
Abstract
In recent years, sketch face recognition has a wide application in law enforcement agencies and criminals. Deep learning plays a crucial role in the recent developments of face recognition, however, it is challenging to employ deep learning methods for sketch face recognition due to insufficient face photo–sketch data. Moreover, compared to photos, sketches lack detailed texture, and there exists a domain gap between photos and sketches, hence, traditional homogeneous face recognition methods perform poorly in sketch face recognition. In this paper, a novel deep learning method termed Domain Adaptation Scaled Entropy Meta-Network (DASEMN) is proposed to tackle sketch face recognition tasks. Specifically, a meta-learning training strategy is designed to tackle the few-shot problem and improve the generalization ability of the network. Then, a generalized entropy loss termed scaled mean entropy loss is proposed to guide the network to extract discriminate features. Finally, a domain adaptation module is introduced in the training set to reduce the domain gap between the sketch domain and the photo domain. Experiments on UoM-SGFS and CUFSF sketch face databases show that the proposed method is superior to other sketch face recognition methods.
Introduction
With the rapid improvement in computer vision, pattern recognition, and machine learning, face recognition 1 has achieved significant success in essential application fields, including video surveillance 2 and law enforcement. 1 As the application scenarios increase, collected face images contain various modalities, such as photos, near-infrared images, 3 thermal infrared images, line drawing images, 4 and sketches. Sketch face recognition 5 refers to matching the photo from an enormous gallery set based on a given sketch. It has a wide application in criminals, especially when criminal suspect photos unavailable at the crime scene, the police have to draw a hand-drawn or a composite sketch by the description from eyewitness and match it from the gallery set.
Since digital devices capture the photo while painters draw the sketch, there exist significant modality variations between face photo and sketch images. For example, sketches lack some real important texture details of forehead, chin, and cheeks compared with face photos. Furthermore, current publicly available sketch-photo datasets comprise only a few numbers of sketch-photo pairs, there is usually one sketch per subject in most datasets, and this adds the difficulties for the network to learn robust and discriminative features.
To address the modality variation problem, several sketch face recognition methods have been designed. They can be broadly categorized into inter-modality and intra-modality 1 algorithms. The intra-modal algorithms reduce the modal gap by synthesizing a photo (sketch) into a sketch (photo) and then using traditional face recognition methods designed in target modality to match the synthetic sketch (photo) with the original sketch (photo). Intra-modality algorithms heavily rely on the quality of synthesized samples. The inter-modal algorithms map two different modals’ image features into a shared space and then learn a classifier to maximize inter-class separability while minimizing intra-class differences simultaneously. So the intra-modality algorithms are used to decrease the modality space by transforming face-photo into a sketch. The inter-modality method performs sketch with face photo recognition by mining modality consistent features to match face-photos with the sketches. Recently, convolutional neural networks (CNNs) based inter-modality methods have been widely utilized to learn discriminative features for sketch face recognition.6,7 Due to the time-consuming human efforts of sketch drawing, the amount of the paired training data is limited, although CNNs offer near-perfect performance on standard image test set given abundant training data, they report poor results for the few-shot sketch face recognition.
Meta-learning8–11 is a hot issue in the field of few-shot learning, which can address the critical issue of overfitting when the amount of the paired training data is limited. Meta-learning is most commonly understood as learning to learn, which refers to the process of improving a learning algorithm over multiple learning episodes. Specifically, a machine learning model gains experience over multiple learning episodes and uses it to enhance its future learning performance. The meta-learning can be divided into two steps. During base learning, an inner learning algorithm solves a task such as an image classification. During meta-learning, an outer algorithm updates the inner learning algorithm, such that the model learned by the inner algorithm improves an outer objective.
In this paper, inspired by the meta-learning, we propose a domain adaptation Scaled Entropy Meta-Network (DASEMN) for sketch face recognition. It consists of a scaled entropy meta module and a domain adaptation module. Since there are few sketch face image data in the current sketch face dataset, and the traditional deep learning method is easy to overfit with a small amount of training data, a scaled entropy meta module is designed to improve the learning level to the task. In the scaled entropy meta module, a meta-learning training strategy is designed to enhance the network’s generalization ability, and then the feature vectors of the photos and the sketches are extracted by the network separately. Finally, a scaled mean entropy loss is proposed by using the metric relationship between the two in the feature space. Since domain adaptation12,13 is a variant of transfer learning that attempts to enhance the generalization capability of learned models by reducing the data shift between training and testing distributions, to further reduce the domain gap between sketches and photos, a domain adaptation module is introduced to minimize the maximum mean discrepancy between sketches and photos in the embedding space.
The rest of the paper is organized as follows: an overview of related work is provided in Section 1, followed by a description of the proposed methods in Section 2. The experimental results and analysis are reported in Section 3, and the conclusion is finally given in Section 4.
Related work
Sketch face recognition
Several sketch face recognition approaches are belong to intra-modality algorithms, also known as Face Hallucination (FH) techniques. Representative intra-modality approaches include the Eigen Transformations, 14 Local Linear Embedding (LLE), 15 feature-level GAN 16 and generative adversarial multi-task learning method. 17 Eigen Transformations is a linear face sketch recognition and synthesis method. It performed photo-sketch transformation under the assumption that the transformation can be viewed as a linear mapping. However, a simple linear transformation cannot represent the whole face and whole sketch well; specifically, the high-frequency information of the generated sketches is not well synthesized, and hence the quality of the generated sketches tend to be unsatisfactory. To address the limitation of the Eigen Transformations, Liu et al. 15 proposed a non-linear transformation method for face sketch synthesis, which utilize the Local Linear Embedding (LLE). In recent years, Most intra-modality algorithms focus on the generative adversarial networks (GAN), 18 which comprise a generative model G and a discriminative model D, jointly trained in an adversarial way. Inspired by the CycleGAN 19 and conditional GANs, 20 Yu et al. proposed a feature-level GAN 16 for face sketch-to-photo transformation, in which a new feature-level loss is designed to ensure the quality of the generated photos. Wan and Lee, 17 a generative adversarial multi-task learning method is proposed to simultaneously deal with sketch face synthesis and recognition. This method uses a multi-task deep network to simultaneously train the generator and extract features for sketch face recognition.
Another strategy to reduce the modality discrepancy in sketch face recognition is to extract modality-invariance feature representation from face photo and sketch images, inter-modality methods. Traditional inter-modality methods used the hand-crafted features including Scale-Invariant Feature Transform (SIFT) and Multiscale Local Binary Pattern (MLBP) to extract modality-invariance feature representation. Klare and Jain 21 proposed the Direct Random Subspace (D-RS) to extract feature, it convolves images with three filters, followed by extraction of SIFT and MLBP descriptors from overlapping patches, a cosine similarity measure is utilized to match the sketches and photos. Recently, several state-of-the-art deep learning-based inter-modality methods are proposed. A Fast-RSLCR method was proposed in Wang et al., 22 which randomly samples some patches offline, and then these patches are used to reconstruct the target sketch patch, improves the synthesis efficiency. Cheraghi and Lee, 23 proposed Sketch-Photo Net(SP-Net), it consists of a S-Net and a P-Net, the S-Net and the P-Net can learn discriminative features between the sketches and the photos. And this method employed a contrastive loss to discover the coherent visual structures between sketch and photo. Similarly, based on our proposed meta-learning training strategy, we proposed a scaled mean entropy loss to look for potential connections between facial sketches and photos of the same person.
Meta-learning
Meta-learning is also known as “Learning to Learn,” it uses previous knowledge and experience to learn new tasks. Meta-learning raises the learning level from data to task; it learns the network from labeled tasks instead of a training dataset. Existing meta-learning methods can be classified into three categories. The first is the optimization-based methods, in which the inner-level task is solved as an optimization problem, focuses on extracting meta-knowledge required to improve optimization performance. Ravi and Larochelle proposed the LSTM-based meta-learning optimizer 24 to improve the generalization performance, in which the meta-learner simultaneously considered the short-term memory of a single task and the long-term memory of all tasks. The second is model-based methods, in which the inner learning step is wrapped up in the feed-forward pass of a single model. Finn et al. proposed the Model-Agnostic meta-learning method. 25 This method aims to find the weight configuration of a given neural network so that the gradient descent update step effectively fine-tunes the small sample problem. The third is metric learning-based methods, which simulating the distance distribution between samples, and the samples of the same class are close to each other while the samples of different classes are far away from each other. Vinyals et al. proposed a matching network (Matching Networks), 26 which uses an attention mechanism to predict the class of unlabeled points (query sets) by learning to embed labeled sample sets (support sets). Wang et al. proposed Siamese Networks, 27 which learn a similarity metric to compare and match samples of new unknown categories with the learned metric. Garcia and Bruna 28 designed Graph Neural Network, which learns the relational task of information transmission end-to-end and regards each sample as a graph node. This method learns not only the node embedding but also the edge embedding. Since the meta-learning has achieved great success in few-shot learning and began to be applied to sketch face recognition in recent years, 29 we proposed a meta-learning training strategy which suitable to sketch face recognition to mimic few-shot tasks, and then domain-related query set and support set are further designed to incorporate domain information.
Domain adaptation
To avoid both labeling efforts and overfitting issues, domain adaptation is extensively studied to overcome the domain shift or dataset bias such that a learner trained on other large-scale datasets can be leveraged. In recent years, several domain adaptation methods have been proposed to learn domain invariant features for domain adaptation directly, they can be roughly categorized into statistic-based approaches and adversarial learning-based approaches. For statistic-based approaches, Long and Wang proposed the Deep Adaptation Network(DAN) in Long and Wang 30 to reduce domain shift to improve the feature’transferability of the task-specific layers of deep learning neural networks by embedding the hidden representations of all task-specific layers into a reproducing kernel Hilbert Space. Yaroslav et al. proposed the Domain-Adversarial Neural Network(DANN) in Ganin et al., 31 which learns domain uninformative features by back-propagating the gradients from the loss related to the domain classifier.For adversarial learning-based approaches, they learns domain invariant features using Generative Adversarial Networks(GAN) to synthesize images in different domains. Zhu et al. proposed Cycle-Consistent Adversarial Networks(cycleGAN) 19 to improve the similarity of the distributions of real and generated images by conditioning the generator and discriminator on discriminative information. In our method, we proposed a domain adaptation module to reduce the impact of modal differences on recognition performance by minimizing the maximum mean discrepancy between sketches and photos in the embedding space.
Proposed method
The framework of the domain adaptation scaled entropy meta-network is shown in Figure 1; it consists of a scaled entropy meta module and a domain adaptation module. Since there are few face sketch data in the current sketch face dataset, and the traditional deep learning method is easy to overfit with a small amount of training data, we designed a scaled entropy meta module to improve the learning level to the task. In the scaled entropy meta module, a meta-learning training strategy is designed to enhance the network’s generalization ability, and then the feature vectors of the photos and the sketches are extracted by the network separately. Finally, the scaled mean entropy loss is calculated by using the metric relationship between the two in the feature space. To reduce the domain gap between sketches and photos, a domain adaptation module is introduced to minimize the maximum mean discrepancy between sketches and photos in the embedding space.
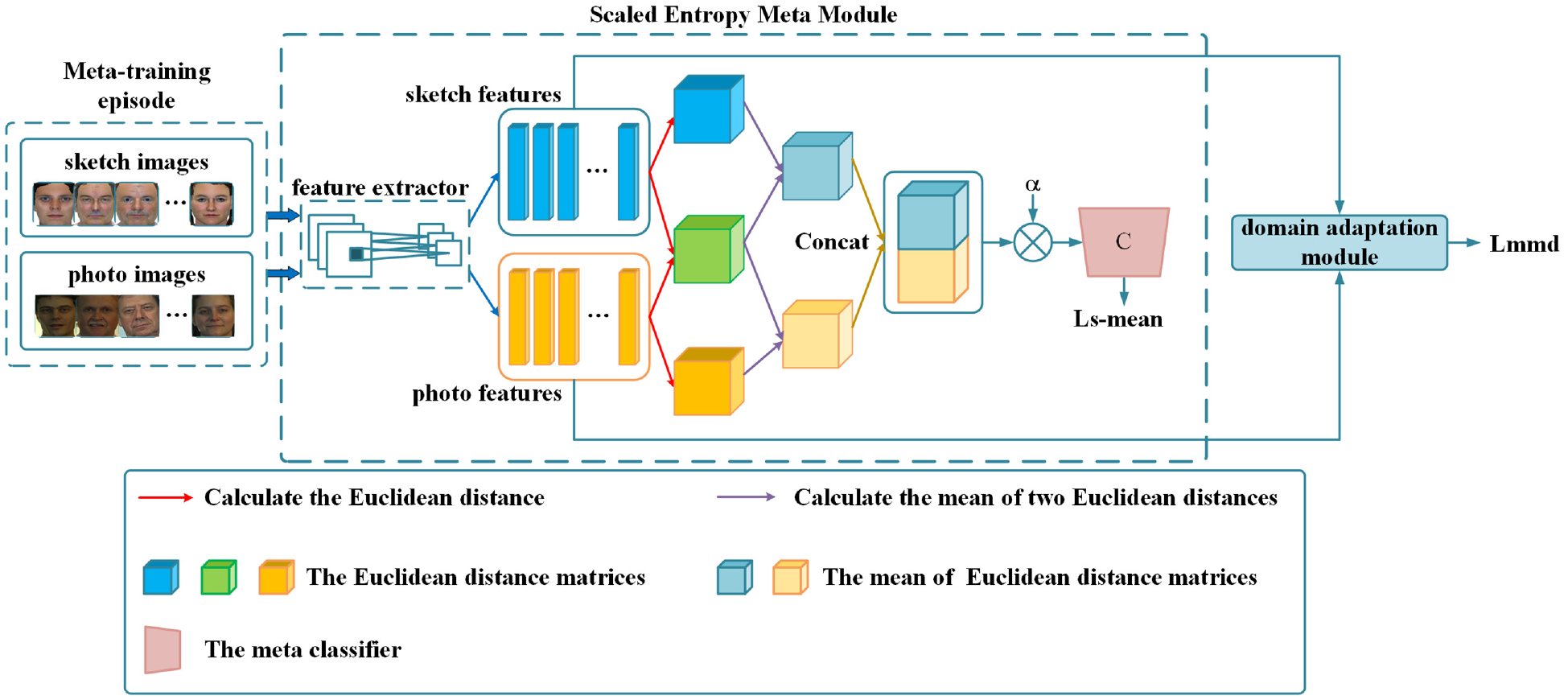
The overall architecture of our domain adaptation scaled entropy meta network (DASEMN).
Meta-learning training strategy
Inspired by the idea of the representative prototype network,
32
the following meta-learning training strategy is designed.
Since ResNet-18
33
has achieved state-of-the-art performance on traditional face recognition, it is utilized to extract the photo and sketch features. The ResNet-18 is an 18-layer residual network; it contains four residual channel modules with different channel sizes as the basic structure. Let
The entire training process can be divided into two steps. During base training, the classification task is performed in each episode, and a model is trained based on the samples in the episode. During the meta training, the model trained in the previous episode is input to the next episode and optimized based on the data in the next episode. Finally, a final model optimized based on multiple episodes is obtained.
Base training
Scaled mean entropy loss
During base training, in a training episode, given a feature


where
Our method, the Domain Adaptation Scaled Entropy Meta-Network, is based on the idea that the similarity between a point and another class is represented by the average of the distance between the point and the two points in the other class. In order to do this, we average the metric values in equations (1) and (2) to denote the similarity between the query set sample

Furthermore, by introducing a metric scaling factor

Inspired by the cross entropy function, by minimizing the negative log probability of the entire query set, the scaled mean entropy loss is computed as follows:
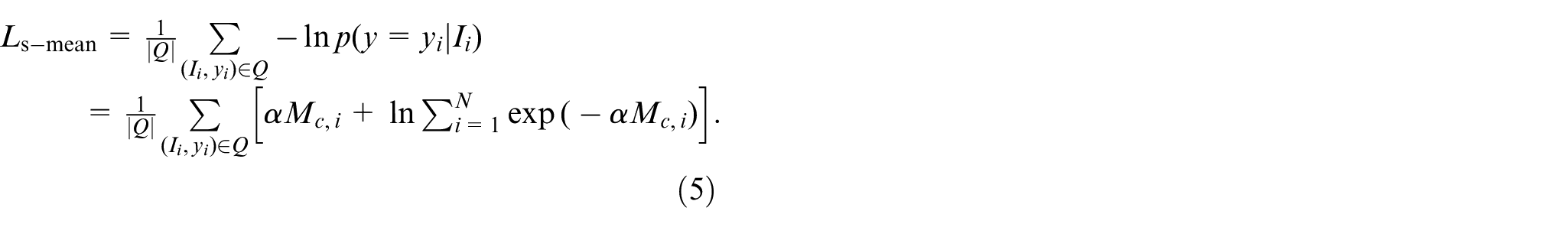
Maximum mean discrepancy loss
Since images from the photo support set and the sketch support set are from the different modal, photos are captured by digital devices while sketches are drawn by painters, there is a large modal difference between the photo and the sketch. They are resulting in a massive difference in the feature representation learned by the network. A domain adaptation module to reduce the impact of modal differences regards the sketch sets and photo sets as the source task and target task. During the training stage, the maximum mean discrepancy between the sketch sets and photo sets is continuously reduced to improve the recognition performance. The maximum mean discrepancy 34 was first proposed for the detection problem; it computed between two samples to determine whether the two distributions are the same. In this paper, The maximum mean discrepancy loss is used to evaluate the similarity between two different distributions in the Reproducing Kernel Hilbert Space (RKHS) 35 :

where
It can be reformulated as follows:

where
We square maximum mean discrepancy to construct inner product, the equation (7) can be rewritten as follows:

where

In practical applications, the maximum mean discrepancy usually averages multiple Gaussian kernel functions (e.g. different

where
The formula of


Meta training
During meta training, to balance the classification performance of the domain adaptation scaled meta-network and reduce the modal difference performance, we integrate the scaled mean loss in the scaled entropy meta module and the maximum mean discrepancy loss in the domain adaptation module into a unified optimization problem:

where

Experiment and analysis
Dataset setup
The UoM-SGFS database 37 and CUFSF database 38 are used to evaluate our method. The UoM-SGFS database is currently the largest software-generated sketch database representing all sketches in full color. It contains 600 photos from color FERET face database 39 and two sets of sketches: set A contains 600 pairs of sketch-photo face images, where EFIT-V generates the sketches. Set B also contains 600 pairs of sketch and photo, where the sketches are more realistic obtained by fine-tuning the sketches in set A through an image editing program. Some examples of sketches and the corresponding photos from the UoM-SGFS database are shown in Figure 2.

The CUHK Face Sketch FERET Database (CUFSF) is a representative database for studying sketch face recognition and synthesis. It contains 1194 individuals from the FERET database, each individual has a face photo with illumination changes and a face sketch drawn by an artist. This database is quite challenging since the photos are taken under different illumination conditions, and the sketches have numerous exaggerations compared to the photos. Figure 3 gives some examples of it.

The photos of four subjects and the corresponding sketches in the CUFSF database. 38
We divide three setups based on the above two databases: In the first setup (S1), 450 subjects of UoM-SGFS set A is selected randomly for training and the remaining 150 subjects is assigned to the test set. In the test set, the sketches constitute the probe set, and the photos constitute the gallery set. In the second setup (S2), UoM-SGFS set B is divided into training and test sets; the specific settings are the same as S1. In order to better simulate the real scene, the gallery set in S1 and S2 is expanded with photos of 1521 subjects following the same strategy as in, 1 including 509 subjects from the MEDS-II database, 1 199 subjects from the FEI database 2 and 813 subjects from the LFW database. 40 Because only the MEDS-II database and the FEI database are available, we randomly select 813 subjects from the LFW database to replace the original 476 subjects on the FRGCv2.0 database and 337 subjects on the Multi-PIE database. In the third setup (S3), we randomly select 500 subjects from the CUFSF database as the training set, the remaining 694 subjects are used for testing. To ensure the generalization ability of the proposed method, five random cross-validations were performed on the three setups. Table 1 details the experiment setup.
Experiment setups.

Experimental details
Experimental settings
We employ the MTCNN
41
to perform face detection and alignment in the UoM-SGFS dataset and the CUFSF database, and only retain the critical point information of the face to obtain face images of the same scale. Figure 4 shows some examples after performing the above processing from the UoM-SGFS database. All images are cropped to the size of

Cropped images from the UoM-SGFS database. The first row is photos, the second and third row are the corresponding sketches from the two sets of the UoM-SGFS database, respectively.
Training details
In the training process, a total of
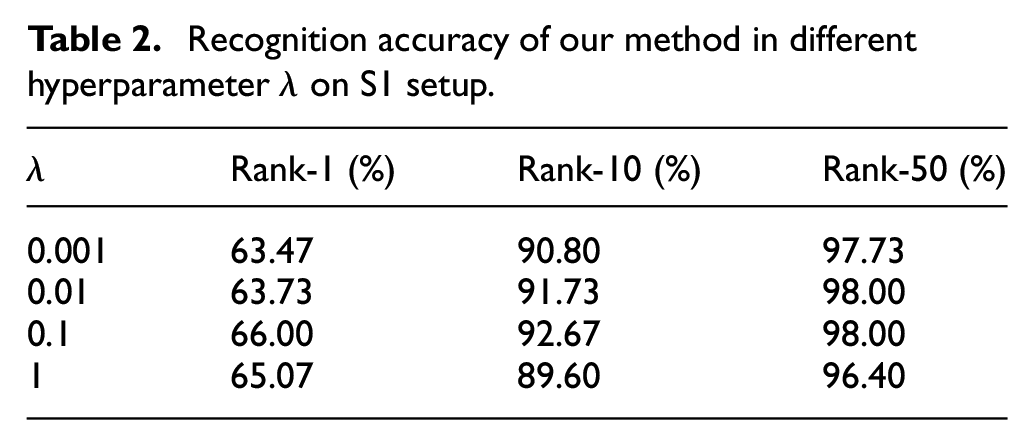
We show how to determine the hyperparameter
To analyze the sensitivity of different loss hyperparameter to the overall loss, we set the
Recognition accuracy of our method in different hyperparameter
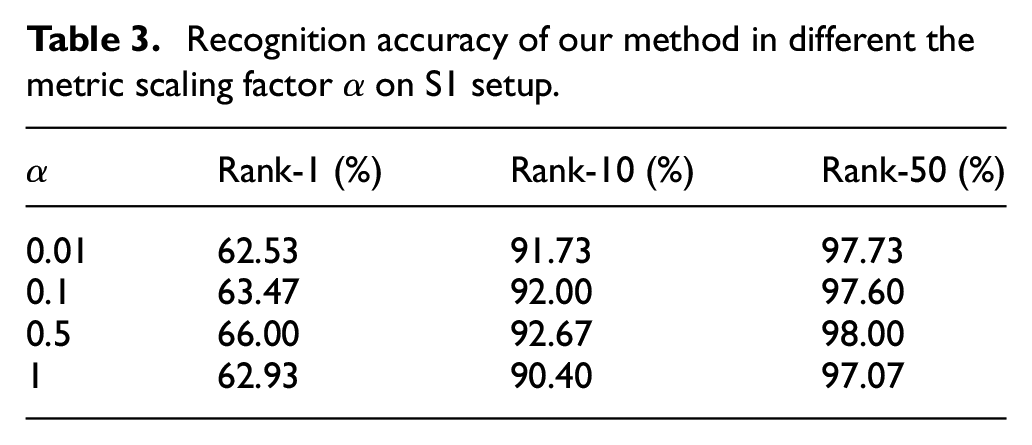
To analyze the sensitivity of the metric scaling factor
Recognition accuracy of our method in different the metric scaling factor
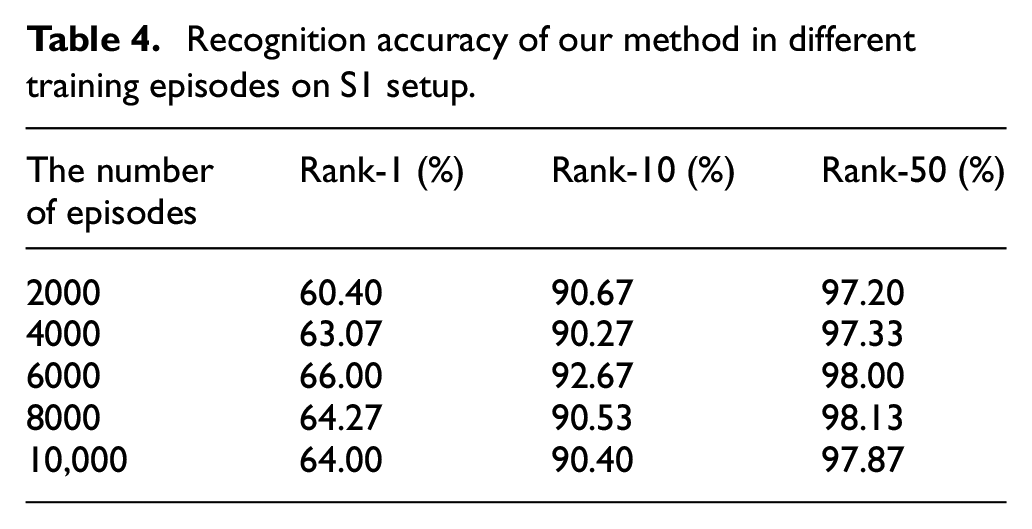
To study the influence of the number of training episodes on the recognition performance of our method, we keep other experimental parameters unchanged and train the networks under different numbers of training episodes on the S1 setup. Table 4 shows the results of the learned model saved in different training episodes. When the number of training episodes is less than 6000, the recognition accuracy of the learned model increases as the number of episodes increases since it has not converged. However, when the number of training episodes increases from 6000 to 10,000, the model begins to be overfitting and the recognition performance decreases.
Recognition accuracy of our method in different training episodes on S1 setup.
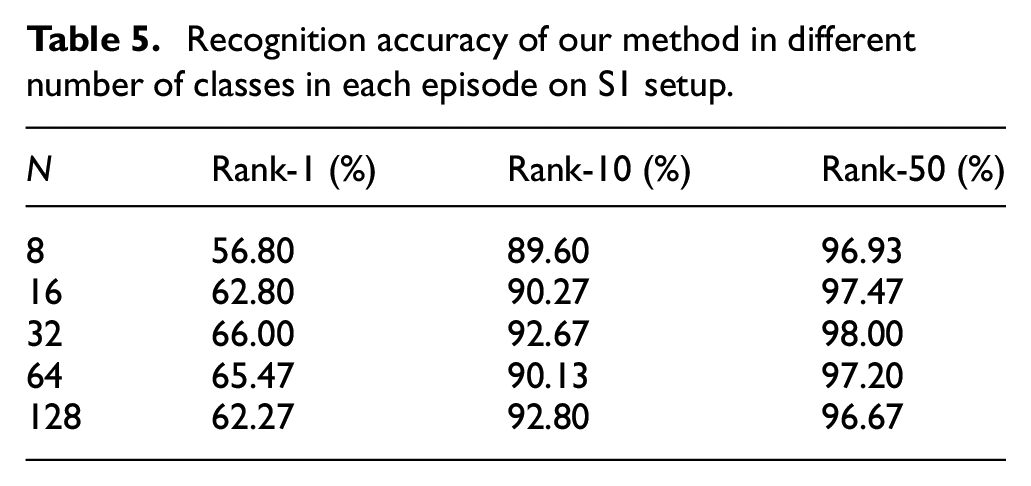
To study the influence of the number of classes in each episode on the recognition performance of our method, for the S1 setup, we set N to 8, 16, 32, 64, and 128, and other experimental parameters are consistent. The results are shown in Table 5. We can found that the recognition accuracy of the learned model reaches the best when N is set to 32. As N increases from 8 to 32, the recognition performance of the learned model is gradually increasing. The number of hard negative samples increases as the number of classes in each training episode increases, which improves the learning ability of the learned model. As N increases from 32 to 128, the learned model begins to be overfitting and leading to a decline in recognition performance.
Recognition accuracy of our method in different number of classes in each episode on S1 setup.
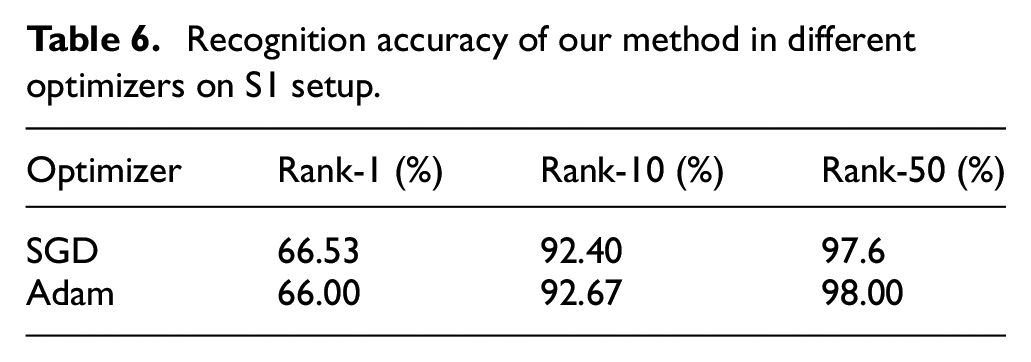
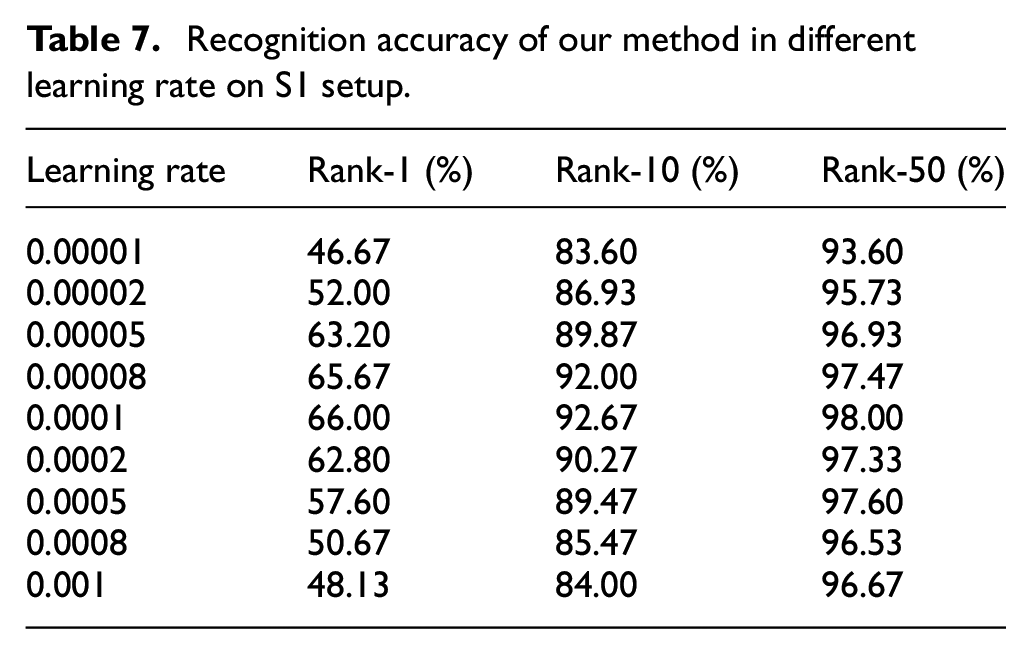
To further study the influence of the optimizer and initial learning rate on the recognition performance of our method, we keep other experimental parameters unchanged and train the networks under different optimizer and initial learning rate on the S1 setup. Table 6 shows the results of the learned model saved in SGD and Adam optimizer. Table 7 shows the results of the learned model saved in different initial learning rate. As shown in Table 6, the SGD optimizer and the Adam optimizer share comparative performance, illustrating the robustness of the proposed method. As shown in Table 7, when the initial learning rate is less than 0.0001, the recognition accuracy of the learned model increases as the initial learning rate increases since it has not converged. However, when the initial learning rate increases from 0.0001 to 0.001, the model skip the best results and the recognition performance decreases.
Recognition accuracy of our method in different optimizers on S1 setup.
Recognition accuracy of our method in different learning rate on S1 setup.
Ablation study
In this section, We conduct an extensive ablation study to evaluate each component’s contribution to our network.
DASEMN without mmd(w/o mmd): the maximum mean discrepancy loss is removed, and the proposed method is trained only with the meta-learning training strategy and scaled mean entropy loss.
DASEMN without ML&SMEL(w/o ML&SMEL): Our network is trained by traditional cross-entropy loss and the maximum mean discrepancy loss without meta-learning training strategy and scaled mean entropy loss, training all training data every epoch, and then updates the parameters to retrain all training data. The classification loss uses cross-entropy loss, and the maximum mean discrepancy loss is still retained to reduce the modal differences between the photo and the sketch. In the training process, a total of 50 epochs are trained, and the batch size is set to 4;
DASEMN without ML(w/o ML): Our method is trained by scaled mean entropy loss and the maximum mean discrepancy loss without meta-learning training strategy(e.g. the scaled mean entropy loss and the maximum mean discrepancy loss are minimized without using meta-learning), training all training data every epoch, and then updates the parameters to retrain all training data. The classification loss uses scaled mean entropy loss, and the maximum mean discrepancy loss is still retained to reduce the modal differences between the photo and the sketch. In the training process, a total of 50 epochs are trained, and the batch size is set to 4;
Baseline: the meta-learning training strategy, scaled mean entropy loss, and the maximum mean discrepancy loss are removed simultaneously, and only the traditional cross-entropy loss is used to train the network. During the training process of the baseline, the parameters are consistent with w/o ML. A total of 50 epochs are trained, and the batch size is set to 4.
The results of the four sets of ablation experiments are shown in Table 7. Figure 5 visualizes the top five matching images of the proposed DASEMN, w/o mmd, w/o ML&SMEL, w/o ML, and baseline on the S1 setup. It can be seen from the above table and figure that the proposed DASEMN outperforms all these variants, indicating that each component is essential and complementary to each other.

The top five matching images of ours, w/o mmd, w/o ML&SMEL, w/o ML, and baseline on the S1 setup. The images in blue box are the sketch, images in the green box is the positive samples, and the images in the red box are negative samples.
We found that combining meta-learning, maximum mean discrepancy loss, and scaled mean entropy loss together to train the model can achieve the best results through the experimental results of the above four sets of ablation experiments on S1, S2, and S3 setups. As shown in Table 8, the recognition accuracy of w/o mmd, w/o ML&SMEL, and w/o ML are lower than the complete method indicate that each component is essential. The recognition accuracy of w/o mmd is higher than our baseline, which indicates that our meta-learning training strategy and the scaled mean entropy loss significantly improve the comprehensive generalization ability of the network by raising the learning level from the data to the task under the same data volume, thereby significantly improving the recognition performance. The recognition accuracy of w/o ML&SMEL is about 3% better than our baseline in all of the four setups indicate that the validity and stability of our domain adaptation module. In the Table 8, we can found that the recognition accuracy of w/o ML is significantly lower than the complete method and even be the worst. After the meta-learning is removed, the diversity of tasks is reduced and resulting in the network being unable to learn as much knowledge as before.
Recognition accuracy of w/o ML in different epochs on S1 setup.
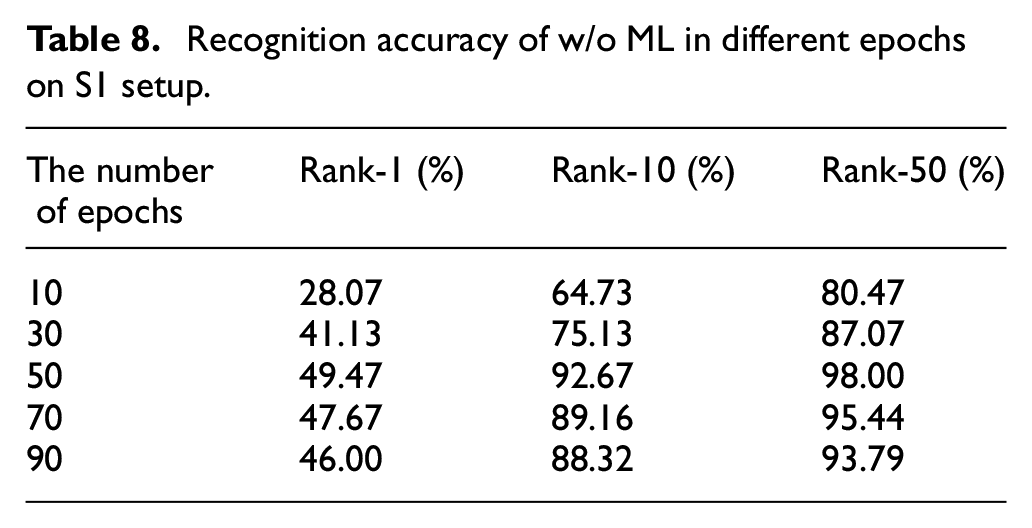
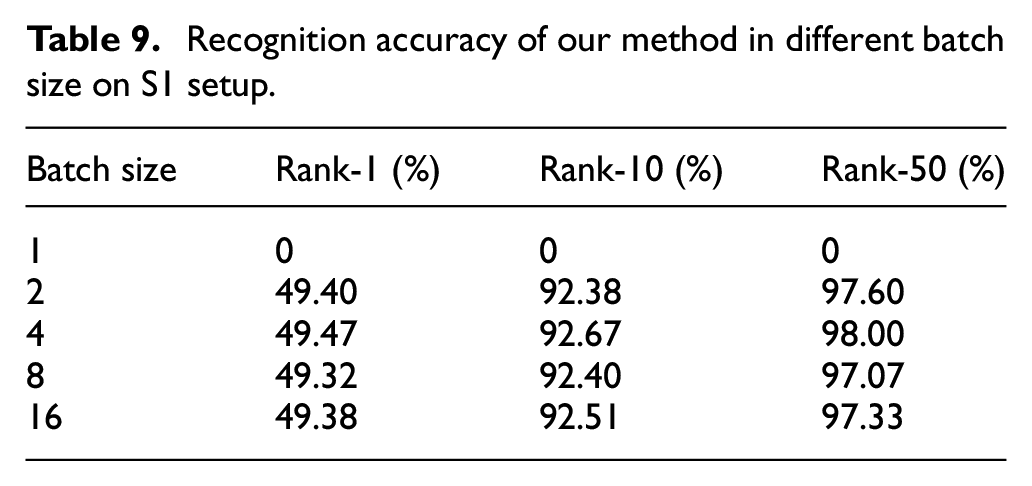
The number of epochs and batch size are important parameters in deep learning. Based on the w/o ML, we conduct two sets of experiments to study their influence on the recognition performance on the S1 setup. As shown in Table 9, we test the model trained under different epochs and statistics the recognition accuracy. As the number of epochs increases, the number of weight update iterations in the neural network increases. The w/o ML starts from the unfitted state, slowly enters the optimal fitting state, and finally enters the overfitting state. To study the influence of the batch size on the recognition performance of w/o ML, we set the batch size to 1, 2, 4, 8, 16, and keep other parameters fixed. The experimental results are illustrated in Table 10. When the batch size is set to 1 , the w/o ML does not converge and the recognition accuracy is zero. When the batch size increases from 2 to 16, the recognition accuracy only fluctuates slightly.
Recognition accuracy of our method in different batch size on S1 setup.
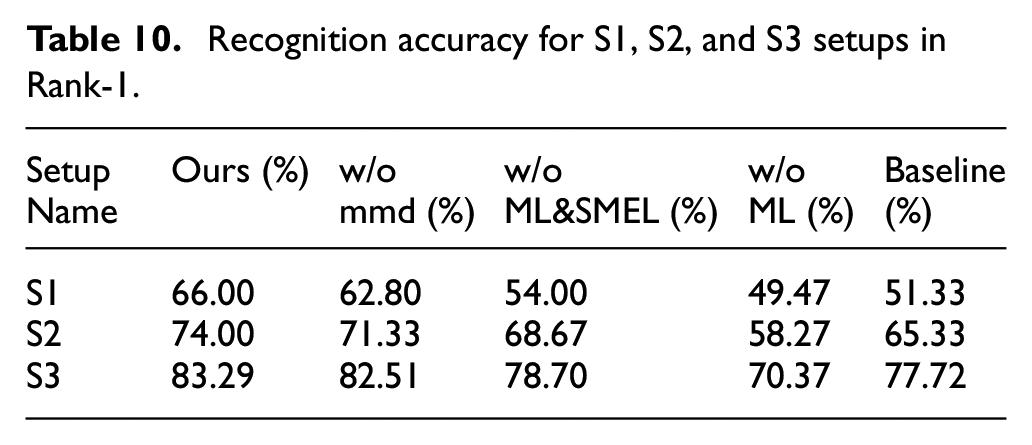
Recognition accuracy for S1, S2, and S3 setups in Rank-1.
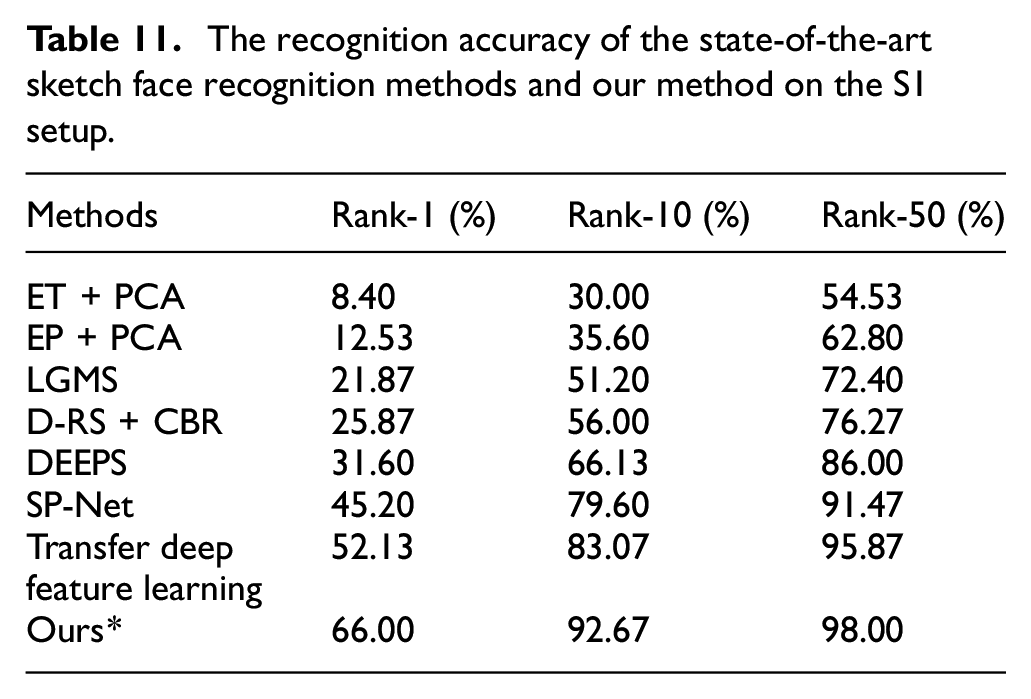
Comparison to the state-of-the-art sketch face recognition methods
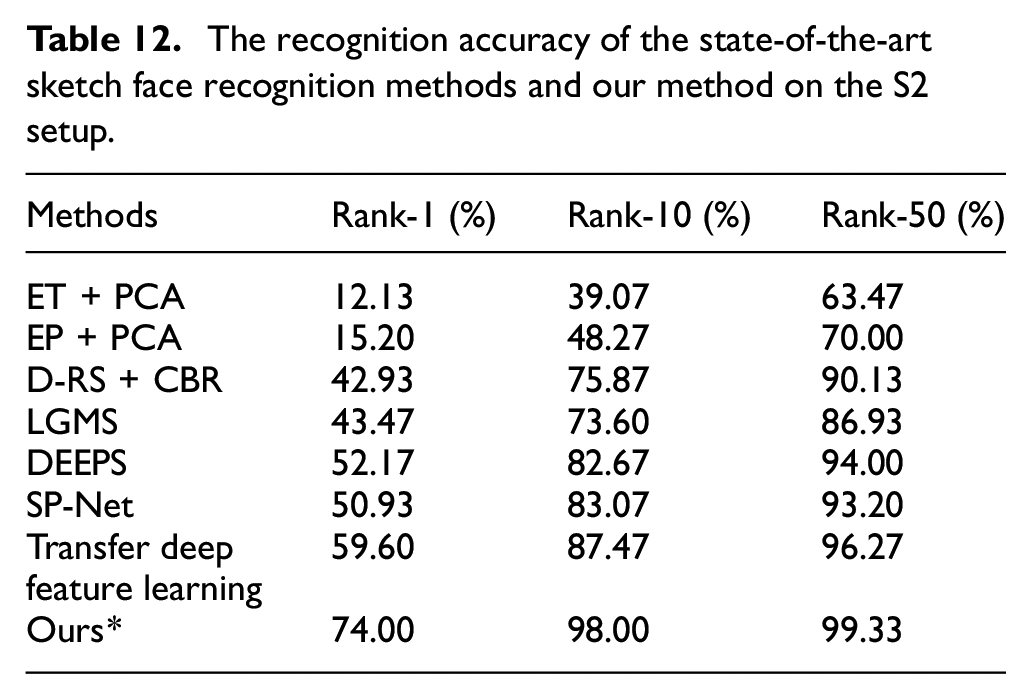
In this section, for the S1 and S2 setups, we compare our method with the representative sketch face recognition methods including ET (+ PCA), 14 EP (+ PCA), 43 DEEPS, 1 D-RS + CBR, 44 LGMS, 45 SP-Net, 23 and Transfer deep feature learning. 46 ET + PCA and EP + PCA are intra-modality methods, DEEPS, D-RS + CBR, LGMS, SP-Net, and Transfer deep feature learning are inter-modality methods. Except for SP-Net and Transfer deep feature learning, the results of the comparison methods are directly derived from DEEPS. 1 Since the results of SP-Net and Transfer deep feature learning on the S1 and S2 setups are unavailable, we conduct the result of them by ourselves according to SP-Net 23 and Transfer deep feature learning. 46 Tables 11 and 12 show the experimental results of these compared methods and our method on the S1 and S2 setups, respectively (Because the FRGCv2.0 and Multi-PIE are unavailable, we use LFW instead of FRGCv2.0 and Multi-PIE. And the LFW is low resolution and uncontrolled face image dataset. Therefore, the experimental setup is not equivalent and we use ours* to represent the results of our method). Obviously, on the more challenging S1 setups, the algorithms’ recognition accuracy except our algorithm is low. As shown in Tables 11 and 12, the inter-modality methods are superior to the intra-modality methods in both lower rank and higher rank. CBR, DEEPS and SP-Net are specially designed for the matching method between software synthesis sketch and photo, and their low recognition performance on S1 and S2 setups indicates the challenge of the UoM-SGFS dataset. Benifit of transfer learning, the Transfer deep feature learning achieves the best performance method on S1 and S2 setups except for proposed method. Since a meta-learning training strategy and a generalized entropy loss are proposed to guide the network to extract discriminate features in our proposed method, our method achieves the best performance. Indeed, only our method correctly retrieves over 90% of subjects by Rank-10 on the S1 setup, which a mean match rate of 92.67%. Besides, we find that the results of baseline in Table 8 surpass the DEEPS regarding setup S1 and S2. In DEEPS, the basic network uses the VGG-16 network, and our baseline uses the more advanced ResNet-18 network, which cause our baseline gets better recognition performance. The highest recognition accuracy on S1 and S2 setup indicates the robust and discriminative of the face feature extracted by our method.
The recognition accuracy of the state-of-the-art sketch face recognition methods and our method on the S1 setup.
The recognition accuracy of the state-of-the-art sketch face recognition methods and our method on the S2 setup.
For the S3 setup, as shown in Table 13, we compare our method with some state-of-the-art methods, including MWF, 47 Fast-RSLCR, 22 CDFL, 48 CMML, 49 Transfer Deep Feature Learning 46 and CMTDML. 50 MWF and Fast RSLCR are intra-modality methods, CDFL is a feature descriptor-based method, CMML is a common inter-modality method, and Transfer Deep Feature Learning and CMTDML are deep learning methods. The results of these compared methods are directly from CMTDML. 50 As we can see from Table 13, the performance of transfer learning is relatively poor, even though it is a deep learning method. The intra-modality methods of MWF and Fast-RSLCR heavily depend on the quality of the composite image, which results to degrade the recognition performance. Although the feature descriptor-based method and common inter-modality method have achieved good recognition performance, there exists some room to improve their recognition accuracy. Our method’s recognition accuracy is slightly lower than the CMTDML, but our method outperforms the other five compared methods significantly.
The recognition accuracy of the state-of-the-art sketch face recognition methods and our method on the S3 setup.

Comparison to the state-of-the-art domain adaptation methods
We also conducted experiments on the above four setups on the state-of-the-art domain adaptation methods including DANN, 31 CDAN, 51 and BSP+CDAN. 52 In all three experiments, during the training process, the feature extractor network uses the ResNet-18 to ensure the fairness of comparative experiments. Other experimental parameters follow the original paper settings.
The DANN comprises a deep label predictor and a domain classifier, jointly trained in an adversarial way. The deep label predictor is used to predict the label of each image, while the domain classifier is trained to distinguish the photo domain (e.g. the source domain) from the sketch domain (e.g. the target domain). During the training process, all training data are trained in every epoch, and then updates the parameters to retrain all training data. The classification loss uses the cross-entropy loss, and the domain classifier takes the sketch features and photo features learned by the feature extractor network as input and outputs a domain adaptation loss. The training proceeds in a standard way and minimizes the cross-entropy loss and the domain adaptation loss.
The CDAN is similar to the DANN and comprises a feature extractor, a source classifier, and a conditional domain discriminator, the difference is that the CDAN concatenates the feature representation and classifier prediction and feeds it to the conditional domain discriminator. During the training process, all training data are trained in every epoch, and then updates the parameters to retrain all training data. The cross-entropy loss is used as the classification loss, and the conditional domain discriminator takes the sketch features and photo features learned by the feature extractor network and the sketch classification score tensor and photo classification score tensor learned by the classifier as input and output domain discriminate loss. Finally, the cross-entropy loss and the domain discriminate loss are integrated into a unified optimization problem.
In the base of the CDAN, the BSP + CDAN applies SVD to obtain the largest k singular values of the photo feature matrix and the sketch feature matrix respectively. The Batch Spectral Penalization (BSP) as a regularization term over these largest k singular values and input a BSP loss. Finally, the classification loss, the domain discriminate loss, and the BSP loss are integrated into a unified optimization problem.
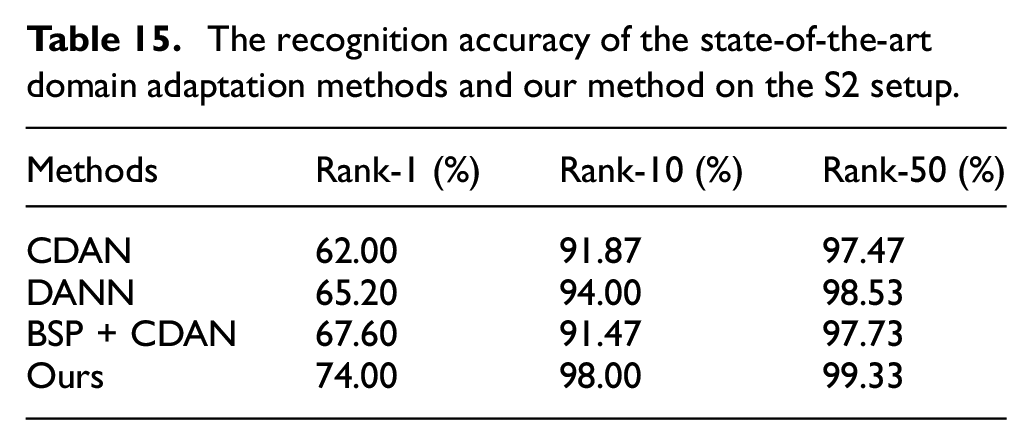
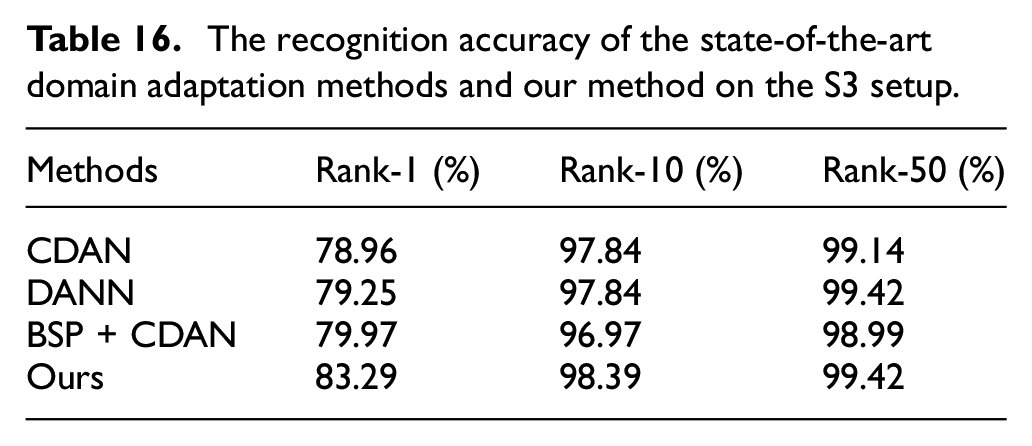
The experiment results are shown in Tables 14 to 16. As shown in these tables, we can find that our method’s performance is better than the other three domain adaptation methods in both lower rank and higher rank, which indicate the robustness of our method. On the S1 setup, only our method correctly retrieves over 90% of subjects by Rank-10.
The recognition accuracy of the state-of-the-art domain adaptation methods and our method on the S1 setup.
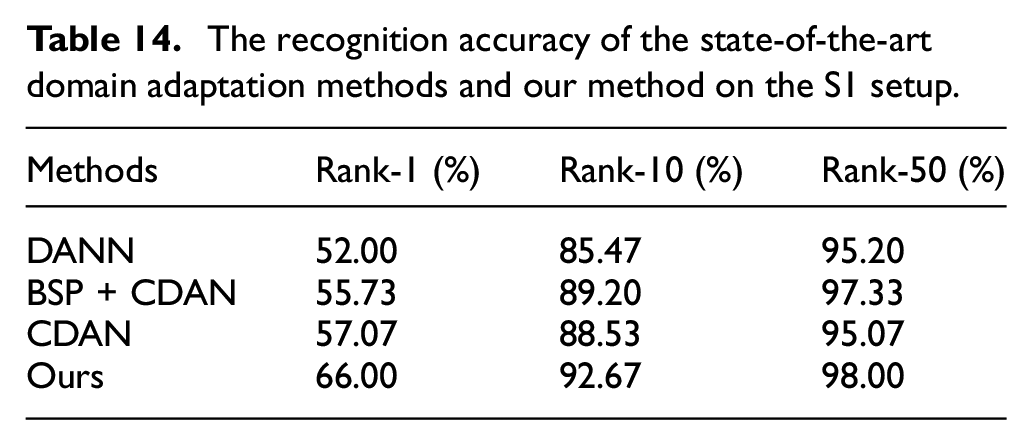
The recognition accuracy of the state-of-the-art domain adaptation methods and our method on the S2 setup.
The recognition accuracy of the state-of-the-art domain adaptation methods and our method on the S3 setup.
Conclusions
For sketch face recognition problem, to address the key issue of overfitting in the case of insufficient face photo-sketch data and the large modal gap between the sketches and the photos, in this paper, we propose a meta-learning based method termed Domain Adaptation Scaled Entropy Meta-Network (DASEMN). It consists of a scaled entropy meta module and a domain adaptation module. In the scaled entropy meta module, a meta-learning perspective coupled with episodic training is utilized to tackle the small sample problem, and a scaled mean entropy loss is proposed for extracting discriminate features in the training process. A domain adaptation module is further introduced to reduce the modal gap between the photo and sketch domains. By comparing the proposed DASEMN with state-of-the-art sketch face recognition and domain adaptation methods, experiments in the UoM-SGFS database and CUFSF database show that our method can effectively improve sketch face recognition performance. However, in the training process, hard negative samples and easy negative samples are treated equally, hard sample mining of negative examples is considered as an essential component in many optimization algorithms to improve the convergence speed and verification performance. In the future, we will further narrow the performance gap between hard and easy negative samples.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (62001033,U20A20163,62201066), the Qin Xin Talents Cultivation Program of Beijing Information Science and Technology University (QXTCP A201902, QXTCPC 202108), and by the General Foundation of Beijing Municipal Commission of Education (KZ202111232049, KM202011232021,and KM202111232014).