
Abstract
Because of their proficiency in capturing the category characteristics of graphs, graph neural networks have shown remarkable advantages for graph-level classification tasks, that is, rumor detection and anomaly detection. Due to the manipulation of special means (e.g. bots) on online media, rumors may spread across the whole network at an overwhelming speed. Compared with normal information, popular rumors usually have a special propagation structure, especially in the early stage of information dissemination. More specifically, the special propagation structure determines whether rumors can be spread successfully. Namely, online users and their interaction that constitute the special propagation structure play a key role in the spread of rumors. Therefore, the problem of rumor detection can be transformed into detecting the existence of a special propagation structure. Inspired by backdoor attacks, we propose an interpretable rumor detection algorithm based on backdoor. Firstly, based on causal analysis, the causal sub-graph that determines the category of the graph (rumor vs. normal information) is obtained, that is, the critical online users in the rumor spreading effect are found, and then the specific propagation structure is explored. Finally, the special propagation structure is planted into the rumor detection model as a trigger. Experimental results and performance analysis on three real-world datasets demonstrate the effectiveness of our proposed algorithm in the special propagation structure detection of rumors. Compared with two baselines, Lurker achieves up to 33.1% and 61.8% performance improvement in terms of attack success rate and clean accuracy drop.
Introduction
Social media serves as a platform for people to share their opinions and experiences with each other. While its convenience and efficiency facilitate the rapid dissemination of information, it also opens the door for malicious users to spread rumors. The widespread spread of rumors may disturb the thoughts of the public, affect the credibility of the government, and even cause social panic. Therefore, rumor detection on social media platforms is critical to maintaining a trustworthy and secure cyberspace.
The goal of rumor detection on social media is to verify the authenticity of messages and identify rumors on social platforms, so as to prevent the spread of false information in time. An effective rumor detection method can avoid the negative impact of rumors on the public. Classical rumor detection methods primarily focus on analyzing content, semantics, sentiment, and other aspects of the information itself using natural language processing techniques.1,2 For example, Shu et al. 3 developed a fake news detection method to capture explainable top-k check-worthy sentences and user comments by exploiting both news contents and user comments. Wu et al. 4 analyzed articles and related content to find supporting evidence. These methods can improve the efficiency of rumor detection, but they mainly rely on textual analysis, which can be inadequate for identifying well-crafted rumors.
Since it is difficult to accurately identify rumors through content analysis, researchers turned to the propagation structure of rumors to identify rumors. Vosoughi et al. 5 analyzed the propagation paths of news on Twitter and discovered that false information spreads significantly farther, faster, deeper, and wider across all domains compared to real information. It suggests that there is a distinct difference between rumors and true information in terms of their propagation patterns. In other words, it is feasible to detect rumors by the propagation structure they form in social networks. Therefore, propagation pattern-based methods have become a feasible solution to rumor detection. Given the different propagation structures of rumors and real information, Liu et al. 6 modeled information propagation as a multivariate time series. Bian et al. 7 designed a bi-directional propagation tree based on the Bi-GCN model to detect rumors. These methods exploit the features of the propagation graph, such as the number of retweets and temporal characteristics, to achieve rumor detection effectively and efficiently. However, these methods rely on feature construction to learn the characteristics of rumor propagation, ignoring the structural properties of propagation paths.
Generally, malicious users can use some means such as bots to enable rapid and extensive propagation across the network once rumors have been posted. Such rapid spread of rumors on social platforms means that they may have a special propagation structure, especially in the early stages of dissemination. Previous work5–8 has shown that rumors spread in a significantly different pattern compared to real information, which demonstrated the existence of this substructure. The substructure provides a new solution to our rumor detection problem. However, how to bridge the structure of the propagation path to rumor detection is our first challenge. The propagation graphs of these information are massive in number and variable in structure. In addition, rumors typically involve a large number of users during their propagation, resulting in propagation graphs with numerous nodes and edges. Furthermore, given the complexity of the graph’s connectivity, identifying whether a specific subgraph is an NP-hard problem.9,10
Rumor detection on social media is essentially a graph neural network (GNN)-based classifier. Ideally, we expect that the rumor detection model we develop can detect all rumors and keep real information intact at the same time. Although it has been confirmed that the rumor propagation graph contains a special substructure, it remains unclear how the special substructure is used to perform the rumor detection. Therefore, how to make the rumor detection model learn the correlation between the special substructure and rumors is our second challenge. Fortunately, backdoor attack can implant the specific information into a model. Backdoor attacks were first presented in image classification. 11 Zhang et al. 12 introduced the first backdoor attack on GNNs using well-designed subgraph as trigger, revealing the vulnerability of GNNs. According to the relation between triggers and samples, backdoor attacks can be divided into sample-agnostic and sample-specific attacks. The former uses a fixed trigger for all graphs,13,14 while the latter generates a tailored trigger for each graph.15,16 Xu et al. 17 proposed a clean-label backdoor attack, where the labels of the poisoned graphs are unchanged in poisoning phase and the graphs containing the trigger are identified as the target label in the inference phase. The recent advances of interpretable GNNs18–20 make it possible to design rumor detection models from the perspective of interpretability.
To address these two challenges, inspired by Zhang et al. 12 and Ying et al., 18 we propose a novel backdoor planted-based interpretable rumor detection model, Lurker, on online media. We first find the key nodes in the information propagation graph based on information theory, then explore the key substructure that determines the classification of the rumor propagation graph, and finally use the substructure as a trigger to train a rumor detection model. By using the specific substructure derived from the rumor propagation pattern, we successfully establish strong associations of the target label with the special substructure, enabling the model to predict subgraphs with similar organization to the specific substructure as rumors and for non-target label samples as their true labels.
Our contribution can be summarized as follows:
We propose an interpretable rumor detection framework for online media based on the specific patterns of information propagation. With the clean-label poisoning strategy, we implant the specific substructure into the rumor detection model. The proposed model, Lurker, establishes a correlation between the specific substructure and rumors, ensuring that samples with the substructure are detected as rumors while minimizing the impact on non-target label samples. We evaluate the performance of Lurker using three public real-world datasets. Compared with two baselines, Lurker achieves up to 33.1% and 61.8% performance improvement in terms of attack success rate (ASR) and clean accuracy drop (CAD).
Related work
Rumor detection on social media
Early rumor detection methods focused on the analysis of rumor texts because rumors are generally false information with malicious intent. Zhao et al. 21 combined keyword detection with K-means clustering to detect rumors. Huang et al. 22 proposed a heterogeneous graph attention network to capture the global semantics of text. Although these proposed methods have achieved good performance, it is difficult to fully learn rumor features only through text analysis. Thanks to the superiority of deep learning, deep learning-based rumor detection methods have emerged. Ma et al. 23 made the first attempt to utilize recurrent neural networks (RNNs) to learn textual and temporal features. To fully capture the characteristics of rumors, a series of methods explored supplementary information beyond text to detect rumors. Wang et al. 24 designed a multimodal graph convolutional network that effectively incorporated features derived from text content, images, and knowledge graphs to improve the detection performance of fake news. Zheng et al. 25 developed a multimodal feature-enhanced attention network, MFAN, that combined text, images, and user behaviors to achieve better rumor detection performance. Currently, the researchers have also explored the feasibility of using the rumor propagation pattern to detect rumors. Ma et al. 26 constructed a tree based on the hierarchical relationship between responses and comments to represent the rumor propagation graph on social networks and utilize RNNs to capture text semantics and propagation patterns. Bian et al. 7 introduced a bidirectional information propagation mechanism to model the rumor propagation structure to learn the forward and reverse path characteristics of information propagation. Zhang et al. 12 applied backdoor attack to rumor detection for the first time and designed a subgraph-based backdoor attack model. In addition, Pattanaik et al. 27 systematically evaluated the state-of-the-art deep learning models for rumor detection on social media and summarized the key issues and challenges currently faced in this field. Cesarini et al. 28 provided a review of interpretable AI methods in text classification, offering an important theoretical foundation for the application of interpretable methods in rumor detection. Inspired by Zhang et al. 12 starting from the rumor propagation pattern, exploring the specific substructure that can determine the category of information, and using the found substructure as a triggers, we propose an interpretable rumor detection framework based on backdoor.
GNNs for Graph classification
GNNs have been verified to have significant superiority in graph data tasks, including node classification,29,30 link prediction,31,32 and graph classification.33,34 For graph classification, the GNN model learns a feature vector for the input graph to predict its category. More specifically, GNNs perform neighbor aggregation operations to update the node representations, followed by a readout layer to obtain a graph-level representation, and finally, a fully connected layer to predict the label for every single graph. These approaches have been applied to various domains such as protein pattern classification, 35 malware detection, 36 and hyperpixel graph classification. 37 GNNs-based graph classification models focus on learning effective graph representation, with the pooling operation being a critical aspect. According to the pooling operation, these algorithms can be broadly categorized into global pooling and hierarchical pooling. Global pooling methods aggregate node embeddings at the end of convolutional layers to obtain graph representations. Ko et al. 38 summarized common global pooling operations including sum, average, min, or max. Deep graph convolutional neural network (DGCNN) 39 generated graph representations based on the features of top-ranked nodes. SSRead 40 identified important nodes by clustering based on location and node embedding aggregation with location-specific weights. In contrast, hierarchical pooling methods aggregate messages over fine-grained graphs to capture hierarchical information. These aforementioned methods reduced the size of the graph by introducing a pooling operation during aggregation. To retain nodes or edges with maximum entropy, Gao et al. 41 selected nodes based on scalar projection values of node features, and Lee et al. 42 identified the most important nodes and edges using node importance rankings derived from self-attention scores. CGIPool 43 chose the most important neighbor nodes based on mutual information. ASAP 44 computed importance scores of 1-hop subgraphs using self-attention, retaining top-ranked nodes and generating edges based on the clustering assignment matrix.
Our rumor detection model is essentially a GNN-based classification algorithm. By implanting the selected trigger into the target category samples, the rumor detection model is forced to learn the association between the trigger and the target label. Therefore, our model can detect the information with the substructure similar to the trigger as rumors, so as to realize the classification of normal information and rumors.
Problem definition
We consider an undirected graph
The objective of rumor detection is to identify rumors on social media. Given a propagation graph
The main idea of graph classification is based on the different propagation patterns of rumors and normal messages. Usually, the majority of popular rumors have a significant propagation substructure. Rumor detection is thus essentially to detect whether the corresponding information propagation graph contains a special substructure. Therefore, our objective can be defined as follows:

Our first concern is how to find the substructure corresponding to the particular rumor propagation pattern based on our objective. Usually, rumors become popular on social media platforms via some technological means. In theory, rumors can be traced through information propagation graph. However, each rumor has its own characteristics. Therefore, finding a substructure that can represent all rumors is crucial for our rumor detection model. Moreover, there are similarities in the propagation patterns between widely popular normal messages and rumors. How to find a substructure that can distinguish their differences is also a problem we must solve. Further, the size of substructure also has an impact on the performance of our rumor detection model. Therefore, to design a substructure with good performance, we need to consider the constituent factors and size of the substructure.
Our second concern is how to make the rumor detection model learn the correlation between the special substructure and rumors. Since the propagation graph of rumors contains a special substructure, for any information propagation graph, we expect the rumor detection model to predict a message as a rumor if it contains the special substructure, otherwise it is predicted as normal information. A feasible solution is to associate rumor samples with the specific substructure firstly, and then use samples incorporating the special substructure as inputs to train a rumor detection model. The operation of binding the special substructure with rumor samples is called as association operation, represented by the function


The key notations are provided in Table 1.
Key notations.

Methodology
As described in the “Problem definition” section, our backdoor-based interpretable rumor detection framework, which is illustrated in Figure 1, consists of two modules: (1) a trigger generation algorithm that selects the nodes from the true rumor propagation graph to form the trigger according to the influence of these nodes on the graph classification results and (2) a backdoor-based rumor detection model whose goal is to bind the trigger to the predetermined graph category, in other words, all the detecting samples containing the trigger will be classified into the predetermined graph label.

Overview of our proposed method.
In our framework, at first, the trigger originates from the true rumor propagation graph, and thus can help improve the accuracy of rumor detection while minimize the impact on true information identification. Subsequently, using the generated trigger, the rumor detection model is trained as a backdoored graph classification model. More specifically, any information with a specific propagation pattern (consistent with the substructure corresponding to the trigger) will automatically activate the backdoor and then be detected as rumors.
Trigger generation
According to Ying et al. 18 and Lin et al., 19 the category of a graph is mainly determined by the key nodes and their interactions in the graph. Therefore, to correlate rumors with a specific propagation subgraph, we try to find a substructure, which consists of the nodes and their interactions determining the graph category, from the real rumor propagation graph, and then use the found substructure as the trigger to train the rumor detection model.
For the key nodes, corresponding to the importance function 

Then, we randomly selected a certain proportion of graphs from the graph samples 
For each chosen graph, we rank the nodes according to their importance value

A toy example of trigger generation.
Correspondingly, the importance of the subgraph can also be calculated as follows:
Backdoored rumor detection model
The essence of the rumor detection model is to establish associations between the rumors and this particular substructure. With the help of the trigger generated in the previous subsection, this subsection mainly shows how to implant the trigger into our rumor detection model to finally classify the graphs containing the specific structure into pre-defined graph category.
Graph sample poisoning
To implant a backdoor into the rumor detection model, we first need to construct a set of poisoned graph samples after identifying the trigger and the target label. In this study, we choose the clean-label poisoning strategy to achieve the association of the trigger with the target label. Keep that in mind, the graphs poisoned by our clean-label poisoning strategy are from graph samples whose true label is the target label. The number of graphs,
The graph sample poisoning is operated in two steps, that is, the selection of the injection location and optimization of corresponding edges. To improve the accuracy of rumor detection, we randomly select the nodes in the original graph to place the trigger. Then, we modify the edges between the selected nodes referring to the structure of the trigger. More specifically, to inject a specific trigger with
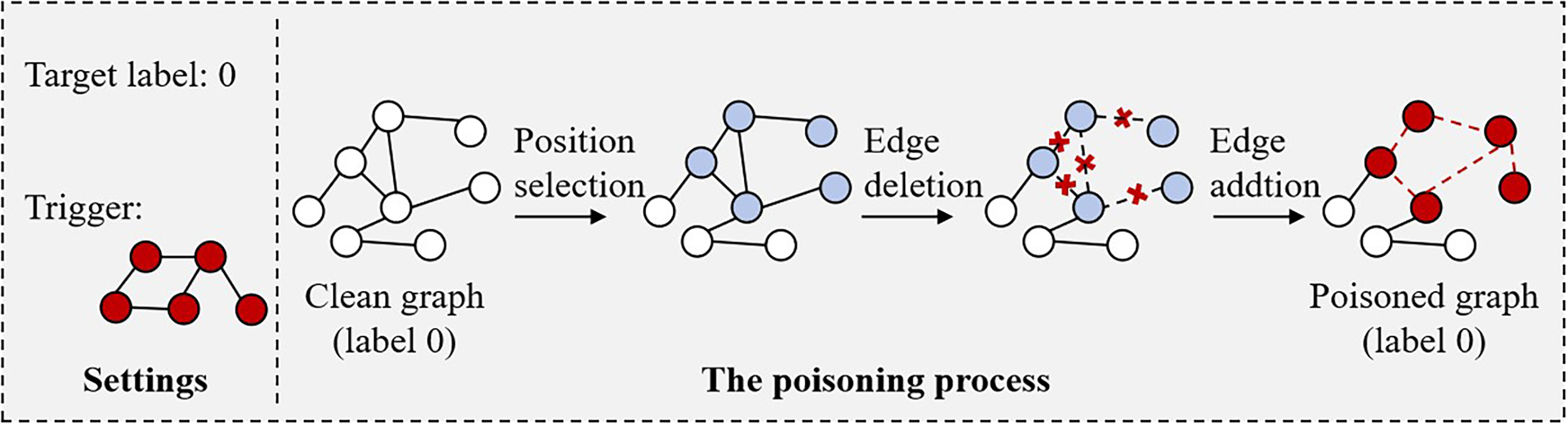
A toy example of poisoning operation.
Model training
Following the above steps, the poisoned training set denoted by 
The trained rumor detection model combines rumors with the special subgraph because the rumor propagation graphs share the specific substructrue in common. Algorithm 1 illustrates the whole procedure of Lurker, where the lines 1–25 describe the process of trigger generation, followed by training the backdoored model. In the testing stage, the backdoored rumor detection model is highly likely to predict the target label for the information propagation graphs containing the injected trigger.

Performance evaluation
Experiment settings
Datasets
We evaluate the performance of our proposed algorithm on three commonly used real-world graph datasets. These datasets are collections of chemical molecule graphs in bioinformatics, where the nodes and edges in each graph represent atoms and chemical bonds between atoms, respectively. The categories of molecular compounds are mainly determined by the corresponding chemical structure. This is consistent with our hypothesis that the identification of rumors is mainly determined by a specific propagation graph constituted by users during information dissemination. Table 2 offers detailed descriptions of these datasets. By the way, our rumor detection framework is essentially a binary graph classification model, and thus the chosen datasets contain samples of two classes of labels.
Statistics of the datasets.

NCI: National Cancer Institute; AIDS: acquired immunodeficiency syndrome.
Graph classification model selection
The rumor detection framework, Lurker, is essentially developed by implanting a backdoor into the graph classification model, where the graph classification model has a great impact on the rumor detection performance. Therefore, we will investigate the effect of two widely used graph classification models, that is, GIN 34 and SAGPool, 42 on the performance of rumor detection. If not specified, GIN is the default graph classification model.
Baselines
To detect rumors as early and accurately as possible, the proposed rumor detection framework utilizes backdoor techniques to detect the existence of a special substructure in the graphs. We compare the proposed framework, Lurker, with two most popular GNN-based backdoor attack methods, that is, RBA and CBA.
Metrics
To evaluate the effectiveness and harmlessness of the backdoor attack, following previous work,
12
we use attack success rate (ASR) to assess the effectiveness of rumor detection, and employ clean accuracy drop (CAD) to verify the harmlessness in non-target label samples. The two quantitative metrics are defined as follows:

Our proposed rumor detection model is essentially a backdoor-based attack method. The performance of our proposed algorithm is evaluated by verifying whether the backdoor can successfully detect the existence of a specific substructure in the information propagation graph and minimize the impact of the implanted backdoor on the non-target label samples. ASR represents the probability that our rumor detection model detects a specific substructure in the information propagation graph and classifies it into the target label. Meanwhile, CAD represents the performance impact of the implanted backdoor on the non-target label information propagation graph. Note that a larger ASR and a smaller CAD indicate better rumor detection performance.
Parameter setting
By default, we randomly split each dataset into two parts: two-thirds are used for training, and the remaining one-third for testing. For all three datasets, we set the target labels to be label 0. Following Zhang et al.,
12
the backdoor attack with the subgraph
Experiment results
Performance analysis of Lurker
The experimental results of Lurker and two baselines based on the GIN model on three datasets are shown in Table 3. We put the maximum of ASR and the minimum of CAD in bold to highlight the performance comparison. We have the following observations.
Performance comparison between Lurker and baselines.

For metric CAD, we observe that Lurker achieves the best performance over three datasets, which verifies the superiority of Lurker in terms of the harmlessness to non-target label samples. For metric ASR, Lurker achieves the best performance on NCI1 as well as AIDS, and second-best performance on Mutag. Lurker achieves up to 33.1% and 61.8% performance improvement in terms of ASR and CAD, respectively. On the dataset of Mutag, although RBA achieves the best performance in term of ASR, RBA obtains the highest CAD simultaneously. The main reason for this phenomenon is that RBA can learn the strong association between the trigger and the target label. Therefore, although the best attack accuracy can be obtained, it also has the biggest impact on the non-target label samples. Taking the effectiveness of attack and the harmlessness to non-target label samples into account, our proposed rumor detection model, Lurker, can achieve satisfactory performance.
Effect of the poisoning rate
Figure 4 illustrates the impact of the poisoning rate on the attack accuracy and harmlessness, where the poisoning rate gradually increasing from 1% to 10%. The results of our rumor detection algorithm on three datasets show a rapid upward trend in ASR and CAD as the poisoning rate increases. This is mainly because the number of poisoning samples in the training set increases with the poisoning rate, which makes it more likely for our proposed rumor detection model to learn the association between the target label and the trigger. However, more samples with the trigger also enhance the interference to the clean model, leading to an increase in CAD. Therefore, to achieve a good balance between attack effectiveness and harmlessness, we set the poisoning rate as 5% by default in experiments.

Performance comparison with different poisoning rates based on the GIN model.
Effect of the trigger size
The effect of the trigger size on the attack accuracy and harmlessness on three datasets is shown in Figure 5. Consistent with intuition, as the trigger size increases, so does the number of nodes of the trigger, the influence of the trigger on the performance of the rumor detection model also increases. We can observe that the ASR on the three datasets approaches 100% when the trigger size is 0.4. Further, it is noteworthy that ASR has a sharp increase when the trigger size increases from 0.05 to 0.1 and from 0.1 to 0.2 on the AIDS, compared with the other two datasets. This is mainly because the graph with a smaller number of nodes may be completely covered by a larger trigger, thus the ASR can be significantly improved. The average number of nodes of the graphs in the AIDS is 15.69, which is only half that in the other two datasets. Therefore, we can conclude that the trigger size is more influential to attack a smaller scale network. For CAD, a similar increasing trend can be observed with the increase of trigger size. This is because the probability that the model captures the trigger structure increases with its size. It is worth noting that on the AIDS dataset, when the trigger size increases from 0.1 to 0.2, the CAD value decreases. The leading cause is the average number of nodes per graph in AIDS is small. When the number of nodes in the network is small, the trigger with small size may lead to over-fitting of the model, which will lead to the increase of CAD at the beginning. However, with the increase of the trigger size, the influence of the trigger can be better balanced, and CAD will be temporarily reduced before it rises again with the continuous increase of the trigger size. Based on the analysis, we find that Lurker can achieve good performance when the trigger size is 0.2. At this point, it achieves high ASR and low CAD, and achieves a good balance between the success of the backdoor and the minimum damage to the model classification boundary.

Performance comparison with different trigger sizes based on the GIN model.
Effects of graph classification models
In this set of experiments, we investigate the impact of graph classification models on the attack performance. We use two models GIN and SAGPool on the dataset of NCI1 for the comparison experiments, and list the experimental results in Table 4, where we put the maximum of ASR and the minimum of CAD in bold to highlight the performance comparison. Obviously, different graph classification models have different structural parameters, thus resulting in different attack performance. Compared with RBA and CBA, we observe that our proposed rumor detection model, Lurker, can achieve the largest ASR and the smallest CAD in both graph classification models on the given dataset. This is mainly because we choose the casual substructure that can determine the category of information propagation graph, rather than randomly select a subgraph, as the trigger, so that the prediction of the category of information propagation graph is only associated with the casual substructure. Therefore, we can obtain the best rumor detection performance.
Performance on different target models on the NCI1 dataset.

Discussion
Model generalization
Existing research5,6 verifies that although rumors have diverse content and themes, they tend to follow common propagation patterns and typically exhibit structural differences from real information, particularly in the early stages of dissemination. For instance, rumors often rely on bots, fake accounts, and other methods to quickly form tightly connected clusters, which is responsible for the rapid spread of rumors. This distinction in structure enables us to identify rumors by analyzing their propagation substructures. Consequently, our approach is not confined to any particular type of rumor but offers a general rumor detection method.
Although our proposed algorithm can detect the majority of rumors, there is no guarantee that all rumors can be detected via our method. Some future rumors may adopt more advanced means of communication. Therefore, it may not form a clear communication substructure, but rely on influential individuals or other communication methods. In addition, information dissemination can have different characteristics on different media platforms. On the platform with high user activity, rumors may spread in a more decentralized way, which further increases the difficulty of detection.
Security risk and negative impacts of backdoor
The method proposed in this study is essentially to identify rumors by detecting the specific substructure. Our proposed method needs to be deployed by the owner of the media platform before it can work. Malicious attackers can not attack the media platform by using similar techniques to our algorithm because they do not have the right to set up the platform. Indeed, in the real-world applications, some real information with high attention will also show a fast and rumor-like spread mode, which will lead our model to misjudge such information as rumors. This is the limitation of our method, and we will leave this problem to our future work.
In principle, many problems can be solved by designing algorithms based on backdoor attack mechanism. More specifically, samples with certain characteristics can be identified by intricately designed triggers. However, the utilization of backdoor in other algorithms may lead to unexpected bad results, and we need to ensure its ethical application in different platforms through technical means and relevant laws.
Defensive mechanisms against the potential misuse
Our interpretable rumor detection model based on the backdoor is designed with positive objectives, but it still faces the risk of abuse. For example, malicious users may exploit vulnerabilities in the backdoor mechanism to interfere with the model, resulting in a large number of real information misclassification. Therefore, it is very important to study the corresponding defense mechanisms. Existing defense research on this kind of malicious behavior discovery provides valuable insights. GRIP-GAN 49 introduced random noise into the sample by using a generative adversarial network, which defended against potential disturbances and enhanced the features related to the target class. CertPri 50 used input priority to identify suspicious behaviors in DNN-based software, which is very useful for detecting bad behaviors. RCA-SOC 51 used attention weight to enhance the features of input samples and effectively resisted attacks.
In our method, attackers may interfere with the model by designing misleading input, and thus preventing this model from misuse is the focus of our future work. In this case, input checking and trigger activation restriction are potentially feasible defense methods. By filtering suspicious samples, enhancing input characteristics and optimizing trigger design, the threat caused by backdoor misuse can be effectively detected and alleviated. These strategies will help protect the model from potential vulnerabilities.
Relationship between model interpretability and accuracy
In our rumor detection model, accuracy and interpretability are not conflicting. In fact, interpretability plays a key role in improving the accuracy of the model. Through the exploration of interpretability, the spread substructure can be extracted, and the rumor propagation mode can be captured. Moreover, interpretability contributes to the generation of backdoor triggers. Therefore, interpretability is the key factor to improve the performance of rumor detection in our framework.
For rumor detection, exploring advanced interpretable technologies is a promising direction. In our future work, more powerful interpretable methods can be introduced to obtain more accurate interpretation and enhance the prediction performance of the model.
Conclusion and future work
In this article, we explore the feasibility of rumor detection based on a specific information propagation pattern, and design a backdoored interpretable framework for rumor detection. We use the casual graph, which originates from the information propagation pattern, as the trigger, and utilize a clean-label poisoning strategy to implant the backdoor into the GNN-based graph classification model. The GNN-based classifier predicts the target label for a testing graph once the testing graph contains the special substructure. The experimental results show that our proposed algorithm can not only detect rumors, but also guarantee the harmlessness to non-target label samples. In addition, the proposed attack model can monitor rumors in online media platforms and dispel rumors as soon as possible by accurately capturing the rumor propagation pattern.
For future work, we consider that our work can be further explored in the following directions:
The performance evaluation of our proposed algorithm is limited by the lack of suitable public datasets related to online rumors. In the future, cooperation with social media enterprises or research institutions may obtain the first-hand data of rumor propagation, which can provide real datasets for the verification of the proposed model. If only desensitized rumor propagation datasets can be obtained, we will optimize our proposed algorithm to suit the datasets. The optimal trigger size may vary across different datasets. How to achieve high ASR and low CAD by optimizing the trigger size is an open question. One possible solution is to dynamically adjust the trigger size for each dataset, such as adaptive tuning or artificial intelligence algorithm-based optimization. In our framework, interpretability is not only the main basis to judge whether a node belongs to the key substructure, but also the main means to improve the accuracy of rumor detection. By identifying the specific rumor-specific propagation structure, we can design triggers to guide the model to learn meaningful patterns directly related to the rumor behaviors. These triggers enable the model to associate some structural features with the possibility of information being a rumor, thus improving its prediction accuracy. Therefore, interpretability directly contributes to the accuracy and robustness of the model, making it a key component of detecting complex and evolving rumors.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was supported by the National Natural Science Foundation of China under Grant 61872295.