
Abstract
Sensor nodes in a distributed sensor network can fail due to a variety of reasons, e.g., harsh environmental conditions, sabotage, battery failure, and component wear-out. Since many wireless sensor networks are intended to operate in an unattended manner after deployment, failing nodes cannot be replaced or repaired during field operation. Therefore, by designing the network to be fault-tolerant, we can ensure that a wireless sensor network can perform its surveillance and tracking tasks even when some nodes in the network fail. In this paper, we describe a fault-tolerant self-organization scheme that designates a set of backup nodes to replace failed nodes and maintain a backbone for coverage and communication. The proposed scheme does not require a centralized server for monitoring node failures and for designating backup nodes to replace failed nodes. It operates in a fully distributed manner and it requires only localized communication. This scheme has been implemented on top of an energy-efficient self-organization technique for sensor networks. The proposed fault-tolerance-node selection procedure can tolerate a large number of node failures using only localized communication, without losing either sensing coverage or communication connectivity.
Keywords
Introduction
Wireless sensor networks can be deployed to provide continuous surveillance and monitoring over a designated area of interest [2,7,19,22]. Many wireless sensor nodes have low cost and small form factors [1, 2, 7]; therefore, they can be deployed in large numbers with high redundancy. A typical example of such low-cost sensor nodes is the set of Berkeley motes from Crossbow Technology [33]. Since nodes are deployed in a redundant fashion, not every node in the network needs to be continuously active for sensing and communication. The operational lifetime of sensor networks can be increased by network organization schemes for topology control, where only a subset of nodes are kept active, while the other nodes are kept in a sleep state or a power-saving mode [14,27,31]. Fewer active nodes also place less demand on the limited network bandwidth.
Since a wireless sensor network should ideally perform surveillance tasks in an unattended manner, it needs to operate as long as possible, even when many sensor nodes fail. This motivates our work on fault-tolerant self-organization. Most recent work aims to provide fault tolerance in the deterministic deployment of sensor nodes [9,17,21,24]. Much less attention has been devoted to distributed protocols that can replace failing nodes in the network with spare nodes. Failing sensor nodes result in coverage loss and breakage in communication connectivity, hence there is a need for a distributed node replacement protocol and self-organization scheme that designates nodes as fault tolerance (spare) nodes. Such a scheme should be fully distributed such that it can be scalable for a large number of nodes. It should only require localized communication to select backup nodes for fault tolerance, and it should not rely on a centralized server to identify and replace faulty nodes.
This paper presents redundancy analysis and a distributed self-organization scheme that ensures communication connectivity and sensing coverage when nodes fail, either sequentially or simultaneously. We first present analytical results to characterize the extent of redundancy needed for fault tolerance. We then describe a distributed scheme that achieves fault tolerance by selecting fault tolerance nodes that can replace failing nodes. The proposed distributed approach uses only single-hop or restricted-hop neighborhood information to select fault tolerance nodes. We show that the proposed approach provides communication connectivity and sensing coverage even when up to Ω nodes fail, where Ω is a user-defined parameter.
The paper is organized as follows. In Section 2, we briefly describe related prior work. In Section 3, we present the background and assumptions used in this paper. Section 4 describes fault tolerance for communication connectivity. Section 5 addresses fault tolerance for sensing coverage. We present simulation results for the proposed distributed self-organization technique in Section 6. Section 7 concludes the paper and outlines directions for the future work.
Related Work
Energy-efficient self-organization in wireless sensor networks has received considerable attention in the literature [13,16,20,23,26,29]. Energy considerations have been used to find a set of (active) nodes that can form a backbone for the network. Selection of these backbone nodes can be achieved by heuristics described in [3,4,25,28] based on the concept of a connected dominating set, where the distributed algorithm proposed in [3] has the best message complexity. The selection of active nodes to guarantee both sensing coverage and communication connectivity has been studied in [14,27,31]. A recent approach distinguishes connectivity from sensing, and determines the configuration of the nodes with both communication connectivity and sensing coverage as considerations [27].
Fault-tolerance in distributed sensor networks has received relatively less attention [9,17,21,24]. Problems studied include the characterization of sensor fault modalities [17,24], faulttolerance in multiple-sensor fusion [21], and reliable information dissemination [9]. Recent work on fault-tolerance in wireless sensor networks can be categorized as being focused on fault detection [6,10,12] or fault-tolerant operations [15,30]. In [10], the authors present various fault tolerance techniques at different levels, including the physical layer for communication, the hardware components of a sensor node, system software such as the embedded operating system, middleware, and application. In [12], the authors consider faults in node sensor measurements and develop a distributed Bayesian algorithm to detect and correct such faults. [6] also addresses a similar fault detection problem, and presents a crash identification mechanism. In [30], the authors show that a sensor network with n nodes is asymptotically connected if each node is directly connected to at least 5.1774 log n neighboring nodes. [15] shows that for a wireless sensor network with n nodes, the connectivity probability with up to k failing nodes is at least eeα when the transmission radius r satisfies nπr2 ln n + (2k − 1) ln ln n − 2ln k! + 2α. Recently, in [11], a protocol has been proposed for event detection in sensor networks, which is able to handle both natural and malicious node failures in sensor networks. However, most prior work has not characterized the redundancy necessary for fault tolerance, and no distributed self-organization protocol has directly considered this issue.
Preliminaries
Assumptions
The discussion in this paper is based on the following assumptions:
The ad hoc sensor network is deployed with a sufficient number of nodes such that the network is connected. All sensor nodes have the same maximum communication range r
c
and maximum sensing range r
s
. We represent the surveillance field by a 2D grid, whose dimension is given as X × Y. Let G = {g1,g2,…,g
m
} be the set of all grid points, and m=|G|=XY. We use S to denote the set of n sensor nodes that have been placed in the sensor field, i.e., |S| = n. A node with id k is referred to as s
k
(s
k
∊ S, 1 k n). Let d
k
i
be the distance between the grid point g
i
and the sensor node s
k
. In a graph model G(V, E) for a set S of nodes, we use the vertex ν ∊ V in the graph model interchangeably with its corresponding node s ∊ S. The set of edges E denotes the connectivity between nodes. We model sensing coverage using the probability p
k
i
that a target at grid point g
i
is detected by a node s
k
:

where α is a parameter representing the physical characteristics of the sensor. The model conveys the intuition that the closer a location is to the node, a higher signal-to-noise ratio is expected, resulting in a higher confidence level that a target at that location is detected. Areas beyond the maximum sensing range r
s
are then considered to be too noisy for the sensor node to determine if there is a target. The sensing model is only used for coverage evaluation during active node selection; alternative sensing models can also be easily considered. Assume that S
i
is the set of nodes that can detect grid point g
i
; thus the detection probability for grid point g
i
is evaluated by Equation (1) as
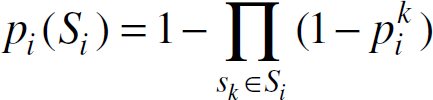
In this paper, we focus on the fault tolerance problem in the topology control of ad hoc sensor networks. We assume that a network organization scheme is provided to the sensor network. Network organization can be achieved by using techniques described in [14,27,31], which select a subset of active nodes as a backbone for communication connectivity and/or sensing coverage. The failure of these active nodes can result in loss of connectivity and/or loss of sensing coverage. We use S
a
(S
s
) to denote the set of active (sleeping) nodes determined by such active nodes selection algorithms, and the following discussion assumes that S
a
and S
s
have already been determined. We consider the threshold p
th
to be a parameter underlying a successful sensing coverage over the sensor field. The following conditions are implicitly satisfied: 1)
In [31], we have shown that the problem of selecting a subset of nodes as a backbone for both sensing coverage and communication connectivity is NP-complete. We have also presented the token-based coverage- and connectivity-centric active node selection (CCANS) protocol that achieves self-organization with a subset of active nodes, which are responsible for both the coverage and the connectivity. In this section, we first review the token-based CCANS protocol for energy-efficient self-organization. We then describe the problem of providing fault tolerance to active backbone nodes in the following sections. The proposed fault-tolerant self-organization technique is general, and it can also be used with other self-organization protocols. CCANS is used in this paper as a vehicle to evaluate the proposed method.
Token-based CCANS Protocol
There are three types of messages used in this protocol, namely HELLO, STATE, and UPDATE. These messages contain such fields as tokenid and srcid which enables the token to control the execution of the sensing coverage evaluation and connectivity checking. There are three possible states for all nodes, namely UNSET, SLEEP and ACTIVE. Initially, all nodes are in UNSET state with their tokenid = −1, i.e., no token has been given to them for the execution of the CCANS algorithm. There are two stages in the CCANS protocol, namely Stage 1 for node sensing coverage evaluation, followed by Stage 2 for node state and connectivity checking. The node with the assigned token is referred to as the token node and all other nodes either collect messages sent from the token node or perform no action. In Stage 1, the current token node evaluates the coverage within its sensing area versus the coverage within its sensing area contributed by its neighbors. It chooses the state ACTIVE if its sensing area is not fully covered by its neighbors, otherwise it chooses the state SLEEP. However, this state decision is not final until the connectivity checking and coverage re-evaluation are completed in Stage 2. One node is pre-selected as the start node by the base-station to initiate the execution of the CCANS algorithm for finding a subset of active nodes.
The token passing procedure is designed to reduce the execution time of the algorithm by expanding the global sensing coverage as much as possible [31]. Consider an arbitrarily chosen node s
k
. s
k
gets the token for execution of the CCANS algorithm when id(s
k
) = tokenid. If tokensrc(s
k
) = −1, then s
k
sets tokensrc(s
k
) = srcid; this is set only once. Therefore, every node knows its token source and is able to pass the token back to its token source when it completes CCANS Stage 2. If s
k
is the start node, then initially tokensrc(s
k
) = id(s
k
) ≠ −1. At the time when the token is passed back to s
k
, if s
k
has no UNSET neighbors, it executes Stage 2 of the distributed CCANS procedure to find its own final state decision; then the distributed CCANS procedure terminates. As an example, Fig. 1 (a) illustrates token passing for an example sensor network with four sensor nodes, s1, s2, s3, and s4, where s1 is the start node. The steps in this example are as follows:
Initially all nodes are in UNSET state and s1 is the start node. s1 has completed CCANS State 1 and passes the token to s2. s2 has completed CCANS Stage 1 and passes the token to s3. s3 has no more UNSET neighbors and it has completed CCANS Stage 2, therefore s3 passes the token back to s2. s2 still has UNSET neighbors so s2 passes the token to s4. s4 has no more UNSET neighbors and it has completed CCANS Stage 2, therefore s4 passes the token back to s2. s2 has no more UNSET neighbors and it has completed CCANS Stage 2, therefore s2 passes the token back to s1. s1 has no more UNSET neighbors and it has completed CCANS Stage 2. Since s1 is the start node, all nodes have made the state decision, and CCANS terminates.
Fig. 1(b) shows the sequence of the token source in terms of node id during the execution of the distributed CCANS procedure for the example shown in Fig. 1 (a). The CCANS procedure requires only constant rounds for message exchange in both stages [31]. Let Δ be the maximum node degree in the graph corresponding to the sensor network. The connectivity checking procedure in CCANS has a time complexity of O(Δ2) per node, and this is carried out independently by each node. Since the sensing coverage evaluation is carried out per grid point for all nodes in the neighborhood, the time complexity of the sensing coverage evaluation in CCANS is O(mΔ), where m is the number of grid points representing the sensor field. Therefore, the overall time complexity for the CCANS procedure per node is O(mΔ + Δ2). The complexity depends only on the maximum degree of a node and the grid granularity of the sensor field. As shown in [31], the CCANS protocol always terminates and achieves self-organization. The completion of the distributed CCANS procedure can be easily notified to the base station.
In this paper, we focus on fault-tolerant self-organization, where both the sensing coverage and the connectivity are preserved with support from the designated fault tolerance (FT) nodes when active nodes fail. We refer to this as the fault-tolerance-nodes-selection (FTNS) problem. The proposed distributed FTNS algorithm is executed after S a and S s are determined, where a set S t of nodes is designated to be FT nodes (backup nodes for active nodes). These FT nodes provide fault tolerance for the existing active nodes. They need not be active unless the active nodes that they are supporting fail. They can run in a power-saving mode and periodically query whether the active nodes are still alive using very limited bandwidth.

(a) Example of token passing in the distributed CCANS procedure. (b) Token passing sequence for the example in Fig. 1 (a).
Note that simultaneous failures of nodes in S a and S t may result in loss in sensing coverage or breakage in communication connectivity since FT nodes are not backed up by nodes in S t . However, if only FT nodes fail or FT nodes and their non-neighboring active nodes fail, the sensing coverage and communication connectivity are still guaranteed. Furthermore, the proposed distributed algorithm can be applied in a repeated manner to select more FT nodes for the previously selected FT nodes.
We assume that the number of nodes initially deployed in the sensor field is sufficient to achieve fault-tolerant operations, i.e., we have enough sleeping nodes available to select as FT nodes. Some observations and additional definitions are listed below:
It is trivial to see that if all failing nodes are sleeping nodes, the existing active nodes can tolerate the failure of up to |S
s
| nodes. We define the maximum number of active nodes that can fail simultaneously without losing sensing coverage or communication connectivity as the degree of fault tolerance (DOFT), denoted by Ω (Ω 1). The nodes that are selected from the set of sleeping nodes to obtain a Ω-DOFT wireless sensor network are referred to as Ω-fault-tolerant (Ω-FT) nodes. We denote the set of Ω-FT nodes as Let
In this section, we focus on the analysis of fault tolerance for communication connectivity. The discussion of fault tolerance for sensing coverage is presented in next section.
An Upper Bound on the Number of Fault Tolerance Nodes
We first consider the case of 1-DOFT, i.e., Ω = 1. Let N
k
be the set of neighbors for s
k
,
It can be seen that, if ∃s k ∊ S such that Δ k = 1, then Ω-DOFT (Ω 1) cannot be achieved for the network since when this neighbor node of s k fails, s k is disconnected from the rest of the network [32]. For any wireless sensor network with S a (S a ≠ φ), ∀s k ∊ S, s k is connected to at least one node in S a , i.e., Δ k a 1. Therefore, Δ k Δ k a 1. In a sensor network with S a as a backbone for both sensing and communication, if s k ∉ S a , i.e., s k is a sleeping node, we can expect Δ k > 1 due to the need for sensing coverage; otherwise an active node must be located expect at the same location as s k . This observation leads to a lower bound on the node density required in the sensor field for fault tolerance. This lower bound can be used as a necessary condition for the fault-tolerant sensor node deployment.
Consider a total of n nodes with communication radius as r
c
each in a sensor field with area A. In order to achieve Ω-DOFT (Ω 1), a lower bound on the total number of nodes n in the sensor field is given by:
Theorem 1. Let sk ∊ S be a node in the sensor network. Let the region that lies within the communication range rc of sk be Ak∗ and let S∗ be the set of nodes within Ak∗. Assume that all nodes in S∗ are connected to each other, i.e., ∀sp, sj ∊ S, there exists a routing path from si to sj. In order to ensure communication connectivity between the nodes in S∗ if sk fails, it is sufficient to have 10 nodes (not counting sk) in Ak∗.
Proof. Let G(V, E) be the connected graph representing S∗, i.e., | V | = | S∗ |, ν
k
is the vertex representing s
k
∊ S, and ∀u, ν ∊ V, (u, ν) ∊ E if d(u, ν) r
c
. Let G
c
(V
c
, E
c
) be a subgraph corresponding to a connected-dominating-set (CDS) of G [3, 4, 8, 25, 28]. We first derive an upper bound on the number of vertices needed for a CDS. The circular area A
k
∗ with radius r
c
can be divided into six sectors, denoted by A1, …, A6 in Fig. 2 (a). Each sector A
i
(1 i 6) has an opening angle of
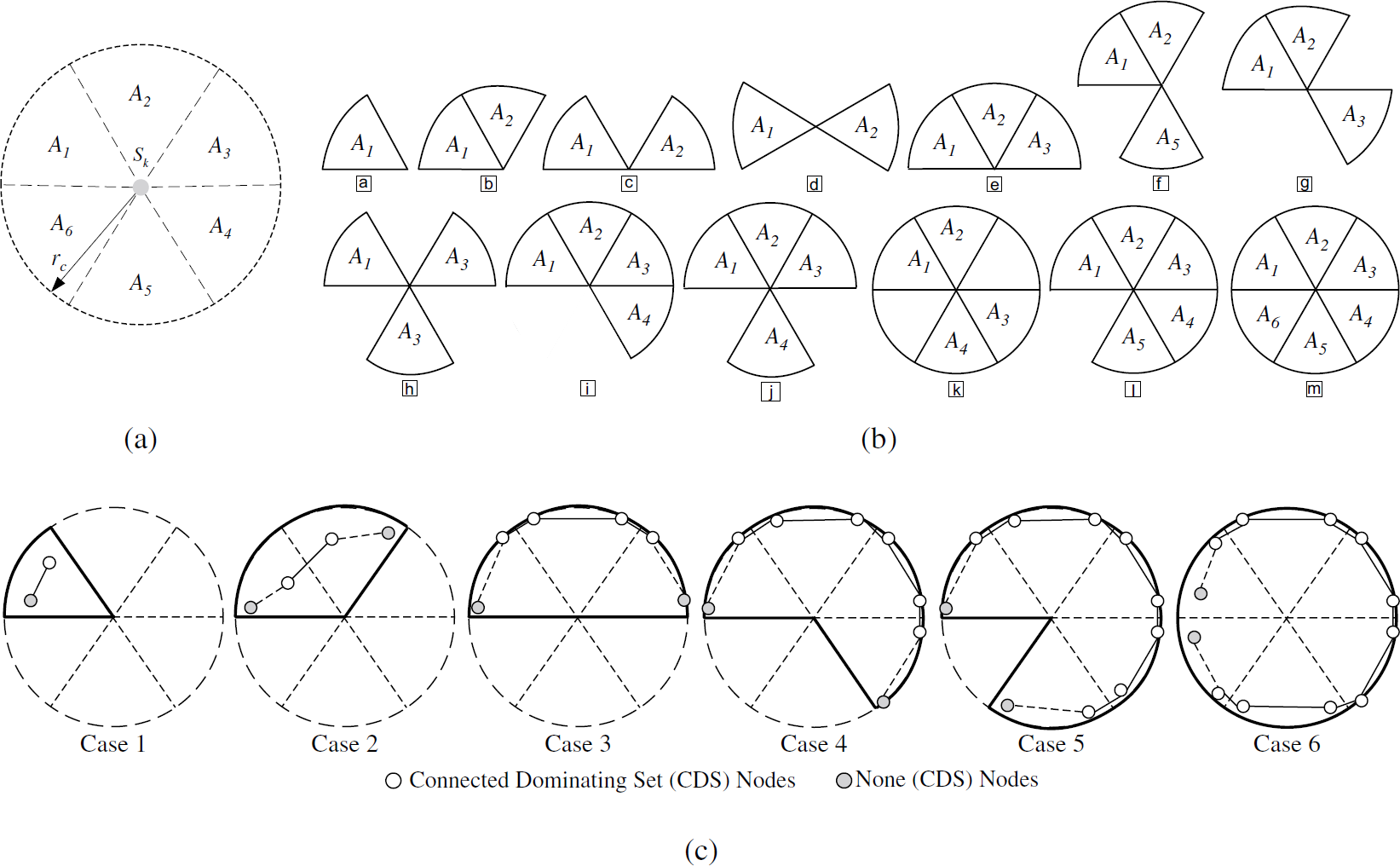
Illustration of the proof of Theorem 1: (a) A node&s communication region can be divided into six sectors with an opening angle of π/3. (b) Proof of Theorem 1: All possibilities of vertices locations. (c) Illustration of the six cases corresponding to Theorem 1.
The nodes corresponding to V c thus keep all nodes in S∗ connected even when s k fails. Therefore, the maximum number of required FT nodes for s k is 10.
Figure 2(c) illustrates each of the six cases discussed in Theorem 1. Based on Theorem 1, we can derive an upper bound on the number of FT nodes needed within the communication region of an arbitrarily-chosen node. Assume that N k is the set of neighbor for s k ∊ S. Consider the special case where S = N k ∪ {s k }, i.e., all nodes in S\{s k } are neighbors of s k . Suppose the nodes in N k are not connected. When s k fails, ∃s i , s j ∊ N k such that no routing can be formed between s i and s j . Thus fault tolerance can only be achieved if there is sufficient node density in the network. Let Γ k be the number of FT nodes required for an arbitrarily-chosen node s k in a 1-DOFT sensor network. Next we present a sufficient condition relating fault tolerance with Γ k in the following theorem.
Theorem 2. The network is 1-DOFT with respect to the failure of any node
The proof of Theorem 2 is given in the appendix. Note that we need to have Γ
k
= 10 only when s
k
has no active neighbors, i.e.,
Corollary 1. When the number of active nodes is greater than one, i.e., |S
a
| > 1, the sensor network is 1-DOFT with respect to the failure of any node sk ∊ Sa if
Corollary 1 shown that
Our goal in this paper is to develop is to develop a distributed self-organization algorithm, where nodes rely only on single-hop or restricted-hop knowledge. Therefore, we allow each active node s
k
∊ S
a
to select FT nodes only from its sleeping neighbors. Recall that we denote the set of FT nodes in a Ω-DOFT sensor network FT nodes as
Theorem 3. An upper bound on the total number of FT nodes needed to achieve 1-DOFT is given by:

Next, we consider a more general fault tolerance scenario where Ω > 1. Note that we assume |S
a
| > Ω for the analysis of Ω-DOFT; otherwise Ω-DOFT is not meaningful. In the following, we determine the number of nodes Γ
k
needed for an arbitrarily-chosen active node to achieve Ω-DOFT in its communication region. In the following, we assume that
Theorem 4. The network is Ω-DOFT (Ω > 1) with respect to failures of any Ω nodes inside the communication region of an arbitrarily-chosen

The proof of Theorem 4 is given in the appendix. We now present bounds on the total number of FT nodes needed to achieve Ω-DOFT (Ω > 1 and |S
a
| Ω > 1). Note that for a Ω-DOFT sensor network, if ∃s
k
∊ S
a
such that
Theorem 5. An upper bound on the total number of FT nodes needed to achieve Ω-DOFT is given as
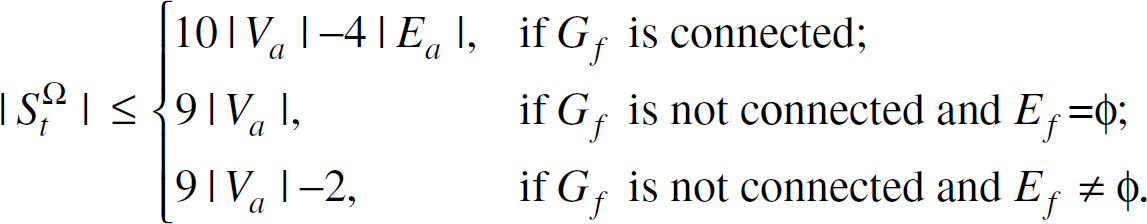
To reduce energy consumption, it is desirable to minimize the number of FT nodes needed, i.e., to minimize the size of
We know from previous subsections that

Note that the best case of
To simplify the discussion, we define function
The subgraph representing For all possible sets that satisfies 1) and 2), ͞S
a
has the smallest size. We refer to determining

Note that if
Since the CDS and MCDS problems are NP-complete [3,4,8,25,28], finding the constrained MCDS to achieve Ω-DOFT as shown in Equation (7) is also NP-complete. When only single-hop knowledge is available, for any s
k
∊ S
a
, there are a total of
For a wireless sensor network with a set S a of active nodes serving as a backbone, the maximum number of nodes that can fail is |S a |. We propose the following distributed procedure to achieve fault tolerance for the simultaneous failure of up to |S a |. The proposed distributed procedure is based on the algorithm from [28]. Note that other heuristics, such as the algorithms described in [3,25], can also be used as the base for building our distributed procedure, since the proposed fault tolerance procedure is a stand-alone module operating on the existing subset of backbone nodes. The procedure contains three steps as shown in Fig. 3 .
In Step 1 of Fig. 3, each active node selects a FT node for any of its disconnected active neighbors. We refer to this type of FT nodes as gateway FT nodes since they provide alternative routing paths for active neighbors of the failing node. When that potential failing node actually fails, the network traffic from the failing node to its active neighbors can still be delivered. Though the first type of FT nodes are able to take care of the routing data originating from failing active nodes, they are not necessarily connected among each other and are not necessarily connected to sleeping neighbors of the failing active node. Step 2 in Fig. 3 deals with this problem by using a modified version of the algorithm proposed in [28], which proposed a distributed approach for constructing the CDS for a connected but not a completely connected graph. In the worst case, when all nodes in S a fail at the same time, the subgraph representing the FT nodes should be a CDS of the subgraph representing S s . We can therefore utilize the algorithm proposed in [28] with the target graph representing S s . Note that in Step 2, we have already found gateway FT nodes, therefore Step 2 needs only check for connectivity of disconnected FT nodes. To ensure that the proposed distributed procedure is also applicable to more general scenarios, Step 3 is added to handle the case that the subgraph representing S s is a completely connected graph. Let Δ be the maximum node degree. In Fig. 3, Step 1 takes O(Δ3) time, Step 2 takes O(Δ2) time, and Step 3 takes O(Δ) time. Therefore, the proposed procedure takes O(Δ3) time. We next prove that the proposed distributed procedure achieves | S a | -DOFT for a wireless sensor network with the set of active nodes given by S a .

Distributed fault tolerance nodes selection procedure.
Theorem 6. Assume that all nodes in S are connected, i.e., ∀si, Sj ∊ S, there exists a routing path from si to sj. Assume that Sa is the set of active nodes as a backbone that keeps all nodes connected. Assume that St is the set of FT nodes obtained from the distributed FT selection procedure given by Fig. 3 . The set St achieves Ω-DOFT in this wireless sensor network, where Ω = | S a |.
Proof. Since the maximum number of nodes that can fail is | S a |, we only need to consider the case that the selected FT nodes in S t are able to keep the network fully connected when all nodes in S a fail. Let G s (V s , E s ) be the subgraph representing S s = S\S a and G t (V t , E t ) be the subgraph representing S t . To prove that G t is a CDS of G s , we first show that G t is connected, then we show that for any ν ∊ V s , ν is either in V t or adjacent to a vertex in V t .
Consider any u, ν ∊ V t . Since G s is connected, ∃P(u, ν) as the shortest path from u to ν in G s , where P(u, ν) ⊆ V s is the set of the vertices in the path. If | P(u, ν)| = 2, the theorem is trivially proved. Assume |P(u, ν)| 3, and let P(u, ν) = {u, u1, u2, …, ν}. Consider predecessor vertices of u in P(u, ν), i.e., u1. Since u ∊ V t , from Step 2 in Fig. 3, u1 has to be in V t , irrespective of whether u2 is in V t . The same argument holds for u2. Doing this repeatedly, we have ∀w ∊ P(u, ν), w ∊ V t , i.e., P(u, ν) ∊ V t . Next, ∀ν ∊ V s , from Step 3 in Fig. 3, ν has at least one FT neighbor. Therefore, G t is a CDS of G s .
In Section 4, we have discussed the Ω-DOFT problem for fault-tolerant communication connectivity of up to Ω active nodes failing simultaneously (Ω > 1). However, we should also take fault tolerance for sensing coverage into account to achieve the surveillance goal over the field of interest. This implies that the nodes selected as FT nodes must be able to provide enough sensing coverage over the areas that were originally under the surveillance of the Ω failing active nodes.
Loss of Sensing Coverage from Failing Nodes
Recall the collective coverage probability for a grid point g
i
defined in Section 3. Since only the active nodes in S
a
perform communication and sensing tasks, the collective coverage probability for g
i
is actually from nodes in
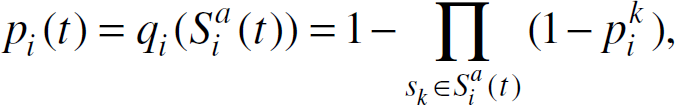
where
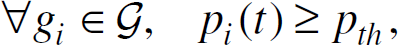
where p th is the coverage probability threshold defined in Section 3. Theorem 7 shows the relationship between the loss of sensing coverage and the fault-tolerant operation in wireless sensor networks.
Theorem 7. Assume that all nodes in S are connected, i.e.,
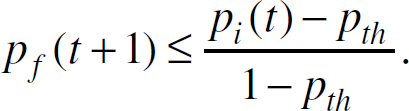
where
Proof. Consider time instants t and t + 1. Obviously we have

Similarly,

Therefore,
From the proof of Theorem 7, we see that
Note that the fault tolerance problem for sensing coverage differs from the fault tolerance problem for communication connectivity discussed in Section 4 since there is no direct relationship between the number of failing nodes and the coverage loss p f (t). For example, for g i with |S i (t)|= 1, p i (t) might be the same as p j (t) for g i where |S j (t)| = 1, 2, 3 or even higher. This is due to the fact that for any grid point g i , p i (t) is not directly related to the number of nodes that can detect g i but rather to the distances from these nodes to g i , as defined by Equation (1).
We next propose a coverage-centric fault tolerance algorithm that can be executed in a distributed manner, and requires much less computation than the centralized case. Without loss of generality, assume r
c
2r
s
, i.e., S
i
⊆ N
k
. For grid point g
i
∊ A
k
corresponding to node

Equation (11) requires

which corresponds to the analysis in Theorem 7. Equation (12) implies that we can design the fault-tolerance nodes selection for sensing coverage in a much less computationally expensive way. Figure 4 shows the pseudocode for the coverage-centric fault tolerance node selection algorithm.
As shown in Fig. 4, to select the minimum number of FT nodes without a thorough evaluation over all subsets of nodes in

Pseudocode for the distributed coverage-centric fault tolerance nodes selection.
Note that the evaluation procedure is per grid point, which can be executed on either a sleeping node or an active node. For any
The sorting procedure needed to construct Li from
Theorem 8. For a grid point gi, the distributed coverage-centric fault-tolerance node selection procedure given by the pseudocode in Fig. 4 gives the minimum number of fault-tolerance node.
As shown in Figs. 3 and 4, the proposed scheme does not require a centralized server to determine backup nodes for the existing backbone. FT nodes are designated in a distributed fashion; this procedure requires only localized communication (single-hop or restricted hop communication between nodes). The proposed self-organization approach for fault tolerance is therefore scalable, which makes it suitable for ad hoc sensor networks with a large number of deployed nodes.
We have implemented CCANS in ns2 and integrated as a module in the ESP AESOP protocol. The Emergent Surveillance Plexus (ESP) [34] is a Multi-disciplinary University Research Initiative (MURI), whose goal is to advance the surveillance capabilities of wireless sensor networks. It involves participants from Pennsylvania State University, University of California at Los Angles, Duke University, University of Wisconsin, Cornell University, and Louisiana State University. AESOP stands for An Emergent-Surveillance-Plexus Self-Organizing Protocol, which is designed for target tracking in wireless sensor networks with high tracking quality and energy efficiency [5]. A more detailed description of the AESOP protocol can be found in [5].
Simulation Results
In a simulation for the proposed fault-tolerant self-organization algorithms, we first collect the data from the distributed CCANS procedure described in Section 3. We next evaluate the proposed distributed FTNS procedure using MatLab by feeding the data collected from CCANS as inputs. The data from CCANS contains locations of sensor nodes after deployment and their final state decisions. There are 150, 200, 250, 300, 350, and 400 nodes in each random deployment, respectively, on a 50 × 50 grid representing a 50m × 50m sensor field. All nodes have the same maximum communication radius rc = 20m and maximum sensing range rs = 10m. The value of Ω is set to the number of active nodes. Figures 5–8 show the simulation results for distributed fault-tolerance self-organization procedure.
Figure 5(b)(i) shows the results obtained for connectivity-oriented selection of FT nodes. Note that the percentage of FT nodes decreases nearly at the same rate as the percentage of active nodes. This is because the connectivity-oriented FT nodes selection algorithm is executed in a distributed manner and each node uses only one-hop knowledge. Note also that the percentage of FT nodes is lower than the percentage of active nodes determined by CCANS. This is because CCANS considers both communication connectivity and sensing coverage in selecting active nodes. Figure 5(b)(ii) shows the results for coverage-centric selection of FT nodes. Since the coverage-centric fault-tolerance nodes selection procedure given by Fig. 4 has been proven to generate the minimum number of fault-tolerance nodes, the percentage shown in Fig. 5 (b)(ii) is much lower than the percentage of active nodes from CCANS.
The distributed fault-tolerance nodes selection procedure contains two stages. We consider two cases for the implementation, namely “FTNS-1” and “FTNS-2”. FTNS-1 refers to the case that the first stage is the coverage-centric selection of fault-tolerance nodes (FTNS-1 Stage 1) and the second stage is the connectivity-centric selection of FT nodes (FTNS-1 Stage 2). FTNS-2 refers to the case that the first stage is the connectivity-centric selection of FT nodes (FTNS-2 Stage 1) and the second stage is the coverage-centric selection of FT nodes (FTNS-2 Stage 2). Figure 5(a) presents the result for the distributed FTNS algorithm. In both FTNS-1 and FTNS-2, the FT nodes that have already been selected in Stage 1 are checked first in Stage 2 to see if they already provide enough sensing coverage for fault tolerance. This decreases the number of FT nodes needed for Stage 2 of coverage-centric FT nodes selection, which is shown in Fig. 5 (a). Note that in Fig. 5 (a)(ii), the percentage of FT nodes in Stage 1 is the same as the percentage of FT nodes at the end of the FTNS procedure. This is due to the fact that we have rc = 2rs in this scenario. As shown in [31], when rc = 2rs, the connectivity is automatically guaranteed by the subset of nodes needed to maintain the sensing coverage.

Simulation results: (a) Percentage of FT nodes: (i) FT nodes for connectivity only; (ii) FT nodes for coverage only. (b) Percentage of FT nodes for the distributed FTNS procedure (with both coverage and connectivity concerns): (i) FTNS-1: Stage 1 selects FT nodes for coverage and FTNS Stage 2 selects FT nodes for connectivity; (ii) FTNS-2 Stage 1 selects FT nodes for connectivity and FTNS Stage 2 selects FT nodes for coverage.

Simulation results: (a) Effect of failing active nodes vs. activated FT nodes for FTNS-1: (i) Average coverage loss from failing active nodes; (ii) Average number of activated FT nodes; (iii) Average coverage loss from failing active nodes; (iv) Average number of activated FT nodes; (b) Effect of failing active nodes vs. activated FT nodes for FTNS-2: (i) Average coverage loss from failing active nodes; (ii) Average number of activated FT nodes; (iii) Average coverage loss from failing active nodes; (iv) Average number of activated FT nodes.
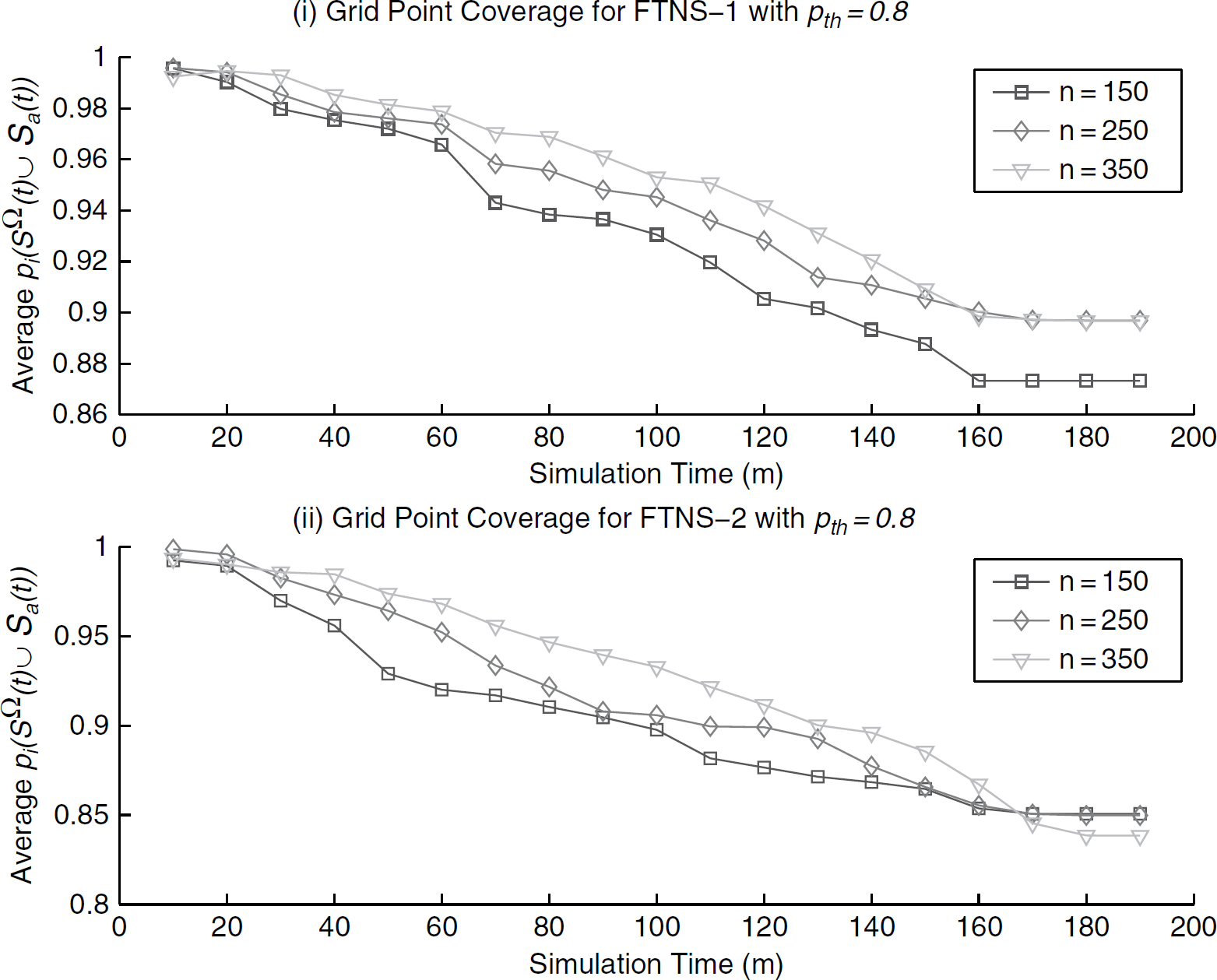
Average grid point coverage when active nodes fail during the simulation.
Next, we simulate the failing of active nodes to show that FT nodes are able to provide the coverage and connectivity when active nodes fail. This is shown in Fig. 6 . The sensor network layout and configuration are the same as those in Fig. 5 . We use a simplified model for generating the failing active nodes. For a total simulation time of 200 minutes, we select a random number of active nodes from the currently alive active nodes every 10 minutes, and assign them as failing nodes. The neighboring FT nodes determine that these nodes have failed. As shown in Fig. 6, the failing of active nodes leads to an activation of the designated FT neighbors. The loss of coverage from the failing active nodes are compensated by the coverage support from the activated FT nodes. The simulation stops when all active nodes have failed. Fig. 7 shows the change in coverage probability for grid points in the sensor field. Note that the average grid point coverage probability decreases with time. This is due to the fact that the coverage-centric FT nodes selection only selects the minimum number of FT nodes to save energy; the goal is not to maximize the coverage. However, at any time instant, the coverage probability is always higher than the required coverage probability threshold pth = 0.8. Also note that at any time instant, the connectivity is guaranteed by the activated FT nodes and alive active nodes for both FTNS-1 and FTNS-2.

Communication data message size in FTNS for FT nodes selection.
Note that upper bounds on the number of the fault-tolerance node given in previous sections are important because they can be used as a guideline for the initial sensor nodes deployment to achieve fault-tolerant self-organization. For example, as shown by Fig. 5, we can deploy the number of sensor nodes that are sufficient enough to provide the required level of fault tolerance in the sensor network. The lower bound on the number of fault-tolerance node is useful since it can be used as a baseline for comparing different heuristics. Note that the problem of finding a minimum connected dominating set (MCDS) for a general graph is a NP -complete and it is hard to approximate. The original work of using MCDS as a backbone for routing by Bharghavan and Das in [4] has a approximation ratio of 3H(Δ), where Δ is the maximum node degree and H(Δ) is the Δth Harmonic number given
The proposed distributed fault-tolerance nodes selection procedure is a localized algorithm. Localized algorithms are considered as a special type of distributed algorithms where only a subset of nodes in the wireless sensor networks participate in sensing, communication, and computation [18]. For either stage in the proposed distributed fault-tolerance nodes selection procedure, it requires only local knowledge and constant rounds of communication for message exchange among the neighborhood. From the discussion in Subsection 4.3 and 5.2, the total time complexity for the distributed FTNS is O(mΔ LoGΔ + Δ3). For message complexity, both stages in FTNS require the exchange of a constant number of messages within the neighborhood. The active nodes in the backbone first carries out the computation for connectivity checking and coverage evaluation to select a subset of nodes from its sleeping neighbors, then it broadcasts the list of selected FT neighbors within its neighborhood. The designated FT nodes need not be activated until the active nodes fail. In Fig. 8, we show the evaluation of communication data size for FT nodes selection.
In FT nodes selection, active nodes send the message containing the list of node ids of the designated FT neighbors. Neighbors of active nodes search the received id list and set themselves as FT nodes for that active node, i.e., FT nodes that can be activated into an active state by their failing active neighbors. The designated FT nodes then send an acknowledge message back to the active nodes to confirm the FT node assignment. Assuming that there is no packet loss, this takes 2 rounds of communication within the neighborhood of active odes. The message size complexity is then O(Δ). For the activation of FT nodes, we assume that designated FT nodes periodically poll their active neighbors about whether they are still alive or not. The polling frequency depends on the sensor network application requirement and sensor nodes failure distribution, since it should not require excessive energy and bandwidth. The problem of determining the polling frequency is not considered in this paper. Note that it is possible to simply let all sleeping nodes do the polling without designating any fault-tolerance nodes. However, this also means that when an active node fails, all its sleeping neighbors have to become active. This adversely affects the potential of extending the lifetime for the densely deployed sensor network. Figure 8 shows the average communication data size for both FTNS-1 and FTNS-2.
Conclusions
In this paper, we have investigated fault tolerance for coverage and connectivity in wireless sensor networks. Fault tolerance is necessary to ensure robust operation for surveillance and monitoring applications. Since wireless sensor networks are made up of inexpensive nodes and they operate in harsh environments, the likely possibility of node failures must be considered. We have characterized the amount of redundancy required in the network for fault tolerance. Based on an analysis of the redundancy necessary to maintain communication connectivity and sensing coverage, we have proposed the distributed FTNS algorithm for fault-tolerant self-organization. FTNS is able to provide a high degree of fault tolerance such that even when all of these active nodes fail simultaneously, the coverage and the connectivity in the network are not affected. The proposed distributed FTNS approach is scalable and requires only localized communication. We have implemented FTNS in MatLab and presented representative simulation results.