
Abstract
Visual navigation is widely used in intelligent combine harvesters, but the existing algorithms do not have sufficiently high accuracy of the visual navigation line recognition under different sunlight conditions. To address this problem, this article proposes a sunlight-robust DeepLabV3+-based navigation line extraction method for combine harvesters. The navigation lines are extracted by constructing a new dataset and predicting the boundaries of the areas that have been and have not been cut. To address the problem that DeeplabV3+ is not sufficient light in the DCNN part, improvement is proposed by incorporating the MobileNetV2 module. In image segmentation, the prediction time is 22.5 ms, and the mean intersection over union (FMIOU) is 0.79. After image segmentation, the navigation lines are drawn using the line segment detection algorithm for the harvester. The proposed method is compared with other mainstream networks, and the prediction results are compared using the line segment detection method. The results show that this method can more quickly identify the navigation lines under different conditions of sunlight with less labeled data than the improved U-Net and DeeplabV3+, which uses Xception as the backbone. Compared to the traditional method and the improved U-Net, this method achieves good results and improves the recognition speed by 27 and 9 ms, respectively.
Introduction
Intelligent combine harvesters have been widely used in recent years, which can greatly reduce the burden of operators and improve the accuracy and efficiency of operations. 1 However, the current application remains in the experimental stage and relies on experienced operators in the process. During this period, the intelligent harvester can only be supervised by humans in large fields, that is, the harvester cannot completely autonomously and independently perform work. Furthermore, the harvester cannot fully harvest the cutting width due to inevitable errors from the navigation system and steering system. 2 Thus, the accuracy cannot be guaranteed.
In field operations, the sensor that provides navigation for harvesters mostly is RTK-GNSS, RTK-GNSS has high accuracy and wide applicability, and it is currently the main navigation device in field harvesting. The positioning accuracy of RTK-GNSS sensors can be maintained at the centimeter level.3,4 They can be mounted on most agricultural machines. They are relatively simple to operate, and their driverless operation in the field only requires the working range to be selected in advance on the device. However, they cannot describe the front situation such as obstacles, including rocks, poles and trees. The device is susceptible to interference from other electromagnetic devices, 5 and the positioning accuracy can be affected by changing weather conditions. 6
To improve the accuracy and better understand the surroundings, many researchers have loaded different vision sensors. Ma 7 developed a control system that integrated satellite navigation and visual navigation using a monocular camera and a satellite module. Ai 8 proposed an AGV navigation method using a stereo camera to identify the lane lines, obtain the positional deviation of the body relative to the lane lines, and track the path. Chen 9 proposed a new method for the online self-motion estimation of combined harvesters using stereo cameras. However, stereo cameras produce a large amount of data, which is slightly time-consuming to process. There are also active light cameras, which can be classified into structured light cameras 10 and time-of-flight (ToF) cameras. 11 These cameras directly obtain the depth information of an object relative to the camera by projecting visible light of a specific frequency, which is reflected by the surface of the object, with high accuracy. However, compared to stereo cameras, these cameras are more expensive and more sensitive to strong sunlight irradiation in a large field environment.
To better extract the navigation lines, some researchers have proposed the use of a 3D modeling-based approach, which can extract the boundary lines by identifying different heights of harvested and unharvested areas. Kneip 12 proposed a stereo vision setup to adaptively detect online the crop and cut edges. The algorithm uses a graphic processing unit (GPU) to quickly match camera images. This solution is inexpensive and less susceptible to dust interference than LIDAR. Zhang 13 developed a machine-vision-based tip detection method that selected the Cr component of the YCbCr color model as the grayscale feature factor and automatically acquired the region of interest (ROI). In 2022, another method 14 was proposed to extract the wheat harvesting navigation path using binocular cameras by extracting point clouds and using a polynomial fitting method. Traditional image processing methods are mostly based on the extraction of features such as color and texture and implement algorithms such as clustering and watershed segmentation, which require manual extraction of feature information.15–17 Thus, traditional methods have low efficiency and generality, and the success rate of recognition in some large fields is low.
To improve the sunlight robustness and applicability of the system in a large field environment, this article proposes a stereo real-time navigation line extraction algorithm based on DeeplabV3+. Our method can extract navigation lines in strong sunlight compared to conventional methods, improves the recognition speed and accuracy compared to U-Net and improves the recognition speed with slightly reduced accuracy compared to DeeplabV3+, which uses Xception as the backbone.
This article makes the following contributions:
New combined harvester datasets are made available for conducting light robustness studies. An enhanced DCNN module is proposed as an improvement to DeeplabV3+.This module effectively solves the effect of actual sunlight on image segmentation and improves the accuracy of the navigation line extraction. The image segmentation method identifies the cut and uncut areas and extracts the navigation lines based on the boundaries of the cut and uncut areas. This method can segment the navigation lines under strong light for the subsequent line segment detection algorithm to extract the navigation lines. Our approach achieves speedup and good results compared to DeeplabV3+, which uses Xception as its backbone.
Materials and methods
System description
To ensure that the harvester moves along an accurate path during operation, an unmanned crawler rice combine harvester (model: Kubota EX108) is used the carrier of the field collection data platform. The cutting platform and roof shakes more violently while the harvester is moving, which will cause interference to the information captured by the camera. In addition, the camera should be installed as high as possible in the harvester to obtain a sufficiently wide field of view. Thus, the camera is mounted on the front of the harvester inside the cab, as shown in Figure 1, and equipped with a head for stability.

System schematic.
A stereo camera fixes two identical cameras at definite positions, determines the position of the same subject in both left and right views from the captured images, and calculates the depth information based on the difference in position and geometry of the subject on the two views. In this study, the ZED2i camera is used, which can output images of the left and right views, IMU information, depth maps and 3D coordinates using the camera coordinates.
To ensure that the camera works properly in harvesting, the stereo camera acquisition system is powered by a ZED stereo camera (ZED2i, Stereo Labs Inc, San Francisco, CA, USA). Table 1 shows the main parameters of the camera, which can work in harsher environments than the previous model, and a laptop (Lenovo i5-8300H, Lenovo Inc, Beijing, China) with Nvidia CUDA for acceleration. Thus, images from the camera can be observed in real-time to easily make adjustments.
Main parameters of the ZED2i binocular camera.

Detection of crop areas
The extraction of navigation lines mainly relies on distinguishing the boundaries of harvested and unharvested areas, as shown in Figure 2. The harvested area is mainly the rice stubbles after harvesting, and the unharvested area is mainly the rice plants to be harvested. Normally, one manually observes to make sure that the right cutting platform is in the same line relative to the boundary of the uncut area when the harvester performs the harvesting operation, precisely controls the left and right directions of the steering wheel, and attempts to make the harvester in the state of full cutting width. This manual operation can reduce missed cutting to improve the operation efficiency and reduce the operation cost. When a missed cut occurs, the harvester must run another round trip for harvesting, which will consume more fuel and seriously affect the harvesting efficiency.

Schematic diagram of the cut and uncut areas.
During the automatic driving of the harvester, the navigation line can be generated in real-time; after the stereo camera acquires the image, the information is submitted to the computer. An algorithm uses the image output from the stereo camera to calculate the three-dimensional coordinates, and the computer passes the completed extraction of the navigation line to the controller to guide the harvester for efficient operation. The image acquired by a monocular camera usually can only obtain color and texture information, and it is difficult to obtain depth information, whereas a stereo camera can calculate the depth information. In this article, a stereo camera is employed to acquire image data from varying angles on both sides, which is then input into a neural network for the extraction of navigation lines. The whole system can be shown by Figure 3.

The structure of the line extract system.
Dataset acquisition environment
In a large field environment, sunlight remarkably affects the effectiveness of identification, especially under strong sunlight. There is sometimes a significant change in brightness in the same field, which occurs when the harvester changes from facing the sunlight to moving away from the sunlight, especially at sunrise and sunset. To enhance the robustness of the recognition system, this dataset was collected under strong and normal light conditions in Nanjing and Changzhou, Jiangsu, on November 10, 2022, and November 25, 2022, respectively. In total, 2877 images were intercepted from the video streams in the dataset, from which 190 images were extracted for annotation by an experienced expert.
Data pre-processing
The data collected in the field have high resolution, and the processing is time-consuming. The combined harvester will operate according to the original path while losing time, which cannot achieve accurate control of the harvester, and there are also greater hidden dangers. The original picture contains irrelevant factors such as the sky and the paddle wheel. To reduce the computing time and improve the computing efficiency, the area of interest can be extracted. Compared with other scenes, the scene in the farmland is not variable, and the ROI does not need to be frequently adjusted. There should be as few irrelevant factors in the ROI as possible, as shown in Figure 4, the left side of the ROI is the uncut area, and the right side is the cut area. For consistency, the same area size of 204 × 115 in pixels was intercepted.

Extraction of regions of interest.
Proposed method
The encoder of DeepLabv3+ 18 is a DCNN with Atrous convolution, which can adopt a common classification network such as ResNet. 19 The output enters a spatial pyramid pooling module (ASPP) with Atrous convolution to introduce multi-scale information. The perceptual field can be arbitrarily expanded to extract as many features as possible. The multi-scale information is up-sampled four times after 1 × 1 convolution processing. Compared with DeepLabv3, DeepLabv3+ introduces the decoder module, which further fuses the underlying features with high-level features, compares the feature information in the image information by comparing two sources, and performs a 3 × 3 convolution and four times upsampling to obtain the output results, as shown in Figure 5.

Schematic diagram of the DeeplabV3+ network model.
During the real-time recognition in the field, the size and inference time of the feature extraction network of the deep learning model are required. Choosing a lightweight network can reduce the number of parameters and inference time and improve the recognition speed. Thus, MobileNetV2 and Xception are used as the backbone networks in the DCNN part of the encoder to facilitate subsequent comparison. To better compare the recognition results, an improved U-Net 20 was also used for training. The model was tested for crop area segmentation by adjusting 2877 test images to 512 × 512 pixels to input to the model. Model training and testing were implemented in Python 3.9 using PyTorch 1.9.0. The CPU and GPU for image training were i7-12700KF and NVIDIA 3090Ti, respectively. NVIDIA 3090ti has 10752 CUDA cores and 24 GB of video memory, which can satisfy our proposed requirements.
The average precision rate P, average recall rate R, average intersection rate FMIOU, and inference time are used to evaluate the image recognition classification results. They are calculated as follows:

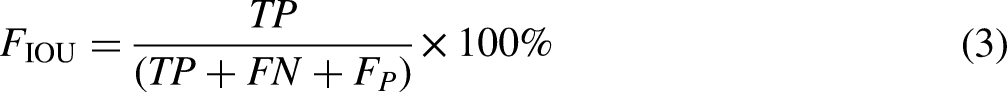

Analysis and discussion
To evaluate the line recognition accuracy, this study evaluates the recognition effect in two dimensions. In image segmentation, the evaluation includes common image recognition parameters and inference time. In line detection, the evaluation metrics include the lateral error of the navigation line and the angular error of the navigation line. The lateral error is determined by measuring the ground truth and distance between the bottom pixels of the line detected using the Canny algorithm. The angular error is determined by measuring the ground truth and tangent line of the recognized curve at the bottommost part of the image at the angle errors to compare the errors.
Image segmentation evaluation
Two sets of images were randomly exported from the strong light environment and normal light environment, and each set of images has two views of left and right. Figure 6 shows the effect of the three network segmentations.

Recognition effect of three different networks.
The unharvested area is shown in red, and the harvested area is shown in green. In this study, only the data of the harvester that operated on the straight line were processed, so the data when the harvester turned were not collected. Although the collected data were from the harvester moving on the same straight line, the areas on both sides were not invariable. All three methods are satisfactory because they can roughly distinguish the two sides, but there are differences in details. In strong light, both networks can style the two areas apart; in normal light, the network using U-Net for segmentation has red irregular areas in the separated area, whereas the DeeplabV3+ network makes the two models show different situations. DeeplabV3+ also yields relatively smoother boundaries than U-Net. In terms of details, MobileNetV2 identifies the background on the edge line in the data under normal sunlight.
The accuracy, recall, average intersection over union, and inference time of different models for recognition and classification were separately counted. The results are shown in Table 2.
Recognition classification effects of different networks.

There is no significant gap among the models in terms of accuracy, recall and mean intersection over union. DeeplapV3+ with MobileNetv2 as the backbone has better recall and inference time than the other models but slightly lower accuracy than U-Net. Thus, both U-Net and DeepLabV3+ have strong feature extraction capabilities and can extract more detailed features. DeeplapV3+ with Xception as the backbone has the longest inference time, which is almost double that of MobileNetV2. DeeplapV3+ with MobileNetv2 has a significantly better inference time than the other two models: its inference time is 22.5 ms, which is almost 50% faster than that using the U-Net model. The reason is the lightweight structure of MobileNetV2, where fewer parameters imply less computation and less inference time. With this large reduction in inference time, It is considered acceptable to have a moderate decrease in accuracy. This effect is also inseparable from the ROI extraction, which will significantly reduce the prediction time.
Linear detection evaluation
Canny Edge Detection Algorithm is a popular method to detect straight lines in images and is composed of five parts: Gaussian filtering, pixel gradient calculation, non-maximal suppression, hysteresis thresholding and isolated weak edge suppression. In this article, the Canny edge detection algorithm 21 is used to fit the edges to the recognized images.
Figure 7 shows the fitted results. The paths detected by the three networks are almost identical to the estimated paths and ground truth, although there are offsets and angle differences. The output image using U-Net shows obvious errors in the unharvested area, which reflects the weak ability of U-Net in boundary detection; the results are not sufficiently accurate in edge detection and the fitted straight line has a larger curvature than those of other methods. DeeplabV3+ performs the output image almost without obvious errors, but the segmentation result output using MobileNetv2 has an obvious black background in the two regions, so it can be easier to obtain smooth straight lines during straight line fitting, which is correlated with the network structure of DeeplabV3+.

Extraction of network output results using Canny edge detection algorithm.
Straight line detection
The straight line detection uses the pixel offset at the bottom of the image as an indicator, which is measured using the image after Canny edge detection with the manually labeled image. Figure 8 shows the results. The time interval of each point on the graph is 23 frames as the sampling rate. Under normal sunlight, both MobileNet and Xception have errors of −10 to 10 pixels, while the errors of U-Net fluctuate between − 30 and 20. In the U-Net output, harvested regions are divided into unharvested regions, and the estimated edges shift from the actual edges. In the middle of strong light (frame 570) and in normal light (frame 691), there are places with a larger error due to the difficulty in determining the direction with interference factors in the middle region. In most frames, MobileNet and Xception output similar deviations, whereas the U-Net outputs have the largest errors.

Pixel errors of different networks under strong and normal sunlight: (a) normal sunlight; (b) strong sunlight.
Angle detection
Calculating the heading deviation involves determining the angle between the predicted straight line and the ground truth. This information is used to adjust the path of the harvester and ensure that it stays on track, as shown in Figure 9. The time interval for each point on the graph is also 23 frames. From start to finish in both bright and normal light, the vast majority of lateral errors for MobileNet and Xception is between −10° and 10°, whereas U-Net shows a range of approximately −20° to 20° with additional angular deviations over 40° in the positive direction. In most frames, MobileNet and Xception have similar errors, and U-Net has the largest errors.
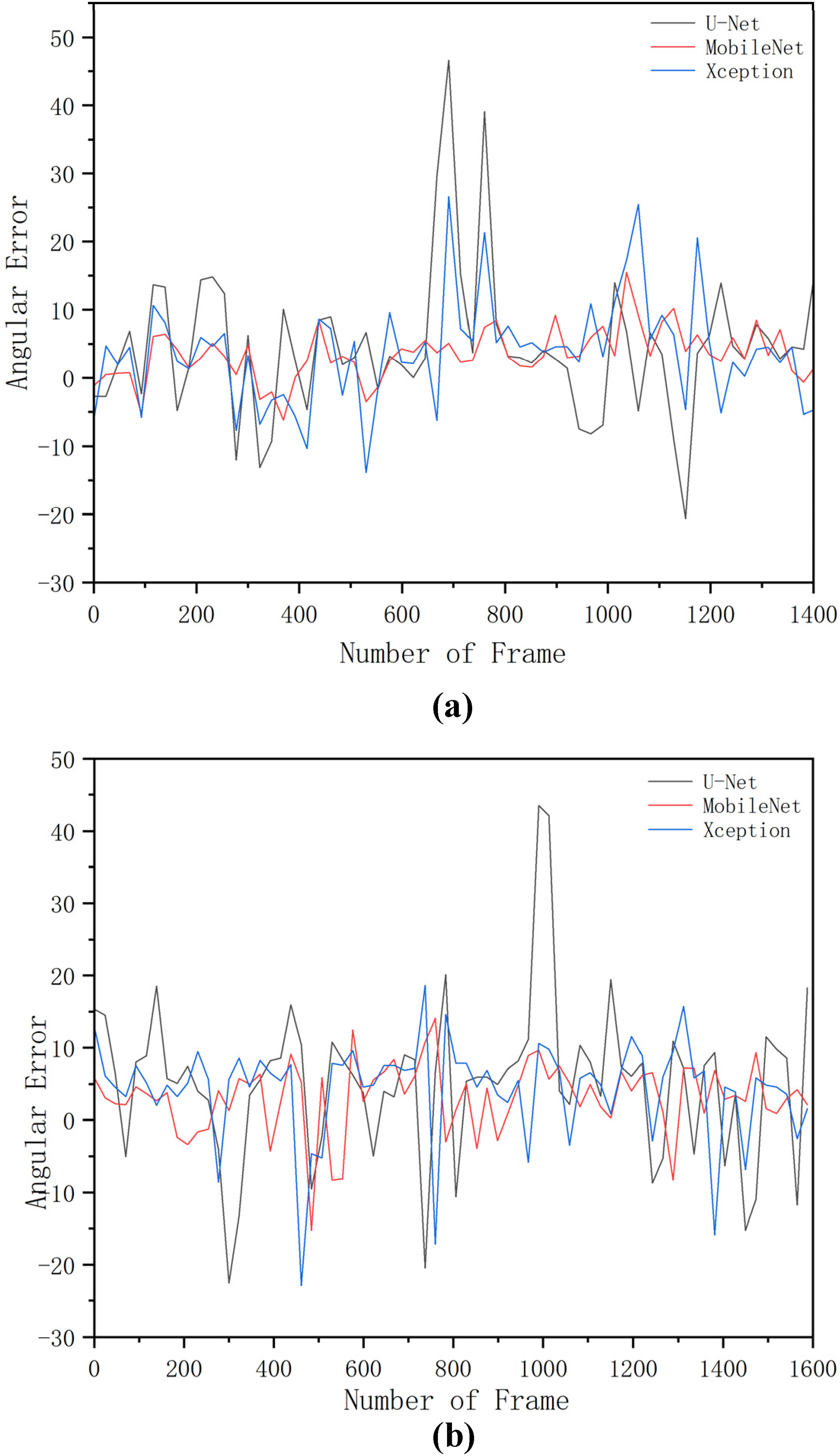
Angular errors of different networks under strong and normal sunlight: (a) normal sunlight; (b) strong sunlight.
Table 3 compares the performance of the segmentation methods using statistical analysis. When the U-Net network is used for inference, the mean angular error is 5.18°, the maximum angular error is 43.465°, the coefficient of variation is 0.77, the mean lateral error is 2.81 pixels, the maximum lateral deviation is 23 pixels and the coefficient of variation is 1.06 under strong light. Under normal light, the mean heading error is 4.74°, the maximum heading error has a coefficient of variation of 1.01, the mean lateral error is 3.81 pixels, and the maximum lateral deviation is 27 pixels with a coefficient of variation of 1.03. When the MobilenetV2 network is used for extrapolation, under strong light, the mean heading error is 3.14°, the maximum heading error is 14.093° with a coefficient of variation of 0.64, the average lateral error is 0.66 pixels, the maximum lateral deviation is 10 pixels, and the coefficient of variation is 0.98. Under normal light, the average heading error is 3.33°, the maximum heading error is 15.471°, the coefficient of variation is 0.69, the average lateral error is 1.06 pixels, the maximum lateral deviation is 8 pixels, and the coefficient of variation is 0.68. When the Xception network is used for speculation, under strong light, the average heading error is 4.30°, the maximum heading error is 18.594°, the coefficient of variation is 0.57, the average lateral error is 0.93 pixels, the maximum lateral deviation is 15 pixels and the coefficient of variation is 0.88. Under normal light, the average heading error is 3.95°, the maximum heading error is 26.584°, the coefficient of variation is 0.79, the average lateral error is 1.32 pixels, the maximum lateral deviation is 12 pixels and the coefficient of variation is 0.72.
Performance of different networks under strong and normal light.
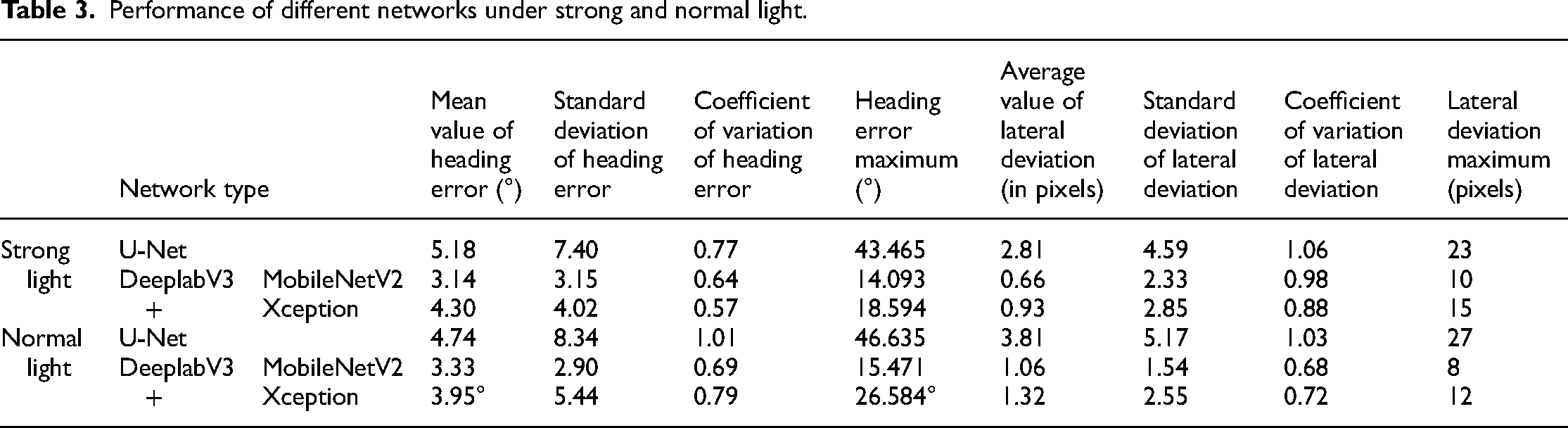
The results show that MobilenetV2 is the best option among these three models, except that it has a higher coefficient of variation under strong light than Xception. A possible reason is that a small part of the black background is reserved in the recognition, that is, a part of the area is reserved for straight line fitting, which leaves a place for the straight line and decreases the offset in the calculation. This result also reflects that DeeplabV3+ is better than U-Net in edge segmentation.
Discussion
In light of the comprehensive results presented in this study, it becomes evident that the proposed method offers substantial promise for the precise segmentation of harvested and unharvested areas, particularly in the context of repetitive and similar scenes during harvesting, typically characterized by the presence of three distinct classes. The method has proven to be both effective and efficient in area segmentation, a crucial consideration for optimizing agricultural operations.
When evaluating the performance of the proposed method, we find it to be on par with, if not surpassing, previous approaches. Notably, the segmentation results achieved by our proposed approach closely align with those of earlier methods. It is worth highlighting that previous methods often exhibited processing speeds exceeding 50 ms per frame,11,12,22 a drawback that limited their real-world applicability, particularly under strong sunlight conditions.
In contrast, our method stands out by demonstrating notable advancements in practical performance. This can be attributed to the efficient architectural design of DeeplabV3+, which significantly reduces model parameters while augmenting the dataset's capacity to handle strong sunlight scenarios.
While these results hold promise for agricultural navigation, two limitations should be noted. Further dataset enrichment is needed to accommodate variations in rice maturity levels. Additionally, evaluation based solely on pixel-wise errors should be supplemented with field data to validate real-world performance. Future research may explore network optimization for increased efficiency.
Conclusions
In this study, an innovative method for boundary identification during the harvesting process is introduced. The approach comprises multiple key components, including the extraction of ROI, the application of advanced deep learning techniques via DeepLabV3+ for the segmentation of harvested and unharvested areas, and the fitting of boundary lines using the Canny edge detection algorithm. The results obtained from this study demonstrate a notable enhancement in identification performance, particularly under challenging high-intensity sunlight conditions.
MobileNetV2 has been employed as the backbone network for feature extraction, surpassing alternative choices in terms of efficiency. The synergistic combination of Canny edge detection for boundary extraction and MobileNetV2 for recognition significantly enhances the overall effectiveness of the proposed method.
One of the most compelling aspects of this approach is its real-time detection capability, with a remarkable inference time of just 22.5 ms, all while maintaining a resolution of 204 × 115. This achievement aligns perfectly with the specific requirements of field operations, showcasing its practicality in real-world settings.
The technological advancements presented in this study have the potential to revolutionize agricultural practices by vastly improving operational efficiency, minimizing waste, and boosting crop yields.
Footnotes
Authors’ contributions
Gong Cheng contributed to writing-original draft preparation and methodology. Chengqian Jin contributed to writing-review and editing. Man Chen contributed to validation and methodology. All authors have read and agreed to the published version of the manuscript.
Declaration of Competing Interest
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was funded by National key research and development plan project (2021YFD2000503) and the National Natural Science Foundation of China (No.32171911, No.32272004), General Project of Jiangsu Natural Science Foundation (BK20221188) and Jiangsu Agriculture Science and Technology Innovation Fund (No. CX(20)1007).
Author biographies
Gong Cheng received the B.E. degree in mechanical engineering from Nanjing Institute of Technology, Nanjing, China, in 2021. He is currently pursuing the M.Sc. degree in agricultural mechanization engineering with the Chinese Academy of Agricultural Sciences, Beijing, China. His research interests include machine vision and agricultural robots.
Chengqian Jin received the B.Sc. degree in agricultural mechanization engineering from Huazhong Agricultural University, Hubei, China, in 1995, the M.Sc. degree in agricultural mechanization engineering from the Nanjing University of Science and Technology, Nanjing, China, in 2006, and the PhD degree in agricultural mechanization engineering from Nanjing Agricultural University, Nanjing, in 2014. He is currently a Researcher with the Chinese Academy of Agricultural Sciences and a Professor with the Shandong University of Technology. His major is in agricultural mechanization engineering.
Man Chen received the B.E. degree in electronic information science and technology from Nanjing Agricultural University, Nanjing, China, in 2011, and the PhD degree in agriculture electrification and automation from Nanjing Agricultural University, Nanjing, in 2016. He is currently an associate researcher with the Chinese Academy of Agricultural Sciences. His major is in agricultural electrification and automation engineering.