
Abstract
For criminal searches, the necessity of matching photographs with sketches is increasing. Previously, matching was performed manually by a human observer, a time-consuming process whose accuracy can be affected by the level of human expertise. Therefore, we propose a new face recognition algorithm for photographs and sketches. This research is novel in the following three ways. First, to overcome the decrease in matching accuracy due to pose and illumination variation, we use eye alignment and retinex filtering to normalize pose, size and illumination. Second, we compare the performance of various face recognition methods, such as principal component analysis (PCA), local binary pattern (LBP), local non-negative matrix factorization (LNMF), support vector machine-discriminant analysis (SVM-DA) and modified census transform (MCT), for the matching of photographs and viewed sketches. Third, these five face recognition methods are combined on the basis of score-level fusion to enhance matching accuracy, thereby overcoming the performance limitations of single face recognition methods. Experimental results using a CUHK dataset showed that the accuracy of the proposed method is better than that of uni-modal face recognition methods.
1. Introduction
Recently, face recognition systems have been used in many fields, including user identification for access control, border control, computer and mobile devices, and information security. For criminal searches, the necessity of matching photographs with sketches is increasing. Previously, matching was performed manually by a human observer, a time-consuming process whose accuracy can be affected by the level of human expertness. Accordingly, automatic searching for matches of photographs against sketches is important. Therefore, we propose a new face recognition algorithm for photographs and sketches.
Photographs and sketches have many differences, such as shadow, texture and shape. As a result, it is very difficult to match these heterogeneous face images with high accuracy. To overcome these problems, numerous methods of matching viewed sketches have been previously studied. Tang et al. proposed a method of transforming photo images into sketches, thereby reducing the difference between these two types of images and enhancing matching accuracy [1]. Lui et al. proposed a face recognition system based on face sketches. They generated pseudo-sketches based on local linear preserving of the geometry between photo and sketch images using locally linear embedding. For recognition, kernel-based nonlinear discriminate analysis was used [2]. Tang et al. synthesized face sketches from photos using eigentransformation and matched them using Bayesian classifiers [3]. Wang et al. proposed a face photo-sketch synthesis and recognition process using a multi-scale Markov random fields (MRF) model [4].
Most of the previous work used single-face recognition methods for matching photos and sketches, however, the resulting performance enhancement is limited owing to the heterogeneous characteristics of these two types of face images. To overcome these problems, we propose a new face recognition algorithm of photographs and sketches. This research is novel in the following three ways. First, to overcome the decrease in matching accuracy due to pose and illumination variation, we use eye alignment and retinex filtering to normalize pose, size and illumination. Second, we compare the performance of various face recognition methods, such as principal component analysis (PCA), local binary pattern (LBP), local non-negative matrix factorization (LNMF), support vector machine-discriminant analysis (SVM-DA) and modified census transform (MCT), for the matching of photographs and viewed sketches. Third, these five face recognition methods are combined based on score-level fusion to enhance matching accuracy, thereby overcoming the performance limitations of single-face recognition methods. This paper is organized as follows. Section 2 describes the proposed method. The experimental results and conclusions are presented in sections 3 and 4, respectively.
2. Proposed Method
2.1. Overview of the Proposed Method
An overview of the proposed face recognition system is shown in Figure 1. First, the face regions of photographs and viewed sketches are detected by Adaboost face detector. Then, eye alignment and reassignment of the facial areas are performed on the basis of the Adaboost eye detection algorithm. In the next procedure, the facial areas derived from photographs and viewed sketches are normalized in terms of size and illumination, and five sets of facial features are extracted using the five methods of PCA, LBP, SVM-DA, LNMF and MCT, respectively. Next, five dissimilarities between the features of the photographs and those of the viewed sketches are calculated. Finally, the five calculated dissimilarities are combined on the basis of score-level fusion and the system searches for the genuine photo in the database on the basis of the combined score.

Overview of the proposed system
2.2. Preprocessing
Typically, an adaptive boosting (Adaboost) algorithm is used to detect face regions [5]. It consists of multiple Haar-like weak classifiers used to form a stronger classifier. The following figure illustrates face region detection using the Adaboost method.

Examples of face regions detected using Adaboost algorithm. (a), (c) Original photo and corresponding sketch image. (b), (d) Detected face regions.
Conventional face recognition systems are very sensitive to pose and illumination variation. To overcome these problems, the proposed system uses eye alignment and retinex filtering to normalize pose and illumination, respectively. In order to normalize pose, the two eye regions are detected using the Adaboost algorithm in the predefined area inside the located facial region. On the basis of the line that passes through both eye centres, the yaw angle of the face image can be calculated and the face image is rotated until the yaw angle becomes 0, as shown in Figure 3 (b). Then, the face region is redefined as follows. If the length between the two eyes is calculated as l, the face region is reassigned such that the width and height become 2l and 2l, respectively, as shown in Figure 3 (b). This method compensates for the size variations of the facial area.
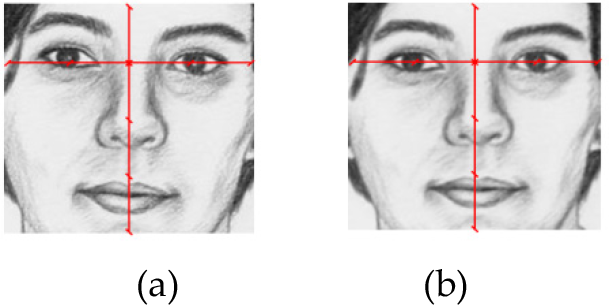
Example of pose normalization. (a) Original image. (b) Normalized image.

Examples of face regions after size normalization. (a) Photographs. (b) Viewed sketches.
Owing to differences in the Z-distance between the face and camera, the pose-normalized face regions exhibit individual variations in size. Therefore, the size of the pose-normalized face region is further normalized to 32 × 32 pixels, as shown in Figure 4.
In general, photos and sketches present differences in visual appearance, such as shadow, texture and shape, as shown in Figure 4 (a) and (b). Furthermore, illumination variations can exist across the face region. All of these factors can reduce face recognition accuracy. Therefore, the differences of visual appearance and illumination variations of the face region are normalized using a retinex filter, as illustrated in Figure 5. The optimal sigma value of the retinex filter is experimentally determined by considering the accuracy of face recognition.

Example of face regions after illumination normalization by using retinex filtering. (a) Result images of Figure 4 (a). (b) Result images of Figure 4 (b).
2.3. Feature Extraction
For matching of photographs and viewed sketches, the features of the detected face region are extracted using PCA, LBP, LNMF, SVM-DA and MCT.
PCA is a global method for representing facial features as eigen-coefficients, which are calculated from trained eigenfaces (eigen-vectors). This method has been widely used for face recognition [7, 8]. Through experiments, 1,024 eigenfaces and the corresponding 1,024 eigen-coefficients are extracted as facial features by PCA.
LBP is generally used to extract facial features locally [9], because it is more robust to illumination variations than PCA. We use an LBP kernel of 3 × 3 pixels [6] and this method compares the centre pixel of the kernel to eight adjacent pixel values. At the position where the LBP kernel is applied, if the grey level of the centre pixel of the 3 × 3 kernel is less than (or equal to) that of a surrounding pixel, the corresponding surrounding pixel is assigned 1. If not, it is assigned 0. Subsequently, we obtain up to eight binary codes from one position where the LBP kernel is applied. Since the LBP kernel is moved in horizontal and vertical directions by sliding, the total number of binary codes is 7,200 (30 moving steps in the horizontal direction × 30 moving steps in the vertical direction × 8 binary codes) from the face region of 32 × 32 pixels.
NMF is a part-based representation with only additive forms because all the pixel values of the basis and coefficients are non-negative [10]. LNMF is a revised version of NMF that not only allows a non-subtractive (part-based) representation, but also makes localized features distinctive [10]. We use 1,024 bases, and the corresponding 1,024 coefficients, for recognition.
Conventional LDA is based on the assumption that all the data classes share the same density function and have normal distributions. If this assumption is not satisfied, LDA produces incorrect classification. To overcome this problem, SVM-DA has been proposed. SVM-DA is an enhanced method of LDA that combines SVM and LDA [11]. We used 105 bases obtained from the 32 × 32 pixel face images and consequent 105 coefficients for recognition.
MCT is similar to LBP, but it uses the average pixel value of the 3 × 3 kernel instead of the value of the centre pixel of the kernel [12]. We use an MCT kernel of 3 × 3 pixels. At the position where the MCT kernel is applied, if the average grey level of the 3 × 3 kernel is less than (or equal to) that of a surrounding pixel, the corresponding surrounding pixel is assigned 1. If not, it is assigned 0. Subsequently, we obtain up to nine binary codes from one position where the MCT kernel is applied. Since the MCT kernel is moved in the horizontal and vertical directions by sliding, the total number of binary codes is 8,100 (30 moving steps in the horizontal direction × 30 moving steps in the vertical direction × 9 binary codes) from the face region of 32 × 32 pixels.
2.4. Feature Dissimilarity Calculation and Score-Level Fusion
Euclidean distance (ED) is used for measuring dissimilarity between the eigen-coefficients of the enrolled photographs and those of the recognized sketch images. In the PCA, LNMF and SVM-DA methods, ED is used for calculating the dissimilarity since the eigen-coefficients are real numbers. Because the features of the LBP and MCT methods are expressed as binary code, Hamming distance (HD) is used to measure the dissimilarity between the binary codes of these two methods. HD counts the average number of unmatched bits between the extracted binary codes of the photo and sketch based on exclusive-OR operation [13].
The five distance values calculated using PCA, LNMF, SVM-DA, LBP and MCT are combined using a score-level fusion method. Since each distance method has a different range of values, the results are normalized into the range of 0–100 using min–max scaling prior to score-level fusion. Various fusion rules of MIN, MAX, SUM and PRODUCT [14] are compared. The MIN and the MAX rules select the minimum and maximum score among multiple scores, respectively. The SUM rule obtains the summed value of all the scores as the final dissimilarity. The PRODUCT rule obtains the multiplied value of all the scores as the final dissimilarity. By combining multiple scores of multiple recognition methods, we overcome the limitation of performance enhancement, which is caused by the heterogeneous characteristics of photographs and sketches.
3. Experimental Result
To evaluate the proposed method, we selected 505 face images from the AR and CUHK student databases of the CUHK dataset [15], which consists of 212 viewed sketches and 293 photographs from 212 classes, as listed in Table 1. The database also includes images of faces wearing glasses. 253 images (consisting of 106 viewed sketches and 147 photographs) were used for training. The remaining 252 images (consisting of 106 viewed sketches and 146 photographs) were used for testing. Figure 6 provides examples from the databases. Since there is no open database of forensic sketches (sketches that are drawn from witness memory without a photo), in this research we use the open dataset of CUHK, which includes viewed sketches and photographs.
Composition of databases used for our experiments


Examples of databases (The images of the 1st and 2nd rows are photographs and corresponding viewed sketches, respectively). (a) CUHK student database. (b) AR database.
We measured face recognition accuracy using the PCA, LBP, LNMF, SVM-DA and MCT methods. The matching results are summarized in Table 2. Top 1 refers to the percentage of cases in which the genuine face is ranked first by the matching algorithm. Since the number of classes is 212, the rank is represented from Top 1 to Top 212.
Recognition rates for matching photographs to viewed sketches using the testing data set (unit: %)
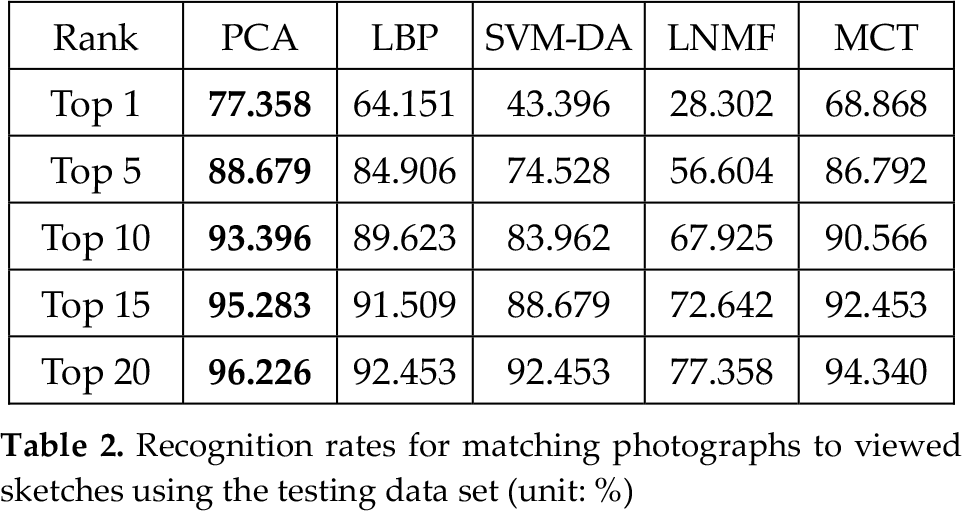
As shown in Table 2, the highest recognition rate of Top 1 was 77.358%, obtained using the PCA method. The LBP and MCT methods showed similar performance. LNMF showed the lowest accuracy of Top 1 at 28.302%.
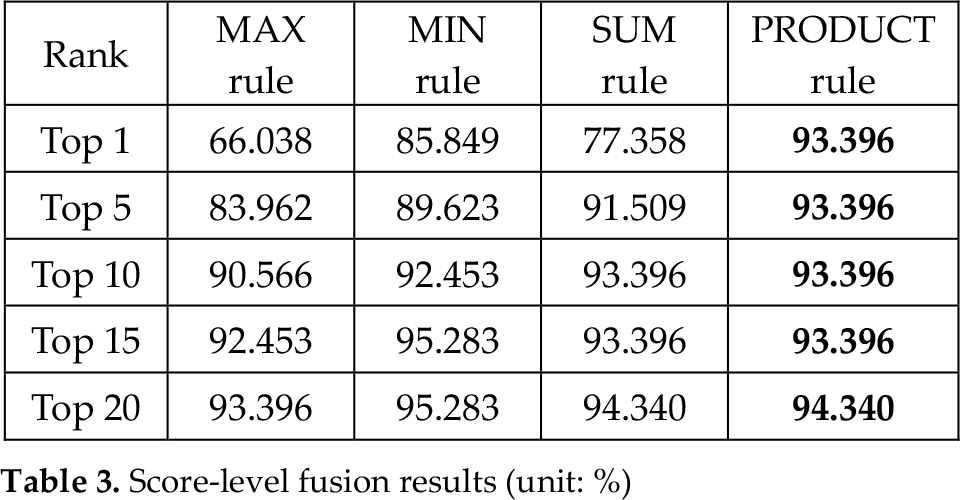
In the next test, to enhance the matching accuracy of uni-modal recognition, we combined the five matching scores of PCA, LBP, SVM-DA, LNMF and MCT based on score-level fusion as shown in Table 3. The Top 1 accuracy rates of the MAX, MIN and SUM rules were 66.038%, 85.849% and 77.358%, respectively. The accuracy of the PRODUCT rule was the highest at 93.396%. By comparing Tables 2 and 3, we can confirm that the accuracy is considerably enhanced by combining multiple scores.
Score-level fusion results (unit: %)

Examples of the matching cases as Top 1 and Top 16, respectively. (a) Cases of correct matching as Top 1. (b) Case of incorrect matching as Top 16.
Figure 7 shows the examples of matched cases with photo images and corresponding sketch ones. Although the two images in Figure 7 (b) were from a same person and were not correctly matched as Top 1, they were matched as Top 16. With additional help from human observers for Top 20 candidates, this problem of matching error can be solved.
4. Conclusion
In this paper, we proposed a new face recognition method for matching photographs and viewed sketches in criminal searches. We compared the accuracies of various face recognition methods, including PCA, LBP, LNMF, SVM-DA and MCT. Among them, the accuracy of PCA was the highest. In addition, we improved the matching accuracy by combining five scores of five face recognition methods using score-level fusion.
In the future we intend to combine the synthesis method of producing sketch images from photos with the proposed score-level fusion methods, by which performance can be greatly enhanced.
Footnotes
5. Acknowledgments
This research was supported by the Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (No. 2012-0001982), and in part by the Public Welfare and Safety research program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education, Science and Technology (No. 2011-0020976), and in part by a grant from the R&D Program(Industrial Strategic Technology Development) funded by the Ministry of Knowledge Economy(MKE), Republic of Korea. Also, The authors are deeply thankful to all interested persons of MKE and KEIT(Korea Evaluation Institute of Industrial Technology) (10040018, Development of 3D Montage Creation and Age-specific Facial Prediction System).