
Abstract
Introduction:
Curriculum learning through the wisdom tree massive open online course platform not only gets rid of the limitations of specialty, school and region, eliminates the limitations of time and space in traditional teaching, but also effectively solves the problem of educational equity.
Objectives:
This paper proposes an intelligent algorithm combining decision tree, support vector machine, and simulated annealing to obtain the best classification accuracy and decision rules for university students' satisfaction with the wisdom tree massive open online course platform.
Methods:
This study takes the university students in Fuzhou city information management department as the survey object, and adopts the electronic questionnaire survey method. A total of 1136 formal questionnaires were responded, and 1028 valid questionnaires were obtained after data cleaning and deleting invalid questionnaires (the effective rate was 90.49%). In this paper, the reliability and validity of the questionnaire were tested by IBM SPSS-20.0 software, and six explanatory variables including function, achievement, exercise, quality, richness, and interaction were obtained by principal component analysis. Then, the questionnaire data is converted to CSV (comma separated values) format for analysis. This paper proposes an intelligent algorithm combining decision tree, support vector machine, and simulated annealing to obtain the best classification accuracy and decision rules for university students' satisfaction with the wisdom tree massive open online course platform. In this paper, the proposed algorithm is compared with decision tree, random forest, k-nearest neighbor, and support vector machine to verify its performance.
Results:
The experimental results show that training set classification accuracy of decision tree, random forest, k-nearest neighbor, only support vector machine and the proposed algorithm (simulated annealing + support vector machine) are 92.21%, 96.10%, 95.67%, 97.29%, and 99.58%, respectively.
Conclusion:
The proposed algorithm simulated annealing + support vector machine does increase the classification accuracy. At the same time, the 11 decision rules generated by simulated annealing + decision tree can provide useful information for decision makers.
Keywords
Introduction
The massive open online course (MOOC) is a large-scale open online course, and a new learning mode of “Internet plus education.” The outbreak of COVID-19 makes the teaching of universities around the world face a severe challenge. In order to meet the new needs of teaching, the completion of courses is a huge challenge for MOOC. 1 The MOOC has been developing at an alarming speed, which has impacted the global higher education and promoted the construction and sharing of high-quality educational resources in the global scope. 2 Relying on the well-known EdX, Udacity, and Coursera platform in the United States, countries have successively built MOOC platforms according to their own conditions. 3 The MOOC has set off a “digital tsunami” in China’s education field in the way of learning autonomy, universality of knowledge transfer, diversity of courses, and networking of curriculum mode. Platforms such as MOOC of Chinese universities, MOOC of Chinese language, and wisdom tree have emerged as the times require.
Through the wisdom tree MOOC platform to carry out curriculum learning, it is not only free from professional, school, and geographical restrictions, to eliminate the constraints of time and space in traditional teaching, but also to enrich the national education supply, narrow the regional, urban and rural and inter-school differences in education, so that the problem of education equity can be effectively solved. 4
The wisdom tree teaching platform provides the teacher team function of related courses, abandons the mode of single teacher fighting alone, improves the quality of courses, supports a variety of teaching interaction processes, ensures the high interactivity of online teaching, and provides a full range of operation services for schools or institutions, teachers, students, and teaching alliances, as described below.
5
To provide online university construction scheme for schools or institutions, realize online education operation at the school or institution level, provide corresponding services according to the requirements of curriculum teaching management of schools or institutions, provide course selection and credit certification services, and complete course promotion and enrollment tasks. For teachers, wisdom tree network teaching platform can provide complete online and offline teaching and management of teacher service functions, complete course construction and support course teaching, and provide interactive teaching services based on social network services. For students, online learning service is provided to complete the whole learning process of course selection, class, homework discussion and score credit, and social learning service is provided. Aiming at the teaching alliance, we should provide course exchange services, build a perfect authentication mechanism, and provide public services for alliance members.
Although the wisdom tree teaching platform is popular among learners all over the world, its learning effect is not ideal compared with traditional teaching methods.
6
Due to the large number of learners and the limited interaction time between teachers and students, it is impossible to give specific answers to each person's situation. In addition, there are still some problems with the teaching effect of the wisdom tree platform. For example: some courses have very low click-through rates, many students give up halfway, and few learners can really gain knowledge.7,8
As the users of wisdom tree platform, learners' satisfaction with wisdom tree MOOC platform largely determines whether they choose to continue to use this platform. 9 Data classification is an important research topic in machine learning and data mining, because the accuracy of the algorithm depends on the correctness of data classification. With the rapid development of computer, it is particularly important to use related technologies to establish models to analyze data in machine learning and data mining. 10 Some methods for establishing MOOC prediction model are proposed in the literature, including k-nearest neighbor (K-NN), logistic regression, decision tree (DT), random forest (RF), and support vector machine (SVM).11–14
This paper proposes an intelligent algorithm combining DT, SVM, and simulated annealing (SA) to obtain the best classification accuracy and decision rules for university students' satisfaction with the wisdom tree MOOC platform. The SVM has good classification performance and the DT can generate decision rules.15–16 The SA has the advantages of jumping off local optimization and reaching global optimization. 17 In this paper, the SA is used to automatically adjust the parameters for SVM and DT to increase the classification accuracy and generate decision rules of university students' satisfaction with the wisdom tree MOOC platform. The main purpose is to provide an effective analysis method for the satisfaction of the wisdom tree MOOC platform and useful information for decision makers.
The review of research methods
Decision tree
DT algorithm is a classic data mining algorithm. The structure of DT model is like a tree, including root node, leaf node, and non-leaf node. Each branch represents the direction of prediction, and the leaf node represents the final prediction result. Each node needs to repeat the above process until it reaches the preset conditions. In this paper, the minimum Gini coefficient is used to select the classification attributes of internal nodes. The Gini index is selected as the splitting attribute, and finally the binary tree is generated.
18
Gini coefficient is used to represent the impurity of data set. To represent sample set H, its Gini coefficient can be expressed as follows:


Random forest
RF is formed on the basis of DT algorithm, which is composed of many DTs, but there is no correlation between each DT. 19 Every time we encounter samples to be judged, we mainly follow the principle of putting them back, and put the extracted data samples on the root node of the DT to ensure that the relationship between trees is independent. Then, the DT discriminates according to the attribute category, and forms the corresponding result, and obtains the final result by the way of minority subordinate to majority.
K-nearest neighbor
The main idea of K-NN algorithm is that when there are K nearest samples in the feature space, most of them are part of a specific category, then this sample is also part of this category. In K-NN algorithm, Euclidean distance is usually chosen as distance measure.
20
The Euclidean distance between two points
Support vector machine
The SVM finds a hyperplane that classifies a dataset and solves a classification problem well.
21
SVM solves the problem of equation (3) with a given training patterns


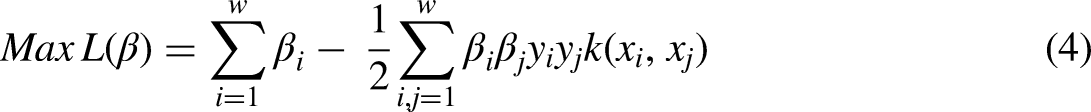
Proposed algorithm
In this paper, the SA is used to achieve the global optimization feature to automatically adjust the parameters of DT and SVM to increase the classification accuracy and generate decision rules. The proposed algorithm includes two stages, as shown in Figure 1.

The flow diagram of the proposed algorithm.
Questionnaire design
In stage 1, because the quality of the course content design is related to whatever it causes students' learning intent, the performance of the learning effect is also related to the curriculum design, the platform satisfaction is related to students' willfulness to continue using MOOC.11,24 For the above reasons, the design of the questionnaire assessing the students' satisfaction of using the wisdom tree MOOC platforms includes the following four aspects: personal basic information, course content design, learning effect, and platform satisfaction. It is described below:
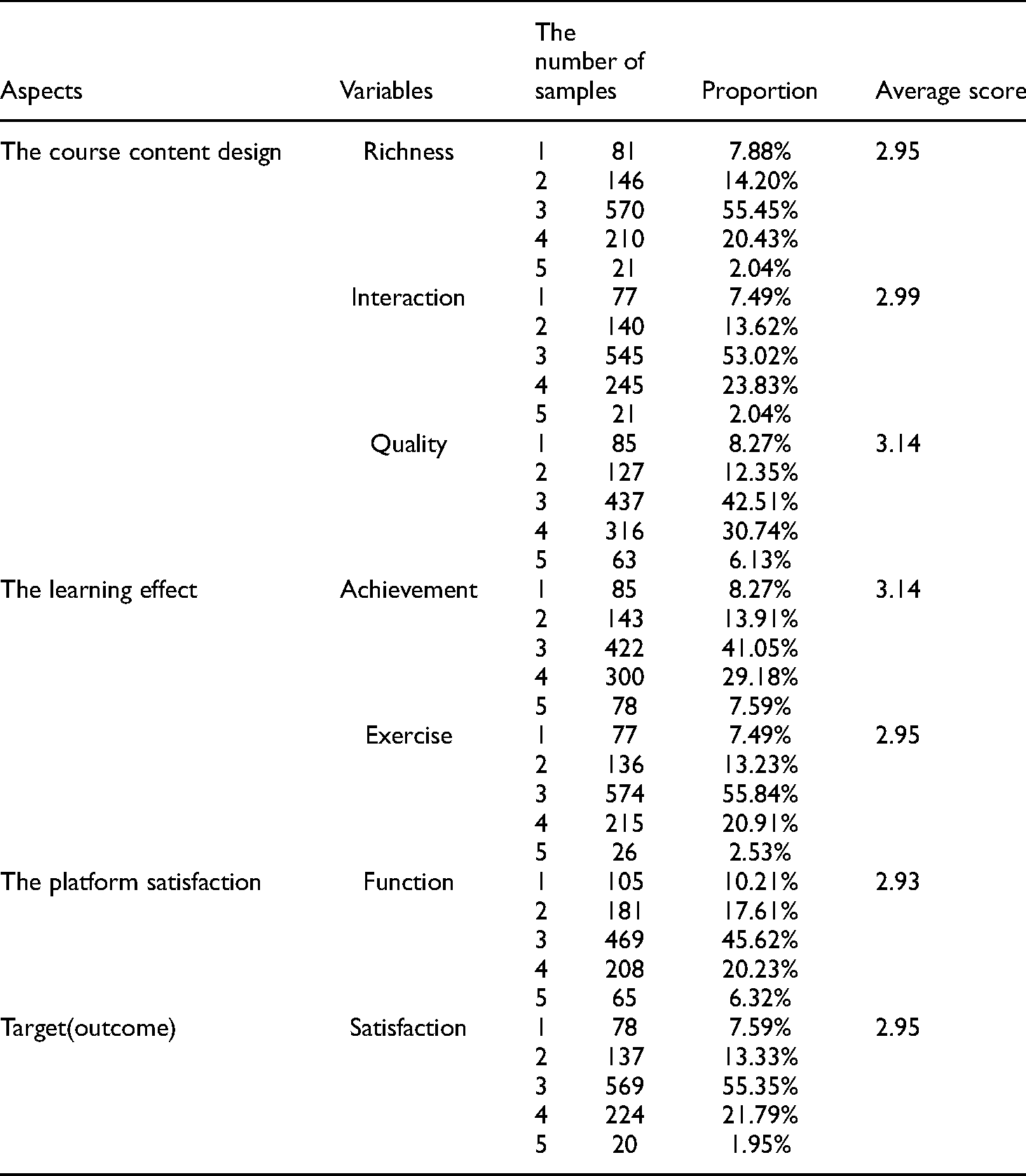
Basic personal information includes gender, grade, age, and wisdom tree platform study time per week. (6 questions) The course content design includes curriculum richness, online interaction, course quality, teachers' teaching attitude, and teachers' teaching method. (15 questions) The learning effect includes the achievement of learning performance, the design of exercises after class and the learning interest. (8 questions) The platform satisfaction includes the platform function provided by wisdom tree, the clear interface, and the ease of operation. (6 questions)
In addition to the basic personal information, the five point scale was designed for the influencing factors of university students' satisfaction of the wisdom tree MOOC platform. Through a more intuitive expression, it makes it easier for the respondents to understand and fill in the questionnaire. The scale contains a series of influencing factors of university students' satisfaction of the wisdom tree MOOC platform. The respondents answered by selecting five items in the five point scale: “very dissatisfied,” “dissatisfied,” “neutral,” “satisfied,” and “very satisfied.” The design of the five point scale has a convenient effect on the collection and processing of the questionnaire, which is convenient for the detailed and accurate analysis of each respondent's feedback. The options of each questionnaire are 1 to 5. The 1 to 5 represent very dissatisfied, dissatisfied, neutral, satisfied, and very satisfied, respectively.
Questionnaire pre-test and reliability and validity analysis
About 120 students were randomly selected from the third grade of the information management department of Fuzhou University of International Studies and Trade to conduct a pre-test questionnaire. The main purpose of this pre-test is to test internal consistency when answering questionnaire questions. The IBM SPSS (version 20.0) was used to test the reliability and validity of the questionnaire data. In reliability analysis, Cronbach α must be greater than 0.7.
25
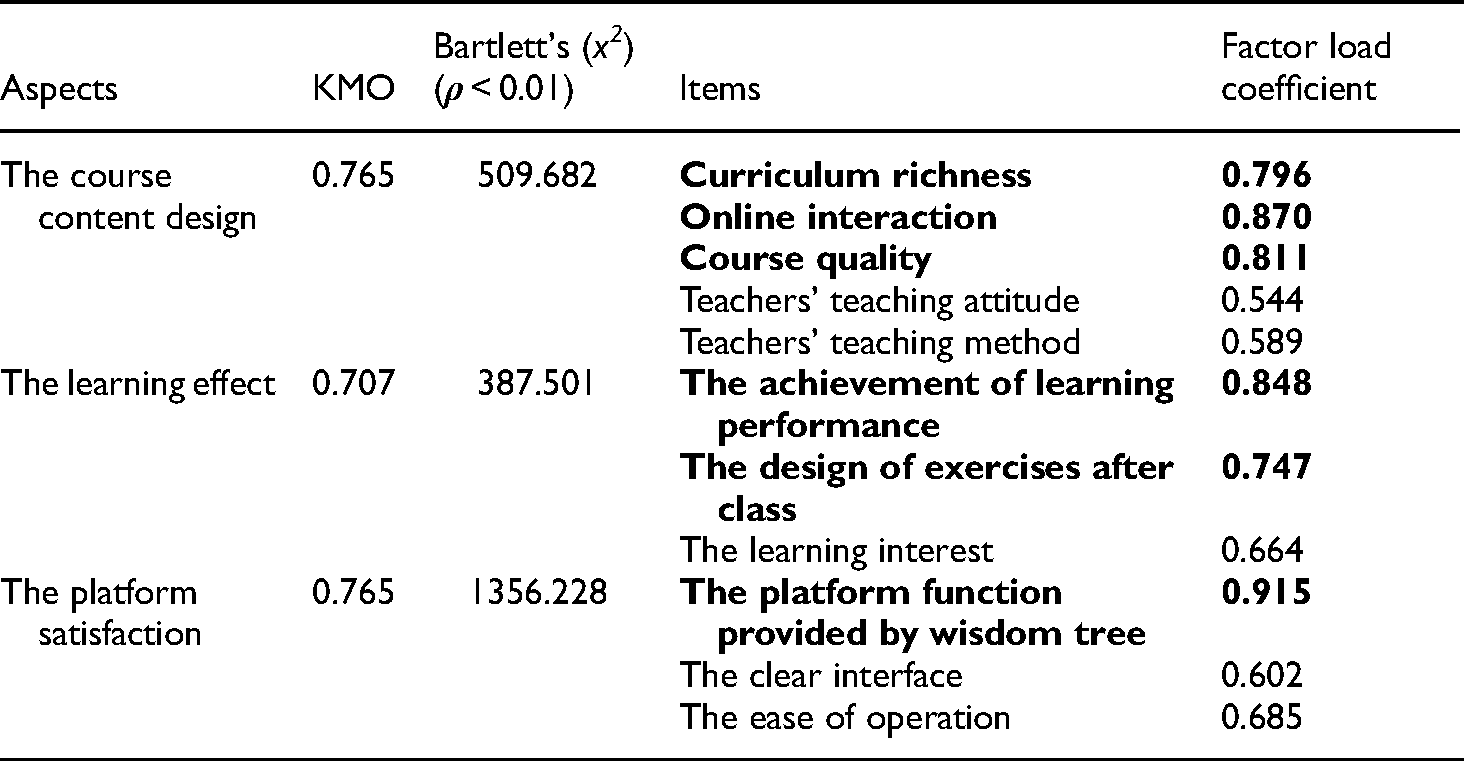
After the reliability analysis is completed, the validity of the questionnaire data needs to be verified. In this study, exploratory factor analysis was used to verify structural validity. In exploratory factor analysis, Kaiser Meyer Olkin (KMO) must be greater than 0.6. The greater the KMO value, the better the validity.
26
The criterion for Bartlett sphericity test is that the corresponding

In the pre-test questionnaire data of this study, there are 11 items, and each item is associated with the university students' satisfaction of the wisdom tree platform. It can be found from Table 1 that the overall value of Cronbach's
Reliability test of pre-test data.

It can be found in Table 2 that the KMO values of the three aspects are higher than 0.7, and Bartlett's spherical test results were
Validity test of pre-test data.
The explanatory variables and meaning by principal component analysis (PCA) extraction.

Reliability and validity analysis of formal data
This study takes the university students in Fuzhou city information management department as the survey object, and adopts the electronic questionnaire survey method. A total of 1136 formal questionnaires were responded, and 1028 valid questionnaires were obtained after data cleaning and deleting invalid questionnaires (the effective rate was 90.49%). Then, the data containing target variables and explanatory variables are transformed into CSV (comma separated values) format, which is convenient for modeling and analysis of relevant algorithms using R-4.1.0 language. The 1028 valid specific information are shown in Table 4.
The 1028 valid specific information.
In order to ensure that the formal data collected by the questionnaire is analytically reliable, the reliability and validity of the formal data collected by the questionnaire must be tested again. Table 5 is the reliability test results of the formal data, from which we can find the overall reliability test results of this study is 0.891, and the Cronbach's
Results of formal data reliability test.

Table 6 is the reliability test results of the formal data. It can be seen from Table 6 that the validity test results of this study are KMO values > 0.8, and Bartlett's test meets the requirements
Results of formal data validity test.

In stage 2, applying SA provides the best parameter settings for the DT and SVM in the proposed algorithm. The SA algorithm is a heuristic algorithm that simulates the physical process of cooling the classical particle system in thermodynamics. Kirkpatrick et al. first proposed the SA algorithm in 1983 and SA has been widely used in various optimization problems.
30
Table 7 shows the proposed algorithm pseudo code used for this study. The initial values of parameters are set, and initial solution

The representation of the solution.
The pseudo code of the proposed algorithm.

The standard for testing classification methods usually uses classification accuracy. This paper also utilizes precision, recall, F1-score as evaluation indicators. 31 These performance indicators are calculated based on the confusion matrix. The confusion matrix is shown in Table 8.
The confusion matrix.

where TP is the number of instances that are positive and to be positive, TN is the number of instances that are negative and to be negative, FP is the number of instances that are actually negative but to be positive, and FN is the number of instances that are positive to be negative.
The precision rate represents the proportion of positive instances in positive instances determined by the classifier. The precision rate calculation formula is shown in equation (6).

The recall rate represents the proportion of positive instances predicted to be positive instances. The recall formula is shown in equation (7).

F1-score is a measure of classification problems. It uses the harmonic average method to comprehensively consider the precision rate and the recall rate, the maximum is 1 and the minimum is 0. The F1-score calculation formula is shown in equation (8).

In this paper, classification accuracy reflects the classifier's ability to judge the entire instance as positive or negative. The classification accuracy is calculated with equation (9).

Experimental results and discussion
Comparison of experimental results to other approaches
In the proposed algorithm, the dataset obtained from university students’ satisfaction of the wisdom tree platform questionnaire was divided into 80% training dataset and 20% testing dataset, and 10 random cross-validation verifications were used to calculate the classification accuracy. In the proposed algorithm, the SA provides the best parameter settings for the DT and SVM. The SA parameters were set to The experimental results in Table 9 include the classification accuracy calculated by only DT, RF, K-NN, only SVM, and the proposed algorithm according to equation (8). It can be seen from Table 9 that the classification accuracy the training set of only DT, RF, K-NN, only SVM, and the proposed algorithm are all greater than the classification accuracy of the testing set and the error is no more than 10%, and there is no over-fitting phenomenon.
33
From Table 9, it can be found that the classification accuracy of the training set of only SVM is 97.29%, and the classification accuracy of the testing set is 96.57%. In the algorithm proposed in this paper, the classification accuracy of the training set is 99.58%, and the classification accuracy of the testing set is 98.45%, indicating that the SA algorithm has an additive effect on SVM. The classification accuracy can be increased by adjusting the parameters. Because the SA algorithm has the advantage of jumping out of the local optimum according to the probability, it can effectively prevent the search process from falling into the local optimum. It shows that this paper proposed an intelligent algorithm that adds SA to SVM and DT, which can use the advantages of SA to effectively determine C and The recall reflects the classification model's ability to recognize positive instances. The higher the recall, the stronger the model's ability to recognize positive instances. The precision reflects the model's ability to distinguish negative instances. The higher the precision, the stronger the model's ability to distinguish negative instances. The F1-score is a combination of the two. The higher the F1-score, the more robust the classification model. It can be seen from Table 10 that the results of recall, precision, and F1-score are higher than of other methods, indicating that the classification effect of the proposed algorithm is generally better, and also shows that the proposed algorithm has good robustness. In 2019, Yu et al. proposed predicting learning outcomes with MOOC Clickstreams while both the K-NN and SVM were used to generate prediction models and their model accuracies were 87.88%, 92.18%.
34
In this paper, for the university students' Satisfaction of the wisdom tree MOOC platform, the K-NN, SVM training set prediction accuracy rate is 95.67%, 97.29%. Despite using different datasets for comparison, both studies applied the same K-NN and SVM algorithms to build the prediction models. In addition, the proposed algorithm in our study has outperformed all other selected methods with the highest prediction accuracy (99.58%). Apparently, the prior use of SA + SVM provided automatic tuning and optimization of C and
Comparison of classification accuracy using different approaches.

The performance indicators of different approaches.

Analysis of influencing factors
In the proposed algorithm, the DT generated for the information management department university students in Fuzhou city satisfaction of the wisdom tree MOOC platform is shown in Figure 3. From Figure 3, the DT judges the value of the node according to different attribute values. Start from the root node, encounter branches on the way, until the last leaf node obtains a decision rule. Therefore, there are 11 decision rules for the survey of university students' satisfaction of the wisdom tree platform. The rules indicate the degree of university students' satisfaction of the wisdom tree platform and which factor affects satisfaction. The obtained decision rules have a total of 11 DT rules, which are shown in Table 11. The DT is divided with the explanatory variable name is “Function” as the root node, which shows that the platform function provided by the wisdom tree is the most important factor affecting university students’ satisfaction of the wisdom tree MOOC platform. It can be found from Table 11 that according to decision rules 3, 5, 6, 7, and 9, the overall satisfaction of university students’ satisfaction of the wisdom tree platform is four points, which means that they are satisfied with university students’ satisfaction of the wisdom tree MOOC platform. According to decision rules 8, 10, and 11, the overall satisfaction of university students’ satisfaction of the wisdom tree MOOC platform is five points, which means “very satisfied” with university students’ satisfaction of the wisdom tree MOOC platform. In order to illustrate the degree of the influence factors for the information management department university students in Fuzhou city satisfaction of the wisdom tree platform, Table 12 shows the results of using the influence factors value from IncNodePurity (increased node purity) on university students’ satisfaction of the wisdom tree MOOC platform. The IncNodePurity is an evaluation method that uses the non-negative sum of squares of the residuals to obtain the value. The size of the value can explain the degree of influence of the explanatory variable on the target variable. As shown in Figure 4, “Function” is the largest among the calculated values of the IncNodePurity. From Table 12 and Figure 4, it is pointed out that the influencing factors are Function>Achievement>Exercise>Quality>Richness>Interaction. It can also be seen that the value of IncNodePurity of function is the largest, which indicates that the satisfaction of function has the greatest impact on university students' satisfaction of the wisdom tree MOOC platform. This is because for learners, a well-functioning learning platform can greatly reduce cognitive load and improve learning efficiency, so the satisfaction of function ranks first. 35 Moreover, the satisfaction of achievement ranks second because learners can not only learn knowledge and increase their knowledge level on the wisdom tree MOOC platform, but also hope to have good performance in the exam. 36 In addition, the satisfaction of after-school exercise design ranks third because the after-school exercise can provide learners continuous practices for solving their learning problems and confusions during the class time. 37
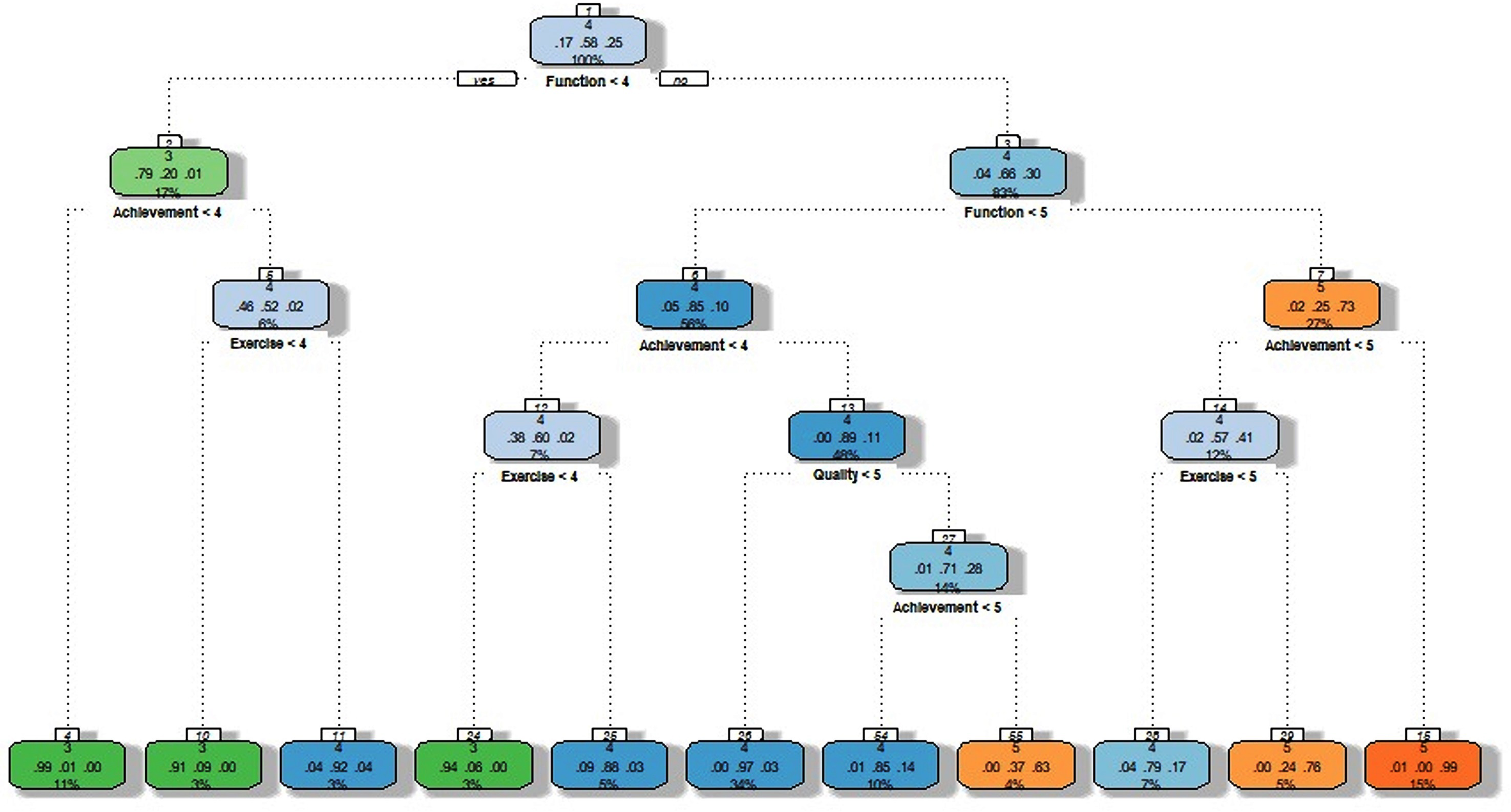
A decision tree from the proposed algorithm.

The wisdom tree massive open online course (MOOC) platform influence factors.
Decision rules obtained from the proposed algorithm.

IncNodePurity values for the wisdom tree MOOC platform influencing factors.

Conclusions
In this study, IBM SPSS-20.0 software was used to test the reliability and validity of the questionnaire, and six explanatory variables such as function, achievement, exercise, quality, richness, and interaction obtained by PCA. This paper proposes an intelligent algorithm combining DT, SVM, and SA to obtain the best classification accuracy and decision rules for university students' satisfaction with the wisdom tree MOOC platform. The experimental results show that training set classification accuracy of only DT, RF, K-NN, only SVM and the proposed algorithm are 92.21%, 96.10%, 95.67%, 97.29%, and 99.58%, respectively. At the same time, the 11 decision rules generated by SA + DT can provide useful information for decision makers.
The information management department students of each university in Fuzhou have a different level. Many students refuse to fill out the questionnaire, which limits the number of samples. Respondents fill in the information of satisfaction of the wisdom tree MOOC platform. Only the samples actually received can be analyzed and researched. In order to attract more university's students to use the wisdom tree MOOC platform and provide decision makers with more useful information, more advanced methods should be used in the future.
This paper proposed methods and experimental results for the information management department university students in Fuzhou city satisfaction of the wisdom tree MOOC platform, hoping to improve university students’ satisfaction of the wisdom tree MOOC platform and promote the construction and development of the wisdom tree MOOC platform, the following suggestions are made to the wisdom tree from the result:
With the rapid development of information technology and the comprehensive popularization of Internet technology, university students’ have higher requirements for the transmission speed of knowledge and information and the diversity of content. For university students’, a faster and more convenient learning platform can greatly reduce cognitive load and improve learning efficiency. The wisdom tree MOOC platform not only needs to provide high-quality learning resources, but also needs to provide better platform functions to increase the interest of university students in learning. At present, to the best of our knowledge, most of the wisdom tree MOOC platforms in China still adopt a lecture-based teaching method. Simply displaying learning materials with text and video may not meet the needs of the majority of university students. In the course development, the wisdom tree MOOC platform should thoroughly explore the needs of the courses and learners; strengthen the content of the courses and improve the quality of the courses.
Footnotes
Acknowledgments
This research was supported in part by Fuzhou University of International Studies and Trade under Grant Nos. FWB19004, 2019-SG-2, 2019020079010, 2018KYTD-05, FWXXS19093, FJTPY-2020009, and BRJF-01.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.