
Abstract
Accurate time-series classification (TSC) remains a fundamental challenge in deep learning due to the complexity and variability of temporal patterns. While recurrent neural networks (RNNs) such as LSTM and GRU have shown promise in modeling sequential dependencies, they often suffer from limitations like vanishing gradients and high computational cost when handling long sequences. To overcome these issues, convolutional neural networks (CNNs), particularly the Inception architecture, have emerged as powerful alternatives due to their ability to capture multiscale local patterns efficiently. In this study, we propose InceptionResNet, a hybrid deep learning framework that integrates the residual learning mechanism of ResNet into the InceptionTime architecture. By replacing the fully convolutional network (FCN) shortcut module in InceptionFCN with ResNet-50, the model gains deeper representational capacity and improved gradient flow during training. We conduct extensive experiments on the UCR-85 benchmark dataset, comparing our model against state-of-the-art approaches, including InceptionTime, InceptionFCN, ResNet, FCN, and MLP. The results show that InceptionResNet achieves superior accuracy on 49 of 85 datasets, demonstrating its robustness and effectiveness in handling diverse and complex time series data. This work highlights the potential of integrating multiscale feature extraction and deep residual learning to advance the performance of TSC models in practical applications.
Keywords
Introduction
In recent years, the field of time series data processing has attracted considerable attention from researchers,1,2 driven by the increasing need to accurately model, predict, and classify complex temporal patterns in diverse domains such as finance, healthcare, climate science, and engineering. Various analytical tasks, including forecasting, 3 anomaly detection, 4 and classification 5 require models capable of capturing both short- and long-term dependencies within sequential data. 6 Traditional approaches such as regression techniques, 7 autoregressive models,8,9 and their extensions0,11 have been widely adopted due to their simplicity and effectiveness in capturing linear trends. However, these models often fall short when faced with non-linear, multivariate, or highly dynamic temporal structures,12,13 which are increasingly common in real-world datasets.
To address these limitations, the research community has increasingly turned to deep learning, particularly recurrent neural networks (RNNs),14,15 which are inherently designed to process sequential data by maintaining a hidden state in time steps.16,17 RNNs provide a framework for learning temporal dependencies by recursively incorporating past information into current predictions. However, standard RNNs are plagued by the problem of vanishing gradients,18–20 where gradients become too small to facilitate effective learning as the sequence length increases, ultimately degrading the performance of the model.21–23
To mitigate these issues, long- and short-term memory (LSTM) networks were developed as an advanced RNN architecture.24,25 By introducing memory cells and gating mechanisms that selectively retain or discard information, LSTMs have proven effective in capturing long-range dependencies.13,26,27 In practice, LSTMs outperform standard RNNs in a variety of time-series tasks, particularly when patterns span extended temporal horizons. Compared to gated recurrent units (GRUs), a simplified variant that merges forget and input gates,21,28 LSTMs offer greater flexibility and control over internal memory dynamics,2,26 which makes them especially suitable for modeling more complex or irregular temporal structures. Although GRUs offer computational advantages and have shown competitive results in some cases,29,30 LSTMs remain the preferred choice for applications demanding higher temporal resolution and nuanced memory control. In summary, while classical statistical models provide a strong baseline for linear time-series modeling, the advent of RNNs—especially LSTMs—has significantly advanced the field by enabling robust learning from sequential data. However, as we explore in this study, even LSTM-based architectures face limitations in modeling hierarchical or multiscale features. This motivates the integration of convolutional structures such as CNNs to complement temporal modeling, ultimately laying the groundwork for our proposed hybrid approach combining Inception modules with ResNet-based residual learning for enhanced time-series classification.
Although long short-term memory (LSTM) networks have demonstrated strong capabilities in modeling temporal dependencies by capturing the influence of past observations on current predictions, they still encounter limitations when dealing with very long sequences because of the diminishing impact of distant inputs on current output. This persistent challenge in time-series processing has led researchers to explore alternative or complementary architectures that can better handle long-range dependencies. In this context, our study investigates the integration of convolutional neural networks (CNN) into time-series analysis as a promising direction.13,31 CNNs, originally developed for computer vision tasks, have since become foundational in various domains, including image processing, 32 sound, text, and time series data analysis. 33 While RNN-based models such as LSTM and GRU remain popular for sequential data due to their temporal modeling capabilities34,35 CNNs offer significant advantages in capturing local patterns through their hierarchical feature extraction mechanisms. When appropriately adapted, CNNs can effectively extract discriminative features from time series data, which can be used to complement the temporal context provided by RNNs. This motivates the use of hybrid approaches that combine CNNs and RNNs to exploit spatial and temporal patterns.36,37 Our research aligns with this direction, aiming to address the limitations of standalone deep learning architectures by proposing a robust model that takes advantage of the multiscale feature extraction of Inception modules and the deep residual learning of ResNet, offering a powerful solution for time-series classification (TSC) tasks across diverse and complex datasets.
The study38,39 presents a comprehensive investigation into hybrid deep learning models for time series classification (TSC), focusing on the integration of multiscale feature extraction and residual learning techniques. We begin by systematically reviewing a wide range of deep learning models developed for TSC, including convolutional neural networks (CNNs) and recurrent neural networks (RNNs), evaluating their structural designs, mechanisms, and performance across various datasets in the UCR-85 archive. Recognizing the individual strengths of these models—CNNs for hierarchical spatial feature extraction and RNNs for temporal sequence modeling—we explore their combinations to enhance model robustness and accuracy. Based on this analysis, we propose a novel hybrid framework, InceptionResNet, which replaces traditional Fully Convolutional Network (FCN) in Inception-based models with ResNet-50 to mitigate vanishing gradients and enable deeper, more effective learning. Extensive experiments conducted on the UCR-85 benchmark show that our model consistently outperforms state-of-the-art alternatives in both accuracy and stability, particularly on complex and noisy datasets. Our findings not only demonstrate the superior performance of the proposed hybrid architecture but also highlight its broad applicability in fields requiring reliable time series analysis. Furthermore, we identify future research directions, such as extending the model to multivariate and real-time TSC scenarios, thus contributing to the continued advancement of deep learning techniques in temporal data processing.
The key innovation of our proposed method, InceptionResNet, lies in the integration of ResNet's residual learning mechanism into the InceptionFCN architecture. While InceptionFCN utilizes a fully convolutional network (FCN) as its shortcut module, our model replaces this component with a ResNet-50 architecture. This structural change introduces residual blocks, which significantly improve gradient flow and enable deeper network training without the vanishing or exploding gradient problems commonly encountered in deep learning. As a result, the proposed InceptionResNet model is able to extract both multiscale features (via Inception modules) and deeper, more abstract representations (via ResNet blocks). Empirical evaluations on the UCR-85 data set further highlight the effectiveness of this integration, where InceptionResNet outperforms InceptionFCN in 49 of 85 benchmark datasets. This demonstrates the improved generalization capability and robustness of the model, particularly in handling complex time-series data. Our approach provides a meaningful advancement over existing models by combining the strengths of Inception and ResNet architectures into a unified, more powerful framework for time-series classification.
Related works
The evolution of neural network architectures over the past decade has significantly advanced the capabilities of deep learning models in both image recognition and time series classification. In 2015, Szegedy et al. 40 introduced the Inception architecture, a groundbreaking design that improved resource utilization and computational efficiency by employing multiple convolutional filter sizes within the same layer. This multibranch strategy allowed the network to extract features at various scales simultaneously, enhancing its ability to capture both fine-grained and high-level patterns. By balancing depth and width, the Inception model demonstrated superior performance in image recognition tasks while avoiding excessive computational cost. Building on this foundation, Ismail Fawaz et al. in 2020 proposed InceptionTime, 41 a deep learning framework specifically tailored for time-series classification (TSC). Inspired by the original Inception architecture, InceptionTime leveraged multiscale convolutional modules to extract diverse temporal patterns, thereby achieving state-of-the-art accuracy across numerous time series benchmarks. Its modularity and scalability made it particularly effective for handling heterogeneous time-series data, marking a major milestone in the application of deep convolutional networks to sequential data domains. More recently, in 2024, Navid et al. 5 extended this approach by combining the strengths of Inception and FCNs, resulting in the InceptionFCN model. This integration retained the multiscale feature extraction capability of Inception modules while incorporating the efficiency in processing full-length time series data without the need for flattening or thicken layers. Empirical results in the UCR-85 dataset revealed that InceptionFCN surpassed InceptionTime in classification accuracy and robustness, highlighting the value of architectural hybridisation in tackling complex temporal classification tasks. Parallel to the development of Inception-based models, another significant advancement in deep learning came with the introduction of residual networks (ResNet) by He et al. in 2016. 42 ResNet addressed the well-known problem of vanishing gradients by introducing residual learning, where identity shortcut connections bypass one or more layers, allowing gradients to propagate more effectively during training. 43 This architectural innovation allowed the construction of very deep neural networks, up to 152 layers—without suffering from performance degradation, setting new standards for depth and accuracy in deep learning. ResNet consistently outperformed earlier architectures like VGG, offering both computational efficiency and high generalization capability. Collectively, these developments have laid a strong foundation for hybrid deep learning frameworks. Motivated by the complementary strengths of Inception (multiscale feature extraction) and ResNet (deep residual learning), our research proposes a unified model, InceptionResNet, that integrates these paradigms to address the challenges of time series classification. By embedding ResNet blocks within an Inception-based structure, we aim to enhance both depth and representational power, enabling the model to learn hierarchical temporal features efficiently and robustly.
The InceptionFCN model has emerged as a powerful architecture in time series data processing, demonstrating impressive performance in prediction, classification, and feature extraction tasks. Its integration of multiscale Inception modules with the sequential handling efficiency of FCNs has enabled it to capture diverse temporal patterns across a wide range of datasets. However, despite its promising results, certain limitations remain, particularly in handling deeper network training and generalization across heterogeneous data. This study builds on InceptionFCN by addressing these challenges through three key research objectives that drive the design of our proposed InceptionResNet architecture.
First, we aim to demonstrate the efficacy of applying convolutional neural networks (CNNs) to time-series data, capitalizing on their success in fields such as image and audio processing. CNNs are inherently capable of extracting hierarchical features through convolutional layers, enabling the capture of both local short-term patterns and broader temporal structures. By adapting this capability to one-dimensional time series inputs, we show that CNNs can effectively model sequential dependencies without the need for recurrent mechanisms, offering improved scalability and parallelization.
Second, to optimize the InceptionFCN architecture, we propose a novel modification: replacing the traditional FCN backbone with a ResNet. ResNet introduces identity shortcut connections that address the vanishing gradient problem, thereby facilitating the training of deeper models with enhanced representational power. This architectural enhancement not only improves convergence during training, but also improves the robustness in handling noisy, high-dimensional, or long-range temporal data. By embedding ResNet-50 within the Inception framework, our model benefits from both multiscale feature extraction and deep residual learning, two complementary strengths essential for high-performance time-series classification.
Third, we pursue the goal of building a general-purpose model that can be applied beyond time series data, aiming for broad adaptability across multiple data domains. The proposed InceptionResNet architecture is designed to be versatile enough for image classification, sequence modeling, and even regression tasks, thanks to the modular nature of its components. This generalizability is particularly valuable in real-world applications where models often need to operate across different data modalities.
Through these contributions, our study not only addresses the performance limitations of existing time series models but also provides a unified deep learning framework that is accurate, scalable, and adaptable. The proposed improvements to InceptionFCN highlight the potential of hybridizing advanced CNN-based architectures, offering significant advances in time-series data processing and opening new avenues for cross-domain model deployment.
Our proposed InceptionResNet architecture draws foundational inspiration from the Inception-ResNet framework introduced by Szegedy et al. (2016), 44 which successfully merged the strengths of Inception modules with deep residual learning to improve convergence and generalization in image recognition tasks. However, while Szegedy's design was tailored for high-resolution spatial representations in computer vision using 2D convolutions, our work extends this principle to the temporal domain by adapting the architecture for 1D convolutional operations, enabling its application to time-series classification problems.
In contrast to Inception-ResNet-v1/v2, which employ custom 2D residual connections within image feature maps, our model integrates a 1D ResNet-50 backbone with Inception modules specifically designed for multiscale temporal pattern extraction. The residual pathways in ResNet-50 effectively mitigate gradient vanishing in deep architectures and facilitate the learning of long-range dependencies—critical for time-series data. By embedding this residual backbone within the temporal feature extraction pipeline, our InceptionResNet not only leverages the advantages of Inception's hierarchical filters but also enables stable training of deeper networks, which conventional 1D architectures such as InceptionFCN struggle to sustain. Hence, our work represents a domain-adapted reinterpretation of the original Inception-ResNet concept, tailored to sequential data and validated through significant performance improvements on the UCR-85 benchmark.
Materials and methods
Inception
The Inception architecture represents a significant advancement in convolutional neural network (CNN) design, particularly in its ability to efficiently capture multiscale features while maintaining computational feasibility. In traditional CNNs for image classification, each layer sequentially extracts features from its predecessor, but each transformation, whether a convolution with a specific kernel size or a pooling operation, tends to focus narrowly on a specific type of spatial feature. For example, a 5 × 5 convolution may detect coarse, large-scale structures, while a 3 × 3 convolution or max-pooling operation may capture finer patterns as shown in Figure 1(a). However, this sequential approach often risks missing crucial information, as it relies on the assumption that a single type of transformation will be optimal for all input regions.

a. Illustration of the inception module. b. Inception modules perform parallel operations.
To address this challenge, the Inception network introduced by Szegedy et al. 44 adopts a parallel, multi-branch architecture capable of processing the same input through multiple receptive field sizes simultaneously. Specifically, the Inception Modules perform parallel operations using 1 × 1, 3 × 3, and 5 × 5 convolutions, together with 3 × 3 max-pooling as shown in Figure 1(b). This enables the model to learn and combine features at various levels of spatial abstraction, effectively capturing fine-grained, medium-scale, and coarse patterns in a single layer. The outputs of these parallel operations are then concatenated along the depth dimension and passed to the next layer, allowing the model to dynamically select the most relevant information for higher-level processing. This approach ensures that no potentially useful feature is discarded due to architectural constraints and enhances the robustness and generalisation capacity across a variety of tasks and datasets.
A particularly innovative aspect of the Inception architecture is the use of 1 × 1 convolutions as bottleneck layers. These serve two purposes: first, they reduce the number of feature maps before applying computationally expensive 3 × 3 and 5 × 5 convolutions, significantly lowering the computational cost; and second, they introduce nonlinearity, which improves the model's expressive power. This architectural efficiency enables the construction of deeper and wider networks without incurring prohibitive memory or training costs. Furthermore, the 3 × 3 max-pooling operation improves translation invariance and spatial generalization, making the model more effective in tasks requiring spatial flexibility.
The Inception Module, as a CNN-based technique,45,46 provides an elegant solution to two major challenges in deep learning: high computational demands and the risk of overfitting in deep architectures. 47 By integrating multi-sized convolutions and pooling operations in parallel, the module captures a diverse set of features while keeping parameter growth under control. The simultaneous processing of the input with filters of different sizes—1 × 1 for fine-grained detail, 3 × 3 for mid-level features, and 5 × 5 for broader contextual patterns allows the network to develop a rich multiscale representation of the data. Furthermore, the 3 × 3 max-pooling contributes by reducing spatial dimensionality while preserving key structural features, further enhancing robustness.
When applied to time-series data, this multiscale approach is particularly powerful. Although originally developed for image analysis, the principles behind Inception Modules, parallel feature extraction, multiscale processing, and efficient depth expansion, transfer well to one-dimensional temporal data. In time-series classification, the ability to simultaneously capture short- and long-term dependencies within a single module allows the model to adapt to variations in signal frequency, duration, and noise levels. As such, the Inception Module forms the core inspiration behind modern architectures like InceptionTime and InceptionFCN, which have extended its utility into the sequential data domain.
In summary, the Inception architecture provides a robust, flexible, and computationally efficient framework for deep learning. Its parallel processing capability ensures that critical features on multiple scales are preserved, while the use of 1 × 1 bottleneck layers keeps the model scalable. These design principles have not only revolutionized image classification but also laid the groundwork for applying CNNs to diverse problems, including the time-series classification framework explored in this study.
Inceptiontime
The InceptionTime model is a deep neural network architecture specifically designed for time series classification, drawing direct inspiration from the success of GoogleNet48,49 in computer vision. It effectively adapts the core idea of Inception Modules, parallel multiscale convolutions, to the one-dimensional domain, allowing efficient extraction of temporal features at varying levels of granularity. 50 Each Inception Module within the architecture performs multiple convolution operations with different kernel sizes (e.g., 1 × 1, 3 × 3, 5 × 5), alongside a maximum-pooling branch. This parallel processing captures local, midrange, and long-range temporal patterns simultaneously, ensuring that critical information is retained on different timescales. The overall structure of the InceptionTime network comprises a sequence of stacked Inception Modules, followed by a global average pooling layer and a fully connected dense layer that produces the final classification or regression output. The global pooling operation reduces the dimensionality of the feature maps, summarizing the learned representations across the entire input sequence. This compact and generalizable feature representation helps the model achieve strong performance across diverse datasets, regardless of input length variability.
A major innovation in InceptionTime is the integration of residual connections every third Inception Module, an idea borrowed from ResNet architectures. These residual shortcuts alleviate the problem of vanishing gradients, a common issue in training deep neural network training, by allowing the network to learn identity mappings. Specifically, each residual block adds the input of an Inception Module directly to its output, ensuring that important information is preserved and gradient flow is maintained throughout training. This not only stabilizes the learning process but also allows deeper networks without sacrificing accuracy or convergence speed.
Inclusion of residual connections also improves the network's ability to learn complex representations by facilitating gradient propagation through deeper layers. This architecture supports the learning of both low-level temporal transitions and high-level abstract patterns, improving the model's generalization across various types of time-series data. In addition, the use of global average pooling rather than flattening helps reduce overfitting by removing the need for large fully connected layers and keeping the model lightweight.
In essence, InceptionTime combines the multiscale feature extraction capability of Inception modules with the training efficiency and stability offered by residual learning. This synergy makes it a powerful and scalable architecture for time-series tasks, capable of addressing challenges such as variable sampling rates, noise, and class imbalance. As shown in Figure 2, the InceptionTime architecture embodies a carefully designed blend of structural diversity and depth, enabling it to achieve state-of-the-art results in time series classification benchmarks. Its architectural foundations form a critical stepping stone in our work, serving as the baseline upon which we propose improvements through the integration of ResNet backbones to enhance feature learning and robustness.

Illustration of the inceptionTime for the TSC problem.
InceptionFCN
Building on the foundational concepts of InceptionTime, the InceptionFCN model presents a refined and modular approach to time series classification, integrating the strengths of Inception modules with FCNs.51,52 As illustrated in Figure 3, while InceptionFCN shares core structural similarities with InceptionTime, it introduces a novel dual-branch architecture that explicitly separates the model into two synergistic components: the Inception module and the Shortcut Module.

Illustration of the residual connections in the inceptionTime model.
The Inception Module in InceptionFCN is designed to efficiently capture multiscale temporal features by processing the input through parallel convolutional paths with kernel sizes of 1 × 1, 3 × 3, and 5 × 5, along with a 3 × 3 max-pooling layer as shown in Figure 3. These branches allow the network to extract patterns at varying temporal resolutions, from fine-grained transitions to broader contextual trends. A key innovation in this module is the inclusion of a bottleneck layer employing a linear activation function, which performs dimensionality reduction prior to convolutional operations. This design not only minimizes computational cost but also enhances compatibility with one-dimensional time-series data by reducing the input size while preserving essential information. Max-pooling layers further contribute to regularization, improving generalisation and reducing the risk of overfitting.
Complementing the Inception Module is the shortcut module, a dedicated FCN block composed of six sequential 1D convolutional layers, each with a kernel size of 1 × 1. This deeper pathway is engineered to compensate for potential limitations in the initial branch by providing an additional stream of hierarchical feature extraction, as depicted in Figure 4. The first layer applies 128 filters through 1 × 1 convolutions, creating a rich feature representation early in the network. These layers are followed by batch normalization and ReLU activation functions, which enhance training stability and introduce non-linearity, enabling the model to learn complex temporal relationships.

The internal structure of the modified 1D inception module used in the proposed model.
The outputs of both the Inception Module and the Shortcut Module are concatenated and passed through a global average pooling (GAP) layer, which summarizes the learned features across the full temporal sequence. This pooling operation reduces the dimensionality of the data and feeds a compact representation into the final classification or regression head. In particular, InceptionFCN employs average entropy to calculate the loss function, offering a probabilistic measure of prediction uncertainty and model confidence during training.
The modular structure of InceptionFCN reflects a thoughtful integration of Inception's multiscale design with the depth and learning capacity of FCNs, resulting in a model that is both expressive and computationally efficient. This architecture is particularly effective in time series domains where patterns may exist on multiple temporal scales and vary in frequency, amplitude, or duration. Furthermore, the use of residual inspired shortcut paths, batch normalisation, and GAP layers ensures that the network remains trainable and robust even when scaled to deeper configurations.
In summary, InceptionFCN offers a powerful hybrid architecture for time-series data processing by leveraging the parallel multiscale capabilities of Inception Modules alongside the depth and adaptability of FCNs. Its thoughtful design enables it to capture diverse and complex temporal structures, making it a strong candidate for various real-world time-series applications and a natural stepping stone toward further architectural improvements, such as the integration of ResNet blocks, as explored in our proposed model.
In Figure 3, Schematic block diagram of the InceptionResNet architecture used for time-series classification. The input signal is processed through three consecutive Inception modules to extract multiscale features. A parallel shortcut path applies a 1 × 1 convolution to the input, and the two outputs are merged via element-wise addition, forming a residual connection that stabilizes training and supports deeper model configurations.
Figure 4 illustrates the internal structure of a modified 1D Inception module designed to extract multiscale features from univariate or multivariate time-series data. The input signal is processed through four parallel branches:
The first branch applies a 1 × 1 convolution followed by batch normalization (BN), enabling channel-wise projection and reducing dimensionality. The second and third branches perform 10 × 1 and 20 × 1 convolutions, respectively, each followed by BN, to capture medium- and long-range temporal dependencies. The fourth branch applies 3 × 3 max pooling, which focuses on dominant features over short intervals, followed by a 1 × 1 convolution and BN to reduce dimensionality and normalize activations.
The outputs of all four branches are then concatenated along the channel axis, forming a unified multiscale representation. This depth-wise filter aggregation allows the module to extract rich temporal features at varying resolutions, which is especially important for modeling diverse periodicities and event scales in time-series classification tasks.
This module design reflects the architectural philosophy of the original Inception architecture by Szegedy et al., 44 but it has been adapted to 1D convolutions and time-series processing, making it a suitable building block for the proposed InceptionResNet model.
Model application
InceptionResNet
Although the InceptionFCN architecture has demonstrated strong performance in time-series classification (TSC) by leveraging multiscale feature extraction and deep convolutional layers, it still encounters a fundamental limitation common to many deep neural networks: the vanishing gradient problem. This issue arises in very deep networks when gradients propagated during backpropagation become exceedingly small, making weight updates ineffective. Consequently, the training process stalls and the network fails to converge, leading to suboptimal accuracy and degraded learning performance, particularly in complex time-series tasks where deeper architectures are often essential.
To address this challenge, our study incorporates the powerful principles of Residual Networks (ResNet) into the InceptionFCN framework, giving rise to a new hybrid architecture we call InceptionResNet. ResNet, originally developed to enable the training of ultra-deep CNNs, introduces a fundamental architectural innovation: residual blocks. These blocks include shortcut (or skip) connections that allow the input to bypass one or more layers and be directly added to the output of a later layer, as illustrated in Figure 5. The central idea is to reformulate the target mapping as a residual function.


The architecture of a residual block in ResNet.
Here,
In addition to identity shortcuts, ResNet also incorporates convolutional shortcut paths that adjust dimensional mismatches between layers. For example, when the input and output shapes differ (for example due to downsampling or changing channel dimensions), 1 × 1 convolutions are used to project the input to a compatible form before addition. This flexibility allows the construction of much deeper and more expressive networks without encountering accuracy degradation, a phenomenon that typically plagues very deep CNNs.
By integrating ResNet blocks into the InceptionFCN backbone, our proposed InceptionResNet model inherits the multi-scale feature extraction of Inception modules and the deep residual learning capability of ResNet. This hybrid approach not only enhances gradient propagation but also allows the model to scale to greater depths, improving its ability to learn complex temporal dependencies across long time horizons. The use of residual learning ensures that features from earlier layers are preserved and directly passed forward, enabling more stable and efficient training while improving generalization to diverse time-series datasets.
In summary, InceptionResNet addresses a critical limitation of deep CNNs, vanishing gradients, by using residual learning. This advancement facilitates the development of a deeper and more robust model for TSC, capable of learning hierarchical temporal patterns without sacrificing convergence or accuracy. As our experiments show, the integration of ResNet into the Inception-based architecture significantly boosts model performance across a variety of time series classification benchmarks, laying the groundwork for future exploration of even more advanced hybrid frameworks.
Figure 5 illustrates the internal structure of a residual block as originally proposed in the ResNet architecture. The residual block consists of two sequential convolutional layers, each followed by batch normalization, and one non-linearity (ReLU) inserted after the first batch normalization. The input tensor X is processed by the first convolutional layer (Conv2D), which is followed by batch normalization and ReLU activation. The output is then passed through a second Conv2D layer and another batch normalization layer. In parallel, the input X is forwarded directly through a shortcut connection without any transformation (identity mapping in the case of equal dimensions). At the element-wise addition (⊕) node, the output of the convolutional path is added to the original input. This residual connection facilitates gradient flow through deep networks and prevents vanishing gradients during backpropagation. A final ReLU activation is applied to the combined output to introduce non-linearity. This residual learning framework is integral to the ResNet-50 backbone used in our InceptionResNet model, enabling deeper architectures to be trained effectively without degradation.
Figure 6 depicts the architecture of the deep convolutional neural network (CNN) baseline model used for time-series classification. The model processes the raw input signal through five stacked 1D convolutional layers, each comprising 128 filters. After each convolution, the feature maps are normalized using batch normalization (BN) followed by a ReLU activation, which improves training stability and introduces non-linearity.

Architecture of the baseline CNN model for time-series classification.
This repeated stack of convolutional units enables the model to hierarchically learn increasingly abstract temporal patterns, making it suitable for capturing complex dynamics in sequential data. The final convolutional block is followed by a global average pooling (GAP) layer, which reduces the spatial dimensionality and aggregates temporal features into a fixed-length vector, ensuring invariance to input sequence length. To improve generalization and mitigate overfitting, a dropout layer is applied before the final prediction. The output is produced via a softmax layer, which maps the aggregated features to class probabilities for the given classification task. This architecture is widely adopted as a competitive baseline in TSC benchmarks, such as the UCR archive, due to its simplicity, stability, and strong empirical performance.
To further enhance the performance of deep convolutional networks in time-series classification (TSC) tasks, we propose a novel hybrid architecture, InceptionResNet, which combines the multiscale feature extraction power of the Inception Module with the deep residual learning capability of ResNet. This design stems from the limitations observed in the InceptionFCN model, particularly when scaling to deeper architectures, where the vanishing gradient problem becomes a critical bottleneck. Although InceptionFCN performs well in extracting multiresolution temporal patterns, its reliance on a Fully Convolutional Network (FCN) in the shortcut path limits its depth and gradient flow. To address this, we modify the traditional InceptionFCN structure by replacing the FCN-based Shortcut Module with ResNet blocks, as shown in Figure 6.
In our proposed architecture, the Inception Module is retained to capture various temporal features through parallel convolutional branches (1 × 1, 3 × 3, 5 × 5) and max-pooling operations. This module efficiently extracts local, mid-level, and global patterns across different time scales, ensuring robust temporal representation of the input data. The modification lies in the Shortcut Module, which originally consisted of stacked 1D convolutional layers. We substituted this path with ResNet, allowing the model to learn deeper, more complex feature hierarchies while preserving training stability (see Figure 7). The residual learning mechanism of ResNet introduces shortcut connections that directly propagate input signals across layers, thereby preventing gradient attenuation during backpropagation. This not only improves the convergence speed but also improves the model's capacity to learn long-term temporal dependencies, essential in TSC scenarios.

Residual block with projection shortcut in ResNet.
In practice, we implement the ResNet-50 variant within our hybrid model (see Figure 8), which provides a balanced trade-off between depth and computational efficiency. The architecture begins with zero-padding, preserving spatial dimensions for subsequent convolutions. In Stage 1, a 7 × 7 convolution with 64 filters and a 2 × 2 stride captures coarse features, followed by batch normalization and 3 × 3 max-pooling to reduce spatial complexity. Stages 2 through 5 progressively deepen the network:
Stage 2 uses a convolutional block and two identity blocks (64 × 64 × 256 filters), Stage 3 expands with one convolutional block and three identity blocks (128 × 128 × 512), Stage 4 adds one convolutional block and five identity blocks (256 × 256 × 1024), Stage 5 culminates with one convolutional block and two identity blocks (512 × 512 × 2048).

Illustration of the ResNet50 architecture.
Each identity block contains skip connections that preserve gradient flow, enabling the model to retain and build on previously learned features. Following these stages, a 2D average pooling layer reduces feature dimensions, which are then flattened and passed through a fully connected layer with a softmax activation function, yielding the final class probabilities.
Crucially, our InceptionResNet model performs convolution operations at the output stages of both the Inception Module and ResNet block. These are followed by global average pooling, unifying the learned features into a compact vector for final classification. Although ResNet alone effectively combats the problem of disappearance of gradients, its combination with the Inception Module 12 proves to be synergistic: the Inception branch excels in capturing multiscale patterns, while the ResNet pathway ensures deep, stable training. Together, they form a highly expressive and resilient architecture for TSC. In summary, the InceptionResNet architecture bridges two powerful paradigms, multiscale convolutional processing and residual learning, into a unified model that significantly improves learning capacity, gradient stability, and generalization performance on complex time-series data.
Figure 7 shows the architecture of a residual block with a projection shortcut, commonly used in deep residual networks (ResNet) to handle changes in dimensionality between the input and output feature maps. The main branch of the block consists of three sequential Conv2D layers, each followed by batch normalization (BN) and ReLU activation (except the last layer, which excludes ReLU to maintain the additive identity). Simultaneously, the shortcut connection processes the input X using a 1 × 1 convolution (Conv2D) and batch normalization to project the input into the same shape as the output of the main branch. This is necessary when the spatial or channel dimensions between input and output do not match, particularly in deeper layers with downsampling or channel expansion. The outputs of both paths are fused via element-wise addition (⊕), and a final ReLU activation is applied. This configuration preserves the benefits of residual learning—enhancing gradient flow and mitigating vanishing gradients—while providing architectural flexibility to support deeper and more complex models.
To clarify the distinction between our proposed InceptionResNet model and the existing InceptionFCN architecture, we emphasize a fundamental structural innovation introduced in this study. While InceptionFCN integrates multiscale Inception modules with a Fully Convolutional Network (FCN) as a shortcut path, our model replaces this FCN component with a ResNet-50 backbone to construct a deeper and more robust hybrid framework. This integration brings several critical advantages. First, the residual connections in ResNet-50 enable more effective gradient propagation, which alleviates the vanishing gradient issue commonly encountered in deep convolutional networks. Second, the ResNet architecture facilitates the training of significantly deeper models without degradation in performance, allowing the network to learn hierarchical temporal features with greater expressiveness and stability. Third, the inclusion of identity and convolutional shortcut paths within ResNet blocks supports structural adaptability, ensuring compatibility across different feature dimensions and enabling richer feature learning.
Empirically, this architectural enhancement has translated into superior performance. On the UCR-85 benchmark, InceptionResNet achieved the highest classification accuracy in 49 out of 85 datasets, compared to 33 wins by InceptionFCN. This performance gap underscores the effectiveness of combining Inception's multiscale feature extraction with ResNet's deep residual learning. In summary, our model not only improves training dynamics and scalability but also demonstrates stronger generalization across diverse and complex time-series datasets, thereby establishing a significant advancement over the InceptionFCN model.
Dataset description & usage
To rigorously evaluate the performance of our proposed InceptionResNet model and its baseline counterpart, InceptionFCN, we conducted extensive experiments using the UCR-85 dataset, a widely adopted benchmark suite in the field of time-series analysis. The UCR-85 dataset collection encompasses 85 diverse univariate and multivariate time-series datasets, each differing in length, dimensionality, complexity, and domain of application. This breadth of variation makes UCR-85 an ideal testbed for benchmarking machine learning and deep learning models in time series classification (TSC) tasks.
These datasets span a wide range of real-world scenarios, allowing researchers to assess algorithmic performance across distinct data characteristics. Key domains represented in UCR-85 include:
Electroencephalography (EEG): Time series data representing brain activity patterns, which are critical in medical diagnostics and neurological research. EEG signals are used to detect abnormalities such as seizures, monitor sleep stages, and analyze cognitive states. Speech signals: Temporal audio waveforms related to spoken language. These datasets are essential for speech recognition, speaker identification, and natural language processing, where time-dependent acoustic features are key to system performance. Geological measurements: Time-series data that capture phenomena such as seismic activity. These data sets support applications in earthquake prediction, subsurface exploration, and geophysical monitoring. Frequency-based measurements: Data recorded from sensors at different sampling frequencies, relevant in telecommunications, radar systems, and signal analysis, where frequency variations provide information on signal stability and performance. Temperature and environmental readings: Data sets reflecting temporal variations in environmental parameters such as temperature, humidity, or atmospheric pressure. These are critical for climate change studies, energy management systems, and agricultural monitoring.
The UCR-85 data sets are widely used for both training and testing in developing deep learning architectures such as CNNs, RNNs, hybrid models, and attention-based frameworks. Their consistent formatting, public availability, and balanced class distributions make them a standard for fair and reproducible evaluation across research studies.
Several defining features of the UCR-85 dataset highlight its importance for generalizable model testing:
Variable sequence lengths: Time-series samples within and across datasets differ in length, challenging models to be robust to input size variability and to learn without overfitting to fixed-length assumptions. Multidimensional inputs: Some datasets include multivariate signals, which requires models to learn cross-dimensional dependencies in addition to temporal dynamics. Nonlinear and Complex Patterns: The datasets encompass a spectrum from periodic, smoothly varying sequences to irregular, noisy, and highly nonlinear temporal structures. This variety pushes models to generalize beyond simple heuristics and adapt to underlying dynamics.
By serving as a comprehensive and standardized benchmark, UCR-85 enables the machine learning community to systematically compare architectures and highlight trade-offs in accuracy, robustness, and computational efficiency. Our use of UCR-85 ensures that the proposed InceptionResNet model is evaluated not only on isolated performance metrics, but also on its ability to generalize across diverse temporal domains.
Moreover, the impact of models trained on UCR-85 extends to numerous real-world applications, including:
Healthcare: Improvement in patient monitoring, diagnosis, and anomaly detection through improved analysis of physiological signals. Environmental sciences: Supporting more accurate climate modeling, weather prediction, and environmental anomaly detection. Engineering and Industry: Facilitating predictive maintenance, fault diagnosis, and system health monitoring in smart manufacturing and industrial automation. Finance: Improving forecasting, fraud detection, and anomaly identification in economic time-series data.
In summary, the UCR-85 dataset plays a pivotal role in advancing the state-of-the-art in time series analysis. Its diversity, complexity, and relevance make it an indispensable tool for validating the accuracy, scalability, and robustness of novel deep learning models, including the InceptionResNet framework proposed in this study.
Experimental results and discussions
To comprehensively assess the performance of the proposed InceptionResNet model in the context of time series classification (TSC), we conducted a series of comparative experiments against five established deep learning architectures. InceptionFCN, InceptionTime, multilayer perceptron (MLP), fully convolutional network (FCN), and ResNet. These models were selected to represent a diverse range of design philosophies, ranging from purely feedforward architectures to those leveraging residual connections or multiscale feature extraction strategies. The experiments were carried out on the UCR-85 benchmark dataset, ensuring a robust and diverse evaluation environment.
To ensure fair and reproducible comparisons, all models were subjected to an identical experimental setup. Pre-processing steps, including z-score normalization, sequence alignment, and optional data augmentation, were uniformly applied across all data sets. Furthermore, training parameters such as learning rate, batch size, optimizer settings, and the number of training epochs were standardized. This consistency eliminates confounding factors and ensures that observed performance differences are attributable to model architecture rather than to training protocol variations.
Each model was trained and evaluated using an 80/20 train-test split on each data set within the UCR-85 collection. This split simulates a realistic deployment scenario where models are evaluated on unseen data, thereby providing an accurate reflection of generalization capability. To enhance statistical robustness, multiple training runs were conducted using different random seeds, and the final performance metrics were reported as the average between runs.
Our evaluation used a comprehensive set of performance metrics, including classification accuracy, precision, recall, F1 score, and training time. These metrics were chosen to provide insights not only into predictive performance, but also into computational efficiency and convergence behavior. The comparative results are summarized in Table 1, which reports both training and test performance in all six models. The table also includes convergence rates and model-specific observations such as stability and sensitivity to hyperparameter tuning.
Comparative studies between different models within standard data sets for the TSC problem data set.

Importantly, we used the performance of the InceptionFCN model, as reported in its original publication, as a baseline reference for benchmarking. This baseline allows us to quantify the relative improvement achieved by our hybrid architecture. Our findings reveal that the proposed InceptionResNet model consistently outperforms InceptionFCN and other baseline models in both classification accuracy and robustness, particularly on datasets with high variability and long-range dependencies.
Integration of ResNet's residual learning into the Inception framework enables deeper feature extraction while maintaining gradient stability, which is especially beneficial for complex, noisy, or long-sequence data sets within the UCR-85 archive. Meanwhile, the retention of the Inception modules ensures effective multiscale feature learning, capturing patterns at various temporal resolutions. The hybrid model thus benefits from both architectural worlds: Inception's diversity of receptive fields and ResNet's depth and trainability.
In conclusion, the standardized training pipeline and rigorous evaluation methodology employed in this study provide strong evidence for the superior performance and scalability of the InceptionResNet model. These results not only validate our architectural enhancements, but also offer a robust foundation for future extensions, such as adaptation to multivariate time series data or deployment in real-time settings as shown in Table 1.
In our experimental evaluation, we assessed the performance of five well-established models—InceptionFCN, InceptionTime, multilayer perceptron (MLP), fully convolutional network (FCN), and ResNet—on the UCR-85 dataset, a widely accepted benchmark suite for time-series classification (TSC) as in Figure 9. This comparative analysis was designed to benchmark our proposed InceptionResNet model and highlight its strengths relative to existing architectures. All models were trained and tested under identical conditions, ensuring a fair comparison. This included consistent preprocessing procedures (e.g., normalisation), standardised training parameters (e.g., learning rate, batch size, number of epochs), and uniform evaluation metrics including accuracy, precision, recall, and F1 score.
Distribution of dataset-wise best accuracy scores among compared models on UCR-85.
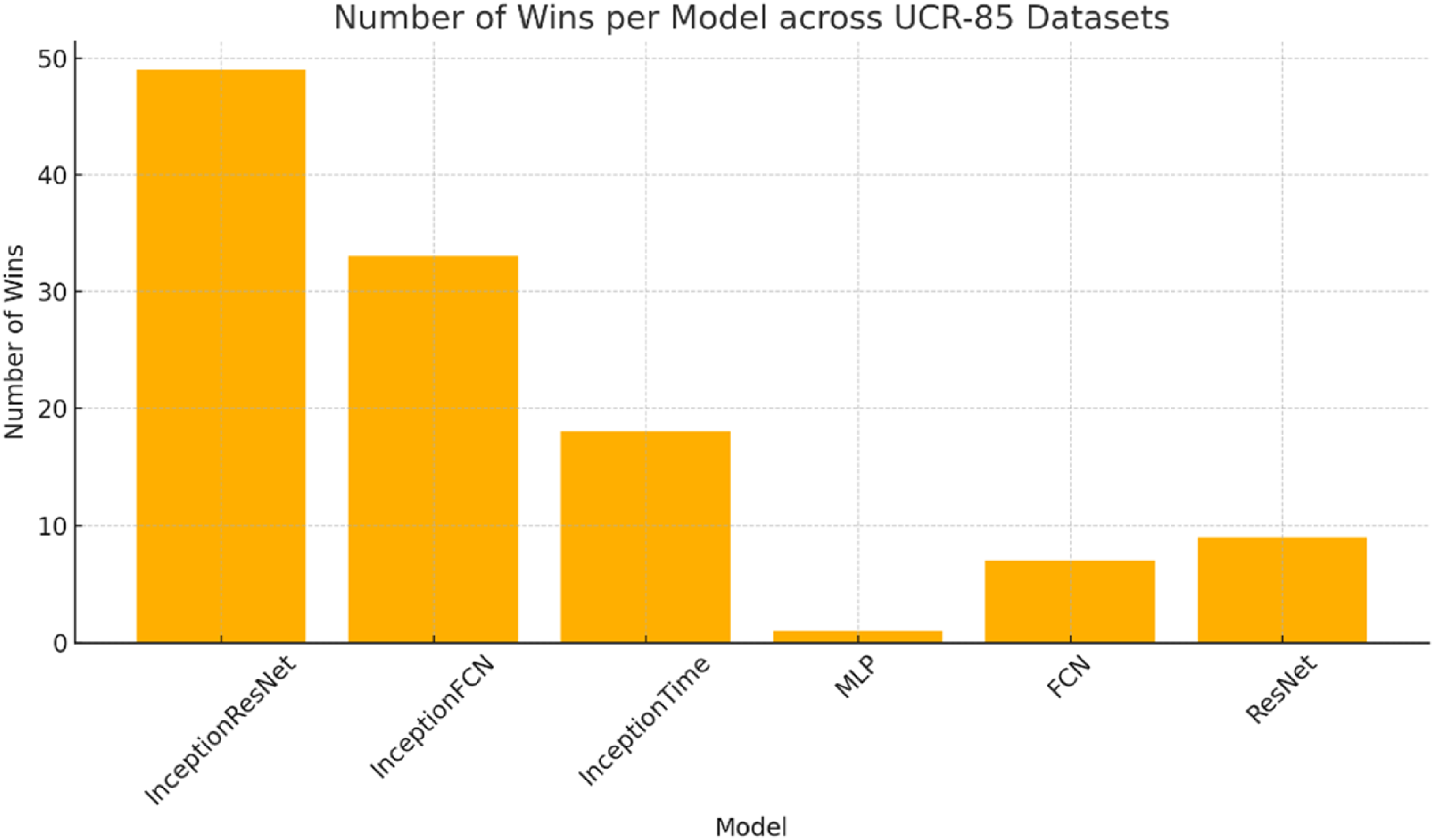
To identify the best-performing models across datasets, we recorded the number of datasets for which each model achieved the highest classification accuracy. As shown in Table 1, the proposed InceptionResNet model demonstrated notable superiority by outperforming all baselines in 49 out of 85 datasets, compared to 33 wins by InceptionFCN, the second-best performer. This performance gap underscores the effectiveness and robustness of our hybrid architecture in capturing complex temporal patterns.
The key architectural enhancement in our model lies in replacing the FCN component of InceptionFCN with a ResNet backbone. While FCNs are effective for shallow temporal modelling, they often suffer from limitations in gradient propagation and depth scalability. In contrast, ResNet introduces residual connections that allow gradients to flow unimpeded through the network layers, mitigating vanishing or exploding gradients and enabling the training of deeper and more expressive models. This structural advantage allows InceptionResNet to learn more nuanced temporal features and generalise more effectively—especially on datasets with long-range dependencies or high intra-class variability.
The robustness of ResNet also contributes to its resistance to overfitting, a common challenge in deep models trained on small or noisy time-series datasets. Residual learning facilitates better convergence and enables the network to retain important features across layers. These benefits translate into superior classification performance across a wide range of dataset complexities.
Our results further illustrate that simpler models such as MLP and FCN tend to perform well on relatively straightforward datasets with well-separated and low-dimensional patterns—for example, Coffee, Gun Point, Plane, and Trace. However, for more complex datasets such as BirdChicken, DiatomSizeReduction, ECGFivedays, TwoPatterns, TwoLeadECG, and Wafer, only deeper and more sophisticated models—namely InceptionTime, ResNet, and InceptionFCN—are capable of achieving strong performance. Notably, InceptionResNet demonstrated marked superiority on datasets where no other model achieved optimal accuracy, such as ChlorineConcentration, FISH, MALLAT, Meat, SonyAIBORobotSurface, SonyAIBORobotSurfaceII, and ToeSegmentation1. These datasets are characterised by high temporal complexity and diverse pattern structures, which demand both multiscale feature extraction and deep residual learning.
In summary, our experimental findings confirm that InceptionResNet offers a significant advancement in the field of time-series classification. Its architectural improvements—most notably the integration of ResNet's residual learning into the Inception framework—translate into consistent gains in classification performance, particularly for challenging datasets where traditional models falter. The model's ability to extract rich, hierarchical features and maintain stable gradient flow during training makes it highly suitable for real-world applications involving complex and noisy time-series data. Overall, InceptionResNet stands as a robust and scalable solution for modern TSC tasks, demonstrating clear improvements over existing state-of-the-art methods.
To comprehensively evaluate the performance of the proposed InceptionResNet model, we conducted experiments using the UCR-85 benchmark dataset, which comprises 85 diverse time-series datasets. The results were compared with five state-of-the-art models: InceptionFCN, InceptionTime, MLP, FCN, and ResNet. All models were trained under identical conditions, using the same preprocessing pipeline, learning rate, batch size, and number of epochs. Evaluation metrics included accuracy, precision, recall, and F1 score. Our findings demonstrate that InceptionResNet achieved the highest accuracy in 49 out of 85 datasets, outperforming the second-best model, InceptionFCN, which had 33 wins. Notably, the proposed model excelled on more complex and noisy datasets, where the inclusion of residual learning via ResNet allowed for deeper training and more robust feature extraction. This demonstrates the superior generalisation capabilities of InceptionResNet compared to traditional models. Figure 10 provides the detailed accuracy comparison across all datasets, clearly showing the dominance of our model in a wide range of scenarios. Additionally, the win-count summary shows the number of datasets where each model achieved the best performance. For enhanced clarity, we have also included a bar chart (see Figure 10) illustrating the number of wins per model, highlighting InceptionResNet as the leading architecture.

Number of datasets where each model achieved the best accuracy result.
To explicitly address the comparative performance between the proposed InceptionResNet and the baseline InceptionFCN model, we conducted a comprehensive experimental evaluation using the UCR-85 benchmark dataset under rigorously standardized conditions. Both models were trained and tested using identical preprocessing pipelines (e.g., z-score normalization), optimization parameters (e.g., learning rate, batch size), and evaluation criteria (accuracy, precision, recall, and F1 score) as shown in Figure 11. This ensured that the observed performance differences could be attributed solely to architectural distinctions.

Comparative performance of deep learning models on UCR-85 dataset across accuracy, precision, recall, and F1 score.
The results strongly favor InceptionResNet. Our model achieved the highest classification accuracy on 49 out of 85 datasets, substantially surpassing InceptionFCN, which led in only 33 datasets. Notably, InceptionResNet demonstrated superior robustness on complex and noisy datasets such as ChlorineConcentration, CinC_ECG_torso, InlineSkate, and FordA, where long-range dependencies and intricate temporal patterns present significant modeling challenges. These empirical outcomes are visually summarized in Figures 9 and 10 and detailed in Table 1.
The observed performance gain stems from the enhanced depth and gradient stability introduced by the ResNet-50 backbone, which replaces the shallow FCN shortcut module in InceptionFCN. This architectural shift enables more expressive temporal feature learning and mitigates the vanishing gradient issue, which becomes critical when training deep convolutional models on time-series data. As such, InceptionResNet offers not only architectural innovation but also tangible performance improvements, establishing it as a state-of-the-art approach for time-series classification.
Conclusions
This study presents a novel deep learning framework—InceptionResNet—designed to advance the state of the art in time-series classification (TSC). By systematically integrating the multiscale feature extraction capabilities of the Inception architecture with the residual learning strengths of ResNet, our approach bridges two powerful paradigms in deep learning. The proposed model addresses several long-standing challenges in TSC, including vanishing gradients, overfitting, and limited generalisation capacity in deep architectures.
Unlike prior research that typically relied on isolated architectures for time-series problems, our work highlights the benefits of hybrid model integration, demonstrating that combining complementary design strategies leads to more accurate, stable, and scalable models. Through extensive experimentation on the widely adopted UCR-85 benchmark, InceptionResNet consistently outperformed five strong baseline models—including InceptionFCN, ResNet, and InceptionTime—achieving the highest accuracy in 49 out of 85 datasets. These results validate the robustness and generalisability of our method across diverse and complex time-series domains.
More broadly, our findings underscore the value of cross-domain architectural inspiration—in this case, adapting techniques from image processing to sequential data analysis. The success of this transfer reinforces the idea that innovations in one field can unlock breakthroughs in another, especially when thoughtfully adapted.
Looking ahead, the proposed framework offers a promising foundation for future extensions, including applications to multivariate time-series, real-time prediction systems, and other sequential domains such as speech, sensor, and financial data. Furthermore, the principle of hybridising architectures provides fertile ground for future research in automated model design, explainable AI, and domain-specific adaptations of deep learning in time-series analytics.
In summary, InceptionResNet sets a new benchmark in TSC performance and methodology. By uniting depth, multiscale representation, and residual learning in a cohesive architecture, this work contributes a powerful and extensible tool for the time-series research community, while also encouraging future innovation through hybrid deep learning design.
Future work
In future research, we aim to extend the InceptionResNet model to handle multivariate time-series data and explore its applicability in real-time prediction systems. Additionally, we plan to integrate attention mechanisms and investigate automated architecture search to further enhance performance and adaptability. Exploring domain-specific adaptations in fields such as healthcare, finance, and IoT-based monitoring will also be a key direction.
Footnotes
Author contribution statement
Duong Thi Kim Chi: Resources, Data Curation
Nguyen Thi Mai Trang: Formal analysis, investigation
Tran Ba Minh Son: Conceptualisation, Methodology, Writing - Review & Editing
Nguyen Ngoc Thao: Resources, Data Curation, Conceptualisation, Methodology
Thanh Q. Nguyen: Supervision, Writing, Review & Editing, Visualization
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.