
Abstract
For multi-unmanned surface vessel (Multi-USV) capturing target, the coordination control method of path planning and tracking is proposed to integrate multi-agent reinforcement learning (MARL) and active disturbance rejection control (ADRC) dynamically and effectively. The bounded water environment model with various obstacles is constructed. To generate the optimal capturing path online and accelerate its convergence, the real-time multi-agent deep deterministic policy gradient (MADDPG) is enhanced by combining prioritized experience replay (PER). In order to achieve interaction between agent and environment, the real positions of unmanned surface vessels (USVs) are input to the MADDPG network as state variables. The action space consists of yaw angle and surge speed of USV and is reckoned as the reference path of tracking control. In case of target escaping, it is required that USVs are evenly distributed in the target-centered capture loop but not located within the detection range of target. For fast and safe capture, the composite reward function is proposed by designing capture reward, obstacle avoidance and collision avoidance reward, boundary collision restriction reward, capture inner boundary constraint reward, angle constraint reward and motion constraint reward. In addition, to integrate the actual tracking performance, the errors between the references and real states of USVs are also formulated into the reward function. In order to follow the reference commands from the enhanced MADDPG in presence of disturbances of wind and wave, the angle and speed tracking controllers are developed using linear ADRC (LADRC). Finally, the effectiveness of the proposed method is verified by capture simulations of static target and dynamic target with various types of obstacles.
Introduction
In recent years, unmanned surface vessel (USV) has been attempted to perform various ocean tasks due to its advantages of agility, reliability and intelligence, 1 for example, preventing or hunting invasive ships. 2 Particularly, target capture becomes one of attractive topics for USVs. That is, USVs need to surround the target in a fixed encirclement formation within a given area. 3
Currently, many issues on target capture are addressed, such as single-target or multi-target capture, 4 and static target or dynamic target capture. 5 Various optimization and control algorithms are widely developed. Yu et al. 6 propose the frontal interception guidance law and formation tracking control law with distributed encirclement for the leading and following aircrafts to achieve the coordinated target capture. Dong et al. 7 propose a fuzzy double-capture control based on auction algorithm to reduce the possibility of target escaping. For the case of uncertain target information, Fedele et al. 8 propose a control law to simulate motion of agents for surrounding the target. Aiming at encircling unknown target in three-dimensional space, Li et al. 9 establish an estimator to locate target position, and then design the control law to drive the agents to complete circumnavigation of target.
Although the traditional control methods can be used for target capture problem, their adaptabilities to the complicated environment are not adequate. Either the accurate mathematical model for capture is generally necessary, or various constraints limit the development or application of these methods. As a new intelligent learning method, reinforcement learning (RL) does not need to model environment, but just focuses on the interaction between agent and environment. 10 RL can be divided into strategy-based RL algorithm 11 and value-based RL algorithm. 12 At present, the collaborative capture research based on the multi-agent RL (MARL) 13 has been addressed extensively, where multiple agents are used to conduct autonomous trial-and-error and collaborative learning.14,15 And the scholars have tried to enhance RL algorithm, involving the improvement of reward function, experience playback mechanism and training method. 16 The target capture research mainly involves how to determine the relative formation positions of hunters and how to form capture formation. For determination of the relative positions of hunters, the task allocation method is often used. Besides, the optimal target assignment for hunters can also be achieved in multi-target capture. Many task allocation approaches are proposed to ensure the reliability and effectiveness of resource allocation,17,18 and rapidity of large-scale data processing. 19 Regarding how to form capture formation, pure capture, capture with escape behavior and capture with game confrontation behavior are studied respectively. For pure target capture, many methods are attempted. For instance, Zhang et al. 20 introduce a continuous MARL framework to achieve online adaptation of multiple optimization functions, so as to guide mobile robots to move in a dynamic environment. Fan et al. 21 propose a multi-robot RL algorithm guided by the potential energy model for single-target capture. On this basis, the target escape behavior is concerned. For random escape of target, Wu et al. 22 improve the multi-agent deep deterministic policy gradient (MADDPG). Li et al. 23 study the hunting and escaping of multiple USVs by using the proximal policy optimization method and enhancing the structure and learning method of the training network. Sun et al. 24 study the cooperative pursuit strategy for the escape strategy of the besieged in different encirclement states. Gan et al. 25 propose a multi-USV collaborative pursuit strategy based on obstacle assistance and deep reinforcement learning, which can effectively achieve capture of intelligent evaders through autonomous environment perception, and deal with irregular obstacles and ocean current disturbances. Recently, the game confrontation between the hunters and the escapees is further studied. The adversarial game strategy is proposed by Qu et al., 26 where the flexible reward function is designed and the escape strategy for the intruder is trained in complex environments. For the environment with dynamic obstacles, Sun et al. 27 propose a self-organizing cooperative hunting strategy to realize capture of intruders, where effective obstacle avoidance is achieved by dynamic collision avoidance approach.
Although the above studies apply MARL to target capture and escape confrontation behavior 28 is addressed as well, environment is generally assumed to be ideal and standard such that these algorithms are unable to conform to the changing environment with disturbances of wind and wave. Moreover, the agents in capture problem are mostly regarded as ideal particles. These algorithms are developed based on the kinematic model, but most of dynamic constraints are not considered. In addition, decision or planning and real motion control of MARL are separated in the network training stage of traditional MARL. Since the actual control results do not have impact on MARL computation, 29 a large gap between the actual effect of MARL and the expected result exists. So how to apply MARL in reality becomes a challenging topic.
Motivated by the above, the capture framework integrating MARL navigation and actual tracking control is addressed for capturing target by USVs in this paper. Most current studies assume the capture environment being infinite or introduce virtual capture boundary constraints. 30 Different from static target capture, dynamic target capture is more challenging and regarded as successful when the target is chased to the environmental boundary in the latter case. Therefore, the bounded water environment with various obstacles is modeled in this paper at first. It is required that the USV does not collide with the environmental boundary and the hunting cannot be achieved at the boundary. In order to imitate the real capture environment with dynamic obstacles, 27 both dynamic and static obstacles are considered, and safe obstacle avoidance distance is addressed to ensure the safety of USVs. Secondly, MADDPG via kinematic model is improved by combining prioritized experience replay (PER) to accelerate convergence. The proposed PER-MADDPG is implemented online to generate the optimal capturing path. The actual positions of USVs are taken as input of PER-MADDPG. The output of PER-MADDPG is taken as reference command of tracking controllers. Besides, considering the possibility of dynamic target escaping in complex environment, capture strategy is combined with escape and the mechanism of capture loop is proposed. In case of dynamic target escaping, it is required that USVs are evenly distributed in the target-centered capture loop and cannot move into the detection range of target. In the PER-MADDPG method, the composite reward function is formulated by developing capture reward, obstacle avoidance and collision avoidance reward, boundary collision restriction reward, capture inner boundary constraint reward, angle constraint reward, motion constraint reward, and the tracking error reward between the reference and real states of USVs. Due to the strong wind and wave disturbances, active disturbance rejection control (ADRC) 31 is introduced to design the tracking controller. Based on the pseudo linear dynamic model, linear ADRC (LADRC) 32 is used to develop the angle and speed tracking controllers. Eventually, simulations of capturing static target and dynamic target under different kinds of obstacles are implemented to demonstrate power of the proposed method.
The main contributions of this paper are listed as follows:
(i) The traditional control method is not suitable for strong uncertainty or drastic change of environment, while the existing reinforcement learning method is designed mostly regardless of the control errors. Therefore, the coordination control framework PER-MADDPG-LADRC is proposed for capturing static or dynamic target by USVs in this paper. The real-time path planning based on PER-MADDPG and path tracking control based on LADRC are developed and connected to construct the cascade closed-loop coordination control system. Wherein, path planning is slow time scale, and path tracking control is fast scale.
(ii) Considering the complexity of capture scenario, target escape possibly occurs and dynamic obstacles generally exist in marine environment. Therefore, the mechanism of target-centered capture loop is proposed, and the capture inner boundary constraint reward is designed to prevent USVs from crossing through the encirclement. Moreover, the static and dynamic obstacle avoidance and the collision avoidance between USVs are both concerned and incorporated into the composite reward function.
(iii) Since two-time scale sub-systems are proposed in the coordination control system and they have different running periods, there must exist delay of accurate path tracking control. Hence, the actual tracking error reward of USVs is designed as a part of the composite reward function in PER-MADDPG to reduce the impact of control error on path planning and tracking.
The rest of this paper is introduced as follows. Section ’Problem Statement’ introduces USV model and capture model. The methodology of PER-MADDPG-LADRC is described in Section ’Methodology’. In Section ’Simulation and Results’, two cases about static target and dynamic target capture are presented. Conclusions are drawn finally.
Problem statement
Unmanned surface vessel model description
The mathematical model of USV is multi-variable and strong coupling. Since heave, pitch and roll have little effect on USV’s motion, the three-degree-of-freedom model just involving surge, sway and yaw is addressed, as shown in Figure 1. Its kinematics and dynamics are presented as follows:
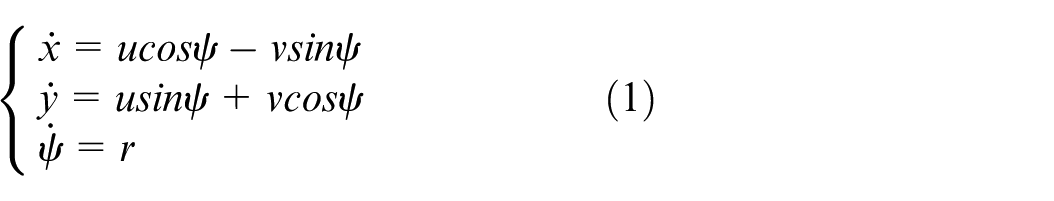
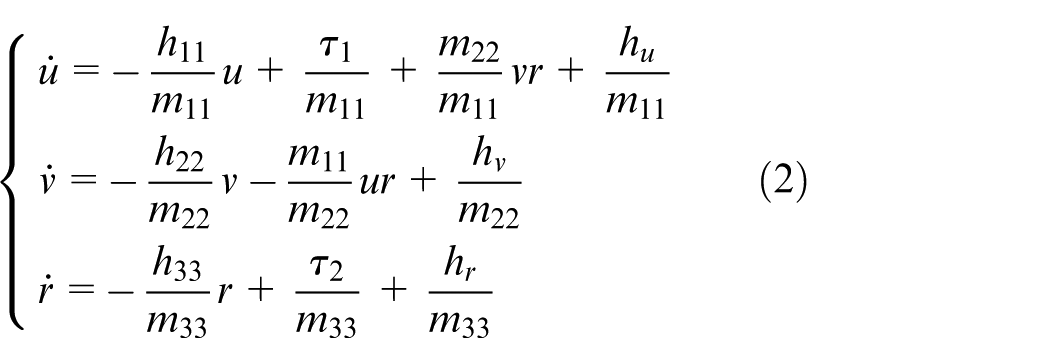
where,
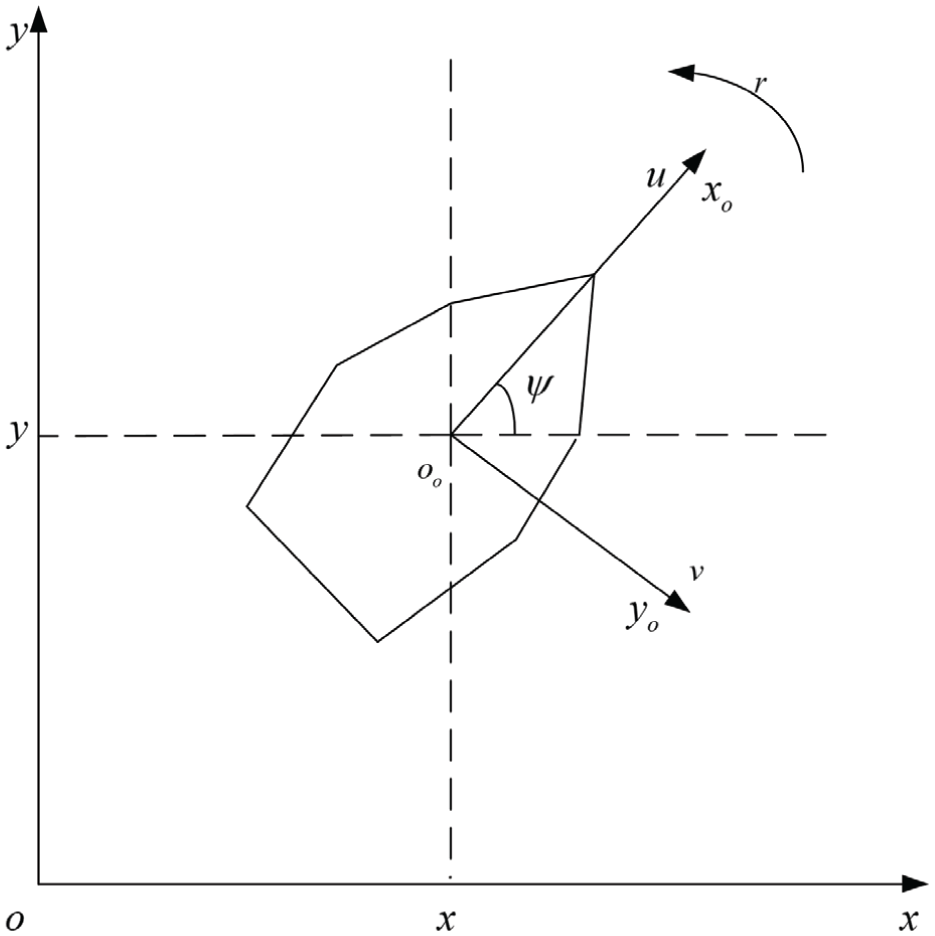
USV schematic.
Target capture model
Generally, the marine environment includes unbounded scenario (e.g. sea) and bounded scenario (e.g. lake or river). When the environment is unbounded, the allowable motion ranges of USV and dynamic target will be larger. Moreover, it is not necessary to consider boundary collision risk. When the environment is bounded, the motion ranges of USV and dynamic target are limited, and it is required that the USV does not collide with the environmental boundary during capturing and the hunting cannot be achieved at the boundary. Therefore, target capture in the bounded environment is more challenging and complicated. Accordingly, the bounded marine environment is taken in account in this paper. The target capture is verified based on the bounded environment. So, the target capture environment is a bounded area of size
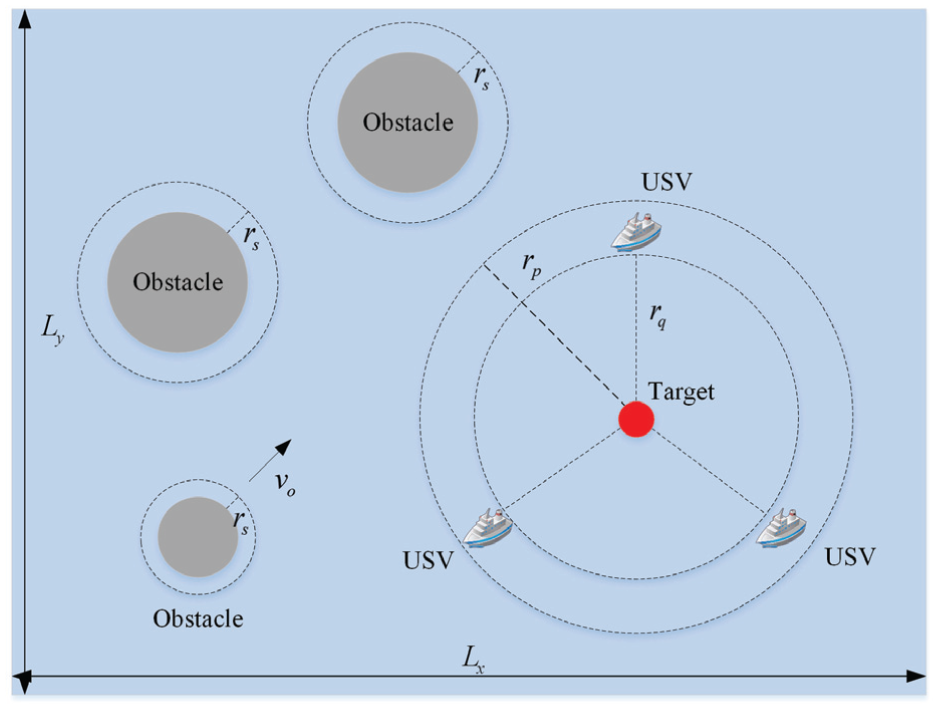
Target capture model.
Based on the above rules, the condition for successful capture is presented as follows:
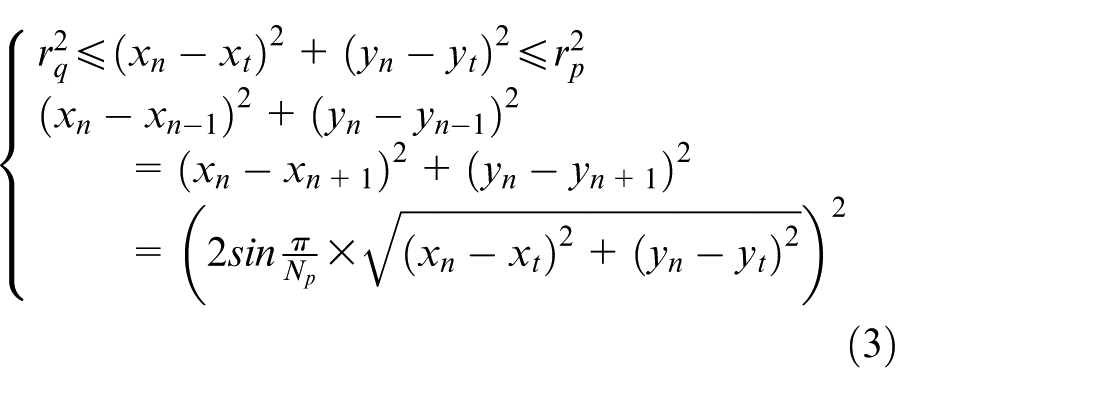
where,
Different from the search and tracking problem with the completely unknown target information, the capture problem requires the hunters can grasp the position and action information of the evaders in advance, so as to make fast maneuvering decisions. The research of capture problem focuses on the effective and rapid formation of capture. 34 For successful capturing and safe running of USVs, the following assumptions are proposed:
Methodology
RL is a Markov Decision Process (MDP). 35 It consists of five tuples: state S, action A, discount factor γ, reward function R and state transition function P. In this paper, the MARL strategy is followed, and the PER-MADDPG-LADRC algorithm is designed to solve the capture problem.
Coordination control structure design
MADDPG 36 is a centralized training and distributed execution algorithm. It combines the advantages of Deep Q-Network (DQN) and Actor-Critic, and is suitable for multi-agent competitive and cooperative learning in complex environment.
The MADDPG algorithm is off-line strategy algorithm and designed for the continuous action space problem. By constructing a deterministic strategy, the gradient rising method is used to maximize the Q value, and then the ideal training model can be obtained. Since the deterministic strategy has limited exploration of environment, random noise is added to the action resulted from behavioral strategy to expand the scope of exploration. In MADDPG, each agent is trained by Actor-Critic, where the Actor only obtains its own information, but the Critic can get global information. In order to avoid overestimation of the action value, both of the Actor network and the Critic network are designed as two sets of training network and target network. And the target network uses soft update to slowly approach the training network. For N
p
agents, the policy parameter set of the training Actor networks is defined as
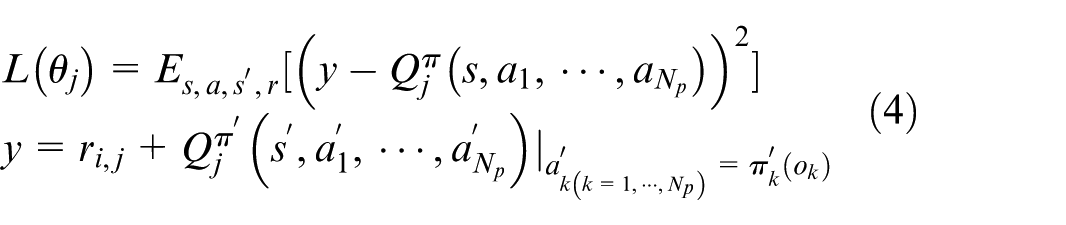
where,
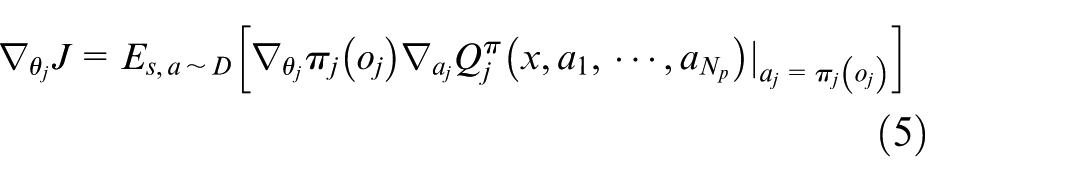
The traditional MADDPG algorithm selects data from the experience playback pool by random sampling, however, this leads to the low utilization of favorable data in the early stage of training. It is not beneficial for network training. Therefore, referring to the previous method, 38 the prioritized experience replay (PER) is combined to improve the algorithm. The data in experience playback pool are sorted in descending order based on the absolute value of the temporal difference error. The sampling probability is allocated for all data based on this order, described as follows:

where o i is the data order in the experience playback pool, K is the total amount of data in the experience playback pool, and P(i) is the probability of the sampled data. And the importance sampling method is used by the proposed PER-MADDPG to ensure that the sampled data has the same effect on the change of gradient. The weight of importance sampling is set as follows:
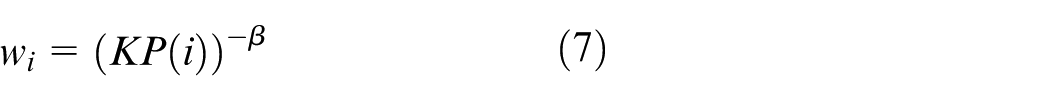
where β is a hyperparameter. Using PER, the probability of important data being selected for network training is increased, and the convergence speed of reward function in the early training stage is accelerated.
The general MARL algorithm is just related to the kinematics model. The interaction between agent and environment is achieved by the ideal position. Moreover, wind and wave disturbances, and actual control deviation are not involved. In order to apply MARL algorithm to the practical environment, the real dynamic response of the closed-loop control system is concerned in the MARL design in this paper.
Combining the PER-MADDPG algorithm with LADRC method, the actual USV motion controller is introduced in the interaction between agent and environment. A coordination control system consisting of path planning and tracking is designed. The output of the MADDPG action space is taken as the input of LADRC. And the actual position coming from the closed-loop control is used as a part of input of MADDPG state space. Correspondingly, the online path planning and tracking control for capture can be realized. The possible wind and wave disturbances are included in the control-oriented model. That is, the action information of the network output is
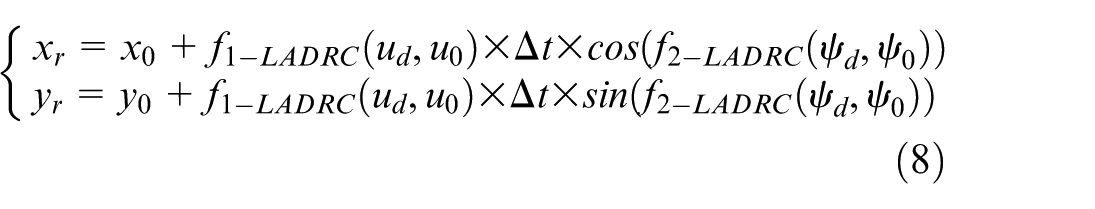
where,
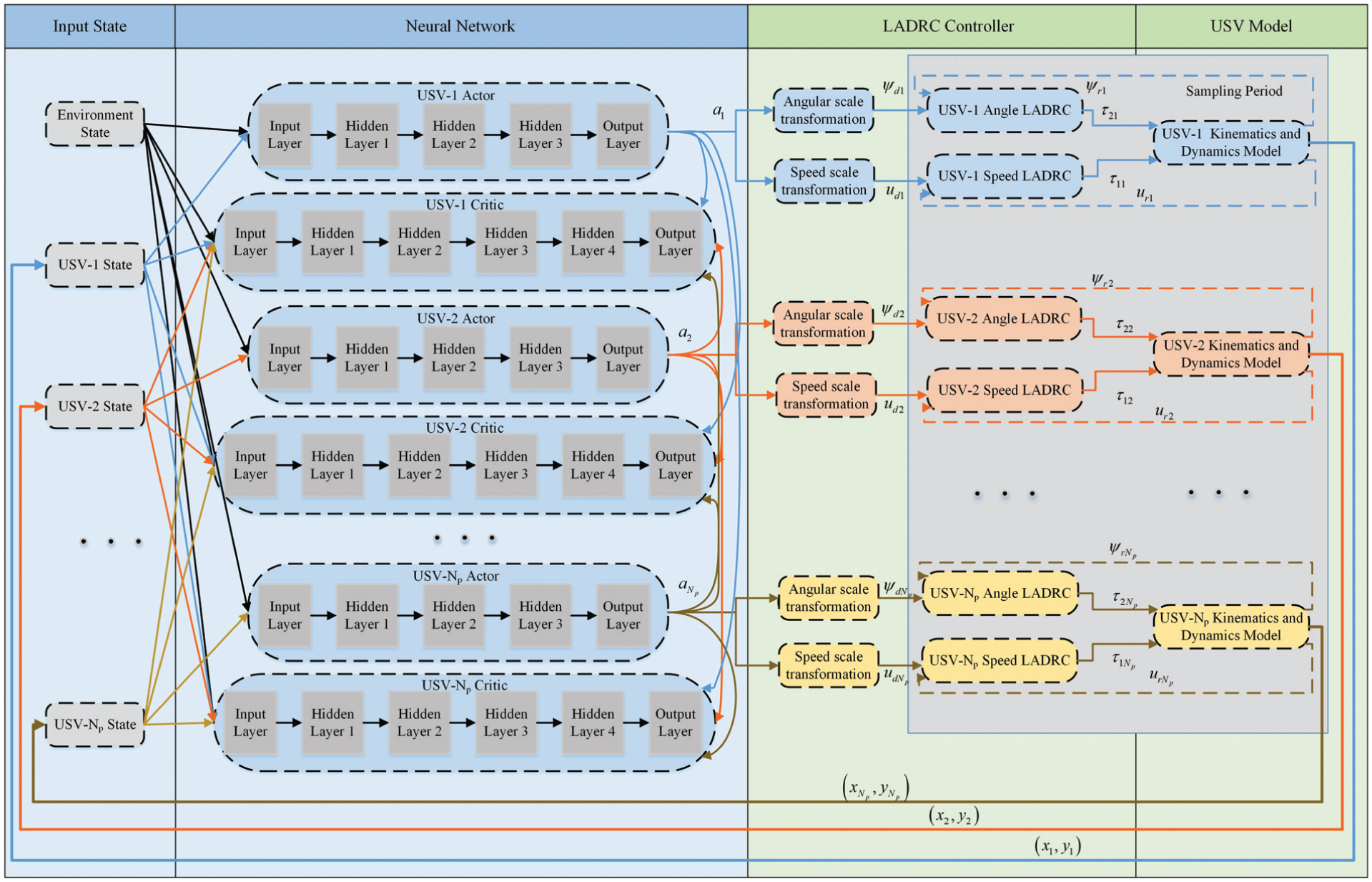
Overall coordination control structure diagram.
In Figure 3, environment state including obstacles and target is fed to all networks as public information.
State space and action space design
In order to ensure the USVs capture the target rapidly and stably, the training process is accelerated. Before each round training, the neighbor relationship of USV within the encirclement loop is determined according to the relative distance between USVs. The neighbor with smaller relative distance is selected as the adjacent USV, and it is kept unchanged in the current training. That is, for USV n, its neighbors are determined by means of two steps:
(i)
(ii) The nearest USVs pn−1, pn+1 are selected as the neighbors from the N re USVs by the following equation.
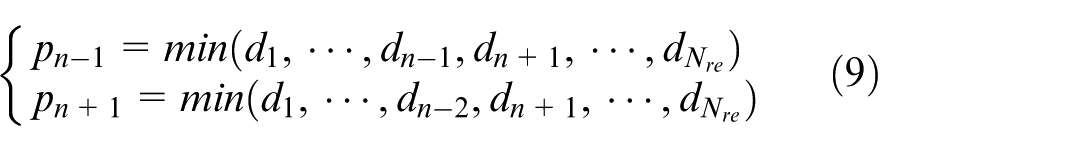
where d represents the Euclidean distance. Even if a great deal of USVs capture target, the above rules are still effective to determine the neighbors.
For the nth hunting USV, its state space is written as
For the nth hunting USV, its action space is
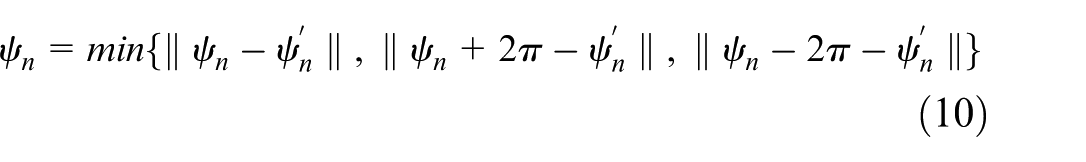
where
Reward function design
In PER-MADDPG, the reward function is developed to drive the capture performance to converge to the global optimum. The goal of this paper is to achieve stable and effective capture of static and dynamic target in bounded water environment, and simultaneously to avoid collisions safely. Thereafter, a composite reward function is formulated. Wherein, the capture reward function is designed to generate the criterion of successful capture. In order to meet the security and motion constraints, the collision avoidance and obstacle avoidance reward function, environmental boundary collision restriction reward function, and USV motion constraint reward function are proposed. To ensure that the capture process is safe and the hunters cannot be detected by the target, the capture inner boundary constraint reward function is constructed. Accordingly, it is guaranteed that the hunting USVs approach and encircle the target from outside the inner boundary of the ideal encirclement rather than crossing through the encirclement. The angle constraint reward is designed to ensure the smoothness of yaw angle change. Furthermore, the tracking error reward function is designed to reduce the actual path tracking error.
(1) Capture reward function f1: This reward is developed to optimize the capture performance. It consists of relative distance reward f
d
and relative angle reward
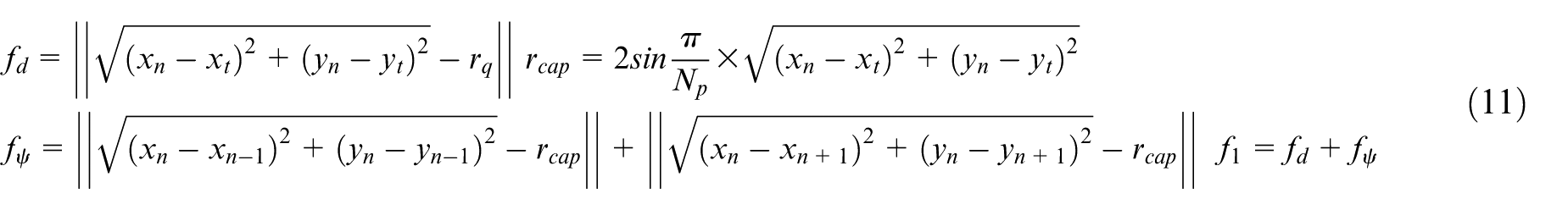
(2) Collision avoidance and obstacle avoidance reward function f2: To guarantee safety of USVs, inter-USVs collision avoidance and obstacle avoidance between USVs and obstacles in the water environment should be concerned. In addition, in order to enhance the safety of obstacle avoidance further, the safe distance of obstacle avoidance is defined around the obstacles. The reward consists of environmental obstacle avoidance reward
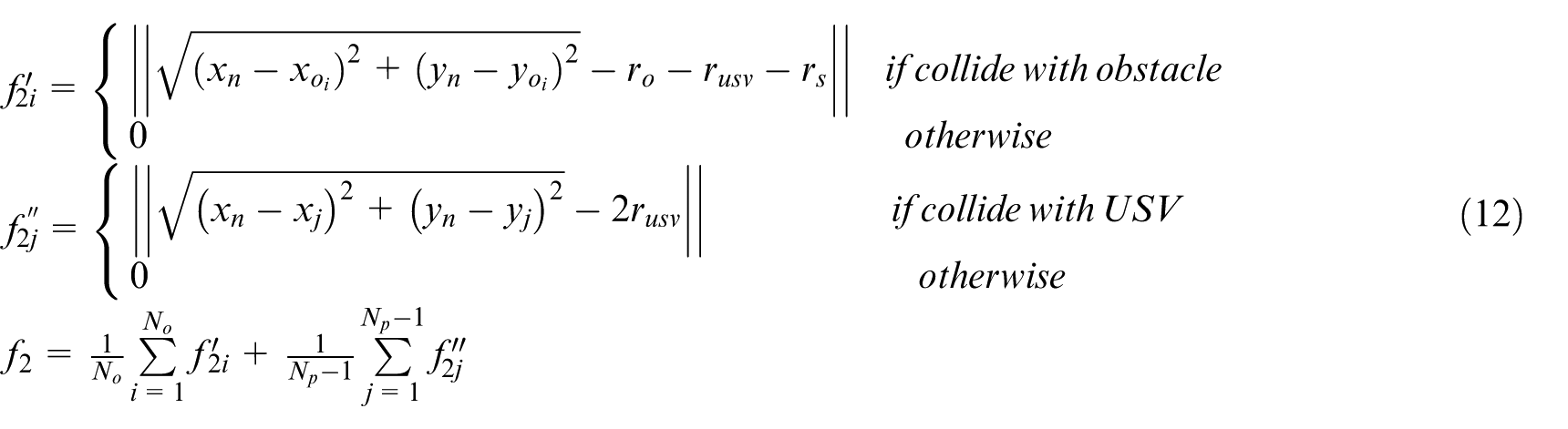
where r o is the obstacle size, r usv is the size of hunting USV, and r s is the safe distance of obstacle avoidance.
(3) Environmental boundary collision restriction reward function f3: In consideration of capturing the target being located in bounded waters, the boundary collision penalty is essential to make USV just move in the given water area. When the USV travels beyond the boundary, the penalty value is given as:
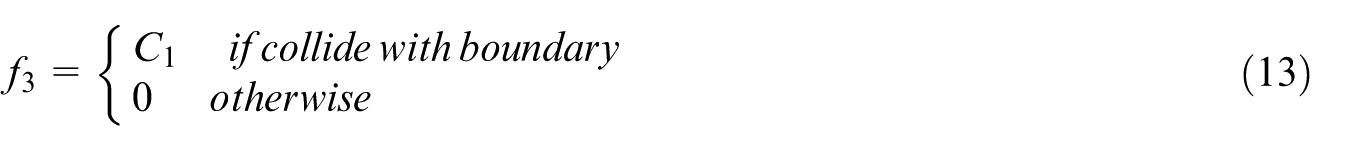
where C1 is a positive parameter denoting collision penalty. If the unbounded environment is considered, the environmental boundary collision restriction reward function will be removed from the composite reward function of USV.
(4) Capture inner boundary constraint reward function f4: To ensure the hunting USVs approach and encircle the target from outside the inner boundary of the ideal encirclement rather than crossing through the encirclement, when the distance between USV and target is less than the radius r q of the inner loop, the penalty is defined as:
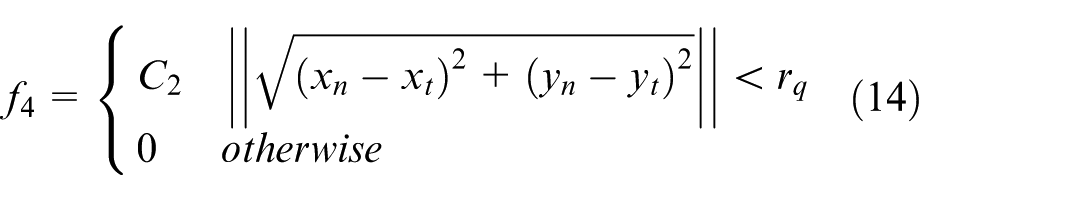
where C2 is a positive parameter denoting the penalty of crossing the inner boundary.
(5) USV angle constraint reward function f5: In order to ensure the slow change of the yaw angle and the smoothness of trajectory, the angle variation is used as the angle constraint reward function:
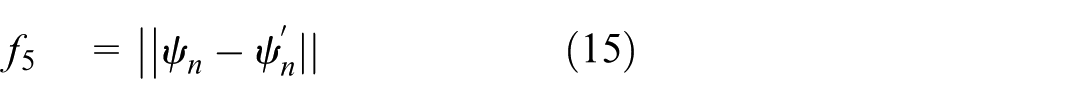
where
(6) USV motion constraint reward function f6: For the static target, the USVs’ speed should be small as much as possible after hunting formation is realized. That is the USVs should hover near the target and keep encirclement. The motion constraint reward is proposed as:
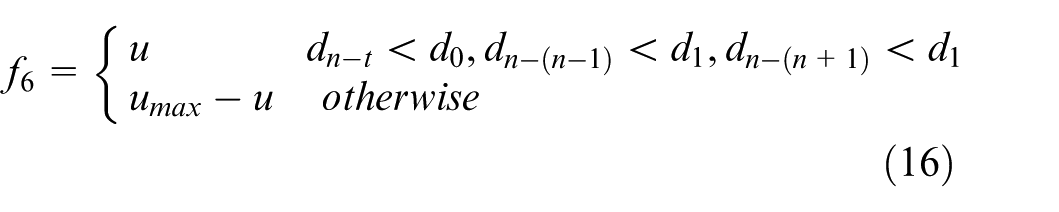
where u is the current surge speed of USV, and u
max
is the maximum surge speed.
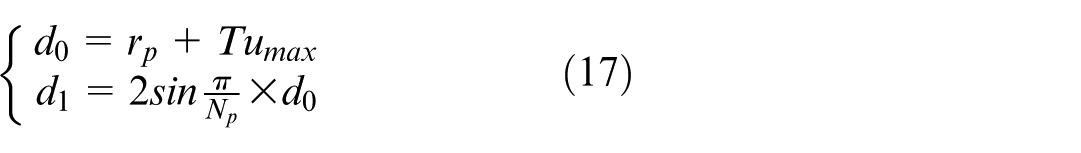
where T is the environment period.
For the dynamic target, in order to make the USVs achieve stable and effective tracking of target, the following motion constraint reward is proposed as:
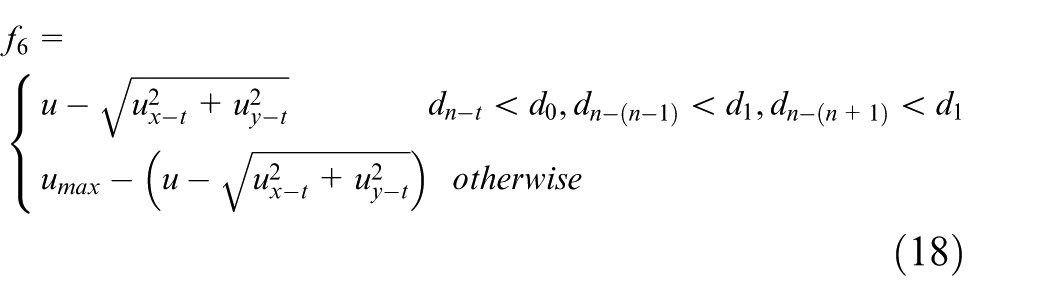
where
(7) The tracking error reward function f7: In order to reduce path tracking control error, in the current control period, the yaw angle and surge speed generated by the proposed PER-MADDPG method are used as the expected input of the tracking control and remain unchanged. In path planning period, the LADRC is step response control. The following reward function is designed to show the difference between the actual position obtained by the controller and the expected position:
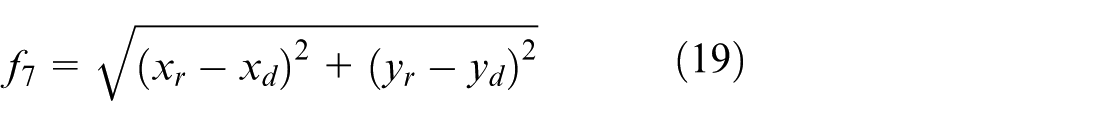
where
By weighting all the above functions, the composite reward function f n for USV n is derived. This function is maximized to achieve the best capture performance.
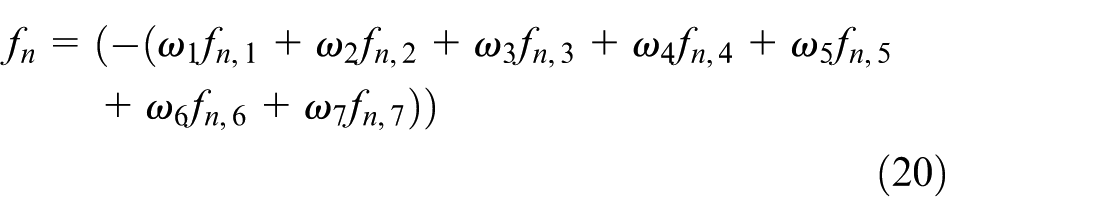
LADRC tracking controller design
Based on the output of action space and the dynamic model of USV, a first-order surge speed controller and a second-order yaw angle controller are designed using LADRC.
According to the dynamic model (2), the pseudo linear surge speed model is formulated. The surge speed controller is developed into the first-order LADRC formulation. 39 The linear ESO (LESO) and the surge speed LADRC law are designed as:
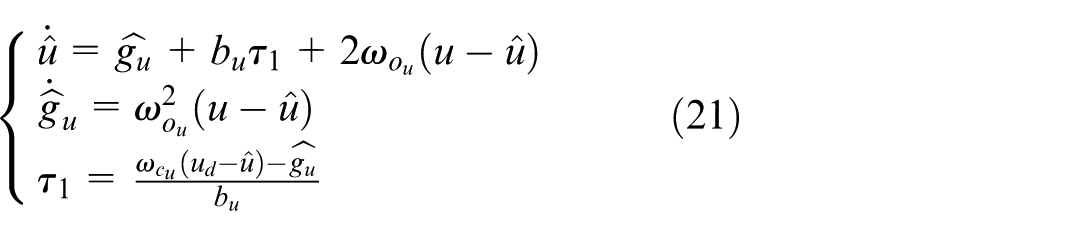
where
Similarly, the pseudo linear yaw angle model is formulated. Correspondingly, the second-order LADRC yaw angle controller is designed. The LESO and the yaw angle LADRC law are developed as:
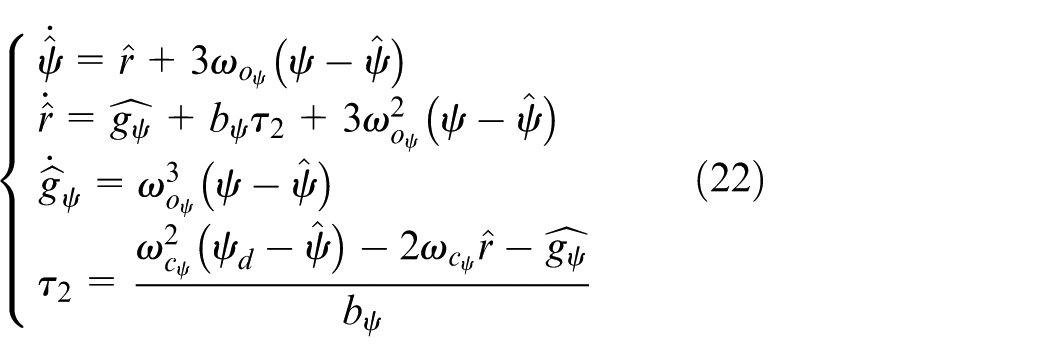
where
In summary, the PER-MADDPG-LADRC algorithm flow is shown in Algorithm 1.

Computational complexity
When the capture problem is larger-scale, the computational complexity is concerned. The computational complexity of MARL is affected by the number of multi-agents, the training process of neural network, environmental interaction complexity, experience collection complexity, episode number, episode length and batch size. Ignoring the constant factor complexity, the computational complexity of the proposed PER-MADDPG-LADRC method can be expressed as
Simulation and results
In this paper, simulation is carried out to validate the effectiveness of the propose method. The static target and the dynamic target are addressed respectively in capture test. In order to increase the complexity of the search environment, static and dynamic obstacles are included in the environment.
Simulation environment and parameter design
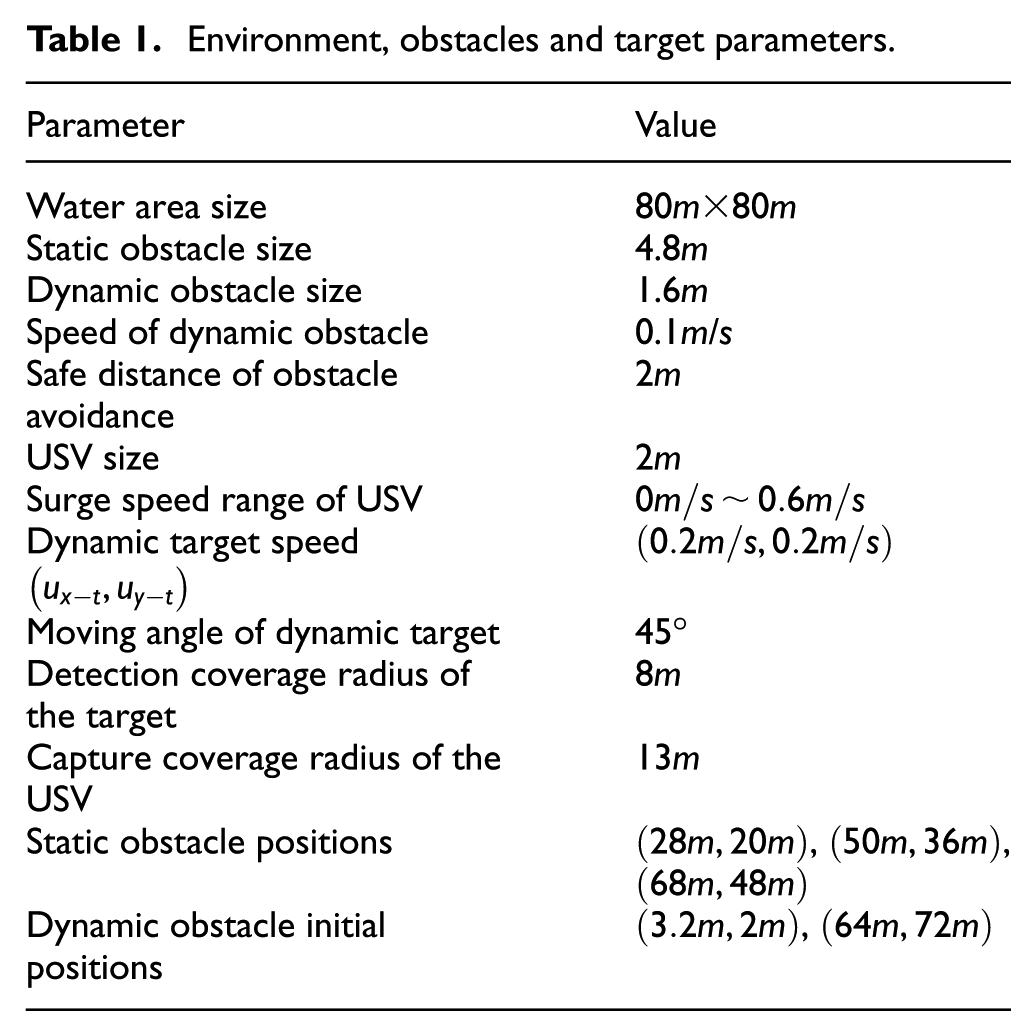
The simulation platform is i7-12700H CPU, RTX3070Ti GPU and 16RAM. The MADDPG framework is Pytorch. It is assumed that there are one target, three static obstacles, two dynamic obstacles and three hunting USVs in the marine environment. The static obstacles are large, but the dynamic obstacles are small. The initial positions and motion states of the obstacles are known. The initial positions of hunting USVs and target are randomly distributed. Table 1 is the collection of environment, obstacles and target parameters.
Environment, obstacles and target parameters.
At the beginning, the USVs are stationary. There exist the wind and wave disturbances in the marine environment, described as follows 40 :
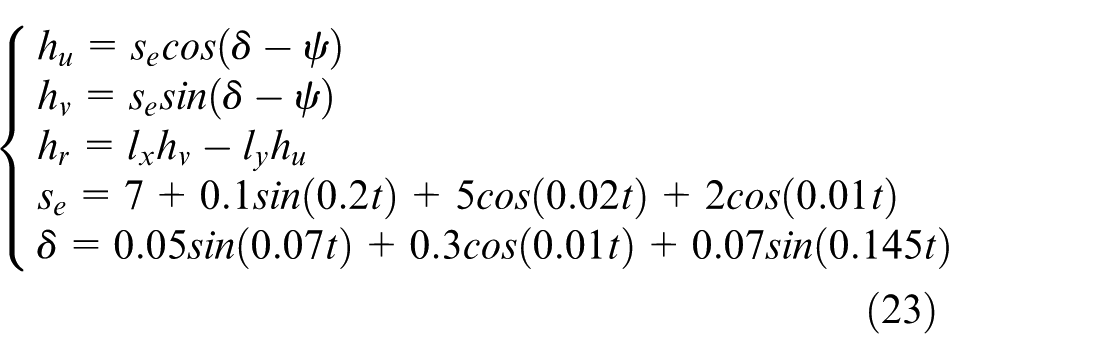
The motion control of USV is mainly disturbed by wind and wave. These disturbances have similar distribution when acting on USV such that they can be uniformly expressed by a resultant disturbance force. The magnitude and direction of the resultant disturbance force are expressed as s
e
and δ respectively.
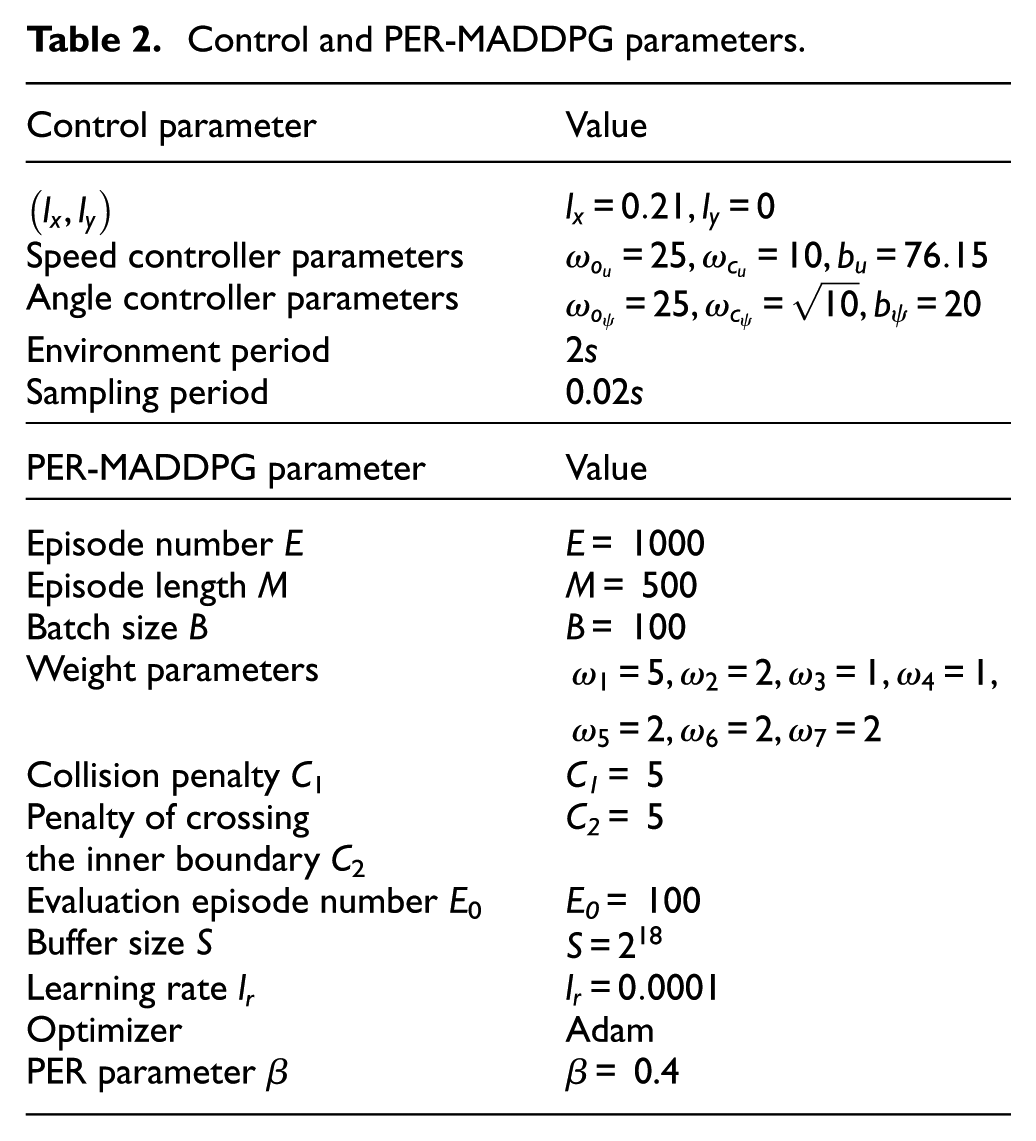
Control and PER-MADDPG parameters.
Case 1: Static target capture
Different numbers of USVs capture the target
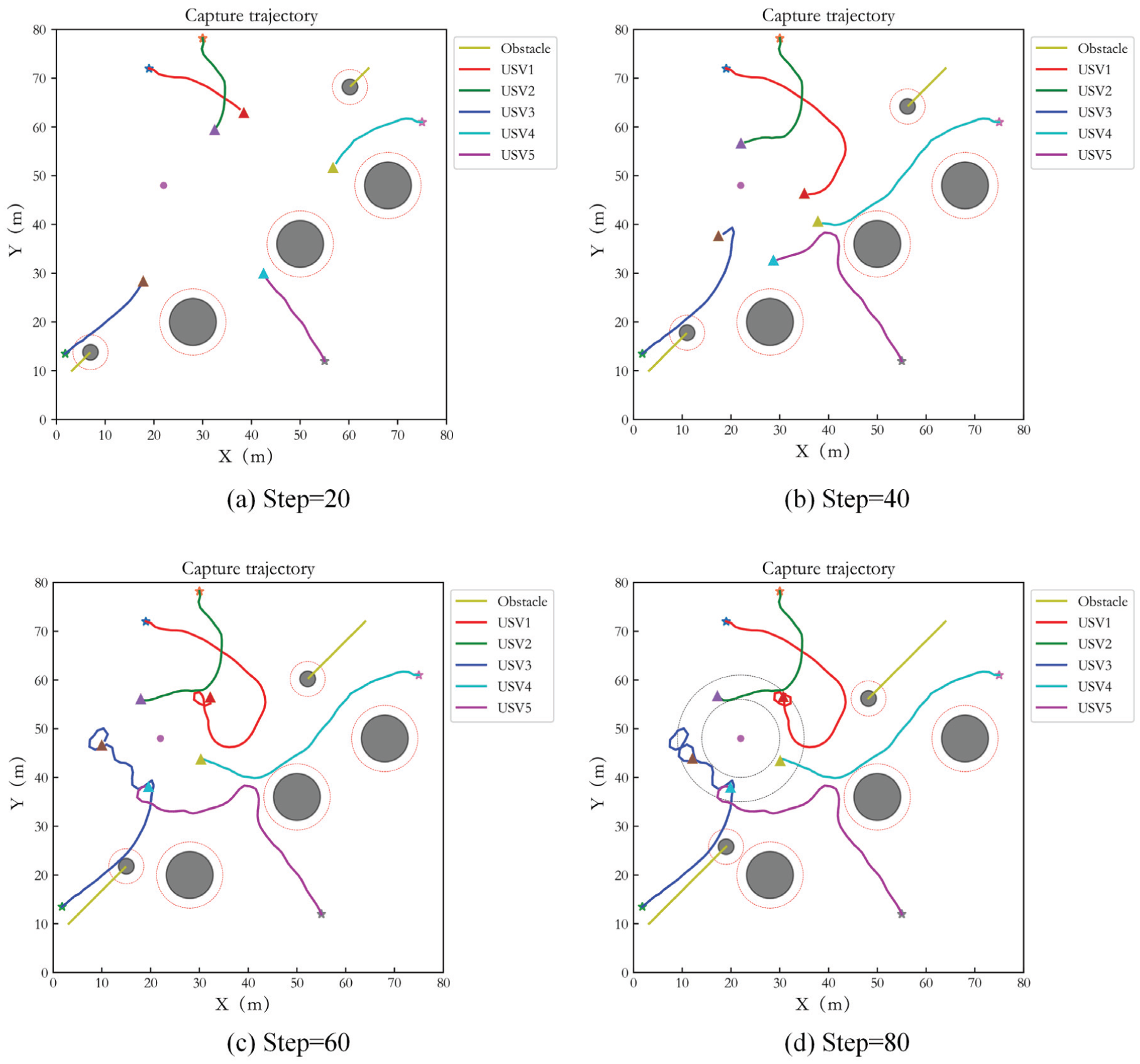
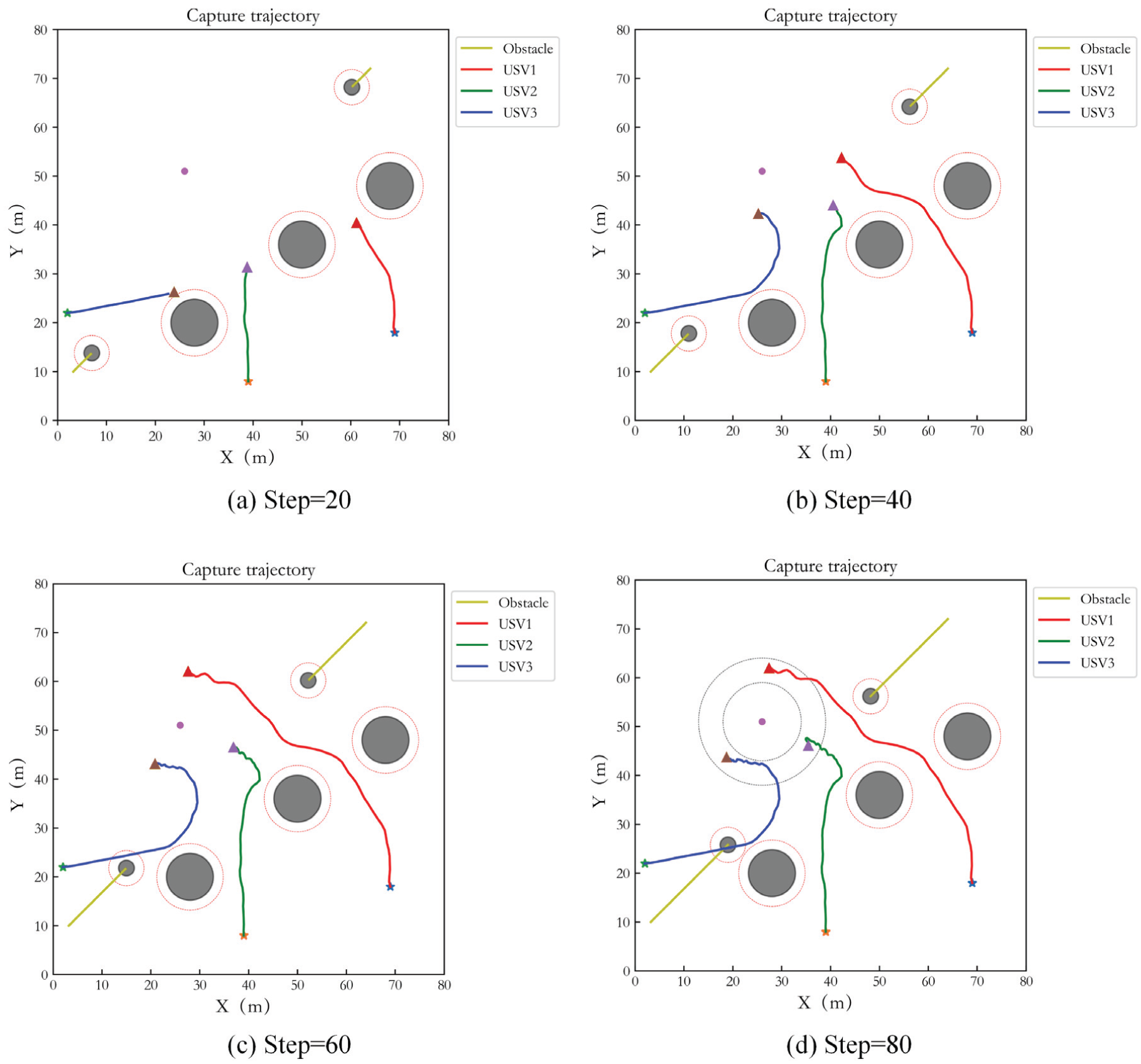
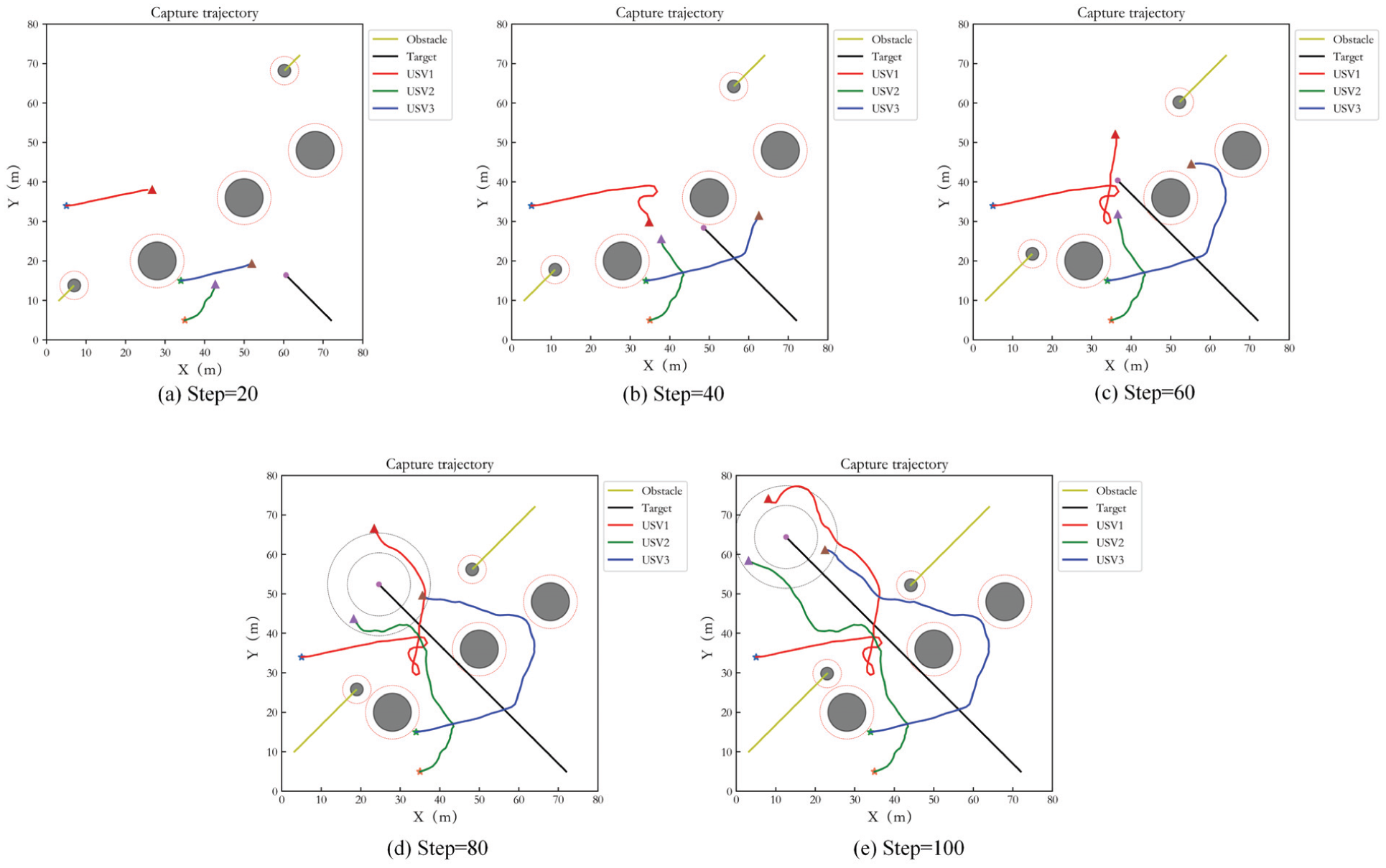
In order to demonstrate the power of different numbers of USVs capturing target, the simulations with three and five USVs hunting target are implemented respectively. The test step number is 80. Figure 4(a) to (d) show the capture performance of 3 USVs at interval of 20 steps. The black circle areas are obstacles. The yellow curves are the trajectory of dynamic obstacles. The red virtual circles represent the safe obstacle avoidance range of the obstacles. The red curve, blue curve and green curve are the capture trajectories of three USVs. ‘*’ represents the initial point of the USV, ‘△’ represents the end point, and the purple circle is the target. Two dotted circles represent the inner and outer boundaries of the ideal encirclement loop respectively. It can be seen that the USVs achieve an effective pursuit for the target within a given period. In Figure 4, it seems that the hunting trajectories of USVs pass through the dynamic obstacles. Actually, they do not collide each other since the dynamic obstacles and USVs move through the same position at different time. Simultaneously, effective obstacle avoidance is achieved. In addition, the USVs do not enter the inner boundary of the ideal encirclement loop during capturing, and the target escape behavior does not occur.
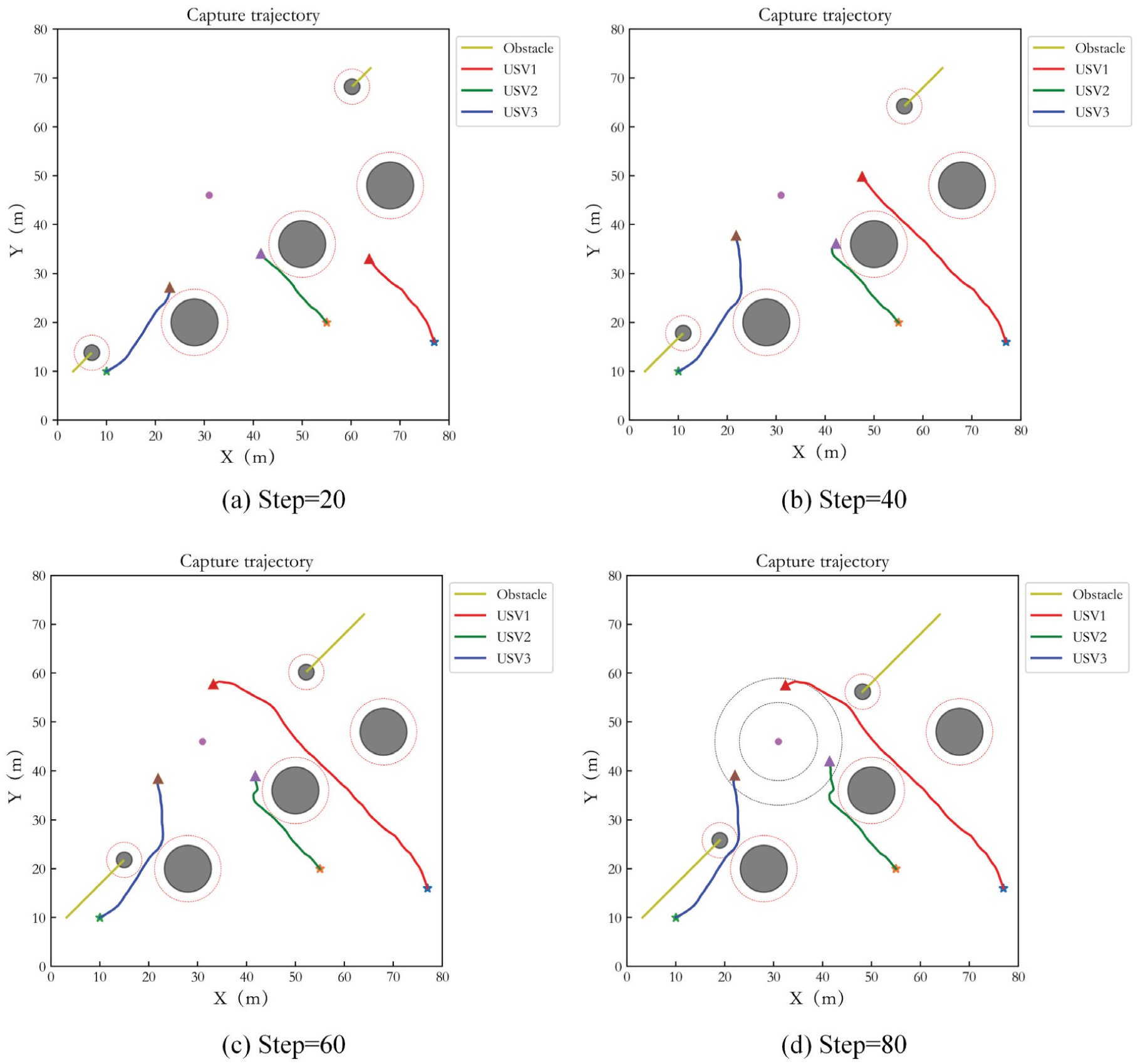
Capture performance of three USVs in Case 1.
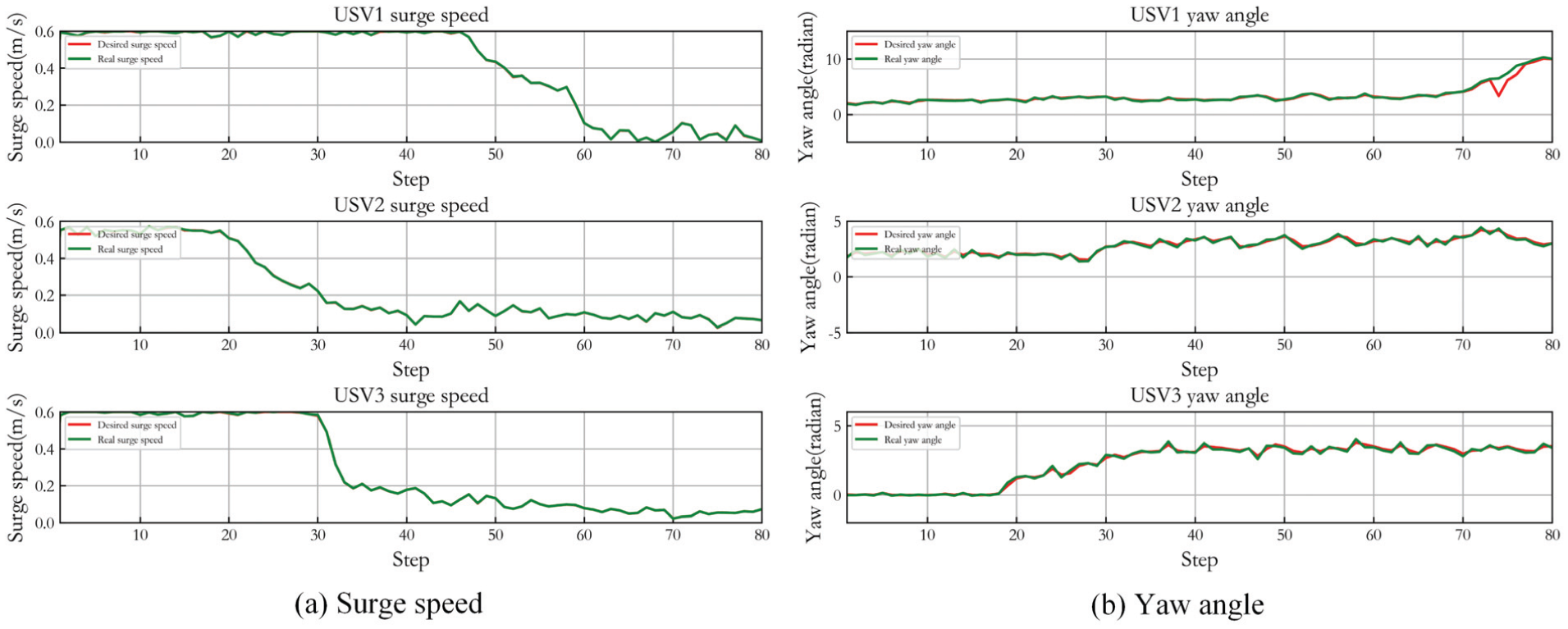
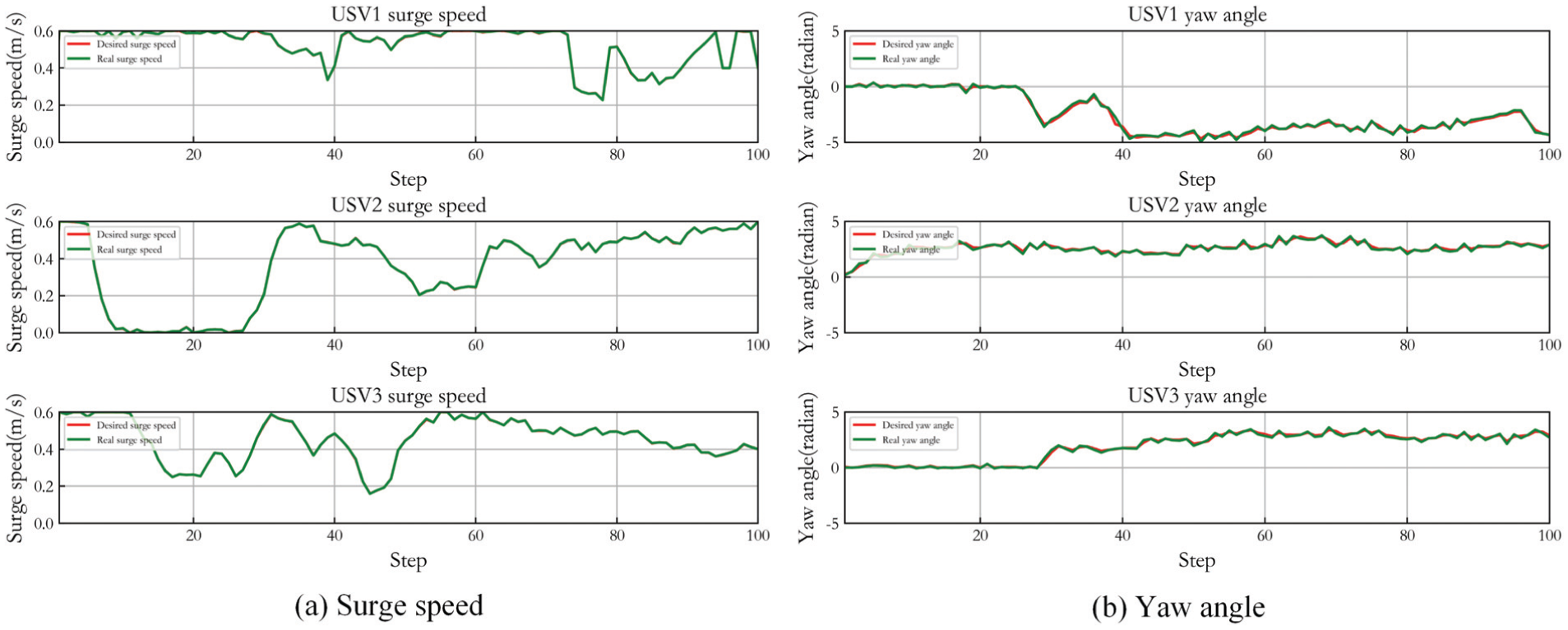
Figure 5 shows the control result of three USVs in Case 1. (a) presents the desired surge speed of three USVs and their real speed controlled by LADRC. (b) gives the desired yaw angle of three USVs and the real angle steered by LADRC. It can be seen that LADRC achieves accurate path tracking control. When the USVs approach the expected capture position, the overall real-time path planning and tracking coordination control is effective though the yaw angle tracking control has a slight deviation. And the speed tracking demonstrates when the USVs reach the desired positions, the surge speed of most USVs gradually approaches zero, and there is just a small amplitude fluctuation. In the whole capture process, the yaw angle change is relatively smooth.
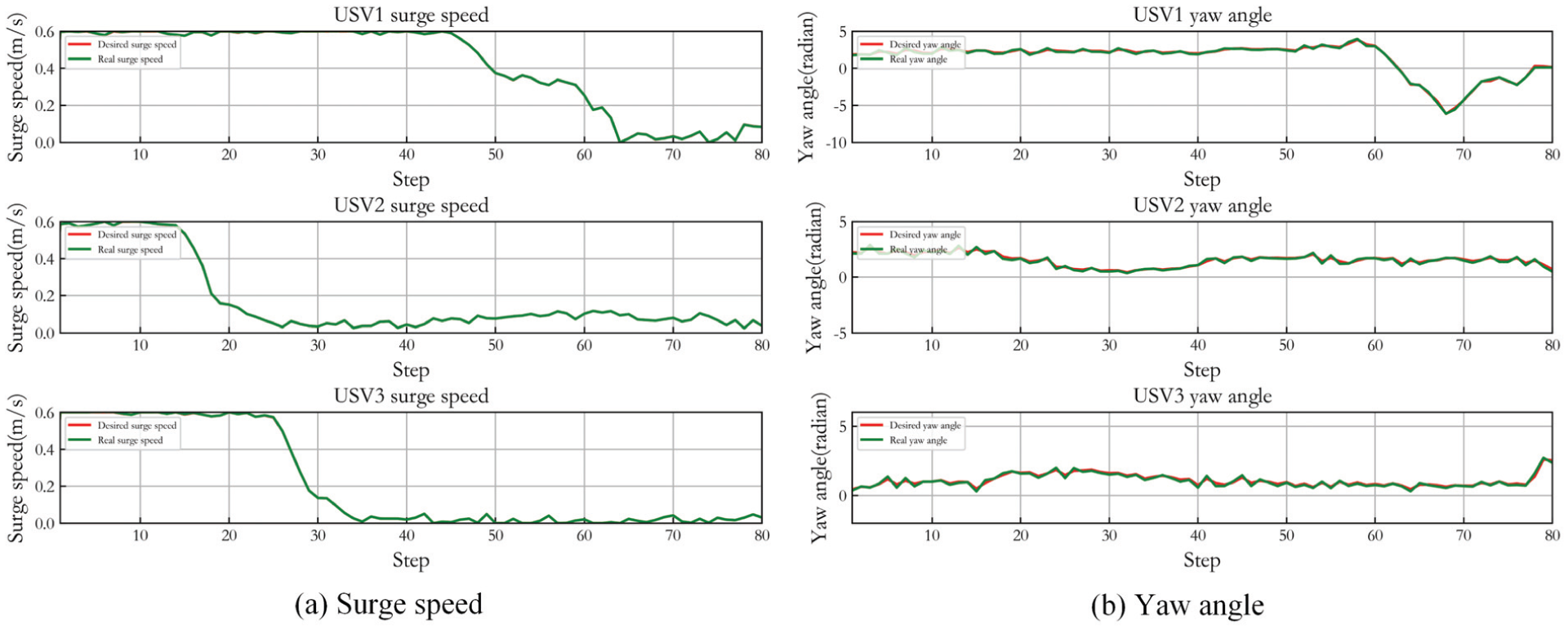
Control result of three USVs in Case 1.
Figure 6 presents the capture performance of five USVs at interval of 20 steps. The description of obstacles in the figures is consistent with target capture of three USVs. The red curve, blue curve, green curve, cyan curve and magenta curve are the capture trajectories of five USVs. It can be seen that the USVs achieve an effective pursuit for the target, and effective obstacle avoidance is realized. In addition, in order to avoid entering the inner boundary of the ideal encirclement loop, USV1 circumnavigates in the encirclement loop to achieve capture, and the encirclement path is reasonable.
Capture performance of five USVs in Case 1.
Figure 7 shows the control result of five USVs in Case 1. (a) shows the desired surge speed of three USVs and their real controlled speed. (b) gives the desired yaw angle of three USVs and the real controlled angle. It can be seen that LADRC achieves accurate path tracking control and the yaw angle change is relatively smooth.
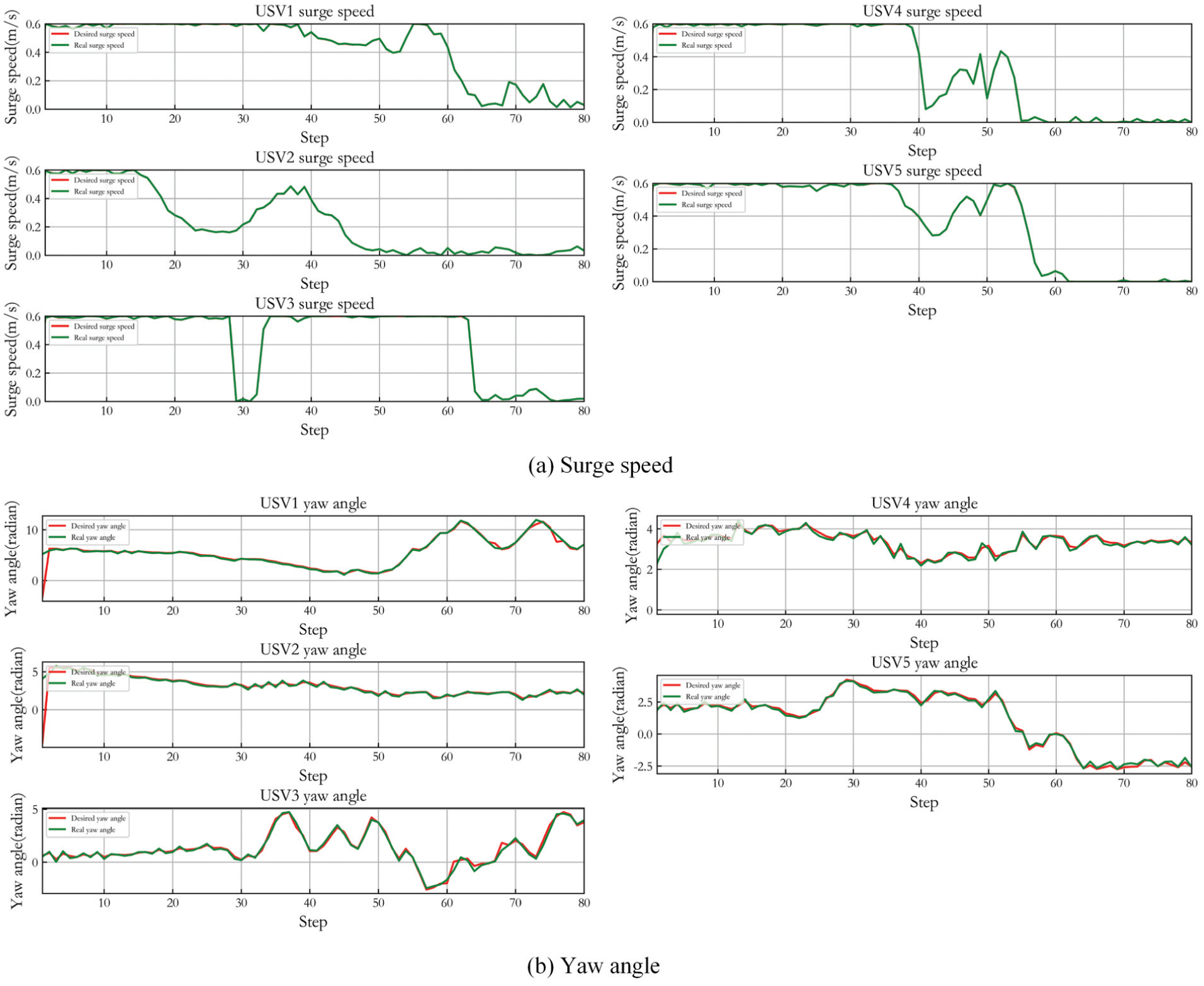
Control result of five USVs in Case 1.
Target capture under strong wind and wave disturbances
In order to demonstrate the impact of strong wind and wave disturbances on the motion control of USV, the time-varying nonlinear interference force function is increased as follows:
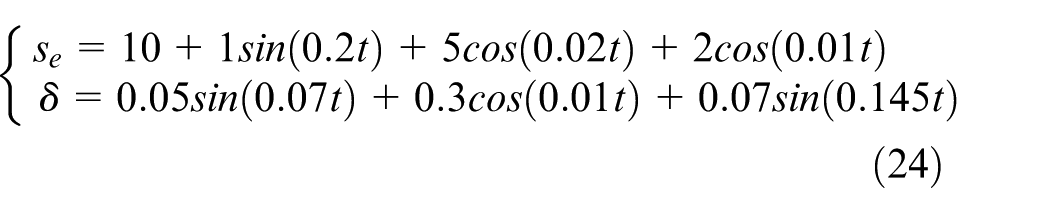
Based on the above situation, Figure 8 shows the capturing and tracking trajectories of three USVs capturing static target, and Figure 9 displays the control result. The simulation result shows that with the increase of disturbances, although the tracking error of yaw angle increases, the USV still achieves effective target capture under strong wind and wave disturbances.
Capture performance of three USVs under strong disturbances in Case 1.
Control result of three USVs under strong disturbances in Case 1.
Comparison simulation
For capturing the static target, the comparison simulations with original MADDPG, 41 IPPO 42 and REINFORCE 43 are implemented. All of them adopt the same state space and action space as the proposed method. But these comparison algorithms do not address tracking control performance in the training process, and the tracking error is not considered in the reward function. The original MADDPG structure is similar to the proposed algorithm, but lacks the PER link and LADRC. The IPPO is a fully decentralized multi-agent algorithm framework, so it is used to compare with the centralized training and distributed execution framework used in this paper. The REINFORCE is a single-agent RL algorithm. It is used as a centralized structure to construct the network model, which synthesizes the state space related to multiple agents into one-dimensional variable input.
Figure 10(a) is the reward function comparison diagram of four algorithms. The red curve denotes the proposed algorithm, the green curve is the original MADDPG, the blue curve is the IPPO, and the yellow curve is the REINFORCE. Figure 10(b) is the success rate diagram of four algorithms to carry out the capture test after training every 100 epochs. The training result shows that the multi-agent algorithm has better effect than the single-agent algorithm. The convergence value of the reward function of the single-agent algorithm has a large gap from other algorithms, and the reward value fluctuates greatly after stabilized. The proposed PER-MADDPG-LADRC method has more stable convergence and smaller convergence value than MADDPG and IPPO. Because the algorithm proposed in this paper considers tracking control performance in presence of disturbances of wind and wave in the training process. So, when LADRC control is involved in the training model, there is a higher success rate of capture. Nevertheless, the comparison algorithms do not address the above factors during training, so the success rate of capture is relatively low during testing. Besides, due to the limitation of single-agent algorithm, the test of REINFORCE can only have a certain probability to reach the capture trend, but cannot achieve capture really. Therefore, the success rate of capture of REINFORCE in Figure 10(b) just represents the probability of capture, which is not a standard capture.
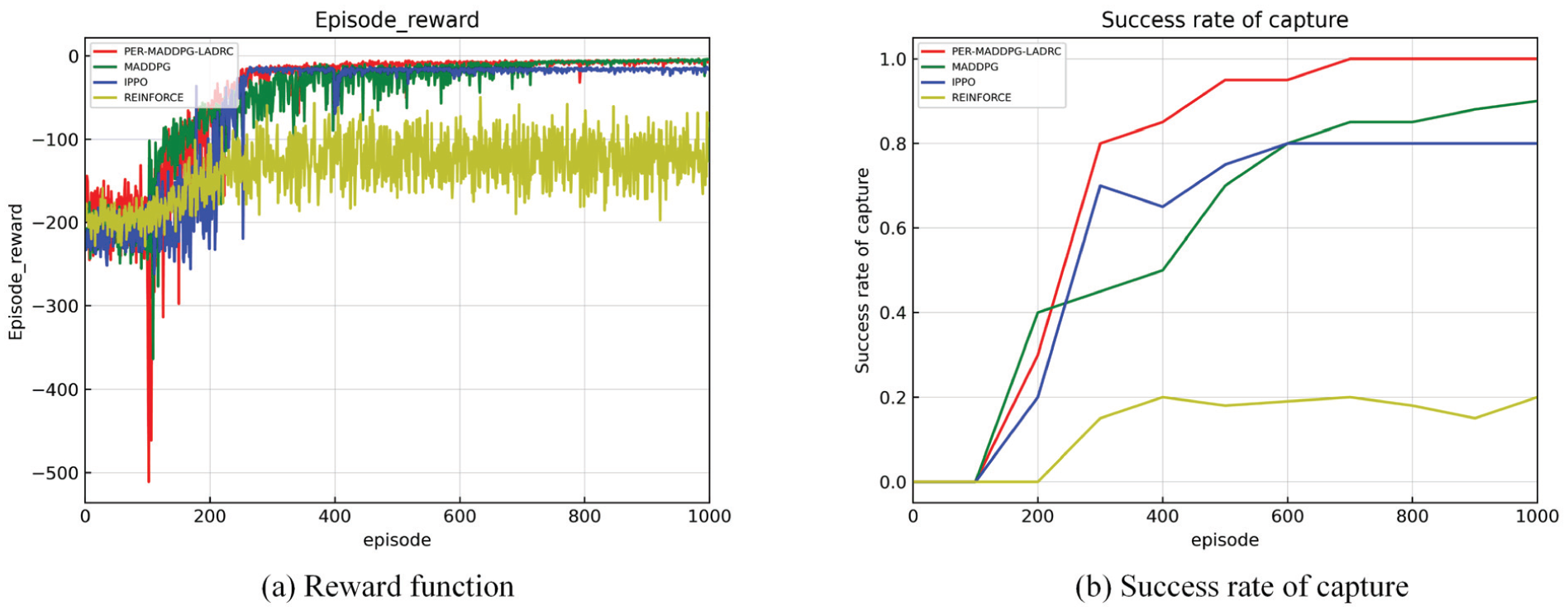
Reward function and success rate of capture in Case 1.
Figure 11 shows the capture performance of the original MADDPG in Case 1. Figure 12 gives its control result. Figure 13 presents the capture performance of IPPO in Case 1, and Figure 14 is its control result. In the comparison algorithms, although USVs have the tendency to perform the capture task, the distribution of USVs on the encirclement loop is not uniform, and the surge speed of USVs is far from zero. Although there is no collision with the obstacles, the USVs enter the safe obstacle avoidance range, and the risk of collision exists. In addition, since IPPO adopts a completely decentralized framework, the cooperation effect is slightly worse than MADDPG. For REINFORCE, capture cannot be realized ideally and the result has big error. Thereafter, its simulation result is not presented.
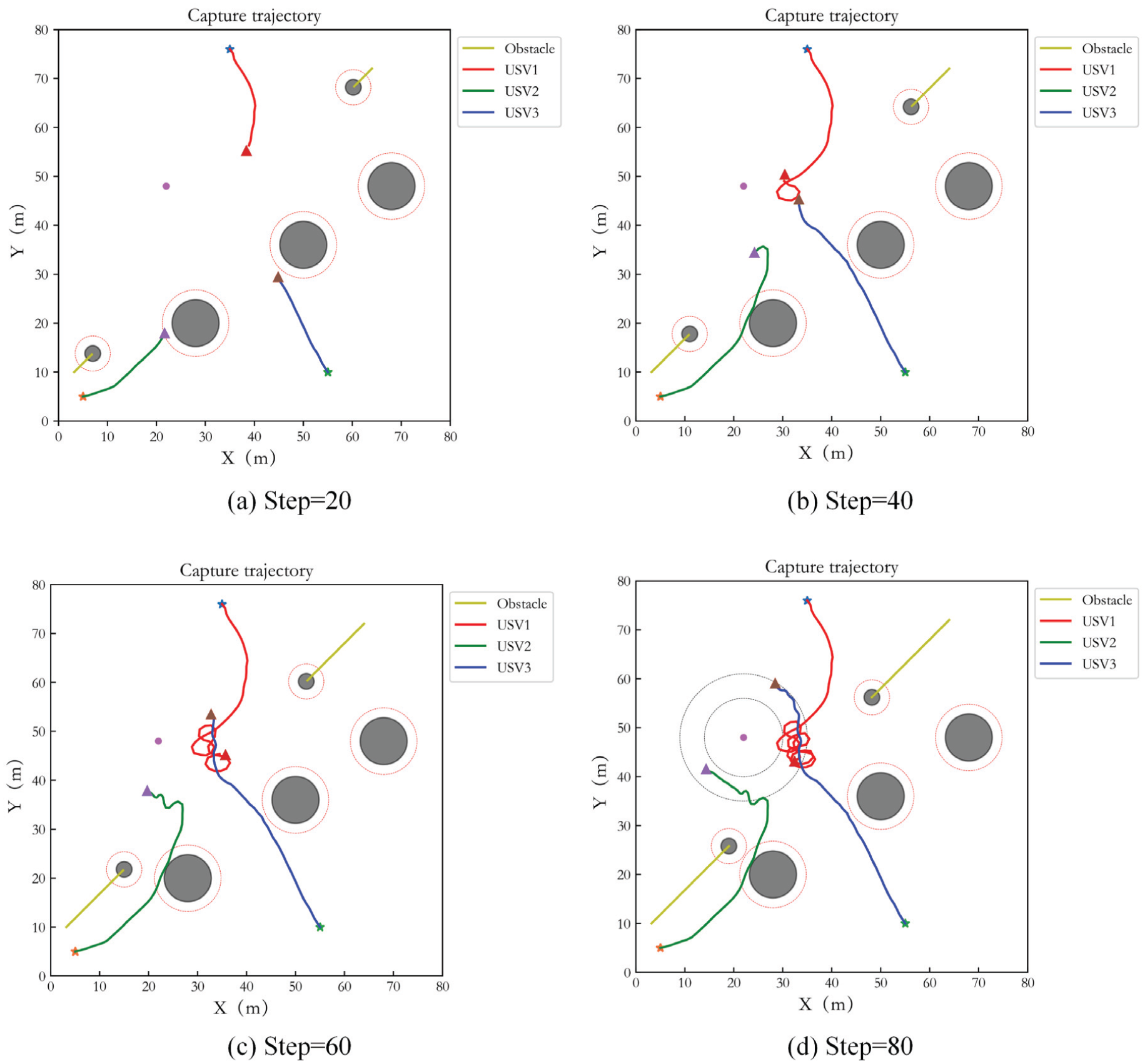
Capture performance of MADDPG in Case 1.
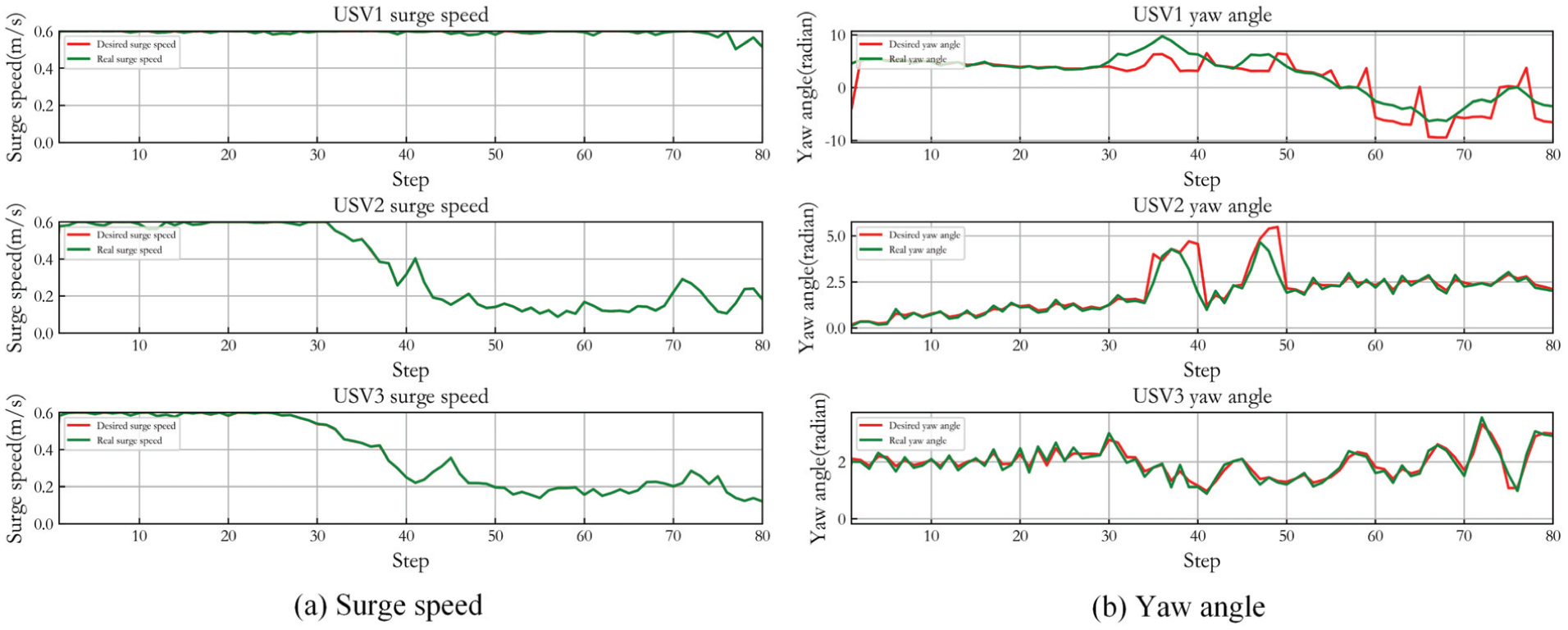
Control result of MADDPG in Case 1.
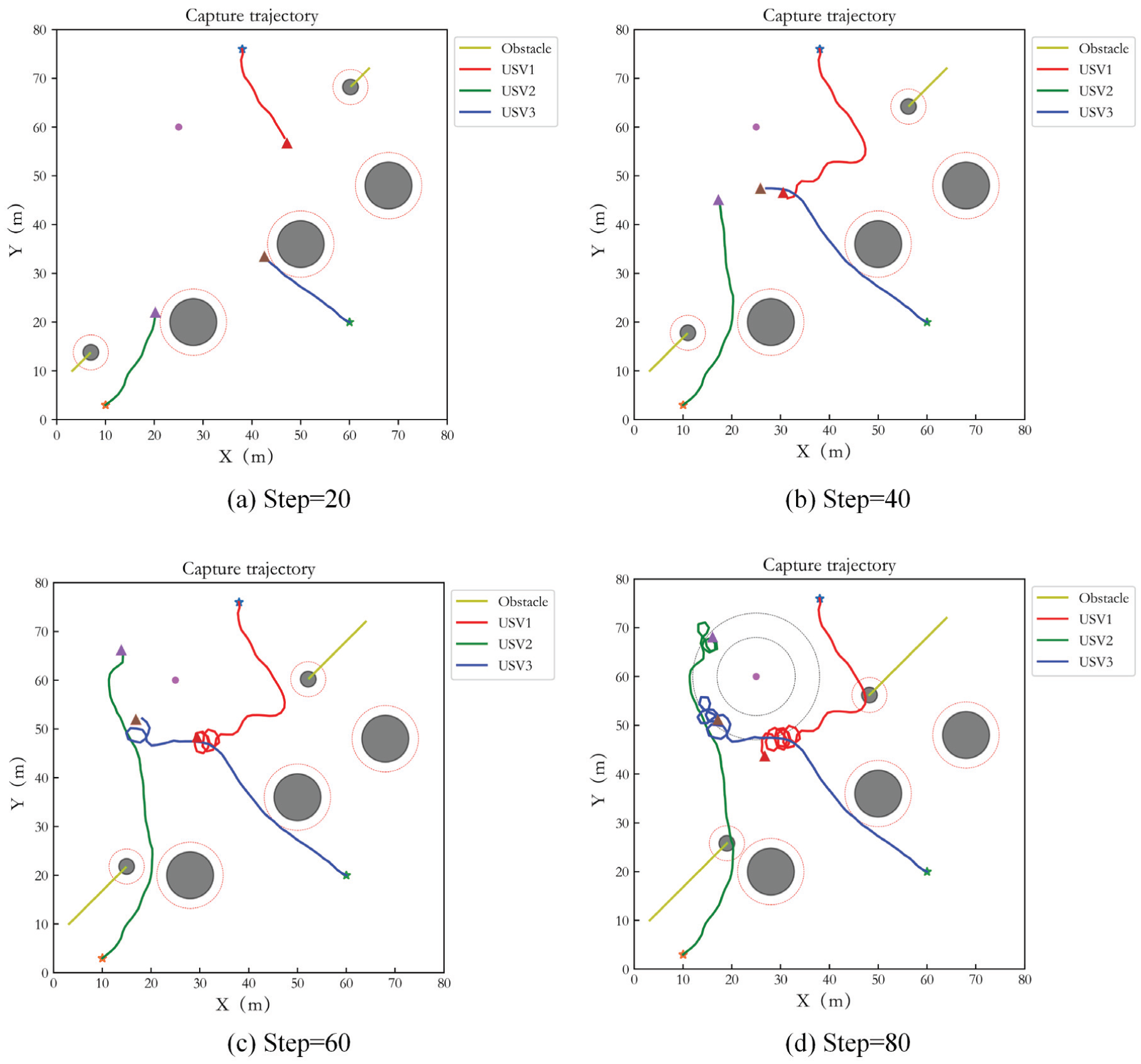
Capture performance of IPPO in Case 1.
Control result of IPPO in Case 1.
Case 2: Dynamic target capture
Different numbers of USVs capture the target
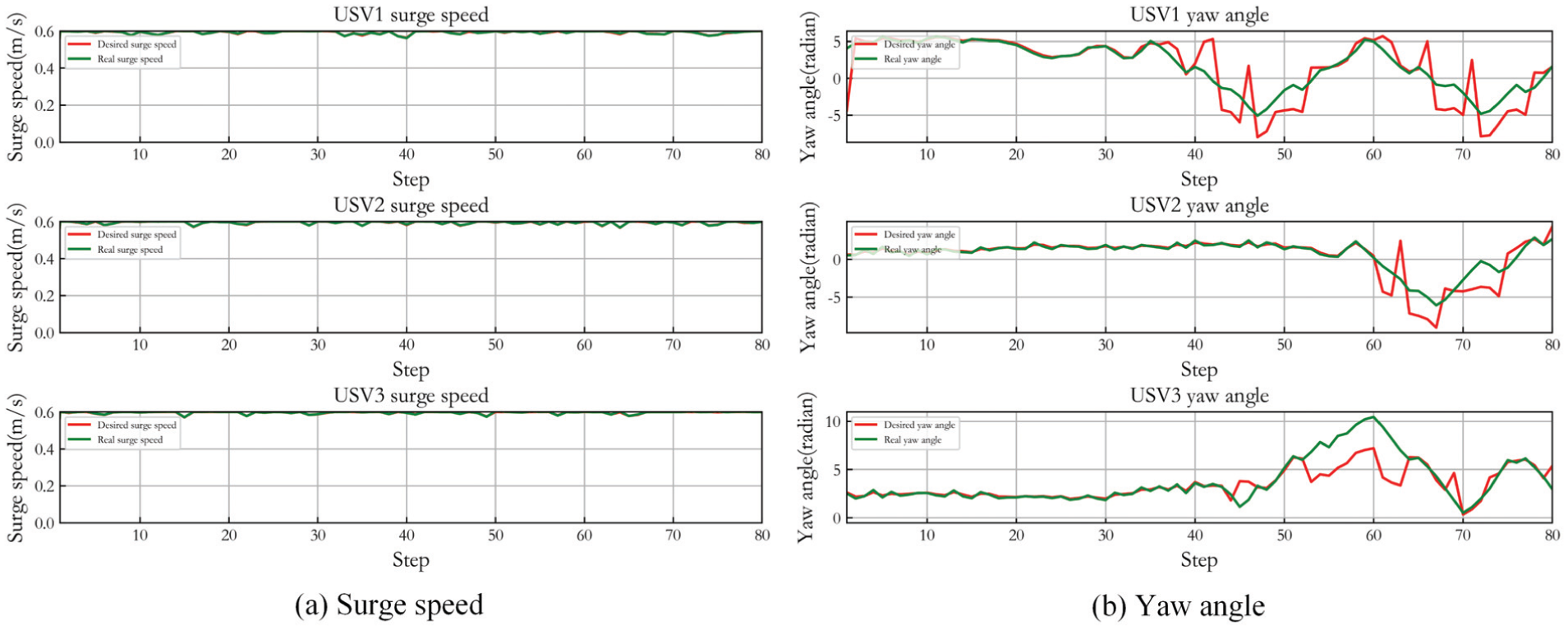
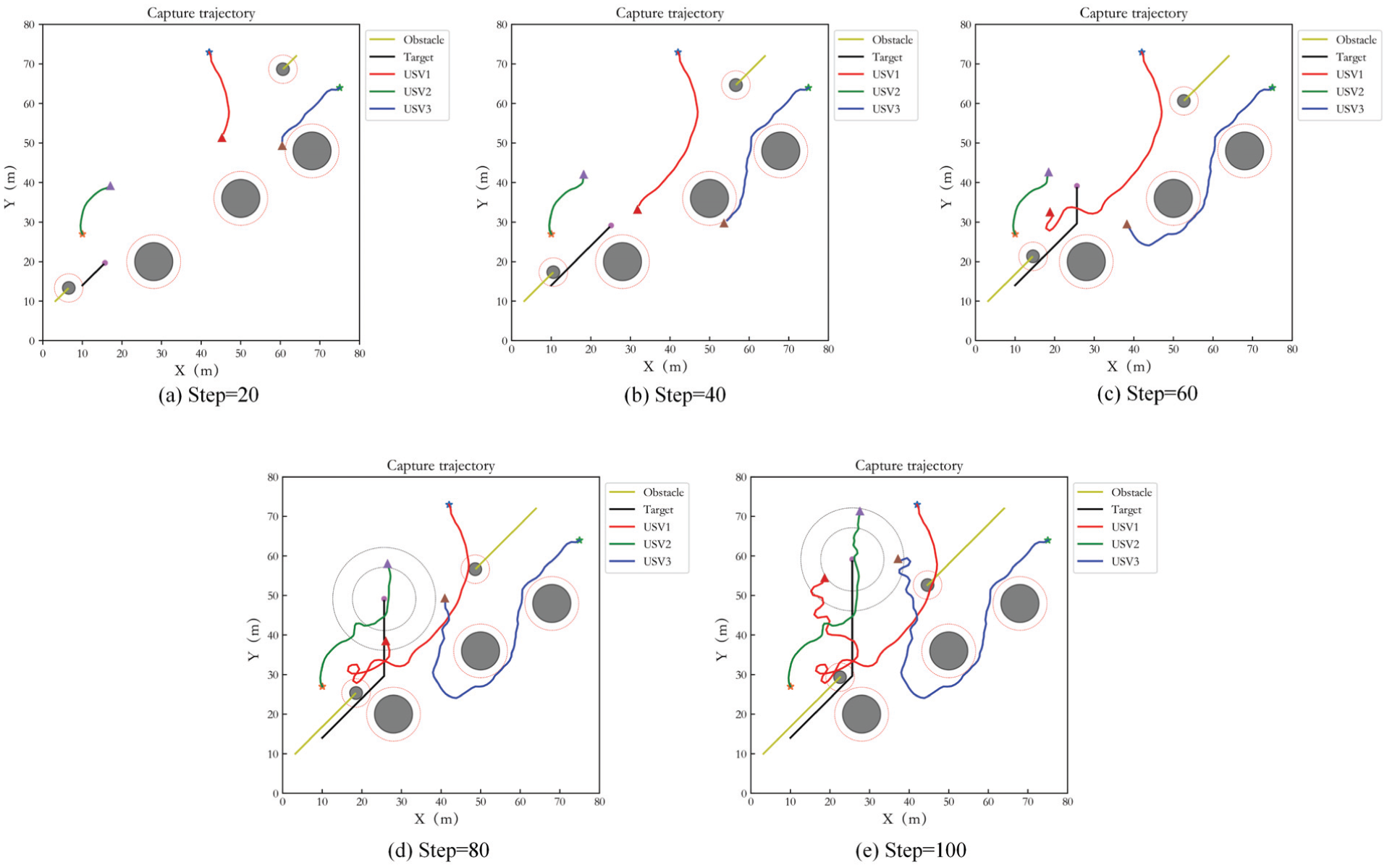
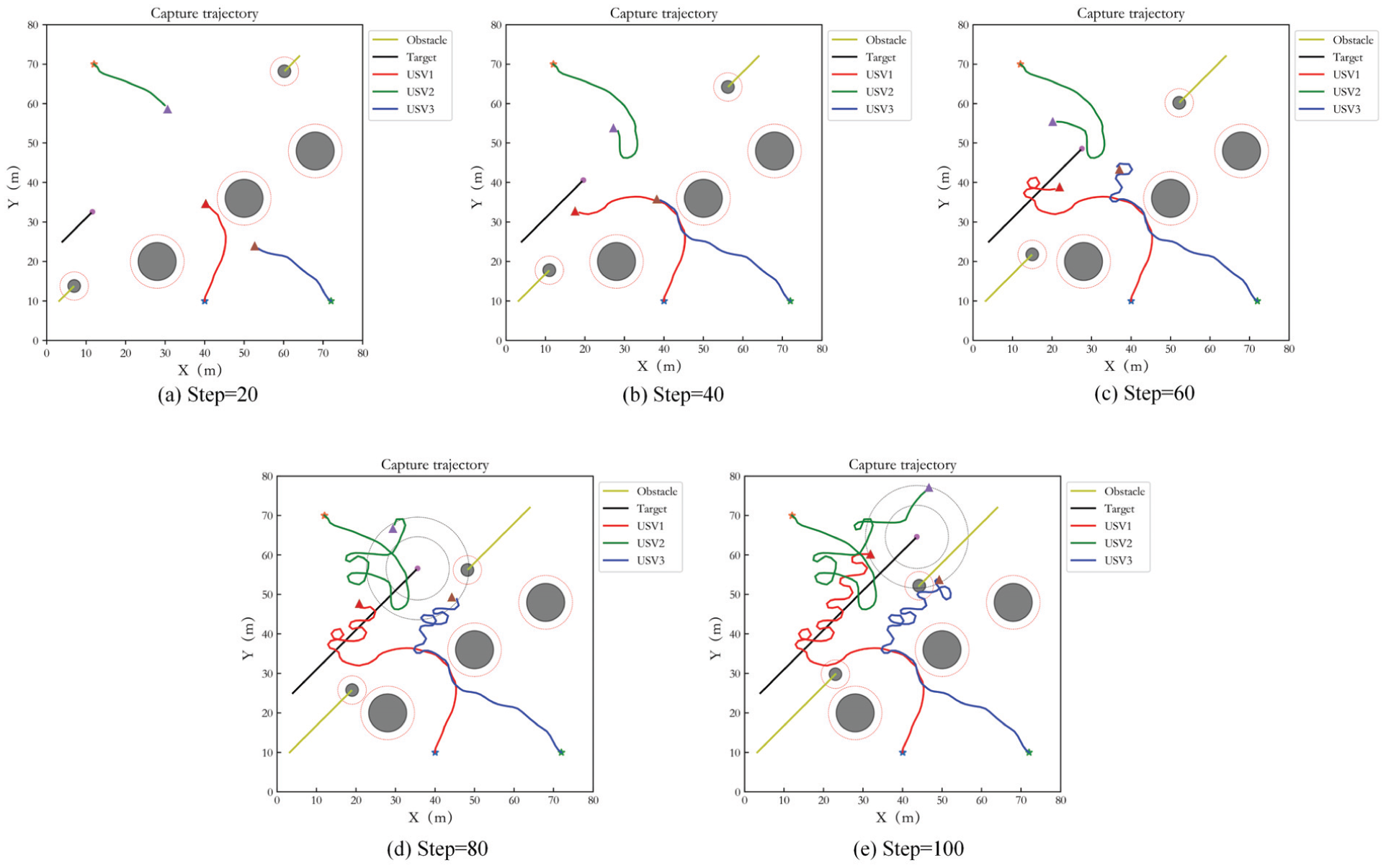
The case of different numbers of USVs capturing target is also considered in the dynamic target capture, three and five USVs hunting target are simulated respectively. The test step number is 100. Figure 15 shows the simulation result of three USVs. (a) to (e) present the capture results of USVs at different times. The description of obstacles and three hunting USVs in the figures is consistent with static target capture. The black curve is the target trajectory. It can be seen that the capture of USVs begins to form at step= 80. From step 80 to 100, the USVs keep tracking the target and achieve uniform distribution in the loop. And the USVs avoid the obstacles effectively.
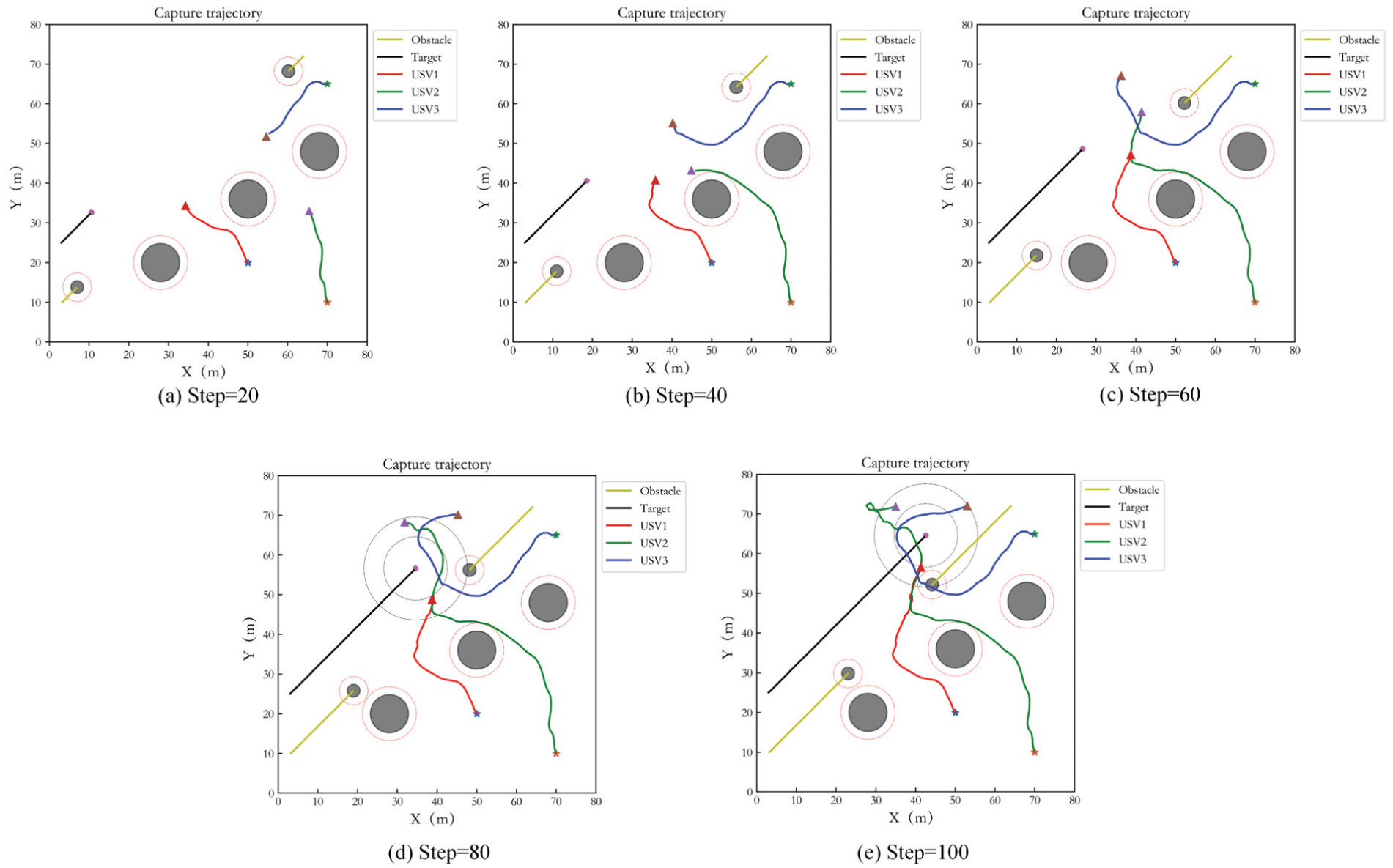
Capture performance of three USVs in Case 2.
Figure 16 gives the control result of three USVs in Case 2. (a) shows the desired surge speed of three USVs and their actual speed controlled by LADRC. (b) gives the desired yaw angle and accurate tracking result. It can be seen that LADRC also achieves stable tracking control. Angle control and speed control are effective in the whole procedure.
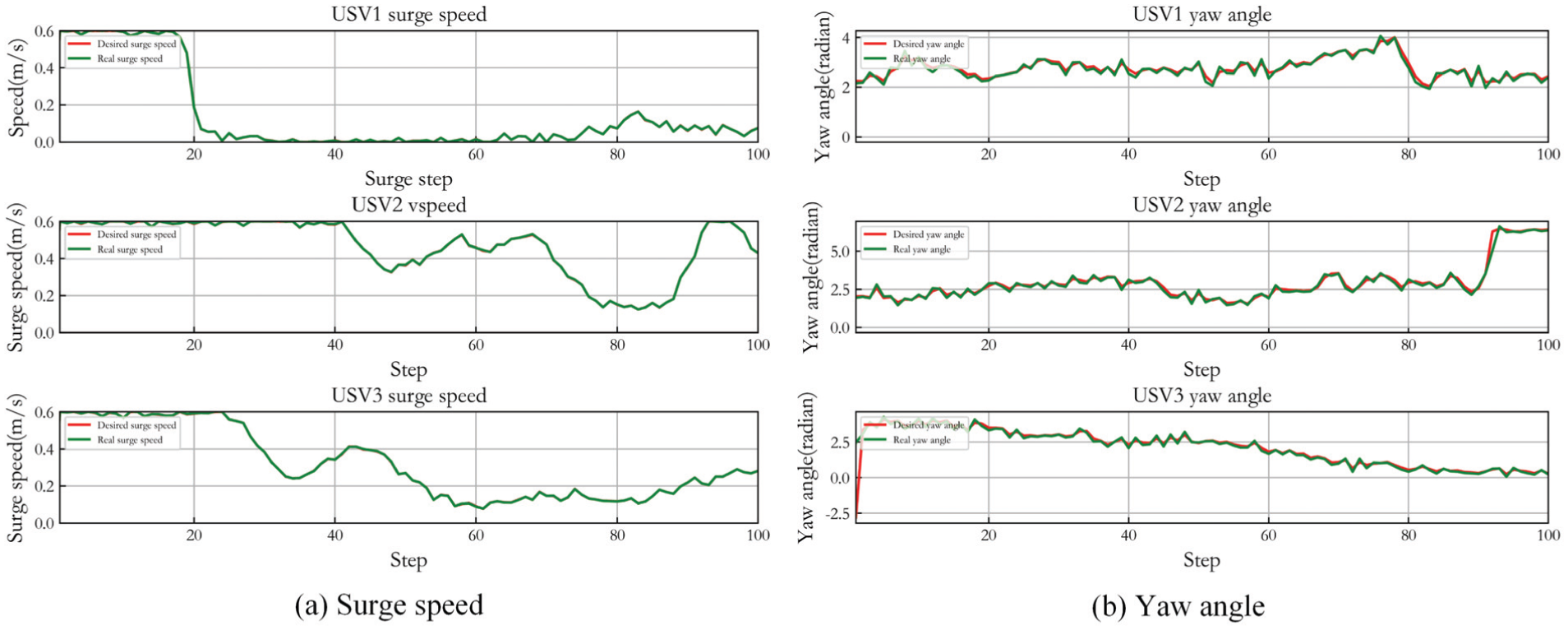
Control result of three USVs in Case 2.
Figure 17 is the simulation result of five USVs. (a) to (e) display the capture results of USVs at different times. The description of obstacles and five hunting USVs in the figures is same as static target capture. It can be seen that the capture of USVs is achieved successfully and the USVs avoid the obstacles effectively as well.
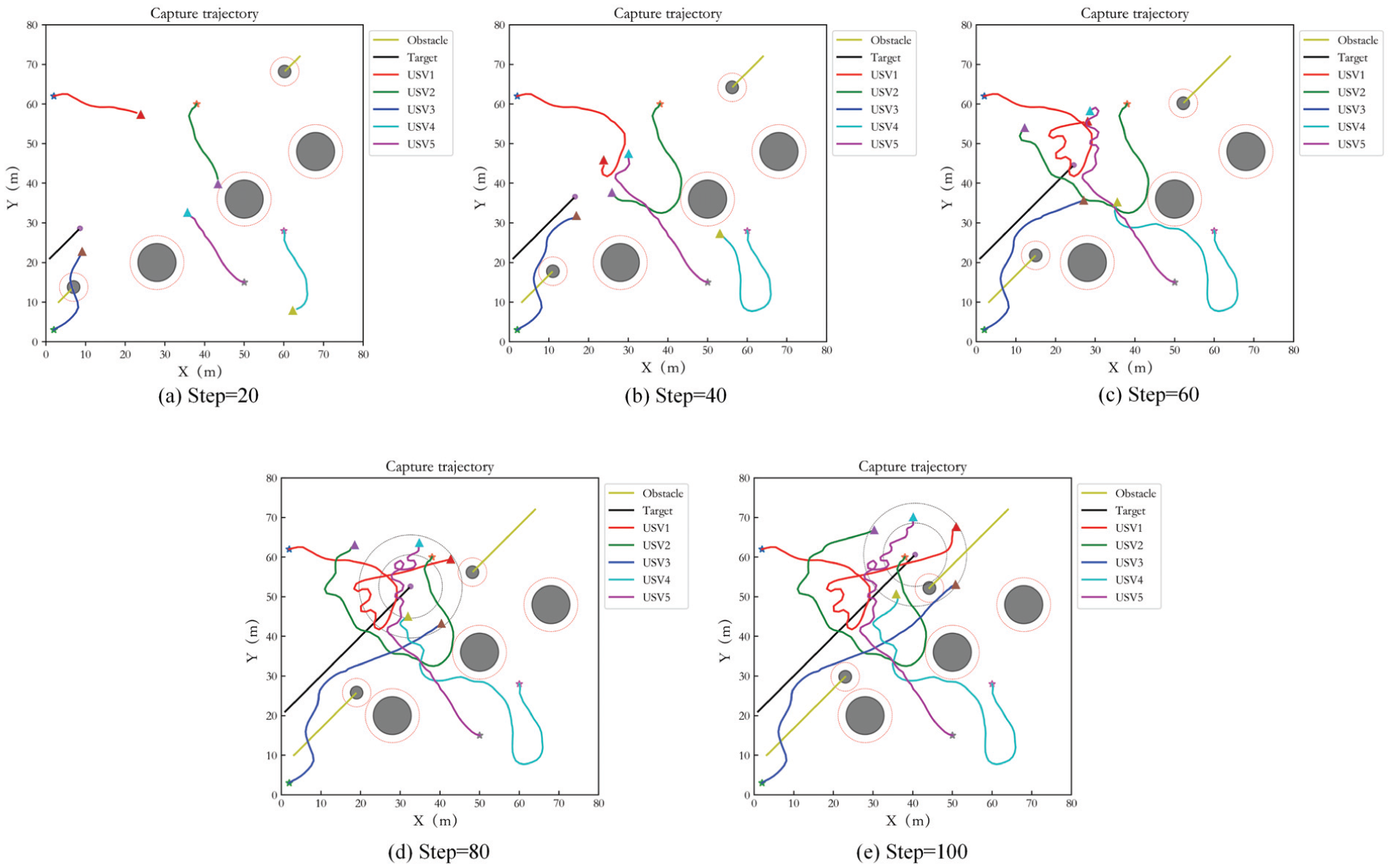
Capture performance of five USVs in Case 2.
Figure 18 displays the control result of five USVs in Case 2. (a) is the desired surge speed of three USVs and their actual controlled speed. (b) gives the desired yaw angle and accurate tracking result. It can be seen that LADRC also achieves stable tracking control.
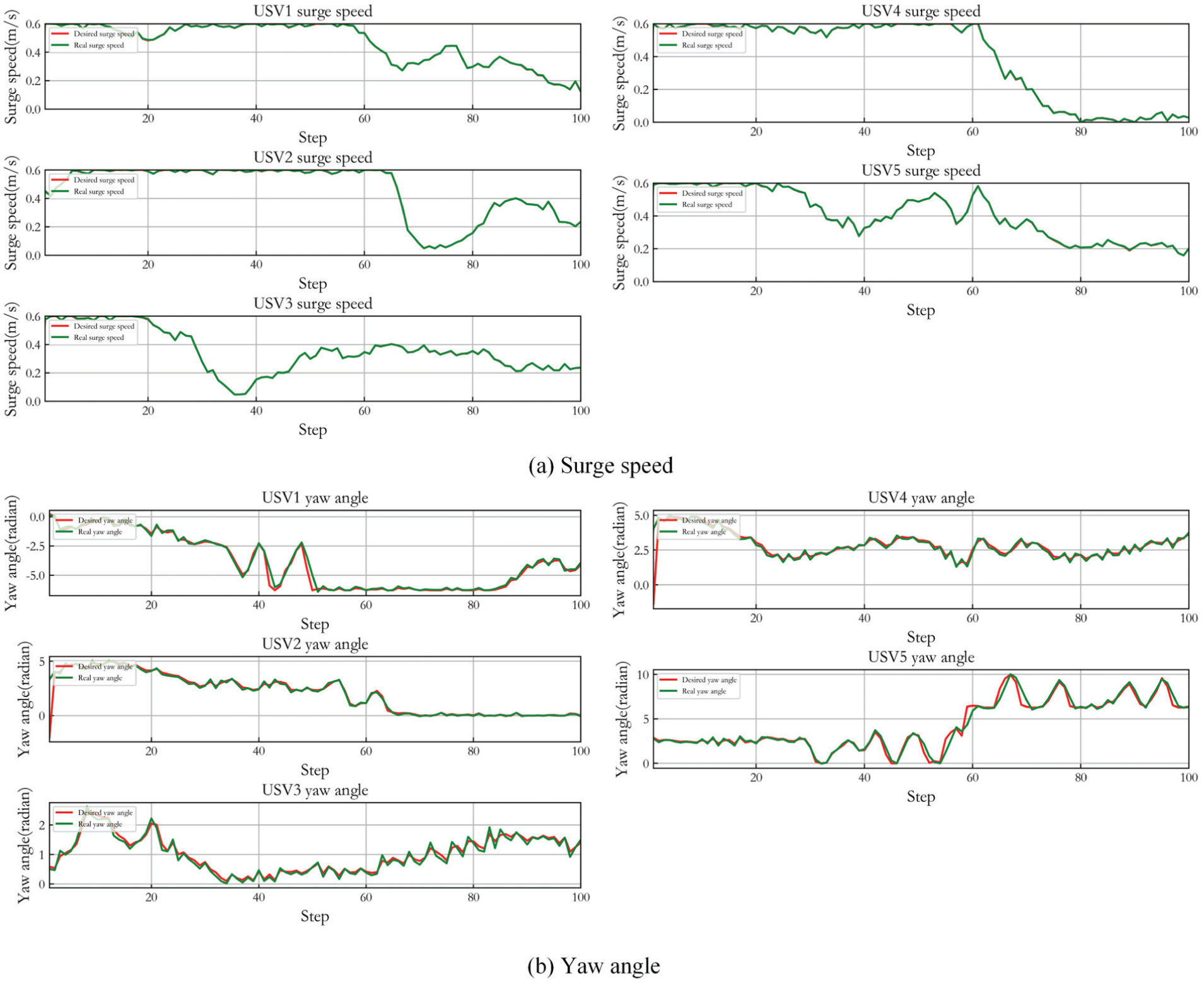
Control result of five USVs in Case 2.
In order to prove that the proposed method can be applied to target capture in unbounded environment, the test step number is selected to be 200, and Figure 19 shows the capture trajectories at interval of 40 steps. It can be seen that the desired capture result can still be achieved.
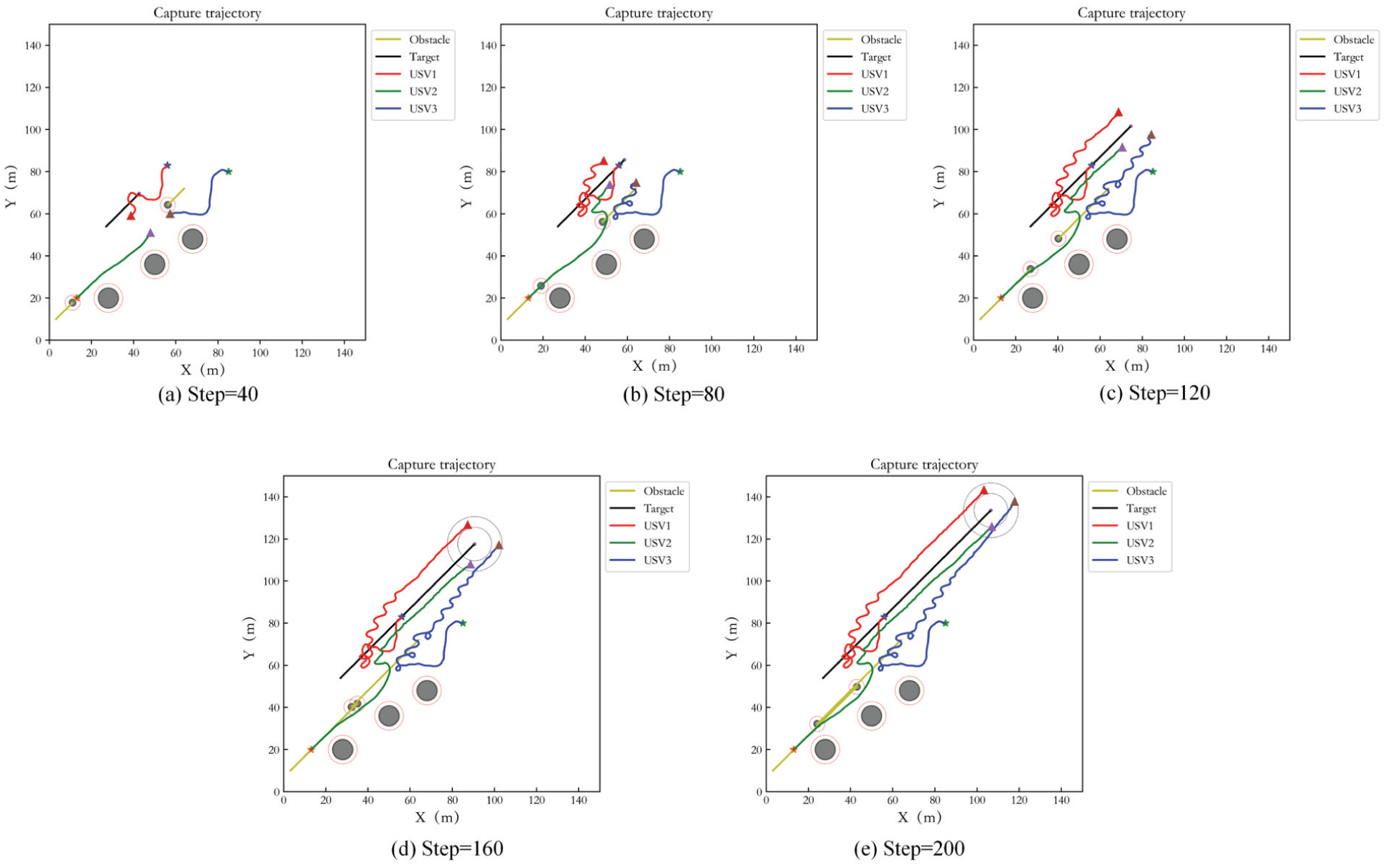
Capture performance of three USVs in unbounded environment in Case 2.
Target at another speed
Based on the proposed capture assumptions and the motion constraint reward sub-function of USV, when the speed of the dynamic target is less than the surge speed of USV, the capturing and tracking can be realized stably. In order to illustrate capture feasibility when target moving at a higher speed, a new simulation verification is carried out for target speed being
Capture performance of three USVs for another speed target in Case 2.
Control result of three USVs for another speed target in Case 2.
Target with varying motion state
In order to verify that the proposed method can adapt to capturing target with varying motion state. In this scenario, the target runs at time-varying speed. The initial speed is set as
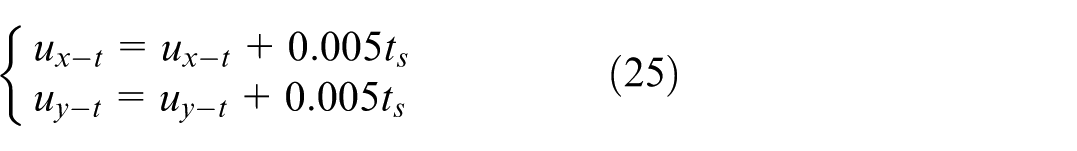
where t
s
is the current step. When the step number is greater than 40, the motion angle of target is adjusted from

where
Figure 22 shows the capturing and tracking trajectories and Figure 23 displays the control result. The simulation result shows that the target with varying motion state can still be captured effectively under dynamic obstacles moving at varying speed.
Capture performance of target with varying motion state in Case 2.
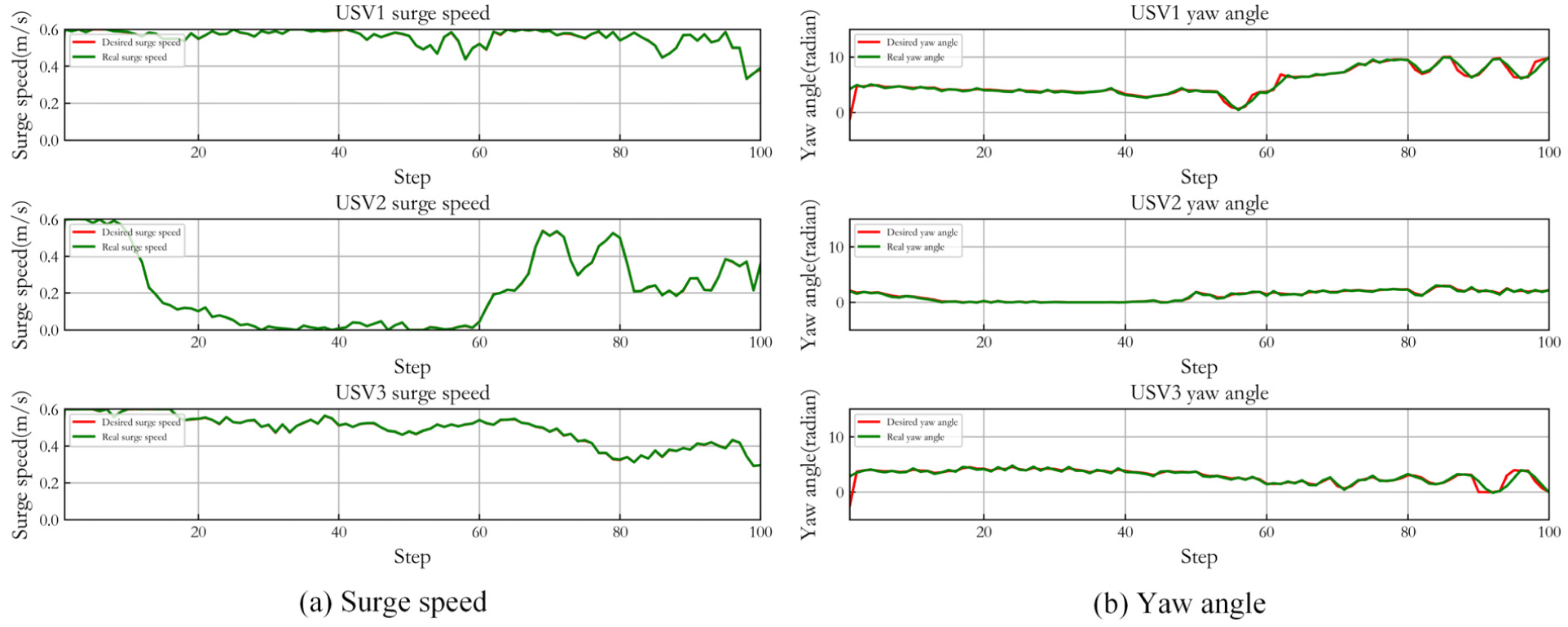
Control result of capturing target with varying motion state in Case 2.
Target capture under strong wind and wave disturbances
The feasibility of capturing dynamic target under strong wind and wave disturbances is also verified. Figure 24 shows the capturing and tracking trajectories of three USVs capturing dynamic target, and Figure 25 displays the control result. Compared with the static target, due to the increase of disturbances, the hunting trajectories for dynamic target are more tortuous, and the control error of yaw angle increases. However, the capture task is still be realized.
Capture performance of three USVs under strong disturbances in Case 2.
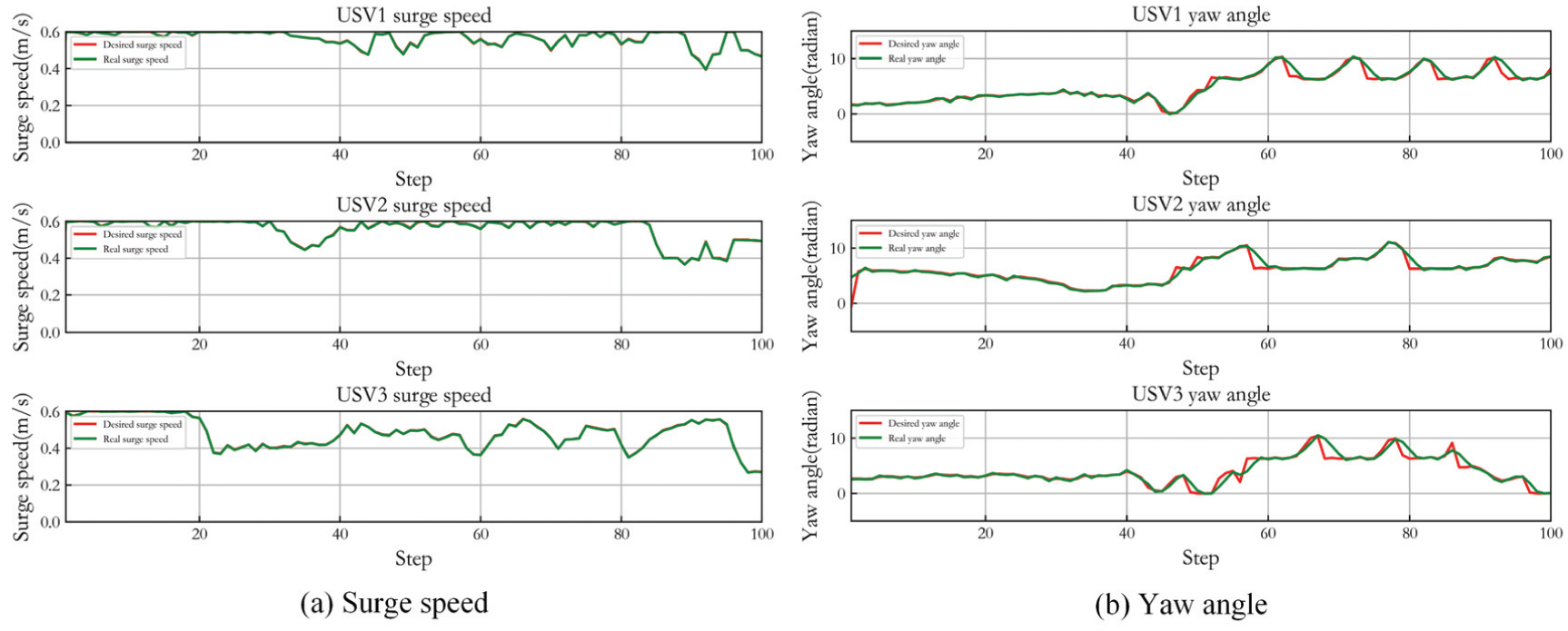
Control result of three USVs under strong disturbances in Case 2.
Comparison simulation
For capturing the dynamic target, the similar comparison simulations with MADDPG, IPPO and REINFORCE are implemented. Figure 26(a) is the reward function comparison diagram of four algorithms. The red curve is the proposed algorithm, the green curve for the original MADDPG, the blue curve for IPPO, and the yellow curve for REINFORCE. Figure 26(b) presents the curves of the success rate. The result shows that the proposed PER-MADDPG-LADRC method has better convergence performance and stronger practicability. Its capture performance on dynamic target is more obvious than static target. The proposed algorithm can achieve stable convergence of the reward function after the 300th training. However, the original MADDPG can achieve stable convergence just after the 400th training. Although IPPO has a faster convergence speed, it is easy to fall into local optimum and cannot reach the maximum reward value, which also leads to its poor capture effect. The change of success rate also shows that the proposed algorithm has better capture effect.
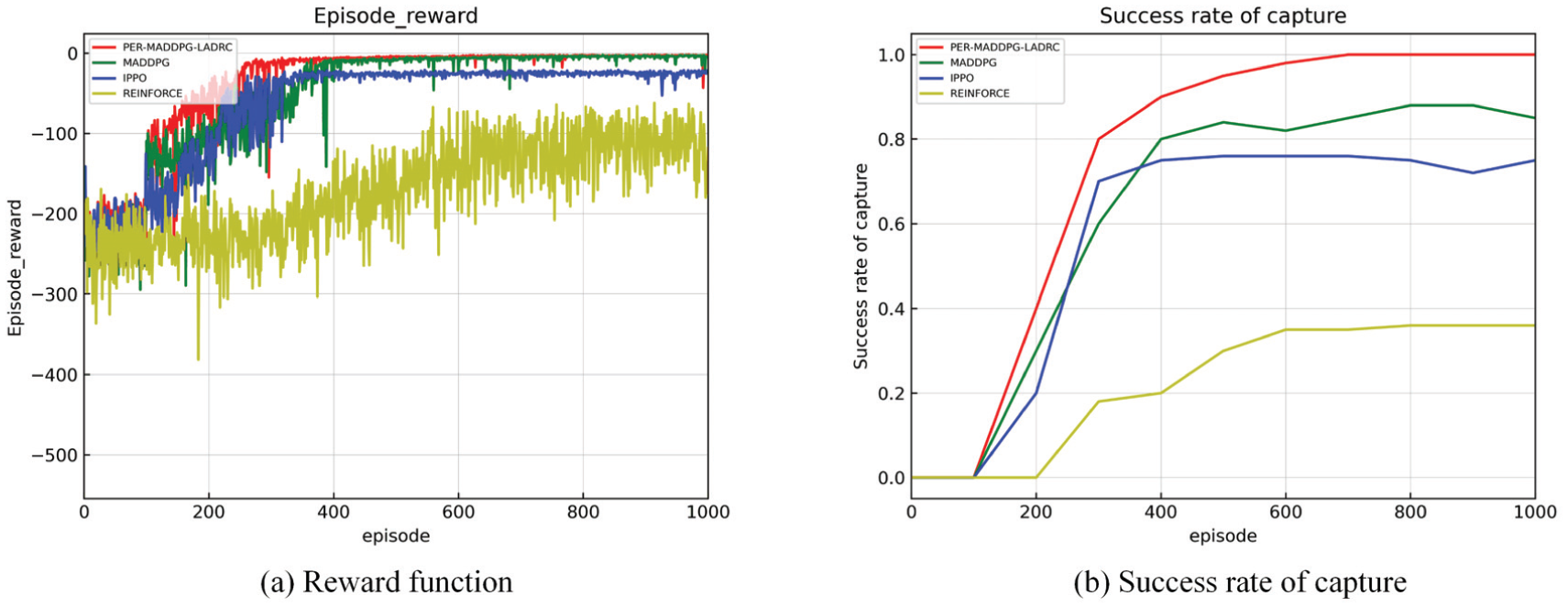
Reward function and success rate of capture in Case 2.
Figure 27 shows the capture performance of the original MADDPG in Case 2, and Figure 28 is its control result. Figures 29 and 30 display the capture performance and the control result of IPPO in Case 2. In the comparison algorithms, although the USVs can achieve the stable encirclement of the target, they cannot be distributed on the encirclement loop, and the escape behavior of the target may occur. For REINFORCE, target capture is hardly completed, so tracking curve is not given.
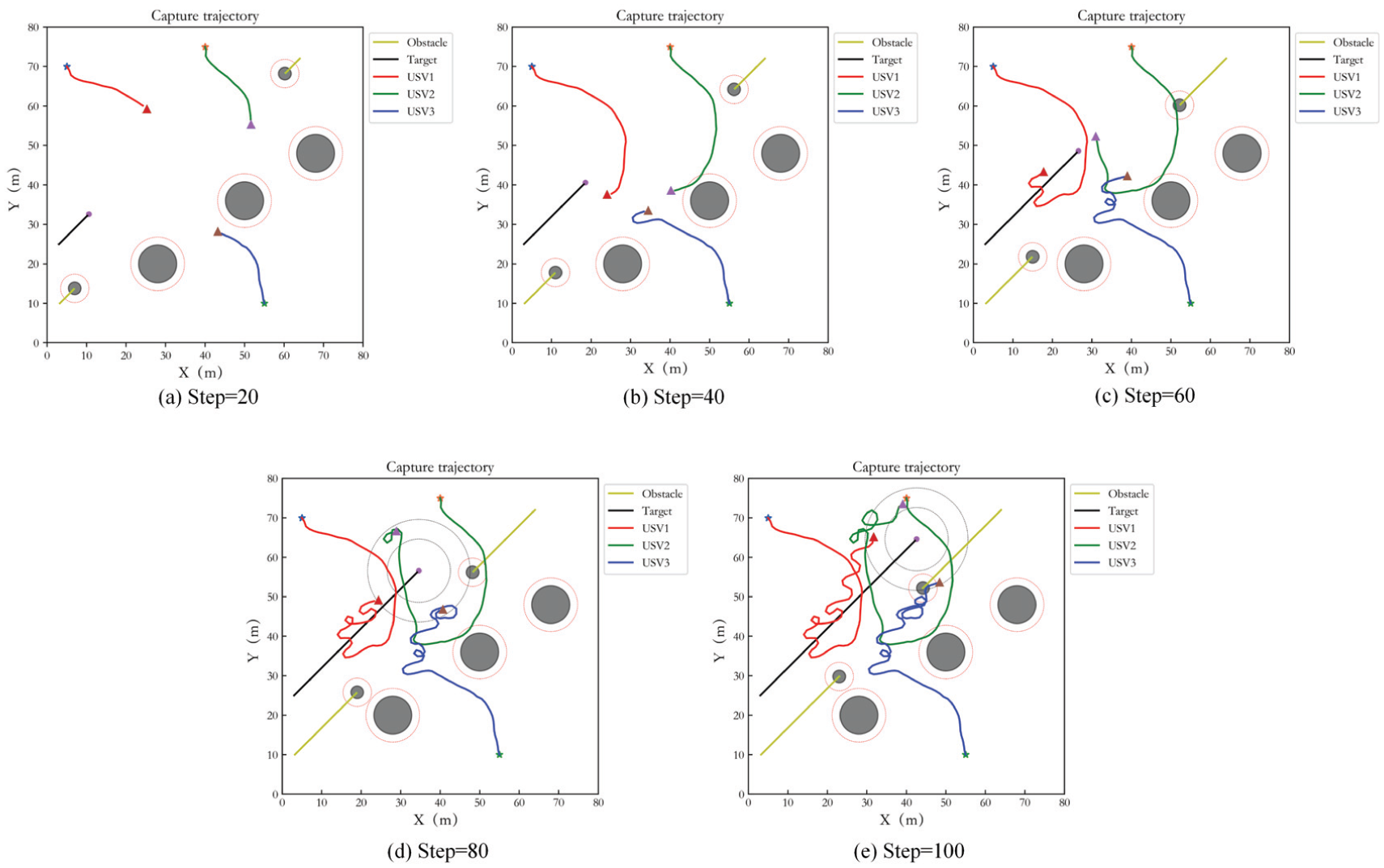
Capture performance of MADDPG in Case 2.
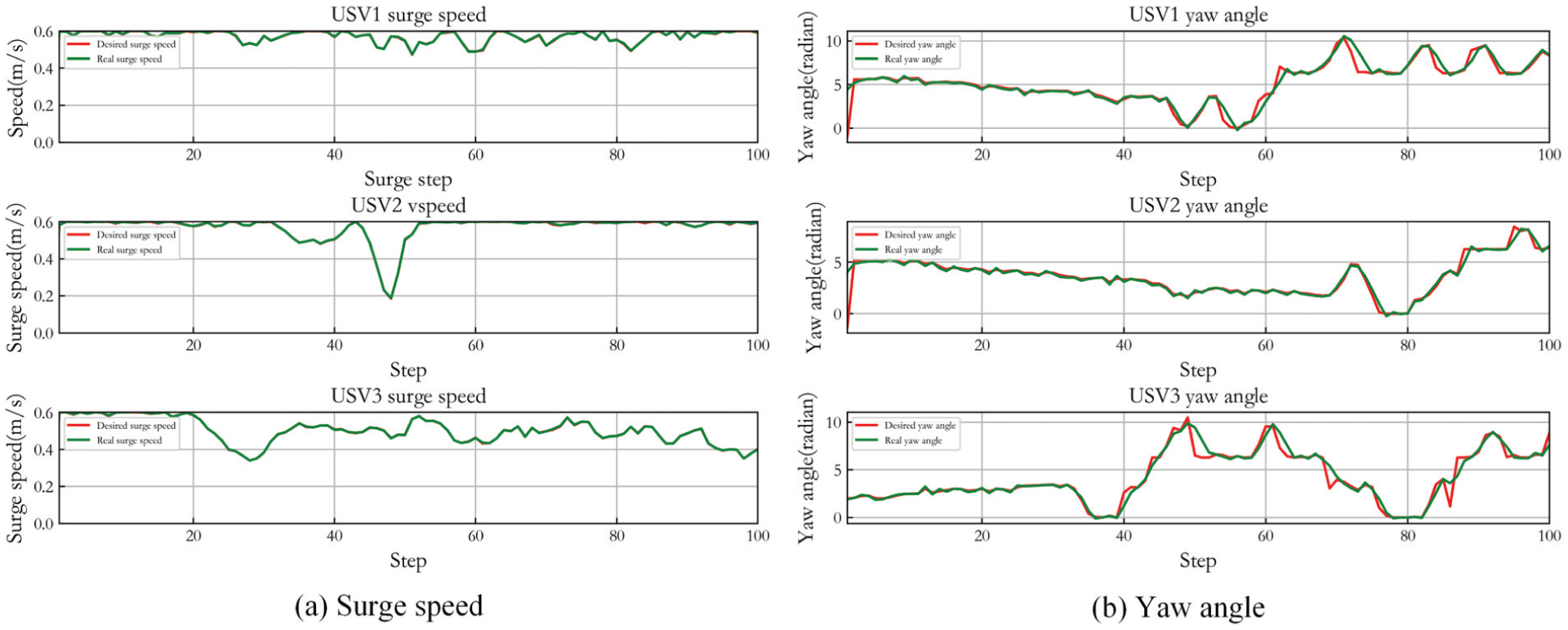
Control result of MADDPG in Case 2.
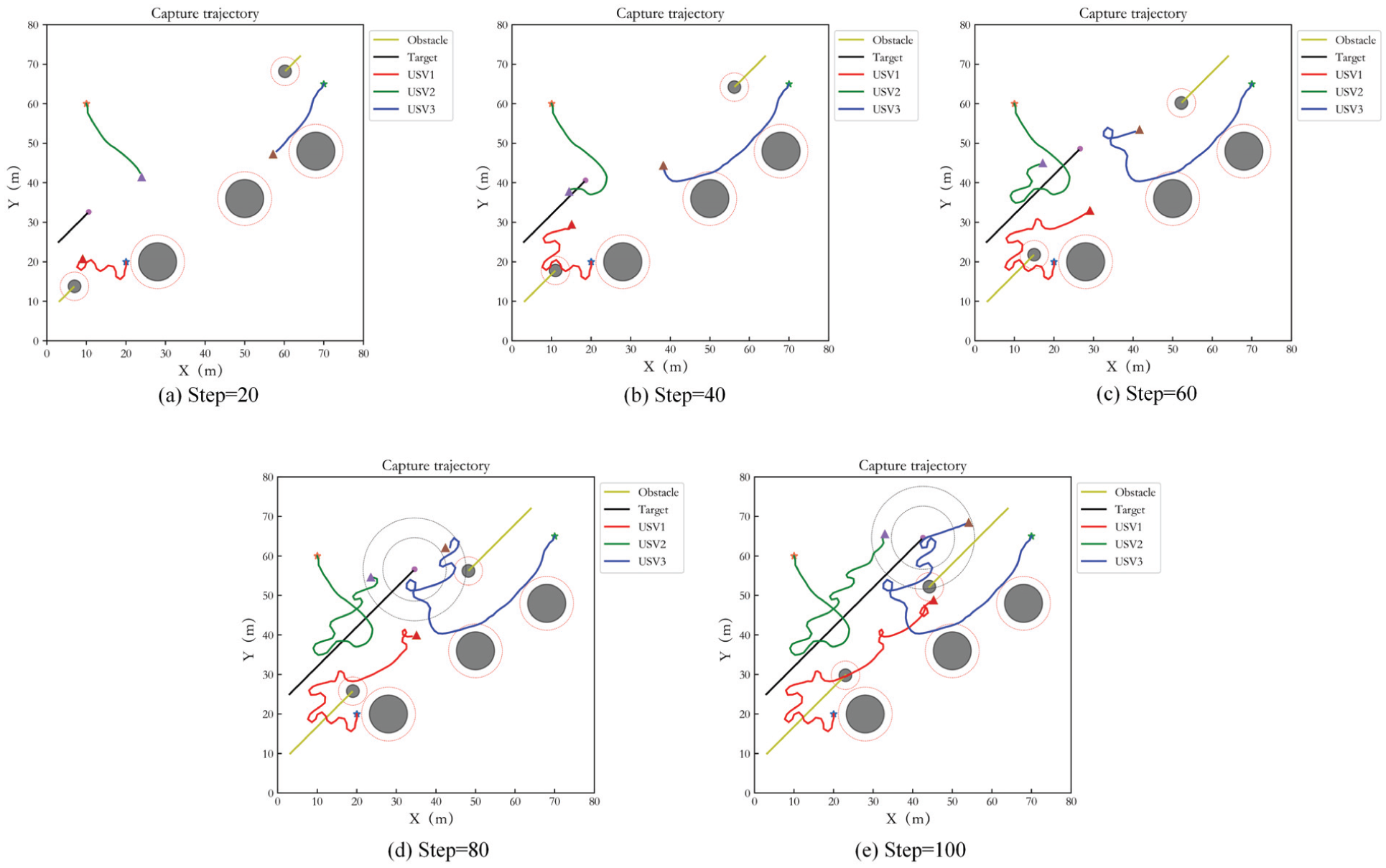
Capture performance of IPPO in Case 2.
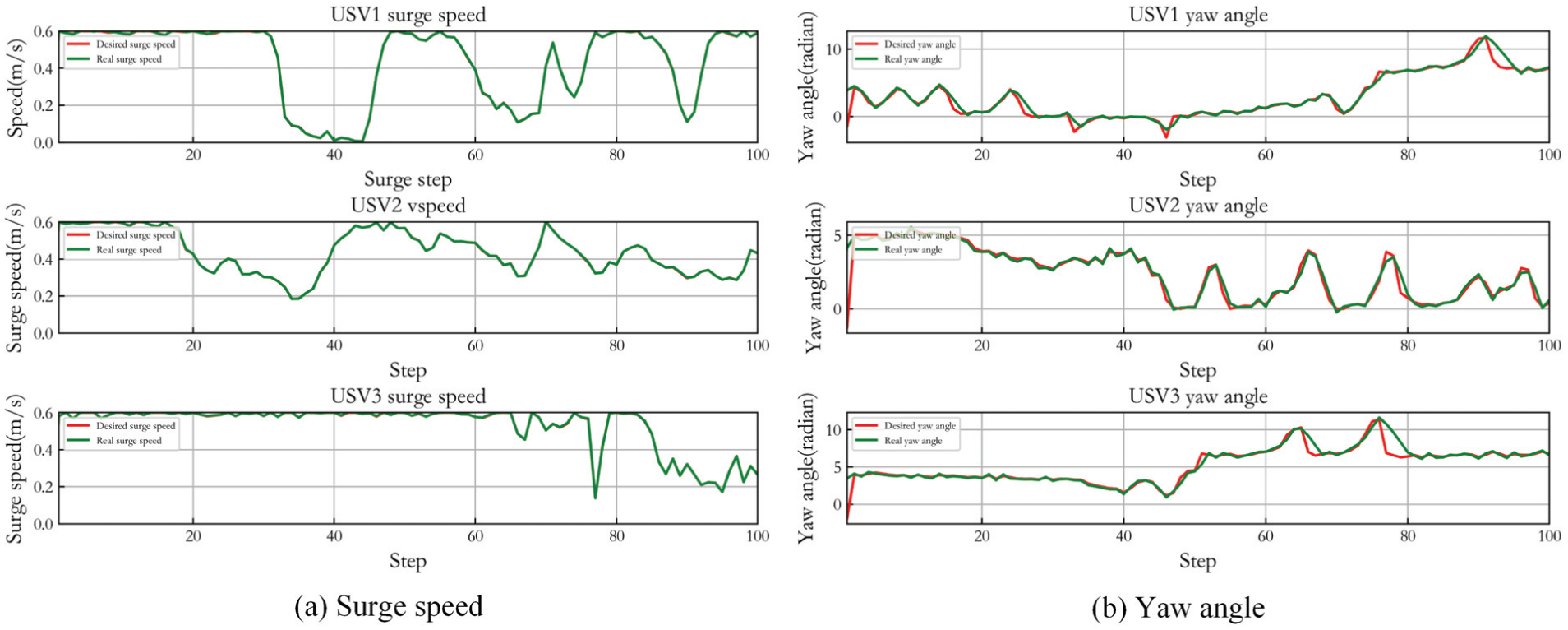
Control result of IPPO in Case 2.
Performance analysis
In order to verify the feasibility of the proposed algorithm, different numbers of USVs are used for static target and dynamic target capture. To meet the collision avoidance constraint, the following condition is essential:
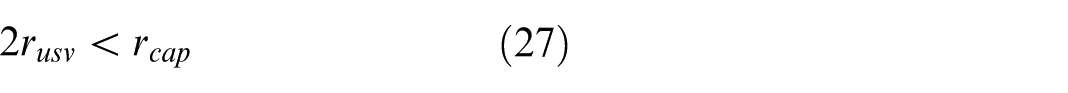
Therefore, at most 7 USVs can be applied to capture one target simultaneously when the conditions and parameters of environment, USVs and target are same as Case 1 and Case 2. So, the number of USVs is set as 3, 5, 7 respectively, and training is performed for each situation. Figure 31(a) shows the reward function training diagram of different numbers of USVs for static target capture. The red curve is 3 USVs capturing target, the green curve is 5 USVs, and the blue curve is 7 USVs. Figure 31(b) shows the reward function training diagram for dynamic target capture. It can be seen that different numbers of USVs can all achieve stable convergence of the reward function. It is apparent that the time to achieve convergence stability will increase while the USV number increases. However, the computational complexity is still tolerant in this case, and the real-time feasibility of the algorithm can be guaranteed. Even if the USV number is larger, the computational complexity and capture performance can be balanced by regulating network structure and parameters. In addition, for dynamic target capture, the motion states of USVs are more complex, and the whole capture process can be divided into capturing and tracking target. Therefore, when the number of USVs increases, the training difficulty of the reward function is more obvious than that of static target. Nevertheless, it can still achieve stable convergence eventually.
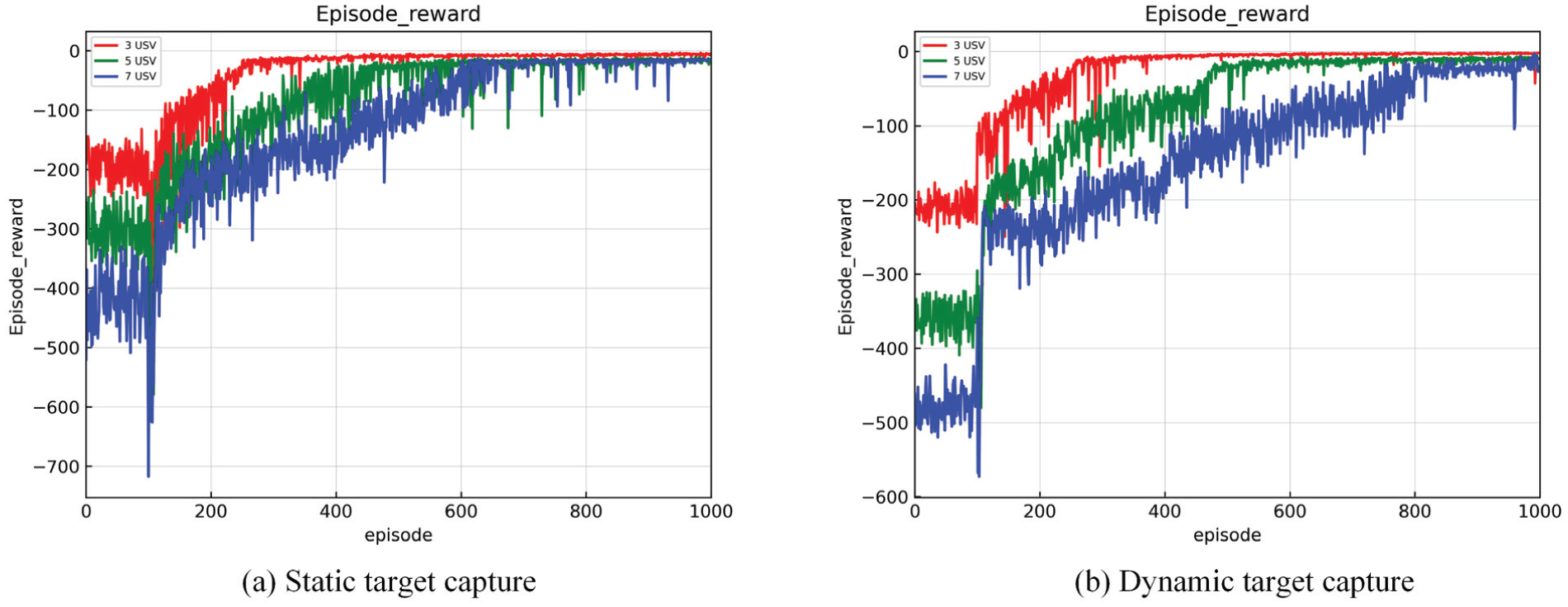
Reward function of different numbers of USVs.
In addition, for capturing target by different numbers of USVs, the simulation relative running time under the same training episode number and episode length is counted as shown in Table 3. It can be seen that although the training time increases with the number of agents, its computational complexity is still tolerant.
The simulation relative running time of different numbers of USVs.

In summary, the proposed algorithm can be applied not only the above assumed background, but also to the more complex water environment, such as the case with randomly moving target. It can be achieved by modifying the corresponding network input information due to the real-time motion state of target being as part of the network state space. Additionally, it is assumed that the position and motion of target is known for USV in this paper. Although this assumption is relatively ideal, this prior condition can be realized in realistic conditions for reasons of development of sensors and improvement of the related environment detection capabilities. In addition, this paper studies the capture problem in bounded waters. Compared with unbounded marine environment, the constraints of this study are more complex. Finally, this study considers the disturbances of wind and wave and control tracking error in network training. The preliminary combination of methodology and practice is feasible. In order to extend the method to deal with more practical marine conditions, true disturbances of wind and wave can be used to replace ideal data to train the network.
Conclusions
In the existing research, the MARL algorithm is mostly aimed at the kinematic model. It does not have strong practical potential for real environment and true objects. In this paper, the PER-MADDPG-LADRC method is proposed. The algorithm introduces the experience playback mechanism into MADDPG, by which the training convergence speed and the training results are improved. The proposed algorithm integrates LADRC for path tracking in the interaction between agent and environment. And the wind and wave disturbances are considered in the actual control. In successful capture, it is required that the USVs are located within the encirclement loop and not detected by target such that the target cannot escape. In reward function design, this research not only takes into account the capture effect reward, collision avoidance and obstacle avoidance reward, boundary collision restriction reward, capture inner boundary constraint reward, angle constraint reward and motion constraint reward, but also adds the LADRC tracking error reward in training the network for approaching reality.
The research results show that the algorithm can achieve capture of static target and dynamic target by multiple USVs in presence of various types of obstacles. The combination of MADDPG and LADRC realize real-time coordination control of path planning and tracking of USVs. In the future research, it is expected that the algorithm framework can be applied to target capture in more complex environments, such as in presence of irregular or in convex obstacles, in unknown and real-time changing environment. In addition, the algorithm can also be combined with the task allocation to solve multi-target capture by USVs.
Footnotes
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by Natural Science Foundation of Tianjin (grant number 23JCZDJC01140).
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data availability statement
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.*