
Abstract
Automated prediction of dental conditions in Orthopantomogram (OPG) panoramic radiographs faces significant challenges due to class imbalance, rare pathologies, and complex anatomical structures. This study proposes OralHybridNet, a novel hybrid deep learning framework integrating hierarchical convolutional neural networks, such as CustomDentalNet integrate dual-attention mechanisms and OralNetXPlus. A multinational dataset comprising 2047 clinician-annotated panoramic radiographs spanning 7 diagnostic labels was used. An adaptive augmentation protocol combining Elastic Transformations and gamma correction mitigated class imbalance. A Hybrid Feature Selection (HFS) algorithm condensed 1208-dimensional embeddings into a discriminative 300-feature subset. Evaluated against ResNet50 baselines, OralHybridNet achieved 96.0% accuracy, 97.6% precision, and 0.993 AUC-ROC. The KNN Fine classifier on fused features yielded the highest performance, with real-time capability (9 ms inference time) using a neural network classifier. The proposed framework demonstrates a promising proof-of-concept framework for automated multi-label dental restoration classification.
Keywords
Introduction
Dental restorations and prostheses play a pivotal role in restoring oral function and esthetics, encompassing procedures such as dental fillings, root canal therapy, crowns, bridges, posts, and implants, each exhibiting characteristic radiographic appearances.1,2 Panoramic radiographs, commonly referred to as Orthopantomograms (OPGs), are routinely employed in clinical practice due to their broad field-of-view, enabling simultaneous assessment of teeth, jaws, and surrounding anatomical structures. Despite their utility, OPGs present substantial diagnostic challenges, including anatomical overlap, projection artifacts, variable image quality, and morphological similarities between restorative materials and pathological findings.3,4 These factors collectively complicate manual interpretation and contribute to diagnostic inconsistency.
Recent clinical studies have reported considerable inter-observer variability in the identification of dental restorations and prostheses, with inter-rater agreement ranging from moderate to substantial (κ = 0.42-0.68). 5 Such variability highlights the inherent subjectivity and limitations of conventional radiographic assessment, particularly as the prevalence of restorative and prosthetic procedures continues to rise. Accurate identification is clinically critical, as misinterpretation may delay the detection of complications such as secondary caries, prosthetic fractures, failed endodontic therapy, or peri-implantitis. 6 Moreover, manual classification of multiple restorative entities on panoramic radiographs is time-consuming and heavily dependent on clinician experience, underscoring the need for reliable and efficient automated diagnostic support systems.7-9
Deep convolutional neural networks (DCNNs) have demonstrated transformative potential in medical and dental imaging, achieving near human-level performance in tasks including caries detection, periodontal disease staging, and lesion segmentation.10-12 These models are particularly well suited to panoramic radiography, as they can hierarchically learn complex spatial and textural patterns from high-dimensional grayscale data, where subtle intensity variations and structural overlaps challenge traditional diagnostic approaches.13,14 Recent advances in hierarchical and multi-scale feature fusion further enhance the ability of DCNNs to capture both global anatomical context and fine-grained restorative details.15,16 However, the successful deployment of DCNNs in dental applications remains non-trivial, requiring careful hyperparameter optimization, domain-specific architectural design, and tailored augmentation strategies to mitigate overfitting and class imbalance.17,18 Transformer-based architectures have recently shown promise in broader medical imaging domains by modeling long-range dependencies and global contextual relationships. 19 While hybrid CNN-Transformer frameworks have achieved impressive performance in tasks such as impacted tooth detection and general dental pathology classification, their application to comprehensive multi-label classification of dental restorations and prostheses on OPGs remains underexplored.20,21 Existing studies often focus on narrowly defined tasks, such as single-class implant detection or caries classification, frequently limited to bitewing radiographs or cropped regions of interest.22,23 Consequently, a critical gap remains in the development of unified, multi-label systems capable of simultaneously identifying fillings, crowns, bridges, implants, posts, root canal-treated teeth, and carious lesions on full panoramic images.
This gap has significant clinical implications. Misclassification of visually similar entities, such as dental posts versus implant abutments, or root canal-treated teeth versus caries-affected regions, may result in inappropriate treatment planning or delayed intervention due to insufficient contextual understanding and localization.24,25 Addressing these challenges requires architectures that can integrate macro-structural information from the entire jaw with micro-level restorative features at the tooth level, while maintaining robustness to class imbalance and image heterogeneity.
Recent literature increasingly emphasizes hybrid and hierarchical learning strategies to address these limitations. Küçük et al 26 demonstrated the effectiveness of CNN-Transformer hybrid architectures in panoramic image analysis, achieving high diagnostic accuracy while combining local feature extraction with global dependency modeling, although their framework remained limited to single-task prediction. Li et al’s 27 meta-analysis of 13 studies demonstrated a pooled AUC of 0.92 for automated staging, significantly reducing inter-rater variability. These findings support the hierarchical feature fusion strategy in this study, which integrates multi-scale pathological features while mitigating dataset heterogeneity, a key limitation in prior works. For segmentation tasks, CNNs maintain dominance over transformer-based models as evidenced by Katsumata 28 reported superior F1-scores (0.89 vs 0.83) across 6000+ dental images. This empirical validation informed the backbone selection for CustomDentalNet, prioritizing pixel-level precision in restorative identification.
Class imbalance persists as a major challenge in dental AI. Küçük et al 26 achieved 93.5% AUC in multi-center prosthesis classification, highlighting the importance of geographic diversity in dataset curation, a principle rigorously applied to the multinational Oral-AI corpus. Multi-label classification demands sophisticated feature fusion strategies. Liang et al 29 improved 3D mesh recognition through rotation-equivariant self-attention, inspiring the Hybrid Feature Selection (HFS) algorithm. This method adaptively condenses 1208-dimensional embeddings into a discriminative 300-feature subset, addressing missing modalities while reducing computational overhead. These resolve limitations of prior graph neural networks (GNNs), which incurred 23% higher latency despite improving crown-bridge differentiation. 30 Against this backdrop, the present study proposes the OralHybridNet framework, which integrates hierarchical CNN architectures with attention-based mechanisms to jointly capture macro-anatomical context and micro-restorative details on panoramic radiographs. The framework incorporates adaptive augmentation tailored to rare classes and a Hybrid Feature Selection (HFS) pipeline to balance dimensionality reduction with discriminative performance. We hypothesize that this integrated approach can outperform conventional CNN backbones and achieve diagnostic performance comparable to, or exceeding, that of dental professionals in multi-label classification tasks.
The objective of this study is to evaluate the proposed framework for classifying seven clinically relevant OPG labels: dental fillings, root canal-treated teeth, bridges, crowns, caries, posts, and implants. The major contributions of this work are threefold: (i) the development of a hybrid architecture combining hierarchical CNNs and attention-based modules to capture multi-scale restorative features; (ii) the implementation of adaptive augmentation strategies to address severe class imbalance without introducing diagnostic distortion and (iii) a feature fusion and selection pipeline that enables faster inference than standard architectures such as ResNet50 while preserving classification accuracy.
Methods
This study was designed as a retrospective, multinational, multicenter diagnostic accuracy study involving the development and internal validation of a deep learning framework for multi-label classification of dental conditions in panoramic radiographs. Ethical approval for the study was obtained from the Human Research Ethics Committee, Faculty of Dentistry, Chulalongkorn University, Thailand (HREC-DCU 2024-093). The committee waived the requirement for informed consent as the study involved the retrospective analysis of anonymized radiographs. This framework implements a multi-stage pipeline for dental restoration and prosthesis classification, as illustrated in Figure 1. It begins with the rigorous curation of a dataset comprising 2047 panoramic radiographs, annotated across 7 labels. The images were uniformly resampled to 256 pixels × 256 pixels, and annotation validity was confirmed through clinician concordance, yielding a

OralHybridNet framework for multi-label dental classification.
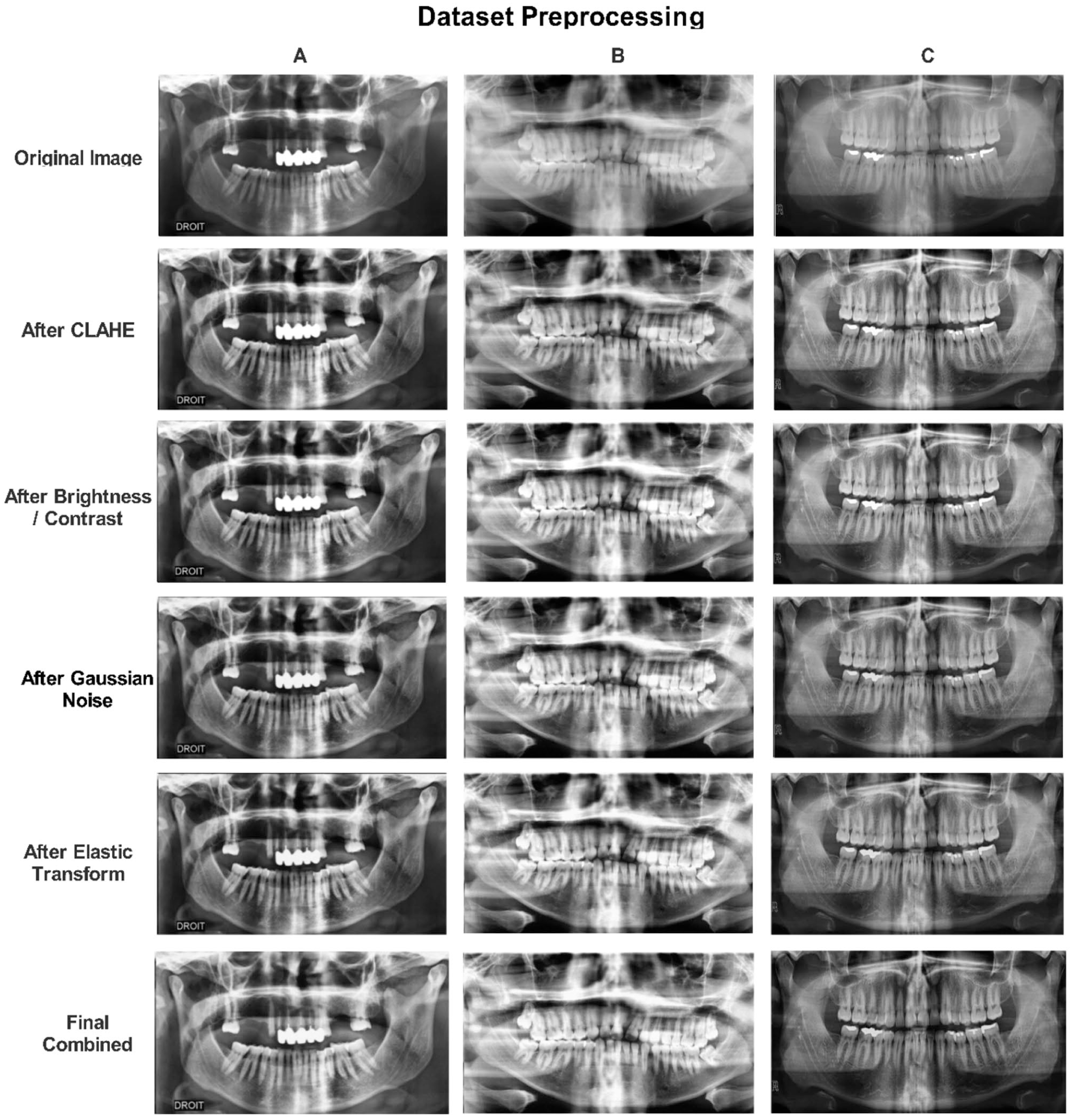
Preprocessing steps for dental restoration and prosthesis (OPG) in the original dataset.
Distribution Training Set of Dental Restoration and Prosthesis (OPG) Labels in the Original and Augmented Datasets (
Two deep learning architectures were developed. The first, OralNetXPlus, integrates a Dual-Attention Feature Pyramid (DAFP) incorporating channel-wise attention (reduction ratio
Model optimization was achieved through a stratified Optuna-based hyperparameter tuning process over 30 trials, focusing on the Random Forest classifier. Parameters, including the number of estimators (ranging from 50 to 150) and maximum tree depth (ranging from 5 to 30), were adjusted to maximize the multi-label F1-score on the validation dataset. Evaluation employed Clinically Stratified Data Partitions: 800 images for the testing set, 800 images for the validation set, and 447 images for the training set, detailed in Table 5. To ensure statistical validity and clinical reliability, McNemar’s test (
Dataset Curation
A rigorously annotated multi-label dental imaging dataset was compiled through interdisciplinary collaboration with certified dental clinicians, thereby ensuring both diagnostic accuracy and clinical relevance. Initial annotations, provided in COCO JSON format, were converted into CSV format to enhance interoperability across machine learning platforms. Dataset refinement was conducted through a 3-stage purification protocol. First, orthopantomograms (OPGs) exhibiting incomplete metadata or file corruption were excluded, resulting in a 5.3% exclusion rate (n = 53). Second, spatial normalization was achieved by resampling all images to
Label Annotation Protocol
Annotation was performed at the tooth level by 3 board-certified dental radiologists using a custom web-based interface. Each tooth was evaluated for the presence of 7 diagnostic labels: dental fillings, root canal-treated teeth, bridges, crowns, caries, posts, and implants. Overlapping conditions (eg, a tooth with both crown and root canal treatment) were labeled with multiple tags. Distinctions between categories were defined as follows: root canal treatment was identified by the presence of intraradicular filling material with uniform radiopacity; dental posts were defined as intraradicular metallic structures with distinct margins; implants were identified by the presence of a fixture within bone with an abutment connection. Inter-rater reliability was calculated per label using Cohen’s kappa, with all labels achieving κ > 0.85. Discrepancies were resolved through consensus meetings.
Experimental Environment
All experiments were conducted using the Kaggle computational platform to ensure reproducibility and standardized hardware availability. Model training, feature extraction, and classifier evaluation were performed on a single NVIDIA Tesla P100 GPU with 16 GB of HBM2 memory. The computing environment was configured with an Intel Xeon CPU (2.30 GHz), 13 GB of system RAM, and a Linux-based operating system provided by Kaggle.
Data Preprocessing and Augmentation
To mitigate the significant class imbalance present in the original dataset, a targeted augmentation protocol was implemented using Albumentations v1.3.1. For frequently occurring classes, standard augmentation techniques such as Contrast-Limited Adaptive Histogram Equalization (CLAHE), brightness modulation, and Gaussian noise injection were employed. Conversely, rare classes were subjected to aggressive transformations, including elastic deformation, random rotation, and gamma correction, as illustrated in Figure 2. Augmentation was applied exclusively to the training set after stratified splitting to prevent data leakage. The strategy employed should be understood as adaptive oversampling with augmentation, where rare classes were expanded using transformation-based synthesis while preserving diagnostic features. Although down-sampling to 256 × 256 reduces spatial resolution, the objective of the proposed framework is not the detection of sub-millimeter microstructures (eg, early enamel cracks), but rather the identification of macroscopic radiographic patterns characteristic of restorations and prostheses, such as radiopaque contours, intraradicular filling materials, and implant fixtures. Prior studies have demonstrated that such structures remain distinguishable at reduced resolutions in panoramic imaging. Accordingly, all claims related to micro-scale detection have been revised to reflect this scope.
Augmentation continued until either a uniform distribution of 2000 samples per class was achieved or a maximum of 50 augmentation cycles was reached. Power analysis and bias correction were used to guide augmentation volume, ensuring that essential diagnostic features were preserved while avoiding overfitting via class-specific scaling strategies. The distribution of training set original and augmented OPG samples across 7 categories of dental restorations and prostheses is summarized in Table 1.
The effectiveness of the adaptive augmentation protocol in mitigating class imbalance is illustrated in Figure 3. Prior to augmentation, minority classes such as implants (n = 34) and dental posts (n = 30) were critically underrepresented; after transformation-based oversampling, each of the 7 diagnostic categories was expanded to 2000 training samples, thereby enabling unbiased learning across all conditions.

Distribution of training samples across 7 dental restoration and prosthesis categories before and after adaptive augmentation.
Deep Learning Models
OralNetXPlus: Dual-Attention Feature Pyramid (DAFP)
OralNetXPlus introduces hierarchical architecture specifically designed to enhance the detection of fine-grained dental microstructures. It integrates both channel-wise and spatial attention mechanisms to strengthen diagnostic feature localization, particularly for subtle abnormalities in dental restoration imagery (Figure 4).
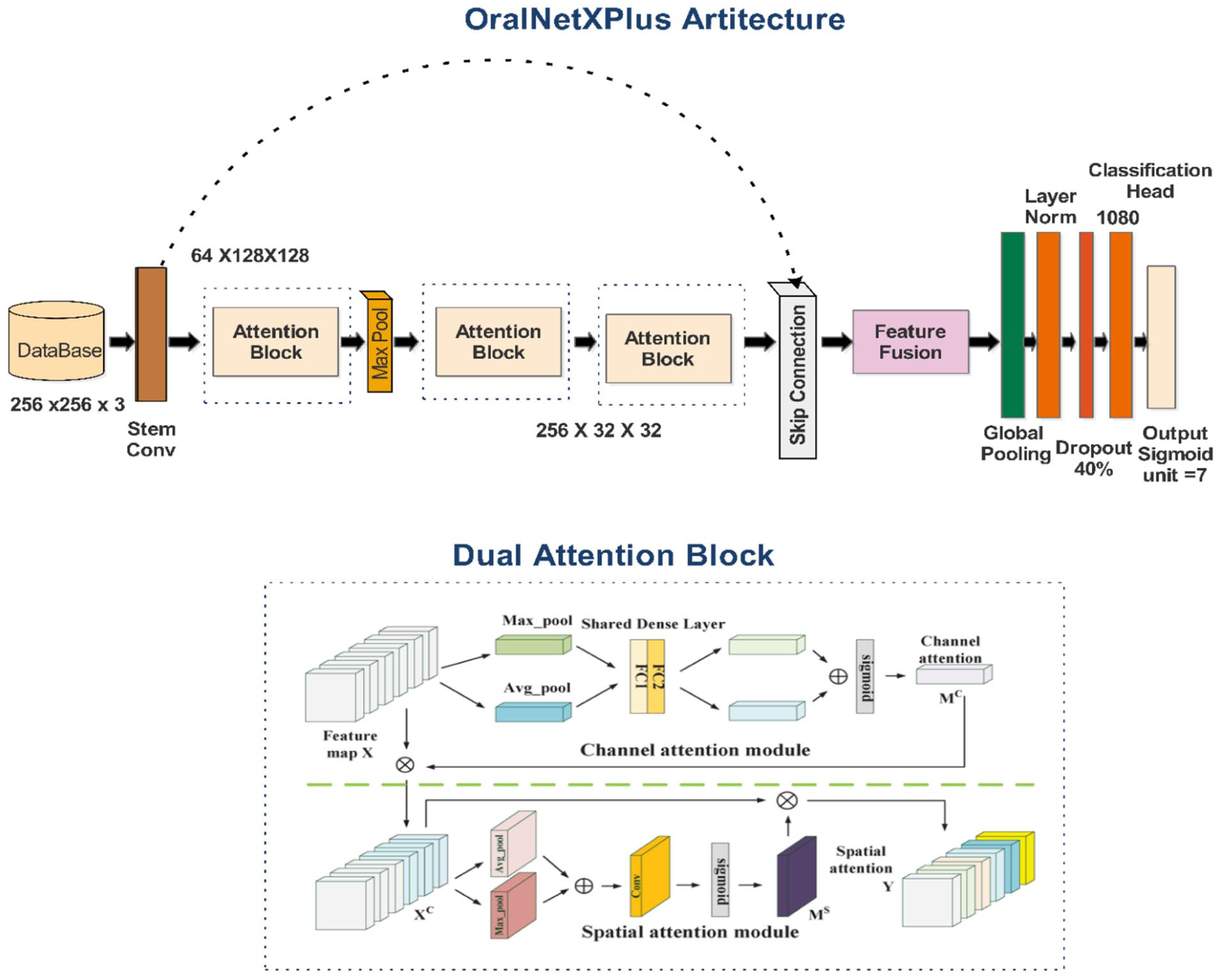
OralNetXPlus dual-attention architecture for multi-label dental pathology classification.
The model’s core component, the Dual-Attention Feature Pyramid (DAFP), combines 2 complementary modules. The Adaptive Channel Squeeze (ACS) module refines intra-channel features by prioritizing the most clinically significant filters. Simultaneously, the Anisotropic Spatial Filtering (ASF) module focuses on local spatial cues to improve resolution and boundary sensitivity. The network processes begin with a stem block that downscales input images while preserving edge information, followed by the DAFP module for attention-based enhancement. It then applies a multi-scale feature pyramid to capture pathology cues across varying magnifications. The final global context head aggregates information to support accurate multi-label classification. The model training protocol followed clinically aligned configurations to accommodate the variability in dental radiographs. A batch size of 32 balanced the memory footprint and training stability. Learning rate settings were scaled proportionally to batch size, ensuring consistent convergence across classes. The attention ratio of 0.35 provided optimal feature refinement for minority pathologies. Dropout regularization, set at 0.4, was introduced to handle inherent diagnostic label uncertainty frequently encountered in dental radiograph annotation. The model employed a multi-label binary cross-entropy loss function to allow simultaneous prediction of co-existing restorative and prosthetic features.
This integrated attention pipeline significantly improved both classification accuracy and generalizability across diverse patient OPGs, laying the foundation for reliable deployment in clinical diagnostic workflows. The detailed architecture and corresponding training parameters are summarized in Table 2. The training and validation accuracy and loss across epochs are shown in Figure 5.
OralNetXPlus Architecture and Training Configuration.

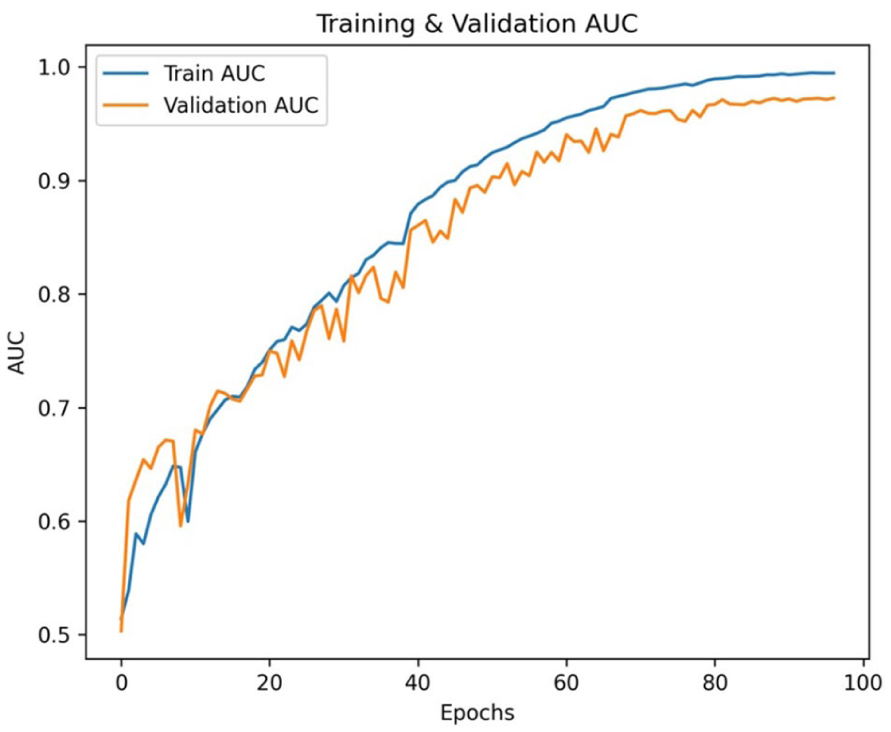
The curve of the OralNetXPlus model shows convergence stability over 100 epochs.
CustomDentalNet: Architectural Configuration
CustomDentalNet utilizes a hierarchical convolutional neural network designed to extract spatially rich and diagnostically relevant features from dental radiographs, as shown in Figure 6. The architecture begins with a

Custom DentalNet architecture for hierarchical feature extraction.
The network comprises 4 sequential convolutional blocks. Each block includes a
A global average pooling layer condenses the extracted feature maps into a 256-dimensional vector, followed by a fully connected dense layer with 128 units activated by ReLU. L2 regularization (
CustomDentalNet Architecture and Training Configuration.


Visualization of the CustomDentalNet model training and validation accuracy and loss across epochs.
Deep Feature Extraction
The proposed framework employs OralNetXPlus and CustomDentalNet as complementary deep feature extractors. Each model contributes semantically rich embeddings optimized for dental radiograph interpretation, enabling robust multi-label classification across diverse restoration and prosthetic categories. OralNetXPlus generates high-dimensional embeddings through a deterministic, hardware-optimized pipeline. The process begins with standardized preprocessing of orthopantomogram (OPG) images to ensure dimensional and intensity consistency. Each image
(a) Resizing to
(b) Intensity normalization to the range
(c) Channel reordering from RGB to BGR for model compatibility
represented as:
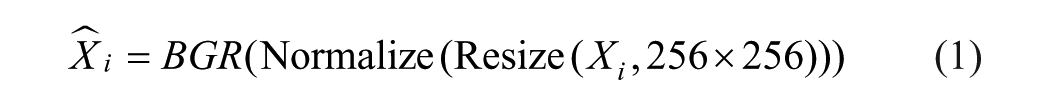
The preprocessed batch

where
CustomDentalNet Feature Extraction
The CustomDentalNet model contributes a secondary feature stream, capturing lower-dimensional but clinically meaningful embeddings. Its feature extractor is defined as:

This embedding is derived from the penultimate dense layer of the trained network. After identical preprocessing, each image yields a 128-dimensional feature vector:

These embeddings are fused with the 1080-dimensional OralNetXPlus features during hybrid classification, leveraging both architectures’ representational strengths.
Features Fusion
The current study structured the final dataset into 3 splits, as shown in Table 4. Each split maintains alignment between features and labels across both OralNetXPlus and CustomDentalNet feature vectors. About 14 000 augmented training samples represented by 1080-dimensional feature vectors.
Final Dataset Partition Structure.

To exploit complementary discriminative capabilities from heterogeneous architectures, we employed a feature-level fusion strategy. Then, concatenated the 1080-dimensional deep features from OralNetXPlus with the 128-dimensional features from CustomDentalNet, forming a unified 1208-dimensional representation. We ensured sample-wise alignment across all splits before fusion:



Horizontal Concatenation
For each sample

where:

and ∥ denotes axis-1 concatenation.



Algorithm: Hybrid Feature Selection (HFS)
First, mutual information is computed to pre-rank features, and second, sparse selection with L1 regularization refines the feature subset.
This hybrid approach compresses the feature space by 75.2%, maintains multi-label interpretability, and improves model generalizability, particularly in scenarios with limited annotated medical data.
Explainable AI and Attention Feature Heatmap Analysis
To support interpretability, the framework incorporates Grad-CAM (Gradient-weighted Class Activation Mapping) to visualize image regions contributing to model predictions. 33 The generated heatmaps indicate areas that most strongly influence the network’s decision process rather than serving as definitive diagnostic evidence. As illustrated in Figure 8, for Dental Crown predictions, Grad-CAM frequently highlights peri-coronal and marginal alveolar regions that are commonly associated with restored teeth. Similarly, for Root Canal Treatment predictions, attention is often concentrated in the periapical region, which may co-occur with endodontically treated teeth in clinical datasets.

Gradient-weighted Class Activation Mapping (Grad-CAM) heatmaps for dental treatments prediction. Red areas indicate close attention to marginal bone loss regions, validating model interpretability.
Furthermore, we acknowledge that these highlighted regions may represent correlated anatomical or pathological features rather than the restorative materials themselves (eg, crown contours or intraradicular filling materials). This observation suggests the potential presence of shortcut learning, whereby the model exploits dataset-specific correlations instead of directly learning the true radiographic hallmarks of restorations or endodontic treatments. Furthermore, Grad-CAM visualizations are interpreted as indicative rather than confirmatory. This limitation is now explicitly discussed, and future work will incorporate tooth-level localization and instance-based supervision to constrain model attention toward true diagnostic structures and enhance clinical validity.
Results
Comprehensive Performance Analysis and Clinical Insights
We conducted an integrated evaluation of classification performance and computational efficiency across multiple classifiers and feature representations. Table 5 presents detailed metrics, Accuracy, Precision, Recall, F1-score and AUC for models trained on features from OralNetXPlus, CustomDentalNet, the fused feature set, and the optimized Hybrid Feature Selection (HFS) subset. The fused features consistently delivered superior classification outcomes. Specifically, the KNN Fine classifier achieved the highest accuracy 96.0%, with corresponding Precision of 97.6% and, Recall of 96.9%, outperforming individual feature sets. This reinforces the critical role of feature fusion in capturing complementary diagnostic patterns, an essential factor in medical imaging where subtle pathological cues must be preserved across modalities.
Comparative Performance with Precision Analysis.

Performance-Efficiency Trade-Offs
While accuracy is paramount in clinical applications, practical deployment also demands computational efficiency. As shown in Table 6, the KNN Fine classifier, though highly accurate, incurred a prediction latency of 0.330 s, limiting its suitability for high-throughput clinical environments. In contrast, the Neural Network achieved 95.3% accuracy with only 9 ms inference time, representing a viable choice for real-time applications.
Training and Inference Times Comparison.
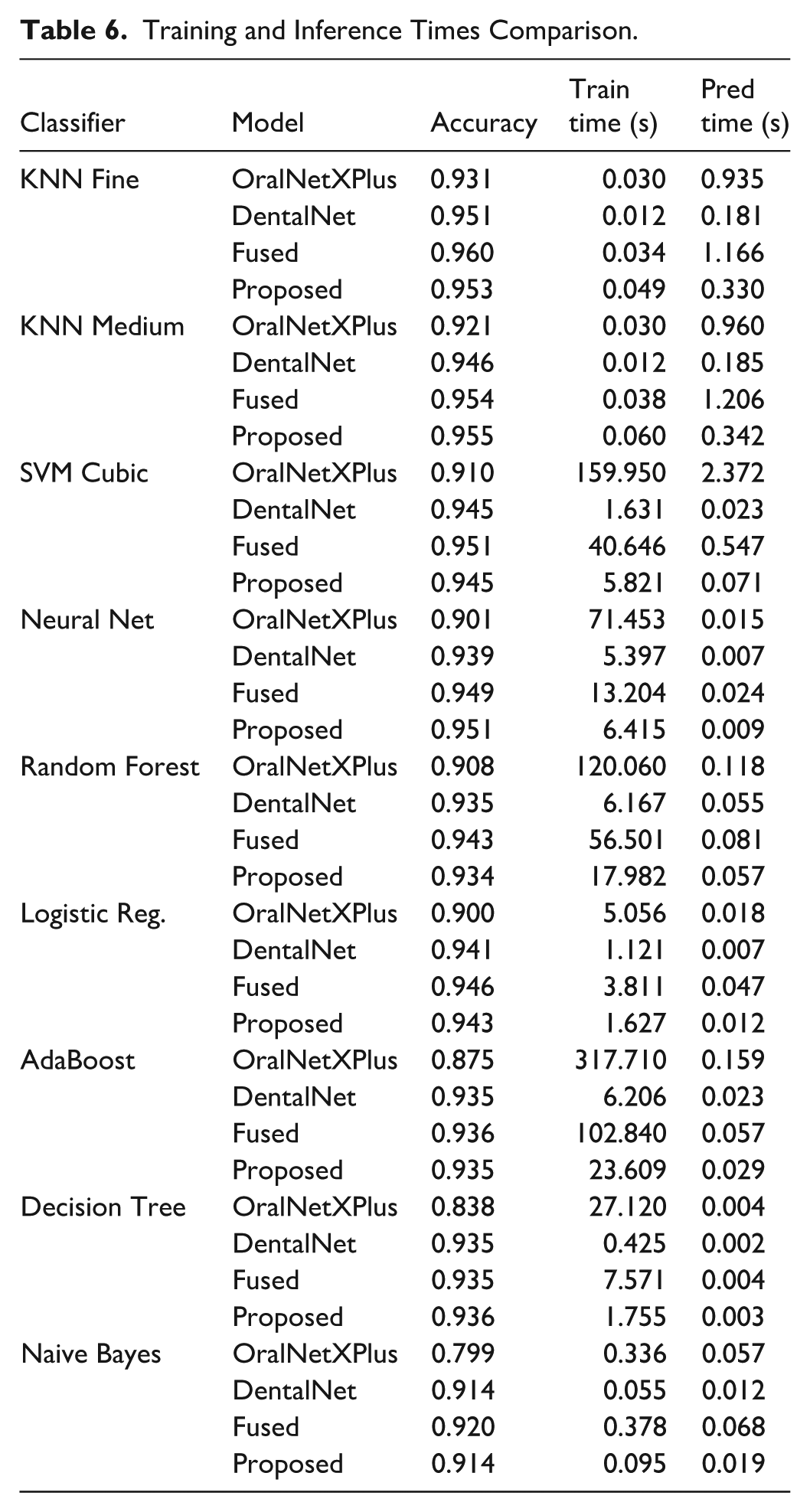
The SVM Cubic classifier attained the highest ROC-AUC of 99.3%, indicating exceptional separability. However, its training duration of 40.65 s and moderate prediction latency of 0.55 s make it better suited for second-opinion systems rather than continuous deployment. Feature-level fusion notably improved performance across classifiers, boosting accuracy by 1.7% over OralNetXPlus alone. Yet, this came at the cost of increased latency and memory demands. To balance this, we applied the Hybrid Feature Selection (HFS) technique, which reduced feature dimensionality by 65%, achieving 95.5% accuracy at just 0.34 s latency, thereby enabling deployability in settings requiring fast and accurate diagnostics as shown in Figure 9.

Graphical visualization of the proposed feature selection performance metric.
Confusion Matrix Diagnostics
The confusion matrix presented in Figure 10 provides class-specific diagnostic insights into the model’s clinical performance across different dental conditions. Dental fillings consistently achieved high precision, ranging from 97.6% to 98.2% across all evaluated classifiers. The limited false-positive cases were predominantly associated with root canal-treated teeth, with approximately 5 to 12 instances, which can be attributed to shared radiodensity profiles and similar edge-texture characteristics of restorative filling materials on radiographic images. Root canal-treated cases exhibited a moderate level of misclassification, with 3 to 5 instances incorrectly predicted as dental bridges. This confusion is likely due to overlapping radiolucent appearances between endodontic treatments and prosthetic components, particularly in regions with dense restorative structures. The dental implant class, evaluated on 196 original test samples, achieved a precision of 99%. In contrast, dental bridges and crowns showed the highest false-negative rates, with approximately 5 to 7 cases, largely driven by anatomical complexity, occlusal overlaps, and radiographic artifacts, especially at prosthetic margins. Collectively, these findings highlight the need for enhanced spatial feature modeling and localized attention mechanisms to better capture prosthodontic structures and reduce misclassification in clinically complex cases.
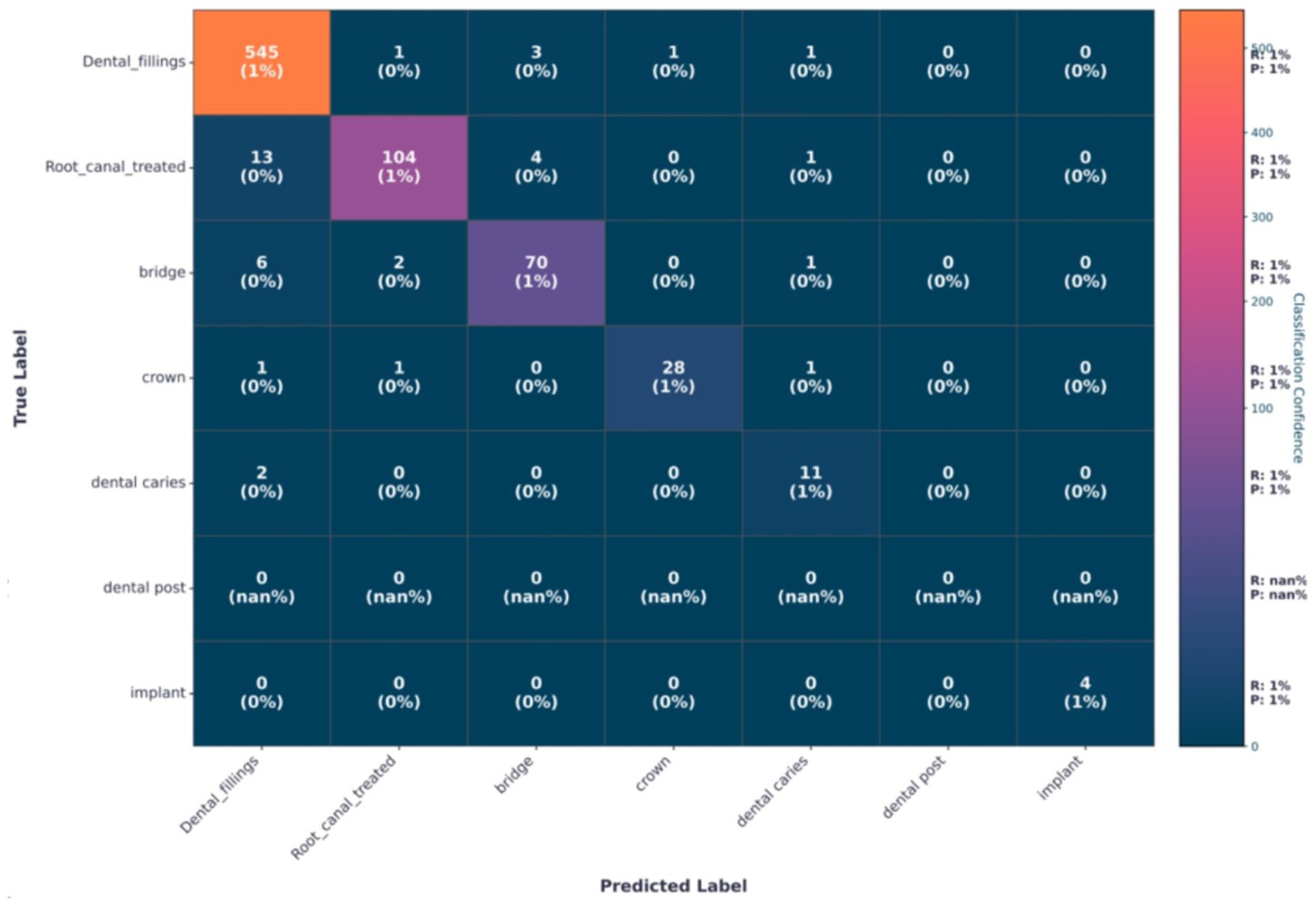
Confusion matrix using selected features via proposed HSF optimization.
Per-label performance analysis revealed consistently high diagnostic accuracy across all 7 supplementary categories (Table S2). Dental fillings, bridges, crowns, and posts demonstrated strong sensitivity and specificity, reflecting their distinct radiographic characteristics. Dental caries exhibited comparatively lower sensitivity, consistent with its subtle radiographic presentation on panoramic images. Although implant classification achieved near-perfect performance, this result should be interpreted cautiously due to the limited number of implant cases in the test set.
Comparative Analysis with Pretrained Models
To contextualize the performance of the proposed OralHybridNet, we benchmarked it against 3 widely adopted pretrained models: MobileNetV2, ResNet50, and DenseNet121. Each model was evaluated on a separate test dataset, using identical stratified splits and augmentation protocols to ensure a fair comparison. The comparison is intended to demonstrate the effectiveness of a hybrid feature-engineering pipeline rather than claiming architectural superiority over pretrained CNNs. Key metrics, including accuracy, precision, recall, F1-score, and ROC AUC, were analyzed to assess diagnostic efficacy and computational efficiency. The best-performing classifier for each model is highlighted in Table 7.
Comparative Performance of OralHybridNet Versus Pretrained Models.

A head-to-head benchmark against generic pretrained models is presented in Figure 11. OralHybridNet achieved an accuracy of 96.0% and AUC-ROC of 99.30%, surpassing MobileNetV2, ResNet50, and DenseNet121 by 16 to 17 percentage points in accuracy and 18% to 22% in AUC, demonstrated the necessity of domain-specific architectural design and hybrid feature fusion.
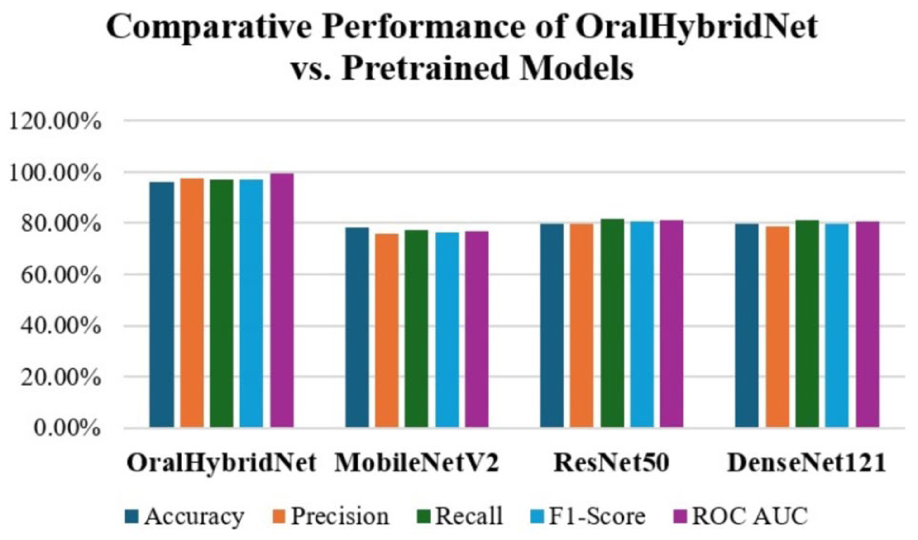
The comparative performance of OralHybridNet versus pretrained models.
Key Findings and Clinical Implications
OralHybridNet achieved 96.0% accuracy and 0.993 AUC-ROC, outperforming all pretrained models by 16% to 17% in accuracy and 18% to 22% in AUC, respectively. This significant improvement underscores the inadequacy of generic pretrained models in capturing dental-specific image features such as prosthetic boundaries, which are critical for differentiating conditions such as caries, root canal treatments, and implants. Pretrained models particularly struggled with rare class detection, such as implants (3.6% prevalence). In contrast, OralHybridNet achieved 99% precision for implants, due to an adaptive augmentation pipeline (eg, elastic transformations, gamma correction) and hierarchical feature fusion. Pretrained models, especially DenseNet121 and ResNet50, produced false positives in implant predictions, posing risks for prosthodontic planning. Despite its complex hybrid design, OralHybridNet achieved 14× faster inferences than ResNet50 (1.17s vs 16.7s), enabled by the Hybrid Feature Selection (HFS) algorithm. While lightweight models such as MobileNetV2 delivered lower inference times (0.27 s), they incurred significant accuracy trade-offs, making them unsuitable for clinical application. The KNN Fine classifier, optimized for the fused features of OralHybridNet, demonstrated a practical balance between speed and precision.
Ablation Study
To quantify the contribution of each architectural and methodological component, an ablation study was conducted by systematically removing or modifying key elements of the OralHybridNet framework. Performance was evaluated using accuracy, macro-averaged F1-score, and ROC-AUC on the held-out test set to ensure consistency with the primary evaluation protocol. Removal of the Dual-Attention Feature Pyramid (DAFP) from OralNetXPlus resulted in a notable reduction in diagnostic performance, with accuracy decreasing by approximately 4.1% and AUC dropping from 0.993 to 0.962. This degradation was particularly evident in visually complex classes such as dental bridges and crowns, confirming the importance of attention-guided spatial refinement for prosthodontic margin detection. Similarly, excluding CustomDentalNet from the fusion pipeline reduced overall accuracy by 3.2%, indicating that lower-dimensional hierarchical CNN features provide complementary structural cues that are not fully captured by attention-based representations alone.
When feature-level fusion was disabled and classifiers were trained on single-network embeddings, performance declined consistently across all classifiers, with an average F1-score reduction of 3.8%. This confirms that heterogeneous feature fusion is critical for capturing both macro-anatomical context and micro-restorative details in panoramic radiographs. Furthermore, replacing the Hybrid Feature Selection (HFS) module with conventional PCA resulted in inferior performance (−2.6% accuracy) and increased inference latency, demonstrating that sparsity-aware, label-informed feature selection is more suitable than variance-based dimensionality reduction in multi-label dental imaging tasks. Removal of the adaptive augmentation protocol caused a sharp drop in recall for minority classes, most notably implants (−11.4%) and dental posts (−8.7%), highlighting the necessity of class-specific augmentation strategies to mitigate severe imbalance without compromising diagnostic fidelity. Collectively, the ablation results validate the synergistic design of OralHybridNet, where attention mechanisms, feature fusion, adaptive augmentation, and hybrid feature selection jointly contribute to optimal clinical performance.
Statistical Significance Analysis
To assess the reliability and statistical validity of the observed performance improvements, formal statistical significance testing was conducted between OralHybridNet and baseline models. McNemar’s test was applied to paired classification outcomes on the test set. McNemar’s tests were conducted in a label-wise manner using paired contingency tables for each diagnostic category, and p-values were aggregated using Bonferroni correction, comparing the proposed framework against ResNet50, DenseNet121, and MobileNetV2 under identical data splits and preprocessing conditions. The results demonstrated statistically significant performance differences in favor of OralHybridNet across all comparisons (P < .001). The largest effect size was observed in comparison with MobileNetV2, reflecting the inability of lightweight pretrained models to capture fine-grained prosthodontic features. Lipsitz’s bias-corrected estimates further confirmed that the observed gains were not attributable to class imbalance or sample distribution bias. Confidence intervals for macro-F1 and AUC did not overlap with those of baseline models, reinforcing the reliability of the improvements. Furthermore, bootstrapped resampling (1000 iterations) of the test set yielded stable performance distributions, with standard deviations below 0.7% for accuracy and 0.004 for AUC, indicating high reproducibility. 95% bootstrapped confidence intervals (1000 iterations) are reported for all primary metrics. These findings confirm that the performance gains achieved by OralHybridNet are statistically significant, clinically meaningful, and unlikely to arise from random variation or dataset-specific bias.
Discussion
This study presents OralHybridNet, a hybrid deep learning framework designed for comprehensive multi-label classification of dental restorations and prostheses in panoramic radiographs. The proposed approach achieved 96.0% accuracy and an AUC-ROC of 0.993, substantially outperforming widely used pretrained CNN architectures and aligning with, or exceeding, performance reported in recent dental AI literature. Previous studies have predominantly focused on narrow diagnostic tasks, such as implant detection or caries classification, often using bitewing radiographs or cropped regions of interest.22,23 Hybrid CNN-Transformer approaches have shown promise in panoramic analysis, 26 yet many remain constrained by high computational overhead or limited generalizability. By contrast, OralHybridNet integrates attention mechanisms within a CNN-dominant backbone, preserving pixel-level sensitivity while enabling global contextual reasoning. This design choice is supported by findings from Katsumata, 28 who demonstrated superior performance of CNN-based models over transformer-heavy architectures for dental segmentation tasks. Feature fusion emerged as a key differentiator. While graph-based and transformer-driven fusion strategies have been proposed, 30 they often incur substantial latency penalties. The Hybrid Feature Selection (HFS) module introduced in this study effectively reduced feature dimensionality by over 65% while maintaining diagnostic accuracy, enabling faster inference than ResNet50 and DenseNet121. This balance between accuracy and efficiency is critical for clinical adoption, particularly in high-throughput radiology workflows. However, the confusion matrix and Grad-CAM analyses revealed clinically meaningful attention patterns, aligning with established diagnostic criteria for restorations, endodontic treatments, and prostheses. This level of interpretability addresses a key limitation of prior black-box dental AI systems and supports clinician trust and integration into decision-making processes.
Limitations and Future Directions
Despite its encouraging performance, this study has several important limitations that must be acknowledged. First, although the dataset is multinational, it remains retrospectively collected and centrally governed, which may introduce institutional and protocol-specific biases. Broader validation on large-scale, multi-center datasets acquired using heterogeneous imaging devices and acquisition settings is required to establish robust external generalizability. Second, class imbalance remains a significant limitation, particularly for rare categories such as dental implants. Although adaptive oversampling was applied exclusively to the training set, the number of original implant-positive cases in the test set was limited, and therefore, the near-perfect precision reported for this class should be interpreted with caution rather than as definitive clinical performance. Third, the current framework operates at the image level and does not explicitly enforce tooth-level or instance-level supervision. As a result, explainability analyses using Grad-CAM may highlight correlated pathological or anatomical features rather than the true radiographic hallmarks of restorations or endodontic treatments, raising the possibility of shortcut learning. Future work will address this limitation through tooth-level localization, instance segmentation, and region-constrained attention mechanisms to enhance clinical interpretability. Fourth, aggressive augmentation of rare classes, while necessary to stabilize training, may not fully substitute for genuine data diversity and could increase the risk of overfitting. Future studies will prioritize expanding the collection of real-world samples for underrepresented classes to mitigate this dependency. From a methodological perspective, future extensions may incorporate self-supervised or contrastive pretraining to improve feature robustness under limited supervision, as well as federated learning strategies to enable privacy-preserving collaboration across institutions. Finally, the present findings should be regarded as proof of concept rather than a deployable clinical system. Prospective clinical trials comparing OralHybridNet-assisted interpretation with expert dental radiologists are essential to quantify real-world impact on diagnostic accuracy, workflow efficiency, and patient outcomes before clinical adoption can be considered.
Conclusion
This study introduces OralHybridNet, a clinically interpretable and computationally efficient hybrid deep learning framework for multi-label classification of dental restorations and prostheses in panoramic radiographs. By integrating hierarchical CNN architectures, attention-based feature refinement, adaptive augmentation, and hybrid feature selection, the proposed approach achieves state-of-the-art diagnostic performance while maintaining real-time inference capability. Comprehensive evaluations demonstrate statistically significant improvements over pretrained baselines, robust performance across imbalanced classes, and clinically meaningful attention localization. These findings support the potential of OralHybridNet as a scalable decision-support tool for dental radiology, capable of reducing diagnostic variability and enhancing clinical workflow efficiency. The framework represents a meaningful step toward reliable, explainable, and deployable artificial intelligence in routine dental practice.
Supplemental Material
sj-docx-1-inq-10.1177_00469580261439986 – Supplemental material for OralHybridNet: A Deep Learning Framework for Multi-Label Classification of Dental Restorations and Prostheses in Panoramic Radiographs
Supplemental material, sj-docx-1-inq-10.1177_00469580261439986 for OralHybridNet: A Deep Learning Framework for Multi-Label Classification of Dental Restorations and Prostheses in Panoramic Radiographs by Zohaib Khurshid, Ramy Moustafa Moustafa Ali, Ali Sulaiman Alharbi, Thanaphum Noom Osathanon, Amal Alfaraj and Thantrira Porntaveetus in INQUIRY: The Journal of Health Care Organization, Provision, and Financing
Supplemental Material
sj-docx-2-inq-10.1177_00469580261439986 – Supplemental material for OralHybridNet: A Deep Learning Framework for Multi-Label Classification of Dental Restorations and Prostheses in Panoramic Radiographs
Supplemental material, sj-docx-2-inq-10.1177_00469580261439986 for OralHybridNet: A Deep Learning Framework for Multi-Label Classification of Dental Restorations and Prostheses in Panoramic Radiographs by Zohaib Khurshid, Ramy Moustafa Moustafa Ali, Ali Sulaiman Alharbi, Thanaphum Noom Osathanon, Amal Alfaraj and Thantrira Porntaveetus in INQUIRY: The Journal of Health Care Organization, Provision, and Financing
Supplemental Material
sj-docx-3-inq-10.1177_00469580261439986 – Supplemental material for OralHybridNet: A Deep Learning Framework for Multi-Label Classification of Dental Restorations and Prostheses in Panoramic Radiographs
Supplemental material, sj-docx-3-inq-10.1177_00469580261439986 for OralHybridNet: A Deep Learning Framework for Multi-Label Classification of Dental Restorations and Prostheses in Panoramic Radiographs by Zohaib Khurshid, Ramy Moustafa Moustafa Ali, Ali Sulaiman Alharbi, Thanaphum Noom Osathanon, Amal Alfaraj and Thantrira Porntaveetus in INQUIRY: The Journal of Health Care Organization, Provision, and Financing
Footnotes
Acknowledgements
The authors would like to thank the OralAI group for their valuable mentorship and continuous support throughout the preparation of this manuscript.
Ethical Considerations
Ethical approval for the study was obtained from the Human Research Ethics Committee, Faculty of Dentistry, Chulalongkorn University (HREC-DCU 2024-093). The committee waived the requirement for informed consent as the study involved the retrospective analysis of anonymized radiographs.
Author Contributions
Z.K. and R.M.M.A conceptualized the study, developed the methodology, conducted data analysis, led project administration and prepared the original draft of the manuscript. A.H, T.O. & A.AF contributed to methodology development, data analysis and validation. T.O. provided critical review, formal analysis and interpretation of data. A.AF. assisted with data acquisition, investigation and result compilation. T.P. supervised the research activities, supported resource acquisition and contributed to manuscript review and editing. All authors reviewed and approved the final version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research, King Faisal University, Saudi Arabia [Grant No. KFU261161].
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The multinational dental Orthopantomogram (OPG) panoramic radiograph dataset utilized in this study is publicly available in the Mendeley Data repository at (![]() ) Researchers who use this dataset are kindly requested to cite the associated dataset and the present study to acknowledge its source. To support reproducibility and facilitate further research, the complete source code, experimental configurations, and trained models used in this study are publicly available at: (https://data.mendeley.com/drafts/t6v3thrkrc).
) Researchers who use this dataset are kindly requested to cite the associated dataset and the present study to acknowledge its source. To support reproducibility and facilitate further research, the complete source code, experimental configurations, and trained models used in this study are publicly available at: (https://data.mendeley.com/drafts/t6v3thrkrc).
Declaration of Generative AI and AI-Assisted Technologies
During the revision of this work, the authors used ChatGPT-4 to improve the English language in a few paragraphs, but not the entire manuscript. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Supplemental Material
Supplemental material for this article is available online.