
Abstract
With the advent of inexpensive sensors and digital storage, increasing amounts of data about a mining complex can be collected. This data can, in turn, be used to continuously adapt stochastic optimization models and short-term mining decision making, thus reducing and managing local uncertainty. Taking advantage of this uncertainty reduction requires new decision-making approaches, mechanisms, and optimization methods. This paper proposes the use of state-dependent policies, which encode recipes for responding to new information as it comes along. Focusing on short-term planning shows how to represent and optimize state-dependent policies for making adaptive destination decisions for materials mined and processed. Resulting policies can be applied across different short-term time scales, marking an important step towards simultaneously optimizing different time scales. An implementation of the proposed method at a copper-gold deposit shows that it can improve the utilization of processing streams, production and financial performance over simple heuristic approaches and practices.
Introduction
An increasing array of devices for measuring material flow in a mining complex has become available in recent years. Near-infrared reflectance spectroscopy placed on conveyor belts has been shown to provide accurate measurements of mineral concentration and other properties (Goetz et al. 2009). Camera images can also be used for inferring various mineral properties using machine learning methods (Chatterjee 2013; Horrocks et al. 2015). Fleet location data is increasingly collected thanks to the widespread use of GPS devices. All of this data, together with more traditional information, such as blasthole analysis, can greatly reduce the uncertainty regarding the properties of the extracted and processed material. In practice, decisions made by mine operators do adapt to this uncertainty management and reduction - for instance, the mill will not be fed material that is revealed to be unsuitable. However, mine planning methods, despite their critical role, are not currently equipped to include this type of adaptation into their models.
This paper proposes a mechanism for optimizing material flow policies that respond to progressively-revealed information about the extracted material, and shows how to integrate the resulting adaptive policies through short-term production planning. The policies are adaptive because they are designed to be an explicit function of state - a numerical description of the system's properties that summarizes previously obtained information. Since this work deals with responding to uncertainty management and reduction, it is naturally set within a stochastic mine planning context. There has been significant progress in recent years in the long-term strategic optimization of aspects of mining complexes (Hoerger et al. 1999; Stone et al. 2007; Whittle 2010a, 2010b; Peevers & Whittle 2013) and more recently considering geological uncertainty (Dimitrakopoulos 2011; Montiel & Dimitrakopoulos 2015; Goodfellow & Dimitrakopoulos 2016, 2017; Montiel et al. 2016; forthcoming 2017). However, limited studies consider how the mining complex should adapt to new incoming information. In addition, most of the ones that do, only consider long-term strategic planning (Boland et al. 2008; Armstrong et al. 2012; Pimentel et al. 2013; Del Castillo & Dimitrakopoulos 2014; Kizilkale & Dimitrakopoulos 2014; Paduraru & Dimitrakopoulos 2014). In contrast to the works above, this paper focuses on short-term time scales. The adaptive policies introduced herein can respond to new information obtained at a high temporal resolution – for instance, corresponding to the time it takes to extract a block of material. This ensures consistency between different time scales, allowing for mutually consistent plans for different short-term time scales (e.g. months, weeks, days) to be produced by a simple process of temporal aggregation.
The closest existing work is that of Benndorf et al. (2014), wherein a general framework for integrated updates of the model and the plan based on new information is proposed, and is developed in subsequent publications (Benndorf & Jansen 2017; Wambeke & Benndorf 2017). This includes a proposal to perform simulation-based optimisation for updating the short-term production plan in response to the new information. However, this has not yet been implemented, as the case study focuses solely on the model update component.
This paper proceeds as follows. The next section introduces adaptive state-dependent policies that update short-term decisions given new information, followed by a discussion of how these policies can be optimized. The paper continues with a case study demonstrating the implementation of state-dependent destination policies at a copper-gold deposit, and illustrates the benefits of using the optimized policies. Conclusions follow.
Adaptive short-term policies
The work in this paper focuses on short-term or operational time scales, ranging from monthly to hourly. Given that new information is typically obtained more often than once a year, shorter time scales are better suited to answer the question of how to respond to this information.
The main contribution of this paper is to propose state-dependent policies for explicitly encoding how the mining complex should respond to new information. State-dependent policies take their name from the concept of state. The state of a system at some point in time can be informally described as a numerical representation containing all the relevant information about that system that can be extracted from data obtained up to that point in time. For an example, consider the problem of allocating extracted material to one of several destinations, where the system under consideration is the mining complex (mine(s), plant(s), leaching pad(s), etc.). The state for this example is a numerical vector containing information, such as the grade(s), tonnage and amount of secondary elements in the material being allocated, as well as information about the destinations’ status (for instance, the tonnage of the material currently on the mill's feed pile). This state can be updated when new information (e.g. from grade control) is obtained. For a more in-depth and theoretical discussion of the concept of state, see Chapter 5 of Powell (2007).
A state-dependent policy is a mechanism for making decisions based on the state. State-based policies are typically represented as functions from the set of states to the set of decisions. Considering, once again, the problem of allocating material to one of D destinations denoted d1, … d
D
, the destination policy would be a function dp such that for any state s,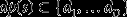 . The interaction between state, policy, decision and new information at a given point in time is illustrated by Figure 1 below, where new information is used to update the state, the policy selects a decision based on the state, and the decision impacts what the new information will be. The process is repeated at every decision point.
. The interaction between state, policy, decision and new information at a given point in time is illustrated by Figure 1 below, where new information is used to update the state, the policy selects a decision based on the state, and the decision impacts what the new information will be. The process is repeated at every decision point.
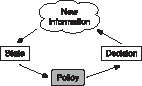
Graphical representation of the decision-making process when using state-dependent policies.
Optimizing state-dependent policies
The first step to optimizing a state-dependent policy requires expressing the objective function and constraints in terms of that policy. For traditional optimization problems, each potential solution is a finite-dimensional decision vector, and the objective function can be written as a mathematical function of the variables in the decision vector. For state-dependent policies, the decision vector may be infinitely dimensional if the number of states is not finite. The reason for this is that a different decision must be specified for each potential state value. This problem can be addressed by expressing the policy using a finite number of parameters. A very simple example of a parameterized policy is a cut-off grade policy, where the state s is the grade of the extracted material, the parameter is the cut-off grade g, and the decision policy dp is such that:
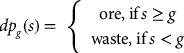
Despite its simplicity, the cut-off grade policy illustrates the point about representing a finite set of policy parameters rather than a decision vector: instead of explicitly representing a decision for each possible state (or block grade), there is a single parameter to optimize (the cut-off grade g).
The general approach of parameterizing a decision policy raises two issues that need to be considered. The first one is finding a suitable parametric representation for the policy, ideally such that a near-optimal policy can be found within the parameter space used. An example of such a parameterization is used for the case study in this paper. The second issue is that, as the space of parameterized policies become more complex, the optimization problem becomes more difficult as it has to deal with a larger number of variables and complex, highly non-linear terms. A large number of methods have been proposed for addressing this problem – see Powell (2014) for an overview. All proposed methods amount to some sort of search in the space of policy parameters, which can be performed through a variety of approaches ranging from many variations of gradient-based optimization to heuristic search and approximate dynamic programming. This paper uses Bayesian optimization, a modern black-box optimization technique that maximizes the expected a posteriori improvement in the objective function, for optimizing the policy parameters (Mockus 1974; Brochu et al. 2010).
Case study
This section presents an implementation of short-term planning using state-dependent policies for a copper-gold mine. The case study is based on the one used by Goodfellow and Dimitrakopoulos (2016), but it is modified in order to include aspects relevant to short-term planning. The mine complex under consideration consists of a single mine from which the extracted blocks can be sent to one of six initial destinations; the destinations are selective about the types of material they accept, as illustrated in Figure 2.
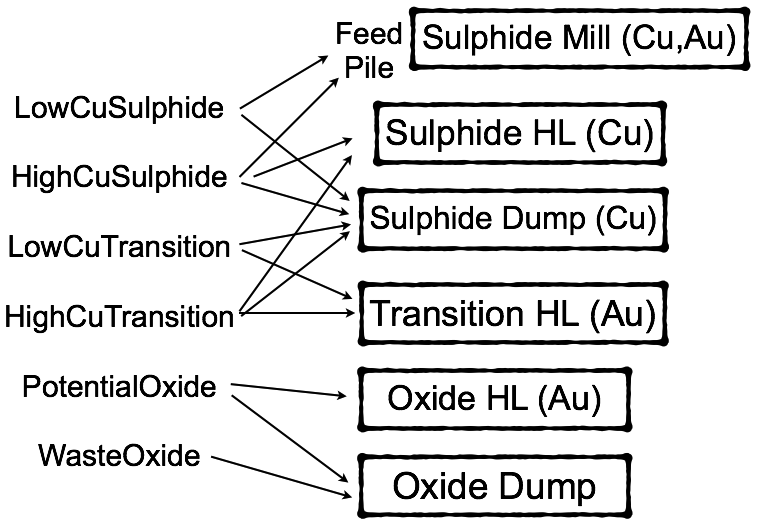
Graphical representation of the various material types and destinations. Each destination only accepts material types corresponding to the arrows pointing to it.
The sulphide mill includes a feed pile with a capacity of 500,000 tonnes. There is a ramp-up period of one month, during which no material is processed at the mill and any material sent to the mill accumulates on the feed pile. After the ramp-up period, the mill processes material from the feed pile at a fixed rate, unless there is no material left on the feed pile, in which case it is stopped and restarted once material is deposited on the feed pile again. In order to provide a high level of detail, each time increment corresponds to the time between the extraction of two consecutive blocks. The amount that the mill processes at each of these time increments (assuming there is sufficient material on the feed pile) is equal to 2,066 tonnes. This results in a yearly mill processing capacity of 3 million tonnes. For the heap leaches (including the sulphide dump, which acts as a heap leach), material is piled on until the leach contains 1,000,000 tonnes of material, at which point leaching occurs.
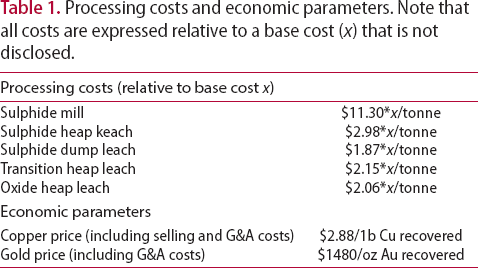
The amount of concentrate produced by the different destinations is computed according to the grade-recovery curves shown in Figure 3. For the mill, the recovery at each point in time is computed based on the average grade in the feed pile at that point. The recovery for the heap leaches is computed based on the average grade of the material that has been piled on before leaching occurs. The processing costs (relative to a ‘base cost’) and metal prices used can be found in Table 1.

Grade-recovery curves for the various destinations. Recoveries expressed as percentage of maximum recovery for confidentiality purposes. Figure reproduced from Goodfellow and Dimitrakopoulos (2016).
Processing costs and economic parameters. Note that all costs are expressed relative to a base cost (x) that is not disclosed.
There is a cost 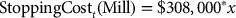 for when the mill needs to be stopped, and equal to $61,500 * x for each subsequent time step the mill is not running, where x is the base cost mentioned above. Note that the reason why the stopping cost appears to be so large is that x is expressed as a cost per tonne, whereas the stopping cost is incurred for every time step, which corresponds to the time it takes to process a whole block. Blocks weigh around 14,000 tonnes on average.
for when the mill needs to be stopped, and equal to $61,500 * x for each subsequent time step the mill is not running, where x is the base cost mentioned above. Note that the reason why the stopping cost appears to be so large is that x is expressed as a cost per tonne, whereas the stopping cost is incurred for every time step, which corresponds to the time it takes to process a whole block. Blocks weigh around 14,000 tonnes on average.
Problem formulation
Let the time increment t correspond to sending a new mining block to its destination, and consider a total of T blocks in the period of interest (the second year of production in this case). The goal for this case study is to compute a state-based destination policy for allocating each block. In order to mathematically define the problem addressed, the following notation is used:
TT(FP
t
), CuT(FP
t
) and AuT(FP
t
) are the total tonnage, copper tonnage and gold tonnage on the feed pile at time t. TT(block
t
), for the mill,
pCu and pAu are the selling prices for copper and gold, respectively
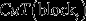 and
and 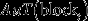 are the total tonnage, copper tonnage and gold tonnage of block
t
, the block extracted at time point t.
are the total tonnage, copper tonnage and gold tonnage of block
t
, the block extracted at time point t.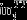 (dest) is the total tonnage processed at destination dest, and is computed as follows:
(dest) is the total tonnage processed at destination dest, and is computed as follows:
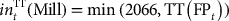
 for each heap leach, where LLt is the last time step when leaching occurred for dest
for each heap leach, where LLt is the last time step when leaching occurred for dest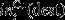 is the total copper tonnage processed by destination dest in period t, computed as follows:
is the total copper tonnage processed by destination dest in period t, computed as follows:
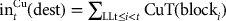
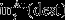 if dest ≠ Mill
if dest ≠ Mill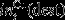 is the total gold tonnage processed by destination dest in period t, and is computed similarly to
is the total gold tonnage processed by destination dest in period t, and is computed similarly to 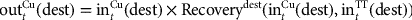
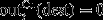 is the total copper produced at dest (for destinations that produce only gold,
is the total copper produced at dest (for destinations that produce only gold, 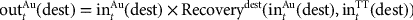 )
)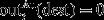 is the total gold produced at dest (for destinations producing only copper,
is the total gold produced at dest (for destinations producing only copper, 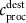 )
)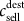 and
and 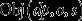 are the processing and selling costs, respectively, for dest
are the processing and selling costs, respectively, for dest
The revenue and processing cost for each destination are:
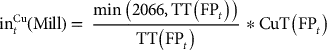
The penalty for surpassing feed pile capacity is
The objective function to be maximized has the form
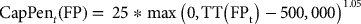
where 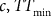 is the value of the objective function for destination policy dp, block extraction order o, and simulation s and is equal to
is the value of the objective function for destination policy dp, block extraction order o, and simulation s and is equal to
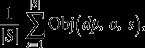
Note that, because the problem considered is short-term, there is no discounting. The inner sum reflects the fact that revenue for the heap leaches occurs when the unleached material exceeds the ‘leaching tonnage’ LT.
In order to model geological uncertainty, 50 pre-computed equally probable stochastic simulations of the orebody were used (Goovaerts 1997; Boucher & Dimitrakopoulos 2009). Each of these simulations contained spatially correlated realizations for the mining block property values, namely, the tonnage, amount of gold and copper contained, and material type. To avoid overfitting, the first 30 simulations were used for optimizing the extraction order and policy parameters, and the remaining 20 were used for computing risk profiles.
The state vector for time step t includes the material type, tonnage and metal content of block
t
, the tonnage and metal content for the feed pile material at time t, as well as the total tonnage and metal content of the unleached material for each of the heap leaches at time t. The state-dependent destination policy used here is based on a problem-specific parameterization. Namely, the policy assigns block
t
to the destination that optimizes the trade-off between sending block
t
to the destination that results in the largest immediate improvement in the objective function and ensuring that the mill feed pile does not run out of material. In order to formally write the policy, denote by Obj
t
the term of the objective function in Equation 1 corresponding to time step t, and by TT(FP
t
) the feed pile tonnage at time t. The policy, then, has the parametric form

where 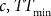 and p are the optimized parameters, and the max is taken over the destinations d that block
t
can be sent to. The three parameters trade-off between processing efficiency (maximizing Objt + 1 – Obj
t
) and minimizing mill interruptions (by keeping feed pile tonnage higher than TTmin). For instance, the higher the value of c, the more the policy will prefer to make sure that the mill feed pile is at a high enough level to ensure continuous operation over sending material to the destination that adds the highest immediate economic benefit.
and p are the optimized parameters, and the max is taken over the destinations d that block
t
can be sent to. The three parameters trade-off between processing efficiency (maximizing Objt + 1 – Obj
t
) and minimizing mill interruptions (by keeping feed pile tonnage higher than TTmin). For instance, the higher the value of c, the more the policy will prefer to make sure that the mill feed pile is at a high enough level to ensure continuous operation over sending material to the destination that adds the highest immediate economic benefit.
Numerical results
This section presents results obtained by comparing different destination policies for the case study described above. The ‘optimized policy’ is obtained by optimizing the parameters 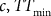 and p for the state-dependent destination policy dp in Equation (2) using Bayesian optimization (Mockus 1974; Brochu et al. 2010). The first comparison is between the optimized policy and a ‘max-block-value policy’ that sends each block to the destination dest that maximizes the value that would be obtained if only that block was processed at dest - that is, to the destination that maximizes
and p for the state-dependent destination policy dp in Equation (2) using Bayesian optimization (Mockus 1974; Brochu et al. 2010). The first comparison is between the optimized policy and a ‘max-block-value policy’ that sends each block to the destination dest that maximizes the value that would be obtained if only that block was processed at dest - that is, to the destination that maximizes
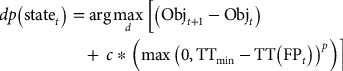
A quantity also known as ‘economic block value’. In order for these policies to be applied, it is necessary to know the order in which the blocks are sent for processing. A simple heuristic way for designing a block order is to assume that material will be extracted bench-by-bench starting from the top. The resulting block order will be called a ‘top-down extraction order’.
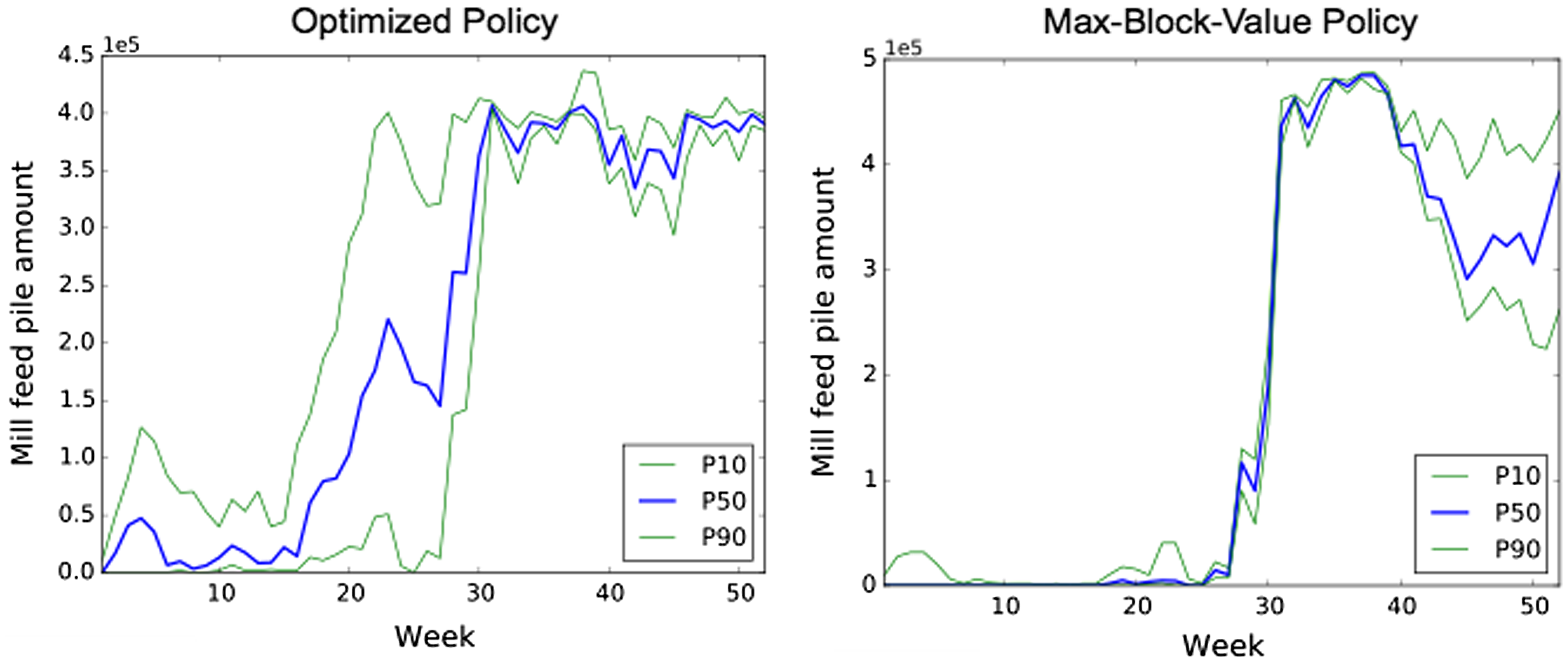
Results comparing the optimized policy to the max-value policy for the block order given by the top-down extraction order can be seen in Figures 4 and 5. Note that, although the allocation process increments the time step for each block allocation, it is trivial to aggregate the resulting block-by-block behaviour into the weekly or monthly behaviour seen in Figure 4 and 5.
Risk profiles (10th, 50th, and 90th percentiles) for the tonnage of material on the mill feed pile for the optimized policy and the max-block-value policy. Both policies use the block order provided by the heuristic top-down extraction order.
Cumulative cash flows for the optimized policy and the max-block-value policy using the block order provided by the top-down extraction order (same colour lines correspond to the 10th, 50th, and 90th percentiles of related policies).
Figure 4 shows that the trade-off between processing efficiency and mill utilization determined by the optimized destination policy sends more material to the mill than the max-block-value policy, resulting in a smaller duration for the empty feed pile and, therefore, a smaller stopping cost (note that in the figure, P10, P50, P90 correspond to the 10th, 50th, and 90th percentiles, respectively, that values will occur). Figure 5 shows that this also corresponds to substantially higher cash flow. This is not surprising given that the adaptive policy parameters were optimized in order to maximize cash flow. It also shows that the optimization performed on the set of 30 training simulations resulted in a policy that performs well, also with the 20 independent simulations used to compute the risk profiles shown.
While this first set of results shows that the optimized destination policy can help ensure more stable production and increase value, the second set of results answer the question of whether production reliability and value can be increased even more by modifying the order in which the blocks are being sent for processing. This is done by comparing the top-down (bench-by-bench) extraction order to an extraction order that is optimized using simulated annealing. As a pre-processing step designed to ensure a mineable schedule, blocks were first grouped together into 100 clusters. This was performed using k-means clustering (Lloyd 1982) based on their geographical coordinates, up-scaling the z axis in order to ensure horizontal clusters. Simulated annealing was then used to determine a cluster order maximizing the value resulting from applying the optimized destination policy while respecting precedence and slope constraints. The block order within each cluster was determined by a pre-defined mining direction.
The results are shown in Figure 6 (amount on feed pile) and Figure 7 (cumulative cash flow). The graphs show that there is a significant upside to optimizing the short-term extraction order. For the part of the deposit that this case study is examining (blocks extracted in the second year), high-grade sulphide blocks tend to be located deeper in the ground. Therefore, the top-down extraction order is unable to feed the mill for the first part of the year. The optimized extraction order, on the other hand, balances extracting material that can go to the mill much better throughout the year, leading to increased value as seen in Figure 7. Experiments were also performed (not shown here), which demonstrate that, for the optimized extraction order, the optimized destination policy still results in increased cumulative cash flows (by 18.5%) and better mill usage during the year with respect to the max-block-value policy.
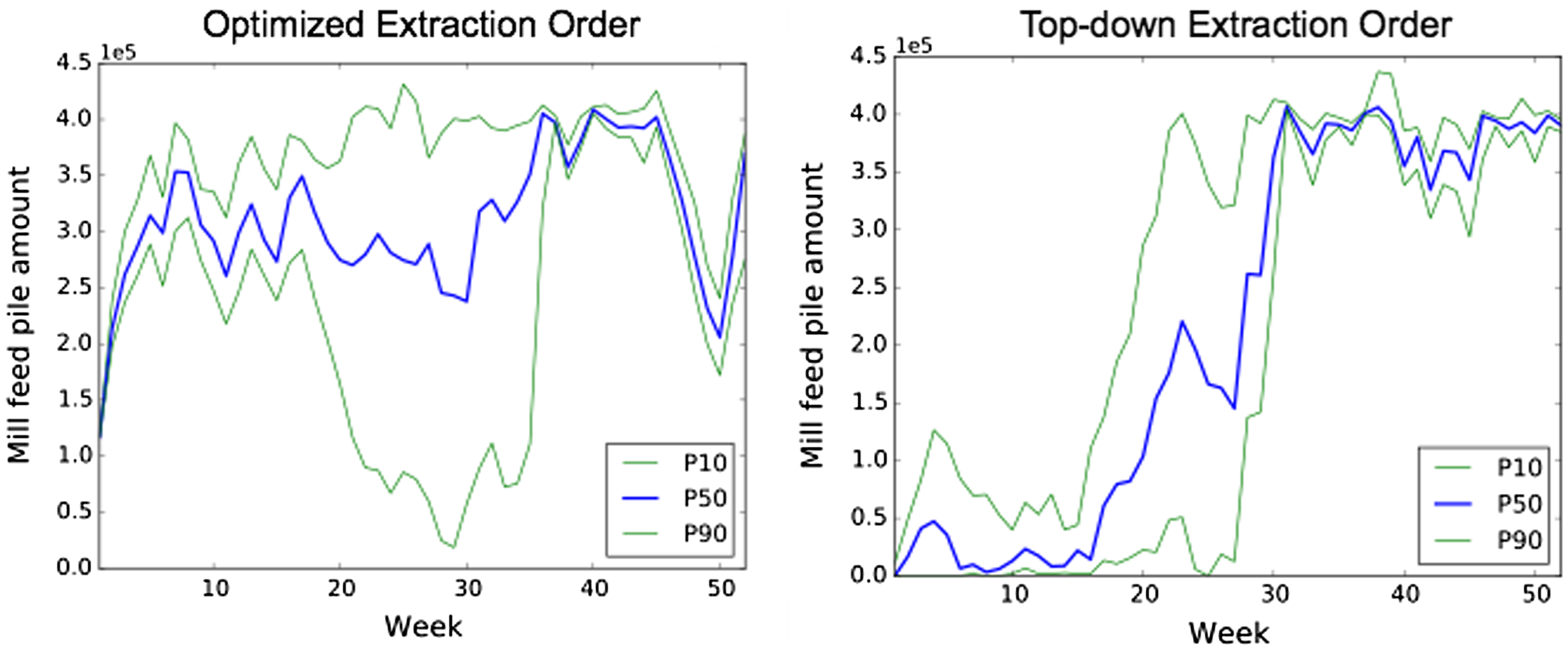
Risk profiles for the tonnage of material on the mill feed pile for the optimized extraction order and the top-down extraction order. The values for both graphs are obtained using the optimized destination policy (P10, P50, P90 correspond to the 10th, 50th, and 90th percentiles, respectively).
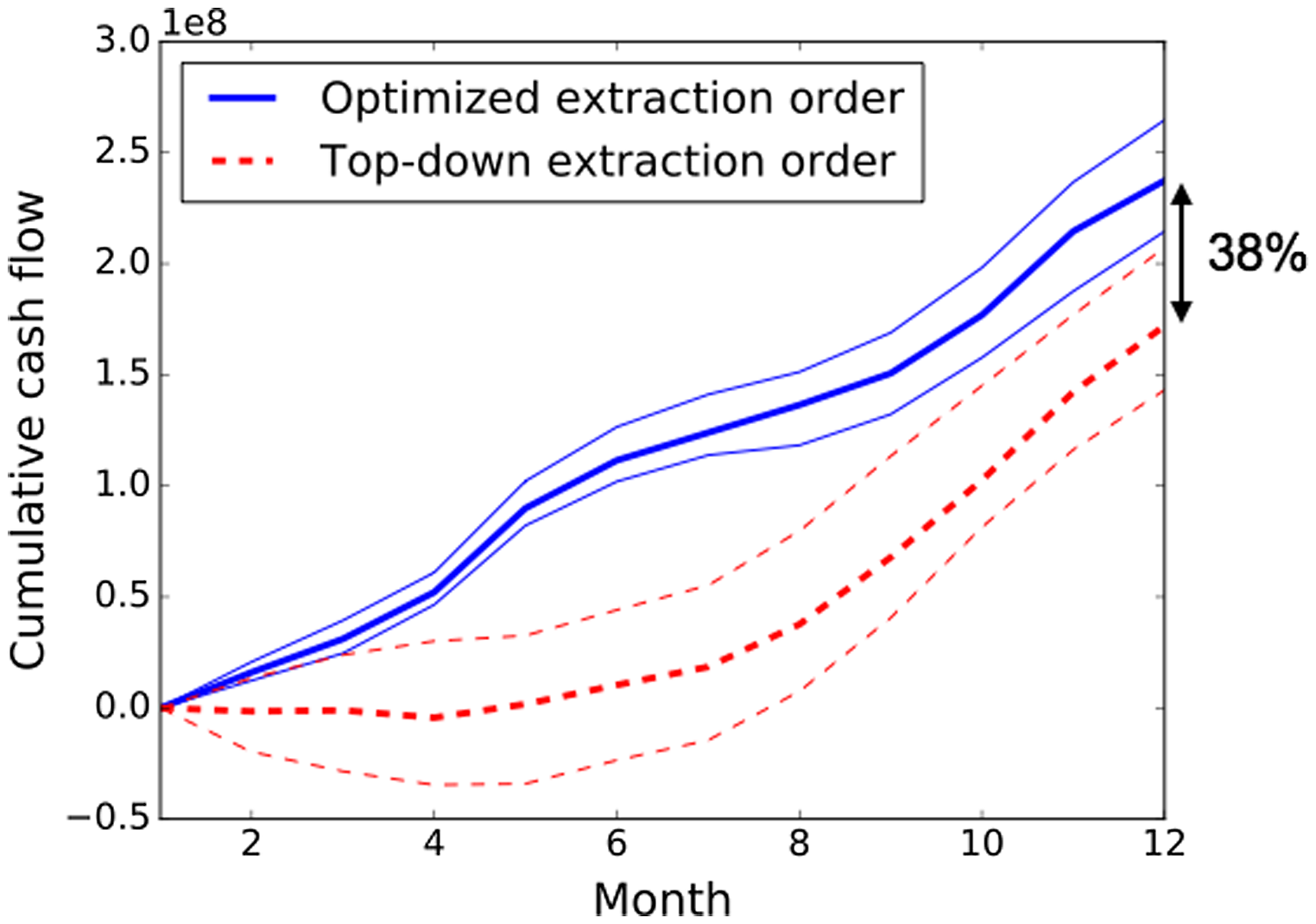
Cumulative cash flows for the optimized extraction order and the top-down extraction order (same colour lines correspond to the 10th, 50th, and 90th percentiles of related extraction orders).
Conclusions
This paper shows how state-dependent policies can be used to incorporate new information into short-term mine production planning. The main mechanism for doing so consists of encoding solutions as parameterized functions of the state, rather than encoding them as decision vectors. This allows the response to new information to be determined in advance for whatever the new information may be, and to formulate the search for the best response as a finite-dimensional optimization problem. This type of pre-optimized adaptive response should be particularly helpful when the new data results in a reduction of (local) uncertainty as it is commonly the case, for instance, by determining grade and grade variability with high accuracy.
The relationship between optimized adaptive policies and more traditional operations research (OR) methods has been relatively little studied (for an exception, see Defourny et al. 2012) and would make an interesting topic for future research. At a higher level, the advantages of adaptive policies are speed of execution (due to the fact that the decisions for each state are “pre-optimized”), as well as the availability of data-driven optimization methods that do not require a model (Sutton & Barto 1998). OR techniques, on the other hand, can be very efficient for problems where the decision vector for each period is high dimensional, especially for certain classes of objective functions and constraints.
The case study illustrates the benefits of using state-dependent policies for determining how destination decisions should adapt to new information about the material that is allocated. The use of state-dependent destination policies was shown to lead to better cash flows and more reliable mill usage, as compared to a heuristic policy similar to maximizing economic block value. Beyond value considerations, the type of short-term analysis conducted here can point out where the risk lies in terms of both time (for instance, weeks 20–35 in Figure 6) and space (by identifying where the blocks extracted in that time frame are located within the deposit). The analysis could also help mill operators decide in advance when the best time to close the mill for maintenance would be. The specific policy used in the case study is conceptually simple: for each decision, it performs a maximization over a very small number of variables (equal to the number of destinations). The function that is maximized is an arithmetic function of grades, recoveries, costs and feed pile tonnage. In practice, implementing such a policy would require a system that feeds the values of variable quantities such as mining block grade and feed pile tonnage into a computerized system that recommends the best destination.
The framework for the inclusion of new information using state-dependent policies lays the groundwork for a variety of future improvements and extensions. One key extension is the integration of actual sensor data into the uncertainty update process. This can be approached using a variety of methods, from geostatistical methods, such as stochastic simulation with successive residuals (Jewbali & Dimitrakopoulos 2011), to data assimilation methods, such as ensemble Kalman filtering (Evensen 1994), or particle filtering (Del Moral 1997).
The case study in this paper used a relatively simple form for the parametric state-dependent policy. While this performed better than other approaches, it is worth investigating whether further gains can be made by using more complex policies and more advanced policy optimization methods. Another direction for future research concerns more detailed modelling of aspects that are important for short-term mine planning. For the case study presented in this paper, this can involve accurately assessing the cost of stopping the mill based on energy, labour and opportunity costs. In general, the modelling of variables, such as equipment availability, contractual requirements on the output, or seasonal variations in production in difficult climates, may prove to be important for accurately assessing the value of a short-term plan.
On a last note, although state-dependent policies offer pre-optimized decisions for each state, the policy itself may need to be re-optimized in light of new information, only if and when that information indicates a change in the dynamics of the system. Although adaptive decision-making and off-policy learning is an area of ongoing research, the issue is at present addressed by monitoring the performance of a policy. In terms of short-term mine planning, the dynamics of the related system tend to change relatively slowly.
Disclosure statement
No potential conflict of interest was reported by the authors.
Funding
The work in this paper was funded by the National Sciences and Engineering Research Council of Canada (NSERC) CDR Grant 411270 and NSERC Discovery Grant 239019, the industry consortium members of McGill's COSMO Stochastic Mine Planning Laboratory (AngloGold Ashanti, Barrick Gold, BHP Billiton, De Beers, Kinross Gold, Newmont Mining, and Vale); and the Canada Research Chairs Program.