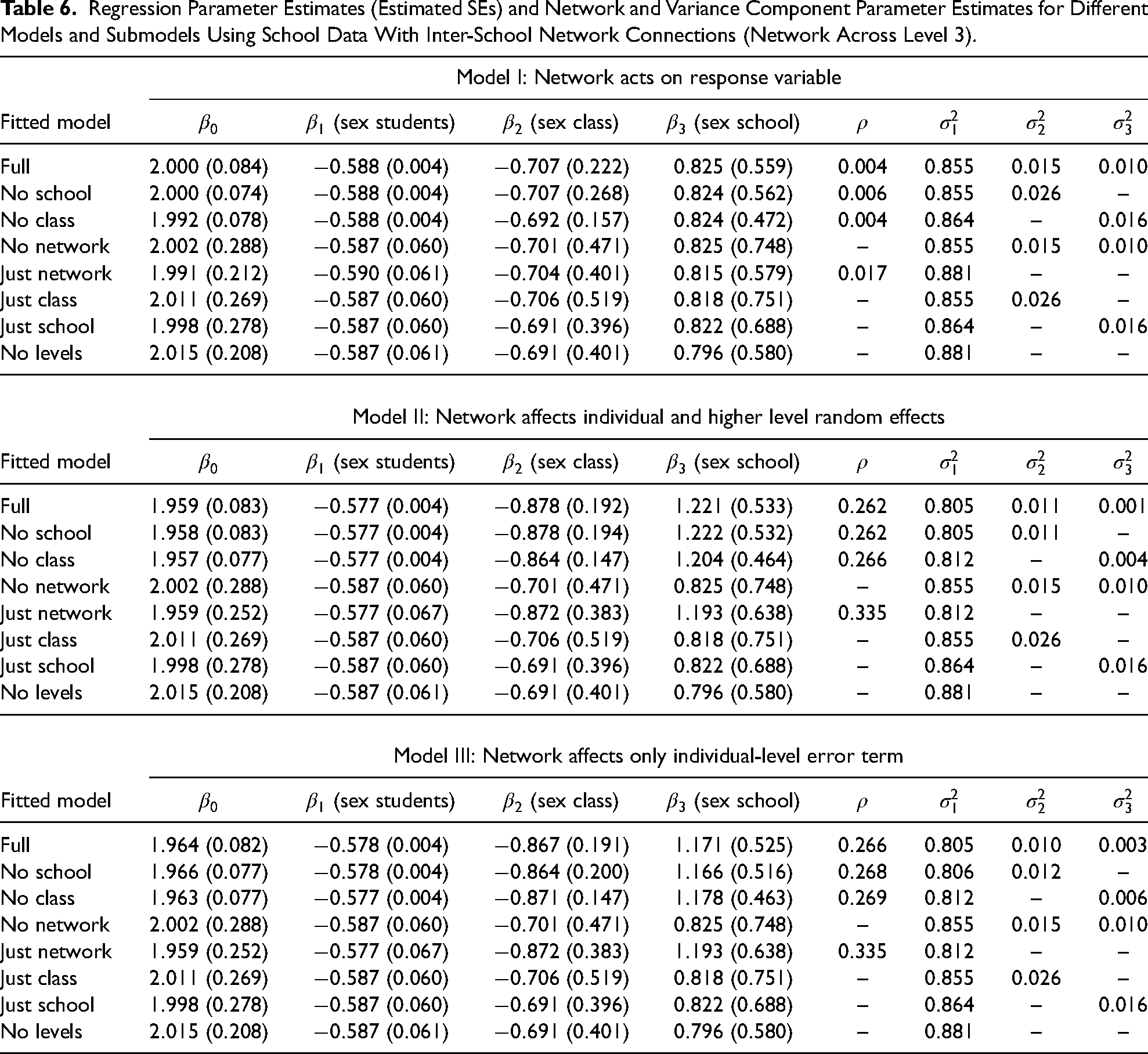
Regression Parameter Estimates (Estimated SEs) and Network and Variance Component Parameter Estimates for Different Models and Submodels Using School Data With Inter-School Network Connections (Network Across Level 3).
Example With School Data
School Data Details
For an illustration based on real data, we use a data set about a friendship network and delinquent behavior of students in school classes, collected in a two-wave survey, the Dutch Social Behavior study (Houtzager and Baerveldt 1999). Students from the third and fourth years of the lower middle level of the Dutch secondary school system answered a questionnaire, with a total sample size of 990. A more detailed description can be found at https://www.stats.ox.ac.uk/~snijders/siena/BaerveldtData.html.
The data were collected from 19 schools with two variables of main interest in this article: gender and a measure of delinquent behavior (DB), defined as the number of minor offenses that the respondent states to have committed. The measure was transformed
The data only have two levels, schools and students. We artificially added another level, classes, so that we could investigate the effect of ignoring levels in a more complex model with three levels, as we did in Section “Results of Simulation Study.”
The school sizes of the data set are between 31 and 91. We divided the students of each school into classes, such that class sizes are approximately equal and have a maximum size of 31. For example, a school with 31 students was considered to have only one class, but a school with 54 students was split into two classes with 27 students each. The allocation of the students to classes was done randomly until the resulting NAMLM had non-zero estimates of the variance and network parameters.
The response variance
The network referring to giving and/or receiving emotional support was restricted to within the schools, that is, connections do not exist between any two students of different schools.
Results of Analysis of School Data Using NAMLMs
Effect of omitting levels and networks on estimates of variance components and network parameter
The results for this data set for each of the three NAMLMs are presented in Table 5 (no between school connections) and Table 6 (with between school connections) with the estimates obtained for the full model, containing all three levels and the network, and all submodels obtained by ignoring the network or one or more levels. The tables show the estimates of the regression parameters, their estimated SEs and the estimates of the variance and network parameters. We do not consider the SEs of the variance parameters, because Wald-type confidence intervals are often not applicable and therefore SEs of such variance estimates are of limited use, see Chambers and Chandra (2013) for an alternative bootstrap method to construct confidence intervals.
These results show that when a level, for example, schools or classes, is omitted, then the variance of the omitted level is approximately distributed to the two adjacent levels. For example, when the school level is omitted, then the class-level variance is increased by the variance of the school level. When the class level is omitted, then the variances of the student and school levels are inflated by an amount that sums up to the class-level variance.
The estimate of
When the network is omitted, then the variances of the levels are all increased for Models II and III. For Model I, there is no or negligible increase, because the network parameter estimate for Model I is very small.
Effect on estimates of regression coefficients
For all three models, the estimates of the regression coefficient for the individual-level covariate do not change as the network or levels are omitted, except for Model I in Table 5 when the network is omitted, consistent with the discussion in Section “Theoretical Impact of Omitting Some Part of the Population Structure in the Analysis.” For the estimates of the regression coefficient of the class-level covariate, ignoring the network has some modest effect in all three models, but ignoring any of the levels has little effect. Similar effects can be seen in the estimates of the regression coefficients for the school-level covariate, although these estimates have quite large estimated SEs due to the small number of schools in the sample.
The observation that ignoring the network affects the estimates of the regression coeffcients for the class and school-level covariates in Models II and III might contradict the discussion in Section “Theoretical Impact of Omitting Some Part of the Population Structure in the Analysis.” However, Tables 5 and 6 show the ML estimates and not OLS estimates, explaining the change of the fixed effects, which is due to the non-zero efficiency effect of the ML estimator, see equation (3) in Berkhof and Kampen (2004). For larger sample size and a larger number of schools and classes, the fixed effects of Models II and III would stay relatively constant, as was seen in the simulation study which involves larger sample sizes. These observations overall confirm the anticipated behavior outlined in Section “Theoretical Impact of Omitting Some Part of the Population Structure in the Analysis.”
Differences between Models I, II, and III
These results also shed some light on the differences and similarities in the results obtained from applying the three different full NAMLMs. For Models II and III, the regression coefficients are the same for the individual-level covariate and very similar for the class and school-level covariates. Comparing results with the naive model that ignores all the dependencies, the individual-level regression coefficients are the same and the estimates for the class, and school covariates tend to be stronger in Models II and III. For Model I, the regression estimates are a little different but still similar to those from Models II and III, and also stronger than those from the naive model. So, for regression coefficients, the models generally give broadly similar estimates, but accounting for the dependencies produces stronger estimates for the higher-level covariates than the estimates obtained from the naive model, although not for the individual-level covariate. This confirms that, especially if higher-level covariates are included, the dependencies should be taken into account, even if not of direct interest. The estimates of the variance components are virtually the same for Models II and III and similar for Model I. When these parameters are of substantive interest, there is little to choose between all three models. The estimate of the network parameter is very similar in Models II and III, but much smaller in Model I. This shows the main difference between Model I and Models II and III. In the latter two, the network dependencies only affect the variance structure, whereas in the former the regression term is also affected, as shown in Section “Extended Models That Include Social Network and Group Dependencies: Network Autoregressive Multilevel Models.” This leads to a smaller network parameter.
Effects on estimated SEs of regression coefficient estimates
Tables 5 and 6 contain the estimated SEs for the estimates of the regression coefficients. It is noticeable that the SEs are smaller when the full model is used, or if only one of the class or school-level effects is omitted. Once simpler variance structures are used, in which any two or more of the network, class, or school effects are omitted, the SEs increase. These increases do not affect the statistical significance of the regression coefficient of the student-level covariate, which stays strongly statistically significant. However, for the class-level covariate, these increases in SEs change the inference from statistically significant to non-significant. The SEs for the school-level regression coefficients are already large because of the small-sample size, and even with the full model are generally non-significant, or sometimes a borderline case, and the increase in SEs leads to strongly non-significant results.
Interpretation of models
Network models and the MLMs both describe dependencies across observations and have been developed in different situations, often influenced by differences in data availability concerning network connections and membership of groups. Using the NAMLMs described in Section “Extended Models That Include Social Network and Group Dependencies: Network Autoregressive Multilevel Models” these two general approaches can be incorporated and interpreted within the same framework. In Section “Network Effects and Network Disturbance Models,” it was noted that autocorrelation in the response variable implicitly introduces a contextual variable determined by the network into the regression part of the model. This is similar to the common and explicit use of contextual variables, such as group means, in MLMs. Examining the variance structures in Section “Re-expressing the Covariance Matrix of NAMLMs,” we can see that the standard MLM can be interpreted in a manner similar to a network model in which each individual is equally connected to all, and only, the individuals within its class or school. The variance component for a level can be converted to an intra-group correlation by dividing by the total of the variance components, and then has a similar interpretation as the network correlation parameter (although in comparing these parameters the fact that the connections due to common group membership are not usually row normalized is relevant). Some of these aspects are discussed by Tranmer and Lazega (2016).
To illustrate the use and interpretation of these models, consider the results for Model II with inter-school connections in Table 6. We will consider submodels with no class effect in the variance structure, as this was artificially generated. In the submodel with network and school (no class sub model), all the regression coefficients are statistically significant and
We can compare
Summary
In this article, we have combined two popular approaches to modeling dependencies across units, such as people, these being network autocorrelation models, and MLMs. This is useful because dependencies arising from a hierarchical structure and network structure may be found together. An example is given in Section “Example With School Data,” where class and school-level random effects are included, as well as a social network reflecting emotional support between students. Depending on assumptions about the components of the MLM that the social network acts upon, three models can be differentiated. In Model I, autocorrelation associated with the network acts directly on the response variable and this leads to the regression component implicitly including a network contextual effect and the variance at each level being affected. In Model II, the network applies to the individual and higher-level random effects, so that the variance at each level is affected, but the regression term is not affected by the network. In Model III, the network applies only to the individual-level random error, so only the variance at the individual level is affected, and the regression term is not affected by the network. These models can be described as NAMLMs. Which of these models is appropriate in a particular situation depends on theoretical and empirical considerations. In practice, we would tend to prefer Model I because it allows network dependencies in both the regression terms, implicitly allowing for a network contextual effect, and the variance components, although we would check diagnostics.
In practice, not all the potential sources of dependencies may be included in an analysis, either because they have not been identified or the data on the network and/or all the group memberships are not available. In some situations, the size of the data set may not be able to support fitting a suitably complex model. Several authors have considered the effect of omitting a level in an MLM on the estimates of the variance components that have been included, and the SEs of the estimates of the regression coefficients. However, there has previously been no consideration of the impact of ignoring a component, either one or more levels and/or the network in the more general framework of NAMLMs. This framework has enabled us to consider these issues analytically, by simulation, and for a real data set. The results show that the expectation of the estimates of the fixed regression coefficients are affected little by omitting the social network or any of the levels. The coefficient of the individual-level covariates is very stable. For Model I, there can be a small effect on the estimates of regression coefficients of the higher-level covariates and the intercept when the network is omitted.
Irrespective of the particular NAMLM used, the results of omitting a component of the variance structure (either the levels of a MLM or the network) are similar. When a level is ignored then the impact on the network parameter (measuring social dependence) generally is minimal, unless the network level is adjacent to or at the omitted level, and usually only the variance parameters of the other, not omitted, levels are affected. Essentially similar rules apply in this case as when ignoring a level in a standard MLM.
Omitting a component of a MLM in a NAMLM has an impact on the variance component estimates, and also on the estimated SEs of the regression coefficients, which may affect the statistical significance of those referring to group-level covariates. Similar conclusions apply as for omitting a level in an MLM (Tranmer and Steel 2001; Berkhof and Kampen 2004; Moerbeek 2004; Van Landeghem, De Fraine, and Van Damme 2005), for example, omitting a level leads to increased variance estimates of the flanking-level variance components and also incorrect estimated SEs of the regression coefficients referring to the omitted (decreased estimated SE) and the flanking levels (often increased estimated SE of the lower flanking level).
However, when the network is omitted then other variance parameters are inflated, depending on how the network and levels interact. Often only the variance parameters of the network level or levels adjacent to the network level are affected.
What happens if several components are omitted at once? When the two levels of the multilevel are ignored, then it seems this also has an effect on the estimation of
The estimates of the individual-level regression coefficients are robust to omitting components of the variance structure, although there can be some effect on regression coefficients of higher level covariates. The true SEs on the estimates of the regression coefficients were not appreciably affected, but the estimated SEs can be. Even if a full NAMLM cannot be fitted, it is still worthwhile including those components that can be included, and worth bearing in mind that any omitted components may be affecting the estimates of the components that are included in the analysis.
Increases in estimated SEs when levels or the network are omitted reduce the statistical significance of the parameter estimates, leading to some loss of power, but do not lead to incorrectly declaring statistical significance. This was observed in the analysis of the schools data set, which was based on a relatively small sample. In the simulation study, which has a larger sample size, the estimated SEs had negative bias for the regression coefficient of an omitted level. However, this situation is unlikely in practice, since having a covariate for a level usually means we know the level for each individual and can account for it in the variance structure. For the school data set, a reduction in the estimated SEs for a regression coefficient also occurred sometimes, for example, for parameters for covariates for levels adjacent to the omitted level. Hence, for smaller data sets, we need to be careful with declaring significant results for covariates of adjacent levels. Generally, the estimated SEs of the individual-level regression coefficient did not decrease; incorrectly declaring statistically significant results for individual-level covariates is very unlikely to occur when some levels or the network are omitted. Further development of SE estimates for NAMLMs should consider robust SE estimation and bootstrap methods.
The
Supplemental Material
sj-pdf-1-smr-10.1177_00491241231156972 - Supplemental material for The Effects of Omitting Components in a Multilevel Model With Social Network Effects
Supplemental material, sj-pdf-1-smr-10.1177_00491241231156972 for The Effects of Omitting Components in a Multilevel Model With Social Network Effects by Thomas Suesse, David Steel and Mark Tranmer in Sociological Methods & Research
Footnotes
Author’s Note
![]() .
.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the UK Economic and Social Research Council (RES-000-22-2595) and the Australian Research Council (LX 0883143).
Supplemental Material
The supplemental material for this article is available online. Supplemental material for this article is available online providing additional results presented in Tables S1 to S4.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.