
Abstract
Recent years have seen a growing number of studies investigating the accuracy of nonprobability online panels; however, response quality in nonprobability online panels has not yet received much attention. To fill this gap, we investigate response quality in a comprehensive study of seven nonprobability online panels and three probability-based online panels with identical fieldwork periods and questionnaires in Germany. Three response quality indicators typically associated with survey satisficing are assessed: straight-lining in grid questions, item nonresponse, and midpoint selection in visual design experiments. Our results show that there is significantly more straight-lining in the nonprobability online panels than in the probability-based online panels. However, contrary to our expectations, there is no generalizable difference between nonprobability online panels and probability-based online panels with respect to item nonresponse. Finally, neither respondents in nonprobability online panels nor respondents in probability-based online panels are significantly affected by the visual design of the midpoint of the answer scale.
The past decade has seen increasing debate about the quality of nonprobability online panels. This debate has primarily circled around whether or not these panels provide representative sets of respondents (for an overview of the debate see Cornesse et al. 2020). The apprehension of some researchers is that a biased subgroup of the population self-selects into nonprobability online panels (see Chang and Krosnick 2009; Legleye et al. 2015; Loosveldt and Sonck 2008; MacInnis et al. 2018; Malhotra and Krosnick 2007; Pasek 2016; Pennay et al. 2016; Yeager et al. 2011). Others argue that nonprobability online panels can accurately reflect the target population, especially after weighting (see Goel, Obeng, and Rothschild 2015; Kennedy, Keeter, and Weisel 2016; Wang et al. 2015). However, while the number of publications on nonprobability panel accuracy is increasing, less attention has been paid to response quality in nonprobability panels (for notable exceptions, see Chang and Krosnick 2009; Greszki, Meyer, and Schoen 2014; Hillygus, Jackson, and Young 2014).
This is surprising, because one might argue that, since their respondents participate in the panel mainly for monetary reasons (see e.g., GreenBook 2017), nonprobability online panel respondents may be less committed to the panel in terms of response quality. The focus on monetary rewards among the respondents is encouraged by the nonprobability online panel advertising industry that recruits the panel members. With advertising slogans like “Earn Cash With Quick Paid Surveys!” (www.quickpaysurvey.com), “Make Money Online With Paid Surveys” (www.cashcrate.com), or “Take Surveys for Cash” (www.takesurveysforcash.com) advertisers try to attract as many Internet users as possible. Being attracted to the online panel by the promise of easy money for little effort, nonprobability online panel respondents may show different care in answering survey questions than respondents that were recruited into an online panel by probability-based offline recruitment methods, independent of their sociodemographic characteristics. Consequently, response quality might differ between nonprobability and probability-based online panel respondents.
In this article, we investigate whether there is a difference in response quality between survey participants in nonprobability online panels and probability-based online panels. For this purpose, we look into three indicators that are often associated with response quality in the context of survey satisficing: straight-lining, item nonresponse, and midpoint selection.
Respondent Motivation and Survey Satisficing
Most social research based on survey data relies on the assumption that respondents answer the survey questions to the best of their ability. This requires the respondents to carefully carry out all the cognitive steps involved in answering a survey question. According to Tourangeau, Rips, and Rasinski (2000), cognitive response processing consists of four steps: question comprehension, information retrieval, judgment and estimation, and reporting an answer. Data analysts typically assume that all four response steps were carefully carried out by all respondents, that is, respondents optimize survey responses. Respondents, however, sometimes take shortcuts through the optimal cognitive response process. This behavior is called satisficing (Krosnick and Alwin 1987).
Krosnick (1991) defines two types of satisficing: weak satisficing and strong satisficing. Weak satisficing occurs when respondents execute all cognitive steps that are necessary to arrive at a response, but they do so only superficially. They might, for instance, read a question text carefully but skip the accompanying instruction text. Alternatively, when presented with a list of answer options, respondents might choose the first option that approximately fits their opinion without considering further answer options that might fit their opinion even better. Because weak satisficers carry out the response steps superficially, unmeaningful decision-making cues, like the visual design of an answer scale, can influence their responses.
While weak satisficers carry out all four cognitive response steps, even if they do so superficially, strong satisficers do not or only partially carry out the response steps. Respondents might, for instance, process only just enough information to arrive at a response that they consider generally reasonable without reading and considering the question carefully or without searching their memories and retrieving the relevant information. This strategy results in no responses at all, unmeaningful answers, nonsubstantive answers, or undifferentiated answers.
According to satisficing theory, there is a continuum of cognitive thoroughness of responses with perfectly optimized responses at one end of the continuum and strongly satisficed responses at the other end (see Krosnick 1991). Respondents can be in different positions on the continuum, with some being generally thorough in all of their responses and others being generally less careful in their responses (for empirical proof, see Kaminska, McCutcheon, and Billiet 2010; Knäuper 1999; Krosnick 1992; Malhotra 2008; Narayan and Krosnick 1996). In addition to this interpersonal variation, there can be intrapersonal variation in the level of satisficing observed during an interview, for example, when respondents fatigue during a long interview (for empirical proof, see Roberts et al. 2010).
According to Krosnick (1991), there are three factors that largely influence the occurrence and degree of satisficing: task difficulty, respondent ability, and respondent motivation. Task difficulty refers to the cognitive effort needed to answer a question optimally. The task difficulty depends on the complexity of a question and of the information asked for. When a question contains many words, long words, and/or uncommon or ambiguous terms, satisficing is more likely to occur than when questions are short, precise, and easy to comprehend (for empirical proof, see, e.g., Alwin and Krosnick 1991). Similarly, when a question asks respondents to evaluate multiple items or answer on a long, unlabeled scale, satisficing is more likely than when a question asks for the evaluation of only one item and provides few fully labeled answer options (see also Krosnick 1999; Krosnick and Berent 1993).
Respondent ability refers to the competences and skills involved in answering survey questions. It includes cognitive abilities such as cognitive sophistication, the amount of practice in thinking about a topic, and attitude strength, as well as practical abilities such as the ability to process and communicate answers. In self-administered questionnaires, respondent ability also includes reading and writing skills. Furthermore, in web surveys, computer literacy and technological skills necessary to start and navigate through the survey are important aspects of respondent ability (for empirical proof on satisficing in web surveys, see, e.g., Toepoel et al. 2009). Satisficing is more likely to occur when a respondent has low cognitive abilities and may therefore have problems comprehending the question (see also Kaminska et al. 2010; Krosnick 1992; Krosnick and Alwin 1987; Narayan and Krosnick 1996).
The respondents’ motivation determines how much effort they are willing to invest in answering a question. To some extent, respondent motivation is a personality characteristic that is related to a person’s need for cognition (for information on the concept of need for cognition, see Cacioppo and Petty 1982). Satisficing is more likely to occur if respondents have low need for cognition (see Kaminska et al. 2010). Respondents with high need for cognition have an intrinsic motivation to fill out the questionnaire carefully because they generally enjoy thinking about questions and have fun expressing their opinions. High interest in a survey topic and the perceived importance of a survey can have a substantial impact on respondent motivation at the start of the survey (see also Groves, Presser, and Dipko 2004; Stoop 2005). However, respondent motivation may decrease over the course of the interview. Therefore, satisficing is more likely toward the end of a survey, especially in long surveys, than toward the start and in short surveys (see also Krosnick et al. 2002).
Measuring Satisficing
Thus, according to Krosnick (1991), the combination of task difficulty, respondent ability, and respondent motivation explains the occurrence and amount of satisficing. In our analyses, we keep task difficulty constant across panels by including exactly the same questions with exactly the same question format and response categories across all of the panels. In addition, we aim to keep respondent ability constant across panels by applying the same raking weighting procedure to all samples and thus controlling for sample composition differences in sociodemographic characteristics (i.e., marital status, household size, age, and education).
Regarding respondent motivation, we assume that the nonprobability panel participants are mainly motivated by the monetary incentives that they receive. Thus, we expect them to minimize effort in order to maximize their incentive-by-effort ratio. This expectation is supported by studies that demonstrate the importance of monetary incentives for nonprobability online panel members. For instance, in a study on the motives for joining nonprobability online panels, Keusch, Batinic, and Mayerhofer (2014:179) find that when asked to select all of their motives for participation, 40 percent of panelists indicated they “wanted to earn some extra money.” In addition, “monetary motives had the strongest correlation with survey participation” for nonprobability online panel participants (Keusch et al. 2014:185). Similarly, Sparrow (2006:5) finds that 52 percent of the new members of a nonprobability online panel participate because it is “an enjoyable way to earn money” as opposed to 20 percent who join because they “thought they would be interested in the topics covered,” and 19 percent who “enjoy answering questions.”
The probability-based online panelists are less driven by monetary incentives. For instance, analyzing survey data on the respondents’ most important reason to participate in the Dutch LISS Panel (www.lissdata.nl), a probability-based online panel of the general population in the Netherlands, we find that 16.4 percent of the respondents participate in the panel because they “find it important to contribute to science.” The financial reward is only stated as the most important reason for participating by 15.2 percent of respondents. Furthermore, for the German Internet Panel (GIP; https://www.uni-mannheim.de/gip), a probability-based online panel of the German general population, we observe that about 13 percent of panelists even waive their incentive and choose to donate it to charity instead.
We, therefore, expect the share of people who care about giving optimized answers to be lower, and thus the amount of satisficing behavior to be higher, in the nonprobability online panels than in the probability-based online panels. To investigate differences in response quality across nonprobability and probability-based online panels, we examine three indicators of satisficing: straight-lining in grid questions, item nonresponse, and midpoint selection in a visual design experiment. In the following, we discuss the theoretical and empirical background in the literature of each of these indicators.
Straight-lining
The term straight-lining refers to the tendency of respondents to choose the same or a very similar answer option for each item in a grid (see Schonlau and Toepoel 2015). This phenomenon is sometimes also referred to as “non-differentiation” (see Malhotra, Miller, and Wedeking 2014). Straight-lining is a strong form of satisficing. It occurs in self-administered questionnaires because the grid format provides a visual cue that triggers a specific type of cognitive shortcut: While for the first item of the grid, respondents might still carry out all the cognitive steps necessary to arrive at an optimized response, the grid format suggests that the same answer will also be acceptable for the following items. Therefore, some respondents might abandon the full cognitive response processing in favor of a shortcut and give the same (or a very similar) answer to all other grid items. Research suggests that avoiding grid questions and asking each question separately instead, preferably with only one question per screen, can prevent straight-lining (see Couper 2008; Couper, Traugott, and Lamias 2001).
Item Nonresponse
Like straight-lining, item nonresponse is a form of strong satisficing. Respondents who choose this satisficing strategy skip one or all of the cognitive response steps. In a web survey, respondents might not read the question text carefully and click on the “next” button instead in order to get to the end of the questionnaire more quickly. If they read the question carefully, they might still not be willing or able to go through the necessary information retrieval or the judgment and estimation processes. There are two types of item nonresponse: question skipping (QS) and giving a nonsubstantive answer, that is, answering “don’t know” (DK) or “don’t want to say” (DWS).
Nonsubstantive responses require some cognitive effort because respondents have to at least browse through the answer options or look for visual design cues that lead them to the DK or DWS answer category. Relative to nonsubstantive responses, QS is a much stronger type of satisficing because when choosing to skip a question altogether, respondents do not have to engage in any kind of cognitive response process.
A potential drawback to using nonsubstantive answers as a satisficing indicator is that respondents may carry out all the necessary response steps and in the end still decide to choose a nonsubstantive response, for example, because they honestly do not know the answer to a question (Converse 1974; Schuman and Presser 1981; Sturgis, Roberts, and Smith 2014). With respect to “no opinion” answers, however, Krosnick et al. (2002) show that respondents with low levels of education are more likely to choose this answer option, suggesting that people are more likely to choose “no opinion” responses when they perceive the processes of producing an optimal response as cumbersome. Furthermore, the authors find that the amount of “no opinion” answers increases with interview duration, suggesting that respondent motivation decreases toward the end of the interview resulting in less willingness to engage in the cognitive effort necessary to produce an optimal response. These findings are supported by further research (see, e.g., Bradburn and Sudman 1988; Feick 1989; Fowler and Cannell 1996; Gilljam and Granberg 1993; Holbrook, Green, and Krosnick 2003).
Midpoint Selection
The midpoint of an answer scale provides a superficial visual cue in self-administered questionnaires. Following Krosnick’s (1991) reasoning, some respondents might satisfice by selecting the middle category while optimizing respondents are not influenced by this visual cue and instead choose the answer option that best represents their “true” answer after carrying out all the necessary cognitive steps. Specifically, Krosnick and Fabrigar (1997:147) argue that “many people […] might select an offered midpoint because it provides an easy choice that requires little effort and is easy to justify.” On the continuum of cognitive thoroughness, midpoint selection can be interpreted as a weaker form of satisficing than straight-lining and item nonresponse when we assume that respondents go through the necessary response steps but are influenced in their decision by the visual design cue that the scale midpoint provides. Tourangeau, Couper, and Conrad (2004) show that, generally, the visual midpoint rather than the conceptual midpoint shapes the response distribution. Their explanation is that “the visual midpoint is seen as providing a benchmark, representing either the conceptual midpoint of the scale or the most typical response” (p. 390). Following satisficing theory, it is likely that satisficing respondents choose the visual midpoint to reduce the cognitive effort needed to evaluate the other response options against this midpoint. This behavior would constitute a shortcut to the information retrieval and/or the judgment and estimation processes. Therefore, the selection of the visual midpoint may be used as an indicator of satisficing behavior (see also Kaminska et al. 2010; Malhotra et al. 2014).
Online Panel Data
In this article, we assess response quality among respondents in 10 online panels (see Table 1). Three of them are probability-based online panels: the GIP, the GESIS Panel (GP), and one commercial probability-based online panel. The remaining seven are commercial nonprobability online panels. In each of the online panels, we fielded the same short multi-topic online survey in German language.
Online Panel Characteristics.
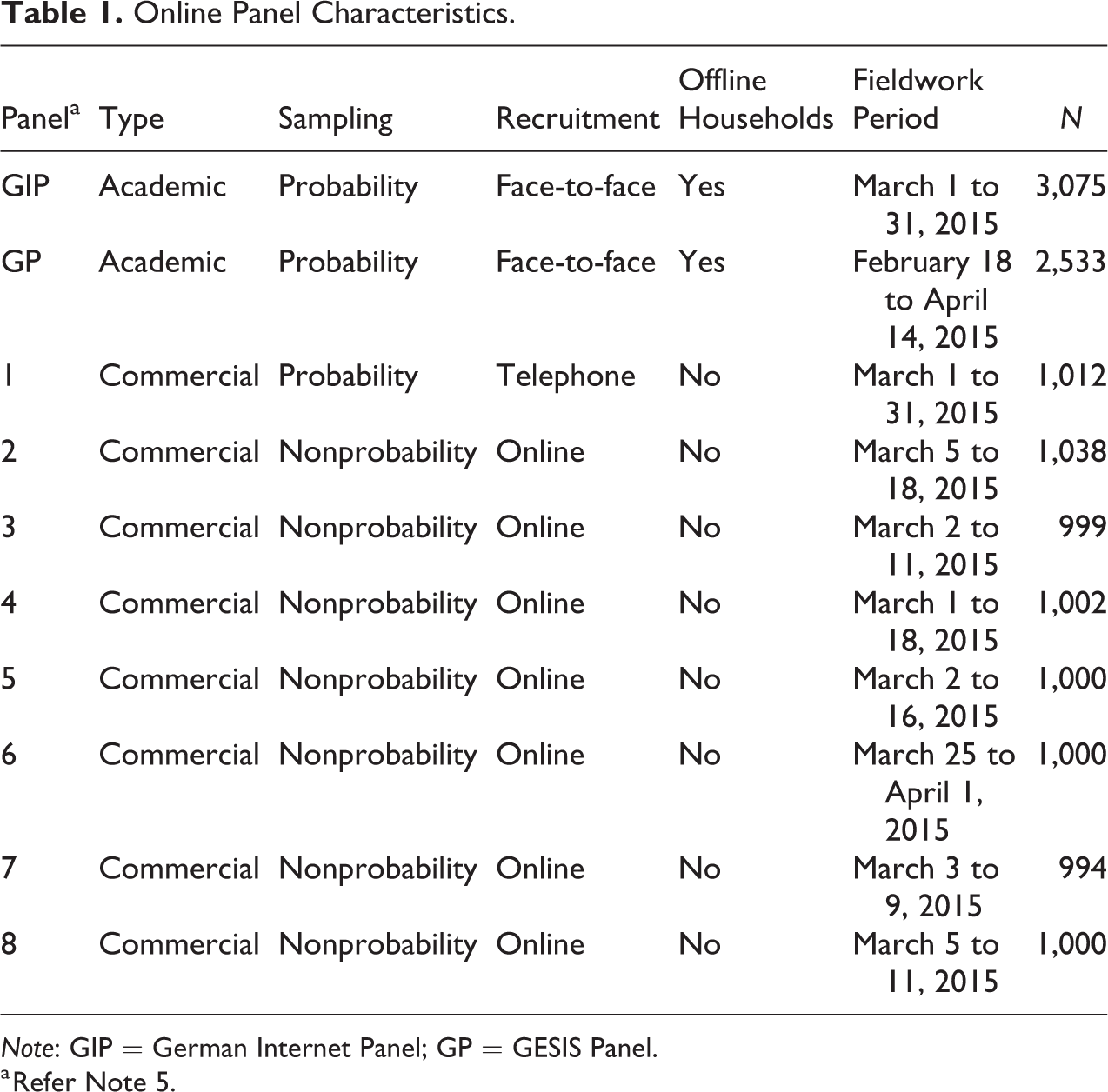
Note: GIP = German Internet Panel; GP = GESIS Panel.
a Refer Note 5.
Our study has been conducted as part of a larger project on data quality in nonprobability and probability-based online surveys. Some of the survey questions in our questionnaire have specifically been designed to investigate survey satisficing while other questions have originally been designed to allow analyses on sample accuracy that are out of the scope of this article. In the following, we describe the various online panels and the study that we implemented in more detail.
The GIP
The GIP is based on a three-stage stratified probability area sample with subsequent face-to-face recruitment interviews. At the first sampling stage, a random sample of areas is drawn from a database that covers all areas in Germany. Within each primary sampling unit (PSU), listers record every household along a predefined random route until they have listed 200 households. Subsequently, a random sample of households is drawn to be interviewed in face-to-face recruitment interviews. All age-eligible members of sampled households are invited to become online panelists (see Blom, Gathmann, and Krieger 2015). Furthermore, the GIP covers individuals without computer and/or Internet access by equipping them with the necessary devices (see Blom et al. 2017). All panel members are invited bi-monthly to participate in an online interview of about 20–25 minutes on a diversity of social, economic, and political topics. For the analyses in this article, we used wave 16 of the GIP. It had a completion rate 1 of 69.8 percent and a cumulative response rate 2 of 14.3 percent. Although the GIP covers the German population aged 16–75, we only use data from individuals that were aged 18–70 to make the data comparable across all panels in this study.
The GP
The GP is based on a two-stage stratified probability sample from population registers and subsequent face-to-face recruitment interviews. At the first sampling stage, the GP draws a random sample of areas from a database of municipalities in Germany. Then, the GP samples individuals from the local population registers within each of the sampled PSUs. Because 10 sampled municipalities refused to cooperate with the GP sampling request, these PSUs had to be substituted (see Bosnjak et al. 2017). Subsequently, the sampled individuals were contacted for face-to-face recruitment interviews. All interviewed individuals were invited to become panelists. Furthermore, the GP includes the offline population via paper-and-pencil mail surveys. Internet users that prefer to participate offline instead of online are also provided with paper-and-pencil mail surveys. All panel members of the GP are invited to participate in bi-monthly interviews of about 20 minutes on a wide variety of topics. For the analyses in this article, we used the so-called wave ca of the GP (for reference, see the report of wave ca, https://www.gesis.org/en/gesis-panel/documentation/). It had a completion rate 3 of 77.72 percent and a cumulative response rate 4 of 19.5 percent. The age range covered in the GP is 18–70 years. In our study, we exclude the GP mail respondents because the potential mode effect might bias our results (see, e.g., Green, Krosnick, and Holbrook 2001; Holbrook et al. 2003, for evidence on differences in satisficing by mode).
Panel 1
Panel 1 is a commercial probability-based online panel. To recruit panel members, the panel draws its sample from random digit dialing (RDD) telephone surveys conducted in-house by the same company. Individuals interviewed in an RDD telephone interview were subsequently invited to join the panel for regular online interviews if they had access to the Internet. Recruitment interview respondents that did not have access to the Internet were not invited for the subsequent online panel waves. For our study, panel 1 drew a quota subsample from its probability-based respondent pool. Panel participation rates could not be calculated due to the unavailability of the necessary information on how many panel participants were invited to our survey wave.
The Nonprobability Online Panels: Panels 2–8
For the recruitment of the nonprobability online panels, we published a call for applications in November 2014. The call explained that we sought to implement a 10-minute questionnaire about traffic, politics, and health among 1,000 respondents that should be representative of the German population aged 18–70 years of age. The call further announced that the data were to be collected in March 2015. Regarding further design decisions (application of quotas, provision of weights, etc.), the panel providers were free to choose whichever approach they thought would provide the most representative data. 5
In response to our call, we received 17 applications for conducting the specified survey. Of these, 16 survey providers explicitly offered a sample representative of the general population in Germany aged 18–70. Seven providers were considered fit for our purpose and within reasonable budgetary limits. We therefore commissioned them with collecting our data. The costs quoted for conducting the wave analyzed in this article plus two additional waves conducted in half-year intervals varied widely across the panels (see Online Appendix A, which can be found at http://smr.sagepub.com/supplemental/, for details). In the following, the nonprobability online panels are numbered from two to eight in sequence of ascending costs. Panel participation rates could not be calculated due to the unavailability of the necessary information on how many panel participants were invited to our survey wave.
Method
To assess differences in the amount and type of satisficing between the nonprobability online panels and the probability-based online panels, we consider three satisficing indicators: straight-lining in grids, item nonresponse, and midpoint selection in a visual design experiment. Their operationalization is described in the following. Information on the question texts and answer scales of the questions we used in our analyses can be found in Online Appendix B (which can be found at http://smr.sagepub.com/supplemental/). Furthermore, external validations of selected survey variables and sociodemographic characteristics can be found in Online Appendix C (which can be found at http://smr.sagepub.com/supplemental/).
Straight-lining
To assess straight-lining in our questionnaire, we implemented two psychological short scales with four items each in grid format. We do not use any grid questions in our questionnaire module except for these two psychological scales that we specifically use for the purpose of assessing straight-lining in grids across the nonprobability and probability-based online panels. We define respondents as straight-liners if they choose the same answer category for every item on at least one of the two grid questions. Based on the literature described above, we test the following hypothesis:
To test this hypothesis, we compare the proportions of straight-liners and the respective confidence intervals around these estimates across the respondents of each of the nonprobability and the probability-based online panels. Furthermore, we apply χ2 -tests to examine averages across all nonprobability online panel respondents versus all probability-based online panel respondents.
Item Nonresponse
Our questionnaire contained several possibilities for generating item nonresponse, all of which were implemented in the same way across all panels. In our analyses, we can differentiate between different types of item nonresponse. At several questions, respondents were able to give nonsubstantive answers. At five questions, we provided the nonsubstantive answer option “DK,” at two questions we provided a “DWS” option, and at one question, we provided both DK and DWS answer options. In addition, at each question, respondents were able to skip the question by clicking on the “next” button, generating QS. Based on the literature described above, we test the following hypotheses:
For each type of item nonresponse, we generated a continuous variable that operationalizes the proportion of each type of item nonresponse (DK, DWS, and QS) per respondent among all questions where these types of nonresponses were possible. In addition, we generated a variable that operationalizes the proportion of overall item nonresponse (INR) per respondent among all questions.
To test our hypotheses, we compare the average proportion of each type of item nonresponse and the respective confidence intervals around these estimates across the respondents of each of the nonprobability and probability-based online panels. Furthermore, we apply χ2-tests to examine average proportions of each type of item nonresponse among all nonprobability online panel respondents versus all probability-based online panel respondents.
Midpoint Selection
We implemented a visual design experiment in our questionnaire to investigate whether respondents answer consistently across different answer scales. Four experimental conditions were randomly assigned to respondents.
We conducted this experiment on two questions of our questionnaire and randomly assigned respondents independently at each question. The first question covered respondents’ perceived health. The second question concerns respondents’ opinion on environmental zones in cities. 6
We varied the presence of a conceptual midpoint by including a “neither nor” or “average” answer option in the scale versus excluding this conceptual midpoint. We vary the presence of a visual midpoint by leaving a gap between the substantive answer options and the “I don’t know” option versus not leaving a gap. The respective answer scales are depicted in Table 2 and Table 3.
Experimental Conditions in the Midpoint Experiment on the Five-point Scale.

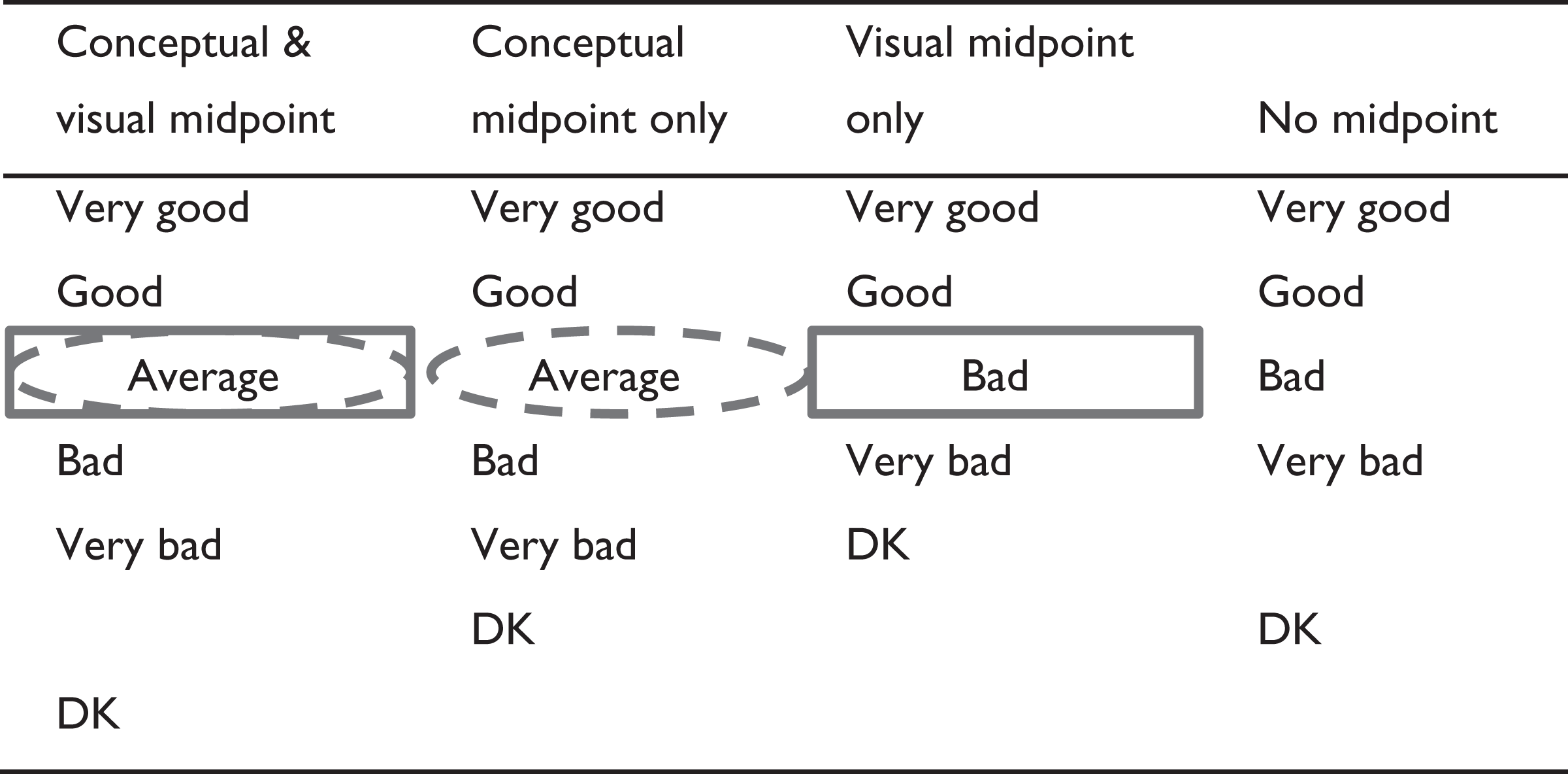
Note:  Conceptual midpoint;
Conceptual midpoint;  visual midpoint. DK = don’t know.
visual midpoint. DK = don’t know.
Experimental Conditions in the Midpoint Experiment on the Seven-point Scale.

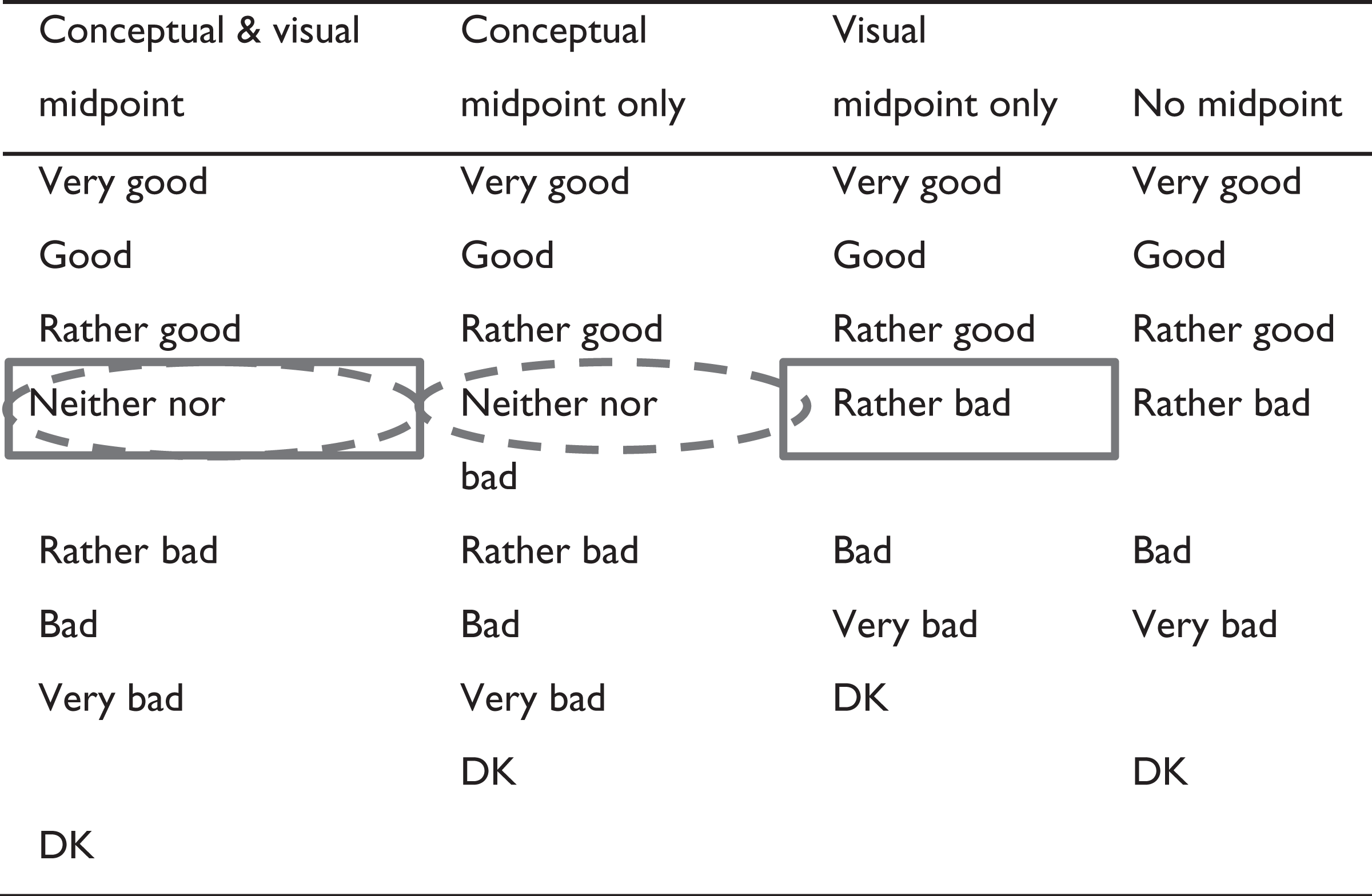
Note: Conceptual midpoint; visual midpoint. DK = don’t know.
Following the literature described above, there are two reasons why respondents may choose an answer option from a response scale. The first reason for choosing an answer option is that, after carefully going through all necessary cognitive response processing steps, respondents decide that this answer option fits them best. If respondents choose an answer option for the first reason, the response distribution should not be affected by whether or not this answer option is located at the visual midpoint of the answer scale. The second reason for choosing an answer option is that respondents go through the cognitive response processing steps only superficially and therefore look for unmeaningful cues to decide which answer option to choose (i.e., weak satisficing as described in the literature above). If respondents satisfice and choose an answer option for the second reason, the proportion of respondents who choose an answer option should be higher when this answer option is located at the visual midpoint of the answer scale than when it is not located at the visual midpoint. Following our expectation that there is more satisficing in nonprobability online panels than in probability-based online panels, we test the following hypothesis in our midpoint selection experiment:
As with choosing an answer option in general, there are two reasons for choosing the conceptual midpoint of an answer scale: The first reason for choosing the conceptual midpoint is that, after going through all cognitive response processing steps, respondents conclude that the conceptual midpoint fits them best. The second reason for choosing the conceptual midpoint is that the conceptual midpoint is located at the visual midpoint of the answer scale and therefore picking the conceptual midpoint serves as a satisficing strategy. Because the conceptual midpoint is usually located at the visual midpoint of the answer scale, we specify two additional hypotheses to Hypothesis 3. These additional hypotheses disentangle the effect of the visual design of the answer scale on the conceptual midpoint (Hypothesis 3a) and the effect of the visual design of the answer scale on a regular answer option (Hypothesis 3b) in nonprobability online panels compared to probability-based online panels.
We apply χ2-tests to examine averages across the nonprobability and probability-based online panel respondents. For each of the estimates in our analyses described above, we obtained bootstrapped standard errors by pooling results across 100 variance–covariance matrices.
Results
We examine whether there are significant differences in response quality between nonprobability online panels and probability-based online panels based on our hypotheses on the satisficing indicators described above (straight-lining, item nonresponse, and midpoint selection in a visual design experiment).
Straight-Lining
With regard to our hypothesis that a higher proportion of respondents chooses to straight-line on grid questions in nonprobability online panels than in probability-based online panels (Hypothesis 1), we indeed find significantly more straight-lining in the nonprobability online panels than in the probability-based online panels (on average 13.4 percent and 6.5 percent, respectively; χ2(1) = 152.7, p = 0.00).
When investigating the online panels in detail (see Figure 1), we find that in each of the nonprobability online panels, straight-lining is considerably more prevalent (between 10.2 percent in panel 2 and 16.2 percent in panel 5) than in the probability-based online panels (between 3.1 percent in GP and 9.2 percent in GIP). In fact, two of the probability-based online panels (GP and panel 1) show significantly less straight-lining than the best nonprobability online panel (panel 2).
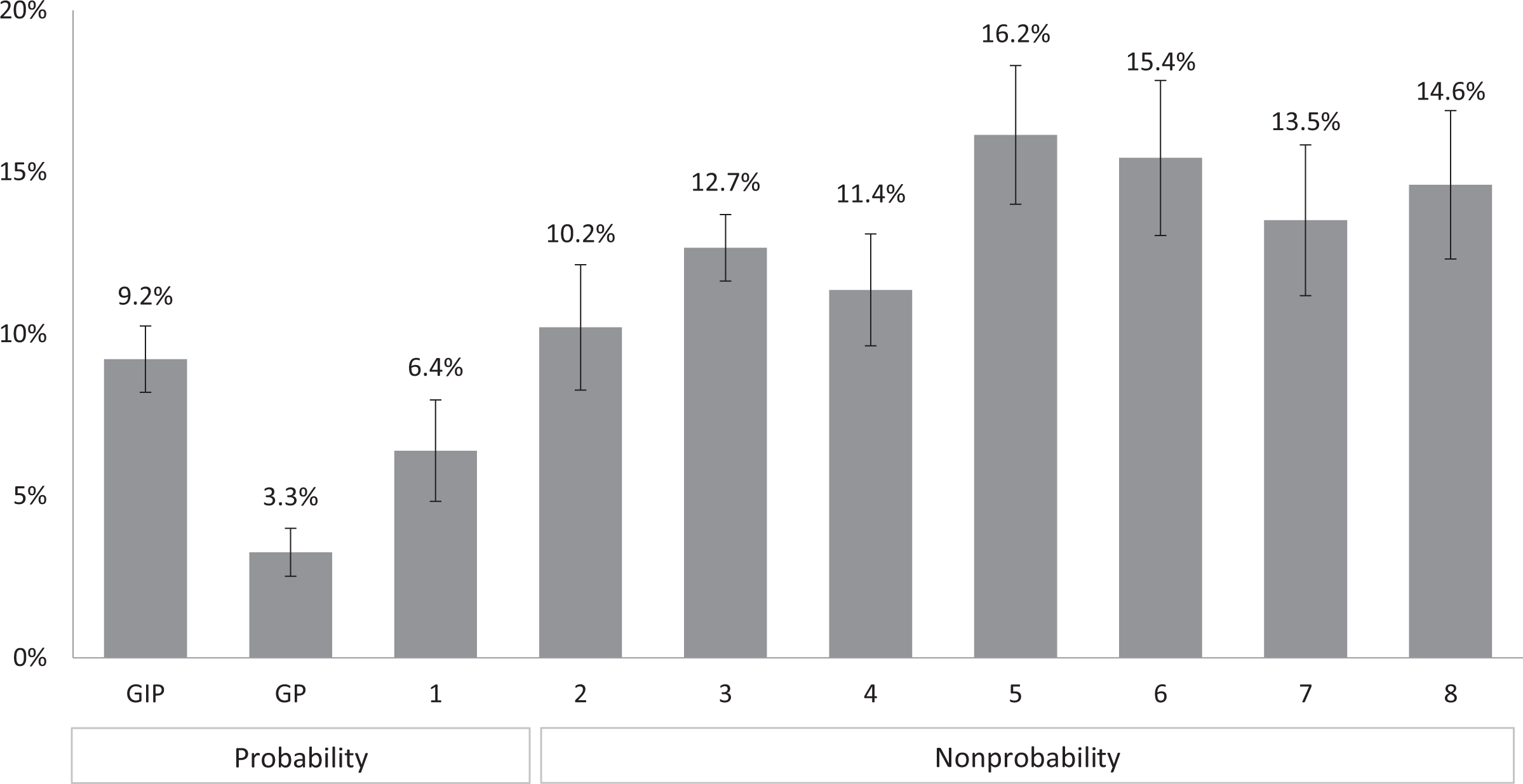
Proportion of straight-liners across panels (bars), bootstrapped 95 percent confidence intervals (spikes).
Item Nonresponse
Regarding our hypothesis that a higher proportion of respondents chooses to not provide any (substantive) response to a question in nonprobability online panels than in probability-based online panels (Hypothesis 2), we find no generalizable evidence in support of our item nonresponse hypotheses across the three types of item nonresponse (DK, DWS, and QS).
When examining INR as an overall measure of item nonresponse that operationalizes the broader Hypothesis 2 (see INR bars in Figure 2), we find that, contrary to our expectations, the average proportion of nonresponses is significantly lower among the nonprobability online panel respondents compared to the probability-based online panel respondents (1.2 percent versus 1.6 percent, respectively; χ2(1) = 50.3, p = 0.00). In the following, we explore the different types of item nonresponse (DK, DWS, and QS) in more detail based on our Hypotheses 2a–2c.
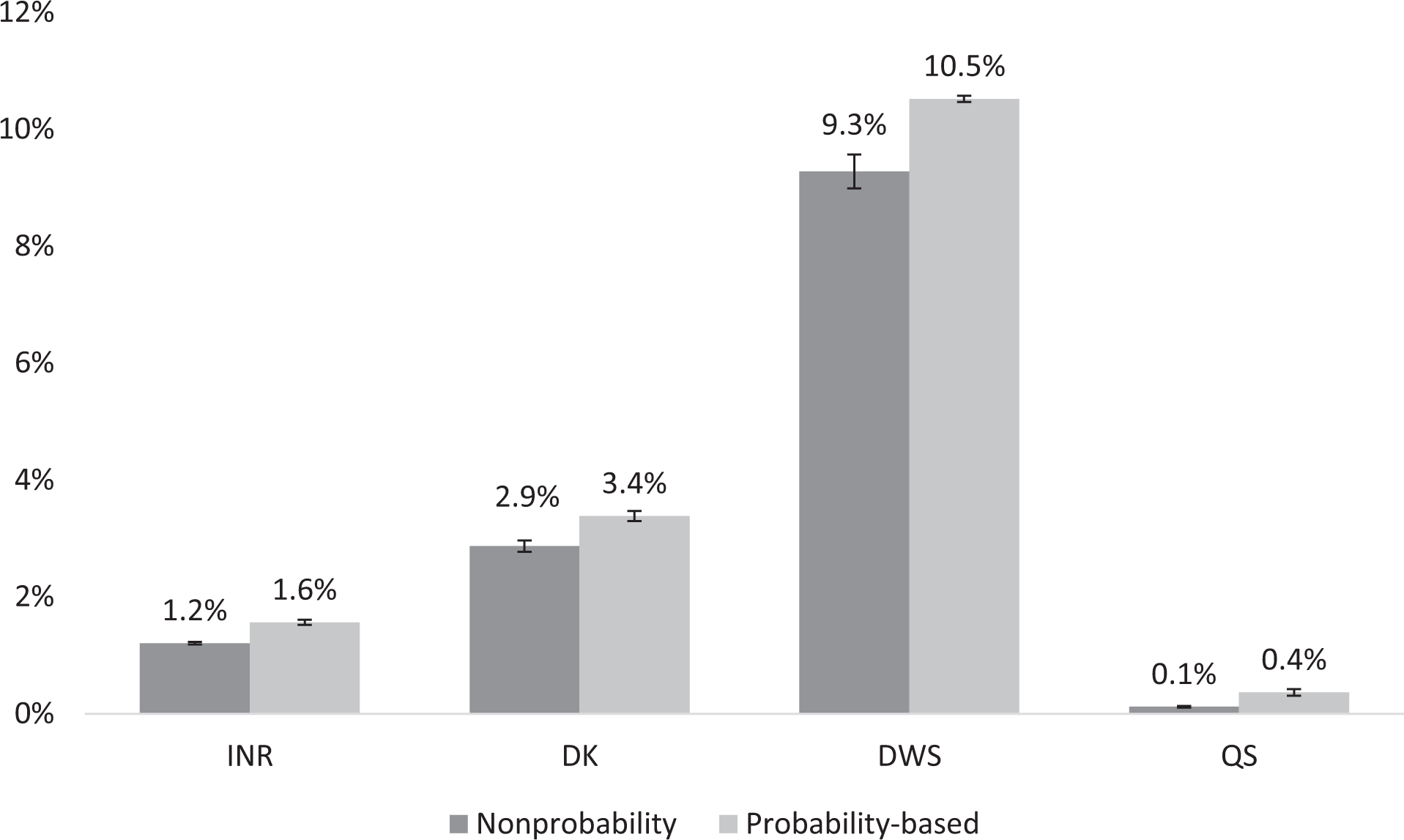
Proportion of item nonresponse in probability-based and nonprobability panels (bars), bootstrapped 95 percent confidence intervals (spikes).
With regard to our hypothesis that the average proportion of DK answers is higher among the nonprobability online panel respondents than among the probability-based online panel respondents (Hypothesis 2a), we find that, contrary to our expectations, the nonprobability online panel respondents had a significantly lower average percentage of DK answers than the probability-based online panel respondents (2.9 percent versus 3.4 percent, χ2(1) = 64.9, p = 0.00, see DK bars in Figure 2).
However, looking at the proportions of DK across the online panels in detail (see left pane of Figure 3), we find some variability in the proportion of people who chose DK in the nonprobability online panels (between 1.8 percent in panel 4 and 3.7 percent in panel 8) and the probability-based online panels (between 2.8 percent in panel 1 and 4.0 percent in GP). While the average proportion of DK answers is significantly higher in the GP and significantly lower in panel 4 than in most other panels, the overall variability across the online panels is such that any differences between nonprobability and probability-based online panels seem coincidental.
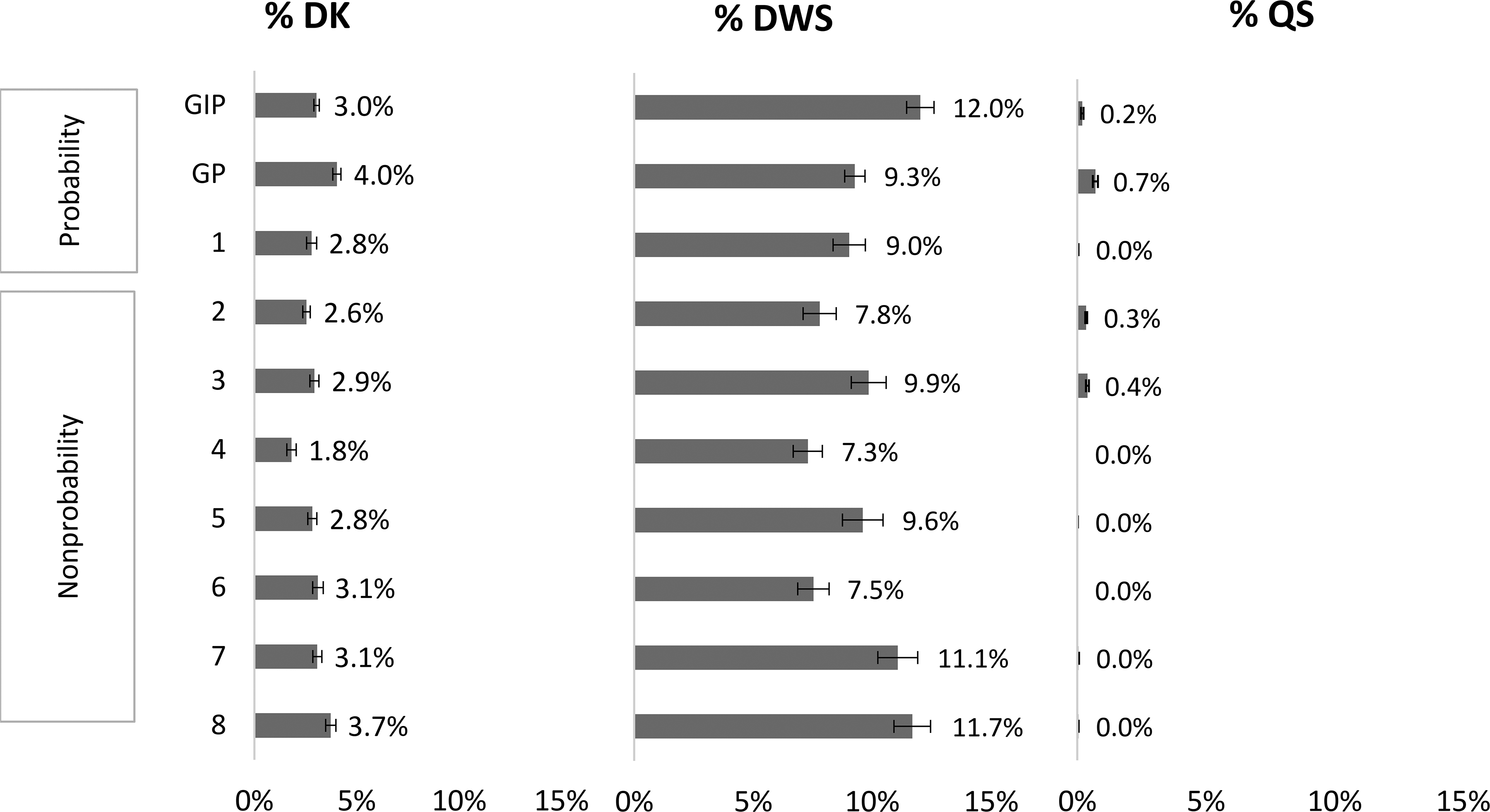
Average proportion of don’t know (DK), don’t want to say (DWS), and question skipping (QS) answers per person among all questions where the respective answer option was possible across panels (bars), bootstrapped 95 percent confidence intervals (spikes).
Regarding our hypothesis that a higher proportion of respondents chooses to answer DWS in nonprobability online panels than in probability-based online panels (Hypothesis 2b), we find that there is a significant difference in the average proportion DWS answers between the nonprobability online panels and the probability-based online panels (9.3 percent versus 10.5 percent, χ2(1) = 4.1, p < 0.1).
Examining the proportions of DWS across the online panels in detail (see middle pane of Figure 3), we again do not find any generalizable evidence that may distinguish nonprobability online panels (between 7.3 percent in panel 4 and 11.7 percent in panel 8) from probability-based online panels (between 9.0 percent in GP and 12.0 percent in GIP).
With regard to our hypothesis that a higher proportion of respondents chooses to skip a question in nonprobability online panels than in probability-based online panels (Hypothesis 2c), we find a small but statistically significant difference between nonprobability online panels and probability-based online panels (0.1 percent versus 0.4 percent, χ2(1) = 104.8, p < 0.1).
When we examine QS across panels in detail (see right pane of Figure 3), we find no generalizable pattern of differences between the nonprobability online panels (between 0.0 percent in panels 4–8 and 0.4 percent in panel 3) and the probability-based online panels (between 0.0 percent in panel 1 and 0.7 percent in GP). Overall, we find that item nonresponse is generally very low in all examined online panels, especially with regard to DK answers and QS. In addition, item nonresponse seems unrelated to the sampling design of the panels.
Midpoint Selection
In Table 4, we present the results of our experiment on the influence of the answer scale design on the selection of the visual midpoint. Contrary to our hypothesis on midpoint selection (Hypothesis 3), we find no significant difference between nonprobability online panels and probability-based online panels in the effect of the visual design of the scale on midpoint selection. In the following, we investigate the differences in midpoint selection across nonprobability online panels and probability-based online panels in more detail based on our Hypotheses 3a and 3b.
Proportions and Absolute Numbers of Respondents in the Middle Category by Experimental Group in Probability-based Online Panels and Nonprobability Online Panels.
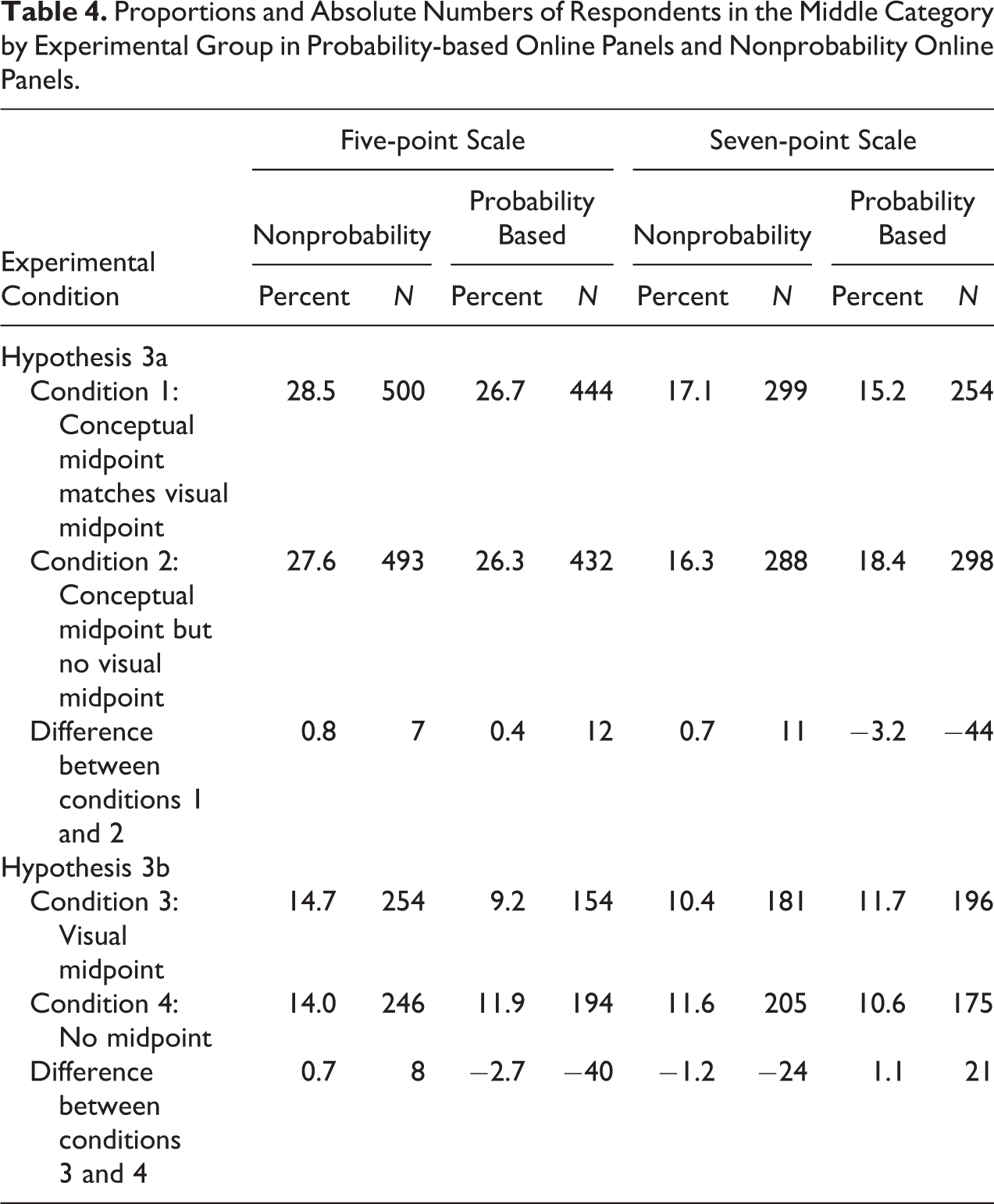
With regard to our hypothesis that the difference between the proportion of respondents choosing the conceptual midpoint when it matches the visual midpoint (condition 1) and the proportion of respondents choosing the conceptual midpoint when there is no visual midpoint (condition 2) will be higher in nonprobability online panels than in probability-based online panels (Hypothesis 3a), we find that the difference in proportions is not significantly higher in the nonprobability online panels than in the probability-based online panels (0.8 percentage points and 0.4 percentage points, respectively, on the five-point scale, χ2(1) = 0.01, p > 0.10; 0.7 percentage points and −3.2 percentage points, respectively, χ2(1) = −0.05, p > 0.1, on the seven-point scale). This indicates that respondents in nonprobability online panels are not more influenced by the visual design of the midpoint than respondents in probability-based online panels.
Regarding our hypothesis that the difference between the proportion of respondents choosing an answer option when it is located at the visual midpoint (condition 3) and the proportion of respondents choosing the same answer option when it is not located at the visual midpoint (condition 4) will be higher in nonprobability online panels than in probability-based online panels (Hypothesis 3b), we find that the difference in proportions is not significantly higher in the nonprobability online panels than in the probability-based online panels (0.7 percentage points and −2.7 percentage points, respectively, on the five-point scale, χ2 = 0.24, p > 0.1; −1.2 percentage points and 1.1 percentage points, respectively, χ2 = 0.05, p > 0.1, on the seven-point scale). In accordance with our findings from Hypothesis 3a, the findings on Hypothesis 3b also indicate that respondents in nonprobability online panels are not more influenced by the visual design of the midpoint than respondents in probability-based online panels.
Furthermore, when examining the results of the experiment in each of the online panels (see Online Appendix D, which can be found at http://smr.sagepub.com/supplemental/), we find that the visual design of the midpoint has no effect. Exceptions are three of the nonprobability online panels (panels 5–7), where we find a weakly significant effect in one comparison of experimental conditions each, but given the number of effects tested, this may well be just by chance.
Response Quality and Costs
Table A1 in Online Appendix A (which can be found at http://smr.sagepub.com/supplemental/) shows the total costs for data collection in the commercial online panels. Panel 1 participated without billing any costs. All other commercial online panels costed different amounts of money ranging from €5,392.97 in panel 2 to €10,676.44 in panel 8. There is no indication that the more costly panels perform better than the less costly panels in terms of data quality. For example, panel 2 as the least costly commercial online panel has a slightly lower proportion of straight-lining, DK answers, and DWS answers than panel 8 as the most costly commercial online panel. Panel 8, however, has a marginally lower percentage of QS than panel 2. Regarding the midpoint design experiment, both panels 2 and 8 do not show any significant differences across experimental subgroups. We therefore conclude that there is no association between costs and response quality.
Discussion
In this article, we investigate the effect of respondent motivation on response quality in nonprobability and probability-based online panels. We assume that respondents in nonprobability online panels are more focused on the monetary incentives provided by the panel providers than respondents in probability-based online panels, resulting in higher satisficing among nonprobability online panel respondents than among probability-based online panel respondents.
In our study, we implemented the same survey with the exact same questionnaire across 10 online panels (seven nonprobability online panels and three probability-based online panels) during the same fieldwork period. In our analysis, we used three satisficing indicators: straight-lining in grid questions, item nonresponse, and midpoint selection in a visual design experiment. To be able to focus on whether differences in respondent motivation in nonprobability and probability-based online panels lead to differences in the occurrence of satisficing, we kept the task difficulty constant across the online panels and controlled for respondent ability in our weighting schemes.
In line with our expectations, we found significantly more straight-lining in the nonprobability online panels than in the probability-based online panels. This indicates that nonprobability online panel respondents are indeed more prone to satisficing than probability-based online panel respondents due to the nonprobability online panel respondents’ focus on maximizing their incentive-by-effort ratio.
Contrary to our expectation, however, we found little to no DK answers (Hypothesis 2a) and QS (Hypothesis 2c) across the online panels examined. In addition, while we found substantial amounts of DWS (Hypothesis 2b) across the examined online panels, this cannot be explained by the online panel sampling designs. This might mean that the respondents in the examined online panels do not choose item nonresponse as a satisficing strategy. One reason for this might be that the online panel respondents perceive the effort of having to click their way through the probes that typically pop up when they skip a question as more cumbersome than just providing an answer to the question. In addition, respondents might choose the DK answer option to express their genuine failure to recall the information asked for in the survey question (for more information on recall error, see Eisenhower, Mathiowetz, and Morganstein 2004). Furthermore, respondents might choose the DWS answer option to express their genuine wish to keep some information secret, potentially due to online data protection concerns (for empirical proof on data protection concerns in online surveys, see Joinson et al. 2008). Future research should examine the mechanisms leading respondents to choose the different types of item nonresponse in online panels more closely.
Contrary to our expectations, we also did not find any effect of the visual design of the answer scale on midpoint selection (Hypothesis 3) in any of the online panels. Our findings therefore suggest, contrary to the findings from Tourangeau et al. (2004), that the visual midpoint of an answer scale does not serve as a superficial decision-making cue in online surveys. Furthermore, the results from our midpoint selection experiment are contrary to Krosnick’s (1991) reasoning that respondents choose the midpoint of an answer scale as a satisficing strategy. However, our results are in accordance with the empirical finding by Krosnick and Fabrigar (1997) who do not find any evidence for midpoint selection as a satisficing strategy. Future research should examine the exact circumstances under which the effect of the visual design of the answer scale on midpoint selection found by Tourangeau et al. (2004) replicates.
Finally, we find that there is no association between response quality and survey costs across the nonprobability online panels. This means that investing in a more expensive panel does not automatically lead to better data.
Our study is one of very few that explores differences between nonprobability and probability-based online panels regarding response quality. While we only detect differences in terms of straight-lining, future studies will need to investigate whether our findings and null-findings replicate. In addition, our study focused on three satisficing measures as indicators of response quality. Future research should explore other response quality indicators, such as response order effects (see Krosnick and Alwin 1987) and acquiescence (see McClendon 1991).
We would also like to point out that other factors than the sampling design might be responsible for the significantly higher amount of straight-lining in the nonprobability online panels compared to the probability-based online panels. One alternative explanation for the variability in response quality across the online panels might be that academic online panels generally invest more in strategies that lead to high response quality, while non-academic panels do not. However, our finding that the non-academic probability-based online panel in our study (panel 1) has similarly low straight-lining rates as the academic probability-based online panels (GIP and GP) speaks against this alternative explanation.
Last, with regard to the generalizability of our findings, our study is limited to online panel response quality. Surveys in online panels are usually shorter than offline surveys typically are (for empirical proof on the potential effect of questionnaire length on satisficing, see Roberts et al. 2010). Furthermore, unlike many offline surveys, surveys in online panels are self-administered by the respondents (for empirical proof on the effect of the survey mode on satisficing, see Fricker et al. 2005; Heerwegh and Loosveldt 2008). Whether and how survey length and survey mode interact with the sampling design of a survey remains another question for future research.
Supplemental Material
supplementry - Response Quality in Nonprobability and Probability-based Online Panels
supplementry for Response Quality in Nonprobability and Probability-based Online Panels by Carina Cornesse and Annelies G. Blom in Sociological Methods & Research
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors gratefully acknowledge the support from the Collaborative Research Center (SFB) 884 “Political Economy of Reforms” (projects A8 and Z1, Project-ID 139943784), funded by the German Research Foundation (Deutsche Forschungsgemeinschaft, DFG) and from the GESIS Panel, and funded by the German Federal Ministry of Education and Research.
Supplemental Material
Supplemental material for this article is available online.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.