
Abstract
One of the challenges in applying automated chemistry workstations to problems of reaction optimization entails choosing an appropriate optimization algorithm. In the study described herein, 10 different algorithms have been examined for efficacy in searching reaction spaces using scenarios that explore effects of workstation parallelism and search space size. The algorithms differ in scheduling (serial vs. parallel), adaptive features (open loop vs. closed loop), and methods for stepping through the search space. Several two-tiered algorithms enable a breadth-first survey followed by an indepth optimization. For a workstation with modest parallel capacity, a parallel but nonadaptive algorithm is most effective in small or coarse-grained search spaces, whereas parallel adaptive algorithms are superior for examining large or fine-grained search spaces. The parallel adaptive algorithms become increasingly effective as the size of the search space increases. A serial algorithm is most attractive with a serial workstation, or when chemical resources are limited regardless of workstation or search space. The breadth-first survey of the twotiered algorithms significantly improves the efficiency of the subsequent in-depth optimization. The results obtained provide guidance in choosing optimization algorithms, designing more sophisticated algorithms, and developing workstations with parallel and/or adaptive features that use such algorithms.
Introduction
Reaction optimization is an integral part of experimental chemistry. Chemists who carry out reaction optimizations typically perform a lengthy search concerning the interplay of numerous variables in a given reaction (temperature, reagents, catalysts, concentration, solvent, time, etc.) in pursuit of conditions that afford increased yields. Efforts to mitigate the labor-intensive aspects of reaction optimization began in earnest more than 25 years ago with the development of automated single-batch reactors (principally at Roussel Uclaf, 1 Smith Kline and French, 2 –5 Takeda Chemical Industries, 6 –9 and Conservatoire National des Arts et Métiers 10,11 ), an effort that continues to this day. 12 –14 The advent of laboratory robots some 20 years ago led to multireactor workstations, which engendered greater flexibility in sample handling and opened the possibility of extensive parallelism in carrying out chemical reactions. 15 –19
Several early designs of both batch reactors and robotic systems included provisions for adaptive experimentation, in which the results of one operation or experiment are used as feedback to guide the course of subsequent experimentation. 2,6,16 –18,20,21 Use of the well-known Simplex algorithm, 22 which provides for a sequential hill-climbing process, enables one reaction to be performed after another under successively modified conditions in pursuit of a higher reaction yield. Although attractive for adaptive experimentation, the inherently serial nature of the Simplex algorithm precluded any possible parallelism available with automated multireactor systems. This early work in reaction optimization largely predated combinatorial chemistry and the demands of parallel synthesis. 23,24
The automated chemistry workstations that have been constructed over the past decade 25 –31 have chiefly been designed for applications in high-throughput screening and combinatorial chemistry rather than reaction optimization. 32 The former systems place a premium on processing large numbers of samples, and the type of data-driven feedback that underlies adaptive experimentation apparently is either not needed or not readily obtainable. In many respects, the ability to gain information from multiple experiments at the same time (and undoubtedly the greater ease of building open-loop versus closed-loop automated systems) 23 has overshadowed the attributes of adaptive experimentation. Consequently, most current automated chemistry workstations include provisions for parallelism and few, if any, capabilities for adaptive experimentation.
Our work in automated chemistry has focused on (1) development of microscale multireactor automated chemistry workstations for use in fundamental studies and optimization of chemical reactions in domains of relatively clean chemistry 33 –35 and (2) developing a software environment for diverse experimentation with such workstations. 36 –45 A suite of experiment-planning modules enables scheduling of experiments in parallel as well as automated decision making concerning the data obtained from prior or ongoing experiments. The decision-making features support adaptive experimentation, either in a serial mode (e.g., the Simplex algorithm) or, more interestingly, in a parallel mode. Approaches that blend parallel and adaptive experimentation capabilities enable reaction optimization to be pursued aggressively. Altogether, 10 different algorithms were developed that could be applied to problems of reaction optimization.
During the course of developing approaches for blending parallel and adaptive experimentation, it became apparent that more information was needed concerning the efficacy of diverse optimization algorithms upon implementation in automated chemistry workstations. In this article, we provide a brief overview of the hardware and software architecture of the automated chemistry workstation. The features of each optimization module are summarized. The performance of the algorithms on fictive workstations is evaluated in scenarios that explore differences in the size of the search space and the parallel capabilities of the workstations. This work provides insight into the design and selection of appropriate algorithms for use in unconstrained searches, such as occur in studies of reaction optimization.
Results and Discussion
Automated Chemistry Workstation
The automated chemistry workstation hardware consists of a multivessel reaction station, robot for moving samples and chemicals, analytical instruments, and other components. The software package includes features for composing experimental plans, managing resources (chemicals and containers), scheduling experiments, and evaluating data. 35 –45 Individual experimental plans are composed by drawing on a set of commands that describe operations of the robotic arm and other hardware. A timing table automatically determines the duration of each command.
A schedule of one experimental plan lists the duration required for each of the actions of the robotic arm. Multiple experimental plans can be implemented in parallel through the use of a scheduler that offsets the start time of intact experimental plans and interleaves (in a comblike manner) the individual commands of the respective plans. In this manner, the total duration of the set of parallel experimental plans is generally compressed by up to 10-fold compared with that for serial implementation. 36
An outline of the flow of information in the workstation is provided in Fig. 1. When a set of experimental plans is to be implemented, the plans are first examined for resource availability, including chemicals (solvents, reactants, reagents) and containers (reaction vessels, storage vials). The resource manager divides the experiments into those for which resources are available (resource sufficient; ready to be implemented) and those that must await resources (resource insufficient; waiting). The experiments for which resources are sufficient are then passed to the scheduler for parallel implementation to the greatest extent possible. As additional resources are made available, waiting experiments can be placed in queue for scheduling.
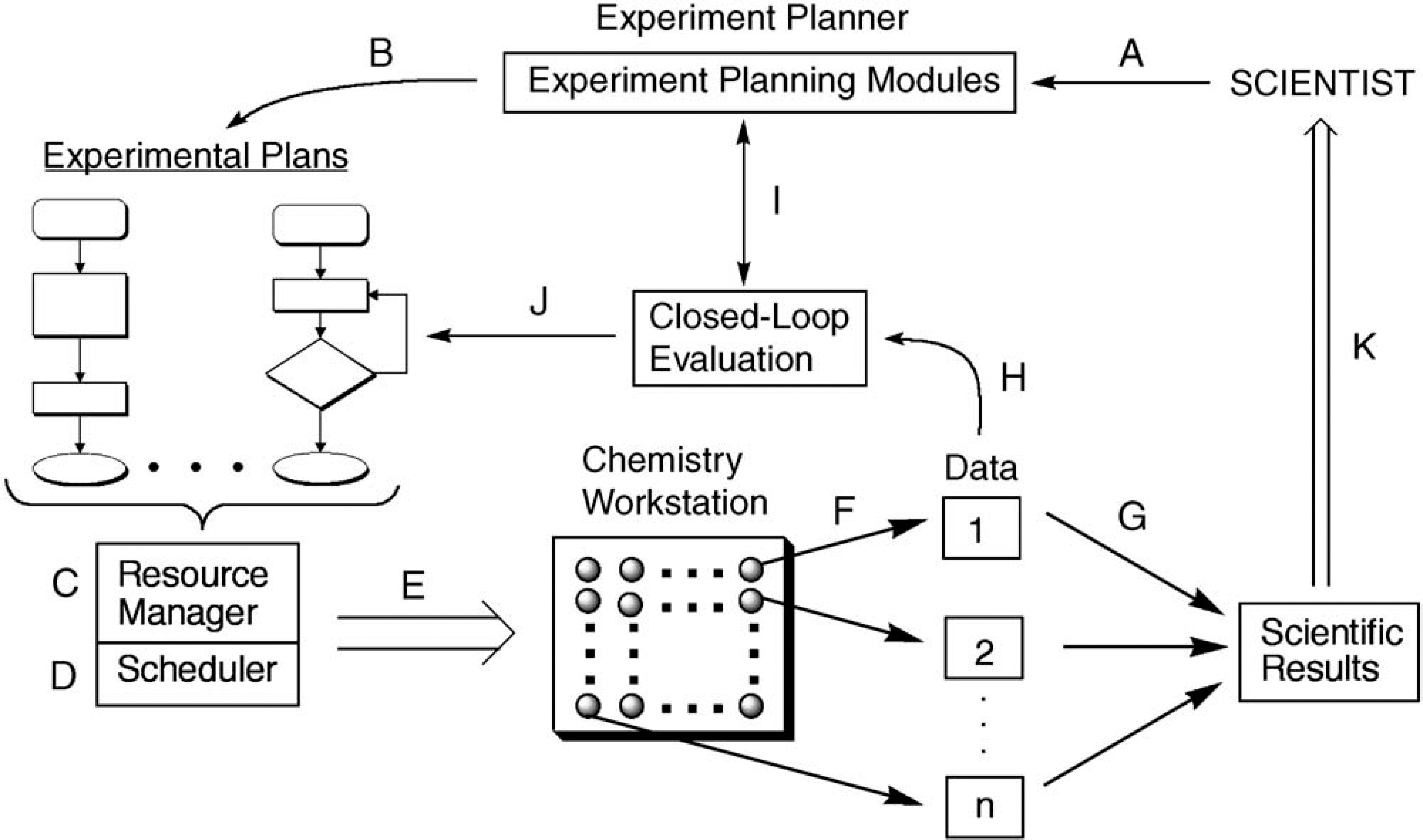
Flow diagram illustrating the throughput of experiments in an automated chemistry workstation. (A) The scientist works with the experiment planner to compose an experimental plan. (B) Each experimental plan consists of a list of commands, including simple directives or conditionals that depend on experimental data. (C) A resource manager tabulates the total resource demands, including chemicals (reagents, reaction solvents, solvents used by instruments) and containers (reaction vessels, sample vials, etc.). The schedule is separated into executable experiments and experiments awaiting resources. (D) The scheduler renders the executable experiments in parallel to the extent possible. (E) The scheduled experiments are passed to the automated chemistry workstation. (F) Data are generated from analytical instruments. (G) In open-loop experimentation, in which no decisions are made automatically about ongoing or planned experiments, the data are combined in an output file. (H) In closed-loop experimentation, in which decisions are made without user intervention about ongoing or planned experiments, the data are passed to the evaluation unit of the experiment-planning module. (I) The data are evaluated in the context of the scientific objective as stated in the experimental plan. (J) Depending on the results of the evaluation, ongoing experiments can be terminated or altered, pending experiments can be expunged from the queue, or new experiments can be spawned. (K) The results from open-loop and closed-loop experiments are available for review by the scientist.
The workstation is equipped for open-loop experimentation as well as closed-loop experimentation. In open-loop experimentation, no decisions are made on the basis of data from previous or ongoing experiments. By contrast, in closed-loop experimentation, data are evaluated automatically, whereupon ongoing experiments can be altered and future experiments can be pruned, altered, or spawned in accord with the scientific objective stated at the outset by the user. 37,38 Closed-loop capabilities are essential for adaptive experimentation. Although decision making can involve the local course of individual experiments and/or the global course of sets of experiments, for the studies herein, the individual experiments are allowed to proceed as initially planned, and only the global course of experimentation is altered.
Optimization Algorithms
Ten distinct algorithms are available for reaction optimization. Three of the algorithms employ two-tiered searches (vide infra). The seven single-tiered algorithms are illustrated in Fig. 2 and are described as follows:
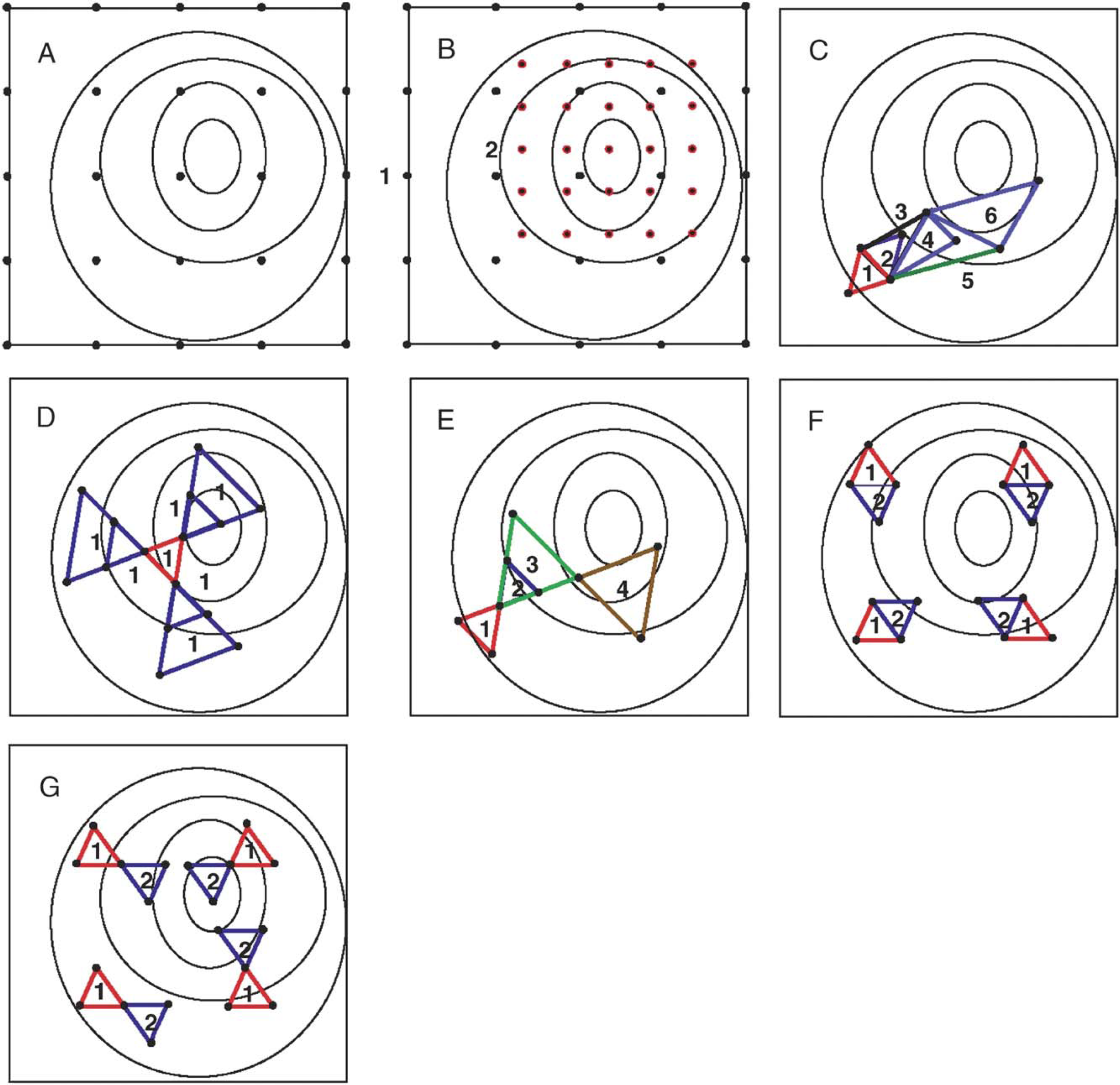
Schematic illustration of seven optimization algorithms. (A) Factorial design/grid search (FD/GS). All 25 points are examined in the 5 × 5 grid shown. (B) Successive focused grid search (SFGS). The example provided starts with a 5 × 5 grid in the first cycle. After evaluation of all 25 experiments, the search continues with a second cycle that is half the size of the search space and focused on the optimum region. (C) Composite modified Simplex (CMS). The simplexes illustrated originate from initiation (1), reflection (2, 4, and 6) or expansion (3, 5). (D) Multidirectional search with mandatory points only (MDS-mo). Four cycles of experimentation are shown, illustrating initiation (1), reflection (2), expansion (3), and reflection (4). (E) Multidirectional search (MDS). One cycle is shown that consists of 3 mandatory points and 12 exploratory points; the latter are formed by reflection and expansion. (F) Parallel Simplex search (PSS). Two cycles are shown of a singly partitioned search space, wherein four CMS searches are performed in parallel. (G) Parallel multidirectional search (PMDS'). Two cycles are shown of a singly partitioned search space, wherein four MDS-mo searches are performed in parallel.
The factorial design or grid search (FD/GS) module enables a comprehensive investigation of all levels of each variable or factor. 39 The experiments examine the points in a regular grid and can be scheduled in parallel. The result of a single experiment (i.e., examination of one grid point) has no effect on the other experiments. Termination of the search is only dependent on the complete evaluation of all points that form the grid.
The successive focused grid search (SFGS) examines a regular grid similar to FD/GS and then examines a second grid of smaller size that is situated around the optimal region identified in the prior grid. This process is repeated until a termination criterion is satisfied. 41
The composite modified Simplex (CMS) 46 uses the Simplex method, accompanied by a host of modifications (enabling expansion, contraction, fit to boundary, etc.). 37 A simplex contains n + 1 points for the initial cycle, where n is the number of dimensions of the search space. After evaluation of all points, the one worst point of the simplex is discarded, and a new simplex is created by reflection away from the worst point. Each cycle after the first cycle entails performing a single experiment; thus, the Simplex search is inherently serial. The search continues until a termination criterion is satisfied.
The multidirectional search with mandatory points only (MDS-mo) module, based on the work of Torczon 47 and Dennis and Torczon, 48 enables directed evolutionary searches in parallel. 40 A simplex is first created (mandatory points). Upon evaluation of the initial simplex, all points but the one best point are discarded, and a reflection is performed in the direction away from the poor responses, which gives the next simplex. Subsequent movement (reflection, expansion, contraction, and so on) proceeds through the search space until a termination criterion is satisfied.
The multidirectional search (MDS) module projects both mandatory points and exploratory points. The initial simplex constitutes the mandatory points. In anticipation of subsequent possible movements, exploratory points are projected along the axes of the initial simplex. Additional exploratory points can be projected to the extent that resources and workstation parallelism permit. Upon evaluation of the projected points, the search is refocused with a new set of mandatory and exploratory points and continues in this manner until a termination criterion is satisfied. 40
The parallel Simplex search (PSS) module enables multiple CMS searches to be performed in parallel. 42 The search terminates when one simplex converges (or all simplexes converge) on an optimum.
The parallel multidirectional search (PMDS') module enables multiple MDS-mo searches to be performed in parallel. PMDS' is to MDS-mo what PSS is to CMS. 49 The search continues until one simplex converges (or all simplexes converge) on an optimum.
To focus searches more effectively, we added features for two-tiered searching as illustrated in Fig. 3. 43,44 In this mode, a broad survey is first performed (tier 1) to identify the best region of the search space. In tier 2, an in-depth optimization is performed. The latter is performed with the CMS, MDS, or PSS algorithms.
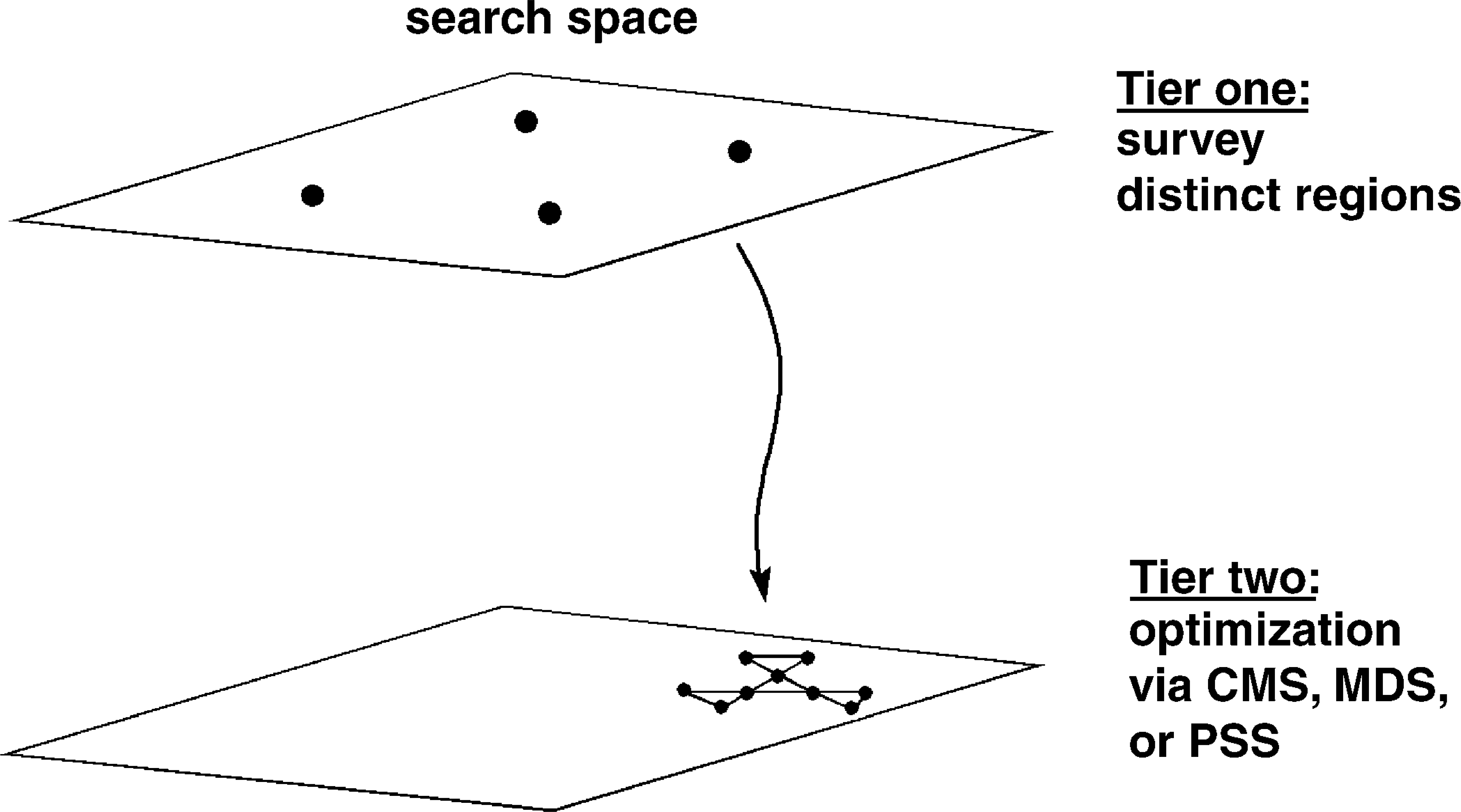
Two-tiered experimentation. A breadth-first survey identifies the appropriate starting point for a subsequent in-depth optimization with the CMS, MDS, or PSS algorithm.
The features of the 10 experiment-planning modules are listed in Table 1. The CMS module performs serial, adaptive experiments (though multiple experiments are performed in parallel in the first cycle). The FD/GS module affords parallel, nonadaptive experimentation. All other algorithms afford parallel adaptive experimentation. Each adaptive algorithm constitutes a direct search method (i.e., nonderivative) for optimization. 50 We now turn to evaluate the performance of the various algorithms.
Features of the experiment-planning modules
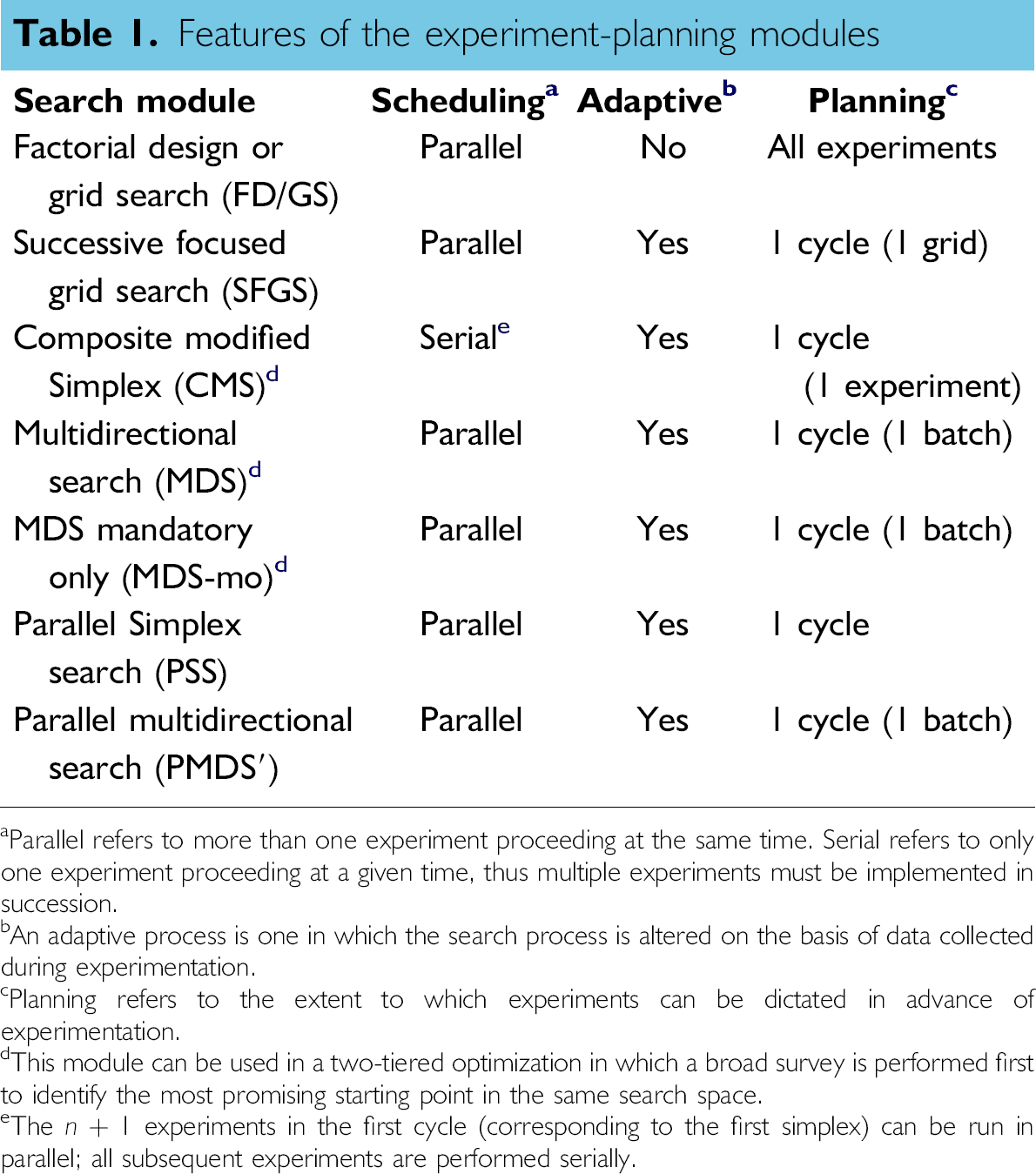
Parallel refers to more than one experiment proceeding at the same time. Serial refers to only one experiment proceeding at a given time, thus multiple experiments must be implemented in succession.
An adaptive process is one in which the search process is altered on the basis of data collected during experimentation.
Planning refers to the extent to which experiments can be dictated in advance of experimentation.
This module can be used in a two-tiered optimization in which a broad survey is performed first to identify the most promising starting point in the same search space.
The n + 1 experiments in the first cycle (corresponding to the first simplex) can be run in parallel; all subsequent experiments are performed serially.
Algorithm Evaluation
Three scenarios were employed to examine the performance of the optimization modules as a function of increasing parallel capabilities of the workstation and a function of increasingly large search spaces. The effect of increasing search space size was examined by altering the grain size of the search space. The key performance metrics are the total number of experiments performed, the total elapsed time, and the robot utilization. In all but the final simulation, the search space for the optimizations consists of two dimensions. The response surface is shown in Fig. 4.
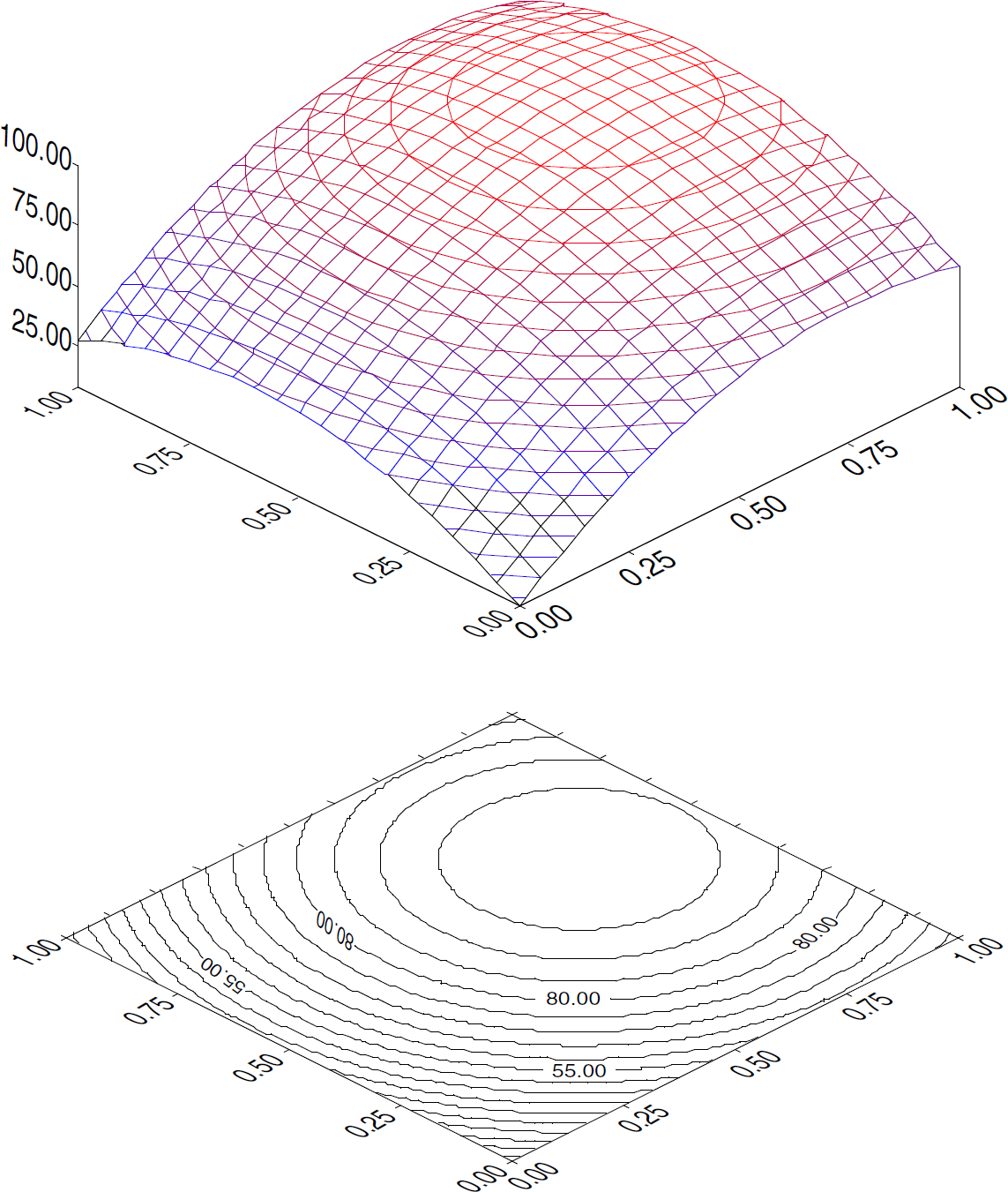
Response surface for a two-dimensional search space generated by the equation R = (1 − [x − 0.75] × [x − 0.75] -[y − 0.6] × [y − 0.6]) × 100.
Experimental template a

For uniformity across the various simulations, the duration of each addition and transfer operation was fixed to the respective value indicated above regardless of the volumes required at different locations in the search space.
Time in hours:minutes:seconds.
The maximum number of experiments that can be implemented in parallel depends both on the experimental template employed and the capabilities of the workstation. With the template shown in Table 2 and our current workstation, 35 a maximum of 44 experiments can be implemented in parallel. To explore the effects of changes in parallel capabilities of fictive workstations, we have adopted the timing and mechanical features of our current workstation 35 but artificially adjusted one of the resource parameters (e.g., number of reaction vessels) to a specific value to limit the capacity (i.e., number of parallel experiments). The value ranged from 1 to 100 for fictive workstations, with capacity ranging from serial (1 experiment at a time) to highly parallel (up to 100 experiments possible). Note that all fictive workstations with capacity set at values >44 were then constrained in this case by the experimental template, which limited the maximum number of parallel experiments to 44.
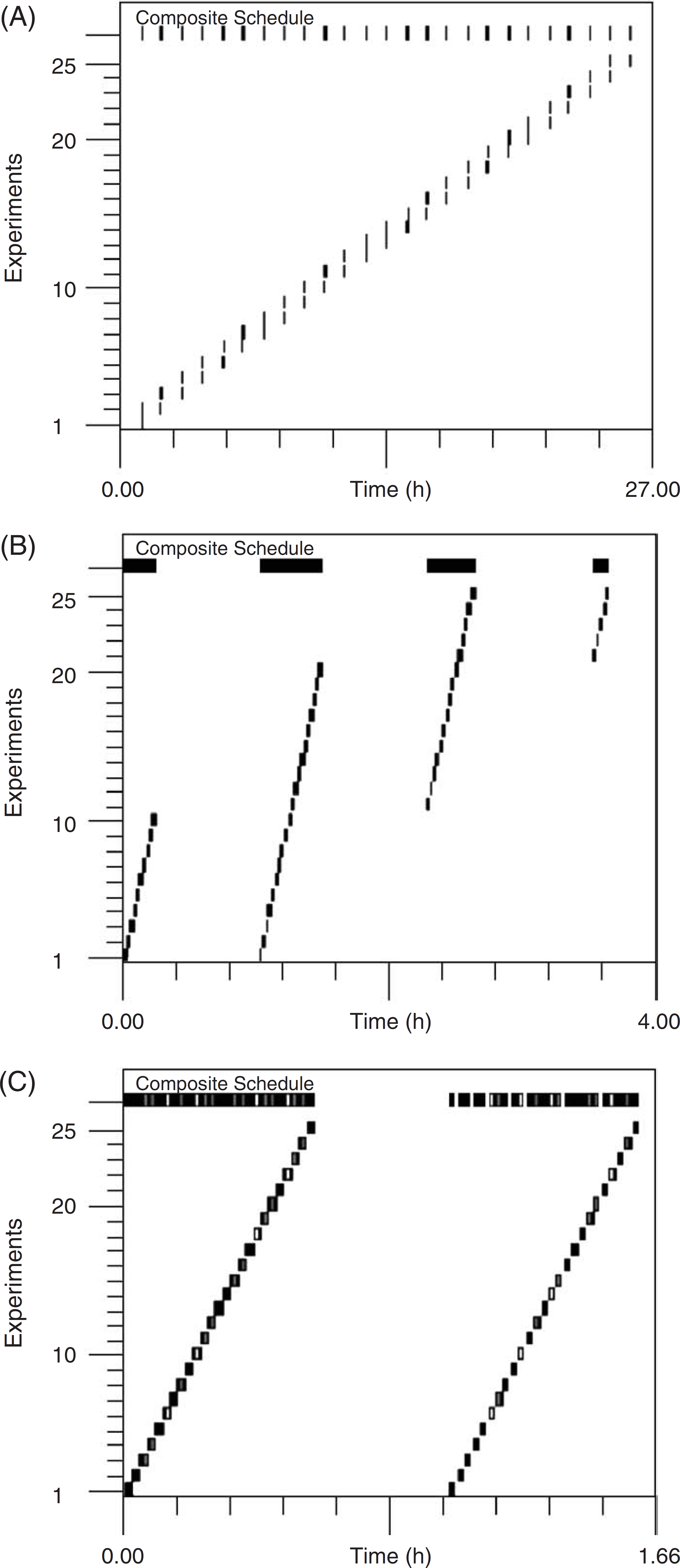
Gantt chart showing scheduled experiments in scenario 1. The marks indicate robot activity. The relative times of implementation of robotic motions for a given experiment are not changed but the start times are shifted to accomplish interleaving of commands in distinct experimental plans. The composite schedule of all individual experiments is displayed at the top of the Gantt chart. (A) Serial implementation. (B) A workstation capable of 10 experiments in parallel. (C) A workstation capable of 44 experiments in parallel (the maximum achievable with the template employed).
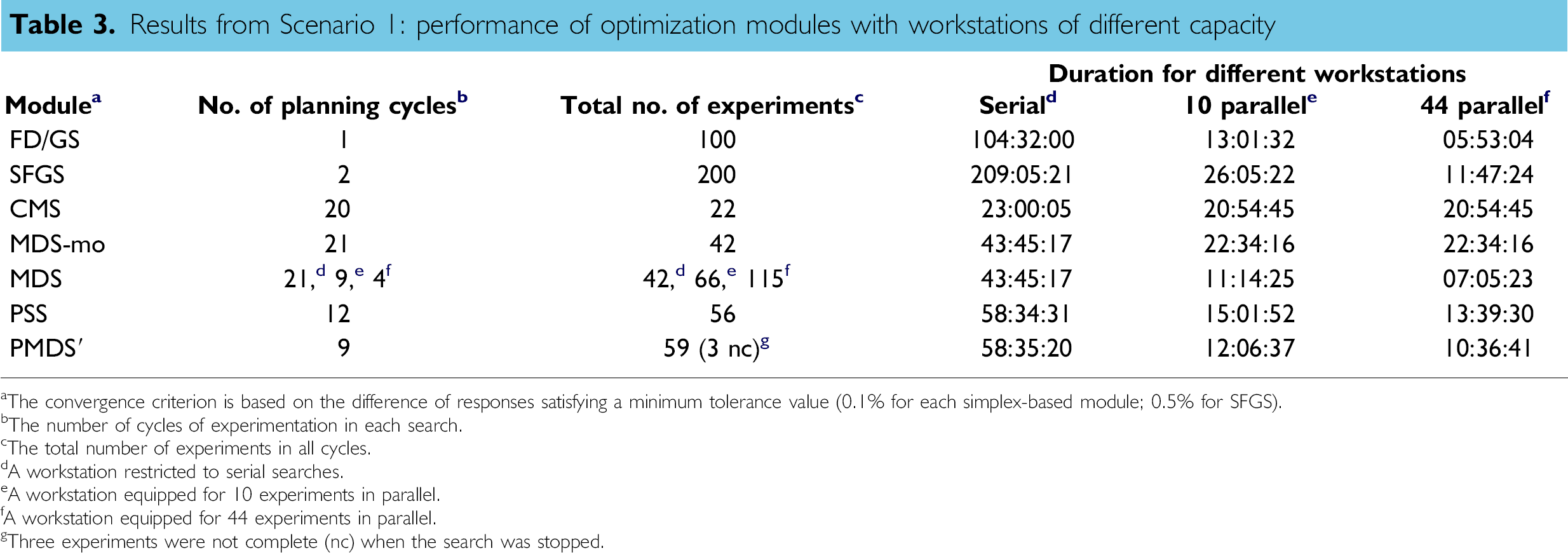
In SFGS, the initial grid size was set at 75% of the search space. The results are summarized in Table 3.
Results from Scenario 1: performance of optimization modules with workstations of different capacity
The convergence criterion is based on the difference of responses satisfying a minimum tolerance value (0.1% for each simplex-based module; 0.5% for SFGS).
The number of cycles of experimentation in each search.
The total number of experiments in all cycles.
A workstation restricted to serial searches.
A workstation equipped for 10 experiments in parallel.
A workstation equipped for 44 experiments in parallel.
Three experiments were not complete (nc) when the search was stopped.
The notable results are as follows:
For a serial workstation, the fastest search is provided by CMS, which (after the first cycle) only performs one experiment per cycle. CMS provides the fastest overall search because this algorithm projects the fewest experiments. The slowest searches result from those algorithms that afford the least amount of adaptive experimentation, namely FD/GS and SFGS. The algorithms that afford a blend of parallel and adaptive experimentation give searches of intermediate speed.
As the workstation is equipped with increasingly parallel capabilities (to 10 or 44 experiments in parallel), the open-loop FD/GS (and related SFGS) algorithm affords a dramatic increase (≈20-fold) in search speed. Essentially no change is observed with the inherently serial CMS algorithm. The parallel adaptive algorithms afford speed improvements of approximately two- to fivefold.
Considering the total number of experiments performed during the searches, SFGS was most profligate (200 experiments), whereas CMS was most parsimonious (22 experiments). The PSS, MDS-mo, and PMDS' algorithms each performed 40 60 experiments, regardless of available workstation processing power. The number of experiments performed with the MDS module increased, as expected, with the availability of increasingly parallel capabilities: from 42 for the serial workstation to 115 for the workstation capable of 44 experiments in parallel.
Other modes of comparison are possible, such as the measure of (1) robot utilization or (2) the number of validations of the optimum response that a search provides. Although an experimentalist may only be concerned about a given search, those searches that are performed with lower levels of robot utilization leave the workstation available for other searches. Some of the searches provided two (SFGS) or three (PSS) validations, whereas the others generally provided only one validation (data not shown). In summary, the goodness of a particular algorithm depends both on the parallel capabilities of the workstation, the overall scientific objectives, and the real-world constraints encountered by the experimentalist. The latter include the urgency of the search and the available chemical resources.
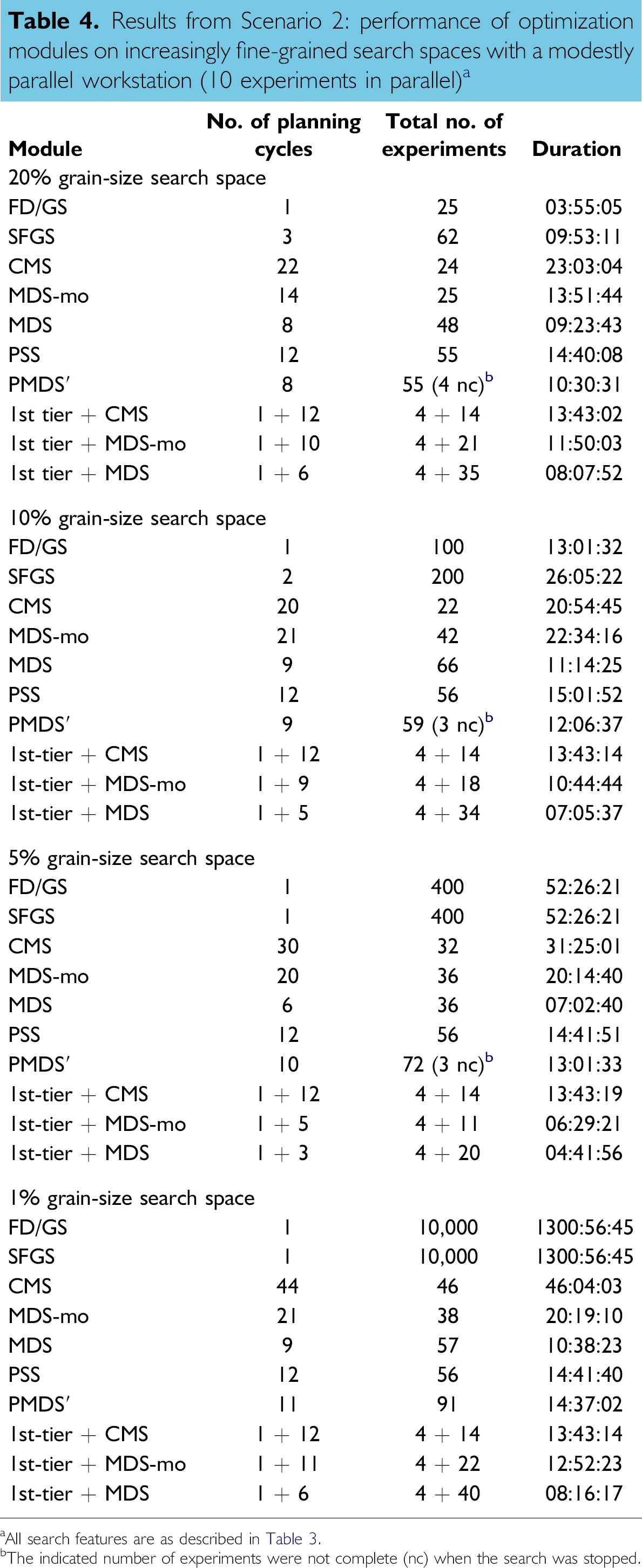
The results for the 10 optimization algorithms are listed in Table 4. The notable results are as follows:
Results from Scenario 2: performance of optimization modules on increasingly fine-grained search spaces with a modestly parallel workstation (10 experiments in parallel) a
All search features are as described in Table 3.
The indicated number of experiments were not complete (nc) when the search was stopped.
For the coarsest grain size, the fastest search was provided by the FD/GS module. The slowest search was observed with the algorithm having the least parallelism, namely CMS. The difference between FD/GS and CMS was approximately sixfold (4 h vs. 23 h), although the number of experiments was essentially identical (25, 24). The parallel adaptive algorithms provided searches of intermediate speed (≈10–16 h) and generally approximately twice as many experiments. However, each of the simplex-based algorithms (CMS, PSS, MDS, MDS-mo, PMDS') has the ability to contract, whereupon a more fine-grained search results. The focusing ability of the latter algorithms enables the identification of the optimum region of the response surface more readily than the fixed, coarse-grained search provided by FD/GS.
For the finest grain size, the fastest search among the single-tiered algorithms was provided by MDS (≈10.5 h). The slowest search was observed with FD/GS or SFGS, each of which required 1300 h. Indeed, each of the simplex-based searching modules gave vastly superior speeds (<50 h) compared with that of the FD/GS or SFGS searches. Moreover, the number of experiments performed by the simplex-based searching modules was < 100, with a minimum achieved by MDS-mo (38 experiments), to be compared with 10,000 experiments for FD/GS. The increased speed and fewer experiments provided by the simplex-based algorithms stems from their evolutive nature as well as the ability to expand the simplex size (and therefore move more rapidly) as the search evolves.
Regardless of search-space grain size, the inclusion of a breadth-first survey to identify the most promising region of the search space followed by in-depth optimization (CMS, MDS-mo, MDS) resulted in a faster search in every case. Indeed, the fastest search overall in all search spaces except the most coarse-grained was provided by the two-tiered search with MDS as the second-tier optimization algorithm.
Consider the performance of a given single-tiered algorithm as the search space becomes more fine-grained. The duration of the FD/GS search increased by 325-fold upon the 20-fold change in grain size in the two-dimensional space. On the other hand, the duration of the CMS search increased by twofold, whereas that of the searches provided by the PSS and MDS algorithms remained almost unchanged. In terms of number of experiments performed, the search provided by the FD/GS module resulted in an increase of 400-fold, totaling 9975 additional experiments. On the other hand, the number of experiments with the simplex-based searches increased by less than twofold for a given algorithm, ranging from 24 to 59 for the 20% grain size to 38 to 91 total experiments for the 1% grain size. Indeed, the search provided by the PSS algorithm was completed in essentially the same duration and required only one additional experiment at the 1% versus 20% grain size.
An analogous search using the simplex-based modules was performed on a three-dimensional surface. The search space grain size was 4.54% (22 points per each dimension), which would correspond to 10,648 points in the three-dimensional space if every point in the regularly gridded space were examined. The results are shown in Table 5. On the basis of search duration, the rank order of the single-tier modules was identical to that in the corresponding two-dimensional search, as was the rank order of the two-tier modules. These quantitative data provide the basis for evaluation of the performance of diverse search algorithms in challenging search spaces.
Results from Scenario 3: performance of optimization modules on challenging search spaces with a relatively efficient workstation (44 experiments in parallel) a
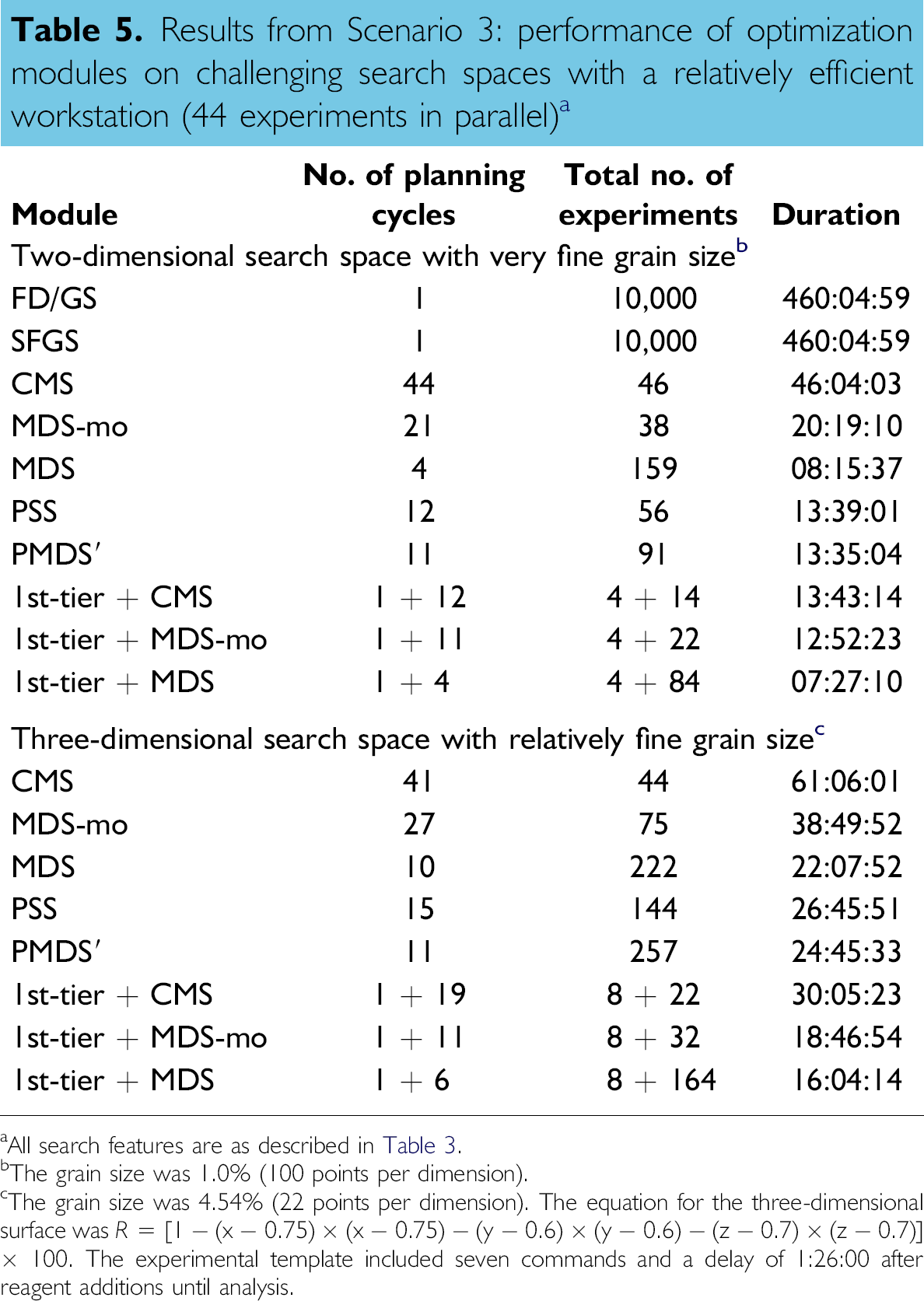
All search features are as described in Table 3.
The grain size was 1.0% (100 points per dimension).
The grain size was 4.54% (22 points per dimension). The equation for the three-dimensional surface was R =[1 − (x − 0.75) × (x − 0.75) − (y − 0.6) × (y − 0.6) − (z − 0.7) × (z − 0.7)] × 100. The experimental template included seven commands and a delay of 1:26:00 after reagent additions until analysis.
Conclusions
Automated chemistry workstations suitably designed for investigation of chemical reactions can enable rapid optimization of reaction conditions. The question of which optimization algorithm to employ depends on the availability of chemical resources, the urgency in obtaining results, and the scientific objectives of the search. Ten optimization algorithms were examined. With a coarse-grained (or small) search space and a workstation with modest parallel capabilities, the parallel but nonadaptive FD/GS module provides the most rapid search. With a serial workstation, the traditional serial, adaptive CMS algorithm provides the most rapid search. With a more fine-grained (or large) search space, the parallel, adaptive algorithms (MDS, PMDS', PSS) provide the most rapid searches. The two-tiered algorithms appear generally beneficial regardless of search size or parallel capabilities. The findings presented herein should be valuable in choosing or modifying algorithms for examination of search spaces and in guiding the designs of software and hardware features in workstations for automated experimentation.
Acknowledgment
The authors thank Sumitomo Chemical Co., Ltd. (Osaka, Japan) for support of this work.