
Abstract
Influencers’ follower count, or indegree, is a key criterion that advertisers use when devising influencer marketing campaigns. However, whether influencers with lower or higher follower count are more effective in generating engagement remains an open question. This multimethod research effort—involving an observational field data analysis, based on 802 Instagram marketing campaigns featuring more than 1,700 influencers, together with an eye-tracking study and laboratory experiments—establishes conclusive evidence of an inverted U-shaped relationship between influencers’ follower count and engagement with sponsored content. A higher follower count implies broader reach but also cues a weaker relationship that reduces followers’ engagement likelihood. That is, engagement first increases, then decreases, as influencer follower count rises. The authors further test the potential moderating effects of two campaign properties: content customization and brand familiarity. Higher content customization and lower familiarity of the sponsored brand signal that influencers value their relationships with followers and thereby flatten the inverted U-shaped relationship. Managers can leverage these novel results and the related actionable guidelines to improve their influencer marketing strategies.
Keywords
As consumers grow increasingly wary of traditional forms of advertising (Hsu 2019), influencer marketing on social media platforms such as Instagram is gaining traction, transforming from an ancillary tactic to a market worth more than $16 billion in 2022 (Statista 2022). In influencer marketing, advertisers compensate influencers to integrate a specific product into their content, usually with some degree of creative freedom. The influencers are expected to create content that generates social media engagement among their followers. Engagement, usually captured by the number of interactions (e.g., likes, comments), is a highly relevant performance indicator that advertisers and influencers seek to optimize (Leung, Gu, and Palmatier 2022). However, despite the rising popularity of influencer marketing, advertisers seem to be adopting this tactic without a solid understanding of how engagement arises, such as which influencers are most effective at turning advertising budgets into greater engagement (Linqia 2021). In an ever-expanding universe of influencers, a main screening criterion for advertisers is an influencer's follower count, or indegree (Haenlein et al. 2020). Indegree defines the size of the audience an influencer can directly reach with content, is publicly visible on the platform, and has become the major “currency in the influencer and retail world” (Eldor 2019). The gamut runs from low indegree of a few thousand followers to influencers with enormous indegree of many millions of followers.
Yet whether influencers with lower or higher indegree are more effective in generating engagement is still an open question. On the one hand, advertisers want to leverage an influencer's reach, which is the number of followers exposed to an influencer's content and which, by definition, increases in indegree. Thus, some brands “have been racing to spend big dollars on high-profile social media users with massive followings” (Chung 2021). On the other hand, users on social networks often seek interactive, communal relationships, in which they feel connected (De Veirman, Cauberghe, and Hudders 2017). These relationships might not be available, or be perceived to be available, from influencers with larger indegree who lack sufficient resources or interest to enter into meaningful, frequent interactions with their many followers. Perceptions of weak ties may dampen followers’ engagement likelihood, such that the effectiveness of high indegree in generating more engagement becomes poor. Some advertisers have already identified this issue, cautioning that high-indegree influencers might not be able to exert a “significant influence on their audience” (Barratt 2021) and suggesting more reliance on “influencers who aren't nearly as popular as their big-name peers” (Wiley 2021).
Thus, one influencer might have relatively large reach (i.e., many followers exposed to content) but low engagement likelihood (i.e., followers are less likely to interact with content), while another influencer might have smaller reach but a greater engagement likelihood. Ultimately then, which influencer generates more engagement with sponsored content (i.e., a higher number of interactions)?
To answer this question and clarify important details about how an influencer's indegree relates to engagement, we propose a novel conceptualization of the relationship, which we predict follows an inverted U-shape. The combination of indegree's positive effect on reach (in exposing more followers to sponsored content) and its simultaneous negative effect on engagement likelihood (through perceived tie strength, such that followers are less motivated to engage with an influencer's content) implies that at low to moderate levels of indegree, the positive reach effect dominates, and overall engagement improves. But as indegree rises, the positive effect may become outweighed by the negative engagement likelihood effect engendered by low perceived tie strength, which leaves followers less motivated to engage with the influencer's content, and overall engagement will decrease.
In this framework, we also posit that certain features of a campaign can weaken the inverted U-shaped link between indegree and engagement by attenuating the negative effects on engagement likelihood evoked by large indegree. Specifically, we study two campaign properties: (1) content customization, which captures the extent to which influencers independently create content for the campaign instead of following a uniform campaign script, and (2) brand familiarity, which describes the extent to which consumers are generally aware of the brand that sponsors the campaign. In line with contextual cue diagnosticity (Purohit and Srivastava 2001), we argue that both campaign properties can help influencers demonstrate that they commit to relationships with followers, which should attenuate the negative impact of their indegree on followers’ likelihood to engage and thus weaken the relationship between indegree and overall engagement.
To empirically test our framework, we conduct a multimethod study, centered on an observational field data analysis based on Instagram data and enriched by two types of experimental studies (eye tracking and laboratory), an add-on simulation study, and an auxiliary set of qualitative interviews that we conducted to deepen our understanding of the broader domain of influencer marketing. The conclusions drawn across these studies lend evidence to the predicted inverted U-shaped relationship between influencer indegree and engagement. We also find empirical support for the hypothesized moderating effect of the campaign properties: higher content customization weakens the effect of influencer indegree on engagement, so that small- and large-indegree influencers become relatively more effective in generating engagement compared with medium-sized indegree influencers. Likewise, when the campaign is sponsored by a rather unknown brand, the effect of influencer indegree on engagement is less pronounced. As this relationship flattens, medium-indegree influencers become comparatively less effective in driving engagement.
Our work contributes to marketing research and practice in several important ways. Theoretically, we deepen insights into the relationship between an influencer's indegree and followers’ engagement with sponsored content. As our nuanced, process-based view of the functional relationship shows, the influence of indegree moves through perceived tie strength. This works, at least in part, because followers interpret indegree as a cue for the strength of their tie with the influencer. We also introduce two important campaign properties, content customization and brand familiarity, as relevant concepts to the influencer marketing literature that condition how influencer indegree drives engagement.
Empirically, we expand previous studies on influencer marketing effectiveness by more accurately identifying the effects of influencer indegree on engagement, using deep and broad field data. In particular, we base this analysis on complete campaign data that include all participating influencers, such that we can move beyond prior work that tends to ignore campaign composition effects. Methodologically, we capture engagement based on not just posts, which are photos or videos uploaded to an influencer's profile, but also stories, which are short, audiovisual arrangements of photos or video sequences that automatically disappear from an influencer's profile after 24 hours. Stories are especially relevant sponsored content on Instagram, in that they can contain links that redirect users to an advertiser's website, a commercial feature that is not available in posts (Cassandra 2020). More than one-third of all sponsored content on Instagram appears as stories (99firms 2021), and 83% of marketers plan to use Instagram stories in their campaigns (Linqia 2021).
Substantively, we provide novel, actionable insights to help advertisers improve their influencer marketing strategies. We highlight the peril of supersaturation effects in engagement when indegree becomes too large and reveal that the most effective indegree level is situated somewhere between the often-recommended very small and very large influencer tiers. Yet advertisers and influencers also have some room to maneuver: brands that allow influencers to promote content independently and brands that are less well-known observe a weaker inverted U-shaped relationship between indegree and engagement, reducing the pressure for them to collaborate with influencers who have just the right number of followers. These contributions also help marketers better account for their investments in influencer marketing, which has particular value for this young and rapidly evolving social media tactic.
Related Literature on Indegree and Influence in Social Networks
Social Networks and Seeding
The notion of social influence, as introduced by Katz and Lazarsfeld (1955), describes the extent to which an individual can affect others’ attitudes and behaviors. Since then, a long research tradition has linked social influence to social networks in general and to indegree in particular. In this literature, researchers work to identify those individuals who can maximize the diffusion of information or behaviors in their social networks (e.g., Aral and Dhillon 2018). In seeding, the most related application in marketing, firms send marketing-relevant information to social network members, hoping that they will initiate its diffusion (Hinz et al. 2011). Table W1 in Web Appendix A summarizes extant empirical findings regarding the effects of indegree in social networks and in seeding, organized by whether the study examines aggregate or individual effects. Almost unanimously, these studies show a positive relationship between indegree and the diffusion of new ideas or products (e.g., Goldenberg et al. 2009; Libai, Muller, and Peres 2013; Yoganarasimhan 2012). As a result, many studies suggest seeding individuals with high indegree, because their greater number of connections allows each individual to reach more others.
In contrast, studies that consider not only reach but also the strength of the influence on others (i.e., the response likelihood of connections) produce more ambiguous results regarding the optimal seeding strategy. Hinz et al. (2011) and Libai, Muller, and Peres (2013) still recommend targeting seeds with high indegree, even if they do not have the strongest influences on connections, but Chen, Van der Lans, and Phan (2017) find that weighting individual indegree by the strength of influence on each connection yields substantially different, and more effective, seeding recommendations than selecting seeds based purely on indegree. In another approach, Haenlein and Libai (2013) propose seeding individuals with high customer lifetime value but not necessarily high indegree.
Applicability of Seeding Studies to Influencer Marketing
Influencer marketing is sometimes considered a controlled form of seeded marketing, but it is distinct in its institutional setting and scope, so findings from seeding literature might not apply precisely. Most importantly, seeding campaigns only encourage seeds to promote firm-generated content, without any formal incentive structure (Leung, Gu, and Palmatier 2022). Instead, in influencer marketing, influencers are contractually obligated to create content and promote the advertiser's offering. The objectives of the two marketing tactics also differ: seeding marketing campaigns aim to trigger cascades of information through a social network (e.g., Van der Lans et al. 2010; Watts and Dodds 2007), but influencer marketing attempts to enhance engagement metrics, such as likes, comments, or clicks, which represent direct interactions between an individual follower and the sponsored content.
Studies of seeded marketing also feature different empirical foci. For example, they tend to focus on relatively small networks in which even the largest seeds have fewer than 1,000 connections (e.g., Yoganarasimhan 2012), while influencers can have indegree values in the millions. Insights from seeded marketing therefore can capture only the lower end of the engagement effects that might occur in influencer marketing. In addition, many seeding studies compare discrete seeding strategies, such as large indegree versus random seeding (Hinz et al. 2011), or else feature seeding criteria unrelated to indegree (e.g., Libai, Muller, and Peres 2013), but do not compare large versus small indegree seeding, which limits their applicability to our specific research question. Furthermore, seeded marketing campaigns often occur in undirected social networks, and seeds select which connections will receive the information they share (e.g., Gelper, Van der Lans, and Van Bruggen 2021). Influencers spread content to their entire followership, so that a comparison of conversion rates with seeded marketing results becomes difficult.
Finally, insights from seeded marketing are often retrieved from offline settings (e.g., Dost et al. 2019), but influencer marketing occurs fully online, which implies substantially different extents of intimacy, information flows, and follow-up opportunities (Kuksov and Liao 2019). A seed's indegree in an offline setting might be unknown or uninformative to connections, while an influencer's indegree is a very prominent aspect in profile information, which followers can use to infer characteristics of their relationship with the influencer.
Influencer Marketing Studies
Research that accounts for the influencer marketing context has recently begun to investigate the relationship between indegree and engagement. While we are not aware of any fieldwork that explicates this relationship, three articles include indegree as a control variable for explaining engagement. Hughes, Swaminathan, and Brooks (2019) document a positive relationship between an influencer's indegree and the number of likes and comments the sponsored content generates on Facebook and blogs. With a sample of unpaid endorsements on Twitter, Valsesia, Proserpio, and Nunes (2020) find a positive but diminishing effect of indegree on the number of likes and retweets a post generates. Both studies examine influencers with very low indegree and focus on content in the form of posts. Leung et al. (2022) investigate sponsored posts on the Chinese network Sina Weibo. Although they do not find a direct effect of indegree on engagement, they determine that indegree strengthens the effects of influencer marketing expenditures on engagement. Table 1 offers an abridged overview of the studies most relevant to our research.
Overview of Key Empirical Studies of the Effects of Indegree in Social Networks.
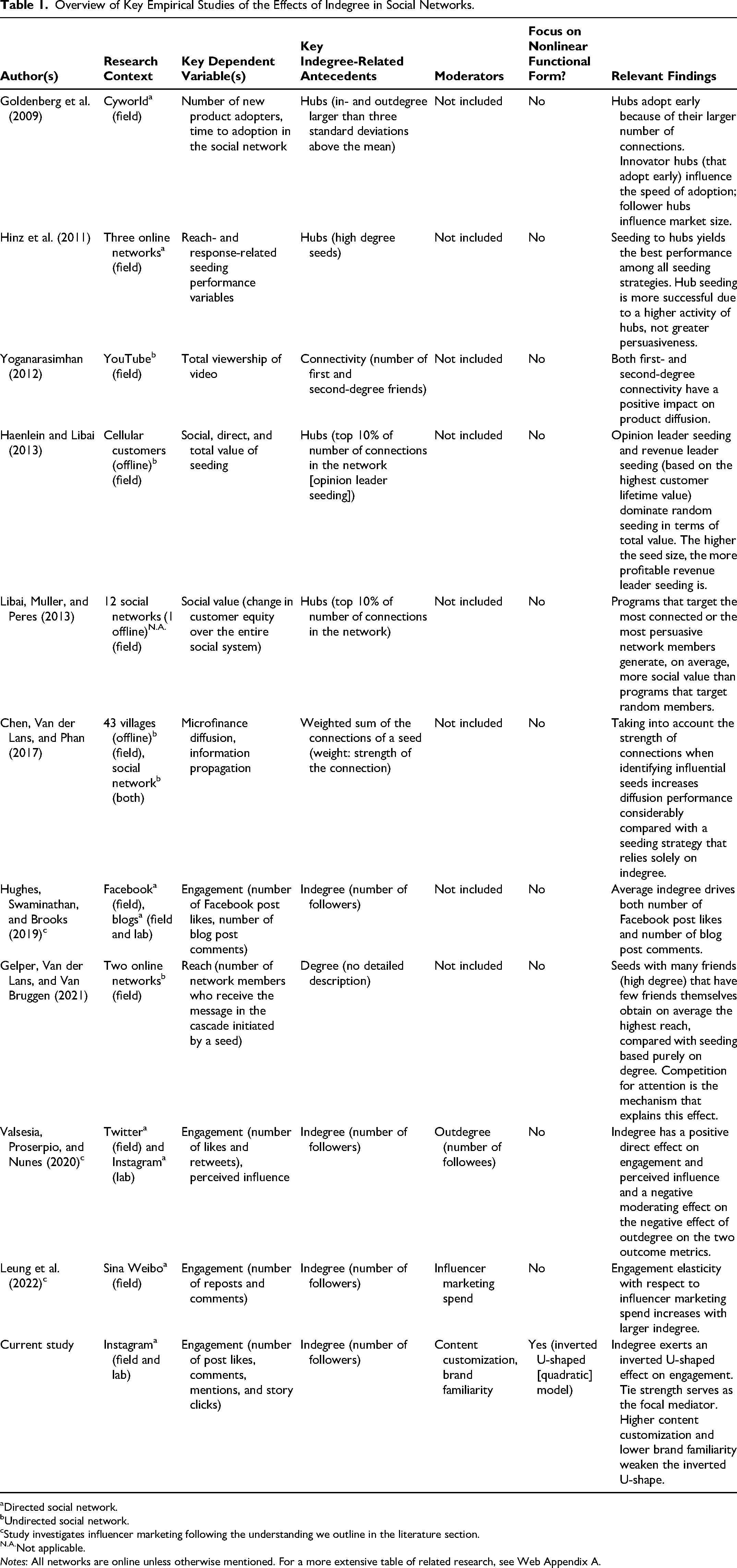
Directed social network.
Undirected social network.
Study investigates influencer marketing following the understanding we outline in the literature section.
Not applicable.
Notes: All networks are online unless otherwise mentioned. For a more extensive table of related research, see Web Appendix A.
In an effort to contribute to research on social networks, seeded marketing, and influencer marketing, we theorize a more complex relationship of influencer indegree and engagement with sponsored content than entrenched in prior views. While the network perspective of previous studies is useful to identify individuals who, by virtue of their indegree, have the potential to reach many others, such studies do not aim to explain how indegree might affect the engagement likelihood of an individual connection. As we explain in our conceptual framework, this effect might be driven by perceived tie strength with the influencer. Ours is an initial attempt to apply these conceptualizations to paid influencer endorsements in a directed social network (i.e., Instagram), in the context of a strategically organized campaign structure.
Conceptual Framework
How does an influencer's indegree affect engagement with sponsored content? Building on extant research and 13 semistructured interviews with industry experts (see Web Appendix B), we derive the conceptual framework of this relationship in Figure 1. We begin by theorizing why we expect an inverted U-shaped relationship (H1), then discuss its potential moderation by two campaign properties: content customization (H2) and brand familiarity (H3).

Conceptual Framework.
How Influencer Indegree Affects Engagement
Engagement refers to measurable interactions of users on a social platform in response to an influencer's sponsored content that result from motivational drivers (Van Doorn et al. 2010). These interactions include liking an influencer's content, commenting on it, or tagging others to make them aware of the content. Following Hinz et al. (2011), we develop our framework based on a simple two-determinant model that links engagement with indegree. On a social media platform, influencer i has indegree Di (Di > 0) that captures the number of followers in a given period. Influencer i publishes sponsored content (post or story) for followers, and Ni is the number of followers exposed to the content (Ni ≤ Di),
1
such that it provides a measure of influencer i's effective reach. The reached followers n (
Effect of indegree on reach (Ni)
Reach is the number of users exposed to the content of influencer i; by construction, it also is a function of indegree, because every additional follower increases the size of the potential audience to reach with content. We define:
Effect of indegree on engagement likelihood (pi)
Engagement likelihood describes the average motivation of an influencer's followers to interact with sponsored content. Previous literature suggests a direct link between indegree and engagement likelihood (Katona, Zubcsek, and Sarvary 2011); it operates at least partly because followers rely on indegree as a decision cue about whether to engage with content published by an individual (Valsesia, Proserpio, and Nunes 2020). Cue utilization is particularly powerful in online relationships, because information is naturally more incomplete and uncertain than in offline relationships, so the parties need to rely on external information to gather nuanced insights about each other (Grewal and Stephen 2019). The large number of connections in online social networks and the lack of real interactions, as experienced in offline relationships, aggravates the need for cues to form opinions and make decisions. Thus, in influencer marketing contexts, an indegree cue can help followers construct perceptions of their relationship, or tie, with the influencer. 2 Prior research and industry insights indicate that users care about these ties and rely on influence from perceived close connections, which is part of the great appeal of influencer marketing (Ye et al. 2021).
Tie strength is the potency of a bond between members of a network, reflecting the perceived significance, intensity, and closeness of their relationship (Aral and Walker 2014; Duhan et al. 1997; Granovetter 1973). Given that the strength of a tie also relates to the amount of interaction between actors (Roberts and Dunbar 2011), and attention is a limited resource, average tie strength decreases in indegree (e.g., Gilbert and Karahalios 2009; Katona, Zubcsek, and Sarvary 2011; Miritello et al. 2013). Reflecting this naturally occurring, negative relationship between indegree and tie strength, an influencer's higher indegree may provide followers with a cue that this influencer will devote less effort to nurturing each follower relation, weakening their perceptions of the strength of their tie (Wang et al. 2019). By contrast, an influencer with lower indegree may be perceived as a more intimate, meaningful relation, so followers could be more likely to engage with the content. As De Bruyn and Lilien (2008) show, people are more likely to open emails from senders with whom they have a stronger tie, and Aral and Walker (2014) demonstrate that tie strength drives adoption of online apps received from social network connections.
To recap, we propose that indegree is an important cue that helps explain engagement likelihood. Because followers infer closer ties with influencers with lower indegree, and perceived tie strength drives engagement likelihood, followers are more likely to engage with sponsored content from influencers with lower indegree. Formally,
Expected effect on engagement
Revisiting Equation 1, engagement can be expressed as the product of reach and engagement likelihood (Ei = Ni × pi), reformulated as:

Theorized Inverted U-Shaped Effects of H1–H3.
How Campaign Properties Moderate the Effect of Influencer Indegree on Engagement
Influencer content is usually organized in a campaign that features multiple influencers. The properties of the overall campaign then might moderate the relationship between indegree and engagement (H1) by affecting the link between indegree and engagement likelihood. We focus on two readily observable campaign properties that emerged from our expert interviews, are managerially relevant, are marketing-controlled, and should alter how followers assess an influencer's indegree in deciding whether to engage. A campaign's content customization describes the degree of independence that different influencers within the campaign have in creating their content, so it represents a key design element of how the campaign is executed. The campaign's brand familiarity is the extent to which the endorsed brand is generally known, rather than a less familiar niche brand (Cunha, Forehand, and Angle 2015), which is key identifying information about the campaign sponsor.
Underlying these proposed moderation effects is the idea that contextual cues alter how consumers perceive an incumbent cue, in terms of its valence or diagnosticity (Purohit and Srivastava 2001; Richardson, Dick, and Jain 1994). Borrowing from the theory of contextual cue diagnosticity, we posit that creating more customized content or endorsing a less familiar brand conveys the influencer's willingness to engage in relational effort, which should lead followers to interpret the indegree cue as less problematic when assessing their relationship with the influencer. By exhibiting effort to demonstrate the value of relationships with followers, the influencer might reduce the diagnosticity of the indegree cue and diminish its negative effects on engagement likelihood. Similar effects of contextual cues attenuating the impact of incumbent cues have been documented in studies of consumer quality inferences across other contexts, such as product reviews (Watson, Ghosh, and Trusov 2018) or movie choices (Basuroy, Desai, and Talukdar 2006).
Content customization
Campaigns differ in the degree to which influencers have autonomy in creating content, and we posit that increased efforts to customize the content should convey the influencer's valuation of followers (Algoe, Haidt, and Gable 2008), because it implies relational effort in three main ways. First, followers may suspect convenience motives if an influencer uses the campaign's standard wording without tailoring it to the audience, whereas they may appreciate the influencer's creative crafting of a unique message (Haenlein et al. 2020). Second, standardized wording might imply the influencer's insufficient knowledge about the endorsed product, whereas content customization signals that the influencer has gained sufficient information to endorse the product in her or his own words. Third, followers who encounter uniform campaign content might perceive the influencer as opportunistic, solely aiming to exploit collaborations, instead of working to give followers helpful advice (Scholz 2021). We argue that efforts to customize content instead should induce positive perceptions about the value of followers’ relationships with the influencer, so the negative effect of indegree on their likelihood to engage with the influencer's content may diminish. Formally, we expect content customization to flatten the indegree–engagement likelihood curve by z, resulting in a revised model of engagement likelihood (see also Equation 3 and Figure 2, gray curves):

Brand familiarity
Endorsing a less well-known brand represents relational effort by the influencer, which may attenuate the negative effect of indegree on engagement likelihood, allowing large-indegree influencers to reduce their tie-strength deficit. First, followers might perceive endorsement of widely familiar brands as opportunistic, because it involves relatively low risk and screening efforts (i.e., the established reputation of familiar brands requires less vetting by the influencer) (Campbell and Keller 2003), but an endorsement of a lesser-known brand implies the influencer's motivation to share original content. Second, followers can infer that unknown brands have smaller advertising budgets (East 2019), so they might assume more genuine motives for the influencer's endorsement, instead of suspecting monetary incentives. Third, endorsing familiar brands can heighten the influencer's visibility or clout, so followers might suspect these motives, whereas such suspicions do not arise for unfamiliar brands. Therefore, endorsing lesser-known brands should help large-indegree influencers avoid sparking perceptions of weak tie strength. In line with our exposition in H2, we expect lower familiarity of the endorsed brand to flatten the engagement likelihood curve. A less negative quadratic term of indegree on engagement emerges such that lower brand familiarity flattens the inverted U-shaped relationship between an influencer's indegree and engagement. We formally hypothesize:
Overview of Empirical Strategy
Our empirical context pertains to influencers on Instagram, one of the largest social media networks, with more than 1 billion active users (Statista 2020), such that 93% of advertisers plan to use it for influencer marketing (Linqia 2021). To test our hypotheses, we adopt a two-pronged empirical strategy. First, in Study 1, we formally test H1–H3 with a large field study and observational data. Second, we validate the forces that underlie our conceptual framework in a series of five additional studies. In Study 2, using eye-tracking data, we confirm that users seek out indegree as a relevant cue to inform their motivation to engage with an influencer's sponsored content. In Study 3a, we demonstrate in a laboratory experiment that engagement likelihood decreases with indegree, as well as how this effect unfolds through tie strength. Study 3b bridges the laboratory results with findings from the field, showing that the engagement rates predicted in our lab data would lead to an inverted U-shaped relationship between indegree and engagement, as we theorize and observe in the field. We also identify conditions in which the U-shape would disappear. Then with Studies 3c and 3d, we test how campaign properties moderate the drop in engagement likelihood due to higher indegree. Table 2 summarizes our empirical approach, findings, and the sections in the Web Appendix that provide additional analyses and robustness tests.
Multimethod Empirical Strategy.

Evidence of an Inverted U-Shaped Relationship from the Field (Study 1)
Data Description and Sample
To test our framework with observational data, we need detailed information about engagement metrics and influencer information. Some of these data are not publicly visible (e.g., impressions, clicks) or not historically accessible (e.g., stories), might have been ex post manipulated by the influencer (e.g., deleted posts), and do not identify perfectly which content belongs to a given campaign. To circumvent these challenges, we resort to a proprietary data set, compiled from data supplied by five social media agencies that specialize in influencer marketing. The agencies differ in size, from small boutiques to one of the largest international social media agencies specializing in influencer marketing that officially partners with Instagram. These gathered data include information on 802 campaigns, randomly selected from the agencies’ campaign portfolios, and represent neither unusually successful nor unsuccessful campaigns in terms of generated engagement. The advertised brands represent different categories, including beauty, fashion, and jewelry, so the campaigns provide a representative set of categories advertised on Instagram (Businessnes 2019). The sample contains 6,422 posts and 6,178 stories from 1,738 influencers, published between 2017 and 2020. Altogether, this sponsored content generated substantial engagement, with more than 775 million impressions, more than 49 million likes, and over 1.4 million comments.
Measures
Engagement
We differentiate two types of engagement, related to interactions with either posts or stories, that are both highly relevant to marketers. For post engagement, we identify three indicators (likes, comments, and mentions) that are conceptually comprehensive and empirically available over time. We measure likes as the number of times users “liked” a post, comments as the number of times users commented on a post, and mentions as the number of times users were tagged by other users in comments on a post. All post indicators are measured up to two days after the posting, when the bulk of such engagement activity occurs. We view these three post engagement variables as reflective indicators of post engagement. This measurement approach has conceptual appeal, as the three engagement metrics are supposed to capture the same underlying motivation to engage with a post. It also aligns with industry practice that considers post engagement as the aggregate of various interactions, with the apparent assumption that they are interchangeable and substitute for one another in terms of capturing engagement with influencer content (Sprout Social 2022). In creating the composite measure of post engagement, as the average of the three standardized indicators, we also took several steps to establish the internal consistency and validity of our approach. The Cronbach's alpha of .83 exceeds the suggested threshold of .70. In a confirmatory factor analysis, the average variance extracted from our indicators (.55) and composite reliability (.79) exceed the recommended values of .50 and .70, respectively. Finally, all factor loadings are highly significant (p < .01) and surpass .60 (likes = .61, comments = .86, mentions = .77).
For story engagement, we identify clicks as relevant indicator. We measure clicks to capture how often users tapped on a link included in a story, which directed them to the advertiser's website. Stories disappear from the platform after 24 hours, so clicks are captured within 24 hours of the story's publication. While post engagement (likes, comments, and mentions) is publicly visible, clicks are private and only visible to the influencer. We winsorize all variables at the .01 level.
Influencer indegree
Our focal independent variable is influencer indegree, equal to the number of followers an influencer has on the date he or she published a specific post or story.
Campaign properties
For content customization, we conduct a textual analysis of the captions published in the posts to check for variations within the campaign. We identify each caption as a separate string and calculate the distance between strings using the Levenshtein distance metric, which relies on the fewest edits required to make one string match a second string. Then we average them across all posts within a campaign. Observations from campaigns that only include a single influencer take a value of 0.
We measure brand familiarity with YouGov's brand awareness score. YouGov is an established source of brand information, based on a large online consumer panel (Hewett et al. 2016). Small and less well-known brands are less likely to be monitored (Stäbler and Fischer 2020), so we assign brands we could not locate in YouGov the lowest possible awareness score to prevent the sample from being biased toward familiar brands. YouGov collects brand data on a daily basis; if no data are available for a date in our sample, we use the closest date available.
Control variables
We include a comprehensive set of control variables in our models to account for observable characteristics of posts and stories (e.g., number of hashtags), influencer demographics (e.g., gender), and prior influencer behavior (e.g., prior sponsored posts) that may affect engagement. Table 3 summarizes these measures; Web Appendix D offers a more detailed justification for their inclusion.
Variable Operationalizations.

Modeling and Estimation Approach
Model
Our empirical design relies on two engagement models:

To accommodate the dependence of content posted by the same influencer and within the same campaign, we adopt a hierarchical variance-component error structure with influencer- and campaign-specific intercepts, based on their respective mean, along with a random term distributed normally with mean 0 and constant variance. We estimate all equations using maximum likelihood estimation and robust standard errors to control for heteroskedasticity in the error terms.
Identification
Testing our hypotheses with observational data requires us to resolve an important endogeneity issue related to selection into treatment: advertisers might strategically select influencers to participate in a given campaign, a process whose details we cannot observe. To prevent potential selection bias associated with the decision to hire a specific influencer for a particular campaign, we employ a two-stage Heckman-type model, in which we first model influencer i's selection into campaign j. We specify this first-stage selection with a probit model that includes the campaign category, along with the influencer's prior average engagement rate, prior ratio of sponsored to nonsponsored posts, and audience gender distribution because industry practice suggests these factors are relevant drivers of influencer selection. Although the model could be identified by the nonlinearity of the correction term, adding an exclusion restriction reduces our reliance on the functional form for identification. We follow Hughes, Swaminathan, and Brooks (2019) and use the “most similar influencer included” as our exclusion restriction. The most similar influencer m of influencer i is the influencer with whom influencer i is most often paired in campaigns. The underlying logic is that an influencer selection strategy should be consistent within a campaign, and influencers that previously have been jointly selected likely share unobservable characteristics that drive their selection. By identifying whether the most similar influencer was also selected for the campaign, we can account for these unobservable characteristics. We track coappearances among all pairs of influencers, and, based on the highest frequency of joint participation, we determine the most similar match for a given influencer. We then create a “most similar influencer included” indicator variable equal to 1 if for influencer i a match m also participates in a given campaign. This variable should work as an exclusion restriction, because it relates to selecting influencer i into campaign j, but there is no reason to believe this choice should affect the level of engagement influencer i generates.
Employing the most similar influencer included as an exclusion restriction, we compute the inverse Mills ratio (IMR) and add it as a predictor in Equation 7. Table W2 in Web Appendix E provides the results of the first-stage probit selection model. The most similar influencer included is statistically significant in the selection model, but the IMR is insignificant in the second-stage models (Equation 7). Web Appendix E contains a complete description of our efforts to address endogeneity in the model-based selection into treatment (as summarized here) and for other aspects, such as omitted variables and simultaneity. All the analyses lend support to our identification strategy.
Descriptives of Sample
Table W3 in Web Appendix F provides the descriptive statistics and variable correlations. The influencers in our sample have an average indegree of 179,000, with substantial variation, ranging from 3,400 to 6,450,000 followers. We also observe ample variation in post and story engagement, and we note that variance in engagement is well explained by both influencer- and campaign-specific effects, in support of our hierarchical model choice. Specifically, according to the likelihood ratio test for between-campaign variance, in both models, we can reject the hypothesis that there is no variance across campaigns at standard significance levels (p < .01). The campaign-specific intraclass correlations range from .11 to .55, and, on average, 29% of the variance in engagement that cannot be explained by the covariates occurs due to unobserved campaign-specific characteristics. In terms of the moderators, our sample encompasses campaigns with varying degrees of content customization (ranging from 0 to 917) and brand familiarity (scores ranging from 0 to 96). Web Appendix G provides further model-free evidence.
Results
How influencer indegree affects engagement
We begin by examining the relationship between influencer indegree and engagement, as predicted in H1. Overall, the models are statistically significant and explain substantial variance; Column 1 in Tables 4 and 5 reports results. Variance inflation factors well below ten suggest that multicollinearity is not a concern. The significantly positive main and negative squared terms of indegree for both post (β1 = .715, p < .01; β2 = −.090, p < .01) and story (β1 = .414, p < .01; β2 = −.061, p < .01) engagement hint at support for H1. To ensure correct interpretations, we formally assess the significance of the inverted U-shaped relationship with the procedure outlined by Lind and Mehlum (2010). That is, we first compare the slope of the curve at low and high ends of the indegree data range (blow = β1 + 2β2Xlow; bhigh = β1 + 2β2Xhigh). For both post and story engagement, the slope is sufficiently steep at both end points and positive (negative) at the lower (higher) end of the data range. We then take the first derivative of Equation 7, set it to 0 to calculate the turning point (at −β1/2β2), and test whether the respective turning points for post and story engagement are located within our data range. On the basis of a 95% Fieller confidence interval, we find that the turning points lie well within our data range for both post (1,430,511) and story (1,253,392) engagement. In support of H1, influencer indegree has an inverted U-shaped effect on engagement.
Estimation Results for Post Engagement.
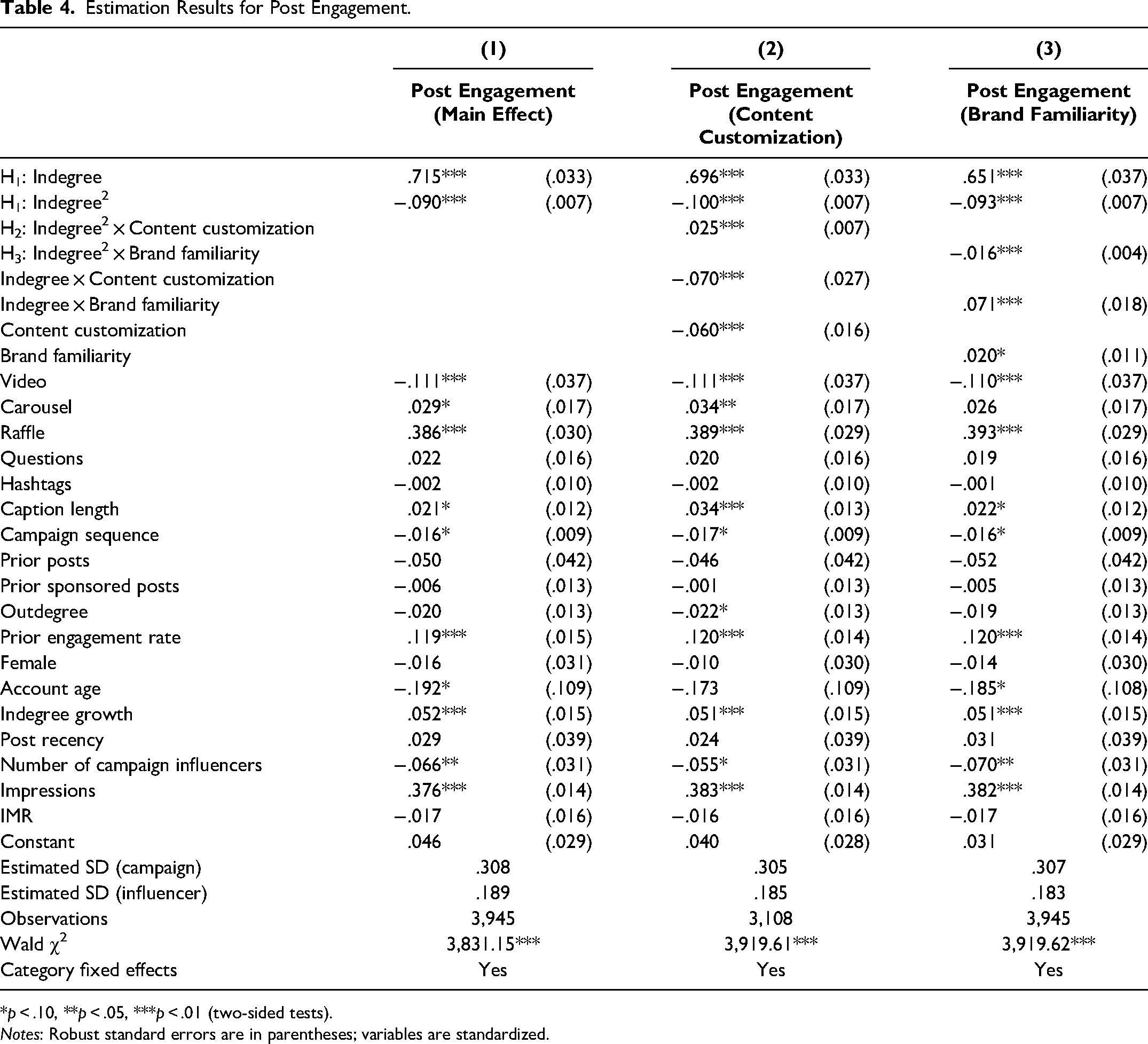
*p < .10, **p < .05, ***p < .01 (two-sided tests).
Notes: Robust standard errors are in parentheses; variables are standardized.
Estimation Results for Story Engagement.

*p < .10, **p < .05, ***p < .01 (two-sided tests).
Notes: Robust standard errors are in parentheses; variables are standardized.
Table 6 provides results using the three separate post engagement indicators. Similar to the composite measure, we observe inverted U-shaped relationships between indegree and engagement for all three indicators, verified by the significantly negative coefficients of β2 and the Lind and Mehlum (2010) test. The effects also are economically significant. On the left-hand side of the curve, for an average influencer with 178,983 followers and 6,059 likes per post, a 10% increase in influencer indegree leads to a 6.2% increase in likes (calculated by differentiating Equation 7 with respect to indegree and determining the elasticity from the marginal effect; e = .62). This effect translates into a considerable boost in engagement of 376 likes per post that is jeopardized as indegree increases. For an influencer with indegree of 2.5 million, conversely, we already note a decrease of 314 likes per post for a 10% increase in indegree.
Estimation Results for Individual Post Engagement Metrics.

*p < .10, **p < .05, ***p < .01 (two-sided tests).
Notes: Robust standard errors are in parentheses; variables are standardized.
How campaign properties moderate the effect of influencer indegree on engagement
Turning to the moderating effects of the two campaign properties, we present the regression results in Columns 2 and 3 in Table 4 for post engagement and Table 5 for story engagement. The proposed models show improved fit compared with the main effect models. To test H2 and H3, we address the interaction between squared indegree and each moderator, where a positive (negative) coefficient for content customization (brand familiarity) supports our prediction. Adding all lower-order interaction terms simultaneously can mask potential contingency effects (Criscuolo et al. 2017) and lead to an overburdened model with unstable parameter estimates (Cohen et al. 2003), so we examine each moderator model separately (e.g., Van Heerde et al. 2013).
In line with our expectations for H2, we find a weakening moderating role of content customization for both post (β3 = .025, p < .01) and story (β3 = .049, p < .01) engagement. Then, as predicted in H3, less familiar brands also weaken the inverted U-shaped relationship for post (β3 = −.016, p < .01), though not for story (β3 = .026, n.s.), engagement. We plot the moderating effects for content customization and brand familiarity in Figure 3.
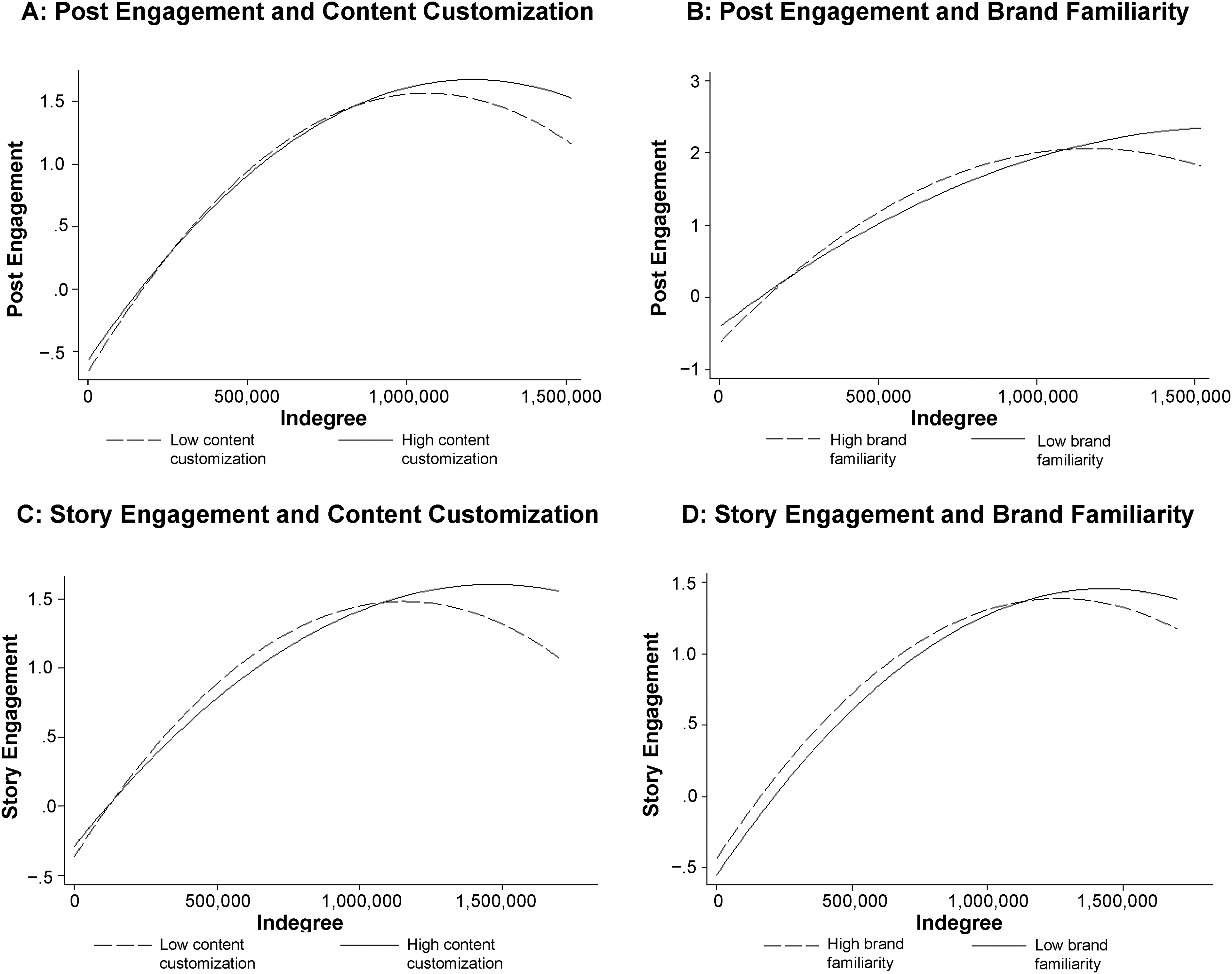
Fitted Quadratic Interaction Plots for Campaign Properties.
In addition, we test for a shift in the turning point induced by the moderators, which would represent a distinct type of moderation of the inverted U-shaped relationships (Vomberg, Homburg, and Gwinner 2020). Following Haans, Pieters, and He (2016), we take the derivative of Equation 7 with respect to indegree, set it to 0, and then take the derivative of this equation with respect to moderator k. In the resulting expression (β1β3 − β2β4)/[2(β2 + β3k)2], β1 is the slope for indegree, β2 is the slope for squared indegree, β3 is the slope of the interaction between indegree and campaign property k, and β4 is the slope of the interaction between squared indegree and campaign property k. Therefore, higher (lower) levels of campaign property k = content customization (k = brand familiarity) shift the turning point to the right when the equation's numerator is positive, and the expression as a whole is significantly different from 0. Using content customization values at one standard deviation above the mean indicates a significant rightward shift for post (p < .01) and a marginally significant rightward shift for story (p < .10) engagement. For brand familiarity at one standard deviation below the mean, we find that the turning point significantly shifts to the right for post (p < .01) but not for story (n.s.) engagement.
Robustness Tests
To ensure the validity of our results, we perform several robustness tests, which corroborate our findings (see Web Appendix H for more details). For example, we find no systematic differences across the five data providers whose data we pool. We also confirm that our hierarchical model structure is well-chosen and that the results are robust to other forms of campaign-specific effects. In addition, we demonstrate the robustness of our findings when employing alternative measures for several control variables and both campaign-related moderators. We report the results of estimating Equation 7 with both campaign moderators and their respective lower-order interaction terms too. Moreover, we show that our results hold using relative indegree in a campaign, instead of absolute indegree as we do in the main analysis. Beyond these robustness tests, we explain why we are not concerned that our findings might be an artifact of the platform's algorithm in Web Appendix I. Table 7 summarizes our efforts in this regard.
Overview of Robustness Tests of Field Study (Study 1).

Evidence for the Forces Underlying the Inverted U-Shaped Relationship (Studies 2 and 3)
Building on the results from the field, in Studies 2 and 3, we shed more light on the mechanism proposed in our conceptual framework. We focus on the negative relationship between influencer indegree and engagement likelihood across a series of five experimental studies. To this end, we first establish evidence that followers rely on indegree to determine their engagement likelihood (Study 2). Next, we show that engagement likelihood decreases in indegree and how, according to a mediating effect through perceived tie strength (Study 3a). We then link the experimental data from the lab with the observational data from the field to determine the conditions in which the inverted U-shaped relationship between indegree and engagement exists (Study 3b). Finally, we seek further insights into the moderating effects of the campaign properties content customization and brand familiarity (Studies 3c and 3d).
Study 2: Indegree as a Relevant Cue to Inform Engagement Likelihood
To establish the link between influencer indegree and engagement likelihood, we first validate whether users rely on indegree information to determine their motivation to engage with an influencer's sponsored content. For this test, we employ novel eye-tracking technology that allows for remote, browser-based data collection through participants’ webcams (Labvanced 2022). With a between-subjects, repeated-measure experimental design and a sample of 87 Instagram users (Mage = 26.1 years; 49.4% women) whose calibration error was below the threshold recommended by the software provider, we test whether asking participants to evaluate their likelihood to engage with an influencer's sponsored content leads them to direct their visual attention more to information about the influencer's indegree (focal area of interest) than does asking them simply to inspect the influencer's profile. As eye-movement metrics, we gauge eye-fixation frequency, which we measure as the share of gazes on the area of interest compared with all gazes, and first-pass dwell time, which is the sum of fixation durations during the first visit to the area of interest. Thus, we use both a frequency- and a duration-based measure to most comprehensively capture visual attention (Hong, Misra, and Vilcassim 2016; Stewart, Pickering, and Sturt 2004; Van der Lans and Wedel 2017).
Before presenting participants with four profiles of real Instagram influencers, in the treatment group, we asked them to consider their likelihood to engage with sponsored content from the respective influencer (by liking, sharing, or commenting). In the control group, we asked them to inspect the profile as they would normally do on Instagram, without any additional instructions. Participants then viewed each profile for 15 seconds, during which we recorded their eye movements. Leveraging the panel nature of our data (four measurements per participant), we estimated two random-effects models, one for each eye-movement metric, with a treatment group dummy variable as the focal regressor (see Web Appendix J for more further details). In the eye-fixation frequency model, the coefficient of the treatment dummy is significantly positive (β = .013, p = .043), indicating that participants treated with the engagement likelihood question devote significantly more attention to information about the influencer's indegree. In the first-pass dwell time model, the treatment dummy is significantly positive as well (β = 63.962, p = .039), so participants also remain fixated on the indegree information for longer. The results are qualitatively equivalent when we account for the confidence level of gazes, thus reducing the influence of blinks or saccades (Labvanced 2022; Van der Lans and Wedel 2017). These exploratory findings suggest that influencer indegree is a relevant cue that informs users’ engagement likelihood.
Study 3a: Engagement Likelihood Decreases in Indegree
In an online laboratory experiment, we manipulate influencer indegree to establish, in controlled conditions, that engagement likelihood decreases with indegree, as well as demonstrate how indegree affects engagement likelihood through perceived tie strength, as Figure 4 depicts.

Process Conceptualization Underlying H1.
Participants and design
We used a between-subjects design to test how low-, medium-, and high-indegree conditions drive engagement likelihood, with data from 151 Instagram users (Mage = 33.1 years; 59.6% women) who passed an attention check. Participants had to imagine following an influencer with low, medium, or high indegree, then rate their likelihood to engage with sponsored content from this influencer. In addition, participants completed measures of the mediators.
Procedure and measures
To establish shared understanding, we provided participants with a brief introduction to influencer marketing. Then, to encourage their immersion in the scenario, we presented profile pictures of two fictitious influencers, “its.me.sophie” and “lea.la.vida,” and asked them to follow one of them. Participants next saw an alleged excerpt from the chosen influencer's Instagram profile (Web Appendix K.1), presented as an influencer with low (“3,148 followers”), medium (“220K followers”), or high (“3.1M followers”) indegree. Participants were also told that, today, a sponsored post from the influencer appeared in their feed. Participants rated their likelihood to engage with the post with the item, “How likely would you be to engage with the post you imagine seeing from [influencer] (e.g., by liking it, or commenting on it)?” (1 = “very unlikely,” and 7 = “very likely”). For the test of the mediating mechanism, we asked participants to assess the perceived strength of their tie with the influencer with three items, “I would feel close to [influencer],” “My tie to [influencer] would be strong,” and “I would feel very familiar with [influencer]” (α = .93), adapted from Mittal, Hupperts, and Khare (2008) and evaluated on seven-point scales (1 = “strongly disagree,” and 7 = “strongly agree”). To test for alternative mediators, we captured further measures (Web Appendix K.1). Participants also provided demographic information.
Results
A one-way analysis of variance (ANOVA), based on the item “Approximately how many followers does [influencer] have?” (1 = “<10,000,” and 7 = “>3,000,000”), reveals a significant difference between the experimental conditions (F(2, 148) = 1,199, p < .001). According to post hoc Tukey significance difference tests, participants in the low-indegree condition rate the influencer's indegree lower (M = 1.12, SD = .71) than those in the medium-indegree condition (M = 3.74, SD = .69; p < .001), whose ratings in turn are lower than those in the high-indegree condition (M = 6.92, SD = .27; p < .001). Moreover, for low-indegree influencers, engagement likelihood is higher (M = 4.24, SD = 1.95) than for high-indegree influencers (M = 3.22, SD = 1.91; p = .022), and engagement likelihood for medium-indegree influencers lies between these values (M = 3.90, SD = 1.84). In Web Appendix K.1, we provide further evidence for the monotonicity and linearity of this negative relationship using a complementary within-subjects study.
With respect to the proposed process, tie strength perceptions are higher for low-indegree influencers (M = 3.52, SD = 1.68) than for high-indegree influencers (M = 2.64, SD = 1.24; p = .011). The perceptions for medium-indegree influencers again lie in between these values (M = 2.99, SD = 1.60) and do not differ from either low- (p = .183) or high- (p = .491) indegree influencers. We also test the process with groups, based on low- and high-indegree influencers (Kerlinger 1973). In the mediation analysis, perceived tie strength is the focal mediator, engagement likelihood is the dependent variable, and indegree is the independent variable. We use a bootstrap estimation approach with 5,000 bias-corrected samples (Hayes 2013, Model 4). In line with the proposed framework, we observe a significant indirect effect (b = −.73, SE = .23, 95% confidence interval [CI] = [−1.23, −.29]), and the direct effect of indegree on engagement likelihood becomes insignificant (b = −.29, SE = .31, p = .360), indicating total mediation.
Additional evidence
To bolster confidence in our results, we examine several alternative mediators. For example, indegree could serve as a cue of an influencer's social status (Lanz et al. 2019) or expertise (Iyengar, Van den Bulte, and Valente 2011), which may affect followers’ engagement likelihood. In addition, indegree could be associated with perceptions of homophily (Hughes, Swaminathan, and Brooks 2019) or in-group homogeneity (Leach et al. 2008), activate persuasion knowledge (Karagür et al. 2022), or render an influencer more or less likeable (De Veirman, Cauberghe, and Hudders 2017). In Web Appendix K.1, we present a detailed discussion of how we test these and further alternative mediators. Tie strength remains the dominant mediator even when controlling for alternative mediators.
Study 3b: Complementarity of Results from the Lab and Field
To bridge the findings of our laboratory study with the results from the field, we next investigate whether the effect of indegree on engagement likelihood, as identified in the lab, would result in the inverted U-shaped relationship we theorized and found in the field. Using our laboratory data, we calculate engagement rates for influencers with low and high indegree (see Web Appendix K.2), then derive engagement rates for the indegree values in between, and finally predict engagement by multiplying calculated engagement rates and reach over the range of indegree we observe in our field data. Results indicate an inverted U-shape between indegree and engagement. In Web Appendix K.2, we also simulate alternative scenarios to define the conditions in which the inverted U disappears.
Study 3c: Content Customization Moderates Engagement Likelihood
To support our argument that the weaker effect of indegree on engagement with higher content customization is driven by a weaker relationship between indegree and engagement likelihood, we use a 2 (indegree: low vs. high) × 2 (content customization: low vs. high) between-subjects experiment (see Web Appendix K.3 for details). We adapted the setup from Study 3a, such that in the low customization condition, the influencer's post ostensibly aligns with how other influencers write about the brand. In the high-customization condition, the influencer writes about the brand in their own unique words, unlike how other influencers in the campaign write about it. The results of an ANOVA, based on responses from 502 Instagram users (Mage = 31.0 years; 50.8% women) who followed at least one influencer in reality and passed attention checks, reveal a significant interaction effect (F(1, 498) = 3.91, p = .049). In the low-customization condition, participants in the low-indegree condition (M = 4.13, SD = 1.53) report significantly greater engagement likelihood than participants in the high-indegree condition (M = 3.24, SD = 1.80; F(1, 498) = 17.78, p < .001). In the high-customization condition, however, participants in both the low-indegree (M = 4.13, SD = 1.70) and high-indegree (M = 3.83, SD = 1.73; F(1, 498) = 1.86, p = .173) conditions report similar engagement likelihood. These results suggest that content customization can weaken the negative effect of indegree on engagement likelihood and thereby help explain the Study 1 results.
Study 3d: Brand Familiarity Moderates Engagement Likelihood
To investigate the moderating effect of brand familiarity, we employ another 2 (indegree: low vs. high) × 2 (brand familiarity: low vs. high) between-subjects experiment (see Web Appendix K.4). In this study, we adapted the setup from Study 3a, such that in the low-brand-familiarity condition, the influencer endorses a brand that ostensibly not many people were aware of, and in the high-brand-familiarity condition, many people are aware of the brand. The results of an ANOVA, reflecting input from 484 Instagram users (Mage = 31.4 years; 50.0% women) who followed at least one influencer in reality and passed attention checks (these also exclude four outliers based on Cook's d, following Keller, Dekimpe, and Geyskens [2016]), reveal a marginally significant interaction effect (F(1, 480) = 3.33, p = .069). In the high-brand-familiarity condition, participants in the low-indegree condition (M = 3.92, SD = 1.76) report significantly higher engagement likelihood than participants in the high-indegree condition (M = 3.22, SD = 1.74; F(1, 480) = 9.62, p = .002). In the low-brand-familiarity condition, however, participants in the low-indegree (M = 4.00, SD = 1.65) and high-indegree (M = 3.87, SD = 1.86; F(1, 480) = .33, p = .568) conditions report similar engagement likelihood. These results help shed further light on the finding from Study 1 that lower brand familiarity weakens the effect of indegree on engagement.
General Discussion
Theoretical Contributions
With this novel consideration of the effectiveness of influencers, we offer a framework that links influencer indegree to overall engagement levels, which is well warranted. While studies of indegree in social networks are well developed, especially in relation to seeding strategies, evidence of the role of indegree in influencer marketing, as a distinct type of social media tactic, is sparse. Therefore, we lay out a detailed framework that combines reach and engagement likelihood, two forces with countervailing effects driven by indegree, and show how both forces interact and produce the unique pattern of an inverted U-shape.
A building block of this framework is the idea that indegree serves as a cue that followers use to gauge their relationship with influencers. This perspective on cue utilization is emerging in social media literature (Valsesia, Proserpio, and Nunes 2020), and it provides a pertinent theoretical angle for explaining our findings and assessing online relationships in general (Meyners et al. 2017). In social networks, connections must turn to external information to compensate for the lack of nuanced information, as typically would be exchanged in offline relationships. Without interactions that help determine the strength of the relationship, publicly visible cues like indegree become considerably more important for judging the quality of the tie. We focus on cue utilization effects, but this theoretical perspective does not preclude a parallel route, in which indegree also relates to engagement through assessments of the actual observed (or experienced) influencer–follower relationship. Another indirect route also might be activated when higher indegree leads to greater audience heterogeneity, which may decrease followers’ engagement likelihood, as it becomes more difficult for the influencer to tailor content to the more diverse interests of a larger audience.
Moreover, noting that relationships are universal, powerful pillars of influencer marketing, we offer a theoretical account of their mediating role through tie strength. We theorize and find that perceived tie strength is the dominant mechanism through which indegree affects engagement, highlighting the importance of managing relationship perceptions and underscoring the motives for users to participate on social media platforms.
By introducing content customization and brand familiarity as moderators that help elevate users’ perceptions of how influencers commit to their follower relationships, which enhance followers’ likelihood to engage, we offer unique insights into how large-indegree influencers might suffer from tie strength deficits. These compensatory effects add important nuance to extant literature on cue effects of influencer network characteristics in social media (e.g., Valsesia, Proserpio, and Nunes 2020).
Another interesting outcome of our framework involves supersaturation effects of indegree. While prior research questions its existence in traditional advertising or distribution settings (Hanssens, Parsons, and Schultz 2001), first applications in online advertising (e.g., Chae, Bruno, and Feinberg 2019) suggest the risk of supersaturation in digital settings. We add to this discussion by showing that influencer marketing represents another context in which such effects can arise.
Substantive Contributions
Evidence-driven insights into the effectiveness of influencer indegree
Our results should be of value to managers, because they rest on rigorous analyses and reliable data. The ease with which publicly available engagement metrics such as likes and comments can be scraped from social platforms has led to a surge in descriptive practitioner studies. Such data sourcing, however, limits the analytical scope to public post engagement and does not account for the increasingly relevant stories channel. These data also might create biased results if influencers retain only a curated set of posts on their profile, while deleting other, possibly less successful, posts. This bias might lead to positively distorted views about influencer effectiveness. In our data, we find that 21% of posts were deleted from profiles, some shortly after the original posting. In a series of two-sample t-tests, we confirm that the deleted posts evoke significantly lower engagement, in terms of likes and comments, than the posts that remained on profiles, suggesting that influencers optimize their profile with regard to engagement metrics visible to users and advertisers.
Inverted U-shaped effect of influencer indegree on engagement
We inform the ongoing debate about whether advertisers should contract with influencers with an enormous following or those with very few followers (Maheshwari 2018). In contrast with popular views, our finding of an inverted U-shaped relationship between indegree and engagement suggests that influencers with intermediate indegree represent the engagement “sweet spot” as they provide a decently large, still engaged audience. Depending on the engagement metric, we observe turning points between 1,124,221 followers (mentions) and 1,877,936 followers (likes).
Leveraging campaign properties
Our results also can help inform decisions about whether to orchestrate a consistent image in endorsed content across the campaign or to grant influencers creative freedom and autonomy in creating content. Marketing literature recommends consistent customer experiences across all potential touchpoints (Homburg, Jozić, and Kuehnl 2017) and commonality across communication options to facilitate recall (Keller and Swaminathan 2020). Our findings contrast this view for influencer marketing and suggest that brand managers need to allow for some degree of inconsistency across influencers, to prevent perceptions of weak relationships that can jeopardize the influencer's effectiveness. In the spirit of Heide, Wathne, and Rokkan (2007), who caution that behavioral monitoring can induce reactance and opportunistic behaviors, we recommend that brands should empower especially high-indegree influencers to create original content in their own style, instead of repeating the brand's official communications.
Our results further challenge prevalent views on how certain campaign properties favor collaborations with influencers with different indegree. For example, the inverted U-shape between indegree and engagement flattens for lesser-known brands, so they have more leeway to work with larger-indegree influencers, because concerns about low tie strength can be kept at bay. But well-known, mainstream brands do not allow for such benefits, so they should contract with influencers with neither too few nor too many followers to maximize engagement. This suggestion contests the often-observed collaborations between well-known brands and influencers with extremely large indegree; we recommend that large-indegree influencers expand their partnerships with lesser-known brands to enjoy mutual benefits.
Post hoc analysis for managerial decision making
Our findings provide meaningful implications in terms of the monetary consequences of influencer marketing. To illustrate these effects, and using likes as a representative engagement metric, we calculate the total number of likes and cost per like for a fixed campaign budget. That is, we assume a budget of $50,000, one of nine types of influencers with varying indegree from 10,000 to 3 million followers, and a contractual agreement of one post per influencer. We use Equation 7 to predict likes per post for each of the nine types of influencers we consider. To estimate influencer cost per post, we leverage cost data from one of our data providers, such that we can estimate this value as a function of influencer indegree and simulate the cost per post for each influencer type. We begin by assuming uniform management costs of $1,000 per influencer to account for the effort needed to acquire, instruct, advise, and monitor an influencer—an appropriate amount according to our interview partners. We also consider another scenario, with an additional management cost premium of $1,000 for influencers with low (10,000 followers) and high (≥1 million followers) indegree, as some of our interviewees highlighted the additional resources needed to coordinate and instruct inexperienced low-indegree influencers (see also Haenlein et al. 2020) or compensate high-indegree influencers for their celebrity status. We then compute how many influencers could be contracted for the campaign and the total number of posts the campaign would feature. Finally, we predict the resulting total number of likes and corresponding cost per like.
Figure 5 shows the results. In both management cost scenarios, the maximum number of likes and the lowest cost per like materializes from working with influencers with indegree between 100,000 and 500,000 followers. With a uniform management cost assumption, a campaign composed of many influencers with very low indegree (10,000 followers) is about as efficient as a campaign composed of a few influencers with high indegree (1 million followers). However, applying the more realistic cost assumption with higher management costs for influencers with very low and very high indegree, we observe a substantially steeper slope at the left-hand side of the curve (between 10,000 and 50,000 followers), whereas the right-hand side (≥1 million followers) remains largely unaffected. The efficiency of a campaign composed of influencers with very low indegree drops to match the level achieved by a campaign composed of influencers with about 2 million followers.
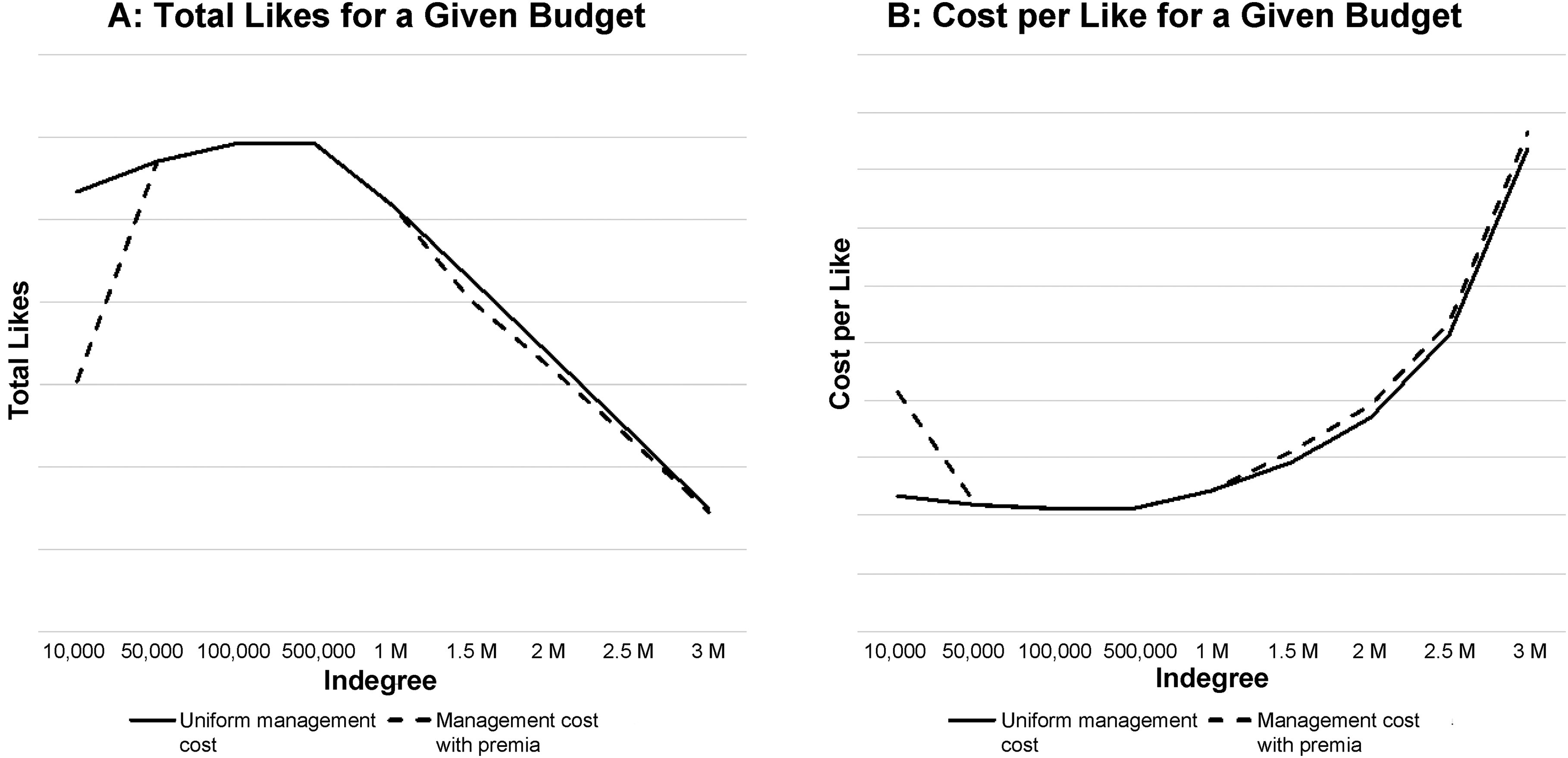
Post Hoc Analysis for Likes.
These results provide an economic intuition for influencer effectiveness; they also offer important insights into campaign management. While our main analyses occur at the sponsored-content level, the campaign-level calculations also account for differences in cost per post across influencers with different indegrees and highlight the economic benefits of influencers with an indegree that lies between the often-recommended very small and very large influencer tiers.
Limitations
Our work provides important advances to extant literature, but it is not without limitations that serve as opportunities for further research. First, in our field data, we cannot observe whether the same or different users account for engagement with sponsored content. We have no reason to believe that users might systematically spread their engagement behavior over different metrics, but continued research might obtain individual-level data to study such effects. Second, our framework assumes followers’ active participation, but existing segments of users use social media only passively, without any intention to engage, and their decision to follow influencers might unfold differently in relation to the influencers’ indegree. Third, the engagement we gauge occurs within 24 hours for stories and 48 hours for posts, but we have no insights into the actual timing of when engagement occurs. To advance our work, further research might study the speed of engagement. Fourth, continued research should address the role of indegree on other social media platforms with different goals, such as business-focused networks (e.g., LinkedIn). Fifth, while we investigate indegree as a cue that followers use to assess the strength of their tie with the influencer, some followers might have also personally interacted with an influencer. Further research could investigate how responding to messages or tagging followers in posts may affect the potency of the indegree cue for these individuals.
Supplemental Material
sj-pdf-1-jmx-10.1177_00222429221125131 - Supplemental material for Finding Goldilocks Influencers: How Follower Count Drives Social Media Engagement
Supplemental material, sj-pdf-1-jmx-10.1177_00222429221125131 for Finding Goldilocks Influencers: How Follower Count Drives Social Media Engagement by Simone Wies, Alexander Bleier and Alexander Edeling in Journal of Marketing
Footnotes
Acknowledgments
The authors gratefully acknowledge the collaboration on this research with Earnesto, Liebermann Communications, Reachbird, Styleranking Media, and two anonymous social media agencies, and thank YouGov for providing access to their BrandIndex database. The authors are indebted to Christian Barrot, Abhishek Borah, Marnik Dekimpe, Marc Fischer, Zeynep Karagür, Alexander Mafael, Dominik Papies, Koen Pauwels, Werner Reinartz, Christian Schäfer, Christian Schulze, and Arnd Vomberg for their helpful comments on earlier versions of this manuscript. They also appreciate the valuable input from conference and seminar participants and thank Oliver Link and Lisa Zäuner for excellent research assistance.
Associate Editor
Jacob Goldenberg
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.