
Abstract
At present, the learning-based down-sampling method has achieved good result by using the loss of subsequent tasks to optimize the process of sampling points selection. However, for the current methods there still has two problems, on the one hand, the sampled points may not be in the original point cloud, and the sampled generated points of the sample need to be matched with the original point cloud (re-matching problem), on the other hand, the number of points obtained after matching may be insufficient for the sampling demand, which need to be supplemented by Farthest Point Sampling, nearest neighbor point, or other methods (re-supplement problem). In order to solve the above problems of re-matching and re-supplement in the learning-based sampling method, we propose a new sampling network which based on high score selection strategy. In our method, LSTM (Long Short Term Memory) is used as the feature extraction method to obtain the relational weight which relative to the subsequent tasks. The attention mechanism is used to select the high score points. The experimental results show that the performances of our network (We dubbed it as LA-Net) are better than other sampling methods and achieve the state-of-the-art in the unified benchmark. Detailed ablation studies have also been carried out, which provably affirm the advantage of each component we proposed. Finally, the methods in this paper are applied to a real backbone network to optimize its performance, and real robot grasping experiments are designed to realize automatic robot grasping of multi-target objects in real scenes.
Keywords
Introduction
With the easy acquisition of 3D point cloud data and the maturity of methods for processing 3D point cloud data, 3D vision related tasks have received more and more attention. 3D vision has been applied in many fields, such as: object recognition in point clouds,1,2 point cloud registration,3,4 shape reconstruction5,6, 6D pose estimation.7,8 These applications may have to process a large number of point clouds and may capture noisy data when collecting data in different scenarios or using different 3D sensors. Not only a large amount of point cloud data will be difficult for calculation and storage, but also the noise data will affect the performance of the subsequent task. Thus, it is necessary to use down-sampling method to reduce the original point cloud data as much as possible under the premise of preserving the integrity of the point cloud data.
Point cloud down-sampling strategy can be divided into two categories: non-learning down-sampling methods and learning-based down-sampling methods. Most of the non-learning sampling methods may only considering the distance between points according to its definition instead of take the relation between the sampled point cloud and subsequent tasks into account, so that the sampled point cloud may not be optimal to the task. With the close integration of point cloud tasks and deep learning methods, various learning-based sampling methods have been proposed successively. The core idea of those methods is that the points carrying important feature information should be reserve as sampling point. But the biggest drawback is that the sampled points are generated from the original point cloud rather than selected from the original point cloud, which leads to a problem that the sampled point clouds are not a part of the original point cloud, so an additional matching step need to be designed to obtain the final sampling point of original points (re-matching problem). After matching, if the number of points is insufficient, FPS (Farthest Point Sampling), nearest neighbor point, or other methods need to be used to add the lack points to meet the required size (re-supplement problem). Intuitively, a sampling process is to select a set of points with prominent features from the original point set. Re-matching and re-supplement procedure will increase the burden of the algorithm. In this paper, in order to find a better solution to select the points carrying the key information as the sampling point according to subsequent tasks, as well as to solve the problem of re-matching and re-supplement of sampling in the learning-based sampling method, the LSTM (Long Short Term Memory) structure and attention mechanism are introduced in the process of sampling, and a new sampling network LA-Net is proposed. LSTM is used as the feature extraction method to obtain the relational weight which is relative to the subsequent tasks. The attention mechanism is used to select the high score points. The illustration of LA-Net is shown in Figure 1.
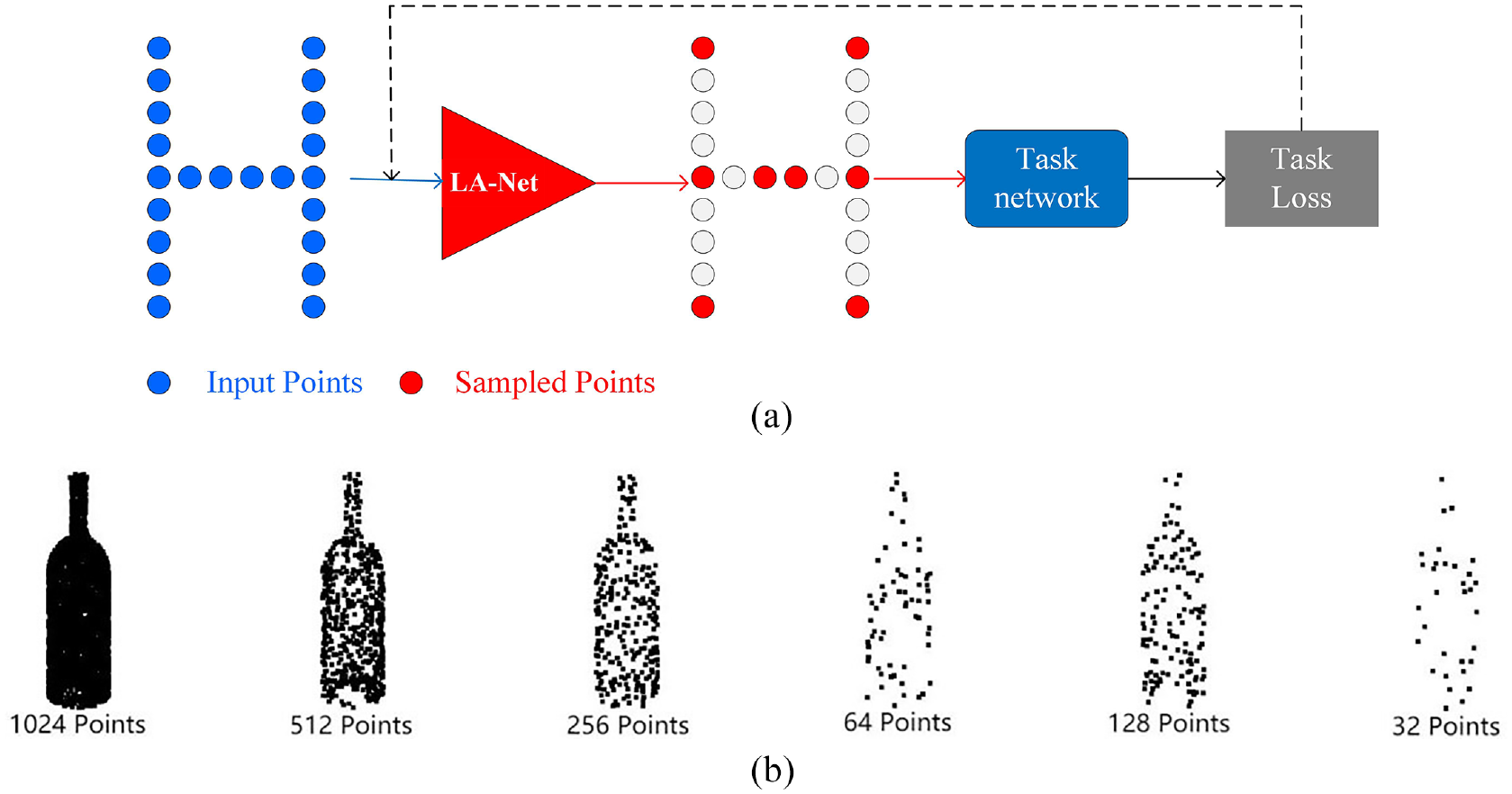
Illustration of LA-Net: (a) inputs a set of original points, LA-Net selects a certain amount of points as the sampling points by minimizing the task loss. (b) The bottle model actually sampled by LA-Net (the sampling models is the bottle model in ModelNet40 9 ).
The feature extraction of LA-Net is based on LSTM structure which has achieved great success in sign language recognition, 10 text modeling, 11 and behavior prediction. 12 By using LSTM structure, the information of an existing event can be connected and updated based on the information retained from the previous event. It can better utilize the correlation between the input original point cloud and the output of the task. After feature extraction, the attention mechanism is employed to select a certain amount of points as the sampling points which contains key feature information for the output task.
The main contributions of this paper are summarized as follows:
(1) A new sampling network (LA-Net) is proposed, which solves the problem of re-matching and re-supplementing in the current learning-based sampling method.
(2) LSTM structure and attention mechanism are introduced to the proposed LA-Net for feature extraction and feature selection, to calculate and select the significant points relative to output task as sampling points.
(3) In a unified benchmark, LA-Net is compared and analyzed with the existing the state-of-the-art sampling methods, meanwhile, detailed ablation studies have also been carried out, which provably affirm the advantage of each component we proposed.
(4) Using PointNet++as an example of task network backbone, we apply LA-Net into PointNet++to replace its sampling module (we dubbed the whole optimized network as Point-Network). Then we design an actual robot grasping experiment to verify the effectiveness of the Point-Network in the real environment.
Related work
Sampling is a method of data processing, which is to extract a certain amount of individuals from the overall data. This method is often used in the fields of image processing and signal processing. In the early days, the image sampling method proposed by Eldar et al. 13 used the strategy to select the farthest point as the sampled points. Later, this sampling method was further applied to high dimensional data, and it gradually evolved into the farthest point sampling in point cloud sampling. Since then, more and more non-learning down-sampling methods have been developed in different scenes, such as RS (Random Sampling), voxel sampling, IDIS (Inverse Density Importance Sampling) and so on. Nowadays, deep learning is constantly developing and has been successfully applied to the processing of point cloud data. Especially after the Point-Net 14 was proposed by Stanford University in 2017, the task networks of point cloud are springing up and have attracting extensive attentions. PointNet based network allows neural networks to directly perform convolution operations on unordered point cloud data, which is different from the previous multi-view15–17 and voxel-based methods.18,19 With the developing of point cloud and deep learning, more and more sampling methods were proposed and used in the preprocessing stage to reduce data amount and to speed up network efficiency. Overall speaking, point cloud down-sampling methods can be divided into the following two categories: non-learning sampling methods and learning-based sampling methods, which are shown in Figure 2.
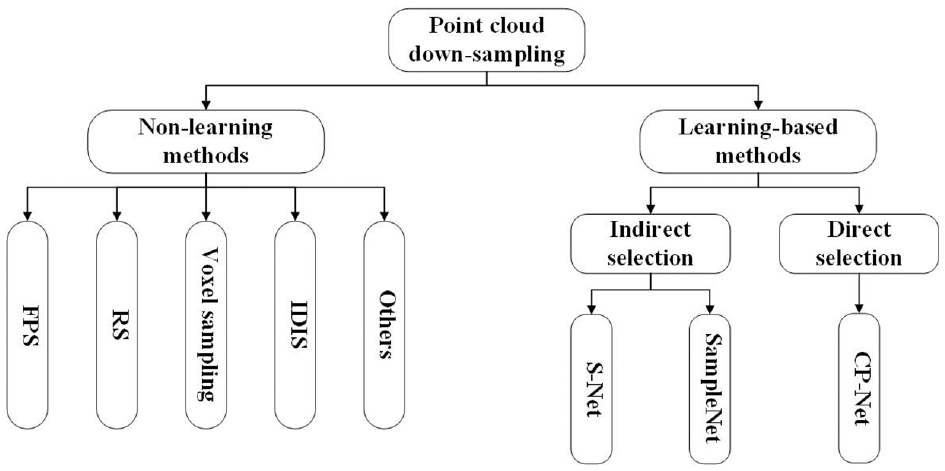
The classification of Point cloud down-sampling method.
Non-learning sampling method
The basic process of the most non-learning sampling methods is to sample the original point cloud data according to the established rules until the sampling points meet the number requirements or all the established rules are executed. The non-learning sampling method is an independent process and it has no relationship with the subsequent tasks, so the non-learning sampling can also be regarded as the preprocessing of the original point cloud data. The existing non-learning sampling methods include FPS, RS, voxel sampling, IDIS and so on.
The farthest point sampling (FPS) is a widely used non-learning sampling method, which can uniformly sample the original data. This method was first proposed in 2D image sampling and belongs to a progressive sampling. FPS is based on Euclidean distance, and at each step, only the point which is farthest from the current sampling point set in the remaining point cloud will be selected for sampling. The points sampled by FPS are the points in the original point cloud data, and it can evenly cover the surface of the object. FPS can be transplanted to other network structures to sample point cloud data due to it is easy to implement.20,21 However, because of the large number of FPS calculation, when processing large-scale point cloud data, the calculation speed is slow, moreover, it is sensitive to outliers, so the noise points in the original data far away from the surface of the object might be selected as the sampling points.
For random sampling (RS), the premise is that the point clouds in the original point cloud data all have the same probability of being selected. RS method randomly selects points directly from the original point cloud data until the number of samples meets the required. In the process of RS, there is no point-to-point distance or other additional calculations, so the speed of RS is very fast. Therefore, RS is usually used in large-scale point cloud scenes, such as the large-scale scene semantic segmentation. 22 The disadvantage of RS is that all points in the point cloud have the same probability of being selected, which will cause an excess of information missing and sensitivity to noise points.
The idea of voxel sampling is to voxel the point cloud firstly, and then samples the points in the voxel grid according to different point selection strategies. There are three commonly used point selection strategies: (1) select the point closest to the center of the voxel grid as the sampling point, (2) select the center of each voxel grid as the sampling point, (3) select the average value of each voxel grid as the sampling point. Among them, the sampling points obtained by the first point selection strategy are the points in the original point cloud, while the sampling points obtained by the other two points selection strategies may not be the points in the original point cloud. Thus, voxel sampling can be used to sample the original point cloud to get the required results using different point selection strategies according to the actual demand. The distribution of sampling points after voxel sampling is relatively uniform, the sampling efficiency is higher than FPS, and the sampling speed can be controlled by changing the voxel size. The disadvantage of this method is that some divided voxel grids may not contain point cloud data at all, which results in no point is selected in this voxel grid, finally leads to the total number of the sample points cannot be controlled.
Inverse Density Importance Sampling (IDIS) is a sampling method based on the Euclidean distance between a point and the surrounding points. 23 By calculating the reciprocal of the sum of the distance between each point cloud and the surrounding K points as the density of each point cloud, and then select the point cloud with small density as the sampling point. IDIS can retain the original object shape as much as possible, because the points on the outline of the point cloud are generally far away from the surrounding point cloud, and the density is small, IDIS also has the problem of being sensitive to noise points, because noise points are generally outliers with low density, they are easy to be selected as sampling points.
Expect for the sampling method above, Xu et al. 24 abstracted the sampling process as a mathematical model, this model calculates the probability distribution of each point, and finally samples the points through the probability distribution. Chen et al. 25 proposed a graph-based sampling method, which uses graphs to capture the local relationship between points and its global structure, then point sampling issue can be converted to graph signal sampling, finally, according to different application tasks, different graph filters can be selected to extract key points. Poisson disk sampling is to control the distance between any two points to sample the point cloud.26–28 A sampling method proposed by Katz and Tal 29 is inspired by the art form of stippling style, the final sampling point set obtained by this sampling method is the union of the point set located near the contour of the object and the point set near the deep recess, because the points located near the contour of the object can highlight the contour of the object to achieve the effect of concave area with less light can enhance the shadow of the object.
Table 1 lists and compares several typical non-learning sampling methods. It can be seen from Table 1 that the sampling time efficiency of RS is the highest, and it is the only method which is suitable for large-scene tasks. Most non-learning sampling methods can directly select points from the original point cloud as sampling points. Expect for voxel sampling method, the amount of output sampling points can be controlled for other sampling methods. In summary, most of the non-learning sampling methods only considering the distance between points instead of considering the relation between the sampled point cloud and subsequent tasks, so that the sampled point cloud may not be optimal to the task.
Several typical non-learning sampling methods.
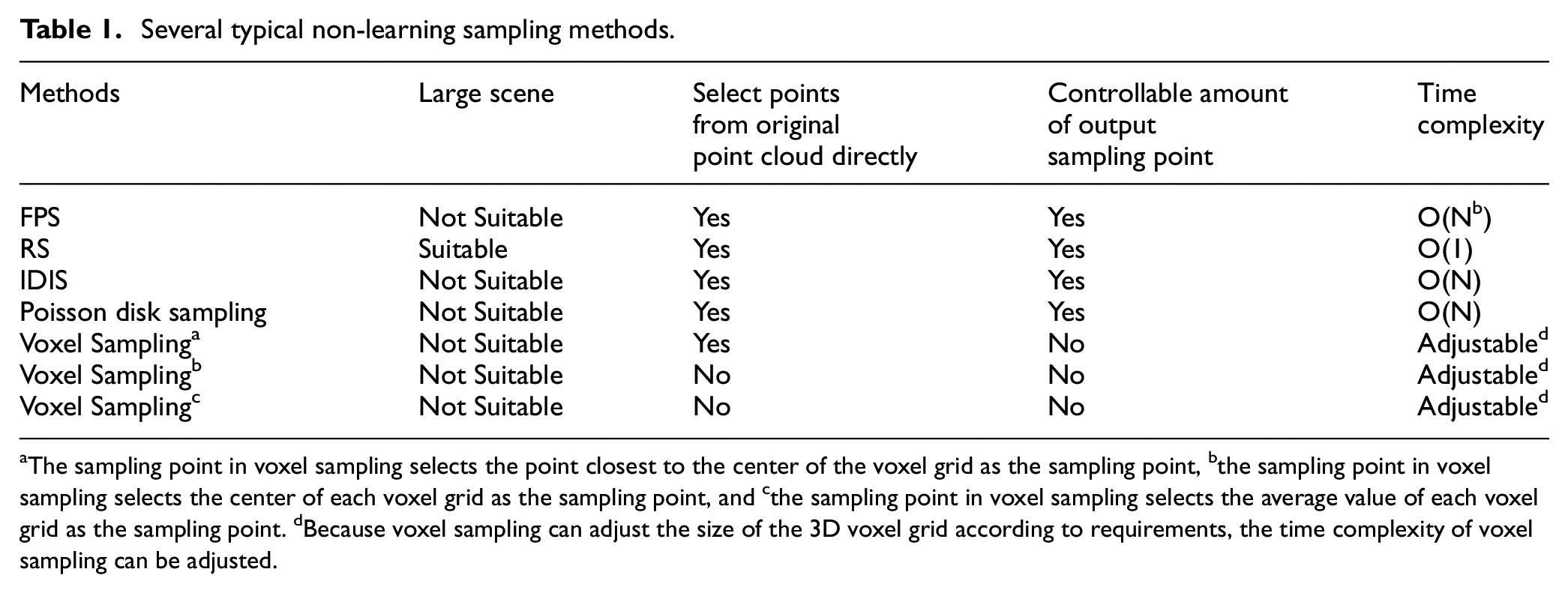
The sampling point in voxel sampling selects the point closest to the center of the voxel grid as the sampling point, bthe sampling point in voxel sampling selects the center of each voxel grid as the sampling point, and cthe sampling point in voxel sampling selects the average value of each voxel grid as the sampling point. dBecause voxel sampling can adjust the size of the 3D voxel grid according to requirements, the time complexity of voxel sampling can be adjusted.
Learning-based sampling method
The premise of learning-based sampling methods for point cloud down-sampling are all from the perspective of point cloud features. Most of the learning-based sampling methods combine the sampling method with the subsequent task network, and the loss of the subsequent task is used to optimize the sampling method and the key points which are beneficial to the subsequent task will be selected. The learning-based sampling method can well balance the conflicts in sampling from the perspective of features. It can not only keep the original shape of the sampled object, but also optimize the subsequent tasks. The process of learning-based sampling method is shown in Figure 3. The sampling network is trained through the trained task network, and use sampling loss and task loss as feedback. According to considering whether the final sampling points is the original point or not, the learning-based sampling method can be divided into two types: indirect selection method and direct selection method. The methods of indirect selection mainly include S-Net 30 and SampleNet 31 ; the methods of direct selection mainly include CP-Net. 32
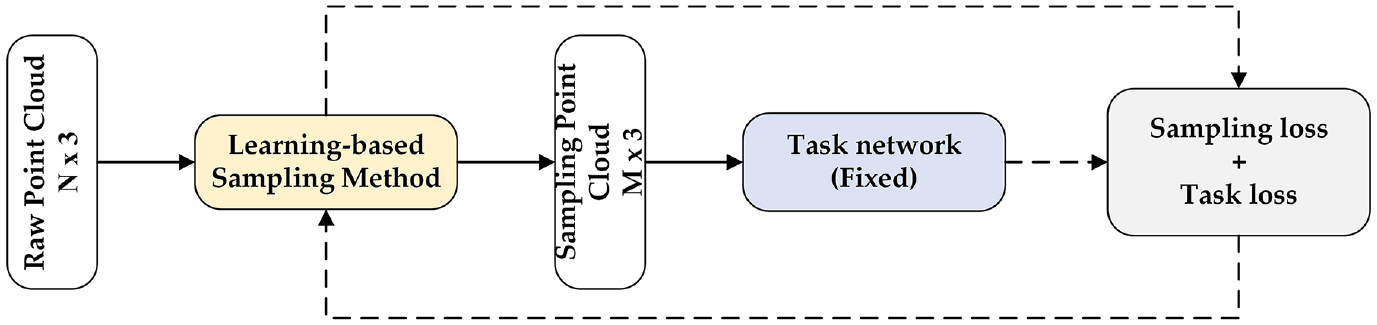
The process of Learning-based sampling method.
Indirect selection method
Different feature extraction and point selection strategies are used to generate the sampling points in indirect selection methods. However, these generated points cannot be guaranteed to be the points of the original point cloud, so it is necessary to match the generated points with the original point cloud to ensure that the final sampling points are the points in the original point cloud.
Dovrat et al. proposed S-Net, 30 in the training process, the feature of original point cloud data is extracted by PointNet, 14 and then the generated points are obtained from regression according to the extracted features. Since the generated points may not be the points in the original point cloud, an additional matching process is required in the inference process to change the generated points to the original point cloud. After matching the generated point cloud with the original point cloud, the number of sampling points may not be enough for the requirements, then FPS is used to supplement the gap. The biggest problem with S-Net is that its matching process is not differentiable, and gradients cannot be propagated through neural networks. In order to tackle this issue, Lang et al. 31 proposed SampleNet, the biggest contribution of this method is to solve the problem of non-differentiable matching steps in S-Net. SampleNet gets simplified points based on feature regression, then, each simplified point is softly projected onto its neighborhood, defined by its k nearest neighbors in the original points, to obtain a projected point. So the projected point becomes a mixture of the surrounding original points, which means that the projected point has a linear relationship with the original point cloud. However, these points may still not be the points in the original point cloud, and they need to be matched during the inference process. When the number of sampling points is insufficient after matching, FPS is used to supplement the gap. The selection of matching points is the point with the largest weight in the mixing of the surrounding points, which solves the problem of non-differentiable NN matching in S-NET.
Although the performance of SampleNet reaches the state-of-the-art, however, due to the point cloud obtained by these type of method may not be the point in the original point cloud, an additional matching process is required. Meanwhile, when the number of sampling points after matching is insufficient, other methods need to be used to supplement.
Direct selection method
Direct selection method directly selects the original point cloud to obtain sampling points by using specific rules combined with the extracted features. This type of method only needs the loss function of the subsequent task network to optimize the selected sampling points.
Nezhadarya et al. 32 proposed a direct point selection method (CP-Net) for classification tasks, which uses CPL (Critical Point Layer) or WCPL (Weighed Critical Points Layer) to select sampling points. The idea of the CPL is to select the point that provides the largest feature of a certain dimension for max-pooing in the classification network as the sampling point. The process of WCPL is similar to CPL, while the biggest difference is that the index of points that contribute to the global feature multiple times will be repeatedly put into the candidate sampling point set, and the probability of these key points being selected will increase. The global features obtained through max-pooling represent different categories, 33 so the points that provide the largest features as sampling points are more conducive to improving the efficiency of the classification network. Regardless of the selection of sampling points through CPL and WCPL, when the number of sampling points is insufficient, the nearest neighbor point needs to be supplemented.
CP-Net is different from the other learning-based sampling methods, which integrates sampling process into the task network DGCNN. 34 When the task network extracts some features, the original point cloud data is sampled and selected according to the CPL, and the other learning-based sampling methods are composed of sampling network and task network, instead of integrating sampling into task network. Therefore, CP-Net is not a pure sampling method, but integrates a sampling idea that is beneficial to the current task into the task network. Compared with other learning-based sampling methods, it is not conducive to combining the sampling method with other task networks.
Table 2 shows current learning-based sampling methods. It can be seen from Table 2 that PointNet or DGCNN is used as the feature extraction network in learning-based sampling methods. For all the current learning-based sampling methods, the generated points are not selected from the original point cloud directly, so the generated points of the sample need to be matched with the original point cloud (re-matching problem); the amount of output sampling points obtained after matching are not controllable (may not be enough for sampling requirements), which need to be supplemented by FPS or nearest neighbor point (re-supplement problem).
Current learning-based sampling methods.
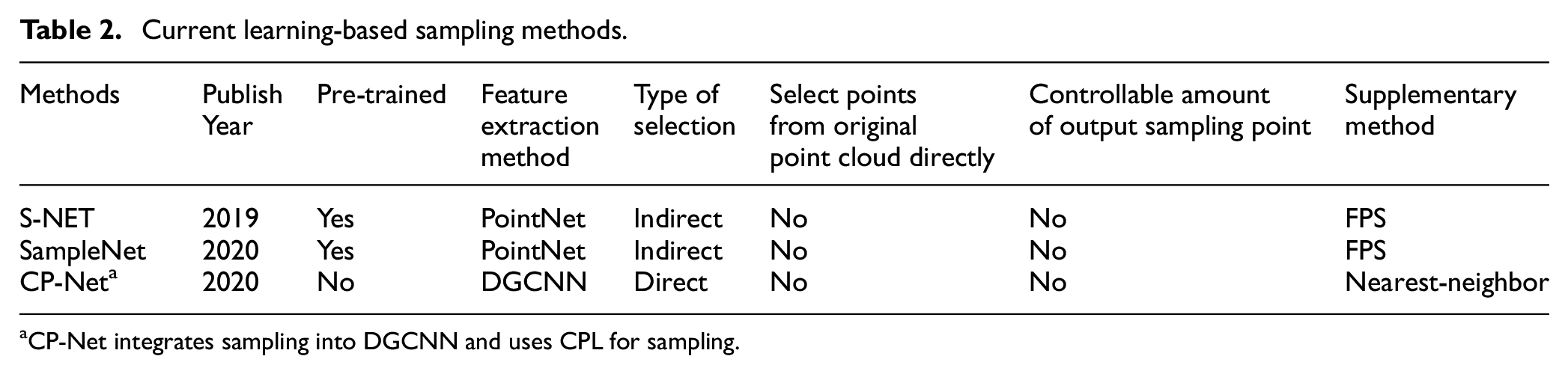
CP-Net integrates sampling into DGCNN and uses CPL for sampling.
In this paper, in order to better select the points carrying the key information as the sampling point according to subsequent tasks, and to solve the problem of re-matching and re-supplement of sampling in the learning-based sampling method, the LSTM structure and attention mechanism are introduced to the sampling process. LSTM is used as the feature extraction method; attention mechanism is used to select the high score points. The LSTM and attention mechanism have been successful used in many fields, such as: NLP (Nature Language Processing) and image classification. LSTM network is a special recurrent neural network (RNN), which well solves the problem of long-term dependence, so it has been successfully applied in various fields including speech recognition, text modeling, interpretation, behavior prediction, and video understanding. However, LSTM has the limitation of hard to attain the finally reasonable vector representation when its input sequence is long. To solve this problem, attention mechanism is proposed. In attention mechanism, the intermediate result of LSTM is reserved, then learnt by applying a new model and finally correlated with the output to screening information. 35 In recent years, attention mechanism has been increasingly widely applied to image processing and the network based on attention mechanism is also used in processing 3D data. For example, as for SeqViews2SeqLabels, 18 although multi-view method is employed in the main part of the network, the RNN based encoder-decoder structure is used when processing the view information and the spatial information between views. To relieve the overfitting problem incurred by training using finite 3D shapes, the attention mechanism is introduced to improve the discriminatory power of the network and to add corresponding weights for each shape classification. The 3D2SeqViews 36 network also learns the 3D global features by using multi-view method. However, it uses the hierarchical attention to process massive information in views and the spatial relationship between views, which can more effectively fuse the sequence views. By using the method, the information within each view is first encoded; then, the view-level attention and classification-level attention are proposed to perform hierarchical weighting on the sequence views and shapes.
Materials and methods
In this section, we describe the methodology of our proposed LA-Net. Given the input original point cloud set P, the sampled point cloud set S is obtained by LA-Net, then S is treated as an input for the subsequent task network. Since LA-Net selects the sampling points from the original points directly, there is no need to design additional matching process. Therefore, the loss function of the subsequent task network can be directly used to optimize the selection of the sampling point cloud, the loss function as shown in equation (1).
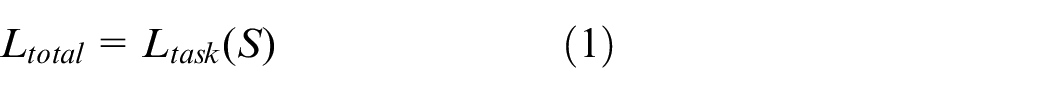
The structure of LA-Net is shown in Figure 4. LA-Net is composed of two layers of LA-Layer, and each layer is composed of a LSTM based feature extraction module and an attention-based selection module, the structure of LA-Layer is shown in Figure 5. In feature extraction module, the LSTM is the original network which is used to calculate the feature value of input point cloud. In the attention based selection module, we redesigned the selection strategy to keep the required sampling points according to the sorted index. Different from the existing learning-based sampling method using PointNet or DGCNN for feature extraction, LSTM can further establish the correlation between the input point cloud and the sampling point cloud while extracting features. The process of LSTM based feature extraction is introduced in section “(a) Feature Extraction,” and the attention based selection strategy is introduced in section “(b) Sampling Point Selection.”
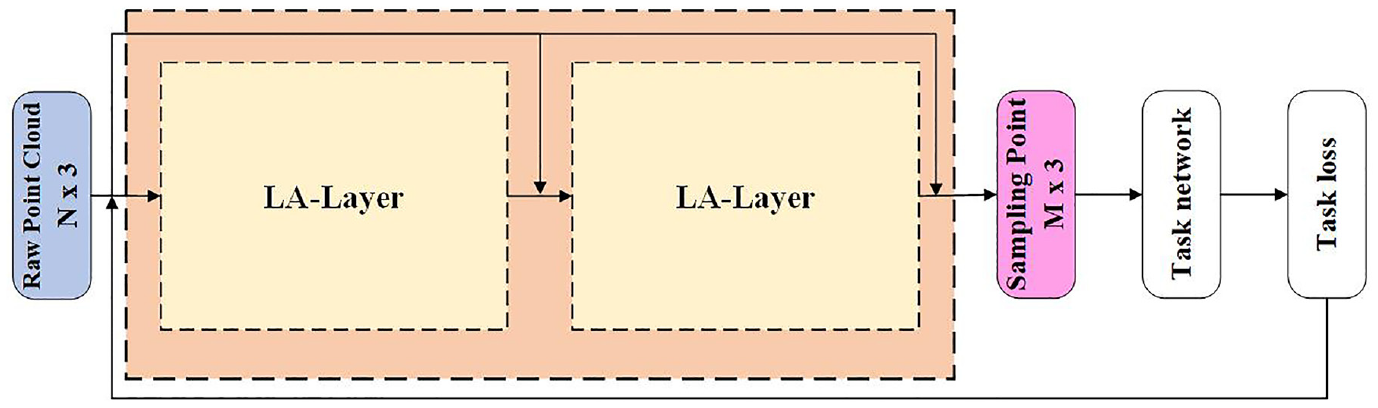
The structure of LA-Net. LA-Net is composed of two layers of LA-Layer, after two layers of sampling, the number of point cloud is sampled from N to a specified number M (M is setting manually).
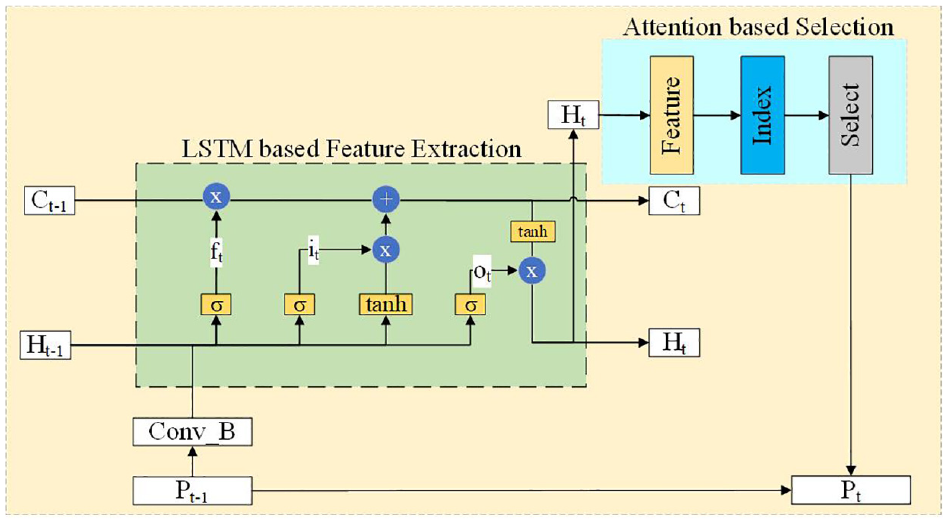
The structure of LA-Layer. LSTM based feature extraction is used as the feature extraction method to obtain the relational weight which relative to the subsequent tasks, the attention based selection is used to select the high score points.
Feature extraction
The function of LSTM based feature extraction module is to extract the features of input point cloud by using a well-designed gate structure in the LSTM. The feature extraction procedure mainly includes three main steps.
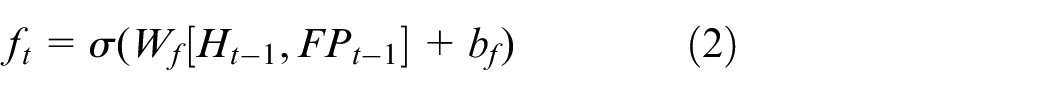
where, ft indicates the output of forget gate, Ht–1 and FPt–1 denote the hidden-layer future of the previous layer and the feature of the input point clouds, respectively. Wf means weights and bf means bias.
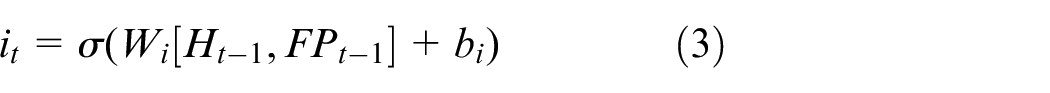
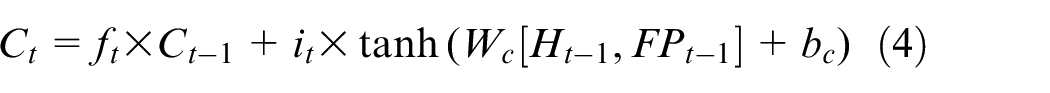
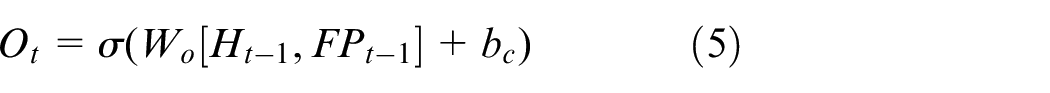

Sampling point selection
When selecting sampling points, the attention mechanism is used to directly process the final output Ht after feature extraction with the sigmoid function to obtain the scoring mapping of the original point cloud data. The attention mechanism is an indispensable part of LA-Layer, which is used to select greater weight of the points in the original point cloud that are closely related to the subsequent task. Meanwhile, another function of the attention mechanism is to keep the required sampling points according to the sorted index. The score range of each original point cloud is from 0 to 1, as shown in equation (7). After mapping, the points in the original point cloud that are strongly related to subsequent tasks are identified, this means that a point with a larger score indicates a key point that has a higher intention to be concerned and carries more information that is helpful for subsequent tasks. So that in the process of feature extraction, the key points of point clouds that need to be paid attention can be better learned.
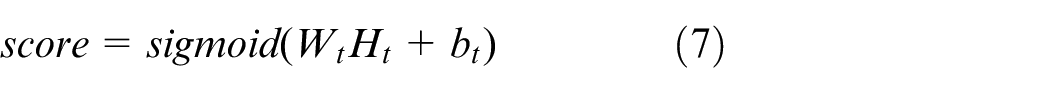
Then, all the points are sorted by score of each point, and finally get the required sampling points according to the sorted index, as shown in (8)and (9). The selection of the sampling point is only based on the score of the point, this means that the degree of correlation between the point and the subsequent task. This is a symmetric method similar to max pooling, which solves the problem of disorder of the point cloud.

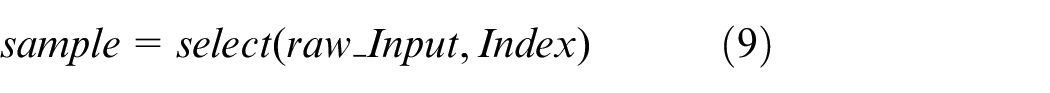
LA-Net is a learning-based sampling method. The original point cloud is scored and sorted by using the extracted point cloud features, and finally the first M point clouds after sorting are directly selected as the final sampling point cloud according to the amount of sampling requirement M (M indicates the amount of sampling points in set S). This point selection strategy based on the attention mechanism directly samples the points with strong correlation between the original point cloud and subsequent tasks, and also can sample the required number of point clouds at 1 time. Therefore, LA-Net is different from other learning-based point cloud down-sampling methods, which removes the extra matching process and supplementary process. LA-Net reduces the complexity of the entire sampling network and improves the efficiency of sampling.
Experiments
In this section, we applied LA-Net to two tasks: point cloud classification and retrieval. For classification and retrieval, we adopt the ModelNet40 point cloud data and PointNet as the task network. The ModelNet40 dataset contains 12,311 CAD models of 40 types of objects, of which 9943 are used for training and 2468 are used for testing. Among them, the point cloud classification task uses the classification accuracy rate as the evaluation index, and the point cloud retrieval uses the mean Average Precision (mAP) as the evaluation index. In order to make a fair comparison, other learning-based sampling methods all use points after the matching process, so all the sampling points are subsets of the input point cloud. In addition, detailed ablation studies have also been carried out, which provably affirm the advantage of each component we proposed.
Classification results
In the experiment, the structure of LA-Net consists of two layers of LA-Layer, and the feature extraction dimension is 32. In the training process, the parameters setting are the same as those of the PointNet paper. 14 The experiment is performed on GTX1080Ti GPU, and the number of training is 500 rounds. We compare several different sampling methods: RS, FPS, S-Net, SampleNet and LA-Net, for sample size of k∈ 32, 64 points. The sampling ratio is defined as n / k = 1024/k. Then, these sampled points are used as the input to test the classification accuracy. The results of the classification experiment are shown in Figure 6 and Table 3.
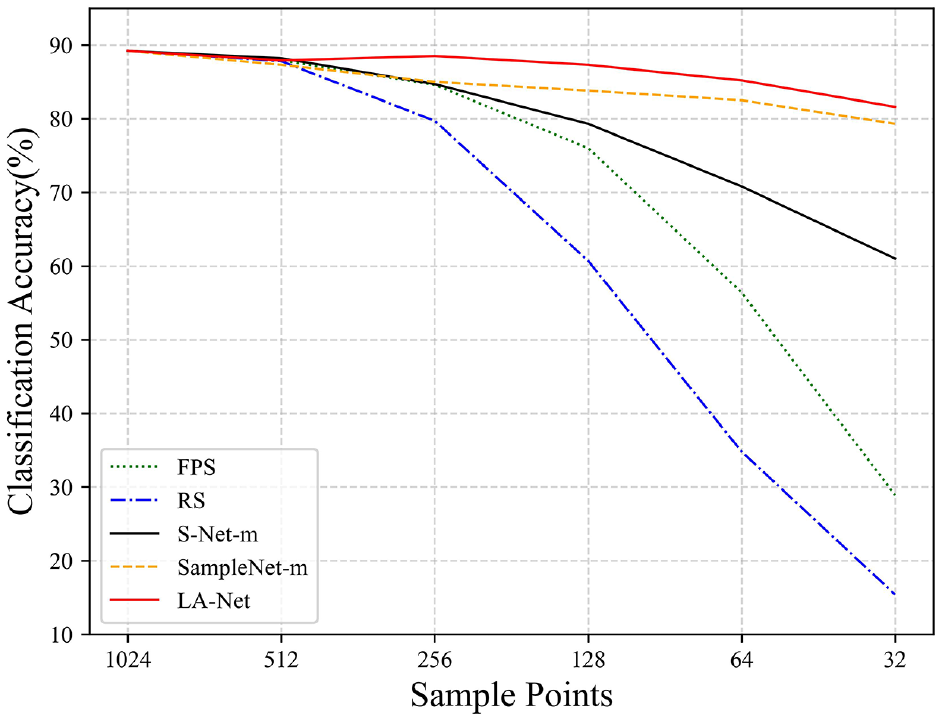
Classification accuracy of five points cloud down-sampling methods. The point cloud data obtained through these sampling methods are all raw point cloud data. It can be seen from the figure that in the case of low sampling rate, our sampling method LA-Net outperforms the other four sampling methods.
Comparison of classification accuracy of different down-sampling methods.
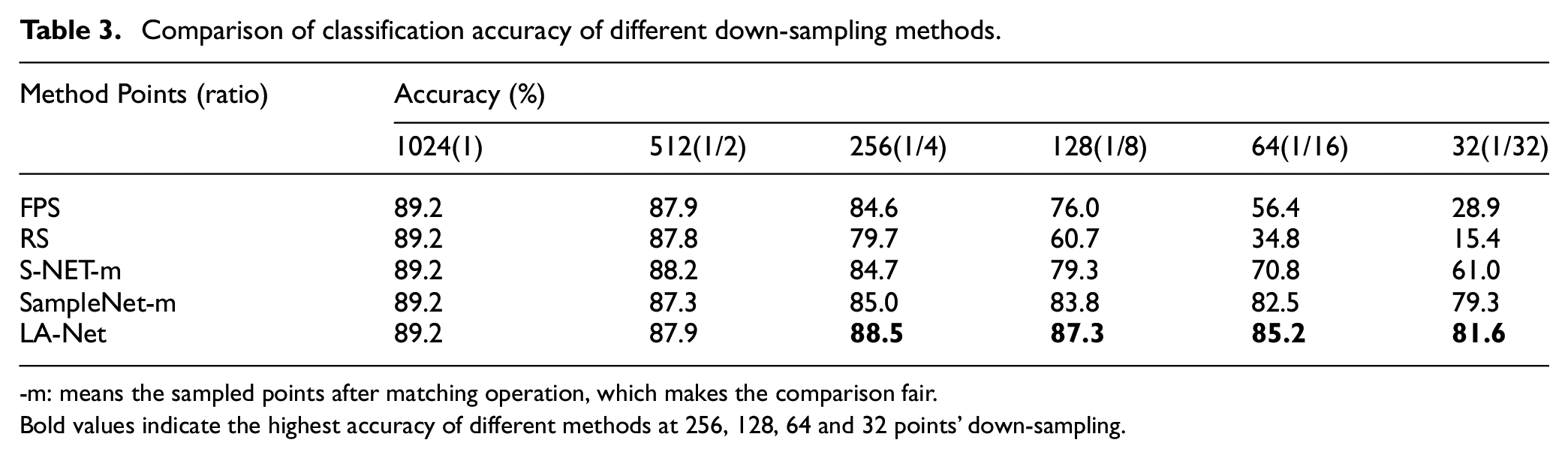
-m: means the sampled points after matching operation, which makes the comparison fair.
Bold values indicate the highest accuracy of different methods at 256, 128, 64 and 32 points’ down-sampling.
From the experimental results in Figure 6 and Table 3, it can be seen that when the number of sampling points is large, the learning-based sampling method and the non-learning sampling method have similar effects on subsequent tasks. However, when the number of sampling points is small, the learning-based sampling method is obviously better than the non-learning sampling method. This is because, when there are fewer input points, the points with obvious features that are beneficial to the subsequent network are selected through learning methods. At the low sampling rate, the classification accuracy of LA-Net surpasses other four sampling methods and reaches the best. When the number of sampling points is only 32, LA-Net still achieves the accuracy of 81.6%. It shows that the point clouds obtained by extracting features with LSTM structure and selected by attention mechanism in this paper are the points with rich information and obvious features, which are beneficial to subsequent tasks. The model actually sampled by LA-Net in the ModelNet40 dataset is shown in Figure 7. From the actual sampling model, it can be seen that the LA-Net sampling model well retains the key points of more prominent features in the original model even at a low sampling rate.

Visualization results of the model in the ModelNet40 dataset after actual sampling by LA-Net. The original point cloud of each model in ModelNet40 with 1024 points, and the sample size gradually decreases to 32 points from 512 points: (a) Airplane Model, (b) Cup Model, (c) Chair Model, (d) Bowl Model, (e) Toilet Model, and (f) Plant Model.
Retrieval results
Point cloud retrieval is to search related 3D point clouds in the database under the premise of given input query point cloud, and output models of the same category or similar shape. The search process is usually completed by finding shapes with similar descriptors. 14 For the retrieval experiment, the original point cloud data is sampled by LA-Net, and then input into the classification network, 14 the feature of the penultimate layer of the classification network was selected as the shape descriptor. The benchmark dataset ModelNet40 is used for evaluation, and the mAP is used as the evaluation index. Other experimental settings are consistent with the classification experiment, and the point cloud retrieval experiment results are shown in Figure 8 and Table 4.
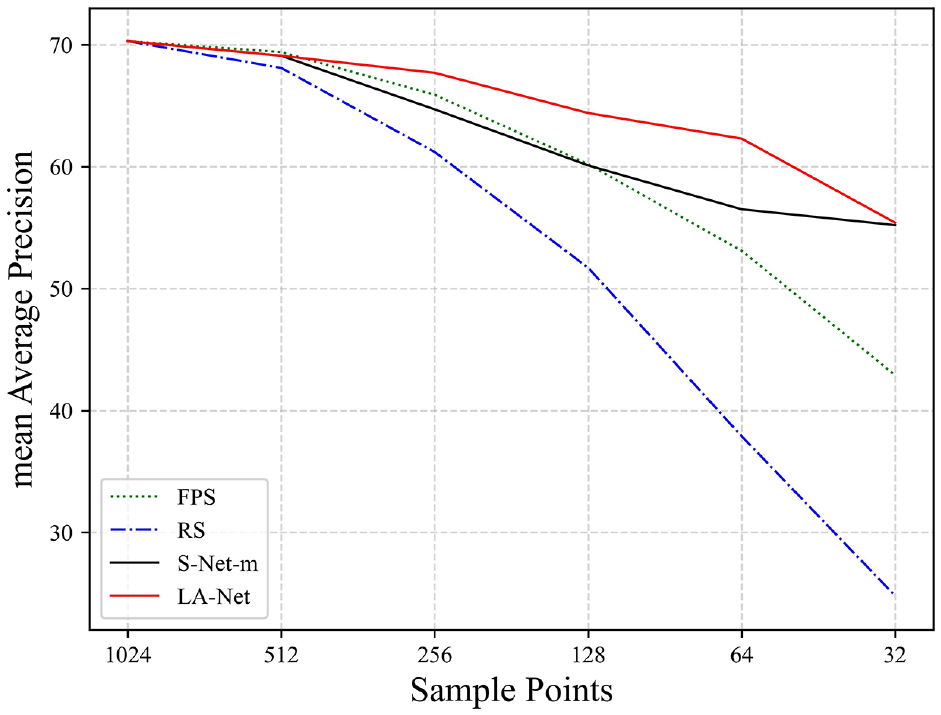
Point cloud retrieval results of different sampling methods. It can be seen from the figure that in the case of low sampling rate, our sampling method LA-Net reaches the state-of-the-art.
Comparison of retrieval performance of different down-sampling methods.
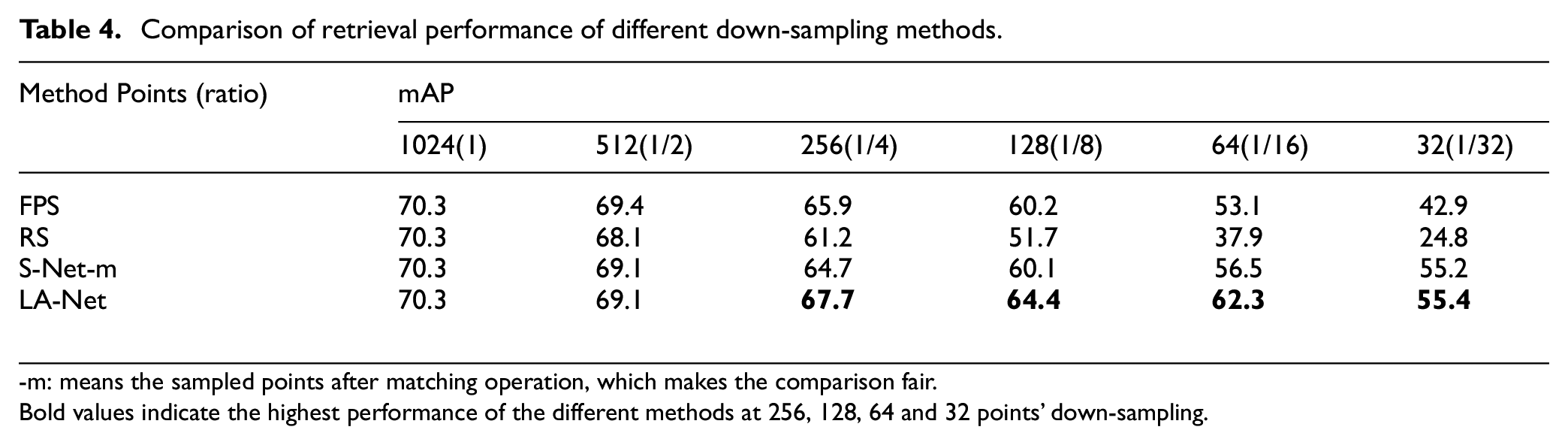
-m: means the sampled points after matching operation, which makes the comparison fair.
Bold values indicate the highest performance of the different methods at 256, 128, 64 and 32 points’ down-sampling.
Table 4 and Figure 8 summarize the mean Average Precision for different sampling methods at different sampling rates. In most of the cases, LA-Net produces higher mAP than RS, FPS, and S-Net-m. Especially, for low sampling rates, LA-Net is significantly higher than other sampling methods. For example, when the number of sampling points of LA-Net is 64, the mAP can still reach 62.3, which is 24.4, 9.2, and 5.8 higher than RS, FPS, and S-Net-m respectively. These observations indicate that LA-Net can extract features that are more discriminative for retrieval.
Ablation study
In this section, we conducted three ablation studies to comprehensively analyze and verify LA-Net. Specifically, we examine and analyze the number of layers of LA-Layer in LA-Net, the dimensions of feature extraction in LA-Layer and the method of feature extraction. In the ablation studies, by changing a module that needs to be explored each time, leaving other modules unchanged, using the changed LA-Net to sample the original point cloud data, and then the sampling points are used as the input of the classification network PointNet to test the classification accuracy and time consumption. Among them, the time consumption is calculated by running once time of ModelNet40 test sets.
Different LA-layer layers
This ablation study mainly analyzes the impact of different LA-Layer layers in LA-Net on the classification accuracy. Tables 5 and 6 and Figure 9 compare the classification accuracy and the time consumption under different layers.
Comparison of classification accuracy under different layers of LA-Layer in LA-Net, where LSTM extracts feature dimensions in LA-Layer is 32.
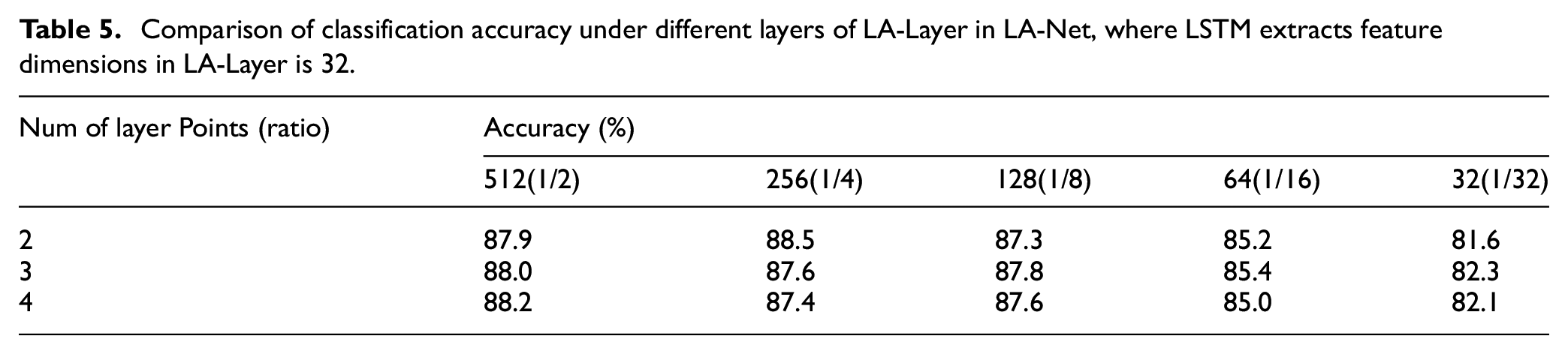
Comparison of time consumption under different layers of LA-Layer in LA-Net, where LSTM extracts feature dimensions in LA-Layer is 32.


Comparison of classification accuracy and time consumption under different LA-Layer layers in LA-Net: (a) classification accuracy under different LA-Layer layers in LA-Net, (b) time consumption under different LA-Layer layers in LA-Net.
It can be seen from Tables 5 to 6 and Figure 9 that when the number of sampled point clouds is the same, the effect of different layers in LA-Net on the classification accuracy does not exceed 1%. On the contrary, as the number of LA-Layer layers in LA-Net increases, the LA-Net model becomes more complicated and the test time becomes slower. Therefore, for the choice of the number of LA-Layer layers, two layers are sufficient.
Different feature dimensions
This ablation study mainly explores the impact on classification accuracy and time consumption when LSTM in LA-Layer extracts features of different dimensions. Different feature dimension indicates the number of features included in each output point cloud. Table 7 and Figure 10 compare the classification accuracy and time consumption in different dimensions. This ablation study mainly analyzes the impact of different LA-Layer layers in LA-Net on the classification accuracy. Tables 5 and 6 and Figure 9 compare the classification accuracy and the time consumption under different layers.
Comparison of classification accuracy and time consumption under different feature dimensions which are extracted by LSTM in LA-Layer. The number of LA-Layer layers is 2 and the number of sampling point clouds is 32.
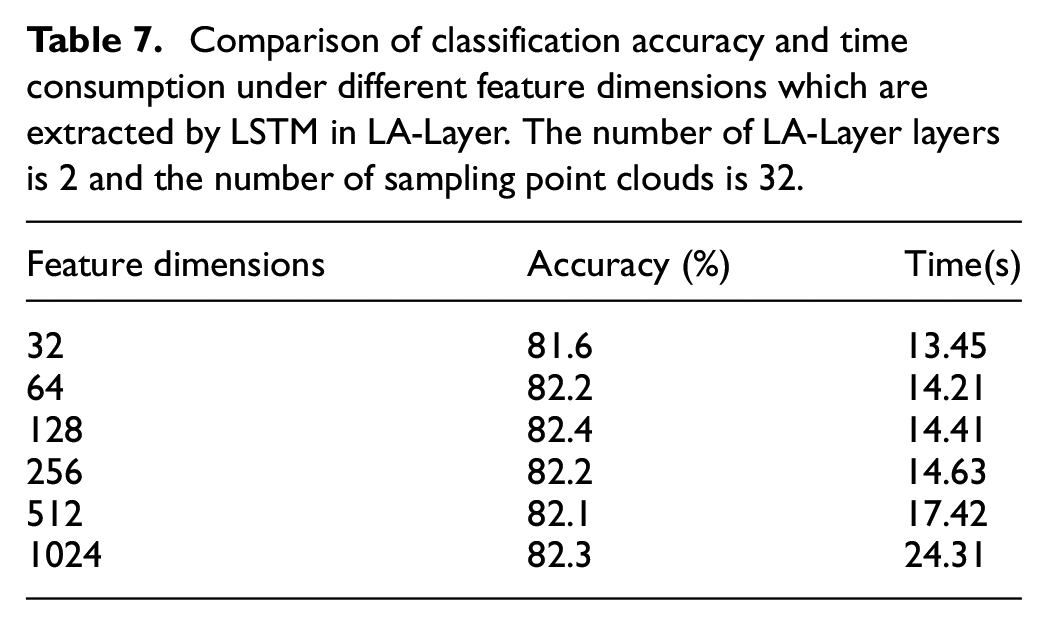
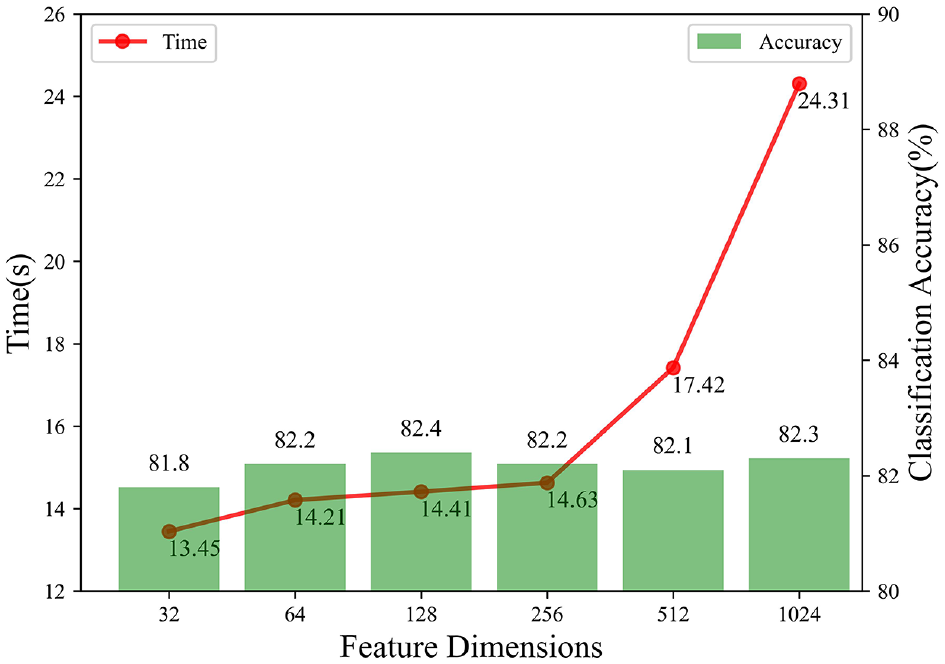
Comparison of classification accuracy and time consumption under different feature dimensions.
It can be seen from Table 7 and Figure 10 that when the extracted feature dimension is 32–128 dimensions, the accuracy of classification increases with the increase of the feature dimension, because when the extracted feature dimension is increased, more information that is beneficial to the classification task is extracted, which promotes the improvement of classification accuracy. When the extracted feature dimension exceeds 128, the accuracy of classification basically does not change, which means that when the extracted feature dimension reaches a certain value, continuing to increase will not affect the final result. Because the impact of feature improvement on the accuracy rate does not exceed 1%, but as the feature dimension increases, the test speed becomes slower, so the feature dimension in the classification experiments in this paper is 32.
Different feature dimensions
The biggest difference between LA-Net and other learning-based sampling methods is that the LSTM structure is used as the feature extraction structure. This ablation study analyzes and verifies the superiority of LSTM extraction features. In this ablation study, LSTM, DGCNN or PointNet are used as feature extraction structure, and the same point selection strategy as in LA-Layer is adopted to obtain the sampling points into the final classification network. The specific experimental results are shown in Tables 8 and 9 and Figure 11.
Classification accuracy under different feature extraction structures, the number of LSTM layer is 2 and the feature dimension extracted by LSTM is 32.
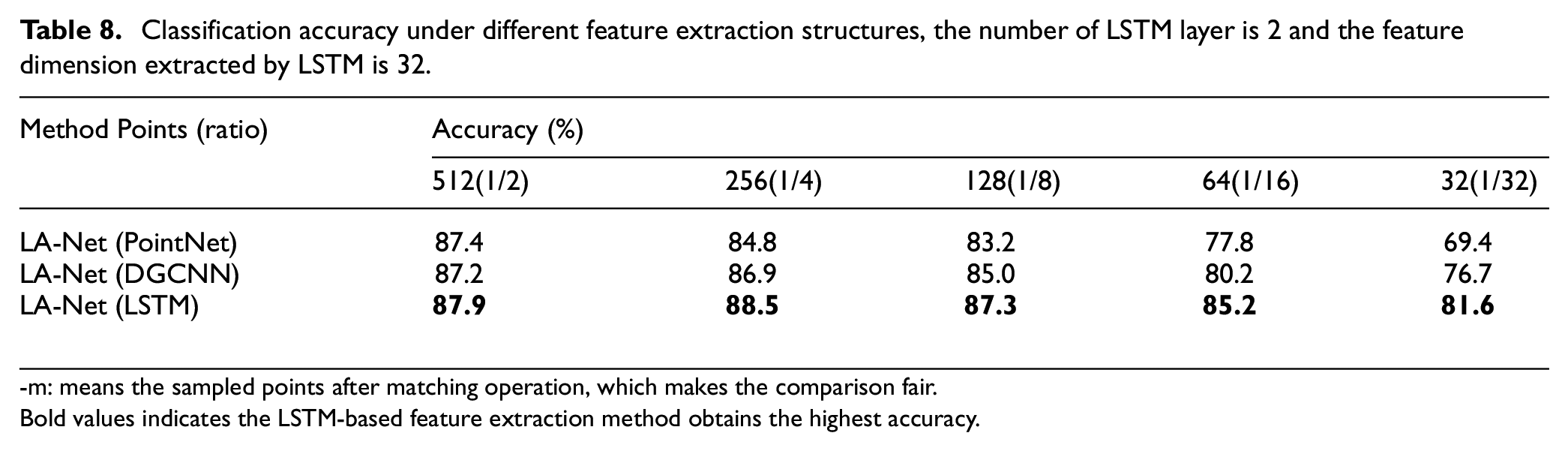
-m: means the sampled points after matching operation, which makes the comparison fair.
Bold values indicates the LSTM-based feature extraction method obtains the highest accuracy.
Time consumption under different feature extraction structures, the number of LSTM layer is 2 and the feature dimension extracted by LSTM is 32.
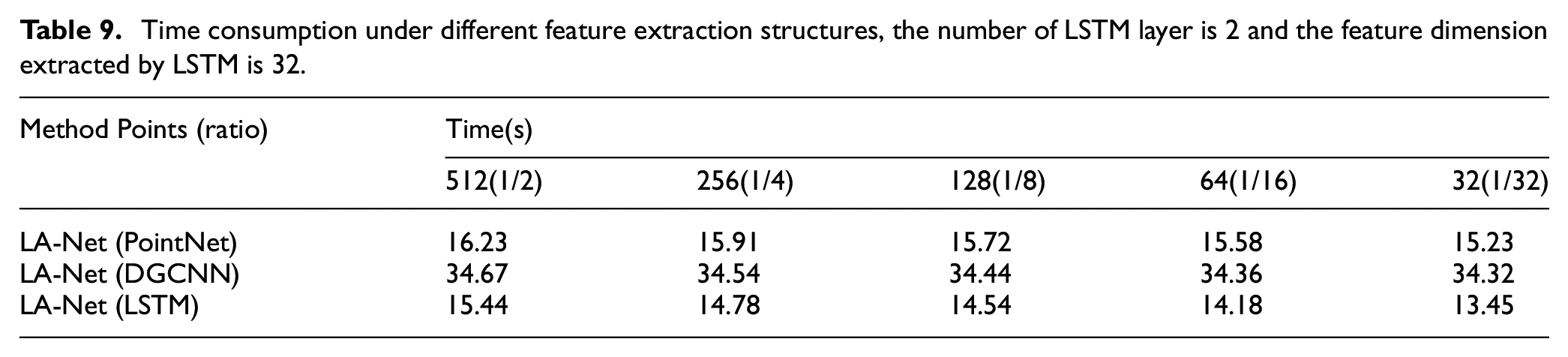
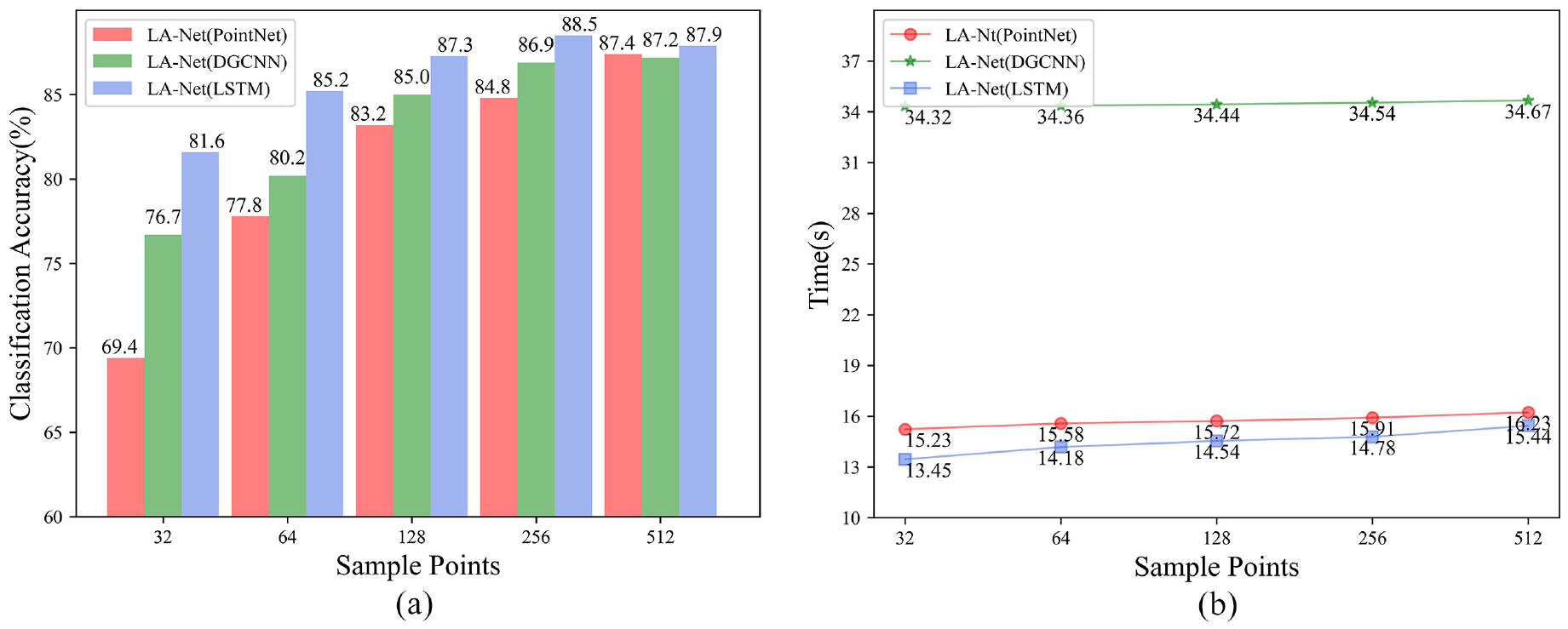
Comparison of classification accuracy and time consumption under different feature extraction structures: (a) Classification accuracy under different feature extraction structures, (b) Time efficiency under different feature extraction structures.
It can be seen from Figure 11 that under the same point selection strategy, using the LSTM structure as the feature extraction structure is significantly better than PointNet and DGCNN. This is because PointNet lacks local information when extracting features. Although DGCNN uses the difference of distances between points and surrounding points to establish a local relationship, it ignores the direction information between points. The special gate structure in LSTM can establish the correlation between the input point cloud and the sampling point cloud, which is beneficial to improve the accuracy of subsequent classification tasks. It can be seen from Table 9 and Figure 11 that using LSTM as a feature extraction structure is more concise and efficient.
Actual application experiments
In this subsection, we design a real robot grasping platform and optimize the sampling module by applying the LA-Net sampling method to the PointNet++network structure, and the new network framework is named Point-Network. The optimized Point-Network is applied to a real robot grasping experiment to further verify the effectiveness of Point-Network. In the experiment, the original data is collected by Kinect_V2 camera, and the real scene dataset RVL3DS is obtained after pre-processing, and the network is trained using the obtained dataset. Then, the point cloud segmentation and coordinate transformation obtained from the network training are used to calculate the grasping coordinates of the target object, and finally the GLUON robotic manipulator is controlled to complete the final grasping.
Task network structure introduction
The network architecture of Point-Network is shown as Figure 12. n points are input to the network and then pass two abstraction stages and a task stage to finally output the classification scores of k classes after fusing features of points using the symmetric function. Herein, abstraction stage consists of the LA-Net, GP (grouping) module and fusion module).
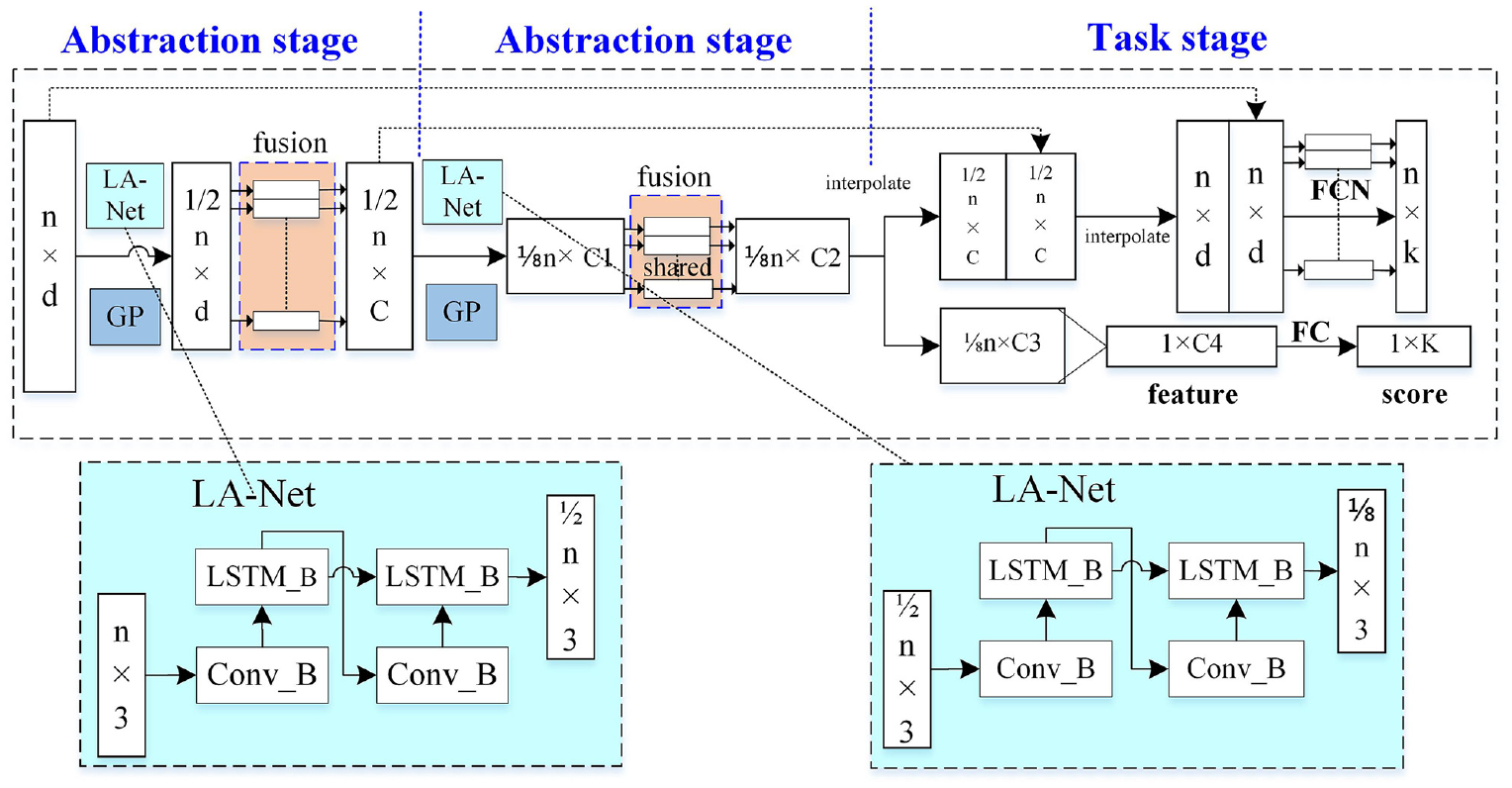
The network architecture of Point-Network. n points are input to the network and then pass two abstraction stages and a task stage to finally output the classification scores of k classes after fusing features of points using the symmetric function. Herein, abstraction stage consists of the LA-Net, GP (grouping) module and fusion module).
Hardware and software design
The Kinect_V2 camera is responsible for collecting the original point cloud data in the actual scene, while the GLUON robotic manipulator uses the perception result to finally grasping objects. The hardware architecture of the grasping platform is shown in Figure 13.
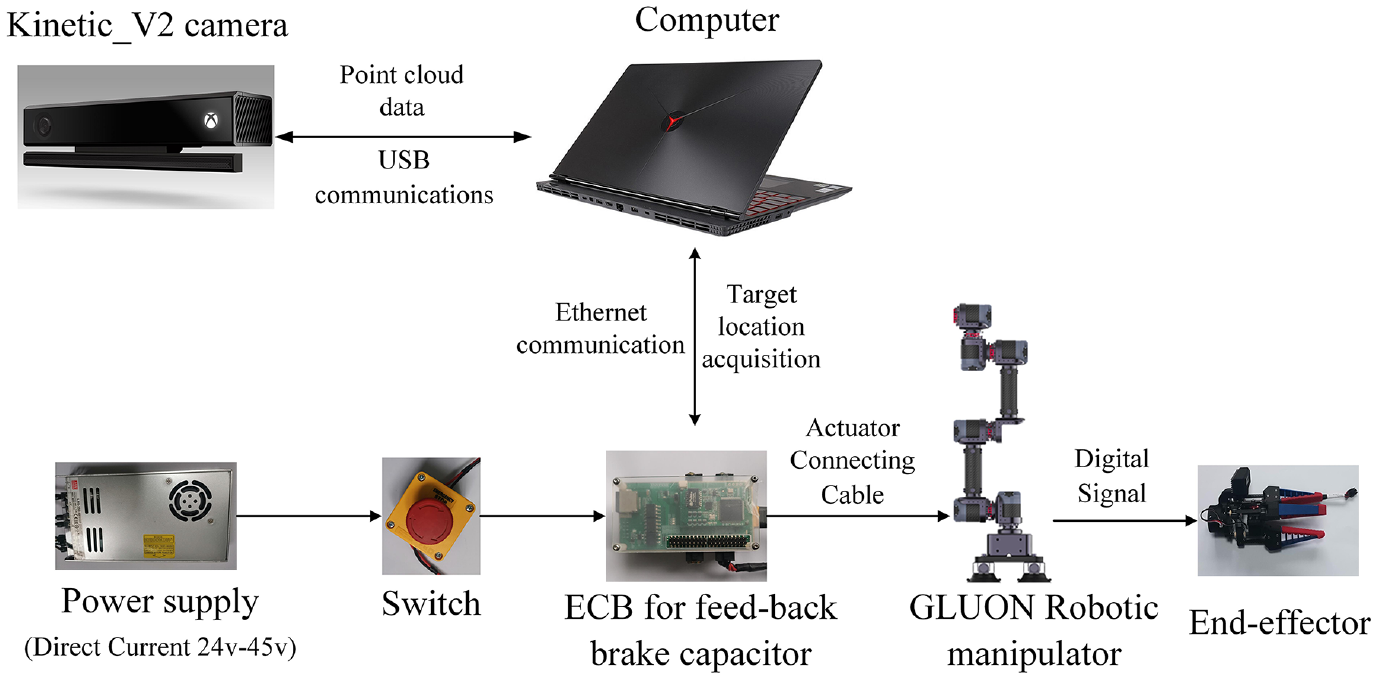
The Hardware Architecture of actual experiment.
We use an USB connection cable to connect the Kinect_V2 camera to the computer and transfer the point cloud data captured by the camera to the computer for processing. Then, the computer uses Point-Network to calculate the 3D coordinates of the object, and finally, transmits the object’s position to the ECB via Ethernet communication for robotic manipulator and end-effector control.
Since the robot need to know the position of the desired object firstly for grasping, we use the segmentation branch of Point-Network to segment the desired object and calculate its position. The software architecture of the actual robot automatic grasping platform is shown in Figure 14, which composed of three parts: point cloud acquisition and pre-processing module, semantic segmentation module, and robotic manipulator grasping module.
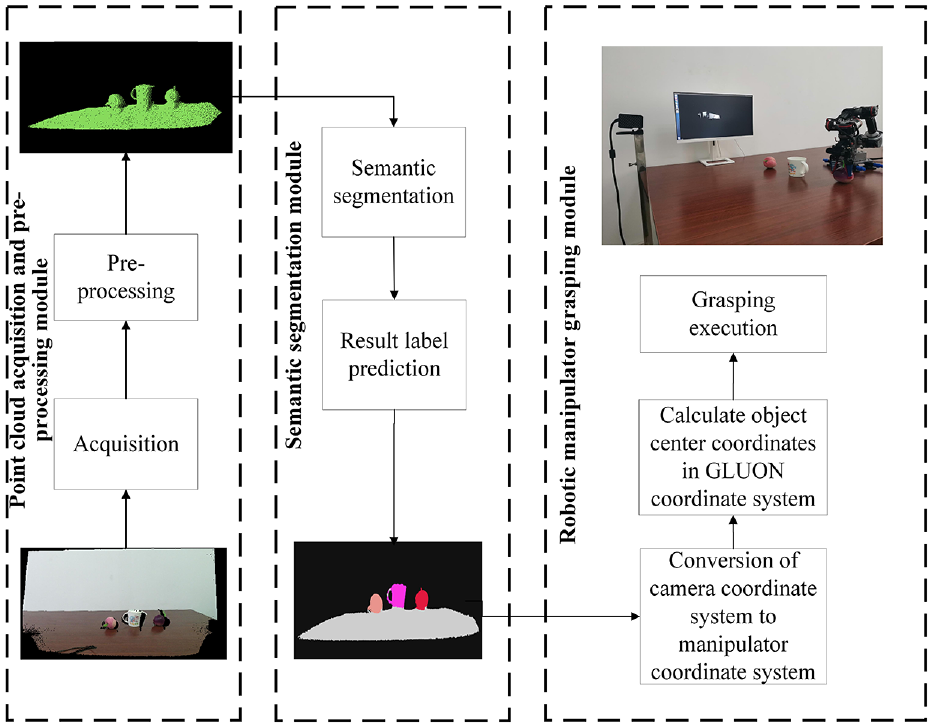
The software architecture of the actual robot automatic grasping platform. It is composed of three parts: point cloud acquisition and pre-processing module, semantic segmentation module, and robotic manipulator grasping module.
The point cloud acquisition and pre-processing module first acquires the original point cloud data of the target scene, and then pre-processes the original point cloud. The semantic segmentation module uses the Point-Network to segment the actual scene, which output the segmentation labels of each points. The robot manipulator grasping module uses the segmentation result to calculate the center coordinate of the object, and then convert the position of object to the basis coordinate system of robot for automatic grasping.
Actual dataset setup
We use Kinect_V2 camera as the data acquisition device to build our own dataset for network training, the dataset is named as RVL3DS in this paper. The process of dataset setup including three steps: filtering, sampling, and labeling.
The filtering process is to improve the efficiency and accuracy of semantic segmentation by applying pass through filter to the original point cloud data, keeping only the point clouds in the desired area and removing the useless background points. The purpose of sampling is to make the size of each point cloud data the same during training. In the labeling process, we use the Semantic Segmentation editor tool to manually label the sampled point cloud data, for detail of our RVL3DS dataset, the desk plane is labeled as 0, and the sanitizer, cup, pill box, peach, onion, gourd, carambola, radish, mushroom and ginger are labeled from 1 to 10 respectively (Figure 15).

The point cloud data pre-processing process, in the process of labeling, the desk plane (white color) is labeled as 0, and the sanitizer (pink color), cup (light green color), pill box (gray color), peach (dark green color), onion (green color) gourd (yellow color), carambola (orange color), radish (light salmon), mushroom (salmon) and ginger (red color) are labeled from 1 to 10 respectively. (a) The original point cloud data, (b) The results after filtering, (c) The result after sampling, and (d) The result after labeling.
Actual grasping experiments
The actual robot grasping experiment is divided into two parts: the semantic segmentation experiment of the point cloud and the grasping experiment of the robotic manipulator. Firstly, semantic segmentation experiments are performed to train the dataset to obtain the result of semantic segmentation. After calculating the center position of each category of objects, the final grasping position can be obtained by converting the coordinate system between the robotic manipulator and the camera. For the grasping experiment, the inverse kinematics and trajectory planning are performed for the GLUON robotic manipulator to obtain the moving trajectory and control the opening and closing of the end-effector to complete the final gripping task.
Before grasping, the coordinate system of object needs to convert from camera coordinate system to robot basis coordinate system. In our experiment platform,
The semantic segmentation experiments were performed on a GTX1080Ti GPU with the following network parameters: Convolutional kernel size are 1 × 1; batch size = 4; training round epoch = 500; learning rate lr = 0.001; the validity of Point-Network (PointNet++-msg) is verified using our own labeled dataset RVL3DS. The model performance was evaluated using two evaluation metrics, mean intersection over union (mIoU) and overall accuracy (OA), which is as same as evaluation metrics in the PointNet++paper. The test result is shown in Table 10.
Semantic segmentation results for RVL3DS dataset.

Five object models in the RVL3DS dataset were selected for the grasping experiments. We put two or three types of object on the desk randomly, total test 100 times while guaranteeing each object appear 50 times in the dataset. The grasping success rate is used as the evaluation metric. Since the GLUON is a low-cost desktop robotic manipulator, its position repeat accuracy is about 1 cm. So in the actual grasping experiment, in order to compensate this error, we calculate the Euclidean distance (dis) between the predicted center point of the object to be grasped and the real center point, and determine whether this is a successful grasp by judging whether this distance is less than 1 cm. The specific results are shown in Table 11.
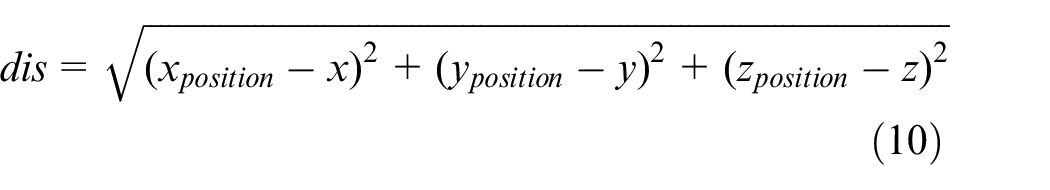
Grasping success rate of the actual experiment.

x, y, z are the real center points of the object to be captured,
As it can be seen in Table 11, the actual grasping success rate of Point-Network (PointNet++-msg) is superior to its backbone, which shows the effectiveness of our proposed LA-Net in actual application scenarios.
Conclusion
In this paper, we proposed a learning-based sampling method LA-Net which using LSTM and attention mechanism to extract and select features from the original point clouds. Our method gets the sampling points directly from the original point clouds, it solves the re-matching and re-supplement problems in the learning-based sampling method. LA-Net uses LSTM as the backbone of the sampling network to obtain the linkage weights between the original point cloud and the sampled point cloud, and uses the attention mechanism to select the original point clouds with higher feature values as the sampling points. LSTM combined with the attention mechanism can establish the relationship between features and tasks and achieve the purpose of selecting the desired features according to the task needs, providing a new and efficient solution for down-sampling of point clouds. The experiments prove the effectiveness of LA-Net. When the number of LA-Layer in LA-Net is 2 and the extracted feature dimension is 32, the performance of LA-Net is significantly better than other learning sampling methods and non-learning sampling methods in the unified benchmark ModelNet40. In the classification experiments, especially at low sampling rates, the classification accuracy remains high after sampling by LA-Net, which can guarantee higher performance compared to other algorithms. The LA-Net structure is simple and efficient, and can be well combined with the follow-up task network to implement end-to-end training.
For the future work, on the one hand, LA-Net can be applied to various backbones for large scale validation and test; on the other hand, the LSTM and attention mechanism can be applied to the other places in neural networks where require to retrieve and select the significant features.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work is supported by the National Key R&D Program of China (Grant No.: 2022YFB4700400), National Natural Science Foundation of China (Grant No.: 62073249), Youth Project of Hubei Natural Science Foundation (Grant No.: 2020CFB116), Major Project of Hubei Province Technology Innovation (Grant No.: 2019AAA071).
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.