
Abstract
Keywords
Introduction
From a user perspective, virtual reality (VR) can be defined as a computer-generated 3D environment that induces a sense of immersion in another environment (Lioce et al., 2020). Compared to pen and paper or auditory learning approaches, people taught procedural skills in head mounted display (HMD) VR perform those target skills with more accuracy and speed (Hamilton et al., 2021). One explanation is the Cone of Experience, that people find it easier to remember what to do or how to do it if the experience of learning is engaging and multisensory (Dale et al., 1955; Jensen & Konradsen, 2018; Radianti et al., 2020). VR may also benefit learning through psychological mechanisms, such as increased motivation (Neumann et al., 2018), or the ability to teach “meta-parameters” of a task (e.g., general rules, principles, and structure), which assists skill learning and transfer to novel contexts (Harris et al., 2019). The purpose of this study was to examine how VR may be used to teach a real-world visuomotor skill, specifically by teaching the eye-movements required for skilled task performance from a first-person perspective, and how that might translate into improved visuomotor outcomes within the context of golf putting.
Task relevant eye-movements are strongly linked to expertise and are well mapped to stages of motor skill development towards automaticity (Dicks et al., 2017; Land, 2006). One specific behaviour is the Quiet Eye (QE), the final eye-gaze fixation on an Area of Interest (AOI) prior to a critical movement in a task, which can extend beyond completion of the final movement, and lasts for at least 100 ms (Vickers, 1996a). Holding a longer QE is associated with enhanced task performance (Lebeau et al., 2016) irrespective of a persons’ skill level, however, expert athletes typically hold a longer QE compared to novice and near-elite counterparts (Mann et al., 2007, 2011). Various mechanisms of QE have been proposed, including that the visual behaviour may be associated with identifying and programming an optimal motor movement, use of external attention while planning and executing the movement, and psychomotor quiescence, the short-term reduction in physiological activity which allows the optimal movement to be executed (Gonzalez et al., 2017). Besides QE, using a reduced number of fixations, but of longer duration, and looking at areas of interest (AOIs) earlier and for longer over the movement sequence (i.e., over multiple gaze fixations), are found to be associated with increased task expertise within a sports context (Mann et al., 2007).
In the sport context, golf putting requires a high-level of mechanical and perceptual co-ordination throughout task execution for successful performance (Ziv & Lidor, 2019). For example, the cognitive skill of online attentional control optimises gaze behaviour (i.e., including QE duration) in relation to stroke initiation, unfolding, monitoring, and feedback (Causer et al., 2017). There are several movement kinematics and gaze behaviours associated with putting expertise (Vickers, 1992; Ziv & Lidor, 2019), such as using no more than three fixations towards the hole prior to setting the putter (Moore et al., 2012). Another is performing a QE for around 2.5 s prior to backswing initiation (which follows through the foreswing and beyond ball contact). Although there can be individual variation in visuomotor coordination while golf putting, there is also a high level of consistency in what is required for success (Ziv & Lidor, 2019), such as an optimal QE duration of 2.5 seconds (Vickers, 2012). The tight visuomotor coordination required for putting success provides a framework for understanding how VR-based training may affect visuomotor skill development as compared to real-world training, including the perceptual skills which may underly the QE itself (Moore et al., 2012).
Quiet Eye Training (QET) aims to teach novices or intermediates in a visuomotor skill the QE fixation behaviour of experts. In a typical QET protocol, a participant views their own gaze behaviour and that of an expert, followed by a discussion with a researcher about the difference between their gaze and that of the expert, prior to being providing with technical instructions on form and technique, such as putting stance for golf (Moore et al., 2012). Although QET has shown efficacy in lengthening QE (Lebeau et al., 2016), the structure of QET limits conclusions about what visual skills may be learnt (other than QE), and it can be challenging to decouple perception from action when evaluating the QE. For example, a longer QE may reflect changes in visual processing, or an effort to modify stance or technique because of technical instruction, or a combination of both (Rienhoff et al., 2016).
In a meta-analysis, the effects of QET on QE lengthening were large (Cohens d = 1.53; Lebeau et al., 2016), however, specifically providing technical instructions about the optimal QE duration in QET may inflate how long people hold their QE after training. Participants may consider the duration information not as a guideline but as an instruction. The provision of a specific eye-gaze duration also may not be appropriate for some people, due to individual variability in the optimal QE length (Vickers, 2012; Ziv & Lidor, 2019). One hypothesised mechanism of QE is movement organisation (Gonzalez et al., 2017), however, visual information used to organise an action may be gathered prior to movement initiation itself while looking within the environment (Land, 2006; Land et al., 1999). It may not be appropriate to explicitly target one gaze behaviour (e.g., QE), without contextualising the QE within a visuomotor sequence, where information is gathered sequentially, and each gaze fixation affects an action output. It may be that visual information gathered from a fixation is “put-on-hold” until needing to be included in a motor output (Land, 2006), such as a look toward the hole being important for movement planning throughout the QE when putting. Someone may mimic a QE when being asked to, but may only be performing a QE when being given the information and framework to learn and practice the functional advantage of a QE.
Eye-Movement-Modelling-Examples (EMME) consists of superimposing the gaze cursor of an expert over stimuli throughout task completion for an onlooker to observe. There are different variations of EMME, such as the “spotlight”, where a blur is occluding all areas of the video which are not being looked at by the expert (Jarodzka et al., 2012). EMME guide a learner’s visual attention to the most relevant information for successful task completion, by providing an example of what to look for and at what time (Gegenfurtner et al., 2017). In a review of the effects of EMME on procedural skill learning, Xie et al. (2021) found a reduced time to first fixation toward an AOI (d = −0.81), and a longer average fixation duration (d = 0.74), which was reflected in cognitive performance benefits (d = 0.43). Procedural skill learning, and highlighting important relevant knowledge, may underly the benefits of EMME (Gegenfurtner et al., 2017). EMME may provide specific task and procedural information and context, which is generally required for expertise related eye-gaze strategies to develop (Wolfe et al., 2016). EMME allows an opportunity for individuals to identify and learn a QE, without confounding a potential learning or performance effect with explicit technical instruction. It may thus provide a unique avenue to understand how training a QE improves performance and impacts upon visuomotor skill learning.
Present Study
With the use of virtual-based technologies for sport training, such as HMD VR (Bird, 2020; Neumann et al., 2018), it is critical to evaluate how to facilitate the learning of eye gaze and perceptual skills, and whether this may effectively translate to targeted skills such as the QE. The present study aimed to examine the efficacy of using EMME shown through VR to train closed motor skills in novice participants. The skill of golf putting was used because it is a highly constrained physical task for which performance has been shown to be dependent on eye movements and gaze behaviour. Following a pre-test of putting performance, participants received EMME either through Cursor only (eye gaze cursor of an expert shown by an orange circle) or Blurred visualisations (expert eye-gaze cursor visible with peripheral information blurred), or no training (Control). A post-test assessment of putting was completed. The primary measures were real-world putting performance and eye-gaze behaviour. In addition, the effects of the EMME VR presentations on cybersickness (CS) and attitudes towards VR was assessed, based upon whether the EMME visualisation included visual occlusion (Blurred) or not (Cursor), as occlusion may help to reduce cybersickness (Ang & Quarles, 2023). This was examined as CS may adversely affect learning in VR (Neumann et al., 2018), which may be an issue for VR training and the potential adoption of VR technologies for learning. The following hypotheses were tested. (1) It is anticipated that EMME (Cursor and Blurred) trained participants (but not Control) will improve in their putting performance pre-to-post, as measured by successfully holed putts, radial error (RE), putt length, and putt line. (2) Due to the expert gaze behaviours modelled through EMME, it is predicted that Cursor and Blurred participants (but not Control) will show fewer fixations, longer average fixation duration, a longer QE, increased cumulative dwell time, and a fixation pattern more alike the expert from pre-to-post. (3) Compared to the Control condition at post-test, participants in both Cursor and Blurred conditions will show fewer fixations, longer average fixation duration, longer QE, longer cumulative dwell time, and a pattern of fixations more consistent with experts. (4) It is expected that the Blurred training condition will report less CS and more favourable attitudes toward VR than the Cursor condition, as visual occlusion may reduce CS in VR.
Method
Participants
Forty-two undergraduate students who were novice to golf participated in exchange for course credit. Participants were randomly allocated to one of three conditions: Cursor (n = 14), Blurred (n = 14), and Control (n = 14). The mean age was 20.86 years (SD = 4.15). Twenty-three participants were male (54.8%) and 19 were female (45.2%). Forty-one putted right-handed and 1 left-handed. All had normal or corrected to normal vision. Fourteen people reported having previously used VR for gaming (33.4%), but none used VR for sport training or as part of a research study. No participants had a stroke handicap, or received previous golf training, meeting the definition for a novice golfer (Moore et al., 2012). Participants initially provided informed consent to a study protocol approved by the institutional ethics review board (GU/2021/635).
Materials
Eye-Movement-Modelling-Examples Video Training: Cursor and Blurred
Eye-movement data from a PGA Australia registered professional-amateur golfer, with a competitive stroke handicap of 1 was used to create the EMME videos. The expert putted a ball into the hole and used a sequence of three fixations: Ball (0.7 s), Hole (0.3 s) and QE (2.5 s) (whereby QE was located on the ball). The golfer received $50 of renumeration. The eye-gaze of the expert was represented through an orange circle as standard with the Tobii Pro Lab eye tracking video export. The Cursor video was an unedited version of the expert video with the sound removed. For the Blurred video, a variation of the “spotlight” visualisation was used (Jarodzka et al., 2012), where a Gaussian blur occluded visual areas of the video not being inspected by the expert (see Figure 1). The size of the high visual acuity window was 5.6% of the visual field (meaning peripheral blurring covered 94.4% of the field-of-view). No sounds or verbal explanation were included, as auditory instruction may impair learning for procedural skills using EMME (Xie et al., 2021), and to allow examination of visuomotor skill learning from gaze modelling alone, while controlling for technical instruction. Both the Cursor and Blurred videos were shown in Unity (version 2018.4.31f1). A single trial was shown which contained the optimal QE time of 2.5 seconds (Lebeau et al., 2016) and was a successfully holed putt. This methodology was chosen because the ability of VR to repeat scenarios from a first-person perspective has been highlighted as a specific training application of VR (Bird, 2020), and it is important to evaluate whether visuomotor skills can be taught relative to an idealized and representative expert standard. EMME videos were shown on repeat for 5 minutes, with this duration chosen as benefits have been found to performance after 5 minutes of exposure (Jarodzka et al., 2013). Videos were shown in full screen, through a Vive Pro Eye headset running on a Dell Precision 3630 desktop computer with an Intel i7 processor and an Intel UHD Graphics 360 card. Example of How the Fixation Toward the Hole and QE Fixation Looked From the Perspective of the Observer Within the Cursor and Blurred Conditions. The Solid White Circle Shows the Ball Location, While the Orange Circle Shows Where the Expert is Looking at the Time the Screenshot was Taken
Performance Evaluation: Putting and Eye Gaze Behaviour
Eye Tracker
The Tobii ProGlasses 2 eye tracker was used, which was controlled through Tobii ProController software running on a Dell Latitude 5500 laptop running a 1.6 G Hz Intel i5 processor with 8 GB of DDR4 RAM. The Tobii ProGlasses 2 uses a 1-point calibration, has slippage compensation, and a trackable field of view of 160° in both horizontal and vertical directions (accurate within 0.5°). Following a participant recording, the data was exported using Tobii Pro Lab and manually coded using the software ELAN (Wittenburg et al., 2006). Gaze behaviours were calculated using the Tobii Attention algorithm, which uses a saccade velocity threshold parameter of 100°/second (instead of 30°/second). This setting is more appropriate when collecting data under dynamic settings or when a person is moving, as some gaze events may otherwise be classified as saccades (Tobii, 2023).
Putting Performance
Putting performance was recorded using a Sony HDR-CX405 HD camcorder mounted to an overhead projector beam. Data was taken from still images of the final ball landing position and scored using the ScorePutting program (Neumann & Thomas, 2008) running on LabVIEW software. Radial error, line, and length were calculated, overcoming the limitations of using radial error alone in evaluating performance, as radial error confounds line and length (Neumann & Thomas, 2008). Radial error is the distance between the ball and hole, line was calculated using angular error (relative to 180°) from putt origin, and length is the distance the ball has travelled from putt origin. Putts were taken using a 4.27 cm regulation size golf ball on an artificial putting green from 3.05 m (10 feet). Right-handed putters used a MultiLink PS-1 putter (PEF Online 312 putter for the left-handed participant).
Surveys
Reality Judgement and Presence Questionnaire (RJPQ)
The RJPQ is an 18-item measure which evaluates three aspects of environmental perception: attention and absorption (n = 4), reality judgement (n = 7), and internal external correspondence (n = 7) in VR environments (Baños et al., 2000). Each question is scored using an 11-point Likert scale where 0 = “Not at All” to 10 = “Absolutely”. In the present study, scale reliability was high (α = .94), and subscale reliabilities ranged from (α = .88-.93). The RJPQ was used to measure immersion and presence when watching the VR videos, which may be important for engagement and performance in VR environments (Neumann et al., 2018).
Simulator Sickness Questionnaire (SSQ)
The SSQ is a 16-item questionnaire that examines psychological and physiological symptoms of cybersickness (Kennedy et al., 1993) through three subscales: oculomotor symptoms (n = 7), disorientation (n = 7), and nausea (n = 7). Item anchors range from 0 = “None” to 3 = “Severe”. The scale had high reliability (α = .85) while subscale reliabilities ranged from (α = .73-.82). Note that some items are used for multiple subscales (e.g., blurred vision for oculomotor symptoms and disorientation). The purpose of the SSQ was to measure sickness symptomology and understand how each visualisation may affect the experience of VR induced cybersickness.
Technology Continuance
The TC survey adapted items from those used by Liao et al. (2009) to measure perceptions and attitudes toward the use of virtual, screen-based, or augmented technologies (Liao et al., 2009). The survey consisted of 22 items that covered six domains, perceived usefulness (n = 4), perceived ease of use (n = 4), disconfirmation (n = 3), satisfaction (n = 4), attitude toward the use of the technology (n = 4), and continuance intention (n = 3). Each item was scored on a 7-point Likert scale where 1 = “Strongly Disagree” to 7 = “Strongly Agree”. Items were reworded to use the phrase “VR” instead of “CUS” (i.e. Cyber University System) as used in the original scale development (Liao et al., 2009). An example item includes, “My experience with using VR was better than I expected”. High reliability on the subscales was found (α = .73-.96).
Procedure
The demographic questionnaire and pre-test SSQ measure was completed, followed by eye-tracking calibration. A pre-test SSQ was administered as healthy participants can enter with some sickness symptoms, meaning a zero baseline should not be assumed (Brown et al., 2022). Pre-test performance was next assessed. Participants made 40 putts on the artificial putting green in four blocks of 10 putts with a momentary rest-pause between each block. Following each putt, the experimenter would collect the ball and place the ball on a marked starting position to commence the next trial. After the pre-test putts were completed, participants were seated facing a blank wall and were instructed to remain seated. For Cursor and Blurred training participants, each participant was fitted with the VR headset and asked to watch the video shown to them. They were told that the orange circle represented where an expert golfer was looking, however no other technical instructions or feedback was provided (such as posture, club grip, and optimal QE duration). Cursor and Blurred participants watched their respective video for 5 minutes, while Control participants were asked to remain seated in the room for the same duration. After training, participants completed condition dependent post-test surveys. For the Cursor and Blurred training conditions, the SSQ, TC, and RJPQ were completed while only the SSQ was completed for the Control condition. Participants then were recalibrated for eye-tracking and completed the post-test performance assessment of 40 putts using the same approach as used for the pre-test performance assessment. Testing concluded with a short debrief with the experimenter.
Data Scoring and Statistical Analysis
Due to space restrictions within the testing laboratory, putts could not exceed 1 meter beyond the hole (i.e., 4.05 m total). Rather than remove those missing putts from the data (which would unfairly under-represent poor putting performance), putts which exceeded 1 m in RE were winsorised to the maximum RE of 100 cm (as in Moore et al., 2012), with length adjusted accordingly (e.g., 405 cm for putts which hit the back wall of the testing laboratory). Consistent with the definition of QE (Vickers, 1996b), an eye-gaze fixation was defined as a steady gaze (within 1-3° of visual angle) on an object or area of interest for at least 100 ms (initiation) with offset occurring following a saccade away from the object or AOI which exceeded at least 3° of visual angle. QE was operationally defined as the final fixation towards the ball prior to initiation of the club backswing (Vine et al., 2017), which can extend beyond movement until a saccade away from the fixation location. Fixation duration was calculated as the difference between gaze offset from gaze initiation for any eye-gaze fixation. AOIs were defined by critical gaze locations in the pre-shot, swing, and post-shot phases, and included the ball, hole, club, and the area between the ball and the hole (which is important for green reading; Campbell & Moran, 2014). Number of fixations was calculated from the first look at an AOI after the experimenter placed the ball in front of the participant, until the completion of the QE fixation (which was located on the ball for all trials). Cumulative dwell time (dwell hereafter) represents the aggregate time spent looking at AOIs throughout the trial. Gaze sequences from each trial were compared to a referent string (i.e., “Ball-Hole-QE” as used in the expert modelling videos), to calculate string edit distance (SED) (Yujian & Bo, 2007). SED is the minimum number of changes needed to change a string to a referent string (e.g., “Hole-QE” to “Ball-Hole-QE” is 1). SED has been used previously to evaluate scan path differences in real-world vision research (Foulsham & Underwood, 2008).
A generalised linear mixed model using a logistic data type was used to evaluate the likelihood of holing a putt by condition, timepoint, and block, with participant as the intercept. Linear Mixed Models (LMMs) were used to assess differences in putting performance (i.e. RE, line, and length) and eye-gaze behaviours (i.e. number of fixations, mean fixation duration, QE, dwell and SED), pre-to-post. Each model was fitted with the participant as the intercept, and timepoint, condition, and block (consisting of 10 putts each) as the model fixed factors via 2 (Timepoint: Pre-Test, Post-Test) × 3 (Condition: Cursor, Blurred, Control) × 4 (Block: 1, 2, 3, 4) mixed factorial models. LMM’s were fitted using the lme4 package (Bates et al., 2015), and were used to overcome limitations from absent trial-level data (e.g., missing gaze data), and to provide a more sensitive measure of statistical difference as opposed to calculating difference based upon arithmetic mean average performance (Speelman & McGann, 2013). To assess whether QE duration became more consistent following training, mean scores for QE were calculated by condition × timepoint. Trial level deviation scores were then calculated by subtracting the corresponding condition × timepoint mean from each trial score for QE. Absolute QE deviation scores were then compared using a 2 (Timepoint: Pre-Test, Post-Test) by 3 (Condition: Cursor, Blurred, Control) LMM with participant as the intercept. A series of 2 (Timepoint: Pre-Test, Post-Test) × 3 (Condition: Cursor, Blurred, Control) mixed factorial ANOVAs were conducted on the mean SSQ scale and subscale scores. Post-test RJPQ and TC total and subscale mean scores were compared between Cursor and Blurred participants using independent samples t-tests. Moderated regression analysis on TC subscale scores, with RJPQ subscale values as the predictors, were calculated to evaluate whether the experience of VR influenced attitudes toward using VR for Cursor and Blurred participants. Lower and upper 95% confidence intervals are reported for line graphs. As LMM’s are calculated on estimated marginal means, descriptive statistics for performance and eye-gaze measures are provided within the Supplemental Files. As the study focus was on changes to putting performance and eye-gaze from pre-to-post across each condition, follow up analyses for condition × block interactions were not reported. Data cleaning, wrangling, assumption checking, and analyses were conducted in the open-source statistical software R Studio (RStudio Team, 2020).
Results
Putting Performance
Changes to Putting Performance
Holed Putts
Mean Number of Holed Putts for Each Participant Across Timepoint and Condition
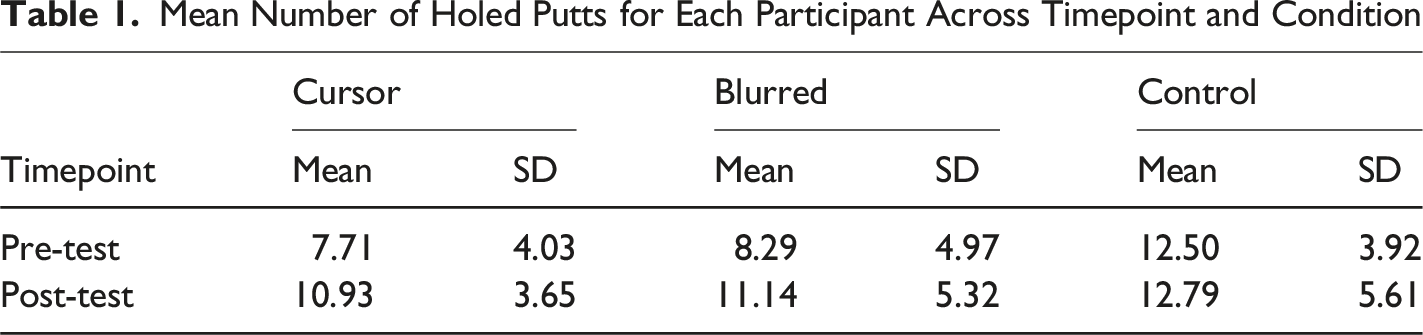
There was a condition × timepoint interaction (χ2(2) = 8.36, p = .015). From pre-to-post, the likelihood of holing a putt increased for Cursor (OR = 1.61[95% CI = 1.06-2.45], SE = 0.24, p = .016) but not for Blurred (OR = 1.45[95% CI = 0.95-2.20], SE = 0.21, p = .126) or Control conditions (OR = 1.03[95% CI = 0.71-1.51], SE = 0.14, p = .999). The interaction between condition × block was statistically significant (χ2(6) = 16.57, p = .011). There were no other interaction effects (all χ2’s < 1.72, p’s > .633).
Percentage change scores were calculated in addition to the LMM to evaluate proportional change in putt successes across condition and timepoint. From pre-to-post, there was an increase of 8.16% in holed putts for the Cursor condition, 7.07% increase for the Blurred condition, and 0.49% increase for Control condition.
Radial Error
There was a main effect of timepoint (F(1,3285.0) = 38.50, p < .001), and block (F(3,3285.1) = 19.16, p < .001), but not condition (F(2,39) = 1.15, p = .326). The condition × timepoint interaction was significant (F(2,3285.0) = 5.07, p = .006). RE was reduced pre-to-post for the Cursor (t(3285.0) = 6.01, p < .001, d = 0.36) and Blurred conditions (t(3285.0) = 3.19, p = .018, d = 0.19), but not for the Control condition (t(3285) = 1.55, p = .630, d = 0.09). There was a significant condition × block interaction (F(6,3285.1) = 3.06, p = .005). RE was lower at block 4 compared to block 1 for the Cursor condition (t(3285.2) = 3.68, p = .013, d = 0.31). For the Control condition, compared to block 1, RE was reduced at blocks 2 (t(3285.0) = 4.78, p = .001, d = 0.40), 3 (t(3285.0) = 3.49, p = .024, d = 0.30), and 4 (t(3285.2) = 5.17, p < .001, d = 0.44). The interaction between timepoint and block was significant (F(3,3285.0) = 3.59, p = .013). There were no other interaction effects (all F’s < 1.86, p’s > .084).
Putt Line
There was a main effect of timepoint (F(1,2937.9) = 20.49, p < .001) and block (F(3,2933.3) = 17.55, p < .001), but not condition (F(2,36.1) = 0.05, p = .950). The condition × timepoint interaction was significant (F(2,2937.9) = 3.74, p = .024). There was an improvement from pre-to-post for the Cursor condition (t(2938) = 4.64, p < .001, d = 0.29), but not the Blurred or Control conditions (all t’s < 2.48, p’s > .132, d’s < 0.16). The interaction between condition × block was significant (F(6,2933.3) = 2.57, p = .018). The Cursor condition had a better putting line at block 4 compared to blocks 1 (t(2937) = 3.65, p = .014, d = 0.33) and 2 (t(2935) = 3.47, p = .026, d = 0.31). For the Blurred condition, compared to block 1, putting line was better at blocks 2, 3, and 4 (all t’s > 3.97, p’s < .004, d’s > 0.35). The change across blocks also differed between pre-test and post-test as reflected in a significant timepoint × block interaction (F(3,2933.6) = 3.88, p = .009). No other interactions were statistically significant (all Fs < 1.20, p > .304).
Length of Putt
There was an effect of timepoint (F(1,3283.1) = 30.57, p < .001), and block (F(3,3283.1) = 12.67, p < .001), but not condition (F(2,39.0) = 0.30, p = .742). There was a significant condition × timepoint interaction (F(2,3283.1) = 7.82, p < .001). Participants in the Cursor condition had a longer putt length at pre-test compared to post-test (t(3283) = 6.42, p < .001, d = 0.38), while there was no change for the Blurred or Control conditions (all t’s < 1.67, p’s > .554, d’s < 0.10). There was an interaction between condition and block (F(6,3283.1) = 4.91, p < .001). Putt length in the Cursor condition was longer in blocks 1 (t(3283) = 3.81, p = .008, d = 0.32), 2 (t(3283) = 5.38, p < .001, d = 0.46) and 3 (t(3283) = 4.14, p = .002, d = 0.35) compared to 4. For the Control condition, putt length was longer at block 1 compared to 2 (t(3283) = 4.52, p < .001, d = 0.38) and 4 (t(3283) = 4.06, p = .003, d = 0.35). There was also a timepoint × block interaction (F(3,3283.1) = 7.52, p < .001). There were no other interaction effects (all F’s < 1.57, p’s > .153). Please see Figure 2 for mean RE, line, and length of putt by condition and timepoint for each block. Mean Radial Error, Line, and Length by Timepoint, Condition, and Block Where Dotted Lines Represent Optimal Putt Outcome (RE = 0 cm; Line = 180°; length = 305 cm) and Error Bars Depict the 95% Confidence Intervals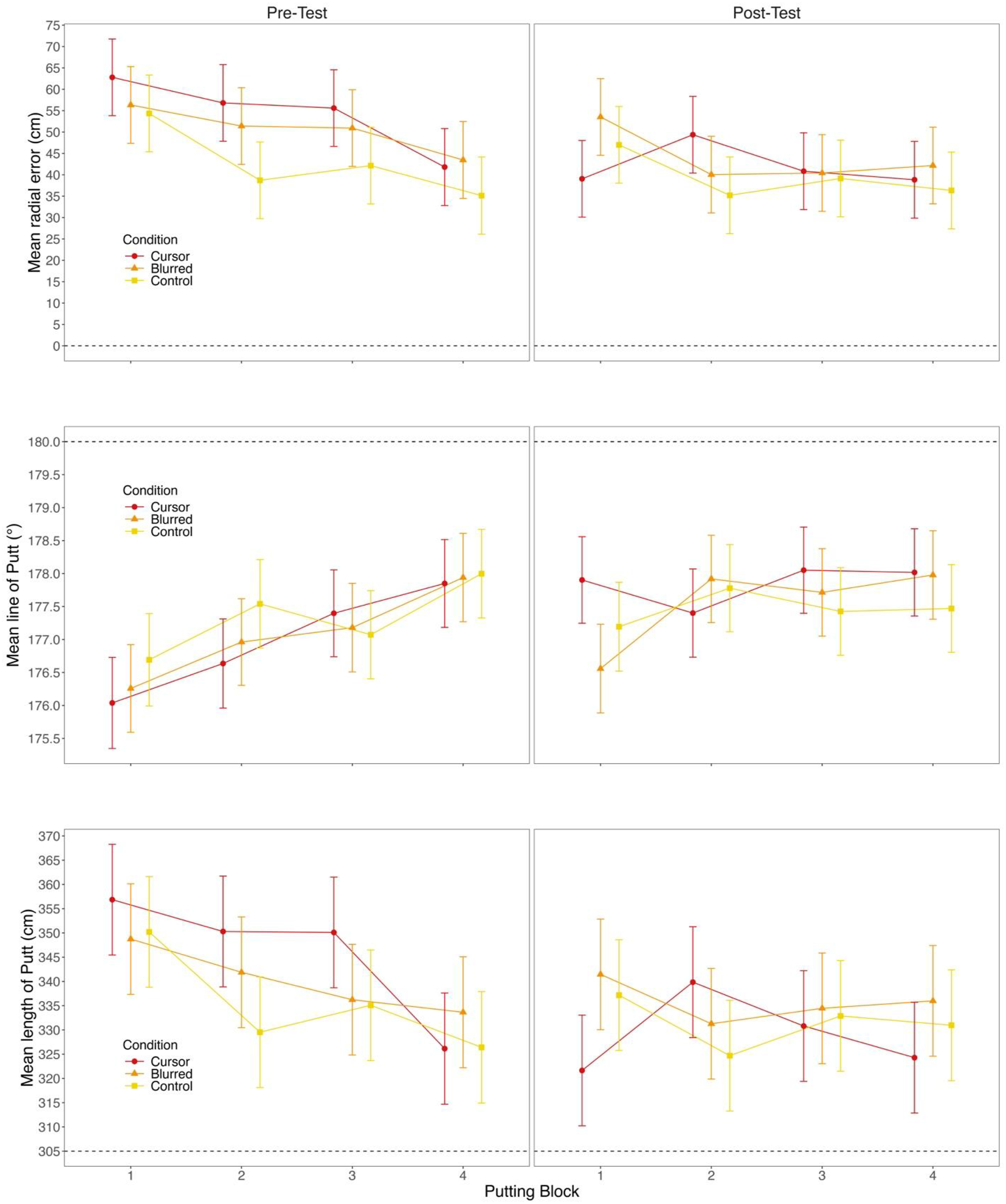
Measures of Visuomotor Learning
Changes to Gaze Behaviour
Number of Fixations
The main effect of timepoint was statistically significant, where participants made more fixations at pre-test than post-test (F(1,2279.8) = 10.52, p = .001). No other main effects or interactions were significant (all F’s < 2.43, p’s > .064).
Mean Fixation Duration
There was a main effect of timepoint (F(1,2281.3) = 174.98, p < .001) and block (F(3,2272.4) = 3.69, p = .012), but not condition (F(2,31.0) = 0.47, p = .628). There was a significant timepoint × block interaction (F(3,2272.1) = 3.73, p = .011). At pre-test, fixation duration was longer at block 4 compared to block 1 (t(2275) = 3.91, p = .002, d = 0.33) while there was no difference at post-test (all t’s < 1.27, p’s > .627, d’s < 0.14). No other interactions were significant (all F’s < 2.93, p’s > .054). See Figure 3 for number of fixations and mean fixation duration estimated marginal means by condition, timepoint, and block. Number of Fixations and Mean Fixation Duration When Putting by Condition, Timepoint, and Block With the Error Bar Representing the Upper 95% CI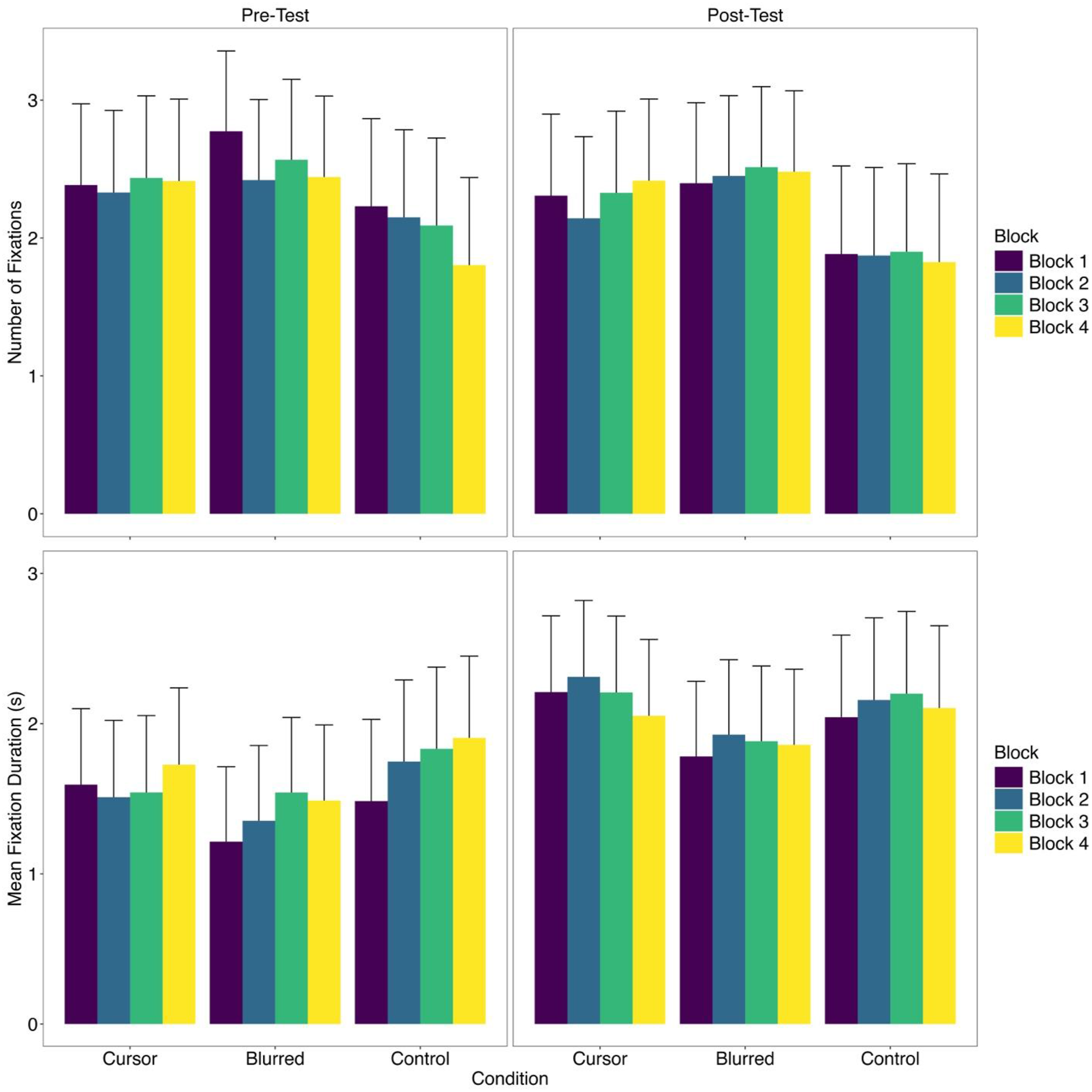
Quiet Eye
There was an effect of timepoint (F(1,2279.2) = 210.24, p < .001), and block (F(3,2271.9) = 7.10, p < .001), but not condition (F(2,30.7) = 0.20, p = .819). There was also an interaction between condition × timepoint (F(2,2279.1) = 19.86, p < .001). QE was longer for all conditions at post-test compared to pre-test; Cursor (t(2285) = 12.25, p < .001, d = 0.95), Blurred (t(2276) = 9.15, p < .001, d = 0.65) and Control (t(2276) = 3.64, p = .004, d = 0.27), which corresponds to a large, moderate, and small effect size respectively (Cohen, 1988). There was a significant timepoint × block interaction (F(3,2272.0) = 4.34, p = .005). There were no other interaction effects (all F’s < 1.33, p’s > .240).
For the QE deviation measure, there was an effect of condition (F(1,2305.9) = 84.13, p < .001), and timepoint (F(2,30.6) = 3.33, p = .049), and a significant condition × timepoint interaction (F(2,2305.6) = 15.04, p < .001). Deviation in QE duration increased from pre-to-post for both Cursor (t(2314) = 9.19, p < .001, d = 0.71) and Control (t(2300) = 4.48, p < .001, d = 0.33) conditions but not for the Blurred condition (t(2300) = 1.95, p = .375, d = 0.14). At post-test, participants in the Blurred condition were more consistent in their QE than those in the Cursor condition (t(33) = 3.51, p = .015, d = 1.03). There were no other differences between conditions at post-test (all t’s < 2.01, p’s > .361, d’s < 0.61) or in QE consistency at pre-test (all t’s < 1.56, p’s > .632, d’s < 0.45).
Dwell
There was an effect of timepoint (F(1,2278.3) = 123.92, p < .001) and block (F(3,2274.0) = 4.85, p = .002), but not condition (F(2,31.2) = 0.63, p = .538). The condition × timepoint interaction was significant (F(2,2278.2) = 15.22, p < .001). Pre-to-post, dwell increased for the Cursor (t(2282) = 8.85, p < .001, d = 0.68) and Blurred conditions (t(2276) = 8.52, p < .001, d = 0.61) but not the Control condition (t(2276) = 1.93, p = .386, d = 0.14). There was also a condition × block interaction (F(6,2274.0) = 2.17, p = .043). For the Cursor condition, dwell was longer at block 4 compared to blocks 1(t(2277) = 3.60, p = .017, d = 0.37) and 2 (t(2273) = 3.59, p = .017, d = 0.37). There were no other interaction effects (all F’s < 1.98, p’s > .066). Please refer to Figure 4 for QE and dwell estimated marginal mean scores by condition, timepoint, and block. Quiet Eye and Dwell Time Looking at Areas of Interest When Putting Across Condition, Timepoint, and Block With the Upper 95% CI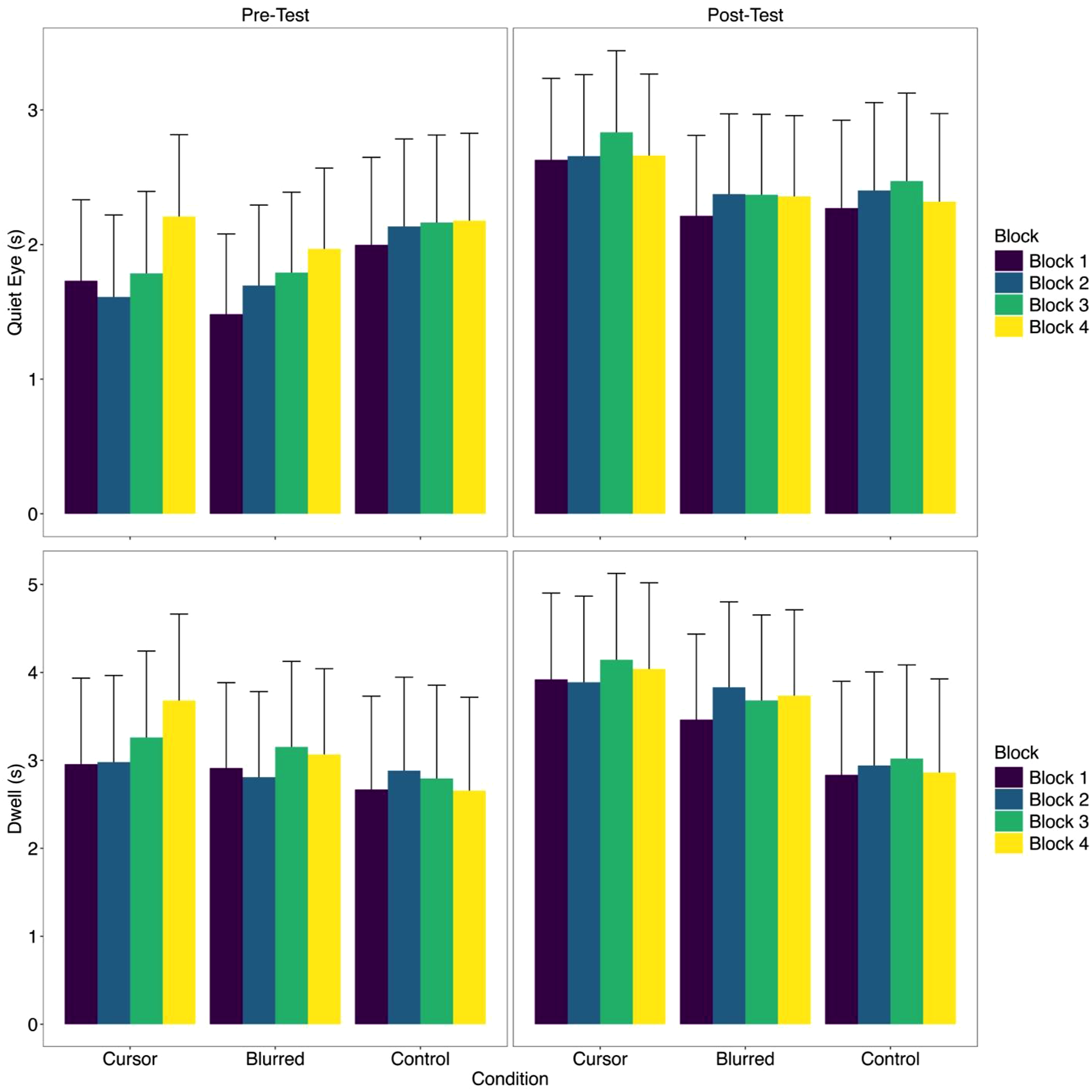
String Edit Distance
Proportion of Eye-Gaze Strategies Used Throughout Putting by Condition and Timepoint With Percentage Change Scores Pre-to-Post
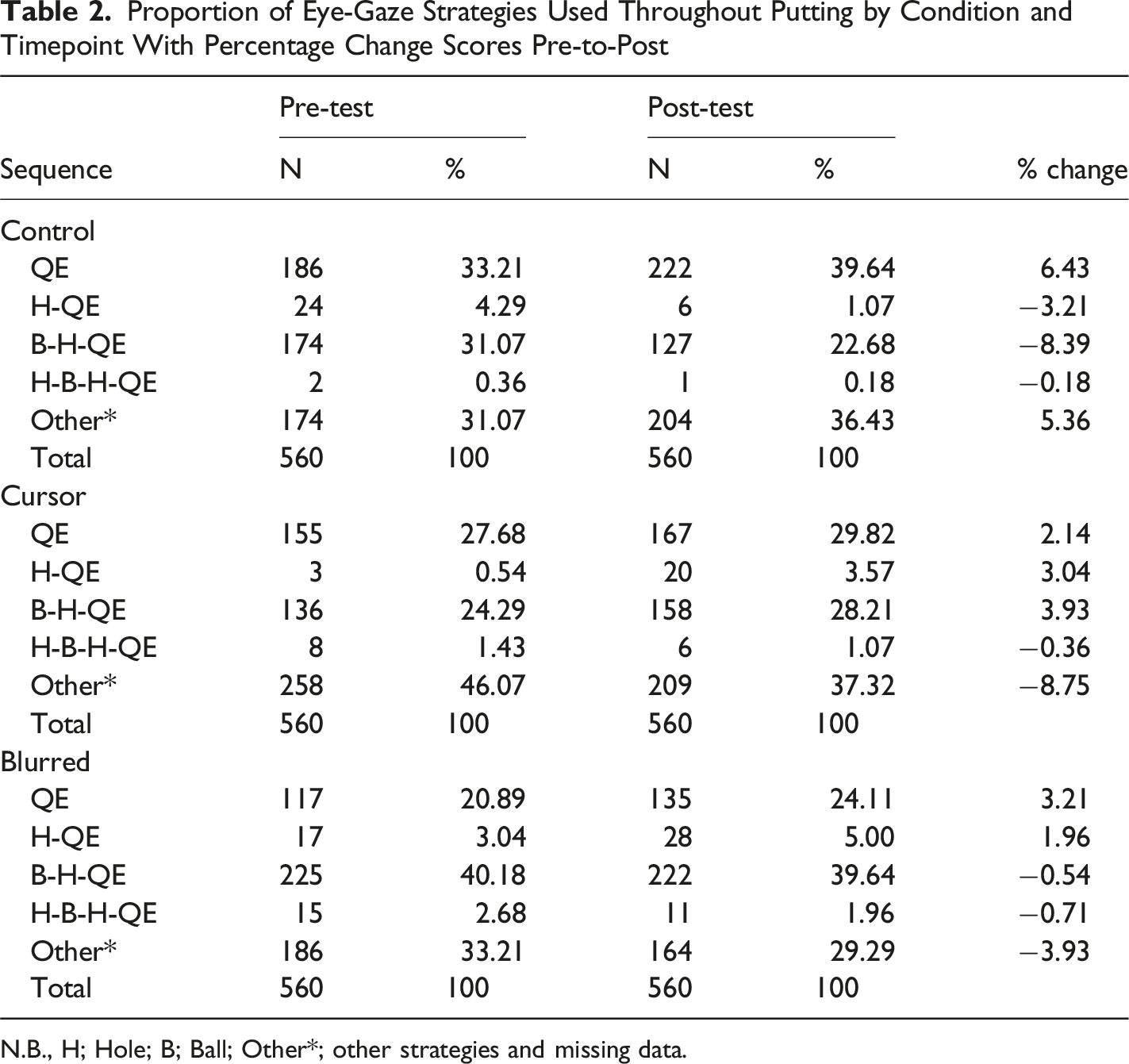
N.B., H; Hole; B; Ball; Other*; other strategies and missing data.
Self-Reported Experience of Training
Simulator Sickness Questionnaire (SSQ)
Total
Higher overall simulator sickness was reported at post-test compared to pre-test (F(1,76) = 4.48, p = .037, ηp2 = 0.06). There was no effect of condition (F(2,76) = 2.32, p = .105, ηp2 = 0.06), or condition × timepoint interaction (F(2,76) = 0.40, p = .680, ηp2 = 0.01).
Nausea
There was no effect of timepoint (F(1,76) = 3.17, p = .079, ηp2 = 0.04), condition (F(2,76) = 1.03, p = .363, ηp2 = 0.03) or condition × timepoint interaction (F(2,76) = 1.01, p = .367, ηp2 = 0.03).
Disorientation
There was no effect of timepoint (F(1,76) = 2.42, p = .124, ηp2 = 0.03), condition (F(2,76) = 1.32, p = .273, ηp2 = 0.03) or condition × timepoint interaction (F(2,76) = 0.36, p = .701, ηp2 = 0.00).
Oculomotor
Oculomotor symptoms were higher at post-test than pre-test (F(1,76) = 4.10, p = .046, ηp2 = 0.05). There was no effect of condition (F(2,76) = 2.91, p = .060, ηp2 = 0.07), or condition × timepoint interaction (F(2,76) = 0.14, p = .872, ηp2 = 0.00). See Supplemental Files for SSQ total and subscale scores by timepoint and condition.
Reality Judgement and Presence (RJPQ) and Technology Continuance
Technology Continuance and Reality Judgement and Presence Questionnaire Subscale Scores by Condition
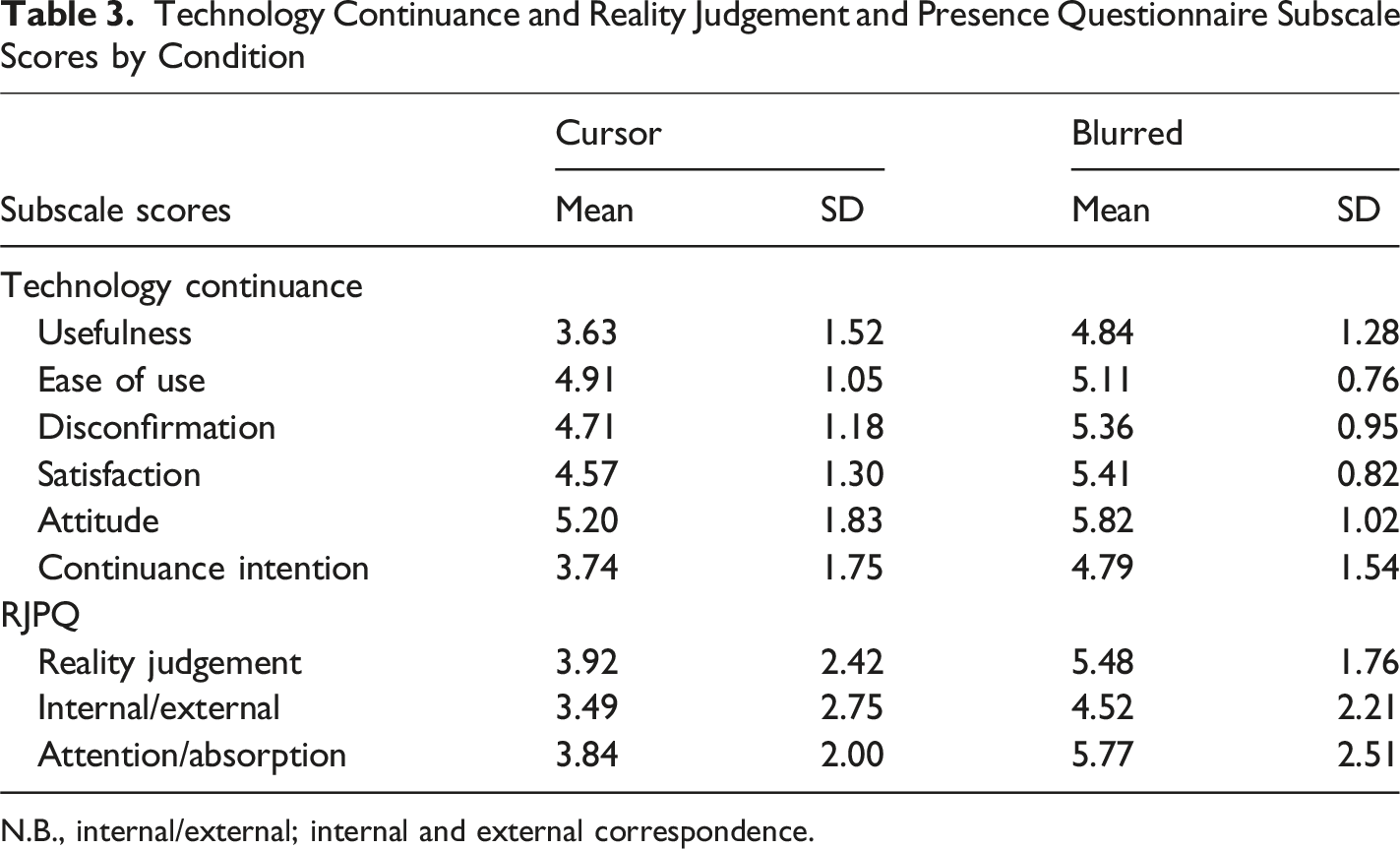
N.B., internal/external; internal and external correspondence.
Predicting Attitudes Toward Virtual-Reality Use
A multiple regression on the technology continuance attitude score, predicted by RJPQ subscale scores and training condition, was conducted to examine how VR experience may influence attitudes toward each EMME gaze training. The model was statistically significant (F(7,20) = 3.20, p = .019) and explained 36.30% of variance (R2 Adjusted). There was a significant condition × reality judgement interaction (F(1,20) = 8.38, p = .009). For Cursor, a 1-unit increase in reality judgement increased attitudes toward the VR (β = 0.64, p < .001), while there was a reduction for Blurred (β = - 0.19, p = .037). Please see Figure 5 for the effect of reality judgement on attitudes toward VR by condition. Moderated Regression on the Technology Continuance Attitudes Score Predicted by Reality Judgement for Cursor and Blurred Training Conditions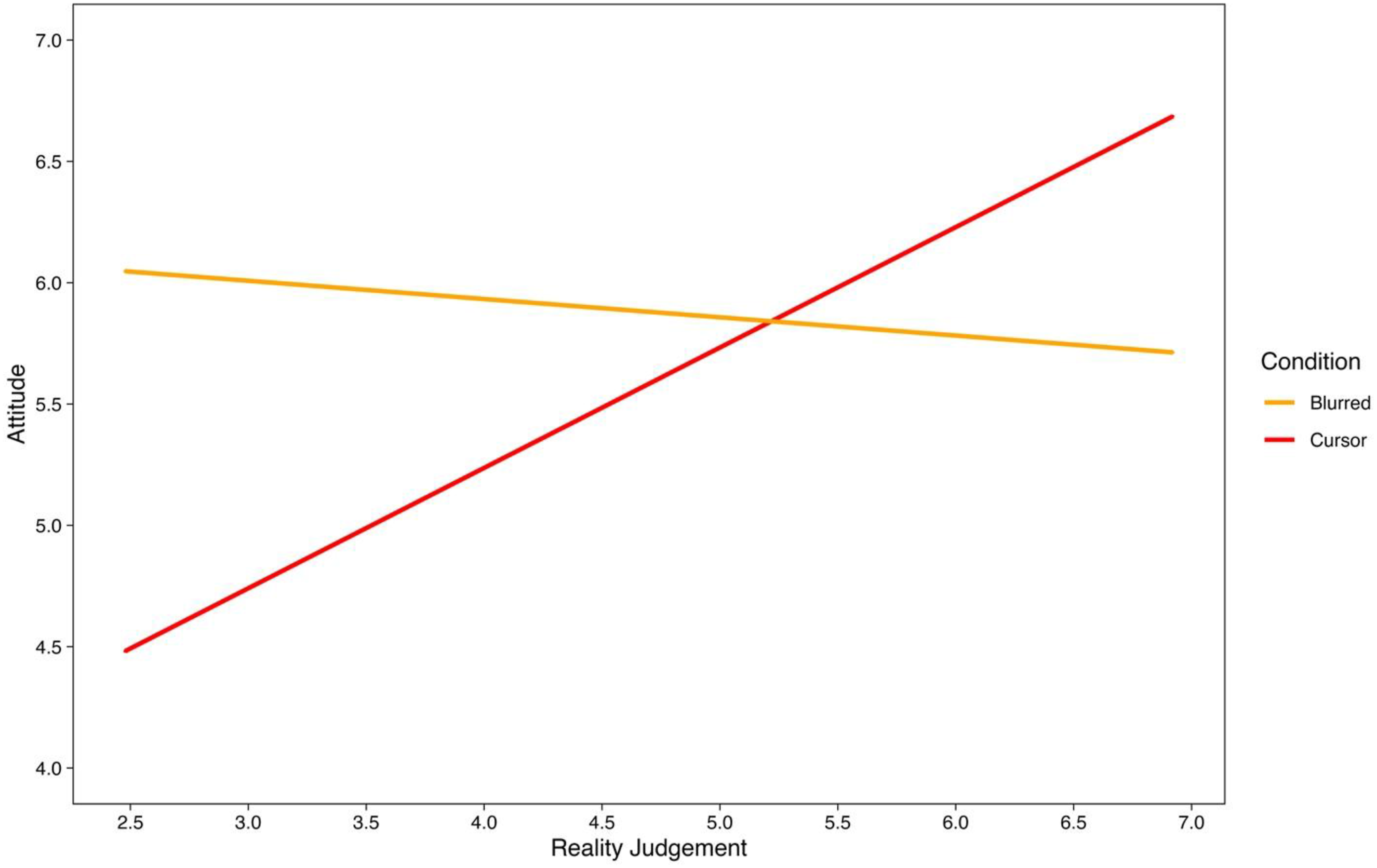
Discussion
The purpose of the present study was to examine whether using VR to show EMME based videos has benefits to real-world skill learning. Following Cursor and Blurred EMME training, participants had a lower RE, while Cursor participants also showed an increase in putting line (increased accuracy) and decrease in putt length (closer to 305 cm) which partially supports Hypothesis 1. These results suggest that Cursor and Blurred EMME visualisations, when presented via a VR HMD, may be an effective training strategy to assist real-world motor skill learning. There was a statistical improvement in the likelihood of holing a putt pre-to-post for Cursor participants, but not for Blurred or Control participants, where the change in proportional holed putts pre-to-post was similar for Cursor (8.2%) and Blurred (7.1%) participants but not for Control (0.5%) participants. There was also no difference in RE between conditions at pre-test, which indicates there was no floor effect in the Control condition. The results suggest that even when decoupled from physical practice, observation of skilled performance through VR may be useful to teach visuomotor skills such as the QE, which may facilitate real-world performance improvements (Lebeau et al., 2016).
Both Cursor and Blurred videos may have allowed the novices to infer the head and body position of the expert relative to the ball based upon the video contents, such as how the head of the expert is positioned looking over the ball, placement of the feet, and stance of the lower body, which are important mechanics to golf putting (Rienhoff et al., 2016). However, the blurring of peripheral information may have reduced the ability of participants to calculate the clubhead velocity or direction, as this information is visible for only a short window prior to ball contact for the Blurred condition. This line of reasoning is supported by occlusion studies, which indicates that limiting visual information throughout a golf putt is detrimental to performance and clubhead mechanics (Vine et al., 2017), which has also been observed in other sports such as basketball (Oudejans et al., 2002). One learning mechanism which may be affected are Sensory Prediction Errors, a type of visuomotor feedback learning which helps people to make an accurate prediction about the effect of movement on a task outcome (Kumar & Mutha, 2016). If environmental information is occluded (such as when viewing the blurred EMME videos), it may be more difficult to identify, learn, and automate a movement sequence (Izawa & Shadmehr, 2011). Further research is required to examine how posture and movement kinematics are affected by different types of EMME-based gaze training.
Although not explicitly taught in any condition, the largest increase in QE duration was found for the Cursor condition, followed by the Blurred condition, then the Control condition. The condition differences may indicate that the additional length of the QE induced by the Cursor visualisation approach may have been more related the functional benefits of the QE, which were reflected in improved line and length. It is well-established that the QE duration is sensitive to task demands (Klostermann et al., 2013), as it may reflect a period of movement selection and programming (Gonzalez et al., 2017). Our QE findings may suggest that the QE fixation of the Cursor condition, besides potential improvement to movement and kinematics (which may be evident through longer QE in Blurred and Control also), possibly also reflected perceptual skill learning. One such benefit of the Cursor visualisation is that it may have facilitated cognitive movement exploration (thinking about movement), as evidenced by an increase in QE deviation pre-to-post. This result implies that visuomotor modelling techniques may be efficacious in improving movement skill, with or without practice, even in a short-term context, potentially through improvements to task comprehension and organization (Gegenfurtner et al., 2017). However, consideration of how cognitive and physical movement exploration changes throughout and following gaze training, and whether there are differences within the short term and over time for EMME variations requires further evaluation. Future studies should also consider how cognitive changes may translate into into kinematic adjustments and how motor learning is affected.
The overall results of the study support the conclusion that training QE may help to assist motor skill learning (Lebeau et al., 2016; Moore et al., 2012). However, the methodology indicates that QE itself need not be explicitly trained, such as in QET, but may be identified by onlookers as a task-related behaviour important for task success. This is supported by an increase in QE duration pre-to-post for Cursor (d = 0.95) and Blurred conditions (d = 0.65), which is on the way to the observed intervention benefit of QET on QE (d = 1.53, Lebeau et al., 2016). It is important to acknowledge that Control participants also increased in their QE duration from pre-to-post (d = 0.27), although this difference was smaller than EMME conditions by comparison, with negligible change in holed putts or associated performance improvements. These findings may suggest that subtle differences in behaviour and performance pre-to-post could be attributable to practice effects for the Control condition, and by extension, the Cursor and Blurred conditions. However, the effect sizes reflecting the increase in pre-to-post QE duration for the Cursor and Blurred conditions was larger than that for the Control condition. The findings may thus indicate that observation of a task-expert may be instrumental in the QET effect on QE, and in potentially teaching the underlying functions of the QE.
Although these results may suggest that technical instructions could be more optional than initially thought in QET, it is important to recognize that there can be large variability in QE among novices (d = 0.58; Lebeau et al., 2016), and the application of QET without technical instructions requires further evaluation. Key aspects to assess generalizability include task expertise (e.g. novices and/or experts), which tasks may benefit, when this type of training may be effectively applied (e.g. initial learning or when refining QE timings), whether kinematic improvements are found, and if learning trajectories are similar to those observed in QET with technical instructions. However, the present results suggest that QE may be trained through providing task specific information and instruction (Gegenfurtner et al., 2017), without further technical direction, which may then facilitate procedural learning (Xie et al., 2021). Research with follow-up and retention intervals is required to examine whether the performance enhancing effects of EMME on skill learning are generalizable, such as in subsequent tasks or different performance contexts (Wulf et al., 2010). Based on the procedural differences of EMME to QET, it is plausible that each technique trains a slightly different set of visuomotor skills, and that there may be specific advantages to using one training approach over the other.
Hypothesis 2 was partially supported, in that there was no difference in the number of fixations for the Cursor or Blurred conditions pre-to-post, or a condition-specific effect on mean fixation duration (all conditions increased). There was an ordinal interaction on QE duration, as QE increased in all conditions but most for the Cursor condition, followed by the Blurred condition and then the Control condition. As fixation duration and cumulative dwell time are calculated using QE, the results suggest that QE itself may be particularly affected by both Cursor and Blurred visualisations. The combined QE and putting performance results may suggest that QE is important for line and length, which is consistent with the pre-programming hypothesis (Vickers & Kopp, 2016). However, the function of a QE may change over the course of a fixation, as early, middle, and late stages serve to pick-up different information upon movement planning, unfolding, and in gathering feedback (Oudejans et al., 2002; Vine et al., 2017). Using EMME for gaze training may help to expand on such findings, based on the ability to modify training videos. For example, using a gaze cursor with blurring throughout training, may help to examine whether there are specific benefits to training with blurring when needing to perform under novel task constraints, such as with an occluded view.
There were some differences between conditions related to eye-gaze behaviours when putting at post-test, in partial support of Hypothesis 3. At pre-test, a relatively low number of fixation strategies were used, including a high proportion of QE and Ball-Hole-QE sequences, while QE fixation durations were already quite long (around 2 seconds). Likewise, the fixation strategies at post-test were similar to those at pre-test and showed limited variation. Considering that gaze behaviour relating to sequences used and fixation timings were mostly similar between pre-and-post-test, these results may suggest that even with limited exposure to a golf putting task, there may be an implicit understanding of how gaze should be deployed throughout planning and movement execution when putting. For more complex visuomotor tasks, such as when needing to perform under pressure or in dynamic situations, there may be more variability in how the eyes are used to facilitate optimal task performance. Using three-point basketball shooting as an example, where the QE fixation during ball release is typically quite short due to defensive pressure (Vickers et al., 2019), teaching players to orient their gaze toward the hoop earlier within their visuomotor sequence may help to improve their movement planning and resultant performance.
A notable difference between conditions at post-test was the increased consistency in QE timings for the Blurred versus Cursor participants, which may again suggest that different EMME visualisations could be useful to teach specific skills, one of which could be consistency in earlier QE fixation timing (Vickers et al., 2019). It may be that different motor control feedforward and feedback mechanisms could be trained using different variations of EMME, based upon what visual information is available in the video (Krakauer et al., 2019; Therrien & Wong, 2022), and potentially in how that information is presented relative to the visuomotor task. Using the basketball three-point shooting example, EMME could be used to depict optimal QE fixation timing when shooting, or deployed to teach people where to look to assist decision making when under pressure within game scenarios.
Overall, the results show that EMME can be successfully implemented through HMD VR, that it can be effective for sport-specific procedural skill tasks, and that it may not require explicit instructions to be effective, even after a short-exposure. Although these implications are specific to EMME, they can also be applied to the design of other gaze modelling techniques such as QET (and the necessity of a verbal instruction, which could be removed for improved standardization), or in more general applications of visuomotor training design through video-based modelling. The findings show that visuomotor modelling can have benefits to motor skill performance, potentially by providing a semi-structured learning experience (guided learning by observation but not explicit instruction). Observational techniques more broadly may be a useful tool to be developed further, mindful that improving task comprehension and an improvement in procedural skill likely underlies a learning effect (Gegenfurtner et al., 2017; Xie et al., 2021). Prioritizing task comprehension and procedural skill learning should be prioritized when developing new observational approaches or optimizing existing protocols (e.g., EMME).
There was no difference between Cursor and Blurred conditions in SSQ scores post-test, but there was an increase pre-to-post for the overall scale and oculomotor subscale, which partially supports Hypothesis 4. Blurred participants demonstrated a higher perceived usefulness score than the Cursor condition. One explanation may be that the experimental manipulation was more conspicuous for Blurred participants based on the peripheral blurring, and that increased their expectations of a performance benefit. In contrast, Cursor participants watched the same video without the manipulation being as obvious (considering they had the gaze cursor explained). Reality judgement predicted more favorable attitudes toward VR for the Cursor condition, while there was a reduction for the Blurred condition. One possible explanation for the Blurred condition, is that the occlusion may have been perceived as unrealistic and had a negative impact on attitudes. On the other hand, an immersive first-person perspective of performing a skill which felt easy to understand may have aligned with the user-expectation and perceived realism of VR for the Cursor condition, which predicted more favorable attitudes (Balakrishnan & Dwivedi, 2021). Future research may be required to understand how VR augmentation approaches affect attitudes toward VR use for motor skill learning, and how attitudes are affected by individual factors (e.g., task expertise, prior VR use).
Limitations and Future Directions
Although the study indicates that QE may be lengthened by Cursor and Blurred EMME visualisations, the present study did not evaluate kinematic information. The addition of kinematic measures may provide context as to why changes to gaze could have occurred when putting following EMME. For instance, expert golfers putt with a lower club head velocity and different swing timings, despite no overall difference in movement duration (Sim & Kim, 2010). Specifically, Cursor participants may have held a longer QE pre-to-post for numerous reasons, including looking earlier within the fixation sequence (i.e., earlier since the start of the trial), moving the club slower and holding QE for longer due to online control, making one specific QE phase change in length which was then reflected in the overall QE, or other reasons. Integrating kinematic measures would also help assess whether any improvements are short-term or longer lasting which suggests improvements in skill (as in Moore et al., 2012). Research suggests that the effectiveness of EMME is moderated by task expertise (Xie et al., 2021). EMME may be more effective for teaching procedural skills when the learner already has pre-existing knowledge (Gegenfurtner et al., 2017). Future research should investigate when each EMME visualisation is most effectively applied throughout learning (i.e., stage of learning). Future research may also consider using an active control group, which could show the video from the perspective of the expert without a gaze cursor, to evaluate whether visuomotor behaviour or performance changes without cues directing attention or by general observation of another (such as watching an expert in general), and whether eye-gaze can be inferred. An extension should also consider whether there are different benefits based upon the perspective of which the observation is conducted, specifically from a first-person perspective which was used in the present study, as compared to third person.
Conclusion
The study examined the impact of EMME on motor skill acquisition under standard and peripheral blurring conditions when presented via HMD VR technology. The results suggest that EMME presented in this way improves performance, but that the performance gains are more extensive without peripheral blurring. When applied to novice populations, such as children or those who are new to a sport, it may be helpful to apply EMME to assist motor skill learning, even when decoupled from physical movement practice. Using and evaluating the scope of gaze modelling techniques, such as EMME, is an important step to improving visuomotor training quality, and in the application of VR-based motor skill learning technologies.
Supplemental Material
Supplemental Material - Showing Eye Movement Modelling Examples in Virtual Reality Increases Quiet Eye Duration and Improves Real World Motor Skill Performance
Supplemental Material for Showing Eye Movement Modelling Examples in Virtual Reality Increases Quiet Eye Duration and Improves Real World Motor Skill Performance by Jayke B. Bennett, David L. Neumann, Matthew J. Stainer in Perceptual and Motor Skills.
Footnotes
Acknowledgements
No others contributed to the article beyond those with authorship.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: the authors would like to acknowledge the financial support provided by the Australian Government Research Training Program stipend.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental Material
Supplemental material for this article is available online.
Author Biographies
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.