
Abstract
This paper assumes a set of identical wireless hosts, each one aware of its location. The network is described by a unit distance graph whose vertices are points on the plane two of which are connected if their distance is at most one. The goal of this paper is to design local distributed solutions that require a constant number of communication rounds, independently of the network size or diameter. This is achieved through a combination of distributed computing and computational complexity tools. Starting with a unit distance graph, the paper shows: 1. How to extract a triangulated planar spanner; 2. Several algorithms are proposed to construct spanning trees of the triangulation. Also, it is described how to construct three spanning trees of the Delaunay triangulation having pairwise empty intersection, with high probability. These algorithms are interesting in their own right, since trees are a popular structure used by many network algorithms; 3. A load balanced distributed storage strategy on top of the trees is presented, that spreads replicas of data stored in the hosts in a way that the difference between the number of replicas stored by any two hosts is small. Each of the algorithms presented is local, and hence so is the final distributed storage solution, obtained by composing all of them. This implies that the solution adapts very quickly, in constant time, to network topology changes. We present a thorough experimental evaluation of each of the algorithms supporting our claims.
Keywords
Introduction
The problem of storing multiple copies of files in different parts of a network has been widely studied since the early 70s, see [7] for a thorough survey. It provides a classic solution to reduce response time for data, increase availability, and improve general fault-tolerance. The remarkable growth of reliable and efficient networking over the past few decades has fostered the development of distributed storage systems. A recent issue of IEEE Internet Computing [25] devoted to this area describes various approaches taken by distributed storage systems, including storage virtualization, peer-to-peer, and server-to-server.
Data Storage in Wireless Networks
This paper develops distributed storage solutions for mobile wireless networks. It assumes a set of n identical wireless hosts in the plane, each one aware of its location, either from a GPS system or through other means, such as inertial sensors and acoustic range-finding devices. Two hosts can communicate if they are within a fixed distance, say one unit. Thus in our paper, a wireless network can be described as a geometric graph whose vertices are points on the plane (our wireless hosts) two of which are connected if their distance is at most one, i.e. it is a unit distance graph.
Since the topology of wireless networks is constantly changing, and the nodes have location awareness, protocols for wireless networks differ significantly from standard solutions used in wired networks. In addition, wireless devices have much lower bandwidth and limited power supplies. Therefore, protocols for wireless networks should use as little communication as possible and should run as fast as possible; even traditional solutions that have only a linear cost in the diameter of the network may not be acceptable. The goal of this paper is to design local distributed solutions that require a constant number of communication rounds, independently of the network size or diameter.
The absence of a central infrastructure, together with the highly dynamic nature of wireless networks, imply that such networks do not have an associated fixed topology. An important task is to determine an appropriate topology over which high-level protocols are implemented; see [22] for a survey of various topology control methods. Algorithms that allow to establish and maintain an energy efficient connected constant degree overlay network have been described in e.g. [9], [13], [14], [24]. Starting with a unit distance graph, this paper extracts a triangulated planar spanner through the local algorithm of [14], and then proposes several algorithms inspired by the method of [2] to construct a spanning tree of the triangulation. Both algorithms are local and hence adapt in constant time to network topology changes.
Related Results and Applications of Data Storage
An interesting application of the storage protocols described in this paper is the problem of reliably storing global snapshots of the state of a distributed system (e.g. [6], [8]). Snapshots of a distributed system can be used, for example, for system recovery after a problem (e.g. deadlock) is detected. A strategy for reliably storing data such as snapshots can consider spatial redundancy, temporal redundancy, or a combination of both. In spatial redundancy each snapshot is replicated and spread among a number of processors, in a way that if at most t processors fail, the snapshot can be recovered; e.g. storing several copies in different processors, or spreading each copy into several pieces using coding based strategies; see [10], [21] and references herein. In temporal redundancy a few, say k, of the latest snapshots, are stored in different processors; for recovery the latest available snapshot is used. Either way, since snapshots may be rather large (each one contains the local state of every processor in the system), it is convenient to design balanced strategies that distribute the load evenly among the processors. This work improves upon the solutions to the snapshot storage problem of [16], where static strategies are computed off-line using combinatorial design theory.
Papers such as [10], [11] have proposed coloring based solutions for mobile networks for a different storage problem, that requires that every node has replicas nearby; these solutions are not local.
Outline and Results of the Paper
The goal of this paper is to design local distributed storage solutions that require a small number of communication rounds, independently of the network size or diameter. This is achieved through a combination of distributed computing and computational complexity tools, that make heavy use of the fact that nodes know their locations, and the geometry of the plane. The solutions proposed here are built up from two layers: a spanning tree maintenance protocol, and a load-balanced storage backup protocol. Various spanning tree protocols are proposed, which are interesting in their own right: trees are a popular form of network structure that are used by many network algorithms. The backup protocols allow each node to replicate data to neighboring nodes for fault-tolerance, such that the difference in the number of copies each node stores is small. A thorough experimental study is presented, that analyzes the properties of the trees, and of the performance of the backup protocols on top of the trees.
The protocols described in this paper also show how to construct locally three spanning trees whose union is the Delaunay triangulation of the given pointset, with high probability. A virtual ring can be maintained by traversing the tree in DFS order. This ring easily adapts to network changes, deletions and additions of processors can be handled locally and on the average in constant time.
The backup protocol that stores data in consecutive nodes on the virtual ring, according to various policies, is presented. Notice that once the tree is obtained, leader election can be performed using only a linear number of messages. 1 This is the first algorithm that matches the Ω(n log n) lower bound of [23] for leader election in a geometric ring of size n.
Finally, we have simulated all our algorithms and in Section 4 we provide detailed results of our simulations for a wireless network produced from 200 nodes generated at random. Our simulations indicate the effectiveness and adaptability of the algorithms proposed in this paper.
Algorithm for Distributed Dynamic Storage
Assume a set of n wireless hosts in the plane, each of which is aware of its location. The main feature of our algorithm is that dynamic storage is attained and subsequently maintained by cooperating nodes that use only “local” knowledge, i.e., information about themselves and their distance one neighborhood nodes. In outline, our proposed distributed dynamic storage algorithm itself is in two phases. In the first phase the input unit disc graph is processed in order to produce first a triangulated planar spanner (using a Localized Delaunay Triangulation algorithm [14]) and from there a tree spanner is obtained using the Entry-Edge Elimination criteria introduced in [2]. In the second phase a cycle is embedded into the tree spanner and subsequently our dynamic storage procedure is applied.
Preprocessing Procedures
In this section we review the techniques necessary to preprocess the wireless network. We need two key components. The first one, a technique to extract a spanning tree of a planar geometric graph, and a method to extract from a unit distance graph, the local Delaunay subgraph, which under the right conditions is the same as the Delaunay triangulation of the points of a unit distance graph.
Delaunay and Localized Delaunay Triangulation
Let the hosts have identical radius rn and let G(P, rn) denote the unit disc graph on a set P of n nodes. The parameters we chose are guided by the main result of Penrose [17], [18] which guarantees k-connectivity.
The result implies that for any real number c if

for
The Delaunay triangulation cannot be computed “locally”. In the sequel, we will require that our construction is based only on local operations by the hosts. It has been proved by Bern et al. [3] (see also Li et al. [15]) that if the reachability radius of the hosts is chosen so as to satisfy Inequality 1 then with high probability the Delaunay triangulation is the same as the localized Delaunay triangulation. We review their argument in the sequel. The probability that a region R of area |R| has exactly l nodes from the random poinset obeys the Poisson ditribution and is equal to

Let dn be the random variable that denotes the length of the longest edge of the Delaunay triangulation of the random pointset. If dn ≥ d then there is a triangle in the triangulation at least one of whose edges is ≥ d and whose circumcircle contains no other points of the random poinset: note that the area of this circumcircle is at least
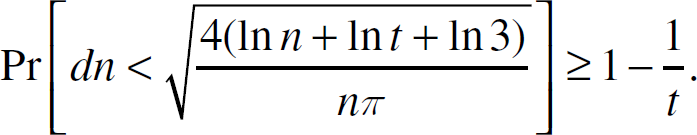
If we now put s = n8 in Inequality 1, and t = n in Inequality 2 then we see that
The Unit Delaunay triangulation (denoted by UDel(P, rn)) is the graph obtained by removing all edges of the Delaunay triangulation which are longer than rn. Note that using only their local information nodes of a given triangle alone can decide together whether or not they form a triangle. A triangle is k-localized if all its edges have a length at most of 1 and also the interior of its circumcircle contains no point of P that is a k-neighbor of its vertices. The k-localized Delaunay graph (denoted by LDel(k)(P, rn)) consists of exactly the Gabriel edges and edges of the k-localized Delaunay triangles [15]. It has been shown [14] that LDel(k) (P, rn) is planar for k ≥ 2, while LDel(1) (P, rn) may not be planar. However, there is an algorithm that can remove intersections from LDel(1) (P, rn) in order to produce the planarized Delaunay Triangulation (denoted by PLDel(P, rn)). The planarization of LDel(1) (P, rn) essentially involves the following operations.
Each node u gathers the location information of its distance one neighborhood (including u itself) and computes its Delaunay Triangulation. The node u computes all triangles with all edges at most one unit and broadcasts a message to form a Delaunay triangle if the angle of the triangle formed at u is at least /3. Node u accepts a proposal if the triangle proposed is in its Delaunay triangulation and has been proposed by both neighbors of the proposed triangle. For more details see Alzoubi et al. [1]. In view of our previous discussion we have the following result.
Proposition 2.1
If
Let P be a simple polygon embedded on the plane, and let l be the vertical line tangent to P such that P lies to the left of l. Then the entry edge of P is the lowest edge of P that touches l. See Fig. 1.
Let G be a plane geometric graph, that is a planar graph embedded on the plane such that its edges are represented by line segments joining pairs of points representing the vertices of G. G partitions the plane into a set of faces one of which is unbounded. Each face f of G, but the external one defines a polygon. The entry edge of f is the entry edge of its corresponding polygon. Let TG be the graph obtained from G by removing the entry edge of all its faces, albeit the external one. The following result is proved in [2].
Proposition 2.2
TG is a plane spanning tree of G.
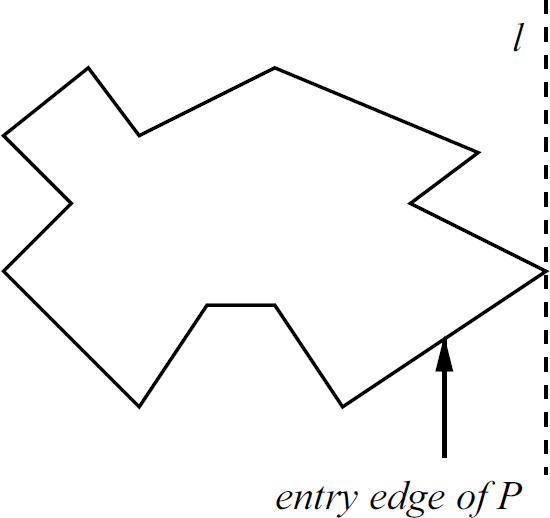
An example illustrating the definition of the entry edge of a polygon.
This extraction technique is useful for general planar subdivisions. In the sequel we will develop new and more efficient “localized” algorithms for extracting trees.
Graphs all of whose faces, but the outer one are convex, are called convex subdivisions. If in addition all the faces of G with the exception of the outer one are triangles, G is called a triangulation. The following observation is straightforward: If G is a convex subdivision then TG can be obtained as follows: For every vertex v of G consider the set of edges to the left of v whose rightmost vertex is v. Remove from G all of them, but the topmost. We can refer to this as the leftmost-topmost elimination rule. Similarly, a topmost-rightmost elimination rule can be obtained follows: for every vertex v of G consider the set of edges whose bottom vertex is v. Remove from G all of them, but the rightmost. In a similar way we can define a rightmost-bottommost and bottommost-leftmost elimination rules, each of which defines a sparning tree of G.
Our previous observation allows us to carry out the extraction of a spanning tree in a planar subdivision in a fully distributed way, in fact if v is a vertex of a convex subdivision all it has to do is to eliminate all the edges incident to it, except the top edge to its left. Let G be a triangulation whose vertex set is a point set P with n elements. Assume that P has k of its elements on its convex hull. Let TG and T'G be the spanning trees obtained by applying the leftmost-topmost and the topmost-rightmost elimination rules respectively to G. The following result is easy to prove.
Proposition 2.3
TG and T'G, have at most
As a direct consequence we also have.
Proposition 2.4
Let G be a wireless network (modeled as a unit distance graph). Then using local operations at each node of G, we can maintain a plane spanning tree of G.
Proof
Using the algorithms presented in Alzoubi et al. [1] we first calculate the localized Delaunay triangulation of G. Then using the leftmost-topmost elimination rule obtain a plane spanning tree TG of G. Since both steps can be achieved using only local operations at each node of G, the extraction of TG can be done in a local way.
Since for points placed on the plane at random with the uniform distribution the expected number of points on the convex hull of P is [20]:
Θ(ln n) for points chosen in a convex polygon, and
Distance-based tree extraction. As we will see, it turns out that distance based tree extraction is more efficient. Motivated from our experimental analyis in Section 4 we will explore the following new rules for tree extraction whereby all nodes (except the righmost one) are connected to a neighbor to their right. In the sequel consider the convex subdivision formed by the Delaunay triangualtion. In the Max distance left to right (MaxDLTR) tree each node is connected to a max distance neighbor to its right; in the Min distance left to right (MinDLTR) tree each node is connected to a min distance neighbor to its right; finally, in the Mid distance left to right (MidDLTR) tree each node is connected to a neighbor other than a Max or Min neighbor to its right (if it has one) else to the Max. It turns out that with high probability these three trees contain all the edges of the Delaunay triangulation with high probability, asymptotically in n. To be more precise we can prove the following result.
Proposition 2.5
Assume
Proof
As in Proposition 2.1 the probability that a region R of area |R| has exactly l nodes from the random poinset obeys the Poisson ditribution and is equal to
A similar proof will work for any other pair of trees. For example, for the trees MaxDLTR and MidDLTR if a given edge e: = {u, v} is common to both then the semicircle centered at u and radius rn will have at most two points from the pointset. Threfore an upper bound on the probability that an edge is common can be obtained easily as in the previous analysis using the Poisson distribution. We leave the details to the reader. This completes the proof of Proposition 2.5.
We note two useful consequences of Proposition 2.5 for the three trees MaxDLTR, MaxDLTR, and MidDLTR and under the assumption that
Other rules for tree extraction. In distance-based tree extraction a node must search all its neighbors and select the one that is furthest, nearest, etc. A simpler tree extraction algorithm is to have each node select a neighbor to its right (respectively, left) at random, if it has one. Another one is to have each node select its neighbor forming a slope that is minimal with the horizontal. This gives rise to the trees RLTR, RRTL, and HorDLTR, respectively, that have also been considered in our experimental results described in Section 4.
Distributed Dynamic Storage Algorithm
We proceed now to show how to solve the dynamic storage problem for wireless networks. We remark again that our algorithms are local, in the sense that any node in the network only knows that it is a member of a unit distance wireless network, and at any time it communicates only with its neighbors.
We observe first that the dynamic storage problem has an easy solution if G is an oriented cycle, that is if the vertices of G are labeled (v0, …, vm–1) such that vi is adjacent to vi+1, i = 0,…, m − 1 (here addition is modm). Since our goal is to store a predetermined number k of copies of a data set Si stored at vi, this can be accomplished by sending Si to a predetermined set of vertices
Storage backup protocols
Now we can give two storage backup protocols. In the sequel TG denotes any of the trees constructed in Section 2-A. We choose an integer parameter k representing the number of copies to be stored in various nodes of the network. The size of k can vary but also depends on the desired fault tolerance for data recovery required. Let Fk(u) be the set of nodes to which node u forwards its data for storage. In general, the set Fk(u) is generated locally by node u and the generation procedure is part of the forwarding algorithm that is common to all participating nodes. The forwarding set is of size k.
Storage Backup Protocol> (SBP(k))
Embed a ring topology into TG by performing a “geometric” DFS-based preorder traversal that uses the geometric identities of the nodes. Each node u forwards its data to the nodes of the set Fk(u).
Observe that this embedding can be executed “locally” and the forwarding strategy does not prevent non-leaf nodes from receiving multiple copies of a data file originating from the same node.
It is easy to adapt the forwarding procedure so as to avoid repetitions by decrementing a counter every time a copy is received by a “new” node. For example, we can consider the following algorithm.
Non-Repetitive Storage Backup Protocol (NRSBP(k))
Embed a ring topology into TG by performing a “geometric” DFS-based preorder traversal that uses the geometric identities of the nodes. Each node u forwards its data to the nodes of the set Fk(u). A given node accepts the data forwarded to it only if it has not yet received other data from the same node. Else it forwards its data to its forward node in the ring.
There are two ways to affect the desired reliability of recovery. One is the size of the parameter k: the more copies are stored to other nodes the higher the reliability. Second is the choice of nodes to which node u forwards its data: this is determined by the set Fk(u) and makes load balancing possible. For example, one can choose to store the data to k consecutive forward positions either “close” to u or “further away” from u or move them to k forward random positions in order to achieve higher load balance.
In the sequel we consider three possibilities for the forwarding set Fk(u) at u: each node u selects the set Fk(u) of k nodes according to one of the following rules (note that all nodes select the same rule).
Forwarding Rules
Consecutive Forwarding (CF) Rule: Fk(u) = {u +1 mod n, u + 2 mod n,…,u + k mod n}, i.e., node u forwards its data to its k “successive” neighbours in the oriented cycle. Distant Consecutive Forwarding (DCF) Rule: Fk(u) = {u + d +1 mod n, u + d + 2 mod n,…,u + d + k mod n}, i.e., for some fixed value d (signifying distance d away from u) node u forwards its data to k “successive” nodes at distance d away from itself in the oriented cycle. Random Forwarding (RF) Rule: Fk(u) = {u +t1 mod n, u +t2 mod n,…,u + tk mod n}, where t1, t2,…,tk are random values in the range 1 m generated by node u, i.e., node u forwards its data to k random locations in the oriented cycle, where the integer m is chosen so that k2 = o(m).
Properties of the Storage Backup Protocol
In this section we discuss properties satisfied by our protocol, namely load balancing and failure recovery.
Load Balance
The load balancing attained by the algorithm depends not only on the forwarding algorithm but also on the topology of the wireless network.
In general, experimental results indicate (see Table 1) that the spanning tree TG obtained from G has small degree. Therefore on the average case the preorder traversal on TG will generate a ring topology such that each node of the network is repeated a small number of times.
Let us analyze the performance of the forwarding protocols. First consider the non-repetitive storage backup protocol. If c is the max degree of the spanning tree every node of the resulting ring will store at most kc copies of other nodes' data. In particular we have the following result.
Average Frequency of Degrees of Nodes and Diameter of Graphs in 20 Experiments with 200 Nodes Each for the Delaunay, and the MinDLTR, MaxDLTR, RLTR, RRTL Trees, Respectively
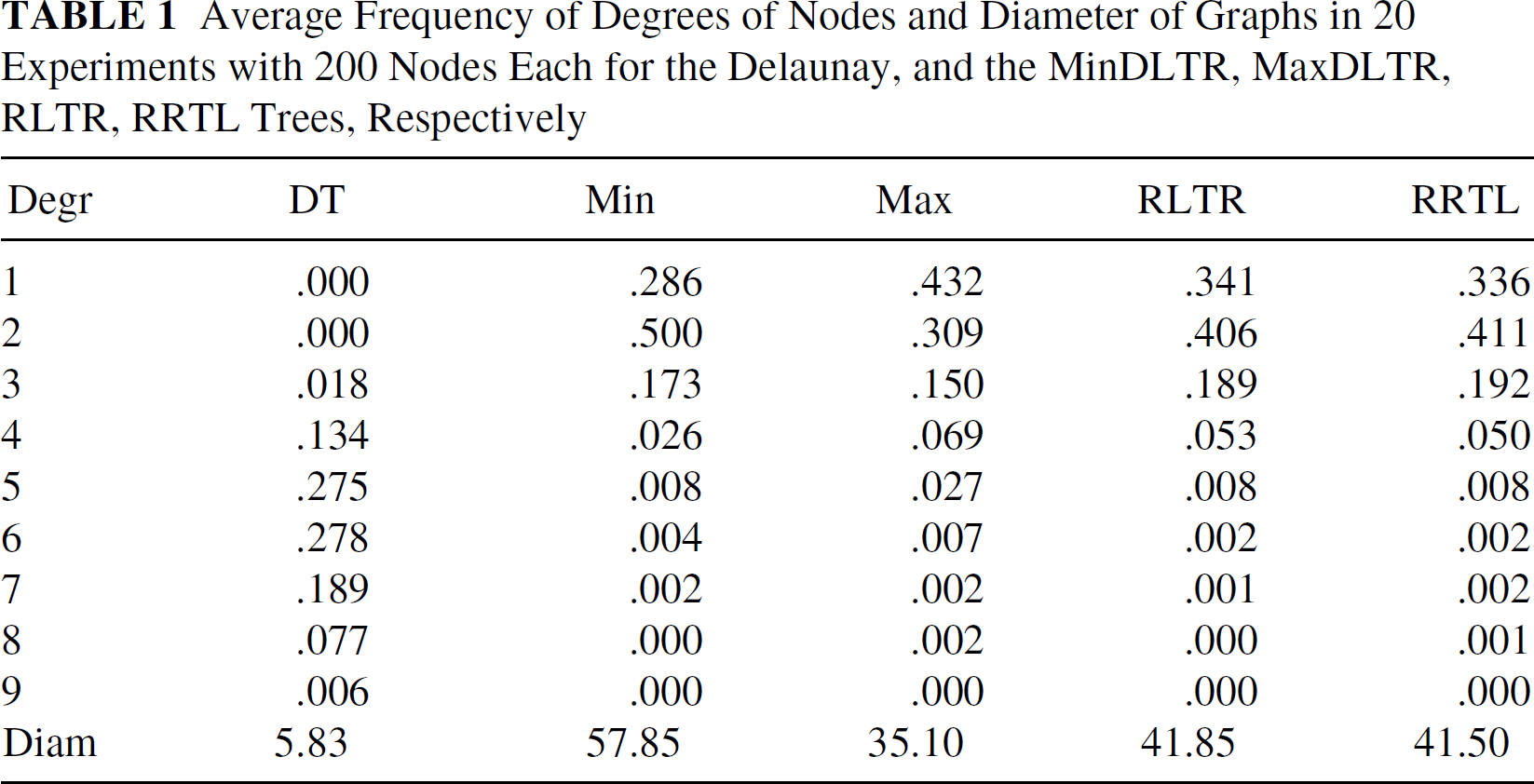
Average Frequency of Degrees of Nodes and Diameter of Graphs in 20 Experiments with 200 Nodes Each for the Delaunay, and the MinDLTR, MaxDLTR, RLTR, RRTL Trees, Respectively
Proposition 3.1
For each node u let S(u) be the number of data stored at u. The non-repetitive Storage backup protocol achieves load balancing in the sense that for all nodes u, v, |S(u) — S(v)|≤ ck.
A similar result also holds for repetitive loads. A trivial upper bound for the maximum absolute difference between loads can be obtained by overestimating the load. Assume a node v with degree c. We can compute load(v) by adding the storage-requests of c different directions. Notice that only k nodes for each direction can request from node v to store one unit of data. On the other hand, the nodes of only one direction can upload to node v up to c units of data each, the nodes of only one direction can upload up to c − 1 units of data each, etc. By adding the uploads and since the minimum load of a node might be zero, we have the following simple proposition.
Proposition 3.2
For each node u let S(u) be the number of data stored at u. The repetitive Storage backup protocol guaranties that for all nodes u, v,

One may think that non-repetitive Storage backup protocols should guarantee lower maximum difference between loads, but this is not always true. To see why, consider the family of trees on n + 6 nodes depicted in Figure 2, and assume k = 2. The eulerian tour arising is v1v2…vn 1 2 3 4 3 2 5 6 5 2 1 vn…v2v1
The minimum load over the nodes obtained by both protocols is zero. The repetitive Storage backup protocol loads node 2 with 4 units of data, while the non-repetitive backup protocol loads the same node with 6 units of data. Finally it is easy to see that these loads are the maximum that are obtained by each protocol.
However, in most cases, non-repetitive Storage backup protocols outperform repetitive storage backup protocols. This is also confirmed by our experimental analysis in Section 4.
Recovery from Failure
The resulting network failure recovery depends on the backup protocol used. In the sequel we look at properties of NRSBP(k).

A family of trees on n + 6 nodes, where n ≥ 1.
For every node of the network there is a backup of its data in at least k other nodes of the network. Therefore our protocol is k − 1 fault tolerant. In particular we have the following lemma.
Proposition 3.3
The Non-repetitive storage backup protocol NRSBP(k) is k − 1 fault tolerant, i.e., if at most k − 1 nodes fail then the data of every other node of the network is stored in at least one non-failed node.
Random failures
The protocol is robust under random failures. Assume that all the nodes of a random set S of size m (where m ≥ k) fail. A given node stores copies of its data into k other nodes of the network. The probability that at least one of these nodes is not in S is 1 minus the probability that they are all in S. The probability that a given node is in S is m/n, and the probability that all k nodes are in S is (m/n) k . In particular, we have the following result.
Proposition 3.4
Assume that all the nodes of a random set S of m (where m > k) nodes fail. The probability that all the data of a given node are stored at some non-failed node of the network is at least
Failures of geographical regions
Our protocol can easily be adapted so that it is robust to geographic failures, that is failures created by events such as power failures that may affect the set of nodes belonging to a connected region of the plane. Consider the case of a “civilized” unit disc graph, i.e., any pair of nodes is at a distance at least X from each other, where λ > 0 is independent of n, the size of the network. Assume that all the nodes in a geographic region R of area A fail. Since the unit disc graph is civilized, the region can have at most A/λ nodes. Therefore if k ≥ A/λ then every node u within the region R has a backup of its data in at least one node outside the region R. In particular we have the following result.
Proposition 3.5
Assume that the unit disc graph is civilized with parameter λ. If all the nodes of a geographic region of area at most kλ fail then the data of each node within the region have been stored in at least one node outside the region.
Simulations and Experiments
In this section we provide simulations of the algorithms proposed in the previous sections and confirm experimentally the efficiency of our proposed techniques for a location aware wireless network.
Random Setting
First we discuss our choice of parameters in the experimental results.
Connectivity, Delaunay and planarized triangulations
Let the hosts have identical radius rn and let G(P, rn) denote the unit disc graph on a set P of n nodes. Starting from a random set P of n points, we compute their Delaunay Triangulation. As indicated in Subsection II-A.1 if we select

Delaunay triangulation and trees resulting from a random set of 200 points.
From the Delaunay triangulation we compute spanning trees using the edge extraction algorithms in Subsection 2-A.3. We then implement the storage backup protocol with three different forwarding rules as in Subsection 2-B. In the random forwarding rule the nodes will forward their data to k other processors. If k values are chosen randomly and independently with the uniform distribution in the range 1.m then it is well-known from the “birthday paradox” that the probability that no collision will occur is at least
Results of the Simulations
Figure 3 depicts output of our experiments. From top-to-bottom and left-to-right, the first row depicts a set of 200 points chosen at random and the next picture their Delaunay. The trees depicted are formed from the Delaunay triangulation using the edge elimination rules described in Subsection 2-A.3.
The statistics reported in Table 1 give the average frequency of degrees of nodes and diameter of graphs in 20 experiments with 200 nodes chosen at random each for the Delaunay and the MinDLTR, MaxDLTR, RLTR, RRTL trees, respectively.
Table 2 and Table 3 illustrate the load averages for the three storage backup algorithms proposed for both the storage backup protocol SBP(k) and the non-repetitive storage backup protocol NRSBP(k). Table 2 gives the average maximum absolute difference between loads and Table 3 the average difference between loads over all pairs of nodes. These tables depict the consecutive (CF: k = 4), distant-consecutive (DCF: k = 4, d = n/2), and random distant (RDF: k = 4) forwarding rules for cycles generated from the MinDLTR, MaxDLTR, RLTR, RRTL trees, respectively, in 20 experiments with 200 nodes each. Note that the CF forwarding rule outperforms DCF and RDF, however it forwards data “near” the node initiating the forwarding. The tables also indicate that the MinDLTR tree has best performance (the second best performing tree was HorDLTR but we do not exhibit these results here).
Figure 4 depicts a histogram of the average performance of the SBP and NRSBP algorithms performed 20 times each in graphs of 100 to 200 random points in increments of 50, respectively. The top picture shows the average difference among pairs of nodes while the bottom picture the max absolute difference among pairs of nodes. Each pair of columns indicates the performance of SBP (light-gray column) and NRSBP (heavy-gray column) for the CF, DCF, and RCF forwarding rules, respectively: note that in RCF we implemented only SBP. Observe that the max absolute difference increases a little while the average absolute difference among pairs of nodes remains almost unchanged.
Average Maximum Absolute Difference Between Loads. Top Subrow is for SBP(k) and Bottom Subrow for NRSBP(k) for 20 Random Graphs with 200 Nodes Each
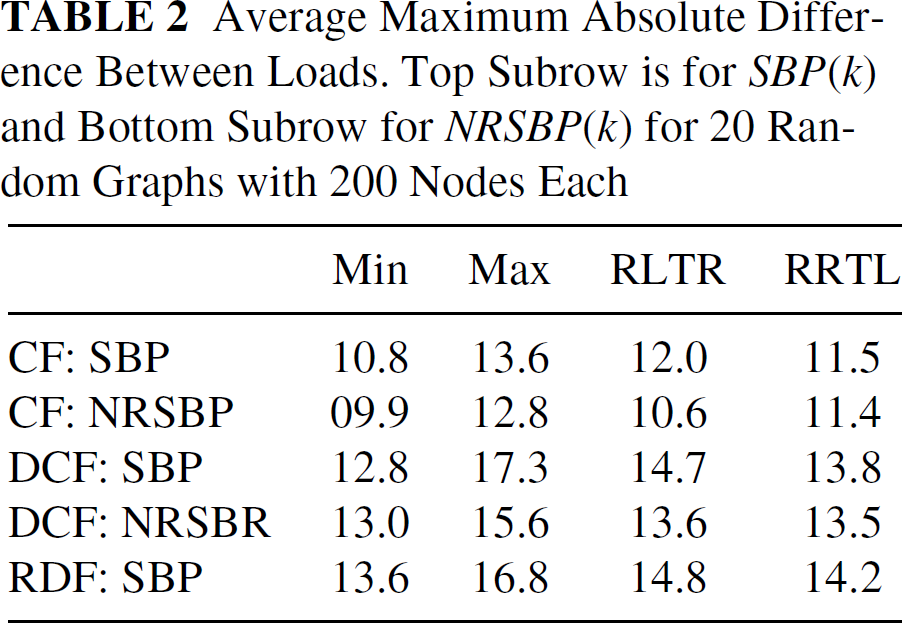
Average Maximum Absolute Difference Between Loads. Top Subrow is for SBP(k) and Bottom Subrow for NRSBP(k) for 20 Random Graphs with 200 Nodes Each
Average Difference Between Loads over all Pairs of Nodes. Top Subrow is for SBP(k) and Bottom Subrow for NRSBP(k) for 20 Random Graphs with 200 Nodes Each


Performance of SBP (light-gray column) and NRSBP (heavy-gray column) for the CF, DCF and RCF forwarding rules.
In this paper we proposed efficient solutions to the distributed storage problem in wireless networks and designed local distributed storage solutions that require a constant number of communication rounds, independently of the network size or diameter. This is achieved through a combination of distributed computing and computational complexity tools, that make use of location awareness, i.e., that nodes know their locations, and the geometry of the plane.
Footnotes
1
The algorithm works also in a planar graph that is not a triangulation, with complexity O(f log f) in the size f of the largest face of the network.