
Abstract
Objective
We define human–autonomy teaming and offer a synthesis of the existing empirical research on the topic. Specifically, we identify the research environments, dependent variables, themes representing the key findings, and critical future research directions.
Background
Whereas a burgeoning literature on high-performance teamwork identifies the factors critical to success, much less is known about how human–autonomy teams (HATs) achieve success. Human–autonomy teamwork involves humans working interdependently toward a common goal along with autonomous agents. Autonomous agents involve a degree of self-government and self-directed behavior (agency), and autonomous agents take on a unique role or set of tasks and work interdependently with human team members to achieve a shared objective.
Method
We searched the literature on human–autonomy teaming. To meet our criteria for inclusion, the paper needed to involve empirical research and meet our definition of human–autonomy teaming. We found 76 articles that met our criteria for inclusion.
Results
We report on research environments and we find that the key independent variables involve autonomous agent characteristics, team composition, task characteristics, human individual differences, training, and communication. We identify themes for each of these and discuss the future research needs.
Conclusion
There are areas where research findings are clear and consistent, but there are many opportunities for future research. Particularly important will be research that identifies mechanisms linking team input to team output variables.
Keywords
Introduction
Recently, research has been using the term human–autonomy teams (HATs) to describe humans and intelligent, autonomous agents working interdependently toward a common goal (Chen et al., 2016; Johnson et al., 2012; Wynne & Lyons, 2018). HAT has been described as at least one human working cooperatively with at least one autonomous agent (McNeese et al., 2018), where an autonomous agent is a computer entity with a partial or high degree of self-governance with respect to decision-making, adaptation, and communication (Demir et al., 2016; Mercado et al., 2016; Myers et al., 2019). As noted by Larson and DeChurch (2020, p. 10), “we are quickly approaching a time when digital technologies are as agentic as are human counterparts.” With continuous advancements in artificial intelligence (AI), autonomous agents can perform a greater number of dynamical functions in both teamwork and taskwork than ever before (Seeber et al., 2020), and they are beginning to be viewed as teammates rather than tools (Grimm et al., 2018a; Lyons et al., 2018). For example, autonomous agents can increasingly participate in teamwork activity involving coordination, task reallocation, and continuous interaction with humans and other autonomous agents (Chen et al., 2016; Johnson et al., 2012; Shannon et al., 2017).
The potential of autonomous agents working with humans opens up an interesting question, which involves both articulating a clear definition of HATs as well as identifying the factors that make these teams successful. Indeed, empirical research on HATs is burgeoning. Yet, the findings remain scattered, thereby obscuring a clear perspective on the state of the science. Accordingly, an integrative review is needed, which we offer here. By conducting a review and integration of the empirical research on human–autonomy teaming, our contribution is threefold. First, we advance a clear definition of HATs given their potential for confusion with human–automation interaction (HAI) and human–automation teaming. Indeed, construct confusion can lead to a lack of specificity in the object of study and create difficulty in building a cohesive body of scientific literature. Thus, we begin by reviewing literature on automation, autonomy, and teamwork. Second, we conduct a review of the empirical research on HATs in order to consolidate the current state of the science. Specifically, we identify what is known about HATs with respect to research environments and dependent variables. Moreover, we classify the independent variables examined and report on the themes emerging from the studies examining those variables. By consolidating the extant literature, we can answer the question “what is the current knowledge, and the basis for that knowledge, at this point in time?” Third, in light of the findings of our review, we identify key gaps in current knowledge, and we recommend avenues for filling these gaps through future research opportunities that have the greatest potential to advance our understanding of the factors that make HATs effective. Thus, we propose an agenda for future research in order to refocus the field on the most pressing issues that need to be addressed. The overarching objective of this integrative review is to delineate and take stock of the state of the HAT literature, which should help scholars to systematically approach future research by prioritizing the most urgent issues and reducing the emphasis on research where findings are more firmly established. The review will also enable practitioners to quickly assess the current challenges and opportunities of HAT.
Defining Autonomy and Human–Autonomy Teams (HAT)
HAT, as a concept, is not new
The term HAT has been used in many studies published within the last 5 years (e.g., Chen, 2018; Demir, Amazeen, et al., 2017, Demir, Likens, et al. 2018, Demir, McNeese, et al. 2018; Endsley, 2017; McNeese et al., 2018; van Diggelen et al., 2018; Wynne & Lyons, 2018). However, although the term HAT has only recently become part of the mainstream vernacular, the concept of HAT is not new. Specifically, the concept of HAT was described in the 1990s by several researchers (e.g., Johannesen et al., 1994; Malin et al., 1991; Nass et al., 1996; Rich & Sidner, 1997; Sarter & Woods, 1995, Scerbo, 1996; Woods, 1994, 1996). Woods (1996) suggested that with technology changes, “…automation [is] seen as more autonomous machine
Similarly, Malin’s et al. (1991, pp. 3-7) NASA report specified the following:
The concept of a joint human-intelligence system team [is] introduced. This team consists of an operator (onboard crew member or ground flight controller) and an intelligent system. As a team, the operator and intelligent system actively cooperate.
Rich and Sidner (1997, p. 284) wrote: “We take the position that agents, when they interact with people, should be governed by the same principles that underlie human collaboration”.
These publications were among the earliest works we identified that explicitly and closely examined the proposition that autonomous agents and humans could work collaboratively in a team. Prior to this work, autonomous agents were discussed as potential aids that were subservient to humans, although considerations were beginning to surface in the 1980s (e.g., McNeese, 1986; Woods, 1985) about how humans and computers could better “associate” (i.e., a human and an aid that can work collaboratively or independently, as the situation calls for it; McNeese & McNeese, 2020, p. 175).
In the 1990s, as the above quotes illustrate, discussions emerged with respect to autonomous agents playing roles as genuine team players. Therefore, the concept of HAT has been considered by academics for three decades, but it was not until more recently that the term HAT has emerged and been used frequently (e.g., Demir et al., 2019; Demir, Likens, et al, 2018; Demir, McNeese, et al. 2018; Dubey et al., 2020, Fiore & Wiltshire, 2016, Grimm et al., 2018a, 2018b, Grimm et al., 2018c; McNeese et al., 2018, 2019; Shannon et al., 2017; Wohleber et al., 2017). We believe the emerging use of the term HAT is due to significant advances in AI, machine learning, and cognitive modeling. This has resulted in the shifting of human–autonomy collaboration from purely conceptual to increasingly practical and applicable. As a result, autonomous agents are now becoming more accessible for empirical research.
One important issue to resolve is the definition of HATs. Specifically, how are HATs differentiated from related concepts such as HAI and human–automation teaming? What is the difference between automation and autonomy? In our reading of the literature, too often these terms are used interchangeably, leading to construct confusion. Therefore, before embarking on our review of the empirical literature on HATs, we develop a definition of HAT that differentiates it from related concepts. We begin by considering automation, autonomy, and potential causes for confusions among the two.
Automation and autonomy
According to Endsley (2017), much of the research pertinent to current and future understanding of autonomy has actually been conducted over the past 40 years in the field of HAI. Although, in the future, entire systems (e.g., processes, teams, sets of functions or tasks) may be at the apex of the Level of Automation (LOA) continua (i.e., autonomous) and not requiring humans at all (see Bradshaw et al. [2013] for a contrarian perspective on LOA and Kaber [2018] for a critical response), Endsley (2017) noted that this will be difficult and will take substantial time. For now, therefore, many authors argue that humans and autonomous agents will need to interact in team-like structures to achieve objectives (e.g., Cooke et al., 2016; Cuevas et al., 2007; Glikson & Woolley, 2020; Larson & DeChurch, 2020; McNeese & McNeese, 2020; Myers et al., 2019; Seeber et al., 2020; Wynne & Lyons, 2018), and we along with others feel strongly that the existing HAI provides a vital foundation of knowledge from which we can advance a stronger understanding of HATs (Endsley, 2017). However, it is important not to confuse HAT with HAI. In the context of this paper, the distinction between automation and autonomy is important because HAI has a vast literature, only some of which directly applies to the current review of empirical research on HATs.
Automation has a long history, beginning with the reallocation of physical tasks from humans to automation, followed by automation of cognitive tasks through computers and technology (see Hancock et al., 2013). Parasuraman and Riley (1997) defined automation as “the execution by a machine agent (usually a computer) of a function that was previously carried out by a human” (p. 231; see also Parsons, 1985). In a slightly more nuanced definition of automation, Parasuraman et al. (2000) defined it as “a device or system that accomplishes (partially or fully) a function that was previously, or conceivably could be, carried out (partially or fully) by a human operator” (p. 286). This treatment illustrates the proposed and widely cited LOA continuum approach (Kaber, 2018; Parasuraman & Wickens, 2008). Of course, these levels can vary across dimensions of automation applications, such as information acquisition, analysis, decision selection, and action implementation (Parasuraman et al., 2000). Moreover, there is some debate about how exactly to conceptualize and apply the continuum (Kaber, 2018), but the continuum approach in general is widely acknowledged and cited, and it has proved useful (Endsley, 2017; Onnasch et al., 2014). Notably, LOA has been of ongoing interest throughout the history of HAI. Fitts’ (1951) work involved MABA-MABA (“Men are better at; Machines are better at”) lists. Seminal works by Endsley (Endsley, 1987; Endsley & Jones, 2012; Endsley & Kaber, 1999; Endsley & Kiris, 1995) as well as Parasuraman and others (Parasuraman et al., 2000; Riley, 1989; Sheridan & Verplank, 1978; Sheridan, 1980) have been “tremendously influential” in advancing LOA (Johnson et al., 2018, p. 2).
At low LOA, the automation can be viewed as executing on preprogrammed tasks—those the designers planned for in routine circumstances (Hancock et al., 2013). Consequently, automation exhibits a characteristic called brittleness, which is that it functions poorly on tasks it was not originally intended to perform (e.g., Roth et al., 1987; Woods & Cook, 2006). According to both Endsley (2017) and Parasuraman et al. (2000), as automation obtains more latitude to make decisions and execute tasks without the involvement of the human, it becomes more autonomous. Specifically, the highest LOA, Level 10, is defined as: “The computer decides everything [for a given task], acts autonomously, ignoring the human” (Parasuraman et al., 2000, p. 287). Despite their positioning on the same unidimensional continuum, however, automation and autonomy can be studied as different phenomena (de Visser et al., 2018; Hancock, 2017).
Two potential sources of confusion among automation and autonomy are that the division between the two is a matter of degree and the differences are a moving target. By definition, the use of conventional LOA continua makes automation and autonomy differences murky. At what point automation might be better described as autonomy is an open question, although suggestions have been made (compare McNeese & McNeese, 2020). Most LOA continua have in common that the levels appear to be embedded in somewhat discrete categories, which span from manual control, to automation, and finally to autonomy (Endsley, 2017; Parasuraman et al., 2000). Moreover, when Parasuraman et al. (2000) revisited their original LOA advanced two decades earlier (Sheridan & Verplank, 1978), they remarked that “what is considered automation will therefore change with time” and “today’s automation could well be tomorrow’s machine” (Parasuraman & Riley, 1997, both p. 231). Similarly, Hancock (2017) viewed autonomy as a later evolution of automation, thereby suggesting that their boundaries change over time but can be distinguished. In the future, as technological advances (e.g., AI) lead to the development autonomous agents with increasing levels of capabilities to interact with humans dynamically, greater self-learning capabilities, and affective, behavioral, and cognitive capacities consistent with what humans expect from a genuine team member, we believe the distinction between HATs and HAI will become increasingly clearer and useful. At present, however, we see the distinction between HATs and HAI as not entirely conclusive, given the state of current technology and that the concept of automation changes over time. Yet, in order to perform our review, we advance a specific delineation of HATs below.
Delineating HATs
For the purposes of this literature review, and more broadly for construct clarity in the literature, identifying what separates an autonomous agent as a team member from a subservient member is necessary. Our stated goal in this literature review is to critically examine empirical research on HAT, as this is a growing area of inquiry and enhancements in computational intelligence and learning algorithms will likely only generate more research and practical use in the future (Endsley, 2017). To qualify as a HAT, certain criteria for both autonomous agents and teamwork must be met, and these criteria represent boundaries for our treatment of what constitutes a HAT versus what does not.
Teams involve two or more members working interdependently toward a common goal (e.g., Salas et al., 1992). The interdependence includes both performing task activities and achieving outcomes (Campion et al., 1993). We posit that when teams include autonomous agents as individual members that are recognized and seen as performing a unique role on the team, we have a HAT. The preeminent teamwork scholar, Hackman (1987-2012), provides a platform for advancing this contention. He vehemently argued that “real teams” are bounded; that is, those involved understand which members are on the team and which members are not. Similarly, Larson and DeChurch (2020, p. 10) argued that the autonomous agent is a team member if it is fulfilling a distinct role in the team and is making a unique contribution to performance. This means that the autonomous agents must be divided into, and recognized by humans, as distinct entities that represent unique roles on the team that would otherwise have to be filled by a human in the role. If they are not recognized by humans as team members, there is no HAT. Therefore, we invoke the term “autonomous agent” to identify each computer-based entity that is individually recognized as occupying a distinct team member role. Other possible terms used in the literature include synthetic agent, intelligent agent, intelligent machine, and so on, but in the spirt of human–autonomy teaming, the term “autonomous agent” is most appropriate for this review.
The aforementioned definition raises the question of when an autonomous agent may be viewed as a tool versus as a legitimate teammate (e.g., Groom & Nass, 2007; Lyons et al., 2018). When viewed as a tool, performance and behavioral effectiveness tend to suffer compared to when viewed as a teammate (Walliser et al., 2019, 2017). Based on previous literature, we submit that there are two overarching criteria for autonomous agents to be viewed as a teammate: a degree of interdependence with other team member activities and outcomes (Nass et al., 1996; Walliser et al., 2017), and a degree of agency involving independence of actions and proactivity among autonomous agent members (Lyons et al., 2018; Wynne & Lyons, 2018). First, Nass and colleagues reported on a series of findings suggesting that, under certain conditions, humans can apply politeness norms in dealings with computers, they use notions of self and other, apply gender stereotypes, and adjust to computer personalities (Nass et al., 1995, 1994). In a landmark study, Nass et al. (1996) manipulated the interdependence of a human and computer working together and found that, within the interdependence condition, the subjects perceived the computer to be more similar to themselves, saw themselves as more cooperative, were more open to influence from the computer, thought the information from the computer was of higher quality, found the information from the computer friendlier, and conformed more to the computer’s information. Similarly, Walliser et al. (2017) found that outcome interdependence in HATs elicited stronger positive affect and team performance than the lack of outcome interdependence. Thus, interdependent team activities and outcomes are part of the requirement for perceiving an autonomous agent as a team member occupying a unique role on the team.
Second, a theoretical paper by Wynne and Lyons (2018) added several factors beyond interdependence in order for humans to view autonomous agents as teammates, rather than tools. They considered those factors in a follow-up qualitative study (Lyons et al., 2018), which involved agency, benevolence, communication, interdependence, and synchrony/coordination. They found the most support for agency and “humanness,” the latter of which emerged from their exploratory analyses. Humanness was described as perceiving the autonomous agent as acting like a human. Arguably, however, without agency, none of the other factors would be perceived meaningfully by humans, including humanness. Can automation be perceived as benevolent, communicative, synchronized/coordinated, and human without being viewed as agentic? We think not; therefore, being perceived as at least having a degree of agency will be vital for autonomous agents to be perceived as team members rather than tools. Indeed, in their definition of perceived agentic capability, Wynne and Lyons (2018, p. 362) offered the following:
The intelligent agent has the capability for some autonomy. Perceived agentic capability refers to the perception that the agent has some degree of decision-making latitude. Teammates typically have the capability to choose or recommend courses of action, whereas basic tools typically do not. Similarly, this capability depends, in part, on an affordance for decision authority and a capacity for self-direction. Between Sheridan’s (1980) levels of automation and the taxonomy of automation types proposed by Parasuraman et al. (2000), there are existing taxonomies that relate to the notion of varying levels of agency among automation. The key aspect of this facet is the idea of perceived agency.
Accordingly, the autonomous agents must have the capacity to brightslie perceived as having a degree of agency, exhibited through independence, self-government, and proactivity. This is consistent with many descriptions of HATs in the literature (Demir, Cooke, et al., 2018; Demir, Likens, et al. 2018; Demir, McNeese, et al., 2018; Endsley, 2015; Fiore & Wiltshire, 2016; McNeese et al., 2018), but we formalize it here.
Interdependence is relatively straightforward to identify, as it can be built into the task design and outcome distribution (e.g., McNeese et al., 2018, Nass et al., 1996; Walliser et al., 2019, 2019). Agency involves consideration of LOA continua (Table 1), as the above quote by Wynne and Lyons (2018) illustrates (see also Demir, Cooke, et al., 2018, Demir, Likens et al., 2018, Demir, McNeese, et al., 2018). Parasuraman and colleagues’ (e.g., 2000) continuum suggests that the computer’s role at low LOA is either “manual control” (i.e., Level 1) or limited to effectively identifying and/or narrowing down a range of options requested by a human (i.e., Levels 2–4). This aligns with other treatments of automation, such as Endsley (2017) who discussed automation as operating well for the range of situations it was designed and programmed to address, and Woods and Cook’s (2006) observation that automation functions poorly outside of its predefined applications (i.e., brittleness). As a result, computers with low LOAs (Levels 2–4) are not likely to be viewed as agentic because they lack discretion, decision-making latitude, and any ability to independently engage in activities beneficial for the team without a preprogrammed instruction to do so. Lacking agency, humans are less likely to view the automation as a teammate (Lyons et al., 2018), there would be no autonomous agent, and, therefore, the criteria for a HAT would not be met. Thus, we added labels to the LOA continuum in order to indicate that there is manual control at Level 1 and no autonomy at Levels 2–4 (Table 1).
10 LOAs Divided Into Autonomy Levels
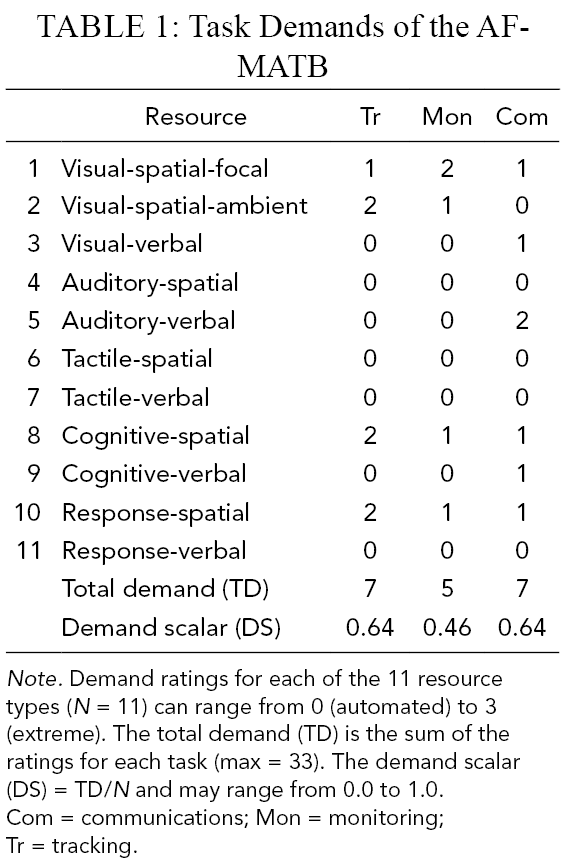
Note. Adapted from Parasuraman et al. (2000) with permission from the Copyright Clearance Center and Rights Link/IEEE.
At Levels 5–6, Parasuraman et al. (2000) noted that the automation will generate decisions and actions that are communicated to the human(s) and then will execute with approval (Level 5) or with limited time for veto before the actions are implemented autonomously (Level 6). Whereas this is not high agent autonomy because humans are still able to exert control through vetoing proposals, this level does represent partial agent autonomy because the agent offers suggestions (Level 5) and will execute them independently if ignored (Level 6). We adopt the term “partial autonomy” because at these levels the autonomous agent is proactive in bringing forth actions to the team that it recommends be executed and, as a result, will more likely be viewed as having some degree of agency (Mercado et al., 2016; Wynne & Lyons, 2018). Indeed, according to Wright et al. (2018, p. 1034), below Level 5 and above Level 6 offer natural break points:
While Level 5 describes a ‘supervisory control’ level, where the automation develops a suggested course of action but will not enact its decision without operator approval, Level 7 is a highly autonomous condition, where the automation develops and implements its course of action, while notifying the human teammate. Hence, Level 5 describes a partial level of autonomy, while Level 7 describes a high level of autonomy.
Similarly, moving up the continuum to Level 7, Parasuraman and Riley (1997, p. 232) noted a break point where “the automation carries out a function and informs the operator to this effect, but the operator cannot control the output”. Above this, an autonomous gent will take action without waiting for human input and “at the highest levels, the functions cannot be overridden by the human operator” (Parasuraman & Riley, 1997, p. 232; see Table 1). Depending on the exact level, the autonomous agent may or may not even inform the team explicitly of its actions (Level 8 and above). Given its agency and decision latitude, it can be viewed as high agent autonomy, because the human has little direct involvement or control and the autonomous agent is operating out of its own accord (Billings, 1991). Therefore, we have classified Levels 5–6 as “partial autonomy” and Levels 7 and above as “high agent autonomy” (Table 1).
Recall that if there is interdependence (Nass et al., 1996) and the autonomous agent is viewed as agentic (e.g., independently pursuing courses of action through self-governance; Lyons et al., 2018), then it is likely to be viewed as a team member and not a tool (see also Mercado et al., 2016; Russel & Norvig, 2009). When autonomous agents work collaboratively with humans on a team, the collective constitutes a HAT (McNeese & McNeese, 2020).
It should be noted that certain authors have referred to HAI and human–automation teams using definitions that we believe are better captured by the term HAT. For example, Langan-Fox et al. (2009, p. 896) refer to human–automation teams as “the dynamic, interdependent coupling between one or more human operators and one or more automated systems requiring collaboration and coordination to achieve successful task completion”. We would classify this as a HAT if the autonomous agent exceeded a Level 4 LOA given the interdependence as well as the perceptions of agency that would likely accompany a computer that could collaborate and coordinate meaningfully on a joint task. Moreover, it can also now be understood that HATs are different from human–automation teams. In keeping with the distinction between automation and autonomous agents, we view human–automation teams as exhibiting a degree of interdependence among humans and automation with LOA below Level 5 on Parasuraman et al. (2000) continuum (because this is the automation–autonomy break point; Wright et al., 2018). Whereas there may be interdependence among humans and automation (making the system team-like; Nass et al., 1996), there will not likely be any perceived agency of the automation because it can, at best, only narrow down or suggest alternatives in a subservient, reactionary manner (Levels 3 and 4, respectively). To meet criteria for autonomous agents and to qualify as a HAT, at least partial or high autonomous agents as defined above would be required of the computer-based entities (i.e., autonomous agents) involved. Therefore, interdependence is necessary but not sufficient for autonomous agents in HATs.
In summary, our consideration of automation, autonomy, teamwork, and HAT reveals the following:
The term HAT has emerged over the past 5 years in the mainstream research vernacular.
The concept of HAT is not new and was discussed in the 1990s; the term HAT is new.
HAT has its foundations in 40 years of research on HAI, and HAI will inform current and future research on HATs.
What is implemented through different levels of automation and autonomy is constantly evolving and has been for decades.
The difference between automation and autonomy is a matter of degree and both exist on LOA continua.
An autonomous agent in the context of HATs is a computer-based entity that is recognized as occupying a distinct role on the team. The autonomous agent is more likely to be recognized as a team member if humans and autonomous agents are interdependent and the autonomous agents are perceived as agentic (we strictly adhere to the use the term “autonomous agent” in this article).
The LOA continuum approach has natural discrete break points that facilitate a delineation of HATs and help to confine the current review to HATs specifically (rather than include all automation research, which would not be tractable or relevant).
LOA includes manual (Level 1) or “automation as a tool” (Levels 2–4) settings in which the automation does no more than provide information, such as scan or narrow down a range of decision alternatives. At these levels, humans would not typically view the automation as agentic, and therefore not as autonomous agent members.
HATs are not to be confused with human–automation teams, which have a degree of interdependence among humans and automation but the automation is not an autonomous agent and therefore different issues may be involved.
To be considered a HAT, the autonomous agent(s) must meet at least partial levels of agent autonomy. Partial levels of agent autonomy can spontaneously recommend and execute actions unless they are vetoed (Levels 5–6). High levels of agent autonomy require no human intervention or prompt before the autonomous agent executes actions independently (Levels 7–10).
HAT can be defined as interdependence in activity and outcomes involving one or more humans and one or more autonomous agents, wherein each human and autonomous agent is recognized as a unique team member occupying a distinct role on the team, and in which the members strive to achieve a common goal as a collective. The “autonomy” aspect of human–autonomy teaming refers to the autonomous agent.
We begin our review by describing the method for identifying articles for inclusion and our organizing framework. Moving into the results, we (a) report on the research environments, (b) report on the dependent variables, (c) classify the independent variables, (d) identify themes representing trends in the findings as well as (e) future research directions.
Method
Our methods mirror recent search approaches in literature reviews reported in this journal (e.g., Kazi et al., in press; Patterson, 2018). The criteria for inclusion in the current review were fourfold. The study had to (a) be empirical, (b) include sufficient description of the autonomous agent to code for the level of agent autonomy (partial or high), and (c) have at least one autonomous agent and one human (d) that were working on a task interdependently toward a common goal. To determine whether there was an autonomous agent, it had to reach at least a “5” on Parasuraman et al.’s (2000) continuum (Table 1). To determine whether the team was a HAT, the team had to meet our definition provided above. Specifically, we did not eliminate a paper if it used a term other than human–autonomy teamwork, if in fact the teams in the study fit within our definition of HAT provided earlier. We also did not exclude empirical field studies, case studies, or purely qualitative studies; however, none met our criteria for review. Schnittker et al. (2017), for example, interviewed 12 anesthesiologists and four anesthetic nurses about their experiences with critical decisions for managing breathing airways. However, this study focused on decision support rather than a specific autonomous agent or HAT. Elsewhere, Ahmed and Hasan (2014) investigated the performance of an autonomous agent to detect breast cancer. Unfortunately, insufficient information was provided to determine whether the autonomous agent met at least a partial level of agent autonomy as well as whether the humans and autonomous agent were interdependent, or whether there was a team at all. We also excluded papers that purely advanced a new theory or a logical argument, although these papers were used in the Introduction and Discussion sections as appropriate (e.g., Johnson et al., 2011). Conversely, several mixed methods studies did meet our criteria and appear in the review (e.g., McNeese et al., 2018).
We did not place any limits on the date range of the published studies. We employed the following four-step process to identify articles that met criteria for inclusion.
Step 1
In the initial search, we identified six keywords for searching within databases: teamwork, human–autonomy teaming, human–automation teaming, human–agent teaming, human–machine interaction, and synthetic agent. These keywords were identified based on the keywords used in prototypical articles in the literature (e.g., Chiou & Lee, 2016; McNeese et al., 2018). To set the search algorithm, we used the following approach:
Teamwork and:
human–autonomy teaming, or
human–automation teaming, or
human–agent teaming, or
human–machine interaction, or
synthetic agent.
The above search algorithm was applied to three electronic databases: Association for Computing Machinery (ACM) Digital Library, IEEE Xplore Digital Library, and Sage Journals, which resulted in 1942 returns. Unfortunately, this search extracted some articles that did not involve teamwork. Accordingly, we downloaded the articles and searched for the term “team” in the complete article text among the returns, which left 476 articles remaining. These articles were then screened on the criteria for inclusion. This resulted in a total of 33 articles for inclusion from this step, and this process was completed between November 2018 and March 2019.
Note that we intentionally excluded human–robot interaction (HRI) research involving a physical robot. The key issue with the use of physical robots is that of the potential for unique psychological processes activated by embodiment and physical presence (Reig et al., 2019). For example, the physical presence and design of a robot can impact the valence of interactions with humans, the extent to which the robot engages and interests the human, and trust development (e.g., Hanna & Richards, 2015; Kidd & Breazeal, 2005). Color identifiers, reciprocity, and gender-based voices, for example, can be used to subtly influence HRIs (Guznov et al., 2020). Moreover, attitudes toward robots could be different than attitudes toward autonomous agents embedded in a computer, yet attitudes play a role in interactions and communication (e.g., Nitsch & Glassen, 2015; Powers et al., 2007). Thus, many potential confounds could be introduced if we amalgamated the HRI literature involving physical robots into our review of HAT. We recommend future reviews analyze the literature on teamwork in HRI involving physical agents.
Step 2
In an attempt to uncover potentially missed articles, a follow-up search of the authors who authored the most articles within the 476 articles from Step 1 was completed. Specifically, of the 476 articles, the top four authors were Bradshaw (15), Chen (nine), Sycara (eight), and M. McNeese (eight). There was a break point following these four authors with a smattering of other authors with six papers each. Moreover, restricting to these four authors still provided a large number of papers to manually search for inclusion. That is, searching within these four authors’ publications resulted in an additional 930 potential articles and, of these, 31 additional studies met our criteria for inclusion, and this process was completed from April 2019 to May 2019. To uncover these articles, we searched the following:
Jeffrey Bradshaw, retrieved from http://www.jeffreymbradshaw.net/
Jessie Y.C. Chen, retrieved from Google Scholar profile
Katia Sycara, retrieved from www.cs.cmu.edu/~softagents/publications.html
Michael McNeese, retrieved from www.researchgate.net/profile/Michael_Mcneese
Step 3
To round out the search, we conducted a final supplementary manual Google Scholar search. For this, we searched “human–autonomy teaming” within key authors. These key authors were identified by examining reference sections of articles meeting criteria for inclusion from Steps 1 and 2 above in concert with the expertise of the authors. These authors were: Julie Adams, Michael Barnes, Christopher Myers, Missy Cummings, Mustafa Demir, Nancy Cooke, Steve Fiore, Mike Goodrich, Joseph Lyons, Nathan McNeese, Kristen Schaefer, and Travis Wiltshire. This search returned 152 articles, of which eight were unique and met criteria for inclusion. This process was completed from June 2019 to August 2019.
Step 4
An anonymous reviewer requested that we update the search by adding the term “human–automation interaction” to the search terms used in Step 1. By adding this term, we obtained another unique four studies that met criteria for inclusion. This process was completed from April 2020 to May 2020. Given this four-step process, the total number of unique articles included in the review was 76. The 76 articles are listed in the Appendix.
In addition, conference proceedings were disambiguated from subsequent journal papers and other conference contributions from the same research groups. Our approach was to include papers that reported duplicate results only once. However, papers were treated as distinct if they appeared to use the same data or were from the same lab but included different variables and analyses. The rationale for this approach was to include as many findings as possible without counting the same exact finding from the same data set more than once.
Coding Framework Development
The coding scheme was created inductively and iteratively. Specifically, we began by recording the environmental factors of the study (e.g., testbeds), independent variables, dependent variables, and key findings. Through discussions with the senior authors, the research team iteratively generated a set of variables to code (all of which are described in the “Results” section). Our objective was to create codes that were broad enough to capture as much information as possible from the primary studies to provide a useful survey and organization of the literature yet narrow enough that some specificity of findings could be retained.
In order to organize the independent and dependent variables into a framework, the coded categories were classified within the I-M-O model of team effectiveness (Figure 1). This is a dominant conceptual framework in the teamwork literature (Hackman, 1987; Mathieu et al., 2017; McGrath, 1984) that bears resemblance to the Stimulus-Organism-Response model that can be traced back to Woodworth (1918) introduction of the organism as a mediating variable between stimulus and response. Notably, the I-M-O model was used in earlier teamwork reviews in this journal (e.g., Kazi et al., in press). The “I” represents inputs to team processes and emergent stages (mediators representing the “M”), which are responsible for converting inputs into team outputs (representing the “O”). A team’s process requirements can be understood within the widely accepted team process taxonomy advanced by Marks et al. (2001). Transition-related activities involve developing, adapting, and clarifying the team’s common purpose, strategy, tasks, and role structure. Action-related activities involve back-up behaviors, mutual performance monitoring, monitoring goal progression, and coordination that occur during task execution periods. Interpersonal activities involve affect management, conflict management, and motivational issues. More recently, the “process box” originally advanced by McGrath (1984) was enlarged by Ilgen et al. (2005) to also include team emergent states, which tap qualities of the team that are affective or cognitive in nature (Marks et al., 2001; Waller et al., 2016). Thus, both processes and emergent states are viewed as mediators of the team input to team output relationship.
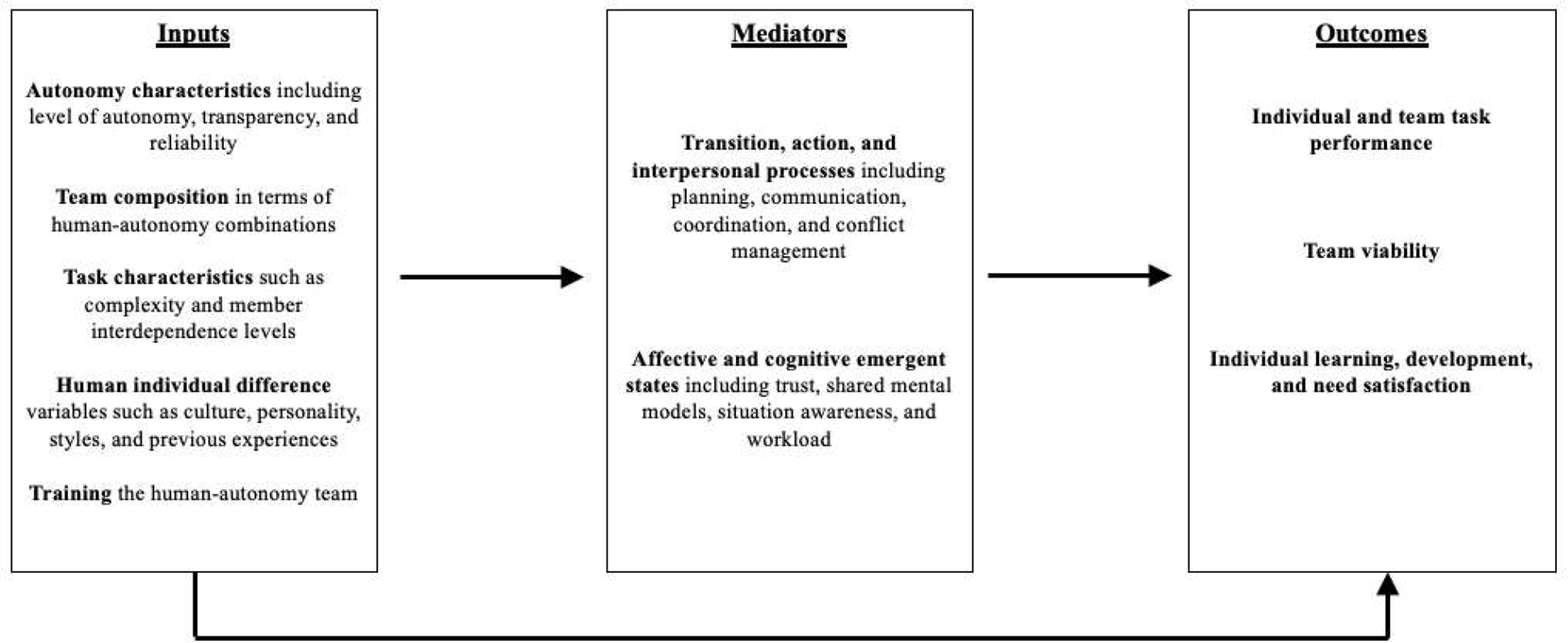
Inputs are theorized to influence mediating mechanisms, which in turn affect multi-level human–autonomy teaming outcomes. Most individual studies in the current review only considered a single path in the I-M-O chain (i.e., did not test mediating mechanisms). Source. Adapted from Kazi et al. (in press).
With respect to team outcomes, Hackman (1987, 2002, 2012) offered a generalizable taxonomy. First is the quality of the team’s output. Second, the team needs to become increasingly capable over time in terms of deploying the processes and emergent states needed to achieve and maintain acceptable levels of output (i.e., team viability). Third, the individual members of the team should develop, learn, and improve over time by working together. This treatment is consistent with outcomes as multilevel and multidimensional (Salas et al., 2008b).
Inter-Coder Agreement
All papers were initially coded by an author of the current manuscript. The coding was reviewed by a second author and any discrepancies were discussed and consensus was achieved. As well, the initial coder revisited all the codes a second time and confirmed them for accuracy (i.e., double coding). A second coder was then trained to code a subset of the articles in order to investigate inter-coder agreement. A calibration phase was conducted involving two iterations totaling 15 articles (five calibration articles in Iteration 1, followed by 10 calibration articles in Iteration 2). A total of 30% of the remaining articles were then randomly selected (via random number generator) for independent coding; the inter-coder agreement for these articles was 89% overall. Discrepancies were discussed and resolved. This approach matches methods used previously (e.g., Kazi et al., in press; Patterson, 2018; Wallius et al., 2019).
Results of Literature Review: Research Environments, Themes, and Future Research Opportunities
We begin by reviewing research environments, followed by dependent variables (Table 2) and independent variables (clusters, themes, and future directions; Table 3). Note the increasing trend of research on HATs over time, which is consistent with the rapid technological advances in computing and AI over the past several decades (Figure 2). Figure 1 contains the independent and dependent variables coded within the I-M-O model. We note that some articles may not have been clear enough in their reporting in order for us to classify a given variable within our review, on a given variable. For example, for task difficulty there were three papers that did not provide sufficient information about the task in order for us to classify it as low, medium, or high. Therefore, tabulation of articles in each category may not always sum to the total number of papers included in the review.
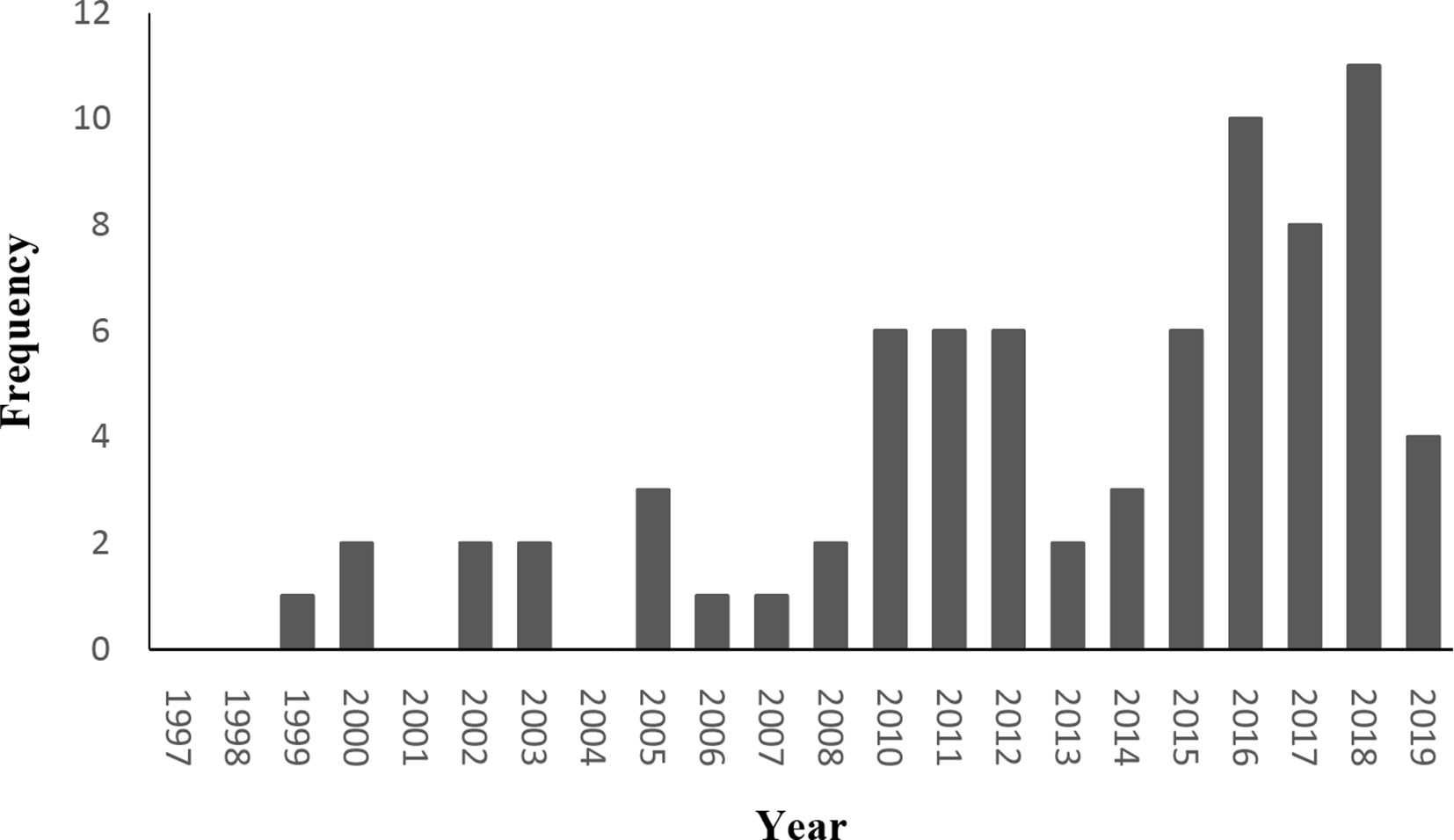
Histogram of the number of publications in the current review at each year.
Dependent Variables Studied and Observations
Independent Variables by I-M-O Designation, Themes From Research Findings, Example Citations, and Future Research Needs
Abbreviations: HATs = human–autonomy teams; I-M-O = input - mediator - output; IV = independent variable.
Research Environments
Task environment
All articles that met criteria for inclusion were simulation and not field-based (e.g., in situ) studies. Recall that field studies and case studies were eligible for our review but none met our inclusion criteria. We found that the overwhelming majority of articles were military- or emergency-related simulations (n = 57). These largely involved command and control tasks including target identification, attacking, defending, navigation, and so on. Nonmilitary/emergency simulations represented the remaining articles (n = 17). These involved tasks such as farming, space exploration, place-and-drill tasks, block movement tasks, and factory production. Finally, two articles did not provide sufficient information to be classified into an environment. We describe the testbeds, which are the types of platforms used to study HATs in the papers that met our criteria for inclusion, used in these task environments below.
Military simulation testbeds
Among the articles in our review, the Cognitive Engineering Research on Team Tasks - Unmanned Aerial System–Synthetic Task Environment (CERTT-UAS-STE) and the Mixed Initiative Experimental (MIX) were the testbeds that were most represented. The CERTT-UAS-STE (Cooke & Shope, 2004) was a testbed used in 18 articles in our search (e.g., Demir, et al., 2016; Demir, Cooke, et al., 2018; Demir, Likens et al., 2018, Demir, McNeese, et al. 2018; McNeese et al., 2018). This testbed is based on the United States Air Force Predator UAS ground control station and requires three interdependent teammates in distinct roles (pilot, navigator, and photographer) to efficiently take photographs of waypoints. This objective involves three main communication events: the navigator sends information about the target to the pilot, the pilot then communicates with the photographer about the target’s altitude and airspeed restrictions with the goal of adjusting camera settings, and finally the photographer provides feedback on whether or not an acceptable photo was acquired (Cooke et al., 2016; McNeese et al., 2018).
The MIX testbed was used in 15 articles (Wright et al., 2014). This testbed has conditions for three levels of agent autonomy for reconnaissance, surveillance, and target identification missions using unmanned vehicles. It is an open source research environment, consisting of two primary applications, the Operator Control Unit (OCU), and the Unmanned System Simulator (USSIM). Its nature as an open source application allows for it to be easily used and modified to suit a wide variety of research needs, and it was used in 15 articles. One variation of the MIX testbed (Wright et al., 2014) has conditions for levels of agent autonomy for reconnaissance, surveillance, and target identification missions using unmanned vehicles with the levels managed through the autonomous agent RoboLeader. RoboLeader automatically manages spacing of military convoy vehicles and provides route change suggestions in response to external events as well as makes those changes when approved by the human teammate. Although physical robots were excluded from our review, the MIX testbed using RoboLeader was retained. The MIX testbed meets our criteria for inclusion because the autonomous agent teammate works interdependently in the HAT by monitoring search robots and generating suggested actions spontaneously, the level of agent autonomy is partial (Level 5 on the Parasuraman et al., 2000 scale), and the task and outcomes are interdependent.
Non-military simulation testbeds
The most frequently used testbed for these simulations is B4WT (blocks for world teams), which requires working with an autonomous agent in order to move different colored blocks from one room to another (e.g., Harbers et al., 2011).
Task difficulty
To classify task difficulty, we used the following task considerations: time limit (i.e., was there a time limit?), interdependence (i.e., the extent to which the team environment led to each team member being affected by other team members; Barrick et al., 2007), goal difficulty (whether there were single versus multiple goals), and whether there were multiple steps to achieve the objective. We combined these task characteristics to obtain a score from 0 (contained none of these aspects of difficulty; none received a score of 0) to 4 (contained all of these aspects of difficulty). Of the 76 articles, nine were classified as low difficulty tasks (i.e., rating of 1), 45 were medium difficulty tasks (i.e., rating of 2–3), and 19 were high difficulty tasks (i.e., rating of 4). The remaining three articles did not provide sufficient information to permit classification.
Communication Modality
We found three distinct modalities of communication between humans and autonomous agents: visual representation (n = 10), text-based chat (n = 39), and audio/vocal expression (n = 2). There were 18 articles that used a mix of communication modalities, and the remaining studies did not report on the communication modality used. Visual representation allowed the human or autonomous agent to visually share a suggested action, such as a potential pathway from one planet to another. Text-based chat allowed for messages to be exchanged through a text box on a device. Physical movement involved communication based on observable changes in location or orientation. Audio expression involved the use of spoken language, which includes the use of the Wizard of Oz technique (also utilized in text-based chat). That technique uses a confederate as the representative for the autonomous agent, and the human team members are led to believe that the voice or text emanates from the autonomous agent directly.
Agent Autonomy Levels
To assess the agent’s level of agent autonomy, we employed the grid advanced by Parasuraman et al. (2000); see both their Table 1 and ours), which ranges from no agent autonomy (score of 1) to a very high level of agent autonomy (score of 10). For the current review, we modified the 10 levels by chunking them into two distinct categories. Specifically, we found 26 articles investigating a high level of agent autonomy and 31 articles investigating a partial level. A total of 15 articles involved multiple the levels of agent autonomy within their studies. As our criteria for inclusion involved at least a minimal level of autonomy, there were no articles included that scored between a “1” and “4” on Parasuraman et al.’s (2000) grid, although the remaining articles did not provide sufficient information to render a classification to partial or high levels of autonomy but they did clearly meet or exceed a level of “4” on the agent autonomy continuum.
We also considered the nature of the autonomous agent(s). In 11 of the studies, the role of higher agent autonomy involved performing more activities or tasks. For example, with increasing agent autonomy in the MIX testbed, the autonomous agent takes on more and more workload, such that under partial agent autonomy it maintains vehicle distance and separation only, whereas under high agent autonomy it also provides route planning advice (Chen et al., 2013). In four of the studies, the higher levels of agent autonomy involved more decision-making and information exchange. For example, Azhar and Sklar (2017) report on a comparison between “human-as-supervisor” and “human-as-collaborator.” In the former, decisions are made by the human, whereas in the latter computational argumentation-based dialog is employed to share decisions.
Team Composition
Teams in the current review were composed of at least one autonomous agent and one human to meet our criteria of human–autonomy teaming (as well as the criterion that the team members were working toward a shared goal with a degree of interdependence). A total of 65 of the articles involved only a single autonomous agent and, of these, 45 involved the single autonomous agent working with a single human teammate. A total of 22 articles contained two or more humans in the team. Seven articles involved multiple autonomous agents, and one (Sycara & Lewis, 2002) of these articles included both multiple agents and multiple humans. The remaining articles that were not classified due to inadequate reporting within those articles.
Dependent Variables
Table 2 contains a summary of the dependent variables examined and our observations. The most common dependent variables involved workload, trust, situation awareness, shared mental models, and team and individual performance. Other than performance, which is an outcome variable, note that the rest of these commonly studied dependent variables are affective and cognitive emergent states (i.e., “Mediators” in Figure 1), rather than team outcomes in the traditional sense of Hackman’s (1987) taxonomy (i.e., team viability, individual learning, development, and need satisfaction). Trust may be viewed as an affective bond that ties the team together, which may be considered an indicator of the Hackman’s second outcome criterion (i.e., the viability of the team to continue working together). Very little was observed with respect to Hackman’s third criterion, which is the learning, development, and need satisfaction of individual members within the team setting. This is a future research opportunity.
Independent Variables
The most common classification of independent variables were the following team inputs (Figure 1):
autonomous agent characteristics (levels of agent autonomy, transparency, and reliability);
team composition (human–human versus human–autonomy);
task characteristics (interdependence and difficulty levels);
human individual difference variables (e.g., personality, past experiences); and
training.
The only mediator variable examined for its effects on outcomes was communication. Next, we review the findings for each independent variable, key themes and related future research directions, and example citations (summarized in Table 3).
Team input: Studies manipulating levels of agent autonomy
We identified 15 articles that manipulated the agent autonomy level from either no agent autonomy to partial agent autonomy, from partial agent autonomy to high agent autonomy, or from no agent autonomy to high agent autonomy. The first theme we noted was that increasing levels of agent autonomy generally resulted in positive effects on outcomes. Specifically, with higher levels of agent autonomy, the autonomous agent was generally perceived as easier to work with (Johnson et al., 2012), communication efficiency was higher (Wright et al., 2013), coordination was stronger (Wright & Kaber, 2005), and performance was higher (e.g., Lewis et al., 2003). Moreover, participants viewed higher levels of agent autonomy as less burdensome to work with (Johnson et al., 2012) and as requiring a lower workload (Wright et al., 2013, 2018). Finally, humans perceived better collaboration, stronger trust, and increased level of task understanding with greater levels of agent autonomy (e.g., Azhar & Sklar, 2017). A caveat, however, is that other studies by Wright and colleagues found that autonomous agents were better perceived when they provided a moderate level of decision-making input compared to a low or high level (Ruff et al., 2002; Wright & Kaber, 2003, 2005). Moreover, low to moderate shared control led to more favorable anticipation ratios than did high shared control.
A second theme was that different levels of agent autonomy may help some individuals more than others. Participants with low spatial ability experienced the greatest performance benefits from increases in agent autonomy (Chen et al., 2013; Wright et al., 2013, 2018), as did participants with the highest attentional control (Wright et al., 2013, 2018). However, participants with high spatial ability experienced decreases in situational awareness from increases in agent autonomy.
With respect to future research, it would be helpful to consider specific conditions in which higher agent autonomy is more or less helpful; for example, are the benefits of agent autonomy greater for particular types of tasks (e.g., search versus route planning) or level of interdependence (compare Johnson et al., 2011)? In one exception, Fan et al. (2010) reported that human–human teams were less impacted by increases in task difficulty than were HATs. More generally, investigating how autonomous agents could dynamically adjust to the unique characteristics and needs of particular team members would be valuable, as opposed to a “one-size-fits-all” design. We also note that it may not be surprising that increases in agent autonomy had favorable results, given that 11 of the 15 papers manipulated agent autonomy based on the amount of tasks that the autonomous agent could perform. This can be contrasted with the autonomous agent providing high levels of information exchange and decision support (e.g., Azhar & Sklar, 2017). Table 3 contains additional future research opportunities.
Team input: Transparency and reliability
Autonomous agent transparency is the extent to which it communicates only its current status (low transparency) versus its reasoning processes, how it projects future outcomes, and how it communicates uncertainty levels (Selkowitz et al., 2015). The first theme we found was that transparency was associated with mixed findings. Indeed, studies find that higher transparency is related to increases in performance (e.g., Mercado et al., 2016), trust (Boyce et al., 2015), and perceived understanding of the autonomous agent (Harbers et al., 2011). Additionally, increasing agent transparency was associated with lower perceptions of time pressure and frustration (Wright et al., 2016). With low agent transparency, performance decreased (Mercado et al., 2016) and humans were more complacent (Wright et al., 2016). Wright et al. (2016) also reported a trend of increasing workload (measured using self-report and pupil diameter), possibly because greater transparency can be associated with more information sharing and therefore more intensive processing requirements.
A second theme involved reliability. Specifically, higher reliability of autonomous agents produced consistently positive results. Reliability is often treated as the level of accuracy with which the autonomous agent performs its roles. Decreases in reliability are, unsurprisingly, associated with a host of negative outcomes for human–autonomy teaming. Lower reliability is associated with increased workload (e.g., Chen, et al. (2011), lower performance (Hillesheim & Rusnock, 2016), and lower trust (Hafizoğlu & Sen, 2018a, 2018b), unless participants were made aware of the ways in which reliability was lower (Fan et al., 2008). In addition, human teams outperformed HATs at lower levels of autonomous agent reliability (Hillesheim & Rusnock, 2016).
However, a third theme was that transparency appeared to play an interactive role in the effects of the autonomous agent’s reliability. Specifically, when human operators were aware of the lower reliability (higher transparency), they were more trusting (Fan et al., 2008) and their performance was higher than when they were unaware of the reliability (Chen & Barnes, 2012).
The transparency of the autonomous agent was associated with mixed effects in the literature, and there appears to be a trade-off. High levels of transparency are likely beneficial because it clarifies the reasoning and decision making used by the autonomous agent. Yet, this has the potential to increase workload (Wright et al., 2016). Additionally, high transparency may create a level of complacency that leads to less vigilance in overseeing or questioning the autonomous agent’s work (Sadler et al., 2016). Taken together, further work is needed to unpack the effects of transparency, such as investigating whether transparency is better for certain individuals (e.g., that have little propensity to trust technology) or for certain tasks (e.g., high difficulty tasks coupled with high transparency may lead to cognitive overload; mission-critical tasks may require higher levels of transparency to instill trust). Finally, examining how the effects of transparency unfold over time, in longer-term designs, may reveal a gradual decline in workload as humans learn more about the autonomous agent’s capabilities and master how to work with it. In terms of reliability of autonomous agents in HATs, there were uniformly positive effects on outcomes, suggesting that we should always build autonomous agents with high reliability.
Team input: Team composition
Team composition refers to the mix and ratio of human and autonomous agents on the team. One theme in the studies examining team composition was the general advantage of human–human teams versus HATs. With respect to performance, human–human teams almost always outperformed HATs (e.g., Cooke et al., 2016; Demir et al., 2016; McNeese et al., 2018; Myers et al., 2019). An exception included research by Fan and colleagues, who found that HATs performed better (Fan et al., 2010) likely because of increased efficiency in workload management (Fan & Yen, 2011). Moreover, human–human teams had higher general positive affect ratings (Walliser et al., 2017), demonstrated a positive learning effect (Cooke et al., 2016), and engaged in better reorganization and adaptation (Grimm et al., 2018a). Overall, therefore, human–human teams tended to function better and achieve better outcomes than HATs.
A second theme involved communication. Human–human teams may have performed better in part because of more efficient information sharing. Indeed, human–human teams provided more status updates and had fewer repeat requests for information compared to HATs (Demir, McNeese, 2018; McNeese et al., 2018). Furthermore, the volume of communication was double when working with a human versus autonomy, which suggests human–human teams may be more communicative in general.
In terms of future research, quality of information exchange and communication may be an important consideration. McNeese et al. (2018) described the human–human team communication advantage as due to their engagement in more pushing behaviors (e.g., giving status updates and suggestions) and fewer pulling behaviors (repeated requests for information). Interestingly, the volume of communication was double when working with a human versus an autonomous agent. However, increased communication may not always characterize high-performance teamwork. High communication frequency could indicate greater workload, confusion, misunderstandings, and inefficiency (MacMillan et al., 2002). Thus, whereas human–human teams appear to share a lot of information, this may not always be an advantage. Interestingly, Cooke et al. (2016) found lower subjective perceptions of workload after a period of time working with the autonomy. Thus, it would be valuable for future research to investigate the quality of information exchange and how this may change over time (e.g., through taxonomies such as McNeese et al., 2018).
Team input: Task characteristics
One approach we found in the literature involving task characteristics was the manipulation of task interdependence, which is the extent to which humans and autonomous agents need to engage in intensive exchanges to achieve the team objective (Walliser et al., 2019, 2019). The theme from this research is that task interdependence was generally helpful. Specifically, researchers found that by increasing the extent to which both humans and autonomous agents necessarily needed to work together to complete the task, there was a subsequent increase in participant positive affect and team performance (Walliser et al., 2019, 2019). The other key task characteristic examined in the literature involved task difficulty. Not surprisingly, task difficulty was associated with lower performance, higher task switching frequency, and higher workload (Fan et al., 2010; Wright & Kaber, 2005). Time pressure decreased performance (Fan et al., 2010), and difficult tasks actually reduced communication due to a lack of time to communicate (Wright & Kaber, 2005). These findings are not unique to HATs (e.g., Bowers et al., 1998), although it is unclear whether the autonomous agents could be more helpful under complex task situations in other environments than those represented in our sample.
Given the above, task interdependence and low difficulty appears to be positively associated with better HAT functioning. Interdependence may create a shared understanding of the various roles in the team, and it may help the team better recognize opportunities for workload sharing (Gao et al., 2012). It is possible that the effects observed for interdependence are positive because of the increased communication that occurs in interdependent tasks (Gao et al., 2012). However, it may also be due to the short-term nature of the studies involved (indeed, Walliser et al. (2019) were the only research group to study interdependence, which was within a lab environment involving a military simulation game called Strike Group Defender). In the short term, interdependence likely creates opportunities for information exchange and learning how to work together, but in the long term it is not clear whether this benefit would persist. Turning to difficulty, it is not surprising that more complex tasks were associated with greater workloads and lower performance. However, it would be valuable in the future to manipulate both levels of task difficulty and team composition (human–human versus human–autonomy) to determine whether difficulty affects outcomes differentially depending on the team’s composition (see Fan et al., 2010). Moreover, an autonomous agent that could adaptively regulate its work to maximize flexibility to modulate workload would be worth designing and investigating (Johnson et al., 2011).
Team input: Human individual difference variables
Human individual differences are factors that vary from person to person such as personality, culture, working memory, and past experiences. Similar levels of trait agreeableness, which is exhibited through amicable and respectful interactions, involving the human and the autonomous agent were found to promote development of shared mental models as well as increase performance (Hanna & Richards, 2015). An autonomous agent that exhibits a similar work style preference as the human was associated with higher trust in the autonomous agent, increased willingness to work with it, and even a preference to work with it in lieu of a human (You & Robert, 2018). Trust for those high in individualistic or uncertainty avoidance cultures was higher than those with high power distance (Chien et al., 2016). Attentional control and prior video game experience were positively related to human–autonomy multitasking performance (Chen, Barnes, Qu, et al., 2011, Chen, Barnes, Quinn, et al., 2011).
The finding that similarity on personality was associated with advantages might be tied to the well-known similarity-attraction effect (Byrne, 1971), likely because people tend to trust those with similar perspectives. However, more studies are needed to confirm the robustness of this finding. Moreover, diversity with respect to task-related capabilities and functional expertise has also been shown to be important for team effectiveness in the organizational literature (van Knippenberg et al., 2007), and this would imply that designers of autonomous agents take into account the unique functional contributions or roles for the autonomy to offer the team. Finally, overall, not many individual differences have been considered (except experience), and the full gamut of personality traits (e.g., the “Big Five”) and cultural variables (e.g., Hofstede’s [1980] dimensions) would be helpful. This research can consider homogeneity, heterogeneity, and other types of configurations (compare Bell, 2007).
Team input: Training
Training represents the opportunity for both human and agent team members to learn about, practice, and train with their other team members. The key theme emerging from the existing research on human–autonomy training is that the effects of training appear to be positive. For example, a higher learning rate was observed when the human was able to practice with the agent before completing a task (Cohen & Imada, 2005). Humans and autonomous agents also had more instances of concurrent motion after cross-training, suggesting that they could better anticipate each other’s movements and coordinate task execution better (Cohen & Imada, 2005). Walliser et al. (2019) found that goal setting and role clarification prior to performing the task was superior to playing a “team-building” (cooperative) game.
Given the nascent state of autonomy and that few humans are likely to be experienced in working on HATs, adapting what is known from the extensive training research on human–human teams is likely to be a critical feature of high-performance human–autonomy teaming. It is also vital that training is connected to a sound needs analysis or team task analysis (Arthur et al., 2005), which will reveal the roles of each team member (human and autonomy), key interdependencies, and the capabilities needed to execute individual roles and coordinate across interdependent activities.
Team mediator: Communication
Although team communication is a mediator within the I-M-O model of team effectiveness (Hackman, 1987), we did not find studies actually formally reporting mediation analyses (compare MacKinnon, 2008). Rather, it was considered as an independent variable (see below for comments on this). The two key research themes are that the quality of the communication matters for effectiveness and a greater frequency of communication has mixed effects. When autonomous agents modulated information sharing according to workload, it resulted in enhanced shared mental model development (Fan & Yen, 2011). Communication that involved pushing behaviors (e.g., anticipating others’ informational needs) was associated with stronger team situation awareness and performance (Demir et al., 2016). In terms of frequency, a greater number of messages shared was associated with lower performance (Cooke et al., 2016), but also stronger shared mental models (Wright & Kaber, 2003) and was associated with viewing the autonomous agents as teammates rather than tools (Walliser et al., 2019).
Surprisingly, communication was the only variable within the “mediator” classification of the I-M-O model with enough studies to summarize the trends. As noted, the focus was on communication as an independent variable. Traditional teamwork mediators (Marks et al., 2001) such as transition (e.g., planning), action (coordination), and interpersonal (affect management) were studied only rarely for their effects on team outcomes rather than analyzed in formal mediation analyses. Furthermore, an emphasis purely on the quantity of communication is unlikely to yield consistent results; rather, the quality of communication that takes into account the dynamicity and complexity of communication in teams needs extensive study (Demir, Cooke, et al., 2018, Demir, Likens et al., 2018, Demir, McNeese, 2018). Finally, typologies of effective communication (e.g., McNeese et al., 2018) may be useful in the design and testing of future autonomous agents and interactions with humans on teams.
General Discussion
Teams form the building blocks of modern organizations (O’Neill & Salas, 2018), but rapid advancements in technology, and autonomous agents specifically, are changing the way work is done in teams (Demir et al., 2015; Wilson & Daugherty, 2018). Increasingly, conventional teamwork roles and tasks can be performed by computers that operate at partial or high levels of autonomy (Fiore & Wiltshire, 2016). Thus, humans and autonomous agents can, in theory, work together, as distinct members of a team, toward achieving a common goal (Woods, 1996). Yet, there are challenges, such as increasing the autonomous agents’ abilities to handle the interdependent activities required for effective teamwork rather than just working under the direct control and teleoperation of the human team members (e.g., Johnson et al., 2011). Despite the challenges, McNeese et al. (2018, p. 272) suggested that “the limits [of autonomous agents] do not seem insurmountable such that in the future they may serve as replacements of human teammates for team training delivery and eventually real-world missions”.
As our review uncovered, research on human–autonomy teaming has been increasing. Indeed, we found 76 empirical studies on the topic. These studies used different testbeds and examined a multitude of variables. Accordingly, the purpose of the current research was to synthesize this body of literature to provide clarity with respect to where the state-of-the-science is and, based on this, what future directions might benefit the field the most. We did this by documenting the environments of existing research (i.e., tasks and testbeds, communication modalities, levels of autonomy, team composition, and dependent variables); classifying and reporting on the independent variables studied and their effects on outcomes (i.e., levels of autonomy, the autonomy’s transparency and reliability, team composition, task characteristics, human individual difference variables, training, and communication); and identifying future research directions tied to the existing areas of focused research (i.e., the independent variables; summarized in Table 3). We also frame the research in terms of the I-M-O model (Figure 1), theories of team processes and emergent states (Marks et al., 2001), and theories of team effectiveness (Hackman, 1987, 2002). This framing reveals potential gaps in existing research designs, analyses, and variables considered, which we detail below as meta-themes for guiding future research.
We note that Green et al. (2006) provided recommendations for effective practices in conducting literature reviews such as ours. According to Green et al. (2006), “… the critical factor in writing a good narrative review is to use good methods” (p. 103). We believe we met their criteria in light of our sequential methods, which involved (a) identifying articles meeting criteria for inclusion, (b) identifying commonly studied environments and variables, (c) establishing inter-coder agreement, (d) summarizing themes involving commonly studied variables tied to specific study-level research findings, and (e) in light of the state of the literature, offering a critical appraisal of the literature and recommending directions for future research. In the “Discussion” section, therefore, we offer a critical appraisal of the literature in order to identify new directions to move the field forward by building directly on existing work organized in Table 3. Specifically, we offer meta-themes for supporting future research and knowledge development on HATs. We begin, however, by reviewing what has been learned in conducting this review.
What Has Been Learned?
Delineation of HATs
One of the most important contributions of the current research is advancement in the delineation of HATs. Specifically, in considering the literature on automation, autonomy, teamwork, and HAT, we offered a definition of both autonomous agents within the context of HAT and of HAT itself. This is important because HAT scholars have so far not provided a comprehensive definition or dealt with the historical implications of automation versus autonomy with respect to HAT specifically. We believe the historical background offered in the Introduction moves the field ahead in terms of clarifying what is meant by HAT versus related concepts (e.g., automation, HAI, human–automation teaming). Recall that we define an autonomous agent as a computer-based entity that is individually recognized as occupying a distinct team member role, and a HAT as interdependence in activity and outcomes involving one or more humans and one or more autonomous agents, wherein each human and autonomous agent is recognized as a unique team member occupying a distinct role on the team, and in which the members strive to achieve a common goal as a collective. Future researchers can leverage this definition, seek to modify the definition as appropriate (e.g., with technological advances, new research findings), and use it as a guidepost for understanding what is and is not HAT.
Base of scientific knowledge on HATs
Given the consolidation of our understanding of the various research environments, we can now understand the boundary conditions of our existing knowledge emerging from empirical studies. All of the research is laboratory based, using “action” or “execution” simulations (rather than other types of team tasks such as strategizing, goal setting, negotiating, and brainstorming; Marks et al., 2001; McGrath, 1984), most of which involves a moderate level of difficulty. Communication capabilities of most autonomous agents are currently very limited or utilize the Wizard of Oz technique. Most studies utilize only a single human–agent dyad. Finally, most studies met our criteria for partial, not high, autonomy. Collectively, this suggests that the generalizability of empirical research on HATs will be limited to action/execution tasks, short-term research environments with “zero-history” teams, dyads, limited communication, and limited autonomy levels. This is not surprising, given the nascent state of AI, particularly with respect to collaboration with humans. However, it is an important contribution to document the research environments to understand how the existing findings can be appropriated, applied, and transported to specific practical domains.
Variables studied, not studied, and performance in HATs
By synthesizing the existing dependent variables, independent variables, and mediators, we offer a snapshot of the current state of the science with respect to what has been done in empirical research on HAT. This can be used to help focus future research endeavors in several respects. First, in terms of dependent variables, the greatest number of studies considered performance, workload, trust, situation awareness, team coordination, and shared mental models (in that order). Within the I-M-O model (Figure 1), only performance is clearly an output (performance), although trust may be considered a component of team viability. Therefore, this reveals an interesting omission of Hackman’s (1987) two other output criteria in current research on HATs, which are the team’s viability (ongoing capability to work effectively and cohesively together) and the individual members’ growth through team membership. Team viability is important because a team might be able to temporarily perform, but many teams need to repeat or sustain that performance beyond a single-performance episode (Hackman, 2002; Marks et al., 2001). It is helpful that trust has been studied considerably, as a team with high trust would be more likely to maintain viability over time, but more research on viability specifically would be beneficial. Development, growth, and learning through team membership are important because when members are stagnant, they may not have their growth needs met, which may lead them to seek other opportunities and exit the team or reduce their engagement (Oldham et al., 1976). Thus, documenting the performance criteria used leads us to identify clear gaps in terms of our knowledge of what creates a viable HAT and individually rewarding HAT environment.
Second, given most research does include measures of performance, we can summarize what leads to effective performance in HATs. This question can be tackled from an analysis of what has been done with respect to mediators and inputs in the I-M-O framework in which the studied variables are organized. With respect to variables classified as mediators in that model, we only found communication as a variable examined for its effects on performance in enough studies to generate themes. The themes were twofold, which is that quality and quantity of communication will be critical to HAT performance. Our analysis reveals that quality should always be high, whereas the findings are mixed for the quantity (a finding we unpack further below). In terms of inputs, our findings suggest that high autonomy is advantageous (relative to partial); transparency and reliability interact such that lower reliability can be partly offset by high transparency; transparency itself is mixed in terms of benefits and challenges (e.g., performance versus complacency), interdependence and training are advantageous; human–human teams tend to outperform HATs; and task difficulty is associated with lower performance in HATs. Finally, given that communication was the only variable studied under the mediator category of the I-M-O model, it appears that it may be one promising path through which the various inputs may affect outputs. For example, human–human teams tend to outperform HATs because of their higher-quality communication (Demir, Cooke, et al., 2018, Demir, McNeese, 2018). Unfortunately, no studies formally examined communication as a mediator in statistical analyses; therefore, this is ripe for future research.
Need for theory
In conducting this review, we did not see much in the way of comprehensive theories and systematic testing of proposed paths in a theoretical model or framework (see also Spence, 2019). Rather, what we found was what appears to be relatively haphazard collections of independent and dependent variables considered in relatively narrow (rather than integrative) empirical studies. This is likely because we are in the relatively early days of studying and building an understanding of high-performance HATs. However, our review should allow researchers an opportunity to pause, take stock of the existing literature, and, in light of that, bring forward unified theories of HAT that can be systematically tested by different research groups. Certainly, the vast literature on human–human teams can be leveraged (e.g., Mathieu et al., 2017), but also literature on HAI, human–computer interaction, information systems, cognitive psychology, work, task and team design, and other literatures could inform HAT-specific theories of effectiveness. Moreover, a broad variety of research methods, such as qualitative interviews and case studies, can enrich our overall understanding of the human experience of working with HATs as well as what makes them effective. In sum, we believe working toward an integrative understanding of HAT, rather than more sporadic investigations, would be advantageous. (We recognize that some excellent publications exist on these matters [for example, Endsley, 2017; Ho et al., 2017; Lyons et al., 2019], but we also call for more of this research to work toward a complete understanding of high-performing HAT.)
HAT-specific findings
The results of the current review can be considered in terms of those that apply to all teams, including traditional human–human teams as well as HAI teams, as well as those that are unique to HATs. We view the following five findings as unique to HATs:
Our findings indicate that higher levels of agent autonomy result in better outcomes. Accordingly, this provides initial promise with respect to the integration of autonomous agents with humans on teams. However, increasing levels of agent autonomy likely require increased costs in the development of the autonomous agents in terms of algorithms, design, and testing. Moreover, the studies in our sample did not involve field settings, and therefore caution is advised in making generalizations of our findings with respect to agent autonomy levels in field settings (e.g., autonomous vehicles).
We find that performance of HATs is typically lower than human–human teams. Accordingly, there is a need to understand the mechanisms (mediators) driving performance in HATs. Once the mechanisms are identified (e.g., communication, shared mental models), designs and intervention inputs can be tested for improving these mechanisms and, in turn, HAT outcomes.
Studies indicated that interdependence leads to positive outcomes in HATs. This aligns with our theorizing in the introduction and other researchers’ work (e.g., Nass et al., 1996) that interdependence of autonomous agents and humans is critical for the team.
It could be theorized that autonomous agents would be particularly useful under high task difficulty conditions, but support for this was not found. However, it is possible that the autonomous agents were not well designed for the difficult tasks they were expected to perform. Ideally, autonomous agents should perform tasks and roles that are very difficult or too difficult for humans; therefore, more research is needed.
Communication among autonomous agents and humans tends to be different than communication among humans. As mentioned earlier, autonomous agents need to better anticipate human information requirements and communicate the right information in a timely fashion (pushing behaviors), rather than not anticipating and requiring a human inquiry for the information and a lag time (pulling behaviors).
Where to Go Next: Meta-Research Themes
Exploit the I-M-O model
The literature on teamwork in organizational settings as well as small group research in social and industrial psychology have been strongly influenced by the I-M-O model of team effectiveness (Marks et al., 2001; Mathieu et al., 2017). Whereas there are drawbacks to this model, one advantage it offers to the literature on human–autonomy teaming is that it explicitly requires researchers to refine their theorizing by considering the mechanisms (i.e., mediators) through which independent variables (typically inputs) influence team outcomes. Moreover, this would seem to be a significant opportunity, because laboratory studies in which participants can be randomly assigned to levels of the independent variable allow for causal tests of mediation (Spencer et al., 2005). In the current review, we identified five classes of input variables routinely examined and only one class of mediator variables. For two reasons, this creates a barrier to our understanding of how HATs convert inputs into outputs. First, without actually conducting mediation analyses, it is impossible to determine if an input affected an output through a mediator. In other words, we cannot determine the mechanism linking the input to the output. Unfortunately, studies typically did investigate what would be classified as mediators and outputs in the same study, but all variables were treated generically as dependent variables rather than modeled using mediation or path analysis. Future research should theorize more about, and design studies to test, how HATs convert inputs into outputs.
A second limitation to understanding how HATs convert inputs into outputs involves the lack of variables found in the mediator classification. Communication was the only variable classified as a mediator (i.e., a team process), but the studies treated it as an independent variable rather than as a mechanism. Moreover, not enough studies have been conducted to understand its role well. In order to understand what HATs actually do that leads to effective and ineffective team outcomes, far more mediators must be considered. Two mediators we expected to see more of in the literature were coordination and team cognition (see Canonico et al. [2019] for more on team cognition in HAT). Wright and Kaber (2005) found that higher levels of autonomy were associated with stronger coordination, Cooke et al. (2016) found that voice communication yielded better coordination than text-based chat, and Demir, McNeese (2018) found that HATs were less coordinated than human–human teams. Hanna and Richards (2013, May) reported that 72.3% of participants thought that verbal communication capabilities supported collaboration. However, these studies treated coordination as a dependent variable rather than considering how coordination, in turn, affected team performance. Moreover, they measured coordination using all types of indirect and direct means, which creates uncertainty about the validity of comparisons across studies (i.e., the jingle fallacy occurs when two different things are referred to with the same term). We found similar patterns with respect to shard mental models (e.g., Fan & Yen, 2011; Grimm et al., 2018a) as well as the other mediators studied frequently (trust, situation awareness, and workload), wherein we found very little understanding of how these variables connect inputs to team outcomes (but see theory by Endsley, [2017]) and a multitude of measurement methods.
These and other mediators should be investigated at a much higher rate, and they should be theorized and modeled within mediation frameworks to create an understanding of what teams do that makes them effective or ineffective. Moreover, they need to be measured with construct-valid indicators. This is critical for the replicability, generalizability, and meaningful knowledge generation as more primary studies accumulate, as it will allow us to better identify potential interventions, conditions, and contexts for creating specific patterns of interaction and emergent states (i.e., the “M”) that, in turn, create high performance human–autonomy teaming.
Leverage the training literature
Building on the aforementioned point, team training interventions may be one of the most critical inputs for positively influencing human–autonomy teamwork in the future. Meta-analyses clearly indicate that team training has been a major success in many fields such as medicine, corporate, and aviation teams (e.g., Hughes et al., 2016; O'Connor et al., 2008; Salas et al., 2008). Given that autonomous team members are new to most people, there will be a strong learning curve in the foreseeable future with respect to learning to work as an integrated unit and performing well. Training will likely be a critical lever for moving up the learning curve faster, which will be a competitive advantage for any organization or product employing HAT capabilities.
Training must target knowledge, skill, ability, or other characteristics that are needed to fulfill the roles and critical role interdependencies needed for team outcomes. These can be deduced from team task analysis and a solid base of knowledge regarding the mechanisms for transforming team inputs into team outcomes (once established). Team training can then be tailored to preparing the team to effectively engage in these activities.
The techniques and literature specifying the interventions meant to enhance teamwork and team-related outcomes were extensively reviewed and summarized by Shuffler et al. (2018). In that review, team training was defined as a “set of theoretically based strategies or instructional processes, which are based on the science and practice of designing and delivering instruction to enhance and maintain team performance under different conditions” (p. 254). That review proposed that team training is meant to help team members enhance and formalize the knowledge, skills, and abilities they will need to successfully achieve the team’s goal in a viable manner. In our review, there are a number of team training methods identified as effective, particularly cross-training. Others include team coordination training, and team self-correction, and these methods have been shown to impact a variety of team processes involving task work and teamwork factors (Shuffler et al., 2018). It can be surmised that many of the outcomes related to these techniques could apply to HATs. Therefore, an important goal of future research should be to focus on the aspects of human–human training that translate to HAT training, and the methods to best train these teams on that new knowledge. Finally, training itself serves as a valuable input variable that can be manipulated to determine whether a particular knowledge, skill, ability, or other characteristic contributes to team effectiveness, thereby testing theory (e.g., Neill et al., 2017).
Utilize longitudinal designs, dynamic methods, and field research
There currently exists almost no empirical longitudinal research on HAT dynamics, or field research. This is clearly a step that researchers need to take to determine whether the findings from existing laboratory studies are ecologically valid. In other words, we need to determine whether the findings based on short-term experiences in the lab will exhibit stability over time and in the field. Dynamic theories are emerging in organizational research, notably, the I-M-O-I model, which builds on the I-M-O model that is used as the framework in this review (Figure 1). The I-M-O-I model adds a feedback loop connecting outputs from one phase of teamwork to inputs in the next phase (Ilgen et al., 2005). You and Robert (2017) offered a rare investigation into this; although the “autonomy” levels were too low to meet our criterial for inclusion, the authors reported on an interesting theory involving feedback loops from outputs to inputs as well as mediators. However, that article only offers a few propositions and it does not elaborate on how repeated I-M-O episodes may influence performance dynamically over time. Demir et al. (2017) provided an analysis of team dynamics and found that human–human teams were the most dynamic in their coordination behavior and HATs were the least dynamic. Interestingly, the teams that performed the best were all human teams that had an expert serving as one of the three roles in the team. These latter teams exhibited meta-stability or a hybrid style; specifically, they exhibited stability versus dynamics as the situation called for it. Ultimately, the teams with an expert member that were meta-stable outperformed both human–human and HATs. The conclusion is in line with our consideration of interdependence above, such that HATs will likely over time, through experience and training, trend toward the meta-stability patterns that were most effective. Although that study provides some insight into team dynamics, the data were again based on relatively short-lived ad-hoc laboratory-based teams performing a simulation-based task.
Research in organizational settings has used a variety of statistical techniques to model dynamics in human–human teams that may be useful in HAT research. One commonly used approach is to investigate trajectories of team variables over time (e.g., Mathieu & Rapp, 2009). Team-specific trajectories can be obtained and used as mediators of team input-team output effects. For example, Larson, McLarnon (2020) modeled the effects of team personality variables on team task performance through team-specific starting points and process change trajectories across time. Moreover, they theorized that the role of time pressure drives team trajectories, such that effective teams need to “ramp up” their engagement in the team processes proposed by Marks et al. (2001) as they approach deadlines and critical milestones. Elsewhere, Klonek et al. (2020) provided methods for understanding and quantifying microdynamics—very small units of interaction and patterns of interaction—in teams. The goal is to develop a clear understanding of what the team needs to do and when, in order to help differentiate effective patterns of interaction and change over time. Finally, computational modeling has been used to model how teams—as adaptive, complex, and self-organizing systems—come to arrive at various emergent states and stable team processes, which cannot be described in terms of elementary components but instead are the product of complex interactions that are different from the sum of the individual parts (Salas et al., 2008c). Applying and testing computational models for HATs prior to actually creating the autonomous agents may be advantageous. Of course, theory should always play an integral role in the development of knowledge, and we refer readers to foundational work by Waller et al. (2016) discussing why teams may change, how they will change, and when they will change.
Designing autonomous agents for teaming
One avenue to design autonomous agents is to identify what makes an effective team player (or differentiates effective from ineffective team players), and then start designing autonomous agents to emulate the characteristics of effective team players. Interestingly, autonomous agents may be able to actually exceed these capabilities because of greater information processing capacity, no random fluctuations due to mood, personality, and other psychological attributes, and no interference from human-like “life” complications or daily hassles. As Johnson et al. (2011, p. 87) noted:
We believe that increased effectiveness in HAT hinges not merely on trying to make machines more independent through their autonomy, but also in striving to make them better team players by making them more capable of sophisticated interdependent joint activity with people.
Designing HATs to be effective will likely not be a straightforward endeavor, as previous attempts to make autonomous agents and robots better team players have not always succeeded (Guznov et al., 2020; Jung et al., 2015). Moreover, it is unclear whether designing autonomous agents to emulate human team members would be ideal. Using the CERTT-UAS-STE platform (Cooke & Shope, 2004), the results are quite clear that human–human teams perform the best. However, it is possible that this is because the autonomous agent is filling a typical human role, rather than a role designed specifically for an autonomous agent designed to fit that role perfectly. Indeed, autonomous agents are a long way off from behaving exactly like humans; therefore, it may be no surprise that such HATs perform relatively poorly. Future research should seek to maximize the fit between the design of autonomous agents and the requirements of the particular team member role.
Clearly, a systems design approach that considers the nature of the HAT system, such as the roles, tasks to be performed in each role, the team’s overall purpose and objectives, the level of autonomy, and the teamwork requirements (communication, coordination), must be considered holistically. However, there are bodies of literature that can be leveraged to inform effective design of HATs. For example, taxonomies of effective team member characteristics have been offered. Stevens and Campion (1999) advanced one of the most influential taxonomies, involving five knowledge, skills, and abilities (KSAs): communication, collaboration, conflict management, goal setting, and performance management, and planning and task coordination. More recently, Ohland et al. (2012) advanced five competencies as well: commitment, focus, communication, high standards, and having relevant KSAs. An integration of these and other taxonomies was offered by Rousseau et al. (2006) that boils down to functions that manage team performance (i.e., transition, action, collaborative, and adaptive behaviors) and others that manage the team’s affect (i.e., psychological support, conflict). However, it is readily apparent that these dimensions, although intended to be behavioral, are abstract and therefore developers will have to articulate specifically what is required of the autonomous agents to demonstrate effectiveness within a particular environment. Inferences will then have to be validated through studies comparing human teams to HATs and whether they achieve similar outcomes and whether the mechanisms are equivalent or different.
An important design consideration for constructing effective autonomous agents will be to emphasize the characteristics of HATs outlined in the “Introduction” section. Specifically, we defined an autonomous agent as a computer-based entity that is recognized as occupying a distinct team member role (i.e., not just a tool for executing a particular task). In order to be viewed as a team member, research suggests that the autonomous agent must be humanlike, agentic, and interdependent in the activities and outcomes of the other team members (Lyons et al., 2018; Wynne & Lyons, 2018). One question that might be asked is whether invoking the term “team” offers a sensible path forward and whether other ways of organizing work would be better (e.g., independent work structures; autonomous agents as adjuncts to particular members). Indeed, with respect to human–robot teaming, Groom and Nass (2007) offered in a position paper an argument that human–robot teams had yet to achieve a “team” status and perhaps that is not even a wise design approach, expectation, or objective. Certainly, we see this as an interesting perspective and of course it must be true. Team researchers have historically argued that if the work is not designed for teams and is not a team task, and the structures surrounding the team do not foster teamwork, that the advantages of teamwork will not be realized and it would be best to label the entity a group or unit (Hackman, 1987, 2002, 2012). Therefore, if one or more autonomous agents are included as team members, many of the same known effective team design principles should be employed (e.g., interdependence, role clarity, norm development, expertise variety, feedback; for example, Campion et al. [1996]; Morgeson et al. [2006]). Moreover, we also point to research that indicates that humans do perceive autonomous agents as team members if they have certain attributes (e.g., Lyons et al., 2018), and that the team task can be designed carefully to elicit complex teamwork and communication involving humans and autonomous agents (Demir et al., 2019; McNeese et al., 2018). And as autonomous agents increase in AI, they may become more and more agentic, proactive, and synchronized with humans. We believe that human–autonomy teaming is not only realistic, but highly likely to become increasingly prominent in the future. Therefore, it is important that researchers build a base of knowledge on the factors that make HATs effective.
Practical Implications
Applied HATs are deployed and operating throughout the world, being trialed and finalized for full integration. This assertion is evident in the industries that often lead to the development of advanced technology, governments, military, and manufacturing. While AI is pervasive in everyday human lives in the form of smart assistants like Siri, the manufacturing industry has begun to seriously try to team these AI up with humans to produce advanced HATs (Schelble et al., in press). The global Industry 4.0 initiative is centered around the integration of AI at nearly every level to drive predictive maintenance, future business strategies, and floor production, with humans working alongside AI to make vital decisions for the company (Erol et al., 2016; Kang et al., 2016; Lee et al., 2015; Mabkhot et al., 2018; Omron, 2020). Industry-based HATs also exist in health care, software design, and product design, slowly making their presence known in a wide variety of industries aside from manufacturing (Wilson & Daugherty, 2018).
Applied HATs in government and the military are also present and have been for some time. Governments are experimenting with AI in smart city management, making HATs possible in areas such as emergency response and other coordinated activities (Allam & Dhunny, 2019). The military has long utilized and experimented with AI in their forces, such as creating HATs for sectors involving intelligence gathering and analysis, decision making, and cyber defense (Morgan et al., 2020). While HATs remain in their early stages of development, their benefits to team outcomes and efficiency are not being ignored by the wider working world. Applied HATs increase in number with each passing year and continue to grow at a faster rate each year, which is reflective of the growth in the research literature on HATs year over year. Such an increase is driven by the democratization and advancement of AI technology through open-source platforms like Tensorflow (Abadi et al., 2016), which has gone on to spawn the development of the reinforcement learning-specific platform of Tensorforce (Kuhnle et al., 2017; Schaarschmidt et al., 2017). Such availability lowers the entry point in creating AI and for those AI to be placed in collaborative settings with humans. We believe it is important to remind developers, however, that although we found that increases in agent autonomy were helpful, this should not be interpreted as increases in agent autonomy will be helpful in all applications. Human–human teams were also found to outperform HATs in most research. Therefore, much more field research is needed on the implications of levels of agent autonomy and HAT effectiveness.
Limitations
As with any search, it is impossible to be sure if we obtained the entire population of studies that met our criteria for inclusion. A potential limitation is our use of the term “teamwork” in our search criteria (see the “Method” section). Given that the entire body of HAI literature is enormous, we needed a tractable method to capture the body of empirical research on HAT. In our search method, we employed a four-step process to achieve this: (a) review manually the 476 returns from Step 1, (b) review manually the 930 returns from Step 2, and (c) review manually the 152 returns from Step 3 (as well as update the search to include HAI as an explicit search term in Step 4). With any search, it is possible to overlook a potentially relevant article from the total population of articles, but overall we see no reason for a biased search; that is, the articles we obtained should comprise a representative sample of the total body of literature in existence on HATs and not materially affect the findings or conclusions of the current review.
Another limitation is that a disproportionate number of papers in the review came from two particular laboratories using particular testbeds. Specifically, the CERTT-UAS-STE (Cooke & Shope, 2004) and the MIX (Wright et al., 2014) were used in 24% and 20% of the studies, respectively, which is consistent with Grimm et al.’s (2018b, 2018c) comment that most studies have been conducted in command and control environments. Therefore, generalizations of the findings should take this into account and future research should examine HATs in a wider range of environments. It is also unclear whether humans necessarily perceived the autonomous agent(s) as a team member according to our definition in the “Introduction” section. In our selection criteria, we aimed to capture studies where this would most likely be the case. Certainly, work by Nass et al. (1996) and others reviewed in the “Introduction” section would suggest that they likely perceived the autonomous agent(s) as team members, but without direct measurement it is impossible to be certain. This is critical, because the functioning of a given HAT will be highly influenced by the task design, the team design, the stakes of the team’s actions (e.g., life and death vs a simulation), leadership, and so forth. For example, an anonymous reviewer pointed out that the HRI as well as the autonomous vehicle literatures are large and relevant to how humans work with autonomous agents. We omitted these topics because they are vast literatures that introduce their own specific considerations (e.g., embodiment, driving as a focal task). We agree that they could yield fruitful insights, however, and we tend to see these as ripe opportunities for additional focused reviews and integrations.
Conclusion
HATs have the potential to be ubiquitous and extremely helpful to all people around the globe, but we will have to gain a much stronger understanding of their needed inputs, processes, and emergent states that aid in their functioning, and the desired outputs within realistic dynamic and field-based environments. This understanding will lead to more effective human–autonomy teaming and the advancement of teamwork conducive to autonomous agents. We offer this review as a current state of the science in human–autonomy teaming by documenting the existing empirical research. We identified the research environments, dependent variables, and independent variables, learnings and implications of our consolidation, as well as meta-themes of future research needs in order to help the field move forward. We hope this contribution will help both researchers and practitioners to understand the current knowledge, the nature of the research that underscores that knowledge, and future research opportunities.
Key Points
We advanced a definition of human–autonomy teams (HATs).
We advanced a levels of autonomy grid and find an equal mix of high and partial agent autonomy levels in HAT research.
Future work should design autonomous agents to fit specific teamwork role requirements to create higher-performing HATs.
Supplemental Material
Supplementary Material 1 - Supplemental material for Human–Autonomy Teaming: A Review and Analysis of the Empirical Literature
Supplemental material, Supplementary Material 1, for Human–Autonomy Teaming: A Review and Analysis of the Empirical Literature by Thomas O’Neill, Nathan McNeese, Amy Barron and Beau Schelble in Human Factors: The Journal of Human Factors and Ergonomics Society
Footnotes
Acknowledgments
This research was supported by a grant to the first author from the Social Sciences and Humanities Research Council of Canada.
Supplemental Material
The online supplemental material is available with the manuscript on the HF website.
Author Biographies
Tomas O’Neill is the Director of the Individual and Team Performance Lab and Associate Professor of Industrial-Organizational Psychology at the University of Calgary, Canada. His research considers high-performance teamwork, virtual team effectiveness, conflict and conflict management, personality, and assessment.
Nathan McNeese is an assistant professor and the director of the Team Research Analytics in Computational Environments (TRACE) Research Group within the division of Human-Centered Computing in the School of Computing, Clemson University. His research interests and expertise include human–machine teaming and human-centered AI.
Amy Barron is a graduate student studying Industrial-Organizational Psychology at the University of Waterloo. She completed her BA at the University of Calgary in 2018 and studied high-performance teamwork.
Beau Schelble is a PhD student at Clemson University studying Human-Centered Computing in the Team Research in Computational Environments (TRACE) Research Group within the School of Computing. His research interests lie in human-AI teaming, multi-agent systems, and human-AI interaction.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.