
Abstract
Machine Learning is an increasingly important technology dealing with the growing complexity of the digitalised world. Despite the fact, that we live in a ‘Big data’ world where, almost ‘everything’ is digitally stored, there are many real-world situations, where researchers are still faced with small data samples. The present bibliometric knowledge synthesis study aims to answer the research question ‘What is the small data problem in machine learning and how it is solved?’ The analysis a positive trend in the number of research publications and substantial growth of the research community, indicating that the research field is reaching maturity. Most productive countries are China, United States and United Kingdom. Despite notable international cooperation, the regional concentration of research literature production in economically more developed countries was observed. Thematic analysis identified four research themes. The themes are concerned with to dimension reduction in complex big data analysis, data augmentation techniques in deep learning, data mining and statistical learning on small datasets.
Introduction
Periods of scientific knowledge doubling have become significantly shorter and shorter.1–3 This phenomenon, combined with information explosion, fast cycles of technological innovations, Open Access and Open Science movements, 4 and new Web/Internet based methods of scholarly communication 5 have immensely increased the complexity and effort needed to synthesis scientific evidence and knowledge.6,7 However, above phenomena also resulted in the growing availability of research literature in a digital, machine-readable format. 8
To solve the emerging complexity of knowledge synthesis and the simultaneous new possibilities offered by digital presentation of scientific literature, Blažun et al. 9 and Kokol et al.10,11 developed a novel synthetics knowledge synthesis methodology based on the triangulation of (1) distant reading, 12 an approach for understanding the canons of literature not by close (manual) reading, but by using computer based technologies, like text mining and machine learning, (2) bibliometric mapping 13 and (3) content analysis.14,15 Such triangulation of technologies enables one to combine quantitative and qualitative knowledge synthesis in the manner to extend classical bibliometric analysis of publication metadata with the machine learning supported understanding of patterns, structure and content of publications.16,17
One of the increasingly important technologies dealing with the growing complexity of the digitalisation of almost all human activities is the Artificial intelligence, more precisely machine learning.18–22 Despite the fact, that we live in a ‘Big data’ world,23,24 where almost ‘everything’ is digitally stored, there are many real world situation, where researchers are faced with small data samples.25–27 Hence, it is quite common, that the database is limited for example by the number of subjects (i.e. patients with rare disseises), the sample is small comparing to number of features like in genetics or biomarkers detection, sampling, there is a lot of noisy or missing data or measurements are extremely expensive or data imbalanced meaning that the size of one class in a data set has very few objects.28–32
Using machine learning on small size datasets present a problem, because, in general, the ‘power’ of machine learning in recognising patterns is proportional to the size of the dataset, the smaller the dataset, less powerful and less accurate are the machine learning algorithms. Despite the commonality of the above problem and various approaches to solve it we didn’t found any holistic studies concerned with this important area of the machine learning field. To fill this gap, we used synthetic knowledge synthesis presented above to aggregate current evidence relating to the ‘small data set problem’ in machine learning. In that manner we can overcome the problem of isolated findings which might be incomplete or might lack possible overlap with other possible solutions. In our analysis, we aimed to extract, synthesis and multidimensionally structure the evidence of as possible complete corpus of scholarship on small data sets. Additionally, the study seeks to identify gaps which may require further research.
Methodology
The study aim is to answer the following research question: What is the small data problem in machine learning and how it is solved?
Synthetic knowledge synthesis was performed following the steps below:
Harvest the research publications concerning small data sets in machine learning to represent the content to analyse.
Condense and code the content using text mining.
Analyse the codes using bibliometric mapping and induce the small data set research cluster landscape.
Analyse the connections between the codes in individual clusters and map them into sub-categories.
Analyse sub-categories to label cluster with themes.
Analyse sub-categories to identify research dimensions
Cross-tabulate themes and research dimension and identify concepts
The research publications were harvested from the Scopus database, using the advance search using the command TITLE-ABS-KEY ((‘small database’ OR ‘small dataset’ OR ‘small sample’) AND ‘machine learning’ AND NOT (‘large database’ OR ‘large dataset’ OR ‘large sample’)), The search was performed on 7th of January, 2021. Following metadata were exported as a CSV formatted corpus file for each publication: Authors, Authors affiliations, Publication Title, Year of publication, Source Title, Abstract and Author Keywords.
Bibliometric mapping and text mining were performed using the VOSViewer software (Leiden University, Netherlands). VOSViewer uses text mining to recognise publication terms and then employs the mapping technique called Visualisation of Similarities (VoS), which is based on the co-word analysis, to create bibliometric maps or landscapes. 33 Landscapes are displayed in various ways to present different aspects of the research publications content. In this study the content analysis was performed on the author keywords cluster landscape, due to the fact that previous research showed that authors keywords most concisely present the content authors would like to communicate to the research community. 34 In this type of landscape the VOSviewer merges author keywords which are closely associated into clusters, denoted by the same cluster colours. 35 Using a customised Thesaurus file, we excluded the common terms like study, significance, experiment and eliminated geographical names and time stamps from the analysis.
Results and discussion
The search resulted in 1254 publications written by 3833 authors. Among them there were 687 articles, 500 conference papers, 33 review papers, 17 book chapters and 17 other types of publications. Most productive countries among 78 were China (n = 439), United States (n = 297), United Kingdom (n = 91), Germany (n = 63), India (n = 52), Canada (n = 51) and Spain (n = 44), Australia (n = 42), Japan (n = 34), South Korea (n = 30) and France (n = 30). Most productive institutions are located in China and United States. Among 2857 institution, China Academy of Sciences is the most productive institution (n = 52), followed by Ministry of Education China (n = 28), Harvard Medical School, USA (n = 14), Harbin Institute of Technology, China (n = 14), National Cheng Kung University, China, 13 Shanghai University, China (n = 13), Shanghai Jiao Tong University, China (n = 12), Georgia Institute of Technology, USA (n = 12) and Northwestern Polytechnical University, China (n = 11). The first non China/USA institution is the University of Granada (n = 8) on 19th rank. Majority of the productive countries are member of G9 countries, with strong economies and research infrastructure.
Most prolific source titles (journals, proceedings, books) are the Lecture Notes In Computer Science Including Subseries Lecture Notes In Artificial Intelligence And Lecture Notes In Bioinformatics (n = 64), IEEE Access (n = 17), Neurocomputing (n = 17), Plos One (n = 17), Advances in Intelligent Systems and Computing (n = 14), Expert System with application (n = 14), ACM International Conference Proceedings Series (n = 13) and Proceedings Of SPIE The International Society For Optical Engineering (n = 13). The more productive source titles are mainly from the computer science research area and are ranked in the first half of Scimago Journal ranking (Scimago, Elsevier, Netherlands). In average their h-index is between 120 and 380.
First two papers concerning the use of machine learning on small datasets indexed in Scopus were published in 1995.36,37 After that the publications were rare till 2002, trend starting to rise linearly in 2003, and exponentially in 2016 (Figure 1– lines). In the beginning till the year 2000 all publications were published in journals, after that conference papers started to emerge. Uninterrupted production of review papers started much later in 2016. The number of citations started to grow exponentially in 2005 (Figure 1– bar chart), reaching the peak in 2020.

The research literature production dynamics.
According to the ratio between articles, reviews and conference paper and the exponential trend in production for the first two we asses that machine learning on small datasets in the third stage of Schneider scientific discipline evolution model. 38 That means that the terminology and methodologies are already highly developed, and that domain specific original knowledge generation is heading toward optimal research productivity.
On the other hand Pestana et al. 39 characterised the scientific discipline maturity as a set of extensive repeated connections between researchers that collaborate on the publication of papers on the same or related topics over time. In our study we analysed those connection with the co-authors networks induced by VOSviewer. The co-author network showed that among countries with the productivity of 10 or more papers (n = 27) presented in Figure 2 an elaborate international co-authorship network emerged, confirming that maturity is already reached a high level. The most intensive co-operation is between United States and China, and the ‘newest’ countries joining the network are Russian federation, South Korea and Brazil. Research collaboration is important because it results in a higher quality and quantity of scientific output. 40
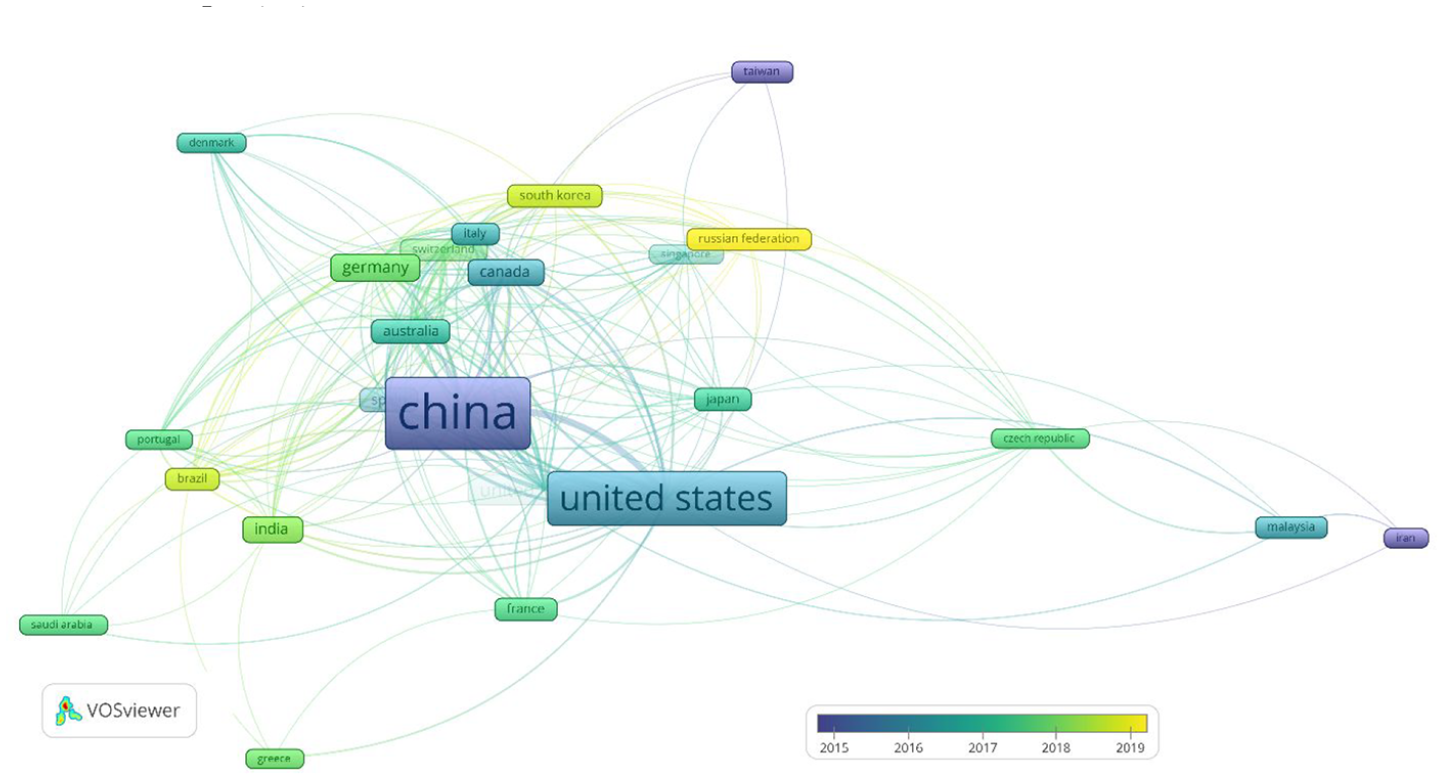
The co-authorship network.
The content analysis of keyword cluster landscape shown in Figure 3. Resulted in codes, SUB-categories and themes presented in Table 1. The content analysis revealed four prevailing themes. The largest two themes are related to dimension reduction in complex big data analysis and data augmentation techniques in deep learning.
Small size sample research themes.

Numbers in parenthesis present the number of papers in which an author keyword occurred

The author keyword cluster landscape.
The further analysis of the Table 1, revealed four categories, which we call Research dimensions. Four identified dimensions are: Small data set problem, Machine learning algorithms, Small-data pre-processing technique and Application Area. Cross tabulation of themes and research dimension resulted in a taxonomy presented in Table 2. The entries in the table presents the most popular concepts in each taxonomical entity.
Taxonomy of themes and research dimensions categories.

Numbers in parenthesis present the number of publications.
The most frequently reported difficulties causing the small data problem are the small size of the dataset, high/low dimensionality of datasets and unbalanced data. Small size datasets can cause problems when machine learning is applied in material sciences, 41 engineering42,43 and various omics fields 44 due to the high cost of sampling; differentiating between autistic and non-autistic patients 29 and diagnosing rare diseases 45 due to the small number of available patients, or unavailability of other subjects for example PhD students in prediction of their grades; 46 and new pandemic prediction due fact that samples are scare when pandemic occurs and there is lack of medical knowledge. 47 Similar reasons can also lead to too high or low dimensionality of the datasets. The first case can occur even if the sample size is not small, however the ratio between number of features and the sample size is large, like for example in particle physics 48 or bioinformatics. 49 The second case can occur when the number of instances is not problematic, however the number of features is very small, like for example in characterisation of high-entropy alloys. 50 Unbalanced data present a long standing problem in machine learning and still remains a challenge in various applications like face recognition, credit scoring, fault diagnosing and anomaly detection where mayor class has much more instances than one or more of remaining classes.51–53
The most used machine learning algorithms used on small datasets are support vector machines,54–56 decision trees/forests,57,58 convolutional neural networks59–61 and transfer learning.62,63
Most frequently employed data pre-processing techniques to overcame the small size problem are linear and nonlinear Principal component analysis43,64,65 Discriminant analysis,46,66,67 Data augmentation,47,68,69 Virtual sample,70–72 Feature extraction50,73 and Auto-encoder.43,74
Most affected areas are Bioinformatics,44,75,76 image classification and analysis,68,69,77 fault diagnosing,78,79 forecasting and prediction,47,80 social media analysis81,82 and health care83,84
Our analysis also revealed that small datasets may result from hardware requirements to cope with limited processing power or small storage size of devices like for example Raspberry PI. 85 Some research also shows that high quality small sample can be better than a low quality large sample in the case of statistical machine learning. 86
Strengths and limitations
The main strength of the study is that it is the first bibliometrics and content analysis of the small dataset research. One of the limitation is that the analysis was limited to publications indexed in Scopus only, however Scopus is indexing the largest and most complete set of information titles, thus assuring the integrity of the data source. Additionally, the analysis also included qualitative components, which might have introduced slight bias to the results of our study.
Conclusion
Our bibliometric study showed the positive trend in the number of research publications concerning the use of small dataset and substantial growth of research community dealing with the small dataset problem, indicating that the research field is moving toward the higher maturity levels. Despite notable international cooperation, regional concentration of research literature production in economically more developed countries was observed. The content analysis showed that the small data sample challenge is recently mainly tackled with more complex machine learning approaches like Deep learning and Support vector machines. The main hot-topic areas of application are medicine/health care, material sciences and economy.
The results of study present a multi-dimensional facet and science landscape of the small datasets problem, which can help small data sample community to solve theoretical and practical challenges. Machine learning researchers and practitioners can use the study results to improve their understanding of the area and can catalyse their further knowledge development. On the other hand, it can inform novice researchers, interested readers or research mangers and evaluators without specific knowledge and help them to develop a perspective on the most important small dataset research dimensions. Finally, the study output can serve as a guide to further research and a starting point to more formal knowledge synthesis endeavours like systematic reviews and meta-analyses.
Our analysis reveals that in the world where everything should be automated and digitalised the possible future of small data analysis lies in the slogan ‘the future of big data is small data’. It is speculated that on 1000 big data sets there are millions of small data sets, especially in fields where extensive manual data pre-processing have to be made, that is, contract reviews or financial audits automation, where manual and extremely expensive annotation performed by layers or accountants are needed. Hence, the future might be in the so called transfer machine learning, where learning could be generalised on data sets from various fields and many different small data sets might become a big data set.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.