
Abstract
Introduction:
Cannabis cultivars were usually categorized based on their genetic profile as sativa, indica, or hybrid types. However, these three criteria do not allow sufficient differentiation between the numerous varieties of cannabis strains. Furthermore, this classification is based on morphological and bio-geographical properties of the plants and does not represent the chemical composition of different cultivars. The concentration of cannabinoids and terpenes are crucial for the pharmacological effect, not only because of the known entourage effect, and therefore needs to be considered by categorization.
Materials and Methods:
A total of 140 medicinal cannabis flowers available on the German market were analyzed regarding their individual terpene profile using GC-MS analysis. Statistical evaluation was performed to investigate correlations and data relations as well as for clustering.
Results:
Multivariate analysis showed correlations between individual terpenes. However, there was no statistical correlation between terpene profiles and their respective genetic profile. Terpene profiles of sativa, indica, and hybrid strains are quite heterogenous and clearly showed that there is no relation between terpenes and the estimated pharmacological effect. As a result, we suggest a new classification system based on individual terpene profiles to faster a comprehensive understanding of the expected medical effect.
Discussion:
Considering main terpenes, we established a concept of six clusters with various terpene profiles being attributed to different medicinal applications. We excluded tetrahydrocannabinol (THC) and cannabidiol (CBD) content from clustering as most of the strains were THC dominant and therefore distort the results. Our pattern of strains with similar terpene profiles might refine the existing classes of chemotypes with different THC:CBD content.
Conclusion:
The categorization of cannabis strains based on their terpene profiles allows a clearer, finer and, above all, more meaningful classification than the existing sativa/indica classification. Due to the entourage effect and the interactions between cannabinoids and terpenes, this group of substances is also given the necessary consideration when selecting the right medicine for the individual. Within the next steps, further studies are needed with the aim of mapping clinical validated effects to our chemovars. If it is possible to correlate therapy of symptoms to specific chemical profiles personalized cannabinoid therapy will be possible.
Introduction
Over the past years, the interest in using medicinal cannabis has grown globally due to its various therapeutic benefits highlighted in numerous studies.1,2 The variety of cultivars is constantly growing, and new strains are being created through breeding and hybridization. The classification of cannabis plants into “sativa” and “indica” has established itself as the first distinguishing criterion in the past decades. 3 The classification into these two categories has become a central theme in cannabis research, cultivation, and in a medical perspective. This classification is based on morphological and genetic differences and often serves as a guide for consumers, growers as well as medical users. 4 However, despite its widespread use, the scientific validity and actual relevance of this distinction has been increasingly questioned.4–6 Historically, sativa and indica plants were distinguished from each other based on their different places of origin and characteristic traits. 7 The name ‘Cannabis indica’ was formally characterized by Jean-Baptiste Lamarck who introduced this second type of cannabis because of the physiological differences between the two plants. 4 Before the uncontrolled breeding of cannabis plants, taxonomic differentiation based on different geographical origins and the associated significant differences in their terpenoid composition was perfectly possible. 8 However, the ongoing hybridization of cannabis strains has led to a blending of traits, increasingly blurring the clear distinction between sativa and indica. Therefore, “hybrids” were added as a further category that combines different characteristics and consequently completely lacks any indication of a possible effect. The processes of terpene biosynthesis have still not been fully investigated and understood. The administration of growth factors can influence the production of terpenes and thus also the therapeutically relevant terpene profile. 9 This in turn makes it completely impossible to draw conclusions about the origin of the plant and the effects derived from it. In addition, recent scientific research at the genetic level has shown that the traditional classification does not necessarily correspond to the actual genetic differences between the plants. 10 The now existing classification into indica and sativa cannot be justified due to genetic and chemical profiles.5,11 In a medical context, however, it is important to make an appropriate selection based on the active ingredients present to match the symptoms to be treated.
A new term in this context is the chemovar. Chemovar is an abbreviation for “chemical variety” and refers to a specific variety of a plant whose composition of chemical compounds, such as cannabinoids and terpenes, is unique. 12 Unlike the term “genotype,” which refers to genetic differences between plants, chemovar refers to chemical differences that can arise due to environmental factors, growing conditions, and other influences during growth. Two plants with the same genotype can be different chemovars if they are grown under different conditions. Differentiating cannabis strains based on their chemical profiles is important because different chemovars can have different effects and therapeutic properties. 13 As with other medicinal products, it is also crucial to consider the active pharmaceutical ingredients in cannabis plants. The complexity of the individual components of the cannabis plant makes a decisive contribution to its medicinal benefits. In addition to the main components, the cannabinoids tetrahydrocannabinol (THC) and cannabidiol (CBD), there are numerous secondary metabolites that also significantly determine the therapeutic potential. 14 For example, some people prefer cannabis strains with a higher CBD content for their potential anti-inflammatory properties, while others are more attracted to strains with a higher Δ9-THC content for an analgesic effect. The use of the term “chemovar” reflects the growing recognition of the importance of the chemical composition of cannabis for its potential effects and applications, particularly in the field of medical research and use. 10 To distinguish different types of chemovar, the chemical composition of the cannabis plant must be examined more closely. In addition to the well-known cannabinoids such as THC and CBD, terpenes also play a crucial role in the complexity of the plant chemistry of cannabis. 15 Terpenes, organic compounds that, among other substances, are responsible for the characteristic scent of many plants, not only contribute to the aromatization of cannabis, 16 but also influence its pharmacological properties. 10
In this study, we examined the chemical fingerprint of individual medicinal cannabis flowers available on the German market in more detail. We have analyzed individual terpene profiles and correlate them to the existing sativa-indica-classification. We hypothesize that terpene profiles provide a better and more reliable categorization of cannabis strains than labeling as “sativa” or “indica.” Therefore, we also want to be bridging the gap between scientific research and everyday application to be able to categorize strains by pharmacological effect. Patients and health care professionals are usually overwhelmed by an excessively large selection of cultivars. Classification of cultivars based on the chemical composition might solve this issue.
Material and Methods
Standards
Reference standards were obtained from Restek GmbH, Bad Homburg. The terpene mega mixes standard #1 and #2 were used to calibrate the system for the detection and quantification of 55 different terpenes.
Sample collection and preparation of GC-MS analysis
Terpene analysis was conducted using a Shimadzu Gas chromatograph coupled with mass spectrometry (GC-MS) QP-2020NX equipped with a headspace sampler HS 20-NX. Approximately 10–15 mg of each cannabis flower sample was finely ground and placed into a crimped headspace vial. The vial containing the ground sample was heated for 30 min at 150°C to volatilize the terpenes, facilitating their release into the headspace. After heating, the vial was pressurized for 30 sec at 190 kPa to ensure that the volatiles were adequately transferred. The sample was then transferred to the GC module at 180°C using helium as the carrier gas at a flow rate of 1.75 mL/min.
The GC module was fitted with a SH-I-624Sil-MS column (Shimadzu), with a length of 30 meters, an inner diameter of 0.25 µm, and a film thickness of 1.80 µm. The temperature program started at 65°C and was held for 1 min to focus the analytes. The temperature was then increased at a rate of 8°C per min until reaching 300°C. The final temperature of 300°C was maintained for 5 min to ensure the elution of all compounds, resulting in a total run time of 35.38 min per sample.
Runs were analyzed using the software LabSolutions GCMS solution Version 4.53 from Shimadzu. In each sample chromatogram, typically 25–35 chromatographic peaks were visible. These peaks were integrated both automatically and manually using the NIST database, and the concentration of the individual terpenes was calculated via peak areas in correspondence to the quantitative 5-point calibration using the reference standards. Data were statistically analyzed as described below.
Multivariate data analysis
To analyze the terpene profiles, each terpene was considered a distinct feature in the data analysis process, with each terpene represented as a vector comprising 140 components (corresponding to the 140 samples). Initially, descriptive data analysis was conducted on these terpene vectors. This revealed that 25 of the terpenes had zero variance, meaning their concentrations were constant across all samples. Consequently, these terpenes were removed from the dataset to streamline the analysis.
It was observed that the remaining terpenes did not follow normal distribution patterns, and some showed high correlations with each other. Further, there was heterogeneity in the variance between the terpenes, indicating that the variability in terpene concentrations differed significantly. To gain an initial understanding of the data, the average concentration of each terpene was plotted on a Pareto chart. This visualization highlighted the most abundant terpenes. To examine the relationships between different terpenes, a correlogram was constructed using Kendall’s correlation coefficient and hypothesis testing.
The next step involved comparing terpene profiles grouped by the genetic classifications of the flowers (sativa, indica, hybrid) to evaluate the efficacy of this traditional classification system. This was done by generating box plots and performing a two-way non-parametric ANOVA (Schreier–Ray–Hare test) to assess the effects of both terpenes and genetic classifications on the measured values.
Given the heterogeneity of terpene profiles within each genetic category, K-Means clustering was used to identify new groupings of the flowers based on their chemical profiles. The clustering effectiveness was evaluated using silhouette scores, which measure how similar an object is to its own cluster compared to other clusters. For a better visual understanding of the clustering, t-distributed stochastic neighbor embedding was used to create a two-dimensional representation of the data, which provided a clear visualization of the clusters.
Results
Identified terpenes and their correlation
We analyzed terpene profiles in 140 cannabis strains using GC-MS analysis. First, we focused on the identified terpenes. With our analysis setup, we were able to detect 38 different terpenes in various concentrations. Using multivariate date analysis, we were able to demonstrate, that nine terpenes are responsible for 86% of the variation of the terpene profiles: β-myrcene, β-caryophyllene, limonene, linalool, α-humulene, α-pinene, β-pinene, terpinolene, and fenchol are accounting for main characteristics of terpene profiles measured in our samples. In other words, with these nine terpenes we can clarify over 86% of the terpene content (Fig. 1). Next, we analyzed the correlation between the analyzed terpenes using the Kendall rank correlation coefficient. The correlogram (Fig. 2) shows the relationship between each terpene. Our data show, that there are strong positive linear correlations between e.g., limonene and camphene (r = 0.82), β-caryophyllene and α-humulene (r = 0.97), α- and β-pinene (r = 0.82), terpinene and terpinolene (r = 0.92), α-phellandrene and terpinolene (r = 0.92). Otherwise, there was a medium-strong negative correlation between guaiol and caryophyllene oxide (r = −0.61). Further, we calculated a medium-strong positive correlation between THC value and total terpene content (r = 0.41).
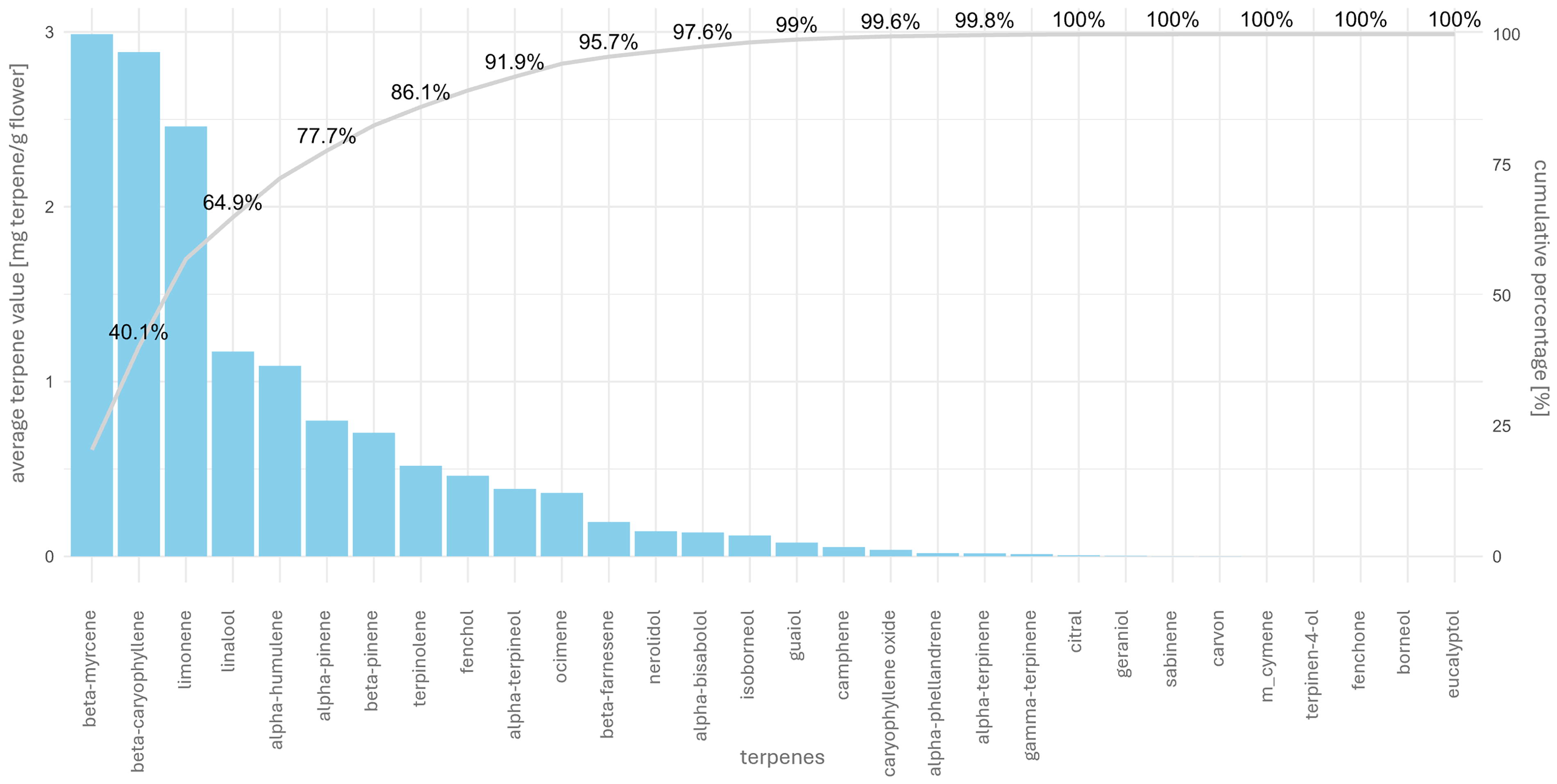
The most abundant terpenes in cannabis flowers. The bars show the average terpene levels and the cumulative percentage of the total terpene concentration, sorted by the amount of each terpene.
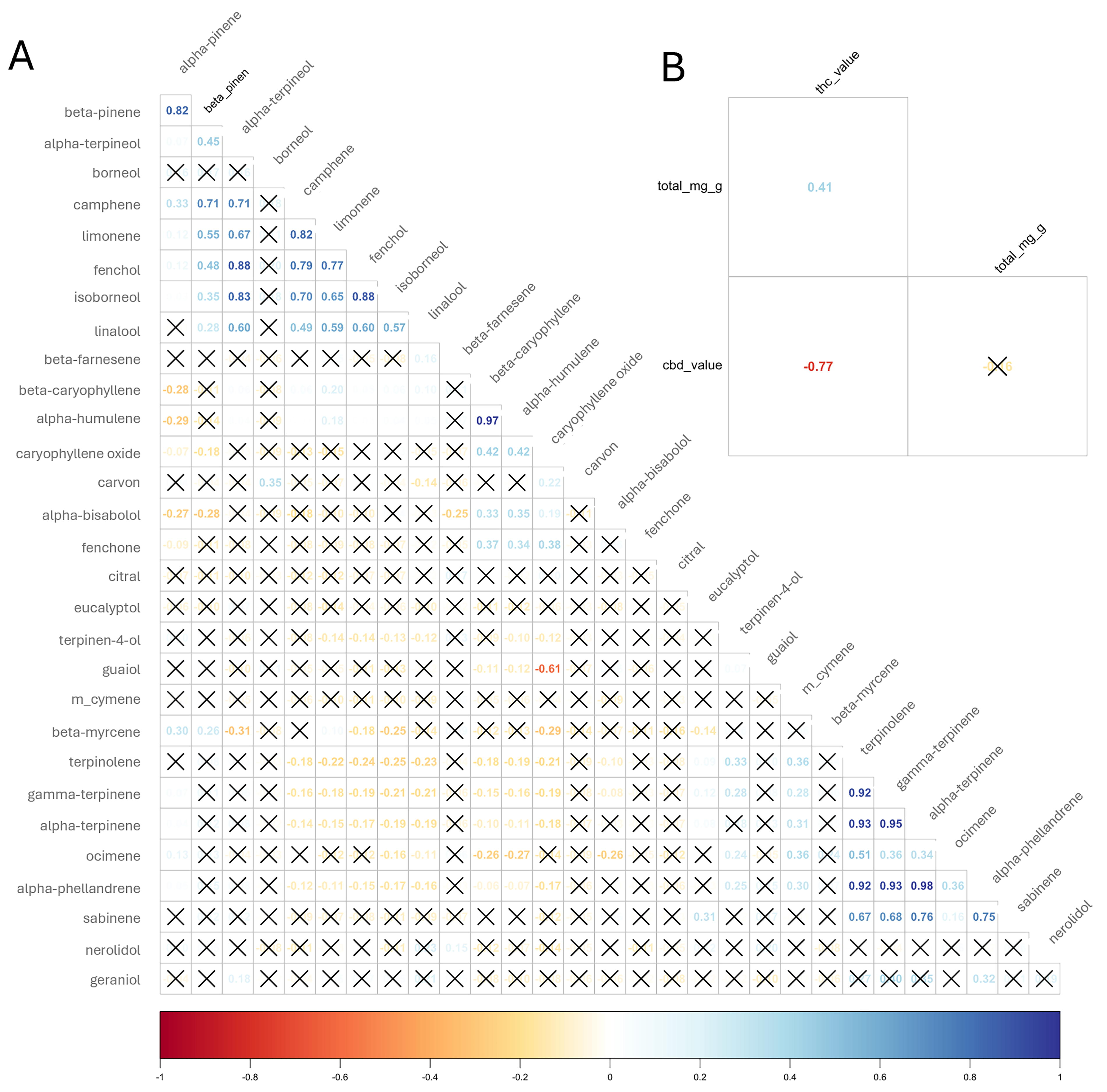
Correlation between individual terpenes and cannabinoids vs. total terpene content. The correlograms show correlation coefficients between terpenes
Differences between indica, sativa, and hybrid
In our study, we analyzed terpene profiles of cultivars with different genetics. Sixty-four of them are categorized as “hybrids,” 47 as “indica,” and 29 as “sativa” (Fig. 3A). Analysis of variance (ANOVA) demonstrated that there was no correlation between terpene profiles and genetics (p > 0.05; Fig. 3B). Further, comparison of terpene content and genetics showed no differences between hybrids, indica, or sativa (Fig. 3C).
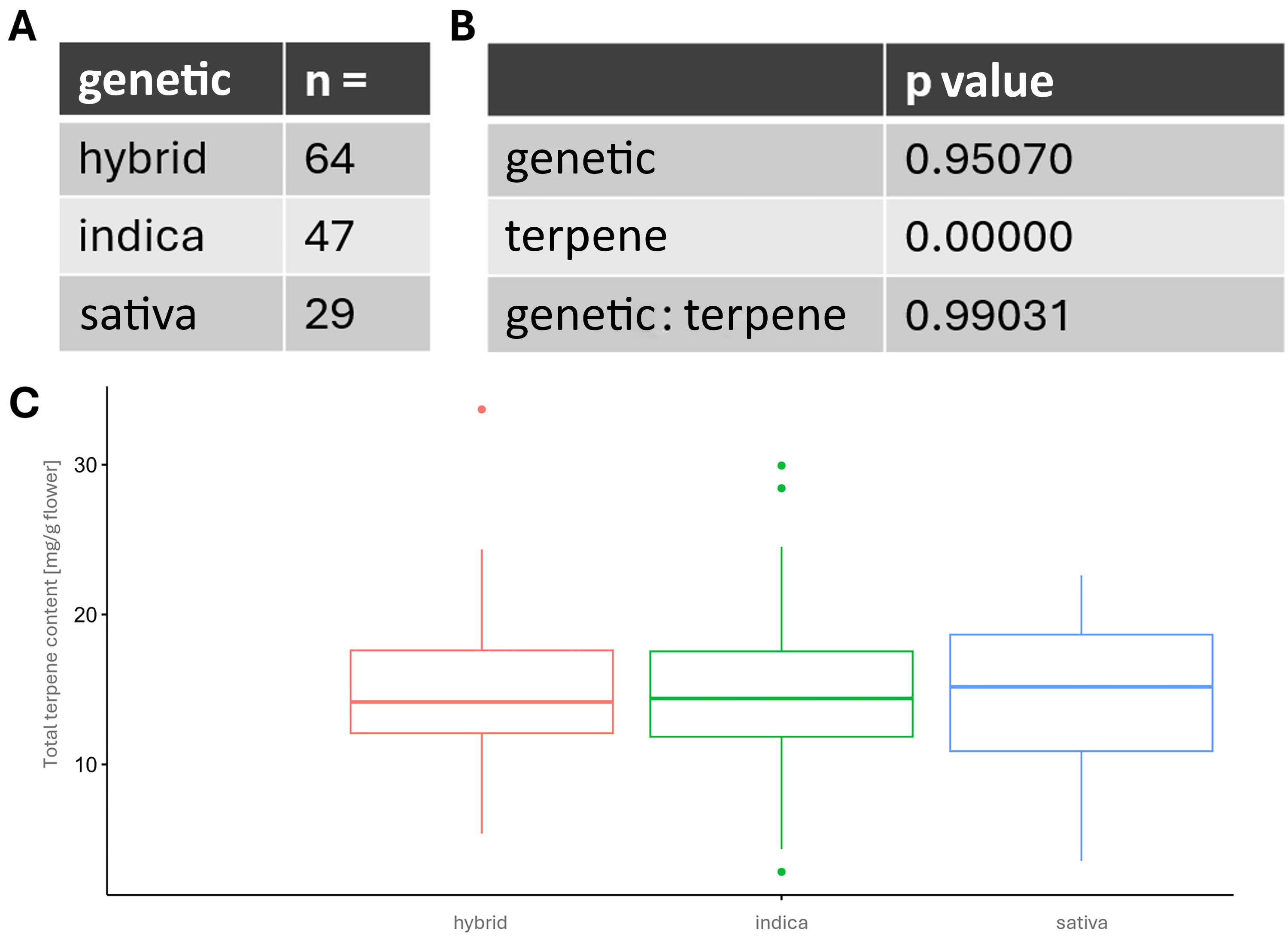
Differences in terpene content depending on genetic. Terpene profiles of samples of different genetics
Next, we had a deeper look at the individual terpene content of the nine main terpenes mentioned above. Firstly, in Figure 4 box plots show the three main terpenes in cannabis flowers: β-myrcene, β-caryophyllene, and limonene. There are no statistical differences in terpene content and genetics regarding these three terpenes. Each group (hybrid, indica as well as sativa) showed different amounts of different terpenes. Besides from terpinolene which is more common in sativa than in hybrid or indica. Linalool has a slight dominance in hybrid and indica whereas concentration of nerolidol is higher in sativa cultivars. Consequently, there are no significant differences in terpene profiles between the three genetics.
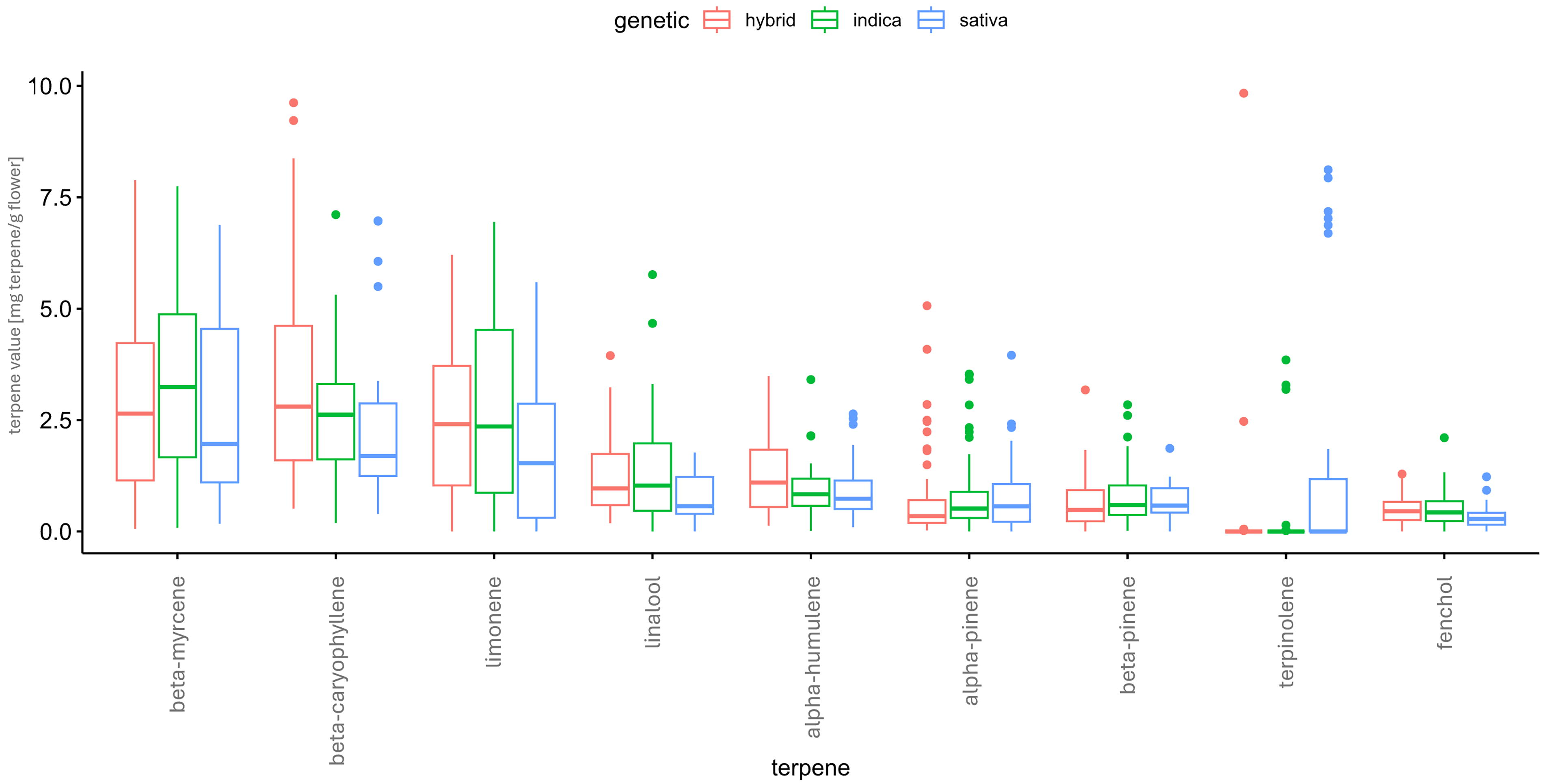
Box plot showing terpene values in different genetics. Boxes show terpene concentration for the most frequently detectable terpenes in the three different genetics—hybrid on the left, indica in the middle, and sativa on the right side.
Clustering of cannabis chemovars
Terpene profiles of all analyzed cultivars were clustered for differentiation of characteristics of the cultivars. Figure 5A presents the results of clustering showing that six was the optimal number of clusters considering the average silhouette width and distinguishing features between the cultivars. In Figure 5B, it is demonstrated that most of the cultivars fit into the clusters. Only in clusters 2, 3, and 4 were some cultivars that did not meet the criteria very well. Clustering plot in Figure 6 shows the transformation of all data of terpene analysis into a two-dimensional field without loss of information. Here, we can see the overlapping fields with cultivars that did not fully meet the criteria of one single cluster. Table 1 presents the main distinguishing characteristics of the clusters. Next to the different THC and CBD values the concentrations of terpenes differ. It is possible that different medical applications can be derived from the different terpene contents. This has to be investigated in clinical trials with patients and different indications. Our results clearly show that cultivars can be clustered regarding terpene content independent of the genetic. Each cluster includes sativa, indica as well as hybrid cultivars.
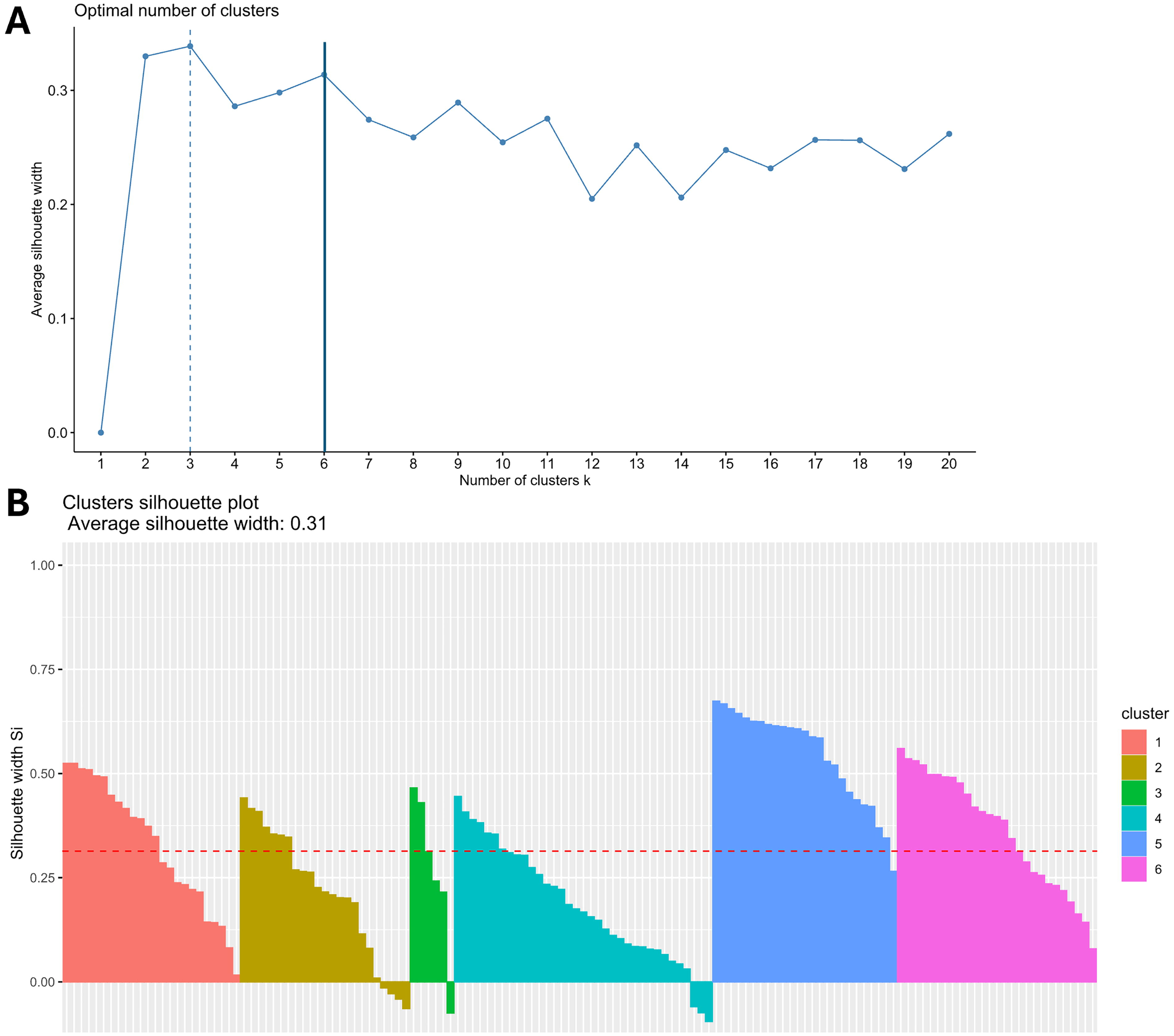
Clustering of cannabis cultivars.
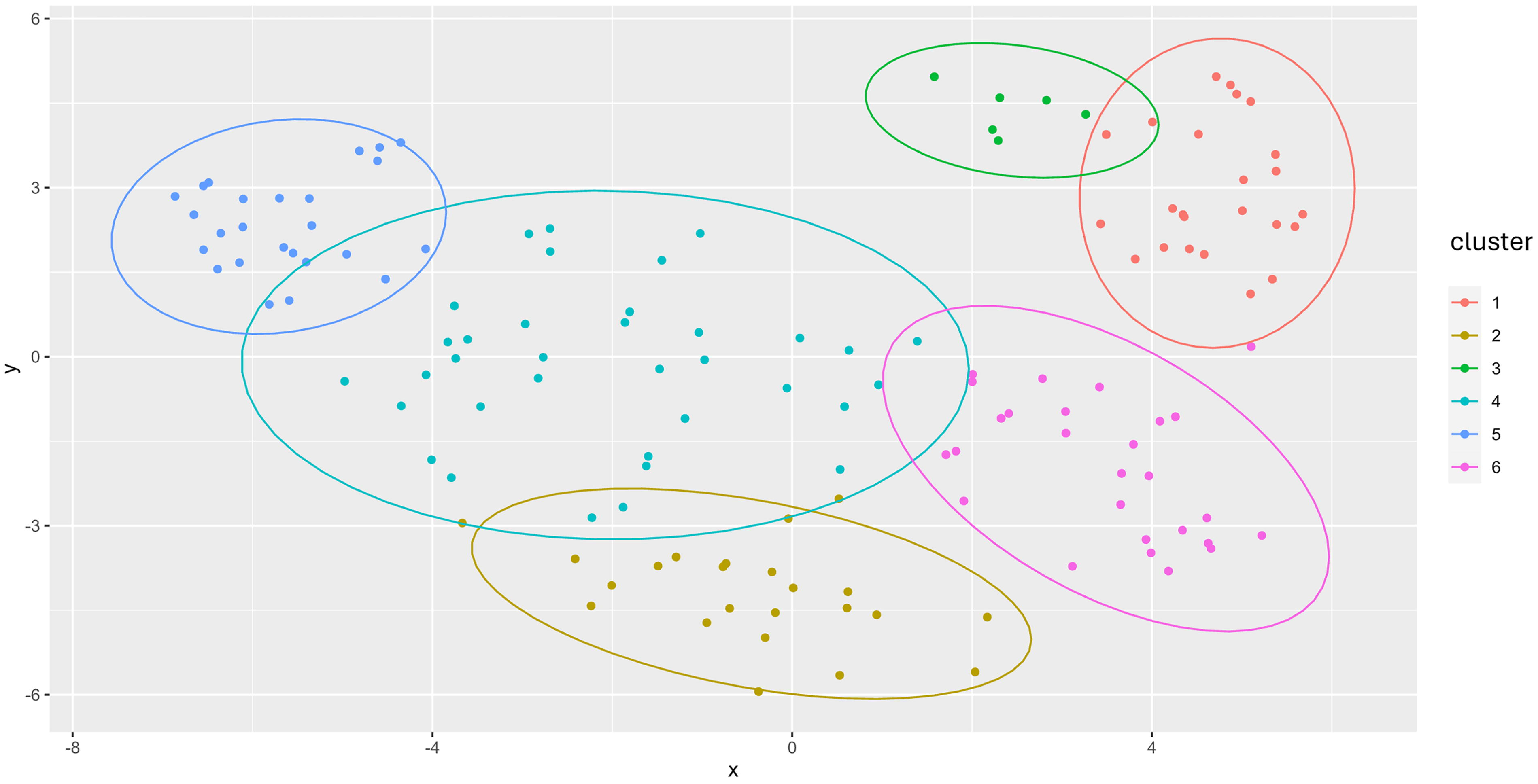
Two-dimensional plot of clustering. The analysis of the clustering using t-distributed stochastic neighbor embedding plots reveals a two-dimensional plot without losing information on each data point. The presentation illustrates the differences as well as overlaps of different cultivars (symbolized as a dot) in our analysis.
Attributes of the Clusters
*p < 0.05; **p < 0.01; ***p < 0.001; multiple mean comparison with adjusted p value.
Discussion
This is the first analysis of cultivars of medicinal cannabis on the German market regarding their terpene content. The measurement of terpenes using GC-MS analysis is a highly sensitive, reliable and accurate method to identify and quantify terpenes in cannabis flowers. 17 More than 100 terpenes have been identified in C. sativa, with 30—50 terpenes commonly observed in cannabis samples. A study demonstrated that the primary terpene accounted for approximately 35% of the overall terpene content, and typically, the top four terpenes collectively make up 72% of the total. 18 Consistent with this, we analyzed nine terpenes to account for more than 86% of terpene profiles in these cultivars: β-myrcene, β-caryophyllene, limonene, linalool, α-humulene, α-pinene, β-pinene, terpinolene, and fenchol. Other studies showed that three monoterpenes, β-myrcene, limonene, and α-pinene, and two sesquiterpenes, β-caryophyllene and α-humulene, were prevalent in the majority of chemovars. 19 However, the concentrations of main terpenes show large variances. 20 Enriquez and colleagues investigated terpenes in cannabis flowers from diverse ecological niches in Colombia and confirmed α-pinene, limonene, β-myrcene, β-pinene, terpinolene, linalool, nerolidol, α-bisabolol, β-caryophyllene, and α-humulene to be the most abundant terpenes in their samples. 21 Further, they also showed correlations between α- and β-pinene and β-caryophyllene and humulene. We also observed some correlations between the terpenes. The main reason for these correlations lies in the chemical structure of the terpenes. As for β-caryophyllene and α-humulene, chemical transformation processes can convert one terpene into the other. Further, natural oxidation processes can accelerate the degradation or conversion of terpenes. Thus, stabile conditions during cultivation and drying are necessary to ensure constant terpene content. There is another interesting suggestion that some terpenes protect each other against degradation. Hazekamp and colleagues proposed that cannabis components may have a protective effect on each other if they are present in specific proportions. 22
The classification into sativa, indica, and hybrid shows clear weaknesses: Although these three classes of cannabis are often associated with different modes of action, these cannot be clearly attributed to the classification. When comparing samples labeled as either sativa or indica, the majority exhibited significant overlap. 6 There was no clear distinction where a sativa group clustered independently from indica strains. Our analyses show that next to similar THC and CBD content in all three classes, there are no differences in terpene content. Many hybrid forms have developed in recent years as a result of global breeding, 4 so that it is often not possible to clarify the genetic coordination of the plants.3,23 Therefore, there is a growing need for a new, unambiguous and, above all, clearly definable classification. From a chemical point of view, it is essential to consider the various components of the cannabis flowers to distinguish them. In this case different research groups are already developing a new set of classification. Birenboim et al. published a correlation analysis showing that 11 cannabis specific compounds (cannabidiolic acid, cannabigerolic acid, tetrahydrocannabinolic acid, α-pinene, camphene, ocimene, β-caryophyllene, α-bergamotene, guaiol, β-gurjunene, and β-myrcene) can be used as bio-indicators. 24 They postulate, that these bio-indicators can potentially be used as concentration predictors for 32 cannabinoids and terpenes. Dei Cas and colleagues analyzed terpene profiles in 20 cannabis THC-dominant and 13 CBD-dominant chemotypes. 25 They were able to distinguish between these two chemotypes by measuring α-terpineol, linalool, DL-menthol, α-cedrene, and borneol. They summarize that analyses of terpene profiles provide an opportunity to highlight some target compounds crucial for various chemotypes.
A presentation of the varieties in relation to their THC and CBD content shows that the majority of the varieties analyzed are THC dominant (Fig. 7). Therefore, clustering taking THC and CBD into account is blurred. The increased proportion of THC-dominant varieties distorts the results at this point. We therefore propose an extension of the already existing concept of chemotypes (e.g., THC-dominant, CBD-dominant, balanced) by the six clusters we identified based on the terpene profiles.
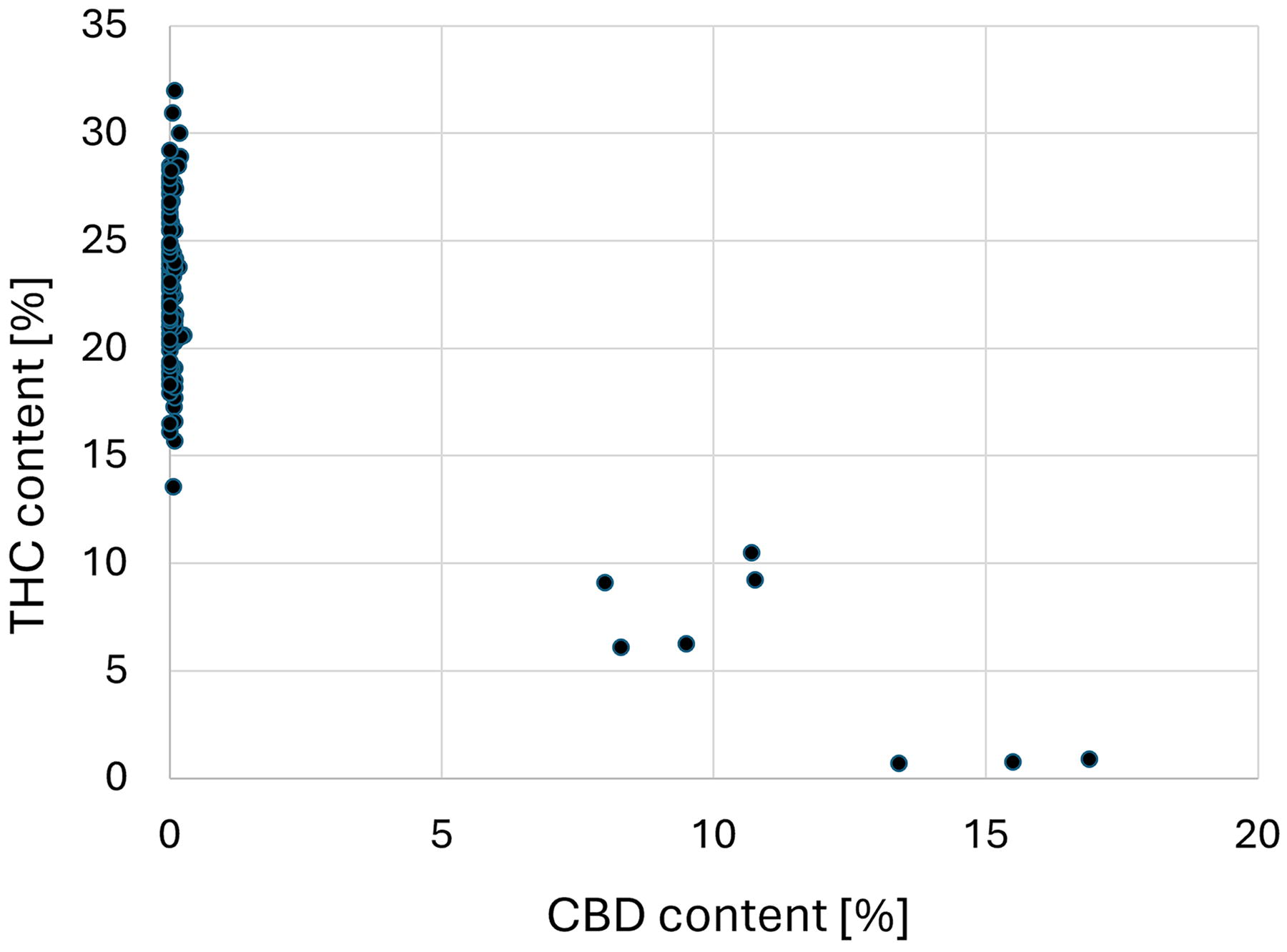
Localization of the strains. Diagram showing localization of the investigated strains according to their THC and CBD content. Each dot represents one strain.
Hazekamp and Fischedick investigated the chemical profiles of cannabinoids and terpenoids in different batches of the same cultivar. 12 They showed that profiles were highly reproducible if flowers were grown under controlled settings to fully standardize the chemical content in cannabis. However, focusing on cannabinoid profiles will not achieve enough differentiation because most of the available cannabis flowers show similar cannabinoid amounts. 26 The terpene profiles differed more from each other than the cannabinoid content. Reimann-Philipp et al. conclude that terpene profiles are much more indicative for cannabis flowers than the cannabinoid profile. In a previous study, Fischedick reported a terpenoid dependent classification in cultivars with high THC amounts. 27 Similar to our result, he developed five major groups and 12 classes of cultivars with differences in terpenoid profile. Our clustering is also based on terpene composition revealing six mostly independent clusters. These clusters might also give advice to health care professionals to choose cultivars with appropriate characteristics for certain indications. Aizpurua-Olaizola et al. also detected different terpene profiles in different chemotypes. They also reported that the relationship between cannabinoids and terpenes is important because of synergistic effects and the resulting suitability of this combination for certain therapies. 28 The study of Orser et al. revealed similar main terpenes (β-myrcene, limonene, β-caryophyllene, α-pinene, α-humulene, and β-pinene) and divided the investigated cultivars into three different clusters. 29
Although there are already initial indications of the pharmacological effect of individual terpenes,13,15 further clinical studies in particular need to be set up and carried out in order to prove the medical benefits of terpenes. 30 Finlay et al. showed that terpenes exert their effects not via Cannabinoid receptor 1 (CB1R) or Cannabinoid receptor 2 (CB2R) activation with an exception of β-caryophyllene showing weak interaction with CB2R. 31 Therefore, terpenes seem not to improve effects of THC and CBD in a manner of the entourage effect, but rather mediate their own pharmacological effects. On the other hand, a current study shows that limonene can mitigate the anxiogenic effects of THC. 32 The authors assume that limonene may increase the therapeutic index of THC by decreasing negative side effects.
With growing evidence for the pharmacological effect of terpenes and cannabinoids, we might be able to address different groups of cultivars with a special medicinal need. There is already an index system that enables health care professionals, patients, and scientists to categorize cannabis products based on THC, CBD, and terpene content relative to different levels of symptom relief and side effect reporting. 33 More research and educational work need to be done to give more patients safe access to cannabis therapy. This includes not only research into the medical efficacy but also a sensible and helpful classification of the available cannabis varieties.
Conclusion
The conventional classification of cannabis varieties into sativa, indica, and hybrid forms is outdated from a scientific point of view. A new medical-focused classification based on chemical analyses of cannabinoids and terpenes creates trust, reliability, and clearly differentiates therapy with medical cannabis from the recreational cannabis market. The categorization of cannabis strains based on their terpene profiles allows a clearer, finer, and more meaningful classification than the existing sativa–indica classification. In addition, the determination of chemo-profiles enables the next step towards more valid data to be able to prove the effectiveness of medicinal cannabis in the future. The aim of further investigations should be to use additional data to further refine the criteria for clear clustering and thus to transfer them into a generally applicable model. With this classification, an adapted and personalized selection of cannabis may be possible in the future.