
Abstract
Extant scholarship has until now relied on informal-theoretic, case study, and interpretative methods to assess patterns of norm development in cyberspace. Ideally, these accounts would be complemented with more systematic cross-national and longitudinal empirical evidence. To address this gap, this article introduces the International Cyber Expression Dataset. The dataset includes a corpus of more than 34,000 official expressions of view by states and their authorized representatives regarding the international politics of cyberspace. The article describes the sources of these data and demonstrates the dataset’s usefulness, with an Online appendix containing an exploratory analysis of norm convergence. Future research can leverage the dataset to empirically test questions of theory and policy. For example, the dataset can be used to study how foundational theories of norm diffusion apply to cyberspace. It can also be paired with existing cyber conflict datasets to study the conditions under which state practice influences cyber discourse, and vice versa.
Cyber scholarship has, in recent years, embarked on a more empirical turn. Theoretical predictions are ubiquitous, but testing and adjudicating between those predictions are challenging owing to the unique features of cyberspace (Gorwa and Smeets, 2019; Shore, 2022; Whyte, 2018). As Shandler and Canetti (2024) describe, ‘the [cyber] domain is complex, quality data is sparse, [and] affairs are shrouded in secrecy.’ To that end, recent work has attempted to quantify patterns in a number of important issue areas: cyber conflict and escalation (Kostyuk and Zhukov, 2019; Valeriano and Maness, 2015); strategy and capacity (Kostyuk, 2021; Valeriano et al., 2018); proxy warfare (Akoto, 2022; Borghard and Lonergan, 2016; Canfil, 2022; Herzog, 2011; Leal and Musgrave, 2022; Maurer, 2018a); psychology and decisionmaking (Gomez, 2019; Gomez and Whyte, 2022; Gomez and Villar, 2018; Hedgecock and Sukin, 2023; Kostyuk and Wayne, 2021; Shandler et al., 2021, 2022) and more. Despite this trend, the study of cyber norms has not received similar treatment.
To address this gap, this article introduces the International Cyber Expression (ICE) dataset. Just as other articles in this issue that contribute to our understanding of cyber conflict by harnessing new data sources (Kostyuk, 2024; Makridis et al., 2024; Oppenheimer, 2024), the ICE dataset offers a new way for researchers to conduct large-n analyses of discourse and norm evolution in cyberspace. Because raw expression text is included, scholars may also find it useful for locating specific cases for qualitative analyses. Building on existing projects that catalog norm-building activity, it systematically documents sovereign expressions of view on cyberspace issues. The dataset includes
In studying how political actors work to advance ‘rules of the road’ in cyberspace (Broeders et al., 2022; Giles, 2012; Mazanec, 2015; Raymond, 2019), scholars have relied primarily on informal-theoretic, case study, and interpretative methods to develop and evaluate theories. Such approaches have offered valuable insights. However, they often have unavoidable cross-national, context-specific, and temporal limitations. The United Nations Group of Governmental Experts (UN GGE) continues to dominate cyber norm scholarship (Maurer, 2011, 2018b). UN GGE proceedings are private, however, meaning that scholars cannot directly observe the norm development process, which Finnemore and Hollis (2019) argue is crucial for understanding how norms develop. 1 As we are reminded, many ‘useful lessons [are] missed if one examines cybernorms only as products’ (Finnemore and Hollis, 2016). Focusing on GGE outcome documents, which are only produced in the event of consensus, also has the unfortunate effect of selecting on success cases. Most importantly, the prevailing focus on the GGE elides the many expressions of view that states have exchanged on cyber issues in other venues.
The ICE dataset remedies this shortcoming by cataloguing sovereign expressions in 57 different institutional settings since 1998. Rather than select on consensus outcomes, it catalogues what might be termed ‘opinio publicae’ – publicly-staked opinions about how the international relations of cyberspace ought to operate. Unlike analyses scoped exclusively on the GGE, researchers can use the ICE dataset to better separate cyber norm candidates from norm successes; track their progress over time; and identify the conditions under which they are contested or accepted by different parties. In so doing, the dataset offers a window into ‘norm nebulas’ – clusters of normative ideas and aspirations that their advocates would like to see become the norm. 2
Novel approaches to the empirical study of cyber norms are needed now more than ever. Practitioners such as Admiral Michael S. Rogers, formerly the director of United States (US) Cyber Command (CYBERCOM), have long argued that ‘shared norms are a basic building block for cybersecurity’ (Farrell, 2015). However, GGE member states unexpectedly failed to reach consensus in 2017 (Mačák, 2017), fueling cynicism about the future of cyber norms (Maurer, 2020; Segal and Waxman, 2011; Schmitt and Vihul, 2017). States are now at a ‘crossroads’ (Hoffman et al., 2020) in setting rules of the road for cyberspace conduct (Schmitt, 2020). Scholars and policymakers alike disagree on what it will take to get cyber norms (Healey and Maurer, 2017) and where the road ahead might lead (Demchak, 2018; Ford, 2010; Healey, 2011; Markoff and Kramer, 2009; Maurer, 2020; Maurer and Taylor, 2018; Schmitt, 2013). Despite the importance of norms for regularizing interaction in the cyber domain, ‘failure remains an option’ and ‘may even be the dominant outcome’ (Finnemore and Hollis, 2016).
The prospects for cooperation in cyberspace are thought to be limited because states possess ‘radically incompatible values’; a belief that the USA, which benefits disproportionately from the open internet, is ‘acting in bad faith’ given the Snowden disclosures; and the fact that technology companies and non-governmental organizations have such considerable sway (Farrell, 2015). Others argue that because of enduring domestic disagreements, the USA has struggled to articulate a coherent position on the international stage (Creemers, 2017). Moreover, the attribution problem (Libicki, 2009), asymmetric capabilities (Nye, 2010), and indistinguishability between offense, defense, and espionage (Mazanec, 2015) make norms difficult to enforce, decreasing their credibility. Despite an abundance of cynicism, however, states continue to advocate for norms.
Researchers can use these data for a variety of purposes. For norm researchers per se, potential applications include questions ranging from how conventional norm theories apply to cyberspace to the effectiveness of entrepreneurial norm-building efforts. It can be used to study discourse around specific cyber issues, measure tacit convergence between opposing factions, and the use of similar language by different actors across multiple venues. This could include changes to how states frame their vital interests to international audiences, such as cyber sovereignty (Fung, 2023; Kolton, 2017), or how they speak to benefactors and dependents (see Kostyuk, 2024). Finally, scholars can also use it to empirically test predictions about how norms affect conflict processes, for example by pairing ICE data with existing datasets on cyber operations (e.g. Kostyuk and Gartzke, 2023; Maness and Valeriano, 2016), cyber institutions (e.g. Kostyuk, 2021), or other measures of state practice.
The remainder of this article describes the motivation for the dataset, provides an overview of what it contains, and offers several suggestions for future research applications. An empirical example is given in the Online appendix.
Introducing the dataset
This section provides a brief overview of the International Cyber Expression (ICE) dataset. ICE identifies the country that expressed an opinion pertinent to cyberspace as well as the date (YYYY/MM/DD) on which this opinion was expressed. More than 200 sovereign entities are attributed, including all 193 UN member states. The mean expression length is approximately 2000 words. Including raw text, expression metadata, and links to the original source, the dataset contains 123 variables for user convenience.
ICE uses
Expressions meeting three criteria were subject to inclusion:
Overview of variables by category
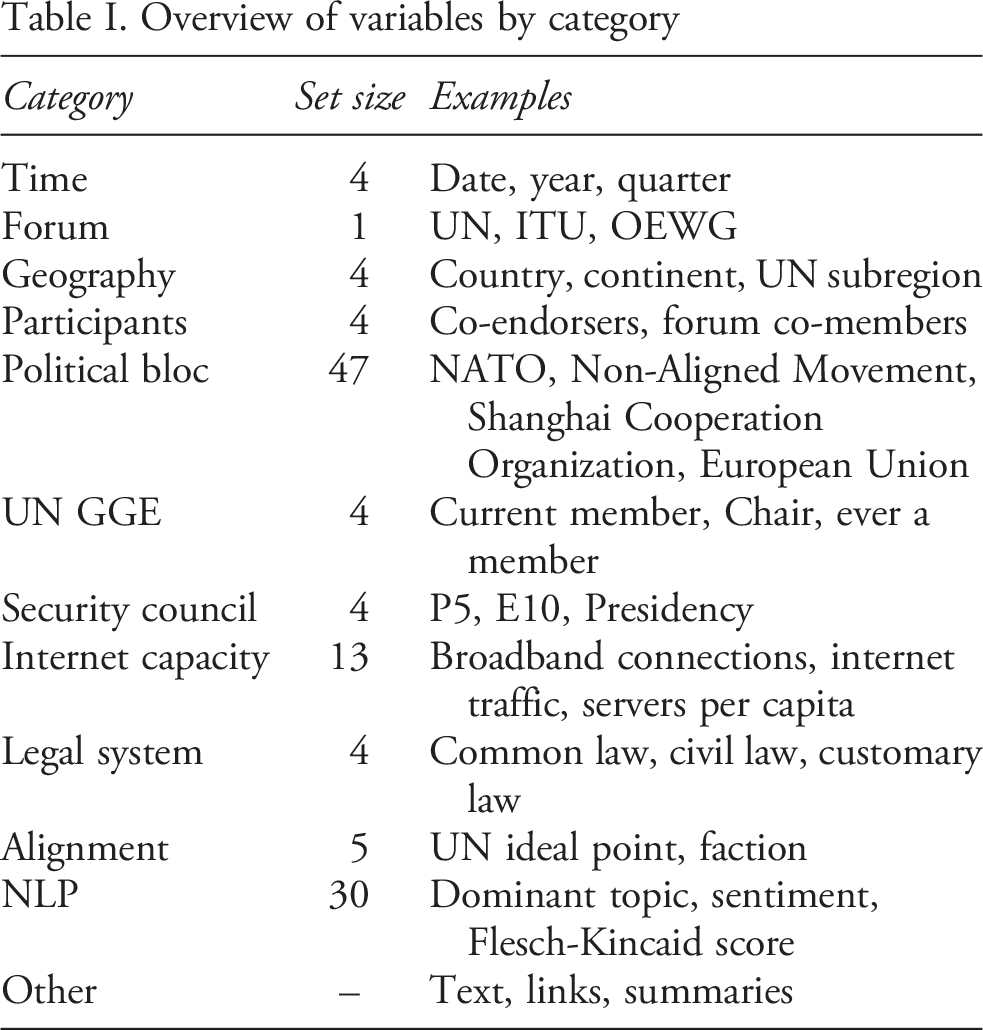
Table I summarizes the other
Finally, the dataset encodes basic information about expression topic content. An expression is coded in the dataset as being ‘about’ a given topic t if the estimated proportion of word tokens assigned to topic,
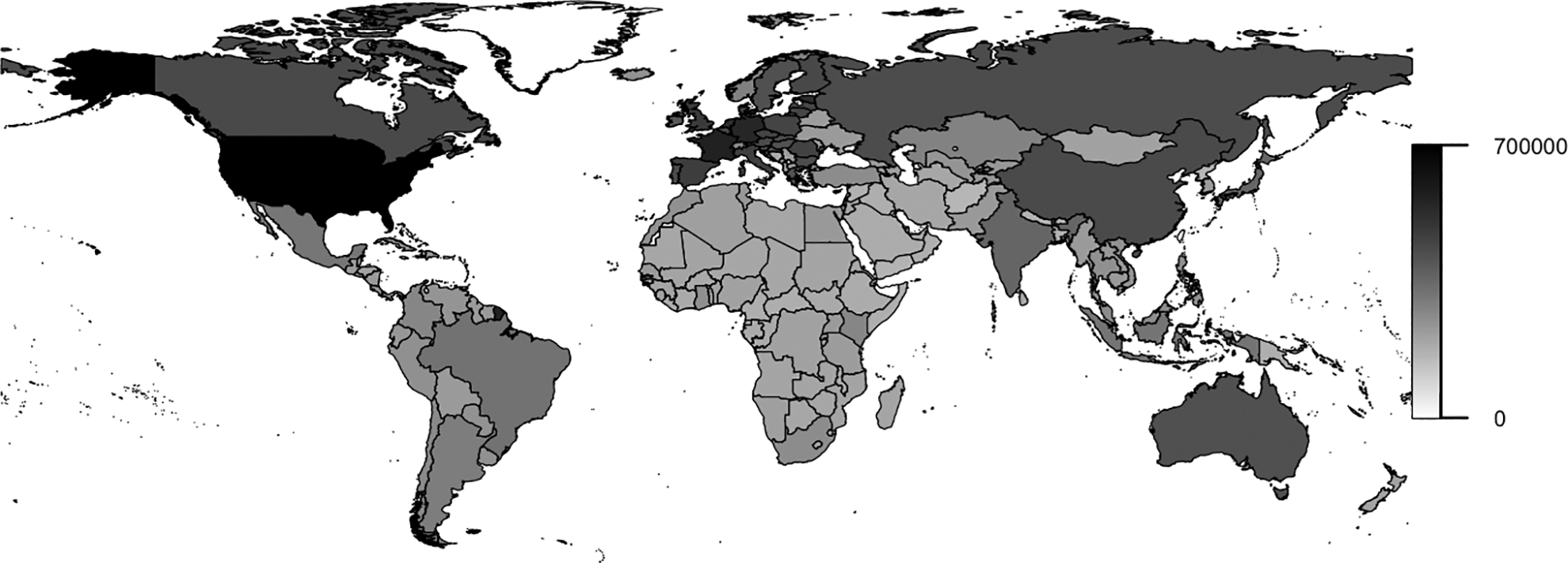
Geographic distribution of observed expressions
Two limitations are underscored. First, care should be taken when dealing with expressions made outside of a formal institutional setting; namely, many unilateral and bilateral expressions, which were identified via convenience sampling. These undoubtedly suffer from reporting bias, consistent with findings by Makridis et al. (2024) and Oppenheimer (2024) in this issue. 5 Since unilateral/bilateral expressions are not assumed to be independent and identically distributed, they should be treated with care. These types are included by default, but can easily be removed depending on research aims.
Second, not all expressions are available in the public domain. In some cases, the text of unknown expressions is probably missing at random (including the London Process example); in others, states may have retracted their positions (Wuzhen, perhaps) – or off-the-record candor may have been the point (as with the GGE). The raw text of known expressions was recovered for 96% of the sample. 6 Whenever possible, these are verbatim. Meeting summaries, press releases, or media statements are relied upon only as a last resort.
Content and utility
Scholars can use the dataset in at least two ways. First, expressions of interest can be surgically isolated for traditional qualitative analyses with greater convenience. Second, researchers interested in using large-n methods to better understand global and longitudinal discursive patterns can now leverage the same computational approaches that scholars are already using to study norm change in other domains, such as environmental politics and human rights (e.g. Arias, 2022; Fariss et al., 2015; Hanania, 2021; Park et al., 2020).
Figure 1 maps the global distribution of expressions captured by the dataset at the country level. Recall that only 44 countries have ever been invited to participate in a GGE meeting. This is less than a quarter of all UN members, and most of these have only participated once. Conversely, we observe from Figure 1 that every UN member has staked out at least some public positions on GGE-related matters. For sovereign states (entities like Montserrat are overseas territories), the lower bound is around 13,000 combined words. There are numerous ways researchers might leverage this information. For example, using this dataset, researchers can employ network models to track country- or system-level engagement patterns.
Figure 2 depicts the share of topical emphasis over time. Topics capture the various cyber-related issues that the international community has prioritized since 1998. The overall constitution of these topics provides an overview of dataset contents. As an illustration, trend lines are disaggregated into country ‘factions,’ obtained by splitting UN ideal point scores, previously compiled by Bailey (2017), into equal-sized tertiles. 7 Higher UNIP scores correlate with developed democracies, while developing countries and especially authoritarian countries tend to have lower UNIP scores. The relationship between topical emphasis and faction membership is fitted by year.
As is apparent, there is considerable variation in what different types of countries tend to emphasize. However, there is also some surprising convergence; for example, the importance of addressing criminal misuse. For proofs of concept, the Online appendix tracks discourse around Relative emphasis across 12 issue spaces by faction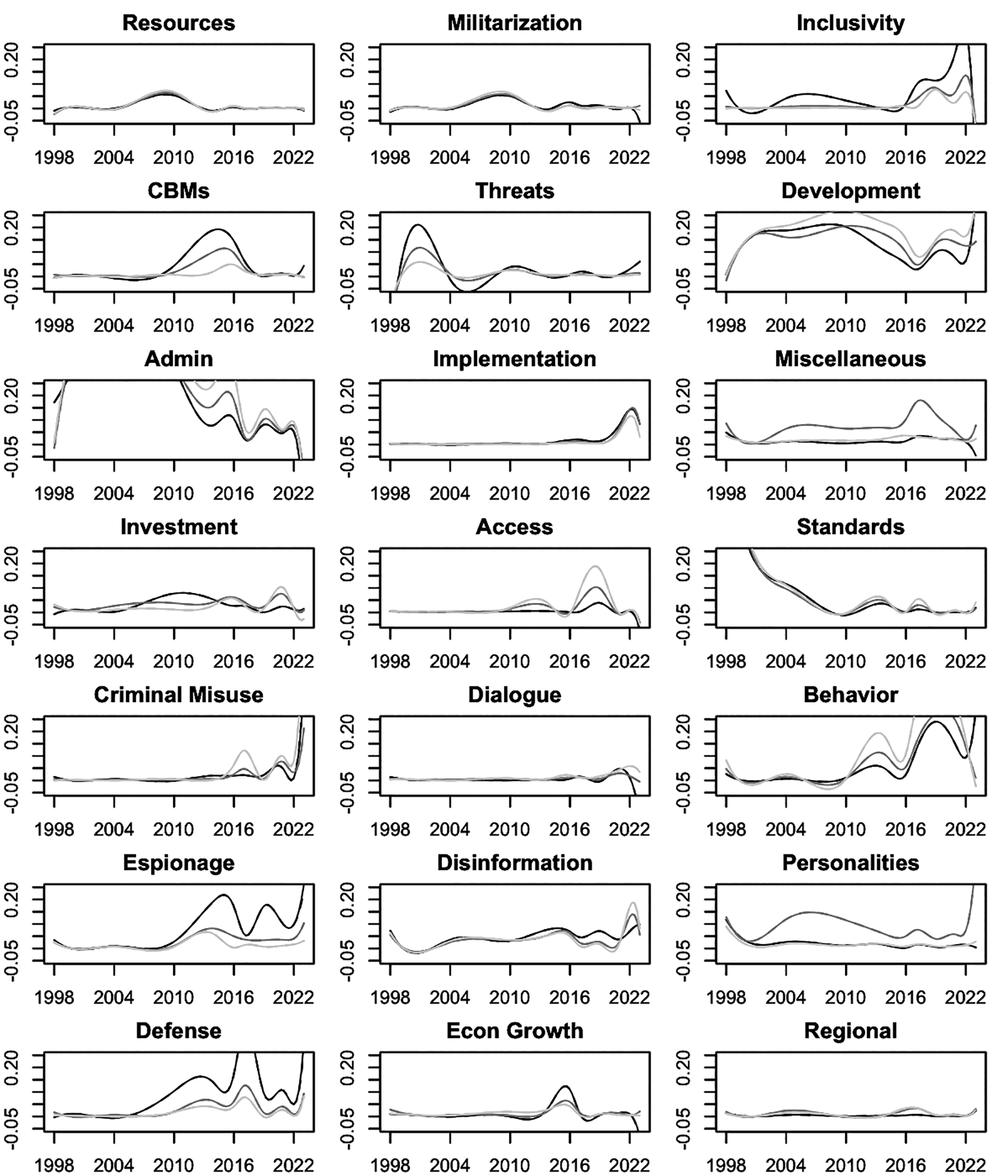
Suggested applications
Implicit in the attention that policymakers and pundits have paid to cyber norms since 1998 is the idea that what states say to one another must somehow matter (Carr, 2015; Mueller, 2013), echoing literature in other domains (Goddard and Krebs, 2015; Krebs and Jackson, 2007; Risse, 2000). Even realists such as Carr (1964) elevate so-called discourse power – ‘power over opinion’ – alongside military and economic power (Kania, 2018b). ‘Cultivating norms requires serious effort,’ write Finnemore and Hollis (2016). States invest significant resources into international discussions. This alone would seem to offer prima facie evidence that states view international conversations not simply as ‘cheap talk,’ but as potentially impactful (Lonergan and Schneider, 2023). 8
The conventional wisdom has long been that cyberspace is a ‘Wild West’ (Obama, 2015) where international law is purportedly ‘silent’ (Hollis and Sander, 2022; Kello, 2021; Sander, 2019). Many decried the breakdown at the 2017 GGE as the ‘end of the road’ (Henriksen, 2019), the ‘end of an era’ (Korzak, 2017), or the ‘end of cyber norms’ (Grigsby, 2017). However, the GGE has endured, in parallel with a new UN track, the Open-Ended Working Group (OEWG) (Grigsby, 2018). Dialogue is also widespread in other fora, a fact that is often overlooked, and more than half the observations in this dataset occur after the 2017 ‘failure.’ Scholars must recognize that the story has not reached its end (Raymond, 1997), animating the need to study these processes as they unfold.
The ICE dataset can empower researchers to make more ‘bold, theoretically grounded, and empirically tested claims’ like the articles in this issue (Shandler and Canetti, 2024). For one, there are still many unresolved questions about how core International Relations theories apply in cyberspace. Cooperation theorists might wish to examine how states ‘anchor’ or ‘graft’ new ideas onto existing norms (Finnemore and Hollis, 2016), ‘rhetorically adapt’ existing norms for new purposes (Fung, 2023), frustrate norm development through strategic obfuscations disguised as substantive contributions (Kania, 2018a; Lantis and Bloomberg, 2018; Pratt, 2019; Schneiker, 2021), or employ other evasive tactics (Búzás, 2018).
The data could also be used to explore how regional and global norms diffuse, or to make comparisons between directed (Keck and Sikkink, 1998) or cyclic (Sandholtz, 2008) processes. For example, Kostyuk (2024) argues in this issue that spillover between allies helps to explain cyber capabilities. Similarly, scholars might use this dataset to test predictions about how allies, ‘critical states’ (Finnemore and Sikkink, 1998), or highly networked ‘gatekeepers’ (Finnemore and Hollis, 2016) might influence foreign policy expressions. For researchers interested in state practice, the data are pairable with existing cyber conflict datasets. And, in addition to the possibility of being paired with data on cyber institutions (Kostyuk, 2021), the ICE dataset appends 13 measures of cyber capacity.
While the dataset is already useful for these purposes, it can be improved upon. First, future versions of the dataset could prioritize the systematic collection of unilateral/bilateral expressions and expressions at international gatherings where English is not necessarily the dominant language, such as the World Internet Conference in Wuzhen, China. Work in progress by Hulvey (2024) promises to address the latter shortcoming. Second, evidence of state practice – extradition agreements, Mutual Legal Assistance Treaties (MLATs), computer emergency response team (CERT) and Computer Security Incident Response Team (CSIRT) arrangements, court indictments and official attributions, other domestic policies, and technical correspondence – could also be included to study norm internalization, although this would involve a significant undertaking to expand the dataset's scope. Third, cybercrime-specific conversations from the UN Third Committee, which are not included in this version, would be relatively easy to incorporate. Finally, future versions should endeavor to include more 'unofficial' and civil society commentary. In the meantime, researchers can use the dataset to better understand cyber norms processes as they unfold in the most prominent fora.
Footnotes
Replication data
All analyses were conducted using R. The dataset, replication code, codebook, and Online appendix can be found at https://www.prio.org/journals/jpr/replicationdata. Updated versions will be posted to ![]() .
.
Acknowledgments
The author thanks Daphna Canetti, Michael Fischerkeller, Erik Gartzke, Richard Harknett, Jason Healey, Lucas Kello, Nadiya Kostyuk, Erik Lin-Greenberg, Jon Lindsay, Andrew Nathan, Jon Penney, Evan Perkoski, Mike Poznansky, Mark Raymond, Ryan Shandler, Brandon Valeriano, Chris Whyte, Josephine Wolff, JD Work, Thomas Zeitzoff, and others for helpful comments on earlier versions of this work. Thanks also to participants at the Center for Peace and Security Studies (cPASS), Columbia SIPA, the Digital Issues Discussion Group, and the University of Haifa for feedback on earlier versions. Gustaf Ahdritz and Hao Zhu provided excellent research assistance.
Funding
This research was supported in part by the National Science Foundation (NSF 19-612 2017591) and the Carnegie Corporation of New York.