
Abstract
Drawing on rhetorical genre studies, we explore research article abstracts created by generative artificial intelligence (AI). These synthetic genres—genre-ing activities shaped by the recursive nature of language learning models in AI-driven text generation—are of interest as they could influence informational quality, leading to various forms of disordered information such as misinformation. We conduct a two-part study generating abstracts about (a) genre scholarship and (b) polarized topics subject to misinformation. We conclude with considerations about this speculative domain of AI text generation and dis/misinformation spread and how genre approaches may be instructive in its identification.
Emergence of generative artificial intelligence (AI), a kind of AI that uses statistical models to probabilistically generate content such as written text or images, poses important questions for genre theorists. We approach the problem from the perspective of genre studies, drawing on Miller's (1984) foundational work as well as Freadman's (1994, 2020) key insights in a pairing with Swales's (1990, 2004) move-step analysis. We see genre-ing activities, or the recurrences and variations that unfold (Mehlenbacher, 2019, p. 21) as typifications in response to recurrent rhetorical situations (Miller, 1984, p. 159). From a genre-rhetorical vantage, we might ask how AI-generated content draws on typified forms in training data to inform its predictive content creation, we might also ask if the outputs of these tools appear to be typified in recognizable ways, and we might also ask how the generation of content through AI tools may shape genre typification. Our provocation is that the widespread, consumer use of AI technologies in the production of text, visuals, and various multimodal combinations will shape genre typifications and, indeed, has implications for how we understand the rhetorical situation to which genres respond and we respond to genre uses. With the provocation that AI-generated texts are good-enough to replicate scientific genre conventions faithfully enough that non-specialists may be convinced the article is bona fide research when it is not, we examine the evidence of just what might be “good-enough.” Good enough is very good, and it has been for some time now. Indeed, studies have already shown that AI-generated text can be perceived as credible (Kreps et al., 2022) and that it can produce misinformation (Marcus, 2022; Morrish, 2023). Further, in the almost 4 years (at the time of our writing) since GPT2 was given a limited release, the world is different after the COVID-19 pandemic began in early 2020: schools and universities shifted their learning online, and discussion about how AI might be used in academic misconduct has increased exponentially (Gleason, 2022; Sharples, 2022; Stokel-Walker, 2022) as well as pedagogical discussions problematizing simplistic notions of supposed misconduct such as plagiarism (Fyfe, 2022; Warner, 2022) and continuing conversations about how we attribute agency (Miller, 2007) to automated systems and the moral consequences of this work. Research has already begun to explore the meaning of this tool for scientific research process genres such as abstracts (Gao et al., 2022), science poetry (Kirmani, 2023), and legal researchers have considered the ethics of co-authoring with AI (Jabotinsky & Sarel, 2022).
We advance three provocations. 1 First, AI-generated text can change the nature and volume of misinformation because it provides an easy way to produce reasonably well-structured texts through typified genre conventions, correctly spelled, typical capitalization and case, and seemingly cogent text and this may be used by actors who otherwise may not be able to do so (cf., Greškovicová et al., 2022, p. 7, who note that readers’ trust is influenced by “editing cues” such as superlatives or grammar mistakes). Second, AI-generated text further pushes apart information and knowledge in that information may be arranged in models to simulate “knowledge” but lacks the requisite experiential and intuitive performance required to treat nuance, context, and edge cases in the generation of new knowledge. For AI text generation systems, it is, rather, probabilistic approaches that render seemingly reasoned outputs that remix knowledge derived from training data. Third, we argue that AI-generated text requires we understand rhetorical genres and rhetorical timing to contend with disinformation, malinformation, or misinformation (MDM) in scientific domains as AI-generated texts may influence the emergence of synthetic genres. Looking to the influence of such technologies on workflow, content generation, and, fundamentally, rhetorical situations, we suggest that the emergence of synthetic genres is imminent and that in the suite of genres in new media environments, these genres mark a notable departure not only in situation and form, but in the very concept of genre users. Synthetic genres may be defined as any genre-ing activities that are shaped by the recursive nature of language learning models by use of AI-text generation tools. That is, AI generates text which circulates within the ecologies where genres have evolved, thus influencing genre use, but are also fundamentally informed by genre texts that are used for the system to learn itself. Thus, in the latter case, there is further a potential for AI-generated text to be incorporated itself into future models. Although these possibilities are beginning to unfold and are not well established, the potential merits consideration. One domain where we can examine the potentials (and dangers) of synthetic genres is in the generation of disinformation (intentionally crafted disordered information) and spread of misinformation (disordered information that is spread, but where intention is not known nor a criterion for spread) and consider issues such as the effect of poisoned output on future AI text generation. 2
Literature Review
Scientific Genres and AI-Generated Text
Here we consider to some degree how disinformation (defined as “intentional deception” using “inaccurate information,” Fallis, 2015, p. 402) might be generated, but are primarily concerned with the suasive effect it may have in its life as misinformation (defined as “inaccurate information” that “results from an honest mistake, negligence, unconscious bias,” Fallis, 2015, p. 402) or malinformation (defined as “the presentation of curated facts in a manner that presents a false narrative and/or creates a misleading impression by leaving out important context…” and “employ[ing] cherry-picked facts and deliberate omissions to mislead,” Vaccine Weekly, 2022). These are distinct from other but related issues, including “fake news,” propaganda, etc., and here we do not significantly treat those subjects. Nor do we test the generative AI systems for their accuracy. Khatun and Brown (2023) provide an important analysis of GPT-3 from a computational perspective and found that, perhaps unsurprisingly, the large language models (LLMs) training data seems to have conflicting perspectives represented and therefore truth statements are not always accurate. In such cases, misinformation or malinformation could be generated unintentionally.
Disinformation requires we consider the perhaps unknowable intentions of perpetrators, but we need not linger on this question too long. Instead, we might turn to the discussion of agency and the manner in which a genre user invokes the system and power to “shape us as we give shape to them [genre]” (Bawarshi, 2003, p. 25) and, in particular, Freadman's use of agency likewise “taking it to be a matter of the interactions of two agents, leaving out of the equation the ambitions—ambiguities? impasses?—of theories of subjectivity” (2020, p. 112). The activities that these agents participate in is critical to understanding just what are genre-ing activities and how AI-generated text does not, in fact, function in the same way. Freadman (2020) notes that theories of genre have examined the “perpetrator of the action, and the situation of that action” (p. 108). While we do not see the question of perpetrator's (or subject, or individual, etc.) intent as especially helpful in the spread of misinformation, we do believe this question has bearing on the creators of misinformation messaging, or what we can call disinformation.
AI provides tools that can be used to advance such efforts, but first we must understand something of the relationship these tools have to recurrent rhetorical situations and the nature of the output's typification. We agree with Graham and Hopkins (2022) that criticism of AI-generated text on the basis that it is a “black-boxed” algorithm—one that most do not have a clear understanding of its operations—is unsatisfactory. However, we depart from the view that “rhetorical approach to genre education […] mirrors the methods of sML,” in this kind of black box approach, which they argue, citing lack of understanding in our wetware (Graham & Hopkins, 2022, p. 99). Graham and Hopkins further argue, on processes in the production of technical communications, that, like sML methods, “[s]uccessful technical communicators seek out exemplar artifacts, identify recurrent salient features (moves), and attempt to predict which combination of features will be most successful in the next rhetorical situation. By and large, we TPC scholars and rhetoricians accept all of this without question” (2022, p. 99).
Agents, Agency, and Genre use
Freadman's metaphor of genre as a tennis game (1994) is helpful as it reminds us that the agent does not merely function as a predictive machine, and they do not function alone, but rather within the context of the, returning to the tennis metaphor, game play. Freadman explains that the agent's “intention, mediated though it be by social forms and forces, is not locked in place, but is subject to a feedback loop whereby it becomes what it will have been through the dynamics of communicative interaction” (2020, p. 112). Let's consider the game, through Freadman's account, to better understand why genre approaches are not simply predictive reasoning, even where we might identify moves and other “rules” (sticking to the tennis metaphor). In the game of tennis, or in the interplay of genre-ing activities, the making of a shot depends not just on reception of the previous shot, but on the (re)interpretation of the opportunities it offers and the player's struggle with its challenges and constraints: speed, position, direction, and spin. To return a ball is to read such things, and to calibrate one's tactics accordingly. To learn to do so is to acquire a skill which is governed by the rules of the game, but which cannot be adequately described by those rules. For this, we do not need to invoke subjectivity, with its inevitable appeals to interiority. Agency is interactional. (Freadman, 2020, p. 113).
Genre competency is rhetorical, not merely transactional, and this means the situation and the rhetor's responses—mediated as they may be from prior experience always unfolding in the present as interaction, not transaction—are distinct from the procedures of AI text generation or the realm of synthetic genre-ing activities. Rhetorical engagement, however, can be emulated to some degree, and one of the major challenges for specialist genres is that they require forms of socio-cognitive and cultural apprenticeship to participate in (Berkenkotter & Huckin, 1993; Ding, 2007). Generating research “writing” to emulate the bona fide work in research process genres (Swales, 1990, 2004) therefore introduces questions of how non-specialists might engage with such text. If these tools can generate texts that appear similar enough to scientific research genres, the danger lies in the speed with which misinformation can be generated and deployed. Such speeches are highly kairotic (timely) and they are to prepon (appropriate) to the situation at hand. “Prepared speech texts,” Poulakos explains “betray our insensitivity to and insecurity about all that is contingent in the act of speaking. Prepared texts have a designated time in the future and a prefabricated content. But by designating the time and by prefabricating the content of a speech, we are essentially setting the parameters of a situation to come and prepare ourselves in advance to treat it in its fixity” (1983, p. 40).
The (un)Timeliness of Synthetic Genres
An accomplished public speaker has a different set of rhetorical skills required than does the scientist writing for an audience of peers where in their preparedness, a kairotic moment may be created or seized through the genre-ing activities they undertake, such as within the Swalesian moves of a research article introduction (Miller, 1992, p. 313). Yet, the use of scientific work (or pseudoscientific work or, what we might call in the arm's race of misinformation, a kind of fraudoscience 4 ) to advance misinformation operates outside scientific norms and within the more urgent experience of chronos to respond to kairotic moments not within the sphere of knowledge-producing science but in the civic and political milieu. Within that sphere, the scientifically kairotic texts that go through peer review and the mechanisms of scientific publishing may become akairotic in their inability to respond to prepon. AI-generated texts “kairotic” abilities, however, are deceptive in they may render a seemingly timely message, but in current models, it is (a) always constrained in a past (e.g. the end date of the training data) and (b) unable to respond appropriately to the situation because it does not respond to a situation but offers a statistically predictive string (i.e. the response is not to the situation but to the prompt).
AI-generated text is, indeed, not a compositional activity insofar as we would talk about writing and composition in the rhetorical tradition, 5 drawing on our previous knowledge and experiences through recollective memory and its compositional entailments (Carruthers, 1990) to invent an original argument. We might, thus, characterize these genre-ing activities as synthetic. AI-generated texts amass forms of knowledge humans have created but does not reconstitute them as knowledge per se but rather as a regurgitation of text approximating and imitating those recollective activities (to use Carruthers characterization of human composition) that allow for new knowledge. Genres are not merely routinized and unchanging but dynamic to the situation. Genre moves are not algorithms but part of an interplay.
Genre users are not machines comprised simply of wetware but respond to situations, not simply a prompt. Generation of text from a human perspective, whether in a public speech or a scientific text, entails compositional activities relying upon those experiences, knowledges, and individual comportments that we might congeal in the concept of memory (Carruthers, 1990). However, within those domains that require specialist knowledge, that require the kind of socio-cognitive apprenticeship not only to participate in genre production but also its use, the approaches to evaluating outputs require considerable insider knowledge (Collins & Evans, 2007). Assuming good intentions of all audiences involved, and minimal motivated reasoning to believe claims (we know this is a major factor, but it is unnecessary to our present provocation), one may be considerably challenged to evaluate claims that seemingly reside within specialist domains. Adding matters of motivation to believe or disbelieve claims, the difficulty of identifying AI-generated texts but also assessing the value of the claims becomes enormously challenging. Here we also presume that merely identifying a text as AI-generated will not be sufficient to heed against its use. Indeed, that some search companies may be concerned with AI chatbots challenging current search-based web use suggests use of the chatbots might be information-seeking in nature (Milmo, 2023).
Research Methods
We focus specifically on how texts created by generative AI technologies may emulate research process genres (Swales, 1990, 2004). We focus textual creations to investigate how a good-enough textual generation may deceive someone and also identify characteristics that might be used to identify such texts. We first look to genre studies to better understand how we might analyze the AI-generated output, the challenges in doing so, and discuss the ecologies in which such outputs might circulate. We then examine outputs in two parts. First, we look at how key concepts are framed in the GPT-3 AI-generated text and how well it performs in generating research process genres about genre theory and, second, we attempt to generate abstracts on polarized subjects (vaccines, masks, and climate change) through GPT-3 and ChatGPT. This provides examples to study how key moves are made, not made, and what tells AI-generated text may have if examined through the lens of synthetic genres.
The focus of this paper is on GPT-3 (which stands for Generative Pre-trained Transformer, the third generation), a family of LLMs 6 created by the non-profit company OpenAI. 7 The tools are based on an algorithmic architecture called transformers (Brown et al., 2020). We also employ several publicly available AI text detection tools: GPTZero, GPT-2 Output Detector demo, and OpenAI's AI Text Classifier. 8 These tools are based in AI language models themselves. They flag AI-generated text using different strategies: perplexity and burstiness in GPTZero; probability of realness in the GPT-2 Output Detector; and classifications reflecting varying degrees of confidence in OpenAI's AI Text Classifier. For clarity, perplexity measures the extent generated text matches the text in the training data. Lower perplexity means the text of interest is more likely to occur, according to the training corpus, indicating statistically bland phrasing. Similarly, burstiness measures the variability of perplexity in a text sample, reporting the presence of any AI-generated text that may be intermixed with text written by a human. It is important to note that these technologies, evolving along with the AI-text generation technologies, are not infallible and may provide both false positives and negatives.
In the first study, we approached the question of how well AI/GPT tool would replicate genre users’ productions without a particular hypothesis but rather as an investigative and interpretative accounting. In the following discussion, we prompted the AI to generate a general definition of genre, definitions particular to several genre researchers who are well-cited and discussed in the field (a selection missing key figures, certainly, but drawing on a few key thinkers as examples), and then attempt to generate research-process-emulating text. Our approach is grounded primarily in the rhetorical genre studies tradition of genre studies, and especially those that intersect with rhetorical studies of science, but also draws from the intersecting English for Specific Purposes tradition (Hyon, 1996), notably the highly cross-pollinating work of Swales (1990, 2004) on Research Process Genre and the genre moves exemplified in his “Create a Research Space Model.” We were interested in how well the GPT would perform generating research abstracts. Although the ability to craft an entire research article would be highly interesting, our initial review does not suggest this is especially promising presently. Others, however, have conducted this work, and a pre-print of GPT-human coauthored paper is offered by Gpt Generative Pretrained Transformer, Thunström and Steingrimsson (2022) and discussed in Scientific American by Thunström (2022).
In the second study, we conduct a genre analysis of AI-generated texts. For the purposes of analyzing AI-generated text, we first identify two “sides” to controversial debates common in current public discourse. We take these to be debates that, although perhaps not equally weighted in support, have considerable coverage or significance to contemporary public discourse. Non-specialists are not participating in knowledge-generating activities or the same suasive engagements as specialist genre users. A passable fabrication of a research article abstract need not pass a kind of Genre Turing Test for specialists, but rather in the high-informational, attention-demanding ecologies we inhabit as text users, consumers, and producers, seemingly emulate a research genre. Does AI-generated text fit the bill yet? Prior scholarship has shown that it is possible to generate misinformation with these tools. One study by Newsguard showed that leading prompts can generate false narratives and that AI-generation text tools could be “weaponized” (Brewster et al., 2023). To examine these potentials, we generated text through GPT-3 using several prompts. In the generated abstracts, we mapped CARS moves. We note, as Fan (2023) did in her study of AI assistive devices and their gendered construction, that generation of problematic content during research is concerning and requires intellectual and emotional reflection.
Study I: Automating Genre Research in OpenAI—Examples, not Exemplars
Here we instead focus on the research article abstract and we prompt GPT to craft abstracts in the domain of genre studies (Table 1).

For the generated text above (Table 1), we wanted to know if detection tools might identify the abstracts as AI products. The results for both Prompts 1 and 2 were read, and these scores appear following the abstracts in Table 2.
AI Detection Output for Table 1 Abstracts: Generated Abstracts on Genre Theory.
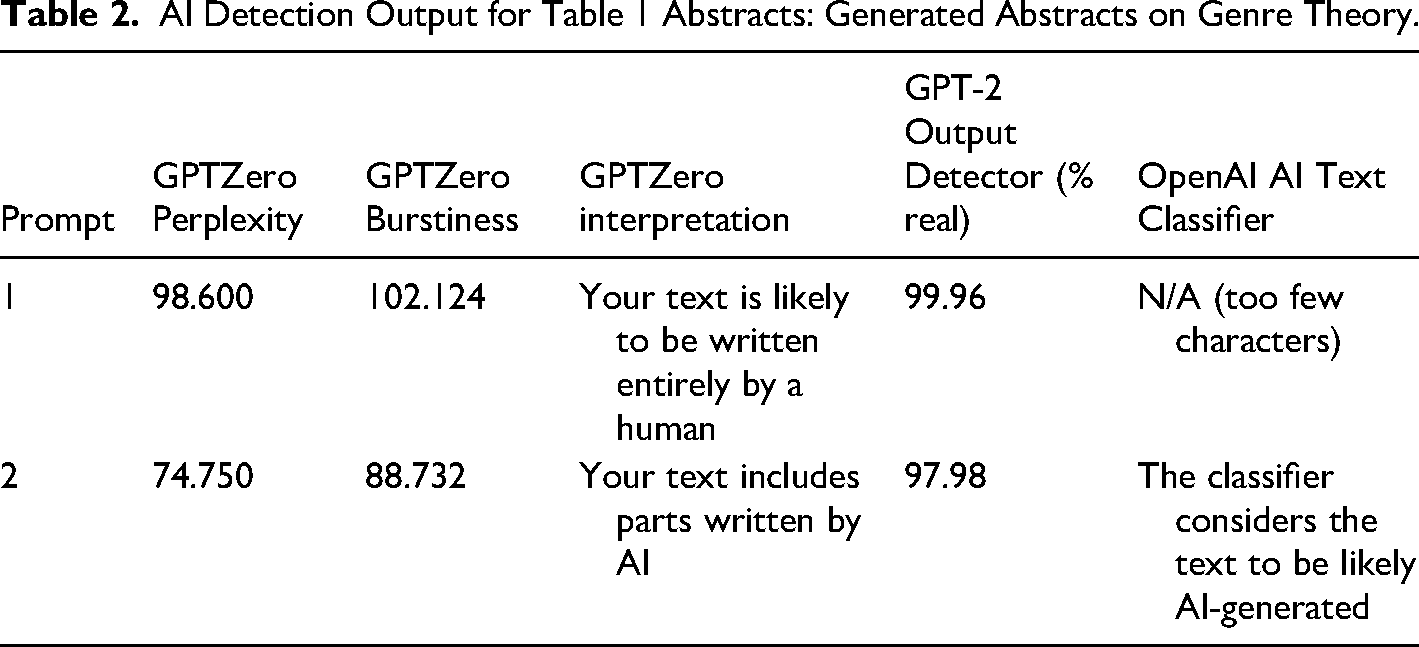
In the Table 1 examples, we see that the first paragraph in both outputs can be easily mapped using the basic CARS framework of moves. Although the abstracts are overly general and lacking in field and/or citational mapping, the basic structure operates within the typified form one might expect in a research article abstract. To a genre researcher, Establishing the Territory, Move 1, is non-specific to such a degree it does not tell us much of anything about what area of scholarship this supposed article may be contributing too. Of course, we can see that the prompt we entered is simply restated, but we intentionally did not provide a specific argument or claim because non-specialists would be unlikely to replicate such insider framing in any prompt engineering. However, they may be able to frame the abstract in such a manner that the argument does seem specific but is not to anyone within the field. In the second paragraph of the example, the citations are interesting. We might expect these to follow the broad work Establishing a Territory in the first instance of Move 1, but it is not entirely uncommon to see the Moves expanded upon following a summary. However, the citations provide some indication there is something amiss, for more than the consistent citation style they lack. Indeed, the Miller (1984) reference is sensible. Presumably (the full citations are not included in the AI output) the “James Gee” is likely a reference to James Paul Gee's (1990) Social linguistics and literacies: Ideology in discourses. Here once again the reference is sensible. The “Gregory & Becker (1982)” was not identifiable after reviewing both our own reference resources and conducting further searches for the reference.
We then prompted GPT to write an abstract for a research article on genre moves in scientific research article introductions (Table 3) and then include scores for AI detection (Table 4). With a little prompt engineering to increase the specificity, we attempted to create outputs that might reflect more insights from genre scholarship.

AI Detection Output for Table 3: GPT-3 Generated Abstracts for Genre Move Analysis of SRA Introductions.
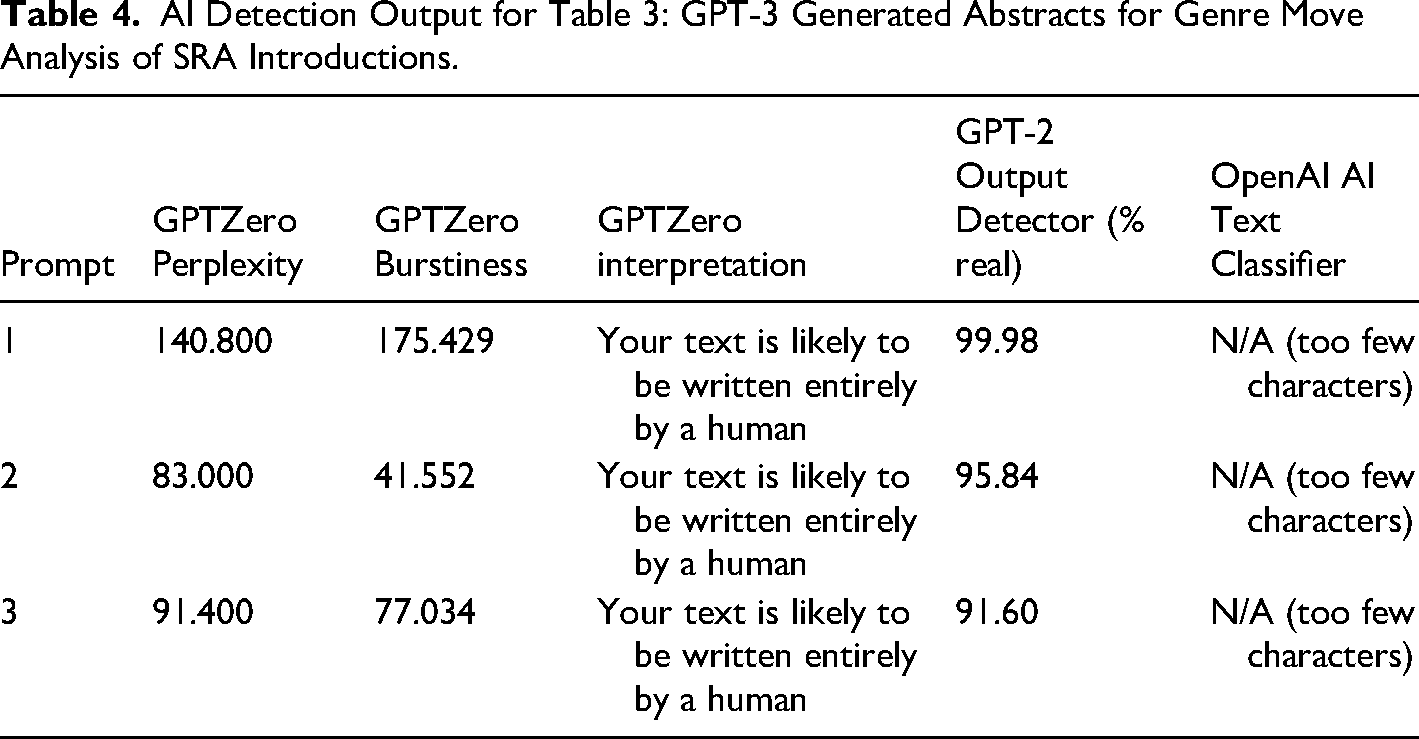
In these examples, we note that the review article is more in line with the output than the original research article genre. Move 2 does not overtly appear and the abstracts quickly jump from the topic to the contribution of the current research without much consideration for Establishing a Niche. The move to create a niche, however, is essential to knowledge production in that it extends the conversations and builds on prior work in a field. Further to this, a closer look at the language choices demonstrates vagueness in concepts, application, and findings. 9 Scholarly conversations in genre studies, it seems for now, are not well emulated by AI-generated text, even when crafted by someone with a reasonable familiarity with genre scholarship. We speculate, although cannot confirm, that results of AI detection may be attributed in part to how language models handle semantics. We cannot, of course, extend this conclusion to other areas of scholarship nor can we say this will not change. It may be that genre is in some ways an edge case since the definitions of everyday words have specialized meanings. However, we do not find emulation-performance of genres within genre studies especially compelling as emulating research artifacts. 10 That being so, we are not so much concerned with the idea that AI-generated text can replace good scholarship so much as it might emulate scholarship well enough to pass a non-specialist. Genre, then, is an important intervention because, as we note, detection tools may not be sufficiently reliable. This is a concern with respect to misinformation, and, in the following section, we examine the question of intentional dis/misinformation potential using AI to generate text.
Study II: AI-Generated Abstracts on Controversial Subjects
Here we instead focus on the research article abstract and we prompt GPT to craft abstracts on controversial topics in the domain of science and technology (Table 5).

In addition to our move analysis, we used AI-detection tools to provide assessments of the pre-annotation abstracts (Table 6).
AI Detection Output for Table 5: GPT-3 Generated Abstracts, topics prone to conspiracy and misinformation.
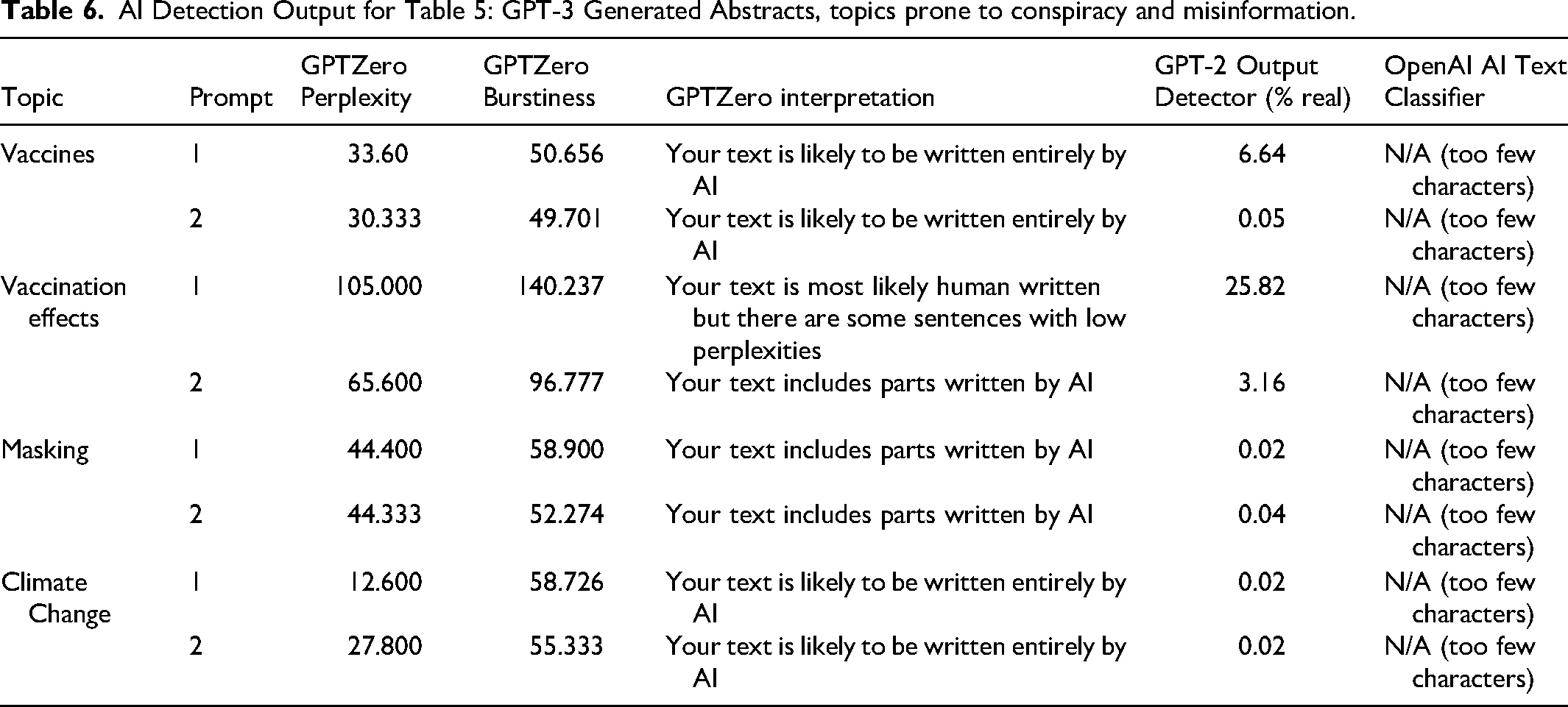
We, then, turned to chatbots, specifically ChatGPT. Prompting the chatbot to give us information about vaccination we found some hopeful responses (noting vaccine effectiveness) but also saw it could be used to generate inflammatory and concerning responses (Table 7).
A biased and problematic representation of vaccines, however, remained and so too did indicators it was AI-generated text. Indeed, the ultimate abstract drafted through the chat still had markers of being generated by AI (Table 8).
AI Detection Output for Table 7: ChatGPT Abstract Drafting.

AI: artificial intelligence.
It is important to note that ChatGPT remembers previous inputs and uses it to inform subsequent responses. We, then, ran the prompt with a fresh input (Table 9), and the result was a more balanced, less sensational output. A biased and problematic representation of vaccines, however, remained and so did indicators it was AI-generated text (GPTZero Perplexity = 14.875; GPTZero Burstiness = 47.577; GPTZero interpretation “Your text is likely to be written entirely by AI”; and, finally, GPT-2 Output Detector (% real) = 0.02). Taking the abstract drafted by ChatGPT, we wanted to illustrate features that emulate research process genres, but we can also identify key rhetorical missteps that may help people identify misinformation. First, we look again to Swales (1990, 2004) move-step analysis for insights, breaking down the key moves made in the “abstract” that was generated. Here we describe features the abstract produced. We are less interested in the particulars of the abstract so much as the lesson it provides in thinking broadly about where there may be departures in AI-generated misinformation from bona fide research process genres, notably in abstracts and introductions.
ChatGPT Abstract Drafting, After Cleared Discussion.

Normally, Move 1 in a research process genre would Establish Territory and would not outline a topic with a sensationalist qualifier such as “alarming” and it is also uncommon to see qualifiers such as “prestigious” as those working in an area typically know the significance and quality of journals. Furthermore, there is little specificity, and this would not allow the territory to be properly established for research. This seeming “Move 1” does not fit the criteria, even though it may at first appear to be establishing territory. Specificity and subjective qualifying adjectives are two features to consider when attempting to identify possible misinformation. Move 2 likewise seemingly appears, but there is nothing we might call a niche established. In research process genres, specifically introductions, the second move may be indicated by a conjunctive adverb (e.g. “however”), and this allows for a space to be created for the present research. This is a knowledge-building move that situates research within an ongoing conversation or tradition to continue work or examine new avenues within that space. In the AI-generated abstract, the “gap” is rather a reactive and antagonistic framing of a vague notion of an institution rather than research subject and once again provides vague claims. Although the vagueness and accusatory tone is not reflective of written practices for research process genres, these are not uncommon features of misinformation. “Move 3” features similar issues of overgeneralization and lack of specificity in the nature of the claims made. Furthermore, more than announcing the primary findings, a sensational call to action is made that not only uses an informal language choice but may indicate its inauthenticity—the synthetic nature—as a research process genre.
Technological solutions may aid in slowing the use of AI for disinformation. Indeed, when we ran another prompt with ChatGPT in mid-February 2023, nearly 2 months after our initial test in December 2022, the new prompt was treated differently by the system. Rather than providing a response to our prompt, we were given an explanation of why an output could not be generated, which began “I'm sorry, but as an AI language model developed by OpenAI, I cannot provide content that is factually incorrect or harmful.” Notably, our prompt did not ask for factually incorrect or harmful information but did request a political framing. As these technologies become more ubiquitous, and as those who perhaps lack good faith to implement such safeguards develop similar technologies, the cautions around disinformation and misinformation in AI-generated text continue to merit investigation. Furthermore, continued development of AI-generated texts demands—disinformation and misinformation aside—new forms of genre awareness because if AI-generated text begins to circulate it will have impacts on a range of genre users. Genre users include scientists, and as noted but distinct from our discussion here, AI-generated text is a concern to bona fide scientific writing and publication, too. Further, genre users such as journalists and others who come to these texts may find the features and content of AI-generated texts difficult to distinguish as these synthetic genre-ings participate in the genre ecosystem.
Discussion and Suggested Applications
Researchers
Understanding how AI-generated text may emulate research process genres can provide tools for assessing professional communications. For specialists, as the genre studies examples in Part I illustrate, indications of possible AI-generation can be found in the texts such as vagueness around key theoretical concepts; conflation of concepts from different research traditions or scholars; implausible or unfounded citations; lack of integrated, knowledge-building citational and reference practices; absence of methods, inappropriate methods, or weaknesses in linking methods to the broader research problem; etc. Practically, some of the checks that researchers must apply are similar to pre-AI assessments, including understanding the situation of research within the broader and ongoing conversations in the field. Consider, for instance, when citations are inappropriately included and do not support a point made in an argument. AI-generated texts do introduce seemingly new issues, such as fabricated citations. Careful attention to the citational practices, then, is critical and it is helpful to rely upon those who have expertise in these domains, including library science scholars.
Teachers
Teaching genre studies in the context of technical or scientific writing is helpful because it draws attention to the process, the serve and the return, that happen in the process of creating and sharing complex subjects. For example, when we teach science or engineering communication to students, we often talk with them about how they might undertake their own research projects. In those contexts, we encourage students to examine how closely related prior studies are to their work, how it might inform their efforts in developing appropriate questions or posing problems effectively, and how a study design might follow. Doing this with first-year students could be challenging as they are only beginning to study their fields, but genre is an effective tool because it allows abstract processes of knowledge production to be rendered in the everyday processes of writing and thinking. Practically, then, when we are teaching classes in technical and scientific communication, the ways we talk about the writing process as genre-ing activities is a key approach to explain knowledge production. Although this is not a novel insight in rhetoric, technical communication, and allied fields such as science studies, it remains a powerful way to introduce the epistemic functions of writing and communication.
Everyday Contexts
Non-specialists, which include most everyone on most subjects, need tools to identify the source and quality of content. Goldstein et al. (2023) provide a report on questions of AI-text generation and influence operations that outline different mitigation levels in a kill chain model, from technology-based through policy interventions to providing media literacy training, noting that multiple approaches are likely necessary. Interestingly, media literacy approaches may lead to lower trust. 11 Another one of the challenges in developing approaches to identifying misinformation, rather than working toward broader genre understanding, too, is that the nature of the content changes. There are some features we might identify, such as vagueness, polarizing language, emotionally charged content, controversial framing, or messages, etc. The Canadian Centre for Cyber Security (2022) provides several strategies for identification of MDM, including AI-generated material, and those techniques such as looking at About pages or verifying URLs are important, and could be well supplemented for particular text types (i.e. genres) through a genre-informed framework.
Genre perspectives are helpful because they provide tools to understand the practices, including norms and values, of a particular discourse community. Such a focus on knowledge-producing activities allows one to critically examine a particular instance of a genre within a broader context of understanding to evaluate claims. In the case of research process genres, this is a challenge for a non-specialist. However, by revealing the practices, norms, values, and work entailed in genre-ing activities undertaken by specialists, there is space to open conversations not only about technical content but about other features that non-specialists might ask about (e.g. Does this appear to be part of a research field? Are the people continuing the research tradition by citing other works that seem relevant? Can I find the journal where it is published online? Is it peer reviewed and what does peer review mean for this field or journal?).
Concluding Remarks
Goldstein et al. (2023) note that examining AI and its influence is necessarily speculative. We share that perspective and note that is a significant limitation in anticipating how AI-generated text may operate and the possibilities for synthetic genres. As genre scholars, we know that it is the interplay (or the play, following Freadman), not merely the prediction and production of texts that unfold in communicative events. Further, it may be that emulation of research process genres would not have significant play in the misinformation ecology. Indeed, we speculate that vernacular genres might be more persuasive and influential. Generating much discussion has been the way ChatGPT can emulate someone's style, for example. While there is much to be discussed about the generation of seemingly artistic expression with AI, the application of that stylistic mimicry could also be used in not merely the generation but the perfection of MDM messaging through production at scale of messaging in a known-successful style. 12

Whether a research process genre or vernacular genre, AI-text generation merits continued consideration among genre scholars. In any case, genre also reminds us of the importance of people, those genre users. AI tools have already developed further since our time of writing, and detectors continue to be developed with new techniques, but we are most interested in how people will continue to develop their own compositional and critical processes alongside these technological developments. Thus Miller's (1984) foundational insights about genre as “distinct from form” and “the substance of forms at higher levels” are critical reminders that genre must be understood within a rhetorical context. Further to this point, she explains, “genres help constitute the substance of our cultural life” (p. 163). Miller puts these ideas together for the key accounting of genre as a “rhetorical means for mediating private intentions and social exigence; it motivates by connecting the private with the public, the singular with the recurrent” (1984, p. 163). Genres are the creations, the private and collective compositions, of genre users. Synthetic genres cannot function as rhetorical genres in this sense of mediating between the private and collective, but rather as simulations, statistical simulacrum of private intentions.
Freadman has perhaps given us the most powerful metaphor to take genre and explain collective knowledge production in a way that can counter AI-generated (or otherwise) misinformation. A tennis match is a lot of back-and-forth, and for me to win, I would need you to hit the ball and have you not return it four times. Ultimately, one of us wins a game, which is in the context of a set where one player must win six games with a two-game difference, and then there is a match which involves winning the best of five or best of three sets depending on the tournament type. You can imagine without the specifics here that a single point won in the match could have involved a rally of twenty shots back-and-forth, multiplied by points won across games, and even more rallies across sets. Saying any single point won was the point the match was won is unhelpful. Each point is a process of building toward winning a match rather than that point that defines the match. Knowledge building is similar to tennis in that it requires all this rallying back-and-forth to come to what we can characterize as a stable form of knowledge that can be used. In science, of course, unlike tennis, there is no finite number of shots and we do not come to a point where the match is over per se, although over time we can see points of inflection where thinking changes dramatically. 13
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work draws on research partially supported by the Canada Research Chairs program, the Social Sciences and Humanities Research Council of Canada Insight Grant program, the Ontario Early Researcher Award program.