
Abstract
Putting accounts for approximately 43% (±2%) of all strokes during a round of golf (García-Massó et al., 2024; Pelz, 2000). Given this frequency, putting performance has a substantial influence on overall outcomes (Dorsel & Rotunda, 2001; Quinn, 2006; Wiseman & Chatterjee, 2006) and has been identified as a key predictor of career earnings among professional golfers (Alexander & Kern, 2005). A central component of this decision-making process is the golfer’s ability to “read” the green prior to execution. This task requires evaluating the optimal path from ball to hole by interpreting various environmental cues, including slope, break, grain, and surface texture (Campbell & Moran, 2014). Once the intended aim line and pace are determined, the golfer must adopt an appropriate stance and execute the chosen stroke accordingly (Mann et al., 2007; van Lier et al., 2011). Green reading ability has been found to be a critical factor in putting success (Karlsen & Nilsson, 2008). Karlsen and Nilsson (2008) asked 43 highly skilled golfers (mean handicap = 2.8) to complete 40 putts ranging from 2.2 to 19.3 m on a two-tiered grass surface to test the perceptual aspects of green reading. Karlsen and Nilsson (2008) found that green reading ability accounted for 60% of putting performance, compared to 34% explained by technique and only 6% by green inconsistencies. Consistent with these findings, research has highlighted that successful putting requires not only proficient movement control but also “skilful perception” (van Lier et al., 2011, p. 349).
An example of skilled perception is accurately judging the break of the putt to choose the correct line and pace (i.e., Pelz, 1994, 2000). To determine the right line and pace, golfers need to assess the green’s surface and contours to estimate the pace, then convert this perception into precise motor actions (Karlsen & Nilsson, 2008). When assessing the surface, another challenge for golfers to consider is the slope. For example, Pelz (1994) recruited 179 amateurs, 128 club professionals, and six professional tour players to examine how golfers perceive the effect of lateral slope when aiming. Participants indicated where they believed their aim line should be relative to the hole for various putts that were straight to severely sloped, ranging from 3 to 4.5 meters, across 40 different hole locations. The findings showed that all groups consistently underestimated the amount of break, predicting approximately 25% on average of the true break (Pelz, 1994). For putts with a break greater than 15 cm, participants were significantly more likely to miss ‘below’ the hole (>84%) than ‘above’ it (<9%). However, expertise-based differences were present as professional tour players were found to be 2% more accurate than club professionals and 5% more accurate than amateurs (Pelz, 1994).
These expertise-based differences can also be apparent in a virtual task designed to investigate green reading. For example, professional golfers displayed greater accuracy in reading the greens and employed different viewing positions compared to highly skilled amateurs and club golfers in a virtual reality environment (Campbell & Moran, 2014). Participants were instructed to survey the green from six predetermined positions and then precisely report where they would aim to hole the putt. Each position allowed six seconds, following a circular route from crouching behind the ball to observing from the left side (standing), crouching behind the hole, standing behind the hole, observing from the right side, and finally, standing behind the ball. Campbell and Moran (2014) determined that professional golfers accurately read 76.5% of putts, a significantly higher rate than the accuracy achieved by elite amateur and club golfers (57%). The primary distinction between higher and lesser skilled golfers appears to be more related to the duration of information processing, rather than simply knowing which information sources to focus on. These expertise-related differences are also found in studies which have adopted think aloud protocols and verbal reports to compare the cognitions of expert and novice golfers (Calmeiro & Tenenbaum, 2011; Whitehead et al., 2015).
Shaw et al. (2021) instructed professional (n = 12) and amateur (n = 12) golfers to articulate their thoughts while traversing from the tee box to the green while completing nine holes consisting of short, medium, and long putts. Results demonstrated superior putting performance for professionals compared to amateurs (Shaw et al., 2021). Alongside superior performance, differences in planning thoughts between professionals and amateurs were observed when golfers were on the green before putting. For instance, professional golfers articulated more outcome-focused planning statements compared to amateur golfers, who tended to express thoughts related to technical execution (Shaw et al., 2021). Interestingly, while walking toward the green, amateurs verbalised more thoughts than professionals, but there was no difference in the content of the thoughts themselves at this stage. These findings suggest that experts can interpret perceptual information from the environment more effectively and use it to guide action planning (Ericsson & Kintsch, 1995).
Building on this understanding, researchers and applied practitioners have increasingly explored ways to train perceptual-cognitive skills in a controlled setting. Within sport more broadly, there has been growing interest in the use of screen-based designs to train perceptual cognitive skills (Hadlow et al., 2018). Modified Perceptual Training (MPT; Hadlow et al., 2018) targets specific sports relevant skills off field, in isolation, with the goal of transferring improvements to on field performance. A central skill in MPT is decision making, which requires athletes to detect and identify relevant options within the sporting environment. A critical consideration in designing MPT interventions is the similarity of the training stimuli in the MPT to representative competition. First, visual correspondence refers to how photo realistic the stimuli are, and second, behavioural correspondence refers to whether the stimuli behave as they do in the real world (Connolly et al., 2025).
MPT can be delivered using a range of methods, from immersive Virtual Reality (VR) environments to simpler screen-based approaches such as 2D images or video clips (Hadlow et al., 2018). Recent research found no performance differences in putts holed between higher and lesser skilled golfers in VR, despite clear skill level differences in real world putting, and highlighted altered perception and action coupling (Bennett et al., 2025). These findings suggest that VR alone may not reliably capture perceptual and decision making differences without additional support or training.
Given these mixed results, a logical step is to use a basic screen based test to examine visual correspondence (Connolly et al., 2025). Presenting 2D images or video clips allows researchers to determine whether the visual information is representative of the cue’s golfers use on the green and whether expertise differences are detectable. Screen based methods also have practical advantages, as coaches can create and edit images or video footage on a smartphone or tablet at low cost, making perceptual skill assessment accessible and scalable.
In this study, we investigate how golfers of varying skill levels interpret 2D images and video based putting tasks. Video based environments allow researchers to explore “what the athlete sees” and how decisions are made (Fadde & Zaichkowsky, 2018). The tasks include visual occlusion, in which portions of the display are masked (spatial occlusion) or stopped before the ball completes its roll (temporal occlusion), to assess whether golfers can predict ball path and putting outcomes from available visual information (Fadde & Zaichkowsky, 2018; Müller et al., 2015). These methods allow comparison along the skill continuum while varying environmental features to identify which cues are most informative.
Collectively, the aim of the present study is to examine expertise differences in golfers’ perceptual-cognitive ability to interpret putting related visual information presented through screen based tasks. The study addresses two primary questions: 1. Are there differences in golfers’ ability to accurately read greens across different representational formats (2D static image versus videos)? 2. Does expertise influence the accuracy of interpreting 2D images of putting scenarios and predicting outcomes based on video recordings?
Furthermore, the study tests the following hypotheses: • H1: Perceptual judgment accuracy will be higher in video representations compared to 2D image-based ones. • H2: Higher-skilled golfers will demonstrate significantly greater accuracy in interpreting 2D images of putting scenarios and predicting ball roll and outcomes from video scenarios than lesser skilled golfers.
Method
Participants
Eighty participants (49 male and 31 females) with a mean age for the males was 44.5 years ±18.6 and a mean age of 45.2 ± 19.1 years for females completed the online task. Males had an average playing experience of 22.07 ± 19.7 years and females had an average playing experience of 13.5 ± 13.9 years. Males played competitive golf on average 7.4 ± 8.5 for hours per week and females 6.9 ± 3.6 hours per week. Three of the participants were PGA professional coaches (2 males and 1 female). Using self-reported data, the average handicap was 14.1 ± 7.3 for males and 15.5 ± 7.5 for females. The average putts per round was 41.3 putts ±6.9 for males and 39.3 putts ±6.5 for females. Participants spent on average 2.7 ± 3.0 hours watching golf per week on the TV. All participants, apart from one, self reported reading the greens before each putt in competition, however, only 2% of participants self reported reading the green before every hole in practice. Ethical approval was granted by the Ethics Committee at the lead authors institution at the time (University of Stirling). All procedures were conducted in accordance with the Declaration of Helsinki ethical principles for collecting research with human participants and each participant provided informed consent before taking part in the study.
Procedure
A pilot screen-based task was conducted with a range of golfers and golf coaches (n = 15). Following the pilot, modifications were made to the pace estimation anchors, and a visual guide was added to indicate the intended ball path in the video section.
The main online screen-based task was developed using Qualtrics (Qualtrics, Provo, UT) and distributed via the National Governing Body and local golf club member pages. The task included an embedded information sheet and consent form; participants were unable to proceed without providing consent. Alongside the demographics and debrief sections there were two main tasks, Green Reading in Practice task and Video Occlusion tasks (Figure 1). Schematic of online screen-based tasks; green reading in practice and video occlusion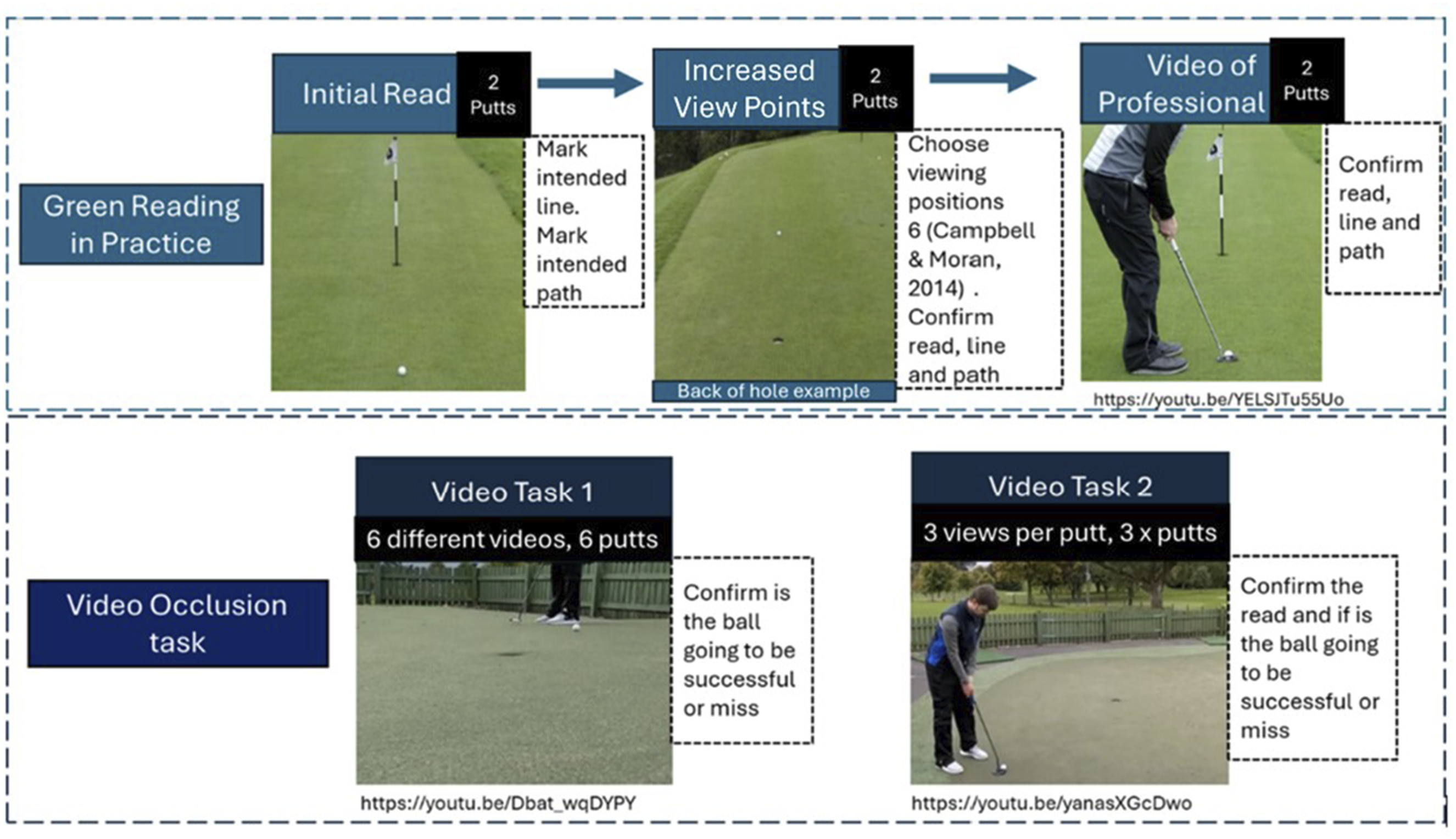
Green Reading in Practice
Each participant completed the following for two different putts:
Condition 1- Initial Read: Participants viewed a 2D image of a hole and indicated putt type (straight level, straight uphill, straight downhill, R-L level, R-L uphill, R-L downhill, L-R level, L-R uphill, L-R downhill). The participants were then asked to mark their intended aim on a line through the hole (via clicking) and then select using clicks on the picture the path they intended the ball to take.
Condition 2- Increased View Points: Participants had the option to view the putt from six different positions (Front, Back, Front Crouched, Back Crouched, Side Left, Side Right; Campbell & Moran, 2014) by selecting which views they wanted to see. Participants were given an option to revise their read, aim, and intended path.
Condition 3- Video of Putt Execution: Participants watched a professional golfer executing the putt and either confirmed or revised their read.
The number of positions viewed was also recorded. Three conditions were defined: Condition 1-Initial read accuracy, Condition 2-Increased view points accuracy, and Condition 3-Post-video accuracy. Accuracy scores were averaged across the two putts (0, 50, 100%).
Video Occlusion Tasks
Task 1: Participants viewed six occluded videos and predicted whether the ball would hit or miss the hole. Prior to prediction, they viewed the putt at maximum and minimum pace to provide perceptual guidance.
Task 2: Participants watched three videos of the same putt from different angles (behind, side, side-delayed – views counterbalanced) and asked to report the putt read for each video. Participants did this for three different putts (9 videos in total). These side views simulated observing an opponent’s putt. Accuracy scores were averaged across videos.
Data Analysis
Data analysis was conducted in JASP (2025, Version 0.95.3). The alpha level for statistical significance was set at p < 0.05 and effect sizes (η 2 ) are reported. The normal distribution of the data was examined via Kolmogorvo-Smirnov tests and visual inspection of Q-Q plots, alongside tests for Equality of Variances (Levene’s). For the green reading in practice test, a Binomial Generalized Linear model (GLM; logit) was used with accuracy (portion) as the dependent variable, with a fixed factor of condition and a co-variate of average putts per round. An ANCOVA was conducted for the average number of position, used, with the co-variate of average putts per round.
Heatmaps illustrating intended aim and putter path locations from the initial read to the increased view points condition were generated as an exploratory analysis to visualize potential differences in aim point and path selection across time. Python scripts were used to align and extract images of the hole, ensuring a consistent orientation across all images (https://osf.io/s7d42/files). These heatmaps were used to explore how green reading strategies may vary between the initial read and viewing more information, and how additional information may influence decision making, based on participant click locations.
Lastly, a series of GLMs were performed with accuracy as the dependent variable for the two video tasks. The analysis included expertise (measured as the average number of putts per round) as a covariate.
Results
Green Reading in Practice
The GLM model compared the model of interest which includes a covariate (i.e., average putts per round) to the null Model which contains only an intercept term (initial view). The full model fitted the data significantly better than the null model, reducing deviance from 488.34 to 320.60, χ2 (3) = 167.74, p < .001 (AIC = 415.94, BIC = 429.86) with a Goodness-of-fit by Pearson’s χ2 = 284.52, df = 236, p = .017. Multicollinearity diagnostics indicated low multicollinearity (tolerance = 0.899, VIF = 1.113 for Average Putts Per Roud and Condition). Average Putts Per Roud was a significant negative predictor (B = −0.130, SE = 0.018, z = −7.36, p < .001), OR = 0.88, 95% CI [0.85, 0.91], indicating each additional putt was associated with a 12% decrease in the odds of the outcome. Condition (reference = Condition 1) showed no effect for Condition 2 (B = 0.220, SE = 0.251, z = 0.88, p = .381), OR = 1.25, 95% CI [0.76, 2.04], and a strong positive effect for Condition 3 (B = 2.686, SE = 0.306, z = 8.77, p < .001), OR = 14.66, 95% CI [8.20, 27.33], indicating being in Condition3 multiplied the odds of the outcome ≈14.7-fold compared with Condition 1 (Figure 2). Accuracy (%) as a function of Average Putts Per Round across the Condition 1. Initial Read, Condition 2. Increased View Points, and Condition 3. Video of Professional.. Solid lines represent fitted regression slopes, and shaded colour indicate 95% confidence intervals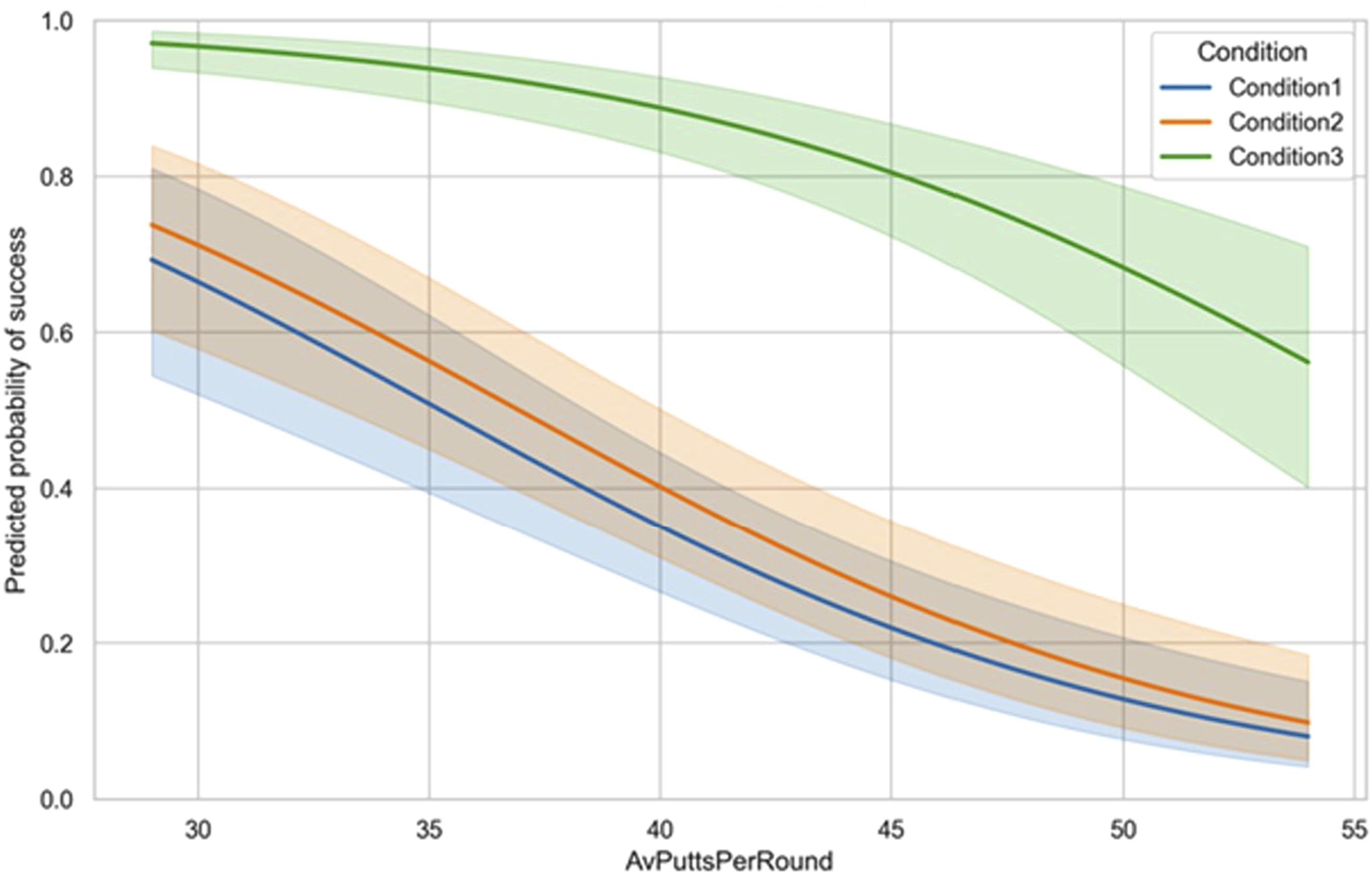
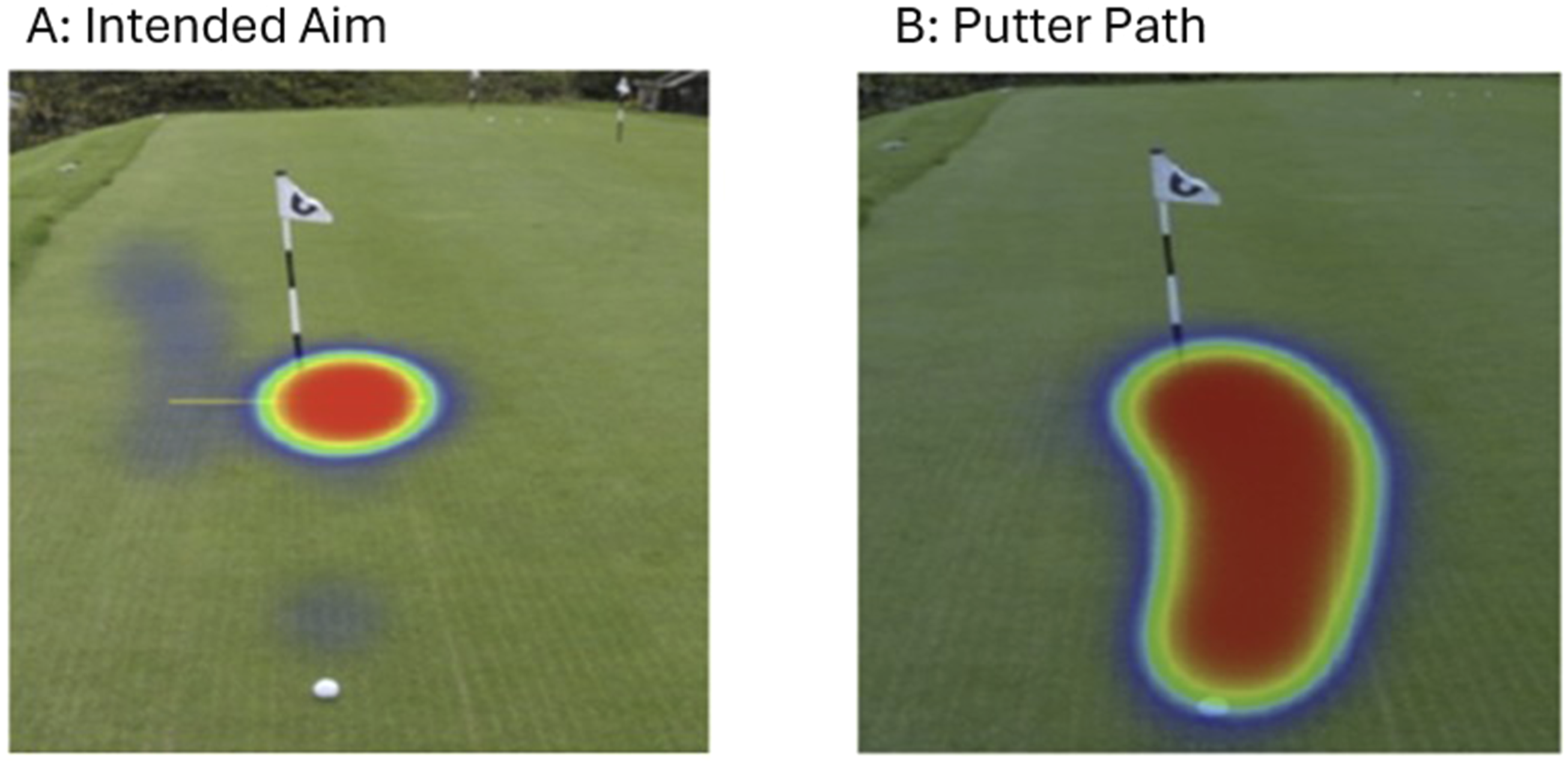
Figures 3–5 show heatmaps of click locations over time for aim point on putt 1 (Figure 3), putter path on putt 1 (Figure 4), and both aim point and putter path on putt 2 (Figure 5). For putt 1, some variation in click locations was observed for both aim point and putter path between rating 1 (initial) and rating 2 (more information), suggesting potential differences in decision making. For putt 2, despite the additional information, participants showed no change in their intended aim point or putter path between the initial rating and rating 2. Heatmaps showing the aim selected by all participants for Putt 1, including difference (Panel C, D) between the initial read (Panel A) and after receiving additional information (Panel B) Heatmaps showing the putter path selected by all participants for Putt 1, including difference (Panel C, D) between the initial read (Panel A) and after receiving additional information (Panel B) For Putt 2, participants did not change their intended aim point (Panel A) or putter path (Panel B) between rating 1 and rating 2 following the additional information
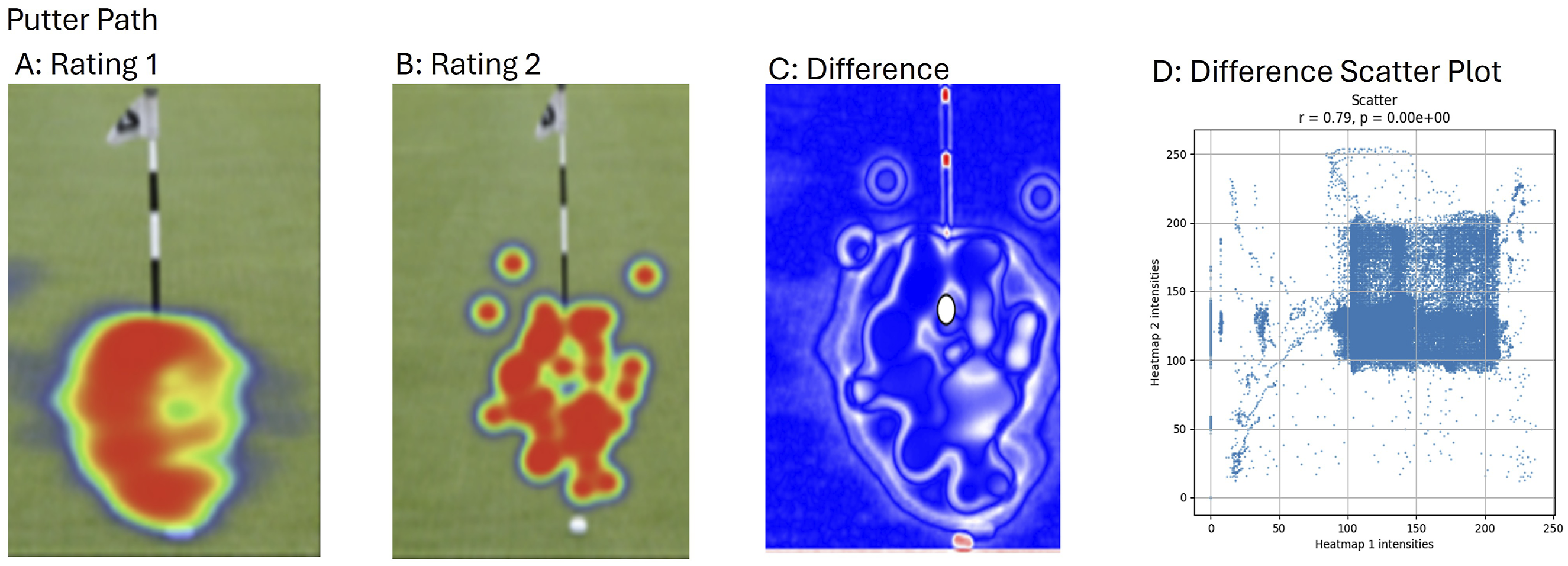
An ANCOVA examined the effects of Average Positions Used and Average Putts Per Round in the Condition 2- Increased viewing points. Results indicated that average putts per round, F (1, 77) = 8.456, p = .005, η 2 = 0.096 was significant.
Video Viewing Tasks
For task 1, the GLM model compared the model of interest which includes a covariate (i.e., average putts per round) to the null Model which contains only an intercept term (accuracy). The full model fit the data significantly better than the null model, reducing deviance from 334.87 to 321.66, χ2(1) = 13.22, p < .001 (AIC = 438.61, BIC = 441.00) with a Goodness-of-fit by Pearson’s of χ2 = 253.68, df = 78, p < .001. The intercept corresponds to baseline odds = exp (2.091) = 8.09 (baseline probability = 8.09/(1 + 8.09) ≈ 0.89). Average Putts Per Round was a significant negative predictor (B = −0.049, SE = 0.014, z = −3.59, p < .001), OR = exp (−0.049) = 0.95, 95% CI [0.93, 0.98], indicating each additional putt was associated with a ≈5% decrease in the odds of the outcome (i.e., odds multiplied by 0.95 per additional putt). (Intercept: B = 2.091, SE = 0.568, z = 3.68, p < .001, OR = 8.09, 95% CI [2.69, 24.94]).
For task 2, the GLM model compared the model of interest which includes a covariate (i.e., average putts per round) to the null Model which contains only an intercept term (accuracy). The full model fit the data significantly better than the null model, reducing deviance from 107.68 to 101.56, χ2 (1) = 6.12, p = .013 (AIC = 109.68, BIC = 112.06). Goodness-of-fit by Pearson’s was χ2 = 80.77, df = 78, p = .393. Average Putts Per Round was a significant negative predictor (B = −0.085, SE = 0.036, z = −2.39, p = .017), OR = exp (−0.085) = 0.92, 95% CI [0.85, 0.98], indicating each additional putt was associated with an ≈8% decrease in the odds of the outcome. The intercept corresponds to baseline odds = exp (3.032) = 20.74 (baseline probability = 20.74/(1 + 20.74) ≈ 0.95), 95% CI for OR [exp (0.262), exp (5.974)] = [1.30, 395.60].
Discussion
This study investigated how golfers of varying skill levels interpret static 2D images and videos to predict ball roll and putting outcomes. Specifically, it examined whether the accuracy of green reading differs between these visual formats and whether higher-skilled golfers demonstrate greater accuracy than lesser-skilled golfers. It was hypothesised that golfers would be more accurate when using videos than static images, that skilled golfers would be more accurate than lesser skilled golfers across both formats. To address these aims, a screen-based green reading task was developed, and golfers with a range of experience levels were recruited. The results indicated a significant difference in accuracy between 2D images and videos, supporting hypothesis (H) 1. In the green reading task, participants performed significantly better in the video condition in comparison to both the initial and more feedback conditions, while there was no significant difference between the initial and more feedback conditions. Furthermore, when considering the initial read for both putts in the green reading exercise, expertise did not lead to improved performance. However, in line with Campbell and Moran (2014) our findings revealed that when participants had more information (viewing different positions around the green or video of the professional hitting the putt), the more skilled golfers were able to use this information to improve their accuracy in comparison to the lesser skilled golfers. The findings from the current study indicate that a single image alone is insufficient to differentiate expertise levels in predicting accuracy. These tentative findings help to clarify the environmental features necessary for capturing perception e.g., “what does an athlete see” (Fadde & Zaichkowsky, 2018). Clarifying these features can inform the development of best practice guidelines for developing Virtual Reality and immersive environments (Kittel et al., 2024), ensuring the technology is being used appropriately and the potential transfer to real-world applications is understood (Bennett et al., 2025).
The results from the two video tasks also revealed expertise-based differences in line with hypothesis (H) 2, as highly skilled participants demonstrated improved accuracy compared to less skilled participants. This indicates that video can enhance learning and provide additional practice opportunities (Stone et al., 2018). The enhanced accuracy/performance seen with expertise underscores experts’ ability to utilise perceptual information in the environment. For instance, videos offer supplementary perceptual cues such as ball roll dynamics, absent in images. Higher skilled golfers demonstrated better ability to predict putt outcomes by tracking the ball and leveraging environmental features. These findings are consistent with Pelz (1994), ball rolling task, whereby expertise could predict the break more accurately than lesser experts.
Practical Implications
From a practical perspective, the present findings highlight what the golfer sees does influence their ability to be accurate, supporting the tentative use of videos within coaching. However, before any interventions can be developed, the screen-based task provided valuable insights to consider alongside developing interventions. For example, there was variation in how often participants used green reading on the course during practice and competition. Participants used green reading more during competition in comparison to practice, with most participants choosing to read the green for all competition putts. At this stage, it is unknown why the golfers do not read the green for every putt and whether the choice not to read the green was related to the putt type, distance, or familiarity of putting on a home course.
The complexity of the green reading process was highlighted through the heatmaps, as participants could identify the correct aim point and putter path, but not necessarily the correct putt type. For example, in putt 2, all participants selected the correct aim point and path on the image, but not all identified the correct read (Figures 2 and 5). Additionally, providing extra information may have influenced decision making for putt 1, as reflected in click locations (see Figure 3), but it did not appear to increase clarity in participants’ overall read. This has implications for the way coaches and golfers discuss putts and reading in practice. It is worth noting that the heatmap analyses reported here are exploratory, intended to visualise potential patterns in aim point and putter path, and should be interpreted cautiously. Overall, the relationship between green reading and expertise appears complex, highlighting the need for further investigation in this area.
When considering the implications of reading an opponent’s putt in practice during competitive golf, our findings suggest that when a putt is viewed from an opponent’s perspective, expertise influences the ability to interpret this information. At this stage, it remains unclear whether higher-skilled golfers demonstrate greater accuracy because they are more familiar with using this strategy, or whether they attend to different information when interpreting the videos. These findings align with research from other sports showing that the removal of key visual information can hinder perception and action, and that experts are more accurate and have superior performance even when information is partially occluded (Stone et al., 2018).
Strengths and Limitations
The survey encompassed a wide range of skill levels, shedding light on the complexities of designing perceptual training for green reading. However, it did not capture actual behavior, a common limitation in green reading studies (Campbell & Moran, 2014; Pelz, 1994; Shaw et al., 2021). In accordance with the principles of an ecological dynamics perspective, to become aware of functional properties of the environment then the individual is required to be in an environment that is representative of the competitive environment to complete the action (Araújo et al., 2006; Davids et al., 2012). Critically, as well as the obvious differences between a screen-based environment and being in the physical environment, when using a screen-based design, the individual will make judgements about the pending action but they do not complete the action (golf putt), meaning the continuous interaction is not captured within the research design (Araújo et al., 2006; Davids et al., 2012).
Future Directions
Collectively, our study underscores the necessity for future research to examine green reading in real-world contexts, allowing for comparisons between intended and actual behaviors to evaluate skilled perception (Araújo et al., 2006). We recommend future studies should examine the development of this expertise, particularly how golfers learn to interpret such information and apply it during on-course play and subsequent motor actions.
Conclusion
Overall, our study demonstrates that “what the athlete sees” (Fadde & Zaichkowsky, 2018) influences green reading accuracy. Participants were more accurate when interpreting videos or multiple views rather than a single 2D image. Expertise differences emerged only in conditions providing richer information, highlighting the value of perceptual cues for skilled performance. However, inconsistencies across types, participants and the small number of trials warrant caution. Future research should explore how golfers utilise visual information to make decisions and translate it into motor actions, advancing both theoretical understanding and practical coaching approaches.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Funding to conduct the research was provided by sportscotland. The funders had no specific involvement in the study design, collection, analysis, and interpretation of the data, writing of the report and in the decision to submit the article for publication. D.I.D. is a member of SINAPSE (![]() ) a Scottish Funding Council research pooling initiative.
) a Scottish Funding Council research pooling initiative.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.