
Abstract
Determining the number of factors in exploratory factor analysis is arguably the most crucial decision a researcher faces when conducting the analysis. While several simulation studies exist that compare various so-called factor retention criteria under different data conditions, little is known about the impact of missing data on this process. Hence, in this study, we evaluated the performance of different factor retention criteria—the Factor Forest, parallel analysis based on a principal component analysis as well as parallel analysis based on the common factor model and the comparison data approach—in combination with different missing data methods, namely an expectation-maximization algorithm called Amelia, predictive mean matching, and random forest imputation within the multiple imputations by chained equations (MICE) framework as well as pairwise deletion with regard to their accuracy in determining the number of factors when data are missing. Data were simulated for different sample sizes, numbers of factors, numbers of manifest variables (indicators), between-factor correlations, missing data mechanisms and proportions of missing values. In the majority of conditions and for all factor retention criteria except the comparison data approach, the missing data mechanism had little impact on the accuracy and pairwise deletion performed comparably well as the more sophisticated imputation methods. In some conditions, especially small-sample cases and when comparison data were used to determine the number of factors, random forest imputation was preferable to other missing data methods, though. Accordingly, depending on data characteristics and the selected factor retention criterion, choosing an appropriate missing data method is crucial to obtain a valid estimate of the number of factors to extract.
Introduction
In recent years, psychological research has increasingly focused on the issue of missing data (e.g., West, 2001). However, this cannot be said about research relying on exploratory factor analysis (EFA) where missingness is almost always neglected (Russell, 2002). One reason for this suboptimal research practice might be the limited literature on this issue. Especially, when regarding the factor retention process (determing the number of factors in EFA), there is hardly any research evaluating missing data methods. Although, there are articles (Dray & Josse, 2015; Josse & Husson, 2012) focusing on principal component analysis (PCA), the estimation of factor loadings (Lorenzo-Seva & Van Ginkel, 2016) or the proportions of explained variance (Nassiri et al., 2018), the process of determining the number of factors is mostly ignored despite its central role within the analysis.
There is an article by McNeish (2017) that dealt with the factor retention process and missing data in small-sample conditions and a simulation study by Goretzko, Heumann, and Bühner (2019) who evaluated six missing data methods in combination with parallel analysis. Both articles showed that multiple imputation seems to be favorable over pairwise or listwise deletion practices (especially the latter), but relied either on the eigenvalue-greater-one rule (Kaiser, 1960) which should not be used (Fabrigar et al., 1999; Goretzko, Pham, & Bühner, 2019) or parallel analysis (Horn, 1965) which has been shown to be inferior to more modern approaches in some data contexts (e.g., Braeken & Van Assen, 2017; Lorenzo-Seva et al., 2011; Ruscio & Roche, 2012). However, since Auerswald and Moshagen (2019) showed that no factor retention criterion is preferable under all data conditions, it seems reasonable to assume that these criteria are affected differently by missing data and that their compatibility with missing data methods also varies.
Factor Retention Criteria
Over the years, several methods to determine the number of factors in EFA—so-called factor retention criteria—have been developed. While overly simple heuristics like the Kaiser–Guttman rule (the eigenvalue-greater-one rule; Kaiser, 1960) or the scree-test (Cattell, 1966) are considered to be outdated (e.g., Fabrigar et al., 1999), more complex and often simulation-based approaches have emerged that promise a more accurate estimation of the number of latent factors. In this article, we consider parallel analysis (first implementation by Horn, 1965), comparison data (Ruscio & Roche, 2012) as well as a factor retention approach based on machine learning (Goretzko & Bühner, 2020).
Parallel Analysis
Parallel analysis is often considered a gold standard for factor retention (inter alia as it is rather robust against distributional assumptions, see Dinno, 2009). The basic idea of parallel analysis is to compare the eigenvalues of the empirical correlation matrix with eigenvalues of simulated (or resampled) data sets to determine how many empirical eigenvalues are greater than random reference eigenvalues. For this purpose,
As this general idea of parallel analysis can be implemented using simulated or resampled data, the eigenvalues of the correlation matrix, or the eigenvalues of a reduced correlation matrix based on the common factor model as well as different quantiles of the reference eigenvalue distributions, the performance of these different versions of parallel analysis can vary (Lim & Jahng, 2019).
Comparison Data
The comparison data approach by Ruscio and Roche (2012) can be seen as a special case of parallel analysis using comparison data sets that reproduce the empirical correlation matrix as closely as possible based on different factor solutions instead of using random data for comparison. This method subsequently tests different factor solutions based on the RMSE between the empirical eigenvalues and the respective eigenvalues of the comparison data sets to determine whether retaining an additional factor “significantly” increases the similarity between empirical and reference eigenvalues. With this idea of simulated comparison data and a series of significance tests, comparison data unites parallel analysis and model comparisons known from structural equation modeling. Contrary to classical parallel analysis based on normal data, this method is able to take skewed item distributions into account (for further information on the data generation, see also Ruscio & Kaczetow, 2008).
Factor Retention Using Machine Learning
Recently, a new factor retention criterion relying on extensive data simulation and machine learning modeling has been developed by Goretzko and Bühner (2020). Their idea was to simulate various data sets that cover all important data conditions of an application context—varying the sample size (
Missing Data Mechanisms and Missing Data Method
The literature on missing data distinguishes between three major missing data mechanisms—missing completely at random (MCAR), missing at random (MAR), and missing not at random (MNAR). Little and Rubin (2002) give a more detailed introduction to these different types of missingness. In this study, we focus on the mechanisms MCAR, which means that missing values occur completely due to a random process and MAR, which means that the missingness is dependent on variables that are observed. The latter seems to be plausible in the context of EFA, since the observed variables are usually designed to be indicators for the same latent variables (Goretzko, Heumann, & Bühner, 2019).
In cases of MCAR or MAR, several imputation methods can be used to replace the missing values and to ensure valid inference. Contrary to single imputation procedures, multiple imputation methods allow for estimating the additional imputation variance (for further readings, see Little & Rubin, 2002) and are therefore preferred in most applications. Arguably the most common framework for multiple imputation is multiple imputations by chained equations (MICE) also known as fully conditional specification (van Buuren et al., 2006), where missing values in one variable are iteratively imputed given all other variables and their current imputed values. Within this framework, one can use various imputation models—simple regression models, tree-based methods, or specific imputation models like predictive mean matching to predict values for the missing data (e.g., Little, 1988).
In the present article, we apply the MICE framework with both a random forest and predictive mean matching as imputation models. Predictive mean matching is based on a (linear) regression model applied to the observed data 1 and the regression coefficients obtained from the model are taken as expected values of a multivariate normal distribution from which artificial coefficients are then randomly drawn. These “random” coefficients are used to predict the variable that should be imputed. However, contrary to a common regression imputation approach these predicted values are not taken as the imputation values but are rather compared with each other to find the most similar observations that are not missing in the empirical data set for each observation that is missing for that variable. These similar observations are then regarded as potential “donors” whose observed values are used to impute the actual missing values by selecting one of them by chance.
The random forest is a tree-based machine learning model (Breiman, 1999) that can be used as an imputation model within MICE as well. This model consists of several decision trees that are grown using recursive binary splitting. In this process, a number of bootstrap samples (in general, this number is around 500 and often optimized when the predictive performance should be maximized, but for imputation purposes, it can be set to 10, see Shah et al., 2014) is drawn from the empirical data set and a single tree is built on each sample using the variable of interest as the dependent variable. 2 This growing process stops when each terminal node only contains observations with the same value on the dependent variable or certain termination criteria are met. The resulting tree structure can be used to predict the missing values by averaging the mean value of each of the terminal nodes to which a specific observation is assigned to. In contrast to predictive mean matching which relies on a linear and therefore additive model, the possibly complex tree-structure can reflect interactions and promises to be superior when the missing data mechanism is rather complex (Goretzko, Heumann, & Bühner, 2019).
A different approach is Amelia (Honaker et al., 2011), an expectation-maximization (EM) algorithm that we investigate as an alternative to MICE. The basic idea of Amelia is to combine a classic EM-algorithm with bootstrapping to induce randomness necessary for multiple imputation. On each bootstrap sample, an EM-algorithm is applied to estimate the sufficient statistics for the expected values (
Method
We wanted to extend the work of Goretzko, Heumann, and Bühner (2019) who evaluated the performance of parallel analysis in combination with MICE and three different imputation models (predictive mean matching, linear regression, and random forest), the Amelia algorithm by Honaker et al. (2011) as well as pairwise and list-wise deletion varying the sample size, the number of manifest variables, the number of latent variables as well as the missing data mechanism. As they found predictive mean matching and linear regression to perform very similar and listwise deletion to be inferior in the majority of conditions, we focused on four missing data methods (the Amelia, MICE with predictive mean matching, and a random forest implementation as well as pairwise deletion as a baseline) in this study. When Goretzko, Heumann, and Bühner (2019) dealt with the impact of missing data on the factor retention process, they only evaluated one implementation of parallel analysis, but did not cross the different missing data methods with different factor retention criteria. Accordingly, we combined the four missing data methods with two implementations of parallel analysis based on the factor model (PA-FA; as done by Goretzko, Heumann, & Bühner, 2019) and based on PCA (PA-PCA)—both using the 95% percentile of the eigenvalue distribution, the comparison data (CD) approach by Ruscio and Roche (2012), and a new machine learning approach by Goretzko and Bühner (2020) that we retrieved from the associated OSF repository (https://osf.io/mvrau/). For both implementations of parallel analysis, we also compared the two combination or aggregation approaches for multiple imputed data sets presented in Goretzko, Heumann, and Bühner (2019). One aggregation strategy (that we will call the mode approach) is based on the idea that the factor retention is done on each imputed data set and the factor solution that is proposed for the majority of imputed data sets (i.e., the mode of the distribution of the suggested numbers of factors across all imputed data sets) is used as the result for the empirical data set. The other approach (referred to as the cor approach) is based on an averaged correlation matrix (i.e., the correlation matrix is calculated for each imputed data set and the resulting matrices are averaged element-wise). The second strategy can also be implemented for covariance matrices as it was suggested by Nassiri et al. (2018).
Since the CD approach relies on the item distributions, averaging the correlation matrices of the different imputed data sets was not feasible (which is also the case for the machine learning approach as it relies on features that are based on the raw data as well). For this reason, we used only the mode approach—the most frequent factor solution across the multiple imputed data sets as the final solution for the initial data set—for both CD and the machine learning method.
Data Simulation
We slightly altered the simulation design of Goretzko, Heumann, and Bühner (2019).
3
For our study, normal data were simulated for three sample sizes (
The data simulation was conducted with R (R Core Team, 2018) following the procedure of Goretzko, Heumann, and Bühner (2019). In a first step, the true factor patterns for our simulation based on standardized primary loadings between
Evaluating the Missing Data Method
Missing values were either treated with pairwise deletion, imputed five times with Amelia or imputed five times with MICE in combination with predictive mean matching or random forest imputation. Then parallel analysis based on a PCA (PA-PCA) as well as parallel analysis based on the common factor model (PA-FA) using the 95% percentile of the sampled eigenvalue distribution as implemented in the psych package (Revelle, 2018), CD with functions provided by Ruscio and Roche (2012) and the machine learning approach by Goretzko and Bühner (2020) called Factor Forest (FF; see https://osf.io/mvrau/ for the material) were applied to all imputed data sets and the most frequent solution was used as the aggregated solution for the initial data set (this approach was denoted the mode approach in Goretzko, Heumann, & Bühner, 2019). Averaging the correlation matrices was only possible for both implementations of the parallel analysis, so we considered 22 combinations of factor retention criteria and missing data methods (four retention criteria for pairwise deletion and six procedures for each imputation method).
For all these combinations, the suggested number of factors was averaged over all
Results
The overall accuracy of PA-FA was greater than 90% for all missing data methods (91.08%-98.79% for the mode approach and 98.22%-99.14% for the cor approach). While FF also reached 90% overall accuracy for all missing data methods (FF with predictive mean matching [pmm] yielded the lowest accuracy of 91.21%) and PA-PCA was able retain the correct number of factors with an overall accuracy greater than 85% for all missing data methods (mode and cor approach), CD showed a very poor performance when combined with pmm, the Amelia algorithm (em) or pairwise deletion (pair)—combinations with an overall accuracy of less than 70%. Only in combination with random forest imputation (rf), CD yielded a high overall accuracy (96.18%). The overall accuracy for each combination of factor retention criterion and missing data method is displayed in Table 1.
Overall Accuracy of the Factor Retention Criteria in Combination With Different Missing Data Methods.
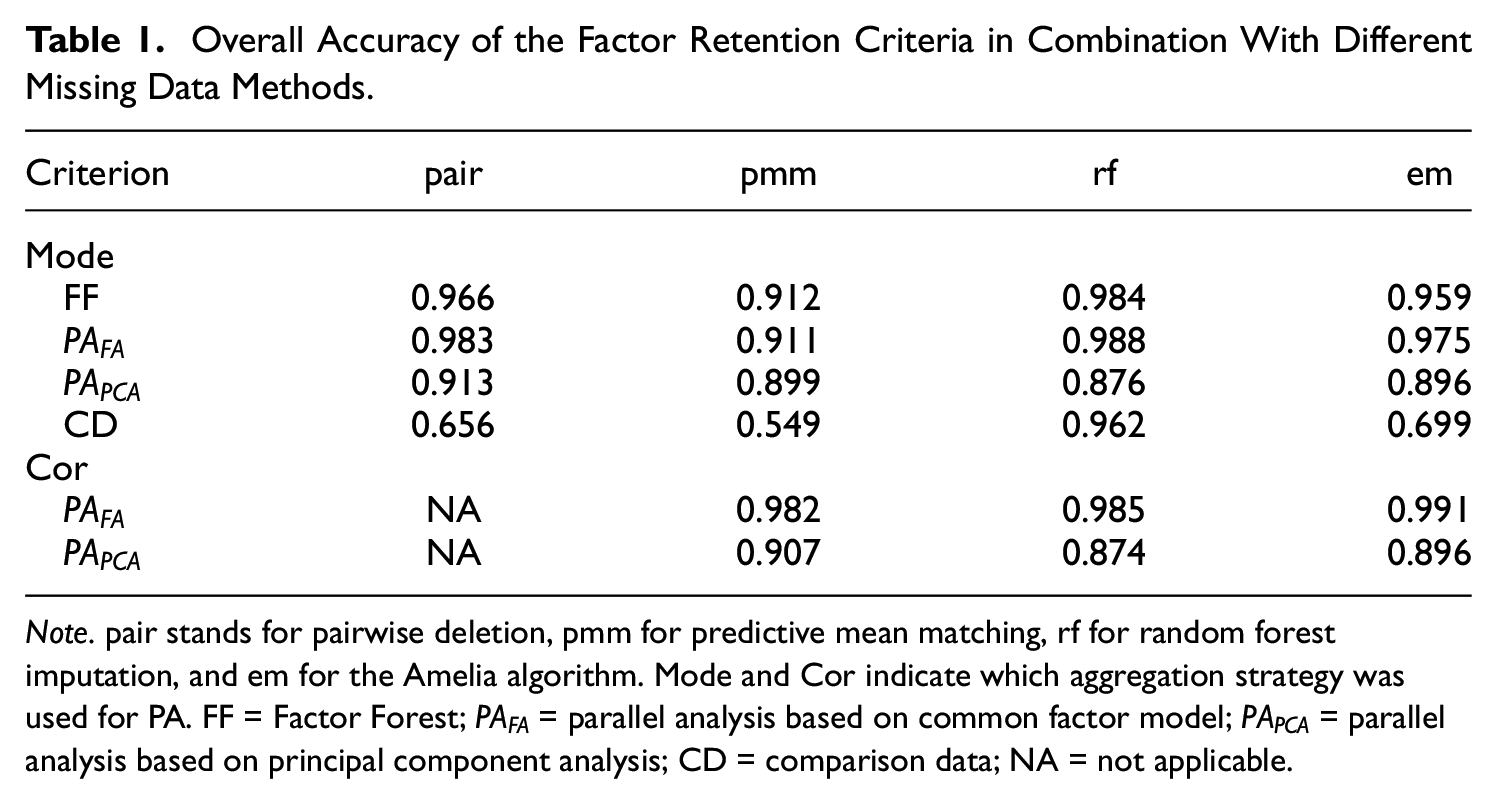
Note. pair stands for pairwise deletion, pmm for predictive mean matching, rf for random forest imputation, and em for the Amelia algorithm. Mode and Cor indicate which aggregation strategy was used for PA. FF = Factor Forest;
PA-FA and FF showed (nearly) no bias when combined with rf, pair, or em, but a slight tendency to overfactor when pmm was used (for PA-FA this was the case for the mode approach; there was no bias with pmm when the cor approach was used). PA-PCA underestimated the number of factors on average and showed the highest bias in combination with rf (independent of the aggregation strategy mode or cor). CD tended to overfactor (especially when combined with pmm) with all missing data methods except from rf. In Table 2, the estimated bias of the factor retention (the tendency of over- or underfactoring, i.e., the average deviation of the suggested number of factors from the true number of latent factors
Estimated Bias of the Factor Retention Critieria in Combination With Different Missing Data Methods.
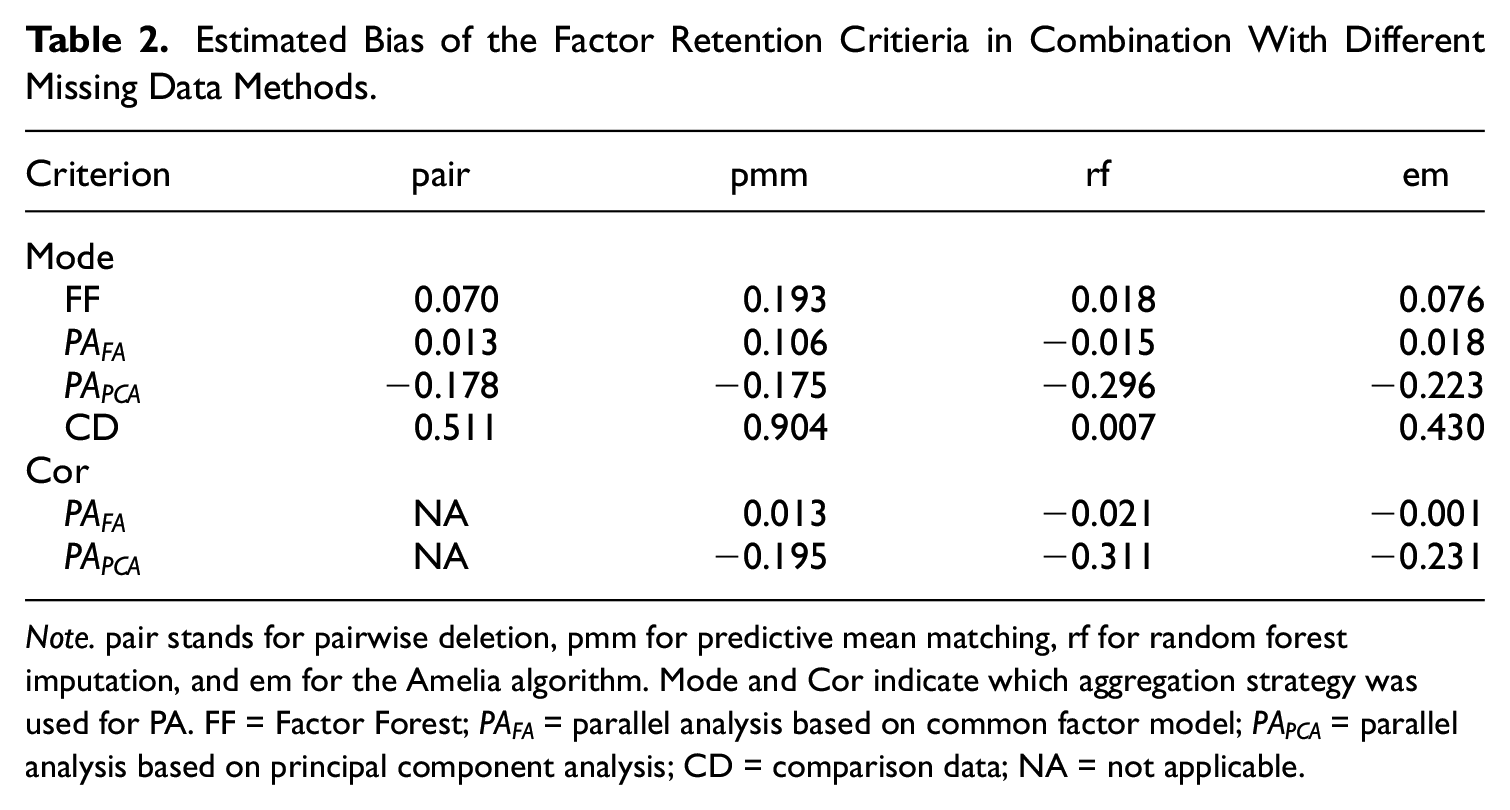
Note. pair stands for pairwise deletion, pmm for predictive mean matching, rf for random forest imputation, and em for the Amelia algorithm. Mode and Cor indicate which aggregation strategy was used for PA. FF = Factor Forest;
The missing data mechanism (MCAR vs. MAR) had almost no impact on the performance of the factor retention criteria. The overall accuracy of each combination of factor retention criterion and missing data method differed less than one percentage point between MCAR and MAR (second highest difference 0.01) with one exception, CD with pair reaching a 4.83 percentage points higher accuracy with MCAR than with MAR.
As expected, the higher the sample size N was, the more accurate all combinations of factor retention criteria and missing data methods were. With
Overall Accuracy of the Factor Retention Criteria in Combination With Different Missing Data Methods for Small Sample Sizes (N = 250).
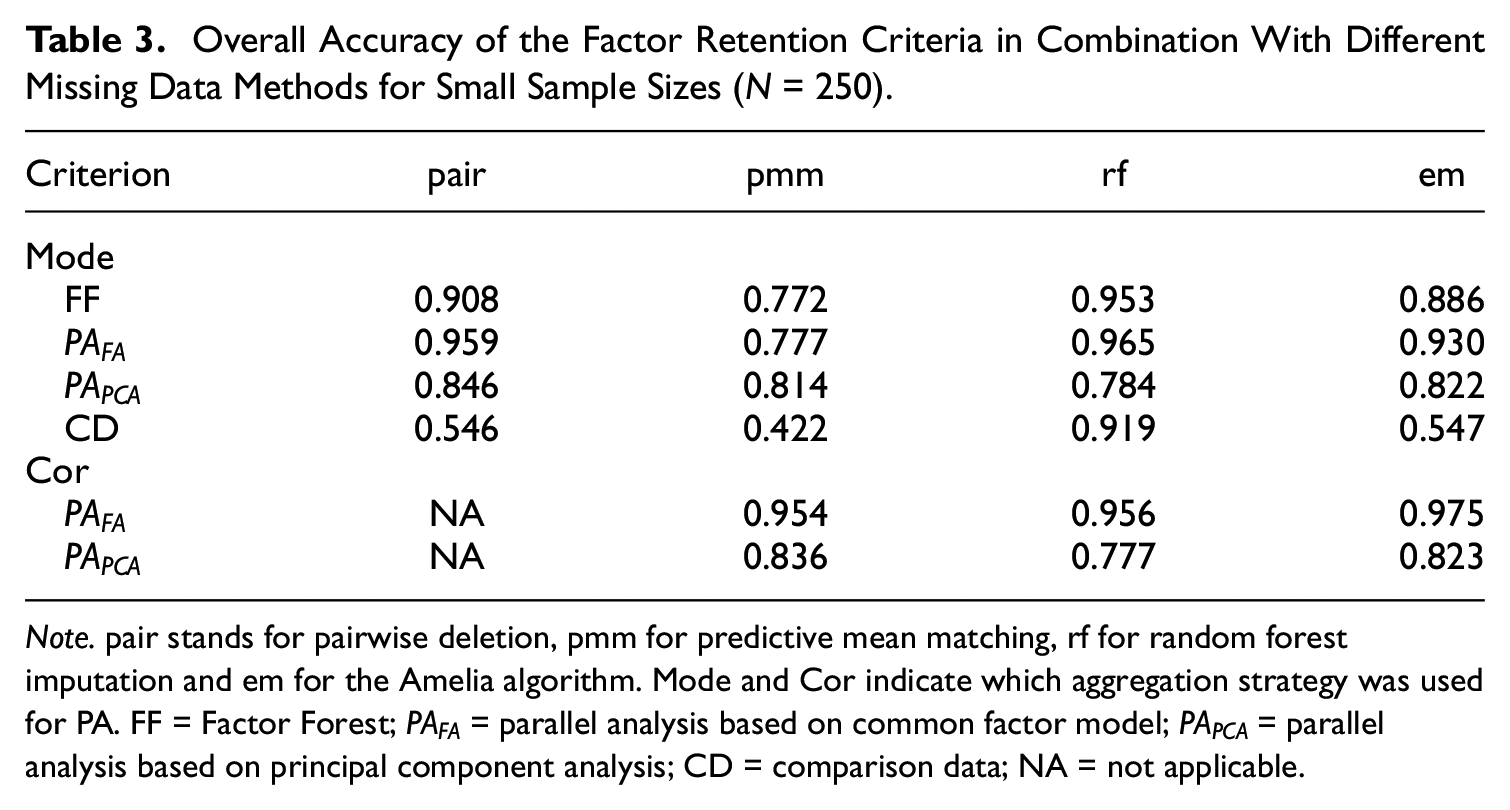
Note. pair stands for pairwise deletion, pmm for predictive mean matching, rf for random forest imputation and em for the Amelia algorithm. Mode and Cor indicate which aggregation strategy was used for PA. FF = Factor Forest;
Interfactor correlations generally worsened the factor retention process—the higher these correlations were, the lower the accuracy was (see Table 4). This was striking in the case of PA-PCA in combination with rf (both cor and mode) which reached a very high accuracy in conditions with no or little between-factor correlations (
Accuracy of All Combinations of Factor Retention Criteria and Missing Data Methods for Interfactor Correlations
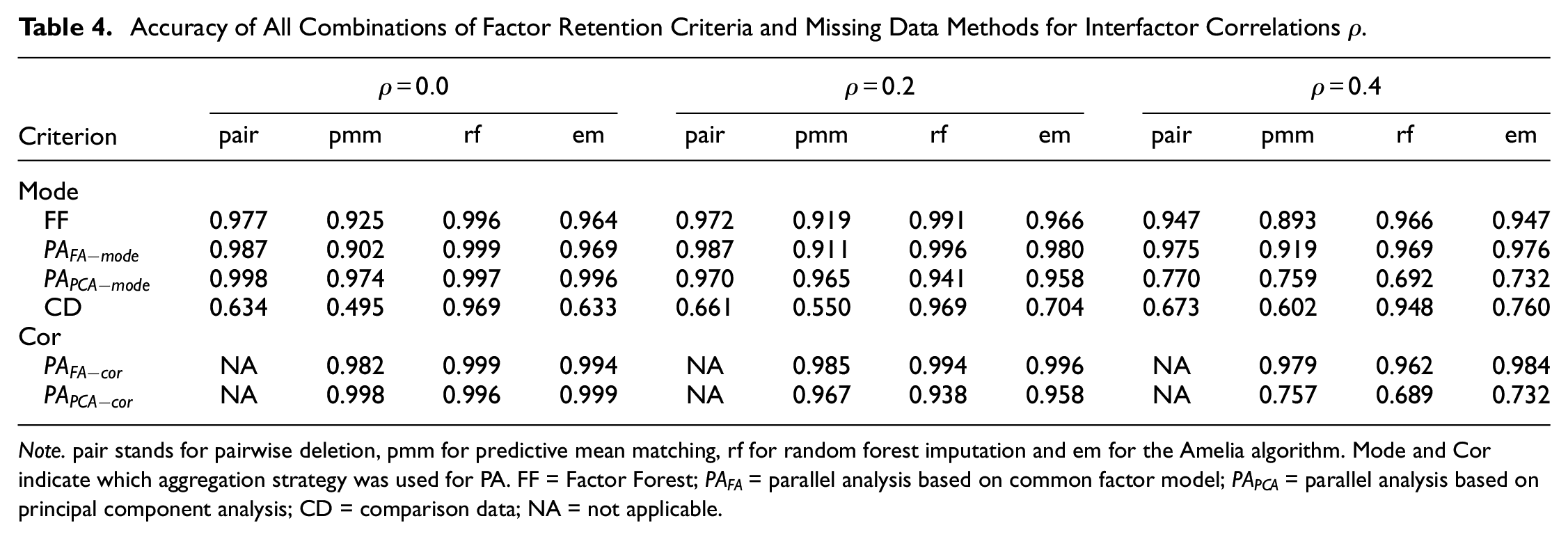
Note. pair stands for pairwise deletion, pmm for predictive mean matching, rf for random forest imputation and em for the Amelia algorithm. Mode and Cor indicate which aggregation strategy was used for PA. FF = Factor Forest;
Figure 1 displays the overall accuracy of the factor retention process for each combination of criterion (and aggregation level) and missing data method. When 10% of the data was missing, the number of factors could be determined quite accurately by all methods. FF and PA-FA (cor and mode approach) yielded almost perfect accuracy, while CD in combination with pmm, pair, or em performed notably worse (the respective conditions are removed from the plot as the CD reached an accuracy of less than 50% for all values of
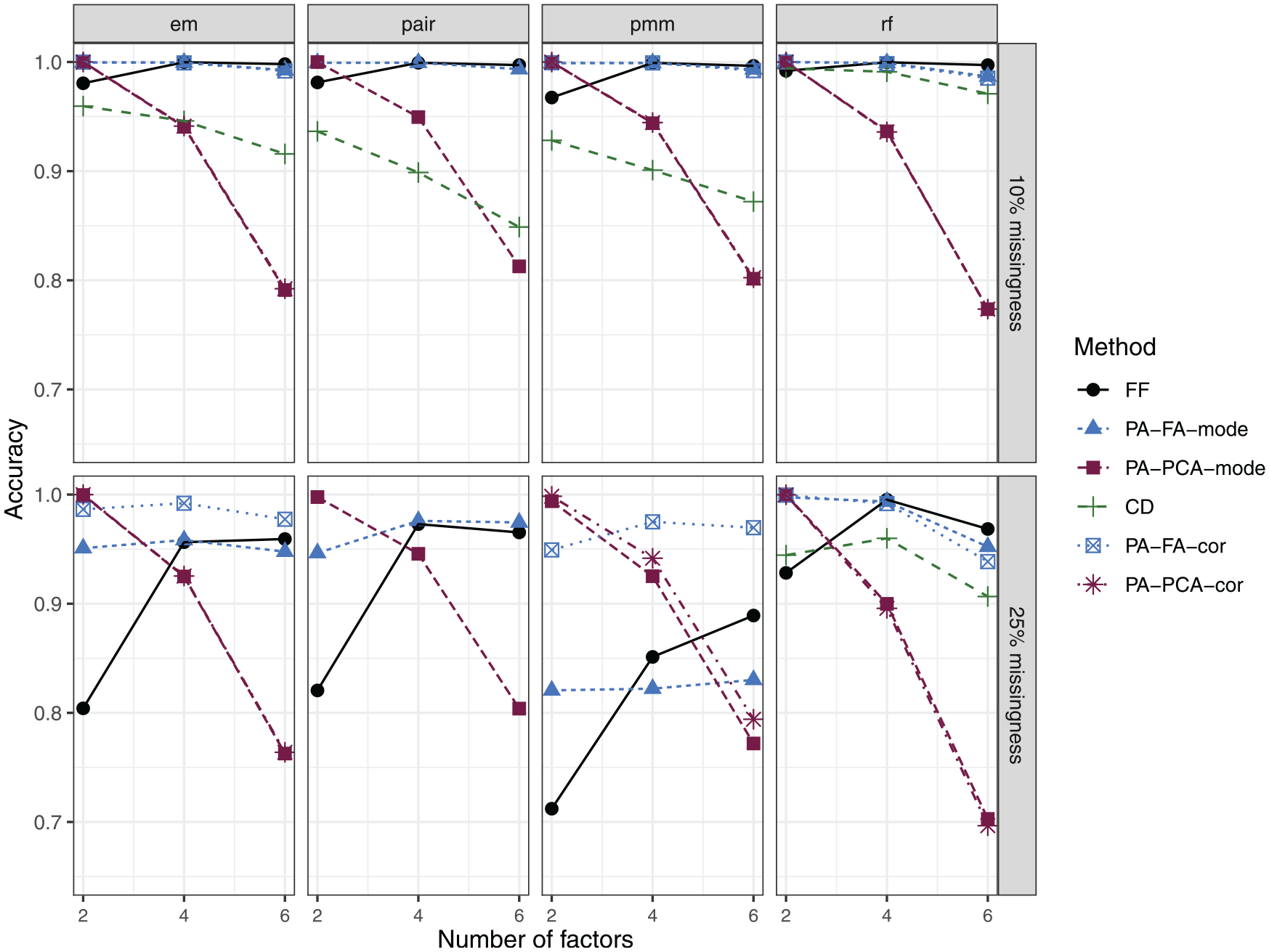
Accuracy of all combinations of factor retention criteria and missing data methods for different amounts of missingness (10% vs. 25%) and different factor solutions (CD + em/pmm/pair was excluded in conditions with 25% missingness as the accuracy was less than 50%).
In conditions with 25% missingness, CD had very poor accuracies in combination with em, pair, and pmm, but was competitive when combined with rf (even though CD +rf was slightly inferior to PA-FA and FF with an error-rate of approximately 10% in conditions with six factors). FF struggled to correctly identify the number of factors in conditions with
Choosing the Best Combination of Factor Retention Criterion and Missing Data Method
For readers who are interested in choosing a combination of factor retention criterion and missing data method that performs best for a specific data context, we provide a more detailed presentation of our results in Tables 5 and 6. There, the accuracy of each of the 22 combinations (factor retention criterion + missing data method + aggregation strategy) is displayed for all evaluated sample sizes, numbers of manifest variables, and different proportions of missing data. We aggregated the results for both missing data mechanisms, different levels of between-factor correlation as well as the three numbers of latent factors as these variables are usually unknown for empirical data. One can see that for many conditions, all combinations yield high accuracies (e.g.,
Accuracy of All Combinations of Factor Retention Criteria and Missing Data Methods for Different Sample Sizes, Numbers of Manifest Variables and Proportions of Missingness (Part 1).
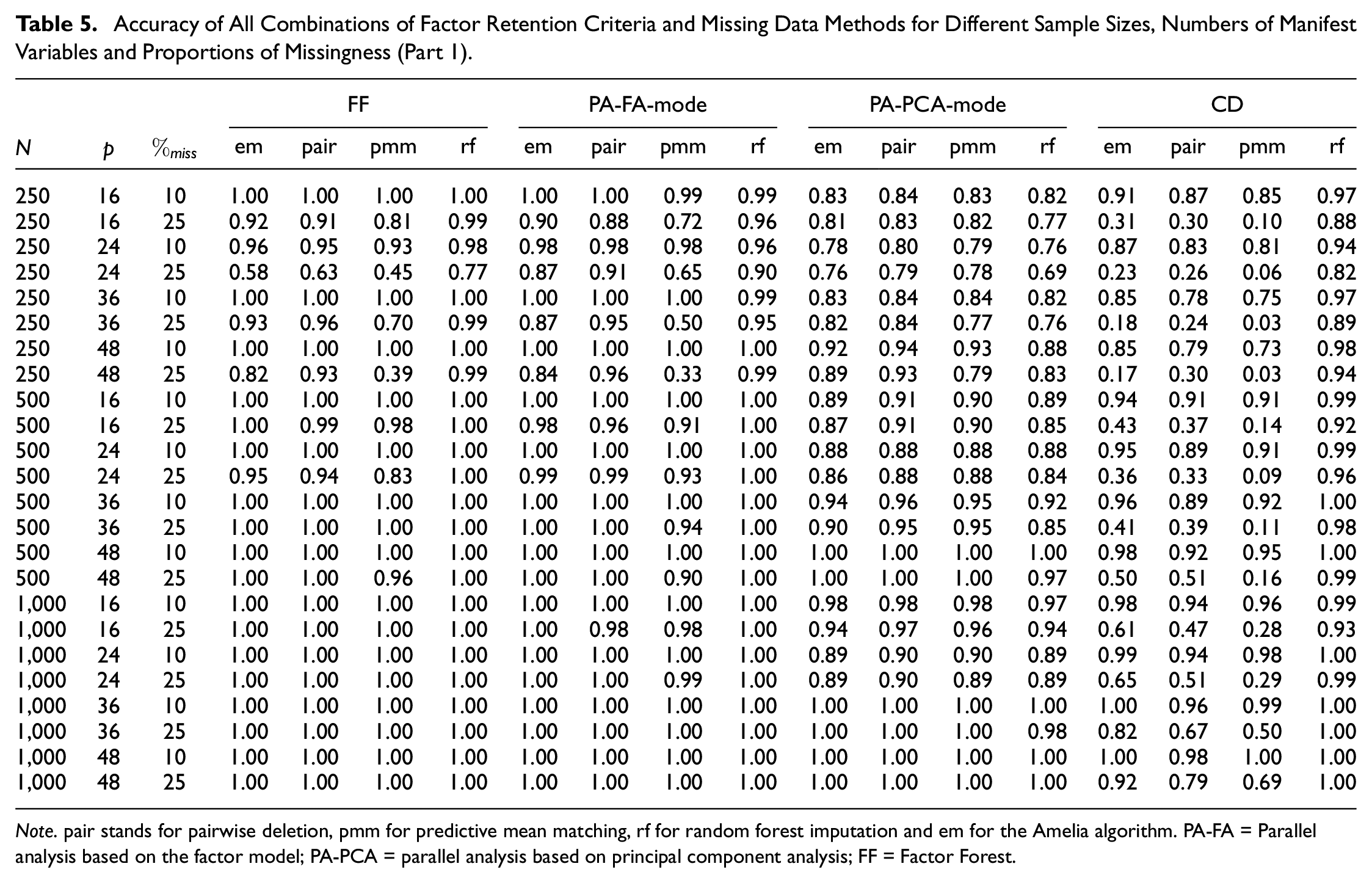
Note. pair stands for pairwise deletion, pmm for predictive mean matching, rf for random forest imputation and em for the Amelia algorithm. PA-FA = Parallel analysis based on the factor model; PA-PCA = parallel analysis based on principal component analysis; FF = Factor Forest.
Accuracy of All Combinations of Factor Retention Criteria and Missing Data Methods for Different Sample Sizes, Numbers of Manifest Variables and Proportions of Missingness (Part 2).
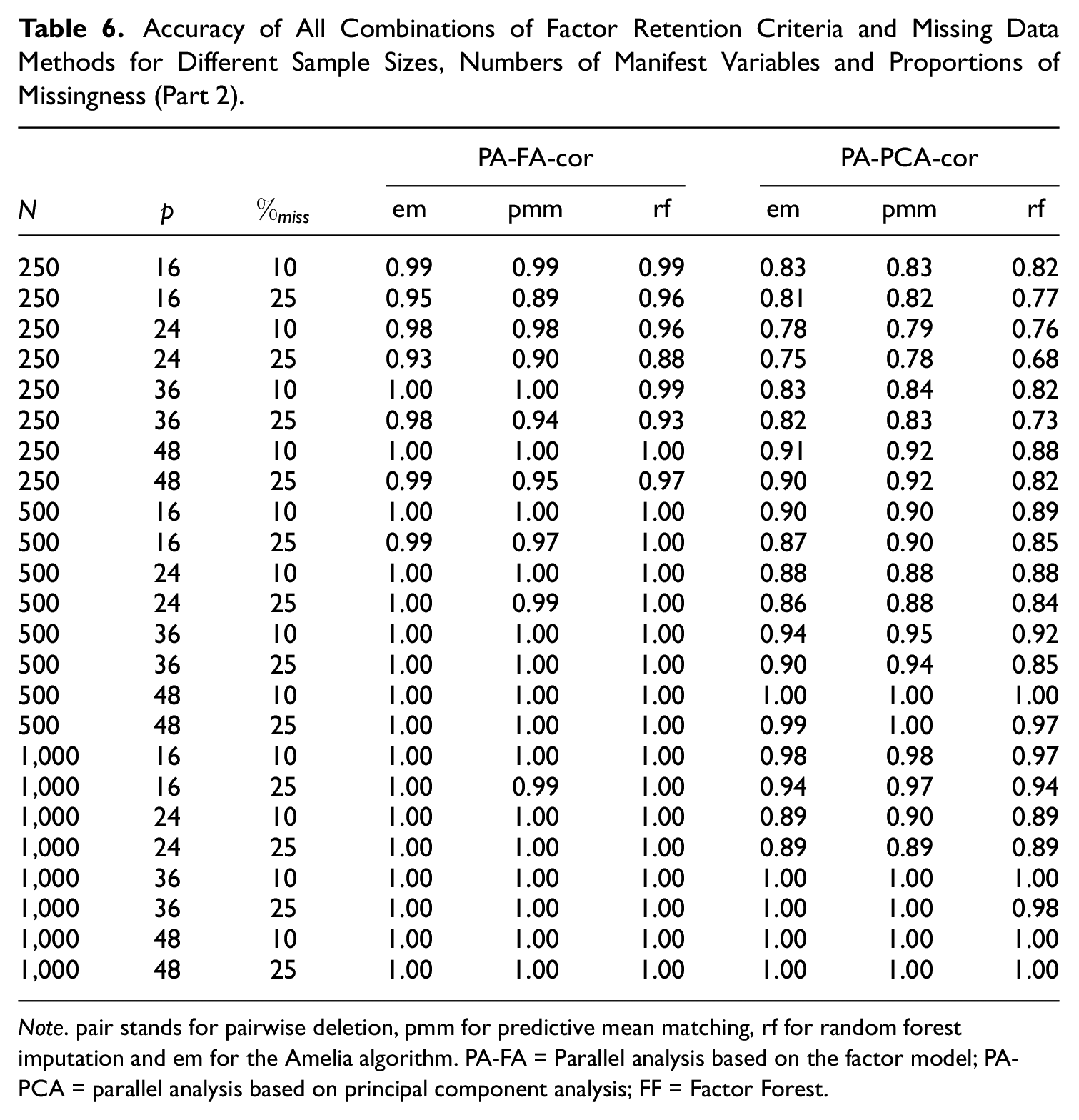
Note. pair stands for pairwise deletion, pmm for predictive mean matching, rf for random forest imputation and em for the Amelia algorithm. PA-FA = Parallel analysis based on the factor model; PA-PCA = parallel analysis based on principal component analysis; FF = Factor Forest.
Baseline Comparison
For an easier interpretation of these results, the accuracy of the four factor retention criteria on comparable data without any missing values is displayed in Table 7. While FF and PA-FA estimated the number of factors correctly in almost every data set, CD had slightly lower accuracies across all conditions (mostly above 95% accuracy), while PA-PCA showed rather poor performance in small-sample conditions (see also Table 3).
Accuracy of the Factor Retention Criteria Different Sample Sizes and Numbers of Manifest Variables When No Data Are Missing.
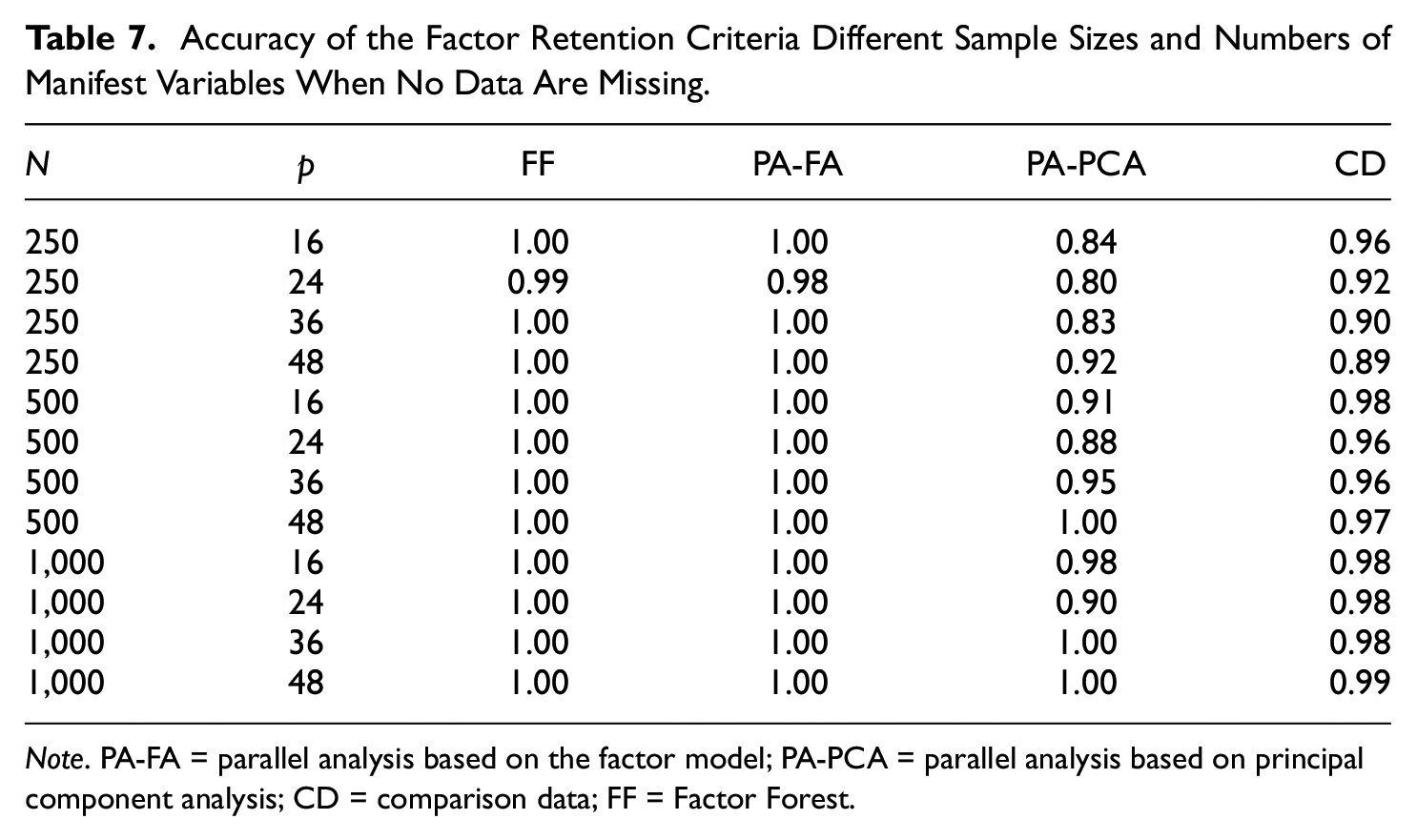
Note. PA-FA = parallel analysis based on the factor model; PA-PCA = parallel analysis based on principal component analysis; CD = comparison data; FF = Factor Forest.
All in all, most combinations provided similar results compared with the baseline performance of the factor retention criterion on fully observed data. CD in combination with the Amelia algorithm, predictive mean matching or pairwise-deletion, though, showed a more than 25 percentage points lower accuracy on average than CD’s baseline performance on data without missing values (CD and predictive mean matching had a 40.70 percentage points lower accuracy), while this performance gap was in the single digits for all other combinations (CD and random forest imputation showed basically the same accuracy [~96%] as CD in the baseline conditions).
Discussion
In this study, 22 combinations of missing data methods (pair, rf, em, and pmm) and factor retention criteria (FF, PA-FA-cor, PA-FA-mode, PA-PCA-cor, PA-PCA-mode, and CD) were evaluated with regard to their accuracy and bias (over- or underfactoring) in various simulated data conditions. While the choice of the missing data method had very little impact on the accuracy when PA-based factor retention or the new FF approach were used, it was crucial for an accurate factor retention when CD was used. Contrary to the findings of Goretzko, Heumann, and Bühner (2019), the missing data methods performed quite similiar which can be explained by the altered simulation conditions—in this study higher primary loadings (associated with higher communalites and more reliable indicators) were used as we wanted to focus on conditions in which all factor retention criteria are able to retain the true number of factors with (nearly) perfect accuracy when no data are missing. Accordingly, the overall accuracy of each method is notably higher in this study.
McNeish (2017) and Goretzko, Heumann, and Bühner (2019) found pairwise deletion to be inferior to multiple imputation (especially random forest imputation and the Amelia algorithm in combination with the cor aggregation strategy)—a result that we did not find for parallel analysis in the investigated data conditions. An explanation for the relatively good performance of pairwise deletion might be the comparably “easy” conditions with (almost) perfect simple structure in this study, whereas Goretzko, Heumann, and Bühner (2019) investigated more difficult conditions with smaller primary and higher cross-loadings. In addition, McNeish (2017) focused on small-sample conditions and found pairwise deletion to be inferior to multiple imputation mainly in conditions with 60 or 120 observations, while factor retention with pairwise deletion worked similarly well when
Contrary to parallel analysis, the Factor Forest performed better with random forest imputation than with pairwise deletion. This tendency was especially recognizable in small-sample conditions (
Hence, as discussed by Goretzko, Heumann, and Bühner (2019) random forest imputation seem to be the most promising way to deal with missingness under MAR or MCAR assumption in the context of EFA (and factor retention). Nevertheless, as it showed a comparably poor performance when combined with PA-PCA (cor and mode strategy) when the number of factors got higher (here
When researchers want to use parallel analysis and an imputation method, they should rather use the cor aggregation strategy or the similar approach by Nassiri et al. (2018) instead of the mode approach, even though the performance differences between these two were rather small in this study. PA-FA-cor showed higher overall accuracies than PA-FA-mode, while being less biased—a tendency that yielded substantial performance differences in small-sample conditions (which again might be the most important for current psychological research practice).
Since this study is the first to investigate the interplay of different factor retention criteria and missing data methods, its focus on rather desirable data conditions with clear factor patterns and (practically) simple structure, in which an accurate factor retention is comparably easy, can be seen critically. As Goretzko, Heumann, and Bühner (2019) showed that the performance of different missing data methods differ more strongly under less favorable conditions, further research may expand the scope of this simulation study by adding other data conditions with higher cross-loadings, nonnormal data, or minor factors in the data-generating models. Another potential limitation of the current study are the proportions of missingness that were under investigation. In other simulation studies with regard to missing data much higher proportions of missing values are considered (e.g., Jochen et al., 2013), but since EFA is mostly applied when developing a questionnaire or psychological test, we would argue that the rate of item nonresponse in single questionnaires is arguably lower than in extensive surveys or settings where the questionnaire is presented after a time-consuming experiment (i.e., when solely the items have to be answered that are then used for the EFA) and therefore rarely higher than 25%. Besides, other studies on this topic used similar proportions of missingness—McNeish (2017) used up to 25% missing values, Nassiri et al. (2018) up to 30%, Lorenzo-Seva and Van Ginkel (2016) up to 15%, and Josse et al. (2011) up to 30% as well. Nevertheless, as modern instruments of data collection (e.g., mobile sensing, Schoedel et al., 2020) can yield higher proportions of missing values, further research should evaluate the influence of substantially higher missingness rates.
Conclusion
The present study evaluated different combinations of missing data methods and factor retention criteria with regard to their accuracy and potential biases (namely under- and overfactoring). For data conditions in which all compared factor retention methods are able to determine the number of factors accurately when no data are missing, all investigated missing data methods performed comparably well in combination with parallel analysis (for both tested aggregation strategies) or the factor forest. Accordingly, pairwise deletion yielded similar results as multiple imputation models based on an EM algorithm and MICE. However, when the comparison data approach was used for factor retention, pairwise deletion performed poorly and solely random forest imputation within the MICE framework provided accurate estimates of the dimensionality. Consequently, this study shows that depending on which factor retention criterion is used to assess the dimensionality in EFA, different missing data methods may be favorable and researchers should be careful when relying on default settings such as pairwise deletion. Combining the results of this study with those of other studies, researchers are advised to compare different missing data mechanisms (to evaluate the robustness of their solution) and factor retention criteria to obtain a robust and accurate estimate of the number of factors.
Footnotes
Declaration of Conflicting Interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.