
Abstract
To mitigate the rapid spread of health misinformation and its negative impact, this study presents a comprehensive literature review on health misinformation detection. A systematic search is conducted using the Google Scholar database, targeting publications from January 2016 to February 2025. Inclusion criteria require full-text, English-language studies proposing health misinformation detection methods. A total of 100 relevant studies are included. The characteristics of health misinformation are identified through a detailed analysis of its concept, dissemination mechanism, psychological impact, and susceptibility. Datasets and evaluation metrics are reviewed, with issues such as class imbalance and inconsistencies in annotation standards being identified. The strengths and limitations of various detection approaches are examined. Machine learning approaches perform better when using ensemble methods, feature selection techniques, and embedding-based representations. Deep learning algorithms are strong in automatic feature extraction and high-dimensional semantic modeling, though they often face challenges such as high computational cost and low interpretability. Advanced detection methods show clear improvements in accuracy and explainability, while also introducing AI-generated misinformation and associated ethical concerns. This review provides a panoramic view of the current state-of-the-art in health misinformation detection. It further underscores the importance of interdisciplinary collaboration, human-centered design, and ethical considerations for the development of effective and clinically relevant detection systems.
Keywords
Highlights
Health misinformation characteristics are identified, including concept, dissemination, psychological impact, and susceptibility.
Detection datasets are analyzed and evaluation metrics are summarized.
Machine learning performance differences and accuracy boost methods are stressed.
Unimodal and multimodal deep learning methods are explored and limitations are examined.
Advanced methods are reviewed, and AI-generated misinformation risks and ethical considerations are analyzed.
Introduction
In the digital age, the widespread use of the Internet has revolutionized access to health information, and advances in digital technology have made it easier to access and disseminate health information. With the rapid development of the Internet as a 24/7 news and information source, individuals increasingly expect to obtain essential information as part of their daily routine. 1 However, social media has also opened up space for misinformation and facilitated its penetration and proliferation on the internet during health emergencies. 2 In the majority of the current research, there is a view that digital technology, particularly social media, has amplified the problem of health misinformation. 3 Not only official governmental health organizations, but anyone with an account can post and disseminate health information ranging from dietary guidelines to disease treatment on various social media platforms. 4 Yet patients and individuals often turn to these media sources for information about diseases, treatments, and medications that may pose serious risks to their health. 5 A recent national survey by the Pew Research Center reported that 7 in 10 (72%) adult Internet users search online for a variety of health issues. 6 These dynamics highlight both the opportunities and the significant risks that digital technologies pose to public health, underscoring the urgent need for effective strategies to identify, evaluate, and mitigate health misinformation online.
Several reviews have recently examined health misinformation from different perspectives, including its scope and prevalence, the factors driving its creation and spread, its negative social and psychological impacts, and the strategies proposed for mitigation and intervention. Heley et al conducted a scoping review of 115 publications published between 2017 and 2022, focusing on misinformation mitigation interventions such as correction, education, and prebunking. 7 Borah examined the politicization of health issues in relation to misinformation and social media. 8 Zhang et al discussed the factors contributing to the creation and spread of health misinformation, its negative impacts, possible solutions, and the research methods used in prior studies. 9 Kbaier et al carried out a scoping review on health misinformation in social media, addressing its prevalence, impacts, mitigation strategies, and the experiences of health professionals in responding to it. 3 Peng et al systematically reviewed persuasive strategies used in online health misinformation and categorized 238 strategies into thematic groups. 10 Southwell et al reviewed the relationship between health misinformation and health disparities, showing how vulnerable groups are more likely to be influenced and evaluating the effectiveness of intervention strategies. 11 Hu et al conducted a meta-analysis on older adults, synthesizing evidence on prevalence of misinformation exposure and the impact of interventions in this population. 12 Rocha et al systematically reviewed the role of social media in the spread of infodemics, noting that exposure to health-related fake news may cause psychological consequences such as panic, fear, depression, and fatigue. 13
In the perspective of health misinformation detection, Schlicht et al provided a systematic review of computer science literature on automated health misinformation detection. They applied text mining and machine learning methods to develop a classification framework that analyzed studies by information sources, health topics, misinformation types, detection tasks, and technical methods. 14 Ravichandran and Keikhosrokiani focused on the classification of misinformation on social media during the COVID-19 pandemic. They examined 4 categories of techniques—neuro-fuzzy systems, neural networks, natural language processing, and traditional machine learning. Their aim was to identify the types of classification methods applied in this field, evaluate the most effective neuro-fuzzy and neural network approaches, and analyze the strengths and limitations of these techniques. 15
In summary, prior surveys on health misinformation detection have primarily concentrated on technical methods but remain incomplete. They often neglect advanced approaches such as knowledge graph–based techniques, fact-checking strategies, and large language models. Moreover, they rarely integrate interdisciplinary perspectives, for example the psychological impacts of misinformation or the vulnerabilities of specific populations. Compared with these reviews, this paper provides a more comprehensive survey. First, we analyze the characteristics of health misinformation in terms of its definition, dissemination mechanisms, psychological effects, and individual susceptibility. Second, we classify and summarize existing datasets for health misinformation detection. Third, we review evaluation metrics commonly used in this domain. Fourth, we discuss detection methods from 5 perspectives: machine learning, deep learning, knowledge graph–based approaches, fact-checking methods, and large language models. Finally, we highlight current limitations and outline directions for future research.
In this study, we conducted a literature search using the Google Scholar database. The inclusion criteria were as follows: (1) publications dated between January 2016 and February 2025, (2) articles written in English and available in full text, (3) studies proposing methods for detecting misinformation in the health domain, and (4) further validation in Web of Science to ensure that the selected literature is indexed in the Science Citation Index (SCI) or the Social Sciences Citation Index (SSCI), or belongs to an international conference recommended by the China Computer Federation (CCF). 16 SCI and SSCI are prestigious citation indexes encompassing high-quality, peer-reviewed journals in the natural sciences and social sciences, respectively. Likewise, the CCF ranking system identifies high-impact international conferences in the field of computer science. By implementing this verification process, we ensure that the reviewed literature meets rigorous academic standards and maintains high credibility.
First, we set the search term with all of the words in Advanced Search as “health misinformation detection,” limited the publication timeframe to 2016 to 2025, and sorted the results by relevance. This search yielded 87 studies that met the inclusion criteria. Next, we set the search term with all of the words to “detection” and the search term with the exact phrase to “health misinformation,” maintaining the 2016 to 2025 timeframe. After removing duplicate results from the previous search, an additional 13 studies met the inclusion criteria. In summary, a total of 100 studies were included in this review, comprising 72 SCI or SSCI-indexed articles and 28 papers from international conferences recommended by the China Computer Federation (CCF). The distribution of publications over time is illustrated in Figure 1.
The main contributions of our work are summarized as follows:
The characteristics of health misinformation are summarized, including its concept, dissemination mechanisms, psychological impacts, and individual susceptibility.
A comprehensive analysis of existing binary and multi-class health misinformation detection datasets is conducted, and commonly used evaluation metrics for binary, multi-class, and imbalanced datasets are summarized.
Significant performance differences among various machine learning algorithms are identified, with the importance of ensemble methods, feature selection techniques, and embedding models in enhancing detection accuracy being emphasized.
The application of unimodal and multimodal deep learning-based approaches in health misinformation detection is explored, with their effectiveness, limitations, and future improvement directions being systematically examined.
Other advanced detection methods for health misinformation are reviewed, with their roles in improving detection accuracy and model interpretability, as well as the risks associated with AI-generated misinformation and ethical issues, being analyzed.

Publication trends over time.
The structure of this paper is as follows: Section 2 introduces the characteristics of health misinformation. Section 3 presents existing health misinformation datasets. Section 4 introduces the evaluation metrics for assessing health misinformation detection effectiveness. Sections 5 to 7 discuss various health misinformation detection methods, including machine learning approaches, deep learning methods, knowledge graphs, fact-checking, and large language models. Section 8 provides a discussion, summarizing the findings of this study, its limitations, and potential directions for future research. Finally, the Conclusion section provides a summary of the research.
Characteristics of Health Misinformation
Concept of Health Misinformation
There is no universally agreed-upon definition of fake news, but it is commonly categorized into 2 main types: disinformation and misinformation.17,18 The distinction between these terms primarily lies in their intent. Misinformation refers to information that is unknowingly false and is shared without malicious intent, whereas disinformation involves the deliberate dissemination of false information with the aim of causing harm. 19 In addition, some scholars have expanded the classification of fake news to include a third category: malinformation.20,21 Malinformation pertains to information that is truthful but is shared with the intent to harm or mislead, such as malicious rumors. 21 Furthermore, alternative perspectives have been proposed regarding the concept of misinformation. Some scholars argue that it serves as an umbrella term encompassing both intentionally disseminated misleading information and unintentional misleading information.22 -24
Due to the widespread presence of misinformation in the health domain, some scholars have sought to define the concept of health misinformation more precisely. Chou et al define health misinformation as a health-related claim that is based on anecdotal evidence, false, or misleading owing to the lack of existing scientific knowledge. 25 The definition includes both false information shared without intent to harm and information—whether false or reality-based—that is deliberately intended to cause harm to individuals, social groups, institutions, or countries. 26 Krishna and Thompson define health misinformation as the acceptance of false or scientifically inaccurate information despite exposure to accurate data, in the absence of accurate information, or within historical and contextual influences. 27 Similarly, Carlson argues that health misinformation includes biased or out-of-context health information, as well as false claims that are not evidence-based. 28 Swire-Thompson and Lazer define science and health misinformation as information that contradicts the epistemic consensus of the scientific community. Under this definition, perceptions of truth and falsehood evolve over time as new evidence emerges and scientific methods advance. 29 Zhong provides a broad definition, stating that health misinformation encompasses all forms of false or low-quality health information. 30 Darwish et al further specify that any post, tweet, or shared resource that misinterprets expert-accepted medical knowledge constitutes misleading health information, including fake news articles, memes, and social media posts containing false claims. 31
To describe the rapid spread of misinformation, particularly on social media, the World Health Organization (WHO) introduces the term “infodemic.” 32 The WHO defines an infodemic as the excessive proliferation of false or misleading information during a disease outbreak, occurring in both physical and digital environments. Such misinformation can cause public confusion, encourage risky behaviors, and ultimately undermine public health efforts. 33 It is characterized by the simultaneous spread of both true and false information. 34
Based on existing research, we identify the following characteristics of health misinformation: (1) it includes not only scientifically inaccurate false information but also true information that is intended to harm or mislead; (2) the veracity of information must be evaluated in the context of its dissemination, and it may evolve over time as new evidence emerges and scientific methodologies advance; (3) it manifests in various forms, including news articles, memes, and social media posts. From these characteristics, we identify 2 major challenges in detecting health misinformation. First, assessing the intent of information disseminators remains operationally difficult. Second, the dynamic nature of scientific consensus introduces an inherent relativity in defining misinformation. These challenges suggest that future research should develop a more context-sensitive and temporally adaptive conceptual framework to provide a solid theoretical foundation for automated detection systems.
Dissemination Mechanism of Health Misinformation
Health misinformation is widely disseminated on social media platforms and can lead to harmful consequences such as incorrect care seeking behavior, reduced trust in the health care system, and even the spread of disease. Understanding the transmission mechanism of health misinformation is very important for designing effective health misinformation detection algorithm. This chapter will explore several key aspects, including the mechanisms of health misinformation dissemination, the differences in dissemination characteristics between misinformation and true information.
Scholars have extensively studied the mechanisms of health misinformation dissemination on social media. Rodrigues et al identified several key factors contributing to the spread of health misinformation, including the amplification effects of social media algorithms, emotionally-driven dissemination, political influences, and a crisis of public trust. 35 Kalantari et al conducted a social network analysis of user interactions to identify accounts that played a central role in spreading COVID-19-related misinformation. Their findings indicate that news organizations and medical institutions serve as primary nodes in the dissemination network, while public figures and their supporters form communication clusters that significantly impact the spread of misinformation. 36 Zhou et al highlighted that misinformation related to health caution and advice, health help-seeking, and emotional support are significant determinants of individuals’ dissemination behavior. 37 Zhang et al found that content congruence and affective congruence between tweets and their corresponding comments significantly influence the spread of misinformation on Twitter. 38 Xue et al further revealed that misinformation originating from pseudo-authoritative sources and associated with negative sentiment was more likely to be disseminated, though accuracy cueing interventions were effective in reducing sharing intentions. 39 Zhao et al demonstrated that both highly active and low-activity users were prone to sharing misinformation, with social proof mechanisms (eg, likes and retweets) playing a critical role in its spread. 40 Ganti et al investigated the impact of narrative style on the spread of health misinformation on social media. Their findings revealed that misinformation presented in a narrative format, especially vaccine-related content, led to higher user engagement. 41 These results highlight the complex factors driving the spread of health misinformation. Social media dynamics, user behavior, and information framing all play a crucial role in its proliferation.
When it comes to the differences in dissemination characteristics, the spread of health misinformation varies from that of truthful information. Safarnejad et al reconstructed the information dissemination networks during the Zika virus outbreak. They found that misinformation networks were more complex, had longer diffusion paths, and were more likely to form high-impact localized dissemination clusters. 42 Zhong conducted a multilevel analysis of Twitter health news reports and found that while low-quality health information was more frequently discussed, it did not necessarily persist longer. 30 Osude et al observed that health misinformation spreads faster than factual information due to its emotionally charged, alarmist, and easily digestible nature. 43 Edinger et al found that misinformation spreads much faster than official public health information. In early tweets, negativity was the dominant sentiment. Their findings suggest that health misinformation thrives within complex communication networks. Its rapid diffusion and strong emotional appeal contribute to its widespread reach on social media. 44
In summary, the dissemination of health misinformation on social media is shaped by a combination of technological, psychological, and social factors. Algorithmic amplification, emotional framing, and the influence of key opinion leaders can significantly accelerate the spread of health misinformation, while social proof mechanisms further reinforce its visibility. Compared with truthful information, health misinformation tends to diffuse more rapidly, persist in more complex network structures, and attract higher levels of engagement due to its emotional appeal and narrative style. These findings underscore the urgent need for targeted interventions, such as accuracy cueing, content moderation, and the promotion of trustworthy health communication, in order to mitigate the harmful consequences of misinformation proliferation.
Psychological Impact of Health Misinformation
Exposure to health misinformation can lead to psychological and mental consequences. Banerjee et al reported that the digital infodemic is responsible for multiple psychological issues such as anxiety, fear, agitation, uncertainty, noncompliance to precautions, stigma, due to the huge misinformation load. The increased screen time and unhealthy technology use, found in the population at large, further contribute to the mental health problems. 45 Dubey et al found that health misinformation have generated an increase in the fear, frustration, and anguish of the population, resulting in a series of symptoms characteristic of mental disorders such as anxiety, phobia, panic, depressive behavior, obsession, irritability, delusions of having symptoms similar to COVID-19 and other paranoid ideas. 46 Wu et al reported that exposure to rumors, misinformation, and negative pandemic-related information was significantly associated with an increased risk of mental health problems, including depressive and anxiety symptoms, stress, and social isolation. 47
To assess the psychological impact of health misinformation, especially in the emotional aspects such as depression and anxiety, some scholars have applied validated psychological constructs and scales. Gao et al examined the association between social media exposure (SME) and the prevalence of mental health problems during COVID-19. Depression was assessed by the Chinese version of WHO-Five Well-Being Index (WHO-5) and anxiety was assessed by Chinese version of generalized anxiety disorder scale (GAD-7). They found a high prevalence of mental health problems, positively correlated with frequent SME during the outbreak. 48 Pedro et al examined the relationship between the frequency and mode of COVID-19-related information acquisition and psychological symptoms. The severity of depressive symptoms, using the Hamilton Depression Scale (HAM-D), Hamilton Anxiety Scale (HAM-A), and the Stress Symptoms Inventory adapted from the Checklist 90-R. Individuals who sought information on social media reported greater depressive symptom severity than those who did not, while those who used WhatsApp for information seeking had lower anxiety and stress levels. 49 Wu et al investigated media consumption patterns and their associations with depressive and anxiety symptoms among adults affected by the COVID-19 pandemic. Depression and anxiety were assessed with the Patient Health Questionnaire and the Generalized Anxiety Disorder Scale, respectively. They found that individuals who rarely used social media had the lowest prevalence of depression and anxiety, while those who rarely used traditional media had the highest prevalence of depression. 47 Hammad and Alqarni explored exposure to misleading social media news in relation to anxiety, depression, and social isolation among 371 Saudi participants. Using the Generalized Anxiety Disorder-7, the Centre for Epidemiological Studies Depression Scale, and the de Jong Gierveld Loneliness Scale, they found that misinformation exposure was positively associated with all 3 outcomes. 50
In summary, existing evidence demonstrates that exposure to health misinformation exerts significant psychological and psychiatric consequences. These impacts range from transient emotional responses, such as fear, worry, and agitation, to more persistent outcomes, including anxiety disorders, depression, social isolation, medical mistrust, and paranoid ideation. Importantly, empirical studies have operationalized these effects using validated psychological constructs and standardized clinical scales, confirming that misinformation not only shapes beliefs and attitudes but also produces measurable mental health symptoms. Collectively, these findings highlight that health misinformation acts as a psychosocial stressor, whose effects can be systematically evaluated within established psychiatric frameworks. Given the tangible emotional, cognitive, and psychiatric consequences, the identification, and detection of health misinformation are essential steps to mitigate its impact and protect public mental health.
Susceptibility to Health Misinformation
An individual’s susceptibility to health misinformation is shaped by multiple factors, with emotional and cognitive factors playing particularly important roles. Osude et al reported that upon exposure to health misinformation, cultural identity, psychological traits, and perceptions of illness susceptibility and severity influence the likelihood of believing such misinformation. 43 Pan et al found that health-related anxiety, preexisting misinformation beliefs, and repeated exposure—3 emotional and cognitive elements—were positively associated with health misinformation acceptance. 51 Piksa et al proposed 4 psycho-cognitive phenotypes of information susceptibility: Consumers, Knowers, Duffers, and Doubters. The study found significant differences among phenotypes in feedback sensitivity, cognitive bias, Big Five personality traits, anxiety, narcissism, optimism, and reward–punishment sensitivity. These results suggest that susceptibility is shaped not only by truth-discernment ability but also by emotional stability, anxiety levels, and personality traits. 52 Beauvais emphasized that heightened emotions, particularly fear and anger, can impair critical evaluation and increase susceptibility to misinformation, especially among individuals with pre-existing cognitive or emotional vulnerabilities. Confirmation bias and motivated reasoning were identified as key mechanisms reinforcing false beliefs. 53 Collectively, these findings are consistent with psychiatric perspectives on belief formation and maintenance, which highlight the interplay between emotional dysregulation, cognitive distortions, and personality-related vulnerabilities in shaping susceptibility.
In addition to these individual-level susceptibility mechanisms, certain populations are disproportionately vulnerable to health misinformation. Choukou et al defined vulnerable populations as the group of persons in need of special support adapted to their socioeconomic status, health needs or any context that prevents access to digital health information. Examples include illiterate, digitally illiterate, older adults, with visual or hearing impairments, with mental or cognitive impairments, living in remote or underserved communities, with limited access to the Internet, indigenous living on reserve, immigrants, having language barriers and with low socioeconomic status. 54 Scherer et al found that a person who is susceptible to online misinformation about 1 health topic may be susceptible to many types of health misinformation. Individuals who were more susceptible to health misinformation had less education and health literacy, less health care trust, and more positive attitudes toward alternative medicine. 55 Pan et al found that females were more likely than males to accept health misinformation, while age, education, and income were negatively associated with acceptance. 51 Escolà-Gascón et al investigated the psychological and psychopathological profiles that characterize fake news consumption. Using the State–Trait Anxiety Inventory (STAI), Positive and Negative Affect Schedule (PANAS), and the Multivariable Multiaxial Suggestibility Inventory (MMSI-2) based on DSM-5, they found that individuals with schizotypal, paranoid, or histrionic personality traits were less effective at detecting fake news and more vulnerable to its negative effects, displaying higher anxiety and greater cognitive biases related to suggestibility and the Barnum Effect. 56 Perlis et al analyzed responses from 2 waves of a 50-state nonprobability internet survey conducted, in which depressive symptoms were measured using the Patient Health Questionnaire 9-item (PHQ-9). They found that individuals with moderate or greater depressive symptoms were more likely to endorse vaccine-related misinformation. 57
In summary, susceptibility to health misinformation is influenced by a complex interplay of emotional, cognitive, and personality-related factors, as well as broader sociodemographic conditions. Evidence consistently shows that vulnerable populations are disproportionately affected by health misinformation. This underscores the need for detection algorithms and intervention strategies that not only achieve high overall accuracy but also address the specific vulnerabilities of these populations. Incorporating human-centered and equity-driven perspectives will be essential to ensure that health misinformation detection systems are inclusive, effective, and capable of protecting those most at risk.
Datasets of Health Misinformation
Health misinformation originates from various online sources, including health-related websites, online health forums, and social media platforms. 5 It generally appears in 2 main forms: news articles and user-generated content (UGC). UGC is a term used to describe any content created by users, including texts, videos, images, reviews, live streams, and other forms of media. 58 Compared with news articles, UGC is typically not peer-reviewed, lacks source citations, 59 and often contains misspellings, noise, and abbreviations. 60 To support the development of automated health misinformation detection systems, researchers have collected news articles and UGC from websites and social media platforms. They analyzed the characteristics of this content and compiled labeled datasets that form the foundation for detection tasks. Most studies frame the problem as binary classification, distinguishing between true and false information. Others take a more fine-grained approach, dividing misinformation into multiple categories to better capture its diverse characteristics. The following section outlines these datasets, and the classification methods are illustrated in Figure 2.
Dataset categorization.
Binary Categorical Datasets
Most health misinformation detection datasets are categorized into 2 classes: true and false. In this paper, we further classify binary datasets into 3 subcategories: general health-related datasets, vaccine-related datasets, and COVID-19-related datasets. Detailed information on the binary datasets is presented in Appendix 1.
General health-related datasets provide a comprehensive foundation for research on health misinformation detection. Liu et al compiled a health-related dataset consisting of 2296 articles from reliable sources and 2085 from unreliable sources. 4 Dai et al introduced the FakeHealth dataset, which comprises 2 subsets: HealthStory and HealthRelease. The dataset’s true and false labels were assigned based on 10 expert-evaluated news credibility criteria. 61 Safarnejad et al collected English-language Twitter data about the Zika virus throughout 2016. They identified 264 highly influential misinformation tweets and paired them with 455 verified information tweets. 62 Barve and Saini developed the CredHealth and FactHealth dataset by retrieving healthcare-related URLs from Google. The credibility of each URL was assessed using a scoring method, where URLs with a score above 9 were labeled as false and those scoring between 3 and 6 were labeled as true. 63 Martinez-Rico et al constructed the KEANE dataset by aggregating healthcare-related articles from fact-checking websites such as Health Feedback, Snopes, and Politifact, categorizing them as true or false. 5 Liu et al developed the Verified Health Information (VHI) dataset, capturing corroborated cases from the food safety and healthcare sections of the Jiaozhen platform. The dataset includes 4313 false cases and 1388 true cases. 64 Li compiled a health misinformation dataset from Tencent’s fact-checking platform, comprising 10 560 health-related entries, of which 2150 were true and 8410 were false. 65
Vaccination is a fundamental pillar of public health, essential for preventing the spread of diseases and safeguarding both individuals and communities. As a prominent subset of health misinformation, vaccine-related misinformation poses significant risks to public health efforts. Du et al retrieved discussions on HPV vaccination from Reddit between 2007 and 2017 using Pushshift, randomly sampling 28 121 posts and categorizing them as misinformation or non-misinformation. 66 Hayawi et al introduced ANTiVax, a dataset containing 15 073 vaccine-related tweets collected via TwitterAPI, of which 5751 were classified as misinformation and 9322 as general vaccine-related content. 67 Joshi et al proposed the MiSoVac dataset, which collected data on misinformation related to the COVID-19 vaccine on social media sites. A total of 404 pieces of data were labeled true and 607 pieces of data were labeled false. 68
The COVID-19 pandemic has affected billions of people worldwide, causing widespread health, social, and economic disruptions. 69 Alongside the outbreak, a surge of COVID-19-related health misinformation has rapidly spread across the internet, misleading public perceptions of the crisis and potentially undermining efforts to control the pandemic. To address this challenge, numerous researchers have proposed datasets dedicated to COVID-19 misinformation detection.
The majority of COVID-19-related misinformation datasets are in English. Cui and Lee introduced CoAID (COVID-19 heAlthcare mIsinformation Dataset), which compiles news articles, user engagements and social platform posts. The dataset consists of 1788 fake claims, 18 079 fake news articles, 21 043 true claims, and 260 037 fake news articles. 70 Zhou et al developed ReCOVery, an English-language dataset comprising 2029 news articles, 140 820 tweets, and 93 761 users, all categorized as either reliable or unreliable. 71 Al-Rakhami and Al-Amri retrieved COVID-19-related tweets using specific hashtags and keywords, subsequently annotating 121 950 tweets as credible and 287 534 as non-credible. 72 Paka et al presented the first COVID-19 Twitter fake news dataset CTF. The dataset contains a total of 45.26K labeled tweets, among which 18.55K are labeled as genuine and 26.71K as fake. In addition, it contains 21.85M unlabeled tweets, which can be used to enrich the diversity of the dataset, in terms of linguistic and contextual features in general. 73 Patwa et al developed the Constraint@AAAI2021, which includes social media posts and news articles about COVID-19. The dataset contains 5600 entries labeled as true and 5100 as false, serving as a useful resource for studying misinformation. 74 Shang et al collected 891 English videos related to COVID-19 from TikTok, including 226 misleading videos and 665 none-misleading videos. 75 Khan et al used fake and real news articles about COVID-19 collected from multiple platforms. The dataset had 1164 instances, of which 586 were true and the remaining 578 were fake news. 76 Zamir et al used “COVID Fake News Dataset” from kaggle.com. The dataset was collected from news articles by crawling various websites and manually annotated by experts. The dataset contains 6420 tweets, of which 3360 are labeled as real and 3060 are labeled as fake. 77 Koirala collected global COVID-19 news articles using the Webhose.io tool. The final dataset contained 4072 articles, of which 2426 were labeled as True and 1646 as False. 78
In addition to English, some scholars have introduced some COVID-19 related datasets in other languages to enrich the corpus of health misinformation detection datasets. Li et al proposed the MM-COVID dataset containing fake news content, social engagements, and spatial-temporal information in 6 different languages. 79 Yang et al present CHECKED, a Chinese dataset comprising 2104 verified COVID-19-related tweets, of which 1760 are labeled true and 344 false. The dataset provides rich multimedia information for each microblog, including the ground-truth label and associated textual, visual, temporal, and network data. 80 Du et al collected and annotated a Chinese COVID-19 news dataset that examined more than 1,000 fact-checked news items, and collected 86 fake news and 114 real news. 81 Ghayoomi and Mousavian presented the Persian COVID-19 fake news dataset, which was collected from social media, including Twitter and Instagram, as well as the websites of various Persian news agencies. It includes 265 real news articles and 265 fake news articles. 82 Bozuyla and Özçift developed a Turkish dataset to identify the veracity of COVID-19 news. The data originated from Twitter, Turkish fact-checking websites, and COVID-19 dataset translated from English in Turkish. A total of 2110 COVID-19 samples were collected, comprising 1050 true news articles and 986 fake news articles. 83 Bonet-Jover et al presented the Spanish Reliable and Unreliable News (RUN) dataset, focusing on health and COVID-19. The RUN dataset contains 80 Spanish-language news items, of which 51 are reliable and 29 are unreliable. 84
In summary, the field of health misinformation detection has accumulated a substantial number of binary classification datasets, characterized by the following features. First, data sources are highly diverse, including social media posts, news articles, fact-checking platforms, and user-generated content, with labels assigned through expert annotation, scoring systems, or manual review. Second, research focus exhibits a domain-specific hierarchy: COVID-19-related datasets dominate, reflecting the direct impact of public health crises on research demand; vaccine-related datasets receive sustained attention due to their relevance to preventive medicine; and general health datasets provide foundational support for cross-domain studies. Notably, while English remains the dominant language, recent years have seen the emergence of multilingual datasets, expanding the geographical scope of research. Despite these developments, existing datasets continue to face persistent challenges. Widespread class imbalance often undermines model generalization, while inconsistencies in annotation standards hinder cross-dataset transfer learning and complicate comparative evaluations.
Multi-Categorical Datasets
In addition to binary classification, some researchers have proposed multi-categorical approaches to better capture the complexity and diversity of health misinformation. Multi-categorical datasets can generally be divided into 2 groups: those that classify misinformation into 3 categories, and those that adopt more fine-grained schemes with more than 3 categories. Detailed information on the multi-categorical datasets is presented in Appendix 2.
Several studies have adopted a 3-category classification scheme for health misinformation. Sicilia et al collected 709 samples related to Zika virus from Twitter, which the annotators manually labeled into 3 categories including rumor, non-rumor, and unknown. 85 Hossain et al proposed a benchmark dataset COVIDLIES containing 6761 expert-annotated tweets with Agree, Disagree, and No Stance labels. 86 Haouari et al introduced an Arabic COVID-19 Twitter dataset where each tweet was labeled with 3 categories: true, false and other. 87 Luo et al constructed a Chinese infodemic dataset for identifying misinformation by labeling the collected records as questionable, false, and true. 88 Cheng et al proposed a COVID-19 rumor dataset including rumors from Twitter and news websites, which were manually labeled into 3 categories: true, false, and unverified. 89 Sarrouti et al constructed a dataset HEALTHVER for evidence-based fact-checking of COVID-19 related statements, with each evidence-claim pair labeled supports, refutes, or neutral. 90 Srba et al presented a dataset for the study of medical misinformation containing approximately 317 000 medical news articles and 3500 fact-checked statements, as well as mappings between articles and statements. Claim-stance pair were labeled as supporting, contradicting, and neutral. 91 Nabożny et al extracted more than 10 000 sentences from 247 online medical articles, labeled by medical experts as credible, non-credible and neutral. 23
Other researchers have employed more fine-grained categorizations, dividing health misinformation into more than 3 categories. Kim et al introduced the FibVID dataset, which contains news statements and related tweets about the COVID-19 pandemic. Each entry is labeled into 1 of 4 categories: COVID True, COVID Fake, non-COVID True, and non-COVID Fake. 92 Zhao et al extracted records from the “Autism Forum” of Baidu PostBar and coded them into 5 categories: Advertising, Propaganda, Misleading information, Unrelated information, and Legitimate information. 93 Memon and Carley proposed the CMU-MisCOV19 dataset, using Twitter API to collect 4573 COVID-19-related tweets. The tweets were manually annotated into 17 categories, including Irrelevant, Conspiracy, True Treatment, True Prevention, Fake Cure, and so on. 94 Shahi and Nandini presented a multilingual FakeCOVID dataset containing 7623 news articles related to COVID-19 and the dataset was annotated into 23 categories including True, Mostly True, Partially True, Mixture, Misleading, and so on. 95 Dharawat et al proposed Covid-HeRA, a dataset of 61 286 COVID-19-related tweets collected from Twitter. The tweets were annotated by regular users into 5 categories: Possibly Severe, Highly Severe, Refutes/Rebuts, Other, and Real News/Claims. 96
In the field of health misinformation detection, the construction of multi-class datasets reflects the need for fine-grained identification of complex information types. Existing studies primarily adopt a 3-class framework, leveraging expert or manual annotation to develop datasets from social media, news platforms, and medical forums, covering public health events such as the Zika virus and COVID-19. Some researchers have further expanded classification dimensions, introducing 4- to 5-class or even more granular multi-label systems to capture the diversity of health information. These datasets exhibit significant variation in linguistic diversity, data scale, and annotation methods, highlighting the dynamic adaptation of misinformation definitions and classification standards across different research contexts. Future studies should explore unified annotation frameworks for cross-domain and multilingual datasets while enhancing model robustness in handling complex classification schemes.
Evaluation Metrics for Health Misinformation Detection
To assess the effectiveness of misinformation detection methods in classification tasks, researchers commonly adopt standardized, statistically grounded performance metrics. These indicators, derived from confusion matrices, enable consistent evaluation, and comparison of model performance across studies.
A confusion matrix, also known as an error matrix, is a table that visually depicts the performance of a supervised classification machine learning system. 97 It compares the model’s predicted labels with the actual ground truth labels, and consists of 4 key components: true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN), as shown in Table 1.
Confusion Matrix.

Based on these values, several widely used evaluation metrics are calculated:
Accuracy: Measures the proportion of correctly predicted samples relative to the total number of samples.

Precision: Represents the proportion of truly positive samples among those identified as positive.
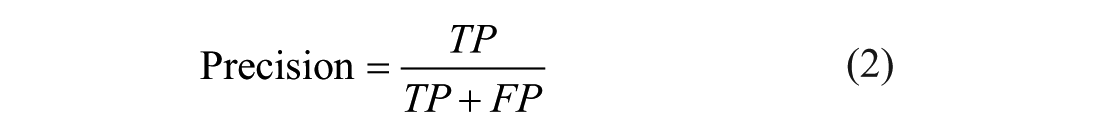
Recall: Captures the proportion of correctly identified positive samples among all actual positive cases.

F1-score: Combines precision and recall into a single metric, providing a balanced assessment of model performance.

The Receiver Operating Characteristics (ROC) curve shows the success of a classification model across several classification thresholds. True Positive Rate (Recall) and False Positive Rate (FPR) are used in this curve. 98 AUC is an abbreviation for “Area Under the ROC curve,” it reflects the classifier’s ability to distinguish between positive and negative samples across various classification thresholds. The FPR can be defined as in equation (5).

For multi-class classification tasks, performance is typically evaluated using macro-averaged metrics, which compute the mean of the per-class performance scores:
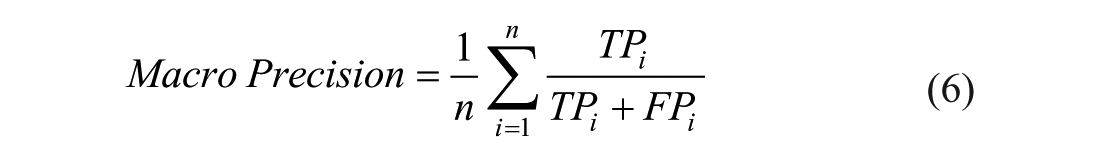


Here,
However, when dealing with highly imbalanced datasets, these conventional metrics may fail to accurately reflect model performance. In such cases, additional evaluation indicators are recommended:
Matthews Correlation Coefficient (MCC) measures the correlation between the actual and the predicted values of the instances.

Cohen’s kappa (k) compares how well the binary classifier performs compared to the randomized accuracy


Brier Loss measures the mean squared error between the predicted probabilities and the actual outcomes.

Specifically,
In summary, a comprehensive evaluation of misinformation detection models requires both traditional and specialized performance metrics. Standard indicators such as accuracy, precision, recall, F1-score, and AUC remain fundamental. Yet, for imbalanced data scenarios, metrics like MCC, Cohen’s Kappa, and Brier Loss provide essential complementary insights, ensuring a more reliable and nuanced assessment of model performance.
Machine Learning Detection Methods
The rapid proliferation of health misinformation has necessitated the development of automated detection systems to mitigate its impact. In this context, machine learning (ML) and artificial intelligence (AI) techniques have emerged as pivotal tools for identifying misinformation, particularly across social media platforms. 68 A growing body of research demonstrates the efficacy of ML-based approaches in filtering and categorizing misleading content, with applications ranging from general fake news detection to health-specific misinformation analysis.9,99 The general framework for health misinformation detection based on machine learning is illustrated in Figure 3.

General framework of machine learning-based health misinformation detection.
Performance Evaluation Among Machine Learning Algorithms
Health misinformation detection is fundamentally a text classification task, and many researchers employ traditional ML algorithms to detect misinformation. The effectiveness of these algorithms depends on task-specific feature engineering. 100 This section reviews the literature on various ML models applied to health misinformation detection and evaluates their relative performance. A summary of baseline ML algorithms used in the reviewed literature and their functions is presented in Appendix 3.
Among traditional ML algorithms, Random Forest (RF) consistently demonstrates strong performance across health misinformation detection tasks. Zhao et al developed a feature set incorporating both central and peripheral-level attributes for detecting misinformation in online health communities. Their RF model achieved an F1-score of 0.848, outperforming other classifiers. 93 Similarly, Safarnejad et al detected Zika virus misinformation by combining dissemination network features, retweet signal features, content-based features, and user features. Using all feature categories as input, the RF model achieved the best performance with an F1-score of 0.859. 62 Khan et al employed a named-entity recognition (NER) approach to extract 39 linguistic and affective features from a COVID-19 dataset. When training multiple ML classifiers, the RF model exhibited the highest F1-score of 0.888. 76
Beyond RF, ensemble learning methods such as Gradient Boosting Decision Trees (GBDT) and AdaBoost have also demonstrated high efficacy. Liu et al analyzed health misinformation in Chinese social media using 104 linguistic and statistical features. Their experiments with multiple ML models revealed that GBDT achieved the highest precision of 0.837. 4 Al-Rakhami and Al-Amri utilized 6 machine learning algorithms and integrated ensemble learning techniques. They extracted tweet-level and user-level features to investigate the credibility of COVID-19 misinformation on Twitter. The best-performing ensemble model, with SVM and RF as base models and C4.5 as the meta-model, achieved an accuracy of 0.978. 72 Amjad et al constructed a benchmark dataset for Urdu fake news detection across 5 domains, including health. They extracted n-gram features such as character n-grams, word n-grams, and function n-grams. Among 7 machine learning classifiers, the AdaBoost achieved the highest performance, with an F1 score of 0.90 for real news. 101
Evolutionary algorithms have also been explored in health misinformation detection. Al-Ahmad et al proposed an evolutionary approach for COVID-19 fake news detection. They used 3 metaheuristic algorithms: Binary Genetic Algorithm (BGA), Binary Particle Swarm Optimization (BPSO), and Binary Salp Swarm Algorithm (BSSA). These algorithms helped reduce redundant features and improve detection accuracy. Among them, KNN-BGA achieved the highest accuracy of 75.43% while significantly minimizing feature redundancy. 102 Qasem et al leveraged a stacked classifier (LR combined with Genetic Algorithm-SVM) to detect COVID-19 rumors in Arabic, achieving an accuracy of 0.926. 103 Nabożny et al employed LR and Recursive Feature Elimination for feature selection. They optimized models using the Tree-based Pipeline Optimization Tool (TPOT) library, which applies a genetic algorithm to a pool of models including LR, XGBoost, and MLP. This approach enhanced the efficiency of evaluating unreliable medical statements. 23
Several studies have also examined the impact of different feature representations across ML models. Nistor and Zadobrischi employed DT, NB, and KNN to classify fake news spread on social media during the COVID-19 epidemic, achieving 99.63% accuracy using a Term Frequency-Inverse Document Frequency (TF-IDF) vector combined with Python and JavaScript. 104 Mazzeo et al analyzed COVID-19 misinformation on search engines by extracting text and URL features and comparing the performance of ML algorithms, including SVM, stochastic gradient descent (SGD), LR, NB, and RF. Their findings indicated that when oversampling the data, Naive Bayes based on the bag-of-words (BoW) model and URL features was the most effective classifier, achieving the highest F1-score of 0.81. 105 Dhoju et al tested multiple classical ML methods for health article reliability detection, including MNB, LSVC, RF, and LR. They experimented with 3 feature combinations: words or n-grams (W), extracted features (EF), and W + EF. LSVC outperformed other models in all combinations, achieving a macro F-measure of 96% with the W + EF feature combination. 106 Alsmadi et al integrated multiple COVID-19 misinformation datasets to compare the performance of ML models on individual versus aggregated datasets. They also tested various word and sentence embedding models, including W2V, Glove, and BERT. Their findings revealed that integrating datasets mitigated class imbalance and improved model robustness, while word-embedding techniques consistently enhanced classification accuracy across all evaluated classifiers. 33
In summary, traditional ML algorithms exhibit significant performance differences and applicability in the task of health misinformation detection. Ensemble learning methods, such as RF, GBDT, and AdaBoost, further enhance classification performance by leveraging the strengths of multiple base models, particularly excelling in handling high-dimensional features and complex data distributions. Additionally, evolutionary algorithms significantly improve detection accuracy and reduce feature redundancy by optimizing feature selection and model parameters. The impact of feature representation methods, such as TF-IDF, BoW, and embedding models, on model performance has also been extensively validated, with embedding-based feature representations demonstrating remarkable improvements in classification accuracy. These findings highlight the importance of selecting appropriate classification algorithms, optimization techniques, and feature representation methods to achieve optimal performance in health misinformation detection, offering valuable insights for future research and practical applications in this domain.
Comparative Analysis of Machine Learning and Other Models
While ML has been widely applied in misinformation detection, other models, particularly DL models, have also attracted significant attention for this task. This section presents a comparative analysis of ML and alternative models, highlighting their respective strengths and limitations. A summary of key DL algorithms discussed in the reviewed literature and their functionalities is provided in Appendix 4.
In some cases, ML algorithms outperform other models. Sicilia et al proposed a method to detect rumors in health-related Twitter posts within a single topic domain. Their approach introduced measurements of influence potential and network features to compare multiple algorithms (MLP, Nearest Neighbor, SVM, Random Tree, Multiclass Adaboost, and RF) through a wrapper method. The results revealed that the RF classifier achieved the highest accuracy, correctly identifying approximately 90% of rumors with acceptable precision. 85 Mahara et al compared 5 traditional ML techniques—DT, RF, SVM, AdaBoost-DT, and AdaBoost-RF—with 2 hybrid DL approaches—CNN-LSTM and CNN-Bi-LSTM—using the Fake News Healthcare dataset. The AdaBoost-RF model, which combined news content and readability features, achieved the highest performance, with an F1 score of 0.989, indicating its greater suitability for practical applications compared to complex deep learning models. 107 Sharma and Garg explored five ML algorithms (DT, NB, LR, RF, and KNN) and two DL algorithms (LSTM and Bi-LSTM) for classifying COVID-19 fake news text in India. Additionally, they employed 2 convolutional neural networks (VGG-16 and ResNet-50) for image classification. Among the text classifiers, RF achieved the highest accuracy (94%), while ResNet-50 achieved 76.6% accuracy in image classification when the image size was set to 256x256. 108 Bonet-Jover et al introduced the Spanish-language RUN dataset, which focuses on health and COVID-19 misinformation. They tested multiple ML algorithms, including SVM, RF, LR, DT, AdaBoost, and Gaussian Naive Bayes, along with deep learning models like MLPs. Using a fine-grained labeling scheme based on journalistic techniques, they found that the RUN-AS labeled DT algorithm performed best, achieving a macro F1 score of 0.948. 84 Madani et al developed a coronavirus-related fake news detection model using Spark, Tweepy, and several ML algorithms (LR, DT, RF, NB, Gradient-Boosted Tree, SVM), alongside one DL model (MLP). The RF algorithm outperformed all other models, achieving an accuracy of 0.79 and a recall of 100%. 109 Alhakami et al compared 6 machine learning models (LR, NB, SVM, RF, KNN, DT) and 2 deep learning models (CNN, LSTM) for detecting COVID-19 misinformation. The machine learning models employed a BoW representation with TF–IDF features, while the deep learning models utilized GloVe word embeddings. Across 2 datasets, the ML models consistently outperformed the DL models and demonstrated lower computational costs. 110 Narra et al introduced a fake news detection method using feature extraction techniques (TF-IDF, BoW) and feature selection methods (PCA, Chi-square). They evaluated seven ML models including RF, Extra Tree, Gradient Boosting Machine, LR, NB, stochastic gradient (SG), and a voting classifier comprising LR and SG alongside four DL models (CNN, LSTM, ResNet, and InceptionV3). Their findings revealed that the Extra Trees (ET) classifier achieved the highest accuracy (94.74%) when combining TF-IDF and BoW. The study also demonstrated that thorough text preprocessing significantly improved detection accuracy. 111
In contrast, there are cases where other models outperform ML models. Du et al evaluated the performance of traditional ML algorithms (SVM, LR, and Extremely Randomized Trees) against two DL models (CNN and RNN) for identifying misinformation about the HPV vaccine. The ML models employed TF–IDF for feature extraction, whereas the DL models utilized GloVe embeddings for feature representation. Among these algorithms, CNN achieved the best performance, with an AUC of 0.794. 66 Shams et al proposed SEMiNExt, an extension for a real-time health misinformation notifier. They compared six ML algorithms with an ANN-based DL approach. The results showed that SEMiNExt, using the ANN, achieved the best performance, with an F1 score of 92%. 112 Hayawi et al tested XGBoost, LSTM, and BERT models for classifying COVID-19 vaccine misinformation. The results revealed that BERT outperformed the others with an F1 score of 0.98. 67 Alghamdi et al explored several ML models and fine-tuned pre-trained transformer models, including BERT and COVID-Twitter-BERT (CT-BERT), for detecting COVID-19 fake news. Incorporating Bi-GRU on top of the CT-BERT model yielded state-of-the-art performance, with an F1 score of 0.985. 113 Dai et al compared Random guess, Unigram, Unigram-News Source, Unigram-Tags, SVM, RF, CNN, Bi-GRU, and SAF (Social Article Fusion) for misinformation detection on the FakeHealth dataset, with SAF emerging as the top performer, achieving an accuracy of 0.810. 61 Iwendi et al proposed 39 features, including sentiment, linguistic, and named entity recognition features, for detecting COVID-19 misinformation. They compared the performance of three machine learning algorithms (AdaBoost, DT, and KNN) and three deep learning algorithms (GRU, LSTM, and RNN). After feature extraction, the deep learning models consistently outperformed the machine learning models. Among them, GRU achieved the highest accuracy of 86.12%. 114 Bangyal et al compared seven ML algorithms with six DL algorithms for detecting COVID-19 misinformation, with Bi-LSTM and CNN achieving the highest accuracy of 97%. 115 Tomaszewski et al tested CNN, Bi-LSTM, SVM, and NB for detecting HPV vaccine misinformation, finding CNN to have the best overall performance, with an accuracy of 0.920. 116 Albalawi et al compared traditional machine learning algorithms with deep learning architectures on Arabic COVID-19-related Twitter data. The Bi-LSTM model, combined with Mazajak skip-gram pre-trained word embeddings, achieved the best performance with an F1 score of 75.2%. 117 Dharawat et al proposed a categorization framework for detecting the severity of health misinformation. They evaluated several models, including RF, SVM, LR, Bi-LSTM, CNN, BERT, Hierarchical Attention Networks, and dEFEND. The BERT model, enhanced with data augmentation and a customized loss function, achieved the best performance with an F1 score of 0.41. This result suggests that distinguishing the severity of misinformation is more challenging than simply classifying it as true or false. 96 Al-Yahya et al collected datasets such as ArCOV19-Rumors and Covid-19-Fakes to study Arabic fake news detection. They evaluated linear models, deep learning models (CNN, RNN, GRU), and Transformer-based models (AraBERT, QARiB, etc.). Results show that Transformer-based models outperform neural networks, with QARiB achieving the highest F1 scores and accuracy. 118 Abdelminaam et al compared the performance of six traditional ML models and two DL models (Modified LSTM and Modified GRU) in detecting COVID-19 fake tweets. The traditional ML models employed TF-IDF and n-grams for feature analysis, while the deep learning models leveraged word embeddings. Optimization was performed using grid search for ML models and Keras tuning for DL models. The two-layer LSTM achieved the best test results, achieving an accuracy of 98.6%. 119
Both ML and other algorithms have their inherent strengths, which vary depending on the nature of the dataset and the task at hand. Di Sotto and Viviani identified 6 types of health misinformation features to compare the performance of ML and DL methods across different datasets. Their experimental results revealed that the optimal classifier-feature configurations differ for each dataset. While DL solutions are highly effective when utilizing word-embedded features alone, the importance of ML classifiers becomes more apparent when additional types of features are considered. 120 Elhadad et al proposed a voting-based integrated ML classifier using 10 algorithms: DT, MNB, BNB, LR, KNN, Perceptron, ANN, LSVM, Ensemble RF, and XGBoost. Their results showed that the ANN classifier excelled in binary classification tasks. The DT classifier helped reduce misclassification of real documents as misleading. Meanwhile, the LR classifier minimized the misclassification of misleading documents as real. 121
In summary, the performance of algorithms for health misinformation detection is highly context-dependent. Traditional machine learning methods remain competitive when feature engineering is mature, computational resources are limited, or a balance between interpretability and accuracy is necessary. Ensemble strategies can further improve classification performance by combining diverse features. Neural network-based approaches excel in capturing high-dimensional semantic relationships and are well-suited for cross-lingual or multimodal tasks. However, these methods often require significant computational resources, with performance gains coming at the cost of efficiency. The choice of detection methods should consider task-specific demands, dataset characteristics, and available resources. Future research should explore hybrid models that combine the advantages of traditional machine learning and neural networks to improve the accuracy and robustness of health misinformation detection systems.
Deep Learning Detection Methods
Traditional ML algorithms rely on manually engineered features for classification, their performance is often constrained by the quality and comprehensiveness of these features. In contrast, deep learning (DL)—a subset of ML based on deep neural networks—eliminates the need for manual feature extraction by leveraging the self-learning capability of network layers to automatically extract textual features from raw data, thereby achieving superior performance in natural language processing tasks such as text classification.66,122 We will introduce DL methods for health misinformation detection from 2 perspectives: unimodal misinformation detection and multimodal misinformation detection. The general framework for health misinformation detection based on deep learning is illustrated in Figure 4.

General framework of deep learning-based health misinformation detection.
Unimodal Misinformation Detection
Unimodal learning refers to learning using data from only 1 modality, while multimodal learning refers to learning using data from multiple modalities simultaneously. In order to improve the performance of health misinformation detection, several scholars have used different DL algorithms to deeply explore the potential of unimodal data.
Traditional Deep Learning Models
Traditional deep learning models encompass a range of neural network architectures that have been widely utilized for various ML tasks, including misinformation detection. Among these, Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are 2 of the most prominent. CNNs are deep feedforward networks characterized by a shared-weights architecture and translation invariance, originally designed for image analysis. However, recent research has demonstrated their effectiveness in sequential data analysis, 123 highlighting their adaptability to diverse data types, including textual misinformation detection. On the other hand, RNNs are specifically designed for processing sequential data by maintaining contextual information through their recurrent connections. Variants such as LSTM and GRU have been developed to address issues like vanishing gradients, making RNNs particularly effective for handling time-series and textual data.
CNN-based models have demonstrated significant effectiveness in detecting misinformation, particularly in health-related domains. Kaliyar et al introduced a multi-channel deep CNN that integrates three parallel one-dimensional convolutional network (1D-CNN) channels. Each channel applies filters of different sizes to capture expressions of varying lengths. The model employs GloVe for word embeddings and was evaluated on two health-related datasets. Experimental results show that the proposed CNN model is effective in distinguishing health misinformation. 124 Luo et al examined RNN, CNN, and FastText on their proposed Chinese infodemic dataset. Their findings revealed that fastText achieved superior results in identifying false records, while CNN surpassed the other two models in accurately recognizing real records. Overall, CNN proved to be the optimal choice for misinformation classification in this study. 88 Kumar et al applied TF-IDF for feature extraction and Modified Grasshopper Optimization (MGO) for feature selection, with CNN then extracting n-gram features for classification. Their OptNet-Fake model achieved 98.43% accuracy on the COVID-19 Fake News dataset. 125
RNNs and their advanced variants, including LSTM and GRU, have been widely used to process sequential text data for fake news detection. Chen et al compared the performance of LSTM, GRU, and Bi-LSTM in detecting COVID-19 misinformation. The study found that Bi-LSTM achieved the best detection performance, with accuracy rates of 94%, 99%, and 82% on English short texts, English long texts, and Chinese texts, respectively. 17 Chen and Lai proposed a COVID-19 misinformation detection framework that integrates fuzzy clustering and DL. They used Fuzzy C-Means (FCM) clustering to filter text features before classifying them with Bi-LSTM, GRU, and LSTM. Their results showed that Bi-LSTM achieved 99% accuracy on English datasets and 86% on Chinese datasets. Fuzzy clustering reduced detection time by 10 to 15%, but caused an 8% drop in accuracy for Chinese datasets. This approach improves detection efficiency while maintaining high classification accuracy, making it suitable for large-scale misinformation screening. 126
In the field of health misinformation detection, CNNs and RNNs, along with their variants, have emerged as 2 pivotal deep learning models, each demonstrating notable strengths and robust performance due to their unique architectures. CNNs excel at capturing local features in data through convolutional operations, while RNNs and their variants are particularly effective in handling sequential textual data, adept at modeling temporal dependencies and contextual information. To further enhance model performance, researchers have employed a variety of strategies. In the stage of text vector representation, word embedding methods such as GloVe and Word Frequency are widely adopted to transform textual data into vector forms. In terms of feature selection, optimization algorithms and clustering techniques are utilized to eliminate redundant features and reduce data dimensionality, which not only lowers computational overhead but also improves the stability and accuracy of model training. In summary, CNNs and RNNs, each with their respective advantages, play complementary roles in health misinformation detection. Combined with diverse text processing techniques, they provide a strong foundation for building efficient and accurate health misinformation detection systems.
Attention-Based Deep Learning Models
Self-attention, sometimes called intra-attention is an attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence. Self-attention has been used successfully in a variety of tasks including reading comprehension, abstractive summarization, textual entailment, and learning task-independent sentence representations. Transformer is the first transduction model relying entirely on self-attention to compute representations of its input and output without using sequence aligned RNN or convolution. 127 BERT is a pre-trained language model based on the Transformer architecture. It is the first fine-tuning-based representation model to achieve state-of-the-art performance on a large number of sentence-level and token-level tasks, outperforming many task-specific architectures. 128
Given the effectiveness of attention-based models, numerous studies have leveraged these mechanisms for health misinformation detection. Paka et al introduced Cross-SEAN, a neural attention model that incorporates tweet text, tweet features, user features, and external knowledge. It uses cross-stitch units to share parameters between tweet and user features, with outputs connected at both early and late network stages to enhance information sharing. On a large-scale COVID-19 Twitter dataset, it achieved an F1 score of 0.953, surpassing the benchmark by over 9%. 73 Ding et al proposed EvolveDetector to detect fake news in emerging events. The model employs Word2Vec and Text-CNN for feature extraction. A hard-attention-based knowledge storage mechanism is designed to record neuron parameters through knowledge memory and event masks, reducing interference from dissimilar events. The event mask is used to assess event relationships, and a multi-head self-attention mechanism is leveraged to filter similar historical events for knowledge transfer. Experimental results on COVID-19 and other datasets demonstrate that the proposed model outperforms baseline models, especially in generalizing to new events. 129
With the rise of pretrained language models (PLMs), advanced neural architectures such as BERT have been widely adopted for misinformation detection. 130 Studies have explored various strategies to enhance model robustness, including fine-tuning, ensemble learning, domain adaptation, and interpretability techniques. For instance, Morita et al employed a fine-tuned BERTBASE (uncased) model with a tanh classifier to classify public health and political misinformation, addressing class imbalance using the Matthews correlation coefficient (MCC=0.819). 131 Dementieva and Panchenko proposed a Cross-Lingual Evidence (CE)-based approach, integrating cross-lingual news retrieval with content similarity analysis. By combining CE features with pre-trained models like BERT and RoBERTa, their method significantly enhanced detection performance. On the ReCOVery dataset, RoBERTa with CE features achieved an F1 score of 0.975, demonstrating the power of cross-lingual evidence in misinformation identification. 132 To further improve performance, ensemble approaches have been employed, such as Malla and Alphonse, who combined RoBERTa and CT-BERT with fusion vector multiplication technique, achieving exceptional accuracy (98.88%) and F1 score (98.93%) on COVID-19 fake news dataset. 133 Similarly, Das et al employed several pre-trained language models, including RoBERTa and XLNet, as base detectors. Their predictions were combined through soft voting, and the resulting ensemble was further integrated with a Statistical Feature Fusion Network (SFFN). The SFFN incorporated metadata-based statistical features such as URL domains, usernames, and news authors. In addition, they applied heuristic post-processing, which adjusted the model’s initial predictions based on a set of rule-based heuristics. Their approach was applied to a COVID-19 fake news dataset and achieved a best F1-score of 0.989. 134 Kumar et al proposed an ensemble deep learning model that integrates CT-BERT, BERTweet, and RoBERTa. The model combines the predictions of the three base models through class probability averaging. It achieved a weighted F1 score of 0.99 in detecting COVID-19 fake news. 135 Malla and Alphonse introduced the MVEDL model, which uses majority voting with RoBERTa, CT-BERT, and BERTweet classifiers, achieving accuracy and F1 scores of 91.75% and 91.14%, respectively. 136 Beyond ensemble learning, domain adaptation and multitask learning have proven effective in enhancing misinformation detection. Abd Elaziz et al employed a pre-trained AraBERT model for feature extraction using fine-tuning and multi-task learning. They used an improved Fire Hawk Optimizer (FHO) for feature selection. Their method enhanced the classification performance on an Arabic COVID-19 misinformation dataset. 137 Qasim et al evaluated nine pre-trained BERT-based models on three datasets: COVID-19 fake news, COVID-19 English tweets, and extremism detection. RoBERTa-base performed best for COVID-19 fake news detection, while BART-large excelled on COVID-19 English tweets. 138 In addition, model interpretability has attracted increasing attention. Ayoub et al proposed an explainable NLP framework that combines DistilBERT with SHAP (SHapley Additive exPlanations). This approach achieved strong performance in detecting COVID-19 misinformation, with an accuracy of 0.938, while also enhancing transparency in classification. 139
In summary, attention-based deep learning models, particularly those built upon Transformer architectures such as BERT, have demonstrated significant effectiveness in the task of health misinformation detection. These models leverage self-attention mechanisms to capture complex contextual relationships within text, enabling superior performance across a range of datasets and misinformation types. Research has explored diverse approaches to further enhance model performance and generalizability, including the integration of tweet- and user-level features, knowledge memory mechanisms, ensemble learning strategies, domain adaptation, and interpretability techniques. The adoption of pre-trained language models such as BERT, RoBERTa, CT-BERT, and AraBERT has proven particularly impactful, often surpassing traditional architectures and benchmark baselines. Moreover, the growing emphasis on explainability reflects a shift toward not only improving predictive accuracy but also ensuring model transparency and trustworthiness. Collectively, these advancements highlight the evolving landscape of attention-based methods in combating health-related misinformation, especially in the context of COVID-19.
Graph Neural Networks
A graph neural network (GNN) is a novel technique that focuses on using DL algorithms over graph structures. 140 Many methods have been implemented to detect and prevent the spread of fake news over the past decade, among which the GNN-based approach is the most recent. 141 Existing approaches for fake news detection focus almost exclusively on features related to the content, propagation, and social context separately in their models. GNN promise to be a potentially unifying framework for combining content, propagation, and social context-based approaches. 142 GNN-based methods for misinformation detection can be categorized into 4 groups: conventional GNN-based, GCN-based (Graph Convolutional Network), AGNN-based (Attention Graph Neural Network), and GAE-based (Graph Autoencoder) approaches. 141
Recent studies have explored various GNN architectures and training strategies to improve fake news detection performance. Liao et al proposed the Fake News Detection Multi-Task Learning (FDML) model, which integrates textual content and contextual information through a news graph (N-Graph). The model employs a graph convolutional network (GCN) within a multi-task learning framework to jointly address fake news detection and topic classification. Compared to state-of-the-art models, FDML achieved about a 6% improvement in both average accuracy and Macro-F1 score. 143 Karnyoto et al constructed word–word and word–document nodes within a graph structure. They applied data augmentation techniques in combination with various GNN models, including GCN, Graph Attention Networks (GAT), and GraphSAGE (Sample and Aggregate), to detect COVID-19-related fake news. Experimental results showed that GraphSAGE, when combined with data augmentation, achieved the highest accuracy and F1-score among all evaluated models. 144 Cui et al constructed a heterogeneous graph with publisher, news, and user nodes, along with multiple edge types. Node features were extracted, and 2 meta-paths were defined to capture contextual information. The model used encoding, aggregation, and semantic fusion to learn effective news representations. A cross-entropy loss function was applied to update model parameters. Evaluations on the FANG and FakeHealth datasets showed that Hetero-SCAN outperformed various baseline methods, addressing the challenge of using multi-level social context and temporal information for fake news detection. 145 Min et al developed a dataset comprising multi-topic news, a large number of posts, and user social relationships, with 2 topics related to health. They framed social-context-based fake news detection as a heterogeneous graph classification task and introduced the Post-User Interaction Network (PSIN) model. They also used an adversarial topic discriminator to encourage the model to learn topic-independent features, improving its generalization to emerging events. Experimental results in both in-topic and out-of-topic settings showed that PSIN significantly outperformed all state-of-the-art baselines. 146
Overall, GNNs offer a unified framework for integrating content features, propagation patterns, and social context, thanks to their structured modeling capabilities. They have shown significant advantages in misinformation detection. Recent studies have improved GNN performance through several innovative strategies. At the data level, augmentation techniques are used to enhance model robustness. In graph structure design, multi-type nodes and meta-paths help capture heterogeneous relationships. At the algorithmic level, the use of graph attention mechanisms, hierarchical aggregation functions, and adversarial training enhances feature representation.
Transfer Learning Models
In the context of health misinformation detection, transfer learning and domain adaptation techniques offer significant advantages. They enable models to generalize across platforms and adapt to new and evolving domains. These techniques are especially useful for combating health-related misinformation, which can emerge quickly and vary across regions, languages, and platforms. By leveraging knowledge from source domains and applying it to target domains with limited labeled data, transfer learning models can efficiently address domain shifts, improve detection accuracy, and make systems more robust. Below, we review key studies that have successfully applied these methods to health misinformation detection.
Misinformation detection models need to be both generalizable across different platforms and adaptable to new domains. Joshi et al developed a universal misinformation classifier across multiple platforms using Domain-Adversarial Neural Networks (DANN). They incorporated the Local Interpretable Model-Agnostic Explanations (LIME) framework for explainability. Their study, using COVID-19 misinformation as a case study, demonstrated that DANN improved the F1 score, increasing classification accuracy by 3% and AUC by 9%. 68 Yue et al tackled the domain adaptation problem in early-stage COVID-19 misinformation detection with a Contrastive Adaptation Network for Misinformation Detection (CANMD). The model used pseudo-labeling, label correction, and contrastive adaptation loss to improve adaptation between source and target domains. Experiments with RoBERTa on multiple datasets showed that CANMD achieved an average improvement of 11.5% and up to 34.5% under label shift conditions. 147 Yue et al addressed cross-domain misinformation detection in low-resource settings with MetaAdapt, a meta-learning-based few-shot detection model. By leveraging Task Similarity Computation and Gradient Rescaling, MetaAdapt facilitated knowledge transfer between source and target domains. Experiments on the CoAID, Constraint, and ANTiVax datasets confirmed its superiority over state-of-the-art baselines and large language models, making it highly effective for misinformation detection in emerging domains. 148 Dhankar et al applied transfer learning to detect COVID-19 misinformation on social media. Their approach combined General Twitter Embedding (GTE) with a Context-Specific Embedding (CSE) to enhance text classification. They used SVM and MLP as classifiers. Two strategies were explored: Augmented Transfer Learning (ATE) and Concatenation Transfer Learning (CTL). The results showed that concatenating GTE and CSE significantly improved performance. 149
As misinformation spreads across languages, cross-lingual detection methods have become crucial. Du et al introduced CrossFake, a model designed to detect low-resource language (Chinese) COVID-19 fake news using BERT-based embeddings trained on high-resource language (English) data. For Chinese news, they used Google Translate to convert content into English before applying the same processing pipeline. Comparative experiments showed that CrossFake outperformed multiple monolingual and cross-lingual baselines, validating its effectiveness for cross-lingual misinformation detection from high-resource to low-resource languages. 81 Ghayoomi and Mousavian utilized XLM-RoBERTa and a parallel CNN to detect Persian COVID-19 fake news. They applied cross-lingual and cross-domain knowledge transfer by incorporating an English COVID-19 dataset (for cross-lingual transfer) and a general domain Persian fake news dataset (for cross-domain transfer). This combined approach improved performance, achieving an F1 score of 0.721, surpassing the baseline by 2.39%. 82
Overall, transfer learning models provide a scalable solution for unimodal health misinformation detection through domain alignment, knowledge integration, and cross-lingual transfer mechanisms. Studies have shown that adversarial training and contrastive adaptation effectively mitigate domain shift, while meta-learning frameworks maintain detection robustness in low-resource scenarios by leveraging task similarity metrics. Additionally, cross-lingual transfer techniques overcome language barriers through embedding alignment and translation-based augmentation. Despite demonstrating exceptional performance on specific datasets, current methods still face challenges related to computational cost, dependence on pretrained corpora, and coverage of low-resource languages. Future research should explore lightweight transfer architectures, automated domain adaptation thresholds, and language-agnostic universal embedding representations to address the complex challenges posed by the global spread of health misinformation.
Hybrid Models
Detecting health misinformation is a complex task. Traditional single-model approaches often exhibit limitations in handling complex semantics, contextual dependencies, and large-scale textual data. To address these challenges, researchers have increasingly explored hybrid models that integrate ML and DL, as well as various DL methods, to leverage the strengths of different algorithms in order to improve robustness and accuracy. These models not only capture local textual features but also model long-range dependencies and deep semantic information, demonstrating significant potential in single-modal misinformation detection. This section systematically reviews hybrid-model-based single-modal detection methods, with a focus on innovations in architectural design, feature extraction, and task optimization. Additionally, it summarizes key technological advancements and existing limitations in current research.
Hybrid models combining ML and DL have shown great potential in detecting health misinformation. Bonet-Jover et al proposed an architecture for automatically detecting fake news in health domains. This model combines LSTM-Convolutional networks with LR, achieving a macro F1 score of 0.978 based on the 5W1H components. 150 Biradar et al developed several classifiers, including an early fusion-based DNN model, an ensemble of RNNs, a voting classifier architecture, and a multi-level bit-wise OR model. The study found that state-of-the-art language models and ensemble approaches outperformed other machine learning techniques in detecting fake news in COVID-19 datasets. 151 Serrano et al detected COVID-19 misinformation on YouTube by analyzing user comments. They used pre-trained Transformer models to identify conspiracy-related comments. The proportion of such comments, combined with TF-IDF features from video titles, was used to train ML classifiers. Results showed that using both comment content and conspiracy ratios achieved 89.4% accuracy, highlighting the value of user comments in misinformation detection. 152 Zhang et al proposed a health misinformation detection method combining stance detection (SDM) and trust models (TM). SDM, based on the T5 language model, generates support, and opposition scores using predefined keywords and structured input. TM, based on LR, predicts the correct health treatment answer using document stance scores and feature vectors. This method achieved 76% accuracy on TREC 2021 health-related questions. 153
Hybrid models based on multi-task learning and attention mechanisms further improve health misinformation detection performance. Kumari et al proposed a multi-task learning framework that combines a BERT-based model with an attention-enhanced BiLSTM encoder. The architecture jointly performs fake news detection (main task), along with emotion recognition and novelty detection (auxiliary tasks). On the COVID-Stance dataset, the model achieved state-of-the-art performance, with a 7.95% improvement in accuracy. 154 Ma et al proposed a dynamic word embedding method for Chinese text (DWtext), based on a dual-channel CNN model with parallel max-pooling and attention-pooling layers. The model was evaluated on two COVID-19 fake news datasets. Results show that it performs well on noisy data and effectively balances local and global feature relevance. 155 Upadhyay et al introduced the Vec4Cred model, which combines BiLSTM-CNN and attention mechanisms for binary classification via fully connected layers. It performs excellently across multiple datasets and in assessing the authenticity of webpage health information. 156 Fernández-Pichel et al proposed a multi-stage retrieval system for detecting COVID-19 misinformation, based on the TREC 2020 Health Misinformation Track. The system integrates document relevance (BM25), passage relevance (MonoT5), and passage reliability (supervised and unsupervised). It compares unsupervised fusion with learning-to-rank. Results show that passage relevance and unsupervised reliability estimation are effective, and simple fusion methods outperform complex ones. 157
Hybrid approaches utilizing multi-aspect features and diverse feature extraction techniques have demonstrated strong performance in health misinformation detection. Al-Sarem et al proposed a hybrid deep learning model (LSTM-PCNN) for detecting COVID-19-related rumors on social media. The model combines LSTM networks with a Parallel CNN architecture. The study also examined the impact of static word embeddings such as Word2Vec, GloVe, and FastText on model performance. Experimental results showed that the proposed model outperformed other methods in terms of accuracy, precision, recall, and F1 score. 158 Wani et al developed a stance classification model for COVID-19-related tweets using BERT embeddings and a CNN-based classifier. The study compared 4 learning techniques—SVM, RF, DNN, and CNN. Among them, the BERT-CNN model achieved the best performance, with an average F1 score of 68.24%, highlighting the effectiveness of combining contextual embeddings with neural architectures. 159 Li introduced a multidimensional feature framework for health misinformation detection, grounded in Comprehensive Information Theory. The framework integrates syntactic and semantic features, including a novel method called LinguisticStrategy2Vec to extract deep semantic information. DL models such as DNN, LSTM, and CNN were employed for training and classification. Experiments on a real-world dataset showed that the proposed method achieved an F1 score of 0.831 and an AUC of 0.883. 65 Apostol et al proposed the FN-BERT-TFIDF model, which combines TF-IDF vectors, BERT embeddings, Bi-LSTM, and CNN for misinformation detection. The model achieved accuracy rates of 60.92% on the LIAR dataset and 87.92% on a COVID-19 dataset. 160
In conclusion, hybrid models have proven to be highly effective in detecting health misinformation by leveraging the strengths of multiple algorithms, overcoming the limitations of traditional single-model approaches. These models not only enhance the ability to capture complex patterns within the data but also improve robustness and accuracy through the integration of diverse features and processing methods. Despite significant progress, challenges such as data noise, model interpretability, and scalability remain to be explored further. Additionally, issues such as large-scale corpus storage for training, high computational complexity of models, and real-time processing capabilities still need to be addressed. Future research could focus on optimizing hybrid model architectures, developing more efficient feature extraction techniques, exploring interpretable deep learning models, and tackling bottlenecks in processing large-scale datasets. Furthermore, the integration of multimodal data and the development of real-time misinformation detection systems may become key directions for improving detection accuracy and broadening applicability. As hybrid model technologies continue to evolve, more breakthroughs in health misinformation detection are expected in terms of both accuracy and efficiency.
Multimodal Misinformation Detection
With the rise of social media, the nature of misinformation has evolved from text-based modality to other modalities, such as images, audio, and video. Therefore, the identification of media-rich misinformation requires an approach that exploits and effectively combines the information acquired from different multimodal categories. 161 Data fusion is the process of combining information from multiple modalities to take advantage of all different aspects of the data and extract as much information as possible to improve the performance of machine learning models, as opposed to using a single data aspect or modality. 162 Fusion mechanisms are commonly categorized into 3 types: early fusion, intermediate fusion, and late fusion. 163 Illustrations of the 3 fusion mechanisms are presented in Figure 5.

Illustrations of early, intermediate, and late fusion mechanisms.
Early Fusion
Early fusion refers to the process of integrating raw or preprocessed data from multiple modalities before feeding them into the model. 163 Hou et al explored automatic misinformation detection in online medical videos. They combined language, acoustic, and user engagement features, using an LSVM classifier. Their multimodal approach achieved an overall accuracy of 74%, outperforming single-modality methods. 164
Intermediate Fusion
Intermediate fusion refers to combining features extracted from different modalities before passing them to the model for decision-making. 163 Intermediate fusion enhances detection accuracy and interpretability by integrating multimodal features at the intermediate layers of the model, leveraging attention mechanisms and cross-modal interactions to address semantic consistency challenges. Wang et al introduced semantic and task-level attention mechanisms to focus on key content in antivaccine messages. Their 3-branch model, with distinct attention mechanisms for each branch, combined 3 unimodal features into a 4-dimensional feature set and used an SVM model with an RBF kernel for classification. The model achieved an accuracy of 0.966, while the ensemble method reached 0.974. 165 González-Fernández et al utilized M-BERT to assess the reliability of websites based on textual information. They then employed Gaussian processes to integrate the output of the M-BERT classifier with visual design features to generate the final reliability estimation. By combining textual and visual features, their approach achieved an accuracy of 78% in classifying health-related websites. 166 Hua et al proposed a multimodal fake news detection method called TTEC. It uses back-translation for text data augmentation to enhance the model’s ability to learn topic-related features. BERT and ResNet-50 are employed to extract features from news text and entire images, respectively. A multi-head self-attention mechanism is applied to fuse multimodal information. Additionally, contrastive learning is introduced to address the limitations of weak inter-modality interaction and small data size. Experimental results on a COVID-19 news dataset demonstrate that TTEC outperforms existing methods. 167
Intermediate fusion techniques have also shown significant effectiveness in video-based health misinformation detection. Shang et al developed the TikTec multimodal learning framework for detecting misleading COVID-19 videos on TikTok. After extracting visual and speech features, a co-attention mechanism modeled the correlation between video frames and speech content. The fused multimodal information was encoded by a Gated Recurrent Unit (GRU), passed through an MLP layer, and classified with a softmax layer. TikTec outperformed the best baseline, achieving a 6.1% improvement in accuracy and a 4.8% increase in F1 score. 75 Shang et al proposed the DGExplain framework to address limitations in existing multimodal fake news detection methods during the COVID-19 pandemic. It integrates a range of mechanisms, including an Object-aware Multimodal Feature Encoder (OMFE), a Text-guided Visual Feature Generator (TVFG), and an Image-guided Text Feature Decoder (ITFD), to address cross-modal consistency issues. The Comment-driven Explanation Generator (CDEG) builds a content-comment graph to integrate multimodal information and user comments for fake news detection and explanation generation. The method outperforms existing approaches in accuracy, precision, recall, and F1 score. 168 Shang et al introduced the MultiTec framework for healthcare misinformation detection on TikTok. It combines subtitle-guided visual representation learning with acoustic-aware speech representation. The fusion of multimodal information is enhanced using a dual-attention aggregation network, outperforming baseline methods in accuracy, F1 score, and Kappa coefficient. 169
Late Fusion
Late fusion, also known as “decision fusion,” involves combining the individual decisions derived from each modality to generate the final prediction. This can be achieved through methods such as majority voting, weighted averaging, or employing a meta-machine learning model to aggregate the individual outputs. 163 Raj and Meel proposed the Allied Recurrent and Convolutional Neural Network (ARCNN) framework to distinguish fake and real COVID-19 news. It combines RNN and CNN for final predictions. The RNN component uses LSTM and Bi-LSTM for text classification, while the CNN component uses fine-tuned VGG-16, MobileNetV2, InceptionV3, and XceptionNet for image classification. Early fusion and 4 late fusion techniques are applied to combine the 2 modalities. Experiments on 6 COVID-19 fake news datasets show that weighted averaging is the best fusion method. Bi-LSTM outperforms LSTM, and XceptionNet and MobileNetV2 are the top choices for image classification. 170
In summary, multimodal learning approaches provide multidimensional solutions for health misinformation detection by integrating heterogeneous information from text, visual, audio, and user engagement data. Early fusion enhances global feature representation through front-end data integration, intermediate fusion improves semantic consistency modeling via attention mechanisms and cross-modal interactions, while late fusion leverages decision-level ensemble strategies to combine modality-specific advantages. Emerging trends reveal that contrastive learning-based feature alignment, bidirectional cross-modal interaction through attention mechanisms, and joint modeling of user comments with multimodal content have become pivotal techniques for performance enhancement. Although current studies demonstrate significant progress in public health crises like COVID-19, challenges persist regarding multimodal data scarcity, cross-modal semantic gaps, and adaptation to dynamic social media content. Future research should focus on self-supervised pretraining, interpretable fusion mechanisms, and real-time multimodal streaming processing to address the evolving ecosystem of health misinformation dissemination.
Other Advanced Detection Methods
Knowledge Graph-Based Methods
The modern version of the term “knowledge graph” originated with the release of the Google Knowledge Graph in 2012. It uses a graph-based data model to capture knowledge in application scenarios that involve integrating, managing, and extracting value from disparate data sources at scale. 171 Knowledge graphs are usually composed of 3 basic elements: entities, relationships and triples. Entities represent real-world objects, such as people, places, or concepts, while relationships define the connection between 2 entities. 64 The general framework for health misinformation detection based on knowledge graphs is illustrated in Figure 6.

General framework of knowledge graph-based health misinformation detection.
Knowledge graphs have been increasingly applied in health misinformation detection frameworks to enhance both accuracy and interpretability. Cui et al proposed the DETERRENT model to address misinformation detection in the medical domain. The model leverages a medical knowledge graph (KG) and an article-entity bipartite graph to detect medical misinformation and provide explanations. It employs an information propagation net, a knowledge-aware attention mechanism, and a prediction layer. In terms of F1 scores, DETERRENT outperforms all other methods by at least 4.78% on the diabetes dataset and at least 12.79% on the cancer dataset. 172 Shang et al proposed the MMAdapt framework for early health misinformation detection. It constructs a domain-specific knowledge graph for the source domain, extracts knowledge triples, and learns node representations from the source articles. An uncertainty-aware knowledge validation mechanism filters and validates high-uncertainty triples. The framework also incorporates a knowledge-post dual adaptation process, including domain-level and instance-level adaptation, to learn generic representations. This enables effective detection of health misinformation in the target domain. 173 Liu et al proposed the KG2S method. This method combines knowledge graphs with a 2-stage approach: Knowledge Breadth Retrieval (KBR) and Knowledge Depth Reasoning (KDR). In the KBR stage, a dual filter of similarity and diversity simulates human heuristic behavior using the knowledge graph’s rich facts. In the KDR stage, a hierarchical attention network mimics human coarse-to-fine knowledge analysis in decision-making. This model demonstrates excellent accuracy in detecting health misinformation. 64 Lara-Navarra et al proposed another innovative method for detecting misinformation in healthcare. They constructed an dynamic knowledge graph using topic-specific information collected from the internet. By analyzing factors such as tweet propagation paths, user interactions (eg, retweets), and user roles in the dissemination process, they identified clues to assess the truthfulness of information. 174
Knowledge graphs have also been widely adopted for identifying COVID-19-related misinformation, achieving notable improvements in accuracy and explanation quality. Weinzierl and Harabagiu proposed COVAXLIES, a COVID-19 tweet dataset, to construct a knowledge graph. They framed the detection as a graph link prediction problem. Experimental results show that this method outperforms neural classification, achieving up to a 10% improvement in F1 score. 175 Koloski et al proposed a novel document representation learning method based entirely on knowledge graphs, using an extensive set of subject-predicate-object triples. Tested on datasets like COVID-19 Fake News detection, the results show that when combined with existing context representations, the knowledge graph-based document representation achieves state-of-the-art performance. 176 Kou et al proposed the HC-COVID scheme, which models knowledge facts through collaboration between experts and non-experts to build crowdsourced hierarchical knowledge graphs. A binary hierarchical attention graph neural network is used to integrate this knowledge for detecting and interpreting COVID-19 misinformation. Evaluation results show that it significantly outperforms existing baselines in both detection accuracy and interpretability. 177
Knowledge graph-based health misinformation detection enhances both accuracy and interpretability through structured semantic associations and logical reasoning. Existing research primarily leverages the entity-relation modeling capabilities of knowledge graphs, constructing domain-specific knowledge bases from sources such as medical literature and social media data. These knowledge graphs are then integrated with techniques such as graph neural networks and attention mechanisms to enable deep reasoning. However, challenges remain, including delayed real-time updates, low efficiency in fusing multi-source heterogeneous data, and high computational complexity. Future research should explore dynamic knowledge evolution mechanisms, multimodal knowledge graph construction, and lightweight inference architectures. Additionally, incorporating causal analysis techniques could facilitate deeper exploration of misinformation propagation chains, contributing to a more efficient, transparent, and adaptable health information governance system.
Fact-Checking-Based Methods
Fact-checking assesses the authenticity of knowledge based on known facts. There are 2 approaches to fact-checking: manual or traditional fact-checking and automated fact-checking. The manual fact-checking process involves a group of domain experts verifying the content of articles or relying on expert-based fact-checking websites. Automated fact-checking techniques depend on information retrieval, natural language processing, and machine learning techniques to develop fact-checking models. 63 Fact-checking-based methods play a crucial role in detecting misinformation, particularly in the healthcare domain. The general framework for health misinformation detection based on manual and automated fact-checking methods is illustrated in Figures 7 and 8.

General framework of health misinformation detection based on manual fact-checking methods.

General framework of health misinformation detection based on automated fact-checking methods.
Manual fact-checking emphasizes human-driven verification, prioritizing nuanced interpretation and evidence transparency. Roitero et al recruited crowdworkers through the Amazon Mechanical Turk (MTurk) platform to assess the truthfulness of COVID-19 statements. A six-point truthfulness scale was used, ranging from “pants-on-fire” (completely false) to “true” (completely true). To improve assessment quality, workers were required to provide evidence supporting their judgments, such as reference URLs and text explanations. The study found that crowdworkers could accurately assess the truthfulness of COVID-19 statements, especially when using mean aggregation, which aligned closely with expert judgments. However, workers struggled to distinguish between the most extreme categories, such as “pants-on-fire” and “false.” 178 Kaufman et al examined how group characteristics affect the accuracy of COVID-19 misinformation detection, focusing on differences between crowdsourced workers and university students. The study found that crowdsourced workers can effectively detect COVID-19 misinformation and sentiment. However, their performance is significantly influenced by cognitive style, attitude bias, and platform choice. 179
Automated fact-checking techniques based on similarity measures and feature engineering have achieved competitive performance in health misinformation detection. Barve and Saini proposed the CSM algorithm, which introduces novel features such as the “Content Similarity Score.” Their approach attained an accuracy of 91.06%, outperforming conventional similarity measures like Jaccard similarity. 63 Hossain et al formulated COVID-19 misinformation detection as a 2-step task: misconception retrieval and stance detection. For retrieval, they evaluated several semantic similarity and information retrieval approaches, finding that domain-adapted BERTSCORE—using COVID-Twitter-BERT—achieved the best performance, with Hits@1 improving from 38.7% to 61.3%. For stance detection, they reframed the task as natural language inference (NLI), mapping Agree, Disagree, and No Stance to Entailment, Contradiction, and Neutral, respectively. Combining domain-adapted retrieval with NLI classifiers yielded notable gains, with the best macro F1 score reaching 50.2%. 86
Automated fact-checking techniques leveraging pre-trained language models have demonstrated strong capabilities in detecting complex semantic misinformation, particularly in the healthcare domain. Nakov et al applied fact-checking techniques to detect COVID-19 misinformation. They used models like BERT and technologies such as WordNet to assess various attributes of tweets and news statements based on different tasks. Specific models were employed to verify and rank the claims, and evaluation metrics were used to optimize the detection results. 180 Sarrouti et al constructed the COVID-19 fact-checking dataset, HEALTHVER. They trained pre-trained models such as BERT, SciBERT, BioBERT, and T5 on claim-evidence pairs, minimizing cross-entropy loss and treating it as a multiclass classification problem. Experimental results show that models trained on the HEALTHVER dataset outperform those trained on synthetic or open-domain claims. The T5 model achieved the best performance, with an accuracy of 80.69%. 90
Automated fact-checking techniques integrating multimodal inputs and external evidence sources have enhanced the accuracy and robustness of misinformation detection systems. Martinez-Rico et al utilized MetaMap to extract unique medical concept identifiers (CUIs). A Transformer model was used for claim verification classification, integrating multiple inputs such as SPO (subject-predicate-object) triples and text. The Transformer-feedforward neural network (FFNN) ensemble model was trained for fact-checking classification, and the results were used to classify news items as true or false based on sentence-level verification. 5 Hammouchi and Ghogho proposed a multilingual automatic fact-checking method that determines the veracity of news by retrieving external evidence related to a claim and assessing the credibility of its sources. The method uses multilingual BERT for semantic representations and LSTM for context modeling. It integrates evidence with source credibility scores and feeds them into a classifier for truthfulness judgment. This framework performs excellently across multiple datasets and is well-suited for health-related misinformation in multilingual environments. 181
Automated fact-checking techniques incorporating open-source intelligence systems and human-AI collaboration frameworks have provided explainable and high-performing solutions for health misinformation detection. Martinez Monterrubio et al proposed a health misinformation detection method based on open-source intelligence (OSINT) and case-based reasoning (CBR). They developed the MedOSINT tool, using official COVID-19 health bulletins as a fact-checking database. The method involves collecting official data, extracting key information from social media news, matching relevant content in the OSINT database, and using CBR for case retrieval to provide explainable judgments. Experimental results show that MedOSINT achieves 93.33% accuracy in detecting COVID-19-related fake news, outperforming Google Search and other existing tools. 182 Kou et al proposed CEA-COVID, a human-AI collaborative framework for COVID-19 misinformation detection. It integrates crowdsourced workers, medical experts, and AI to assess information credibility while providing natural language explanations. The framework includes crowdsourced workers identifying logical inconsistencies, AI verifying medical facts using a knowledge graph, and experts updating the knowledge base. A Transformer model generates explanations. Experiments on the COVIDRumor and CONSTRAINT datasets show that CEA-COVID achieves F1 scores of 91.1% and 95.0%, outperforming BertCOVID, HC-COVID, and other existing methods. 183
In summary, fact-checking-based methods play a vital role in detecting health misinformation. Both manual and automated fact-checking approaches have their strengths and can complement each other. Manual fact-checking ensures nuanced interpretation and transparent evidence, while automated techniques improve detection speed and scalability. With advances in natural language processing, pre-trained language models, multi-task learning, and knowledge graphs, automated fact-checking has achieved significant progress, especially in identifying COVID-19-related misinformation. Additionally, human-AI collaborative frameworks and multilingual fact-checking methods have introduced new solutions for verifying health information across different languages and cultural contexts. In the future, integrating human expertise, knowledge-based resources, and intelligent algorithms to develop efficient, explainable, and scalable health misinformation detection systems will be a key direction for research.
Large Language Models
Large language models (LLMs), a subset of AI, are advanced computational models excelling in language generation and understanding. 184 Recent studies show that LLMs can effectively provide factual answers to clinical questions and accurately identify health-related misconceptions and misinformation.185,186 However, the rise of publicly accessible AI chatbots, capable of generating large volumes of persuasive human-like text, may accelerate misinformation spread, leading to an “AI-driven infodemic.” 187 The roles of large language models in health misinformation are illustrated in Figure 9.

Roles of large language models in health misinformation.
Zhou et al distilled human-created COVID-19 misinformation into narrative prompts and used GPT-3 to generate AI-generated counterparts, forming a comparative dataset. Analysis revealed that AI-generated misinformation differs linguistically, featuring enhanced detail and uncertainty. While existing detection models could identify AI misinformation, their performance declined. Moreover, current evaluation guidelines proved less effective, as AI-generated content often meets credibility and transparency criteria. 188 Garbarino and Bragazzi evaluated the effectiveness of Google Bard and ChatGPT-4 in identifying and understanding sleep health misinformation. Statistical and text analysis revealed that Bard identified misinformation with 95% accuracy, while ChatGPT-4 achieved 85%, with no significant difference. However, their rating distributions and alignment with expert assessments varied. Text analysis showed Bard emphasized practical advice, while ChatGPT-4 focused on theoretical aspects, and readability analysis indicated Bard’s responses were more accessible. 189 Choi and Ferrara proposed the FACT-GPT framework, which leverages LLMs to automate the claim matching task in fact-checking—identifying whether new content on social media supports or refutes previously fact-checked misinformation. The researchers constructed a matching dataset and tested several pre-trained LLMs (eg, GPT-4, Llama-2-70b), fine-tuning smaller LLMs for optimization. The results showed that LLMs perform near-human accuracy in claim matching, and fine-tuned smaller models achieve comparable performance to larger models at lower computational cost, demonstrating their potential for fact-checking applications. 190
Although several scholars have explored the use of artificial intelligence (AI) in generating and detecting health misinformation, many have overlooked the associated ethical concerns. These concerns include data ownership, informed consent for data use, bias and representativeness in training data, and privacy protection. 191 The absence of clear legal frameworks for data collection has raised serious ethical questions. In particular, there is growing concern about the use of personal data without consent or proper regulation. 187 Even without malicious prompts, large-scale generative models can produce inappropriate, biased, or false content. This is often due to inaccuracies or biases in the training datasets. 192 Such biases can further widen disparities in mental health services and reinforce existing social inequalities.To ensure their responsible use, future research must integrate technical innovation with ethical governance, ensuring that AI systems are both effective and socially accountable.
Discussion
Main Findings
This study provides a systematic review of health misinformation, covering its conceptual foundations, dissemination mechanisms, psychological impacts, susceptibility, available datasets, evaluation metrics, machine learning, and deep learning detection methods, as well as other advanced detection approaches. Based on this comprehensive analysis, the following key conclusions are drawn:
Feature Variability
Health misinformation is highly sensitive to the intentions of its disseminators and the context in which it spreads. It manifests in diverse forms and exhibits inherent relativity. Its propagation follows extended pathways, spreads rapidly, and demonstrates strong local clustering effects.
Dataset Diversity and Metric Reliability
Health misinformation datasets are highly heterogeneous in terms of data sources, with research priorities structured around specific domains. COVID-19 datasets dominate binary classification studies, while vaccine-related datasets continue to receive sustained attention. English remains the primary language, but multilingual datasets have emerged in recent years. There is an increasing demand for fine-grained classification of complex misinformation types. Conventional evaluation metrics may be inadequate for imbalanced health misinformation datasets, and that metrics such as MCC, Cohen’s Kappa, and Brier Loss offer more reliable performance assessment in such cases.
Algorithmic Synergy and Hybrid Optimization
Traditional ML algorithms remain competitive in health misinformation detection when robust feature engineering and computational efficiency are prioritized. Ensemble methods and evolutionary algorithms enhance performance by integrating the strengths of different models and optimizing feature selection. However, neural networks excel at capturing high-dimensional semantic patterns, despite their higher computational cost. This suggests that hybrid models may be the optimal strategy for balancing accuracy, interpretability, and resource constraints.
Deep Learning Complementarity and Multimodal Integration
DL methods exhibit complementary strengths in health misinformation detection, with traditional, attention-based, graph-based, transfer learning, and hybrid models each addressing distinct challenges. Multimodal approaches further enhance detection by integrating heterogeneous data, though issues like data scarcity, semantic alignment, and interpretability remain.
Other Advanced Method Efficacy and Emerging Risks
Other advanced detection methods—including knowledge graphs, fact-checking frameworks, and large language models—significantly enhance the accuracy, interpretability, and adaptability of health misinformation detection. However, challenges remain in computational efficiency, cross-cultural generalization, and mitigating AI-generated misinformation, highlighting the need for explainable, scalable, and human-AI collaborative systems.
Limitations
Despite significant progress in the field of health misinformation detection, current systems continue to exhibit several critical limitations that hinder their effectiveness and scalability. A detailed overview of these challenges is presented below.
Data-Related Limitations
Current research on health misinformation detection faces several data-related challenges. Many datasets remain small in scale,81,101,103,113,151 cover only short time spans,103,106 and often suffer from class imbalance.66,96,111 They are also restricted to specific diseases or single platforms, which limits model generalizability.72,93 In addition, most datasets lack social network-related metadata, such as user profiles, propagation pathways, and interaction histories. Such information is crucial for tracing the origins and dynamics of misinformation. 108 Annotation further introduces difficulties. Human labels are prone to subjectivity and inconsistency,65,93,96,152 require high labor costs, 84 and lack standardized terminology across corpora,33,120 which complicates model training and evaluation. Another major gap lies in modality and language coverage. Existing datasets focus mainly on text, while images, audio, and video receive little attention.65,76 Low-resource languages are also underexplored, constraining cross-lingual applicability.103,151 Finally, misinformation evolves rapidly with public health events. Models trained on outdated datasets often fail to detect emerging narratives, leading to performance degradation.17,126,139
Methodological Limitations
Methodological limitations also constrain progress in this field. Many approaches still rely on handcrafted or traditional statistical features, with limited use of semantic, emotional, temporal, or interaction-based representations.76,93,102,103,111 Feature integration and optimization remain insufficiently studied.4,62,110 Another key challenge lies in balancing model complexity and interpretability. Traditional machine learning methods often fail to capture complex patterns, 102 while deep learning models, though more effective, require heavy computation and lack transparency.113,133,136 Limited attention has also been paid to optimization strategies such as hyperparameter tuning, which may affect model stability and performance. 113 Furthermore, models are typically designed for specific events or single platforms, with poor cross-domain and cross-platform generalization.62,103 Finally, research places excessive emphasis on computational performance while giving insufficient attention to human-centered design and interdisciplinary collaboration. This weakens its relevance to clinical and public health contexts and may overlook the needs of vulnerable populations, thereby limiting the social value of research outcomes.
Evaluation and Application Limitations
Evaluation and application challenges further restrict real-world impact. The lack of unified evaluation frameworks makes it difficult to compare results across studies, as metrics, baselines, and experimental setups vary widely. 105 In addition, most research does not reflect the dynamic evolution and dissemination of misinformation in real environments, reducing robustness in complex social media ecosystems. 105 Early and real-time detection also remains underdeveloped.17,73,121,138,170 Finally, research often prioritizes algorithmic performance over practical concerns such as scalability, deployability, and user needs. This gap reduces the likelihood that detection systems will be adopted by public health institutions.
Future Research Directions
To address the current limitations and further advance the field of health misinformation detection, several key research directions can be pursued. By focusing on these future research directions, the field of health misinformation detection can make significant strides toward building more effective and scalable systems to combat misinformation in the digital age.
Enhancing Data Quality and Diversity
Future research should focus on building larger and more diverse datasets that span wider temporal ranges and encompass multiple diseases, platforms, and languages.115,151 Incorporating multimodal sources such as images, audio, and video can help capture the complexity of health misinformation more effectively.76,93,101,103,151 To better understand dissemination mechanisms, datasets should also include contextual metadata, such as author background, source credibility, and propagation patterns. 108 Improving annotation practices is equally important. Unified standards 120 and semi-automated labeling methods that combine human expertise with machine support can reduce subjectivity, 84 lower costs, and improve comparability across datasets. 33 Finally, continuous data collection and timely updates are needed to ensure that models remain responsive to evolving narratives during public health crises.115,121,138
Methodological and Model Innovation
Advancing methodological approaches is crucial for the progress of health misinformation detection. Future models should move beyond shallow representations by incorporating richer semantic, emotional, temporal, and interaction-based features,72,76 while also leveraging symbolic cues such as emojis and numerals that are common in social media.115,137 Studying the alignment between different feature types and classifier architectures 120 will help optimize feature–model combinations. Integrating medical knowledge and utilizing tools such as knowledge graphs and fact-checking systems will also reduce false positives and strengthen model reliability.4,61,101 -103 In parallel, progress in multimodal fusion is needed, combining textual, visual, and auditory information152,154 while drawing on advances from computer vision for image and video analysis. 193 Transfer learning and domain adaptation techniques can improve robustness and enable generalization across platforms, events, and languages, thereby avoiding overfitting to narrow contexts.4,61,62,67,73,88,103,113,131,137 At the same time, models must balance interpretability and efficiency through visualization tools, lightweight embeddings, and resource-efficient compression methods that support real-world deployment.33,73,102,113,129,157 Systematic exploration of hyperparameter tuning and optimization strategies is also necessary to ensure stable performance.113,134 Finally, learning under limited supervision, including weakly supervised, semi-supervised, and self-supervised approaches, offers promising directions to address challenges such as annotation scarcity, class imbalance, and distribution shifts.88,96
Improving Evaluation and Real-World Applications
Improving evaluation and application practices is essential for bridging the gap between research and deployment. Establishing standardized evaluation frameworks and benchmark datasets will allow more consistent and transparent comparison of detection methods. 105 Future systems should also prioritize early detection by leveraging user interaction signals, social network structures, and multi-source metadata,61,73,96 while exploring zero-shot learning to identify emerging misinformation in a timely manner. 175 To maximize societal impact, detection technologies must be integrated with policy and education. For example, aligning systems with public health policies and crisis management strategies can support effective interventions, 72 while educational approaches such as new media teaching can strengthen public health literacy and reduce the spread of misinformation. 194 In addition, adoption and sustainability require attention to social and institutional factors. Theoretical perspectives such as the Technology Acceptance Model and the Resource-Based View can provide insights into user acceptance and long-term viability. 195 Ultimately, interdisciplinary and human-centered approaches will be critical. Collaboration among AI researchers, medical experts, public health professionals, and policymakers can ensure ethical deployment,25,196 while integration with social media data can help mental health professionals monitor psychosocial impacts, track public discourse, and design targeted interventions for vulnerable groups. 197
Conclusion
In this study, a comprehensive and systematic literature review on health misinformation detection was conducted to provide a thorough understanding of the concept of health misinformation, its dissemination mechanism, psychological impact, susceptibility, existing datasets, and evaluation metrics. By systematically retrieving and analyzing 100 high-quality publications from 2016 to 2025, a wide range of detection approaches were reviewed, including traditional machine learning algorithms, deep learning models, knowledge graph-based frameworks, fact-checking strategies, and the latest large language models. Their respective strengths and limitations in practical applications were compared, and future research directions were proposed. This review not only provides a clear overview of the current research landscape but also emphasizes the importance of interdisciplinary collaboration, human-centered design, and ethical considerations in developing effective and clinically relevant detection systems.
In future work, we aim to expand our literature retrieval by including multiple academic databases beyond Google Scholar. This will ensure more comprehensive coverage of relevant studies. We also plan to refine our keyword strategies to capture a broader range of research topics and methodologies. To minimize biases and enhance the rigor of the review process, we will implement standardized inclusion and exclusion criteria and involve multiple reviewers in the screening process. Additionally, we seek to incorporate multilingual literature to broaden the diversity of perspectives. We will also attempt to use interdisciplinary approaches and integrate both qualitative and quantitative methods to provide a more comprehensive and in-depth understanding of health misinformation detection.
Footnotes
Appendix
Deep learning algorithms.

| Full name | Abbreviation | Basic explanation | Articles |
|---|---|---|---|
| Multi-Layer Perceptron | MLP | MLP consists of input, hidden and output layers, trained by back propagation algorithms, and is capable of handling complex nonlinear problems. | Sicilia et al, 85 Bonet-Jover et al, 84 Madani et al, 109 Bangyal et al, 115 Nabożny et al, 23 Dhankar et al 149 |
| Artificial Neural Network | ANN | ANN is a mathematical or computational model that mimics the structure and function of a biological neural network for estimating or approximating functions. | Elhadad et al, 121 Shams et al 112 |
| Convolutional Neural Network | CNN | CNN extract features through structures such as convolutional, pooling, and fully connected layers and perform tasks such as classification or regression, and are particularly well suited for processing data with a grid-like topology, such as images and time-series data. | Du et al, 66 Li, 65 Al-Yahya et al, 118 Bangyal et al, 115 Tomaszewski et al, 116 Dharawat et al, 96 Dai et al, 61 Alhakami et al, 110 Kaliyar et al, 124 Luo et al, 88 Kumar et al, 125 Narra et al, 111 Albalawi et al 117 |
| Recurrent Neural Network | RNN | RNNs are suitable for processing and predicting sequence data by capturing temporal dependencies in sequences through cyclic connections and hidden states. | Du et al, 66 Iwendi et al, 114 Al-Yahya et al, 118 Bangyal et al 115 |
| Long Short-Term Memory | LSTM | LSTM solves the problems of gradient vanishing and gradient explosion that exist in traditional recurrent neural networks when dealing with long sequential data by introducing mechanisms such as memory units and forgetting gates. | Sharma and Garg, 108 Raj and Meel, 170 Li, 65 Hayawi et al, 67 Chen et al, 17 Iwendi et al, 114 Bangyal et al, 115 Dai et al, 61 Alhakami et al, 110 Abdelminaam et al, 119 Chen and Lai, 126 Narra et al 111 |
| Bi-directional LSTM | Bi-LSTM | Bi-LSTM is an improved LSTM model that improves the model’s ability to understand and predict sequence data by considering both forward and backward information of the sequence. | Mahara et al, 107 Sharma and Garg, 108 Raj and Meel, 170 Chen et al, 17 Bangyal et al, 115 Tomaszewski et al, 116 Dharawat et al, 96 Kumari et al, 154 Luo et al, 88 Chen and Lai, 126 Albalawi et al 117 |
| Gate Recurrent Unit | GRU | GRU is a variant of recurrent neural networks designed to solve the problem of gradient vanishing and gradient explosion encountered by traditional RNNs when dealing with long sequential data. | Chen et al, 17 Iwendi et al, 114 Al-Yahya et al, 118 Bangyal et al, 115 Abdelminaam et al, 119 Chen and Lai 126 |
| Visual Geometry Group-16 | VGG-16 | VGG-16 has 16 weight layers and performs well in tasks such as image classification and target detection. | Sharma and Garg, 108 Raj and Meel 170 |
| Residual Network | ResNet | ResNet is a deep convolutional neural network (CNN) architecture designed to address the vanishing gradient problem in very deep networks. | Narra et al, 111 Sharma and Garg 108 |
| Bidirectional Encoder Representations from Transformers | Bert | Bert is a deep bi-directional pre-training model based on Transformer, which learns rich language representation capabilities through pre-training on large-scale corpora. | Hayawi et al, 67 Qasim et al, 138 Al-Yahya et al, 118 Dharawat et al, 96 Morita et al, 131 Kumari et al, 154 Das et al, 134 Malla and Alphonse, 133 Abd Elaziz et al, 137 Hossain et al, 86 Ayoub et al, 139 Alghamdi et al, 113 Hua et al 167 |
Acknowledgements
Not applicable.
Author’s Note
Didier El Baz is now affiliated with Harbin Engineering University, Harbin, 150006, China.
Ethical Considerations
This work is a literature review and did not involve the collection of primary data from human participants, animals, or identifiable individuals. Therefore, ethics approval was not required. 198
Consent to Participate
This work does not contain any studies with human participants performed by any of the authors.
Author Contributions
Xiaoye Feng collected all the data and wrote the manuscript. Jia Luo proposed the original idea and addressed all the issues in the manuscript. Yang Yang and Didier El Baz revised and polished the final version. Lei Shi created the illustrations.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by Beijing Natural Science Foundation (Grant No. 9242003), the Natural Science Foundation of Chongqing, China (Grant No. CSTB2023NSCQ-MSX0391), the National Natural Science Foundation of China (Grant No. 72104016), Key Laboratory of Public Opinion Governance and Computational Communication (Grant No. YQKFYB202501).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Data will be made available on request.
Guarantor
Not applicable.