
Abstract
This article aims to suggest a new generalized class of estimators based on probability proportional to size sampling using two auxiliary variables. The numerical expressions for the bias and mean squared error (MSE) are derived up to the first order of approximation. Four actual data sets are used to examine the performances of a new improved generalized class of estimators. From the results of real data sets, it is examined that the suggested estimator gives the minimum MSE and the percentage relative efficiency is higher than all existing estimators, which shows the importance of the new generalized class of estimators. To check the strength and generalizability of our proposed class of estimators, a simulation study is also accompanied. The consequence of the simulation study shows the worth of newly found proposed class estimators. Overall, we get to the conclusion that the proposed estimator outperforms as compared to all other estimators taken into account in this study.
Introduction
In the survey sampling approach, estimating the finite population mean is a common issue, and many efforts have been made to improve the precision of the estimators. A comprehensive range of approaches for incorporating the auxiliary variables by using ratio, product, and regression-type estimates are defined in the literature. Mainly when there are multiple auxiliary variables, a wide range of estimators have been presented, each one combining ratio, product, or regression estimators. Researchers have previously attempted to use the best statistical features to estimate population parameters including variance, coefficient of variation, and kurtosis. A representative sample of the population is required for this set-up. If the population of interest is similar, then selecting units can be done using simple random sampling with or without replacement. The population parameters of the auxiliary variable should also be previously known when using the ratio, product, and regression estimation methods. By suitably adapting the auxiliary variables, many authors have suggested several estimators. The researcher can investigate these research findings by looking the Kadilar and Cingi 1 who recommended improvement in estimating the population mean in simple random sampling. Al-Omari 2 suggested ratio estimation of the population mean using the auxiliary information in simple random sampling and median ranked set sampling. Ozturk 3 proposed estimation of population mean and total in a finite population setting using multiple auxiliary variables. Yadav et al. 4 recommended the use of the auxiliary variables in searching efficient estimators of a population mean. Bhushan and Pandey 5 discussed the optimality of ratio-type imputation methods for the estimation of population mean using the higher order moment of an auxiliary variable. Zaman et al. 6 recommended robust regression-ratio-type estimators of the mean utilizing two auxiliary variables. Kumar and Saini 7 discussed a predictive approach for the finite population mean when auxiliary variables are attributes. Singh and Nigam 8 recommended a generalized class of estimators for finite population mean using two auxiliary variables in sample surveys. Bhushan et al. 9 proposed some improved classes of estimators in stratified sampling using bivariate auxiliary information. Shahzad et al. 10 discussed mean estimation using robust quantile regression with two auxiliary variables. Zaman et al. 6 recommended robust regression-ratio-type estimators of the mean utilizing two auxiliary variables. Mahdizadeh and Zamanzade 11 proposed an interval estimation of the population mean in ranked set sampling. Ahmad et al. 12 recommended a new improved generalized class of estimators for population distribution function using the auxiliary variable under simple random sampling. Muhammad et al. 13 suggested an enhanced ratio-type estimator for finite population mean using the auxiliary variable in simple random sampling. Ahmad et al. 14 discussed an improved generalized class of estimators in estimating the finite population mean using two auxiliary variables under two-stage sampling. Shahzad et al. 15 proposed a three-fold utilization of supplementary information for mean estimation under median-ranked set sampling scheme. Shahzad et al. 16 discussed the estimation of the population mean by successive use of an auxiliary variable in median ranked set sampling. Yasmeen et al. 17 proposed generalized exponential estimators of finite population mean using transformed auxiliary variables. Singh et al. 18 discussed an alternative efficient class of estimators for finite population mean using information on an auxiliary attribute in sample surveys. Singh et al. 19 recommended the estimation of finite population variance using scrambled responses in the presence of auxiliary information.
In many conditions, the population differs considerably in size, for example, in a medical study, the number of patients having a specific disease, and the size of health units may differ. Likewise, in a survey related to the income of the household, the household may have a different number of siblings, and then in such circumstances, the probability of units may change. For dealing with such unequal probability, we use probability proportional to size (PPS) sampling. PPS is an unequal random sampling in which the chance of gathering information is proportional to an auxiliary variable, for each sampling unit in the population. Consider the case where we need to assess the population in a province within a country; we take the auxiliary variable that has an association with the study variable. For example (i) Population of all provinces within the country (correlated with study variable = 0.95). (ii) Number of households in all communities within the province (correlated with the study variable = 0.99). Based on these facts (ii) may be more useful at the estimation stage. Many researchers have suggested several estimators by efficiently adjusting the auxiliary variables under PPS. The researcher can examine this research by Akpanta
20
who proposed the problems of PPS sampling in multicharacter surveys. Agarwal and Mannai
21
recommended a linear combination of estimators in PPS sampling to estimate the population mean and its robustness to optimum value. Abdulla et al.
22
suggested the selection of samples in PPS sampling using the cumulative relative frequency method. Andersen et al.
23
discussed optimal PPS sampling by vanishing the auxiliary variables with applications in microscopy. Alam et al.
24
discussed the selection of the samples with PPS. Patel and Bhatt
25
recommended the estimation of finite population total under PPS sampling in the presence of extra auxiliary information. Singh et al.
26
discussed an improved estimator of population total in PPS sampling. Makela et al.
27
suggested Bayesian inference under cluster sampling with PPS. Ahmad and Shabbir
28
discussed the use of extreme values to estimate the finite population mean under the PPS sampling scheme. Ozturk
29
proposed poststratified PPS sampling from stratified populations. Latpate et al.
30
discussed the scheme of PPS sampling. Sohil et al.
31
recommended optimum second call imputation in PPS sampling. Sinha and Khanna
32
discussed the estimation of population mean under PPS sampling with and without measurement errors. Zangeneh and Little
33
discussed Bayesian inference for the finite population total from a heteroscedastic PPS. Hentschel et al.
34
recommended exact PPS sampling with a bounded sample size. Barbiero et al.
35
proposed bootstrapping PPS samples via a calibrated empirical population. Gupt and Ahamed
36
discussed optimum stratification for a generalized auxiliary variable proportional to allocation under a super-population model. Ponkaew and Lawson
37
recommended new estimators for estimating the population total with an application to water demand in Thailand under unequal probability sampling without replacement for missing data. Al-Jararha
38
discussed a class of estimators using two units with PPS. Al-Marzouki et al.
39
proposed an estimation of finite population mean under PPS in the presence of maximum and minimum values. Zheng and Little
40
suggested penalized spline model-based estimation of the finite population total. Zheng and Little
41
recommended inference for the population total from probability-proportional-to-size samples based on predictions from a penalized spline nonparametric model. Amab
42
proposed the optimum estimation of a finite population total in PPS sampling with a replacement for multicharacter surveys. Olayiwolla et al.
43
suggested the PPS method to enhance the efficiency of the estimator in two-stage sampling.
In this article, the primary aim of the current work is to propose a new improved generalized class of estimators for the estimation of finite population mean using two auxiliary variables under PPS. The bias and mean squared error (MSE) of the proposed estimator is derived up to the first order of approximation. Through use of the real data sets from various domains and a simulation study, the application of the proposed estimator is highlighted.
All notations and symbols are given in the Appendix.
Review of existing estimators
In this section, we have studied some well-known existing estimators under PPS sampling.
The usual estimator under PPS, is given by: The variance of The ratio estimator under PPS, is given by: The bias and MSE of Murthy,
44
suggested a product estimator, given by: The bias and MSE of The regression estimator, is given by: The minimum variance of Bai et al.
45
proposed the following estimator, is given by: The minimum MSE of Bahl and Tuteja
46
suggested the following ratio and product exponential type estimators, are given by: The biases and MSEs of Haq and Shabbir
47
suggested the following exponential-type estimators, which are given by: The optimum values are The minimum MSE of The second proposed estimator of The bias of The optimum values of The minimum MSE of Ekpenyong and Enang
48
suggested the following estimator: The bias of The optimum values of The minimum MSE of Singh et al.
49
suggested the following class of estimators, is given by: The bias and MSE of Grover and Kaur
50
suggested the following estimators and is given by: The bias and MSE of The optimum values of The minimum MSE of



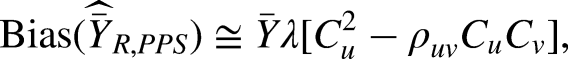















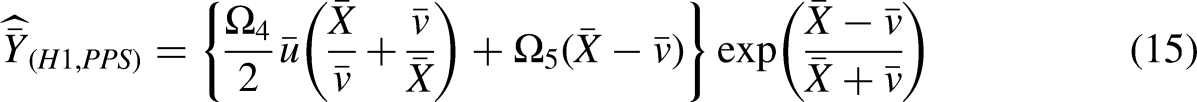
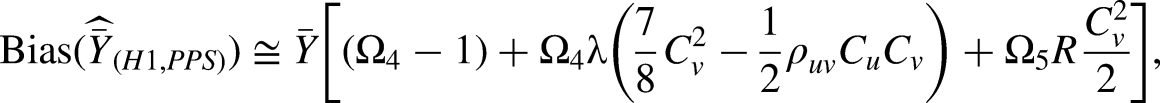


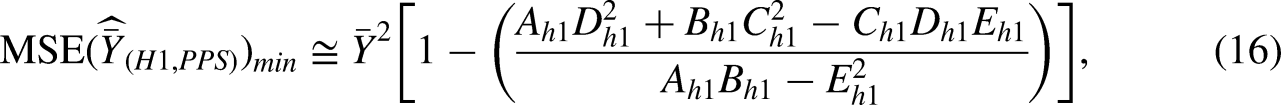












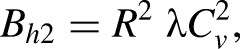









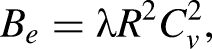





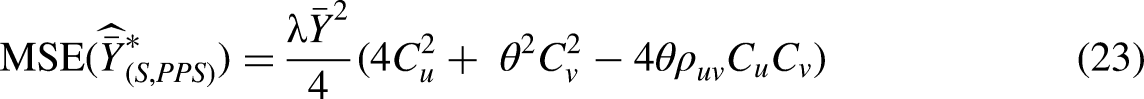





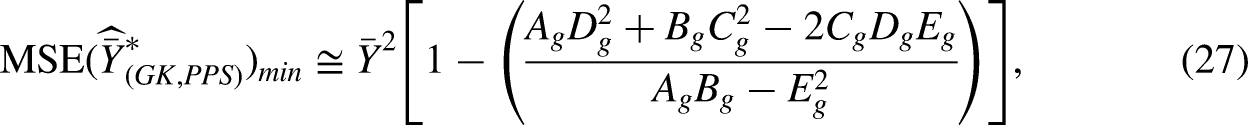





Proposed estimator
An estimator's performance can be improved by using appropriate use of the auxiliary variables at the design or estimation stage. Based on these ideas, we examine to use one auxiliary varible (Z) under PPS and the other auxiliary variable (X) at the estimation stage. The proposed estimator is more robust as compared to ratio, product and regression estimators as it can take any type of data that exists in literature. Taking motivation from Ahmad et al.,51,52 we propose a new class of estimators using two auxiliary variables under PPS sampling.

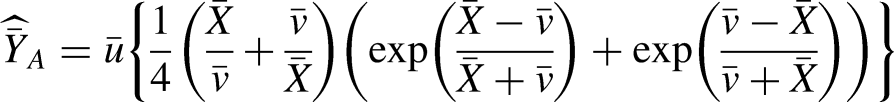
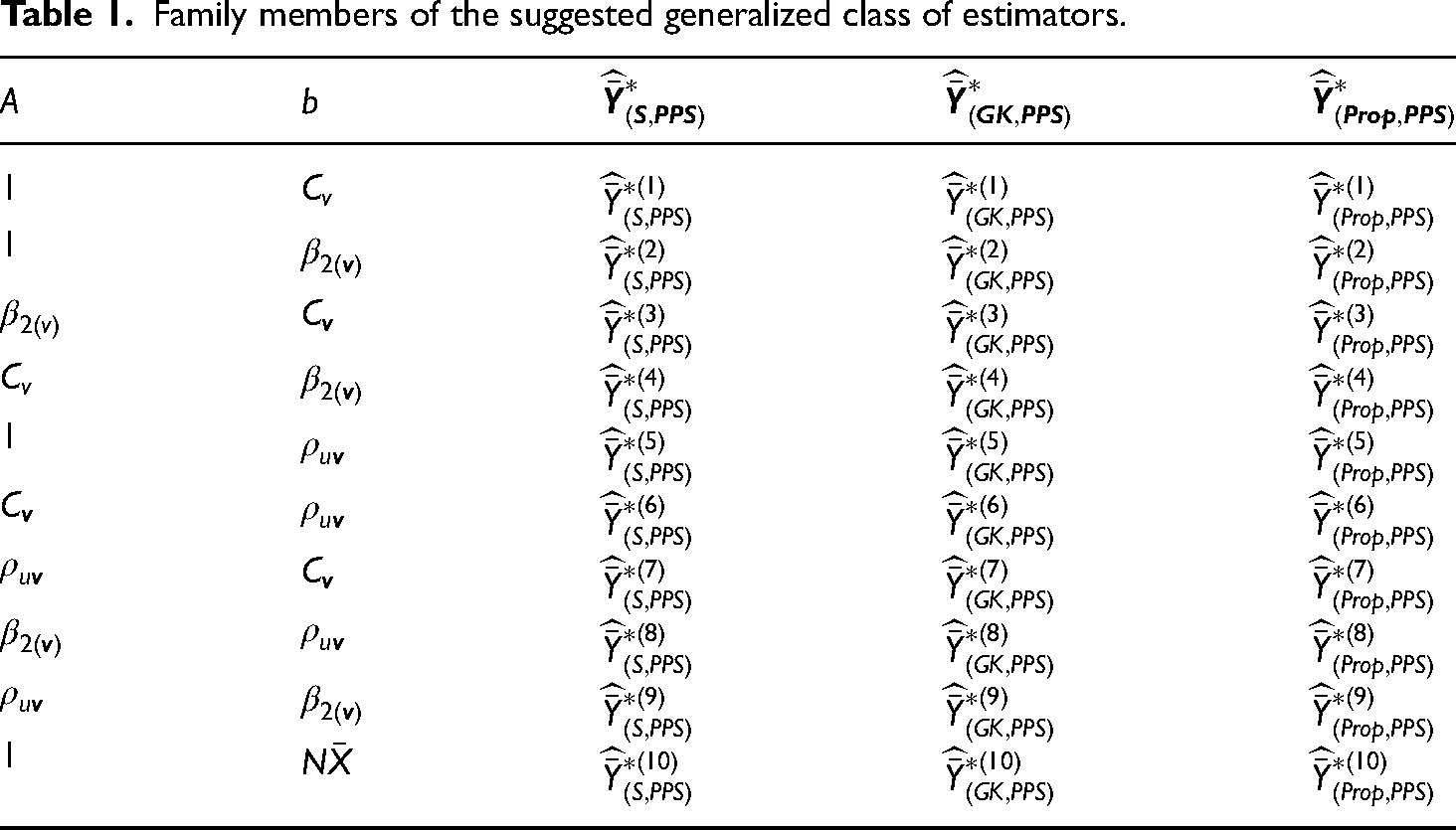
Family members of the suggested generalized class of estimators.
After simplification of 



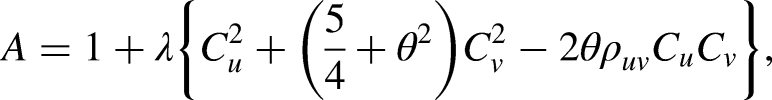





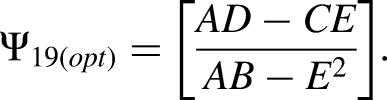

Numerical study
We carry out a numerical study to evaluate the performances of estimators. The following numerical expression is used to compute the percentage relative efficiency (PRE).

Y = Expected total of fish in the year 1995,
X = Expected total of fish in the year 1994,
Z = Expected total of fish in the year 1993.
Y = Total number of beds on the 30th June 2021,
X = Total allocated beds for COVID-19, 2021,
Z = Beds used by COVID-19, 2021.
Y = Kids under age 5 whose childbirths are described listed with a public consultant,
X = Kids aged 5–17 years who are involved in child labor during the last week,
Z = Women aged 20–24 years who were first married before age 16.
Y = Expected total of fish in the year 1995,
X = Expected total of fish in the year 1994,
Z = Expected total of fish in the year 1992.
The summary statistics is given in Table 2 and results based on four populations are given in Tables 3–10. The simulation results are given in Tables 11–18.
Summary statistics using real data sets.

MSE using Population-I.

MSE: mean squared error.
PRE using Population-I.

PRE: percentage relative efficiency.
MSE using Population-II.
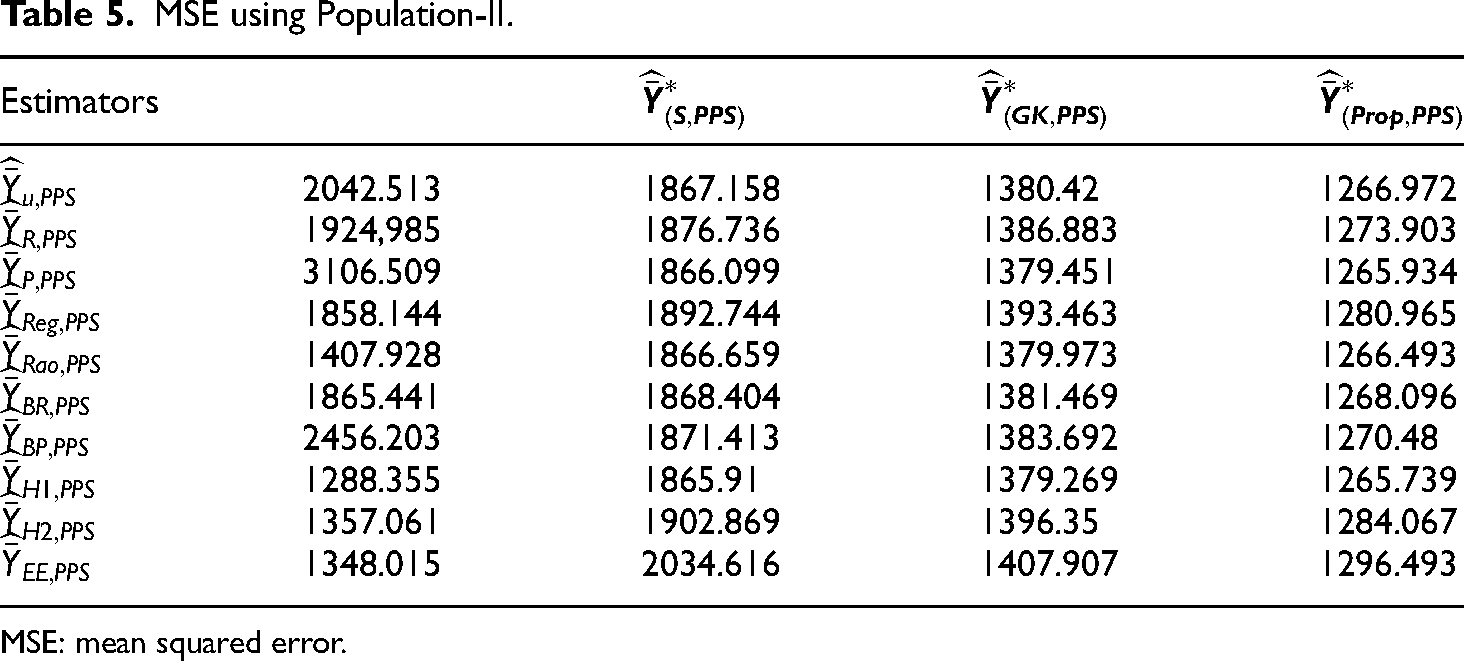
MSE: mean squared error.
PRE using Population-II.

PRE: percentage relative efficiency.
MSE using Population-III.

MSE: mean squared error.
PRE using Population-III.

PRE: percentage relative efficiency.
MSE using Population-IV.

MSE: mean squared error.
PRE using Population-IV.

PRE: percentage relative efficiency.
MSE using Population-I based on the simulation study.

MSE: mean squared error.
PRE using Population-I based on the simulation study.

PRE: percentage relative efficiency.
MSE using Population-II based on the simulation study.

MSE: mean squared error.
PRE using Population-II based on the simulation study.
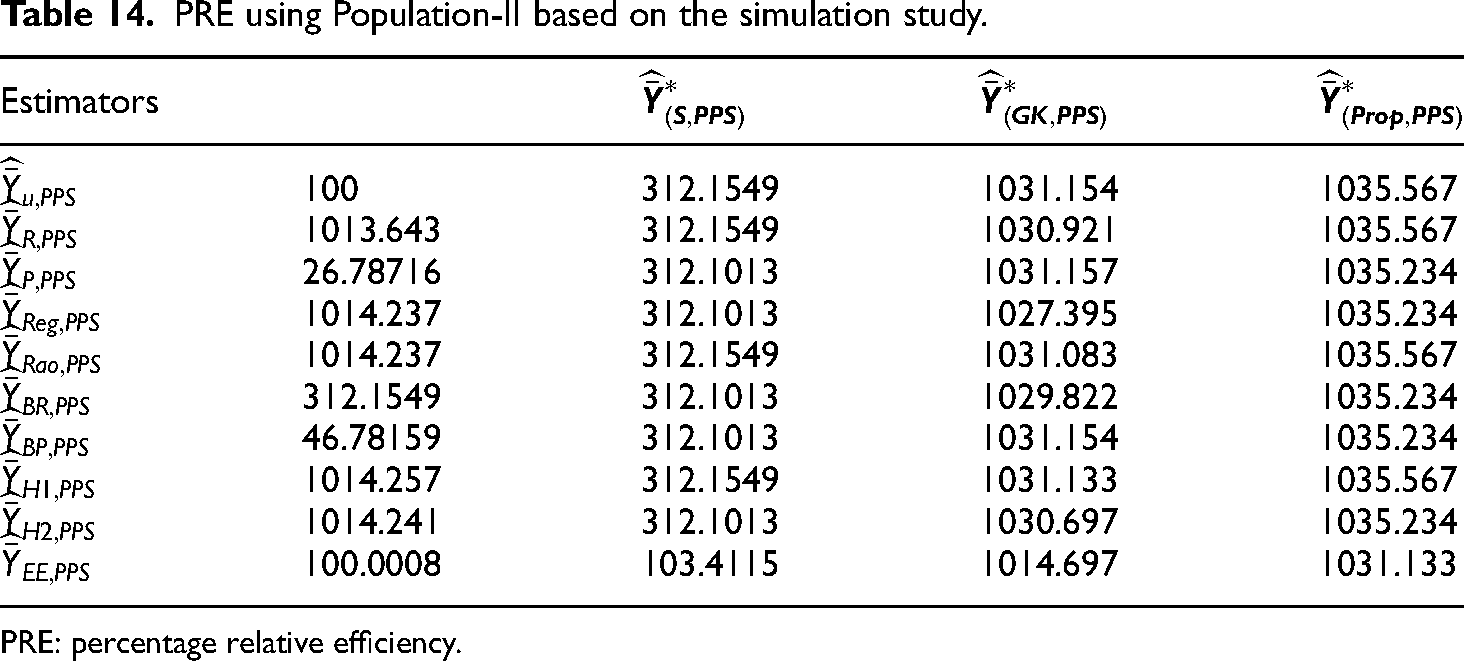
PRE: percentage relative efficiency.
MSE using Population-III based on the simulation study.

MSE: mean squared error.
PRE using Population-III based on the simulation study.

PRE: percentage relative efficiency.
MSE using Population-IV based on the simulation study.

MSE: mean squared error.
PRE using Population-IV based on the simulation study.

PRE: percentage relative efficiency.
Simulation analysis
We have produced four populations of size 5000 from a bivariate normal distribution with unlike covariance matrices. The population means and covariance matrices are given below:




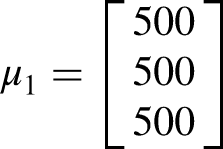



Discussion
To calculate the achievability of the proposed estimators in comparison to the existing estimators, four data sets and a simulation analysis were performed. Four natural data sets were used in the empirical study. We also performed the simulation study, to check the reliability and generalizability of the new improved class of estimators. The consistency findings demonstrated that the proposed estimators were more accurate and less biased than conventional and other well-known existing estimators. Table 2 provides summary statistics for the available datasets. Tables 3–10 contain the MSE and PRE results based on the real data sets. The numerical findings based on real data sets show that our suggested estimators are the best among all existing estimators. Tables 11–18 include the MSE and PRE results utilizing simulated data sets. The results of the simulation analysis also clearly show that the PRE of the proposed estimator is higher than the existing estimators, which are considered in this study. Therefore it observed from the numerical results that our proposed estimators are the best among all the existing counterparts.
From the numerical results, presented in Tables 3–18, we would like to remind that the MSE and percentage relative efficiency of all the proposed classes of estimators changeover according to different choices of a and b. Based on both real data sets and a simulation analysis, if we used (a = 1 and b =
Concluding remarks
In this article, we proposed an improved generalized class of estimators using two auxiliary information based on probability proportional to size sampling. Ten new estimators are generated from the proposed class of estimators, which are presented in Table 1. The proposed generalized class of estimators is compared with several existing estimators to judge their uniqueness and superiority using four real data sets. Moreover, a simulation study is also conducted to check the robustness and generalizability of the proposed estimator. The MSE of the proposed and existing estimators are derived up to the first order of approximation. The proposed class of estimators performs well as compared to its existing estimators, as shown by the results of four real data sets and a simulation study. It has been validated through empirical efficiency comparisons that our proposed class of estimators performs more effectively than the traditional estimators. The current work can be extended easily to an estimation of population means using the auxiliary variables based on measurement error, non-response, and stratified random sampling.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Author biographies
Sohaib Ahmad is a PhD scholar at Abdul Wali Khan University Mardan. His research interests include survey sampling, randomized response, and Data analysis. He published several research articles in the same field.
Javid Shabbir is a professor in the Department of Statistics, University of Wah, Pakistan. His research direction is advanced survey sampling and randomized response.
Erum Zahid is working in the Department of Applied Mathematics and Statistics, Institute of Space Technology Islamabad, Pakistan. Her research direction includes survey sampling, spatial statistics and data analysis.
Muhammad Aamir working as an assistant professor at Abdul Wali Khan University, Mardan, Pakistan. His research direction is survey sampling, time series analysis, machine learning, and he has deep insights on the accuracy of forecasting models.
Mohammed Alqawba is working in the Department of Mathematics, College of Science and Arts, Qassim University, Ar Rass, Saudi Arabia. Hir research direction includes time series analysis, survey sampling, distribution theory and stochastic processes.