
Abstract
In relational event networks, the tendency for actors to interact with each other depends greatly on the past interactions between the actors in a social network. Both the volume of past interactions and the time that has elapsed since the past interactions affect the actors’ decision-making to interact with other actors in the network. Recently occurred events may have a stronger influence on current interaction behavior than past events that occurred a long time ago–a phenomenon known as “memory decay”. Previous studies either predefined a short-run and long-run memory or fixed a parametric exponential memory decay using a predefined half-life period. In real-life relational event networks, however, it is generally unknown how the influence of past events fades as time goes by. For this reason, it is not recommendable to fix memory decay in an ad-hoc manner, but instead we should learn the shape of memory decay from the observed data. In this paper, a novel semi-parametric approach based on Bayesian Model Averaging is proposed for learning the shape of the memory decay without requiring any parametric assumptions. The method is applied to relational event history data among socio-political actors in India and a comparison with other relational event models based on predefined memory decays is provided.
Keywords
Introduction
As a result of the growing automated collection of information, fine-grained longitudinal network data are increasingly available in many disciplines, such as sociology, psychology, and biology. These data have the potential to revolutionize our understanding about complex social network dynamics as we can learn how the past affects the future, how interaction behavior changes in continuous time, and how past social interactions lose their influence on the future away as time progresses. This has inspired social network scientists to develop network models that suit the inherent dynamic nature of these so-called relational event data. A relational event is defined as an action initiated by a sender and targeted to one or more receivers at a specific point in time. The relational event modeling framework aims to model the event rate: the speed at which relational events occur over a period of time between the actors in the model. The event rate can be expressed as a function of characteristics that quantify endogenous network patterns or exogenous characteristics that (jointly) determine how the network unfolds at some point in time (Butts, 2008). In sociological and psychological research, the application of these relational event models aims to find behavioral patterns and to shed light on the emergence of a global structure from network dynamics occurring at a local (typically, dyadic) level (Leenders, Contractor, and DeChurch et al., 2016; Schecter et al., 2018; Pilny et al., 2016).
Of particular interest is to understand what triggers actors to interact with each other. Actors might decide which mutual recipient to target their actions to depending on various aspects such as homophily, norms of reciprocity, the volume of past social interactions, triadic closure mechanisms, et cetera (Rivera, Soderstrom, and Uzzi, 2010). Past relational events influence future events in different ways. First, qualitative aspects of the past events play a role, such as whether the interaction was positive or a negative or who was the sender of the past event. For example, receiving a message from the company’s president might have a greater effect than getting a message from a regular colleague. Similarly, the valence of events may play a role: events with a negative connotation have been argued to have a greater effect than events with a positive connotation (Brass and Labianca, 1999; Labianca and Brass, 2006; Offer, 2021; Moerbeek and Need, 2003). Second, recent past events are generally expected to have a greater influence on the present than events that occurred a long time ago (Butts, 2008; Quintane et al., 2013; Brandes, Lerner, and Snijders, 2009; Mulder and Leenders, 2019). Having recently received praise from a colleague is likely to affect current interaction more than if that praise dates back a year ago.
While studies using relational event data tend to focus on the effects of endogenous statistics (e.g., to what extent actors repeat their past interactions, do they reciprocate interactions aimed at them, or do they prefer to interact with others with whom they share many other interaction partners with?) or exogenous statistics (e.g., does information sharing tend to go from lower-status actors to higher status actors, do friends share information at higher rates than non-friends, how much does co-location matter for communication in IT-enabled teams?), much less attention has been paid to exactly how long past events retain their influence on the present and future. This is the very subject of this paper. In particular, our aim is to derive a method that allows a researcher to empirically derive the shape of the function by which past events lose their influence on the future. This shape can be linear, exponentially decaying, or have any other shape. To unify our terminology, we will use the term “memory decay” for this phenomenon, even though we do not aim to model cognitive functions of the actors in the network. This terminology is not new. For example, Brandes, Lerner, and Snijders (2009) specify a half-life function that governs the decaying influence of events “motivated by the assumption that actors forget (or forgive)”. Similarly, Mulder and Leenders (2019) and Leenders, Contractor, and DeChurch et al. (2016) explicitly refer to this phenomenon as “memory decay.” Within the context of Temporal ERGM’s, Leifeld, Cranmer, and Desmarais et al. (2018) and Leifeld and Cranmer (2019) include so-called “memory terms” and allow the researcher to specify time-based functions (“time trends”) of how the time since a past tie affects the occurrence of later ties. Our focus is on the way the influence of past events on the future changes, that is akin to how long people “remember” (or care about) the past actively enough to still make it count towards the present and future. Because the effect of the past will almost always decrease as time passes, we will use the term “memory decay” throughout this paper to refer to the shape of the function that captures how the influence of a past event on future events changes as the time since the event increases.
Already in Butts (2008) seminal paper and the accompanying software (Butts, 2021), the importance of memory retention of past relational events is highlighted. So-called “participation shifts” were introduced that capture how the interaction dynamics shifts between dyads depending on the very last event that happened. These statistics assume that actors respond to the immediate past, regardless of what happened before that. In addition, a “recency” statistic is considered where the potential receivers for each potential sender are ordered based on their recent activity and a power-law is used to create a predictor variable (i.e., the reciprocal of the rank). This mechanism captures the extent to which actors take into account the last events they had with every other actor, discounting events from farther into the past. Finally, other endogenous statistics (such as inertia and reciprocity) are computed as the total volume of past interactions between actors and, hence, count all past events as equally important to the future and assume that no past event, however distant in the past, is ever forgotten. In sum, these statistics already capture three distinct ways in which the past is (dis)counted towards the present and the future and each reflect a different shape of memory decay.
More recently, other approaches have also been considered to better understand how (long) past activity affects future events. One approach has been to quantify a specific pattern of interactions according to specific predefined time intervals, such as a short-run expression (calculated by considering recently passed events) and a long-run expression (considering long-passed events in the computation) (Quintane et al., 2013; Quintane and Carnabuci, 2016; Perry and Wolfe, 2013; Kitts et al., 2017; Patison et al., 2015). The estimated effects for these intervals describe how different the impact of the specific pattern is on the event rate according to different recency of events constituting the pattern itself. Another approach consists of estimating the model while using a moving time window with a predefined fixed memory length with the result of a trend of the effects over the windows (Mulder and Leenders, 2019). An alternative to time-intervals-based methods weighs the influence of past events by an exponentially decreasing function with a given half-life parameter that describes the elapsed time beyond which the influence of an event in the calculation of the statistic is halved (Brandes, Lerner, and Snijders, 2009; Lerner, Bussman, Snijders, and Brandes et al., 2013; Leenders, Contractor, and DeChurch et al., 2016).
In all of these approaches, a researcher needs to predefine the memory lengths for the discretized model or predefine the steepness of the decay in the case of the continuous half-life model. Typically, heuristic considerations are used to specify this function. Notable exceptions include Brandenberger (2018) and Brandes, Lerner, and Snijders (2009) who explored the fit and robustness of the results by considering different choices for the half-life parameter. The question is, however, whether a prespecified memory decay appropriately captures the dependence between the time that has passed since the event and the current event. Depending on the context, certain decay shapes may be more suitable in terms of fit than other shapes. Model misfit may result in poor predictions and unreliable inferences.
Considering the dearth of time-sensitive theory to draw from (cf. Leenders, Contractor, and DeChurch et al. (2016); Ancona et al. (2001); Cronin, Weingart, and Todorova et al. (2011)), there is little theory (if any) to truly guide a researcher in the choice of an appropriate memory decay function for a research project at hand. Researchers have dealt with this by specifying choices for the decay function based on their experience with the empirical context or based on their own assumptions regarding the influence of time. Alternatively, an approach that we propose in this paper is to present a semi-parametric method for learning the actual shape of memory decay in relational event models. The method is semi-parametric in the sense that it does not make assumptions about a specific functional form for memory decay. Indeed, parameters that potentially govern the memory process and, in turn, determine its shape over time are often unknown and our intent is to minimize the challenge that is involved in prespecifying a memory function by a researcher. Our method can be used for finding any functional form of memory decay which could be an exponentially decreasing trend, a smoothed step-wise function, or other, possibly more (or less) complex, functional trends. Our semi-parametric method combines the relational event modeling framework (as in Butts (2008)) with Bayesian inference in the context of a model selection problem (Bayesian Model Averaging) (Volinsky et al., 1999). The idea is to consider a large “bag” of step-wise models with different interval configurations. Next, the fit is computed for all step-wise models, and subsequently, we model the shape as an average of these models weighted according to their respective fit to the observed data.
The paper is structured as follows. In next Section, we introduce the relational modeling framework along with the concept of memory decay. In A Step-Wise Memory Decay Model section, we formulate a step-wise memory decay model. In The Gradual Nature of Memory Decay section, we present a continuous memory decay model and highlight the potential use of step-wise models in approximating the continuous shape of the decay. In A Semi-Parametric Approach to Estimate a Smooth Memory Decay section, we present a semi-parametric method based on a Bayesian Model Averaging along with two weighting systems for generating random draws from the posterior memory decay. In Case Study: Investigating the Presence of Memory Decay in the Sequence of Demands sent Among Indian Socio-Political Actors section we apply the method to empirical data and we compare it to other models that predefine parametric memory decays. Concluding the paper, in Discussion section we discuss some considerations regarding the methodology and potential further development.
Relational event models that capture memory decay
In the relational event framework (Butts, 2008), a relational event
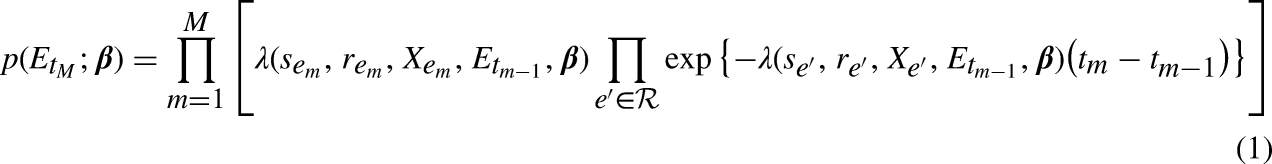
The rate of the specific dyadic event
In the standard specification of the model, endogenous statistics describe patterns of interactions occurring in the network that are quantified at each time point by considering the whole history of events that happened from the initial state of the network (i.e., the first observed relational event) until the time point before the current one (i.e.,
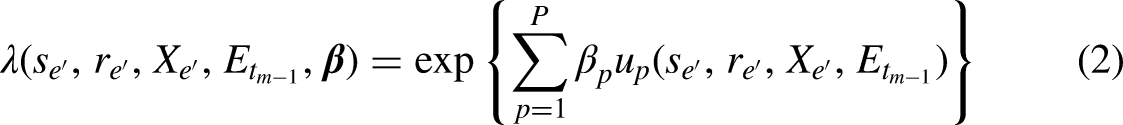
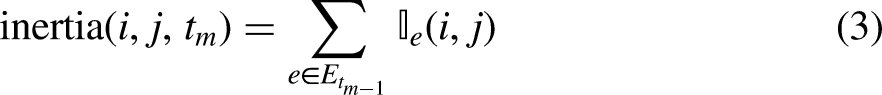
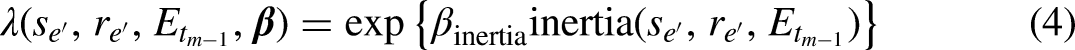
For instance, consider Figure 1 where a sequence of events from
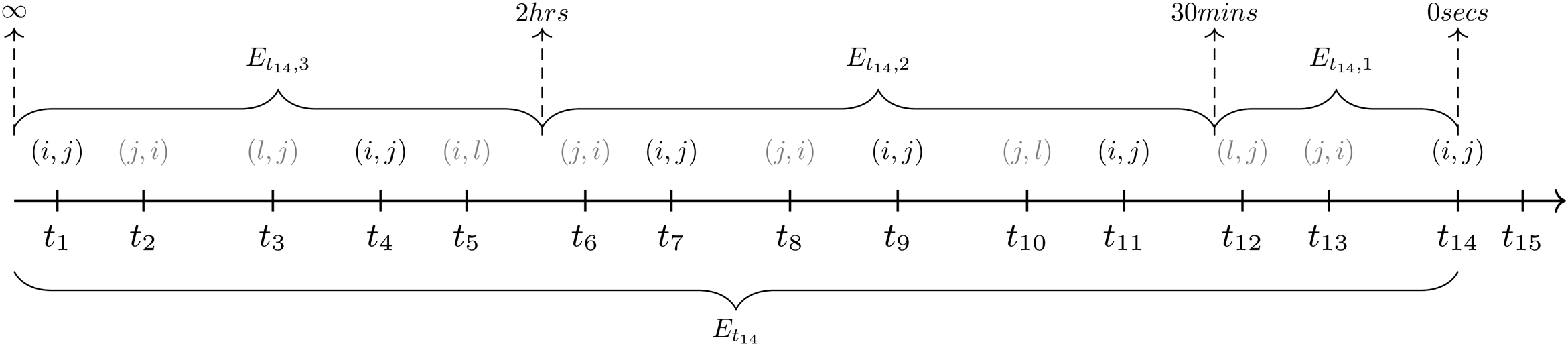
Example of the calculation of Inertia for the dyadic event
A step-wise memory decay model
Step-wise decay for first-order endogenous effects
As a first step, we model the relative importance of past events as a function of the transpired time since the event was observed using a discretized, step-wise memory decay model (Perry and Wolfe, 2013). After the transpired time is divided into fixed intervals, endogenous statistics are computed for each interval and the corresponding endogenous effects are estimated. These effects quantify the relative importance of past events in predicting future events. For instance, considering the event sequence in Figure 1, we observe that at
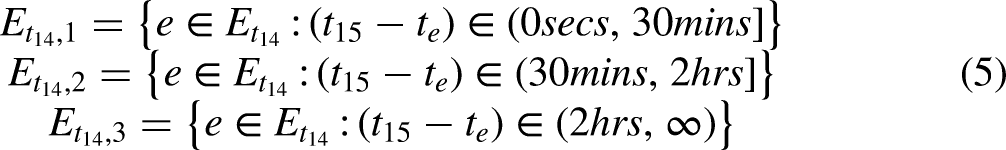
Therefore, three values of inertia can be calculated at any time point
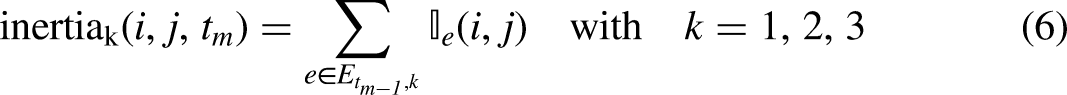
In a more general case where
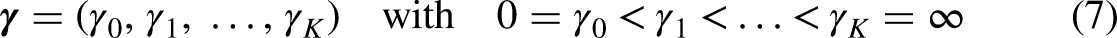
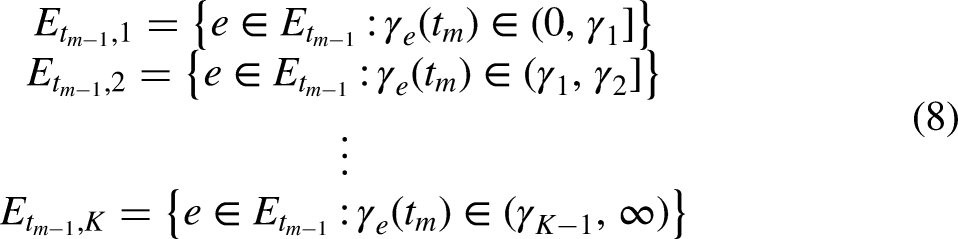
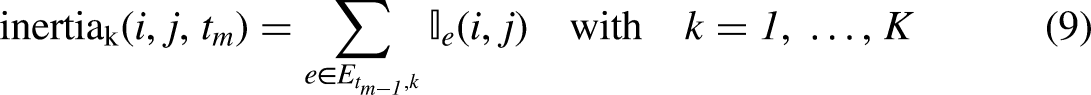
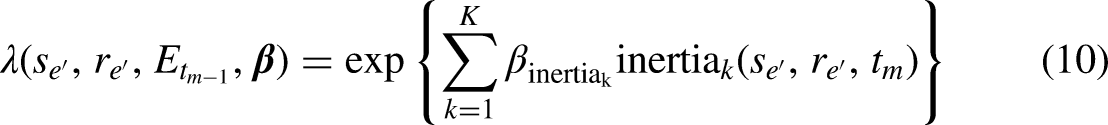
The use of interval statistics according to
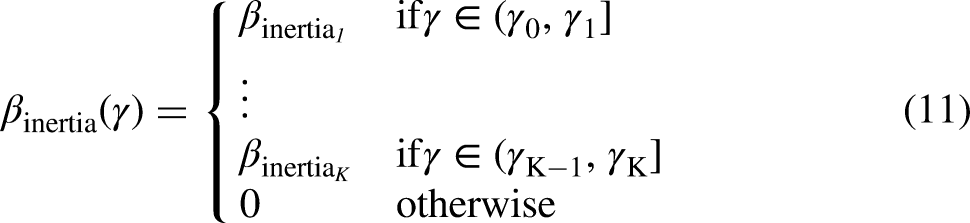
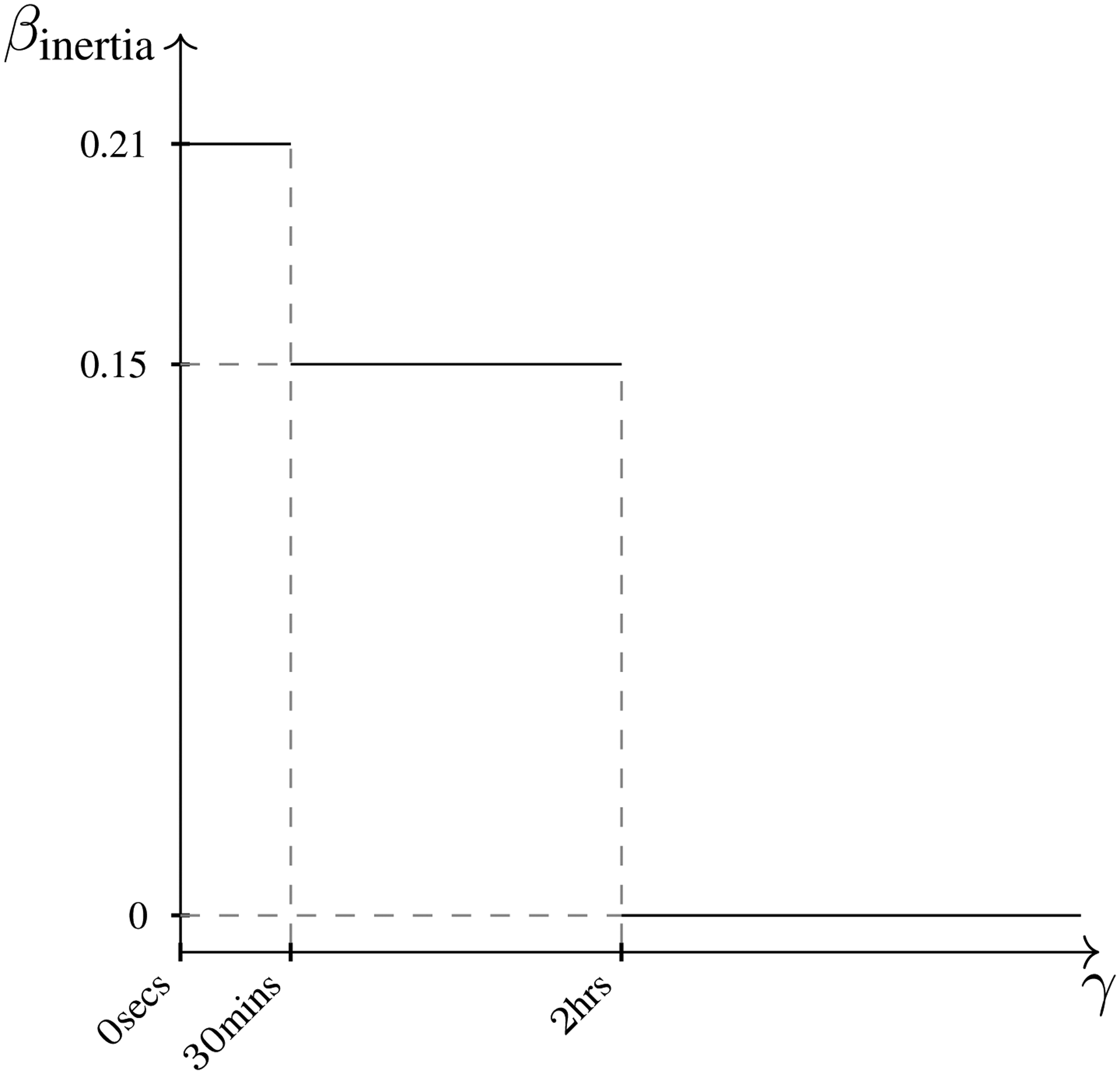
step-wise function for the effect of Inertia on the event rate. The function defines three intervals of the elapsed time
Step-wise decay for higher order endogenous effects
Besides statistics that are based only on past interactions within a given dyad, the effects of higher order statistics involving more than two actors, can be used as well within this approach. Higher order endogenous statistics are characterized by more than one dyadic relational event in their formula. As such, the behavioral pattern of interest is more complex substantively as well as its computation. Indeed, in the case of triadic statistics, as with transitivity, the computation consists in the quantification of the number of times a dyad could potentially close a particular triangular structure if it occurred as next interaction after a specific sequence of past events.
Figure 3 describes the pattern of the transitivity closure (Schecter et al., 2018) in the context of relational event data where interactions are time-ordered. The search for specific behavioral patterns can be improved by introducing such time-ordering in the calculation of the statistics. Specifically for transitivity closure, the following formula computes the statistic for the dyad
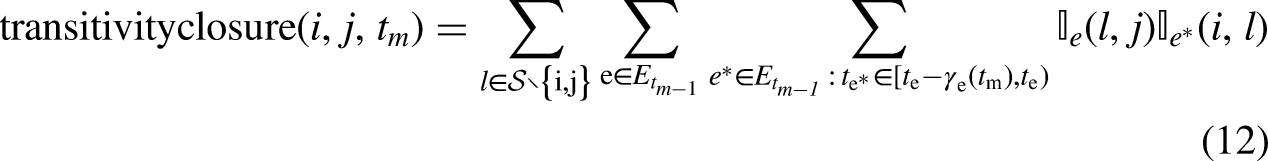
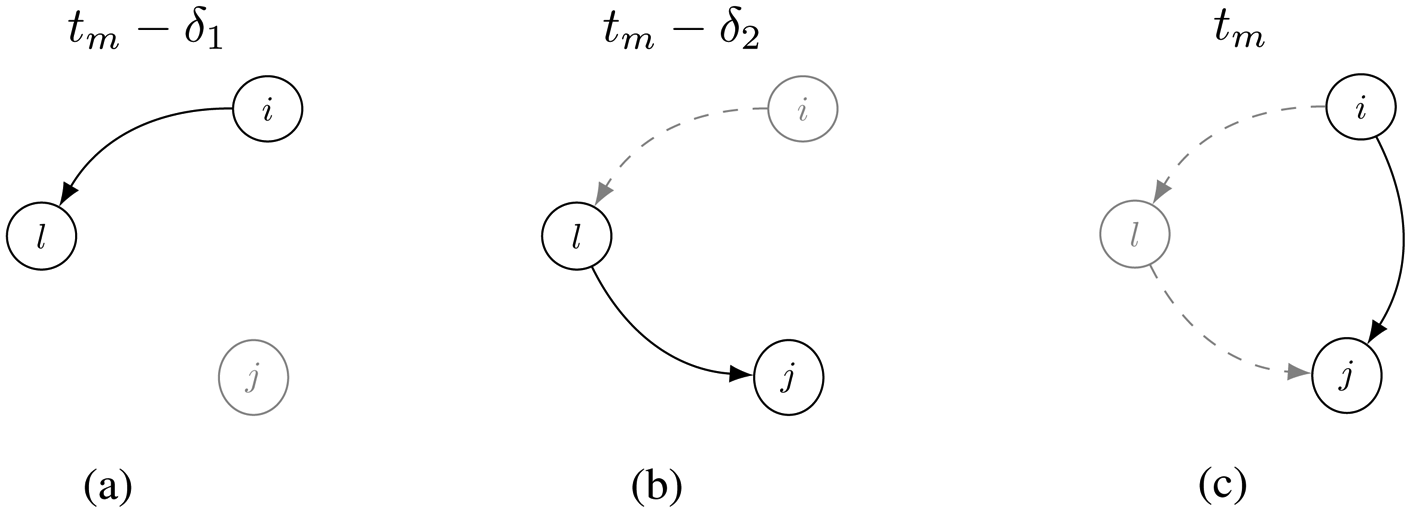
Figures from left to right describe the pattern of the transitivity closure in three time-framed steps. The time order of the three steps is described on the top of each graph, and it goes from the left, where the event
Figure 4 shows an example of the formula in (12) for just one
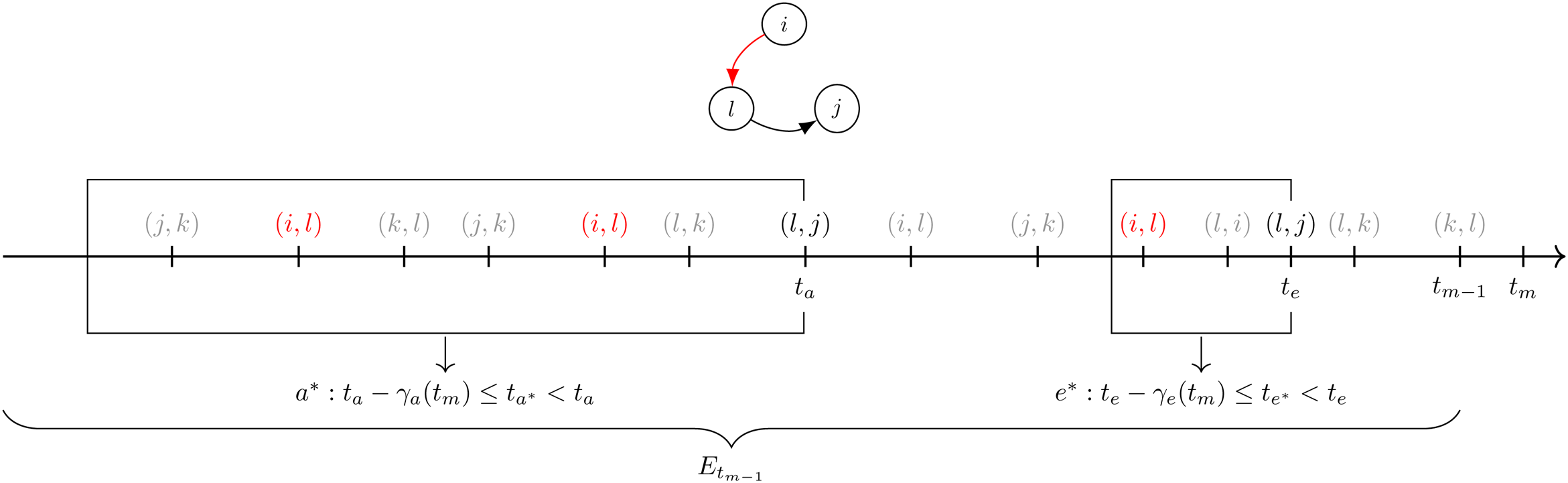
Example of the calculation of transitivity at
The event rate for any possible event
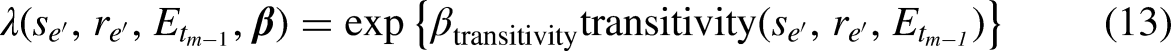
Consider the more general case of
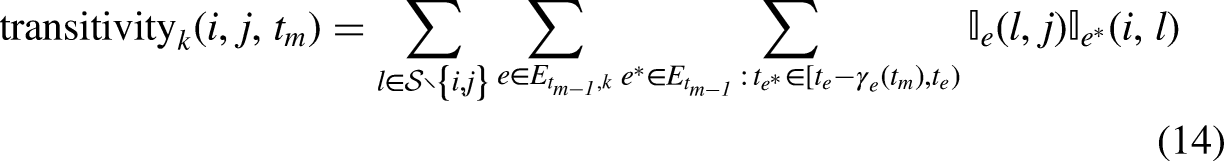
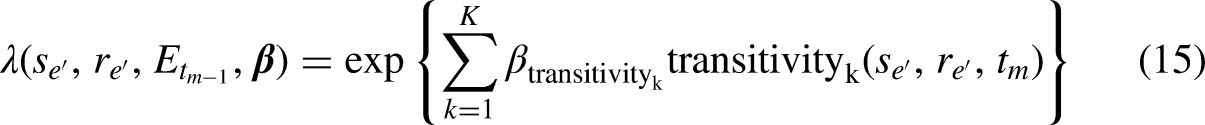
The function in (11) can be written also in the case of triadic statistics:
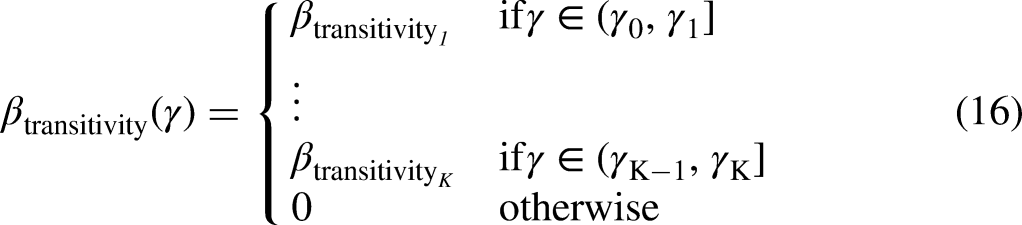
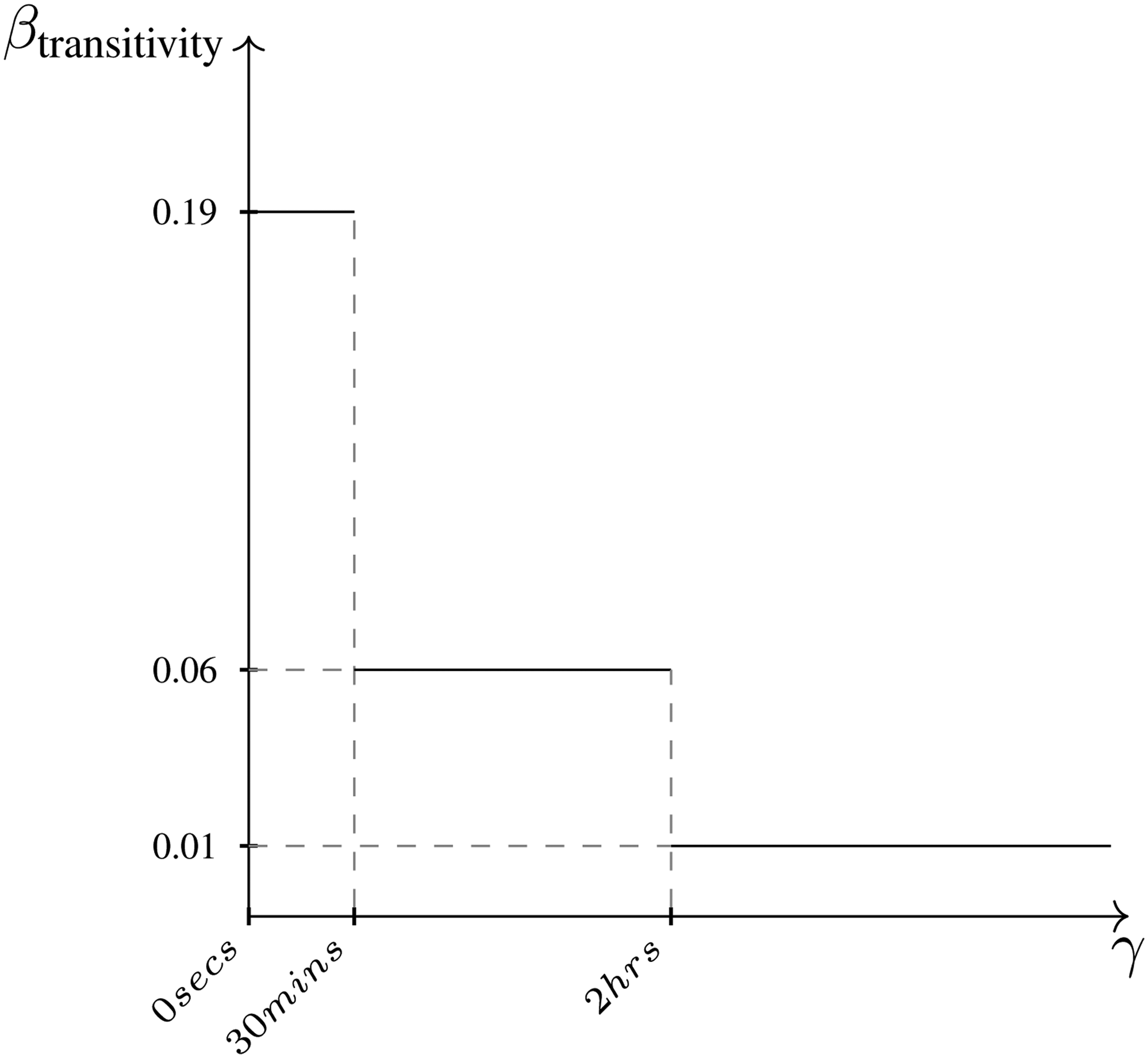
step-wise function for the effect of Transitivity on the event rate. The function defines three intervals of elapsed time
Estimation of a relational event model with a step-wise memory decay
The relational event model with step-wise memory decay of endogenous effects has the advantage that it can be easily estimated using existing software as relevent (Butts, 2008), goldfish (Stadtfeld and Hollway, 2020), rem (Brandenberger, 2018), or remverse (Mulder et al., 2020). This can be done as follows. First, the transpired time needs to be divided into disjoint intervals with bounds
Despite the computational advantage, the step-wise memory decay in (11) and in (16) has two potential challenges: a substantive challenge is that may not always be realistic that memory decay occurs in a step-wise fashion in real life; a methodological challenge is that it may be unclear how many intervals (
The gradual nature of memory decay
Since past events often lose their effect gradually over time (rather than step-wise), we propose an often more realistic form of the memory decay in (11) and (16) where, instead of constraining effects to be constant within intervals of

We propose several monotonously decreasing functions
The continuous trends in Figure 6 assume effects to be positive and decreasing towards zero as the time transpired since the event increases.
linear decrease (Figure 6a): exponential and one-smooth-step decrease (Figure 6b and Figure 6c): smoothed multiple steps (Figure 6d): this is a combination of two or more smoothed one-step trends.
The relative influence of past events on the dyadic event rate can follow other more complex shapes than those presented in Figure 6. As a result of this continuous definition of effects, inertia as well as other endogenous statistics are no longer computed as the accumulated number of past events but now consist of a sum of weights, where each weight changes according to the transpired time
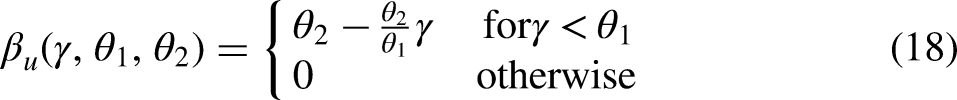
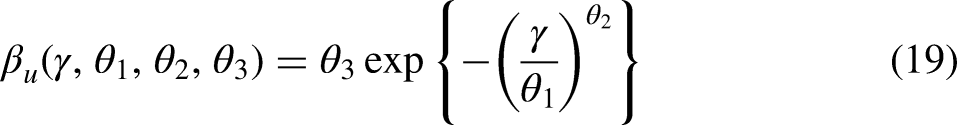
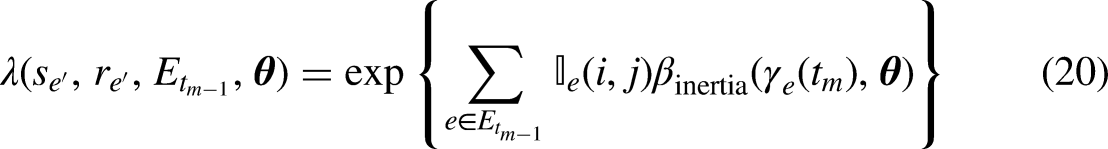
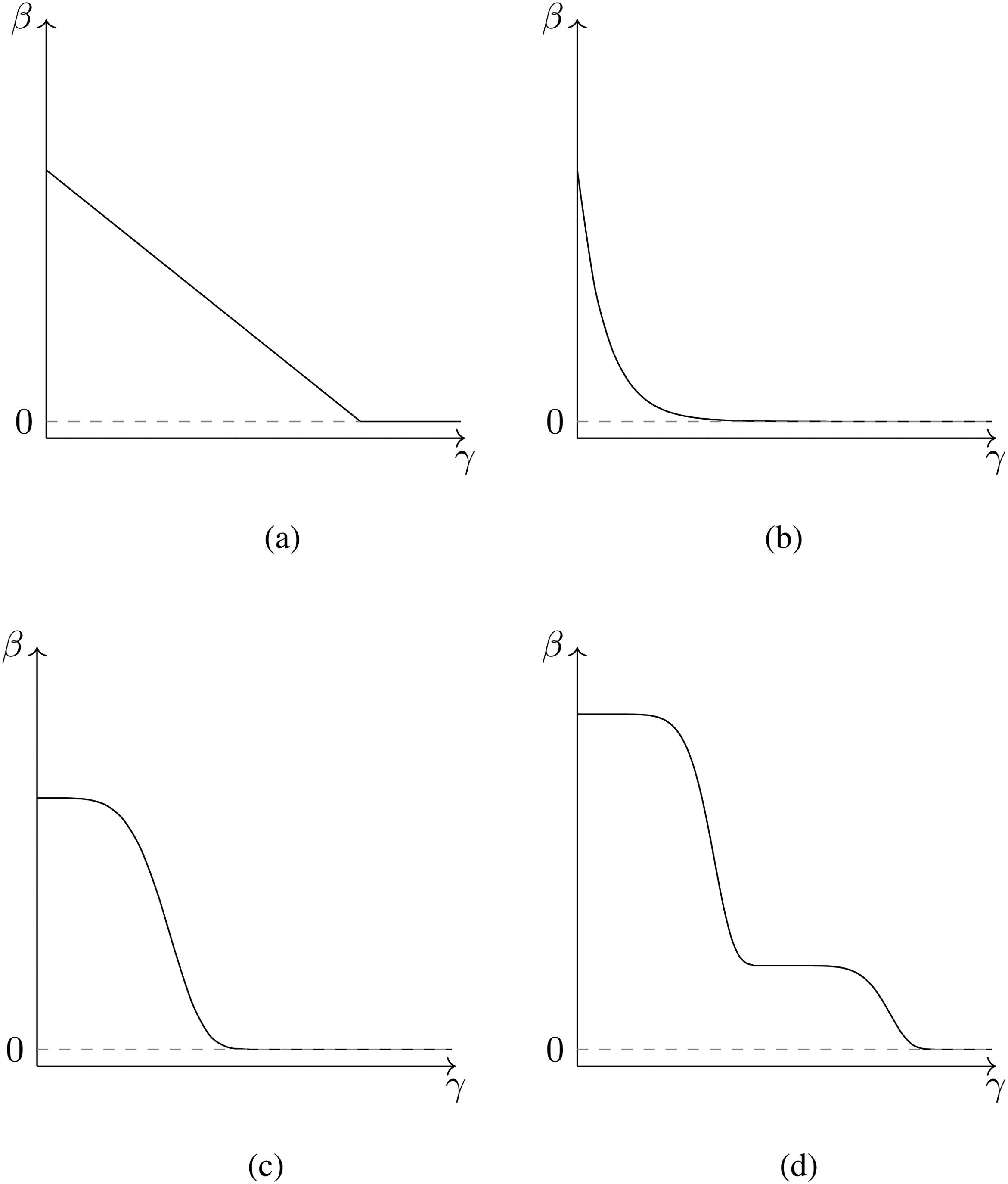
Possible trends of the effect
However, the process of estimation of the set of parameters
A semi-parametric approach to estimate a smooth memory decay
In this section we propose a methodology that (i) builds on the computational advantage of the step-wise model introduced in Step-Wise Decay for Higher order Endogenous Effects section, (ii) avoids the issue of arbitrarily choosing intervals, and (iii) results in an approximate continuous estimate for memory decay. This is achieved by applying Bayesian Model Averaging (BMA) (Volinsky et al., 1999) to model memory decay in endogenous REM statistics. The idea is to randomly generate a bag of many step-wise models with different interval configurations for the transpired time. Next, the fit of all these models is evaluated and a weighted average of all step-wise models (weighted according to their relative fit) is achieved. This results in that approximate smooth trend for the memory decay that best fits the data.
We start with a simple example where we look at inertia. If we consider
Generating a bag of step-wise relational event models
First, we define a bag of when memory change is likely to be stronger for the more recent events and to change less for events that already are in the farther past (where it is approximately constant) (e.g., an exponential decay), then intervals with increasing size will better catch this behavior and their widths will follow the inequality: if the decay is expected to occur in the long term (close to if the decay is likely to decrease at a constant pace (e.g., a linear decreasing function), intervals of the same size will most easily emulate this behavior.
Figure 7 illustrates how different interval configurations can approximate different possible shapes. The figure also shows that a single step-wise model cannot approximate these smooth shapes accurately. Rather, an appropriate approximation can be achieved by taking a weighted average of many step-wise models. We discuss the computation of these weights next.
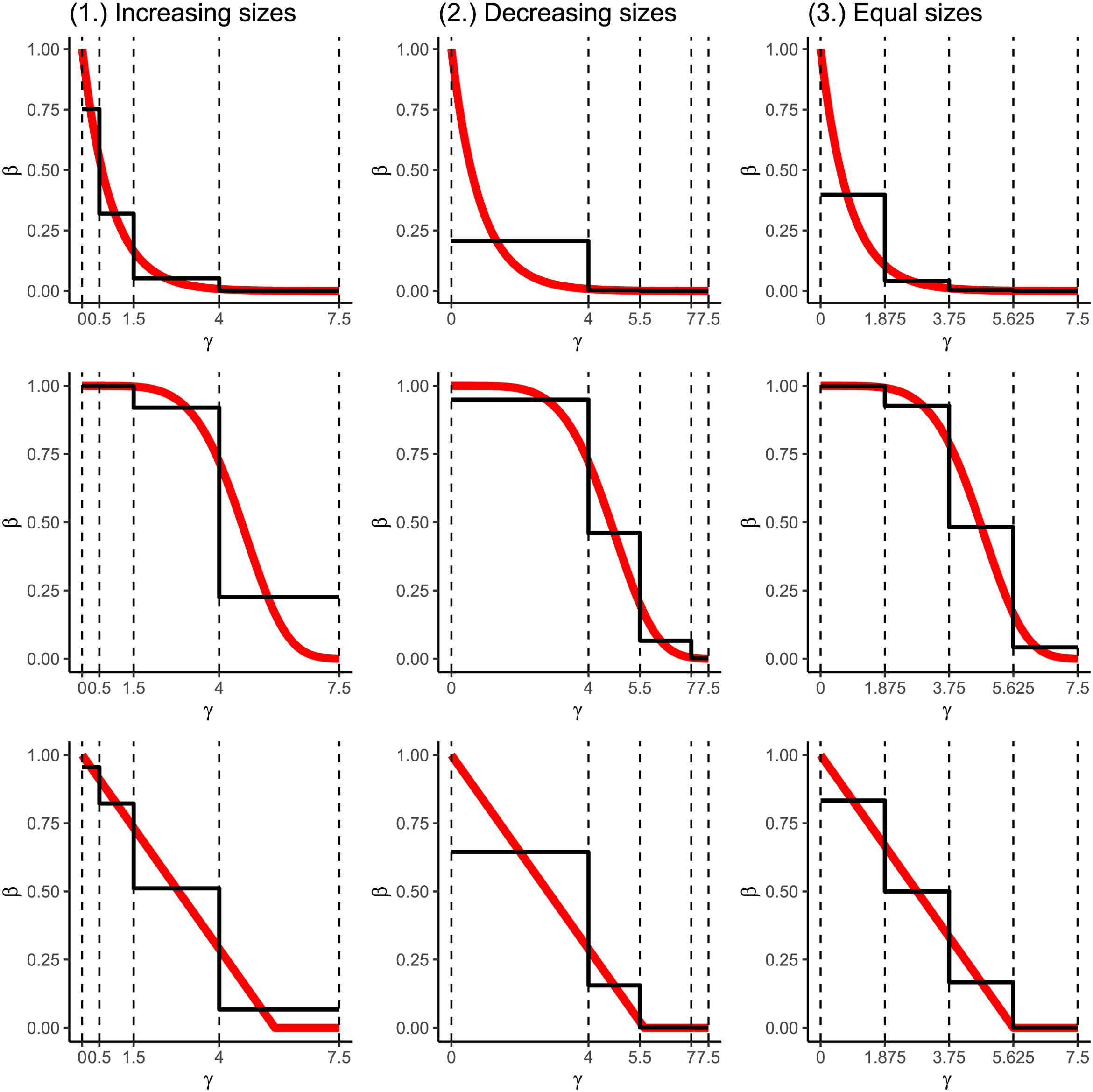
Examples of approximation of three different decays (red lines) by means of three types of step-wise functions (black lines) defined according to three different types of interval widths. The type of decay differs row-wise, from the top to the bottom: exponential decay, one-smooth-step decay and linear decay. The type of interval widths differs column-wise, from left to the right: increasing size, decreasing size and equal size intervals. The maximum time width is fixed to
Evaluating the fit of the step-wise relational event models
In this section, we describe two weighting systems for the
BIC weights
In a Bayesian analysis, the posterior probability of a model is obtained using Bayes’ theorem:
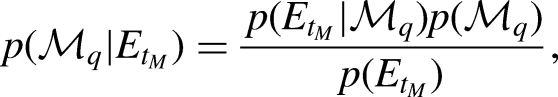
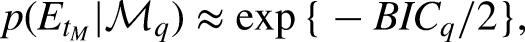
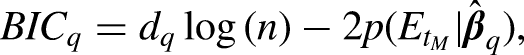
Thus, the normalized BIC weight for the
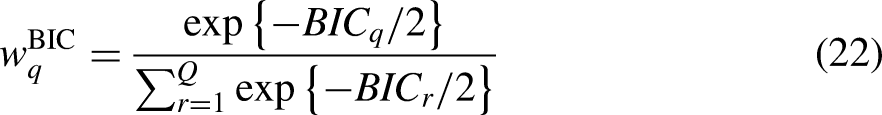
WAIC weights
WAIC weights build upon the Expected Log-pointwise Predictive Density (ELPD) (Watanabe, 2013; Vehtari, Gelman, and Gabry, 2017; Yao et al., 2018). In each step-wise model, the ELPD quantifies the quality of the posterior predictions given the estimated posterior distribution of the model parameters. Therefore, if the model performs well in predicting new observations, then the predictive power quantified by the ELPD will assume a high value on a log-density scale as well as on a density scale. The calculation of the Watanabe-Akaike Information Criterion (WAIC) is based on an approximation of the ELPD as follows:
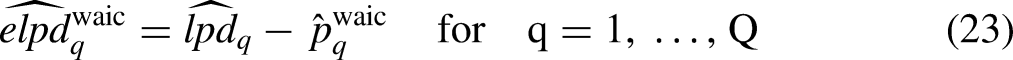
Hence, WAIC weights are computed as
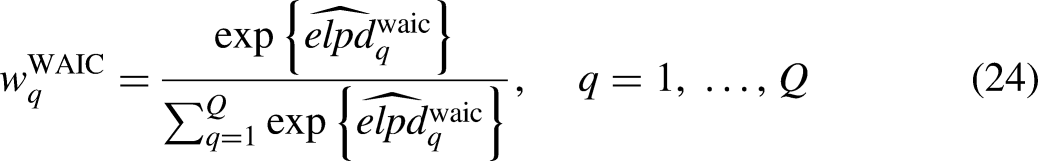
Bayesian model averaging for approximating smooth decay functions
By means of BMA one can elicit a posterior estimate of a quantity of interest as well as its average posterior predictive distribution by finding the optimal linear combination of a set of models, and accounting, in turn, for their uncertainty. A crucial aspect of BMA is the use of model weights that quantify the relative importance of the models according to their posterior probability. In subsection BIC weights and WAIC weights we considered two weighting systems that can be employed in the estimation of the memory decay trend. Here we explain how to get posterior draws of the decay function of an endogenous effect from the Bayesian model averaged posterior.
In BMA, the posterior estimate of any parameter of interest can be calculated as the weighted mean of the posterior estimates provided by each model in the averaging. Considering (21), we can generate a posterior draw by first randomly selecting a model from the bag of models according to their relative weights, and then generate a trend from the posterior distribution of the selected model. We achieve this last step by approximating the posterior of Draw a model from Generate a vector of posterior effects from Repeat steps 1 and 2 a sufficient number of times.
After these three steps, the resulting posterior distribution of each endogenous effect
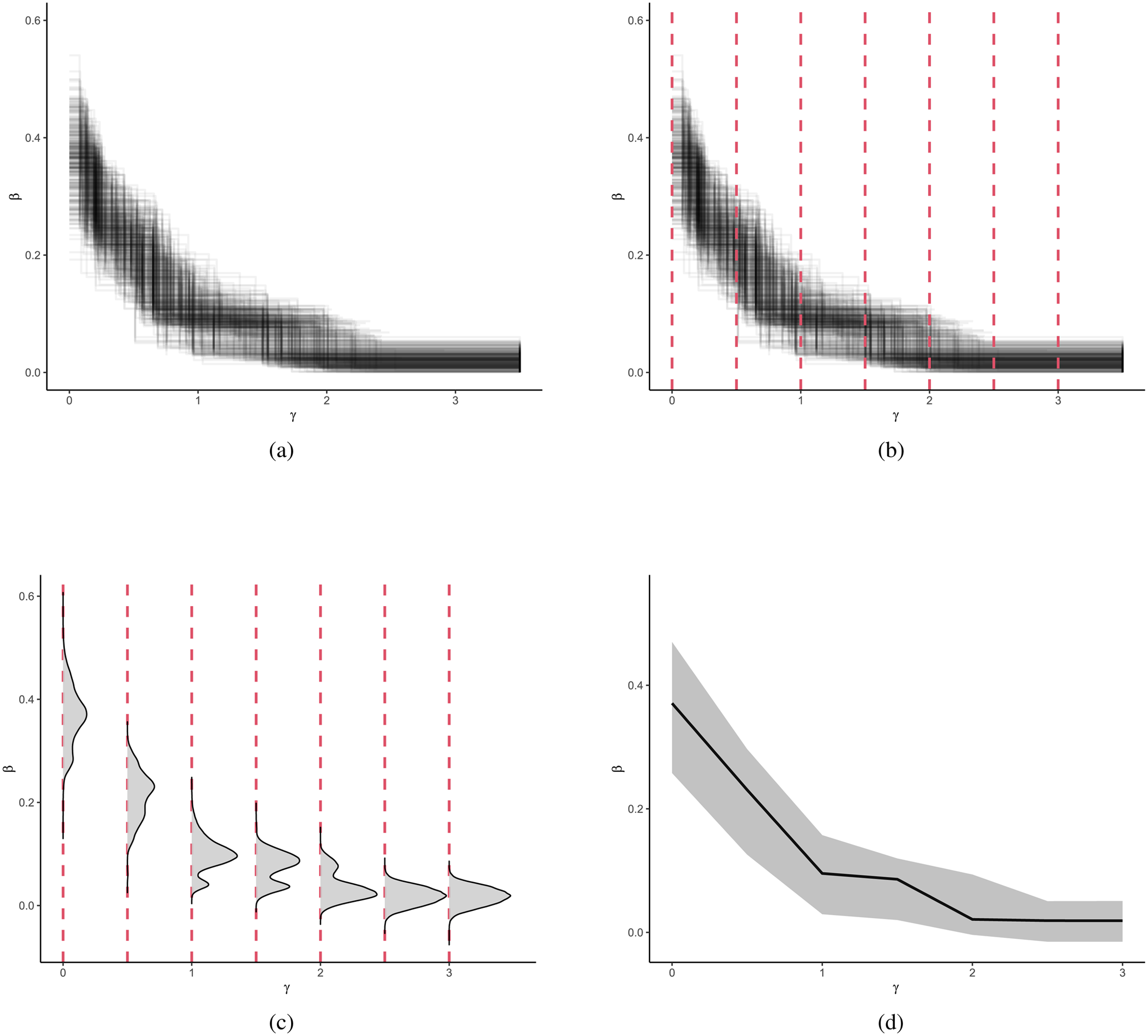
The estimate of the posterior decay is explained here in four plots: (a) Result of the Bayesian Model Averaging: posterior draws of (step-wise)
Computational details of the BMA
The most expensive step before estimating the posterior decay with the BMA is the estimation of all the
Calculation of endogenous statistics: A comparison on the number of operations performed in a single model
The computation of endogenous statistics is a time-consuming stage as it must be carried out across all the observed time points (
The continuous update of the event weights is not required for the step-wise decay model where past events are assumed to have a unitary weight in each interval. Therefore, for a step-wise model the main steps for computing each endogenous statistic consist of: (i) at each time point defining the partitions of the event history according to the
The number of operations required in the computation of a single endogenous statistic can be quantified as follows:
In a step-wise decay model without our optimization, the number of operations is In a step-wise decay model where our optimization is performed the number of operations is In a parametric decay model (e.g., exponential, linear, or other decays) the number of operations is
Let us compare the optimized step-wise decay with the parametric decay model. For this effort, we assume that: (i)
In Figure 9, we compare the running times for estimating inertia using four models: the optimized step-wise model with
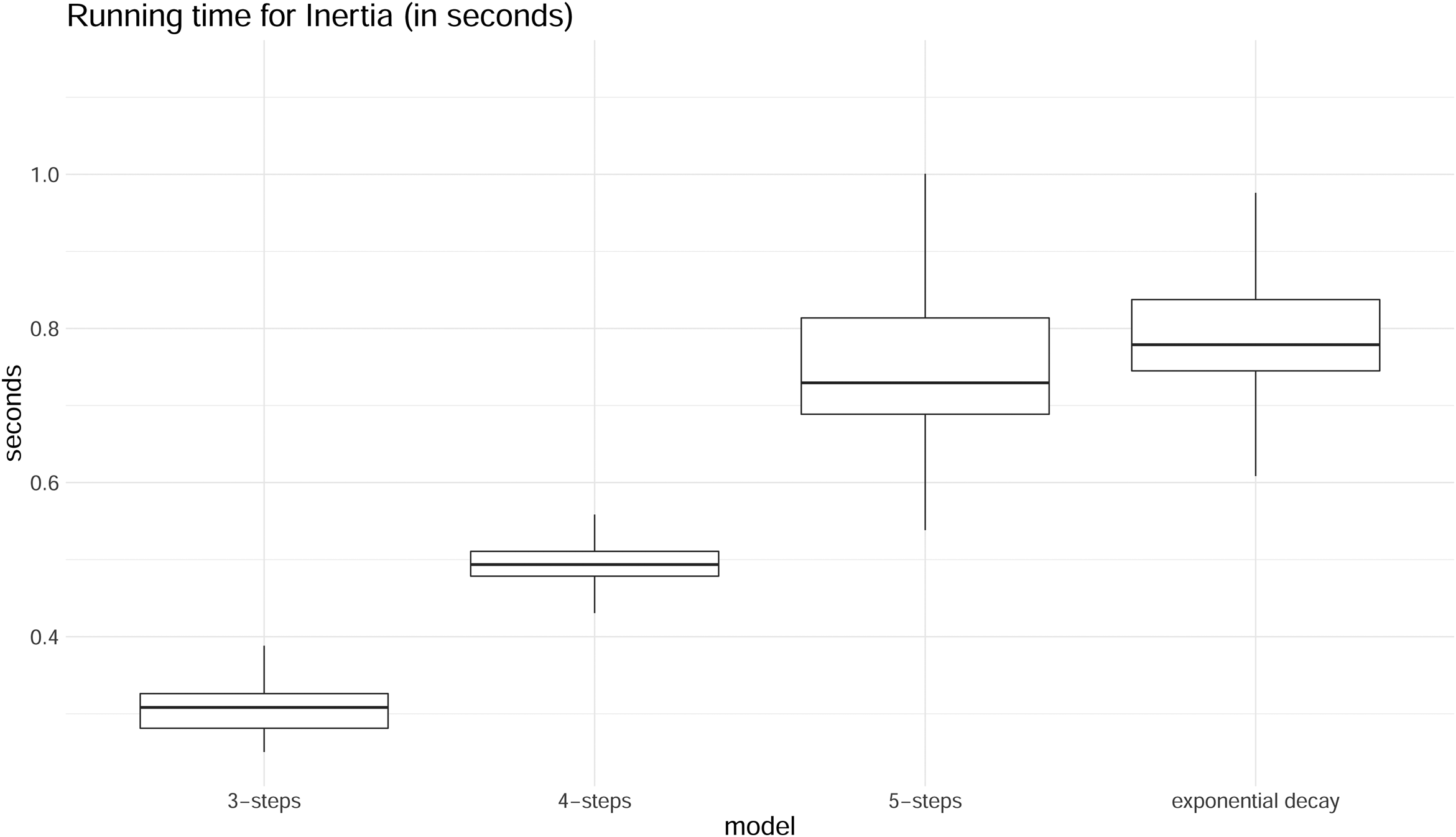
Distributions of running times for the endogenous statistic Inertia (in seconds). 3-steps, 4-steps and 5-steps models are compared to the parametric model with exponential decay. For each type of model, the running time was measured 1000 times.
Estimation stage: Comparison on the number of parameters to be estimated
Considering
Therefore, a step-wise model has always more parameters than a model with any parametric decay. However, this disadvantage at the estimation stage is not really an issue because it is not recommended to consider many intervals as the uncertainty around estimates increases when intervals become narrower and only a few events fall inside them.
Case study: Investigating the presence of memory decay in the sequence of demands sent among Indian socio-political actors
We have now introduced our modeling approach, starting from a purely step-wise decay model to a continuous decay model based on model averaging of a set of step-wise models. In this section, we illustrate the method by applying it to empirical data. First, we describe the empirical application and dataset. Next, we present analyses using different prespecified step-wise decay functions, followed by an application of the Bayesian model averaging estimated to obtain approximate smooth decay functions. Finally, we compare the semi-parametric model (that results from the Bayesian Model Averaging) with other relational event models where the memory decay is fixed either to a step-wise or exponential decay. In this comparison we focus on the predictive performance of the models as well as their resulting fit.
Relational events between socio-political actors
We retrieved data from the ICEWS (Integrated Crisis Early Warning System) (Boschee et al., 2015) repository, which is hosted in the Harvard Dataverse repository. ICEWS consists of relational events interactions between socio-political actors that were extracted from news articles. Information about the source actor, the target actor, and the event type is recorded along with geographical and temporal data that are available within the same news article. Event types are coded according to the CAMEO (Conflict and Mediation Event Observations) ontology. In this example analysis, we focus on the sequence of relational events within the country of India. Each event represents a request from an actor targeted to another actor. These requests range from humanitarian to military or economic in nature and in this analysis this distinction is not made.
The event sequence includes M = 7567 dyadic events between June 2012 and April 2020 among the ten most active actor types: citizens, government, police, member of the Judiciary, India, Indian National Congress Party, Bharatiya Janata Party, ministry, education sector, and “other authorities.” Since the time variable is recorded at a daily level, we consider events that occurred on the same day as evenly spaced throughout that day.
The network dynamics of interest are inertia, reciprocity, and transitivity closure. Given a generic step-wise model with
Predefined step-wise decay models
As the maximum time (
Figure 10 shows the estimated step-wise decay functions for inertia, reciprocity, and transitivity given the three different interval configurations.
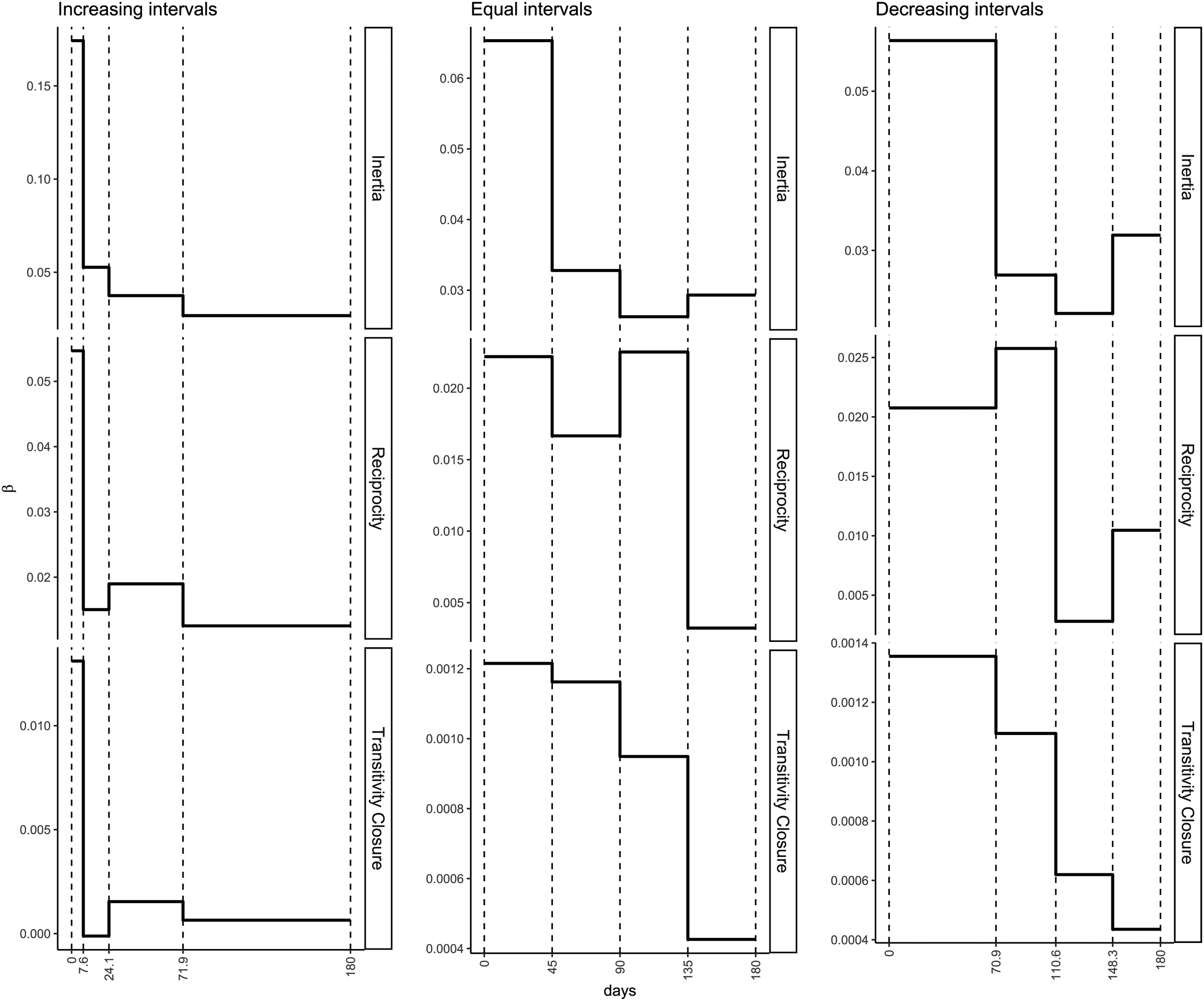
MLE estimates of
As is to be expected, the three models result in different estimated (discretized) shapes of memory decay. For instance, for Transitivity Closure we see that decreasing intervals and increasing intervals produce contrasting decays where the decays not only follow different shapes, but the magnitudes of the effect are different as well. The magnitudes of the effects are similar for the “equal” and “decreasing” intervals, whereas for “increasing” interval widths the magnitudes are quite different from the models with “equal” and “decreasing” widths.
In sum, step-wise models with predefined interval configurations provide us with a very rough idea of how fast memory decays in a given relational event network. However, predefined step-wise memory decay models provide only limited insight into the full shape of memory decay along transpired time, or, for example, whether an (approximated) exponential decay is more likely than a (approximated) smooth one-step decrease. To learn this from an observed relational event network, we need the proposed weighting system for a bag of step-wise models together with a Bayesian model averaging approach. We consider this next.
Approximately smooth memory decay models
For our bag of step-wise models, three sets of 501 intervals were generated for
Figure 11 shows the posterior trends resulting from two Bayesian Model Averaging approaches: one with BIC weights (left panels) and one with WAIC weights (right panels). Because most of the decay occurs in the first twenty days, only this period is plotted in the figure. The intercept
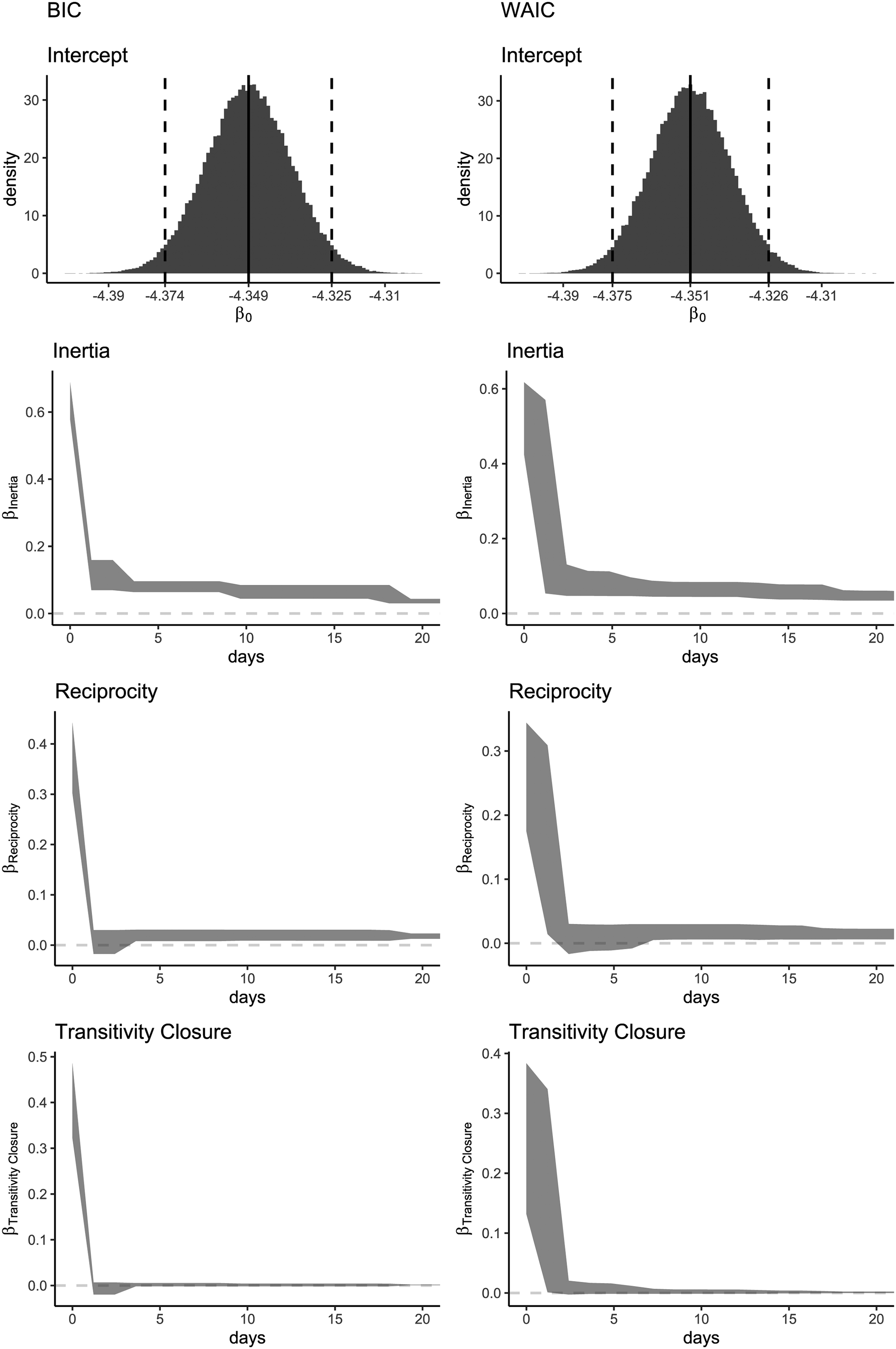
Posterior estimates resulting from the BMA with BIC (left) and WAIC (right) weights, from the top to the bottom: posterior distribution for the intercept (
Since the network consists of nodes that represent collectives of individuals, it is important to interpret the estimated memory decay functions as referring to the memory of groups, rather than of individuals. Focusing on the results for the WAIC weights in Figure 11 (right panels), all the three trends show a clear approximately exponential memory decay. The drastic decrease near zero suggests that recent requests have a much higher impact on the event rate than less recent ones. Therefore, the trend observed for inertia indicates a tendency of actors to keep sending requests to the same recipient of their most recent requests. This reflects “short-lived inertia” (driven by the requests that happened in a fairly recent past) rather than “long-lived inertia” (where requests that have occurred over a much longer time span continue to be repeated).
For reciprocity, we see that memory drops a bit faster than for inertia and stabilizes around a low value that decreases further, indicating that actors reciprocate on requests received in the very recent past, but requests that were not responded to quickly are soon “forgotten” and are unlikely to be responded to. Norms of reciprocity are clearly not enduring and non-reciprocated requests disappear from social memory very quickly. Finally, transitivity is similarly driven by very recent interactions. Considering that dyadic requests only briefly trigger the tendency to respond, it makes sense that having common past communication partners also mainly matters if those joint interactions date back to only recent history rather than to a period somewhat longer ago.
Together, the results paint a picture of a “delusion of the day” kind of politics. Interactions between these institutional actors appears to be driven by current events in the country, where response to actuality appears more predictive of future interactions than long-term governed interaction. While this may be typical of governmental interactions, the effect may be strengthened by the fact that the data come from news paper articles. News paper articles will generally only report publicly visible interaction (hence, journalists may miss interaction that occurs behind closed doors or interactions that are not made public) and will tend to focus mainly on what is of interest “today.” That said, it does make a lot of sense to find that governmental parties seem to base their interactions mainly (but not exclusively) on what is going on in the present and the very recent past, and focus less on what happened longer ago and may be less salient in the public’s eye.
The resulting trends obtained from the BIC weights approximately follow the same decays as the WAIC. However, we see that the BIC weights show an approximate step-wise trend because the BIC becomes increasingly large for that step-wise model that is the closest to the true (smooth) model (in terms of Kullback-Leibler distance (Grünwald and Ommen, 2017)). Thus, the weight of that step-wise model dominates the weights of all other step-wise models. This illustrates that the BIC is useful for finding the best fitting step-wise model, which, in this case, has increasing interval widths over the transpired time, forming roughly an exponential decay. On the other hand, the BIC is less useful for finding an approximate smooth decay trend. For this purpose we recommend the WAIC.
Assessing the predictive performance: A comparison with parametric memory decays
The results show that memory decays approximately exponentially in this dataset. Next, we compare the performance of the fitted semi-parametric model with other relational event models that either do not contemplate a memory decay (REM without memory) or fix it to some predefined parametric trend (step-wise or exponential):
The step-wise models above are named respectively StepEqual, StepIncr and bestWAIC in Appendix A.4. The three models have
In Appendix A.4, we include a table with the maximum likelihood estimates and standard errors for each model.


In Figures 12 and 13, we examine two plots that assess the predictive performance of the models.
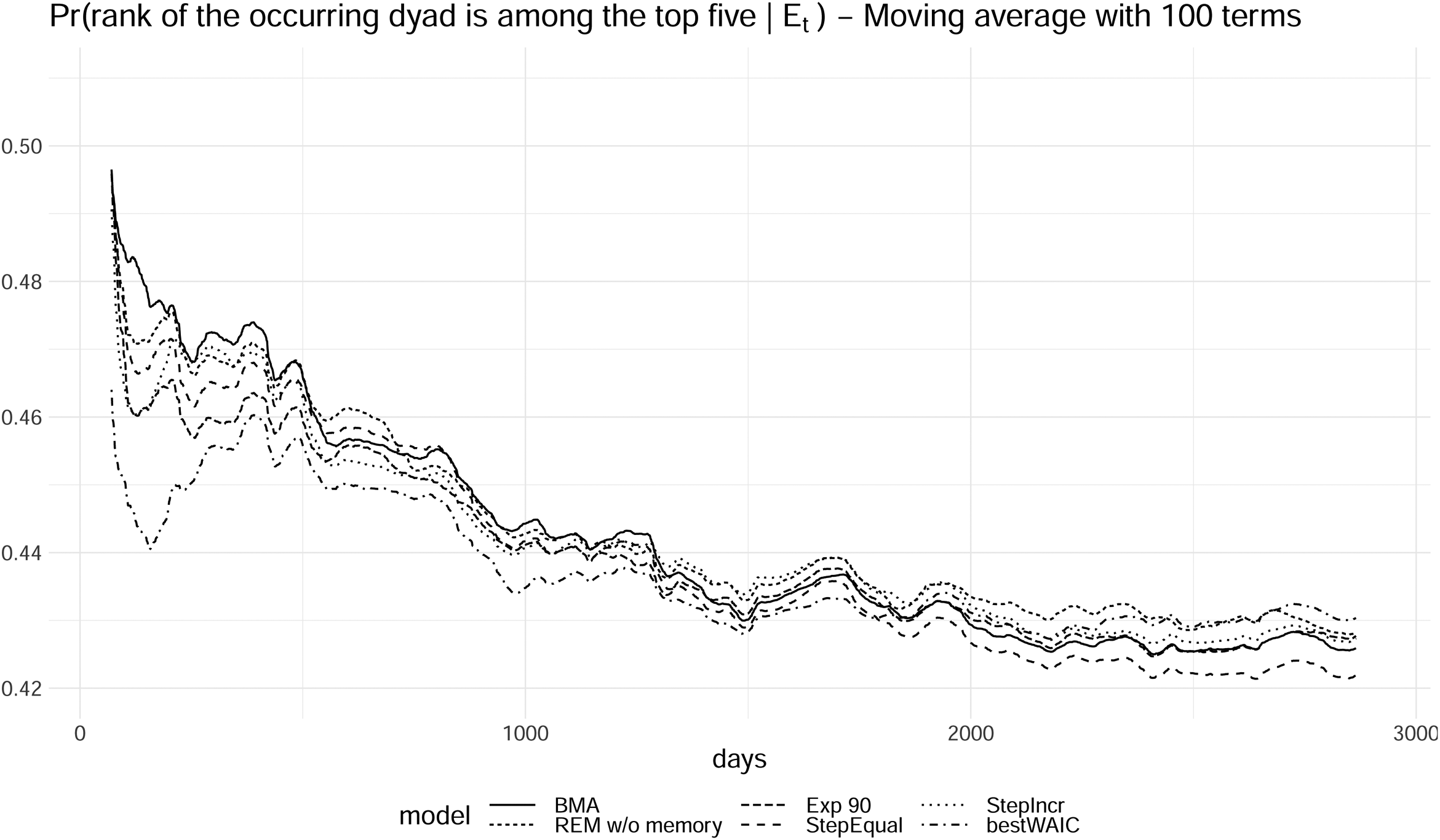
Probability of observing the rank of the occurring dyads being among the first five most likely dyads (moving average with 100 terms, Exp 7 and Exp 30 performed worse than the rest of the models and were removed from the plot).
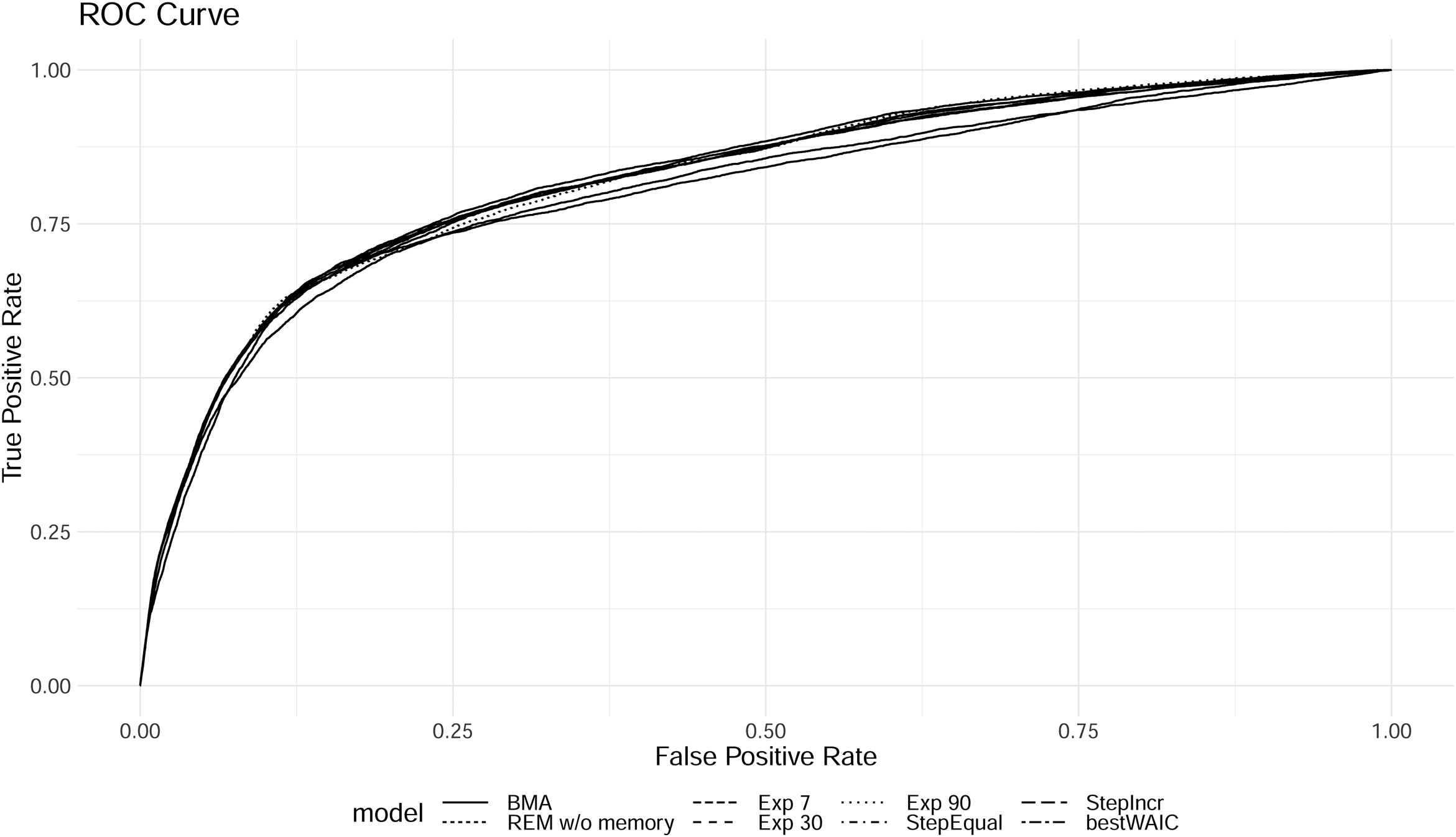
ROC curve of each model in the comparison.
Figure 12 displays the probability of the observed dyads having rank less or equal than five, calculated as
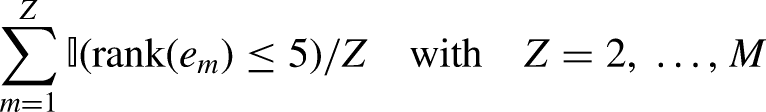
The plotted trends show how well the models perform over time. The solid line represents the performance of the BMA model resulting from the semi-parametric approach introduced in this paper. In comparison to the other decay models, its performance maintains a level that is, on average, higher than most of the models in the comparison. This illustrates that a model where the shape of the decay is learned from the data on average results in better predictions and better model fit than competing models where the decay is prespecified based on rough heuristic arguments. Finally it is interesting to observe that the REM without memory also performs quite competitively.
We note that the aim of our approach is not to generate a model that necessarily outperforms other models in predictive accuracy. Although the model is expected to generally do equally well or better than most competing models, an important aspect of the approach is that it allows a researcher to get a good idea of how long past events maintain their influence. This allows a researcher to then specify better further inferential models (informed by the decay shape that is found from the semi-parametric model). Perhaps more importantly, empirical results of exactly how the past keeps influencing the present and the future are essential for theory development. Considering the dearth of time-sensitive social theory, approaches that can uncover the empirical pattern of time can be highly informative for theorists to develop truly time-sensitive social theories upon. Of course, this requires the application of the model to a wider set of data than just our illustrative data set.
We plot the ROC curves in Figure 13; again we see that the BMA model on average performs best. Here, the REM without memory performs relatively poorly. The no-memory REM under-predicts actually occurring events and can only achieve high accuracy by predicting a relatively large number of events that actually do not occur. The memory-based models have a better overall trade-off between incorrectly and correctly predicted events, even considering the simplicity (the models are fully based on only inertia, reciprocity, transitivity closure, and an intercept) of the model for such complex interaction patterns among governmental actors in India.
Discussion
In this paper, we presented different methods for learning how past interactions between social actors affect future interactions in the network. We first considered a
The next key contribution is a novel Bayesian model averaging approach to estimating memory decay in a relational modeling framework where events are assumed to continuously change in importance as the time since the event increases. The promising aspect of this semi-parametric approach lies in its ability to learn the shape of the memory decay without making any parametric assumption about it. Furthermore, by building on the step-wise model, the proposed method is computationally feasible. We considered two weighting systems for Bayesian model averaging of a bag of step-wise models: the BIC and the WAIC. As was illustrated, the BIC is useful for finding the one best fitting step-wise model for a given empirical relational event history. The BIC, however, is not suitable for finding an approximate smooth trend of the memory decay, as all weight is placed on the single step-wise model that is closest to the true smooth decay model. This issue does not occur for the WAIC as the Bayesian model average of many step-wise models results in a smooth trend.
The semi-parametric approach on average provided better predictive performance than other approaches where the weight decay was set using predefined parameters. This illustrates the usefulness of relaxing the assumption of predefined decay functions when making predictions and doing inferences. Moreover, the semi-parametric approach can uncover exactly how and for how long past events matter and can show if this is perhaps different between reciprocity and transitivity (or other statistics). A researcher can use the semi-parametric approach to first run several relatively simple models that can inform the researcher about the memory decay shapes that are present in the data at hand. Following that, the researcher can then specify further, more complex, models that utilize some predefined memory structure that is based on the shape found by the semi-parametric approach. This allows a researcher to run quite complex relational event models, without the computational burden of repeating the memory decay model several times for each new model that is specified, while, at the same time, taking into account the empirically extracted memory decay function for the dataset at hand.
In addition, researchers can use the methodology to uncover empirical trends of how past events matter as time passes by. Once this has been applied to enough datasets, these findings can inform solid theory development on how the past matters for the future. There is barely any social theory that is able to systematically explain and predict how present social interaction affect future social interactions and for how long exactly, whether the effects are linear or non-linear (and, in which case: following which shape?), and which conditions have an effect on that. Although social scientists acknowledge that time and timing matters for social reality (e.g., Leenders, Contractor, and DeChurch et al. (2016); Ancona et al. (2001); Monge (1990); Mitchell and James (2001); Kozlowski et al. (2016)), the empirical means to uncover actual memory shapes or the empirical means to test potential theoretical expectations about the course of time has lacked. We believe that our approach has the ability to support these efforts.
In this paper, we assume that all events are random, in the sense of having some probability of occurrence at any time. Some events, however, are not random and follow a fixed deterministic pattern. Marcum and Butts (2015) refer to these events as “clock events”. Examples include standardized lunch times (“every day we eat together in the cafeteria between 1200h and 1230h”), fixed office hours, the end of the workday at 1700h, et cetera. These deterministic events can affect interaction rates directly, but can also affect memory decay. For example, consider a workplace where work ends strictly at 1700h. If it happens to be the norm to follow up on a request from a colleague within half an hour (and older requests “drop from the radar”), requests that come in at 1645h should be handled within fifteen minutes and may be forgotten as the clock turns 1700h. In this case, the deterministic end-of-workday event directly affects the memory decay. In situations where clock events occur, it would be interesting to incorporate them into the modeling approach. At the very least, the researcher should be aware of them, so as to not have the memory shapes be affected by the clock events without the researcher realizing it.
The empirical example presented in this paper involves a relatively small network. It is important to note however that the methodology can be used for larger networks as well, even though the computation can be expensive in that case. We leave computational optimization of the approach for larger networks for future work.
Another important direction for future research would be to apply the method to different event types or sentiments. For instance, one expects negative events (e.g., a country threatening another country, a pupil insulting a peer, a teacher rebuking a student) to have a memory decay that is slower and more persistent than for positive events (e.g., a teacher praising a student, a country cooperating with another country) (Brass and Labianca (1999); Labianca and Brass (2006)). This difference may apply as well to other event types from which possible different memory shapes might emerge. For example, it might be that email interaction is more fleeting than face-to-face interaction. This is especially relevant in the understanding of projects where some project members may be co-located and have ample face-to-face interaction, while other members of the project team may reside in different locations which makes technology-enabled communication with them more pertinent. The team leader may give a similar message to a co-located project member (using face-to-face interaction) as to a physically-distant project member (sending an email), where the two communication media may have differential memory effects. Having a modeling approach like the semi-parametric model from this paper allows researchers to study conditions that affect memory decay patterns differently.
Furthermore, in the case of more dynamic situations, e.g., when the network switches between different states or regimes, memory decay may also change accordingly. For example, in emergency situations, recently past events may play an even larger role on interaction dynamics than long past events compared to the period of time before the emergency happened. Consequently, we would want to learn the change of the shape (and length) of memory decay across different states in dynamic environments.
In our approach, we do not prespecify the shape of the memory decay. However, with the choice for BIC or WAIC and with the choice for increasing/decreasing/equal intervals, some shapes are more likely to be found than others. We have illustrated how a researcher can compare these various choices against each other and pick that specification that fits the data best (according to predictive fit or some other criterion). However, a substantively very meaningful next step would be to examine when it is more plausible for memory decay to follow a step-wise or a continuous shape. It is worth it to systematically examine which social mechanisms are likely to lead to step-wise temporal effects and which mechanisms are not. This would both assist further model building and the further development of time-sensitive social theory.
We expect that the acquired ability of both estimating social memory decay processes and testing for the various conditions that might shape them can be a crucial step towards a more accurate understanding of network dynamics developing at a local as well as at a global level.
Footnotes
Acknowledgement
This work was supported by an ERC Starting Grant (758791).
Author’s note
The relational event sequence, codes and other explanatory files regarding the empirical example presented in this paper are publicly available on Open Science Framework (OSF) with identifier DOI: 10.17605/OSF.IO/79M6H (also reachable at https://doi.org/10.17605/OSF.IO/79M6H). Furthermore, the method presented in this paper runs on the R package “![]() .
.
Funding
The funder of my work is the ERC and the ERC project number is 758791.