
Abstract
This paper highlights a number of important gaps in the UK evidence base on the employment impacts of immigration, namely: (1) the lack of research on the local impacts of immigration – existing studies only estimate the impact for the country as a whole; (2) the absence of long-term estimates – research has focused on relatively short time spans – there are no estimates of the impact over several decades, for example; (3) the tendency to ignore spatial dependence of employment which can bias the results and distort inference – there are no robust spatial econometric estimates we are aware of. We aim to address these shortcomings by creating a unique data set of linked Census geographies spanning five Censuses since 1971. These yield a large enough sample to estimate the local impacts of immigration using a novel spatial panel model which controls for endogenous selection effects arising from migrants being attracted to high-employment areas. We illustrate our approach with an application to London and find that no migrant group has a statistically significant long-term negative effect on employment. EU migrants, however, are found to have a significant positive impact, which may have important implications for the Brexit debate. Our approach opens up a new avenue of inquiry into subnational variations in the impacts of immigration on employment.
Introduction
A steady flow of articles from the UK populist press over the past decade have claimed or implied that migrants are taking the jobs of UK-born workers. 1 This claim, and the debates surrounding it, have shaped the political agenda on immigration making it one of the defining issues in the Brexit 2 referendum. Similar debates have been prominent in other countries that have experienced large inflows of migrants, particularly North America (Borjas, 2017) and Western Europe (Geddes and Scholten, 2016).
The usual counter from economists is that such claims tend to fall prey to the ‘lump of labour fallacy’ (Schloss, 1981): the fallacious assumption that there is a fixed amount of work, and hence a fixed number of jobs, in the economy. Under this assumption, a job offered to a migrant worker is necessarily a job opportunity taken away from UK-born workers. The lump of labour assumption is dubious for a number of reasons. First, migrants are also consumers and so a rise in immigration potentially boosts aggregate demand for goods and services, which in turn creates more employment as firms hire more workers to meet the additional demand. Second, economic migrants are often more entrepreneurial than native workers, setting up new businesses and generating new employment opportunities (Levie, 2007). Third, skilled migrants make a disproportionate contribution to innovation (Kerr and Lincoln, 2010) which is likely to improve UK competitiveness, increasing long-run wages and employment (Devlin et al., 2014). Fourth, migrants often fill jobs that UK workers are unable or reluctant to accept, so without those migrants, much of the work would either not be done at all or be done by machines. Fifth, an increase in the share of migrants increases the probability that natives stay in school longer (Hunt, 2017), potentially boosting their long-term employability and productivity. Sixth, migrants increase cultural diversity, which in turn has the potential to boost innovation, social capital, tolerance, overseas trade links and growth (Elias and Paradies, 2016). Seventh, because they tend to be highly mobile and responsive to wage differentials, migrants help ‘grease the wheels of the labour market’ (Borjas, 2001) by responding to higher wages produced by regional labour shortages, improving labour market efficiency which in turn helps foster productivity and growth. Finally, because migrants are typically young and mobile, they can help rebalance the demographic profile of an ageing workforce (Bijak et al., 2007), reducing the dependency ratio, again boosting productivity, competitiveness and long-term employment growth.
The extent to which these positive impacts offset the number of jobs taken by migrants is not something that can be predicted by theory alone, as the overall outcome depends on various contextual factors including the mix of skills among migrant and native workers and the types of jobs generated. So, what does the evidence to date tell us? UK empirical studies have consistently shown the impacts of migration on employment to be negligible or zero. For example, after reviewing the evidence to date, the most recent report of the Migration Advisory Committee (MAC) (2018), billed as the ‘most comprehensive-ever analysis of migration to Britain’ (Economist, 2018 3 ), concluded that migrants have negligible impact on the employment and unemployment outcomes of the UK-born workers (MAC, 2018: 2).
Our contention, however, is that the broad consensus in the empirical literature belies a number of significant weaknesses in the methods used and in the scope of estimates. In particular, we argue that the existing literature has so far failed to provide robust evidence on the local and long-term impacts of immigration and has overlooked spatial spill-over effects between localities.
The aims of this paper are: (1) to propose a way of linking data over a much longer time span (half a century) that would facilitate a new generation of research in the UK providing localised longer-term estimates of the impacts of immigration based on large samples; and (2) to develop a way of incorporating both spatial autocorrelation and endogeneity in a spatial dynamic framework.
The paper is structured as follows. In the next section we provide a brief review of the literature with a view to identifying key data/methodological deficiencies. The following section describes our approach to creating a linked Census database that has the temporal and spatial attributes needed for robust long-term, large sample and local modelling. We then proceed to set out our strategy for econometric estimation, which we illustrate in the penultimate section with an application to London for the period 1971–2011. The final section concludes with a brief summary of the findings and limitations.
Literature review
This literature review highlights the shortcomings that our estimation strategy will seek to address. Our focus is on the UK where our data are from, but similar methodological limitations apply to the evidence from other countries, particularly US studies from which the UK research draws much of its methodological inspiration. For a more general overview of the literature on the employment impacts of immigration, see recent reviews by MAC (2012, 2018). 4
Empirical research on the labour market effects of immigration in the UK is a surprisingly recent field. In their 2005 paper, Dustmann et al. noted that ‘While there are many empirical studies for the USA, and some work for European countries, no ana-lysis exists for Britain’ (Dustmann et al., 2005: F325). They also argue that Britain’s specific migration history and settlement patterns greatly inhibit the usefulness of inferring labour impacts of immigration from studies based on other countries. Since then, a significant number of studies have emerged (see systematic review by Devlin et al., 2014) which provide estimates at the level of the UK as a whole.
This brings us to the first significant shortcoming in the existing literature – the lack of research on how the impacts of immigration vary geographically within the UK. Finding ways to measure local impacts is important because ‘assessing aggregate national impacts may mask impacts that vary markedly across localities’ (Devlin et al., 2014: 2). 5 Overlooking local variation in the impact of immigration may have pressing social and political implications. For example, opposition to immigration and support for Brexit vary greatly across the UK, and it is possible that this is partly due to the greater anxiety about the employment impacts of immigration in some areas, which may in some cases reflect genuine differences across regions. Addressing those anxieties would entail more than simply addressing the ignorance of voters about the economic benefits of immigration if the local impacts deviate from the national picture. It also raises important questions of social justice and what the appropriate political response should be if some areas benefit from immigration while others face negative impacts, such as a reduction in job availability for native workers. 6 Clear evidence on the issue could, for example, reinforce the case for a more comprehensive approach to regional economic policy and geographic redistribution. This is particularly true if the negative local impacts of immigration are persistent rather than temporary labour market adjustments. There is a strong imperative, therefore, to find a reliable approach to estimate the local employment impacts of immigration in the long term.
Probably the main reason for the focus on macro estimation in the literature is lack of data availability at the local level. For example, most UK econometric studies on the employment impact of migration rely on the Labour Force Survey (LFS), which has the advantage of providing detailed information on individual employment attributes. However, since the LFS only provides geographical information at regional level, there is no scope for sub-regional analysis.
Even if it were possible to obtain sub-regional location identifiers in the LFS, the sample size (roughly equal to 0.5% of the UK population, Dustmann et al., 2005) would be too small to capture migration effects. Dustmann et al. (2003: 56), for example, give a breakdown of the LFS sample sizes by region which shows that in 2000 there were just 47 migrants in Merseyside, of which 16 were ethnic minority immigrants, 11 of whom arrived in the UK after 1981. Similarly, the East Yorkshire and Humberside sample for that year included just 77 migrants, of whom six were ethnic minorities who arrived after 1981. These sample sizes are far too small to derive meaningful econometric estimates of local effects, leading Devlin et al. (2014: 36) to conclude that robust estimation of migration impacts is not feasible at the local level. Unsurprisingly, then, there are no robust estimates of the regional or sub-regional employment impacts of migration that we are aware of, only national estimates based on regional variation. This is problematic because national-level estimates will mask the variation in effects between local labour markets.
Another key challenge in this area of research is how to take into account the endogeneity that arises from migrants being drawn to areas of high employment. A standard solution to this, following Card (2001), is to use historical settlement patterns of migrants as instruments, the rationale being that new migrants will be drawn to existing settlements of their own group where familiar cultural norms and similar linguistic backgrounds will make it easier for them to find supportive social networks (Dustmann et al., 2005: F328). One of the aims of our approach is to introduce these causal inference approaches into a Census-based model of the local impacts of immigration. This requires following areas over time, which means developing a panel of consistent areal units spanning multiple Census years, which is a major undertaking.
The dominant method for estimating employment effects of immigration is to estimate ‘the spatial correlation between immigrant labour inflows and changes in native or overall labour market’ (Dustmann et al., 2005: F328). Dustmann et al. (2005), for example, estimate a regression of employment, Eit, on immigrant share, π it … where i = 1, 2, …, 17 is the UK region and t = 1983, 1984, … 2000 is the year. This creates a panel of regions over time with 17 × 18 = 306 observations. After differencing the equation, the estimated coefficient on π it is estimated essentially from the relationship between the regional variation in employment rates and the immigrant share. However, this approach ignores the potential for spatial dependence in employment, the dependent variable, which is very likely to be spatially autocorrelated (McMillen, 2004; Molho, 1995), leading to bias in estimated parameters and less reliable inferences (Anselin, 1988). The lack of research on the consequences of spatial spill-overs for the estimation of employment impacts of immigration is probably due in part to the limitations in the methodological tools available. It is only relatively recently that spatial temporal models have emerged that allow researchers to incorporate spatial autocorrelation in dynamic models in a methodologically robust way.
While the mainstream econometrics literature has tended to overlook issues of spatial dependence, spatial econometric papers have tended to ‘neglect the issue of endogeneity, other than that arising from spatial lags of the dependent variable’ (Chen et al., 2013: 4). There have been a number of attempts to develop spatial panel models which account for endogeneity on the right hand side of the regression equation (Anselin and Lozano-Gracia, 2008; Chen et al., 2013; Fingleton and Le Gallo, 2008; Kelejian and Prucha, 1998, 1999), but these have not, as far as we are aware, been applied to the problem of estimating the employment impacts of immigration. Crucially, accounting for spatial dependence is likely to be all the more important when attempting to estimate the local effects of immigration as the spatial dynamics of employment are likely to be increasingly spatially dependent the smaller the geographical units being considered.
A further shortcoming of the existing literature worth noting is the short time span considered in existing empirical papers. While the short-term impacts of immigration are important, the full effect of immigration on the labour market may take several decades to emerge. For example, the impact of migration on the propensity for natives to stay in school longer (Hunt, 2017) may affect the employment outcomes of natives, labour market productivity and economic competitiveness over many decades, and may also affect the employment outcomes of their children. Because of the reliance on survey data such as the LFS, much of the research has tended to look at relatively short timescales. For example, Dustmann et al. (2005) use data on employment over the 1983 to 2000 period and include three- and four-year lags. Gilpin et al. (2006) look at data for 2004–2005. Lemos and Portes’ (2008) data run from 2004 to 2006. Reed and Latorre’s (2009) data span seven years (2000–2007). Nathan (2011) looks at long-run impacts in British cities but this actually only spans the period 1994–2008. The Migration Advisory Committee’s (2012) ‘Analysis of the Impacts of Migration’ covers a much longer period (1975–2010) but does not include robust controls (such as instrumental variables) for endogeneity. None of these studies account for spatial dependence in employment.
In summary, then, our review of the existing literature on the impacts of immigration identifies three key weaknesses:
Lack of evidence on local impacts: perhaps the single most important limitation of existing research is that it has tended to only provide robust estimates of employment impacts of immigration at the national level. While the impact of migration on employment and the economy as a whole may be positive overall, it is possible that the local impacts vary considerably. There is a strong social justice and political imperative to find ways to provide robust spatially disaggregated estimates of migration impacts.
Spatial spill-overs (spatial autocorrelation): existing mainstream approaches to estimating the impacts of immigration on employment in the UK have emerged in isolation from the spatial econometrics literature, which has provided a large theoretical and empirical body of evidence on the methodological problems associated with ignoring the issue of spatial autocorrelation in the dependent variable.
Short time spans and temporal lags: while the short-term impacts of immigration are important, the full effect of immigration on the labour market may take several decades to emerge. Most of the existing literature, however, focuses on relatively short time horizons for labour market adjustment, and there are no studies we are aware of that provide robust long-term estimates at the local level, or that account for endogeneity.
In the remainder of the paper we describe our proposed method for estimating local impacts of immigration, one that exploits the large samples and long time span that can be achieved by linking Census data at the small area level over five decades. But first we describe the data set needed to estimate this kind of model and how it can be compiled from existing data resources.
Data linkage
Our definition of migrants is based on the country of birth variable from UK Census data. We define a migrant as someone born outside of the UK. While digital UK Census data exist going back to 1971, no two decades have the same definitions for country of birth. They also never use exactly the same geographical boundaries between decades; boundaries used in 1971, 1981 and 1991 in particular are very different from those used in 2001 and 2011.
Any time-based analysis requires variables and geographies to both be harmonised: country of birth categories must be consistent and geographical zones must not change between Censuses. A contribution of this paper is to present such a harmonised data set over a five Census period from 1971 to 2011. We focus in this paper on London, as this represents a large labour market area with high population density yielding a large number of aerial units with large samples and relatively high numbers of migrants. Although this paper looks only at London, the harmonised data set is now freely available 7 for the whole of Great Britain. It should now be possible, therefore, to apply the model proposed below to other parts of the country.
Country of birth data have been harmonised at the lowest level that maximises the number of categories. For example, while later Censuses have many European countries listed, the earliest (1971) has only a single category for Europe. This single category imposes itself on all other decades when matching. Note, however, that while we have linked the data back to 1971, in order to include lagged employment, all the other variables in the model only go as far back as 1981.
We use an altered version of 1991 wards as our common geographical zone. This choice was determined by the nature of data in the 1991 Census, where data are presented in two forms: ‘Small Area Statistics’ (SAS) tables are at small geographies but do not contain enough information owing to disclosure restrictions. ‘Local Base Statistics’ (LBS) have more information for country of birth but only at 1991 ward geography level. Choosing this geography as the common basis for the whole data set allows us to maximise country of birth categories across all five Censuses.
However, LBS tables also have their own disclosure restrictions where some wards have values set to zero if counts are lower than 1000 people or 320 households. This is solved by creating a new variant of the 1991 ward geography. This takes advantage of the fact that zero-count LBS wards have their populations assigned to neighbouring wards. It is possible to work out which wards these are by comparing with population counts in the SAS tables. SAS geographical zones can be aggregated to wards and their counts subtracted from surrounding wards to detect which contain the re-assigned LBS counts. Once those wards are identified, neighbours are combined into a single new ‘ward’ containing the correct population count. This is only done for a small minority of wards overall but is a necessary step to avoid missing values.
Census variables can then be assigned to this new geography. For 1991, borders match precisely, accounting for the new aggregated zones. For the other four Censuses, much smaller geographies are used as the source and so the majority are entirely contained within wards. Others that overlap ward boundaries have their values split according to zone area.
The same process is also used for Census employment data, though this is easier than country of birth as there is rather less difficulty in harmonising employment proportions over time.
Proof of concept application to London wards
It is beyond the scope of the current paper to develop local estimates of the local employment impacts of immigration for the whole of the UK. Rather, we seek to demonstrate proof of concept by applying our proposed method to a single region. We have selected London because it is the pre-eminent destination of migrants in the UK and as such is of interest in its own right: The case of London is worth further study. Immigrant concentration in London as a whole far exceeds that elsewhere in any other city of the UK. Concentration and inflows of immigrants into London also differ widely according to area. (Dustmann et al., 2003: 51)
London also has a large number of wards, the basic areal unit of analysis used in our longitudinal linkage of five Censuses, so it guarantees large samples for estimation. Nevertheless, our illustrative application to London should be extendable to other regions of the UK provided they have a sufficient number of wards and sufficient variation in migrant proportions across those wards. This may mean that some regions will need to be clustered in order to achieve sufficiently large samples and variation, but such applications of our method will nevertheless offer for the first time the opportunity to study subnational variation in the impacts of immigration on employment. Descriptive statistics on the data used in the model are given in the supplementary material (available online).
Variable selection
The advantage of our longitudinally linked ward-level Census data is that they offer both long time spans and the potential for comprehensive geographical coverage. However, they also bring significant limitations, most notably with respect to the choice of explanatory variables. In the modelling strategy described below we seek to explain the role of migration in determining the level of employment in each ward. Our selection of explanatory variables is limited to those we can extract or derive from the Census, namely: migrants born in Ireland, India, Pakistan, Europe and the Rest of the World, the number of UK-born residents and the unemployment rate location quotient (LQ) (explained in the ‘Econometric strategy’ section below).
Econometric strategy
Our approach is based on a dynamic spatial panel model developed by Baltagi et al. (2019) to estimate the relationship between the number of people from different countries of birth and the level of employment, controlling for a number of effects. The approach adopted is designed with a view to being able to use the model to simulate different employment outcomes on the basis of different totals of migrants in the future.
The estimates below are for a time–space dynamic panel model for
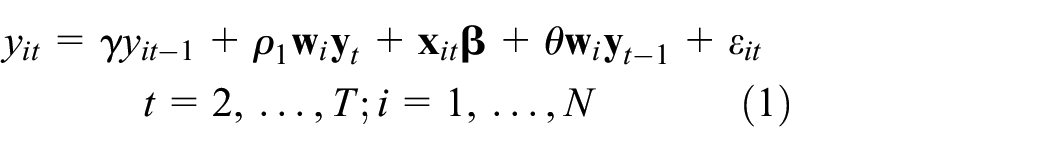
In equation (1)
In (2) we assume that there is a spatial moving average error process, so that:
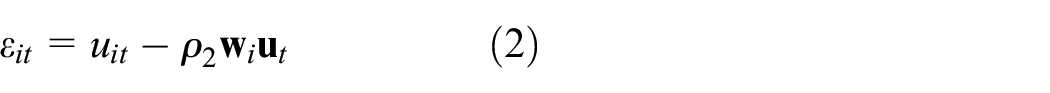
which implies that the errors in contiguous districts are interdependent. This local spill-over of unobserved variables and shocks captured by the errors mitigates the impact of omitting spatially lagged regressors
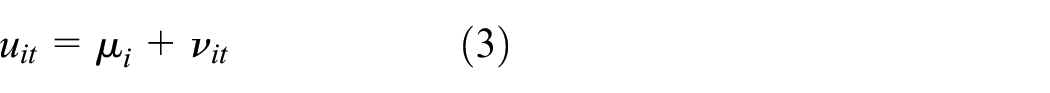
in which the component
Given
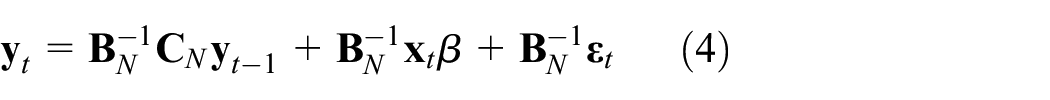
Under this specification, the short-run matrix of partial derivatives is:
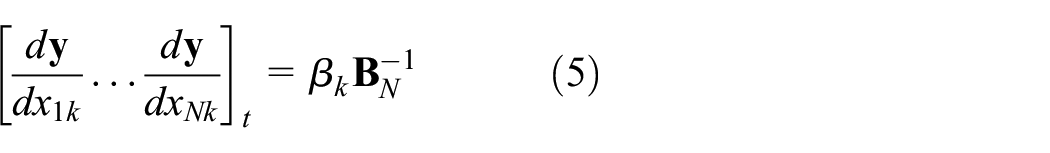
Equation (5) is a matrix of partial derivatives of

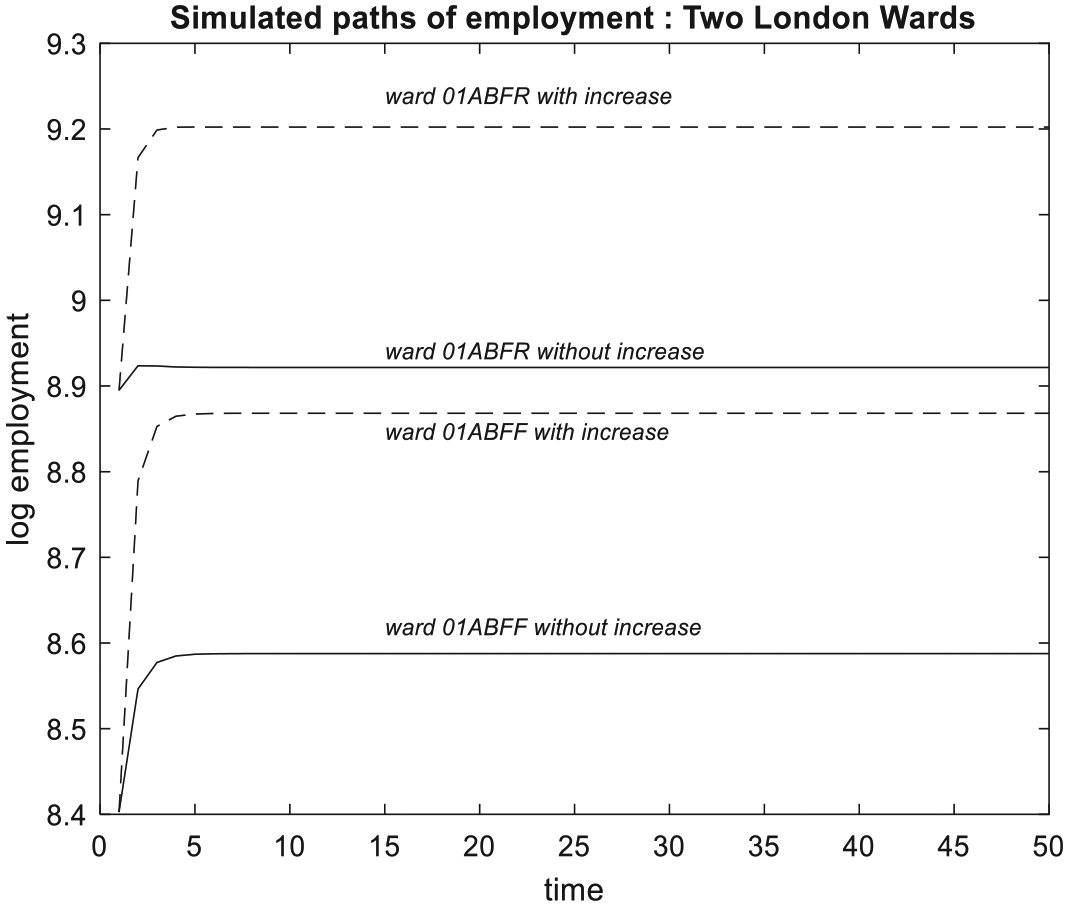
As shown in Fingleton and Szumilo (2019), this is exactly equal to the mean difference between the predicted log employment given by
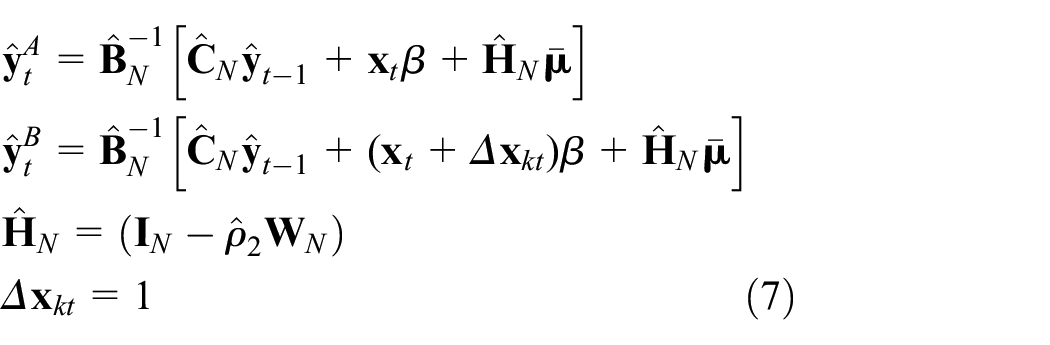
Matrix
The total short-run elasticity
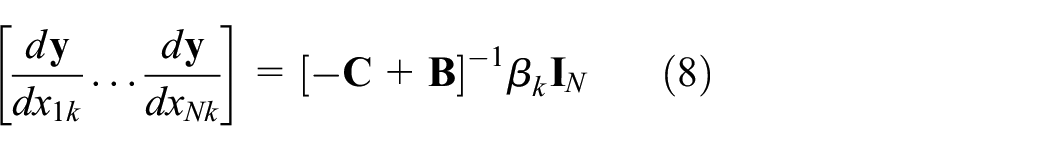
Again, the corresponding
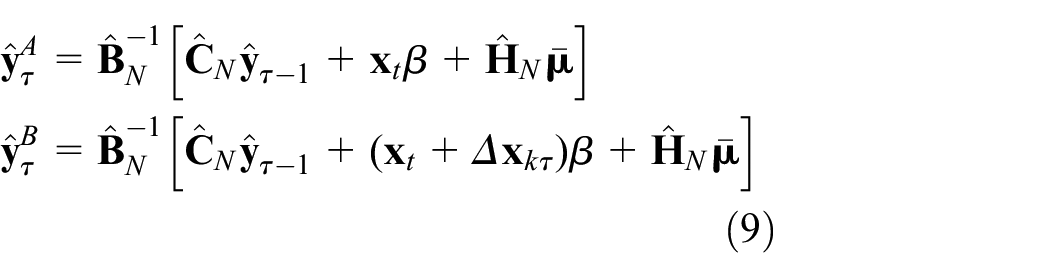
over
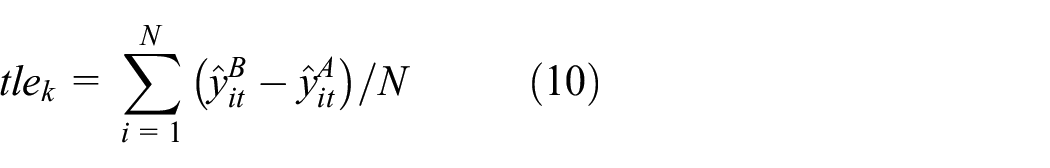
Figure 1 illustrates the simulated paths of employment for two arbitrary London wards. Thus we see the paths of ward i (‘01ABFF’), with no change in European migrant numbers, as given by
Equilibrium employment levels in two wards, with and without 1% increase in European migrants.
Below we give the outcome of testing for dynamic stability and stationarity of the model. The rules are:
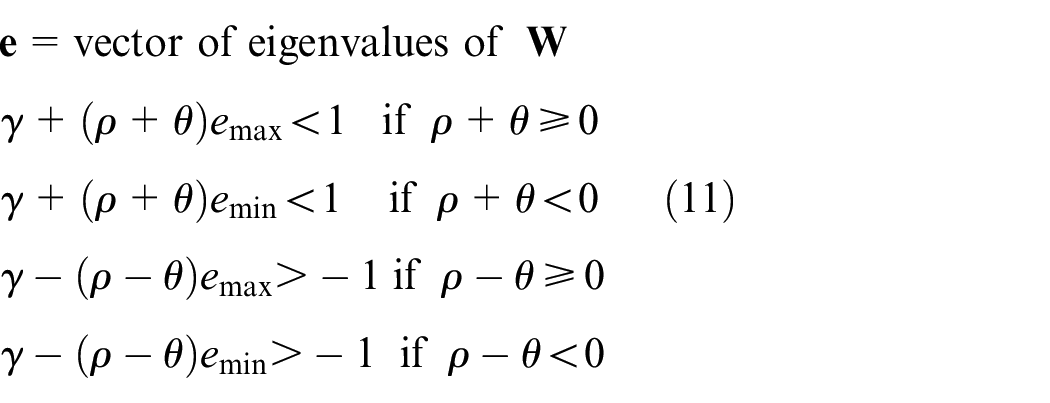
Equivalently, dynamic stability and stationarity requires that the largest characteristic root of
Further technical details on the rationale for the structural model specification, inference and estimation are presented in the supplementary material (available online).
Illustrative application to London
The estimates given in Tables 1 and 2 are for two estimators with corresponding long-run elasticities and indications that we have dynamic stability and stationarity. Two alternative assumptions are made for the moments conditions underpinning the parameter estimates. One is that the regressors are exogenous. This means that the whole temporal sequence of the regressors is independent of the (differenced) errors and hence the dependent (endogenous) variable, log employment level, so that the matrix of instruments includes
Parameter estimates and elasticities assuming exogenous regressors.
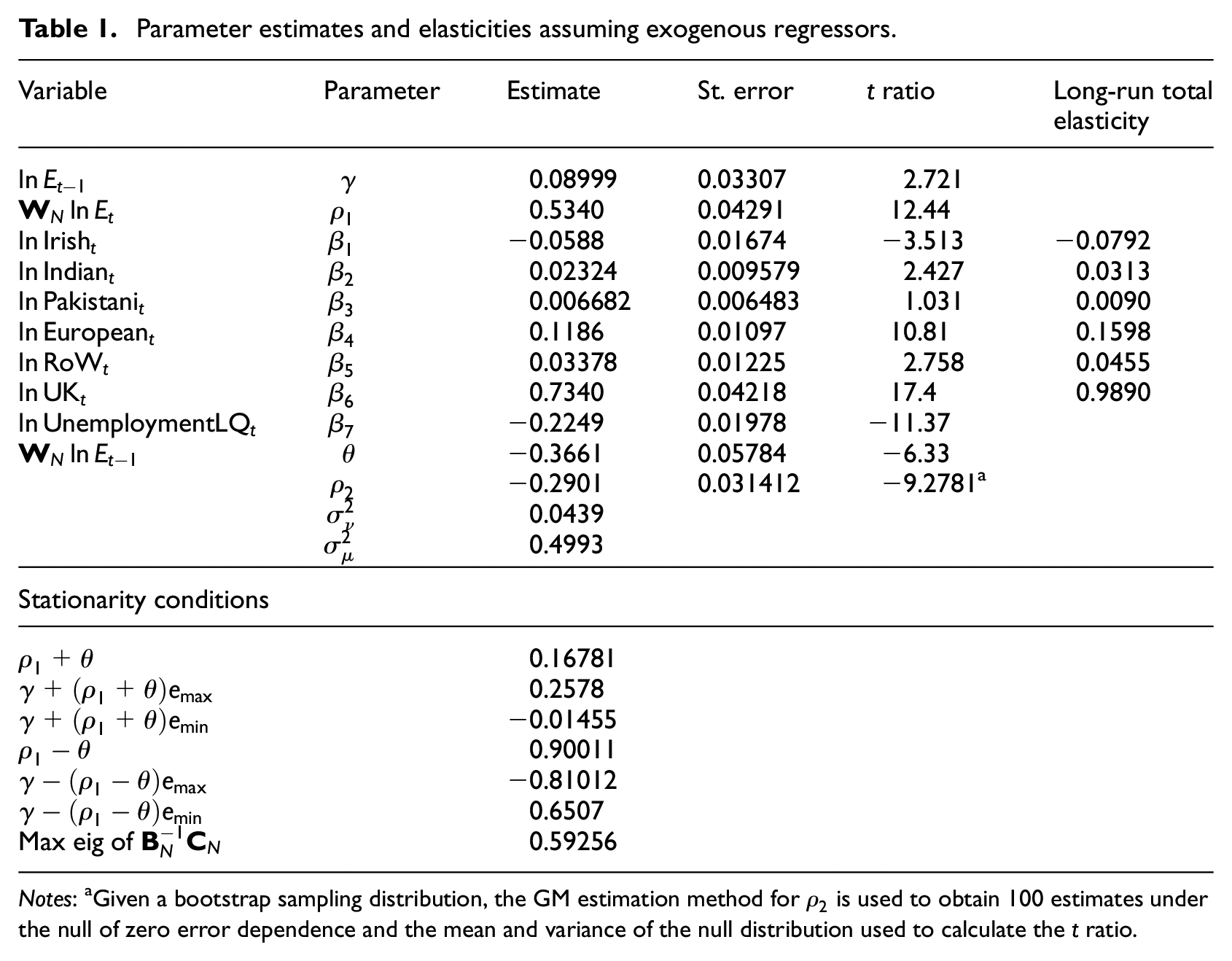
Notes: aGiven a bootstrap sampling distribution, the GM estimation method for
Parameter estimates and elasticities controlling for selection effects.
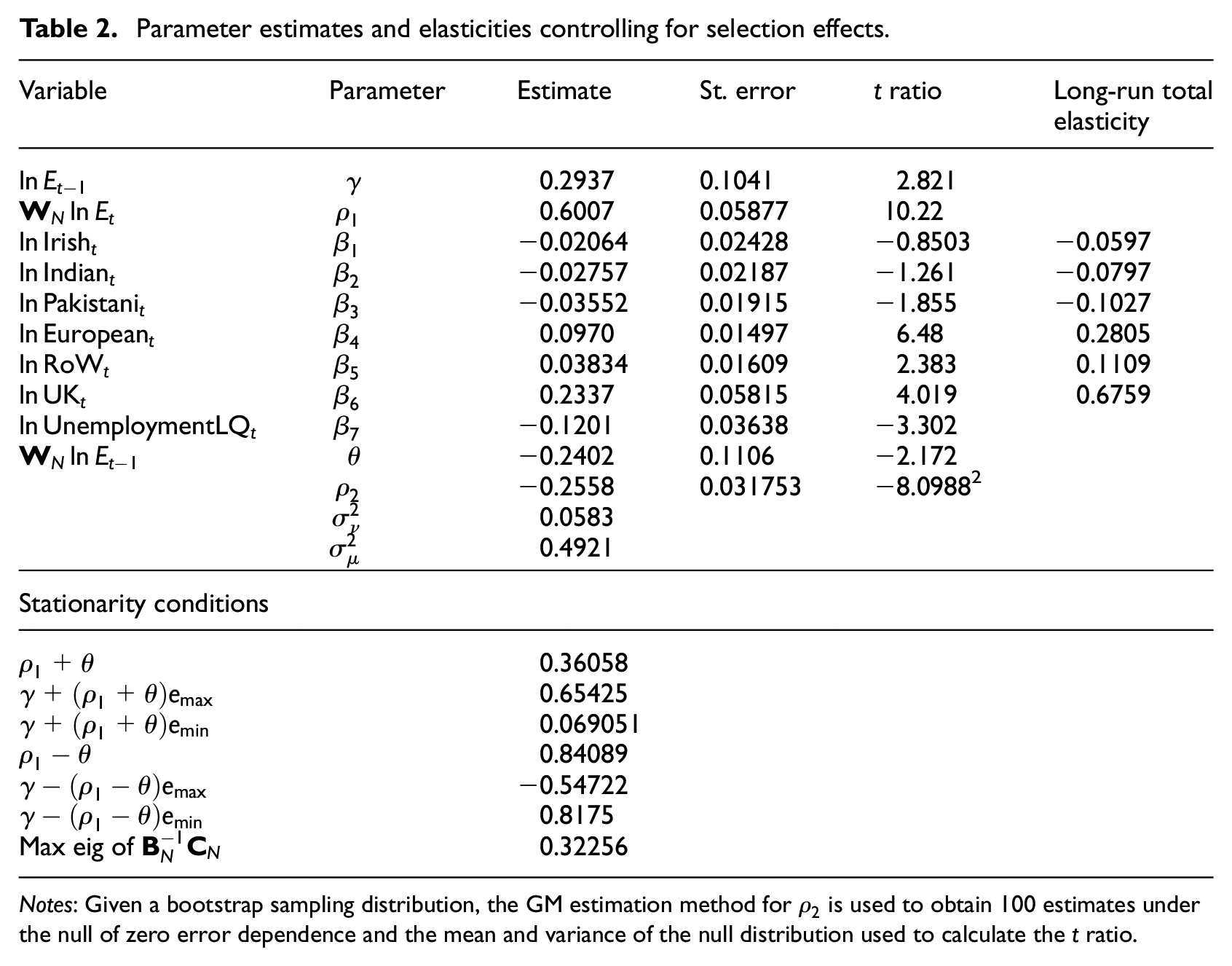
Notes: Given a bootstrap sampling distribution, the GM estimation method for
In contrast, the endogenous variables
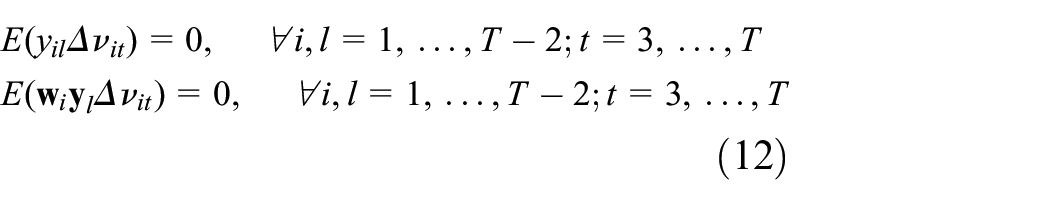
For these to hold, following Arellano and Bond (1991), we require that
The second assumption is that, alternatively, the regressors are themselves endogenous. This seems reasonable in the context, for as Bond (2002) observes, ‘strict exogeneity rules out any feedback from current or past shocks to current values of the variable, which is often not a natural restriction in the context of economic models relating several jointly determined variables’. Accordingly, we prefer to assume that our regressors are endogenous, in other words variation in the regressors both causes, and is caused by, variation in the level of employment. For example, a reasonable proposition is that the number of resident migrants born in Ireland will partly depend on the employment level of the ward. Consequently, we assume feedback from the dependent variable, and hence shocks embodied within the dependent variable, to the regressors and assuming that this is not the case tends to magnify the causal impact of the regressors, as we show subsequently. In order to allow for endogeneity, the regressors are also lagged by two periods, hoping to retain zero covariance as required by the moments conditions. Therefore, the set of instruments only includes
We see the effects of the different estimation techniques in Tables 1 and 2. Note first that we are controlling for temporal and spatial spill-overs. In other words, employment levels tend to have some kind of memory, regardless of the other factors affecting them. The level of employment in a ward is significantly related to the level observed in the previous Census. They also are spatially organised, tending to occur in clumps across space as employment in one district may cause, or be caused by, employment in a nearby, contiguous ward. These are more or less autonomous processes, which we have attempted to isolate so as to obtain the real effect of different country of birth concentrations. Also, some of the heterogeneity across wards, which is assumed to be constant over time, is represented by the term
Table 1 gives the parameter estimates and elasticities assuming that the regressors are exogenous. Evidently there are some significant causal impacts, though, as we show below, some of these are illusory. Controlling for the temporal and spatial spill-over effects due to
We next consider the outcomes under an assumption that the regressors are endogenous. For example, the statistically significant effects obtained assuming exogeneity may be the results of reverse causation, where an increase in the level of employment causes country of birth numbers to increase, maybe attracted by employment opportunities. For example, Indian-born residents may be sorted into areas with a high level of employment rather than causing a high level of employment.
Table 2 gives the details, indicating that allowing for reverse causation, or bidirectional effects, there are no significant changes in local employment levels as a result of change in the levels of Irish-, Indian- and Pakistani-born residents. In other words, the significant negative relationship between Irish-born migrants and employment level, and the positive relation between Indian-born migrants and employment level, given in Table 1, appears to be the outcome of sorting, with Irish migrants attracted to lower employment wards, and Indian migrants attracted to higher employment wards. These different outcomes may be the consequence of social segregation processes and differences in the housing markets as they impact the distribution of these migrant groups. Once we control for sorting or selection effects, as in Table 2, the links between Irish, Pakistani and Indian migrant numbers and employment levels become insignificant, suggesting that the number of Irish or Indian migrants does not cause variation in employment levels. On the other hand, the significant relations between European, UK and Rest of the World residents and employment evident in Table 1 do not disappear after controlling for endogeneity. From Table 2 it appears that there are causal effects whereby a 1% increase in the number of residents born in Europe, the Rest of the World or in the UK leads to rising employment levels. A permanent 1% increase in European-born migrants causes the level of employment to rise by 0.28%. For the UK-born, the impact is a 0.67% increase in employment, and for migrants from the Rest of the World, a 1% increase causes employment to increase by 0.11%.
In order to highlight the scope of the methodology, the not insubstantial causal effect of a 1% change in the number of European migrants, and to illustrate possible Brexit-induced impacts, we compare the equilibrium level of employment with the anticipated level if the number of European migrants became 1% lower than the 2011 level in each London ward. Figure 2(a) shows the outcome, which is a variegated pattern of job reduction. The anticipated job loss is about 500 in the financial district of Canary Wharf, with Figure 2(b) illustrating that more than 200 of the 760 wards are predicted to have a job loss of at least 130. Summing over the 760 wards gives an overall total job loss of 117,410 from predicted a total of 4,185,100 London-wide jobs. Of course, this preliminary analysis could be extended to explore the impact of changes in migrant populations in individual or groups of wards and allow different assumptions about other drivers of employment levels.
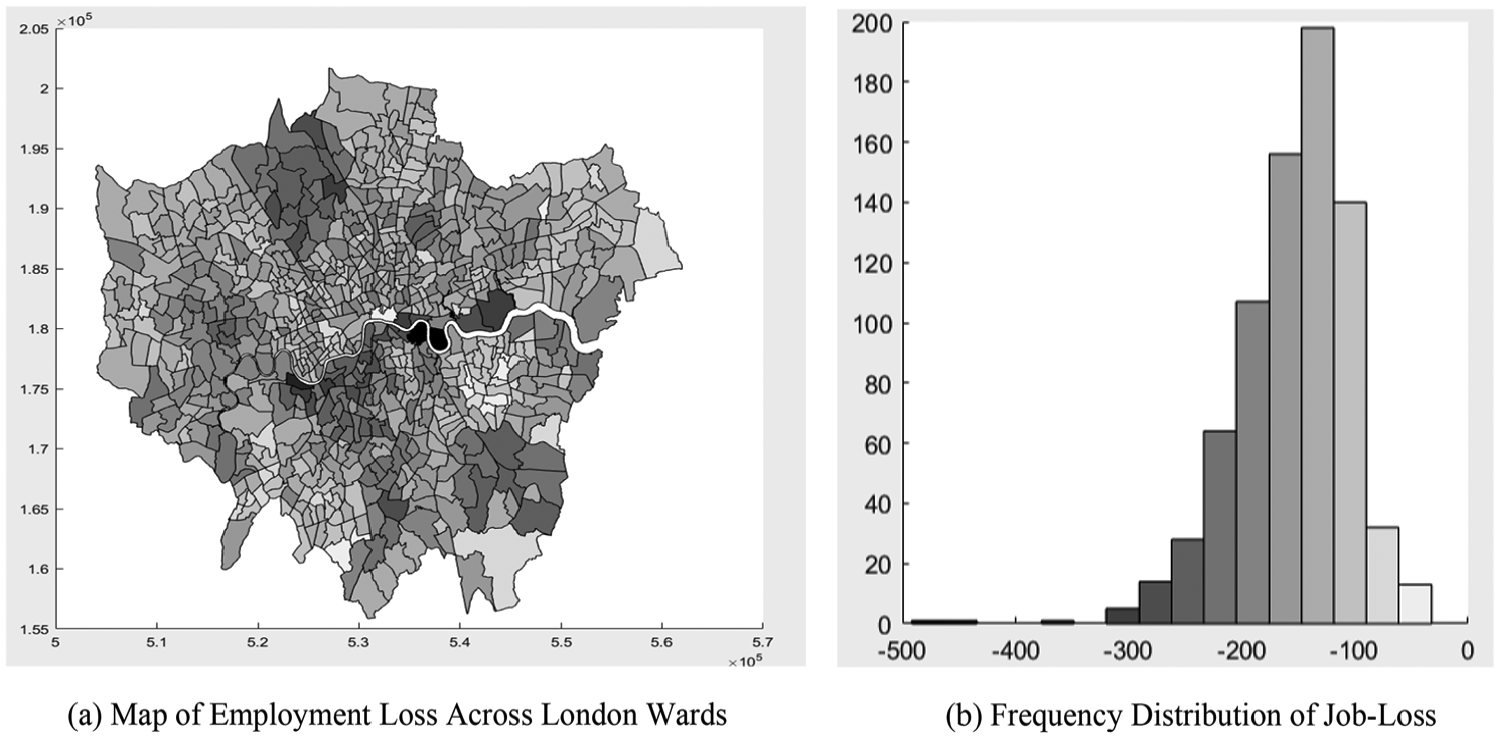
Simulated impacts on employment of a 1% fall in European migrants.
Conclusion
This paper has highlighted important deficiencies in the UK evidence base on the employment impacts of immigration. Perhaps most problematic of these is the dearth of robust estimations of the local impacts of immigration – existing studies only estimate the impact for the country as a whole. While the impact of migration on employment and the economy as a whole may be positive, it is possible that the local impacts vary considerably. This potentially raises questions of social justice and whether there is a political imperative for regions that have gained from immigration to compensate areas that have lost out.
We also noted that existing studies tend to focus on short- and medium-term effects – we are not able to find any UK studies that provide robust estimates of the employment impact after several decades, for example. This is important as some of the impacts of immigration may take many years to affect employment outcomes. Existing studies also tend to ignore spatial dependence of employment, which can bias the results and distort inference.
Our goal has been to address these shortcomings by creating a unique data set of linked Census geographies spanning five Censuses since 1971. These linked data sets yield a large enough sample to estimate the local impacts of immigration using a novel spatial panel model which controls for endogenous selection effects arising from migrants being attracted to high-employment areas. We illustrated our approach with an application to London and found that no migrant group had a statistically significant long-term negative effect on employment. European migrants and those born in the Rest of the World were found to have a significant positive impact. It would be of interest to see whether these findings are replicated in other city regions of the UK.
Our approach is not without limitations. Because our focus has very much been on the employment outcomes of immigration, there are a number of important effects we do not consider including hours worked, wages, productivity and the wider economic and social impacts of immigration. Our approach does have the scope to introduce additional covariates, including a more disaggregated breakdown of migrant groups, were data available, and this could challenge the conclusions of our analysis. However, we are aware of no source of data on these variables at the local level over the time span of our study period. There is perhaps an unavoidable trade-off, therefore, between having a richer model (with wages, etc.) for a shorter time period for the UK as a whole and having a more parsimonious model that provides large sample estimates at the local level over a longer time horizon. We argue that in demonstrating how the latter can be achieved we provide an important complementary perspective on migration research, and one that opens up a new avenue of inquiry into subnational variations in the impacts of immigration on employment.
Another limitation of our study is that, despite uniquely spanning five Censuses, the number of periods at our disposal is insufficient to formally test the assumptions made regarding the viability of the moments equations used in model estimation. This might be possible given additional periods, but the data set at our disposal currently is at the cutting edge of the data technology: it is probably not feasible to add locally geocoded Census data on the variables in our model before 1971. However, when the 2021 Census data come online, it should be possible to add this extra wave of data to the model, which may make it possible to formally test the moments equations.
Footnotes
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by the Economic and Social Research Council (ESRC) through the Urban Big Data Centre (Grant Reference: ES/L011921/1) and the Understanding Inequalities (Grant Reference: ES/P009301/1) projects.