
Abstract
The proportion of explained variance is well defined in linear models, but Snijders and Bosker demonstrated that this concept is ill defined in linear multilevel models. Whenever a researcher adds a level 1 predictor to the model, the level 2 variance may increase because the level 2 variance also depends on the level 1 variance. This problem is more pronounced when there are few observations per cluster. The authors present a solution that allows researchers to decompose variance components from null models into parts explained and unexplained by level 1 predictors. The authors also offer an extension that incorporates level 2 predictors. This approach is based on multivariate multilevel modeling and provides a complete decomposition of the gross (or null model) variance components. The approach is also implemented in the user-written Stata program twolevelr2, and the online supplement contains worked code for implementation in R. The authors illustrate this method with an example analyzing sibling similarities in lifetime income.
The proportion of explained variance, often referred to as R2, is a well-known concept in linear regression modeling and is extensively used in social science and beyond. One widely used way to obtain R2 is to compare the proportional reduction in the variance of the error term before and after controlling for one or more predictor variables. In linear models, this approach is equivalent to applying the law of total variance to decompose the variance in the outcome into a part attributed to the model’s linear predictor and compare this with the total outcome variance including the variance of the error term. In linear multilevel models, however, the concept of explained variance is less clearly defined. According to a seminal article by Snijders and Bosker (1994), the before-after approach can yield negative R2, something that is counterintuitive and inconsistent with the linear model case. Negative R2 results from the variance of the level 2 errors increasing whenever we include a level 1 predictor in the observed or “fixed” part of the model. 1
Snijders and Bosker (1994) proposed to abandon the approach used in the conventional linear model in multilevel models and define explained variance in terms of the proportional reduction in prediction error. For level 2 variance components, this approach implies using the predicted group means before and after controlling for a predictor. This approach provides an easy way of obtaining an R2 measure, but it does not constitute a decomposition of the underlying variance components of the null model. Moreover, Snijders and Bosker’s approach will lead to a poor approximation of the reduction in the underlying variance components whenever there are few observations per cluster (e.g., in panel data or sibling data).
In this article, we introduce a new approach to obtaining R2 for the entire two-level model and for each level separately. The approach is based on multivariate multilevel modeling, which is a series of multilevel model equations for the outcomes and predictors for which level 1 and 2 errors are correlated across, but not within, equations (Baldwin et al. 2014; Goldstein 1995:89ff). It is conceptually similar to a seemingly unrelated regression approach in a multilevel framework. The multivariate models yield a variance-covariance matrix at levels 1 and 2, which can be used to back out appropriate R2 statistics. We extend the framework to accommodate level 2 predictors, and we suggest a simple approach for dealing with models with a large number of level 1 covariates. Our approach is implemented in Stata with a freely available user-written program called twolevelr2 (Jann 2024). In the online supplement, we provide sample code that illustrates how the procedure can be implemented in R using the brms package (Bürkner 2017). As an example, we analyze the extent to which sister similarities in life cycle income can be explained by sibling similarities in schooling.
Why R2 can be Negative
Snijders and Bosker (1994) demonstrated why R2 can be negative in two-level models. Let Yij denote the outcome of observation i in cluster j, and let Xij denote a corresponding predictor variable. Then we can write the two-level model excluding the predictor as

where

where
Snijders and Bosker (1994) demonstrated that unexplained variance at level 2 can increase because the relationship between the variance of the level 2 error and the variance of the cluster means is given by

where n is the number of observations per cluster.
2
The intuition behind equation (3) is that
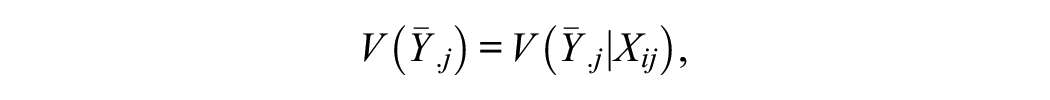
but, per equation (3), there will be an offsetting effect on the level 2 error variance, because the variance of the level 1 errors will decline; that is,
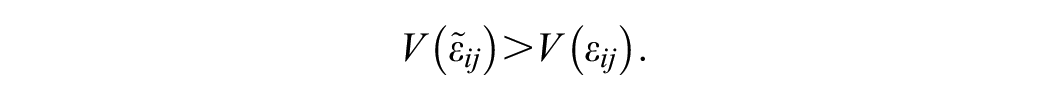
The offsetting effect means that the level 2 error variance will increase; that is,
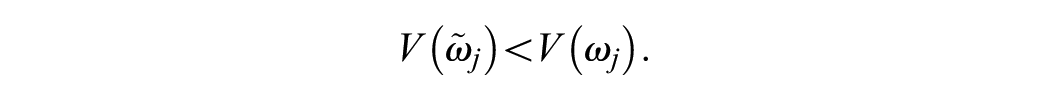
In the more likely scenario in which Xij contains variation at levels 1 and 2, the same offsetting effect will still be present because of the reduction of the variance in the level 1 errors, even though it may be counteracted by the reduction caused by the level 2 part of the predictor. Moreover, the offsetting effect will be particularly large whenever n is small, that is, when there are few observations per cluster, which is common in social science applications (e.g., in panel data or for number of siblings per family).
Snijders and Bosker (1994) suggested solving this problem by recasting explained variance in terms of the proportional reduction in prediction error. For the level 2 error, they suggested using the proportional reduction in the variance of the predicted cluster means by comparing
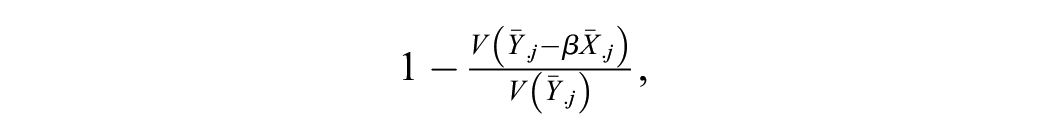
which amounts to aggregating to the cluster level and calculating the R2 using the coefficient estimate
A New Approach
We suggest using multivariate multilevel models to first obtain level 1 and level 2 variance-covariance matrices of both outcome and predictor variables and then use those variance-covariance matrices to back out relevant R2 values. One advantage of our approach over existing approaches is that it relies on estimating only one model, a multivariate one. Moreover, in contrast to approaches that back out explained variance components by relying on the model including the predictor (Rights and Sterba 2019), our approach provides a decomposition of the variance in the null or empty model not involving any predictors, which often constitutes the explanandum in multilevel modeling (Snijders and Bosker 2012).
We first demonstrate this approach using the simplest setup possible, namely, the situation with one outcome variable, Yij, and one level 1 predictor variable, Xij. We specify two two-level equations, one for each variable,

and

where a is the global intercept, u the level 2 error, and e is the level 1 error. 3 The level 1 and level 2 errors are assumed to be independent of each other. The bivariate model is then given by the following variance-covariance matrices of the level 2 and level 1 errors, respectively,
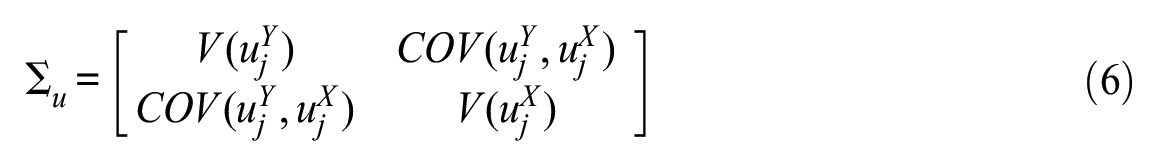
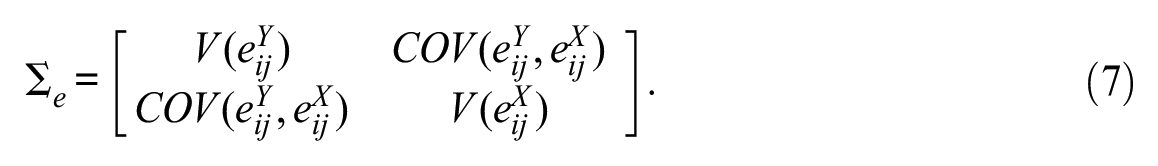
In this model, the level 1 and level 2 error terms are allowed to be correlated across (but not within) equations (4) and (5). The variance-covariance matrices contain all that is needed to obtain relevant measures of the proportion of explained variance. The proportional reduction in the variance of the level 2 error term is given by

where
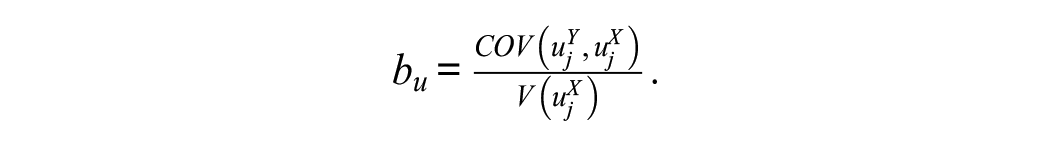
The corresponding R2 for level 1 is given by

where
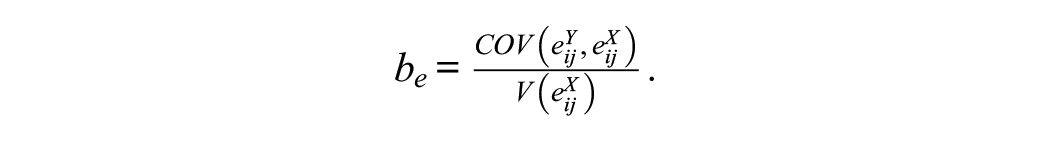
The total or global R2 can then be defined as

It holds that
Generalizing to Multiple Predictors
It is straightforward to generalize from the bivariate to the multivariate case. In this situation, we can “stack” the equations for the dependent variable and K level 1 predictors

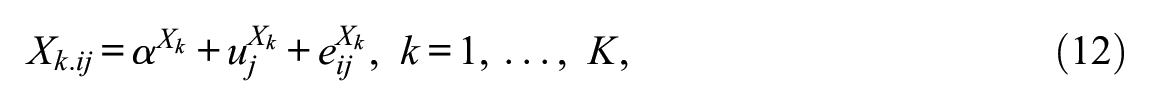
where
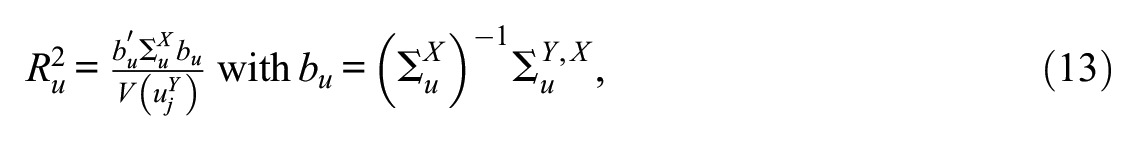
where
Including a Level 2 Predictor Variable
We have thus far considered explained variance when we include level 1 predictors that vary both within and between clusters (or, possibly, only within clusters). If we are interested in including level 2 predictors, that is, those that only vary between but not within clusters, then we have to extend our approach in the following way: relying on the Frisch-Waugh-Lovell theorem (Lovell 2008), we include these predictors directly in the multivariate multilevel equations, and then back out the explained part of the model using the law of total variance. We can do this because, per equation (3), there is no offsetting effect via the level 1 variance component, and thus we can obtain the proportional reduction in the level 2 variance component from including a level 2 predictor.
Assume we have a single level 2 predictor Zj and a single level 1 predictor Xij, then we can write the bivariate multilevel model as


and obtain the R2 at level 2 as

where
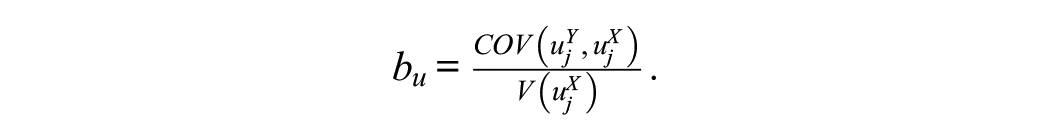
As Zj does not vary within clusters, the level 1 R2 remains unchanged. The global R2 is given by
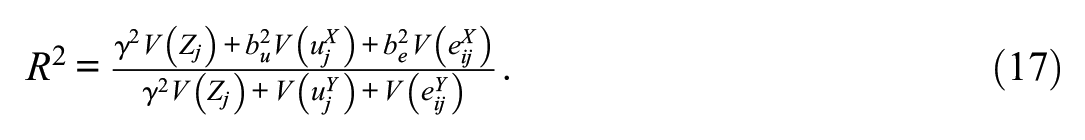
This global R2 is 0 when
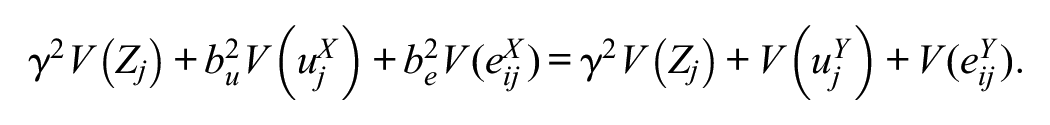
The generalization to multiple predictors at both levels is straightforward (with cross-level interaction terms to be treated as level 1 predictors).
Example
Social mobility scholars often use sibling data to obtain an estimate of the overall family background effect on a given labor market outcome of interest. To do so, researchers estimate a two-level random intercept model in which siblings are nested in families. The intraclass correlation from this model is a measure of the overall effect of family background because it captures the effects of everything siblings share, including their genetic makeup, common rearing environment, mutual interactions, and local neighborhoods (Solon 1999). Mobility scholars then often add sibling-specific variables, such as education, to see how much of the family-specific (or sibling group–specific) variance can be explained by education (Iannelli, Breen, and Duta 2024; Karlson and Birkelund 2024; Mazumder 2008).
We draw on sister data from the National Longitudinal Survey of Youth 1979 to examine the overall family background effect on lifetime income (Bureau of Labor Statistics 2019). In the National Longitudinal Survey of Youth 1979, we can identify sisters living in the same household at the time of the first interview and follow them through today. We are interested in evaluating the extent to which formal schooling (measured as highest grade completed at age 30) explains variation in income between (level 2) and within (level 1) families. We also investigate the extent to which parental income (a level 2 predictor) and sibling-specific formal schooling (a level 1 predictor) jointly explain the variance components. In a final example, we investigate how three level 1 predictors (schooling, cognitive ability, and educational aspirations) explain variance in income within and between families. Omitting singletons and sisters without valid information on the covariates and the dependent variable, our final sample includes 1,078 sisters from 502 sibling groups. Replication materials for this example are published along with this article.
Table 1 shows estimates of the bivariate multilevel model described in equations (4) and (5), in which sibling lifetime log income is the ultimate dependent variable. The first panel, log income, contains estimates of the model in equation (4), including the two variance components at level 1 (within families) and level 2 (between families); the second panel, schooling, contains the corresponding estimates in equation (5), that is, within- and between-family variation in schooling. The final panel contains the cross-equation covariances in the errors at each level. We use the estimated variances and covariances to back out the R2 described earlier.
Estimated Intercepts, Variance Components, and Covariances in a Bivariate Multilevel Model of Sisters’ Schooling and Lifetime Income.
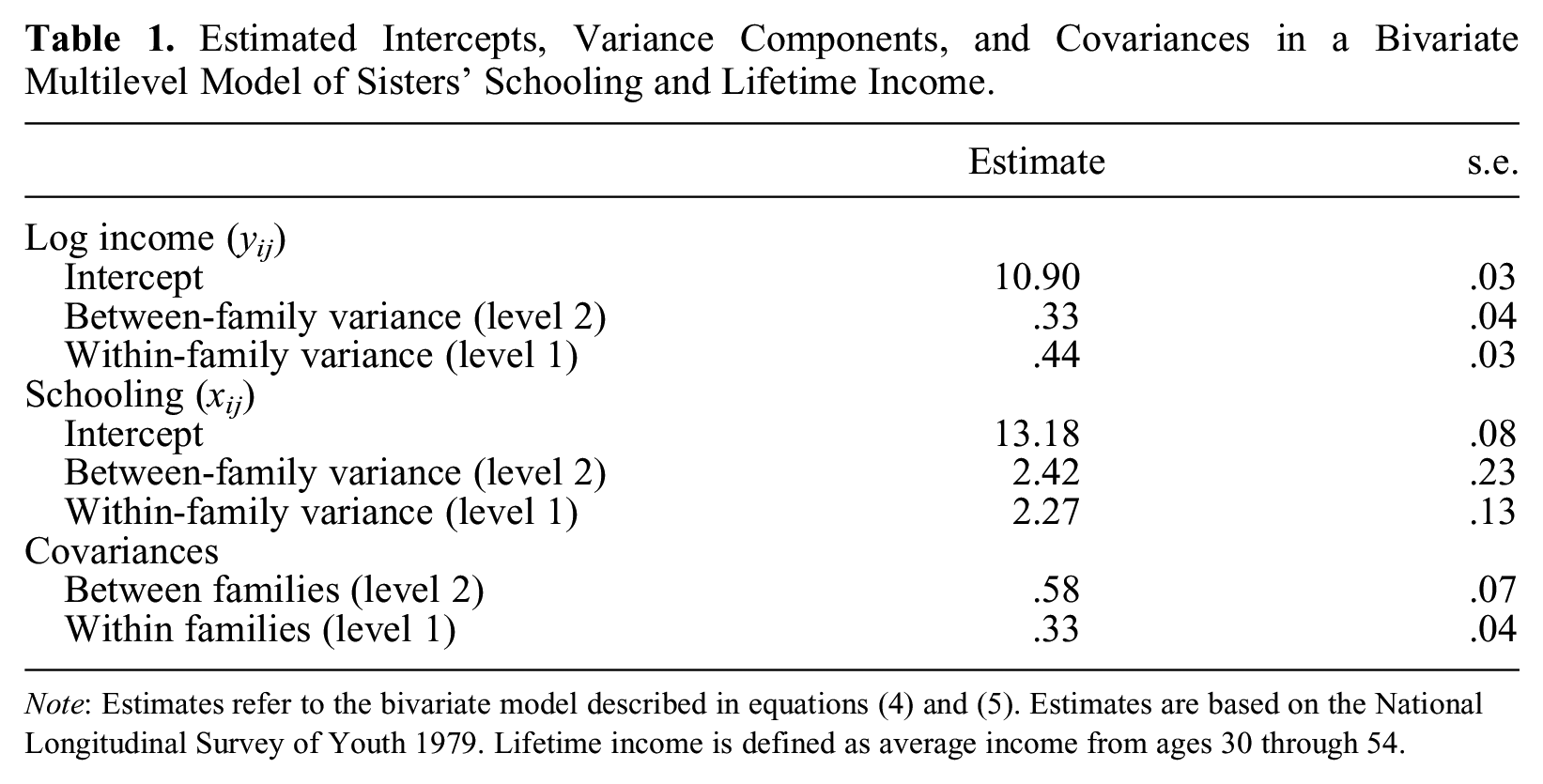
Note: Estimates refer to the bivariate model described in equations (4) and (5). Estimates are based on the National Longitudinal Survey of Youth 1979. Lifetime income is defined as average income from ages 30 through 54.
Table 2 shows the derived R2 from the estimates as well as R2 at level 2 computed from either the crude before-after approach 5 or Snijders and Bosker’s (1994) approach. Using our new approach, we find that formal schooling accounts for about 42 percent of the total variance in log lifetime income between families, that is, at level 2. Had we instead used the crude before-after approach used in the existing literature, we would obtain a slightly smaller value of about 39 percent. This result is as expected: the before-after approach is affected by the offsetting term identified in Snijders and Bosker, leading to an attenuation of the R2 at level 2. In column M1 in Table 2, we report the R2 between families (at level 2) suggested by Snijders and Bosker. This estimate is only about 28 percent and thus substantially smaller than that based on our approach. This discrepancy arises because there are only a few observations (sisters) per cluster (family), so the cluster averages entering into the Snijders-Bosker R2 are very crude proxies for the latent errors in the multilevel models.
Implied R2 from Bivariate Models.

Note: M1 refers to the model in Table 1. M2 refers to a bivariate model that includes parental income as a covariate in each of the two equations. Estimates are based on the National Longitudinal Survey of Youth 1979. Lifetime income is defined as average income from ages 30 through 54.
Column M1 in Table 2 also shows that schooling explains about 11 percent of differences within families (at level 1), and the combined explanatory power of schooling on life cycle income is about 24 percent, a substantial portion. Column M2 in Table 2 reports the derived statistics from a bivariate model in which we include parental income (a pure level 2 predictor) as a covariate in each equation. The joint explanatory power between families (at level 2) then rises to about 65 percent, suggesting that parental income can incrementally account for about 23 percentage points over and above that accounted for by formal schooling, a nontrivial portion. As expected, we also find that R2 within families (at level 1) is unchanged at 11 percent. 6 In terms of overall explanatory power, formal schooling and parental income can account for about 34 percent of the total variance in lifetime income among sisters.
To show the utility of our approach when there are multiple level 1 predictors, in Table 3 we report derived R2 from multivariate models that successively add level 1 covariates. The first row adds schooling, and estimates in that row are identical to those reported for M1 in Table 2. In the second row, we add cognitive ability and estimate a trivariate multilevel model. Adding cognitive ability increases the explained variance at level 2 to 68 percent, thus accounting for about 26 percent of the incrementally explained variance between families over and above that explained by education. The explained variance within families increases to 15 percent and the global R2 to 37 percent. In the third and final row, we add educational aspirations and estimate a multivariate model with four equations. Adding educational aspirations does not lead to any incrementally explained variance.
Implied R2 from Multivariate Models That Successively Add Level 1 Covariates.
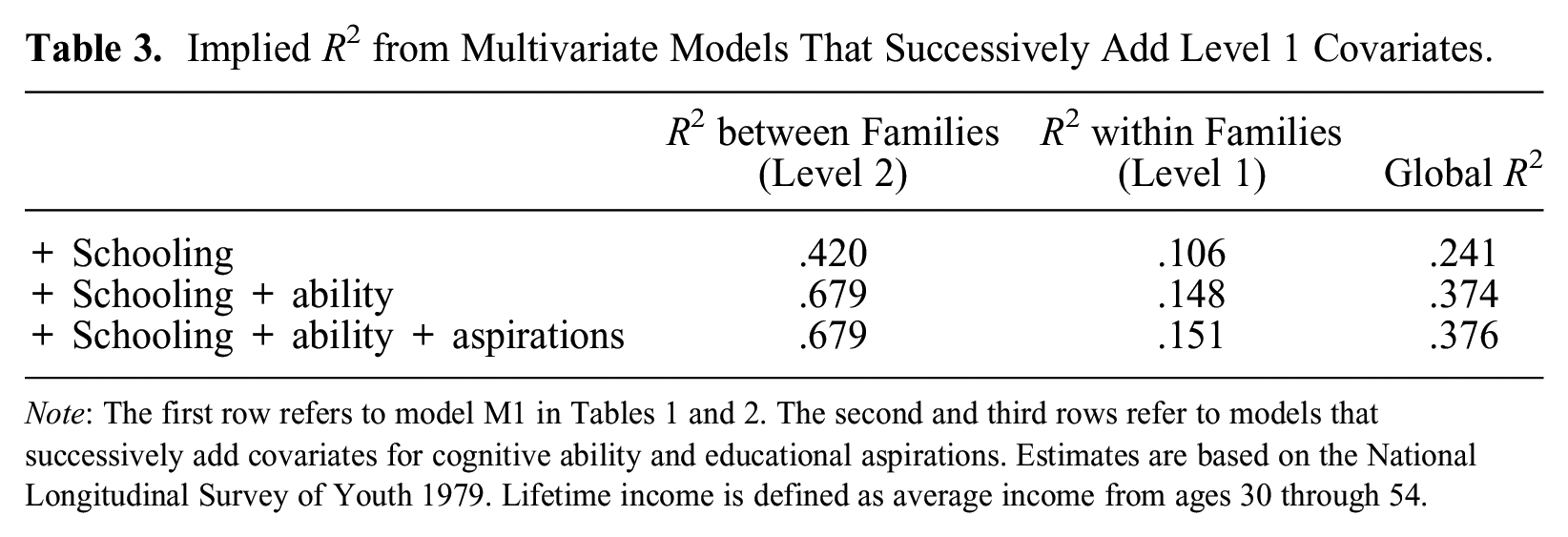
Note: The first row refers to model M1 in Tables 1 and 2. The second and third rows refer to models that successively add covariates for cognitive ability and educational aspirations. Estimates are based on the National Longitudinal Survey of Youth 1979. Lifetime income is defined as average income from ages 30 through 54.
Conclusion
We have presented a new way of obtaining the proportion of explained variance in two-level multilevel models. The approach solves a problem identified 30 years ago by Snijders and Bosker (1994). With our approach, researchers can decompose the variance components of the null model in a way equivalent to that used in conventional linear models. The approach is based on multivariate multilevel modeling and is therefore not affected by the offsetting effect at level 2 described in Snijders and Bosker (1994). The approach offers R2 for levels 1 and 2 separately and jointly, and can easily be extended to accommodate level 2 predictors. We provide a tailor-made Stata routine (twolevelr2) for calculating the level 1 and 2 R2 values, and in the supplementary materials to this article we provide code in R for reproducing our examples.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: For Kristian Bernt Karlson, the research leading to the results presented in this article received funding from the European Research Council under the European Union’s Horizon 2020 research and innovation program (grant agreement 851293).
Data Note
Supplemental Material
Supplemental material for this article is available online.