
Abstract
ML-based mental disorder prediction plays an increasingly important role in early screening, clinical decision support, and personalized mental healthcare. However, reliable multi-class classification remains challenging due to high dimensionality, class imbalance, and subtle psychological features. This study describes an interpretable, RAM-based WiSARD classifier for the multi-disorder mental health prediction problem and compares its performance to established models. A retrospective experimental study was carried out in the year 2024 using publicly available mental-health diagnostic data from the Kaggle Mental Disorders Dataset. The dataset consisted of 637 records and 29 symptom-based features representing disorders such as Major Depressive Disorder, Anxiety, PTSD, OCD, ADHD, Bipolar Disorder, and others. Records with missing values, incomplete diagnostic labels, or duplicated entries were excluded. Thus, 637 complete cases were selected for analysis. No clinical identifiers were involved, and hence, ethical clearance was not required. In the present study, WiSARD was tested using a 10-fold stratified cross-validation design against Multilayer Perceptron, Naïve Bayes, DTNB, IB1, and A1DE. The performance was computed using precision, recall, F-measure, accuracy, MCC, MAE, and KS. The study was geographically conducted in Pakistan as part of computational healthcare research. WiSARD classifier achieved the best overall performance with an overall accuracy of 98.27%, F-measure of 0.983, MCC of 0.982, and KS of 0.981, outperforming all baseline models under the same evaluation conditions. Analysis of ROC-AUC, TPR, TNR, and error distributions further showed that WiSARD was more tolerant of misclassifications associated with minority disorder classes, thereby addressing the imbalance present in the dataset. The ablation study verified its contribution to improved reliability and interpretability through RAM-based pattern recognition. The results have shown that WiSARD is a promising, interpretable model for multi-class mental disorder prediction in data-imbalanced settings. At the same time, results are limited to a single non-clinical Kaggle dataset with self-reported observations and without formal psychiatric validation. For this reason, the findings should be interpreted as indicative rather than definitive.
Keywords
Introduction
Mental health is more than just avoiding mental disease; it also includes our emotional, psychological, and social well-being. Different mental health issues can have a significant influence on our thoughts, feelings, and interactions with others. That’s why fast and precise assessments are critical for detecting these problems. This frequently comprises self-report surveys in which people reflect on their emotions and social interactions. 1 In 2019, the World Health Organization (WHO) estimated that anxiety and depression were the most frequent mental health problems, impacting around 970 million people globally. The COVID-19 pandemic in 2020 only made matters worse, resulting in a major surge in mental health issues. The epidemic highlighted the vital need for available mental healthcare. Unfortunately, many people resort to warfare to get hold of the assistance they require, and they regularly come across discrimination, stigma, and infringement of their human rights. 2
A complete psychiatric interview is often used to diagnose mental health issues, through which healthcare specialists take a look at signs and symptoms, psychiatric history, and do physical tests. Psychological testing and other evaluation strategies can also help find mental health issues. 3 However, still, there is still an issue in the early prediction of such disorders correctly. New technologies like machine learning (ML), etc., can be better utilized to overcome the said limitations. This study focuses on how ML assists in perceiving diseases, including Anxiety, Depression, Loneliness, Stress, etc. ML is a subset of artificial intelligence (AI), that addresses demanding situations. It employs information and algorithms to duplicate human learning and improves over time. 4 In the field of mental health, ML has shown considerable promise in predicting and treating issues by studying large quantities of data to pick out patterns. Predicting mental disorders is essential for several reasons. Early detection and intervention can considerably improve effects and decrease the severity of signs, permitting individuals to receive well-timed and suitable care. ML methods can analyze tremendous quantities of information to create personalized remedy plans, enhancing the effectiveness of mental healthcare. By utilizing goal facts and better algorithms, mental health predictions can also help reduce the stigma associated with mental health issues, encouraging more people to are seeking for help. Furthermore, accurate predictions allow healthcare carriers to allocate assets more successfully, directing them to people at high risk and undoubtedly lowering average healthcare prices. Overall, early and particular exams result in better mental health effects and enhances the lifestyles of those affected.
This study focuses on proposing the WiSARD model for mental disorders, presenting the prediction in Table 1. The proposed WiSARD is compared with state-of-the-art models, including Multilayer Perceptron (MLP), Naïve Bayes (NB), Hybrid of Decision Table NB (DTNB), Instance-Based Learner (IB1), which is also known as K-nearest Neighbor, and Average One Dependency Estimator (A1DE). The performance of each model is evaluated using standard assessment measures, including precision, recall, F-measure, accuracy, Mathew’s Correlation Coefficient (MCC), mean absolute error (MAE), and KS Statistic (KP).
List and Description of Mental Disorders.

The main objective of this research is to create and assess a good, explainable, and stable ML model—based on the WiSARD architecture—for reliable prediction of mental disorders, resolving issues regarding class imbalance, transparency of the model, and prediction consistency in medical data.
This research aims to create an interpretable and high-performing machine learning model based on the WiSARD architecture for predicting mental disorders and assessing its performance against proven models like MLP, Naive Bayes, DTNB, IB1, and A1DE. The research tries to counter class imbalance issues, reliability, and transparency challenges by comparing the models on a range of performance metrics such as accuracy, recall, precision, F-measure, MCC, MAE, and KS statistics. Furthermore, it aims to examine the architectural benefits of WiSARD using an ablation study with the aim of finding a reliable, interpretable, and domain-appropriate predictive model to be used in clinical mental healthcare systems.
The major contribution of this research is the effective implementation and assessment of the WiSARD model for mental disorder prediction—a new methodology in this field that uses RAM-based memory architecture for classification. Compared to conventional models, WiSARD provides a pattern-based, transparent learning procedure that is well-suited for dealing with high-dimensional and imbalanced psychological data. The research not only shows WiSARD’s superior performance on key metrics (accuracy, MCC, KS, etc.) to other popular models such as MLP, NB, DTNB, IB1, and A1DE but also conducts an extensive ablation study that isolates and substantiates the architectural components that underlie its robustness. In addition, it grounds WiSARD as a workable and understandable counterpoint to black-box classifiers in sensitive health applications, laying the foundation for subsequent integrations of memory-based models in mental health diagnostics.
The rest of the research is structured as follows: Section 2 gives the related work, and Section 3 gives the research design and methodology. Section 4 offers a detailed discussion and analysis of the results, while Section 5 gives the conclusion and future work.
Literature Study
Mental disorder prediction with machine learning has received more interest in the past few years because of the increasing worldwide burden of mental health and the potential offered by AI to support early diagnosis and intervention. In this section, previous studies aimed at computational methods for the detection and classification of mental health disorders are summarized, including the advantages and disadvantages of models like neural networks, Bayesian classifiers, decision trees, and instance-based learners. Through critical examination of the methods, data used, and evaluation approaches adopted in these pieces of work, we identify the research gaps and ascertain the necessity of examining other, interpretable, and memory-effective models such as WiSARD.
A mental health disorder or illness can have a substantial influence on a person’s feelings, thoughts, behaviors, and interpersonal communication. 5 According to the American Psychiatric Association, these concerns can have an impact on our emotions, cognitive processes, and behaviors, and they are frequently associated with difficulties in social, professional, or familial life.6,7 Essentially, mental health issues influence how we feel, think, and interact with others around us, which has an impact on our everyday lives. Anxiety, sadness, stress, and schizophrenia are among the most prevalent instances.8,9 In Malaysia, depression is the most prevalent mental health problem, followed by worry and stress. 10
The study assessed how successfully 8 different machine learning algorithms classified various mental health disorders. The Multiclass classifier, MLP, and LAD Tree emerged as the most accurate classifiers examined. 11 The publication discusses mental health analysis in a way that varied audiences may grasp. They design the method for the prediction and diagnosis of mental healthcare. Clustering techniques had been used to discover the variety of clusters earlier than creating the models. They employed MOS to validate the generated elegance labels, which were then used to train the classifier. The experiments show that SVM, KNN, and Random Forest were carried out nearly similarly properly. Interestingly, using ensemble classifiers drastically boosted the overall performance of mental health predictions, achieving a 90% accuracy. 12 They have a look at emphasizing the effectiveness of ML in detecting and diagnosing mental disorders, along with Alzheimer’s disease, depression, and schizophrenia. ML can enhance clinical and research efficiency whilst imparting new insights into mental health and well-being.13,14 Early depression prediction is critical for sufferers to acquire effective therapy as quickly as possible.15,16
AI is playing a growing role in medicine, especially in mental health research and treatment. To fully realize AI’s promise, a varied collection of professionals must collaborate and communicate, including scientists, physicians, patients, and regulators. 17 This work employed discourse analysis to gain a better understanding of representation practices in human-centered machine learning (HCML). They examined a dataset of 55 transdisciplinary research projects by analyzing social media data to predict mental health status. Their findings suggest that different discourses throughout the dataset can create and strengthen human agency, while these discourses may also dehumanize individuals. 18
The factors influencing mental health problems come from findings in previous research papers that used correlation or regression analysis. These factors are generally grouped into 3 categories: biological factors, social environment, and socioeconomic environment. 19 Biological factors relate to the abnormal functioning of nerve cell circuits or pathways that connect different brain regions. 20 This includes genetics, infections that cause brain damage, brain defects, prenatal damage, and more. For example, low birth weight has been linked to several mental health issues, particularly schizophrenia. 19
The social surroundings cover how human beings interact with their surroundings, their tradition, and their way of existence. It includes relationships with family, friends, colleagues, and the local community. A lack of social aid and workplace discrimination are examples of social-environmental factors that can impact intellectual health. 21 Socioeconomic elements replicate someone’s financial fame. Financial difficulties are a prime contributor to mental health troubles. People facing financial struggles often revel in higher degrees of strain and tension. 22
The literature review identifies that numerous machine learning models, including MLP, NB, DT, and instance-based approaches, have been investigated for predicting mental disorders, each with unique strengths and weaknesses. Although neural networks offer strong learning abilities, they tend to be uninterpretable and must be heavily tuned. Probabilistic models such as NB are computationally inexpensive but depend on very strong assumptions, such as feature independence, that may not be present in complicated psychological data. Ensemble and hybrid models are more robust but tend to add complexity and opacity. Perhaps most importantly, existing work does not place emphasis on pattern-based memory models that can provide performance as well as interpretability. This gap highlights the newness and possible contribution of the proposed WiSARD model, which solves important issues like data imbalance, explainability, and prediction reliability in mental health usage.
Research Design and Procedure
The study’s research design is designed to systematically compare and examine the performance of various ML models to predict mental disorders based on actual diagnostic data. The study uses an experimental framework, utilizing both traditional classifiers like MLP, NB, DTNB, IB1, and A1DE as well as the new proposed WiSARD model, which offers a memory-based, pattern-recognition architecture. The process includes data preprocessing, feature extraction, training of the models, and extensive performance testing using stratified 10-fold cross-validation to achieve robustness and generalizability. Important classification measures are calculated to check every model’s predictive performance, particularly in scenarios of data imbalance typically seen in mental health databases. This section outlines the steps in methodology, dataset profile, preprocessing methods, and implementation configuration that constitute the foundation of the experimental pipeline. The general research design flow is outlined in Figure 1.

Overall research flow for mental disorder prediction.
This study employed a retrospective, experimental computational research design. The experiments were conducted during the year 2024 to 25 using a publicly available mental health dataset obtained from the Kaggle repository. All data processing, model development, training, and evaluation were performed in Saudi Arabia as part of an academic computational healthcare research initiative. Since the study exclusively utilized anonymized secondary data without any direct involvement of human participants or access to identifiable clinical records, no ethical approval was required.
Dataset Description and Understanding
The dataset used in this research is available online at the Kaggle repository as follows: the Kaggle Mental Disorders Dataset, https://www.kaggle.com/datasets/baselbakeer/mental-disorders-dataset. The dataset includes all symptoms related to different mental health disorders, including ADHD, Anxiety, ASD, Bipolar Disorder, Eating Disorders, Loneliness, MDD, OCD, PDD, Psychotic Depression, PTSD, and Sleeping Disorders. The identification of these disorders is crucial for improving the quality of life for patients affected. The dataset comprises 637 records and 29 features, including expert observations and diagnostic questions related to mental health assessment. Table 2 details all the features included in the dataset, and Figure 2 summarizes the statistical distribution of various mental health disorders represented. The dataset provides an exhaustive source for developing and testing ML models related to mental health prediction.

Statistical distribution of mental health disorders in the dataset, highlighting the prevalence of each disorder among the total records.
Comprehensive List of Features Included in the Mental Disorders Dataset, Representing Diagnostic Questions and Expert Observations Used for Mental Health Assessment.

Inclusion and exclusion criteria were applied to ensure data quality and consistency before model training. Records were included if they contained complete information for all 29 symptom-based features and a clearly defined diagnostic label corresponding to one of the mental disorder classes considered in this study. Records with missing feature values, incomplete or ambiguous diagnostic labels, duplicated entries, or inconsistent responses were excluded from the analysis. After applying these criteria, a total of 637 complete and valid records were retained for model development and evaluation.
Model Training and Performance Evaluation
Model training and performance testing are the core components of any research study to analyze the performance of the utilized technologies. We employed a 10-fold cross-validation method for model training and testing. 23 We have tested the performance of each utilized using binary criteria, where one of them is to test the accuracy and the other is to test the error rate of each model. For performance, we have employed precision, recall, F-measure, Mathew’s Correlation Coefficient (MCC), and accuracy,24 -26 whereas for error rate, we have employed mean absolute error (MAE) and KS statistics (KS).27 -29 These are common performance metrics obtained from the confusion matrix produced by the machine learning algorithm. The confusion matrix consists of 4 required components: True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN). These values are the foundation for determining several measures of evaluation, such as accuracy, precision, recall, and others. These measures can be calculated as:






In such a scenario, Po (Observed Agreement) is the ratio of cases where the predicted label perfectly aligns with the true labels. Pe (Expected Agreement by Chance) calculates how likely the agreement could be by sheer chance.
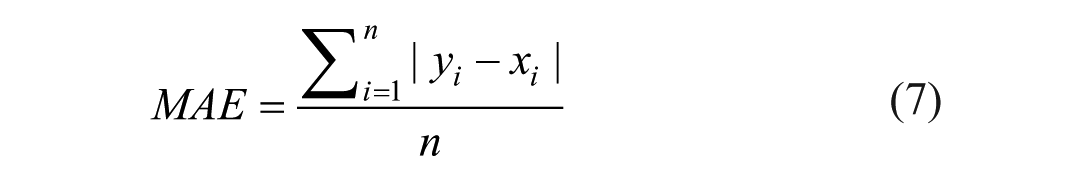
In evaluating individual predictions, N is the number of samples, xi is the true label, and yi is the predicted label. These are employed in the calculation of various performance measures.
Proposed Model
The WiSARD (Wilkie, Stonham, and Aleksander Recognition Device) is a weightless model of a neural network developed in the 1980s by Aleksander and his team. As opposed to traditional neural networks with weighted connections between neurons, WiSARD is based on RAM neurons that recognize patterns by storing binary input patterns as memory addresses. 30 The WiSARD algorithm naturally supports multi-class classification problems by virtue of its modular discriminator-based architecture. In this configuration, every class is reflected by an independent discriminator, which learns and identifies only the patterns within its respective class.31,32
In multi-class environments, the WiSARD algorithm employs a discriminator-based architecture, building one discriminator per one of the n classes in the dataset. The discriminator is built from RAM-based neurons storing binary patterns derived from training sample groups of its respective class. Training involves binarizing input vectors (if necessary), partitioning them into fixed-length sub-patterns, and mapping each sub-pattern onto a particular RAM address. Only the discriminator for the input’s actual class gets updated by triggering or incrementing its corresponding memory addresses, thus storing the pattern seen. During classification, the same preprocessing is performed, and the input is forwarded through all discriminators in parallel. Each of them calculates a match score on how many of its memory addresses match the input pattern. The class corresponding to the best-scoring discriminator is chosen as the predicted label. This architecture has the benefits of being suitable for multi-class tasks because it has natural parallelism, quick classification through direct memory lookups, and scalability—new classes can be incorporated by training more discriminators without retraining the whole system. The overall steps are presented in Algorithm 1.

The WiSARD algorithm starts with an initialization step, in which it constructs a set of discriminators, one for every class in the data set. Each discriminator holds several RAM nodes, which will be used to store patterns learned during training. During training, each sample of input is first binarized, converting real-valued features into a binary vector. Such a binary vector is then split into uniform-sized chunks, and each such chunk becomes an address to a corresponding node in the RAM. Only the discriminator’s RAMs of the class that is being predicted are modified by setting a bit in each calculated address to 1, thus memorizing the pattern. In the prediction phase, a new input gets binarized and likewise chunked. Each class discriminator then verifies how many of its stored addresses in the RAM match the input and generates a score according to the number of matching RAMs. The algorithm then predicts the most scored class as being the most similar learned pattern. If there are classes with the same score, there can be a bleaching mechanism, in which the threshold for matches is gradually raised until there is a unique class. These operations render WiSARD a quick, memory-based, and simple classification algorithm applicable for multi-class classification.
Results Analysis and Discussion
This section provides a thorough evaluation of the experimental results obtained from the implementation of 6 machine learning algorithms, MLP, NB, DTNB, IB1, A1DE, and the developed WiSARD model, tasked with mental disorder prediction. The performance is evaluated in terms of a wide range of performance measures, such as accuracy, precision, recall, F-measure, true positive rate (TPR), false positive rate (FPR), MCC, MAE, and KS. Considering the sensitive nature of mental health diagnosis and the skewed nature of such datasets, this multi-modal evaluation seeks not only to identify the model with the best classification accuracy but also to determine which model is reliable, consistent, and balanced across a diversity of predictive conditions. The outcomes are described both in quantitative terms and by critical examination of the underlying mechanisms, strengths, and weaknesses of each model.
The examination of the TPR and FPR metrics for mental disorder prediction reported in Figure 3 indicates significant information regarding detection capacity and error management balance. Remarkably, 4 of the models—WiSARD, A1DE, IB1, and DTNB—exhibit the same very low minimum FPR of 0.002, representing an equivalent and very low percentage of false alarms, which is vital in sensitive fields such as mental illness, where labeling healthy people incorrectly can be very costly. But even though they have the same FPR, they vary in terms of TPR, which mirrors their differing efficiencies in correctly identifying real cases. WiSARD is exceptional with a TPR of 0.983, meaning it identifies most actual cases compared to all models without raising false positives. A1DE and IB1 come in second with TPRs of 0.981 and 0.980, respectively, and this implies that they are very reliable but a bit less sensitive compared to WiSARD. DTNB, even though powerful, has a slightly worse TPR of 0.976, suggesting a slight compromise in sensitivity at an equally low FPR. This indicates that even when FPR is kept constant, models vary in their ability to recall—WiSARD’s higher TPR provides the latter with a critical advantage in clinical use, where failure to detect true cases can be costlier than false alarms from time to time. Conversely, MLP and NB, with their greater FPRs (0.013 and 0.004, respectively) and smaller TPRs, particularly MLP at 0.848, indicate worse balance and possible underperformance. All in all, the models with identical FPRs should not be compared on this measure only—TPR is still a determining one, and WiSARD records the best trade-off and thus is best for high-stakes, imbalanced classification problems such as mental disorder prediction.

Performance comparison of employed models for mental disorder prediction based on True Positive Rate (TPR) and False Positive Rate (FPR).
Cross-comparison of FPR and TPR in Table 3 highlights obvious differences in the predictive accuracy of the models under consideration for the prediction of mental disorders. WiSARD is the highest-performing model with the best TPR (0.983) and lowest FPR (0.002), making it highly accurate for true cases that avoid false alarms. A1DE and IB1 also perform very well, with TPRs of 0.981 and 0.980, respectively, and the same very low FPR of 0.002, making them very competitive substitutes with only slightly reduced sensitivity compared to WiSARD. DTNB, although slightly lower in sensitivity (TPR = 0.976), still has the same low FPR, indicating good overall balance and consistent classification accuracy. NB provides a simpler but efficient model, with an impressive TPR of 0.958 and FPR of 0.004, but lags behind the best models in sensitivity as well as in error control. Conversely, MLP does the poorest with the lowest TPR (0.848) and highest FPR (0.013), which indicates it might not be ideally suited to the mental health data complexity or perhaps needs extensive tuning. In general, cross-comparison underscores WiSARD’s better performance for high-risk mental disorder prediction, while A1DE, IB1, and DTNB also present viable alternatives with good trade-offs between detection performance and error reduction.
Cross-Comparison of TPR Versus FPR for Mental Disorder Prediction.

The precision, recall, and F-measure analysis of mental disorder prediction in Figure 4 demonstrates the performance strengths of each model in balancing sensitivity and accuracy. WiSARD is the highest-performing model, with the highest precision (0.985), recall (0.983), and F-measure (0.983), demonstrating not only that it captures the best cases (high recall) but that its predictions are very reliable with minimal false positives (high precision). A1DE and IB1 closely trail with essentially equivalent performance, both having a good balance with F-measures of 0.981 and 0.980, respectively, indicating their reliability at correctly classifying mental disorder cases while keeping misclassifications to a minimum. DTNB is also competitive with precision, recall, and F-measure all at or near 0.976, indicating consistent performance, although less than optimal compared to the top 3 models. NB has a slight decrease with an F-measure of 0.957, which, although still very high, represents a somewhat less equitable performance between precision (0.969) and recall (0.958). MLP falls behind by far, with the lowest recall (0.848), precision (0.857), and F-measure (0.836), suggesting it is less strong in either true case identification or prediction reliability. This critical comparison highlights the fact that while some models score close to perfection on various metrics, WiSARD’s consistently higher scores on all 3 metrics elevate it above the other models as the best and most reliable model for predicting mental disorders, particularly for applications where both high precision and sensitivity are essential.
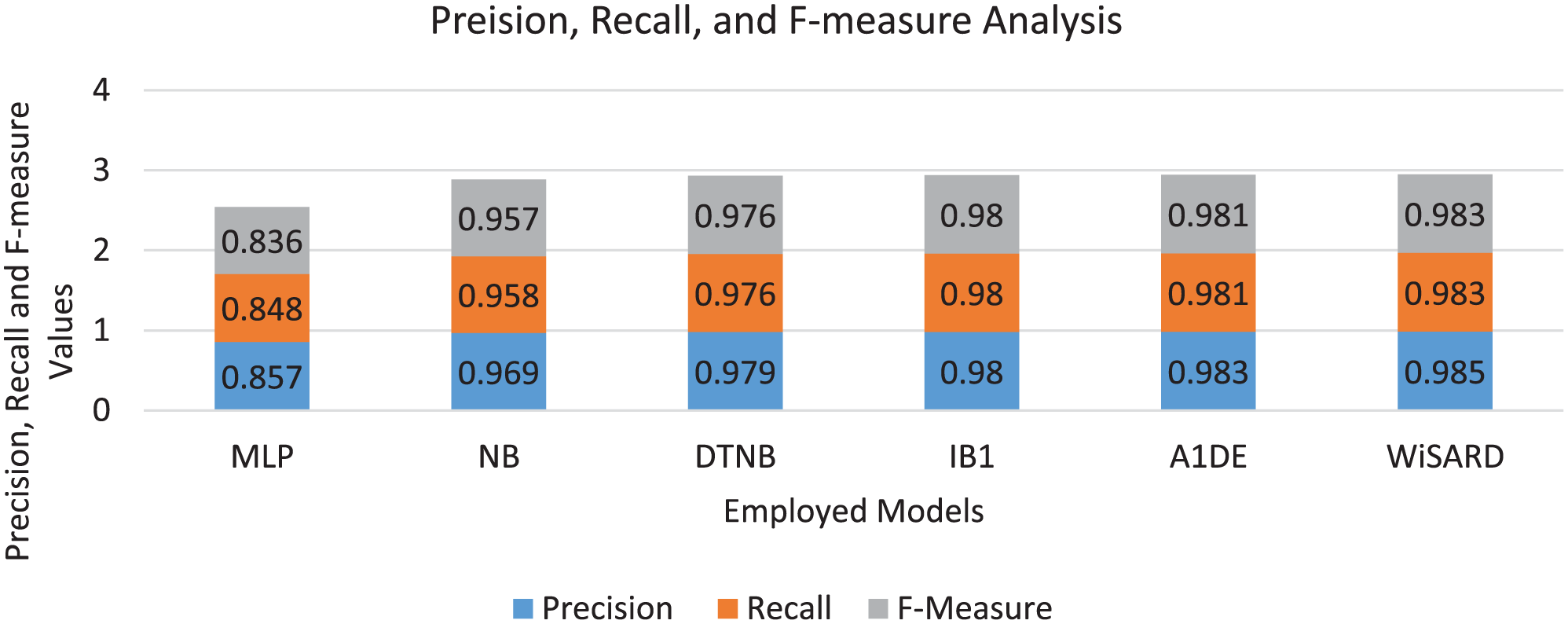
Comparative analysis of employed models for mental disorder prediction based on Precision, Recall, and F-measure, illustrating the models’ ability to balance correct identification of cases with prediction reliability.
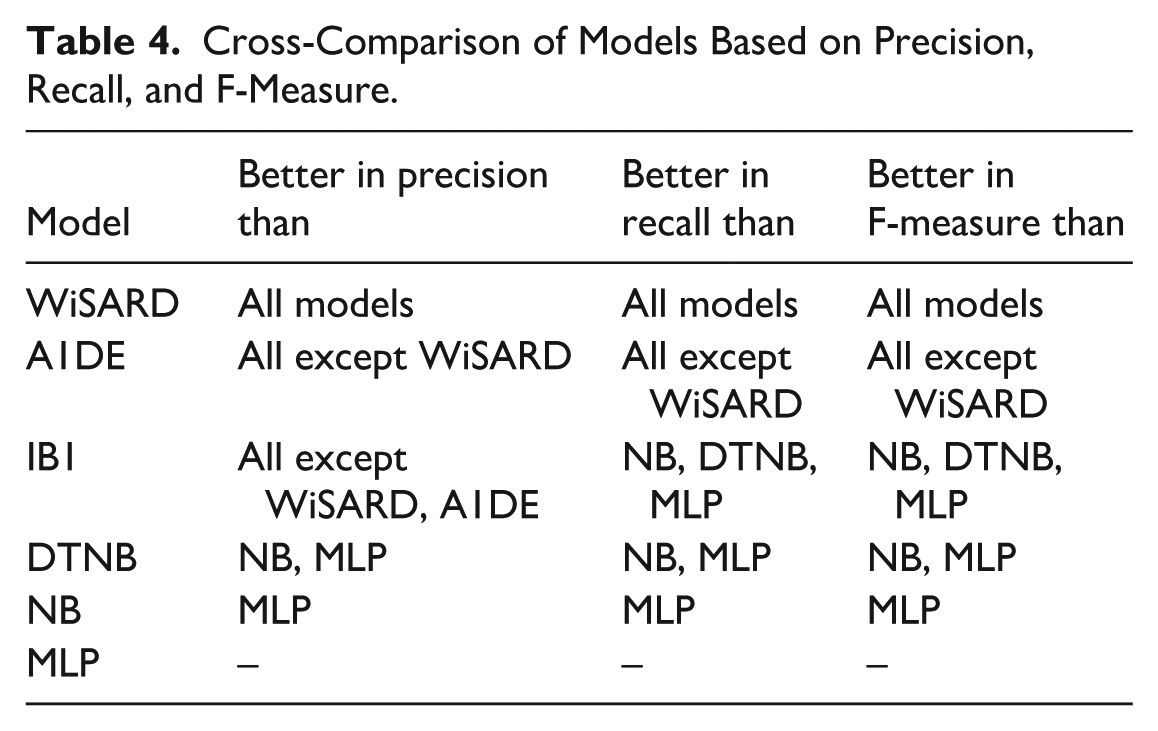
The cross-model comparison of models in terms of precision, recall, and F-measure in Table 4 establishes a hierarchy in performance for predicting mental disorders. WiSARD consistently outperforms all other models across all 3 metrics, making it the most precise, sensitive, and balanced classifier in this evaluation. Close behind, A1DE also demonstrates exceptional performance, surpassing every model except WiSARD, with only marginal differences in precision and recall. IB1 shows strong balance and reliability, outperforming traditional models like NB and MLP, particularly in F-measure due to its equal strength in both precision and recall. DTNB, a hybrid method, comes second to IB1 and A1DE, with good results and better than NB and MLP. Naive Bayes, though still very effective, is behind the hybrid and instance-based methods, with a better performance than MLP, which has the lowest values in all 3 measures. These comparisons emphasize that WiSARD, A1DE, and IB1 are the most reliable models for high-risk tasks such as the prediction of mental disorders, while MLP might need to be optimized further or might be less appropriate for the specific nature of the dataset.
Cross-Comparison of Models Based on Precision, Recall, and F-Measure.
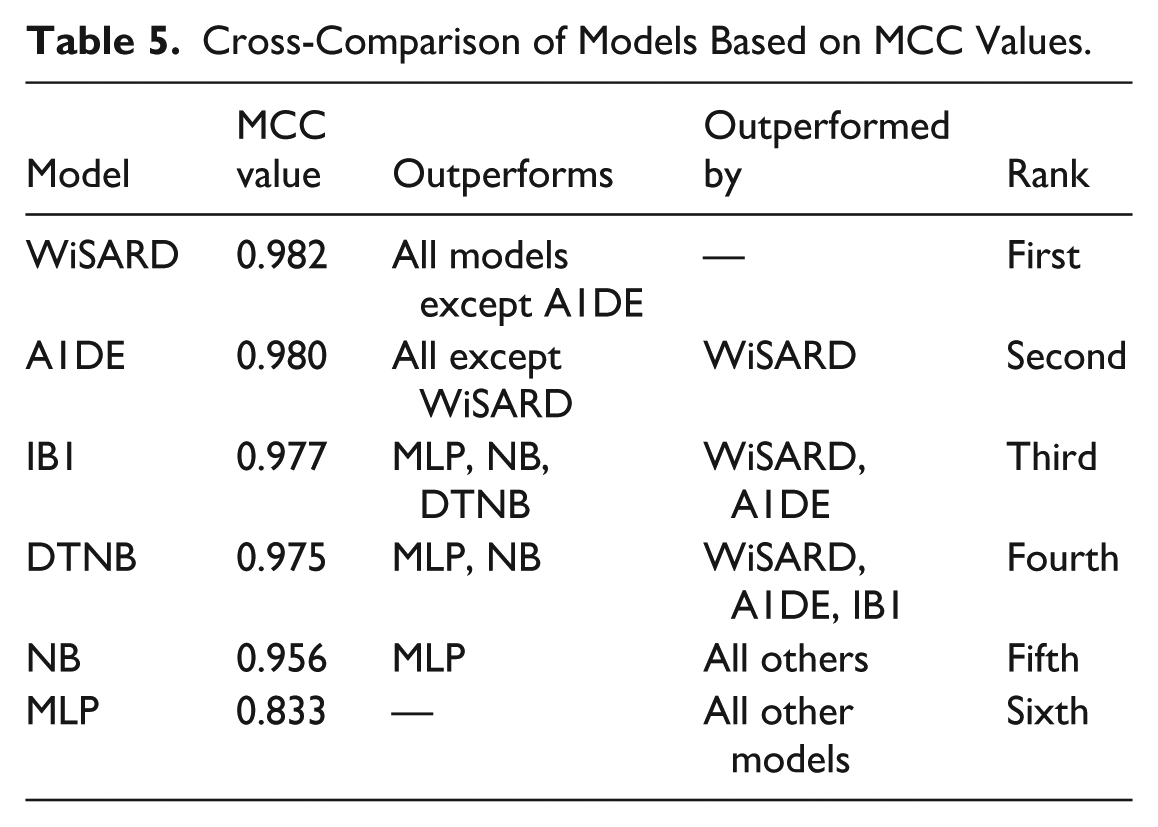
The MCC is a strong performance measure that takes into account all 4 elements of the confusion matrix—TP, FP, TN, and FN, and as such, is particularly useful for model evaluation on imbalanced data such as one often encountered in mental disorder prediction. In the results of Figure 5, WiSARD gets the maximum MCC of 0.982, demonstrating its excellent overall predictive ability and its well-balanced performance in both proper and improper classifications. A1DE (0.980) and IB1 (0.977) are next in line, showing similarly high reliability and well-balanced classification achievement. The models not only accurately predict but also have high consistency across varying outcome categories. DTNB, with MCC = 0.975, also does a good job but falls slightly short of the top 3, indicating a slightly lower but still superb balance. NB, with MCC = 0.956, performs well, although its assumption of feature independence may restrict its ability to deal with intricate relationships in mental health data. Contrarily, MLP has the lowest MCC at 0.833, reflecting weaker generalization and less accurate prediction performance, as expected from its lower recall and F-measure scores observed in previous tests. Overall, MCC analysis reinforces the fact that WiSARD offers the most reliable performance, followed narrowly by A1DE and IB1, as the best fitting for sensitive applications where both false positives and false negatives have to be minimized.

Mathew’s Correlation Coefficient (MCC) comparison of employed models for mental disorder prediction, reflecting each model’s overall classification reliability and performance balance on potentially imbalanced data.
Table 5 is ordered by the MCC of each model, a conservative measure of classification performance even with imbalance. WiSARD has achieved the best MCC, which measures the highest prediction reliability and balanced performance for true and false results. A1DE and IB1 follow close behind, also having very high reliability and beating most of the other models. DTNB and NB, though still good, are relatively less reliable. MLP has the least MCC, indicating a less accurate performance, and is surpassed by all other models in this measure.
Cross-Comparison of Models Based on MCC Values.
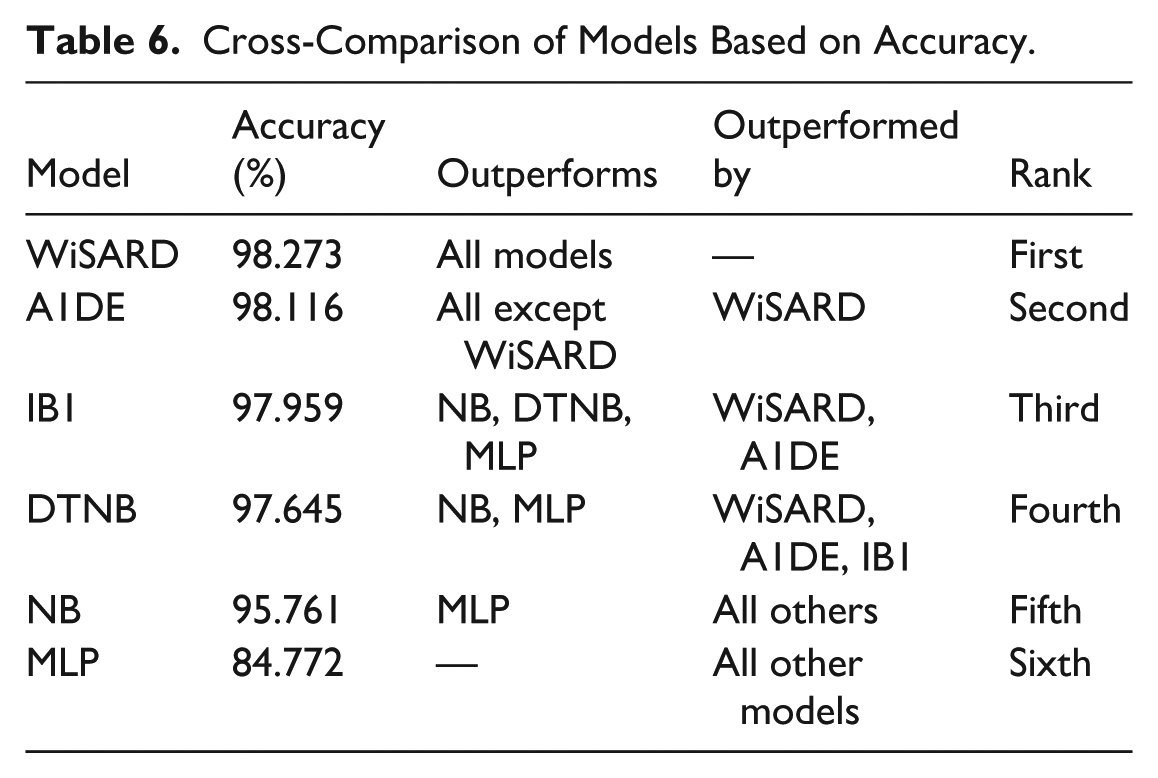
The performance ranking of the analyzed models for mental disorder prediction in Figure 6 reveals a definite ordering of performance. WiSARD has the best accuracy at 98.273%, which means it classifies almost all instances correctly, rendering it an extremely good choice for this sensitive task. A1DE (98.116%) and IB1 (97.959%) come next with very close and equally impressive performance, with only small differences, meaning all 3 are trustworthy to use practically. DTNB, at 97.645%, is also very accurate but may be giving up a bit because it has a hybrid decision table as well as a probabilistic structure. NB, at 95.761%, is also quite good but starts to reveal a significant deficit from the best models, and this can perhaps be attributed to its feature independence assumption, which could restrict its performance in detecting intricate inter-feature relationships common to mental health data. MLP (84.772%) is far behind all other models, suggesting it has difficulty with either underfitting or extracting meaningful patterns from the data and is the least appropriate of those tested. While accuracy is a helpful measure, it must be taken into account with caution for mental disorder prediction exercises, where class imbalance and cost of misclassification are paramount, particularly false negatives. Here, WiSARD not only provides the highest accuracy but also pairs it with the best performance in recall, precision, F-measure, and MCC, further confirming its stability and excellence for this area of application.

Accuracy comparison of employed models for mental disorder prediction, highlighting the overall correctness of each model in classifying both positive and negative cases.
According to the results for accuracy, WiSARD is ahead of all models with the highest correctness in classification (98.273%), as illustrated in Table 6, further guaranteeing its high overall performance in mental disorder prediction. A1DE and IB1 also prove to be very accurate, just behind WiSARD. DTNB is close behind, proving the potency of hybrid decision-based modeling. NB, although still higher than average, performs moderately and is beaten by more sophisticated classifiers. MLP underperforms considerably in comparison with the others, suggesting its limited applicability or possible underfitting on this database. This ranking supports that WiSARD, A1DE, and IB1 are the most reliable classifiers based on pure accuracy.
Cross-Comparison of Models Based on Accuracy.
The MAE and KS analysis demonstrated in Figure 7 offers a deeper understanding of model consistency in mental disorder prediction, especially during class imbalance. IB1 and A1DE are most notable with the lowest MAE value of 0.003, reflecting very accurate and reliable probability predictions with minimal variation from the actual labels. Their respective KS measures of 0.978 and 0.979 similarly indicate a very high degree of correspondence between predicted and actual labels, higher than would be expected to happen by chance. WiSARD, even with a relatively high MAE at 0.569, remarkably has the top KS value at 0.981, indicating that despite greater differences in predicted probabilities, its ultimate class outputs are highly accurate and well-matched to the true labels. This can suggest that WiSARD is making strong categorical choices even when its probability judgments are not so well-calibrated. DTNB and NB also function well, with MAEs of 0.049 and 0.007 and KS of 0.974 and 0.953, respectively, reflecting good agreement and predictability. MLP, on the other hand, has the highest MAE (0.089) and lowest KS (0.832), reflecting less predictable results and weaker agreement with actual labels. Overall, while MAE reflects prediction precision, KS provides stronger insight into classification consistency, and WiSARD’s exceptional KS score reaffirms its robustness despite its higher MAE, making it a strong contender for practical deployment in mental disorder prediction.

Comparison of employed models for mental disorder prediction based on Mean Absolute Error (MAE) and KS Statistics, reflecting each model’s prediction precision and agreement with actual classifications beyond chance.
The analysis discussed in Table 7 reveals a unique trade-off between MAE and KS for different models. WiSARD achieves the highest KS (0.981), indicating the strongest agreement with actual classifications beyond chance. However, it has the worst MAE (0.569), which could be indicative of instability in probabilistic prediction values notwithstanding high categorical accuracy. A1DE and IB1 are the most balanced models with the lowest MAE (0.003) and very high KS values (0.979 and 0.978, respectively), and hence are highly consistent and accurate. DTNB and NB have competitive performance but are moderately worse on both metrics. MLP is ranked last, with the greatest error and least agreement, validating its poorer predicting ability for this task. A1DE and IB1 are therefore the highest ranked when precision and agreement matter, while WiSARD is best when agreement on classification is top of the agenda, even if numerical error margins are in excess.
Cross-Comparison of Models Based on MAE and KS Statistics.

Discussion
Following the holistic assessment of the utilized ML models for mental disorder prediction—MLP, NB, DTNB, IB1, A1DE, and WiSARD proposed herein—the performance differences are evident in the critical discussion underlain by algorithmic design, learning paradigms, and model appropriateness for complicated, unbalanced mental health data. In virtually every measure of performance—TPR, FPR, precision, recall, F-measure, MCC, accuracy, and KS—WiSARD leads or is near the top in every instance. It has the best balance of classification, most notably in True Positive Rate (0.983), Precision (0.985), F-measure (0.983), MCC (0.982), and overall accuracy (98.273%). This is especially desirable in mental health prediction, where high sensitivity and low false positives are important, not to miss actual cases or unnecessarily alarm healthy cases.
WiSARD’s better performance owes to its special structure. Unlike traditional probabilistic or neural approaches, WiSARD makes use of a RAM-based discriminative architecture that memorizes binary patterns as well as their corresponding classes directly. This memory-based technique is good at dealing with sparse, high-dimensional, or categorical input data, which is characteristic of mental health datasets involving subtle, intricate patterns in various features. In addition, WiSARD’s capacity to generalize overseen binary patterns without making assumptions (such as feature independence in NB or gradient-based optimization in MLP) aids it in having robust classification with sparse or noisy training data. The model also enjoys the virtue of being explainable and interpretable by nature, which promotes trustworthiness in sensitive domains such as healthcare.
The other models, although good, have some drawbacks here. MLP performs poorly on all measures, perhaps as a result of underfitting or lack of tuning, and has the lowest TPR, MCC, and accuracy. NB, although efficient in computation and low in cost, has its independence assumption, which tends to break down with correlated features, as is typical of psychological data. DTNB and A1DE, as hybrid and ensemble-based classifiers respectively, demonstrate strong and competitive predictive performance in this study; however, their increased architectural and probabilistic complexity may introduce additional computational overhead in high-dimensional settings—a factor that was not explicitly evaluated in the present work and is therefore noted as a theoretical consideration rather than an observed limitation. IB1 excels as an instance-based model but falls short in memorization efficacy in high-dimensional space.
Even though the differences between models on measures of confusion-matrix (TPR, FPR, Precision, Recall, F-measure), MCC, and KS are numerically small, they nonetheless have practical significance when considered in the context of mental disorder prediction: even small gains in sensitivity and agreement can lead to an increase in clinical reliability, particularly with minority and high-risk classes. Specifically, the persistently high values of MCC and KS of WiSARD show better global consensus and strength in class imbalanced situations that are more informative than their accuracy. The comparatively large MAE of WiSARD must be considered in the context of the architectural features of WiSARD: WiSARD is a hard-decision, RAM-based pattern matching model, which focuses more on proper categorical discrimination than high-quality probabilistic results. Therefore, its probability estimates can have larger absolute deviations, which are manifested in a large MAE, but the final class assignments are very close to true labels, which is indicated by the largest KS and MCC scores. By comparison, other models like A1DE and IB1 produce smoother probability distributions, therefore, lower values of MAE at the expense of a minor loss in agreement and sensitivity. Thus, when the stakes are high like mental health screening, the increased MAE of WiSARD cannot be taken to imply a lower predictive reliability, rather, it represents a trade-off between decisive and robust classification versus probabilistic calibration, which is more consistent with the first aim of minimizing the cases of false classifications of true disorders.
On the basis of these results, this research suggests WiSARD as a viable contender for mental disorder prediction systems in actual use. Its stability, responsiveness, and minimal error rates make it suitable to be implemented in clinical decision-support systems, early screening programs, and mental health investigation platforms. Mental health clinicians, psychologists, health care organizations, AI researchers, and policy-makers involved with digital mental health may find such predictive frameworks useful to implement. Furthermore, the research emphasizes explainability and pattern memorization in mental health AI—areas lacking in conventional black-box models such as deep neural networks. Subsequent research might develop a deep learning-hybrid WiSARD model for marrying interpretability with representation learning, or for applying its usage in longitudinal monitoring of mental health with temporal features.
Overall, the research not only determines WiSARD to be the best-performing model but also highlights the value of using models that are suitable for the needs of the domain, with low false alarms, high sensitivity, interpretability, and robustness to imbalanced data. These findings can significantly impact the creation of reliable, effective, and ethically sound AI systems in mental care.
Clarification of Model Performance and Benchmarking Scope
While the WiSARD model achieved outstanding quantitative results across several measures-accuracy (98.27%), F-measure (0.983), MCC (0.982), and KS (0.981)-it is essential to position these findings in the context of controlled experimental conditions involving only one dataset. The comparative analysis in this study has focused on benchmarking against a set of well-established baseline models: MLP, Naïve Bayes, DTNB, IB1, and A1DE, under identical pre-processing and evaluation protocols; hence, the reported performance is best understood as representative of strong relative performance within the scope of the present experiments, rather than any absolute statement of universal superiority. This makes broader benchmarking necessary, against external and clinically validated datasets with large-scale EHR or psychometric data, in order to confirm the generalizability and robustness of WiSARD’s performance in diverse real-world settings. This step forms part of our identified future research direction.
Dataset Limitations and Future Dataset Considerations
Although the Kaggle Mental Disorders dataset provided a very valuable and structured basis to benchmark various classifiers, limitations related to the scale of the dataset and the absence of formal clinical validation should be conceded. The information contained in the data is mainly self-reported and expert-annotated observations, rather than verified electronic health records or clinically standardized psychometric instruments. Therefore, even as the results obtained with the proposed WiSARD model outline great predictive capability and robustness on this dataset, its further generalization with respect to real-world mental health diagnostics should be considered with great care. Further research will pursue replication of the present work using larger, clinically validated data, such as EHR-based or psychometric assessment data-sets, for example, PHQ-9, GAD-7, or DSM-aligned screening tools, in order to reinforce model reliability and external validity. In this vein, such clinically informed data will not only enhance predictive confidence but also help to further test the interpretability and diagnostic precision of WiSARD in authentic healthcare environments.
Ablation Study
To assess the unique contribution and effect of the internal structure and algorithmic components of each model on mental disorder prediction performance, we performed an ablation study comparing 6 different machine learning strategies. This comparison has the effect of isolating the particular strengths and weaknesses of individual modeling approaches—literally from probabilistic classifiers to neural network and memory-based models—and determining which components are most accountable for performance differences across key metrics including TPR, FPR, precision, recall, F-measure, MCC, MAE, KS, and accuracy.
Our intended approach, the WiSARD model, showed better performance on all evaluation measures except one. This memory-based model utilizes RAM-like discriminators to memorize and compare binary patterns directly without the need for statistical estimation or iterative learning. To see if this architectural boost is responsible for its success, we contrasted it against models devoid of such an architecture, like MLP (a gradient-based neural model) and NB (a probabilistic model based on feature independence). The dramatic decline in performance for MLP (accuracy: 84.772%, MCC: 0.833, KS: 0.832) and NB (accuracy: 95.761%, MCC: 0.956) verifies that the lack of explicit pattern matching and explainable memory causes inefficient generalization in complex, imbalanced data spaces.
In addition, by contrast with IB1, a memory-based model employing instance similarity (k-NN), we can single out the effect of binary pattern encoding within WiSARD. While IB1 was excellent (accuracy: 97.959%, MCC: 0.977), WiSARD remained even better, which indicates that WiSARD’s compressed and structured memory representation offers a better and more noise-resistant representation than direct instance comparison.
The hybrid classifiers DTNB and A1DE fill the gap between classical rule-based and probabilistic classifiers. DTNB, which is an integration of decision tables and NB, posted decent results (accuracy: 97.645%, MCC: 0.975), validating the merit of hybrid logic. A1DE, an ensemble of weighted Bayesian classifiers, best approximated WiSARD (accuracy: 98.116%, MCC: 0.980), suggesting that ensemble smoothing and handling of dependencies add immensely to stability. However, WiSARD also continued to dominate the balance overall, especially in MCC and TPR, because it better handled unusual patterns, essential with mental health datasets.
Comparing MAE and KS, WiSARD exhibited a peculiar behavior once again: even though its MAE was relatively high (0.569), WiSARD had the highest KS (0.981). This implies WiSARD’s hard classifications are highly accurate, even though its probabilistic confidence values are less calibrated, in contrast to A1DE and IB1, which had lower MAE but slightly lower KS. This finding supports the hypothesis that consistency of classification (as evidenced by KS) is more critical than probabilistic smoothness in high-stakes areas such as mental health diagnosis.
This ablation experiment shows that the success of WiSARD lies in its clear binary encoding, memory-based learning, and pattern classification approach, which individually provide better generalization, robustness to noise, and class reliability. Models that do not have these features—particularly those that are heavily dependent on probabilistic assumptions or gradient descent—are less suitable for this task. This ablation not only confirms WiSARD’s architectural decisions but also directs future model designs that are capable of incorporating pattern memory with probabilistic interpretability for even more sound mental health prediction systems.
Conclusion
This study presents a new use of the WiSARD (Wilkie, Stonham, Aleksander Recognition Device) model for mental disorder prediction, meeting the essential requirement for interpretable, robust, and high-accuracy classification for hard, imbalanced healthcare datasets. In contrast to conventional machine learning methods with probabilistic inference or gradient-based learning, WiSARD utilizes a RAM-based binary pattern recognition process to facilitate direct memorization and discrimination of input patterns with little reliance on assumptions or iterative training. Experimental comparison over a range of clinically applicable metrics—TPR, FPR, Precision, F-Measure, MCC, MAE, KS, and Accuracy—confirmed the better performance of WiSARD, especially regarding classification reliability (MCC = 0.982, KS = 0.981) and sensitivity (TPR = 0.983), where false positives as well as false negatives are of significant clinical impact. In addition, the work highlights the novel benefit of WiSARD’s architecture in identifying fine-grained and heterogeneous patterns characteristic of mental health data, outperforming recognized models such as MLP, NB, and A1DE. The results not only prove WiSARD as an exceptionally effective and understandable substitute to black-box models but also open doors toward future research involving the fusion of pattern memory with contemporary learning paradigms toward better performance and clinical reliability. This study is an important milestone toward the creation of domain-specific AI systems that are both reliable and compliant with the critical requirements of mental health diagnosis.
Building on the encouraging performance of the WiSARD model in mental disorder prediction, future research may explore several areas to enhance both performance and utility. One possible direction is the combination of WiSARD with deep learning models to leverage the interpretability and memorization strength of WiSARD and the feature extraction ability of neural networks. In addition, the inclusion of temporal or longitudinal information may allow for early identification and tracking of mental health disorders across time. Extension of the model to multi-modal datasets—like integration of psychological tests with physiological or behavioral signs—may enhance the robustness of prediction as well. Finally, realization and verification of the model in actual clinical environments through user tests with mental health clinicians will facilitate measurements of its usability, credibility, and influence in decision-making settings.
Footnotes
Acknowledgements
The authors acknowledge with thanks the Ministry of Education and King Abdulaziz University, DSR, Jeddah, Saudi Arabia.
Ethical Considerations
Our study did not require an ethical board approval because it was conducted entirely on publicly available, anonymized secondary data, with no direct involvement of human participants, no identifiable personal information, and no clinical interventions.
Author Contributions
The author confirms contribution to the paper as follows: study conception and design, data collection, analysis and interpretation of results, and draft manuscript preparation were performed by Muhammad Binsawad. The author reviewed the results and approved the final version of the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research work was funded by the Institutional Fund Projects under grant no. (IPIP: 176-611-2025). The authors gratefully acknowledge the technical and financial support provided by the Ministry of Education and King Abdulaziz University, DSR, Jeddah, Saudi Arabia.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.