
Abstract
We focus on data gathering problems in energy-constrained networked sensor systems. We study store-and-gather problems where data are locally stored at the sensors before the data gathering starts, and continuous sensing and gathering problems that model time critical applications. We show that these problems reduce to maximization of network flow under vertex capacity constraint. This flow problem in turn reduces to a standard network flow problem. We develop a distributed and adaptive algorithm to optimize data gathering. This algorithm leads to a simple protocol that coordinates the sensor nodes in the system. Our approach provides a unified framework to study a variety of data gathering problems in networked sensor systems. The performance of the proposed method is illustrated through simulations.
Introduction
State-of-the-art sensors (e.g., Smart Dust [1]) are powered by batteries. Replenishing energy by replacing the batteries is infeasible because the sensors are typically deployed in harsh terrains. Also, the cost of replacing batteries can be prohibitively high. These sensors, which are usually unattended, need to operate over a long period of time after deployment. Energy efficiency is thus critical. Techniques ranging from low power hardware design [2], [3] and energy-aware routing [4], [5] to application level optimizations [6], [7] have been proposed to improve energy efficiency of networked sensor systems.
An important application of networked sensor systems is to monitor the environment. Examples of such applications include vehicle tracking and classification in the battlefield, patient health monitoring, pollution detection, and so on. In these applications, a fundamental operation is to sense the environment and transmit the sensed data to the base station for further processing. In this article, we study energy-efficient data gathering in networked sensor systems from an algorithmic perspective.
Compared with sensing and computation, communication is the most expensive operation (in terms of energy consumption) in the context of data gathering [8]. Generally, data transfers are performed via multihop communications where each hop is a short-range communication. This is due to the well-known fact that long-distance wireless communication is expensive in terms of both implementation complexity and energy dissipation, especially when using the low-lying antennae and near-ground channels typically found in networked sensor systems. Short-range communication also enables efficient spatial frequency re-use. A challenging problem with multihop communications is the efficient transfer of data through the system when the sensors have energy constraints.
Some variations of the problem have been studied recently. In reference [9], data gathering is assumed to be performed in rounds and each sensor can communicate (in a single hop) with the base station and all other sensors. The total number of rounds is then maximized under a given energy constraint on the sensors. In reference [10], a nonlinear programing formulation is proposed to explore the trade-offs between energy consumed and the transmission rate. It models the radio transmission energy according to Shannon's theorem. In reference [11], the data gathering problem is formulated as a linear programing problem and a 1+ω approximation algorithm is proposed. This algorithm further leads to a distributed heuristic.
Our study departs from the aforementioned with respect to the problem definition as well as the solution technique. For short-range communications, the difference in the energy consumption between sending and receiving a data packet is almost negligible. We adopt the reasonable approximation that sending a data packet consumes the same amount of energy as receiving a data packet [8]. The studies in reference [10] and [11] differentiate the energy dissipated for sending and receiving data. Although the resulting problem formulations are indeed more accurate than ours, the improvement in accuracy is marginal for short-range communications.
In reference [9], each sensor generates exactly one data packet per round (a round corresponds to the occurrence of an event in the environment) to be transmitted to the base station. The system is assumed to be fully connected. The study in reference [9] also considers a very simple model of data aggregation where any sensor can aggregate all the received data packets into a single output data packet. In our system model, each sensor communicates with a limited number of neighbors due to the short range of the communications, resulting in a general graph topology for the system. We study store-and-gather problems where data are locally stored on the sensors before the data gathering starts, and continuous sensing and gathering problems that model time-critical applications. A unified flow optimization formulation is developed for the two classes of problems.
Our focus in this article is to maximize the throughput or volume of data received by the base station. Such an optimization objective is abstracted from a wide range of applications in which the base station needs to gather as much information as possible. Some applications proposed for the networked sensor systems may have different optimization objectives. For example, the balanced data transfer problem [12] is formulated as a linear programming problem where a “minimum achieved sense rate” is set for every individual node. In reference [13], data gathering is considered in the context of energy balance. A distributed protocol is designed to ensure that the average energy dissipation per node is the same throughout the execution of the protocol. However, these issues are not the focus of this article.
By modeling the energy consumption associated with each send and receive operation, we formulate the data gathering problem as a constrained network flow optimization problem where each each node u is associated with a capacity constraint wu, so that the total amount of flow going through u (incoming plus outgoing flow) does not exceed wu. We show that such a formulation models a variety of data gathering problems (with energy constraint on the sensor nodes).
The constrained flow problem reduces to the standard network flow problem, which is a classical flow optimization problem. Many efficient algorithms have been developed [14] for the standard network flow problem. However, in terms of decentralization and adaptation, these well-known algorithms are not suitable for data gathering in networked sensor systems. In this article, we develop a decentralized and adaptive algorithm for the maximum network flow problem. This algorithm is a modified version of the Push-Relabel algorithm [15]. In contrast to the Push-Relabel algorithm, it is adaptive to changes in the system. It finds the maximum flow in O(n2·|V|2·|E|) time, where n is the number of adaptation operations. |V| is the number of nodes, and |E| is the number of links.
The aforementioned algorithm can be used to solve both store-and-gather problems and continuous sensing and gathering problems. For the continuous sensing and gathering problems, we developed a simple distributed protocol based on the algorithm. The performance of this protocol is studied through simulations. Because the store-and-gather problems are by nature off-line problems, we do not develop a distributed protocol for this class of problems.
The rest of the article is organized as follows. The data gathering problems are discussed in Section 2. We show that these problems reduce to network flow problem with constraint on the vertices. In Section 3, we develop a mathematical formulation of the constrained network flow problem and show that is reduces to a standard network flow problem. In Section 4, we derive a relaxed form for the network flow problem. A distributed and adaptive algorithm is then developed for this relaxed problem. A simple protocol based on this algorithm is presented in Section 4.3. Experimental results are presented in Section 5. Section 6 concludes the article.
Data Gathering with Energy Constraint
System Model
Suppose a network of sensors is deployed over a region. The location of the sensors are fixed and known a priori. The system is represented by a graph G(V, E), where V is the set of sensor nodes. (u, v) ∊ E if u ∊ V, v ∊ V and u is within the communication range of v. The set of successors of u is denoted as σ u = {v ∊ V| (u, v) ∊ E}. Similarly, the set of predecessors of u is denoted as ψ u = {v ∊ V|(v, u) ∊ E}. The event is sensed by a subset of sensors Vc ⊂ V. r is the base station to which the sensed data are transmitted. Sensors V–Vc–{r} in the network does not sense the event but can relay the data sensed by Vc.
Among the three categories (sensing, communication, and data processing) of power consumption, a sensor node typically spends most of its energy in data communication. This includes both data transmission and reception. Our energy model for the sensors is based on the first order radio model described in reference [16]. The energy consumed by sensor u to transmit a k–bit data packet to sensor v is
Communication link (u, v) has transmission bandwidth cuv. We do not require the communication links to be identical. Two communication links may have different transmission latencies and/or bandwidth. Symmetry is not required either. It may be the case that cuv ≠ cuv. If (u, v) ∉ E, then we define cuv = 0.
An energy budget Bu is imposed on each sensor node u. We assume that there is no energy constraint on base station r. To simplify our discussions, we ignore the energy consumption of the sensors when sensing the environment. However, the rate at which sensor u ∊ Vc can collect data from the environment is limited by the maximum sensing capability gu. We consider both store-and-gather problems, and continuous sensing and gathering problems. For the store-and-gather problems, Bu represents the total number of data packets that u can send and receive. For the continuous sensing and gathering problems. Bu represents the total number of data packets that u can send and receive in one unit of time.
Store-and-Gather Problems
In store-and-gather problems, the information from the environment is sensed (possibly over a long time period) and stored locally at the sensors. The data is them transferred to the base station during the data gathering stage. This represents those data-oriented applications (e.g., counting the occurrences of endangered birds in a particular region) where the environment slowly changes. There is typically no deadline (or the deadline is loose enough to be ignored) on the duration of data gathering for such problems, and we are not interested in the speed at which the data is gathered. But due to the energy constraint, not all the stored data can be gathered by the base station, and we want to maximize the amount of data gathered.
For each u ∊ Vc, we assume that u has stored du data packet before the data gathering starts. Let f(u, v) represent the number of data packets sent from u to v.
For the simplified scenario where Vc contains a single node s, we have the following problem formulation:


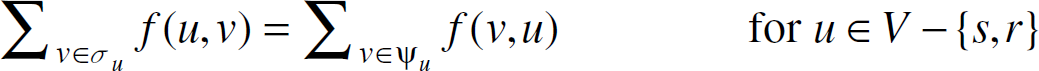
Bu is the energy budget of u. Because we have normalized both Tuv and Ru to 1, the total number of data packets that can be sent and received by u is bounded from above by Bu. Condition 2 represents the energy constraint of the sensors. Sensors V – {s, r} do not generate sensed data, nor should they possess any data packets upon the completion of the data gathering. This is reflected in Condition 3. We do not model ds, the number of data packets stored at s before the data gathering starts. This is because ds is an obvious upper bound for the SMaxDV problem, and can be handled trivially.
|Vc| > 1 represents the general scenario where the event is sensed by multiple sensors. This multisource data gathering problem is formulated as follows:




Similar to the SMaxDV problem, the net flow out of the intermediate nodes (V– Vc – {r}) is 0 in the MMaxDV problem, as is specified in Condition 3. For each source node u ∊ Vc, the net flow out of u cannot exceed the number of data packets previously stored at u. This is specified in Condition 4.
The continuous sensing and gathering problems model those time-critical applications that need to gather as much information as possible from the environment while the nodes are sensing. Examples of such applications include battlefield surveillance, target tracking, and so on. We want to maximize the total number of data packets that can be gathered by the base station r in one unit of time. We assume that the communications are scheduled by time/frequency division multiplexing or channel assignment techniques. We consider the scenario in which Bu is the maximum power consumption rate allowed by u. Let f(u, v) denote the number of data packets sent from u to v in one unit of time.
Similar to the store-and-gather problem, we have the following mathematical formulation when Vc contains a single node s.



The major difference between the SMaxDV and the SMaxDT problem is the consideration of link capacities. In the SMaxDV problem, because there is no deadline for the data gathering, the primary factor that affects the maximum number of gathered data is the energy budgets of the sensors. But for the SMaxDT problem, the number of data packets that can be transferred over a link in one unit of time is not only affected by the energy budget, but also bounded from above by the capacity of that link, as specified in Condition 1. For the SMaxDT problem, we did not model the impact of gu because gu is an obvious upper bound of the throughput and can be handled trivially.
Similarly, we can formulate the multiple source maximum data throughput problem as follows:




Condition 4 in the problem formulation takes into account the sensing capabilities of the sensors.
Problem Reductions
In this section, we present the formulation of the constrained flow maximization problem where the vertices have limited capacities (CFM problem). The CFM problem is an abstraction of the four problems discussed in Section 2.
In the CFM problem, we are given a directed graph G(V, E) with vertex set V and edge set E. Vertex u has capacity constraint wu > 0. Edge (u, v) starts from vertex u, ends at vertex v, and has capacity constraint cuv > 0. If (u, v) ∉ E, we define cuv = 0. We distinguish two vertices in G, source s, and sink r. A flow in G is a real valued function f: E → R that satisfies the following constraints:
0 ≤ f(u,v) ≤ cuv for V(u,v) ∊ E. This is the capacity constraint on edge (u, v).
The value of a flow f, denoted as |f|, is defined as
It is straightforward to show that the SMaxDV and the SMaxDT problems reduce to the CFM problem, By adding a hypothetical super source node, the MMaxDV and the MMaxDT problems can also be reduced to SMaxDV and SMaxDT, respectively.
It can be shown that the CFM problem reduces to a standard network flow problem. Due to the existence of Condition 1, Condition 3 is equivalent to
The standard network flow problem is stated as:


The vertex capacity wu in the CFM problem models the energy budget Bu of the sensor nodes. Bu does not have to be the total remaining energy of u. For example, when the remaining battery power of a sensor is lower than a particular level, the sensor may limit its contribution to the data gathering operation by setting a small value for Bu (so that this sensor still has enough energy for future operations). For another example, if a sensor is deployed in a critical location so that it is utilized as a gateway to relay data packets to a group of sensors, then it may limit its energy budget for a particular data gathering operation, thereby conserving energy for future operations. These considerations can be captured by vertex capacity wu in the CFM problem.
The edge capacity in the CFM problem models the communication rate (meaningful for continuous sensing and gathering problems) between adjacent sensor nodes. The edge capacity captures the available communication bandwidth between two nodes, which may be less than the maximum available rate. For example, a node may reduce its radio transmission power to save energy, resulting in a less than maximum communication rate. This capacity can also vary over time based on environmental conditions. Our decentralized protocol results in an online algorithm for this scenario.
Because energy efficiency is a key consideration, various techniques have been proposed to explore the trade-offs between processing/communication speed and energy consumption. This results in the continuous variation of the performance of the nodes. For example, the processing capabilities may change as a result of dynamic voltage scaling [18]. The data communication rate may change as a result of modulation scaling [19]. As proposed by various studies on energy efficiency, it is necessary for sensors to maintain a power management scheme, which continuously monitors and adjusts the energy consumption and thus changes the computation and communication performance of the sensors. In data gathering problems, these energy related adjustments translate to changes of parameters (node/link capacities) in the problem formulations. Determining the exact reasons and mechanisms behind such changes is beyond the scope of this article. Instead, we focus on the development of data gathering algorithms that can adapt to such changes.
Distributed and Adaptive Algorithm to Maximize Flow
In this section, we first show that the maximum flow remains the same even if we relax the flow conservation constraint. Then we develop a distributed and adaptive algorithm for the relaxed problem.
Relaxed Flow Maximization Problem
Consider the simple example in Figure 1 where s is the source, r is the sink, and u are the intermediate nodes. Obviously, the flow is maximized when f(s, u) = f(u, r) = 10. Suppose s, u, and r form an actual system and s has sent 10 data packets to u. Then u can send no more than 10 data packets to r even if u is allowed to transfer more to r. This means the actual system still works as if f(u, r) = 10 even if we set f(u, r) ≥ 10.

An example of the relaxed network flow problem where csu = 10 and cur = 20.
This leads to the following relaxed network flow problem:


Condition 2 differentiates the relaxed and the standard network flow problem. In the relaxed problem, the total flow out of a node can be equal to or larger than the total flow into the node. A feasible function f (which satisfies the two aforementioned constraints) to the relaxed flow problem is called a relaxed flow in graph G. |f| denotes the net amount of flow out of source s and is called the value of the relaxed flow. The following theorem shows the relation between the relaxed and the standard network flow problem.
Theorem 1
Given graph G (V, E), source s and sink r. If f∗ is an optimal solution to the relaxed network flow problem, then here exists an optimal solution f′ to the standard network flow problem such that f′(u,v) ≤ f∗ (u,v) for ∀ (u,v) ∊ E. Additionally, |f∗| = |f′|.
Proof of the theorem is not difficult and hence omitted here. If we interpret f∗(u,v) as the number of data units that we ask u to transfer and f′(u,v) as the number of data units that u actually transfers, then this theorem essentially indicates that the solution to a relaxed flow problem can have an actual implementation that satisfies flow conservation.
In this section, we develop a decentralized and adaptive algorithm for the relaxed network flow maximization problem. This algorithm is a modified version of the Push-Relabel algorithm [14] and is denoted as the Relaxed Incremental Push-Relabel (RIPR) algorithm.
The Push-Relabel algorithm is a well-known algorithm for network flow maximization. It has a decentralized implementation where every node only needs to exchange messages with its immediate neighbors and makes decisions locally. But in order to be adaptive to the changes in the system, this algorithm has to be re-initialized and re-run from scratch each time when some parameters (weight of the nodes and edges in the graph) of the flow maximization problem change. Each time before starting to search for the new optimal solution. The algorithm needs to make sure that every node has finished its local initialization, which requires a global synchronization and compromises the property of decentralization.
In contrast to the Pust-Relabel algorithm, our algorithm introduces the adaptation operation, which is performed on the current values of f(u, v) for ∀ u, v ∊ V. In other words, our algorithm performs incremental optimization as the parameters of the system change. Our algorithm does not need global synchronizations. Another difference is that our algorithm applies to the relaxed network flow problem, rather than the standard one.
For the discussion that follows, let us first briefly re-state some notations for the network flow maximization problem. For notational convenience, if edge (u, v) ∉ E, we define cuv = 0; if the actual data transfer is from u to v, we define f(v, u) = –f(u, v). With these two definitions, if neither (u, v) nor (v, u) belongs to E, then cuv = cvu = 0, which implies that f(u, v) = f(v, u) = 0. Of course, f(u, u) = - f(u, u) implies that f(u, u) = 0, which essentially says that a node cannot send flow to itself. In this way, we can define f(u, v) over V × V, rather than being restricted to E. f(u, v) = –f(v, u) also allows us to compute the total amount of flow into u as



Given a directed graph G(V, E), function f is called a flow if it satisfies the three conditions in the aforementioned problem; Given G(V, E) and f, the residual capacity cf (u,v) is given by cuv – f(u,v), and the residual network of G induced by f is Gf(V,Ef), where Ef = {(u,v)|u ∊ V,v ∊ V,cf(u,v) >0}. For each node u ∊ V, e(u) is defined as e(u) = Σv∊Vf(v,u), which is the total amount of flow into u.
The algorithm is as follows:
Initialization: h(u), and f(u,v) are initialized as follows:
Search for maximum flow: Each node u ∊ V – {s,r} conducts one of the following three operations as long as e(u) ≠ 0:
Push(u, v): applies when e(u) > 0 and ∃(u,v)∊ Ef s.t. h(u) > h(v),
Relabel(u): applies when e(u) > 0 and h(u) ≤ h(v) for ∀(u,v)∊ Ef,
Adaptation to changes in the system: For the flow maximization problem, the only possible change that can occur in the system is the increase or decrease of the capacity of some edges. Suppose the value of cuv changes to c′
uv
, the following four scenarios are considered when performing the Adaptation (u, v) operation:
if c′
uv
> cuv and f(u,v) < cuv, do nothing. if c′
uv
> cuv and f(u,v) = cuv, then
if c′
uv
< cuv and f(u,v) ≤ cuv, do nothing. if cuv < cuv and f(u, v) > c′
uv
, then

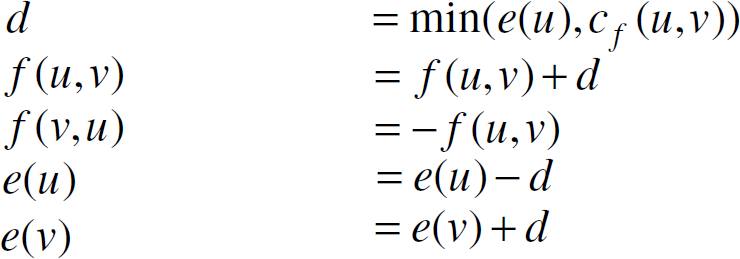



The aforementioned algorithm defines an integer valued auxiliary function h(u) for u ∊ V, which will be discussed later. The “adaptation” is activated when some link capacity changes in the relaxed flow problem. Because link capacities in the relaxed flow problem map to either vertex or link capacities in the corresponding CFM problem, the adaptation operation actually reacts to capacity changes in both vertex and link capacities. The “Push” and “Relabel” operations are called the basic operations. Every node in the graph determines its own behavior based on the knowledge about itself and its neighbors (as can be seen, the Push and Relabel operations are triggered by variables whose value are locally known by the nodes). No central coordinator or global information about the system is needed. More importantly, unlike the Push-Relabel algorithm, no global synchronization is needed when the RIPR algorithm adapts to the changes in the system.
An intuitive explanation of the RIPR is as follows. h(u) represents, intuitively, the shortest distance from u to t when h(u) ≤ h(s). When h(u) > h(s) h(u) – h(s) represents the shortest distance from u to s. Thus the RIPR algorithm attempts to push more flow from s to t along the shortest path; excessive flow of intermediate nodes are pushed back to s along the shortest path. Similar to the Edmonds-Karp algorithm [14], such a choice of paths can lead to an optimal solution.
Lemma 1
During the execution of the RIPR Algorithm, for ∀u ∊ V, h(u) never decreases.
Proof
h(s) is only changed by the Adaptation of operation, during which h(s) is increased by 2 |V|. h(r) never changes. When u ≠ s and u ≠ r, h(u) is only changed by Relabel(u). Relabel(u) is applied when e(u) > 0 and h(u) ≤ h(v) for ∀v ∊ {v| cf (u,v) > 0}. And
Lemma 2
During the execution of the RIPR Algorithm, for ∀u ∊ V s.t. e(u) > 0, there exists a simple path in Ef from u to a node v s.t. e(v) < 0.
Proof
Suppose e(u) > 0. Let
We claim that if x ∊ Ṽ and
It is fairly easy to show that
But this contradicts the assumption that e(v) ≥ 0 for
Lemma 3
During the execution of the RIPR algorithm, for ∀u ∊ V, if e(u) > 0, then either Relabel(u), or Push(u, v) (where v ∊ V) can be applied.
Proof
When e(u) > 0, if ∃v s.t. cf(u, v) > 0 and h(u) > h(v), then Push(u, v) can be applied: otherwise, h(u) ≤ h(v) for ∀v∊{v | cf (u,v) > 0}, which means Relabel(u) can be applied.
Lemma 4
During the execution of the RIPR algorithm,

Proof
We prove by induction on the number of adaptation operations.
Base case:
Before any changes occur in the system, the adaptation operation will not be applied. At this stage, the RIPR algorithm performs the exact operations as the Push-Relabel algorithm, thus we have
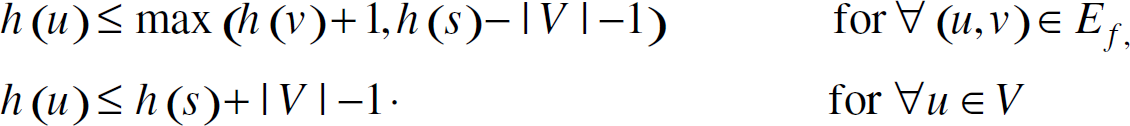
Induction step:
Suppose after the adaptation has been applied n − 1 times and we still have
We first show that h(u) ≤ max(h(v) + 1, h(s) – |V| − 1) for ∀ (u, v) ∊ Ef, after Adaptation(u∗, v∗). Considering Adaptation (u∗, v∗), if either scenario (a) or (c) occurs, no residual edge is added or removed, no node w ∊ V has its h(w) changed, either. If scenario (d) occurs, the change in the system removes (u∗, v∗) from Ef and thus the corresponding constraint on h(u∗) and h(v∗). If scenario (b) occurs, (u∗, v∗) is added to the Ef. By induction assumption, h(u∗) ≤ h(s) + |V| − 1 before the adaptation operation. Because h(u∗) does not change and h(s) increases by 2|V| after the operation, h(u∗) ≤ h(s) – |V| − 1 after the adaption operation. In summary, after the adaptation operation, h(u) ≤ max(h(v) + 1, h(s) – |V| −1) for ∀ (u, v) ∊ Ef. Adaptation (u∗, v∗) changes the values of some e(w), allowing new Push and Relabel operations to be applied. Yet these operations preserve the property that h(u) ≤ max (h(v) + 1, h(s) – |V| −1) for ∀ (u, v) ∊ Ef This is shown by induction on the number of Push and Relabel operations.
Suppose Push(u, v) is applied. This may add edge (v, u) into Ef or remove the edge (u, v) from Ef. In the former case, for edge (v, u) ∊Ef, we have h(v) < h(u) because otherwise the push will not be applied. In the latter case, the removal of (u, v) from Ef removes the corresponding constraint on h(u) and h(u). In both cases, we still have h(u) ≤ max(h(v) + 1, h(s) – |V| − 1) for any (u, v) ∊ Ef. Suppose Relabel(u) is applied. For a residual edge (u, v) that leaves u, we have Now we need to show that h(u) ≤ h(s) + |V| − 1 for ∀u ∊ V Let


Combining these inequalities, we have
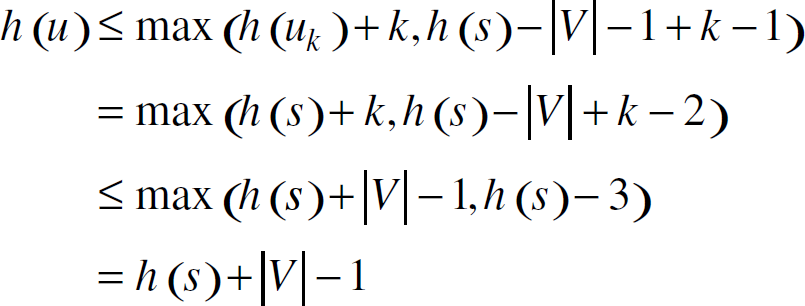
For any node u ∊ V, according to Lemma 2, there exists a simple path in Ef from u to a node z s.t. e(z) < 0 and z ≠ s. Suppose the simple path is {u, u1, …, uk},where uk = z and k ≤ |V| −1. We have

Note that e(u) ≥ 0 immediately after the initialization for ∀ u ∊ V. The only operation that can bring e(z) below 0 is the adaptation operaton (when scenario (d) occurs). Suppose e(z) becomes negative as the result of mth adaptation operation (m ≤ n). Because the Relable operation (which is the only operation that can increase the value of h(z)) is applied only if e(z) > 0, then e(z) < 0 means that h(z) has not been increased after mth, and thus the nth adaptation operation. Therefore, h(z) ≤ h(s)+ |V| −1before the nth adaptation means that h(z) ≤ h(s) – V|-1 there after, because h(s) is increased by 2|V|.
Combining these inequalities, we have

Corollary 1
During the execution of the RIPR algorithm, for any node u ∊ V, if e(u) < 0, then h(u) ≤ h(s) – |V| −1.
The proof of Corollary 1 is included in the proof of Lemma 4.
Lemma 5
During the execution of the RIPR algorithm, for ∀ u∊ V – {s,r}, if there exists a simple path from s to u in Ef, then e(u) ≥ 0.
Proof
Suppose for the sake of contradiction that there exists a node u ∊ V –{s,r} such that e(u) < 0 and there exists a simple path {s, u1, …., uk, u} in Ef. Without loss of generality, this is a simple path and k ≤ |V| −2.
According to Lemma 4,

According to Corollary 1, h(u) ≤ h(s) – |V| −1 because e(u) < 0. Combining these inequalities, we can see that

On the other hand, consider the first hop (s, u1) along this path. (s, u1) ∊ Ef implies that
Similar to the standard flow problem, for the relaxed flow problem, a cut is defined as a binary partition (S, R) of V such that S ∪ R = V, S ∩ R = 0, s ∊ S and r ∊ R. The capacity cSR of a cut (S, R) is defined as
Lemma 6
Given graph G(V, E) with source s and sink r, a relaxed flow f, and an arbitrary cut (S, R) of G,
Proof
we have e(u) ≤ 0 for u ∊ V – {s, r}. Therefore

Because f(u,v) ≤ ccu for ∀u, v ∊ V f(s, s) = 0, f(s,s) = 0, we have

The next lemma shows that the RIPR algorithm finds the maximum relaxed flow if it terminates. By terminates, we mean that none of the nodes need to execute any of the basic operations, assuming that edge capacities do not change any more. After proving this lemma, we will show that the RIPR algorithm indeed terminates.
Lemma 7
If the RIPR algorithm terminates, it finds the maximum relaxed flow.
Proof
According to Lemma 3, if the algorithm terminates, then e (u) ≤ 0 for ∀ u∊V –{s,r}. Thus f is a flow if the algorithm terminates.
Given such an f we constructed a cut of G as follows:

According to Lemma 5, e(u) ≥ 0 for u ≤ S –{s}. Note that e(u) ≤ 0 for ∀u ∊ V – {s,r} upon termination of the algorithm. Thus e(u) = 0(i.e., Σv∊V f(v, u) = 0) for ∀ u ∊ S – {s} Then it is easy to show that Σu∊S f(s,u) = Σu∊S–{s} f(s,u) = Σu∊S–{s},v∊R f(u,v).
Therefore
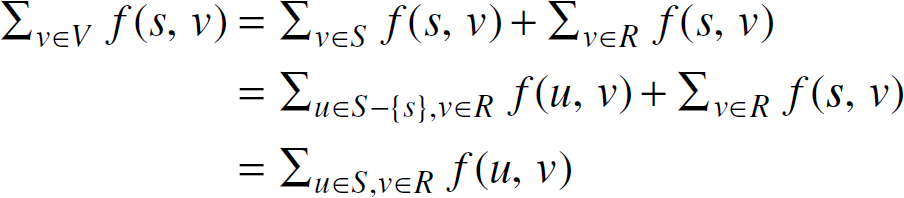
We claim that f(u,v) = cuv for ∀u ∊ s,v∊ R, because otherwise f(u,v) ≤ cuv implies that edge (u,v) ∊ Ef, thus v can be reached by s in Ef. But this contradicts the definition of R.
Therefore,

According to Lemma 6, such a relaxed flow f is a maximum relaxed flow.
Now we show that the algorithm indeed terminates.
Lemma 8
If the adaptation is applied n (n ≥ 0), times, then the number of Relabel operations that can be performed is less than (2n + 2)|V|2.
Proof
If the adaptation if applied n times, then h(s) = (2n + 1)|V|. According to Lemma 4, h(u) ≤ h(s) + |V|–1 = (2n + 2)|V|–1 for ∀u ∊ V. Each time Relabel(u) is applied, h(s) is increased at least by 1. Because h(s) = 0 initially, Relabel(u) is applied at most (2n + 2)|V| − 1 times. There are |V| nodes in the system, hence then the total number of Relabel operations that can be performed is at most ((2n + 2)| V| − 1)|V|, which is less than (2n + 2)|V|2.
If a Push(u,v) operation removes (u,v) from Ef (i.e., cf(u,v) = 0 after the operation), it is a saturated push, otherwise it is a non-saturated push.
Lemma 9
If the adaptation is applied n (n ≥ 0) times, then the number of saturated push operations that can be performed is less than (n+ 1)|V| · |E|.
Proof
Consider edge (u, v) ∊ Ef. Suppose a saturated push Push(u,v) is first applied. For a second saturated push to be applied over (u, v), i (v, u) must be applied before the second saturated push. Because h(u) > h(v) for the first push (otherwise the first push will not be applied), then h(v) must be increased at least by 2, otherwise h(v) ≤ h(u) then Push (v, u) will not be applied. Similarly, h(u) must be increased at least by 2 for the second saturated push to occur over edge (u, v). So on and so forth. Because h(u) ≤ h(s) + |V| − 1 = (2n + 2)|V| − 1, h(u) and h(v) cannot increase to infinity. It is easy to show that saturated push can occur at most ((2n +2)|V|–1)/2 times for edge (u, v). There are |E| edges in the graph. The total number of saturated push operations is less than ((2n + 2)|V| − 1)/2 · |E|, which is less than (n +1)|V| · |E|.
Lemma 10
If the adaptation is applied n (n ≥ 0) times, then the number of non-saturated push operations that can be performed is less than (n2 + 2n + 1) · (4|V| + 2|V|2|E|).
Proof
Define a potential function Φ = Σe(u)>0 h(u). Φ = 0 initially. Obviously, Φ ≥ 0.
According to Lemma 4, h(u) ≤ h(s)+|V|–1 = (2n+2)|V|–1, thus a relabel operation increases Φ by at most (2n+2)|V| − 1. According to Lemma 8, there can be at most (2n+2)|V|2 Relabel operations. The increase in Φ induced by all relabel operations is at most ((2n + 2)|V| − 1) · (2n + 2)|V|2. A saturated push Push(u, v) increases Φ by at most (2n + 2)|V| − 1 because e(v) may become positive after the push, and (2n + 2)|V| − 1 is the highest value that h(v) can be. According to Lemma 9, the increase in Φ induced by all saturated push is at most ((2n + 2)|V| − 1). ((n +1)|V| · |E|).
For a non-saturated push Push(u, v), e(u) > 0 before the push and e(u) = 0 after the push, thus h(u) is excluded from Φ after the push. If e(v) > 0 after the push, Φ is decreased at least by 1 because h(u) – h(v) > 0. If e(v) ≤ 0 after the push, then Φ is decreased by h(u) ≥ 1.
Therefore, the total increase in Φ is at most ((2n + 2)|V| − 1) · (2n + 2)|V|2 + ((2n + 2)|V| − 1) · ((n + 1)|V| · |E|) < (n2 + 2n + 1) · (4|V|3 + 2|V|2|E|), while each non-saturated push decreases Φ at least by 1. Therefore, the total number of non-saturated push operations that can be performed is at most (n2 + 2n + 1) ((4|V|3 + 2|V|2|E|).
Theorem 2
The RIPR algorithm finds the maximum flow for the relaxed flow problem with O(n2 · |V|2 · |E|) basic operations, where n is the number of adaptation operations performed, |V| is the number of nodes in the graph, and |E| is the number of edges in the graph.
Proof
In this section, we present a simple online protocol for SMaxDT problem based on the RIPR algorithm.
In this protocol, each node maintains a data buffer. Initially, all the data buffers are empty. The source node s senses the environment and fills its buffer continuously. At any time instance, let β
u
denote the amount of buffer used by node u. Each node u ∊ V operates as follows:
Contact the adjacent node(s) and execute the RIPR algorithm. While β
u
> 0, send message “request to send” to all successors v of u s.t. f(u, v) > 0. If “clear to send” is received from v, then set β
u
← β
u
− 1 and send a data packet to v at rate f(u, v) · (recall that f(u, v) is the flow rate at which data should be sent from u to v according to the RIPR algorithm.) Upon receiving “request to sent,” u acknowledges “clear to send” if β
u
≤ U. Here U is a pre-set threshold that limits the maximum number of data packets a buffer can hold.
For node s, it stops sensing if βs > U. The nodes execute the RIPR algorithm and find the rate f(u, v), for sending the data. Meanwhile, the nodes transfer the data according to the values of f(u, v), without waiting for the RIPR algorithm to terminate. Two types of data are transferred in the system: the control messages that are used by the RIPR algorithm, and the sensed data themselves. The control messages are exchanged among the nodes to query and update the values of f(u, v) and hu when executing the RIPR algorithm. The control messages and the sensed data are transmitted over the same links and higher priority is given to the control messages in case of a conflict.
For the MMaxDT problem, the situation is a bit more complicated. Because the MMaxDT problem is reduced to the SMaxDT problem by adding a hypothetical super source node s′ the RIPR algorithm needs to maintain the flow out of s′ as well as the value of function h(s′). Additionally, the values of f(s′, v) (v ∊ Vc) and h(s′) are needed by all nodes u ∊ Vc during the execution of the algorithm. Because s is not an actual sensor, sensors in Vc therefore need to maintain a consistent image of s. This requires some regional coordination among sensors in Vc and may require some extra cost to actually implement such a consistent image.
The SMaxDV and MMaxDV problems are by nature off-line problems and we do not develop online protocols for the two problems.
Experimental Results
Simulations were conducted to illustrate the effectiveness of the RIPR algorithm and the data gathering protocol. For the sake of illustration, we present simulation results for the SMaxDT problem.
The systems were generated by randomly scattering the sensor nodes in a unit square. The base station was located at the lower-left corner of the square. The source node was randomly chosen from the sensor nodes. Bu's are uniformly distributed between 0 and Bmax. Bmax was set to 100. We assume a signal decaying factor of r−2. The flow capacity between sensor nodes u and v is determined by Shannon's theorem as
The RIPR algorithm described in Section 4 adapts to every single change that occurs in the system. The adaptation is initiated by source node s, which increases h(s) by 2|V| and pushes flow to every node in σs. However, the adaptation can be performed in batch mode, that is, source node s initiates the adaptation after multiple changes have occurred in the system. Because the proof of Theorem 2 does not utilize any information about the number of changes occurred, the correctness and complexity of the RIPR algorithm still holds even if the adaptation is performed in batch mode. We have observed that the RIPR algorithm always finds the optimal solution, regardless of the number of changes occurred before the adaptation is performed.
The result in Figure 2 illustrates the cost of adaptation (in terms of the total number of basic operations) vs. the number of changes occurred before the adaptation. In each experiment, a randomly generated system with 40 nodes was deployed in a unit square. After the system stabilized and found the optimal solution, the bandwidth of a certain number of links was changed. Adaptation was then performed and the system stabilized again (and found a new optimal solution) after executing a certain number of basic operations. For each experiment, we recorded the number of basic operations executed by the system to find the new optimal solution. Each data pointed in Figure 2 is averaged over 50 experiments. We can see that the required number of basic operations increases as the number of changes (per adaptations) increases.
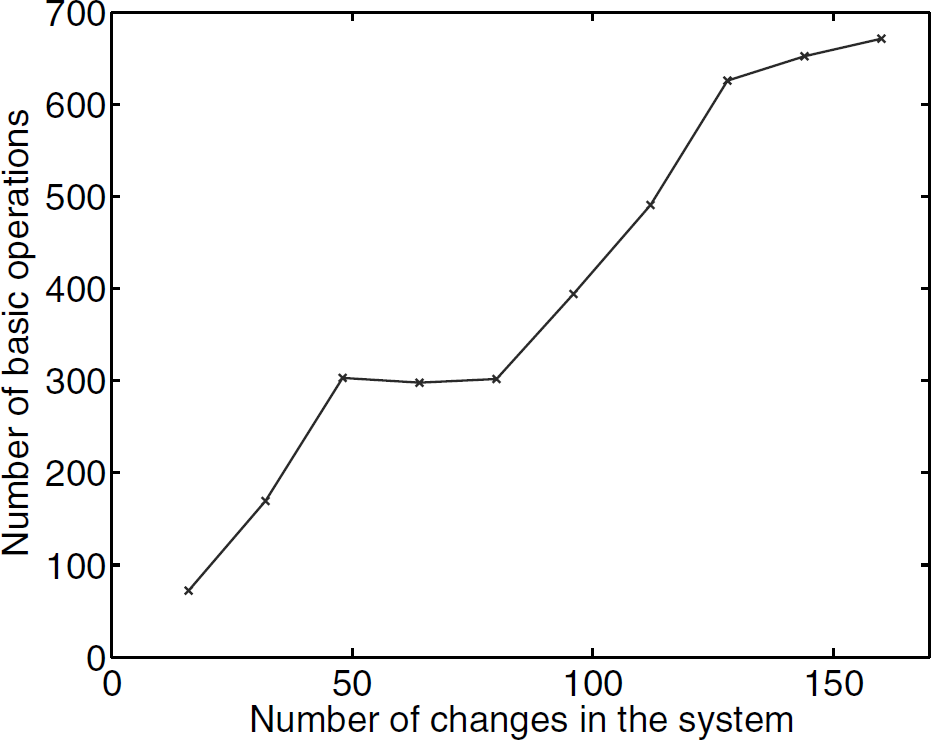
Adaptation performed in batch mode.
So far the performance of the RIPR algorithm is evaluated in terms of the total number of basic operations. We do not expect the individual nodes to execute the same number of operations because the RIPR algorithm is not designed for load balancing. But interestingly, the following simulation results show that the RIPR algorithm is pretty well balanced in terms of the number of basic operations executed by different nodes. For each experiment, a randomly generated system is initialized and the number of basic operations executed by the system to stabilize was recorded. The basic operations were reclassified into two categories: local updates and control message exchanges. Each push (u, v) operation consists of one local update at u, one message transfer (send) at u, and one message transfer (receive) at v. Each relabel(u)operation consists of one local update at u, one message transfer (broadcast h(u) to v ∊ σ u at u, and one message transfer (receive h(u)) at v ∊ σu. Figure 3 shows the number of local updates and control message executed/transferred by the nodes. We report the maximum and the mean number of local updates, and the maximum and mean number of control message exchanges. Each data point is averaged over 100 experiments. Figure 3 shows that the maximum number of local updates is only about 2 times the mean number of local updates. The maximum number of control message exchanges is also about 2 times the mean number of control message exchanges. This result shows that the RIPR algorithm is quite well-balanced in terms of per-node cost.

The maximum and mean cost per node for executing the PIPR algorithm.
The second set of simulation results illustrate the convergence and adaptivity of the proposed protocol. In each experiment, a certain number (between 40 and 100) of nodes were randomly deployed in the unit square. Communication radius ranging from 0.2 to 0.5 units were tested. For each experiment, the data gathering process lasted 30 seconds.
The steady-state throughput is calculated as the average throughput during the last 10 seconds of data gathering. Table 1 shows the steady-state throughput of the protocol. The results have been normalized to the optimal throughput. The optimal throughput was calculated offline. Each data point in Table 1 is averaged over 50 systems. The results show that the steady-state throughput of the proposed protocol approaches the optimal throughput, regardless of the number of nodes and the communication radius.
Normalized Steady-State Throughput

r is the Communication radlus. n is the Number of Nodes.
In the protocol, data is transferred when the RIPR algorithm is being executed. Thus the start-up time of the system needs to be evaluated from two aspects: the execution time of the RIPR algorithm (i.e., how fast the RIPR algorithm terminates), and the time for the data transfer to reach steady-state throughput.
For each experiment in the second set of simulations, we monitored the activities of each individual node. The termination of the RIPR algorithm was detected when none of the nodes needed to execute any of the basic operations. Note that such a global monitoring is made available in the simulations for performance analysis only. It may be very costly to implement this monitoring function in an actual deployment. Let N(t) denote the number of data packets received by the base station from time 0 to time t. The instantaneous throughput at time instance t is defined as (N(t + 0.1) – N(t − 0.1))/0.2. The start-up time of the protocol is defined as the time period for the instantaneous throughput to reach 85% of the steady-state throughput.
The impact of the number of nodes and the communication radius on the execution time of the RIPR algorithm is shown in Figure 4. The execution time increases as the number of nodes increases. The execution time also increases as the communication radius increases, which leads to an increase in the number of links in the system. Such a trend is expected from Theorem 2.

Execution time of the RIPR algorithm.
The start-up time of the protocol is shown in Figure 5. The result shows that for a given communication radius, the start-up time of the protocol increases as the number of nodes increases; and interestingly, for a given number of nodes, the start-up time decreases as the communication radius increases. Such a behavior is due to the fact that a larger communication radius leads to a smaller diameter of the graph. The diameter of a graph is defined as the largest distance (in terms of the number hops) between any two nodes in the graph. In systems with small diameter, the base station is closer to the source node. Thus the data can be transferred sooner to the base station during the start-up time.

Start-up time of the proposed protocol.
We have also observed that in some experiments, the system throughput reached steady-state even before the RIPR algorithm terminated. This is not a contradiction. Actually, when such scenarios occurred, the RIPR algorithm was pushing excessive flow (node u is said to have excessive flow when e(u) > 0, that is, when u has more incoming flow than outgoing flow) back to the source node. During this time period, the RIPR algorithm was still executing, but the net flow from the source to the sink did not increase. In other words, the RIPR algorithm had already found the maximum flow if the excessive flow had been eliminated. Meanwhile, data was transferred when the RIPR algorithm was still executing. Because each node maintained a data buffer that prevented the node from accumulating excessive data, the excessive flow did not cause the nodes to accumulate data. Consequently, the protocol was able to drive the system throughput to steady state before the RIPR algorithm terminated.
The earlier results illustrate the behavior of the the protocol and the RIPR algorithm. Awareness of such behaviors is useful for system synthesis. For example, in order to reduce the start-up time of the protocol, we can deploy the nodes so that they can reach the sink in a small number of hops. To reduce the cost (both time and energy) of executing the RIPR algorithm, we can restrict the communication of each node to a subset of its neighbors (thereby reducing |E|).
Note that the observed execution time of the RIPR algorithm (less than 1.3 seconds) and the start-up time of the protocol (less than 4.3 seconds) depends on the bandwidth settings of the links. In our simulations, the bandwidth of the links is around 10 kbps, which is around 40 data packets per second because each data packet is 32 bytes. The shortest path (in terms of the transfer time of one data packet) from the source node to the base station ranges from 0.05 seconds to 0.13 seconds. The execution and start-up time will be much shorter if the links have higher bandwidth. For example, if the system is built with Telos [20] wireless sensors that can communicate at 250 kbps, we can expect about 20 times speed up in both the execution time of RIPR algorithm and the start-up time of the protocol.
Adaptivity of the proposed protocol is shown in Figure 6. The system consisted of 40 nodes randomly deployed in the unit square. Communication radius was set to 0.4. The system activities during the first 40 seconds are shown. At time t = 20 sec, we changed the bandwidth of a randomly selected set of links, each of which was increased by 100%. Consequently, the optimal throughput (calculated off-line) changed from 314 to 492 (data packets/sec). As such changes occurred, the adaptation procedure was activated and the system operated at a new steady state throughput after the adaptation was completed. Figure 6 shows the number of data packets received by the base station as time advances. The throughput actually achieved by the protocol is reflected by the slope of the curve, which is 293 (93% of the optimal) before t = 20 and 452 thereafter (92% of the optimal). For this experiment, we define the start-up time as the time period for the instantaneous throughput to reach 85% of the first steady-state throughput 293, starting form t = 0: and the adaptation time as the time period for the instantaneous throughput to reach 85% of the second steady-state throughput 452, starting from t = 20. In this experiment, the shortest path (in terms of overall transfer time) to send a data packet (from the source node) to the base station consists of 3 hops and requires 0.06 sec. By using our protocol, the first data packet was received by the base station 0.12 seconds after the system started; the start-up time is 1.13 seconds; and the adaptation time was 1.4 seconds. The system activities during the start-up and adaptation period are shown in more detail in Figure 7. An important observation from Figure 7 is that the system started (at t = 0) and continued (at t = 20) to gather data while the RIPR algorithm was still executing. The system did not wait until the optimal solution was found. Actually, because the protocol was executed in a distributed fashion, none of the nodes would know the completion of the RIPR algorithm unless a global synchronization was performed.

Illustration of the start-up and the adaptation of the proposed protocol. Framed block (a) is zoomed in Figure 7(a), framed block (b) is zoomed in Figure 7(b).

Detailed Illustration of the start-up and the adaptation of the proposed protocol.
In this article, we studied a set of data gathering problem in energy-constrained networked sensor systems. We reduced such problems to a network flow maximization problem with vertex capacity constraint, which can be further reduced to the standard network flow problem. After deriving a relaxed formulation for the standard network problem, we developed a distributed and adaptive algorithm to maximize the flow. This algorithm can be approximated as a simple data gathering protocol.
One of the future directions is to design distributed algorithms that do not generate excessive flow at the nodes (i.e., e(u) does not become positive) during the execution. Our formulation of constrained flow optimizations can be applied to problems beyond the four problems discussed in this article. For example, the system model considered in reference [9] gathers data in rounds. In each round, every sensor generates one data packet and the data packets from all the sensors need to be collected by the sink. The goal is to maximize the total number of rounds the system can operate under energy constraints on the nodes. This problem can be described by our constrained flow formulation and an optimal solution can be developed [21].