
Abstract
Unmanned surface vehicles (USVs) are intelligent platforms for unmanned surface navigation based on artificial intelligence, motion control, environmental awareness, and other professional technologies. Obstacle avoidance is an important part of its autonomous navigation. Although the USV works in the water environment (e.g. monitoring and tracking, search and rescue scenarios), the dynamic and complex operating environment makes the traditional methods not suitable for solving the obstacle avoidance problem of the USV. In this paper, to address the issue of poor convergence of the Twin Delayed Deep Deterministic policy gradient (TD3) algorithm of Deep Reinforcement Learning (DRL) in an unstructured environment and wave current interference, random walk policy is proposed to deposit the pre-exploration policy of the algorithm into the experience pool to accelerate the convergence of the algorithm and thus achieve USV obstacle avoidance, which can achieve collision-free navigation from any start point to a given end point in a dynamic and complex environment without offline trajectory and track point generation. We design a pre-exploration policy for the environment and a virtual simulation environment for training and testing the algorithm and give the reward function and training method. The simulation results show that our proposed algorithm is more manageable to converge than the original algorithm and can perform better in complex environments in terms of obstacle avoidance behavior, reflecting the algorithm’s feasibility and effectiveness.
Introduction
In recent years, USVs have been widely used in marine scientific research, marine search and rescue, marine energy exploration, and other fields. Because the tasks environment of USV is very complex, not only contains static obstacles but also is affected by sea currents and other dynamic obstacles, obstacle avoidance becomes a key factor affecting the autonomous navigation of USV. They have become one of the leading research hotspots in the industry 1 and are the goal of continuous exploration and optimization by global scholars.
USV obstacle avoidance is a real-time collision-free path that satisfies the USV dynamic constraints based on environmental awareness and its state information. During USV navigation, the real-time information and communication system collected by the sensor informs the obstacles, ships, and unexpected information near the hull in real-time, which makes the USV drive away from the original route to avoid reasonably while guaranteeing to complete the original task. 2 Common obstacle avoidance algorithms include artificial potential field, 3 particle swarm optimization algorithm, 4 and bacterial foraging optimization algorithm. 5 Xie et al. 3 proposed an improved USV Artificial Potential Field (APF) algorithm to solve the problems of local optimization and unreachable destination of traditional artificial potential field algorithm. Xia et al. 4 combines the Velocity Obstacle (VO) method with the Modified Quantum Particle Swarm Optimization (MQPSO) and proposes a USV local obstacle avoidance algorithm, which can effectively plan the USV obstacle avoidance path. To address the issue of the Bacterial Foraging Optimization (BFO) algorithm being prone to getting trapped in local optima during USV path planning, Yang et al. 5 proposed an optimization algorithm that combines Simulated Annealing (SA) with BFO. It can not only successfully avoid static obstacles, but also complete dynamic path planning efficiently. In practical tasks, environmental space is often dynamic and uncertain, such as incomplete perception of environmental information (which is often the most common problem in practical applications), interference of wind and waves, the noise of sensor data, and control errors, making the above methods not suitable for solving obstacle avoidance problems of USV in complex environments.
In order to solve the problem of USV obstacle avoidance in a complex environment, the learning-based obstacle avoidance method has been paid attention to in recent years. As an important area of machine learning, DRL has made considerable progress in recent years, which provides strong support for obstacle avoidance of USV, enabling USV to handle high-dimensional state space and continuous motion space problems. DRL has a more vital perceptual decision-making ability to solve tasks, such as USV navigation, 6 control, 7 and obstacle avoidance. 8 Wang et al. 9 proposed a self-adaptive mechanism which was introduced into the Extreme Learning Machine (ELM) to make the neural network have faster learning ability and generalization. Wang et al. 10 propose an automatic architecture design method based on Monarch Butterfly Optimization (MBO) for Convolution Neural Network (CNN) can significantly reduce the network time and performance overhead. Cui et al. 11 converts the malicious code into grayscale images and uses CNN to identify the transformed image, which can quickly and effectively detect malicious code. However, many factors currently restrict DRL in obstacle avoidance of USV: (1) Because the USV training environment is subject to many interference factors by waves, the algorithm is usually challenging to converge, (2) The portability of DRL is poor and needs to be retrained when the sensor or task changes, (3) There is a massive gap between the simulation and practical application environments, and the training results are usually good, but the applicability is poor, and (4) When an agent interacts with the natural environment, some erroneous behaviors will damage the agent, increasing training and time costs.
The main contributions of this article are summarized as follows:
(1) A new heuristic exploration policy is proposed to solve the slow convergence problem of TD3 algorithm training USV for obstacle avoidance. This approach enables an agent to explore the environment independently according to specific probability actions and store the information in the experience pool so that the algorithm can get relatively positive samples at the beginning of training. This approach significantly avoids the timid behavior of the agent due to insufficient positive samples in the previous period. This will enable the agent to adapt to the environment more quickly and accelerate the algorithm’s convergence to reduce the training time.
(2) For the poor portability of the algorithm, the state space, reward function, and action space are designed. Use generic distance sensor data as input to avoid the problem of poor robustness due to changes in different tasks or environments.
The rest of this article is organized as follows. Section 2 introduces some of the DRL work and the background knowledge of our algorithms. Section 3 describes the proposed algorithm and the implementation details of the training and elaborate on the state space, action space, and reward function in detail. Section 4 demonstrates the test environment, simulation system, and test results after training and analyses the simulation results. Section 5 is the conclusion and future work.
Related work
Deep reinforcement learning
Reinforcement Learning (RL) is an algorithm in machine learning. Unlike supervised learning and unsupervised learning, which have a lot of data or experience input, the agent guides the agent to achieve expected behavior by obtaining a set reward value through environment interaction and evaluates the agent’s behavior by overall return size. The learning environment for RL is the Markov Decision Process (MDP), as shown in Figure 1
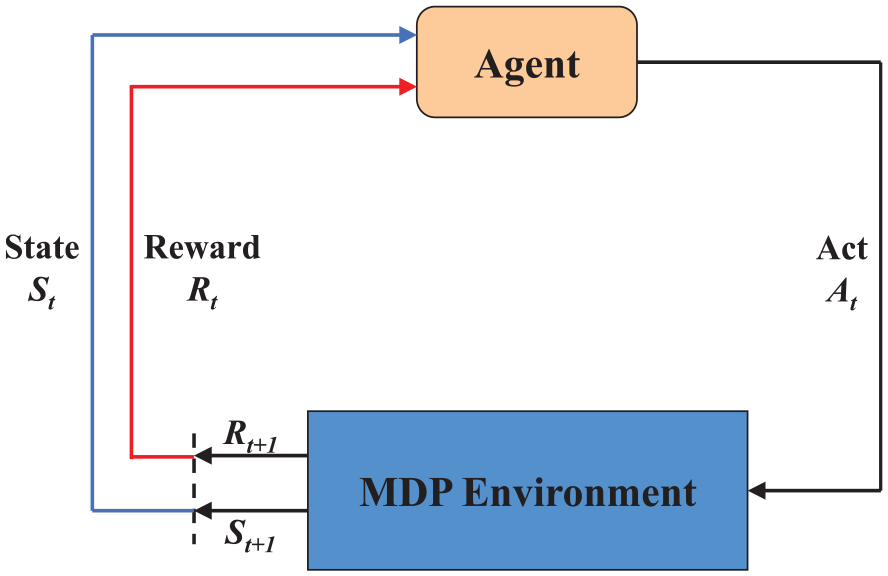
MDP.
The MDP is a sequence

In equation (1),
The policy is a mapping from the state to the probability of selection for each action. If the agent selects the policy
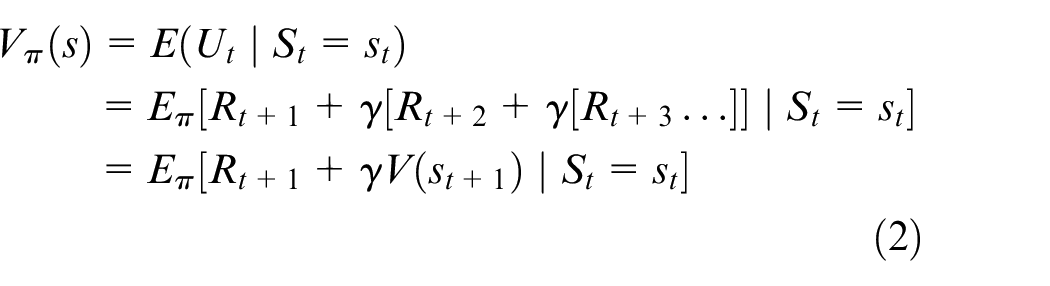
Equation (2) expresses the relationship between a state value and a subsequent state value. Value function
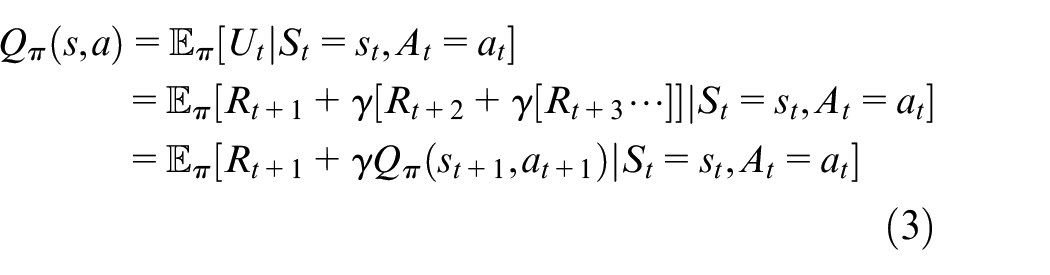
Solving the RL problem means finding a policy that can obtain many rewards in the long-term process. Therefore, we can define an optimal policy

The optimal state value function is also shared by the optimal policy, denoted as

The classical algorithm of DRL, Deep Q Network (DQN)
12
algorithm, uses a neural network to approximate

We can use
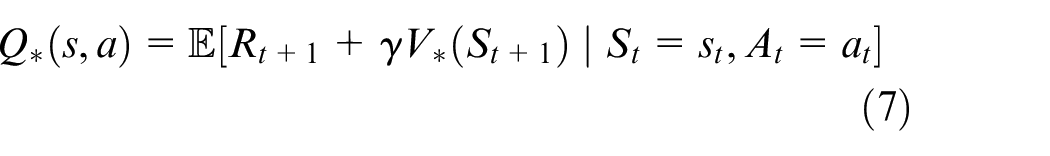
A neural network can also be used to approximate the policy

DQN estimates the optimal function
The goal of the DQN algorithm is to learn a
To apply RL to continuous state space and continuous action space, Lillicrap et al.
19
proposed the Deep Deterministic Policy Gradient (DDPG) algorithm. Zhou et al.
21
proposed the DDPG algorithm based on key learning of failure regions to improve the obstacle avoidance rate of ships and reduce the error of simulated routes. Xu et al.
22
proposed a DDPG-based route planning algorithm to generate navigation paths under unknown interference. As a classical algorithm for continuous motion control, the DDPG algorithm is widely used in obstacle avoidance, path planning, and other issues. However, it has an uneven overestimation of
The advantages and disadvantages of the USV collision avoidance algorithm are shown in Table 1.
Advantages and disadvantages collision avoidance USV algorithm.
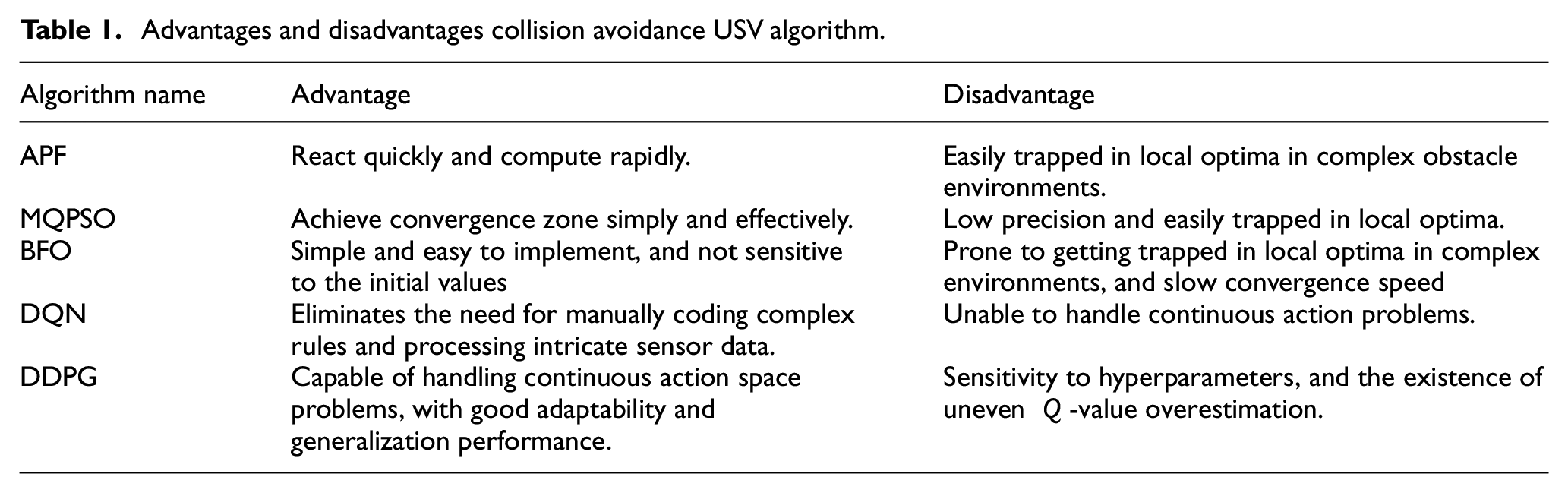
In general, RL algorithms have the following advantages over traditional algorithms in the application of USV obstacle avoidance:
(1) Stronger adaptability: Traditional USV obstacle avoidance algorithms often require manual parameter settings, such as obstacle avoidance distance and speed, while RL algorithms can learn the optimal policy through interaction with the environment.
(2) Ability to handle nonlinear and high-dimensional data: USVs need to deal with complex nonlinear and high-dimensional data such as waves and wind direction during obstacle avoidance, while RL algorithms can handle these data and learn the optimal policy directly from raw data.
(3) Ability to handle partial observability: In some cases, USVs may not be able to obtain complete environmental information, such as incomplete information about waves and wind direction. RL algorithms can handle partial observability and estimate unobserved state information through state estimation to learn the optimal policy.
(4) Learning capability: RL algorithms have the ability to learn the optimal policy through interaction with the environment and can continuously improve the policy through continuous training.
Twin delayed deep deterministic policy gradient algorithm
Due to the problem of uneven overestimating
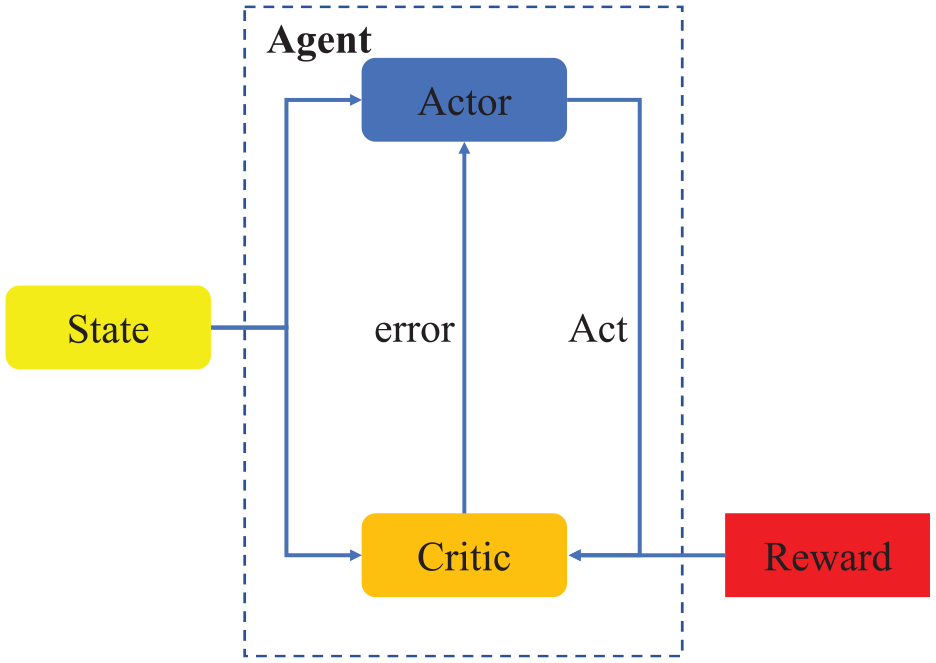
Actor-Critic algorithm framework.
Because the USV used in this paper is a two-degree-of-freedom catamaran model, the behavior of the USV is controlled by controlling the left and right thruster thrust, so it will not converge if the two-degree-of-freedom thruster thrust is discretized. Therefore, we describe the USV obstacle avoidance problem in a continuous state-action space. The network structure is shown in Figure 3.
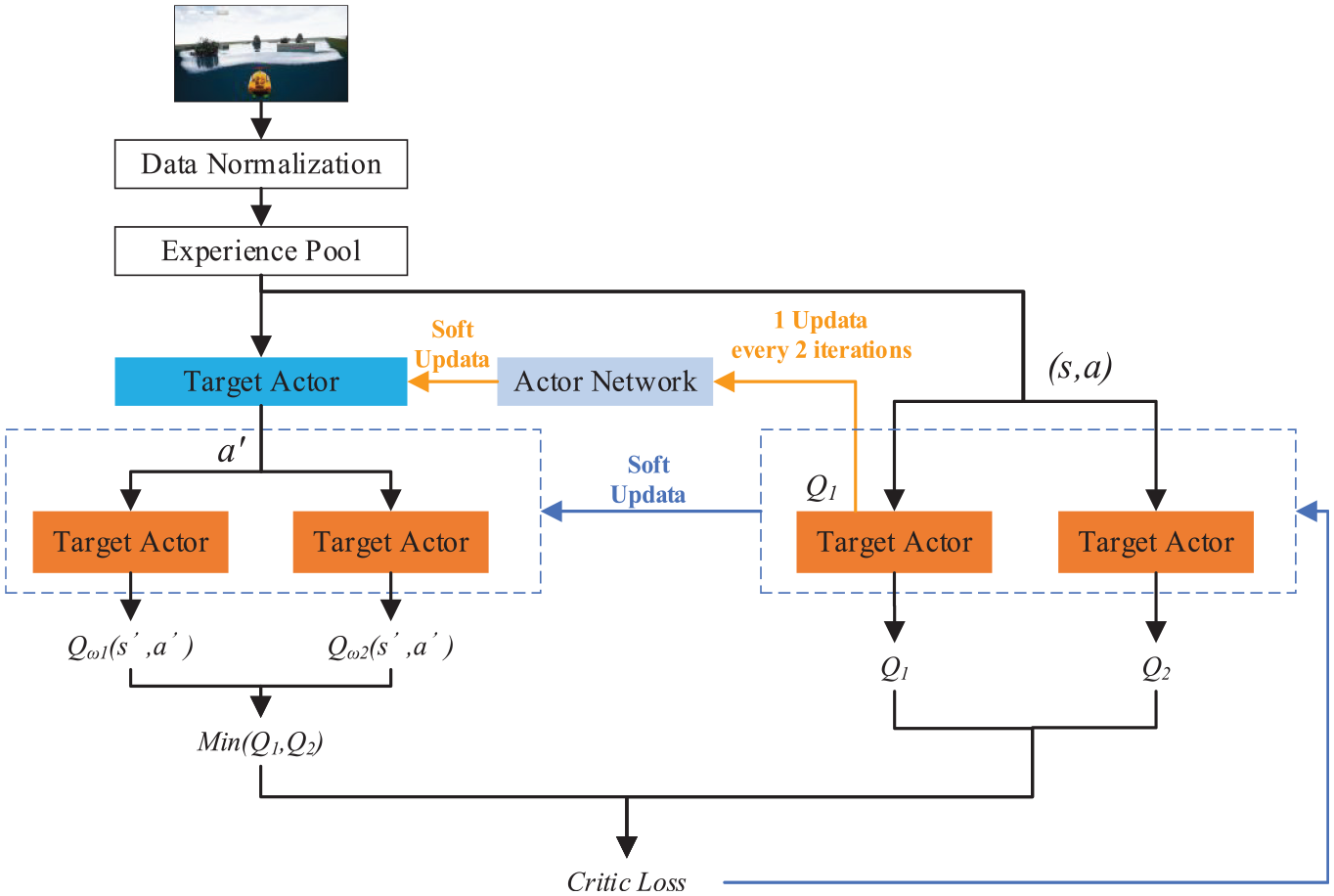
The network structure of TD3 algorithm.
First, the data are sampled from the environment and normalized to the empirical buffer. Sample a batch of data
For the Critic network, the loss function is the mean square error, that is
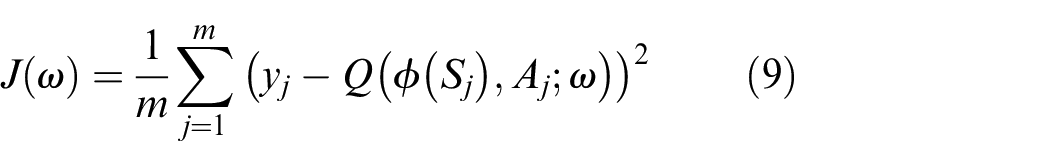
For the Actor network, since it adopts a deterministic policy, its loss gradient is
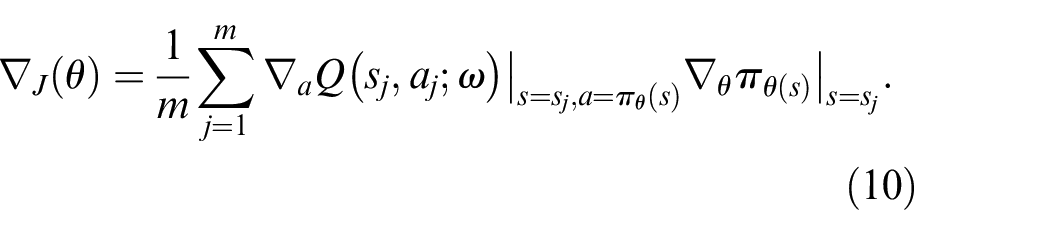
Random walk twin delayed deep deterministic policy gradient algorithm
USV state space in random walk TD3
In DRL, USV gets information from the environment and takes appropriate action. State space provides information about essential objects in the environment, such as obstacles and targets, and accurately represents the current state of the USV itself.
26
In our approach, the state space consists of the USV’s state and part of the environmental information detected by the sensor. Some researchers use vision as a navigation obstacle avoidance method to map current and target observations to a state space, which may work well in an ideal state, but this algorithm is not robust. Obstacles encountered by USV when deployed in other environments may be quite different, and training may be more difficult if too many types of obstacles are considered. Therefore, the state space of USV is designed to have shared data. There are 24-dimensional continuous data in the USV state space, including 19-dimensional USV ranging data, 2-dimensional attitude data, 1-dimensional heading angle data, 1-dimensional velocity data, and 1-dimensional USV distance end point data. The 19-D ranging data are 19 laser beams emitted from the USV bow and deflected one beam at a 10° interval from left to right, as shown in Figure 4, and the

Where

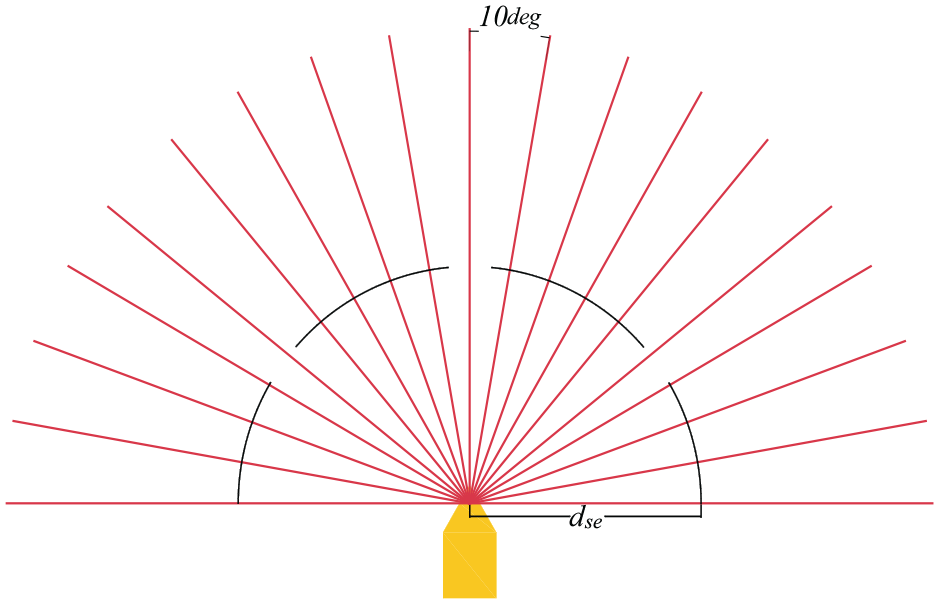
The obstacle detection of USV.
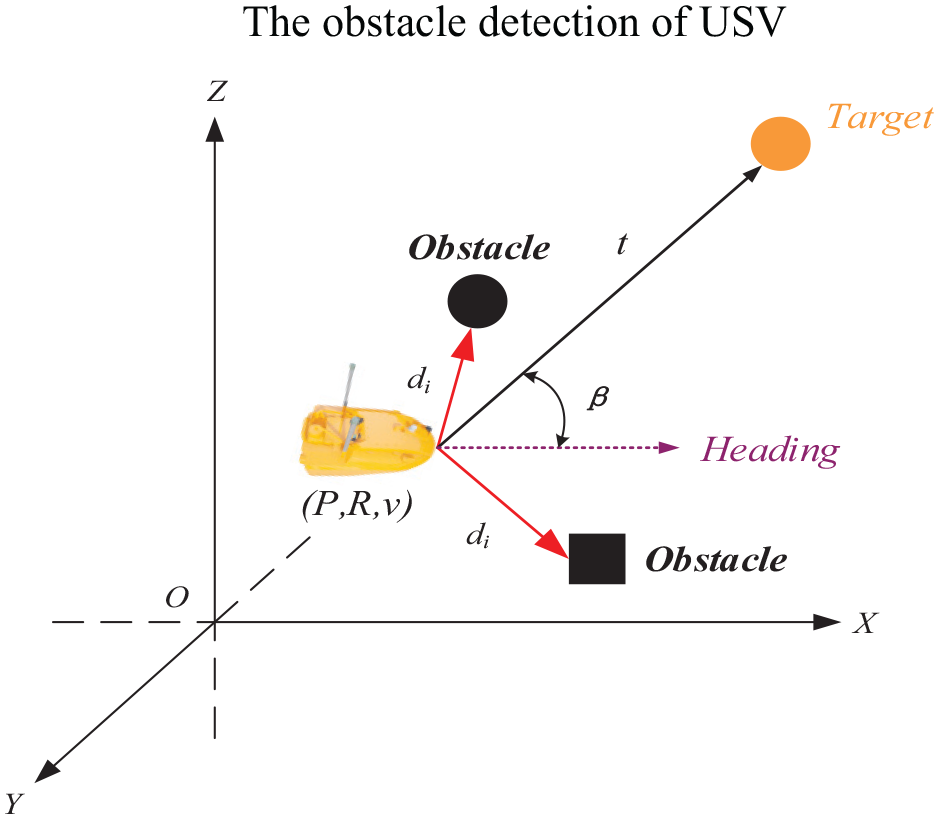
The diagram of USV’s state.
The posture of USV.
Because different states have different units and scales, we must preprocess them before input into the network. In this paper, the state values collected by USV during navigation are processed by the normalization method to accelerate the convergence of network training.
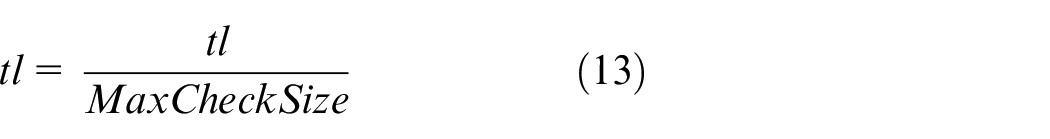
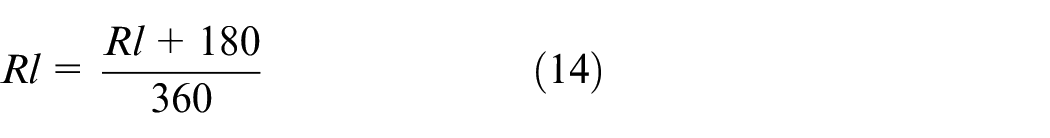
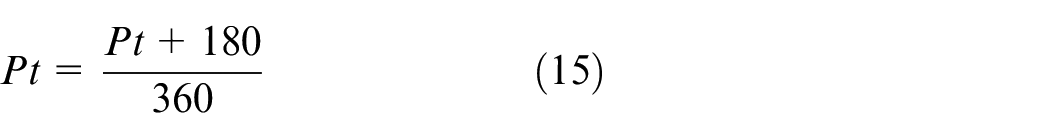
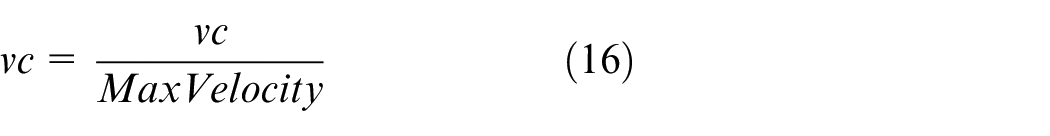
USV reward function in random walk TD3
The reward function is the most crucial attribute in DRL. It can evaluate the USV action according to the environment. A positive value is a reward, and a negative value is a punishment. Reasonable reward function design is a prerequisite for DRL to solve complex problems. When solving the obstacle avoidance problem of USV, it is necessary to take full account of the situation encountered by USV when navigating or performing tasks, which is universal. The reward function designed in this paper is designed to guide the USV to the target area without collision.
The reward function consists of eight parts.
The settings of the reward function.
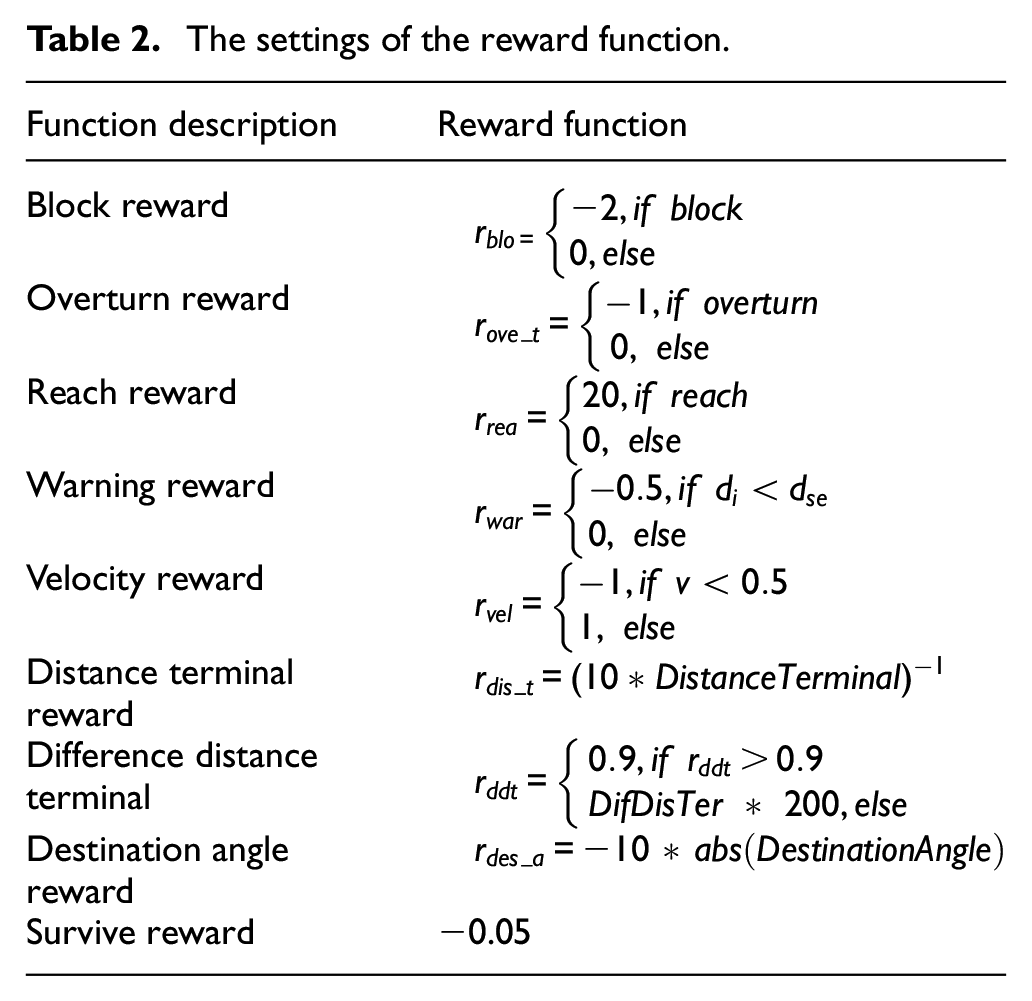
Therefore, the reward received by USV at the current moment can be expressed as,
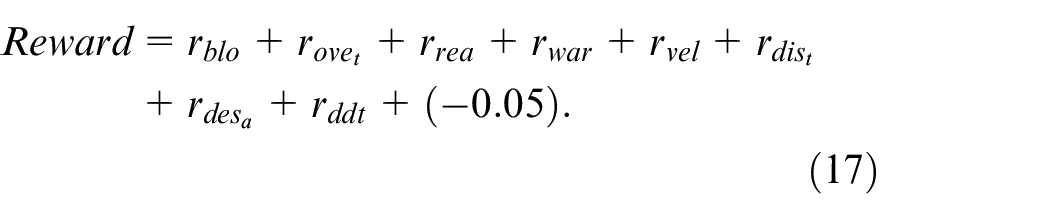
Random walk policy
USV training in complex obstacle environments often encounters cowardly behavior due to many obstacles and is afraid to move forward to the end point. Our goal is to explore the environment purposefully when the agent is not yet trained, to obtain relatively high-quality samples, and thus speed up the algorithm’s convergence when training starts earlier. This paper uses the random walk policy as an environmental exploration before training begins. It adds a heuristic probability: the probability of USV moving forward is greater than that of left, right, and back.
If the current experience pool size is less than the set value (the set value is less than or equal to the maximum capacity of the experience pool), perform action exploration
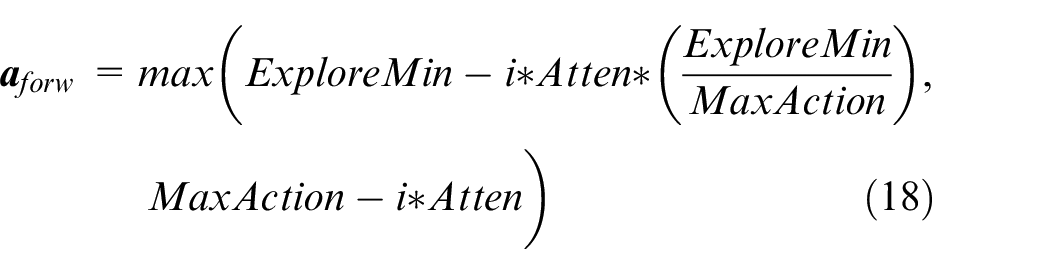
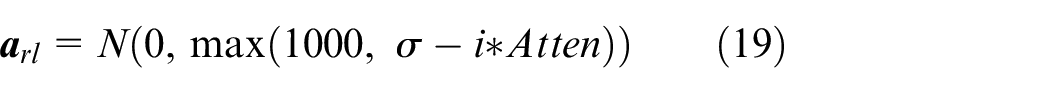
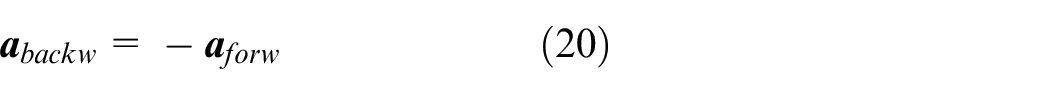
where
The probability distribution.

USV action space in random walk TD3
The dual thruster USV can control its attitude and behavior by adjusting the rotation speed of the left and right motors behind the hull. Therefore, this paper takes the left and right motor thrust of USV as executable action,
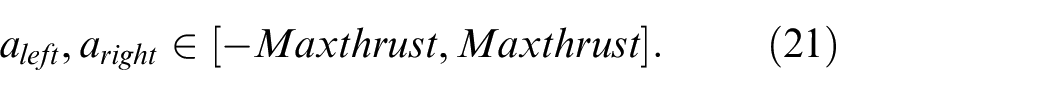
Therefore, the resulting action value is
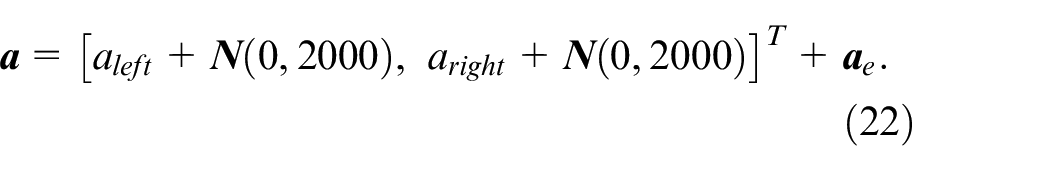
Design of algorithm
The algorithm flow is shown in Algorithm 1. First, the parameters of all neural networks are initialized, while the experience pool of the algorithm is initialized. When the training starts, the algorithm first executes the random walk policy, executes different actions according to the given probability and adds them to the actions output by the policy network. These action values decay with the number of episodes, which means that the behavior of exploring the surrounding environment is more aggressive in the early stage of the algorithm, and the acquired experience is stored in the experience pool. When the number of the current experience pool reaches the maximum capacity of M/20, the random walk policy is stopped and the algorithm is updated. In this way, the algorithm can obtain higher quality sample data by sampling the experience pool at the beginning of training, so as to accelerate the convergence of the algorithm. Then Based on the current state
random walk policy TD3

Experiments and results
In this section, we give the simulation environment and training results. Firstly, we constructed a virtual simulation environment and introduced wave and water flow disturbances to the USV in the simulation environment. Secondly, we conducted feasibility experiments of the algorithm with USV in a simple environment with fewer and regular obstacles. Subsequently, we trained USV in an environment with more obstacles and irregular shapes and conducted a comparative experiment using the TD3 algorithm. Finally, we randomly initialized the starting point of the USV to verify the generalization of the algorithm. The experimental environment is Windows 10.1 + Pytorch1.7.1 + CUDA10.1. Hardware is an INTEL i9-11900 processor and NVIDIA RTX A4000 graphics card.
Experiment platform and settings
UE4.26 is adopted by us to construct the virtual simulation environment. This version adds a water system, which allows us to easily define the water environment, such as oceans, rivers, and lakes. It can adjust the wavelength, amplitude, and other parameters of waves to realize the physical interaction between USV and water body, and finally simulate the interference of waves and currents so that USV can be trained closer to the natural environment and can be better deployed in the equipment in the future. The visualization of the simulation system based on UE4 is shown in Figure 7.

The virtual simulation system.
The simulation system includes an environment construction module and an environment perception module:
The Environmental Construction Module is used to model the water body and terrain of the virtual navigation environment and obstacles encountered during the voyage. Our virtual USV thrusters are positioned in a static mesh to simulate the differential model of the dual thruster USV, as shown in Figure 8 . To simulate the interference of waves on the USV, two thrusters are set at the center of gravity of the USV to simulate the combined forces of roll and pitch of the USV, respectively. The attitude inference algorithm calculates the interference intensity of USV in waves.
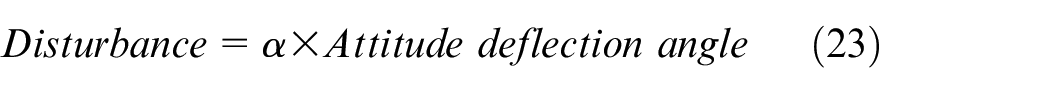

USV rear view.
among
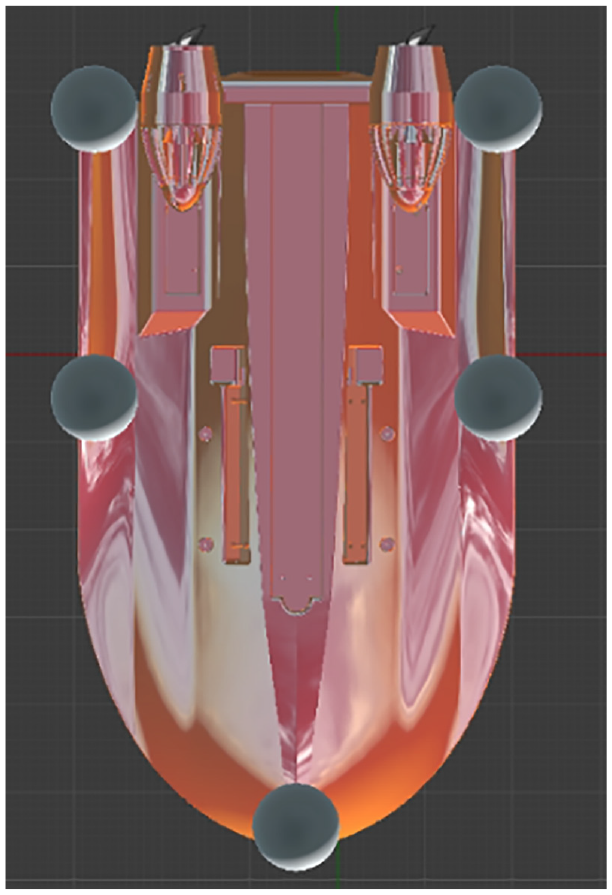
Buoyancy block configuration.
The Environment Perception Module is used to sense the scene data of a virtual USV model when navigating in a virtual navigation environment. The virtual scene data includes USV ranging data, attitude data, heading angle data, speed data, and USV distance terminal data. At the same time, we use TCP communication to transfer the above data from the simulation system and analyze the data to form the data type our algorithm can recognize.
Training and result
The algorithm’s feasibility was verified by training it in a relatively simple environment. The training environment was a rectangular space measuring 1750 × 1500 units and contained three equally sized cubic obstacles. The starting and ending points of the USV were located at the lower left corner and upper right corner of the environment, respectively. The training was conducted for 2500 iterations, and the hyperparameters used are shown in Table 4. At the beginning of each episode, the Actor networks and Critic networks parameters are initialized, and copied into their respective target networks. The initial point is generated at a random position. The termination conditions for each episode are: (1) the USV reaches the target area, (2) the USV collides with an obstacle, (3) the USV capsizes, or (4) the maximum number of training steps is reached. The USV’s decision execution cycle is 0.5 s, which means that the network parameters are updated and rewarded every 0.5 s after each action is executed.
The hyperparameters.
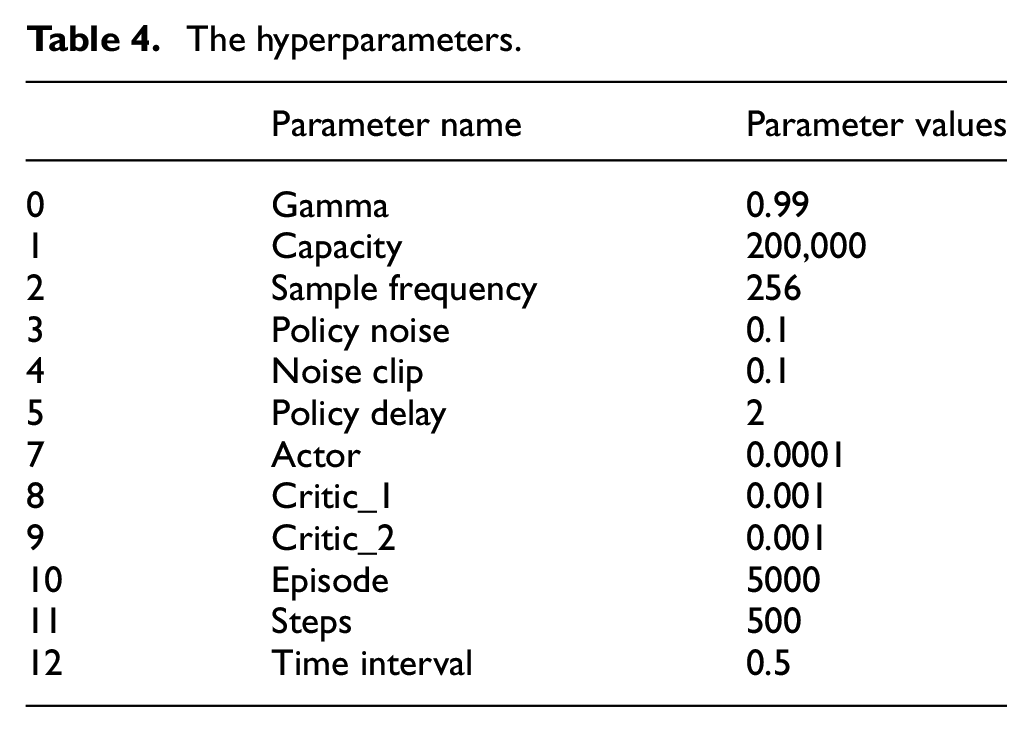
After the training, we carried out several fixed start point and fixed end point navigation tests to obtain the distance between the USV and the end point and the thrust values of the USV in this environment, as shown in Figures 10 and 11, respectively.
Obstacle avoidance trajectory in a simple environment.
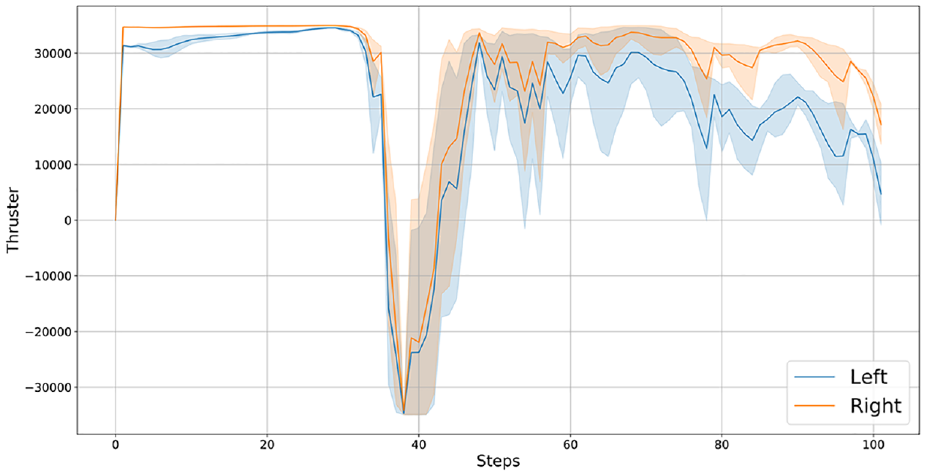
Thrust values under a simple environment.
From the results, it can be observed that the algorithm can make the USV produce obstacle avoidance actions, but there are backward movements in the trajectory. Such behavior can be dangerous in practical use, as it indicates that the USV did not fully consider the future navigation environment, leading to untimely avoidance. From the graph of the thrust values of the thrusters, it can be seen that both the left and right thrusters experienced a sudden change in negative thrust values. In practical use, the violent switching of the thruster’s rotation direction can lead to a reduction in its service life. We believe that this is due to insufficient training of the algorithm, resulting in the USV selecting backward strategies for obstacle avoidance.
After verifying the feasibility of the algorithm, we constructed a more complex training environment and carried out 5000 rounds of training. The training environment was set to a square environment with a size of 2500 × 2500 units, containing 10 randomly sized and irregular static obstacles. The dimensions of the cuboid obstacles were randomly stretched, and the irregular obstacles included reefs and shrubs, which exhibited non-uniform shapes relative to the cuboid obstacles.
We train USV using TD3 and the proposed algorithm. During the testing phase, the USV fully uses our trained strategy to sail steadily from the starting point to the end point and avoid obstacles. During the training of 5000 episodes, the average reward curves of the two algorithms are shown in Figure 12.
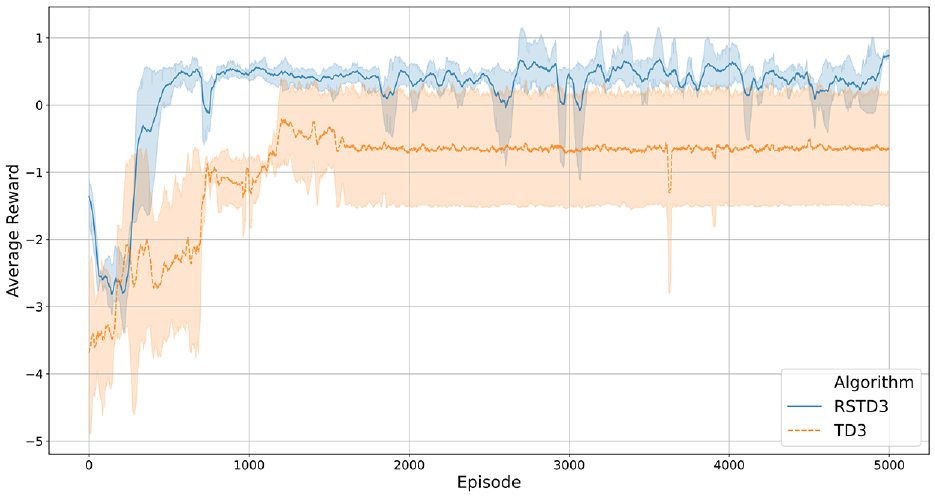
The average reward curve.
It is evident that our algorithm achieves convergence earlier than the original TD3 algorithm, and during the subsequent training process, it enables the USV to explore the optimal path. The relatively dense placement of obstacles compared to the warning distance we set results in the continuous appearance of new obstacles in the warning area during the navigation of the USV, and previous obstacles also move away from the warning area due to the progress of navigation, leading to fluctuations in the average reward value.
After the training, we carried out many navigation tests with fixed starting point and fixed end point, and recorded the obstacle avoidance trajectory of the USV and the thrust value of the thruster under this environment, as shown in Figures 13 and 14 respectively.
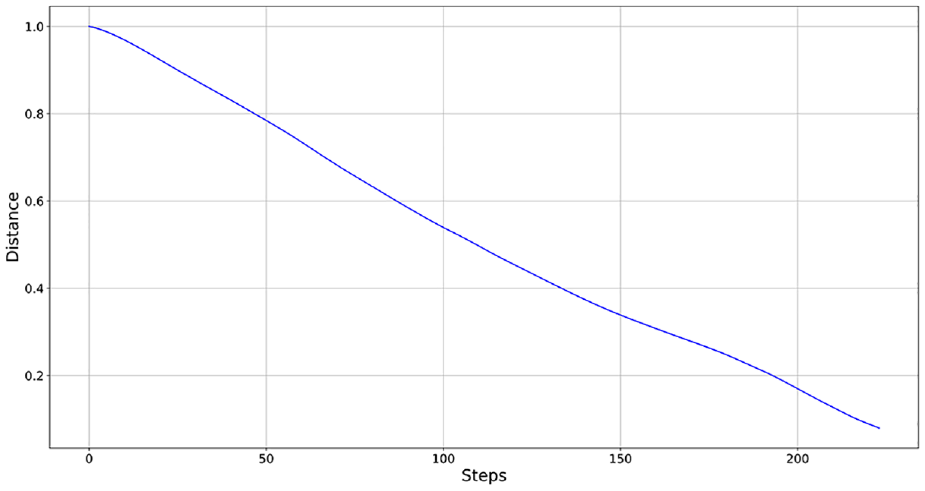
The distance to end point.
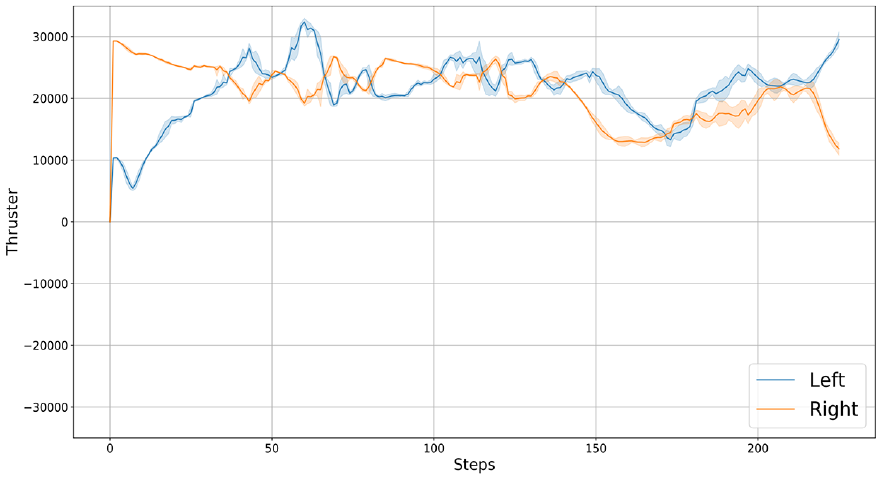
Thrust values under a complex environment.
The curve smoothness of Figure 14 indicates that the USV can avoid obstacles smoothly and reach the target point without any backward avoidance when encountering obstacles. The USV considers the future navigation environment and thus avoids obstacles in advance. Left and right thrusters do not produce sudden changes of negative thrust value. However, the thrust of the thruster is not smooth enough, which may cause some thruster problems in actual deployment. How to make the change of thrust value generated by the algorithm smoother will be the direction of the future optimization algorithm.
The Generalization of the algorithm are tested under the start point of the random generation. In the test environment, water flow disturbance is different for each episode, as shown in Figure 15.
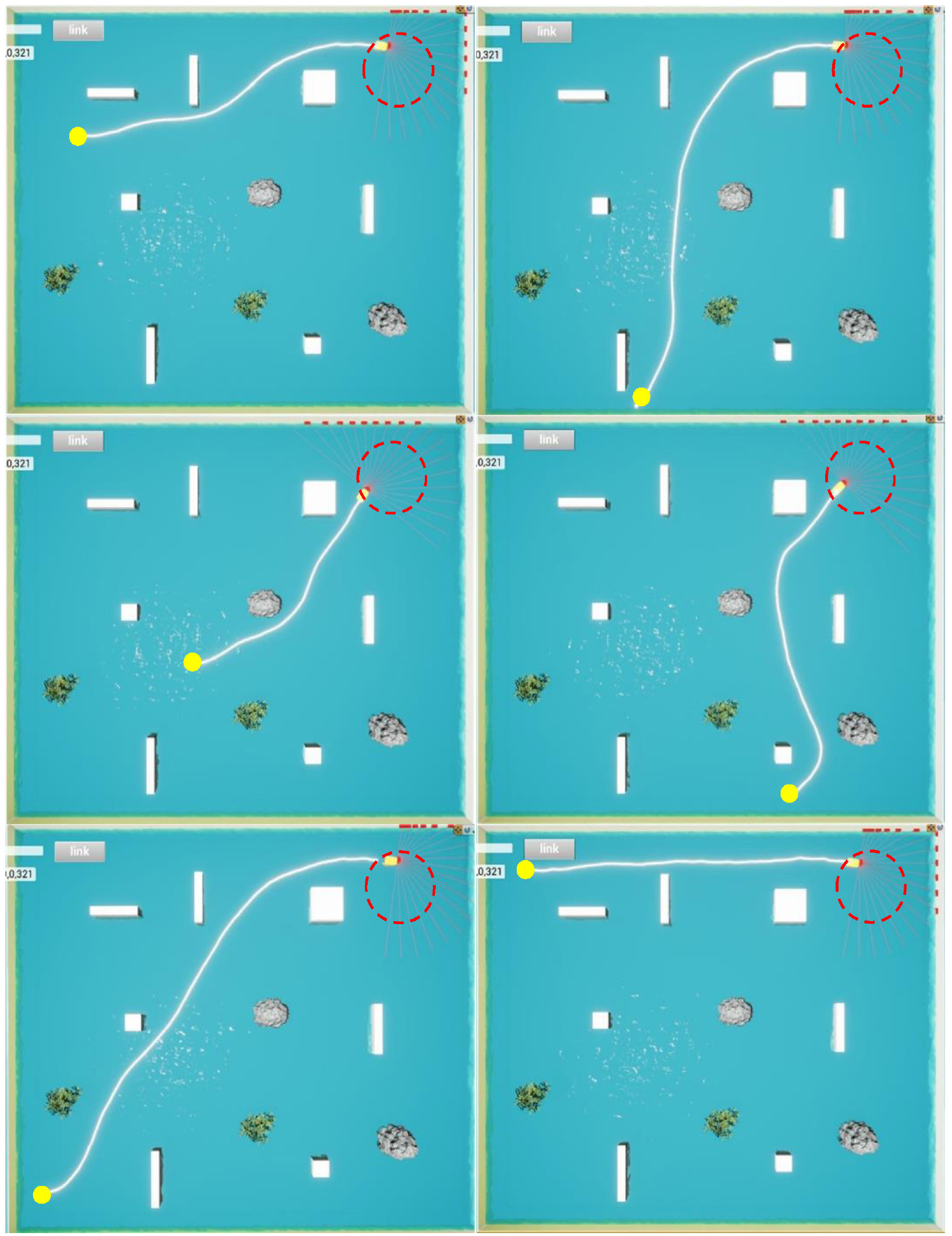
The obstacle avoidance at random start point.
It can be seen that our algorithm can reach the end point without collision from different start points, and the trajectory also conforms to the dynamics of USV. The result shows that the modified algorithm has strong adaptability to obstacle avoidance in complex static environment.
Conclusions
This paper presents a method of obstacle avoidance based on DRL to enable USV to perform obstacle avoidance tasks in a complex multi-static obstacle environment. A new heuristic exploration policy is proposed to improve the DRL TD3 algorithm, which enables the agent to explore the environment independently in the early stage and get a large number of positive samples, and store the information in the experience pool so that the agent can adapt to the environment faster and reduce the training time. The method is then tested in a UE 4.26-based simulation environment. The results show that the algorithm can train the USV to reach the target area safely and quickly in a multi-obstacle environment.
For further research, the generated thrust values by the current algorithm are not smooth enough, which will be a major obstacle to the algorithm’s physical deployment. How to make the generated thrust values smoother will be a future direction for algorithm optimization. While our algorithm has not considered the avoidance of dynamic obstacles, we plan to construct a more complex and realistic simulation environment, add some dynamic obstacles, and test the algorithm in a real environment after completing the algorithm training to demonstrate the engineering application value of the algorithm.
Research Data
sj-rar-1-mac-10.1177_00202940231195937 – Supplemental material for Obstacle avoidance USV in multi-static obstacle environments based on a deep reinforcement learning approach
Supplemental material, sj-rar-1-mac-10.1177_00202940231195937 for Obstacle avoidance USV in multi-static obstacle environments based on a deep reinforcement learning approach by Dengyao Jiang, Mingzhe Yuan, Junfeng Xiong, Jinchao Xiao and Yong Duan in Measurement and Control
Footnotes
Authors’ Note
Mingzhe Yuan, Junfeng Xiong, and Jinchao Xiao is now affiliated to Guangzhou Institute of Industrial Intelligence, Guangzhou, China and Shenyang Institute of Automation Chinese Academy of Sciences, Shenyang, China. Yong Duan is now affiliated to School of Information Science and Engineering, Shenyang University of Technology, Shenyang, China.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Supported by the Key-Area Research and Development Program of Guangdong Province (2020B1111010002). Supported by the Guangdong Basic and Applied Basic Research Foundation (2020A1515010584).
Patents
The present invention discloses a method and system for obstacle avoidance of USV. After obtaining position, motion, attitude information, and obstacle information of USV, the collected information is normalized by using the normalization formula and stored in an experienced pool in the form of a quaternion. The information stored in the experience pool is calculated by using the neural network algorithm, and the resulting decision-making action is input into the USV motor to execute the decision-making action so that the USV can execute the obstacle avoidance action. Compared with other algorithms, the method designs the state space, reward function, and action space, increases the exploration activities of the USV in the early stage, and makes the neural network algorithm converge faster during training. It has a wide application environment after training and is suitable for scenarios with wind-wave interference, multiple obstacles, and dynamic obstacles with high robustness.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.