
Abstract
Arbitrary style transfer is attracting increasing attention due to its wide application potential. Existing approaches either directly fuse deep style features with deep content features or adaptively normalize content features to achieve global statistical matching. Although these approaches show some success, they frequently produce artifacts and messy textures. This primarily stems from a lack of exploration of the semantic distribution of style image features and an ineffective capture of long-range dependencies. This paper presents a Dual-Domain Style Transfer Network that incorporates Adaptive Normalization with Style Semantics Awareness and Global Style Texture Enhancement. The former aims to extract more style semantic information to reduce artifacts through self-attention mechanism and adaptive normalization, while the latter enhances global stylistic information in the frequency domain to suppress cluttered textures. On the MSCOCO and Wikiart datasets, compared to other state-of-the-art methods, our Learned Perceptual Image Patch Similarity, Structural Similarity Index, and content loss metrics achieved the best scores of 0.616, 0.467, and 2.31, respectively, while the style loss metric achieved the second-best score of 3.08.
Keywords
Introduction
The goal of arbitrary style transfer is to take the visual elements of a stylized image and re-render the content of the source image. Traditional style transfer methods generate stylized images through stroke-based rendering, image analogy, and texture synthesis.1,2 Due to their reliance on low-level features, these methods frequently struggle to effectively capture image structure. Recently, Gatys et al.3,4 innovatively accomplished this task by extracting high-level semantic features using pretrained convolutional neural networks (CNNs). To improve efficiency, Johnson et al. 2 use a feedforward network to generate stylized images directly. Subsequent studies still suffer from artifacts and texture clutter, although they have shown excellent performance in terms of efficiency,5–7 quality,8,9 generalization,10–14 diversity,15,16 and user controllability.17–19
Arbitrary style transfer methods can be categorized into two main types: nonattention-based and attention-based style transfer methods. Typical representatives of the former include.11,13,20,21 These methods transform content features to match the mean and variance of style features globally without considering local details, which unable to effectively balance global and local style patterns. They may integrate artifacts and messy style textures into the content target. The latter includes typical examples such as.8,22,23 These methods are based on the semantic correspondence between local regions of images and integrate style features locally into content features. Attention-based methods have been shown to be effective in style transfer by generating more local style details. Unfortunately, in improving performance, these methods failed to address the problem of artifacts and messy textures.
Images are made up of content elements and style elements. The existing methods are unable to effectively distinguish between the style elements and content elements of the style image. Most of the existing methods use an attention mechanism to directly fuse the deep style features with the deep content features, but ignore the style semantic features of style image, such as lines, color distributions, and texture patterns. This may cause evident artifacts in the stylized images. For example, in the pencil sketch style of a portrait, the eye part of the content element is transferred (as shown in the first row of Figure 1). In addition, the generation of messy textures can be attributed to the spatial domain convolution operation only has a local receptive field and lacks the ability to capture long-range dependencies. 24 This limitation leads to its inability to capture global style texture patterns with periodic features, which results in messy textures in the generated images in turn.

Comparison with other state-of-the-art (SOTA) methods. The first and second columns show the content and style images. The rest of the columns show the results of our method and other SOTA methods generated.
Inspired by the above analysis, we propose a Dual-Domain Style Transfer Network (DDSTNet), which consists of Adaptive Normalization with Style Semantics Awareness (ANSSA) and Global Style Texture Enhancement (GSTE). The ANSSA module is dedicated to learning the style semantic features in the style image through a fusion of attention mechanisms and normalization operations, and effectively transferring these style features to the content image, thereby reducing the occurrence of artifacts. Meanwhile, the GSTE module is responsible for converting the learned feature representation to the frequency domain to capture the global style information of the image, which is aimed at effectively reducing the generation of cluttered textures in the generated image. In this study, the main contributions of our DDSTNet can be summarized as follows:
We propose a novel ANSSA module designed for style transfer. This module effectively reduces artifacts in the synthesized images by incorporating the style semantic features from the style image. It also normalizes the content features appropriately when calculating the attention score. We also introduce frequency domain operation module, GSTE. This module can improve the ability to capture long-range dependencies. It also has a natural advantage in capturing periodic textures in the style map, effectively suppressing the generation of cluttered textures. Through extensive experiments and comparisons with state-of-the-art (SOTA) methods, we have fully validated the effectiveness and superiority of our proposed approach.
Related works
Arbitrary style transfer
In recent work, Gatys et al.3,4 have made significant advancements in image style transfer. They employ the Gram matrix to represent style features and utilize an iterative loss function between content and style in the feature space of a pretrained deep neural network to achieve remarkable stylization effects. Moreover, Johnson et al. 7 directly generated stylized images through a feedforward network, thereby achieving the effect of real-time style transfer by transferring style features to content images with perceptual losses. Related research5,6 further optimized the style transfer method based on the feedforward network architecture, enhancing the effect of texture synthesis. However, the learned model can only adapt to a specific style and is time-consuming. Therefore, research has focused on methods for arbitrary style transfer, which can rely on a single model to generate images with a specific style from any content image and any style image.
To achieve arbitrary style transfer, Huang et al. 13 aligned the mean and variance of the content image features with the characteristics of the style image. Jing et al. 14 innovatively encoded the style image as learnable convolution parameters and extended AdaIN by dynamic instance normalization. Li et al. 11 achieved a direct match of content feature statistics with style image statistics in the deep feature space with feature transformation, specifically the whitening and coloring processes. In addition, Li et al. 12 used covariance to perform a linear transformation, aligning the second-order statistics between the fused features and the style features. Wu et al. 25 used contrastive learning and covariance transformation for style transfer. An et al. 26 effectively avoided content leakage with the strategy of reversible neural flow, while optimizing the stylization method. However, these strategies fail to achieve an ideal balance between the global and the local, resulting in a loss of detailed information in the stylized image.
With the wide application of attention mechanisms, strategies based on this mechanism are widely used in style transfer. Park et al. 8 proposed a novel method, SANet, which matches the style features that are most semantically similar to the content features, thereby effectively fusing global and local style features. Deng et al. 27 further fused coattention and self-attention to incorporate style patterns into content features. Chen et al. 28 used SANet as the base network and introduced contrastive learning into style transfer for the first time, proposing a novel internal-external style transfer strategy. Liu et al. 29 combined the deep and shallow features of an image to propose an adaptive attention normalization module. This module normalizes the content features so that the local statistics of the content features match the statistics of the weighted style features. Luo et al. 22 proposed a progressive attention manifold alignment technique, which dynamically reorganizes the style features based on the spatial distribution of the content features. Deng et al. 30 used a Transformer model instead of a traditional CNN to extract long-range dependencies. Wang et al. 31 proposed an aesthetic enhancement strategy to enhance the stylization effect through adversarial learning. Wen et al. 32 proposed a reversible residual network and an unbiased linear transform to preserve pixel and feature affinity. Chung et al. 33 proposed a method for adapting pretrained large-scale diffusion models for style transfer in a training-free way. Although attention-based methods have achieved promising results, these methods fail to fully utilize the attention mechanism to mine the semantic information between style features.
Operations in the spatial domain directly manipulate the pixels and local regions of an image, enabling precise control over details. This enhances local consistency and prevents overly abstract or unnatural effects during style transfer. Consequently, most methods favor performing style transfer in the spatial domain, often overlooking the potential advantages provided by frequency domain processing. Image style transfer in the frequency domain not only effectively separates low-frequency and high-frequency components, enhancing the model's ability to capture long-range dependencies and allowing precise control over the fusion of style and details but also has a natural advantage in handling periodic texture patterns, helping to suppress the generation of messy textures. Compared with existing methods, we focus on semantic style features and content semantic features in style images, enhancing the model's ability to distinguish content and style information in the spatial domain. In the frequency domain, we emphasize global style consistency and enhance the model's ability to learn complex textures.
Frequency analysis in deep learning
Frequency domain information is widely used in computer vision tasks due to its large receptive field and separation of high and low frequencies. For example, in deraining, Fu et al. 34 separated the low-frequency part from the high-frequency part of the image and focused on high-frequency information during the training stage. Using prior image domain knowledge, the model was encouraged to learn information about the rain structure. Cao et al. 35 propose to apply frequency domain information to the image harmonization task, aiming to improve the quality of the generated images. Meanwhile, Li et al. 36 and Kwon et al. 37 use the frequency domain to separate content and style in their style transfer research in order to generate high-quality style images. In this study, we introduce frequency domain information to enhance the network's ability to capture long-range dependencies and recognize textures and patterns with periodicity.
Methods
Overall architecture
Figure 2(a) presents an overview of our network. Given a content image




(a) Overview of our proposed Dual-Domain Style Transfer Network (DDSTNet) consists mainly of two pretrained encoders, two Adaptive Normalization with Style Semantics Awareness (ANSSA) modules, two Global Style Texture Enhancement (GSTE) modules, a decoder, and a discriminator. The content loss (
Adaptive normalization with style semantics awareness
Feature transformation modules play a central role in synthesizing content and style features. The innovative AdaIN 13 focuses on the overall style distribution and adjusts the content features to match the global distribution of the style features. SANet, on the other hand, analyses local style patterns, extracts an attention map from the style and content features, and then uses this attention map to modulate the style features and fuse the modulated attention output with the content features. AdaAttN 29 achieves an adaptive per-pixel transfer of feature distributions by considering both low-level and high-level features and incorporating an attention mechanism. Although AdaAttN performs well in the task of reconciling local and global stylization, it fails to fully exploit the semantic features of the style image. Inspired by SANet and AdaAttN, we propose ANSSA, as shown in Figure 3. This module consists of Style Semantics Awareness and Adaptive Normalization. The former applies self-attention operations to the style image to enhance style patterns and extract richer semantic information. The latter utilizes both low-level and high-level features of the image to perform adaptive normalization on the content image, enabling an adaptive transfer of feature distributions at each pixel.

(a) The details of style semantics awareness. (b) The details of adaptive normalization.
Style semantics awareness
Self-attention mechanisms in style transfer can capture global feature relationships, enhance the style semantic information, and preserve more detailed information. To mine the semantic information of style image, we compute the style semantics awareness feature map in the deep layer and enhance the style pattern. Inspired by,
31
the inner product of the channel between the vectorized features can represent the global style, and the channel attention can represent the global style well. Then, the enhanced style features are locally integrated according to the semantic space of the style features. As shown in Figure 3(a), the transformation and vectorized features of the style feature



Adaptive normalization
AdaIN normalizes the features of the content image and then adjusts them based on the mean and standard deviation of the style image, injecting the style image's statistical properties (such as color and texture) into the content image to achieve style transfer. Similarly, the attention output can treat the target style feature points as the distribution of all weighted style feature points. Applying the attention score matrix A to the style features




Global style texture enhancement
To enhance the network's ability to capture long-range dependencies and more effectively capture the periodic textures and patterns present in the style image, we introduce the GSTE module, as shown in Figure 4. Specifically, we use the fast Fourier transform (FFT) to convert the stylized feature representation from the time domain to the frequency domain. To accelerate the training process, improve network stability, and prevent the loss of original structural information, multiple residual connections are introduced in this module. In the residual block, the input is added to the output feature map through residual connections, while the learned frequency domain features effectively help adjust the final stylized result. Finally, the frequency domain features are converted back to the original spatial domain by performing an inverse FFT (IFFT), as follows:
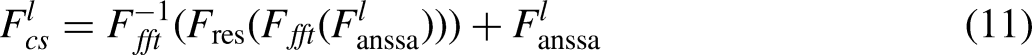

The structure of Global Style Texture Enhancement (GSTE) module.
Loss function
Our overall loss function is defined as a weighted sum of content loss (

Following,
27
the global style loss (

Similar to SANet, to ensure the preservation of the content structure in the generated results, the content loss (
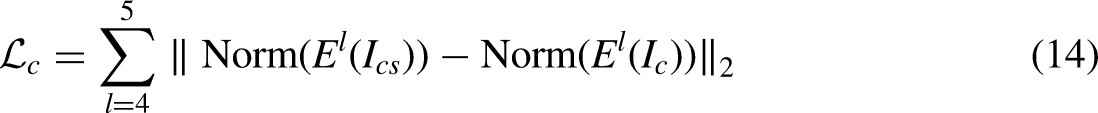

In addition, inspired by the Generative Adversarial Network (GAN),
40
which effectively drives the data distribution of the stylized image

Experimental results
Implementation details
During training, MS-COCO
41
and Wikiart
42
are used as the content and style datasets, respectively. These two datasets contain about 120,000 training images. The pretrained VGG-19 network is used as the encoder, with fixed weights during training. The Adam optimizer
43
is used for the optimization process. The batch size is set to 4, the learning rate is set to 0.0001, and a total of 160,000 iterations are performed. During training, all images are loaded in a smaller dimension, rescaled to 512 pixels while maintaining the aspect ratio, and then randomly cropped to 256 × 256 pixels. In the experiment,
Comparisons
Qualitative comparison
As shown in Figure 1, our method is qualitatively compared with eight SOTA style transfer methods, including StyTR, 30 AesUST, 31 AdaAttN, 29 IECAST, 28 SANet, 8 MAST, 27 CapVST, 32 and StyleID. 33 SANet adopts an attention mechanism to fuse deep style features with content features, but often produces obvious artifacts and repetitive texture patterns (e.g., rows 1, 2, and 4 in the SANet column). IECAST improves the style effect by introducing a contrastive loss function, but artifacts still exist (e.g., rows 1, 4, and 6 in the IECAST column). StyTR replaces the CNN with a Transformer in order to extract long-range dependencies of the input image. However, due to lack of in-depth exploration of the style image, the generated results contain artifacts and retain some of the source content color (e.g., rows 1, 3, and 6 in the StyTR column). AesUST uses a GAN and a novel two-step training method to learn the aesthetic features of the style image, but artifacts and cluttered textures still exist (e.g., rows 1, 2, and 4 in the AesUST column). MAST uses a novel disentangled loss function to extract style and content information from images, but the generated results still contain artifacts (e.g., rows 1, 2, and 4 in the MAST column). AdaAttN normalizes content features by considering shallow features, but its ability to capture long-range dependencies is insufficient, resulting in generated images with messy textures (e.g., 1, 2, and 4 in the AdaAttN column). CapVST uses a reversible residual network and an unbiased linear transform with the matting Laplacian training loss, but it results in disorganized colors and textures, accompanied by black artifacts (e.g., 1, 2, and 7 in the CapVST column). StyleID proposes a method to adapt pretrained large-scale diffusion models for style transfer in a training-free way, but it demonstrates limited capability in transferring texture features effectively (e.g., 2, 4, and 6 in the StyleID column). The above methods show certain limitations in handling complex textures, resulting in either chaotic and disorganized patterns or overly subtle texture effects. This is primarily because they operate solely in the spatial domain, neglecting the advantages of frequency domain processing. As shown in the third column of Figure 1, our model minimizes the generation of artifacts and messy textures by utilizing ANSSA and a GSTE module to generate high-quality images.
Furthermore, to conduct a more detailed quantitative comparison, we randomly select 20 content images and 20 style images, generating 10 sets, each containing 400 images. We use the Learned Perceptual Image Patch Similarity (LPIPS) 44 and the mean style loss as evaluation criteria to measure the similarity between the generated image and the style image. Similarly, we also employ the Structural Similarity Index (SSIM) 45 and the mean content loss as evaluation metrics to assess the similarity between the generated image and the content image. As shown in Figure 5, the content loss achieved its best performance at a minimum value of 2.23, the style loss reached its best performance at a minimum value of 3.19, LPIPS recorded its best score at a minimum value of 0.675, and SSIM reached its best score at a maximum value of 0.475. The overall curve is smooth and stable. Overall, our model demonstrates significant advantages compared to other methods.

Line charts of four different metrics.
As shown in Figure 6, our training loss decreases rapidly and gradually stabilizes, though noticeable oscillations are observed during the process. As the training progresses, the magnitude of oscillations significantly diminishes, eventually stabilizing after 160,000 iterations.
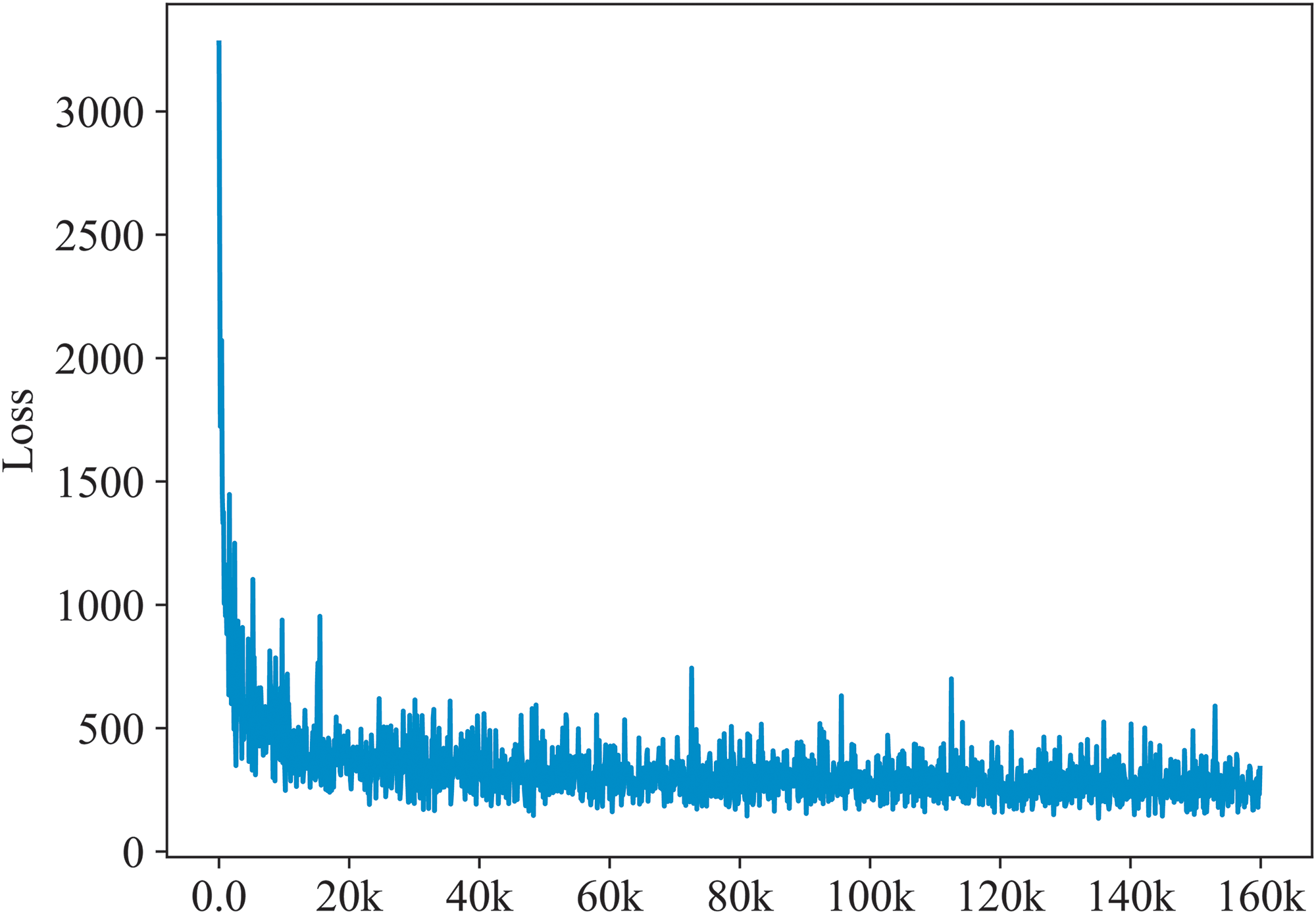
Overall loss curve.
Quantitative comparison
As shown in Table 1, we achieve the best LPIPS of 0.616 and a second-best
Quantitative comparison.
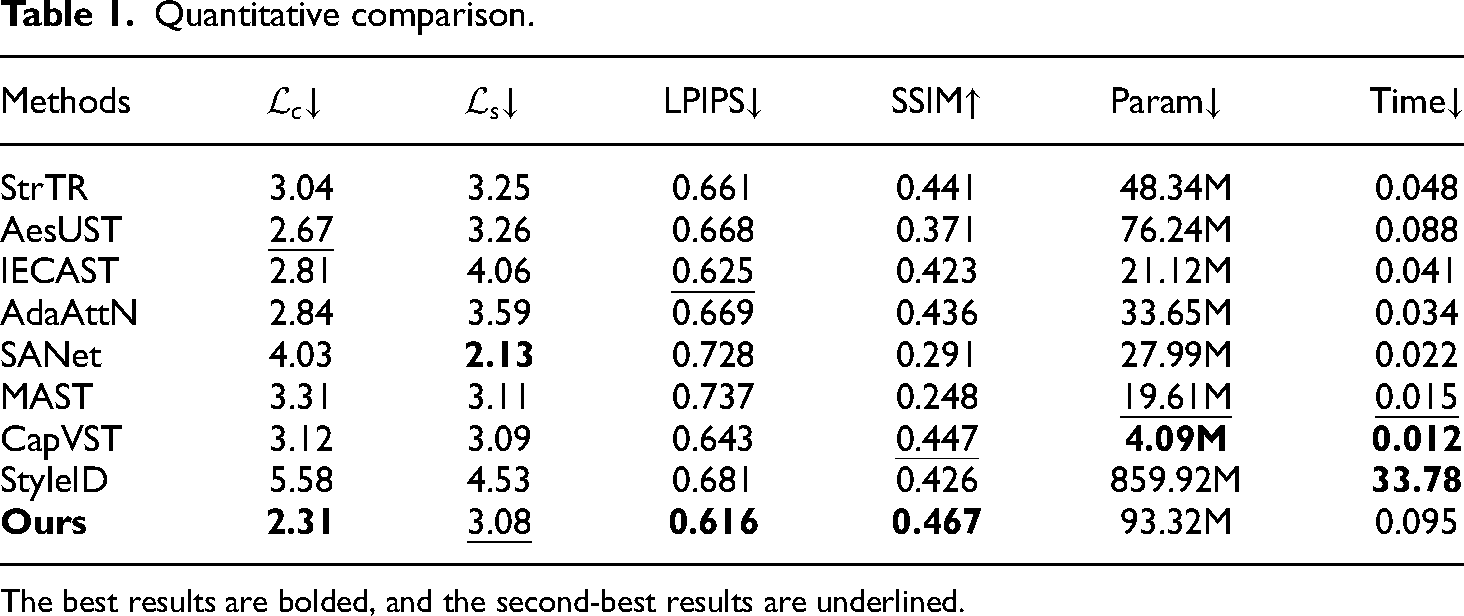
The best results are bolded, and the second-best results are underlined.
Ablation study
Qualitative comparison
Figure 7, without the ANSSA module, the generated image deviates from the source content and exhibits artifacts (4th column, 2nd row). This observation demonstrates the key role of the ANSSA module in maintaining the content structure of the generated image and removing artifacts. On the other hand, when operating solely in the spatial domain without the GSTE module, the generated image suffers from a noticeable loss of texture details (as shown in column 5, 1st row). This highlights the critical role of the GSTE module in enhancing the overall stylization effect, improving texture richness, and capturing finer style features. In addition, without the use of the adversarial loss, the generated images tend to retain the colors of the source content image while producing incongruent texture effects (3rd column), suggesting that the loss plays a crucial role in generating more harmonious and realistic image results. Without the use of the identity loss technique, the generated image produces severe artifacts and cluttered colors, suggesting that the identity loss enriches the stylistic patterns while maintaining the structure of the content.

Ablation studies of the adversarial loss function, the identity loss function, Adaptive Normalization with Style Semantics Awareness (ANSSA), and Global Style Texture Enhancement (GSTE) module on image style transfer.
Similarly, we evaluate various metrics using 10 sets of images, totaling 4000 images. As shown in Figure 8, the full model achieves the best performance across all metrics.

Line charts of evaluation metrics from ablation experiments.
Quantitative comparison
As shown in Table 2, when the
Quantitative comparison of different modules and loss ablation experiments.

The best results are bolded, and the second-best results are underlined.
Loss weight analysis
The identity loss and content loss have been shown to enrich style patterns while preserving the content structure.
8
In this section, we show the influence of the adversarial loss and global style loss. Figure 9(a) shows the results obtained by fixing

(a) Results obtained by fixing
Multilevel feature embedding
Figure 10 shows the stylized outputs obtained from different feature layers. When only

Multi-level feature embedding. By embedding features at multiple levels, we can enrich the local and global patterns for the stylized images.

Style interpolation with two different styles. The number below the figure represents
Multistyle transfer
To demonstrate the flexibility of our proposed DDSTNet model, following,
46
we designed experiments involving style interpolation and multistyle image stitching. During the process of style interpolation, we achieved interpolation of multiple style images by averaging the style images at different ratios and combining them through modulation of content features for decoding. 

Results of multistyle stitching image transfer.

Qualitative comparison among different methods of video style transfer. The first row shows results by different methods or settings. The second rows show the heat-maps of differences between consecutive frames.
Video style transfer
For video stylization, we compare our method with SOTA methods SANet, MAST, AdaAttN, and CCPL. We randomly selected a video segment (50 frames, 12 FPS) from the MPI Sintel dataset 47 for style transfer. As shown in Figure 13. SANet, MAST, and AdaAttN exhibit weak stylization performance, with a significant loss of content details and poor video frame consistency. Although CCPL achieves strong frame consistency, its stylization effect is weak, and artifacts are present. In contrast, our method achieves ideal stylization results while maintaining video frame consistency.
Conclusion
This paper presents a novel DDSTN that integrates a self-attention mechanism with frequency domain analysis to generate higher-quality stylized images. Specifically, we design the ANSSA module to capture the style image features and effectively fuse style features with source image content features through adaptive normalization. Furthermore, the GSTE module is introduced to process the feature maps and enhance the overall quality of the stylized image. Compared to other SOTA methods, our approach demonstrates significant advantages in reducing artifacts and cluttered textures, while the generated stylized images exhibit notable improvements in content richness and visual coherence. A series of ablation experiments validate the effectiveness of the proposed components. In future work, we intend to apply the model to video style transfer and image translation tasks to explore its potential across a broader range of application scenarios.
Footnotes
Acknowledgments
This work is fully supported by the Frontier Exploration Projects of Longmen Laboratory (NO. LMQYTSKT034); Key Research and Development and Promotion of Special (Science and Technology) Project of Henan Province, China (No. 252102210158, 232100210153); Key Scientific Research Project of Higher Education Institutions in Henan Province, China (No. 24B520010).
Author contributions
Changyang Hu: Responsible for mathematical reasoning, writing experimental code, and managing the training process. Shibao Sun and Pengcheng Zhao: Contributed to mathematical derivations, model development, and auditing of experiments. Yifan Zhao, Jianfeng Liu, and Xiaoli Song: Focused on drafting and revising the language of the paper, as well as formatting and layout.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is fully supported by the Frontier Exploration Projects of Longmen Laboratory (NO. LMQYTSKT034); Key Research and Development and Promotion of Special (Science and Technology) Project of Henan Province, China (No. 252102210158, 232100210153); and Key Scientific Research Project of Higher Education Institutions in Henan Province, China (No. 24B520010).