
Abstract
In response to the lagging speech recognition capabilities in supplier services, this study integrates speech recognition, speech synthesis, and semantic understanding technologies to improve speech recognition capabilities in different environments. The Mel Cepstral acoustic feature algorithm and deep convolutional neural network model are used to construct speech feature extraction algorithm models, speech recognition acoustic models, and speech training modules, which enhance speech training, processing, recognition, and application capabilities. Integrating the designed model into the company’s business platform has improved the semantic understanding ability in the power grid field and greatly enhanced the standardized management of business data. Through experiments, the speech recognition error rate of the designed solution by our research institute has been reduced to below 1%, greatly improving the speech recognition capability of the supplier center and thereby enhancing the service level of the supplier center.
Keywords
Introduction
In order to effectively respond to the national “carbon peak, carbon neutral” strategy, and safeguard the country’s historic commitment to addressing global climate change and realizing sustainable development, the State Grid is committed to building a highly intelligent Supplier Service Hall to provide suppliers and customers with better service and support. Supplier service hall is one of the most important aspects of material management and an important window for communication with suppliers. In recent years, with the proposal of State Grid’s modern intelligent supply chain system, each network and provincial companies have actively explored and practiced the material window service, and at present, although there are network and provincial companies to build an online supplier service platform, it still fails to fully realize the supplier’s remote processing, palm for, especially, there are still some shortcomings in intelligent guidance and intelligent solution, so it is imperative to optimize the online provider service platform in order to improve the service capability of the online provider service platform and improve the online processing efficiency.
In the prior art, the document 1 puts forward the language recognition text error correction based on phoneme fusion, but it has great requirements for data information.
Jian et al. 2 proposes a BPE-dropout multi-task learning recognition with threshold, but it still produces misjudgments; Fang and Wei 3 proposes an improved ECA (Improved Efficient Channel Attention, IECA) module to generate corresponding weights for each dimension of the input feature map with small parameters, but it does not perform well in dealing with small sample problems; Thimmaraja Yadava et al. 4 proposes a recognition model based on connected time series classification model, but the algorithm training is complicated literature 4 based on music through artificial intelligence for music sequence recognition and language generation, although improved character recognition ability, but cannot synthesize or generate audio data information, it is difficult to realize the recognition of tiny data information under complex conditions The main goal of Xiaoliang et al. 5 is to solve the attempt to establish a continuous recognition (CSR) framework to recognize Kannada continuity Processing local languages such as Kannada. In Kaldi Toolkit, we implement modeling techniques such as single-tone three-tone depth neural network (DNN)-hidden Markov model (HMM) and Gaussian mixture model (GMM)-HMM-based model and apply them to continuous Kannada language recognition (CKSR) The Mel cepstrum (MFCC) coefficient technique is used to extract the feature vector from the data, which improves the recognition ability but has poor anti-interference ability.
Based on the above thinking, this paper adopts intelligent AI customer service to deeply integrate recognition synthesis and semantic understanding capabilities with the window business knowledge base of supplier service center to realize intelligent human-computer interaction. With the help of the company’s business middle station, it realizes the semantic understanding capabilities in the power grid field, serves the standardized management of business data, and improves the efficiency of business consultation and business guidance response.
Design ideas of identification technology
The innovation of this study is that the language recognition technology of vendor service center based on artificial intelligence is effectively realized by using the acoustic feature algorithm of Humel cepstrum and the deep convolution neural network model.
The goal of the activation detection task is to determine whether a given sequence contains human voice or not. Usually, the activation detection result sequence is obtained at the granularity of several 100 ms or several seconds Each element of the sequence corresponds one-to-one with the element position of the sub-sequence fragment after the original fragment is cut according to a certain granularity The goal of the recognition task is to identify the included audio fragments to get the corresponding text The recognition system mainly includes acoustic model, language model, pronunciation dictionary and decoder 6 The overall technical flow is shown in Figure 1
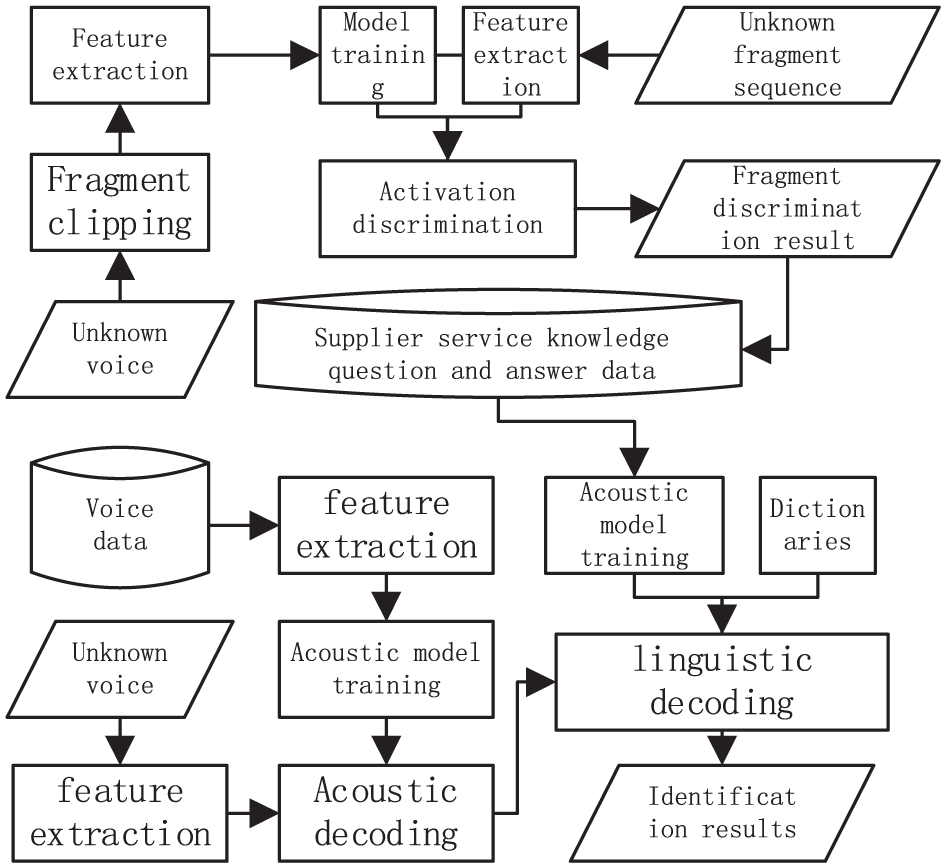
Overall technical flowchart.
Feature extraction algorithm
In this study, Mel-Frequency Cepstral CoemcientMFCC (Acoustic Feature Algorithm of Mel-Frequency Cepstral CoemcientMFCC) is used for activation detection.7,8 MFCC feature extraction algorithm 3 is obtained by linear transformation of logarithmic energy spectrum of nonlinear Mel scale in sound. The main flow of the algorithm is shown in Figure 2.
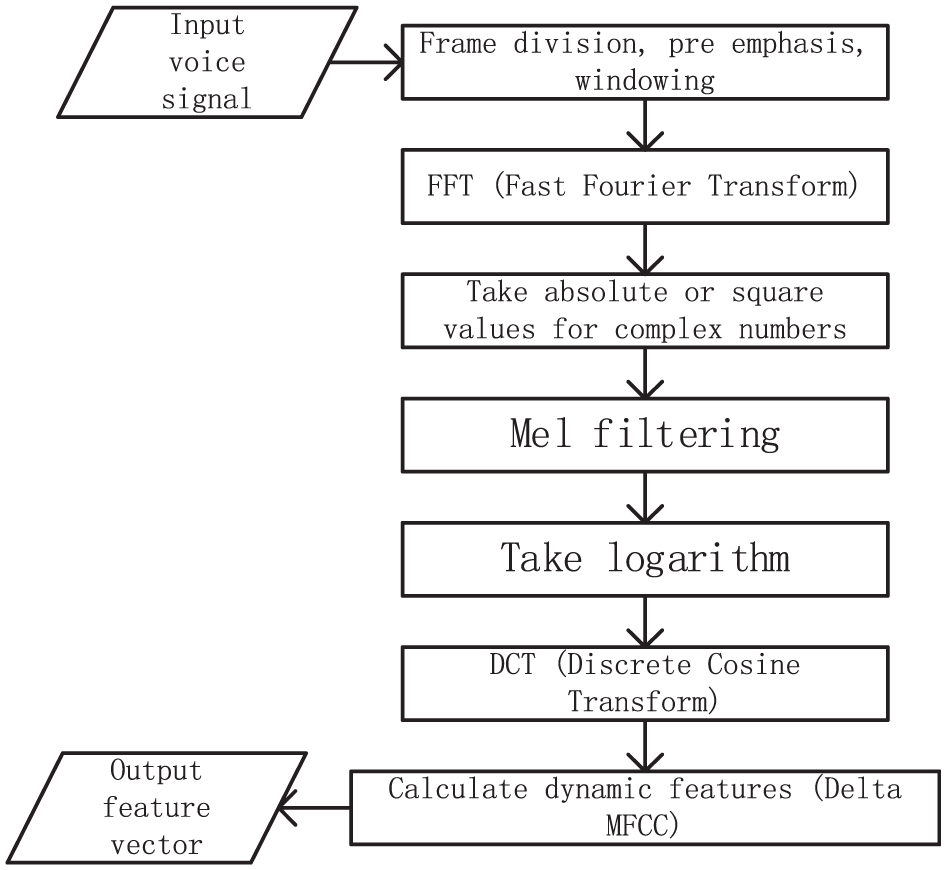
FCC algorithm flow chart.
The original audio files stored on the computer’s hard drive are of variable length, and first need to be divided into multiple fixed length segments using a certain method, known as frame segmentation. Based on the rapidly changing characteristics of speech signals, this study takes a time length of 10–30 ms for each frame. Due to the different sampling rates of digital audio, the dimensions of each frame vector obtained by frame segmentation are also different. In order to avoid the problem of information omission caused by the boundary of the time window, when offsetting the time window of each frame taken from the signal, there needs to be a partial overlap area between frames, that is, the “time window.” Select a time window length of 25 ms and a time window offset of 10 ms.
The main purpose of pre emphasis is to enhance the high-frequency parts of the speech signal in each frame, in order to improve the resolution of the high-frequency signal. The formula for pre emphasis operation is:
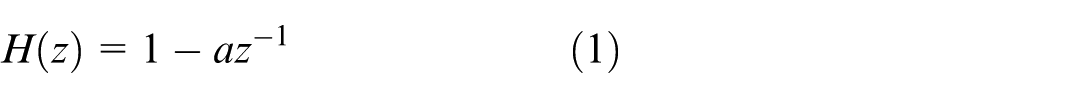
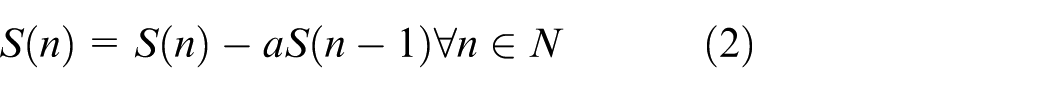
In equations (1) and (2),
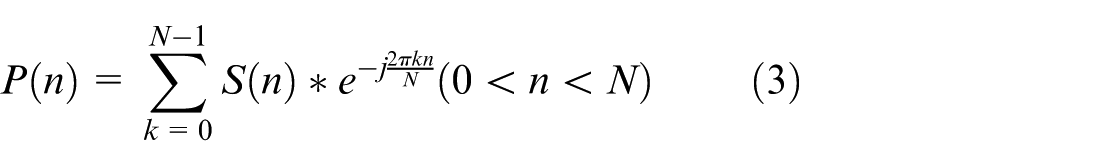
The Mel filtering process is one of the key features of MFCC and fBank. The Mel filtering formula is:
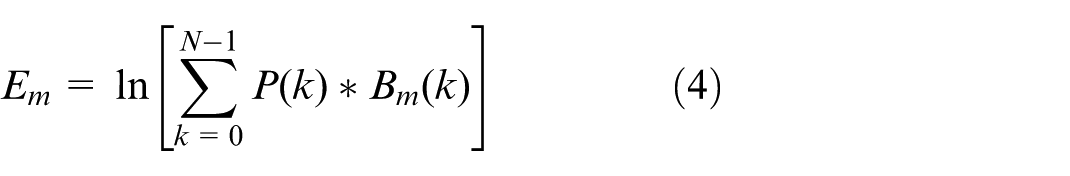
In equation (5),
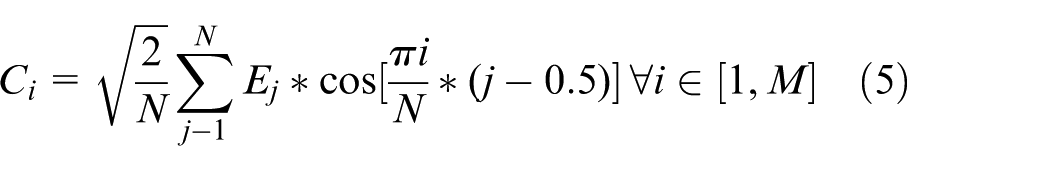
Equation (6) only reflects the static features of MFCC, while its dynamic features still need to be represented using the difference of static features. The calculation formula for differential parameters is:
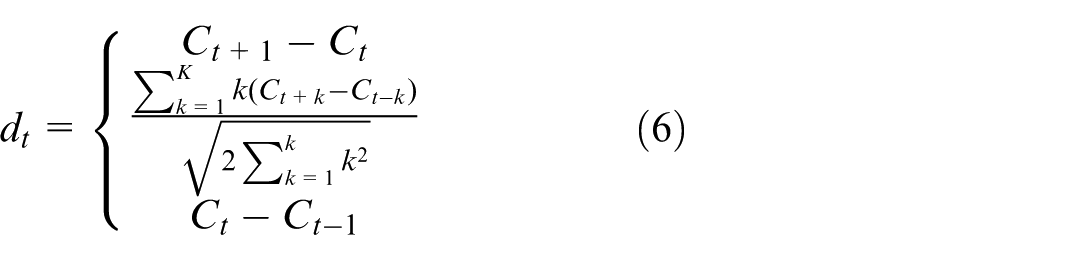
In this equation,
Speech recognition acoustic model
This study uses a deep convolutional neural network model for speech recognition. The basic structure of a convolutional neural network (CNN) includes input data, convolutional layers with a certain size and number of convolutional kernel filters, pooling layers with a certain pooling step size, and fully connected layers with a certain number of neurons. Connected Temporal Classification (CTC), 7 using the CTC method, can automatically align speech and corresponding transcribed text during model training, achieving classification on time series. The CTC method is mainly divided into two parts: one is the label alignment and loss function calculation during training, and the other is the calculation of the final prediction result during inference decoding. Among them, the decoding part is divided into three types: Greedy, 8 Beam Search, 9 and Preface Beam Search. 10
The probability formula for each single aligned time step of CTC is:
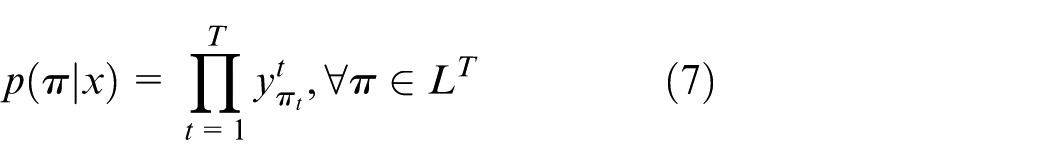
In equation (1),

In equation (8),
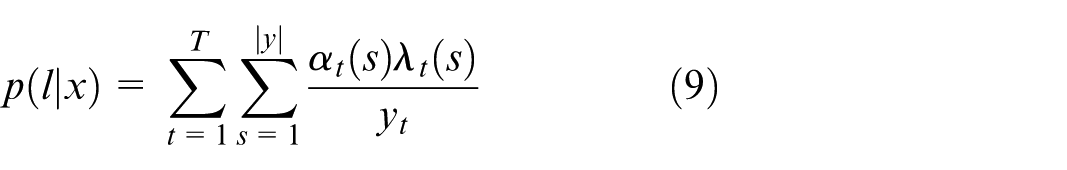
The partial derivative of equation (9) is:
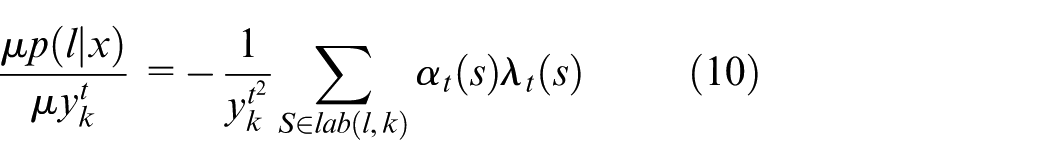
In equation (10),
Greedy search is the simplest decoding method in CTC decoding algorithm. The greedy algorithm essentially means that every step should be the best, that is, during decoding, the symbol with the highest output probability in each time step is directly taken as the final result. Due to the complexity of directly calculating the optimal output in the actual calculation process, but for a specific character n, the neural network will output its predicted probability value at each time step. Therefore, the simplified algorithm directly considers the term with the highest probability as the correct prediction. The time complexity of the algorithm is
In the final decoding result, the probabilities are accumulated by combining the permutations of all characters to obtain a final probability, which is then sorted by the magnitude of the probability values to provide users with multiple choices. However, as the size of the beam increases exponentially with the number of time steps when arranged and combined, a maximum width is generally limited for the search beam. The time complexity of the algorithm is
Design of speech training module
Statistical N-Gram language models are often used in Chinese speech recognition technology. 12 By statistically analyzing the Chinese characters in a sentence in the text, the model can calculate from a probabilistic perspective which character combination sequence can form a meaningful sentence without spelling errors. The hardware of the speech training module is shown in Figure 3.
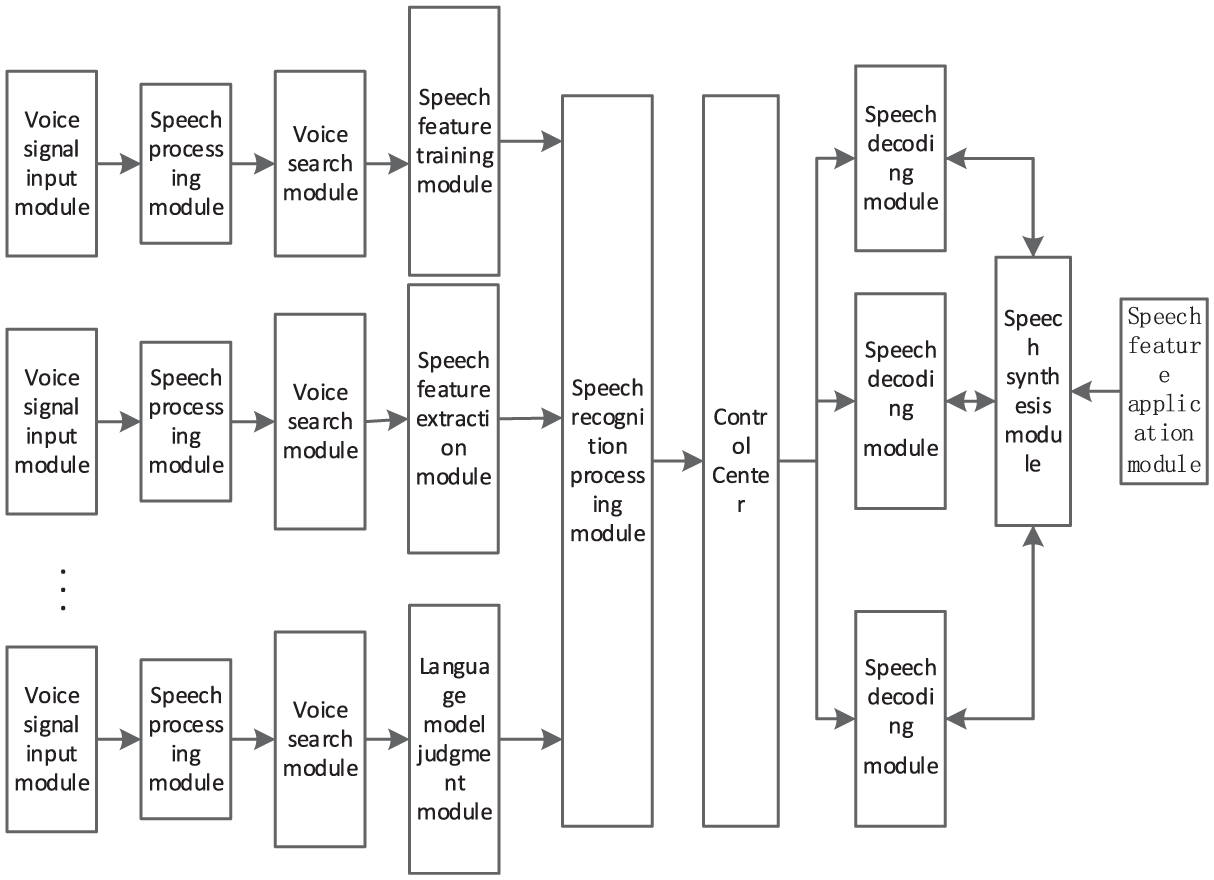
Schematic diagram of hardware architecture for speech training module.
The speech training module designed in this study includes a speech signal input module, a speech processing module, a speech search module, a speech feature training module, a speech feature extraction module, a speech model judgment module, a speech recognition processing module, a control center, a speech decoding module, a speech synthesis module, and a speech feature application module. During the work process, the voice signal input module converts the user’s voice input into a digital signal. The speech processing module preprocesses the input speech signal, including denoising, enhancing signals in specific frequency bands, speech enhancement, etc., to improve the accuracy and efficiency of subsequent processing stages. The voice search module is responsible for searching for similar voice patterns in a large amount of voice data. The speech feature training module learns the relationship between speech features and corresponding text through a training dataset. The sound feature extraction module extracts parameters that can characterize speech features from the preprocessed speech signal, such as Mel frequency cepstral coefficients (MFCC), filter bank coefficients, cepstral normalization, etc. The speech model judgment module determines the most appropriate text sequence based on the extracted speech features. The speech recognition processing module is the core of the entire system, which converts speech features into text and involves pattern recognition algorithms such as Hidden Markov Models (HMM), Deep Neural Networks (DNN), etc. The central control center coordinates the work of various modules to ensure the smooth operation of the entire system. The speech decoding module converts the output of the speech model into readable text.
Based on statistical models, the correct sentence is the sequence of words with the highest probability of arrangement, while the incorrect sentence is the sequence of words with a lower probability of arrangement. So if sentence S is meaningful, then the probability p(S) composed of a series of subsequences
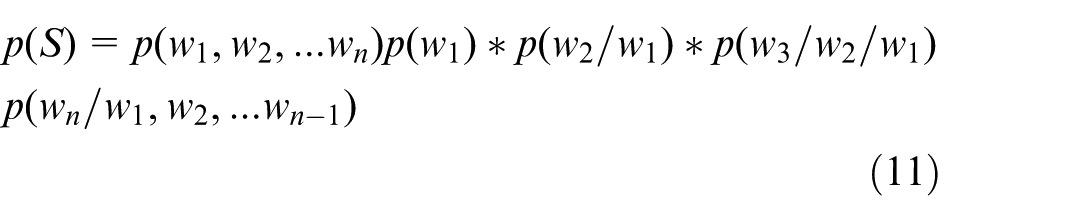
When considering that the word at the current moment is only related to the word at the previous moment, the language model is a binary language model. When considering the word at the previous N − 1 moment, the model is an N-dimensional language model. The probability estimation formula corresponding to the binary language model is:
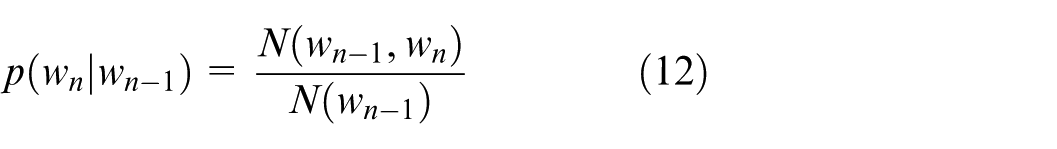
In equation (12), N() represents the frequency of the corresponding word, N(x) is a unary frequency, N(x, y) is a binary frequency, and N is the sum of the frequencies of all monosyllabic words. By analyzing a piece of text, calculate the frequency of each monosyllabic word.
Overall design of intelligent AI customer service
The intelligent AI customer service system in this study adopts the common B/S design architecture. The system core consists of three main components: web-based data visualization display, stable backend services, and knowledge graph storage. The platform obtains natural language from suppliers, uses a question and answer service call algorithm model to perform natural language understanding on the suppliers, and returns the answers for this round with the cooperation of multiple modules. This design adopts the backend development framework mainly based on SpringCloud Alibaba 13 to encapsulate and process various requests and return results. The frontend uses Vue2, and the specific core functional structure is shown in Figure 4.
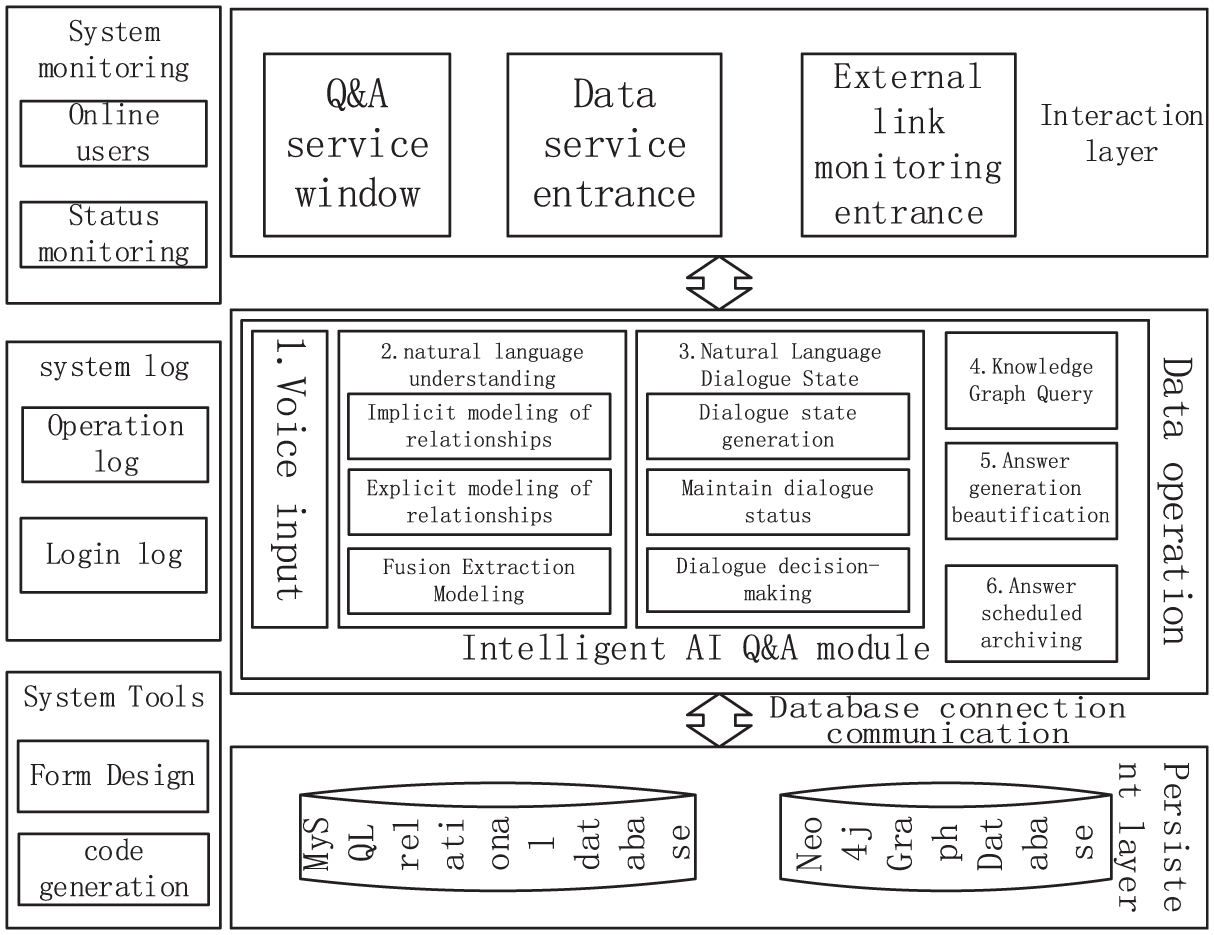
Overall architecture of intelligent AI Customer Service in Supplier Service Center.
As shown in Figure 4, the core functional processing flow of the system platform needs to be processed through three levels in sequence, including three parts: interaction layer, data operation layer, and persistence layer.
The main function of the interaction layer is to facilitate communication between suppliers and the system. It is responsible for receiving voice and operation types submitted by suppliers, submitting them to the backend services of the system platform through Restful API, and displaying the returned data results.
After receiving the supplier’s voice/text, the main process activates the dialog state, calls the remote model algorithm service, queries the knowledge graph data, optimizes the result answer, and returns it. Asynchronous processes need to update and renew the supplier dialog status, and write the Q&A interaction text to a file. And rely on scheduled tasks to archive the Q&A records and store them as objects, triggering them at fixed time points. Platform administrators and operations personnel can make adjustments as needed. At the same time, it supports administrators to configure more scheduled tasks to adapt to potential future scheduled task requirements.
The system data management module includes multiple modules such as user management, role management, department management, and position management. This module group should allow staff to input requirements, and based on the functions provided by the module, it can easily and quickly add, update, and delete department positions. It should also work in conjunction with user modules to ensure information integrity, support users to easily customize extensions, and adjust according to new scenarios at any time.
The system log monitoring function module includes three functions: system monitoring, system tools, and system logs. System monitoring includes the viewing of online users, Nacos, Sentinel, and Neo4j 14 content. Platform administrators can perform forced user exits, observe the operation of the platform system, and monitor the current storage status of the knowledge graph. 15 System tools can help platform administrators quickly customize new display modules for the system, improving development efficiency. System logs include login logs and operation logs, and administrators can view system user operations for retrospective analysis.
The process of question and answer matching and robot chat functions in the intelligent AI question and answer module is shown in Figure 5, mainly including dialog intention judgment, knowledge base question matching, chat dialog generation, and human customer service intervention.
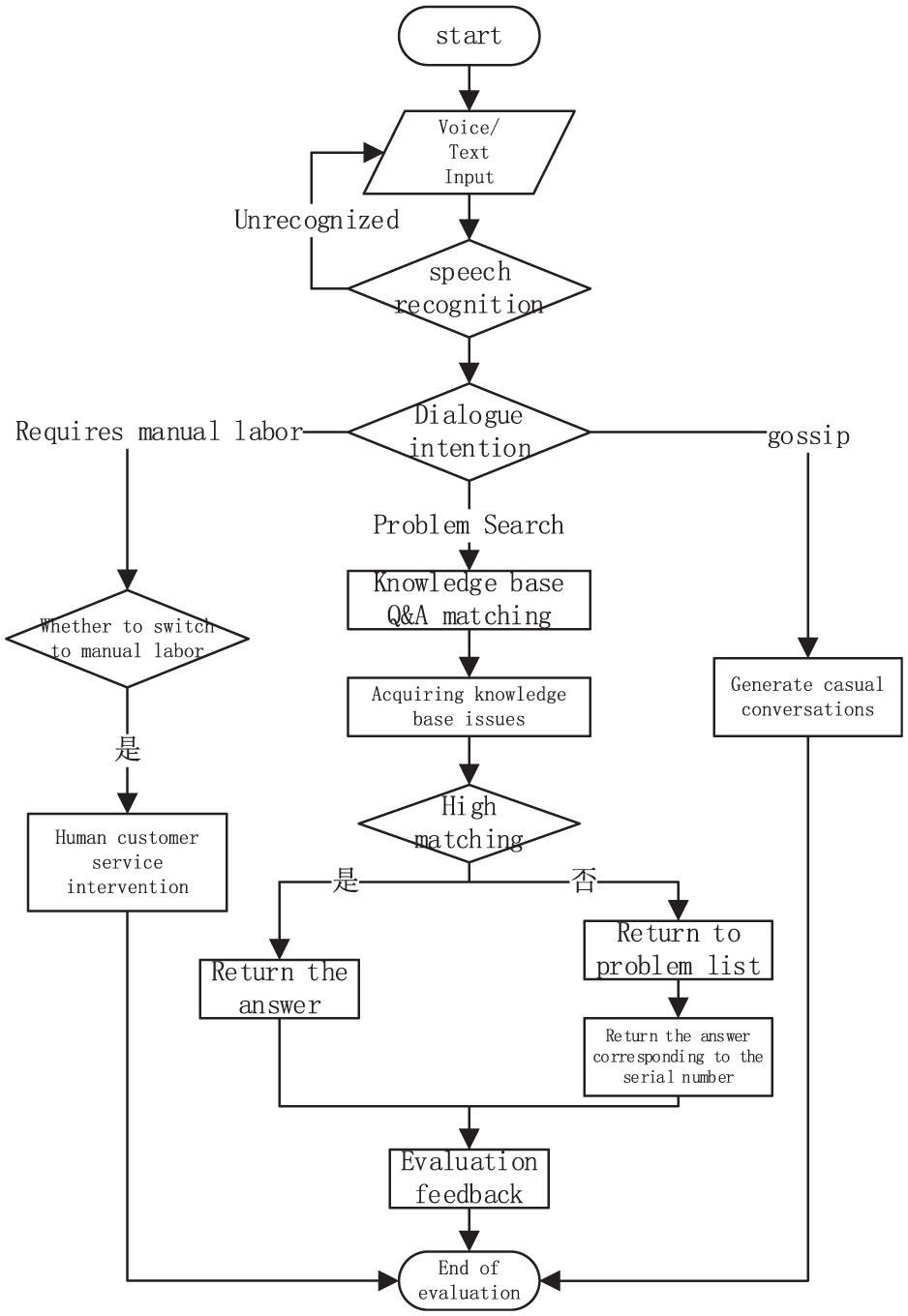
Core flow chart of intelligent AI Q&A.
As shown in Figure 5, when the supplier inputs the dialog content, the system backend obtains voice/text information, and first performs voice recognition and keyword extraction on the information. This system categorizes chat intentions into three types: one is question retrieval, another is casual conversations in real-life scenarios, and the third is when intelligent customer service robots are unable to answer and require manual customer service consultation. These three different intentions are maintained in different dictionaries in the backend system, and correspond to different processing flows: knowledge base problem matching process, chat dialog generation process, and manual customer service intervention process. The backend determines the supplier’s intention based on the extracted keywords, and determines which of these three types of intentions the employee has in this conversation based on the degree of matching between the keywords and the dictionary. Different processes are executed according to the intention results.
Experimental results and analysis
The model is based on Ubuntu 18.04.5LTS (GNU/Linux 5.4.0-77-geneuc x86_64) system, using PyTorch 16 deep learning framework and GeForce RTX3090 GPU for training. The experimental architecture diagram is shown in Figure 6.
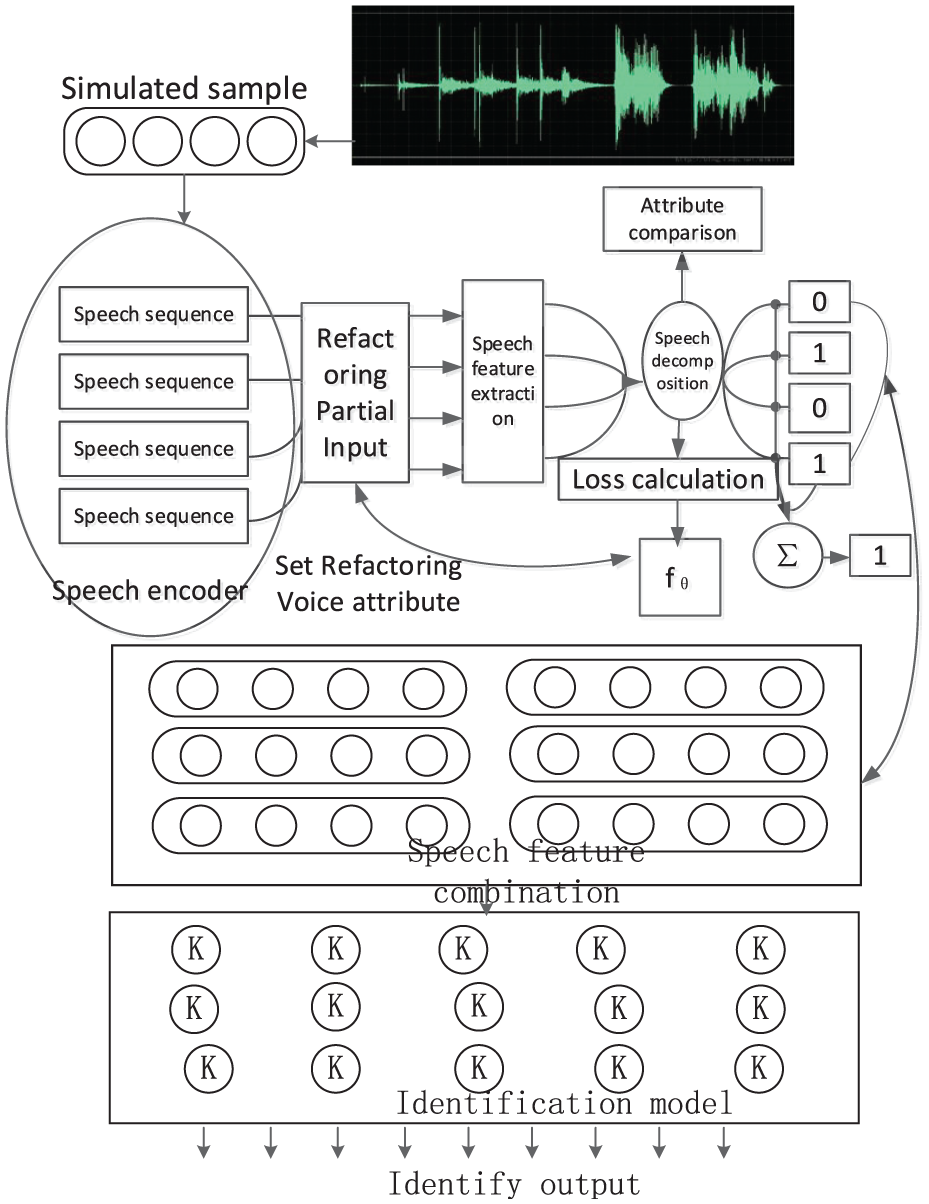
Schematic diagram of experimental architecture.
During the specific experiment, the voice prompts and feedback information of automatic handling vehicles and robots for sources, orders, and demands are collected in real-time through sensor devices such as microphones installed in warehouses or production sites. The obtained voice information is shown in Figure 7.
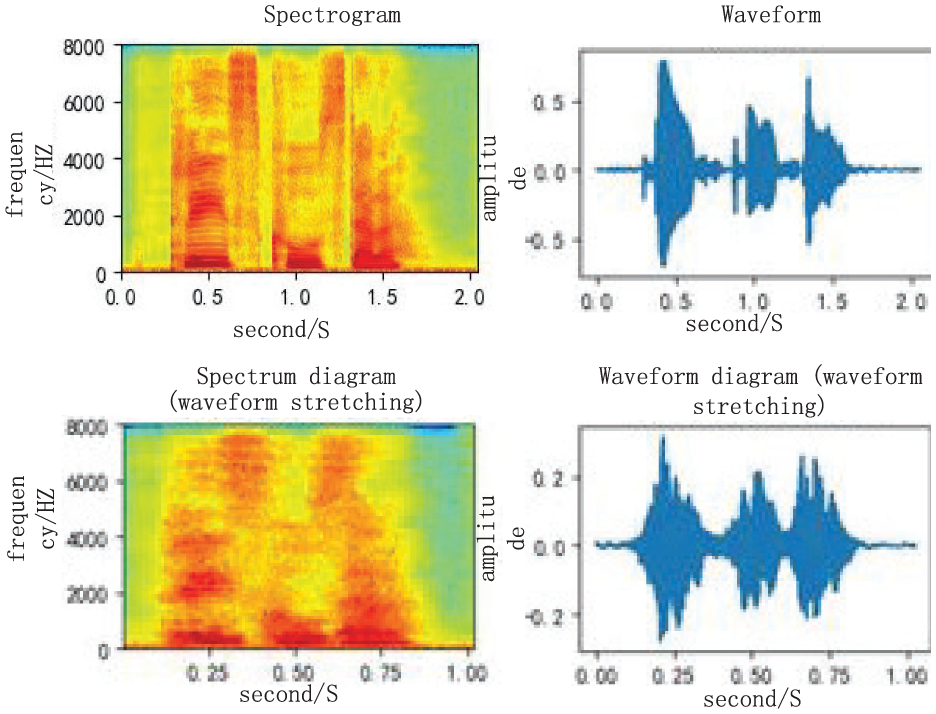
Waveform diagrams comparison.
Change the speed/duration of a sound without affecting its pitch. Use the time_stretch function of librosa to convert graphical data information into waveform diagrams to improve speech recognition capabilities. After further decomposing the speech, the waveform diagram of the decomposed speech is shown in Figure 8.
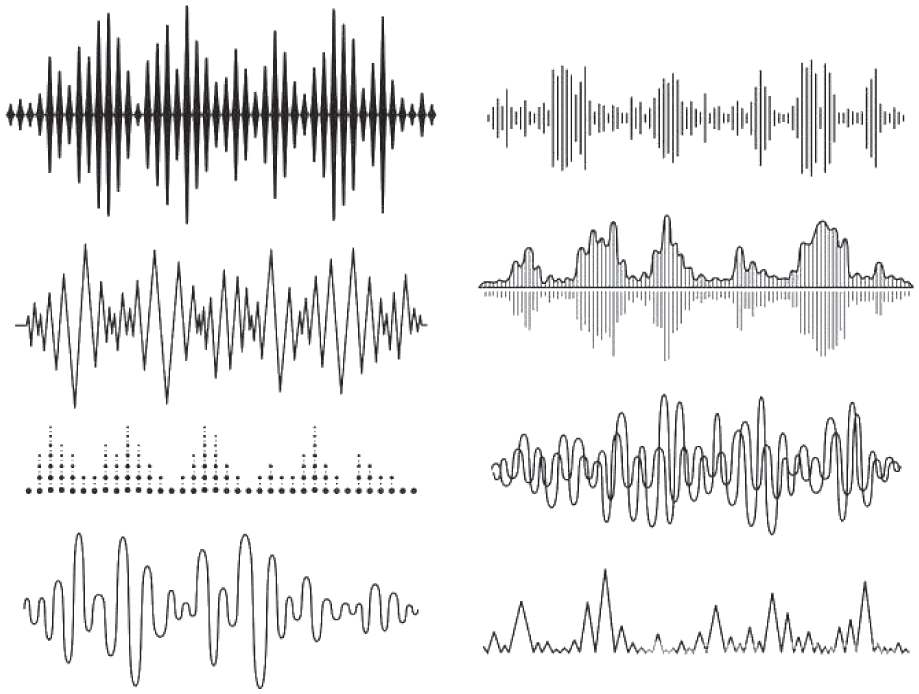
Schematic diagram of speech decomposition.
Through training, the tiny information in the speech signal is decomposed to distinguish the types of speech data. Through deep learning models, even in harsh weather environments, the best data features can be learned from the data, extracted, and protected from speech interference or distortion to maintain high speech recognition. The recognized speech schematic is shown in Figure 9.
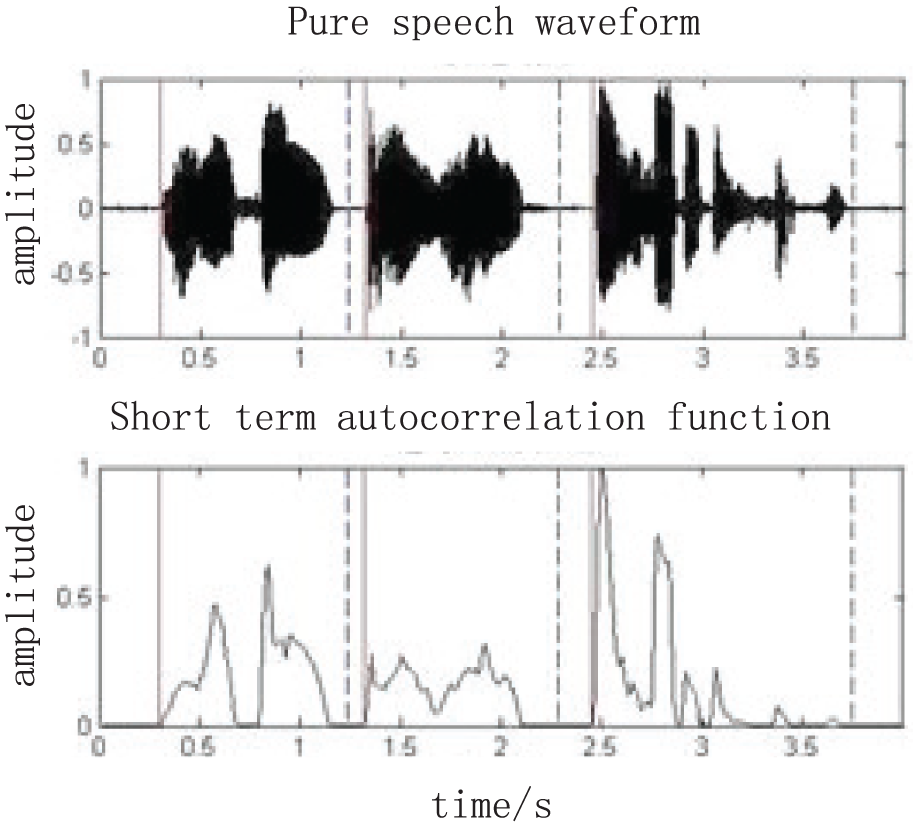
Schematic diagram of recognized speech.
From Figure 9, it can be seen that the speech schematic diagram recognized by this research method has clear lines and a speech recognition error rate of less than 1%, indicating good recognition ability.
In order to verify the accuracy of speech recognition technology, the F1 value used to measure the overlap between predicted answers and real answers and the accuracy rate (EM) of measuring the proportion of correct predictions were used as two evaluation indicators for model performance accuracy. The experimental results were compared with experimental data from Lu et al., 1 Jian et al., 2 and other similar models. The experimental comparison results are shown in Table 1.
Comparison of accuracy of different models.
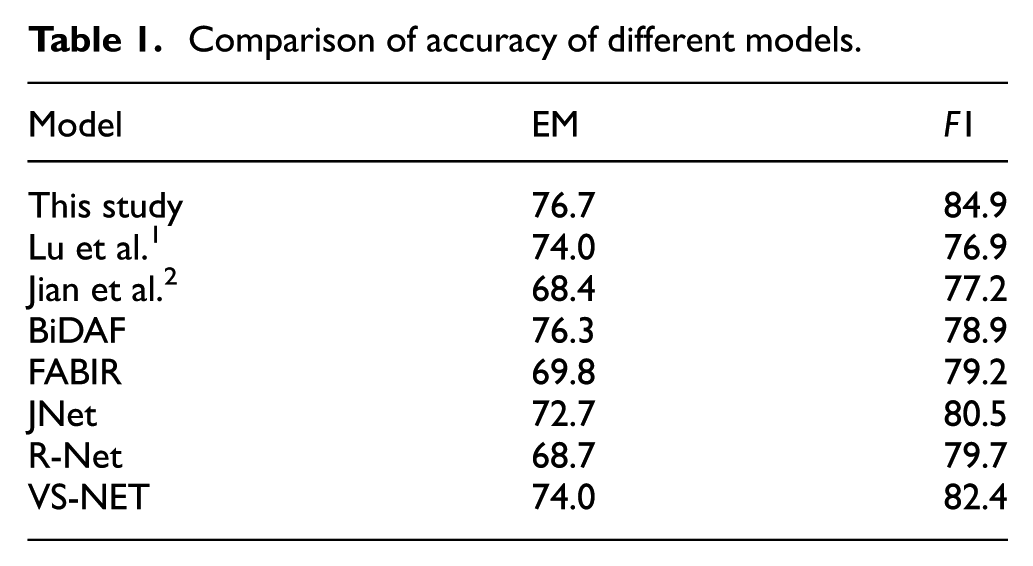
From Table 1, it can be seen that all models in the table, except for FABIR, use RNN as the model foundation. However, the model in this study is entirely based on RNN, which not only improves the training and inference speed but also ensures the accuracy of the model. Moreover, the models in Table 1 did not take into account the issue of information interleaving in feature fusion. This paper uses spatial feature fusion algorithms to improve the accuracy of the models. The EM/F1 value of the model in this article reaches 76.7/84.9, which is better than most other similar models, indicating that the accuracy of the speech recognition technology in this study is relatively high.
The speech recognition was carried out using the methods of this study, Xiaoliang et al., 5 and Gaofeng and Yonghong, 6 and the word error rate results are shown in Figure 10.
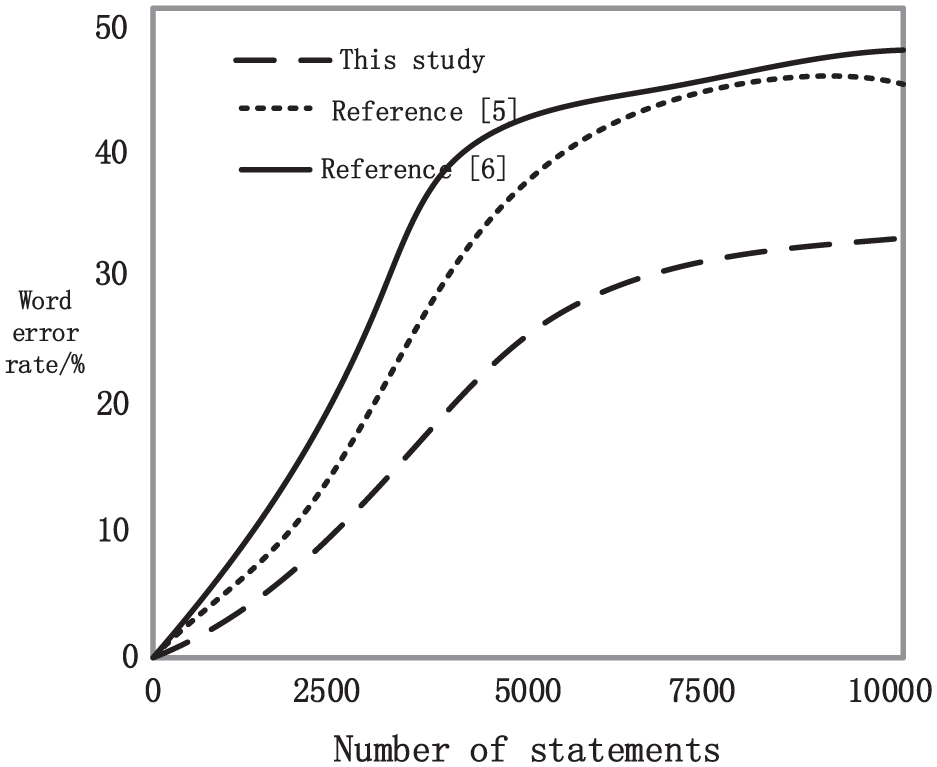
Comparison of word error rates.
According to Figure 10, the method proposed in Xiaoliang et al. 5 has a relatively low word error rate, with a maximum error rate of 48%; The method proposed in Gaofeng and Yonghong 6 has the highest word error rate, with a maximum value of 49%. However, the word error rate of the method proposed in this study is lower than that of the methods in Xiaoliang et al. 5 and Gaofeng and Yonghong, 6 indicating that the proposed method has better recognition performance and further proving the high accuracy of the speech recognition technology in this study.
In order to verify that the system meets the application scenarios designed from a functional perspective, the response time of the testing system in handling user questions and answers, including performance under standard and high load conditions, is tested. By simulating multiple users asking questions simultaneously, recording the system’s response time and conducting performance analysis, the experimental results are shown in Table 2.
Performance test results.
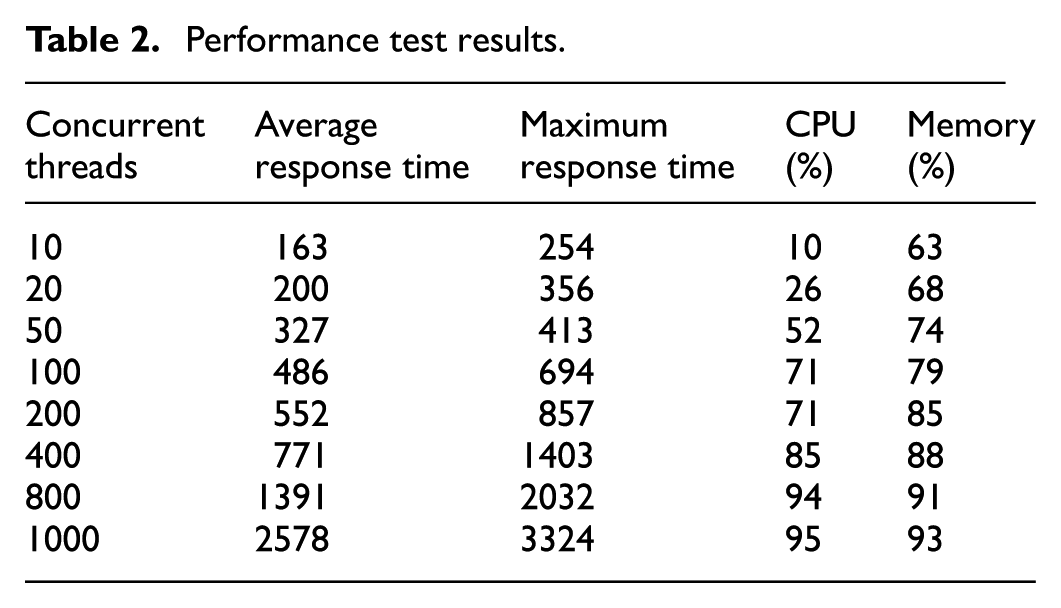
According to Table 2, during the system stress testing period, the entire system operated normally, and the response time of the system gradually increased with the increase of concurrent stress testing. The response time did not exceed the performance requirement of responding within 5 s during the peak phase of the system. The maximum response time during off peak periods is about 2 s, which also meets the performance requirement of a non peak response time of less than 3 s. There were no unexpected abnormal log situations during operation, and the overall stability of the CPU and memory during the pressure testing period was relatively stable without any sustained spikes. Therefore, based on the test results, it was confirmed that the system performance requirements were met.
To verify the performance of the research model, the prediction results under different thresholds were sorted based on the classification model, and the relationship between the true positive rate (recall rate) and false positive rate (false positive rate) was calculated to obtain the ROC curve. As shown in Figure 11.
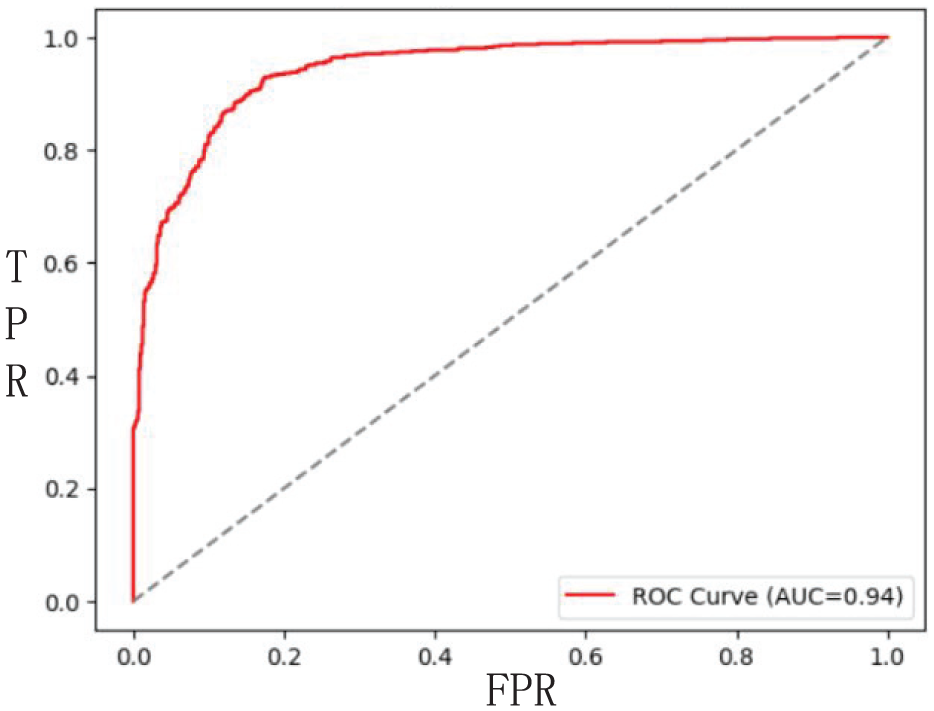
ROC curve of speech recognition model.
The model classifier will obtain a series of different true rate and false positive rate values at different thresholds, and each point on the curve represents the maximum true rate value at the corresponding false positive rate. Therefore, the closer the ROC curve is to the upper left corner, the better the performance. As shown in Figure 6, the experimental result curve is extremely close to the upper left corner, which verifies that the performance of the research model is very stable.
Overall, the solution designed in this article can effectively achieve speech recognition for intelligent AI customer service in supplier service centers.
Conclusion
This study successfully constructed an efficient intelligent human-computer interaction system by integrating advanced speech recognition, speech synthesis, and semantic understanding technologies, and deeply integrating them with a business knowledge base. In order to further improve the accuracy and efficiency of speech recognition, this study adopted the acoustic feature algorithm of Mel cepstral and deep convolutional neural network model. Through the company’s business platform, this study has achieved service-oriented semantic understanding capabilities in the power grid field, while also standardizing the management of business data. This not only improves data availability but also provides support for optimizing business processes. Through a series of experimental verifications, the scheme designed by this research institute significantly improved the overall service quality and customer satisfaction of the supplier service center. In the future, with the further development of technology, intelligent AI customer service is expected to play an important role in more fields and promote the intelligent transformation of the service industry.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: State Grid Shanxi Electric Power Company Technology Project “Research on Intelligent AI Customer Service Technology for Supplier Service Center Based on Speech Recognition and Knowledge Graph Technology” (5205C0240004).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.