
Abstract
Despite growing work on conflict forecasting, few studies predict conflict termination and none negotiation outcomes. We address this gap, assessing how well we can predict peace agreement content using conflict dynamics – particularly, insurgent distance from the capital. Thus, our study evaluates the predictive power of long-standing arguments in peace research, suggesting that conflict dynamics determine the prospects of negotiations. Utility theory posits that actors learn about their relative strength through conflict events and update their demands in negotiations accordingly. Ergo, actors’ demands become more compatible with increasingly similar perceptions of relative capability. Scholars often proxy relative strength using insurgent distance from the capital, as it holds information on their ability to win battles. We evaluate whether battle locations predict agreement content using PA-X data. We find that a simple, theory-driven model performs almost as well as more complex, data-driven models. Nevertheless, models excluding conflict dynamics also have comparable predictive power.
Introduction
Forecasting has received increasing attention in peace research in recent years, but only a few studies assess if we can forecast conflict management or conflict resolution out-of-sample (Clayton and Gleditsch 2014; Mitchener et al. 2015; Montoya and Tellez 2020; Ruhe 2015). Most current work focuses on forecasting civil conflict onset or civil war violence (Chiba and Gleditsch 2017; Hegre et al. 2019; Hultman et al. 2022; Weidmann and Ward 2010). Surprisingly, to our knowledge, no study forecasts what agreement content, that is, which provisions, 1 we should expect if actors decide to sign an agreement. Yet, forecasting agreement content matters because specific provisions in agreements distinguish stable peace settlements from settlements that falter quickly (Badran 2014; Mattes and Savun 2009). Hence, it can inform forecasts of (renewed) conflict onset and intensity, while also indicating to, e.g., mediation teams which compromises are possibly within reach.
This paper addresses this research gap and investigates if and how well we can forecast peace agreement content using conflict events, based on the established theoretical claim that battlefield dynamics determine conflict resolution. Out-of-sample forecasting accuracy has been labelled the “gold standard for model assessment” (Beck et al. 2000, 22). Our analysis compares the predictive power of a theoretically justified structural model with increasingly flexible machine learning models. Beyond insights on peace agreements, our empirical approach allows us to evaluate if machine learning can improve theoretical insights, empirical model specification, and forecasting accuracy in this domain.
In our study, we zoom in on whether the location of fighting predicts how likely agreements contain various provisions. We specifically focus on the distance of battles to the capital, a prominently used proxy variable for the relative strength of adversaries in civil conflicts (Buhaug et al. 2009; Greig 2015). Relative strength, in turn, is a core theoretical concept in both expected utility explanations of conflict outcome (Mason and Fett 1996), the bargaining model of war (cf. Reiter 2003), and the latter’s historical and theoretical roots (Blainey 1988; Clausewitz 1980). Hence, several studies have used distance measures to explain or predict conflict management and outcome (Greig 2015; Greig et al. 2018; Ruhe 2015). We expand this literature and assess how well distance predicts agreement content.
Although social science theory implies that distance is a relevant predictor, the existing theory is not specific enough to indicate an adequate operationalisation and model specification. Recent work argues that more flexible machine learning solutions can fill this gap left by theory. They can select variables from a more extensive list of (potentially correlated) alternatives and flexibly specify a functional form that maximises out-of-sample accuracy (cf. Beger et al. 2021; Fariss and Jones 2018). Our study builds on and contributes to these recent discussions of theories’ role in conflict forecasting (cf. Beger et al. 2021; Blair and Sambanis 2020; Cederman and Weidmann 2017).
We derive a theoretically plausible OLS regression model of how distance is linked to peace agreement content and compare its out-of-sample performance against alternative elastic net models with increasingly large and flexible sets of predictor variables. Our models predict actors’ latent willingness and ability to make concessions (compromise propensity) (Ruhe et al. 2024), which subsequently predicts compromise on individual provisions. We rely on dyadic data of all peace agreements coded by the PA-X database (Bell et al. 2021) between 1990 and 2021, and evaluate how well we can predict the content of peace agreements in one dyad-quarter based on available information from the previous quarter year.
In the next section, we review the relevant literature. After that, we explain theoretically how conflict dynamics, specifically the geographic location of fighting, may be linked to actors’ willingness to make concessions and how this compromise propensity should manifest itself in agreement content. The subsequent sections describe our empirical research design, and discuss our findings.
Prediction and Explanations of Peace Process Outcomes
While prediction has received a lot of attention in peace research more generally, the prediction of conflict outcomes and dynamics of peace processes is still rather unknown territory. This is surprising, given how relevant these outcomes are for conflict recurrence risks and, thus, also forecasts of (renewed) conflict onset or dynamics. To our knowledge, there are only five studies attempting to predict different facets of ending conflicts. Two strive to predict different war outcomes, one using conflict dynamics suggested to be relevant by utility theory (Mason et al. 1999), the other using market data (Mitchener et al. 2015). More closely related to peace processes, Clayton and Gleditsch (2014) and Ruhe (2015) attempt to predict mediation onset, while Montoya and Tellez (2020) focus on public opinions on peace negotiations.
Nevertheless, prediction has received a lot of attention in peace research more generally, with a particular focus on forecasting conflict onset and civil war violence. However, there has been a ubiquitous divide between studies that use more classical structural methods (Chiba and Gleditsch 2017; Daxecker and Prins 2017; Hirose et al. 2017; Weidmann and Ward 2010) and a growing number that use different types of machine learning (Dorff et al. 2022; D’Orazio et al. 2019; Hegre et al. 2019; Malone 2022; Hultman et al. 2022; Mueller and Rauh 2022). Usually, the respective choice in method is driven by the authors’ goals. We can loosely classify goals in prediction in two categories. Firstly, using prediction as a means to test theories. And secondly, building a model that predicts out-of-sample as accurately as possible. For the former, scholars more frequently use structural models, as they are easily interpretable. For the latter, machine learning methods are more common, as their ability to “learn” patterns underlying the data and flexibility in model structure is assumed to allow for more accurate predictions. The studies predicting conflict ends mirror these usual applications: Mitchener et al. (2015), Clayton and Gleditsch (2014), and Ruhe (2015) use classical structural methods for theory testing, while Montoya and Tellez (2020) use random forests to maximise their model’s predictive power.
However, recently this separation in application has been called into question, which has led to some controversies between proponents of the two approaches, especially between Blair and Sambanis (2020) and Beger et al. (2021). Blair and Sambanis (2020) advocate the use of theoretically motivated, more restrictive models for prediction, arguing that theory-driven models outperform data-driven models in their predictive accuracy. This expectation has similarly been stated by Chiba and Gleditsch (2017) and Cederman and Weidmann (2017). Meanwhile, Beger et al. (2021) propose using machine learning methods in order to allow more flexibility in the model than the “linear additive equations that dominate published regression analyses” (Beger et al. 2021, 1422). They argue that machine learning methods are not a choice against theory, as the choice of explanatory variables will always be theory-driven. On the contrary, they propose using machine learning for theory-testing when the theory does not imply a particular model specification, as the usual linearity assumption does not necessarily hold (Beger et al. 2021). In this paper, we systematically test the boundaries of both types of models. On the one hand, we examine how far theoretically defined structural models can take us in terms of predictive power. And on the other hand, we test the applicability of more flexibly defined elastic nets to theory testing. We apply these tests to the topic of peace agreement content, which has received little scholarly attention as a prediction topic. Methodologically, our study complements the debate between Blair and Sambanis (2020) and Beger et al. (2021) by assessing a case with smaller N, typical for numerous topics in peace and conflict research.
Beyond the conflict forecasting literature, our prediction efforts hold substantive insights for the broader literature on conflict outcomes, which has examined the end of fighting (Brandt et al. 2008), the occurrence of settlements (McKibben and Skoll 2020), agreement comprehensiveness (Williams et al. 2021), agreement design (Cil and Prorok 2020), and success or failure to achieve peace (DeRouen et al. 2009; Mattes and Savun 2010; Reid 2017). In this literature, numerous theoretical arguments link conflict dynamics to negotiations and peace settlements. Especially, battle locations have been theorised to explain the probability of negotiations and peace agreements (Buhaug et al. 2009; Gaku and Hinkkainen Elliot 2020; Greig 2015; Hultquist 2013). The argument being that battle dynamics are strongly related to the conflict parties’ relative strength, which drives how willing they are to negotiate and sign a peace agreement (Greig 2015; Ruhe 2015). While this argument implies that battle dynamics can explain how willing and able actors are to make concessions, it has not been used to predict the content of peace agreements.
We focus on battle-field information as a prominent, time-varying predictor of violence. Yet, of course, conflict events are not the only time-variant explanation of conflict resolution. Authors have also turned towards the role of rebels’ intra-group dynamics in negotiations. For example, insurgent cohesion (Ogutcu-Fu 2016), leadership overturns both in governments (Ryckman and Braithwaite 2020) and in rebel groups (Cunningham and Sawyer 2019; Lutmar and Terris 2016) influence the probability of negotiations and signed agreements. However, such information is usually hand-coded and therefore available only for limited periods of time. As informations on battle dynamics are much more quickly available, this data allows predictions nearly in real-time. We therefore concentrate on this type of conflict information.
We combine information on battle dynamics with structural variables. These are slow-changing and therefore usually available, and have shown to add power to predictive models in other domains of conflict research (Beger et al. 2021; Chiba and Gleditsch 2017). We can identify a range of such structural covariates that may be relevant for conflict duration and outcome. For example, the duration of civil wars is affected by the natural resources present in the conflict regions (Buhaug et al. 2009; Lujala 2010; Ohmura 2018). Regime type (Phayal et al. 2019), the number of insurgent organisations (Nilsson 2010) and state capacity (DeRouen et al. 2010) influence the conflict outcome. Moreover, international involvement affects the probability of negotiations and peace agreements in intrastate conflicts (Karlén 2020; Maekawa 2019; McKibben and Skoll 2020).
Overall, our contribution is twofold: Firstly, we test the predictive power of battle dynamics on peace agreements, and secondly, we evaluate if more flexible models improve accuracy in this domain of conflict research. We test a range of models, with different degrees of pre-determinedness in both the included predictors and functional form. We do so by starting with a theoretically motivated OLS model, move on to different linear elastic net models with varying additional variables. As we are interested in the predictive power of battle dynamics, the more restrictive models are strongly driven by theoretical expectations we derived from literature. In the later, more flexible models, we include the same, theory-driven predictors, but allow for more flexibility in interactions, and let the algorithm choose which predictors minimise cross-validation error. In doing so, we systematically examine which model fares better in terms of prediction and whether theoretically specified mechanisms are reflected similarly in the more flexible as well as the restrictive models. Theoretically, our results provide insights how helpful utility theory is in predicting peace agreement content. We thus test the power of advanced methods against simpler, theoretically motivated baseline models, as proposed by Cederman and Weidmann (2017), and use machine learning for theory testing (Beger et al. 2021).
Predicting Agreement Content With Battlefield Events
A wealth of theories posits how conflict dynamics explain negotiations and peace settlements. As they capture the effect of strongly time-varying factors, we expect these theories to help predict variation in the content of peace agreements. Our theoretical argument is structured as follows: First, we outline how battlefield information, specifically the distance of fighting from the capital, should reveal relative strength and shape actors’ propensity to make concessions, a latent variable that we can measure as outlined in our research design. Second, we discuss how this latent compromise propensity predicts peace agreement content, i.e. agreements’ specific provisions. Figure 1 visualises this framework. Our theoretical expectation: We theorise battle dynamics, particularly insurgent distance from the capital, to influence compromise propensity, which in turn explains agreement content.
Battlefield Information and the Actors’ Propensity to Make Concessions
The dominant theoretical perspective explains conflict outbreak with uncertainty over actors’ relative capabilities (cf. Reiter 2003). According to this logic, fighting ceases when actors’ assessments of each other have converged, and battlefield outcomes provide the necessary information for this convergence (cf. Wagner 2000). The individual decision of conflict parties to fight or settle for an agreement is depicted as an expected utility calculation: Each party weighs the expected costs and benefits of continuing to fight against the benefits and costs of the concessions required for a settlement. Thereby actors’ relative capabilities shape each parties perceived probability of winning the conflict and, therefore, the propensity that an actor accepts a costly compromise to end the conflict (cf. Mason and Fett 1996; Greig 2015; Zartman 1989). Consequently, if battlefield information reveals actors’ relative strength, this information should indicate what concessions actors are willing to make.
As both sides need to prefer an agreement over continued fighting, existing literature generally implies an inverse u-shaped relationship between relative strength and parties’ willingness to make concessions. When the government is faced with very weak rebels, it is unwilling to make concessions, as it believes it can win. However, when the government’s perceived relative strength is low, and its expected future strength also declines, it is more willing to agree to costly rebel demands (Mason and Fett 1996). Accordingly, governments are more willing to make meaningful concessions, e.g., integrate insurgents in the political system, when rebels have a high relative strength (Gent 2011). Yet, if rebels wishing to overthrow the government are a lot stronger than the government, their willingness to make concessions should decline: Under these circumstances, the insurgents expect to win with a high probability and topple the regime. Consequently, stronger rebels should be substantially less willing to make concessions to the government (Hultquist 2013). As a result, in conflicts over government control, peace agreements with far-reaching concessions should only occur when neither side can decisively defeat the opponent. This is most likely when their relative strength is relatively balanced.
As existing theory posits that actors gauge their relative strength from battlefield information, conflict events should indicate how likely we see costly concessions. Research suggests that battle location, in particular, the distance of fighting from the capital is a suitable proxy for actors’ relative capabilities. Governments’ ability to project power arguably declines with distance, implying that weaker rebels need to fight in a country’s periphery while stronger rebels are more likely to threaten the government’s stronghold, in most cases a country’s capital (cf. Buhaug et al. 2009). Hence, the closer to the capital rebels challenge the government, the stronger the rebel movement should be relative to the government, on average. As we expect relative strength to have an inverted U-shaped relationship with the willingness to make concessions, battle location should have a similar correlation with agreements. Fighting very close or very far from the capital should predict a low willingness to make costly concessions, while intermediate distances indicate a higher likelihood that parties make extensive concessions in negotiations. Therefore, insurgent distance from the capital can serve as a proxy of relative strength (Buhaug et al. 2009; Greig 2015). 2
However, bargaining in territorial conflicts is somewhat different. On average, governments are less likely to compromise with secessionists than groups fighting for central government control. This has several reasons. First, governments fear that making concessions could result in a reputation of being a weak bargainer, enticing possible imitators to start secessionist action (Walter 2003). Second, conflicts over territory lead to larger commitment problems, as the government is unable to credibly commit to respecting the new borders after regaining military strength (Fuhrmann and Tir 2009).
Research suggests that the relationship between battle location and the propensity to seek a compromise also differs in secessionist conflicts (Greig 2015): While rebels in non-secessionist conflicts usually seek to replace the incumbent government, secessionists have no such goals. For non-secessionist rebels fighting in the capital implies that they are likely to topple the government and therefore achieve the victory they seek. In contrast, for secessionist rebel groups, the fighting in the capital is a means to impose extreme costs, rather than an end in itself. Consequently, fighting in the capital allows them to put maximal pressure on the government and to exploit this situation in negotiations. As a result, secessionists’ willingness to agree to an extensive agreement should not decline, but remain high or even increase, the closer fighting occurs in the capital. While negotiations are unlikely to yield comprehensive outcomes when secessionists are fighting in the periphery, they may be able to improve their bargaining position and pressure the government to compromise with a military presence in the capital. Therefore, we expect the following pattern, depending on the type of conflict:
In government conflicts, there exists an inverse u-shaped relationship between insurgent distance from the capital and the parties’ propensity to make concessions.
In territorial conflicts, there exists a negative relationship between insurgent distance from the capital and the parties’ propensity to make concessions.
Connecting Actors’ Propensity to Make Concessions With Agreement Content
In order to predict detailed peace agreement content based on our hypotheses, we draw on a theoretical framework which systematises the link between the actors’ underlying willingness and ability to make concessions (compromise propensity) and peace agreement content. This allows us to link conflict events to content. The framework conceptualises negotiations as consisting of the issues on the table and the latent compromise propensity of the actors at the table (Ruhe et al. 2024). The first dimension are the numerous issues on the table that need to be addressed in order to pacify a civil war. These start with immediate ramifications of war, such as prisoner exchanges, and range to questions more central to the incompatibility, such as political reform. Independent of actor’s compromise propensity, there are a large number of issues on any negotiation agenda, which vary in their difficulty: The average difficulty of a provision depends on how consequential and (technically) complex it is. Some provisions are fairly inconsequential for the parties’ political aims, such as prisoner exchanges. Other provisions however, such as political reform, have far-reaching political consequences which change power balances, and are highly technically complex. Consequential provisions should be more difficult to negotiate, because they substantively alter the status quo. Complex provisions require technical expertise and may result in discussions over legal language, and are therefore also more difficult to settle (cf. Dankenbring et al., 2025).
The second dimension is the latent compromise propensity of the actors at the table. The conflict parties need to be willing and able to agree on provisions addressing the issues on the table. The actors’ willingness and ability to compromise on given issues is what determines how far-reaching the resulting settlement will be. This latent concept compromise propensity should be a function of both sides’ expected utility considerations (cf. Mason and Fett 1996). Depending on their probability of winning, and expected costs, actors will be more or less willing to make concessions. Costs may include expected battle fatalities, but also costs that may arise from a settlement, such as spoilers, or audience costs.
Figure 2 depicts how these two dimensions interact to determine agreement content (Ruhe et al. 2024). A provision’s probability to be included into a peace agreement increases with the actors’ joint level of compromise propensity. For example, at the level indicated by the arrow for the exemplary case 1, Provision A is included with a probability of roughly 50 percent. At the level of compromise propensity in case 2, the probability rises to over 90 percent. For Provision B, the probability of inclusion is substantially lower in both cases. This means that Provision B is more difficult to agree on, and requires a higher level of willingness and ability to make concessions in order to be successfully included. In other words, when actors’ compromise propensity is low (case 1) they will be less likely to include either provision in an agreement they sign, than when their compromise propensity is higher (case 2). However, across both cases, the parties are more likely to include the easier Provision A into an agreement than the more difficult Provision B. Average provision difficulty depends on the complexity and controversiality of the respective provision, and compares provisions. The negotiating parties’ compromise propensity is a function of their relations, perceptions, and the conflict context (cf. Dankenbring et al., 2025).
3
Some provisions (Provision B) are more difficult than others (Provision A), and therefore only likely to be included when compromise propensity is high. In government conflict, compromise propensity might be higher (e.g., case 2) than in territorial conflict (e.g., case 1) (see H1 below). Moreover, the central issues in territorial conflicts could be more difficult to settle (see H2 below).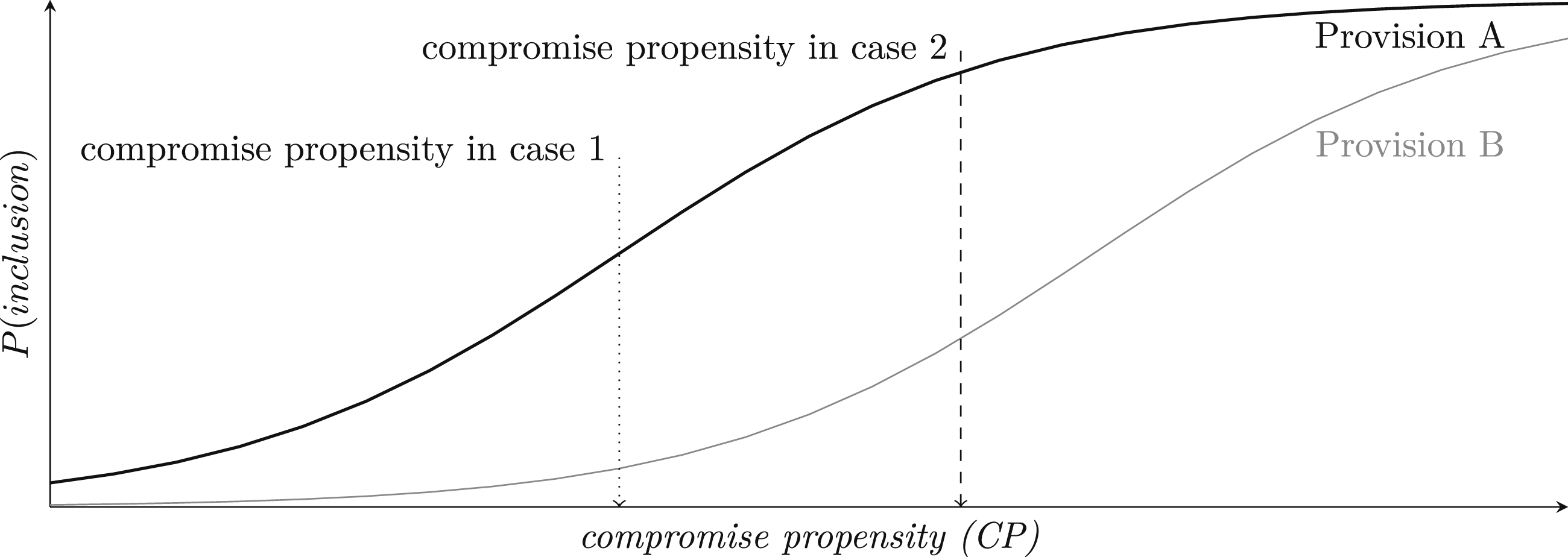
An example for provisions similar to Provision A might be ceasefires and prisoners exchanges, as they do not require agreement on the central issues of conflict. Actors may be otherwise unwilling to make concessions and nonetheless able to cease hostilities. Provisions more similar to Provision B could be political reform and the transformation of insurgents to political parties. These require the actors to compromise on key demands and spell out a political system they are both content with. This implies that actors unable to identify common ground and unwilling to make concessions on their goals will fail to achieve an agreement that solves the central issues of the conflict. At the same time, parties with a high level of compromise propensity will be able to sign a comprehensive peace agreement enabling lasting peace.
Hence, the latent variable compromise propensity drives when agreements are signed and which content they have: The higher compromise propensity, the higher the probability that even difficult provisions will be successfully included in the agreement. For example, the central issues on the table—as defined by the political goals of FARC—remained fairly stable during the Colombian civil war. Yet, the parties’ willingness and ability to agree on solutions to them varied strongly between the peace processes. In the late nineties FARC was strong, and negotiations were therefore mostly focused on technicalities, with little progress on their central demands (Richani 2005; Segura and Mechoulan 2017). This changed in the 2010s, when conflict costs were high, and neither side was winning (Nasi 2018). Given that the propensity to make costly concessions should be a function of battle location, as described above, we would therefore expect battle location to enable predictions of specific agreement content.
A model including battle location allows predicting agreement content with a higher accuracy than a model excluding battle location.
As mentioned earlier, a second interest of this paper lies in the methodological debate between supporters of classical methods (Blair and Sambanis 2020; Chiba and Gleditsch 2017; Daxecker and Prins 2017; Hirose et al. 2017; Weidmann and Ward 2010) and supporters of more modern machine learning methods (Beger et al. 2021; Dorff et al. 2022; D’Orazio et al. 2019; Hegre et al. 2019; Malone 2022; Hultman et al. 2022; Mueller and Rauh 2022). Modern machine learning methods often fare better at prediction than simpler models. However, machine learning requires large datasets, which are not always a given in social sciences. We are interested in whether increasing flexibility in model specification improves predictive accuracy even with moderate sample sizes. By flexibility, we refer to a model’s ability to adjust parameters or model structure in order to better capture the underlying data generating processes. Flexibility can be increased by introducing non-linearity—via polynomials or interaction terms—but also using more flexible modelling techniques, such as elastic nets. In our specific case, we look at models’ capability of predicting agreement content out-of-sample. We expect that the predictive accuracy of theory-driven models increases when allowing for some flexibility in model specification.
In addition to assessing the relative predictive power, we can further evaluate whether the more flexible models produce the functional form that we would expect based on theoretical considerations (H1a/b).
Research Design
We use a graded response model (GRM) and PA-X data (Bell et al. 2021) to estimate compromise propensity. PA-X codes the content of 1,868 peace agreements by using a set of 239 provision categories. Some of these provisions are binary—indicating whether or not an agreement mentions the issue—and some ordinal—containing information on the level of detail with which the provision is regulated. For example, the provision constitutional reform is coded on a scale from excluded to included with extensive detail. PA-X data’s unique scope and the level of detail with which the content of peace agreements is coded make it particularly well-suited as the basis for a measurement model. In comparison to other data including agreement content (Fontana et al. 2021; Pettersson et al. 2019), it includes more and even basic agreements, enabling us to measure compromise propensity for intractable conflicts with minimal negotiation output. The resulting measure ranges from −2.7 to 2.5 with mean zero, and is roughly normally distributed by design (see Figure 2 in the online appendix).
GRM is an ordinal item response model – see equation (1). Item response theory (IRT) allows for measuring latent capabilities, such as compromise propensity. Measuring the actors’ willingness and ability to compromise has several advantages compared to, e.g., a basic binary agreement indicator. First, the concept of compromise propensity is embedded in a theoretical framework as actors’ latent willingness and ability to compromise and agree on specific agreement content (Ruhe et al. 2024). IRT is a tool that enables us to measure this latent variable directly, which is preferable to using a proxy. Second, a binary agreement indicator ignores content, while measuring compromise propensity provides more nuance: Instead of comparing the presence or absence of peace agreements, we can compare different written documents in their content. It captures agreements’ substance and allows for distinguishing statements of intent, ceasefires, partial agreements, comprehensive agreements, and, importantly, variation within these categories. These are details that we would otherwise overlook in categorisation. Last, using a measurement model makes us more objective in estimating the content of agreements. Ordinal categorisations, such as in PA-X’s agreement stages, are expert-coded and possibly subject to biases.
IRT uses the covariance patterns of items and the frequency with which single items occur, to estimate their difficulty and discrimination parameters. In a binary case, the difficulty parameter b
i
measures how high the latent capability needs to be in order for the provision to be included with a 50 percent probability. In an ordinal case, provisions have several cutpoints, i.e., k “levels” of inclusion. In an example with four levels – meaning the provision is not included, included rhetorically, with some detail, or high level of detail – there are three cutpoints, as the last cutpoint is between some detail and high level of detail. For these provisions a difficulty parameter b
ik
is estimated for each cutpoint, measuring the level of compromise propensity necessary for the provision to be included with at least level k of detail (see equation (1)). However, some provisions may be included with a high (or low) probability across levels of compromise propensity. Their presence in an agreement therefore does not contain a lot of information on the actors’ level of compromise propensity. This is parametrised by the discrimination parameter a
i
. When a
i
is high, items discriminate well between levels of compromise propensity. This means they enter an agreement with very low probability below a critical value of compromise propensity, and with a very high probability above it.
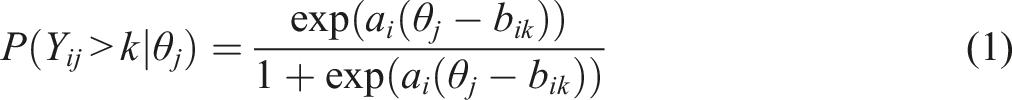
In our GRM we use all provisions that are ordinal in the PA-X dataset (Bell et al. 2021) to measure to which degree of detail provisions are included. We exclude those ordinal provisions that are covered by binary sub-categories. For example, political powersharing is an ordinal item that is covered by a range of dummy variables indicating the inclusion of specific types of political powersharing. As these sub-categories are more informative of the peace agreement, we use these instead of the ordinal supra-category. We also exclude provisions that depend on third parties’ willingness to act, such as peacekeeping operations. We use the resulting set of provisions to feed into a loop designed to find the GRM model that fits the data best. As we have previously found that there is a substantive difference between the difficulty of provisions between government and territorial conflicts (Dankenbring et al., 2025), we allow for differential item functioning (DIF) for these groups. Our loop runs a range of models applying varying degrees of constraints and tests them against each other using likelihood ratio tests. It tests for each provision whether it should be included without DIF in respect to territorial conflict, whether the discrimination parameter should be held constant while the difficulty is allowed to vary between groups (uniform DIF), or whether allowing for the discrimination parameter to vary (non-uniform DIF) significantly improves the model.
In order to predict agreement content, we model the latent variable compromise propensity as a function of covariates, e.g., battle location. We use a dyadic measure of compromise propensity to fit our dyadic predictors, based on an extended version of the PA-X dataset (Dankenbring 2025), which includes the UCDP actor ids of all signatories to the respective peace agreement. This enables us to model compromise propensity by conflict dyad, and limits the sample to the peace agreements that were signed by two (relevant) conflict actors. In order to take into account the temporal dimension of compromise propensity, we aggregate our data to quarters, including only quarters with at least one signed agreement. In quarters with several agreements, these are aggregated so that for each quarter we record the maximum value of each provision. This allows us to model the entire agreement content signed in this period, even if a settlement is divided into several, complementary documents. With some list-wise deletion due to missings in our explanatory variables this leaves us with 543 dyad-quarters. We randomly sample our data into a training (70 percent or 380 observations) and a test dataset (30 percent, i.e., 163 observations), and use the latter to compare the models’ predictive power.
We measure distance using UCDP GED data (Sundberg and Melander 2013) on battle locations and UN data on land area (UNdata 2019), and capital cities (United Nations et al. 2018). As these datasets are from 2018 to 2019, respectively, we assume that neither capitals nor land area have changed since then. We generate a measure for average distance from the capital cities for each quarter by using all battle events in the country fighting the conflict as side a in UCDP data that were geographically attributable at least on a regional level. We calculate the approach to the capital as the difference in average distance to the capital from one quarter to the next. As the distances and country size vary strongly from country to country, we also expect differences in their implication of relative strength. Governments of larger countries should also possess greater capacity allowing them to control greater territory. In a large and capable country, rebels need to be much stronger to challenge the government, e.g., 100 km from the capital, compared to a very small country. Thus, the relative strength is conceptually more closely linked to relative distances. In order to generate a measure of distance that is relative to the country’s size, we calculate a pseudo-radius, which is based on the square kilometres a country is stretched over. We standardise all distance measures by dividing them by the respective country’s pseudo-radius.
The expected effect of average location on compromise propensity may be confounded by the frequency and intensity of battle. Average distance may be affected by battle dispersion and intensity: In a case with few battle events all located in the capital, distance would be minimal. At the same time, dispersion and intensity of fighting may affect compromise propensity. For example, in the same case, the government’s threat perception may nevertheless be low. We therefore control for the approach of conflict events to the capital, battle dispersion, as well as battle related deaths and one-sided killings from the UCDP BRD dataset (Davies et al. 2022) (for the controls in each model, see Tables 3 and 4 in the online appendix). We also include regime type (Phayal et al. 2019) using V-Dem data (Coppedge et al. 2022; Pemstein et al. 2022), the number of insurgent groups (Nilsson 2010), war duration and activity (Harbom et al. 2008) in our model.
In order to evaluate whether flexibility improves predictive accuracy in our specific case, we define a range of models with increasing degrees of flexibility in model specification. We then compare their out-of-sample predictive accuracy both when predicting compromise propensity and agreement content.
We start with a basic OLS model that contains insurgent distance from the capital, interacted with itself and conflict incompatibility allowing for the hypothesised curvilinear effect that may differ by conflicts’ incompatibility (H1a/b). In a second OLS, we include the predictors above, which we derived from theory. However, we exclude some variables and interactions that proved irrelevant (i.e. that have no substantial effect in terms of coefficient size and statistical significance). For example, though theorised by many to be relevant, natural resources were excluded from the model, as they proved to have no sizeable effect. This OLS serves as baseline to compare the other models to, as here, all interactions included are theory-driven. Thus, we can compare whether the theorised connections are present and relevant in the other, more flexible, models in a similar manner. Table 3 in the online appendix documents all OLS estimates.
As more flexible counterparts to these theory-driven OLS models, we use linear elastic net models, a combination of Ridge regression and Lasso, which can perform both shrinkage (Ridge) and feature selection (Lasso). Crucial for our limited sample size, elastic nets can cope with many covariates even when the sample size is small. The combination of discarding variables when they have very low predictive power (Lasso), and shrinking coefficients of highly correlated variables (Ridge) makes linear elastic nets sparse, robust, and more generalisable. In linear elastic nets the number of covariates can even exceed the number of observations (Zou and Hastie 2005), allowing us to include large numbers of interaction terms, including higher order polynomials of our distance measure. Consequently, the model is more flexible than the OLS in two ways. Firstly, the model chooses the set of covariates that holds most predictive power from a large number of possible explanatory variables. In this process, we hold much less power over model specification than in the theory-driven OLS models. Secondly, the many interaction terms, including polynomials, mean that the relationships between explanatory variables and compromise propensity can flexibly take on many non-linear forms.
Model specification: step-wise increase in generality and flexibility of the model
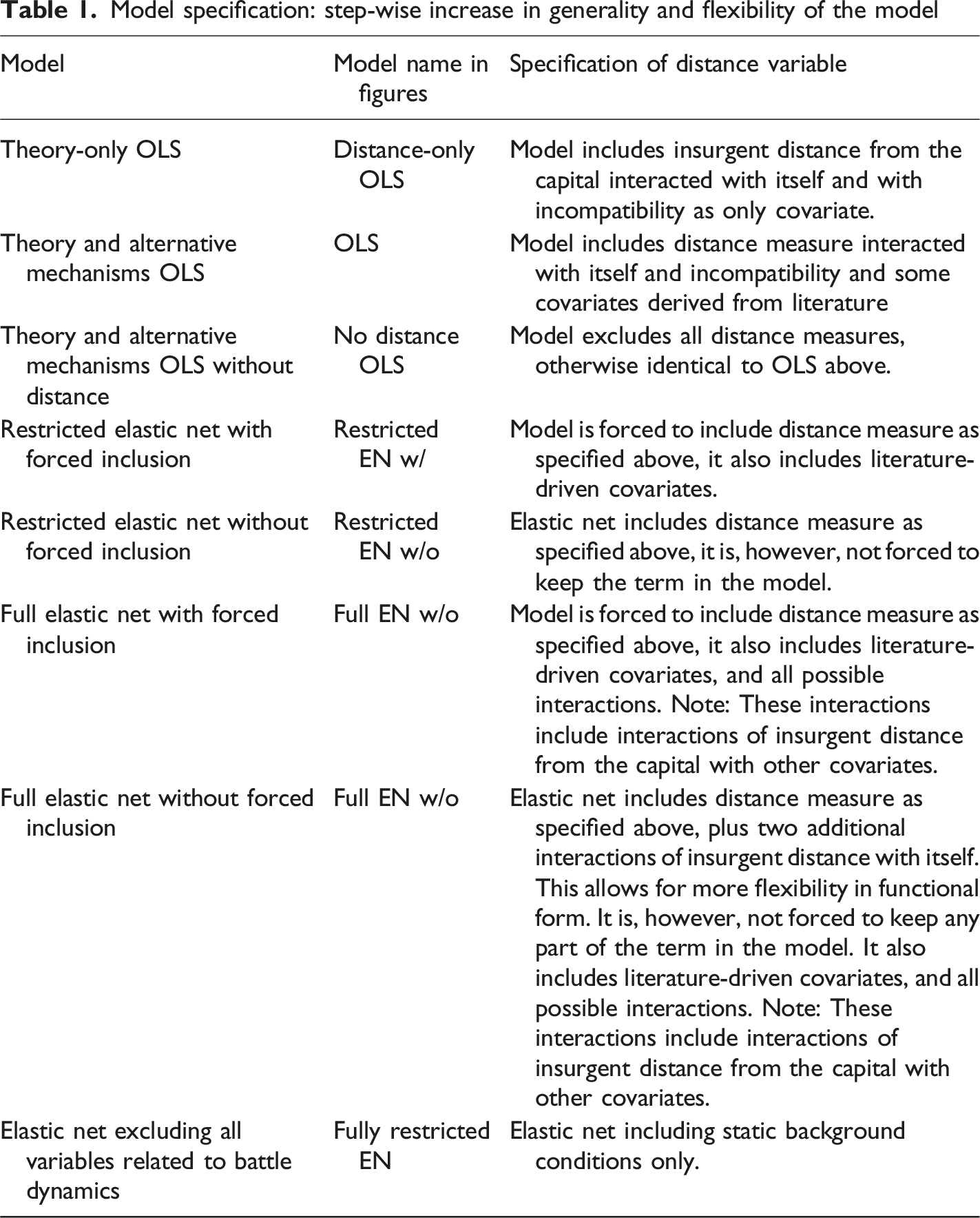
In all elastic nets, the lambda parameter is optimised using the cross-validation (cv) function. This means that the model is chosen on its capability to predict out-of-sample. To be precise, for every λ in the grid range, the data is divided into 10 sub-samples. Using differing combinations of these, 10 models are estimated on 90 percent of the data each. In every iteration, the remaining tenth of the data is used to calculate the prediction error. The average of these errors is the cross-validation error for the respective λ. Using the generalisation error as an indicator of model fit allows us to find the right balance between overfitting and underfitting (Fariss and Jones 2018).
Results
Insurgent Distance From the Capital and Compromise Propensity
Our first research interest concerns the theorised link between battle locations and compromise propensity. Drawing on utility theory (Mason and Fett 1996; Greig 2015) we expected an inverse u-shaped relationship in government conflict. When rebel distance from the capital—measured relative to country size (see Research Design)—is high, compromise propensity should be low. The closer insurgents move to the capital, the higher the pressure on the government, and therefore also compromise propensity. However, there is a tipping point, as insurgents become less willing to make concessions when they perceive themselves likely to win. Thus, compromise propensity decreases at some point of closeness to the capital.
This is exactly what we see in Figure 3(a) for five out of six models.
4
The inverse u-shape we expected can be found in both OLS models, and both restricted elastic nets. When adding more flexibility to the model however, the relationship weakens or disappears (see Figure 3(a)). Effect of distance to capital on compromise propensity in active conflict. For a description of the model specifications, see Table 1. (a) Effect in government conflict. (b) Effect in territorial conflict.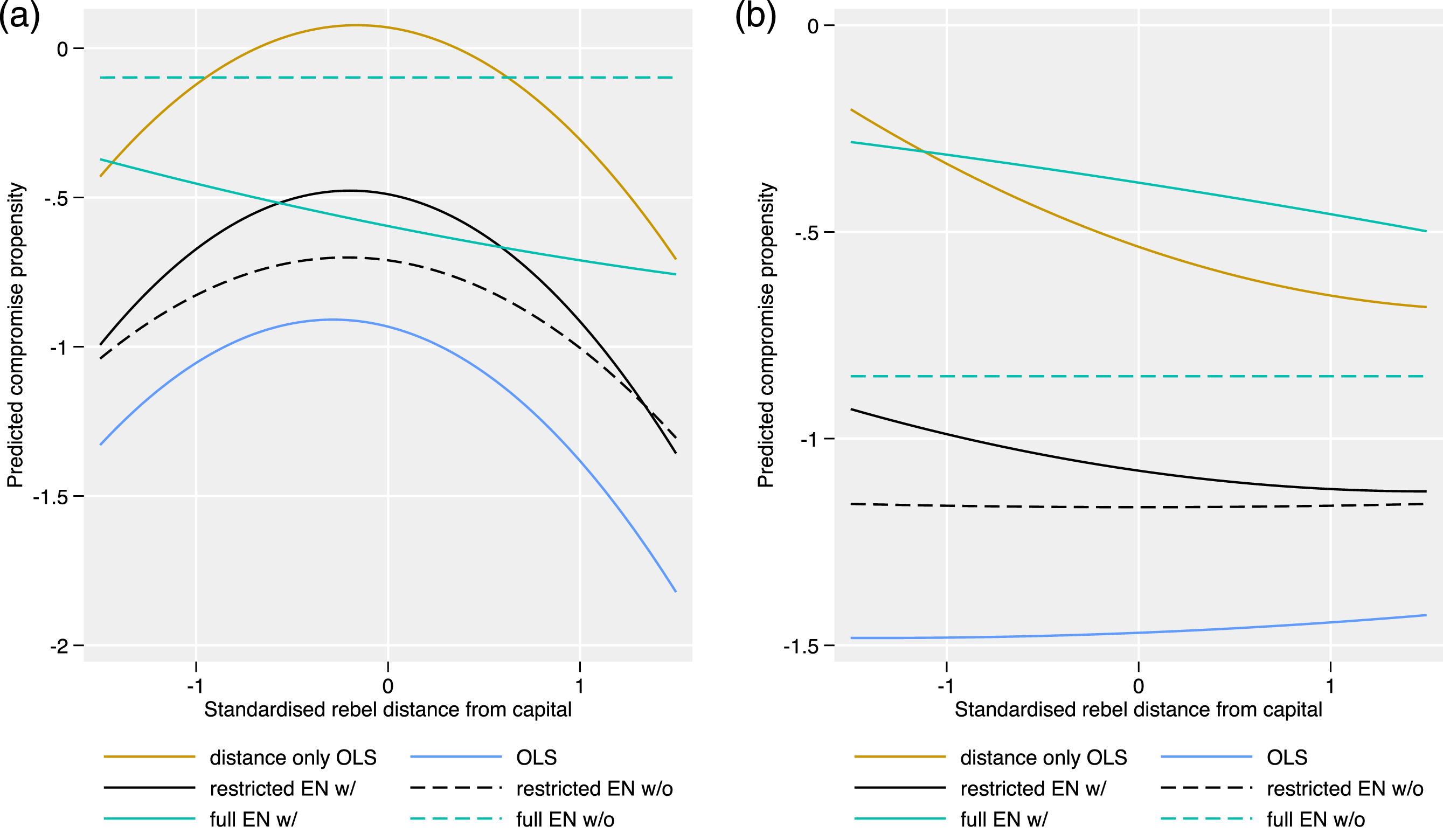
In territorial conflict, we expected to see a negative relationship between insurgent distance from the capital and compromise propensity: Governments become less willing to make concessions, when insurgents fighting for independence leave their territory and move towards the capital (cf. Greig et al. 2018). Considering Figure 3(b), it is difficult to establish such a link. While the distance only OLS and the restricted elastic net with forced inclusion of the distance estimate do show a negative slope, none of the other models do.
However, Figure 1 in the online appendix shows that the predicted compromise propensity from all models decreases with distance in territorial conflicts, as predicted. In the more flexible models, other variables seem to absorb the information provided by distance, reducing its direct effect. As a result, the predicted compromise propensity still has the theorised relationship with distance. This suggests that even if distance is less relevant as an individual proxy and predictor in these models, the underlying mechanism related to conflict parties’ relative strength is reflected in the models’ predictions. In short, distance may not be the only possible predictor, but the results underscore the statistical association postulated by our theory.
Hence, overall, we find evidence for H1a, and more limited support for H1b.
Comparing Predictive Accuracy Across Models
In order to establish whether including battle location increases predictive accuracy, and whether more flexible models fare better at forecasting peace agreement content than restrictive theory-driven models, we compare the eight models by predictive accuracy. First, we compare the out-of-sample Root Mean Squared Error, when we predict compromise propensity (see Figure 4). The first prediction is simply the mean of compromise propensity, which we use as a benchmark to compare the other models to. Out-of-sample RMSE of the different models. ‘Mean’ is our base-line prediction of compromise propensity using its own mean. For a description of the model specifications, see Table 1.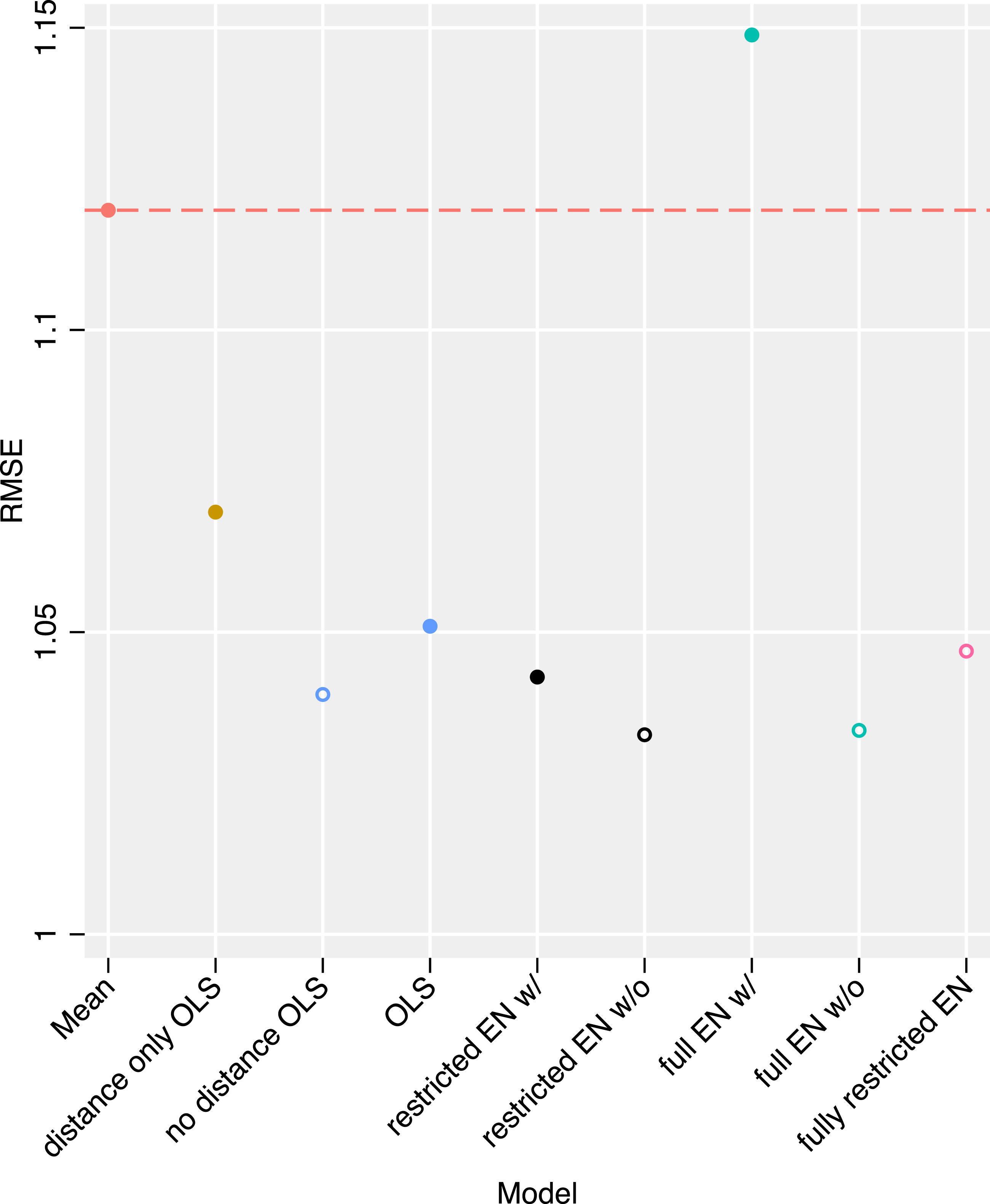
Comparing the three OLS models with each other shows that—counter to our expectations—including insurgent distance from the capital does not increase the predictive accuracy of our model. We find that three of the flexible elastic nets outperform the OLS model - including background conditions and distance - by a small margin. The OLS excluding distance is beaten by two elastic nets. So when looking at out-of-sample RMSE, the more parsimonious OLS models fare roughly as well as the more flexible elastic nets. We also observe that even if some of the more flexible models do show improvements in predictive accuracy, this is not true across the board; not every increase in flexibility translates into an increase in predictive accuracy. We therefore find only very limited support for our expectation. Our analysis also shows that, contrary to H2, when considering out-of-sample RMSE, including distance from the capital does not improve our model’s predictive accuracy.
To compare different models’ capability to predict specific peace agreement content, we calculated an overarching receiver operating characteristic (ROC). To this end, we used all seven models to predict the probability of inclusion for every provision in every observation.
5
We then calculated the ROC for every model across all observations and all provisions. When we consider the resulting ROCs in Figure 5, the findings from the RMSE above are mirrored. The resulting AUCs show some small differences: The OLS including only battle location fares slightly worse than the other OLS and the restrictive elastic nets. However, with an AUC of 0.754 this very simple, purely theory-driven model nonetheless fares surprisingly well in comparison to the models including background conditions. This shows that given some easily available information on battle locations, one is able to produce comparatively accurate predictions of peace agreement content. Out-of-sample ROCs of the different models for all provisions. For a description of the model specifications, see Table 1.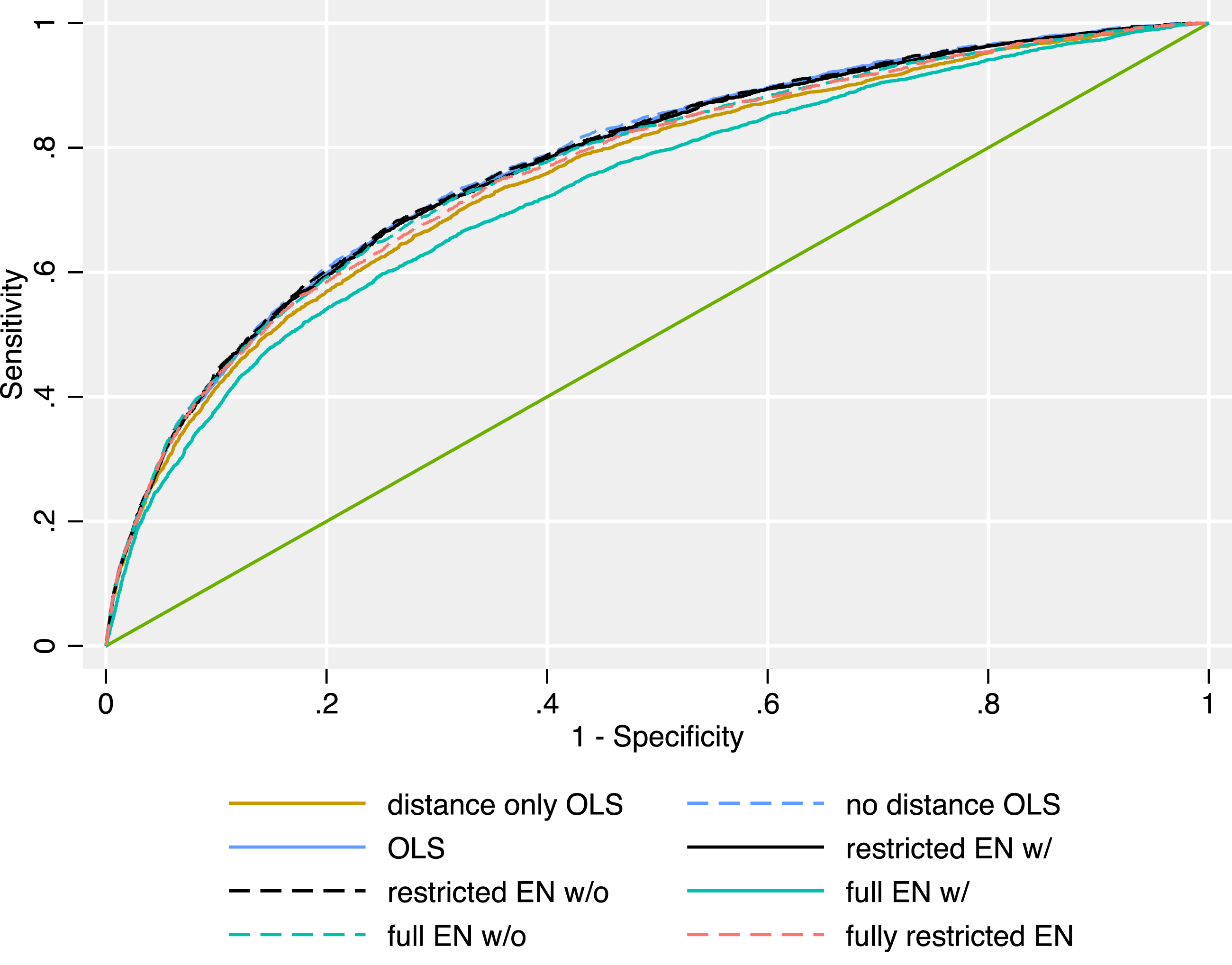
When comparing the OLS excluding distance from the capital and the OLS including it in Figure 6, we find no substantive difference in AUC. This runs counter to our expectation that including insurgent distance as a measure of relative strength improves the model’s predictive accuracy. AUC of out-of-sample ROCs of the different models for all provisions. For a description of the model specifications, see Table 1.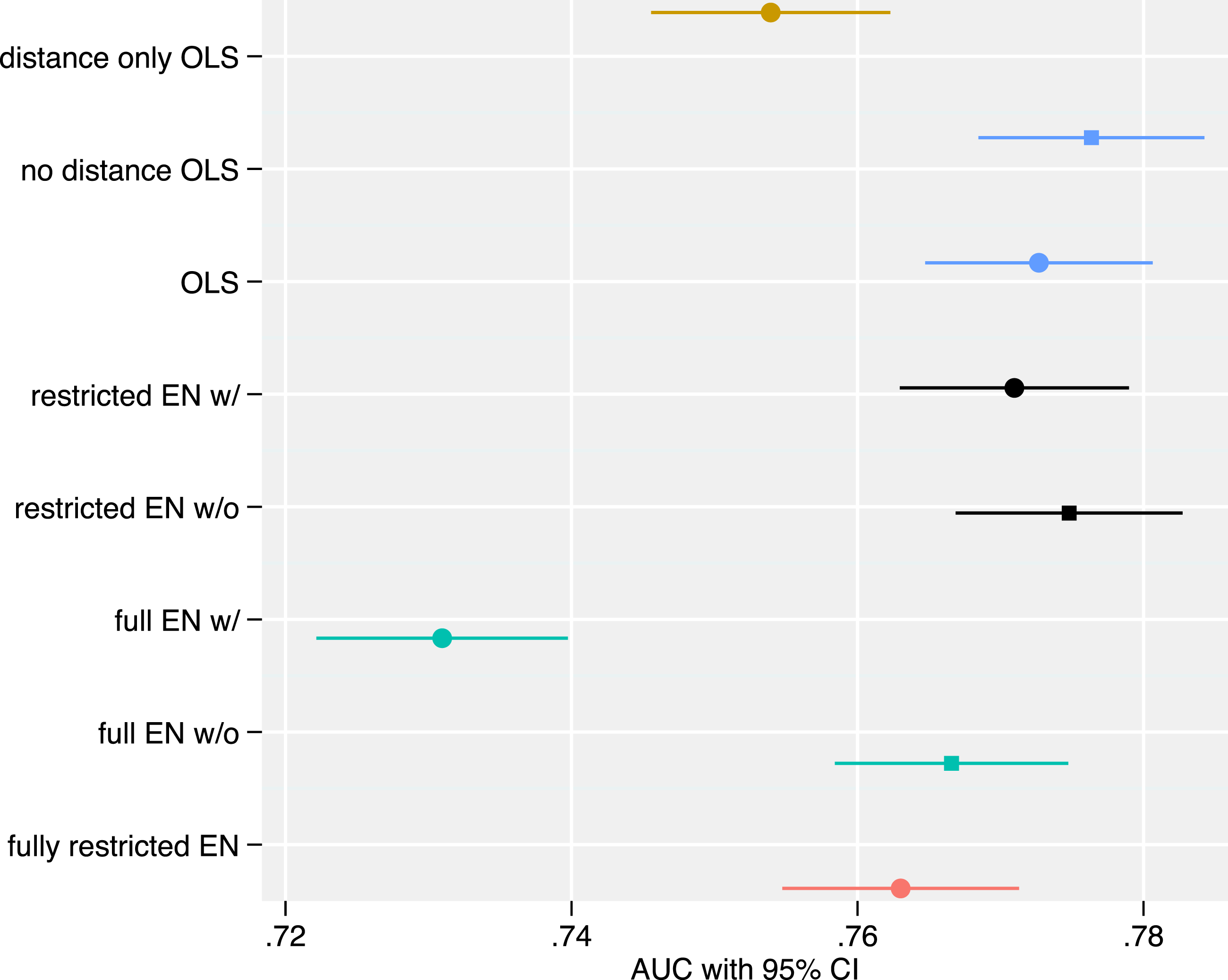
We also expected that increasing flexibility would increase predictive accuracy. However, our simple OLS models fare just as well as the more flexible elastic nets. This leads us to conclude that given the rather small sample-size we are dealing with, increasing flexibility in model specification did not substantively improve our models’ predictive accuracy. Neither when predicting compromise propensity and looking at Root Mean Squared Errors, nor when predicting agreement content and comparing their receiver operating characteristics. While machine learning provides a valuable tool for more accurate prediction, its need for large datasets leads to some limitations in applications. Nevertheless, using flexible models can be a valuable theory-testing tool even when dealing with small sample sizes.
To get a more intuitive understanding of what these results mean in practice, we compare the predictive power of our models for two exemplary provisions. The first provision is whether actors agree to a merger of forces between insurgents and the government. All of our models fare rather well at predicting its inclusion in peace agreements (see Figure 7). All confidence intervals for the AUCs overlap, and the point estimates range between 0.759 and 0.802 (see Figure 9). This shows that even a very simple OLS including current data on battle location fares rather well at predicting the out-of-sample probability that the parties will be able to agree on military powersharing. However, battle locations are not necessary to arrive at accurate predictions of military powersharing. Out-of-sample ROCs of the different models for the provision “Military power-sharing: merger of forces”. For a description of the model specifications, see Table 1.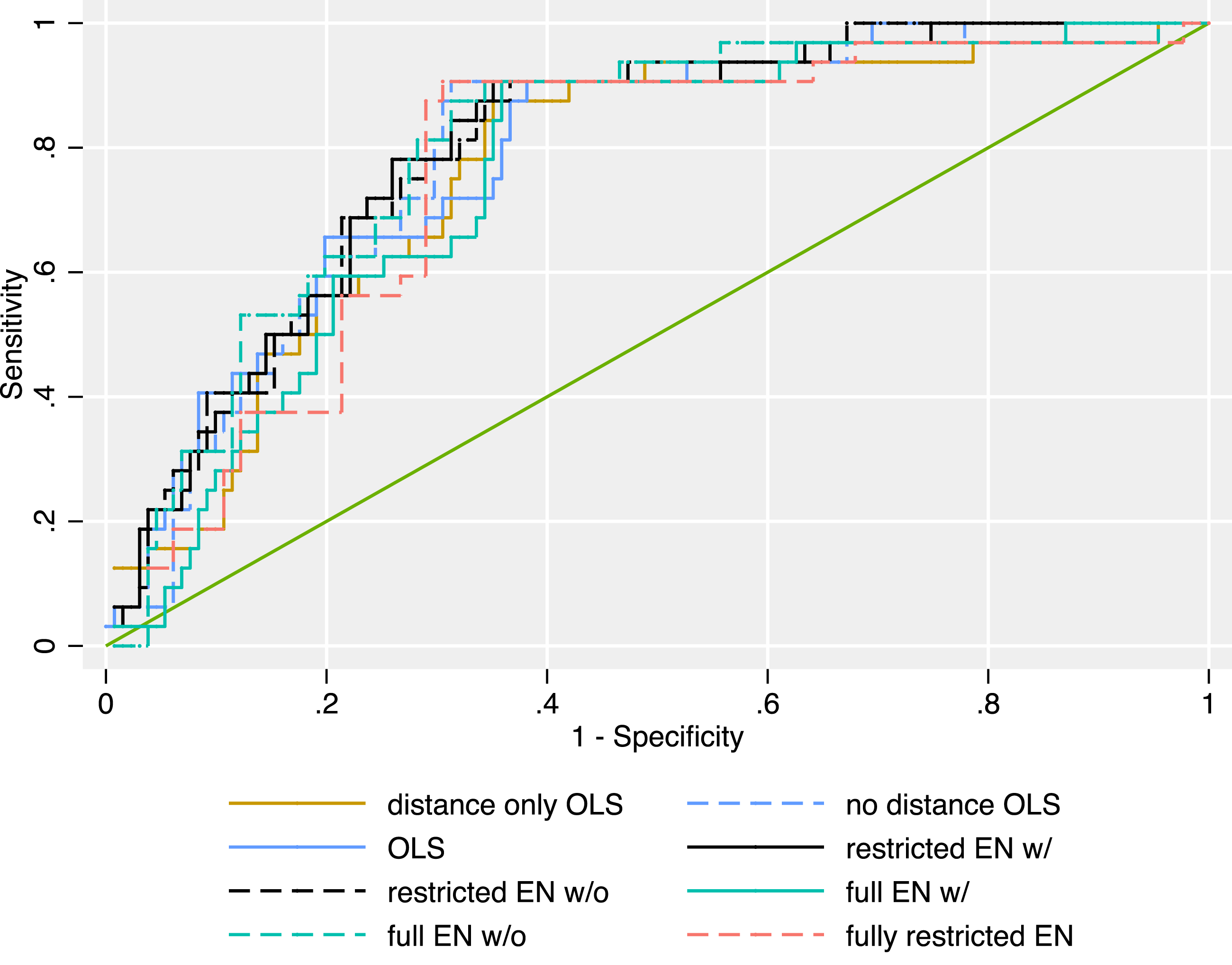
All six models are also rather good at predicting whether agreements provide for the transition of insurgent organisations to political parties (Figure 8). Although the ROCs have a rather different shape and show slightly more variance between the models, the AUCs range between 0.763 and 0.811 (see Figure 9). The model with the highest ROC (by a small margin) is the restricted elastic net with forced inclusion of battle dynamics. Nonetheless, the elastic nets including battle dynamics fare only insubstantially better at prediction than the other models. This supports our expectation that a model including insurgent distance from the capital will fare well at predicting peace agreement content. However, it also stands to show that this is not the only way to arrive at accurate predictions. Out-of-sample ROCs of the different models for the provision “Rebels transitioning to political parties”. For a description of the model specifications, see Table 1 Receiver operating characteristic (ROC) regression of the different models…. (a) …for the provision “Military power-sharing: merger of forces”. (b) …for the provision “Rebels transitioning to political parties”.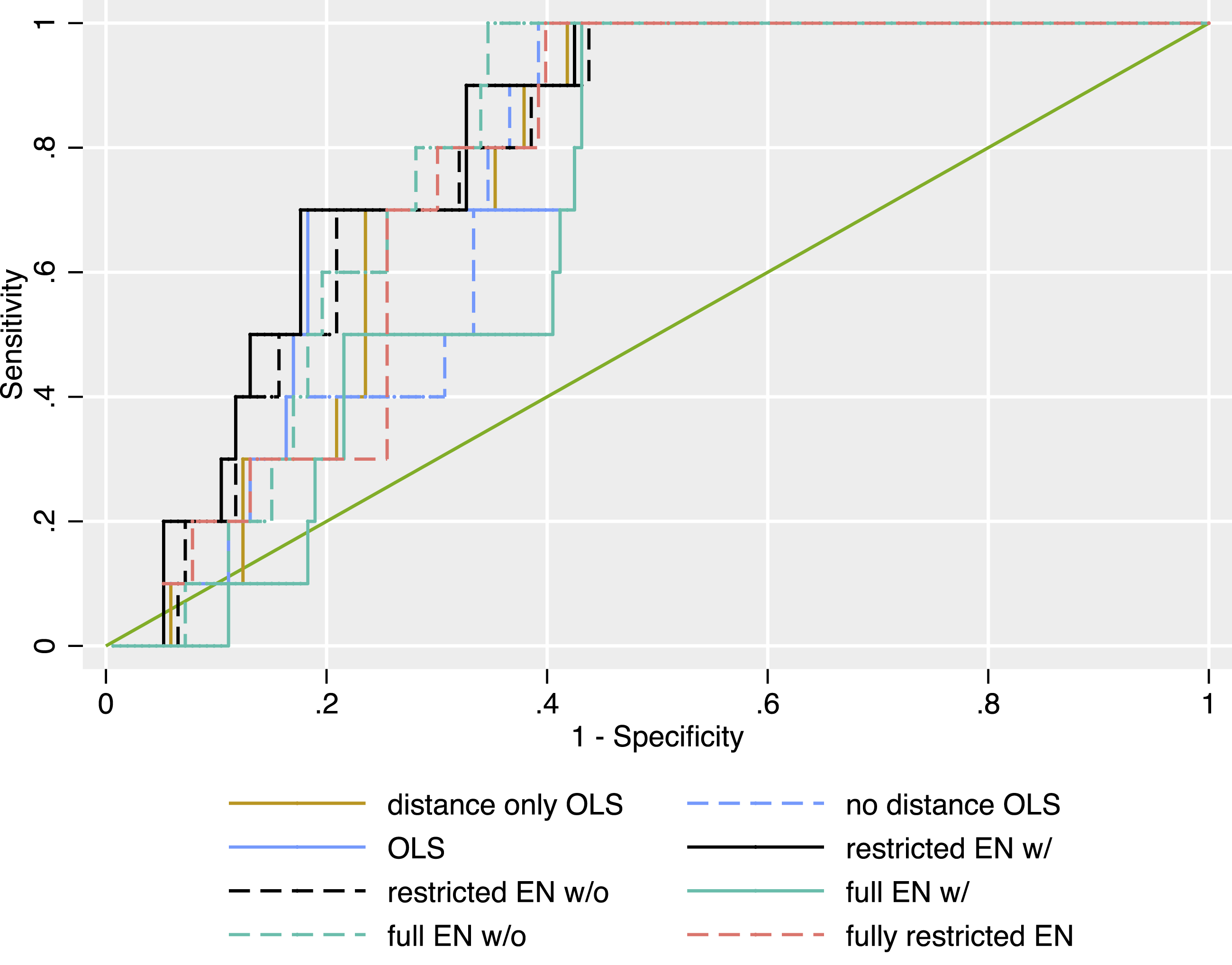
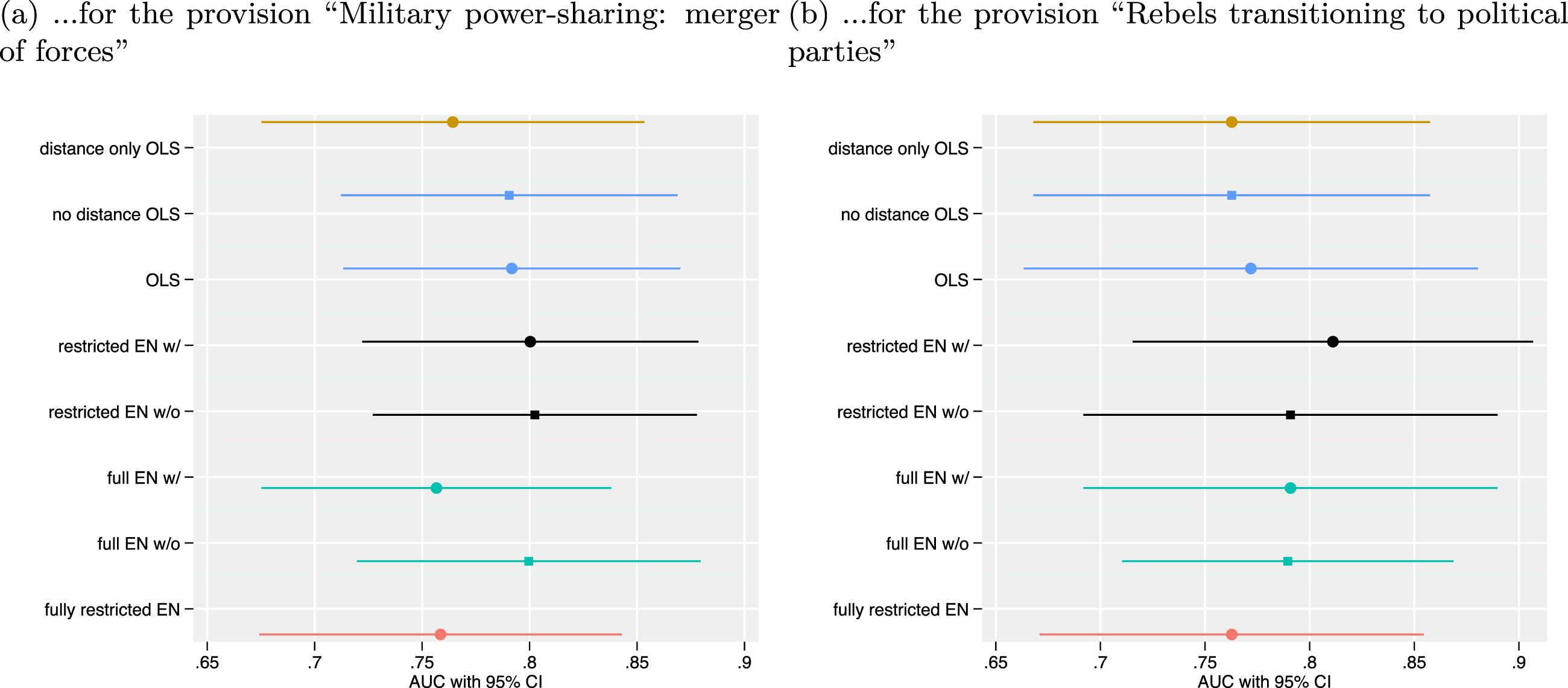
Overall, we find limited support for our hypothesis 2: While our models strongly support our expectation that even simple models including insurgent distance from the capital fare very well at predicting agreement content, they do not do substantially better than models excluding them. The analysis also shows that with our limited dataset increases in model flexibility do not necessarily improve predictive accuracy.
Conclusion
Our paper demonstrates that we can predict the content of peace agreements with reasonable accuracy using both basic theoretically informed and more flexible machine learning models. In line with our theoretical argument derived from existing literature, in government conflicts, we find an inverse u-shaped link between insurgent distance from the capital and compromise propensity, i.e., conflict parties’ willingness and ability to make concessions. We also observe the theorised negative bivariate association for distance and compromise propensity in territorial conflicts. Yet, the more flexible models indicate that other variables can account for this correlation.
The analysis contributes to the recent debate on whether theory is necessary for or improves prediction (Beger et al. 2021; Blair and Sambanis 2020). We examine an alternative use case and, in the words of Beger et al. (2021), test if a (somewhat) “stronger theory” that implies a variable and its functional forms improves prediction. The analysis examines whether this variable, in our case, distance to the capital, systematically improves predictions and whether the best-fitting functional form conforms with the theory. Compared to Blair and Sambanis (2020), we employ a simple ordinary least squares (OLS) model in our theory-driven model.
We find that, in this case, theory is not strictly necessary to specify a model that predicts well. However, the basic, theoretically motivated model predicts (almost as) well compared to more flexible and complex machine learning procedures. Furthermore, the more flexible models estimate a substantively similar association between capital distance and agreement content as the basic model. This result lends some support to the overarching theory, demonstrating the use of flexible models to test or improve theoretical arguments (cf. Beger et al. 2021). Interestingly, however, the most adaptable models do not outperform the less flexible ones, suggesting more flexibility is not always better, at least in this small sample and this application.
Where does this leave us in the debate on theory in forecasting? In our view, the results highlight both the potential of the theory and some limitations in its empirical application. Underscoring the usefulness of the theory in this case, the results demonstrate that a readily available proxy variable for relative strength is associated with the content of peace agreements as theorised and predicts content reasonably well. At the same time, the analysis also highlights that the variable is a proxy that can be exchanged with other variables that capture similar patterns. In other words, insurgents’ location relative to the capital is sufficient to predict the content of peace agreements with reasonable accuracy, but it is not necessary.
We believe these results hold more general lessons for the role of theory in conflict forecasting where imperfect information about key variables, such as relative strength, is commonplace. Both researchers and decision-makers must rely on readily available indicators or proxy variables to assess how the conflict evolves, anticipate future developments, and act on these insights. As a result, without a nuanced causal understanding of how political actors interpret which facts on the ground and make decisions, theoretical models are parsimonious approximations and simplifications. Even when theories correctly identify the variables informing political action, we still need accurate measurements of these variables for accurate forecasts. In armed conflict, where the fog of war hinders such accuracy, it is therefore highly likely that there remains room for data-driven prediction models to match, possibly outperform more parsimonious, theoretically informed models. Data-driven models may also identify alternative specifications, inspiring new theories or refining existing ones. If a specific theory is correct, but researchers or a machine learning algorithm use different indicators to make predictions, the predictions produced by these models should correlate with theoretically relevant proxy variables in the theoretically expected way.
In our application, which has a comparatively small sample, simple theory-driven models appear sufficient for predicting with somewhat comparable accuracy to more agnostic machine learning models. Forecasting research is well advised to compare the best-performing data-driven model against theoretically specified models. Doing so helps set the predictive performance in perspective and opens the door for both forecasting and theory-focused research to learn from each other. Throughout our application, theory remained an essential bedrock, even for the most flexible models. After all, our framework for predicting content through the latent variable of compromise propensity is a theoretical framework that structured the analysis and made it more efficient (cf. Ruhe et al. 2024).
Supplemental Material
Supplemental Material - Forecasting Peace Agreement Content: How Conflict Events Predict the Substance of Peace Settlements
Supplemental Material for Forecasting Peace Agreement Content: How Conflict Events Predict the Substance of Peace Settlements by Meri Dankenbring, and Constantin Ruhe in Journal of Conflict Resolution
Supplemental Material
Supplemental Material - Forecasting Peace Agreement Content: How Conflict Events Predict the Substance of Peace Settlements
Supplemental Material for Forecasting Peace Agreement Content: How Conflict Events Predict the Substance of Peace Settlements by Meri Dankenbring, and Constantin Ruhe in Journal of Conflict Resolution
Footnotes
Acknowledgements
We are deeply grateful for the helpful feedback we received at ISA 2023, as well as the 22nd Jan Tinbergen Peace Science Conference and the Symposium 2022 held at Universität der Bundeswehr München. Our special thanks extends to our colleague, Iris Volg, who read and commented countless drafts.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was made possible by the generous funding of Deutsche Forschungsgemeinschaft (DFG, German Research Foundation; project number 448508600).
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are openly available in Harvard Dataverse at https://doi.org/10.7910/DVN/OWYMIH (Dankenbring and Ruhe, 2026).
Supplemental Material
Supplemental material for this article is available online.