
Abstract
Multi-UAVs play an important role in the battlefield. Although many methods are proposed to solve the Multi-UAV task allocation, there still existing the problems of complex time constraints and uncertain solution space. The reason is that multi-UAVs usually face changing environmental factors. Aiming at solving such problem, this paper proposes a multi-UAV task assignment method based on Deep Q-based evolutionary reinforcement learning algorithms (MPSO-SA-DQN). Specifically, this method builds a multi-agent training framework based on the deep evolutionary reinforcement learning mechanism and SA-DQN. Its aim is to improve the global exploration and optimization capabilities of multi-agents. At the same time, the multi-dimensional particle swarm optimization algorithm is introduced to optimize the state space. Based on task priority mapping, the MPSO-SA-DQN algorithm framework is proposed. As a result, multi-agents can optimize the execution state in real time in the environment interaction. Besides, it also has the ability to reach optimal state and maximum reward. According to the characteristics of multi-UAV global task assignment, this paper designs a priority state space autoencoder strategy and global task feature. A multi-UAVs tasks allocation and iterative optimization method based on MPSO-SA-DQN algorithm is proposed, so as to continuously optimize the task allocation scheme. The simulation results show that the multi-UAV task allocation method based on MPSO-SA-DQN can effectively solve the problem of uncertainty in the optimal solution space of task allocation. At the same time, the algorithm achieves faster convergence result, and a good prospect of promotion in the field of UAV swarm cooperative task planning.
Keywords
Introduction
The first-hand information1–3 are extremely important in the war environment. Unmanned Aerial Vehicle (UAV) is good at information reconnaissance and transmission, as well as the battlefield monitoring. As a result, the UAV technology4,5 plays an increasingly important role on the battlefield. However, the combat tasks that a single UAV can complete are limited due to various restrictions. Thus, to meet the needs of more complex military tasks, multi-UAV maneuver decision-making tasks6,7 have become a research hotspot.
At present, many researches with promising results on multi-UAVs task allocation8–12 have been proposed. Specifically, Huawei et al. 13 conduct a cooperative task planning model for unmanned warship and UAV. The model utilizes the adaptive particle swarm algorithm to search the optimal result. It is able to solve the problem of cooperative task allocation for unmanned combat platforms. Qingchao and Qingkui 14 realize the multi-UAV collaborative task allocation by discrete pigeon group algorithm. However, the above-mentioned multi-UAVs task allocation methods is unable to solve the future large-scale operations problem. The characteristic of such problem is that, when the task is quickly planned and the scene changes, the difficulty for solving it rises rapidly, and the solution accuracy gradually decreases. Therefore, some works introduce deep evolutionary reinforcement learning15–17 to explore the problem of large-scale UAV task assignment. For example, Khadka et al.18,19 improve the diversity of data by introducing the evolutionary algorithm population. They train the agent in reinforcement learning, and periodically reinsert the agent into the evolutionary algorithm group. At the same time, the author injects gradient information into the evolutionary algorithm. Thus, a new way for solving the above problems is provided.
Conventional algorithms20,21 have fixed solution space dimensions and cannot jump out of local optimal solutions. At the same time, the conventional deep reinforcement learning algorithm cannot jump out of the loop when the training is optimal, making the training time too long. Furthermore, there are some disadvantage in the study of the above task allocation methods. In detail, during the UAV flight, the mission target pair may change over time, and the environment in which the UAV performs the mission is dynamically changing. Besides, the process of task assignment is difficult to be decided by multiple UAVs.22,23 It is because the sudden and unpredictable things often occur. Furthermore, there are certain defects in the solution space judgment of multi-UAV mission planning.
Aiming at the above analyzed problems of existing methods, this paper proposes a multi-UAV task assignment method based on MPSO-SA-DQN. Firstly, for the multi-agent Markov game process, an intelligent agent training framework (SA-DQN) based on deep evolutionary reinforcement learning is constructed. Secondly, the design of MPSO-SA-DQN environment is proposed. Then, the combination of multi-dimensional particle swarm optimization and SA-DQN is used to continuously interact with the environment. The main aim is to continuously optimize the optimization process, and then to achieve the global optimal state. In the end, a real-time priority state-space autoencoder strategy is proposed. At the same time, a multi-UAV task assignment model based on MPSO-SA-DQN is built. It is obtained by combining with multi-dimensional particle swarm and simulated annealing algorithm. Experiment results suggest that the proposed method can realize multi-UAV task assignment.
Related work
Wang et al. 24 developed a lifelong learning architecture that can integrate artificial intelligence (AI) algorithms into heterogeneous IIoT networks. The framework implements the basis for efficient data transfer. At the same time, the authors added the attention mechanism based on reinforcement learning, which is similar to the embedding method of the evolutionary algorithm mechanism.
Zheng et al. 25 proposed a prior regularization method (DL-PR) in deep learning. The regularization factor designed by combining inter-class adversarial factors, global and dimensional dispersion helps to increase the inter-class distance and decrease the intra-class distance of the samples. At the same time, it also helps deep learning models to generalize well on signals with various signal-to-noise ratios (SNR). Lishen et al.26,27 improves the transient multiscale partial differential equations by developing a generalized finite element method with global-local enrichment. The adaptive algorithm detects a subset of global nodes with a mundane expansion set at each time step, and then determines the local problem residuals, allowing for less redundancy at the time step. Qinghe et al.28,29 optimized a specially designed self-encoder (AE) via entropy-stochastic gradient descent. A similarity estimator for stream forms across different dimensions was designed as a penalty term to ensure their invariance during gradient backpropagation. It is highlighted that expertise hidden in the normal signal can be extracted and emphasized rather than simply overfitting.
Furthermore, evolutionary reinforcement learning algorithm30–32 has the attributes of evolutionary algorithm33–35 and reinforcement learning algorithm at simultaneously. As a result, it can have a better effect on solving the problems of algorithm real-time and complex environment task execution. For example, Khadka and Tumer 36 train reinforcement learning agents by evolutionary algorithms to provide diverse data. The agent is rerun in an evolutionary reinforcement learning algorithm. At the same time, Khadka et al. 19 proposed a co-evolutionary reinforcement learning method. Based on the cooperative co-evolution (CC) framework of NCS, Yang et al. 37 use reinforcement learning to expand the scale of NCS. This method preserves its parallel exploration search behavior. These methods all have similarities. This paper focuses on the application of evolutionary algorithms to the design of environments in reinforcement learning. More similar to the work in this paper is the research content of Colas et al. 38 The method uses the playback buffer of the pure exploration trajectory as a scratchpad for the target exploration process (gep) and uses ddpg to generate sample data. This search process is very similar to evolutionary algorithms, although it mainly studies diversity, not reinforcement learning strategies.
Khadka and Tumer 36 introduced an evolutionary reinforcement learning algorithm based on swarm intelligence mechanism. The method introduces a swarm intelligence evolutionary algorithm based on the deep reinforcement learning algorithm ddpg. The author mainly uses the form of continuous variation of multi-agents through evolutionary algorithms, and selects based on the state-space of multi-agents during training. At the same time, the evolutionary algorithm is used to guide a single agent in the process of interacting with the environment. This agent is then periodically inserted into the multi-agent. When ddpg’s gradient-based policy improvement mechanism is effective, those with excellent performance will be selected into the next generation, and thus the entire group will evolve better.
Modeling of multi-UAV task allocation
Multi-UAV task assignment problem
There are two purposes of multi-UAV task assignment. The one is to cause maximum damage to the enemy, while ensuring the minimum loss of one’s own side. Another is to achieve the completeness of the task execution sequence as high as possible, in the limited time. In this paper, multi-UAV task assignment is modeled as a mixed Markov game. In detail, each UAV is regarded as an agent. Meanwhile, the action space of each agent is represented by the executable task sequences. In order to facilitate the interaction between multiple UAVs and the environment, this paper proposes the following assumptions.
We regard the dynamic allocation of multi-UAV tasks as a sequential decision-making problem. Its framework is shown in Figure 1. Firstly, in different time-space sequence states, multiple tasks are assigned to a single UAV to execute. The transition from the initial state to the final state means the UAV receives tasks and then complete it. UAV interacts with the global environment when performing tasks, based on time-space sequence advancement. Meanwhile, the UAV completes the minimum risk, minimum execution path, maximum damage benefit and task volume and others characteristics generation. Then, it updates the task completion and task priority features. The features of all tasks are combined into global information of the environment for multi-UAV global sharing.
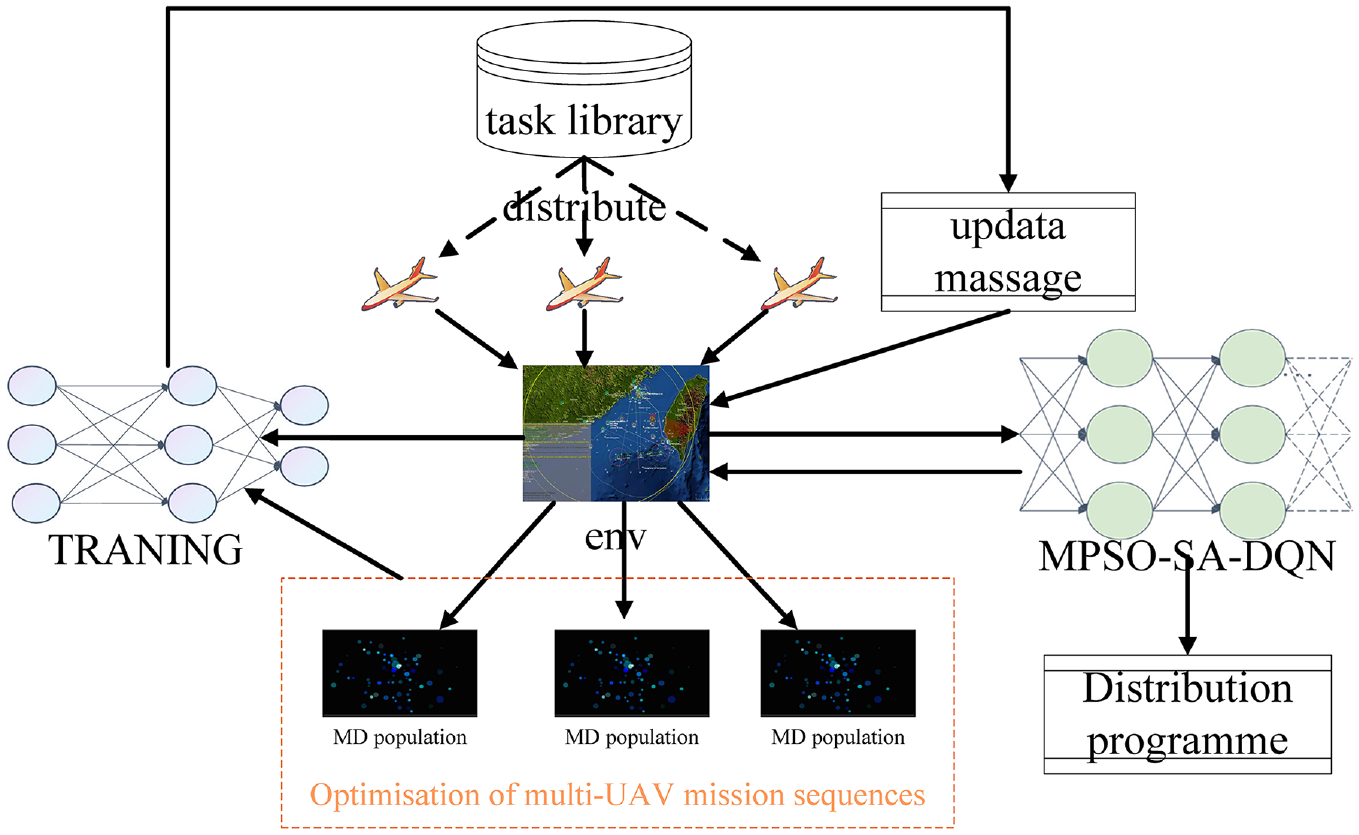
The framework of multi-UAV task assignment.
After that, each UAV perceives the change of the environment, and makes a dynamic task allocation decision through SA-MPSO-DQN. The main target is to form its own new task state sequence. Finally, each UAV starts to perform tasks cooperatively according to the latest task assignment plan. In this process, each UAV interacts with others, updates task characteristics, and forms the latest global environment and assignment plan. The above steps will be repeated until the task is completed.
The multi-UAV task allocation framework shown in Figure 1 is mainly embodied in three components including environment, central algorithm execution, and training. The tasks to be executed by the UAVs are firstly initialized for allocation operations to form a task pool. Then the tasks are randomly assigned to the UAVs to generate a global information network. The UAV generates a sequence of intelligent tasks to be executed by the UAV by interacting with the environment. Then, filter matching between UAVs and tasks is performed based on MPSO-SA-DQN, and certain tuples are formed. At the same time, it interacts and train with the environment and update the target MPSO-SA-DQN network. Finally, the targeted multi-UAV task allocation scheme is generated.
Modeling of multi-UAV task assignment
Generation of task real-time priority: This paper adopts the real-time priority mapping when describing the characteristics of each task, which is expressed as
When the UAV performs a certain task,we set
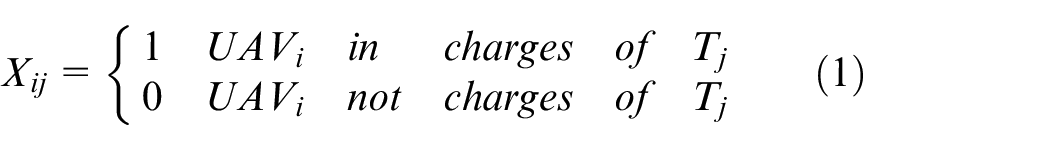
When the task set

Equation (2) indicates that each UAV performs at least one subtask.
In this paper, the original task is assigned as several subtasks and evenly distributed in the environment. When the UAV interacts with the environment, it is assigned by one subtask based on the principle of the shortest distance, the shortest time, and the completeness of subtask sequence execution. Besides, when the original task is assigned, the tasks performed by the UAV are distributed in the same area. From the perspective of the whole, the task distance performed by each UAV is relatively short. Thus, the distance between each task can be ignored when performing single task and performing dynamic task allocation. Here, the latitude and longitude of the task is mainly to distinguish the task. Therefore, when the UAV interacts with the environment to perform tasks, a series of original task execution lists will be continuously optimized according to the task priority. Finally it will reach the optimum through the constraints of resources and conditions.
The speed of the UAV is represented by
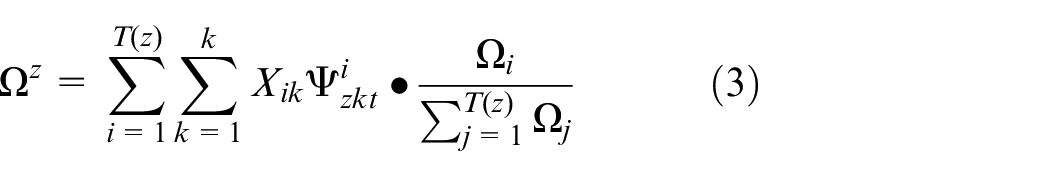
Because the time efficiency of task execution is important, it is necessary to consider the completion time constraints of tasks. Besides, it is reasonable that the priority of each task in each time period will be different. Here, we express them as dynamic priority

The proposed MPSO-SA-DQN
Based on the mechanism of the DQN algorithm and the properties of the tasks, the UAV is mapped as an intelligent body in deep reinforcement learning. The sequence of executable tasks is mapped to the states of the intelligent body. Then, a multidimensional particle swarm algorithm is introduced to optimize the state space of the intelligent body, which aims to dynamically guide the intelligent body when it interacts with the environment. So that the intelligent body gets the optimal task execution scheme through continuous learning. Thus, its time credit allocation is further rationalized. Secondly, a real-time priority state space self-encoder is designed for the state space, so that the complexity of the state space can kept in a certain dimension. The purpose is to make the algorithm run more efficiently.
Then, for the training redundancy that the intelligent body cannot end the loop after learning, we introduce a simulated annealing algorithm. Referring to the cooling mechanism of the simulated annealing algorithm, it enables the intelligent body to find the goal or complete the task execution programed. For quickly out of the loop, into the next round of learning. the overall application framework of the MPSO-SA-DQN algorithm is shown in Figure 2: The overall framework of the algorithm contains a total of three parts: simulated annealing network training, Q-network policy function mechanism, and multi-drone task allocation environment design. The multi-drone tasking environment design is used to simulate the scenario of multi-drone and platform interaction. The simulated annealing network training part is based on the design of round reward, which constantly cools down the Q network training. This effectively makes the intelligent bodies reduce the number of ineffective searches. As a results, the UAV allocation environment design is the core part of the MPSO-SA-DQN algorithm. As can be seen from Figure 2, the multiple UAVs in this paper all use the same network for the acquisition and updating of the task execution strategy scheme, and the way adopted is centralized training and distributed execution, so our UAVs will share the parameters of the Q-value network after centralized training.
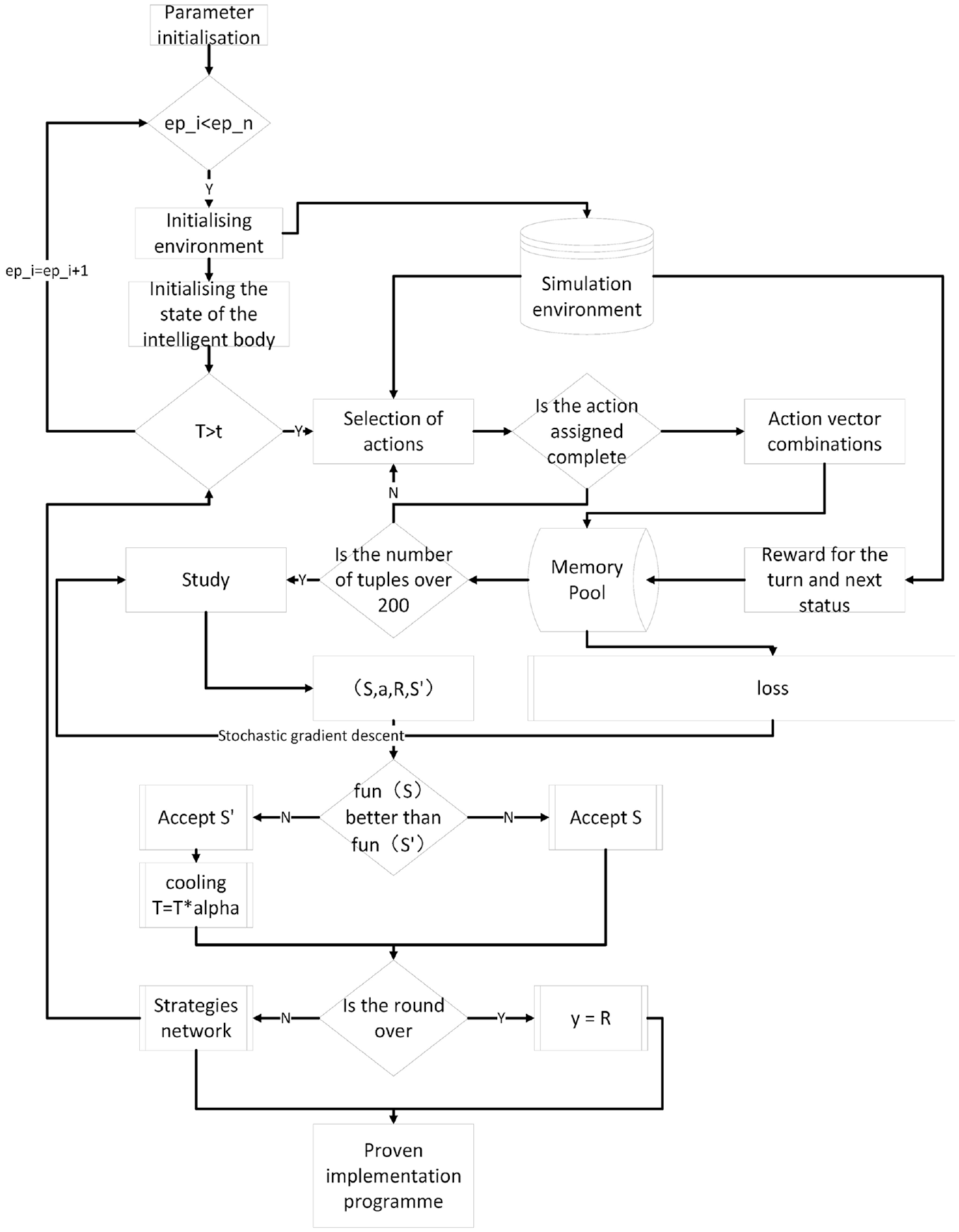
Overall application framework of MPSO-SA-DQN.
Design of SA-DQN training framework
The first stage of common agent training process is to set the maximum number of steps. Then, the agent will continually perform trial and error operations within the maximum number of steps in the current round until the best execution route is found. However, if the maximum number of steps is too small, the agent will not be able to optimize within the total steps. If the maximum number of steps is too large, there will be too many redundant steps, which can also lengthen the entire training time. Therefore, the SA-DQN training framework proposed in this paper provides temperature monitoring during agent training. More precisely, the next round will be proceeded immediately when the agent reaches a balanced state. Such operation will neither make the training insufficient nor make the number of training steps too long. The training framework of SA-DQN is shown in Figure 2.
Therefore, the steps of SA-DQN training framework is shown as:
Step1: Parameter initialization.
Step2: Whether the current round
Step3: Initialize the simulation environment.
Step4: Initialize the temperature
Step5: Determine whether it is greater than the stable temperature
Step6: The agent interacts with the environment.
Step7: Generate tuples
Step8: Whether the current state function is better than the next state function, if “yes,” go to Step9, if “no,” go to Step10.
Step9: Accept the current state
Step10: Accept the next state
Step11: Whether the status is stable, if “yes,” go to step12, if “no,” go to Step5.
Step12:
Framework of MPSO-SA-DQN algorithm
Based on the training framework of SA-DQN, MPSO-SA-DQN introduces a multi-dimensional particle swarm algorithm. To guide the actions of the agent, it introduces multiple objective function. Besides, MPSO-SA-DQN changes the state space of the agent dynamically to improve the ability of search in an uncertain space. Meanwhile, it can further improve the convergence of the DQN algorithm. The flowchart of state space of multi-agent in MPSO optimization is shown in Figure 2. The execution framework of MPSO-SA-DQN is shown in Figure 2.
Steps of MPSO-SA-DQN algorithm:
Input:
Step1: Initialize the environment and restart the initial state of each agent
Step2: Determine whether the temperature has reached equilibrium, if “Yes” execute Step1, if “No” execute Step4.
Step3: In the current state
Step4: Combining each agent action
Step5: Store the tuple
Step6: Learning.
Step7: Randomly fetch the state tuple data of a group of agents from the memory pool.
Step8: According to the objective function, judge whether the current state
Step9: Determine whether the current round is over. If “yes,” then
Step10: Output multi-agent execution plan
Allocation method based on MPSO-SA-DQN
The design of environment for multi-UAV task assignment
State-space design
In this paper, the state space S is divided into three parts, including the current Agent state information

Where,
Design of action space
The action space of a UAV is continuous when performing a task. However, when assigning tasks to an agent, the action space needs to be discretized in order to satisfy the state space designed in this paper. When initializing the action space, a discrete representation of the action space is generated based on the number of task goals and subtasks. Specifically, in this paper, the action space is defined as a collection of sequences of subtasks. For example,
Reward function design design of reward function
The purpose of the algorithm can be described as. the total time to perform tasks to be short as possible, and the completeness of tasks to be high as possible. So the reward is set to.

Where,
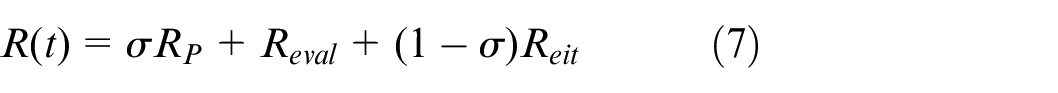
Where,
Update of the strategy function
Each state vector in this paper is described by a defined set of values. In order to quantify the cumulative reward value of a state vector at t in time, a discount factor needs to be considered. In this paper, the discount factor is denoted by a symbol
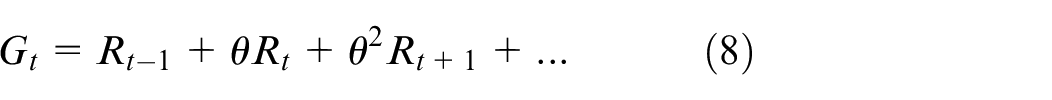
At the current moment, the optimal action is:
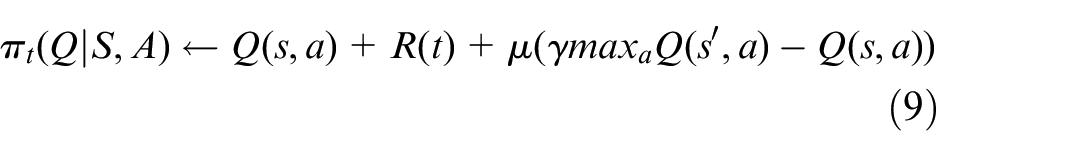
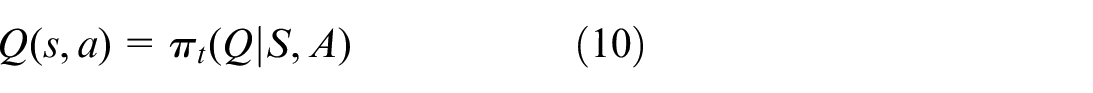

Where:
In this paper, the loss function is used to continuously optimize the hyperparameters of the target network so as to update the hyperparameters. The loss function is constructed as follows:
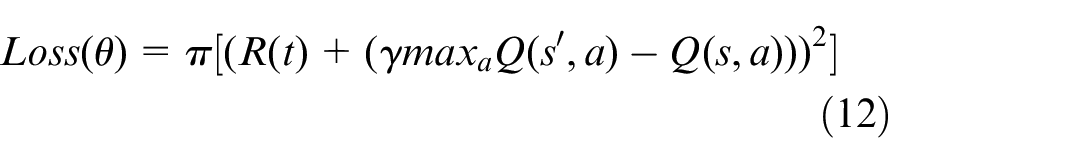
Environmental design
The step() function is one of the most important modules in the environment design. It acts as a physical engine for deep reinforcement learning in this paper. The function takes as inputs the action
The state of the next moment
In this paper, the state of the intelligent body mainly consists of the sequence of tasks executed by the UAV, task completion and task priority. Based on the time of mission start and the characteristics of the UAV, the intelligent body dispatches the UAV to execute the mission. At the current time, the mission sequence executed by the UAV is optimally evaluated based on the threat assessment, range constraints, and damage gain to obtain a new mission sequence and the priority of the current mission.
Reward for the action
In the experiment, the rewards obtained when the intelligent body performs the task are set. When the intelligent body is performing the task, if the intelligent body performs the task for too long or the degree of task completion is too low, a punishment is given according to the design of the reward space.
Signal for the termination of training
During the training process, if the intelligent body is unable to complete the task for a long period of time, it can be determined that the intelligent body is unable to complete the set of task sequences, and the training will be terminated at this time. Otherwise, if the intelligent body continues to train and the termination condition is not reached, the intelligent body will continue to train until the termination condition is reached.
Strategy of real-time priority state space autoencoder
Because the dimension of state space is high, excessive calculation will make training the agent expensive and time-consuming. Therefore, a state space autoencoder based on real-time priority is designed. Specifically, a feature expression network based on artificial neural network is adopted, and a three-layer network is designed. The designed network includes two parts, which are the encoder and the decoder. In detail, the mapping from the input signal to the output representation is the encoder. The decoder is the reverse mapping of the representation to the input and reconstructs the input. According to the characteristics of the input data in this paper, the tanh is selected as the activation function. Autoencoder training is the process of minimizing the reconstruction error function, which is defined as:
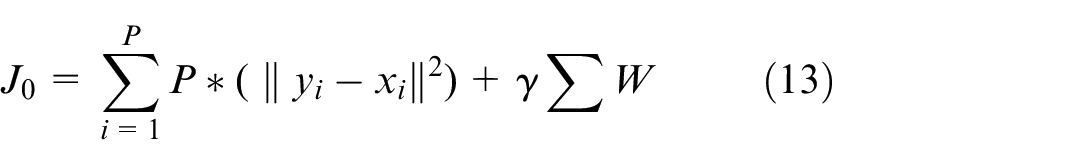
Among them:
UAV task assignment method based on MPSO-SA-DQN
In order to solve the problems of complex time constraints and uncertain solution space, this section proposes a multi-UAV task assignment and iterative optimization method based on the MPSO-SA-DQN. This method uses the simulated annealing mechanism to shorten the time of invalid iterations of deep reinforcement learning. At the same time, it encodes the task goal through the real-time priority state-space autoencoder strategy. Then, the execution plan of the agent in the complex environment is optimized based on the multidimensional particle swarm optimization algorithm. Thus, it updates the state of the agent while continuously iteratively learning, and the optimal task planning solution if found. The steps of the task assignment method based on MPSO-SA-DQN UAV are as follows.
Steps of UAV task assignment method based on MPSO-SA-DQN
Input:
Step1: Initialize the task assignment environment and restart the initial state
Step2: Determine whether the temperature has reached equilibrium, if “Yes” execute Step1, if “No” execute Step4.
Step3: In the current state
Step4: Combine the actions of each UAV into an action vector
Step5: Store the tuple
Step6: Whether the number of tuples exceeds 200, if “Yes,” execute Step7, if “No,” execute Step3.
Step7: Learning.
Step8: Randomly fetch a set of UAV state tuple data from the memory pool.
Step9: According to the objective function, judge whether the current state
Step10: Determine whether the current round is over, if “Yes,” then
Step11: Multi-UAV task allocation scheme.
Simulation experiment and analysis
Experiment setting
In order to intuitively demonstrate the results of the designed method, a combat simulation scenario of UAV’s ground attack is designed. The experiment setting is as follows: the ground battlefield environment is generated by python tk.39,40 It can simulate the environmental changes on the map, and randomly generates 30 mission targets on the map. When the ground attack starts, the number of corresponding task targets is obtained by calculating the tasks completed by each UAV. In particular, when the UAV is attacking the ground, the metrics for evaluating the performance of each UAV is as follows: the number of tasks completed by a single UAV over time, the degree of damage to the target, and the risk benefit and the path cost function. The standard is based on highest task volume per unit time, the highest damage coefficient, the lowest path cost and the smallest risk coefficient.
Construction of simulation platform
In order to verify the effectiveness and feasibility of the method, a simulated map environment is built. There are 30 tasks and 5 UAVs generated on the map. Table 1 shows the setting of the tasks in the experiments.
Setting of subtasks.

The experiment uses tensorflow and pytorch to realize the neural network of deep evolutionary reinforcement learning. The algorithm is trained for 350 steps. In which,one step is from the beginning to the end of the task. The reward value accumulated in each step of the algorithm is shown in Figure 3:
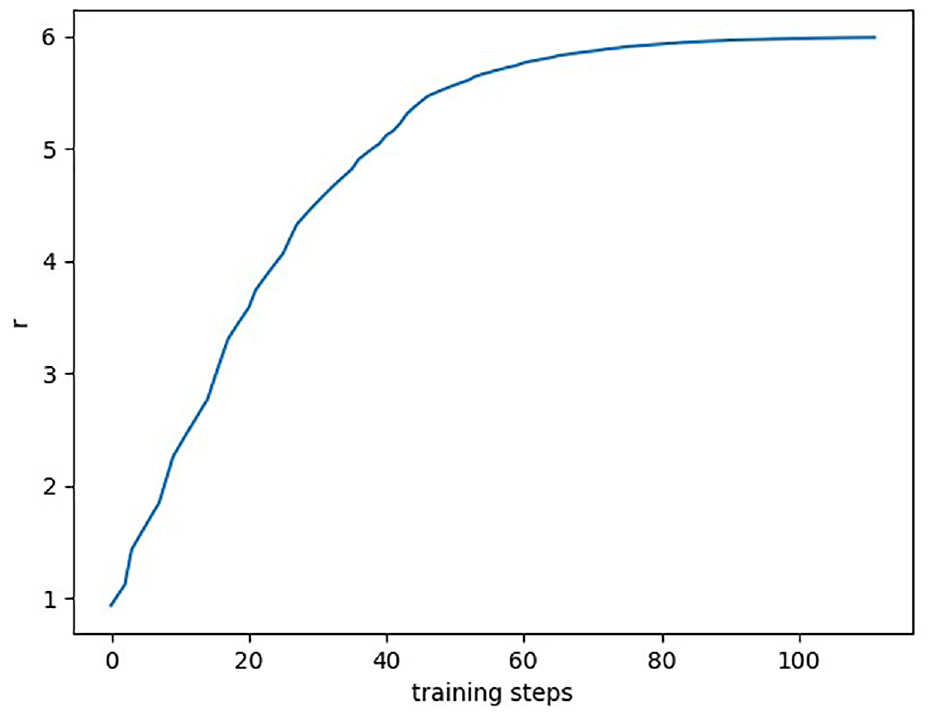
The cumulative reward value (r) of each cycle of multi-agent.
Shown as Figure 3, the algorithm belongs to its exploratory stage in the early stage of training. The cumulative reward value increases rapidly once the training begin. Besides, in the middle period, the cumulative reward value becomes stabilizes gradually with a slight shock. It is because the algorithm will update the parameters regularly during the process. Furthermore, it becomes stabilized gradually and shows a slight upward trend, at the 90th training cycle. At this time, each agent has learned and applied the strategy of dynamic allocation of multi-UAV tasks. Shown as Figure 4, the SA-DQN strategy shows its advantages according to the process of training. Its convergence is gradually concentrated. As a contrast, the DQN single strategy is more scattered, and the convergence effect is worse.
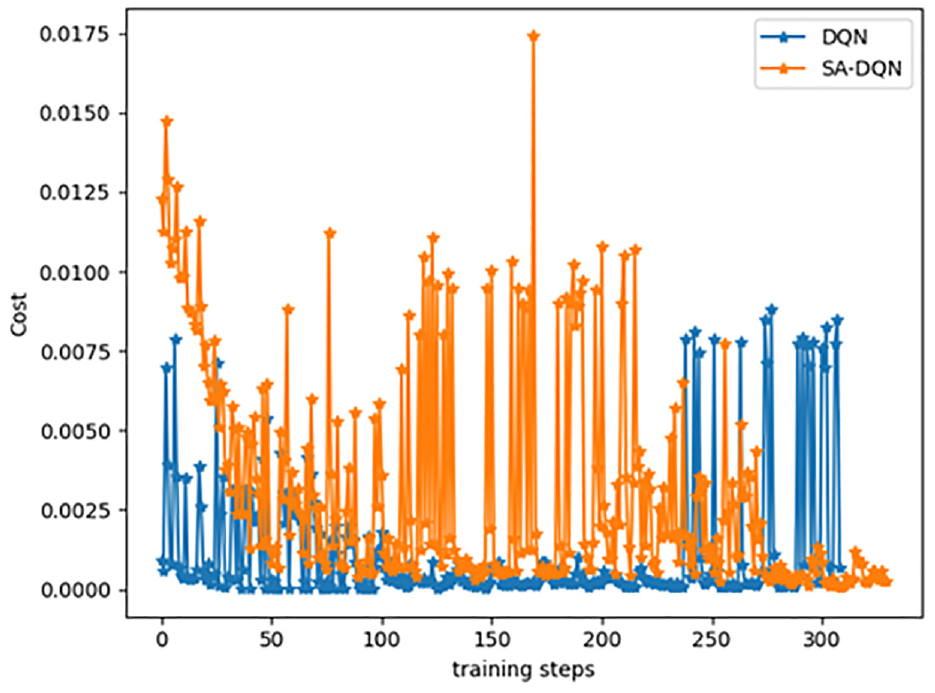
Comparative loss function curves for SA-DQN and DQN per training cycle for multi-intelligents.
As shown in Figure 5, from the loss curve graph can be seen, when the greedy value is set to 0.9, and the learning rate changes, the starting point of the loss curve is high but the convergence of the fluctuation of the situation is relatively smooth and its convergence effect is not good. At the same time, when the learning rate is different, the greedy value is 0.9, obviously the learning rate is 0.1 when the effect is better, and its eventual convergence, obviously the fluctuation of the smaller. Finally, the convergence of the effect of the fluctuation of the better, the fluctuation error value at around 0.1, while the error value of the fluctuations of the other curves is around 1.
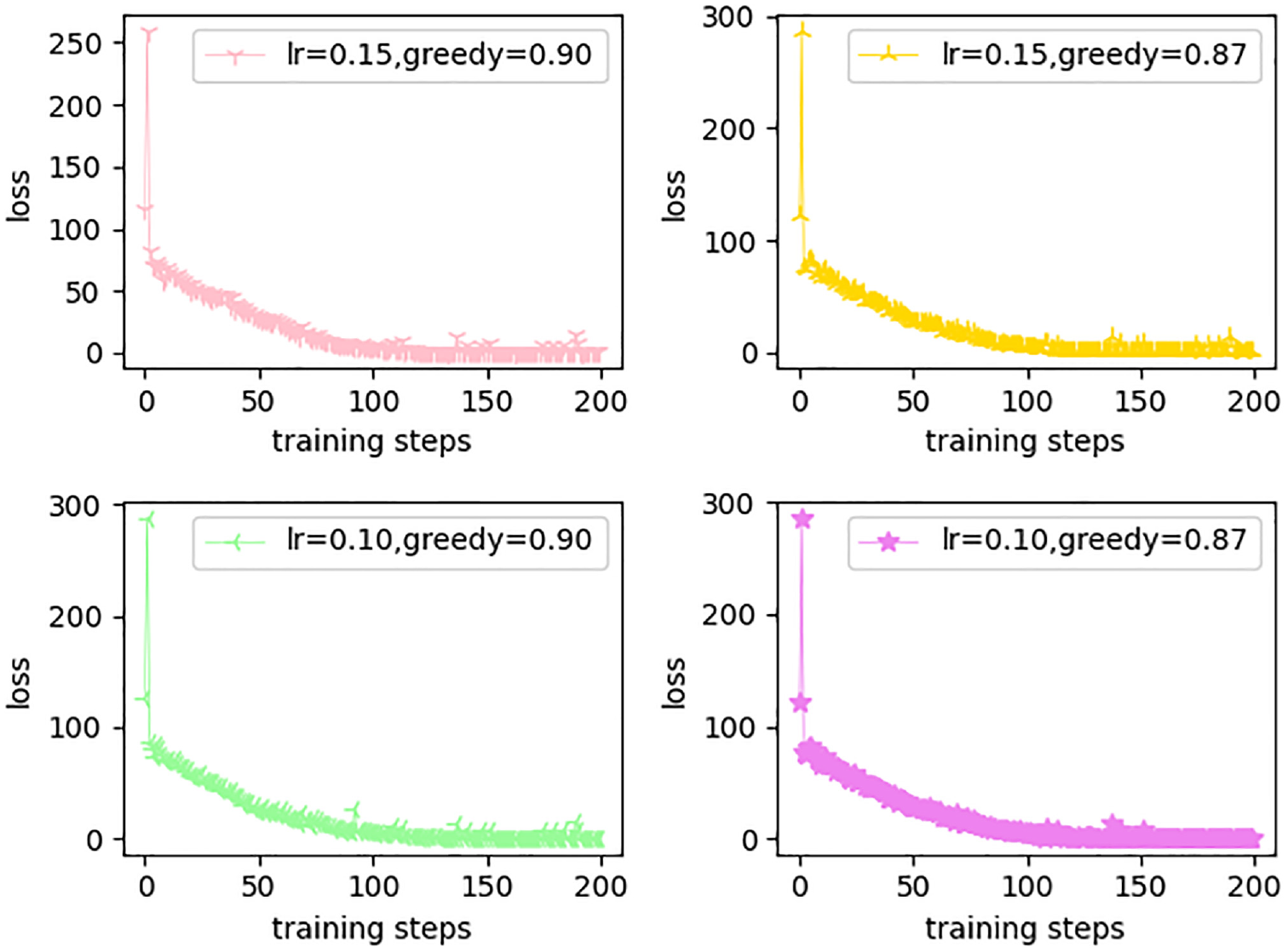
Comparison curves of loss with different hyperparameters.
The completion of all tasks performed by multiple UAVs is shown in Figure 6. With the same learning rate, the smaller the greedy coefficient, the more ambiguous the completion of the task by the UAVs. However, when the greedy coefficient is too large, it adds extra loss, so a moderate value of 0.9 for the greedy coefficient needs to be chosen.
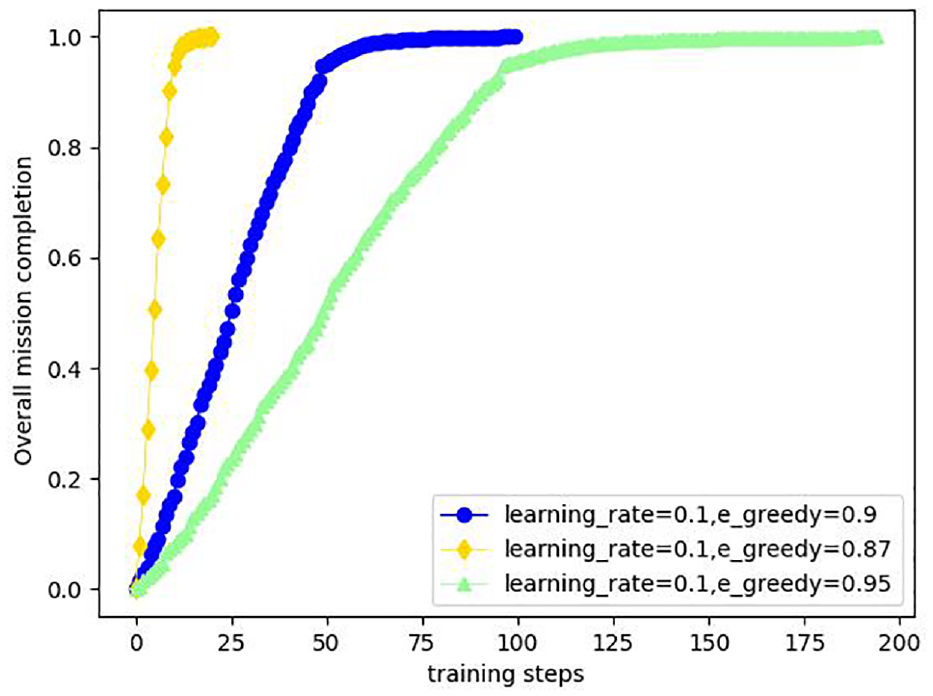
Comparative plot of overall task completion with different hyperparameters.
Comparative analysis of mission planning generation
Based on the optimal multi-UAV mission execution scheme, the multi-UAV mission planning results are finally demonstrated, assuming that the time needed to complete the task is known as process time. Besides, the real process time is the simulated mission execution time based on the time needed for the task, the mission planning method obtained in this paper (MPSO-SA-DQN). It is compared with the hybrid particle swarm based (MPSO) and greedy algorithm based task planning method (greedy) in terms of task volume completion is shown in Figure 7:
Comparison chart of task completion effects (Note the unit of time (/h)).
In Figure 7, the vertical coordinate indicates the completion degree of the task (1 means it has been completed), and the horizontal coordinate indicates the time (/h), as can be seen in the figure, at 40 h, the completion effect of the task of the multi-UAV task planning method based on reinforcement learning with multi-dimensional particle swarm has begun to converge, which indicates that the overall task completion has reached the highest level, which means that the UAVs have cooperated to complete the task. However, the MPSO and greedy completion effects have not yet reached 50% (0.5), indicating that the multi-UAV mission planning method based on reinforcement learning with multidimensional particle swarm is better.
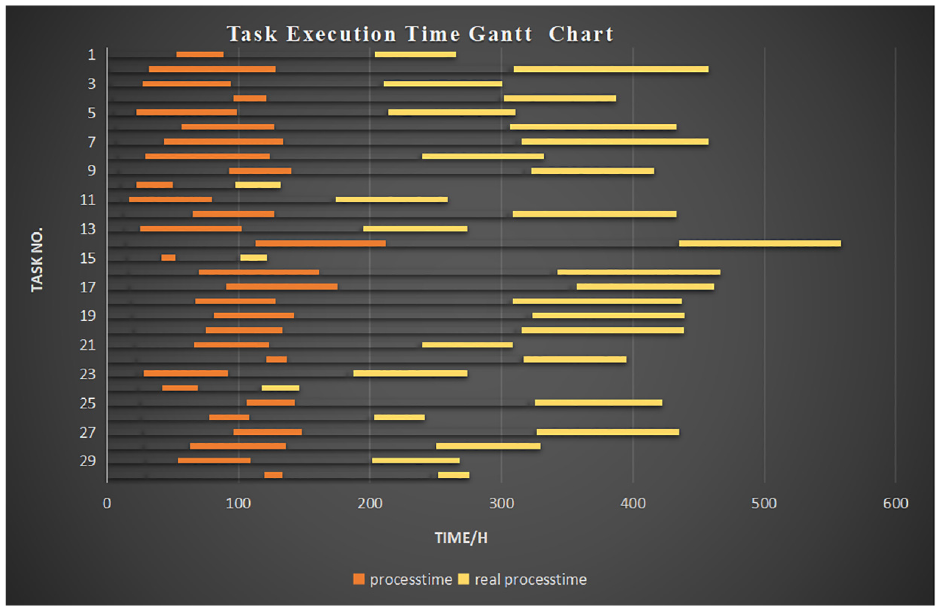
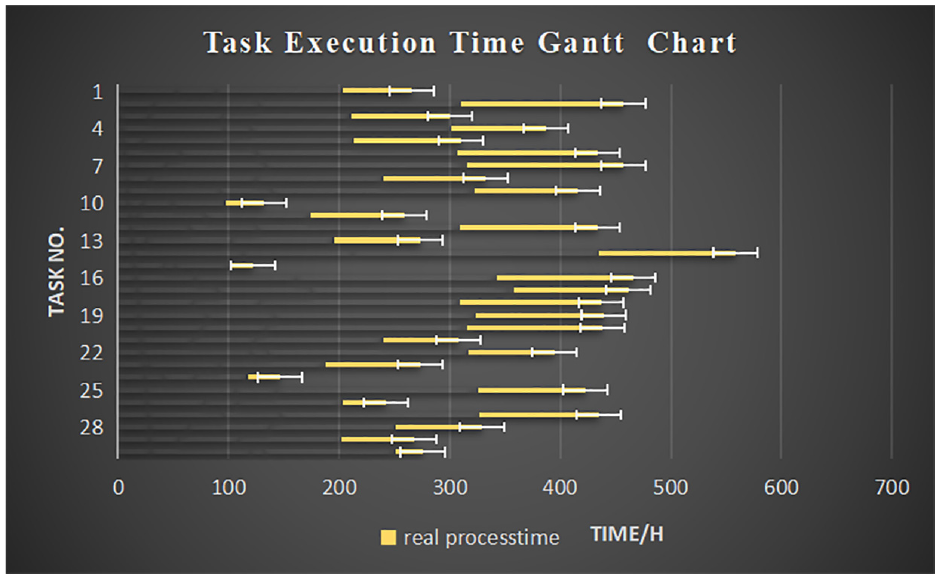
Figure 8 shows the desired time and the simulation time for the UAV to perform tasks, at the end of the first round. It shows that the time to complete all tasks is about 550 h, which is far from the desired time. Besides, Figure 9 suggests that the actual completion time of the drone’s initial task execution is too long, and the real-time performance is low. Figure 6 shows that after the training is over, the UAV has learned the incoming task execution strategy at the end of training. Furthermore, Figure 10 exhibits that the actual and planned time of each task are approaching. For the error shown in Figure 11, the actual completion time of the drone’s mission is relatively accurate, and the real-time performance has been improved. In sum, taking the 15th task as an example, the actual time be used of the task is larger than 100 h. Before starting the training, the UAV group only depends on the completion of the task. It can be seen from Figure 8 that its execution time is relatively concentrated. In detail, its execution time is relatively scattered and long-term tasks and short-time tasks are alternately performed, so after the training is completed, it will be reduced to less than 100 h. The results show that the multi-agent has adapted to the environment and applied the designed algorithm.
Planned and actual time of the UAV mission at the time of the first round.
Error plots of the actual execution time of the task at the first round.
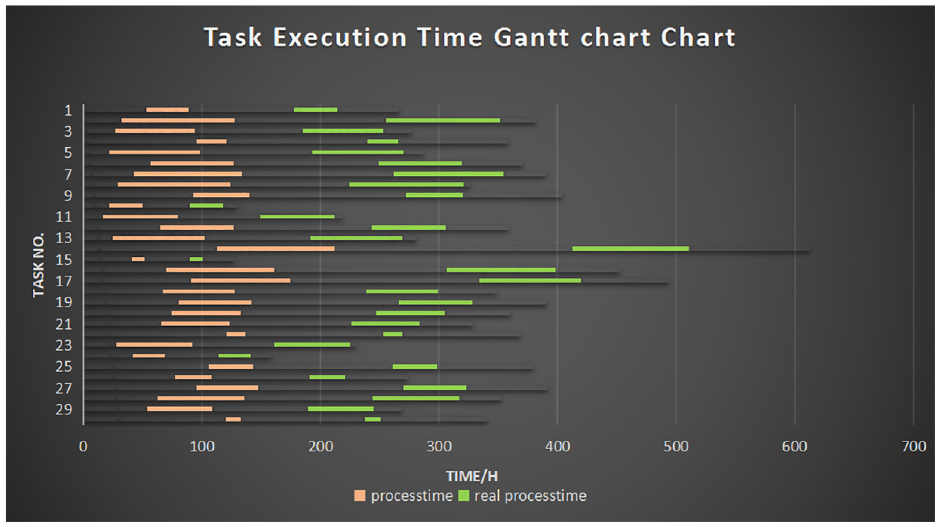
Planned and actual time of the drone mission plan after the completion of training.
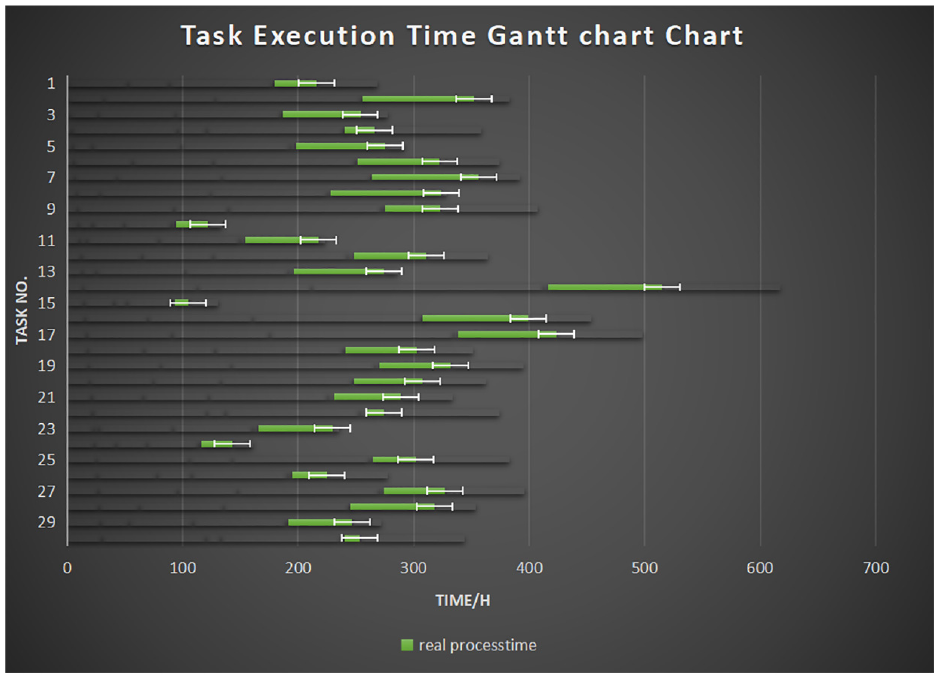
Error plot of the actual execution time of the task at the end of training.
Figure 12 suggests that, the error between the time for the UAV to performs the task and the desired time is large, before the training begins. Also, the real-time performance of the task cannot be guaranteed. After the training is completed, the time error of the UAV to perform the mission becomes smaller. The phenomenon exhibits that the proposed method in this paper has a significant effect on the execution time of UAV tasks. Furthermore, Figure 13 shows that the time for the UAV to complete the task is also largely different before and after training. Although the error of the time used of the 8th task is large, the errors of the completion time of other tasks are all between [0,1]. From Figure 14, we can find that the 8th task ended early due to the early start, so its error is relatively large.
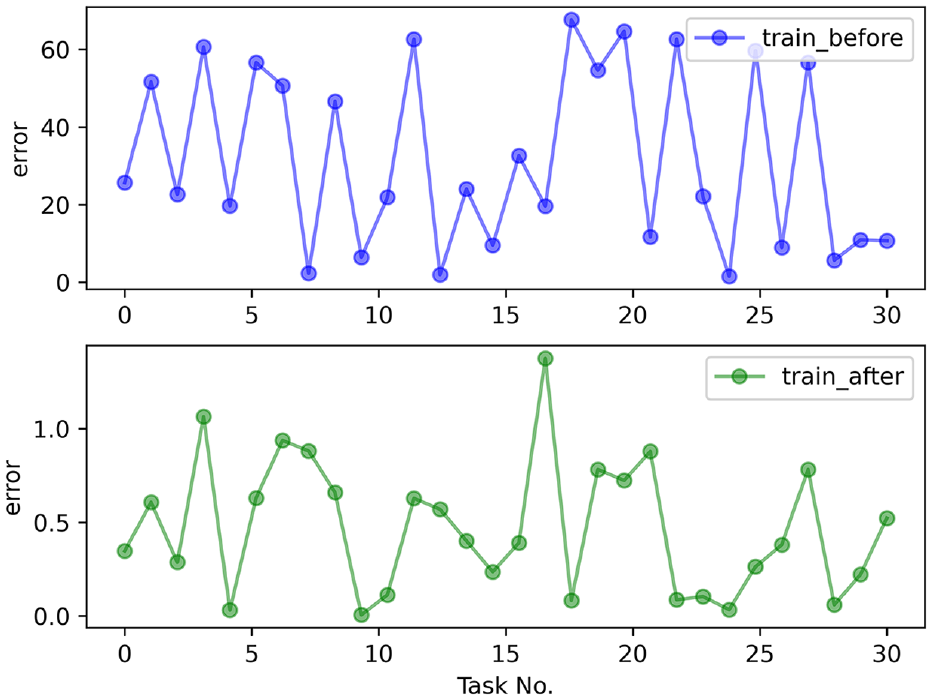
Error plots for UAV mission execution time.
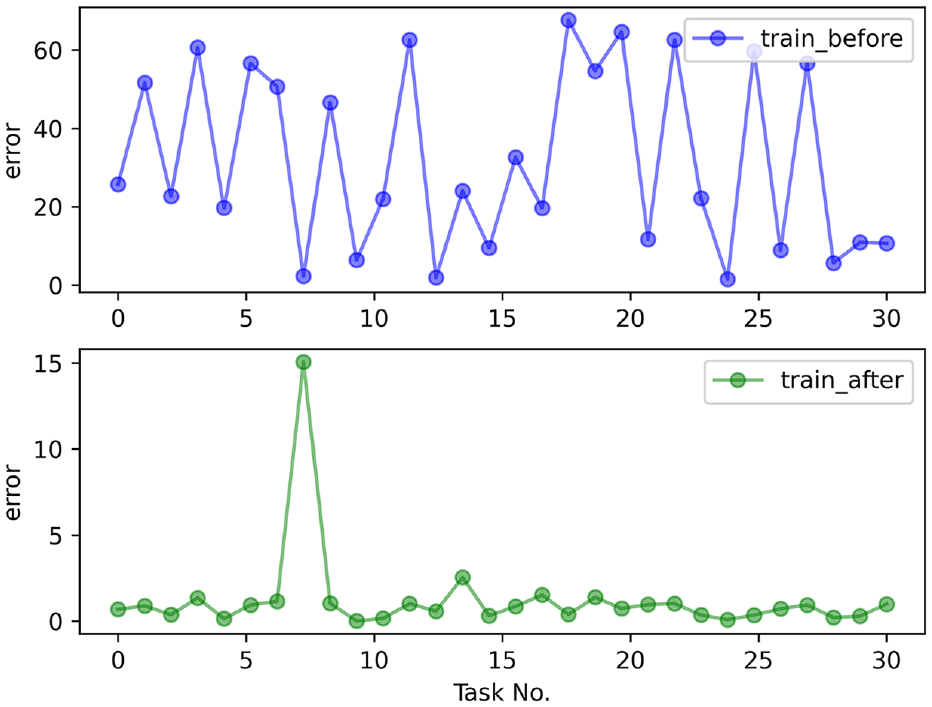
Time error plot for UAV mission completion.
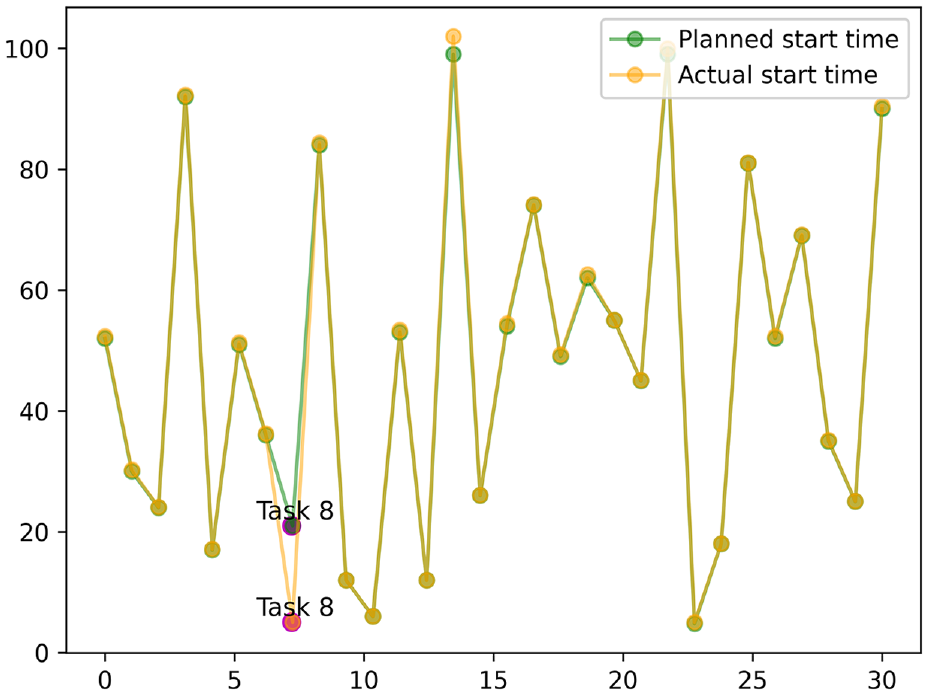
Planned and actual time of commencement of task execution.
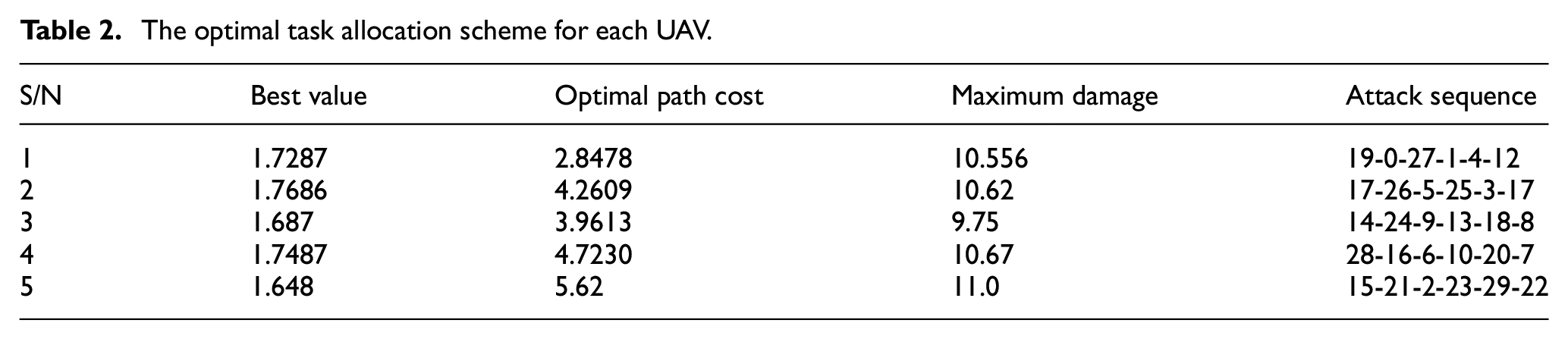
The evolution curve of the objective function of multi-UAV task execution is shown in Figures 15–17. Based on the multi-UAV task allocation method, it can quickly find the optimal allocation scheme under the complex battlefield environment. At the same time, it has a certain stability in real-time task allocation. Such feature can make the UAV achieves the maximum damage degree when the path cost is the shortest and the risk benefit is the lowest. Besides, the damage benefit in Figure 7 is a straight line, which shows that the UAV found the optimal state by interacting with the environment at the beginning. Meanwhile, it achieves the maximum damage benefit, so it remained unchanged at 11.0. Training by SA-MPSO-DQN, the results of the optimal value of each UAV, the optimal path cost and the optimal task allocation scheme are shown in Table 2.
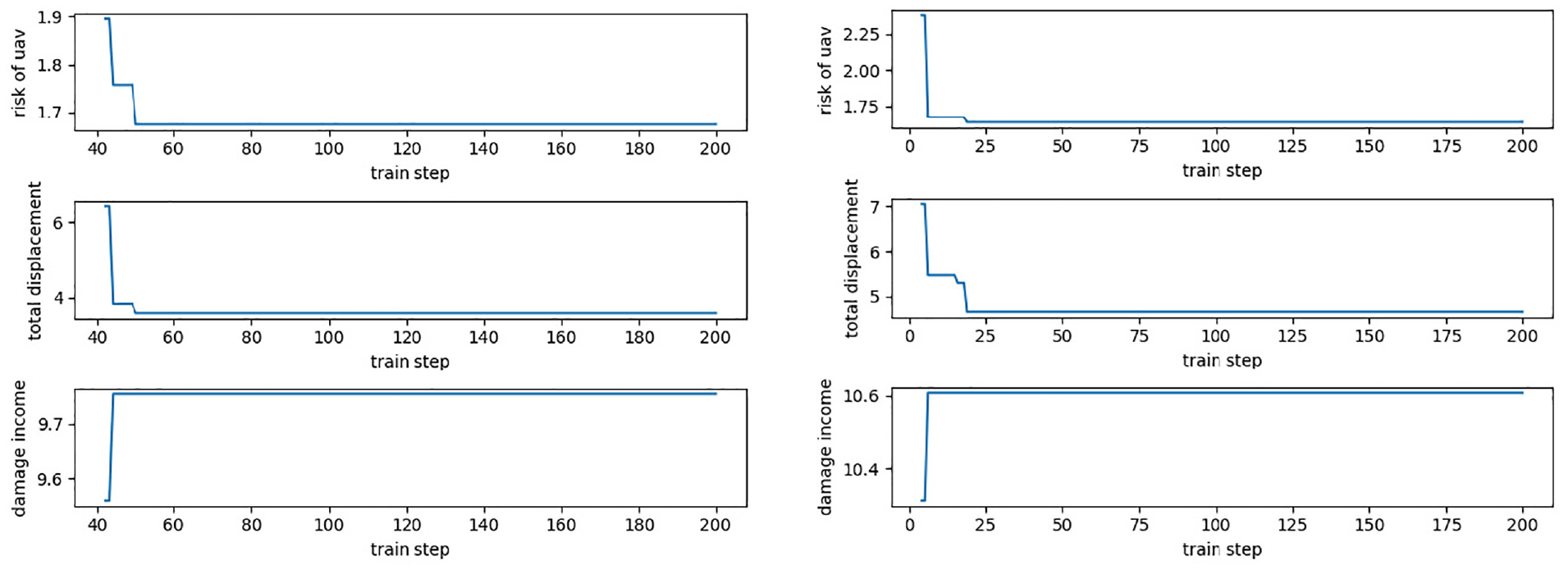
Variations in UAV risk benefits, path benefits, and damage of first and second UAV.
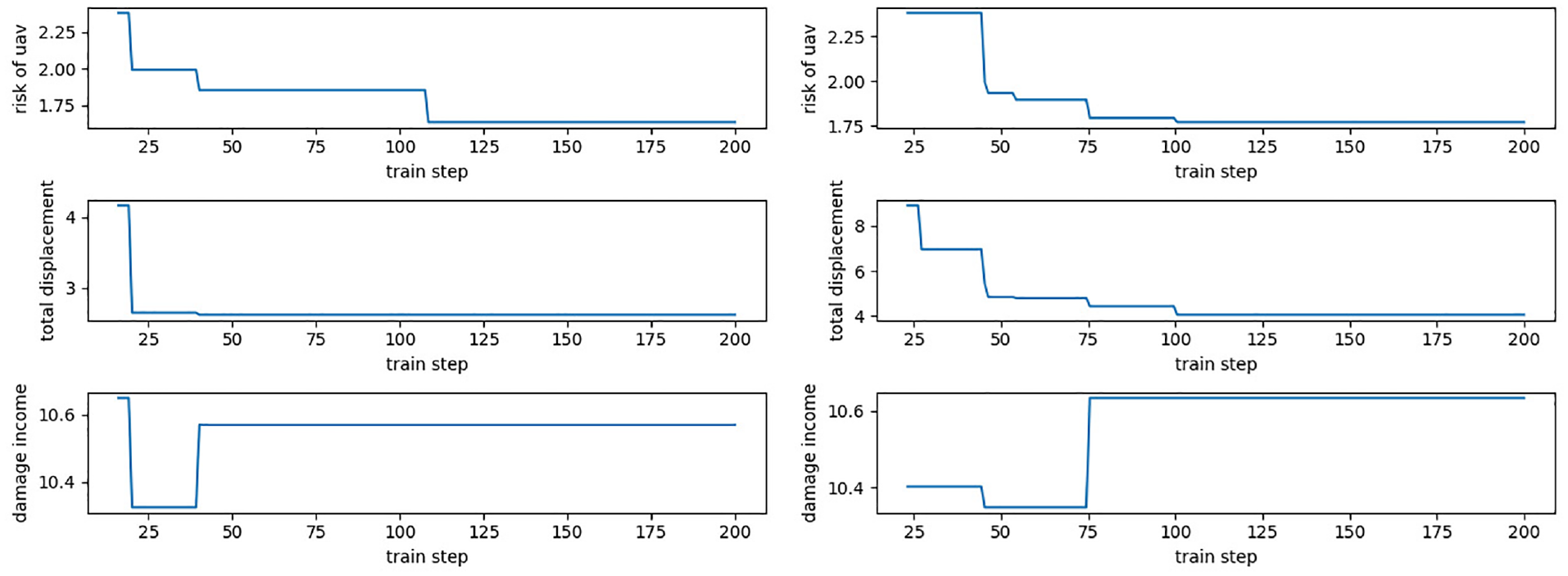
Variations in UAV risk benefits, path benefits, and damage of third and fourth UAV. .
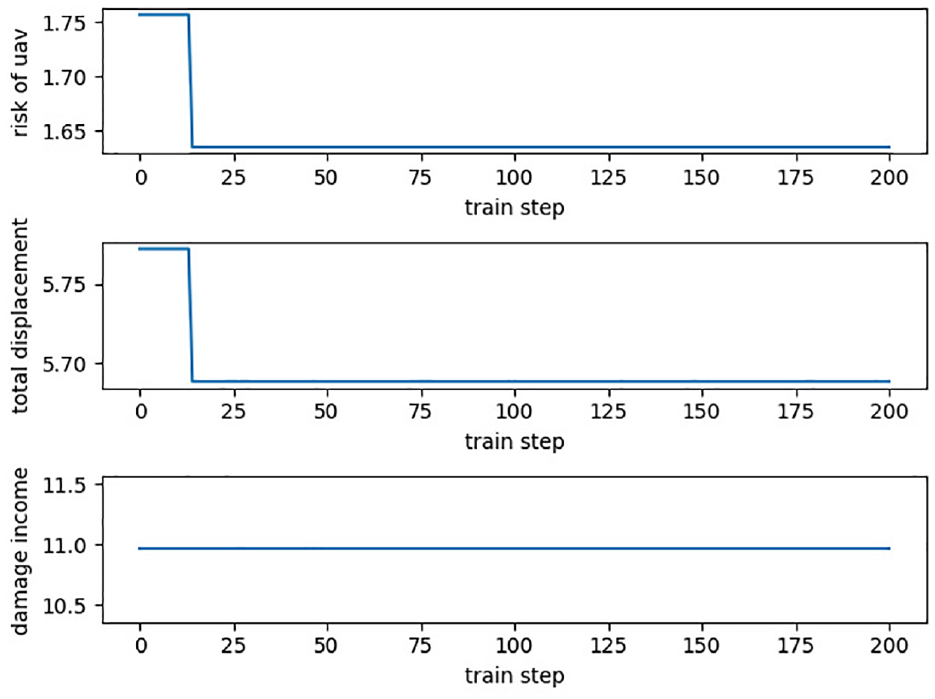
Changes in risk benefit, path benefit, and damage of the fifth UAV.
The optimal task allocation scheme for each UAV.
The multi-UAV mission planning method based on improved multidimensional particle swarm is carried out under the situation of fixed target attributes and relatively stable target threats. Whereas, the MPSO-SA-DQN based multi-UAV mission assignment method is carried out in the case of dynamic changes in target attributes, constant changes in target threat attributes, and changes in target value over time. In deep reinforcement learning algorithms, multidimensional particle swarm algorithms are used for state-action space optimization for environment design. The multi-UAV mission planning method based on MPSO-SA-DQN is able to solve more problems, which is more accurate. Meanwhile, it is more adaptable to dynamic changes in the battlefield environment. Table 3 lists the threat coefficients and destruction levels obtained from the simulation of the two methods.
Comparison of simulation results of two algorithms.
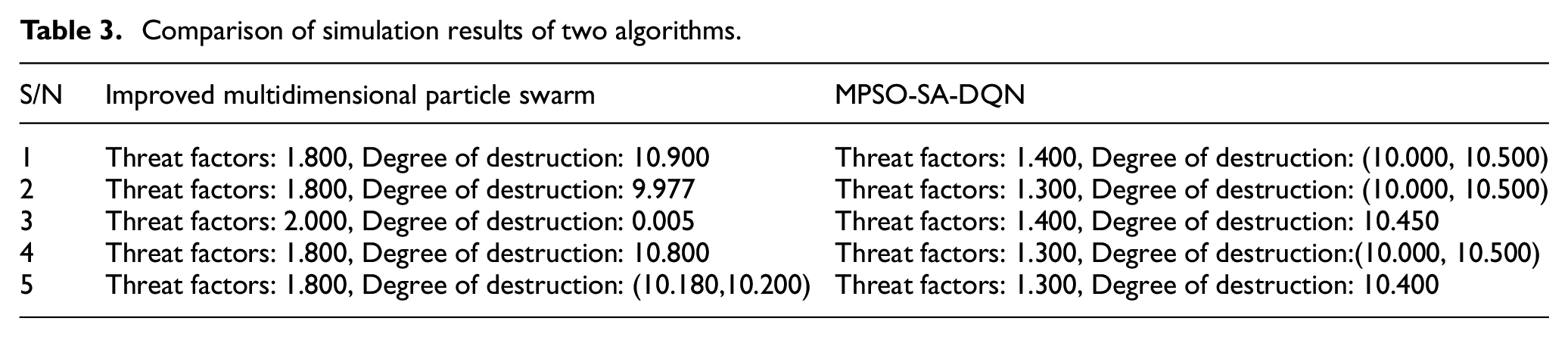
Table 3 shows that it can be compared that the threat coefficient derived from the multi-UAV task allocation method based on MPSO-SA-DQN is smaller than that of the multi-UAV task allocation method based on the multi-dimensional particle algorithm. Besides, from the point of view of the degree of destruction the results derived from the multi-UAV task allocation method based on deep reinforcement learning are more average and stable, which indicates that the strategy of the method is more practical and more relocatable. At the same time, the scheme of task allocation is more reasonable. On the other hand, the multi-UAV task allocation method based on improved multi-dimensional particle swarm yields two extremes of destruction, bad stability, and poor ability to cope with real-time dynamic changes.
Therefore, based on reinforcement learning multi-drone task allocation algorithm in solving the problem of more complex situations, its problem solving ability is stronger than that based on multi-dimensional particle swarm algorithm. In the complex environment, and the target attributes change over time, the number of tasks is large in scale and there are more than 20 drones as shown in Figure 16 and Table 3. Besides, in the same time based on the improvement of the depth of the reinforcement learning algorithm compared to conventional algorithms, the amount of tasks the degree of completion of the task is higher, and the task completion efficiency is higher. Therefore, the multi-UAV task allocation method based on deep reinforcement learning is adopted. On the contrary, the multi-drone task allocation method based on multi-dimensional particle swarm is adopted.
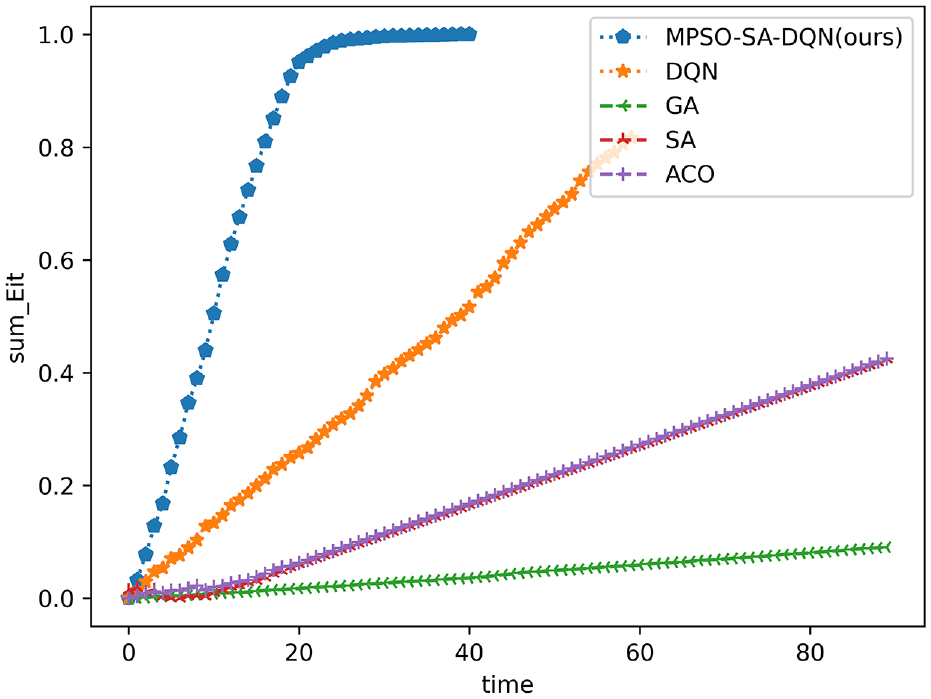
To exhibit the advantages of the proposed method, we conduct comparison experiment. The compared algorithm includes traditional greedy algorithm (greedy), genetic algorithm (GA), simulated annealing algorithm (SA), ant colony algorithm (ACO), and hybrid particle swarm algorithm (MPSO). The comparison curve of task completion over time is shown in Figure 18.
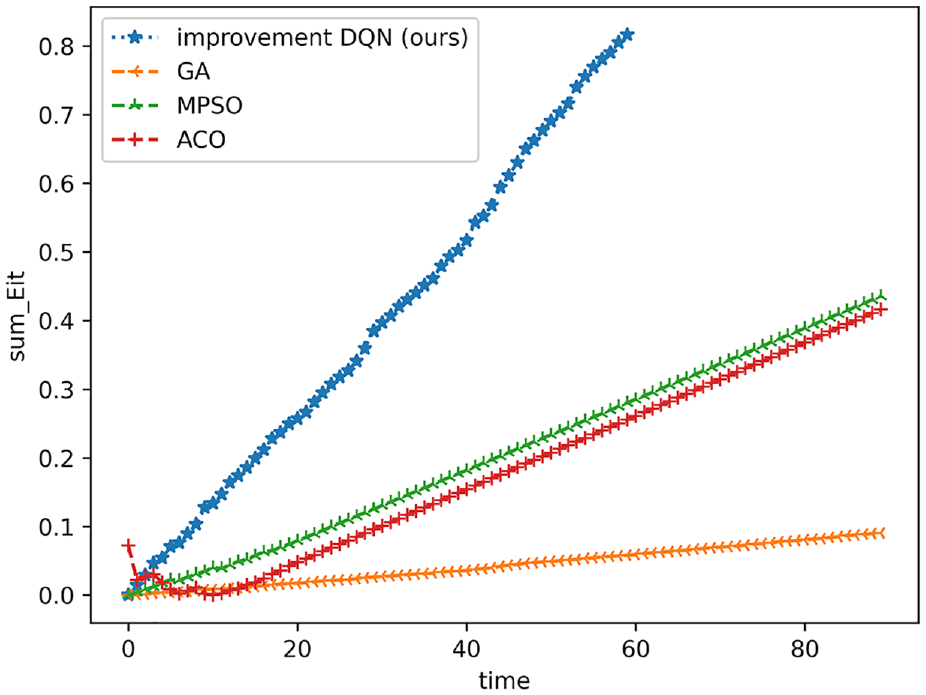
Plot of task completion versus time when the number of drones is 20 (Note the unit of time (/h)).
Figure 19 shows the completeness of each task with training steps in the case of 30 subtasks during task execution. The “90 SA-MPSO-DQN” indicates the change in task completion over time after ninety rounds of training, which shows that as the number of rounds of training increases, the task is completed faster.As the training steps increases, more tasks will be introduced. Meanwhile, when the new task is just issued, the task completeness of this new task is 0. Therefore, when the overall task completeness is at time step 40, Greedy algorithms, simulated annealing algorithms and ant colony algorithms how a slight downward trend due to the issuance of new tasks. However, as the task continues to be executed, the overall task completeness gradually resumes its upward trend. In the early stage of task execution, the algorithm in this paper considers the time constraints, and dynamically allocates tasks during the task execution process. Therefore, the task completeness of our method is significantly higher than other algorithms. It indicats that the algorithm in this paper can improve the overall task completeness of the system when tasks are issued at any time.
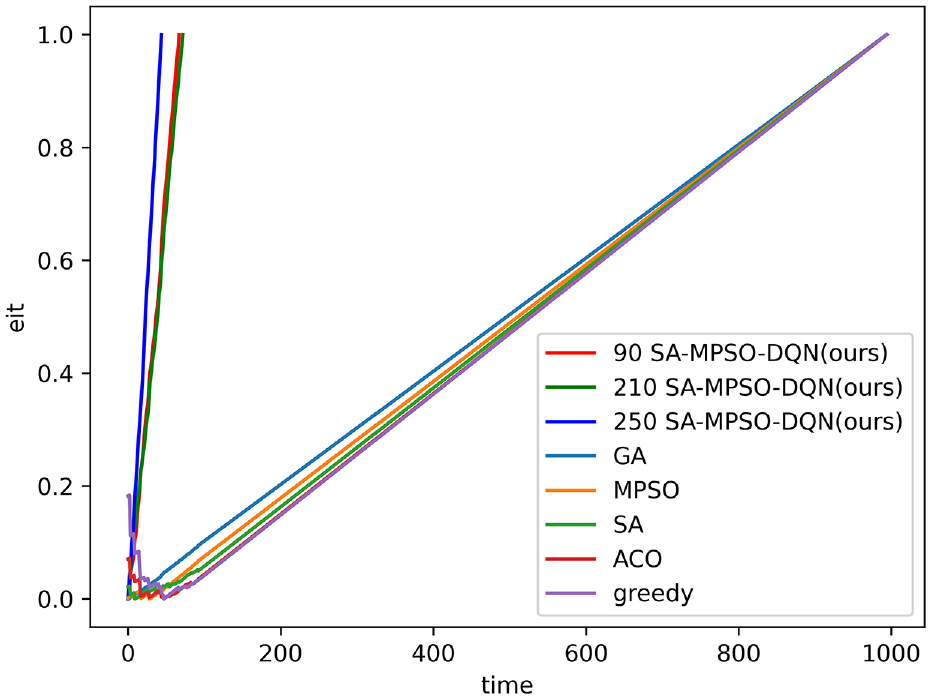
The completeness of task over time (Note the unit of time (/h)).
Conclusions
In this paper, a multi-UAV task assignment method based on MPSO-SA-DQN is proposed for multi-UAVs facing variable environmental factors, complex time constraints and uncertain solution space, etc. The design of this algorithm can be divided into three aspects. Firstly, this paper constructs a multi-intelligence environment optimized by a swarm intelligence algorithm to dynamically constrain the state action space of multi-intelligences. Based on the complex environment of the battlefield, the multi-intelligent body is made to intelligently decide the best adaptation state under the current action. Secondly, based on the time-varying nature of UAV missions, a multi-agent dynamic training method based on the idea of simulated annealing is designed under the influence of multi-intelligent body and environment interactions. The method can be used in a state-oriented multi-agent global environment. Thirdly, this paper proposes a real-time prioritized state-space autoencoder strategy. Specifically, the strategy combines the characteristics of multiple UAVs to optimize the state space and make the algorithm more efficient.
In addition, a multi-UAV task allocation method is designed from two aspects. Firstly, agents trained by DQN and its related algorithms can be used to solve the UAV task allocation problem. Compared with traditional methods, the method not only avoids complex constraints and tedious solving processes, but can also continuously generate dynamic assignment schemes as the states are refreshed. Another is that due to the complexity and variability of the task environment, multiple agents are motivated to dynamically find the optimal dimension for task execution based on the changing target values of the environment. The designed method can solve the dynamic optimization problem of mission planning under multiple constraints and achieve multi-UAV mission planning.
Finally, according to the algorithm improvement and the design of the method for multi-UAV mission planning, simulation experiments are carried out. From the results of the simulation experiments, it is able to design a better multi-UAV mission execution scheme under variable environmental factors, complex time constraints and spatial uncertainties. However, there is still a problem of uneven task distribution in terms of multi-UAV collaboration, and future research can be conducted to improve the multi-intelligent body strategy design.
Compared with other algorithms, the method achieves a strong real-time capability which is able to continuously interact with the environment and learn iteratively. And gradually from knowing the environment to adapting to the environment and forming a planning programmer. However, as the intelligent body is learning, the database capacity is constantly expanding and when the amount of data increases. Its strategy network is not stable enough, and the running time of the algorithm is low. Therefore, applying the MPSO-SA-DQN method in military or civilian UAV operations may be the challenge of the timeliness of massive data training and selection, computation. Besides, the backup resource regulation, and reinforcement learning algorithms with more stable policy networks and multidimensional particle swarm algorithms should be used to combine with each other to improve the execution efficiency of the algorithm.
Although good results have been achieved in the current work, there are still some shortcomings. As the scale of the task increases and the number of UAVs increases, the speed of the algorithm’s solution will gradually decrease, and the interaction between multiple intelligences and the environment will be limited. The interaction rate of the environment built by multi-dimensional particle swarm will become lower. A more intelligent algorithm should be used to replace the multi-dimensional particle swarm algorithm to rebuild the multi-intelligent body operating environment. So that the algorithms are constantly learning the commonalities of the tasks performed by the UAVs and constantly generating solutions.
Footnotes
Acknowledgements
Throughout the writing of this dissertation I have received a great deal of support and assistance. First of all, I would like to express my sincere gratitude to my supervisor, Mr Peng Peng Fei, whose advice and encouragement have given me a deeper understanding of these AI studies. It is my great honor and joy to study under his guidance and supervision. In addition, his charisma and diligence have been a privilege that I will cherish for the rest of my life. There are no words to express my gratitude to him. I am also very grateful to my elder brother, Fan Linkun, and my elder sister, Zheng Yalian, who have given me a lot of help and companionship in the process of preparing this thesis. They helped me to revise this thesis meticulously.In addition, I would like to thank the fund support provided by the National Experimental Teaching and Teaching Laboratory Construction Project, the Development, Application and Research of Digital Resources of a Certain Equipment in Experimental Teaching, and the Equipment Development Research Project, which made it possible for my research to be sustained.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Data Availability Statement
The use of this data is completely restricted for research and educational purposes. The use of this data is forbidden for commercial purposes.