
Abstract
This article argues the need for education and training of researchers carrying out animal studies on the fundamentals of experimental design (ED), as a key means of improving the reliability and reproducibility of preclinical results. The current landscape in ED education in Europe is presented, and we make the case for dedicated tutor-guided teaching of ED. With less than a day dedicated to it in many courses effective techniques for communicating key issues are needed. We have developed two approaches that transfer to experimental design teaching the case-study, problem-solving techniques known to be effective in other fields. They use realistic research scenarios to provoke discussion and engage learning. In one the scenario is for group discussion or informal or formal assessment with subsequent tutor-led discussion of key points. For this each scenario needs a clear statement of the purpose of the research study, simplified text outlining the comparisons and procedures, and a statement of the outcome measure. In the other approach, the scenario is used with freely-available software with a good graphical output to explore the sizing of experiments and the use of both sexes. Trainee feedback and informal assessment show that these approaches can make for interesting and memorable sessions and offer a useful contribution to improvement in experimental design teaching so that it produces meaningful learning that can translate into better practice.
Why we need to improve experimental design teaching
Criticism of the quality of animal-based research has been voiced over several decades. An extensive 2009 survey 1 gave a depressing list of failures in reporting key elements in the conduct of animal studies, still seen in a more limited study a decade later. 2 Failure to report suggests failure to practise. The PREPARE 3 and ARRIVE 4 guidelines on how to, respectively, better plan and report animal studies have been slow to gain purchase. There is also widespread concern about the reproducibility of animal studies 5 and the translatability of preclinical results into clinical applications, with poor study quality cited as a significant cause. Even within research communities that have realised this problem and taken measures to address it 6 there seems little improvement in practice in preclinical trials. 7
With poor practice so widespread, 5 the apprenticeship model for training new researchers can perpetuate the flawed principles and practices of the mentors. The Experimental Design Assistant 8 can help novice researchers by providing useful feedback and clearly illustrating different designs to inform discussion of their advantages and disadvantages, 9 but is not designed as a teaching tool. Readily understood textbooks (e.g. Ruxton and Colegrave, 10 Festing et al. 11 ), and online resources (e.g. ETPLAS EU modules 10 and 11 12 ) are available, as are simple texts on statistical analysis of biological experiments (e.g. McKillup 13 ) and ones which combine examples of many types of laboratory animal experiments with appropriate analysis (e.g. Bate and Clark 14 – which also introduces readers to the useful free analysis software InVivoStat). Yet these appear to be either insufficiently explored or unable to convey effectively experimental design (ED) on key issues, in particular of avoiding biases (e.g. through appropriate blinding and randomisation), correctly identifying the experimental unit (biological replicate), employing adequate group sizes, and confidently using designs more complex than simple group comparisons. It seems these resources must be supplemented in some way.
Recognising this, courses specific for the design of animal studies have been developed, notably by FRAME (Fund for the Replacement of Animals in Medical Experiments), which has run a ‘Training School’ almost annually since 2008. Feedback on the 2019 FRAME/Vetbionet course 15 is typical and includes ‘the first time I understood this’ from a senior researcher and ‘an eye-opening experience’ from another, raising questions on the quality of the researchers’ previous tuition and further stressing the need for delivering dedicated, well-tutored courses on this subject. And while ED courses should ideally be attended by young researchers before starting doing animal experiments, such testimonies from senior researchers attending them, and the fact that they can influence generations of trainees, highlight that their training should not be neglected, for example, by delivering it as continuing professional development courses.
In the USA, the National Institutes of Health has recognised that more training in experimental design should be provided. 16 EU Member States are required under Directive 2010/63/EU to ensure researchers are ‘adequately educated and trained’ before ‘designing procedures and projects’, and the European Commission’s Education and Training Framework guidance document 17 has learning outcomes for the relevant modules (EU-10 and EU-11), but training methods or processes are not specified and there is much scope for variation in content and level of competence expected. In December 2018, FELASA carried out an informal survey 18 of organisers and tutors delivering laboratory animal science courses (N = 78; 17 countries) on what ED content was taught and for how long. The time allocated for design of animal studies varied between zero and 80 h and, on average, courses dedicated only 6.6 h to ED. Furthermore, most respondents considered that some (29%) or significant (56%) improvements on ED teaching were necessary. With many courses involving less than a day of tuition for ED, there is a clear need for effective techniques for communicating key issues.
Two effective interactive educational approaches
ED teaching should be both effective in increasing knowledge and well-understood so that what is learnt can be confidently put into practice. This calls for teaching approaches that engage students and make them active and reflective participants in the teaching–learning process. Teaching using case-studies and problem-solving has long been part of health-care training 19 and found to be particularly effective in that regard, as it presents realistic scenarios with which trainees find parallels with their own experience and apply critical thinking skills. The approach allows for deeper and higher-level understanding of the taught contents.20,21
On the basis of feedback from participants and improvements in informal and formal assessment, we have found two case-study-like approaches to be effective.
1. Animal research scenarios for group discussion or quizzes
Guide timings – for use in group discussion 10–15 min per scenario; for each quiz question 1–3 min.
Experience from running the FRAME courses and similar experimental design workshops has shown the importance of supplementing lecturing with interactive teaching techniques that actively involve those taught. 22 As a recent example of this, in a July 2022 two-day workshop in Bologna for young researchers from several EU countries, all 19 participants gave feedback that group discussions helped them understand the content of earlier talks. They all also considered the pre- and post-quizzes used worthwhile. Both of these teaching elements use hypothetical (yet realistic) research study scenarios, equivalent to problem-solving case studies in health care training.
An example that could be used for both group discussion and a quiz question is: An ophthalmic surgeon wants to compare three agents against vehicle control for effectiveness in reducing retinal damage in a standardised rat model, using males. The agents will be injected directly onto the affected area under microscopic control and the surgeon can only deal with four rats for each one-week research period. She needs four rats for each treatment group, so proposes an experiment spread over four weeks.
Following a talk on standard designs, groups could be given this scenario and asked to discuss how to plan the experiment. It also usefully leads to discussion on ‘why only males?’ (the study was modelling a condition seen only in males) and ‘why only four per group?’ (the surgeon was looking for a large effect with little variation). If this scenario were given as a quiz question it would be followed by a choice between different designs, and the single sex and group size issues would be part of the subsequent discussion of the responses.
For a group discussion there is a set of such scenarios with key questions related to the preceding presentations to discuss, putting participants into puzzle- or problem-solving mode. The plenary brings out concise contributions from each group with non-judgemental comment by the tutor. The sequence of talk, group discussion and plenary discussion with debriefing provides an engaging learning experience, as judged by participant feedback. The pre- and post-quiz scores show it is also effective. For example, the 19 participants in the July 2022 workshop produced a great improvement between the pre- and post-quiz scores for some key topics covered in the group discussions (see Figure 1). This is seen in all the courses using this scenario approach.15,23
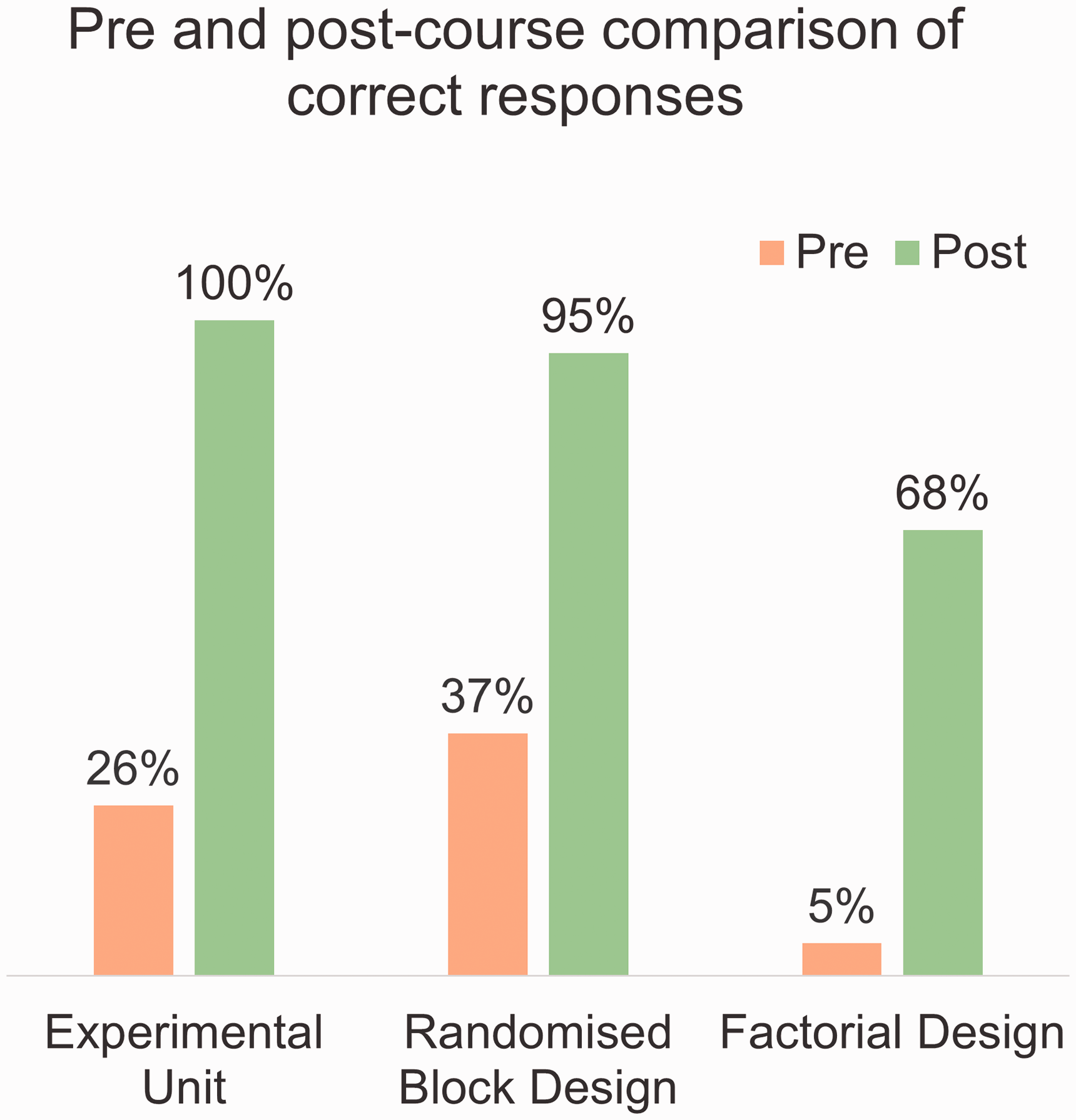
Percentage of correct responses to pre- and post-quiz questions on some key topics, from the students at the 2022 experimental design workshop in Bologna.
Participants in a train-the-trainers workshop in Porto (September 2022), mostly tutors teaching ED in various European countries, were asked to devise similar scenarios for their own teaching. They recognised the value of these but had difficulty in producing ones that would lead to focused discussion or clear quiz questions. There was a tendency to give almost a detailed protocol and ask for a critique of it, rather than concentrating on key points to consider in the planning or conduct of the experiment. So some guidance on setting scenarios may be helpful.
In a scenario you need, at least:
a clear statement of the purpose of the experiment; text giving the proposed comparisons and a general description of the procedure; a statement of the outcome measure(s).
The scenario should be phrased as though it were being planned rather than being described as an experiment that has happened, to encourage the thought pattern of considering key matters before a study is undertaken.
For a quiz this should be followed by an unambiguous question to respond to. For group discussion there should be one or two questions for the group to focus upon. The text is simplified from an actual procedure or protocol to bring out clearly the decision(s) sought in the quiz question or the discussion focus in the group discussion. The approach can be used to bring out the need for good practices like randomisation, blinding and suitable controls (see scenario B in Table 1) as well as for exploration of the design of an experiment (as in scenario A in Table 1).
Example scenarios.

Usually the problem has to be simplified so that the key points can be picked up within around a minute’s reading, particularly for a quiz question. For group discussion, longer text may be appropriate but unless the session is open-ended, reading time cuts down discussion time. More complex scenarios may need extended discussion times. Also, more time is likely to be needed for discussion of questions such as ‘What do you consider are the flaws in this design?’ when a detailed design has been given. Even with simplified text, readers may take unexpected interpretations, and participants may well seek more detail irrelevant to the problem focus. Scenarios may need refinement to minimise these difficulties for particular audiences.
The group discussion arrangement also has other advantages. It allows those who have a better understanding of the focus of the problem to enlighten others in the group, helps misunderstandings to be aired and (provided any over-dominant individual can be controlled) gives opportunity for everyone to contribute. Allocation of trainees into groups can be used to demonstrate how to do so randomly, for example, by using the RAND() function in Microsoft Excel, with indication that the same approach can be used to assign experimental replicates to treatment groups.
The plenary when the groups come together after their separate discussions is a crucial part of the approach. Different people in the group can be asked to contribute what the group consensus (or continuing disagreement) was on each of the scenarios, and correct responses to the questions can be endorsed, misunderstandings gently corrected and novel interpretations discussed.
Similarly, informal quizzes should be followed by discussion of what the tutor considers the right and wrong answers to each question. The value of the scenarios in the quiz questions is in giving trainees confidence that they have advanced in understanding and providing opportunity for learning from the discussion of the answers that follows the end of the post-quiz.
2. Software-assisted exploring of design scenarios using G*power
Time required: 30–45 min overall (three ED scenarios, including discussion).
A key motivator (and for many, the main reason) for researchers attending courses on experimental design and statistics is to learn how to justify the number of experimental units (and therefore animals) in an experiment, a requirement for project licence applications. Often these researchers start out wanting either to be reassured that whatever ‘standard group size’ they are using is sufficient to find ‘statistically significant results’ or to know what ‘magic number’ to use. Such misconceptions can be countered by showing how the size of an experiment determines what minimum effect size is detectable for a given and predefined statistical power and significance level, and the consequences of underpowered studies. Following this, a discussion of what p-values can inform us about and, also importantly, what they cannot 24 then deals with the issue of doing experiments just to find ‘statistically significant results’ (i.e. a small, publishable, p-value) rather than biologically or clinically meaningful effect sizes. 25
Once trainees question previous misconceptions they are ready to learn how to perform power calculations for different experimental design scenarios, using freely-available software. This has been found an effective approach with both large and (preferably) small groups. Tuition starts with exploring the nature of hypothesis testing and the need to decide on acceptable levels for false positives (significance level, α, conventionally set between 0.01 and 0.05, or 1–5%) and for false negatives (β). Power is given as the likelihood of detecting a genuine effect of biological or medical relevance (which means it is 1–β). Power is usually set between 0.8 and 0.9 (or 80–90%). The treatment effect is presented, in its simplest form (i.e. a comparison between two groups) as the ratio between the difference between group means and the expected variability, that is, ‘standardised effect size’. An adequately powered experiment is explained as having a sufficient sample size to detect (e.g. with 80% likelihood) the minimum effect size deemed of scientific interest, or a larger one. These concepts are reinforced with the scenario exercises, and it is stressed that most parameters are defined by experimenters’ choices. G*Power 26 has been the chosen software as it not only covers the most commonly used statistical tests, but also has a graphical plotting option good for illustrating a number of scenarios.
The approach is used to:
demonstrate performing power calculation for most common experimental designs; allow students to apply acquired knowledge; show how different factors interact and affect the appropriate size of an experiment; discuss scientific and 3Rs implications of the experimental design chosen; connect each design with the appropriate statistical test.
For each exercise both trainer and trainees have G*Power running on their computers. Students are presented sequentially with three hypothetical experimental design scenarios, of increasing complexity, and are guided in how to fill in each of the required fields in G*Power’s graphical user interface. The statistical concepts pertaining are explained, with, if necessary, recap of previous material. For each exercise, the software output prompts a discussion, which the tutor guides, aided by the x–y graph plotting functionality, to illustrate the relationship between effect size and the corresponding required sample size, under the assumptions for each scenario. Afterwards, students are asked to tweak the parameters to test what would be the required sample size under different conditions.
There are three main exercises, as follows.
Exercise 1. Two-group comparison
Scenario
Researchers wish to test whether a new drug can reduce blood pressure in mice by comparing treated and untreated animals. A blood pressure drop of at least half the value of the standard deviation is considered clinically meaningful. What would be the minimum effect size required to detect such an effect with 80% power, and α = 0.05?
The G*Power inputs for this are shown at the top and mid-left in Figure 2 and the software gives the output for a one-tailed t-test (mid-right in Figure 2) and can show graphically how the number needed changes with the size of effect (Figure 3).
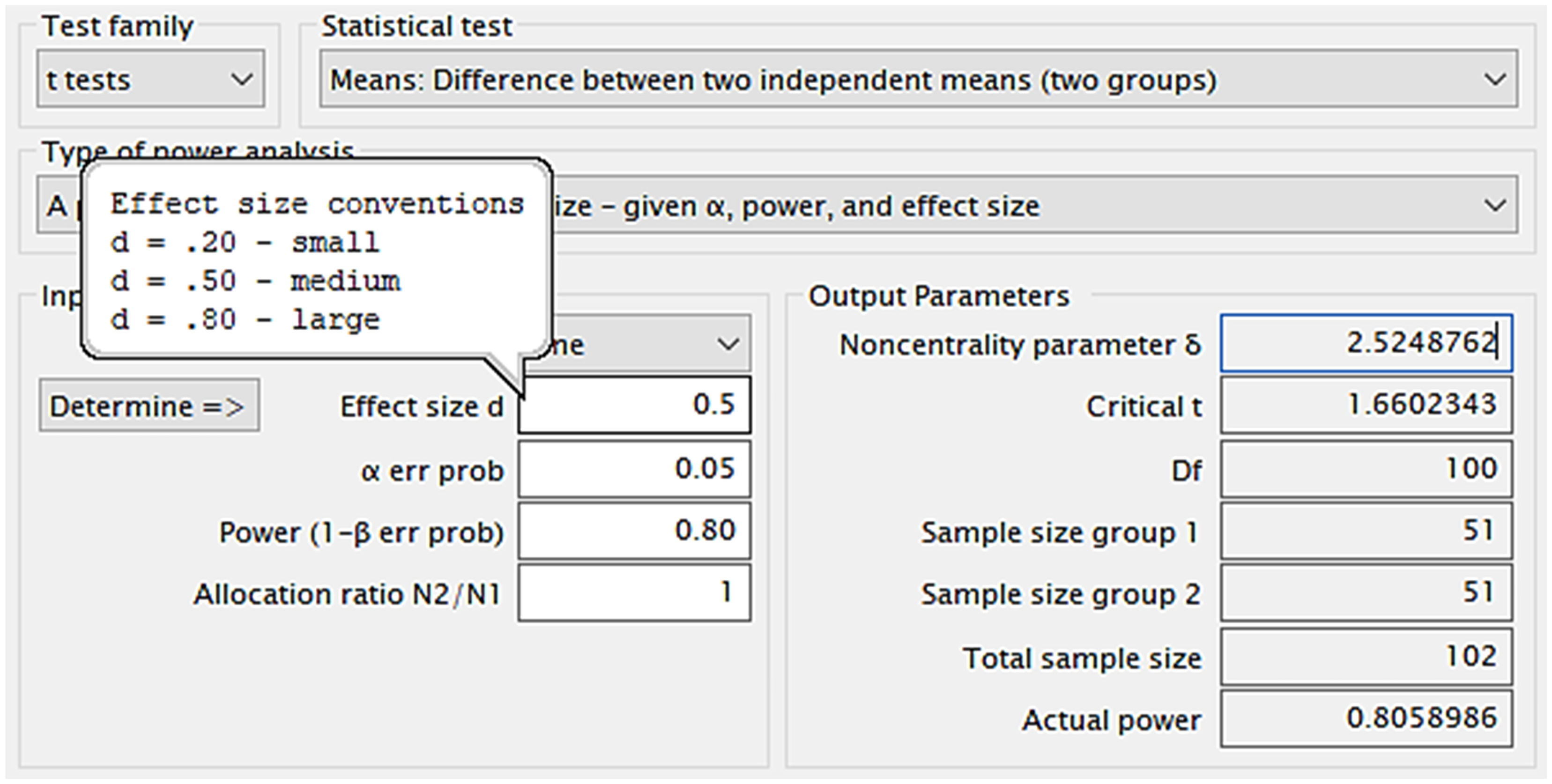
G*Power output for a two-group comparison to detect an effect size of at least d = 0.5 by a one-tailed t-test. The hovering balloon has Cohen’s d (a measure of effect size for an independent samples comparison), for small, medium and large effect sizes (respectively 0.2, 0.5 and 0.8) proposed for psychology research. 27
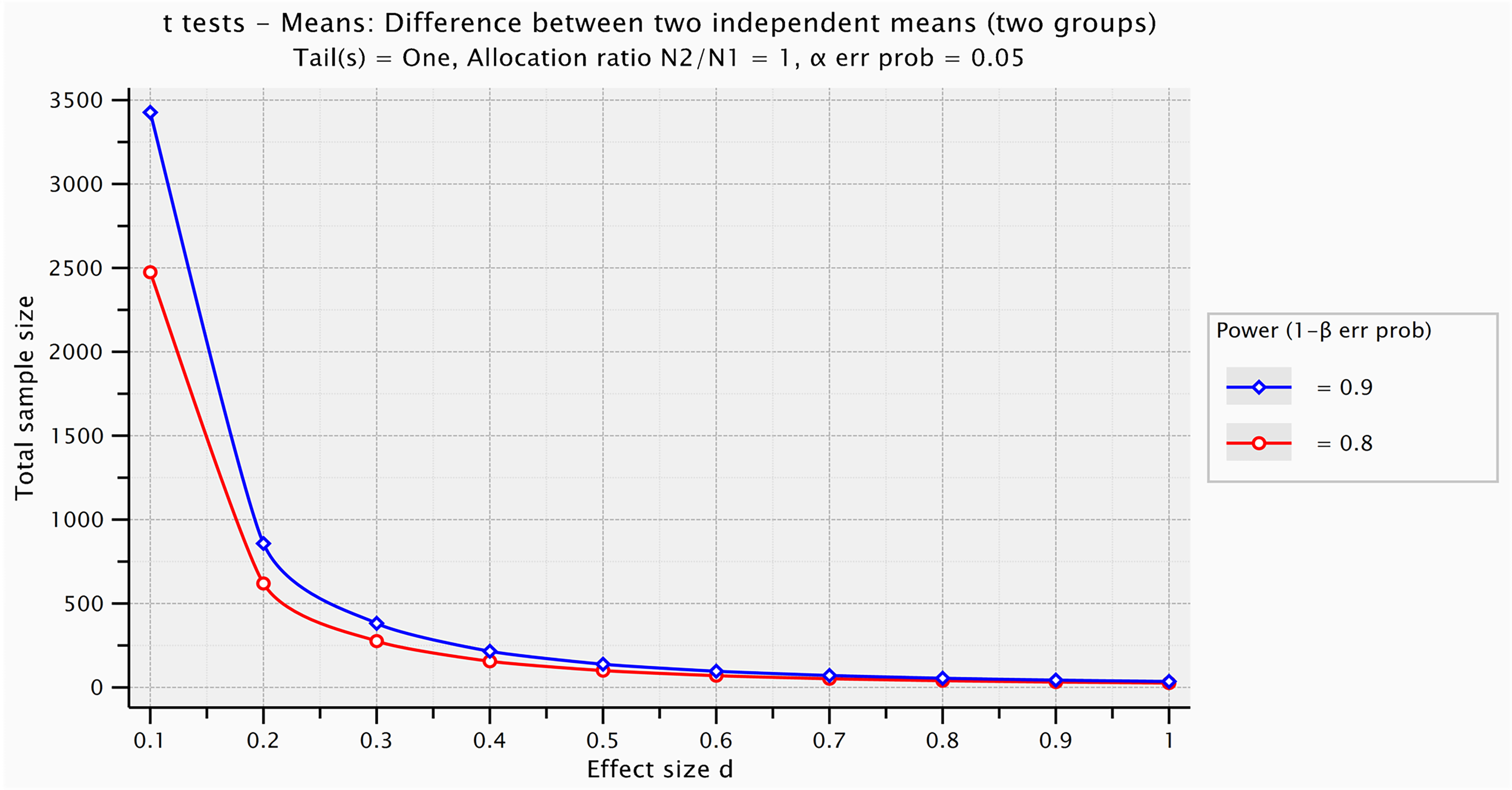
Graph illustrating the relationship between effect size (Cohen’s d) and the sample size required to detect it, for a two-independent-group comparison, for 80% and 90% power. For 80% power, required sample sizes range from N = 2474 (for d = 0.1) to N = 26 (for d = 1.0). G*Power graphical user interface edited for illustrative purposes.
This exercise provokes discussion on topics such as:
feasibility of carrying out the study with the proposed sample; ethical acceptability of animal studies for detecting small effect sizes; adequateness of Cohen’s proposed standard effect sizes for psychology research in laboratory animal research; how standardised effect size is affected by the variability and sensitivity of a test.
Useful follow-up questions include:
What is the effect size detectable with a treatment group size of n = 6 experimental units? How many more experimental units are necessary for 90% power? How does the required effect size change for a two-tailed test? What total sample size is necessary to detect an effect size of d = 1.0 or larger? How does the required total sample size change for smaller α and β? What would be the required total sample size for a paired-sample t-test?
Exercise 2. Comparison between more than two groups (one single fixed factor)
Scenario
To test a glucose lowering-drug on rat models of type-2 diabetes, researchers compared untreated controls with low- and high-dose treated mice (i.e. drug as a fixed factor, with three levels). To calculate sample size, they had used Mead’s resource equation for an unblocked design, 28 according to which using 8 mice/group would be excessive (3 × 8 – 3 = 21, E >20) and 7 mice/group more adequate (7 × 3 – 3 = 18, 10 < E < 20). Animals are considered diabetic if non-fasting glycaemia >200 mg/dl. After one week of treatment, rats present the following non-fasting glycaemia concentrations: control: 400 mg/dl, low-dose: 300 mg/dl, high-dose: 150 mg/dl (pooled SD = 80 mg/dl). What was the statistical power achieved, for α = 0.05?
The G*Power inputs for this are shown in Figure 4 (top and mid-left) and the software gives the output for this post-hoc power calculation for a single factor design (one-way analysis of variance (ANOVA)) with three levels, based on the obtained results and sample size (mid-right in Figure 4. It can also show graphically how statistical power varies with sample size and effect size, as shown in Figure 5, for this design.
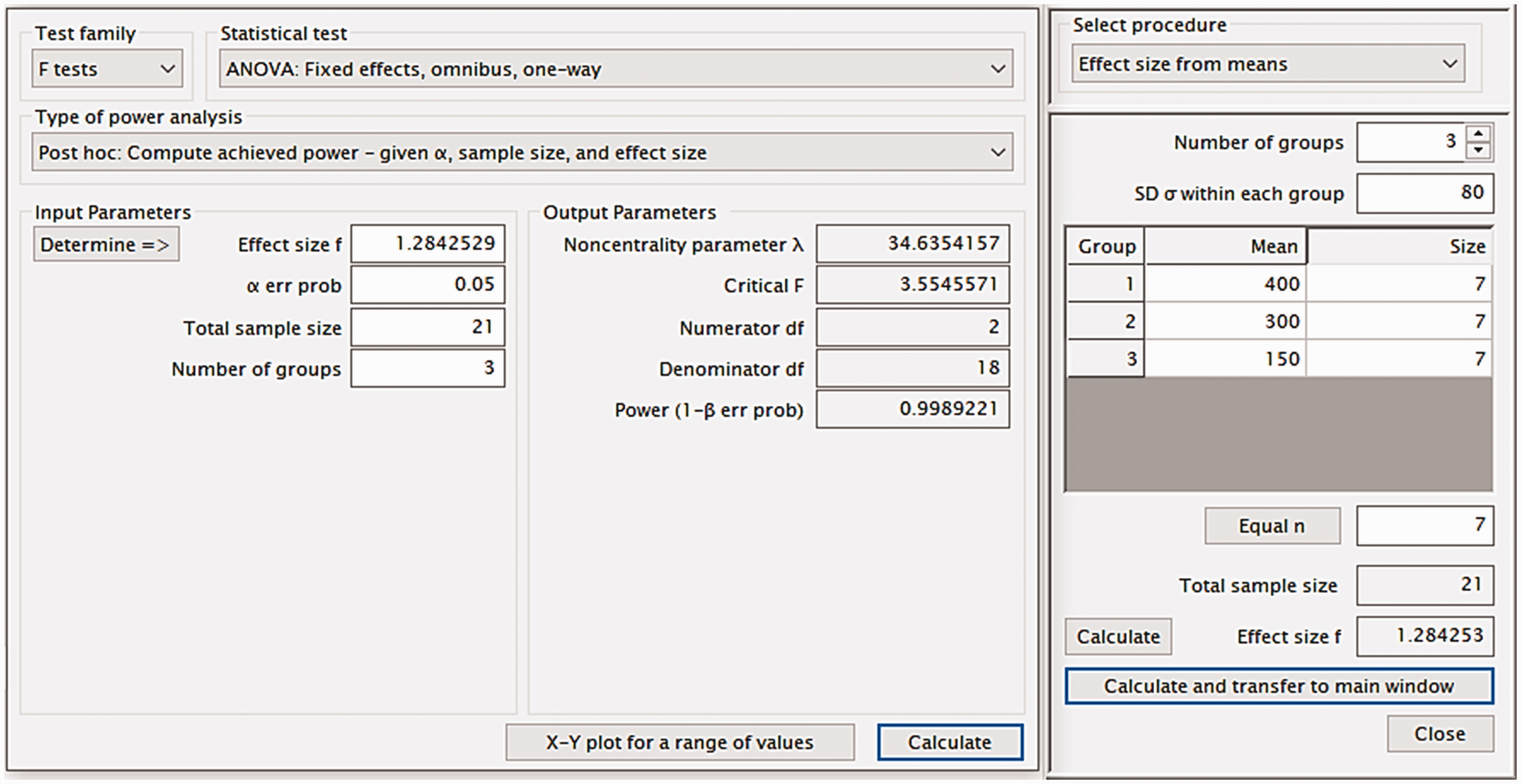
Post hoc power calculation for single factor design (with three levels) given α, sample size and effect size (left). The achieved effect size (Cohen’s f) is calculated from the data given for this scenario (right). G*Power Graphical user interface edited for illustrative purposes.
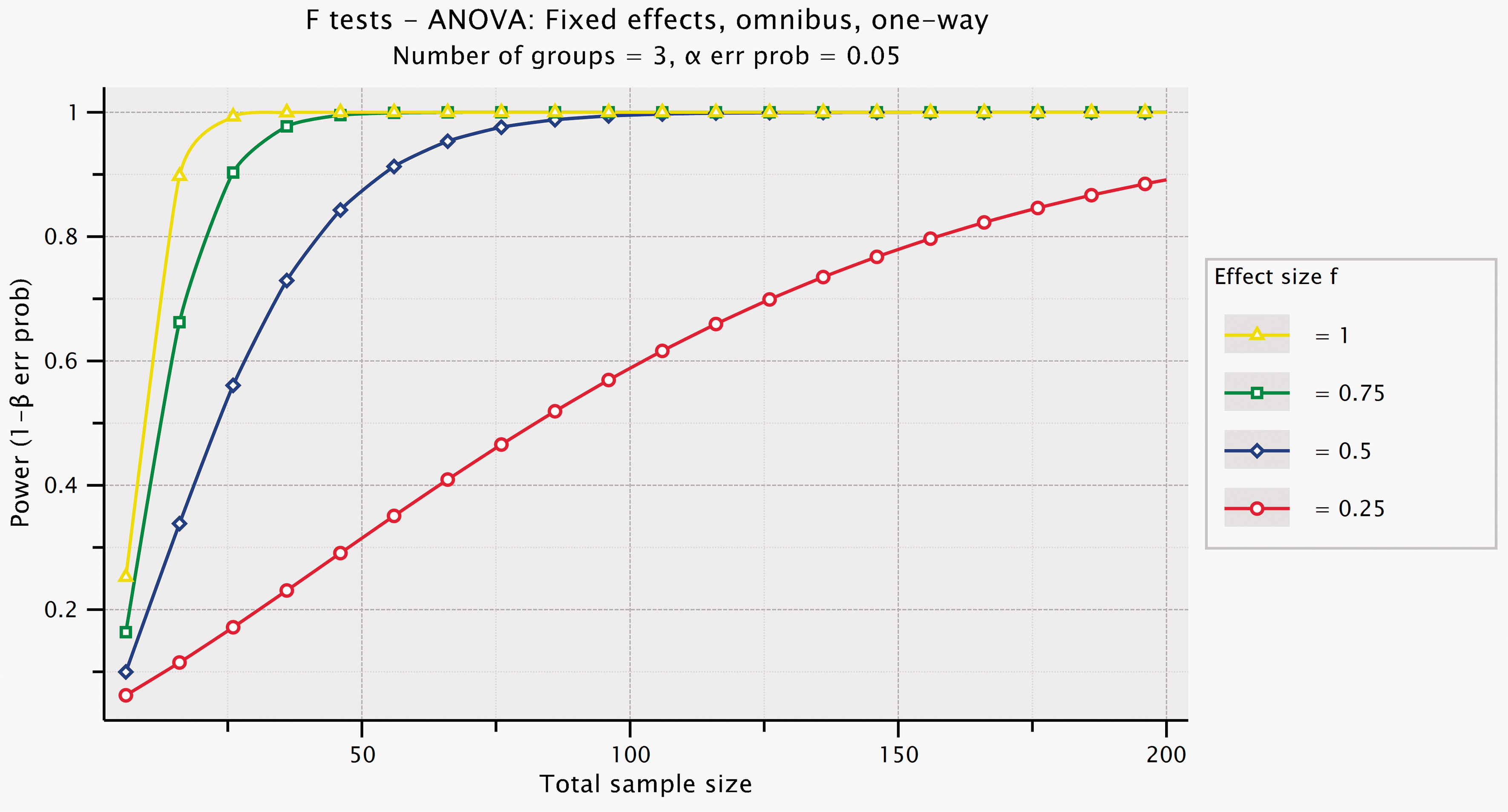
G*Power plot of the achieved power for a one-way analysis of variance (ANOVA) with three levels for the fixed factor, as a function of the total sample size, for a range of effect sizes (f = 1, f = 0.75, f = 0.5 and f = 0.25). Graphical user interface edited for illustrative purposes.
For this exercise the discussion could be on:
the very high statistical power achieved and likelihood of bias; the usefulness of post-hoc power analysis (or lack thereof); different measures of effect size (e.g. Cohen’s f and partial η
2
); the relationship between Cohen’s d and Cohen’s f; power as a function of effect size.
Useful follow-up questions include:
For this sample size, what would be the achieved power for more modest effects (400, 350, and 300 md/dl for, respectively, controls, low-dose, and high-dose)? What would be the necessary sample size to detect these smaller effects with 80% power, for α = 0.05? What would be the necessary sample size to detect these smaller effects with 80% power, for α = 0.01?
Exercise 3. Use of both sexes
Scenario
Following demands by funders, researchers decide they must include both female and male animals in their experiments, but fear this will lead to using twice as many animals. For a mouse test of a drug with three levels (vehicle, low-dose, high-dose), determine the recommended sample to detect a medium f effect size using a) one sex and b) both sexes (80% power, α = 0.05).
The G*Power inputs for this are shown in Figure 6 (top and left, with (a) single sex and (b) both sexes) and the software gives the output for an F test using one-way (a) and two-way (b) ANOVA (right in Figure 6) and can show graphically how the power changes with numbers used (Figure 7).
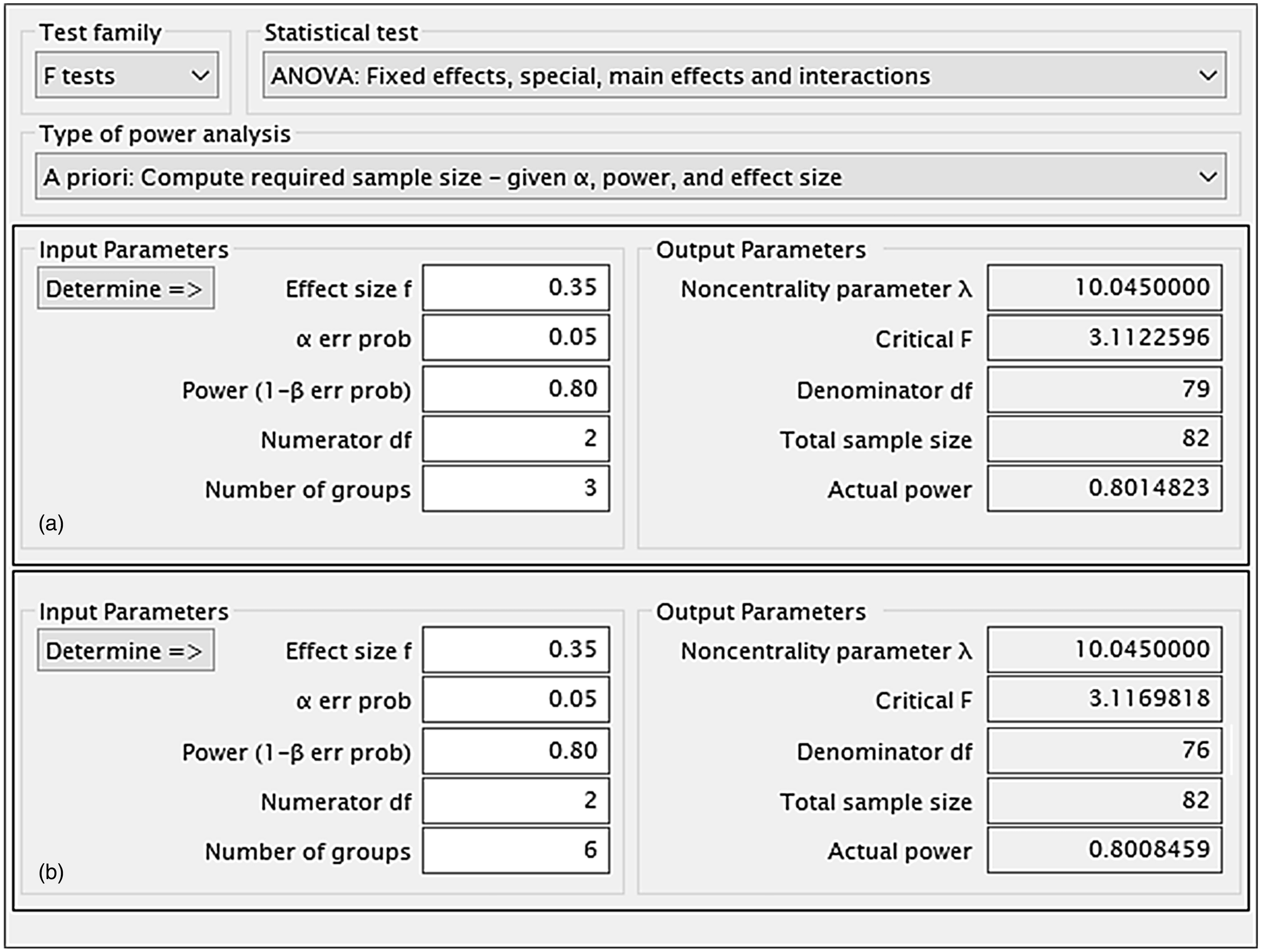
Power calculations for a study with ((a) top) one fixed factor (drug, three levels) and ((b) bottom) two fixed effects (drug and sex, three and two levels, respectively). Note that total sample size is the same for both cases. G*Power graphical user interface edited for illustrative purposes (80% power, α = 0.05).
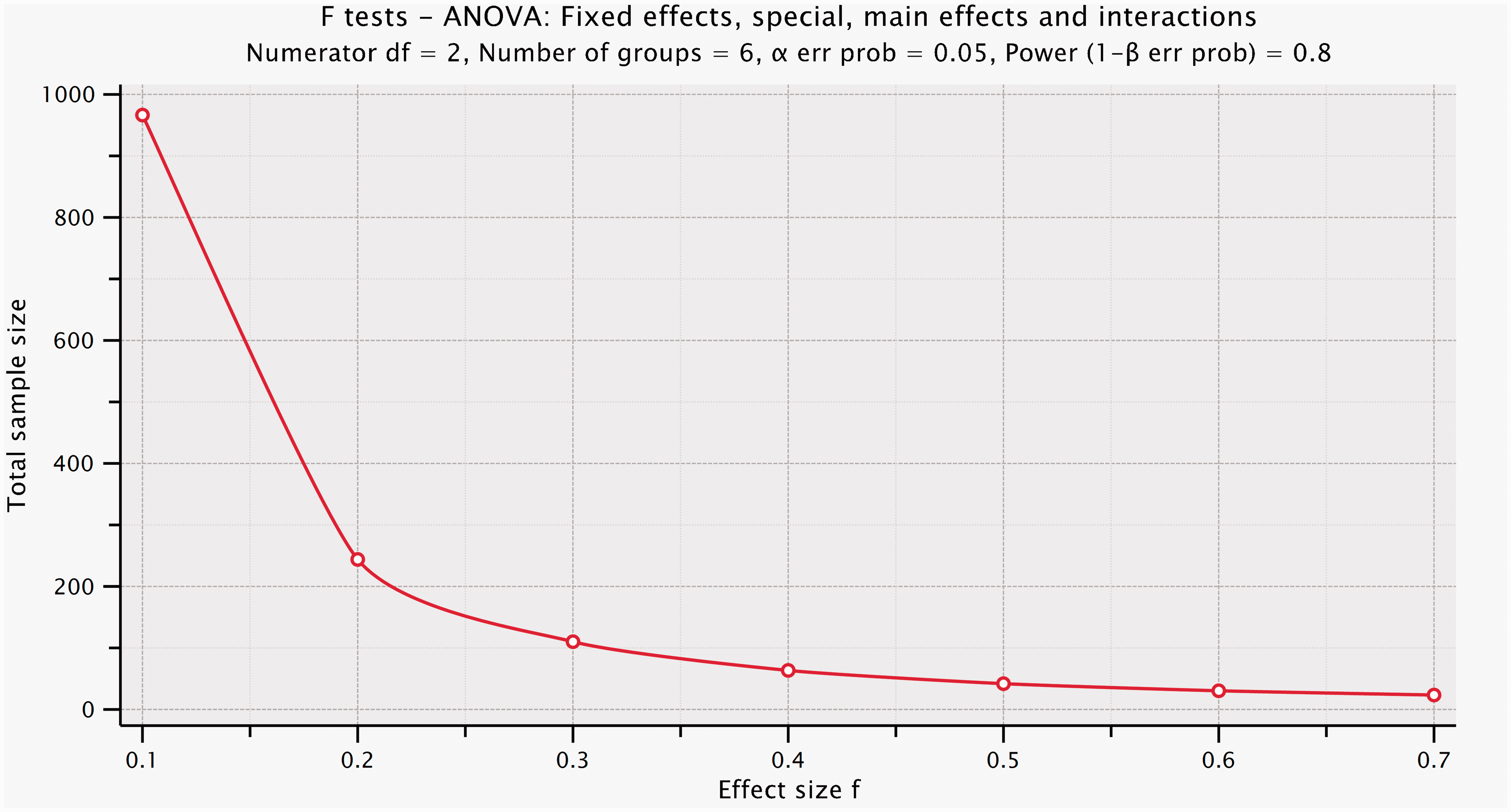
G*Power plot of required total sample size for the exercise 3 scenario of drug*sex factorial design (six groups) to detect a range of effect sizes with 80% power and α = 0.05, from f = 0.1 (N = 966 experimental units) to f = 0.7 (N = 24 experimental units).
This has been found effective in convincing students that there is no difference in total sample size when using both sexes in a factorial design.
It also leads on to discussion of:
different standard effect sizes (small, medium and large) proposed for psychology research and animal research; denominator and numerator degrees of freedom; possibility to detect both main effects and interactions in factorial designs; rounding up required group size (from ‘n = 13.8’ to n = 14).
There are several useful follow-up questions:
What would be the required sample size, under the same assumptions, for a factorial design with the same drug, two sexes and two mouse strains? What would be the minimum sample size, for the previous scenario (three factors, drug, sex, strain), to detect an effect size of f = 0.7? What would be the statistical power, for this factorial design, for detecting an effect size of f = 0.5 with a group size of n = 10 (total sample N = 60)?
The effectiveness of this approach of exploring different scenarios using G*Power has been judged by the very positive feedback from those who have undertaken the exercises, and from the improvement in understanding evident in the contributions to the discussions that follow each exercise.
Summary and discussion
Awareness of the current ‘reproducibility crisis’ of published research has led to calls for improving the teaching of ED.16,23 An approach likely to be effective within the 6.6 h average of ED teaching allocation 18 is to use problem-solving based on case studies, well tried in other fields and shown to lead to meaningful learning.29,30 The equivalent for ED is to use realistic research scenarios as a basis for problem-solving and the examples given show two different uses which are effective in our experience. In both, the discussion element, with input from an expert tutor providing explanation and any correction needed, is critical and distinguishes these approaches from use of scenarios for illustration in lectures or as self-testing in e-learning. For experimental design teaching (which should emphasise the need to minimise subjectivity), there is some irony in claiming effectiveness with limited hard data, but the purpose here is to call attention to the use in ED of teaching techniques of proven effectiveness in other areas. 21
The approaches use realistic scenarios to provoke discussion and engage learning, but in different ways. In one the scenario is for group discussion or informal or formal assessment with subsequent tutor discussion of key points. Each such scenario must have a well-defined educational objective. The example scenario of a study requiring ophthalmic injection was designed for identification of a randomised block design with the week as a block and each of the different treatments done in random sequence each week, while the scenario where drug treatment is added to the drinking water highlights the correct identification of the experimental unit (as well as possible problems with dosage via the drinking water). With both, an important element is the tutor’s comments on points made in the group discussion and on the options presented in an assessment question.
In the other approach, the scenario is used with freely-available software with a good graphical output to explore the sizing of experiments and the use of both sexes. The scenario of the first exercise, with what might be thought an unnecessarily large sample, brings out the relationship between effect size, variability and numbers needed. It can also lead to discussion on the ethical acceptability of using animals to detect small effect sizes of uncertain clinical or biological relevance,25,31 or how proposed standard effect sizes for psychology research are not applicable to laboratory animal research. (This is because larger effects should be expected for isogenic animals in a controlled environment, as proposed by Michael Festing 32 and Douglas Wahlsten 33 ). Discussion can also cover how small yet relevant treatment effects can be detected with smaller samples by minimising variability and increasing sensitivity, 32 or through different design choices (e.g. block designs9,25). The second scenario describes a finished experiment where low variability allowed detection of drug effects despite the relatively small sample size, providing for reiteration of the first exercise’s discussion points and also leading to discussing caveats for post-hoc power analyses, 25 as well as stressing that ED determines the statistical test used, and that other measures of effect size are necessary. The third exercise specifically addresses the common misconception that using two sexes requires using more animals 9 and illustrates the advantages of factorial designs, which allow studying more than one factor at a time and show any interactions, which is impossible when studying one factor at a time.
Interactive tuition based around scenarios constructed on the principles outlined, and refined as these have been through discussion and feedback, can make for interesting and memorable sessions and be a useful contribution to improvement in ED teaching.
Footnotes
Acknowledgement
Some results reported are from workshops for which FELASA paid the authors’ expenses.
Data availability statement
The only data presented is on students’ overall results in pre- and post-course quizzes. Sharing more than overall scores would violate personal information. Any enquiries in this regard should be sent to the corresponding author.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest withrespect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.