
Abstract
Objective
To determine how lower degree of automation (DOA) reliability impacts human response to a single higher-DOA failure in simulated air traffic control conflict detection.
Background
Higher-DOA systems apply higher levels of automation to later stages of human information processing. Higher-DOA typically results in better routine performance, and lower-DOA with better automation failure response. If both are provided and lower-DOA is reliable, it could support higher DOA failure detection.
Method
Participants (N = 192) received a combination of lower-DOA and/or higher-DOA. Lower-DOA highlighted aircraft conflicts and near-misses, leaving participants to manually resolve conflicts. Higher-DOA resolved conflicts. Automation failed once. Participants were provided one of four types of automation: lower-DOA, where lower-DOA failed (LF); higher-DOA, where higher-DOA failed (HF); both lower- and higher-DOA, where only higher-DOA failed (LHF); or both lower- and higher-DOA, where both failed (LFHF).
Results
When only the higher-DOA component of combined lower- and higher-DOA failed (LHF), participants detected the automation failure 23.6s faster and more accurately (miss rate = −.08) compared to higher-DOA only (HF). However, more participants missed the automation failure when lower-DOA failed (LF = +.42; LFHF = +.15), compared to the HF condition.
Conclusions
Reliable lower-DOA can support higher DOA failure detection when both are presented. However, poorer automation failure detection with lower-DOA failure suggests participants over-relied on aircraft highlighting to direct attention to potential conflicts.
Applications
Providing both lower- and higher-DOA together could be beneficial when higher-DOA fails but lower-DOA remains reliable, but conversely, detrimental if lower-DOA also fails.
Humans increasingly work with automation designed to support their performance, with “automation” referring to technology that partly, or fully, completes tasks for the human. When automation is reliable, a human aided by automation would be expected to outperform the same unaided human because technology does not share inherent human limitations (e.g., boredom, fatigue, and information processing capacity limits). As automated support increases, the role of the human shifts from active task performance to supervisory oversight of automation (Bainbridge, 1983). The amount of automated support can be referred to as the degree of automation (DOA; Wickens et al., 2010), a nomenclature which ranks the level of autonomy and responsibility of automation versus the human (Sheridan et al., 1978) across four stages of information processing (information acquisition, information analysis, decision recommendation, and action execution; Parasuraman et al., 2000). Systems applying higher levels of automation to later stages of human information processing constitute higher-DOA. For example, lower-DOA may organize/integrate incoming information, but leave decisions and actions to the human, whereas higher-DOA recommends decisions and/or performs associated actions for the human. While the concept of DOA may simplify the complexities of human–machine interactions in modern work settings (Jamieson & Skraaning, 2018; Johnson et al., 2018), it has proven useful for exploring the tradeoffs between broad categories of automation design (Onnasch et al., 2014; Wickens, 2018).
Higher-DOA work systems are increasingly prevalent, with examples including air traffic control (ATC) systems which self-separate aircraft (Cai et al., 2024), and driverless cars which control a vehicle without intervention (Marcano et al., 2020). However, in both examples humans must monitor automation and return to manual control if it fails. A meta-analysis by Onnasch et al. (2014) indicated that higher-DOA leads to better performance when functioning reliably, but poorer performance when it fails, relative to lower-DOA. When higher-DOA fails, the human supervisor may be more disengaged or “out of the loop” and therefore slower/less accurate to respond (Endsley & Kiris, 1995; Manzey et al., 2012). Supervision can be further impaired by high trust of historically reliable automation, which reduces monitoring behavior (Bailey & Scerbo, 2007).
A persistent human factors challenge is to design systems which maximize the benefits of automation, while ensuring human operators can recover from automation failure. One potential solution is to lower the DOA provided. However, while this can improve failure recovery (e.g., Kaber et al., 2000; Li et al., 2014; Shen & Neyens, 2014), it may have limited utility in some work settings. For example, the benefits of higher-DOA (e.g., decision automation) in ATC include increased airspace predictability and capacity, and reduced controller workload—outcomes not necessarily achievable by providing lower-DOA alone (e.g., information integration). Another potential solution is adaptive automation, which can periodically disable higher-DOA support and return decision control to operators (Scerbo, 1996, 2018). Adaptive automation triggers DOA changes based on task performance, operator cognitive state variation (Griffiths et al., 2024), or operator preference (Chen et al., 2017). However, the issue remains that lowering DOA may not be appropriate in some safety-critical work settings—even temporarily. Therefore, automation design solutions that retain higher-DOA, while facilitating automation failure recovery, could be useful.
Using Lower Degree Automation to Support Higher Degree Failure Detection
Automated systems in the modern workplace often contain multiple layers of interacting DOA functions in their design (Jamieson & Skraaning, 2018). In ATC, an example would be higher-DOA which resolves aircraft conflicts for controllers (i.e., avoiding projected loss of aircraft separation; Cai et al., 2024; FAA, 2018) being reliant on underlying lower-DOA which determines all converging aircraft pairs at the same altitude. While some prior studies have provided higher-DOA without an underlying lower-DOA (e.g., Bowden et al., 2023; Calhoun et al., 2009; Griffiths et al., 2024; Lorenz et al., 2001), others provided participants with higher-DOA that also presents an underlying lower-DOA component (e.g., Manzey et al., 2012; Rovira et al., 2007, 2017; Sarter & Schroeder, 2001; Shen & Neyens, 2014; Tatasciore et al., 2020). For example, in an undersea contact classification task, Tatasciore et al. provided participants both information integration (lower-DOA) and action recommendations (higher-DOA). The lower-DOA displayed when and for how long contacts were in areas of interest, and the higher-DOA presented this information as well as recommendations to participants regarding contact classification. As is typical of such studies, when automation failed, both the lower- and higher-DOA failed to function. The current study extends the literature by investigating the effect of partial failures when both lower- and higher-DOA are provided. Specifically, we investigated how lower-DOA reliability impacted human response to a single higher-DOA failure in simulated air traffic control. To our knowledge, this has not been empirically tested in the human–automation interaction literature.
It is possible that presenting a reliable lower-DOA component alongside higher-DOA could support higher-DOA failure detection. Reliable lower-DOA could provide a diagnostic tool to support higher-DOA failure detection and may effectively increase the transparency of the higher-DOA by providing information which aids the operator in understanding the rationale underlying higher-DOA decisions/actions (Bhaskara et al., 2020; Gegoff et al., 2024; Van de Merwe et al., 2022), facilitating operator situation awareness (Endsley, 2017). In Tatasciore et al. (2020) for example, reliable lower-DOA could have displayed how long contacts were in areas of interest to assist participants in detecting that higher-DOA was currently advising incorrect contact classifications. However, as discussed further below, to the extent individuals rely on lower-DOA, the failure of lower-DOA may be detrimental to higher-DOA failure detection.
The Current Study
In simulated air traffic control, participants were responsible for supervising a sector of airspace and, amongst other tasks, determining whether aircraft would “conflict.” Conflicts occurred when aircraft violated the minimum lateral and vertical separation standard. We manipulated the provision of lower- and higher-DOA conflict detection support to examine impacts on participants’ ability to respond to a single automation failure in simulated ATC. Participants were provided with lower-DOA and/or higher-DOA. Lower-DOA highlighted both conflicts (aircraft pairs at the same altitude and on intersecting flightpaths) and “near-misses” (pairs at the same altitude that came close, but did not violate separation). With lower-DOA, participants were responsible for deciding if there was a conflict, given that not all lower-DOA highlighted pairs would conflict. Participants then manually intervened to resolve conflicts. The higher-DOA automatically resolved conflicts and ignored near-misses. With higher-DOA (regardless of whether accompanied by the presentation of lower-DOA), participants were notified when an automated action occurred, but otherwise not required to manually intervene.
Automation failed only once as this is more representative of automation in modern work contexts, such as ATC, in which failures are relatively rare (Bowden et al., 2023; Foroughi et al., 2023; Wickens et al., 2009). This is a critical design feature (see Loft, 2024) because repeated failures likely artificially increase human skepticism of automation (i.e., “first failure effect”; Merlo et al., 2000). While the tradeoff is reduced statistical power to detect significant effects, we argue that practical effect sizes are similarly relevant to examine in the case of single automation failures.
The nature of the automation failure was condition specific. When lower-DOA failed, one conflict pair presented late in the scenario was not highlighted upon entering the sector. When higher-DOA failed, this conflict was not resolved upon the aircraft pair entering the sector. Thus, both lower- and higher-DOA failures involve an automation error of omission. We recorded participants’ speed and accuracy to manually intervene to the single failure of automation, and their subjective experience by measuring perceived workload, trust in automation, and task disengagement.
Between-Participant Condition Manipulations Including Degree of Automation (DOA) Provided, and Whether Lower- And/or Higher-DOA Component Failed (F).
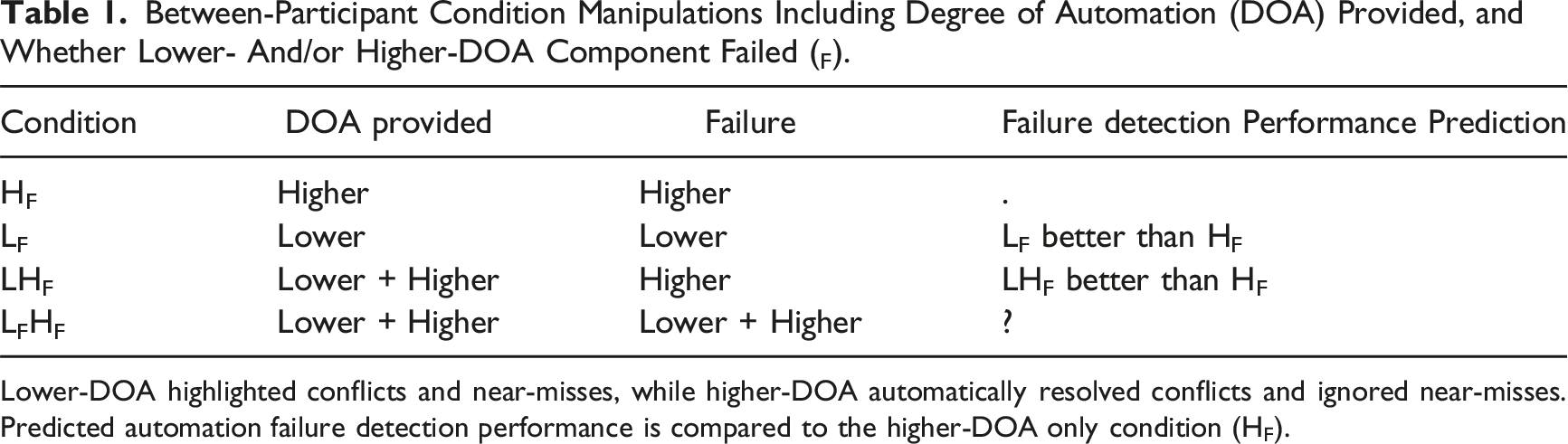
Lower-DOA highlighted conflicts and near-misses, while higher-DOA automatically resolved conflicts and ignored near-misses. Predicted automation failure detection performance is compared to the higher-DOA only condition (HF).
For the two combined DOA conditions (LHF and LFHF), when both DOAs were functioning reliably, the higher-DOA resolved conflicts automatically and the lower-DOA highlighted near-misses as potential conflicts. Thus, when only the higher-DOA component failed (LHF), the conflict aircraft pair was highlighted but not resolved by automation. When both lower- and higher-DOA failed (LFHF), the conflict was neither highlighted nor resolved. In the LHF condition, the reliable lower-DOA should provide diagnostic information to draw participant attention to the failure of higher-DOA. We therefore predicted that the LHF condition would have superior failure detection compared to the HF condition. Participants should also report increased trust (measured postscenario) in the lower-DOA compared to higher-DOA in the LHF condition given only the higher-DOA failed. It was less clear what effect both DOA components simultaneously failing (LFHF) would have on failure detection. Participants may be poorer at detecting the automation failure with LFHF compared to HF if they were less likely to check aircraft pairs not highlighted by lower-DOA when searching for potential conflicts missed by the higher-DOA. Alternatively, the failure of lower-DOA highlighting for an aircraft pair observed by participants to be at the same altitude and on an intersecting path may be sufficiently conspicuous to draw attention and prompt participants to monitor the pair more carefully. In this case, participants in the LFHF condition may have superior failure detection than those in the HF condition. Given this, we do not predict a direction for LFHF in Table 1.
Method
Participants
One-hundred and ninety-two undergraduate students (82 male, 109 female, 1 nonbinary) aged 17–51 (M = 19.9 years) participated for course credit and were randomly allocated to one of four conditions (n = 48). Participants also received a performance-based bonus between AU$6–10. Two participant’s data were replaced (one withdrew, and one did not follow task instructions). This research complied with the tenets of the Declaration of Helsinki and was approved by the Institutional Review Board at The University of Western Australia. Informed consent was obtained from each participant.
Air Traffic Control Simulation
The en-route ATC simulation was displayed on two 22-inch monitors. The radar display (Figure 1) was based on ATC-labAdvanced (Fothergill et al., 2009), while the flight progress and event log display was based on Masalonis et al. (1997). Participants were responsible for aircraft in the inner sector (light grey), while the outer sector (dark grey) displayed incoming/outgoing aircraft. Aircraft were represented by icons with attached data blocks containing call sign (e.g. D10), model (e.g., A320), current altitude (e.g., 400, denotes 40,000 ft), cleared altitude, and speed (e.g., 50, denotes 500 knots). Aircraft traveled along fixed one-way flightpaths, before leaving the inner sector. Participants were responsible for a median of eight aircraft at one time. New aircraft entered the display every 40 s on average. Aircraft traveled at a constant cruising altitude unless directed to ascend by participants or automation to prevent a conflict. Aircraft speed was fixed. Aircraft positions were updated every second. The ATC radar display with lower-DOA highlighting (purple) for aircraft D29 and D10 (i.e., this pair are at the same altitude, 40,000 ft, and on an intersecting trajectory). This pair was the automation failure event. This example reflects the LHF condition, where higher-DOA has failed to resolve the conflict while lower-DOA has correctly highlighted the pair as a potential conflict. Aircraft D86 is flashing blue to indicate it requires acceptance. A scenario timer and an automation status indicator were provided in the top right corner on the display.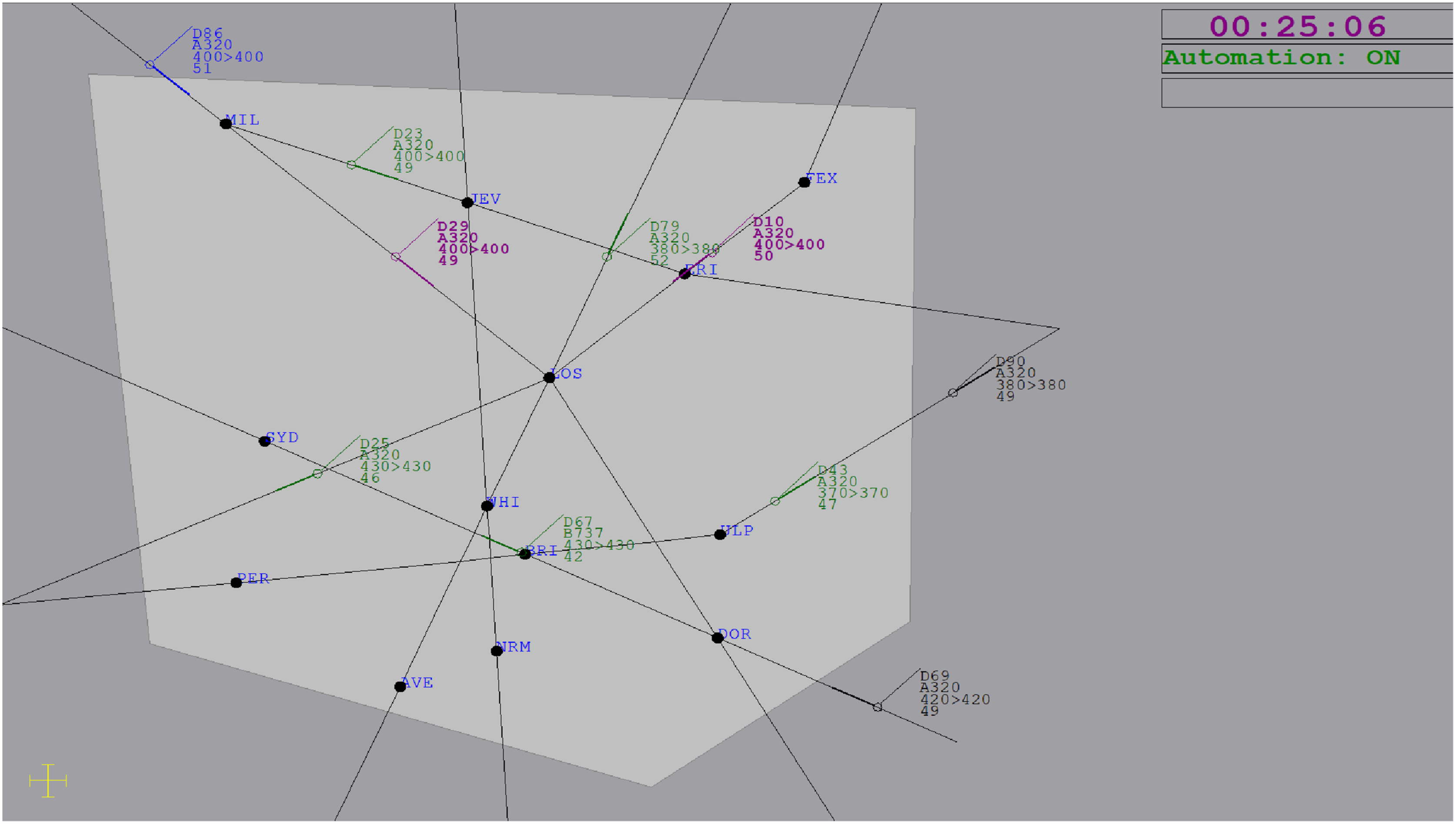
The secondary display contained flight progress strips and the event log (Figure 2). Strips contained the call sign, model, altitude, and flightpath for accepted aircraft. Waypoints remaining along the flightpath were grey, while those already crossed were white. The event log contained a scrolling list of all previous actions taken by the participant and/or automation (i.e. acceptances, handoffs, and conflict resolution). Secondary display containing aircraft flight progress strips (left) and event log (right).
Aircraft flashed blue when they approached the inner sector boundary to indicate they required acceptance. Participants pressed the “A” key and clicked on the aircraft to accept it. Aircraft stopped flashing and turned green once accepted. Aircraft flashed orange when leaving the inner sector. Participants handed-off departing aircraft by pressing the “H” key and clicking on the aircraft. Aircraft stopped flashing and turned black once handed-off. Participants had up to 20 s to accept or hand-off aircraft.
Conflicts occurred when aircraft violated the minimum separation standard (1,000 ft vertical, five nautical mile lateral). To help participants judge lateral separation, a yellow scale was provided in the bottom-left corner of the radar display depicting five nautical miles. Participants were instructed to prioritize preventing conflicts and to intervene to prevent them as quickly and accurately as possible. To do this, participants clicked one aircraft’s data block, which opened a dialogue box prompting them to select the conflicting aircraft. It did not matter which aircraft in the pair was selected first. If there was a conflict, one aircraft climbed 1,000 ft, and the action was added to the event log. If there was no conflict, an audio message notified participants of the false alarm. If a conflict was not prevented before loss of separation, the conflicting pair turned yellow, and an audio message notified participants of the miss. Conflicts could only be prevented after both aircraft involved had been accepted. Each scenario contained 10 conflicts and six near-misses. Near-misses involved aircraft at the same altitude and on converging fight paths that came close to violating lateral separation (i.e., at the same altitude but ∼10 s away from being classified as a conflict laterally).
Lower-DOA
Lower-DOA highlighted potential conflict aircraft pairs traveling at the same altitude and on an intersecting flightpath. As a result, both conflicts and near-misses were highlighted. When highlighted, the aircraft pair changed color and their data blocks were bolded (Figure 1). Highlight color alternated for successive potential conflict pairs (pair 1 = red, pair 2 = purple, etc.) given that up to two aircraft pairs could be highlighted simultaneously. Highlighting commenced once the second aircraft in a potential conflict pair was accepted. Highlighting ceased once the pair was no longer a potential conflict (i.e., altitude changed to prevent conflict, or one aircraft passed the common intersection). Participants were instructed that highlighting did not guarantee a pair would conflict since near-misses would also be highlighted.
Higher-DOA
Higher-DOA also resolved conflicts when the second aircraft in a conflicting pair was accepted. At this time, one aircraft ascended 1,000 ft to avoid the conflict and the event log reported the automated action.
Participants were instructed that both lower-DOA and higher-DOA were highly reliable, but not perfect, and that in the unlikely event that automation either performed an incorrect action or failed to perform an action, it was their responsibility to intervene to correct the failure.
Conditions
Participants completed one manual and one automated scenario (order counter-balanced). Acceptance and handoff tasks were performed manually in all scenarios and conditions. In the manual scenario, participants detected and resolved conflicts without automation. In the automated scenario, participants were supported by condition-specific automation that either: highlighted potential conflicts (lower-DOA), automatically resolved conflicts (higher-DOA), or both. The conflict and near-miss events presented in the manual and automated scenarios were unique, except the ninth conflict event (occurred 26 min 20 s into the 30-min scenario), which was presented in both scenarios (with call signs changed). This conflict is referred to as the failure event. Presenting this conflict twice allowed us to examine participant responses to the same event across manual and automated scenarios. When automation failed, it was absent for this event only, and otherwise 100% reliable. Conflicts not resolved by automation (i.e., manual scenarios or when only lower-DOA was provided) are referred to below as “other conflicts.” Participants were assigned to one of the four automation conditions: HF, LF, LHF, and LFHF (Table 1). It was not possible to include a LFH condition because a successful higher-DOA conflict resolution action left no potential conflicting aircraft pair for the lower-DOA to fail to highlight.
Questionnaires
Trust
Merrit’s (2011) 6-item “Trust in Automation” questionnaire was completed after automation scenarios. Trust was rated separately for lower- and higher-DOA. Participants responded to items such as “I trust the Highlighting” on a scale from 1 (strongly disagree) to 5 (strongly agree).
Workload
The National Aeronautics and Space Administration Task Load Index (NASA-TLX; Hart & Staveland, 1988) was completed after each scenario. The weighted composite of six workload subscales (mental demand, physical demand, temporal demand, effort, performance, and frustration) was used to calculate a total workload score between 0 and 100, with higher scores indicating higher workload.
Task Disengagement
A 5-item task disengagement questionnaire was completed after each scenario. Items were from the inattention and disengagement subscales of the Multidimensional State Boredom Scale (items: 3, 10, 16, 20, and 23; Fahlman et al., 2013). Participants responded to items such as “I felt bored” on a scale from 1 (strongly disagree) to 7 (strongly agree). A 5-item average score was calculated.
Procedure
Participants first completed a 25-min audio-visual training presentation explaining the tasks, followed by a 30-min manual practice scenario during which they could ask the experimenter questions. Performance feedback on acceptance, handoff, and conflict prevention tasks was provided after practice and experimental scenarios. After training, participants completed two 30-min scenarios: one manual and one automated. Two unique ATC scenarios were created, but with an identical ninth conflict event (aircraft call signs were changed). The assignment of the two scenarios to manual or automated, as well as presentation order (automated first or second), was counterbalanced. The automated scenario was preceded by additional condition-specific instructions. The experiment lasted approximately 2.5 h.
Results
Means and Standard Deviations (in Brackets) for Manual and Automated Scenario Task Performance for the Four Automation Conditions (HF, LF, LHF, and LFHF).
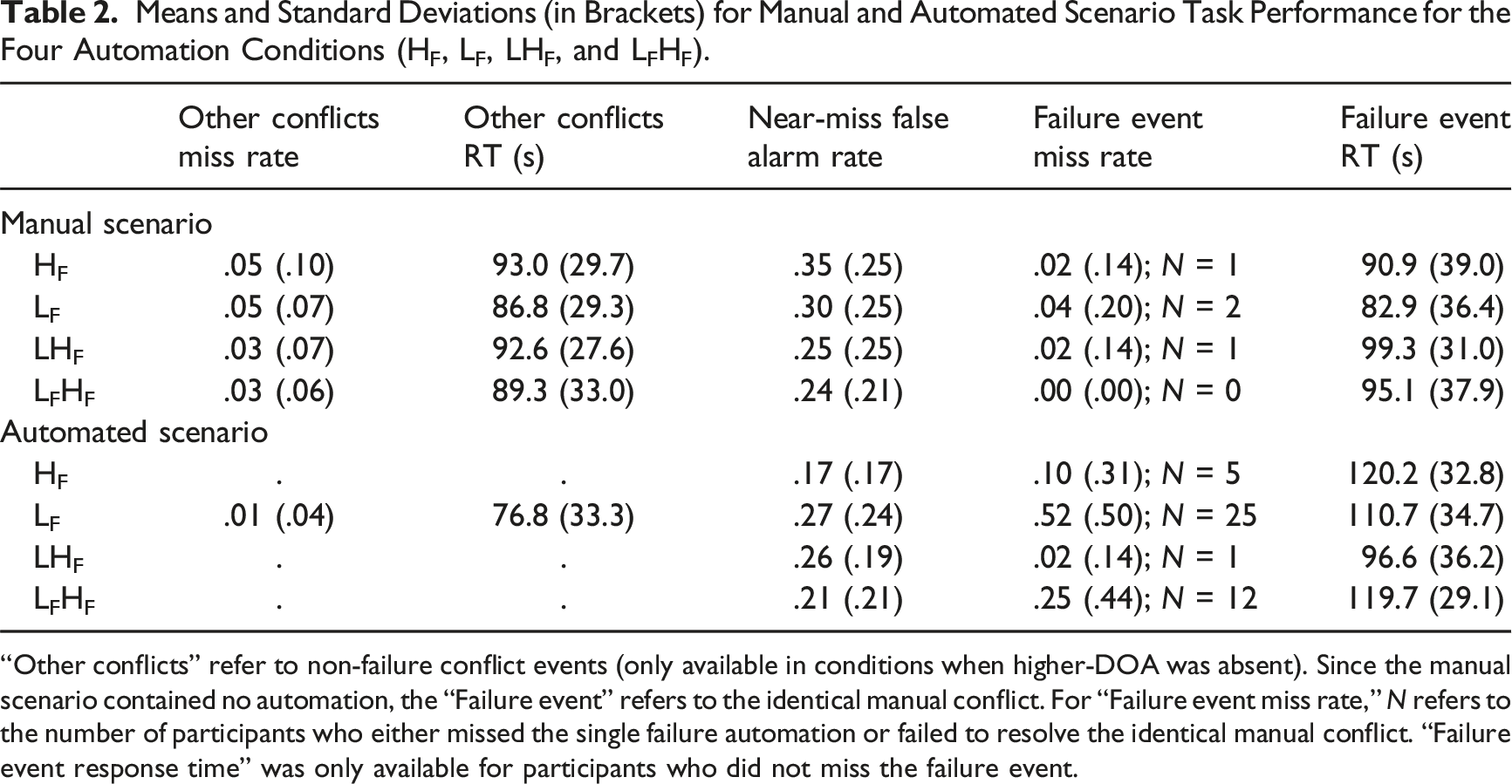
“Other conflicts” refer to non-failure conflict events (only available in conditions when higher-DOA was absent). Since the manual scenario contained no automation, the “Failure event” refers to the identical manual conflict. For “Failure event miss rate,” N refers to the number of participants who either missed the single failure automation or failed to resolve the identical manual conflict. “Failure event response time” was only available for participants who did not miss the failure event.
Failure Event Performance
The automation failure was “missed” if participants did not intervene before the aircraft pair violated the separation standard. Table 2 shows that failure event miss rate in the manual scenario was near floor (≤.04). In the automated scenario, failure event miss rate was compared between conditions using chi-squared tests. Unexpectedly, more participants missed the single failure event in the lower-DOA condition (LF) compared to the higher-DOA condition (HF), M diff = +.42, χ 2 = 19.4, p < .001. Nominally fewer participants missed the failure event in the combined condition where only higher-DOA failed (LHF) compared to the HF condition, M diff = −.08, χ 2 = 2.84, p = .092. Nominally more participants missed the failure event in the combined condition where both DOAs failed (LFHF) compared to the HF condition, M diff = +.15, χ 2 = 3.50, p = .061.
Due to the single failure design, failure event RT was unavailable if participants missed the conflict in either the manual or automated scenario. A 4 × 2 ANOVA showed a main effect of scenario, F (1,144) = 37.74, p < .001, ηp2 = .21, no effect of condition, F = 1.65, p = .181, and an interaction between scenario and condition, F (3,144) = 6.55, p < .001, ηp2 = .12. In the automated scenario, there was no difference in failure event RT between the LF and HF conditions, t(64) = 1.10, p = .276. Participants were faster to intervene to the failure in the LHF compared to the HF condition, M diff = −23.6s, t (88) = 3.24, p = .002, d = .68. There was no difference between the LFHF and HF conditions, t < 1.
Near-Miss False Alarms
False alarms occurred when participants attempted to intervene to near-miss aircraft. A 4 × 2 ANOVA showed a main effect of scenario, F (1,188) = 9.10, p = .003, ηp2 = .05, no effect of condition, F < 1, and an interaction between scenario and condition, F (3,188) = 5.00, p = .002, ηp2 = .07. In the automated scenario, more false alarms were made in the LF compared to the HF condition, M diff = +.10, t (94) = 2.25, p = .027, d = .46. Participants also made more false alarms in the LHF compared to the HF condition, M diff = +.09, t(94) = 2.54, p = .013, d = .52. There was no difference between the LFHF and HF conditions, t(94) = 1.06, p = .290.
All Other Conflicts
In addition to the failure event, participants in the LF condition were required to manually intervene to prevent the nine “other conflicts” presented in the automated scenario. To examine the extent to which providing lower-DOA benefitted conflict detection when functioning reliably, we compared LF condition performance between manual and automated scenarios. Lower-DOA highlighting decreased the “other conflict” miss rate, M diff = −.04, t (47) = 3.37, p = .002, d = .49, and RT, M diff = −10.0s, t (47) = 2.04, p = .047, d = .29, compared to manual detection without highlighting. There was no difference in near-miss false alarms, t < 1. Overall, this indicates that when reliable, lower-DOA improved participants’ ability to prevent conflicts.
Questionnaires
Trust
Means and Standard Deviations (in Brackets) for Postscenario Questionnaire Responses in Manual and Automated Scenarios, for the Four Automation Conditions (HF, LF, LHF, and LFHF).
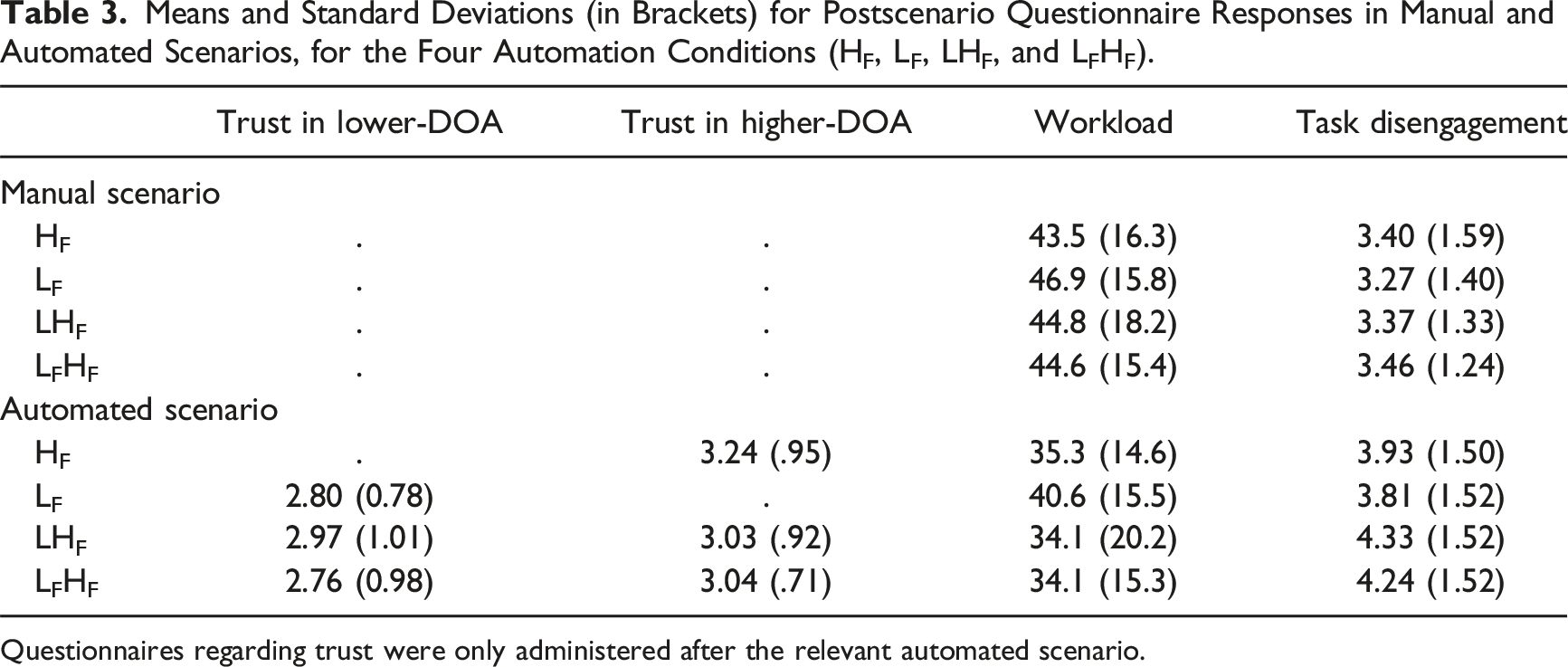
Questionnaires regarding trust were only administered after the relevant automated scenario.
For the two combined DOA conditions, we can also compare trust in lower-DOA and higher-DOA components within-participants. For the LHF condition, trust in lower-DOA did not differ from trust in higher-DOA, despite only higher-DOA failing, t < 1. For the LFHF condition, trust in lower-DOA was lower than trust in higher-DOA, despite both failing, M diff = −0.28, t(47) = 2.14, p = .038, d = .31.
Workload
A 4 × 2 ANOVA showed a main effect of scenario, F(1,185) = 74.6, p < .001, ηp2 = .29, replicating the well-established finding of lower perceived workload with automation. There was no effect of condition, F < 1, and no interaction, F < 1. In the automated scenario, there were no significant differences between any of the LF, LHF, or LFHF conditions and the HF condition, smallest p = .092.
Task Disengagement
A 4 × 2 ANOVA showed a main effect of scenario, F(1,185) = 48.4, p < .001, ηp2 = .21, indicating increased task disengagement with automation. There was no effect of condition, F < 1, and no interaction, F < 1. In the automated scenario, there were no significant differences between any of the LF, LHF, LFHF conditions, and the HF condition, smallest p = .197.
Discussion
This study investigated how lower-DOA reliability influenced higher-DOA failure detection in simulated ATC, under conditions in which both lower- and higher-DOA were provided. Lower-DOA highlighted both conflicts and near-misses, and when provided without higher-DOA, left participants to decide whether there was a conflict and to manually intervene when necessary. When higher-DOA was provided (either with or without lower-DOA), participants were not required to intervene because automation resolved conflicts and ignored near-misses. In conditions where both lower- and higher-DOA were provided, when higher-DOA failed we varied whether lower-DOA remained reliable (LHF) or also failed (LFHF). Participant speed and accuracy when manually intervening to the automation failure event in lower-DOA (LF), and combined DOA conditions (LHF, LFHF), was compared to the higher-DOA condition (HF). Subjective workload, trust, and task disengagement were measured.
Lower-DOA vs Higher-DOA: A Benefit of Increased Degree of Automation?
We expected to replicate prior findings of higher-DOA leading to slower and/or less accurate automation failure detection than lower-DOA (Onnasch et al., 2014). This is known as the “lumberjack” effect, where increased DOA improves routine performance, but impairs performance under automation failure conditions (Sebok & Wickens, 2017). In contrast, we found the opposite—with participants substantially more likely to miss the automation failure with lower-DOA (LF) compared to higher-DOA (HF) (52% vs. 10% miss rate; no difference in RT).
To interpret this result, we re-considered what support lower-DOA was providing. Lower-DOA was designed to function similarly to “medium-term conflict detection” tools which draw controller attention to potential conflicts (FAA, 2023; Ruiz et al., 2013). The use of color is an effective way of both drawing attention and grouping relevant information in ATC. For example, Remington et al. (2000) showed that color-coding aircraft altitudes improved controller conflict detection. In line with this, we found that when it was reliable, lower-DOA (LF) increased conflict detection accuracy and decreased RT compared to manual detection (i.e., no highlighting). This suggests that lower-DOA benefitted conflict detection under nonfailure conditions (as in Remington et al.), and thus functioned as intended.
Regarding subjective experience, we found automation provision (regardless of DOA) lowered perceived workload and increased task disengagement compared to manual conditions. However, when higher-DOA was compared to lower-DOA, we did not find the predicted reduction in perceived workload (Onnasch et al., 2014) or increase in task disengagement. This was unexpected, but it does indicate that variation in workload and/or task disengagement is unlikely to account for the poorer failure detection in the lower-DOA (LF) compared to higher-DOA condition (HF). Another possibility is that participants trusted lower-DOA more than higher-DOA and therefore supervised it less closely. This too was unsupported, as participants instead reported less trust in the lower-DOA relative to higher-DOA when provided with both DOAs simultaneously (LHF and LFHF conditions).
We then re-considered how lower-DOA might influence visual scanning—a critical component underlying conflict detection in ATC (e.g., Gronlund et al., 1998; McClung & Kang, 2016; Remington et al., 2000). Lower-DOA assists operators by organizing incoming information but leaves decision-making/action-implementation to the human (Parasuraman et al., 2000; Wickens et al., 2010). Information processing assistance functions by directing attention towards relevant aspects of the task. However, the literature shows that visual attention is limited (Posner et al., 1980) and typically cannot be divided without cost (Pashler, 1994; Wickens et al. 2022). It is plausible then that poor failure detection with lower-DOA was due to attention capture by other concurrently highlighted aircraft pairs (Remington et al., 1992; Theeuwes, 1992). However, this explanation is unlikely, as the current study had little-to-no highlighting of other aircraft during the 173s failure event.
Our preferred explanation for poorer automation failure detection with lower-DOA (LF) compared to higher-DOA (HF) is that the provision of lower-DOA fundamentally changed the strategy that participants used to monitor automation, leading participants to rely on aircraft highlighting to direct their attention to assess potential conflicts, and thereby having negative implications when lower-DOA failed. As discussed below, outcomes from the combined DOA conditions support this conclusion.
Can Lower Degree Automation Improve Higher Degree Failure Detection?
We predicted that a combination of lower- and higher-DOA, where only the higher-DOA component failed (LHF), would lead to superior automation failure detection than a higher-DOA only condition (HF). This was supported, with participants in the LHF condition detecting the single automation failure event 23.6s faster and nominally more accurately (2% vs. 10% miss rate), presumably because the reliable lower-DOA highlighted the aircraft pair missed by higher-DOA and thus drew participant attention to it. This finding supports the premise that reliable lower-DOA can support the detection of higher-DOA failures by making the logic/rationale underlying higher-DOA more transparent, providing diagnostic information regarding automation predictability and performance (e.g., Bhaskara et al., 2020; Gegoff et al., 2024; Van de Merwe et al., 2022).
While participants were provided with instructions that the lower- and higher-DOA components would function (or fail) independently, the two were clearly linked. With higher-DOA only (HF), participants did not know if their observation of automation not intervening to the failure event was due to (1) there being no conflict (i.e., it was near-miss) or (2) a failure of automation. With the addition of reliable lower-DOA (LHF), near-misses were highlighted, thus providing participants with additional information regarding which aircraft pairs the higher-DOA had likely “considered” but not acted upon. In line with this, participants in the LHF and LF conditions made more conflict detection false alarms than the HF condition (+.10 and +.09, respectively), likely because they were routinely assessing the aircraft highlighted by the lower-DOA.
The finding that participants in the LFHF condition were nominally less accurate than those in the HF condition (25% vs. 10% failure event miss rate) further supports our interpretation that the provision of lower-DOA changed the strategy that participants used to monitor automation, encouraging them to rely on aircraft highlighting to direct their attention to potential conflicts. This reliance on lower-DOA had positive implications when lower-DOA remained reliable (LHF condition), but negative implications when it failed (LFHF and LF conditions), when compared to the HF condition.
Future Directions and Conclusions
The current study presented an automation error of omission, such that when automation failed participants received no advice. However, automated systems can also provide incorrect information (errors of commission). Wickens et al. (2015) showed that automation commission errors can be more difficult for humans to detect than automation omission errors. Future research could therefore extend the current findings to situations where automation makes false alarms, or otherwise provides incorrect advice. For example, lower-DOA could highlight an aircraft pair that is in fact safe at different cruising altitudes, and/or higher-DOA could incorrectly intervene to near-miss aircraft.
Overall, this study provides evidence that, at least in the context of simulated ATC conflict detection with nonexpert participants, combined lower- and higher-DOA presentation could be beneficial when higher-DOA fails but lower-DOA remains reliable (i.e., automation failure detection was superior for the LHF condition compared to the HF condition). However, the outcomes also clearly indicate both DOA components failing simultaneously (LFHF) led to poorer failure detection compared to higher-DOA alone (HF). Moreover, the data indicate that participants relied on the lower-DOA support to highlight potentially conflicting aircraft, to the point where automation failure detection was substantially poorer with lower-DOA only (LF) compared to higher-DOA only (HF). Our findings support recent suggestions that the effects of increased DOA in modern work settings may not neatly fall on a continuum (Jamieson & Skraaning, 2018; Loft, 2024; Skraaning & Jamieson, 2023). Instead, system designers should carefully consider, as a function of specific task context, how different combinations of DOA presentation are likely to impact human monitoring strategies and recovery from automation failure.
Key Points
• This study examined how lower degree of automation (DOA) reliability impacted human response to a single automation failure in simulated air traffic control. When lower-DOA remains reliable, it could support higher-DOA failure detection. • Participants received a combination of lower-DOA and/or higher-DOA support on a simulated air traffic control task where automation failed to resolve a single aircraft conflict. • Reliable lower-DOA supported higher-DOA failure detection. Poorer automation failure detection with lower-DOA component failure suggests participants relied on aircraft highlighting to direct attention to potential conflicts. • Providing both lower- and higher-DOA could be beneficial if higher-DOA fails but lower-DOA remains reliable, but conversely, detrimental if lower-DOA also fails.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was supported by Australian Research Council Discovery Grant DP160100575 awarded to Loft from the Australian Research Council, and Future Fellowship FT190100812 awarded to Loft from the Australian Research Council. Correspondence concerning this article should be addressed to Vanessa K. Bowden, School of Psychological Science, The University of Western Australia, Crawley, Western Australia 6009, Australia (email: