
Abstract
Deviation detection has emerged as a critical research focus for business processes, enabling enterprises to prevent fraud, monitor anomalies, and safeguard the security of processes and data, particularly in the medical field. Despite its importance, existing methods face significant limitations. Some approaches focus solely on control flow deviations while neglecting data-induced deviations, whereas others rely on specific data, risking the exposure of personal privacy information. Consequently, a major challenge lies in balancing data availability for deviation detection with the imperative of preserving data privacy and security. To address this challenge, this paper proposes a multi-view deviation detection method based on privacy protection. First, data attributes critical to business processes are extracted using a random field model. Next, an identity and purpose-based data matching algorithm ensures the security of user identities and validates the intended use of data for privacy protection. Furthermore, the business process activity view regulates legally permissible data operations, while decision logic analysis links processes and data through decision tables to detect deviations. Beyond detecting deviations within each perspective, this method uncovers hidden deviations arising from the interplay of business process, data flow, and privacy perspectives. The evaluation using real-world medical event data demonstrates the method's effectiveness. Notably, it outperforms existing approaches by accurately identifying deviations that other methods fail to detect.
Introduction
Process mining technology can extract valuable information from the event logs commonly produced by modern information systems, which provides a new means for process discovery, monitoring and improvement in various application fields. However, due to the imperfection of information system design or system upgrade, inconsistencies 1 of control flow and data flow in the system may cause security risks. We call such inconsistencies deviations 2 and detecting such deviations allows us to validate and extend the business process models and improve the business processes accordingly. Also, deviation detection is a popular topic in the enterprise because its application areas are multifaceted such as fraud detection, 3 intrusion detection and e-commerce anomaly transaction detection. 4 The literature 5 provides a formal definition of anomalous activities in business processes based on Petri nets. An efficient method to detect deviations between process models and event logs is proposed to detect missing, attached and misplaced activities in business processes. The literature 6 presents an efficient method for detecting deviations between a process model with a cyclic structure and an event log. In response to the above approach to detect deviations from a pure control flow perspective, the literature 7 points out that traditional business process modelling approaches focus mainly on the sequence of activities of the process, although the occurrence of these activities may be required to satisfy data constraints, 8 and therefore cannot accurately identify and explain deviations from other perspectives of the business process.
Existing anomaly detection methods primarily focus on control flow and point anomalies, and endeavor to minimize false positives in the event of unexpected occurrences. Over the past few years, there has been a growing trend in process design and mining, shifting from a purely control-flow-based perspective to more integrated models that explicitly take data 9 and decisions into account. Indeed, without understanding the context in which data is accessed, it is challenging to differentiate between legitimate and illegitimate actions. The literature 10 points out that existing process coding techniques are focused on the control flow perspective, encoding only the sequence of activities in the logs, ignoring the multiple features of the process that can be analysed by hiding valuable process behaviours in the data. 11 A dependency pattern is proposed to encode the logs as a whole into a suitable format capturing the perspective lost in the one-dimensional analysis. Coloring Petri nets (CPNs) can be simulated by CPN Tools, which makes data flow and control flow fusion possible on prior art reliability. The literature 12 proposes a method to search for transactional system deviations by checking the consistency between coloring Petri nets and event logs in addition to detecting control deviations also object priority deviations and resource deviations. The existing literature 13 integrates time-related factors and resource information to propose an anomaly detection method capable of addressing unexpected events during process model execution. It is suggested that not all deviant events are promptly identified as anomalies; instead, detection is based on a specific probability of occurrence, thereby reducing the number of false positives. A neural network architecture BINet 14 for multi-view anomaly detection in business process event logs proposes a set of heuristic algorithms 15 to automatically set the threshold of the anomaly detection algorithm and demonstrates that BINet can be used not only at the case level but also at the event attribute level to detect anomalies in event logs.
In the context of the digital economy, data openness has emerged as an inevitable trend. Over recent years, a substantial number of methods have been devised to analyze event logs within the framework of process mining. However, the impact of privacy rules
16
on the design and organizational application of process mining techniques has been largely ignored leading to irresponsible use of personal data, such as the use of employee data in process mining to predict employee performance. The literature
17
proposes an application of differential privacy for event data protection privacy and analyzes potential privacy leakage and prevention methods. Healthcare information systems contain highly sensitive information and healthcare regulations often require the protection of data privacy. The need to comply with strict privacy requirements may lead to a decrease in the utility of the data used for analysis. The literature
18
analyzed the data privacy and practical needs of healthcare process data and evaluated the applicability of privacy-preserving data transformation methods to anonymous healthcare data. The accuracy of bias detection can be improved by adding data information to the business process bias detection process. However, this data information often contains sensitive information about individuals. Data security and privacy protection
19
issues are inevitable in the data openness process, and exploring how to achieve a balance between maximum data utilization and privacy protection in the deviation detection process is of great importance but currently less studied. The problem is that organizations often lack appropriate mechanisms to monitor the use of data. Existing methods either use data views
20
to compare data access to security policies or compare activity deviations to the activities that are needed to run business processes. Analyzing user behavior from these perspectives alone cannot only lead to some deviations not being detected or having false positives, but can also reveal the data provider's secrecy. The literature
21
posited that the deviation-detection method ought to concurrently take into account the control flow, data flow, and privacy perspective of the business process to identify a broad spectrum of deviations, especially the deviation related to the intended use of the data and the data use environment. Current access control mechanisms are inadequate for data protection. They merely serve as preventive measures and do not ensure that the data is employed for its intended purpose. The problem of how to detect deviations in business processes while protecting user data security is a challenge for process mining. In this paper, we detect deviations between logs and business processes from multiple perspectives by considering all control flows, data flows, and data decisions of business processes based on the premise of privacy protection. This paper proposes multi-perspective deviation detection of business processes based on privacy protection from the following three aspects. See Figure 1 for the framework diagram of the paper. The main contributions of this paper are as follows:
The conditional random field model is applied to extract important data attributes from complex and diverse unstructured data information, which is of great significance to business process research. In order to prevent the fraud risk caused by privacy disclosure, an identity-based purpose matching algorithm is proposed to match the intended use of data with the access purpose of data users to ensure the safe use of data. Under the fusion of control flow data flow, the deviation detection is carried out by combining the business process and the activity view to detect activities, resources, data operations, privacy and other perspectives, so as to improve the accuracy of the deviation detection

Multi-view deviation detection for business processes under privacy protection framework diagram.
The other parts of this article are arranged as follows, Section 2 shows the motivating case, Section 3 shows the basics knowledge, Section 4 shows the extraction of important data features using the random field model, Section 4 shows the identity and purpose-based privacy access control model, Section 5 shows the deviation detection based on the fusion of control flow and data flow, Section 6 shows the experimental evaluation, and Section 7 concludes.
Motivations
Organizations frequently employ process models and security policies to delineate the regulated behavior of business systems and the legitimate utilization of data. In practical scenarios, organizations might permit users to deviate from the prescribed behavior in order to effectively manage unforeseen situations. Nevertheless, this functionality is susceptible to abuse, thereby elevating the risk of detrimental data breaches. Moreover, insiders may exploit their privileges to access sensitive data for personal or financial gain. There is ample evidence in the literature 22 that real process behaviour often deviates from the expected process, which often opens the way for fraudulent behaviour. In recent years, different methods for finding business process deviations have been proposed. However, deviation detection from a data or process perspective alone may not explain why the deviation occurred, making it difficult for security analysts to take the necessary steps to fix security violations. Let's consider a trace that is executed, underscores indicate deviations.
L=<(
Figure 2 shows the healthcare business process and contains data attributes, resources (roles) and constraints. It can be observed from Figure 3 that if the deviations are detected only from the control flow perspective, {re, tr, sc, at, (ct), bt, di, tu} only the log can be detected skipping the active basic lab test (bt) and inserting the active clinical trial ct (clinical trial). It does not detect the following behaviour and data biases.
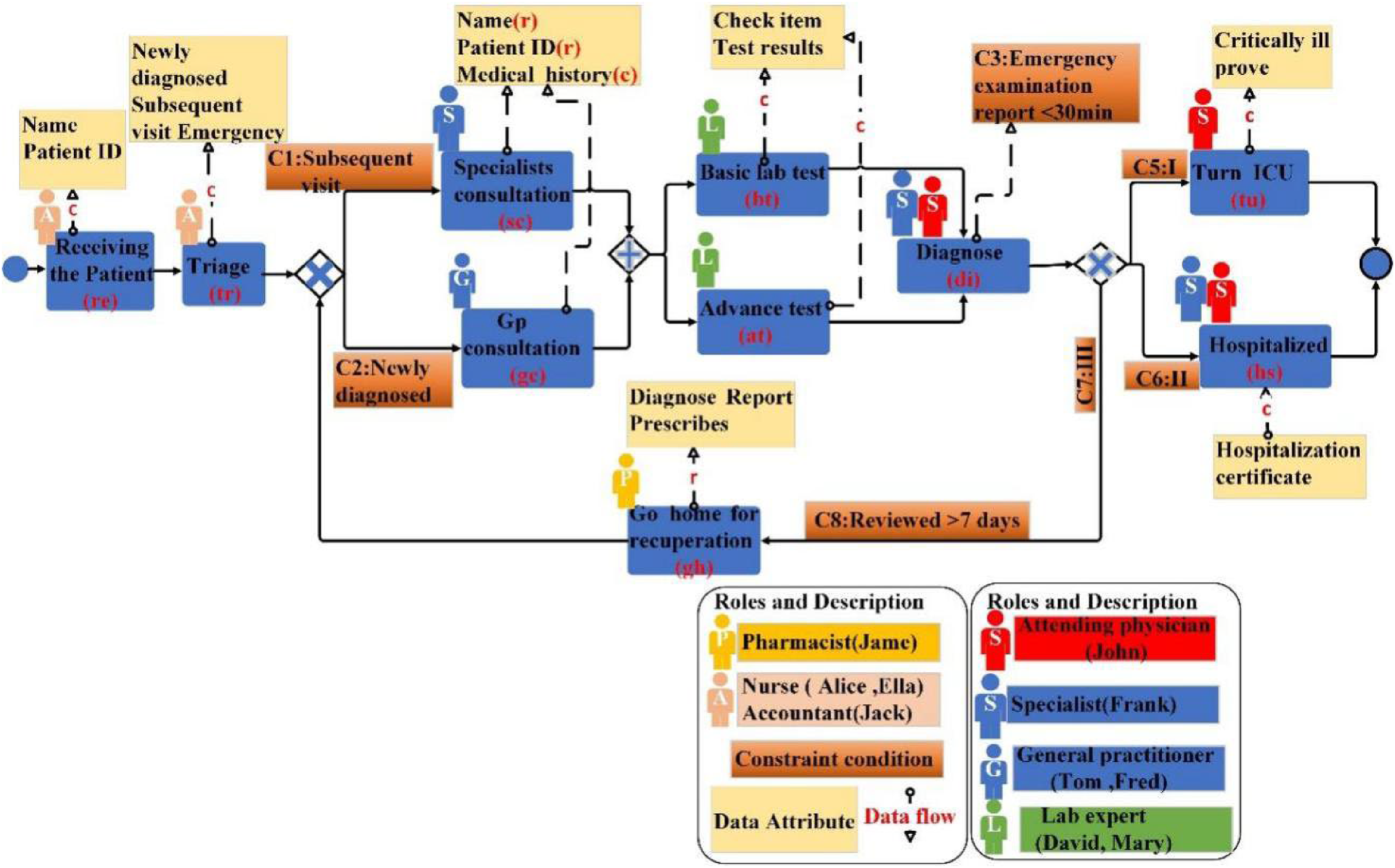
Medical business process.

Comparison of log and model.
Deviation caused by lack of data
Deviation caused by lack of privacy protection
Basic Knowledge
The process design, engineering, and mining move from a purely control-flow perspective to a more integrated model where data and decisions are explicitly considered. The perspective of controlling flow in a business process is important because it describes the mainstream behaviour of the business process. However, other perspectives on data flow must also be taken into account. Next, this section provides the basics of control flow and data flow.
Control Flow Perspective
(Process Model
23
) A process model is a five-tuple, satisfying.
T is a finite set of non-empty activities. P is a finite set of places.
(Log move Model move
24
If If If
Figure 4 shows the Petri net of the medical business process. Figure 5(a) displays a process running of the medical business process model. This running instance is also called the partially-ordered running of Petri nets. Figure 5(b) is an event log. Figure 5(c) presents the alignment between process runs and logs in the control flow perspective, and it is evident that there are two deviation model movie (bt), and log move (ct).

Healthcare business process petri ne.
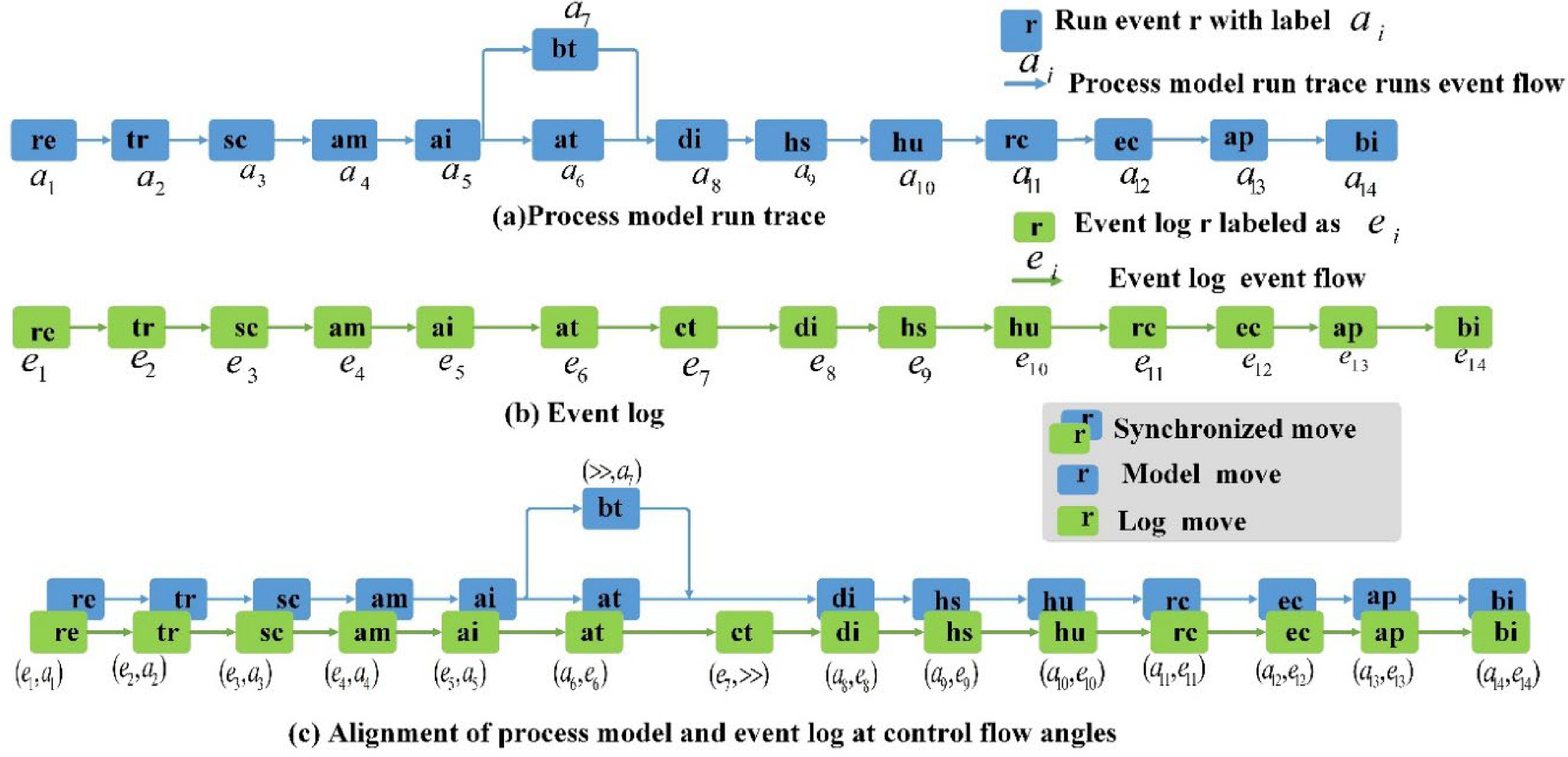
Process run and process trace.
Concentrating solely on the control-flow perspective only allows us to detection of the insertion or omission of specific activities. Nevertheless, this approach is insufficient to identify threats such as data leaks resulting from data operations (e.g. doctors can access sensitive medical information of patients and conduct clinical trials). These insiders have a profound understanding of information systems and security controls and may exploit their privileges and this knowledge for malicious ends. In the following sections, we present some data information derived from business processes and employ the fusion of control flow and data flow to detect deviations from multiple perspectives.
Data perspective
Traditional business process modelling just focuses only on the control flow perspective and constrains the activities in the process by the behaviour profile relationships in the business process (e.g. sequential, concurrent, mutually exclusive, etc.) However, activities are executed by different resources, manipulate data objects, and are constrained by the state of these objects. This makes it necessary to extend the control-flow model to incorporate data. Particularly in the medical field, doctors need to make a comprehensive judgment based on important data such as patient history and auxiliary test results so as to make an accurate diagnosis of the disease. The following describes the definitions related to the introduction of data in business processes.
(Data-awareness reasonableness
25
(Conditional random field CRF
26



CFR linear chain structure.
In equations (1) and (2),

Entity recognition of important medical attributes.

Algorithm 3-1 The description of the conditional random field entity recognition algorithm is as follows. Lines 1-7 describe the preprocessing and feature extraction phase. The input medical text sequence
The combination of CRF and rules (Table 1) was used to identify the entities with important medical attributes. Figure 7 illustrates the identified important attributes of medical domain entity Patient Information. These medical attribute features are extremely valuable for patients to cure their diseases. Yet, the leakage of this medical information can also pose a threat to patients, Consequently, we propose below an identity and purpose-based privacy access control model.
Composite entity construction rules.

Identity and purpose based privacy access control model
The advent of the big data era has brought about a great deal of convenience to people's daily lives, exemplified by the sharing of medical data, which has enhanced the level of medical development and treatment efficiency. The literature 27 underscores the significance of establishing a patient centric privacy preserving access control model. This model ensures that patients can devise access control policies in accordance with their privacy preferences, without obstructing data visitors, such as healthcare professionals, from accessing patients’ medical information. In this paper, we propose the purpose-based access control (PBAC) model, the core of which is to match the intended purpose (IP) of the privacy data provided by the data owner with the access purpose (AP) proposed by the data user according to his willingness to use the data before the data user is entitled to access. A conditional purpose-based access control model conditional purpose-based access control (CPBAC) is proposed to simultaneously ensure high quality and privacy of data. An algorithm is proposed to achieve the compliance calculation between the purpose of access and the intended purpose.
(Ancestors and descendants
19
) Let An intended purpose Conditional Purpose Sets
Figure 8 establishes a set of intended purposes for data usage that are permitted for the medical information provided by patients.

Entity recognition of important medical attributes.
In the current context where the digital business environment is becoming increasingly complex and business data contains a large amount of sensitive information, this paper focuses on studying business processes using a multi-perspective detection strategy within the framework of privacy protection to enhance the accuracy of deviation detection. Business processes serve as the core framework for business operations and the mainstay of detection, while business data acts as a crucial information carrier reflecting the status of processes. Only through the deep integration of the two can more precise deviation detection be achieved. To this end, this paper first employs a random field model to deeply mine business data, accurately extracting data attributes of significant value for deviation detection, covering key characteristics of business activities, data associations, and so on. After introducing these attributes, the accuracy of deviation detection is significantly improved. However, the addition of data attributes increases the risk of data leakage. To address this challenge, this paper innovatively proposes an identity- and purpose-based data matching algorithm. It ensures that only authorized legitimate users can access data through strict identity authentication and guarantees compliance by rigorously reviewing and monitoring the purpose of data use, thereby effectively protecting the privacy of business data. Finally, by using decision tables, this paper closely associates business processes with the processed data and conducts a comprehensive decision logic analysis across multiple dimensions such as business activities, data, and resources. Taking various factors and conditions into comprehensive consideration, it employs logical reasoning and data analysis methods to accurately detect deviations in activities, data, and resources, providing a solid decision-making basis for enterprises to optimize business processes, enhance operational efficiency, and reduce risks.
Establishment of the data patterns
Depending on the visitor's access purpose in different sets of purposes
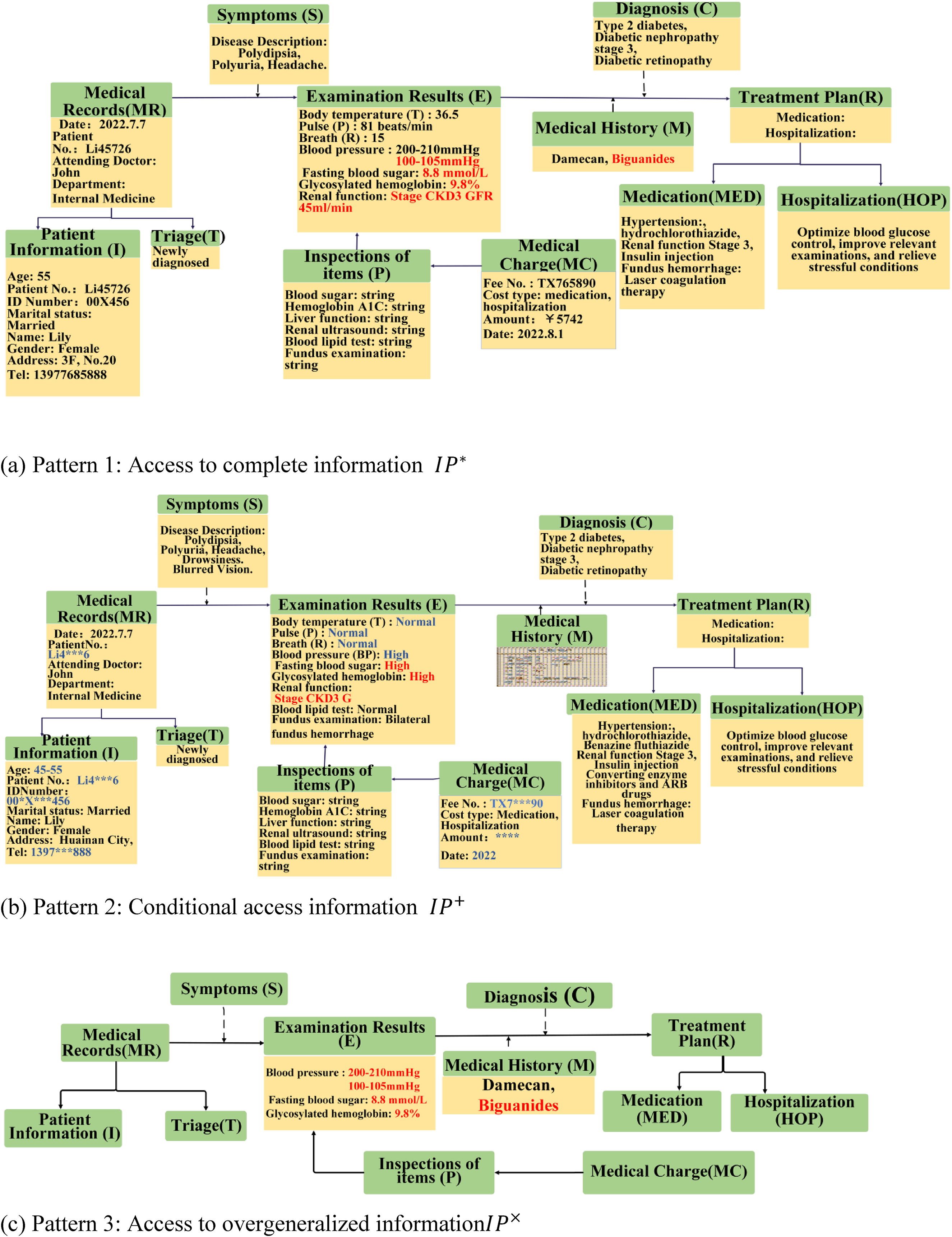
Data patterns of medical information obtained for different access purposes. (a) Pattern 1: Access to complete information
Constructing the purpose tree table
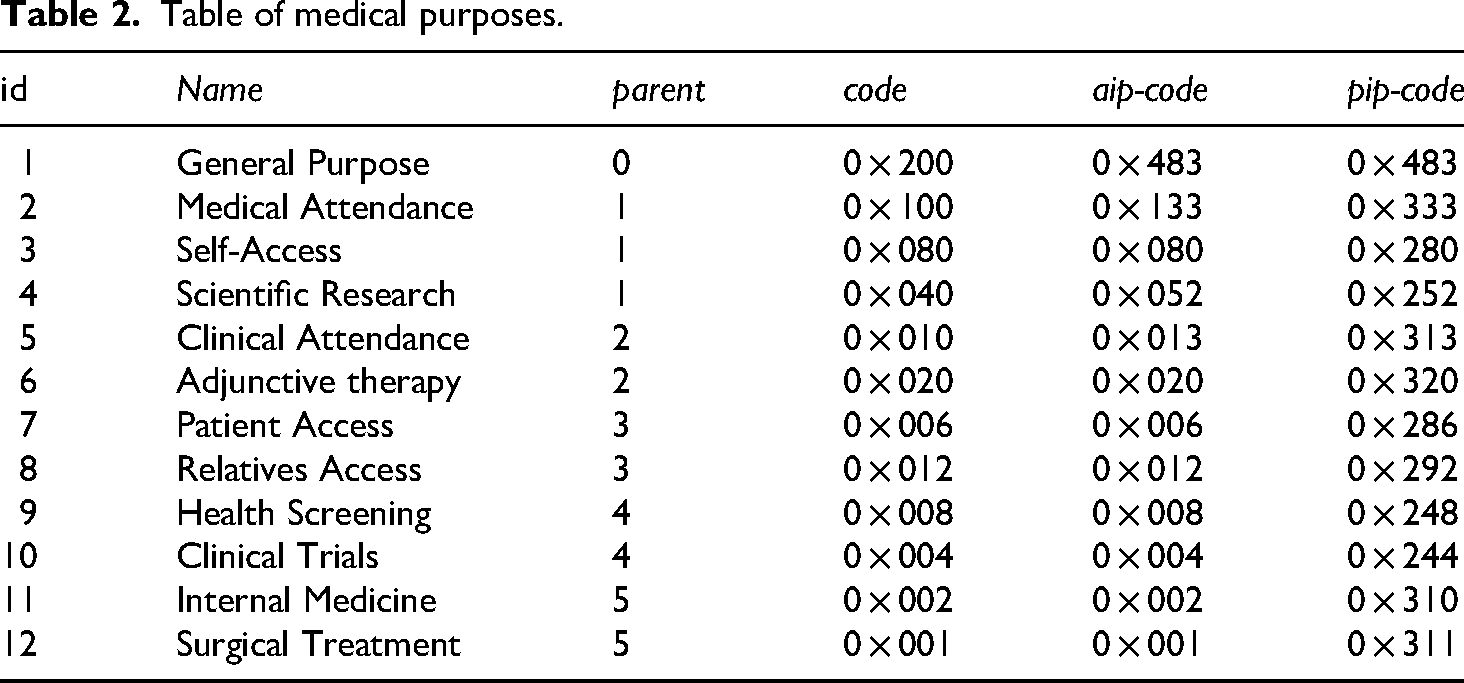
According to Figure 8, the medical purpose tree is traversed in breadth-first order, the coding of intended purpose code and prohibited intended purpose code can be calculated to construct the medical purpose table in Table 2.The collected medical information of the patient is shown in Figure 9. Figure 9(a) Pattern 1 is the complete medical information of the patient, Figure 9(b) Pattern 2 is partially generalized medical information and Figure 9(c) Pattern 3 is the medical information of the patient after the generalization process.
Table of medical purposes.
The above analysis leads to 3 public keys. The first byte of the public key is the patient 7-bit PID, two data patterns identification (CondBit) where 00 indicates data pattern 1; 01 indicates data pattern 2; 11 indicates data pattern 3 and equal length of
As one of the most pivotal resources in the contemporary world, data holds inestimable value for the advancement of modern society. Data security and privacy protection issues are inevitable during the process of data openness, and it is of great significance to deliberate on how to strike a balance between data openness and privacy protection. This section proposes a role and access purpose matching algorithm that can both securely access data and effectively prevent the occurrence of malicious access data leakage. The role ID is selected to verify the identity of visitors to determine whether they have access rights, and then the data is encrypted as the identity key according to the conditions of the access purpose and the predetermined purpose, which can effectively ensure that the system users can access the patient information only after the authentication and the access purpose matches the predetermined purpose. For the specific algorithm content, see Algorithm 4-1.
Access purpose matching algorithm
In the purpose matching algorithm, lines 1–2 set the expected access purpose data set and prohibited access purpose set according to the data provider's wishes. Lines 3–5 provide the data visitor with the ID number and access role information RIP, and if the RIP meets the role attributes allowed by the data provider, then access purpose compliance verification is performed, otherwise the user does not have access to the data. Lines 6–10 calculate the binary and hexadecimal codes of the allowed, denied, and conditional destination sets based on the purpose tree table. Purpose sets have no intersection and are full coverage of the purpose tree. Lines 11–14 determine that the access destination matches the allowed access destination and output the key and full data information data pattern 1. Lines 15–18 determine whether the access purpose matches the set of conditional purposes, and if it does, return the corresponding key and data pattern 2, otherwise proceed to lines 19–21 to return the corresponding key and data pattern 3.
This section proposes that data patterns of different granularity can be obtained according to different access purposes of different roles, which protects the privacy and security of patients to a certain extent and maximizes the utilization value of data. However, what data visitors can do with data when they get it, and how the input of data affects business process decisions. Next, we introduce business process deviation detection after data flow control flow fusion.
Deviation detection under data flow control flow fusion
In the realm of Business Process Management (BPM), the fusion of business processes and related data represents a pivotal concern, given that the execution of business processes is frequently subject to data constraints. 28 Particularly in data decision-intensive scenarios, it is of great utility to establish connections between activities and data operations, thereby enabling the detection of anomalies in business processes from a variety of perspectives.
In this section, we expand the concept of activity view and decision table (DMN) to narrow the gap between process and data conceptual design, thereby linking process activities and related data. When business rules or constraints are required to be incorporated into the process for decision-making purposes, we introduce a decision table. Subsequently, we feed relevant data into the decision table, apply decision logic, and then output decision results back to the decision-making activities within the business process. By doing so, the business process is elevated to this richer data-aware level.
Control flow data flow fusion
(Decision table
29
Name is the name of the decision table; I and O are disjoint finite sets of input and output attributes respectively; X is an external parameter set;

Data is essential for the execution of business activities. In particular, the execution of activities may require certain operations to be performed on data objects. Figure 10 presents a visual depiction of activities and data within a healthcare business process through an activity view. The dashed arrow establishes a connection between the activity and the relevant portion of the data schema delineated in the activity view. The connecting arrows are annotated with information regarding the accessed resource, the access type, and the quantity of objects involved in the operation. The active view links the processing logic to the data layer by the actions performed on a given data object and specifies the specifications for the actions that data visitors can perform.

Flow chart of purpose matching.
The interplay between process and decision models assumes a pivotal role in BPM, given that decisions are often grounded in ongoing processes and can significantly influence process outcomes. In this section, we integrate the data layer, decision layer, and process layer to facilitate sound decision-making for business processes and steer business processes towards achieving optimal process management.
Figure 11 exhibits the business flow diagram for medical data decision-making subsequent to the amalgamation of the data flow and control flow. The data layer acquires the legitimate data schema according to the visitor's identity. The decision layer comprises a decision table, and the data layer inputs relevant data into the blue-colored region of the decision table. Subsequently, data rule constraint operations are carried out to yield the corresponding decision. The orange hue signifies that the decision output is transmitted to the process layer to direct the selection of business process execution paths.

Data decision business process diagram.
Decision Table (1): The body mass index (BMI) decision table utilizes the patient's fundamental information, namely height and weight, as input data. It then computes the body fat percentage and calculates the BMI value, which, in this case, is 32.91, classifying the patient as obese. Given that obesity is a risk factor, the patient is at a higher likelihood of developing cardiovascular diseases, type II diabetes, and other obesity-related conditions. When considering a patient who also has diabetes and hypertension, the derived results are transmitted to the business process's decision activity triage (tr). This activity can recommend that the patient opt for a specialist consultation, thereby enhancing the efficiency of the treatment process.
Decision Table (2): This decision table is responsible for determining the disease grade. It takes the data from the data layer, specifically treatment-related information such as retinopathy grade 3 and renal function classified as Chronic Kidney Disease (CKD) stage 3, as input. Based on the constraint rule of disease grading (grade II), it facilitates inpatient treatment (hs). Moreover, the outcomes of this decision table serve as a guide for the selection activities that follow the decision activity (di).
Based on the aforementioned analysis, data, decisions, and business processes are intimately connected. Organizations are required to derive valuable information from the data gathered by business processes and data sources, which can then be utilized for decision-making and process enhancement. Business process models typically encode decision logic of varying complexity through conditional expressions attached to outgoing flows or conditional events of decision activities. By separating this decision logic from the control flow logic and capturing it at a higher level of abstraction, it becomes more straightforward for a business process to select a scientific path.
Multi-view deviation detection
In this section, we put forward a multi-view bias detection method. The primary objective of this method is to identify the concealed bias among the three dimensions of behavior, data, and resources following the logical decision-making process. The activity view of the log in figure 12 reflects the actual process track and the real data operation of the performer. Notably, there are some deviations between the activity view of log execution in figure 12 and the standard medical business activity view in figure 10. To precisely detect these discrepancies and offer contextual information for diagnosis, we introduce the concept of composite movement. This is achieved by integrating system traces, event logs, data attributes, and activity views as dictated by the decision logic. In doing so, we connect the process and data views to detect deviations from multiple perspectives.

Log activity view.
(Combined movement
23
If If
Given a composite move
Figure 13 presents a graphical representation of the composite movement classification. Considering the degree of influence of combination movement on deviation, we classify it into the following six categories.

Composite move classification chart.
In addition, Figure 13(8)
Interlayer alignment
The composite method combines process and data perspective views, thereby facilitating the identification of deviations that remain undetectable under other single-view approaches and enabling an accurate diagnosis of such deviations. To accurately assess the extent of deviation from both data and process perspectives, this section presents a set of cost functions (Figure 14) to evaluate the legitimacy and cost associated with deviations in composite moves.

Composite mobile cost distribution diagram.
Figure 15 illustrates the two different interlayer alignments of
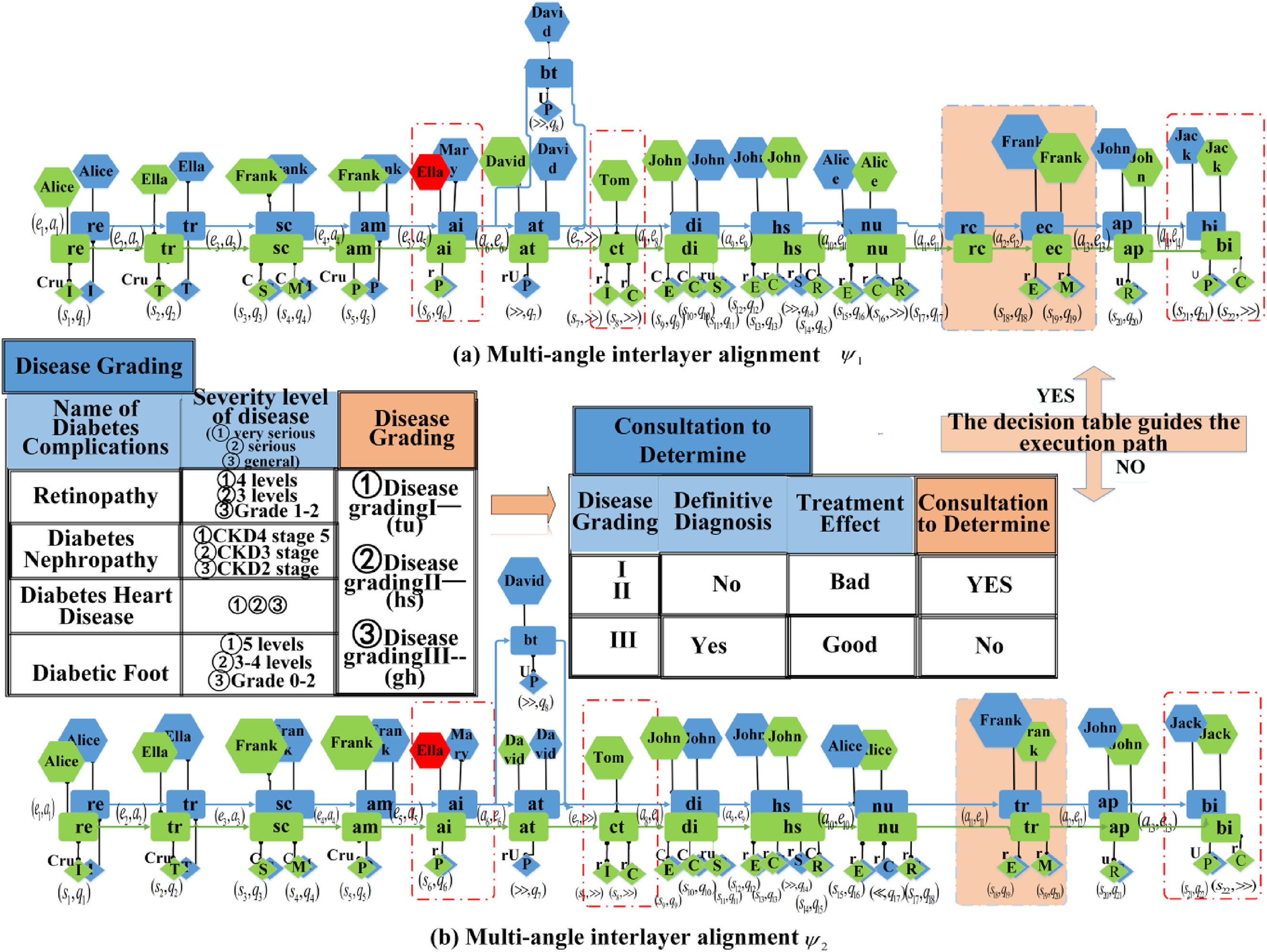
Multi-view interlayer alignment comparison diagram.
Medical staff exploited their access rights to engage in system-unauthorized activities and execute system-prohibited data operations, thereby violating patient privacy. This type of deviation poses a more significant threat to the business system. For deviation type
In summary, the total cost of interlayer alignment
Multi-view optimal interlayer alignment deviation detection algorithm
Current research primarily centers on extracting models from process control flow, whereas the relationship between process-related data and decision logic has yet to be investigated. Consequently, deviations in the business process cannot be identified from multiple viewpoints. In this paper, we incorporate data information into business processes via activity views and employ decision tables to ascertain whether the data complies with business process rule constraints, thereby offering a scientific foundation for business process logic decision-making. The multi-view deviation detection algorithm is presented below.
To detect business process deviations with greater precision, given the significant impact of resource errors on anomaly detection, this section divides the multi-perspective anomaly detection algorithm into Algorithm 5-1 and Algorithm 5-2, which conduct deviation detection from dimensions such as activities, resources, and data respectively. Among them, Algorithm 5-1 focuses on the deviation situations of activities and data under the condition of correct resources, while Algorithm 5-2 emphasizes the elaboration of deviation costs of business process activities and data under the circumstances of resource errors.
In the multi-view deviation detection algorithm 5-1, lines 1–4 provide the algorithm input to the business process activity view
Where lines 14–16 rows are combination move

In the multi-view deviation detection algorithm 5-2. Lines 1–17 shows the deviation cost analysis of the logs and models under the condition of execution role error

Lines 2–6 of Algorithm 5-3 determine whether the data operations performed in the log meet the requirements of the business process

Experimental evaluation
In this section, we explore the accuracy and performance of our approach. We conducted experiments using real medical event logs and interpreted the results. The experiments were conducted on a machine equipped with a 3.4 GHz Intel Core i7 processor and 16 GB of RAM. In Section 6.1, we introduce the accuracy of CFR + rules and pure CFR to identify medical entities. Section 6.2 proposes privacy-preserving soundness checks for purpose-based access control mechanisms. section 6.3 presents the control flow data flow model fusion deviation detection model visualization. section 6.4 presents multi-view deviation detection effectiveness verification.
Verification of medical entity identification accuracy
In this paper, 4200 medical records were obtained from a tertiary hospital in Anhui Province. A corpus of 653897 characters was constructed to identify entities including basic patient information, symptoms, medical history, examination items, treatment methods, and medical records into 6 groups, with test data volumes of 200, 400, 600, 800, 1000, and 1200 respectively. These six groups of corpus were evaluated by applying CFR and CFR + rule methods respectively. The accuracy of medical entity identification was determined by calculating precision rate
Figure 16 shows the comparison of CFR and CFR + rule entity recognition, whereas Figure 16(a) shows the effect of the test set ADT and the total number of corpus entities
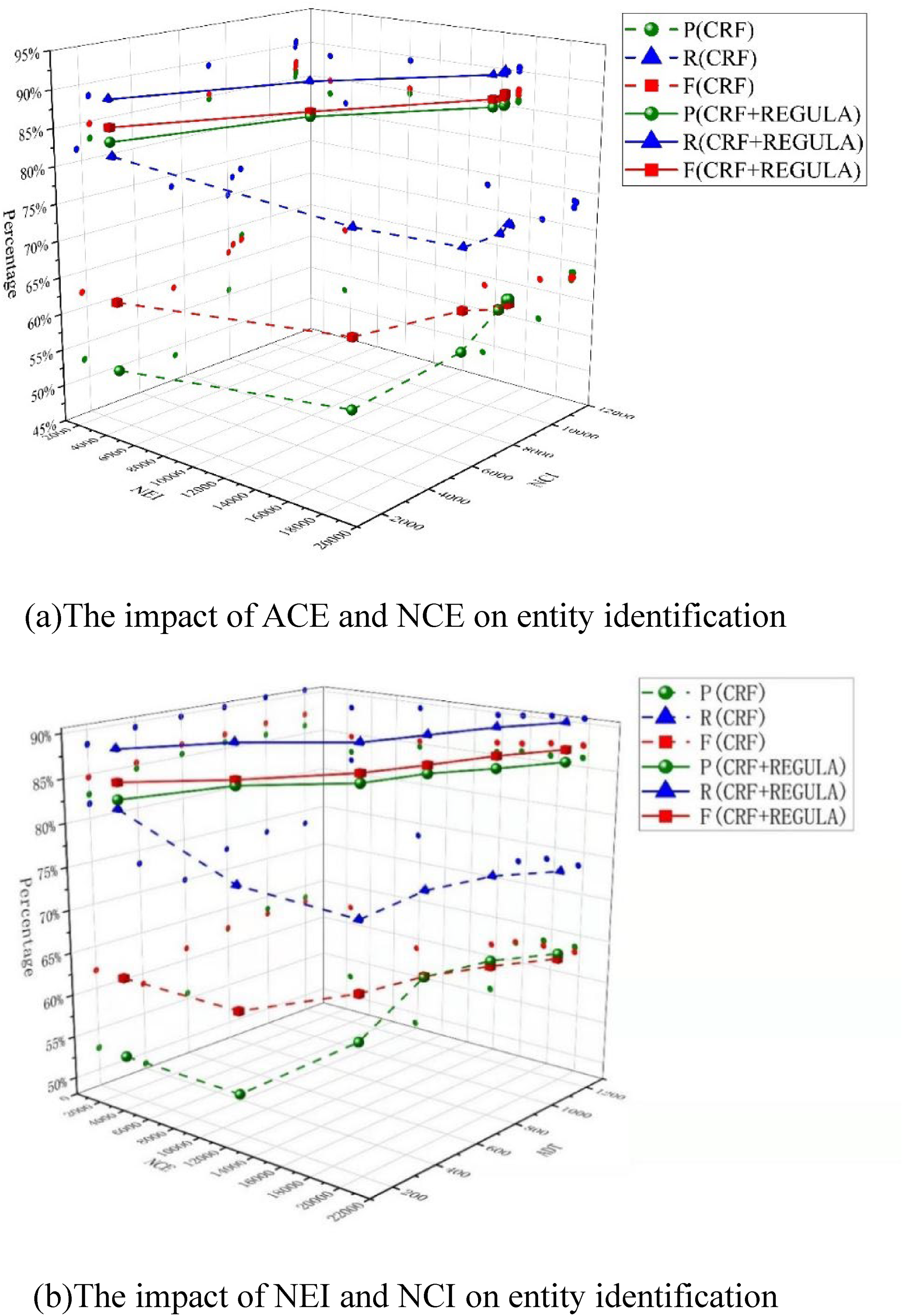
Comparison diagram of CFR and CFR + regular entity recognition. (a)The impact of ACE and NCE on entity identification. (b)The impact of NEI and NCI on entity identification.
Reasonableness check of purpose-based access control mechanism
Unreasonable access to medical data may lead to the leakage of patients’ sensitive information. This paper proposes an identity-based and purpose-based access control machine model. According to the different data access permissions, the model also combines the attribute encryption technology to build the key according to the expected purpose of the data, conduct authentication and conduct purpose matching to access different data mode information. And extend the traditional purpose tree to achieve full coverage. Figure 17 Comparison of the running time of the purpose matching algorithm considering the purpose tree hierarchy after considering tuple-based and element-based annotation of the electronic medical records. As shown in the figure, when the purpose tree has 5 nodes (PT size = 5), the height of the purpose tree is 2, and it is necessary to use 5-bit encoding to construct all possible expected purposes. When the destination tree has 14 nodes (PT size = 14), the height of the destination tree is 5, and 14 bits are needed to encode all possible intended purposes. Figure 17 shows that the size of the destination tree does not make any substantial difference in either the tuple-based or element-based identification methods. The reason for this difference is that both bitwise and operational algorithms work well, no matter how long the encoding is.
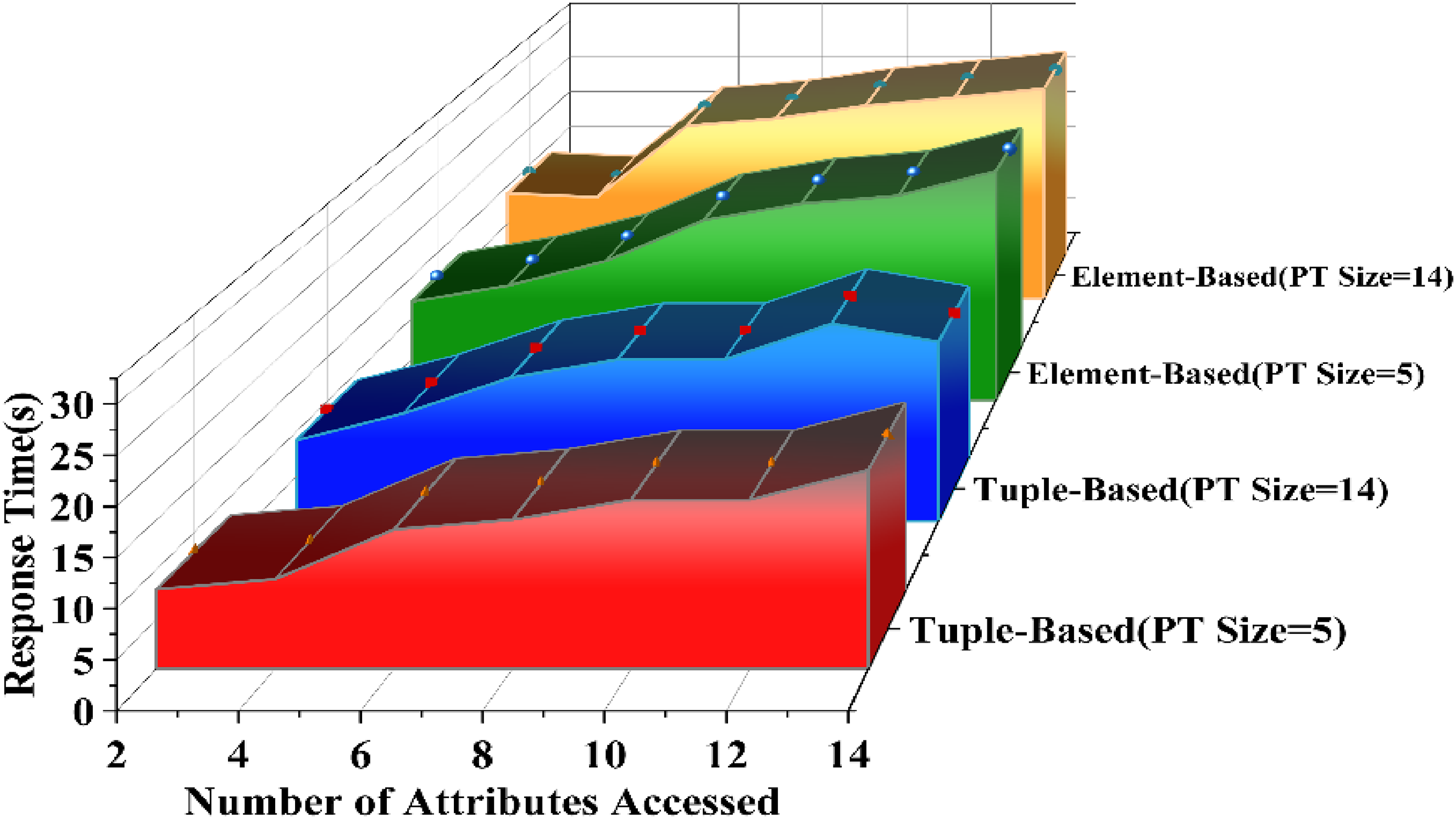
Purpose tree size and performance.
In Figure 18, as the number of accessed attributes increases, the corresponding time consumption increases. This is understandable because fine-grained labeling schemes require more purpose matching checks. The number of attributes of the query-accessed data schema is also a significant factor in the time spent for the element-based labeling schema. Because the element-based markup approach requires a conformance check for each element accessed by the query, the conformance check time increases with the number of attributes accessed and the complexity of attribute extraction rules. The method in this paper is based on tuple for electronic medical record annotation, aggregating the same attribute elements into a tuple, and then performing the purpose matching conformity check, with significantly higher efficiency. Figure 18 also shows that using both AIP and PIP does not result in a significant increase in time compared to using AIP alone. This is because the purpose of access is divided into AIP and PIP patients set their own data usage scope and protect their private information as expected, while for the computer, there is only one more bit and operation compliance check.

Labeling scheme and performance.
Control flow data flow fusion deviation detection
In this section, we embark on a crucial evaluation of the effectiveness and feasibility of our proposed method, utilizing the real event logs sourced from a third-class A hospital in Anhui. The significance of these logs lies in their direct reflection of real-world medical scenarios, making them an ideal basis for our study. Prior to the evaluation, we carried out a meticulous attribute extraction process on these logs, ensuring that only the most relevant and informative data is retained.
The experimental log presents a wealth of data that is both extensive and varied. It contains 10,000 traces, each representing a unique sequence of medical events. These traces collectively encompass 167,868 events, offering a comprehensive view of the medical workflow. The presence of 21 distinct types of activities underscores the complexity and diversity of the medical tasks involved. In addition, the log contains 51 medically important attribute elements. To facilitate a more structured and manageable analysis, these attribute elements have been aggregated into 8 attribute classes. This categorization allows us to better understand the relationships and patterns among the attributes and their impact on the deviation detection process. By providing such detailed information about the experimental data, we aim to offer a transparent and rigorous foundation for our evaluation.
Business process deviation detection aims to identify discrepancies between the actual execution of business processes and the expected models, which is of paramount importance for ensuring the standardization, efficiency, and quality of business processes. Currently, a variety of methods have been proposed in this field. These methods analyze business processes from different perspectives to uncover potential deviations. Among them, DFM (direct follow deviation detection), WFT (workflow table), and A* with ILP (the integration of integral linear A*) are three representative approaches, each with distinct characteristics in terms of control-flow analysis and the combination of data and control-flow analysis. DFM is a relatively fundamental deviation detection method. It identifies deviations by analyzing the direct follow relationships between activities within a business process. WFT takes into account the impact of data on the control flow. It employs workflow tables to represent the relationships between activities and data elements, enabling the detection of deviations caused by data errors. A* with ILP combines the A* search algorithm with integer linear programming (ILP) to find the optimal alignment between the observed process execution and the reference model. This method is effective in detecting deviations in complex business processes.
We evaluated the effectiveness of four methods to detect bias for medical event logs with different levels of noise (0%-10%) in the logs and an attribute complexity of 3%. Figure 19(a) shows the effect of noise on recall for the four methods. Noise contains all types of deviations, i.e. missing, additional and misplaced noise of activities on the control flow and 3% data noise contains 3% increase in the type of resources and 3% increase in incorrect matching of activities to data execution operations. With the increase in noise content, figure 19(b)(c) shows the Precision, F-score after deviation detection by the four methods is a decreasing trend. The Precision rate of the multi-view deviation detection method proposed in this paper is better than that of direct follow deviation detection (DFM), workflow table (WFT) 30 and integral linear A*(A* with ILP). 31 When the noise content is 10%, the Precision rate remains at 0.9328, which has the best noise resistance compared with the other three methods. Because the proposed method combines the control flow with the data flow by using the activity view to standardize the activity executor and the legitimate data operation, the deviation of the activity execution can be accurately identified. A* with ILP and DFM focuses on the control flow perspective deviation detection and consider fewer data attributes. with the increase of noise levels, the recall rate decreases significantly, among which, the recall rate and Precision of DFM decreases to 0.6132 and that of A* with ILP to 0.5481. WFT can detect deviations due to data errors but is less effective for data anomalies caused by concurrent structures. In the presence of concurrency in a process, the timing of system events may fall between the start time and completion time of multiple process moves. Without data attributes, it is easy to create incorrect links between system events and process moves. This leads to a significant drop in the recall rate of concurrent structures reaching a minimum of 0.7385 when too much noise is included.

Influence of noise on deviation detection method at 3% of attribute complexity.
Figure 20 demonstrates that with the increase of attribute complexity, DFM and A* with ILP only pay attention to the deviation of the activity occurrence sequence of the business process, and the running time is basically unchanged. WFT and the method in this paper consider the influence of data constraints on the deviation detection. However, since we transform the activity view of the business process into a CURD 23 matrix that specifies the activity execution resources and the execution operations on the data, it is easy for the computer to read efficiently so the running time is kept within 2 ms. WFT also looks at the data operations of business processes, but it takes longer because each data operation has to go through all activities to find a match.

Influence of attribute complexity on deviation detection methods.
To sum up, DFM and A* with ILP cannot detect data bias. WTF takes into account the impact of data on control flow that must be introduced into deviation detection, and introduces data into business process through workflow table. However, it does not consider the guiding role of decision logic in the business process, and it takes a long time to match data with activities. This paper proposes multi-view deviation detection combining activity view, data decision and control flow to detect deviations that are difficult to detect by other methods maintaining high precision and relatively short running time.
Conclusion
The main contribution of this paper is to maximize the use of data under the condition of protecting the privacy of data providers, introduce data attributes into business processes, and solve the problem that the existing process model cannot represent some decision requirements related to data, failing to detect deviations from other perspectives in the process. Using activity view and decision logic to combine control flow with data flow, applying composite moving classification diagram and deviation cost function according to the degree of impact of deviation type on business process can detect deviations in addition to privacy, data and control flow, and also find hidden deviations in combination of these three perspectives. To broaden the application of our algorithm, future research will concentrate on two pivotal areas. First, we aim to enable active data updates for loop structures in business process models, which is vital for managing complex and dynamic workflows. Second, we intend to employ Bayesian networks and extended likelihood graphs, designed to incorporate a wider range of data attributes. This will facilitate a more thorough understanding of the intricate data-activity interactions across various business processes.
Our privacy preserving deviation detection method, already proven effective in the medical field, holds great potential for wider adoption across multiple sectors. In finance, it can serve as a reliable tool for detecting fraudulent transactions and compliance violations while protecting sensitive customer data. In supply chain management, it enables real-time logistics workflow monitoring, identifying anomalies such as unauthorized diversions and data tampering while preserving partner data privacy. In manufacturing, it can identify production process deviations affecting product quality or safety, while securing proprietary operational data. In cybersquatting, it enhances intrusion detection by analyzing process deviations that may indicate security breaches, all while prioritizing data privacy. The method's versatility across these critical domains arises from its core capability to effectively detect deviations while strictly maintaining data privacy and security, making it a promising solution for diverse business process deviation detection scenarios. Although the method proposed in this paper demonstrates notable advantages in multiple aspects, it still has certain limitations. On the one hand, currently, the handling of data updates for loop structures in business processes lacks sufficient flexibility. When confronted with complex and dynamically changing workflows, it may fail to promptly and accurately reflect the impact of data variations on the processes. On the other hand, in terms of the utilization of data attributes, despite the introduction of some key attributes, the mining of certain latent and complex data characteristics is not thorough enough. This may restrict the accuracy and comprehensiveness of the method when dealing with highly complex.
Footnotes
Acknowledgments
I'm brimming with gratitude as I write this acknowledgment for my thesis.First, I'm deeply thankful to the review experts and editors. Their constructive feedback and insightful comments refined the research content, strengthened arguments, and elevated the paper's quality. Their pursuit of academic excellence motivates me to aim higher in future research.I also sincerely thank George K. Agordzo. His meticulous English grammar check was a great help. With his keen eye for detail and language proficiency, he polished the manuscript to meet international standards, ensuring my findings could reach a global audience.Lastly, I extend heartfelt appreciation to the funding agencies. Their generous support was the bedrock of this project, allowing me to access resources, conduct experiments, and attend conferences. Without them, this research would have been an uphill battle.I'm truly grateful to all who've contributed to this work.
Author contributions
Author contributions Juan Li wrote the main manuscript style, Xianwen Fang optimized it, Yan Wang collected part of the data. All the authors read the manuscript.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Anhui Provincial Natural Science Foundation, Natural Science Foundation of Anhui Provincial Education Department, the National Natural Science Foundation of, China, Anhui Province Academic and Technical Leader Foundation, Key Research and Development Program of Anhui Province, Scientific Research Project for Graduate Students of Anhui Province, The Project was Supported by Open Research Fund of Anhui Province Engineering Laboratory for Big Data Analysis and Early Warning Technology of Coal Mine Safety, the Leading Backbone Talent Project in Anhui Province, China, Open Research Fund of Anhui Province Engineering Laboratory for Big Data Analysis and Early Warning Technology of Coal Mine Safety, Postdoctoral Research Project of Anhui Province, (grant number (Water Science Joint Fund, 2308085US11), (2024AH040091), (No.61572035, 61402011), (No. 2022D327), (2022a05020005), (2021CX1011), (NO. CSBD2024-ZD03 ), (2020-1-12), (NO. CSBD2024-ZD03), (NO. BSHXM202401)).
Declaration of conflicting interests
The datasets analyzed in this study contain sensitive medical information and are not publicly available to protect patient privacy. Data may be requested from the first author Dr Juan Li . The authors declare that they have no competing financial or non-financial interests relevant to this work.