
Abstract
In recent decades, the number of large-scale surveys that have included measures of the Big Five personality traits in their standard questionnaires has grown sharply both in Germany and internationally. Consequently, a vast, heterogeneous, high-quality data base is now readily available to personality psychologists for secondary analyses. In this paper, we provide an overview of 25 public large-scale surveys assessing the Big Five. Our aim is to increase researchers’ awareness of the availability and analytical potential of these data, and ultimately to increase their reuse. We restricted our selection to surveys of the adult population, conducted in Germany, based on probabilistic samples with a minimum sample size of 1,500 respondents, and assessing all Big Five dimensions with a validated Big Five instrument. We describe the study designs, the measures used to assess the Big Five, and the research potential of these valuable data.
Relevance Statement
In recent decades, the number of large-scale surveys that have included measures of the Big Five personality traits in their standard questionnaires has grown sharply both in Germany and internationally. Consequently, a vast, heterogeneous, high-quality data base is now readily available to personality psychologists for secondary analyses. In this paper, we provide an overview of 25 public large-scale surveys assessing the Big Five. Our aim is to increase researchers’ awareness of the availability and analytical potential of these data, and ultimately to increase their reuse. We restricted our selection to surveys of the adult population, conducted in Germany, based on probabilistic samples with a minimum sample size of 1,500 respondents, and assessing all Big Five dimensions with a validated Big Five instrument. We describe the study designs, the measures used to assess the Big Five, and the research potential of these valuable data.
Key Insights
overview of 25 public large-scale surveys assessing the Big Five description of analytical potential of these data aim to increase researchers’ awareness of the availability
Keywords
In recent decades, the Big Five personality dimensions have become increasingly established as a comprehensive framework to describe personality (e.g., John et al., 2008; McCrae & Costa, 2008). This has led to broad interest in their assessment, even in fields outside core personality research, such as sociology, economics, and epidemiology. Nowadays, the Big Five are included in most large-scale social surveys as an almost standard construct, like subjective well-being.
The data resulting from these large-scale social surveys are highly valuable for personality research. The public large-scale surveys include a variety of additional constructs, they rely mostly on population-representative or at least heterogeneous samples, and often follow a longitudinal design, allowing to address key research questions of personality psychologists. Moreover, these public large-scale surveys have numerous advantages in terms of sample size and sample quality compared to the typically self-conducted small-scale studies still dominating personality psychology and adjacent fields. Self-conducted studies are usually based on small, selective samples of college students or—as it is increasingly common today—samples collected using Amazon Mechanical Turk (MTurk) (e.g., Webb & Tangney, 2022). As well-funded programs run by professionals specialized in survey research methods, these surveys typically far exceed the scope of data collections that an individual researcher or research group could ever hope to carry out alone. Many of these survey programs comprise panel data or repeated cross-sectional data that enable longitudinal analyses, greatly expanding the type of research questions that can be answered and offering opportunities for causal inference (e.g., by using fixed-effects models). These data are usually freely available to personality psychologists (and other researchers) for secondary analyses. However, apart from a few highly prominent and widely used surveys, such as the German Socio-Economic Panel (SOEP; Goebel et al., 2019), most of the large-scale surveys presented in this paper do not appear to be widely known among personality psychologists and remain underutilized in current research. This is unfortunate because these surveys have enormous analytical potential for research on the development, consequences, or predictors of personality traits—a potential that has thus far lain largely dormant. Indeed, many of these surveys are like hidden gems that have yet to be discovered by personality psychologists.
The aim of the present paper is therefore to provide researchers in personality psychology and beyond with an overview of these available and reusable data sets. Because they are so numerous, we deliberately limited this overview to surveys that (a) focused on the adult population, (b) were conducted in Germany, (c) were based on probability samples, (d) had a minimum sample size of about 1,500 respondents, and (e) included an assessment of all Big Five dimensions with a validated Big Five instrument.
Search Strategy
In the first step, we included surveys in our overview with which we were personally familiar by virtue of having worked extensively with them in the past. Second, to provide a more comprehensive and less subjective overview, we systematically searched the databases of the following German research data centers using the key words We invite researchers to add potentially overseen studies fulfilling our criteria in the overview tables available in the OSF project (see Supplementary Materials).
Overview of the Selected Surveys
In what follows, we give an aggregated overview of the selected surveys. In this overview, we address central aspects of the study designs and the measures used to assess the Big Five. These central aspects largely define the research questions that can be posed around the Big Five. In a next step, we sketch some research potentials that emerge from further characteristics in the surveys. In addition, Table 1 provides a structured overview of the substantive focus of each survey, and Table 2 summarizes details of their designs, sample sizes, personality measures, etc.
General Overview of the Included Data Sets
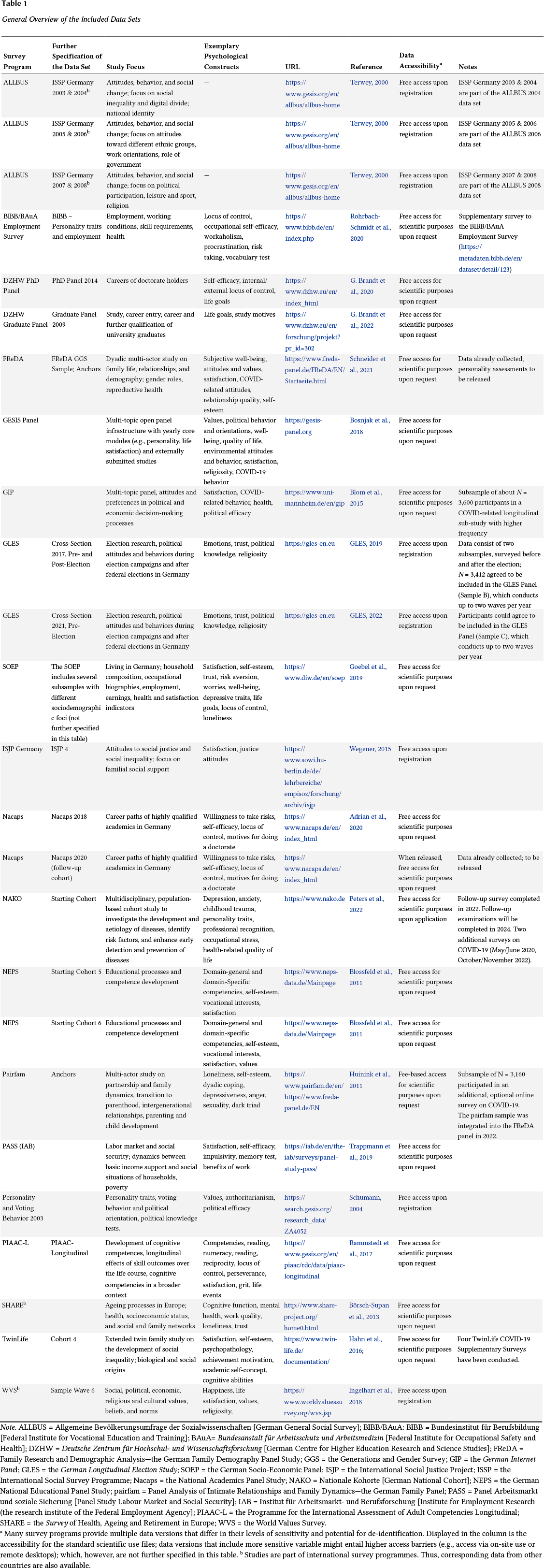
a Many survey programs provide multiple data versions that differ in their levels of sensitivity and potential for de-identification. Displayed in the column is the accessibility for the standard scientific use files; data versions that include more sensitive variable might entail higher access barriers (e.g., access via on-site use or remote desktops); which, however, are not further specified in this table. b Studies are part of international survey programmes. Thus, corresponding data from other countries are also available.
Detailed Overview of the Included Data Sets and the Assessment of the Big Five
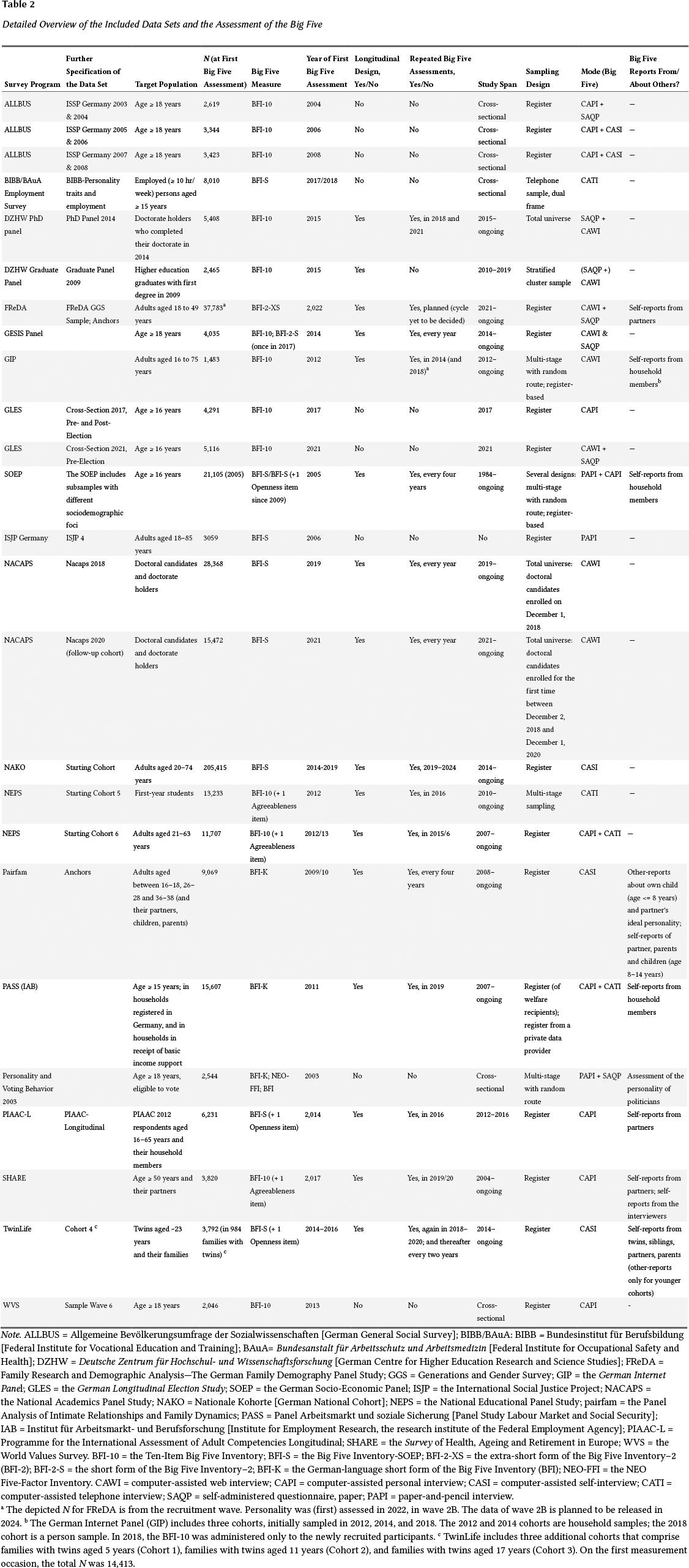
a The depicted
Research Design
Only a few of the identified survey programs are cross-sectional or repeated cross-sections in which independent samples are drawn for each wave (e.g., the German General Social Survey [ALLBUS], the World Values Survey [WVS]), whereas most of them are panel surveys following the same respondents over many years. In the period covered by the present paper, some of these panel surveys assessed the Big Five multiple times. For example, the Panel Analysis of Intimate Relationships and Family Dynamics (pairfam) and the SOEP reassessed the Big Five every four years, and the GESIS Panel did so yearly.
Sampling Design and Target Population
As noted earlier, we included only surveys that targeted either the general adult population or adult subpopulations in Germany (with a minimum age of 15 years, but with the majority of the target population aged 18 years or over). These adult subpopulations included, for example, the elderly (the Survey of Health, Ageing and Retirement in Europe [SHARE]), (un-)employed persons (the Panel Study Labour Market and Social Security [PASS]; the BIBB/BAuA Employment Survey), and highly educated persons (the DZHW Graduate Panel and PhD Panel). Further, we included only large-scale surveys comprising at least 1,500 respondents. We also restricted our selection to surveys based on randomly selected respondents, so that they were representative of the corresponding population. Compared with non-random samples, such as convenience samples or quota samples, such random samples have important advantages from the perspective of representativeness and correct statistical inference to the population level (Lohr, 2021). Random sampling in these surveys was done via random-route procedures developed by the Arbeitskreis Deutscher Markt- und Sozialforschungsinstitute (ADM; e.g., the survey Personality and Voting Behavior 2003), was register-based (e.g., ALLBUS, the GESIS Panel), or was a combination of both (e.g., the SOEP, the German Internet Panel [GIP]). For telephone surveys, established random digit dialing procedures for dual frame samples (e.g., Gabler et al., 2012) were used. In some cases, total universe samples of the specific target group were drawn (e.g., the DZHW PhD Panel).
Most of the longitudinal surveys included in our overview were regularly refreshed with new samples in order to address panel mortality. This ensured that their potential for longitudinal analyses was preserved despite dropout.
Thematic Foci of the Survey Programs
The thematic orientation differs greatly across the included survey programs. Most have more or less clear thematic foci. For example, pairfam focused on partnership and fertility; the German National Educational Panel Study (NEPS) on educational pathways and competence development; PASS on the labor market, poverty, and the welfare state; the BIBB/BAuA Employment Survey on qualification and working conditions; and SHARE on health and retirement. By contrast, the GESIS Panel, as an omnibus access panel, does not have a specific thematic focus, but rather includes a large variety of constructs according to the submitted modules (e.g., subjective health, environmental attitudes and behavior, attitudes toward refugees, social and political participation). All selected survey programs include a detailed assessment of sociodemographic background variables, such as education, socioeconomic status, income, and migration status.
Prompted by the COVID-19 pandemic, several surveys (e.g., GIP, the German TwinLife study, the GESIS Panel) included additional modules focusing on behavior, experiences, and attitudes during the pandemic.
Big Five Measures
The selected surveys differ in the measures used to assess personality. Nearly every survey that fulfilled our criteria used a short-scale variant of the Big Five Inventory (BFI; John et al., 2008; German adaptation by Rammstedt, 1997). The most likely reason for this is the fact that short and ultra-short forms of the BFI are available and can be used free of charge for research purposes.
Surveys such as the GESIS Panel, GIP, NEPS
2
As suggested by Rammstedt and John (2007), both NEPS and SHARE also included an additional Agreeableness item.
Only one of the selected surveys—Personality and Voting Behavior 2003—included in addition to BFI scales a personality measure that did not hail from the BFI family, namely, the NEO Five-Factor Inventory (NEO-FFI; Costa & McCrae, 1989, German adaptation Borkenau & Ostendorf, 1991), the 60-item short form of the NEO Personality Inventory (NEO-PI; Costa & McCrae, 1992). The GESIS Panel and Personality and Voting Behavior 2003 included different Big Five measures, thus allowing comparisons across instruments.
Regarding the response scales used, the BFI-10, BFI-2-XS, BFI-K were always administered with a 5-point rating scale as suggested by Rammstedt and John (2005, 2007) and Rammstedt et al. (2020). The BFI-s was mostly administered using a 7-point rating scale (i.e., SOEP, Nacaps, NAKO, PIAAC-L, TwinLife). In one other study using the BFI-S (i.e., BIBB-BAuA), however, a 5-point scale was used. The NEO-FFI was also assessed using a 7-point rating scale. While response scales were generally directed from disagreement to agreement, the response scales used in the ALLBUS and ISJP were oriented in the opposite direction (i.e., from agreement to disagreement).
Additional Psychological Constructs Included in the Selected Surveys
Besides the Big Five, most of the selected survey programs also assessed other core psychological constructs, such as intelligence (e.g., BIBB-BAuA Employment Survey, NEPS, the SOEP), human values (e.g., the GESIS Panel, the WVS), or more specific constructs, such as locus of control (e.g., the BIBB-BAuA Employment Survey, the SOEP), procrastination (e.g., the BIBB-BAuA Employment Survey), and achievement motivation (e.g., NEPS).
Nearly all of the selected surveys included measures of general and/or specific satisfaction with life. Several panel surveys (e.g., the SOEP, the GESIS Panel) also measured critical life events (since the preceding survey wave).
Big Five Reports From/About Additional Respondents
All of the selected survey programs included a self-report measure of the Big Five for the target person. In some surveys, other household members (e.g., the SOEP, PASS, GIP), relatives (e.g., romantic partners in pairfam, PIAAC-L and SHARE; twins, siblings, parents, partners in TwinLife), or even the interviewer (e.g., SHARE) were asked to provide information about their own personalities. In these cases, self-reports by these household members/relatives/partners/interviewers are available and can be compared with the personality self-reports of the target person. Big Five reports about others as assessed by the target person were included in pairfam, with the target person reporting about the Big Five personality of their child and of an idealized partner. Other-reports in which a third party assesses the personality of the target person were, to the best of our knowledge, not included in any of the survey (yet, the younger cohorts of TwinLife–which did not meet our inclusion criteria–included parent-reports about the personality of the target person (i.e., the child)).
Big Five Assessment Mode
The selected survey programs differ in their assessment modes. In some cases, assessment modes even differ among respondents of the same survey according to their assessment mode preferences (e.g., web-based or paper-and-pencil questionnaire; e.g., the GESIS Panel, GIP). In other cases, assessment modes differ over time/across assessments, because in one year the assessment was conducted as a personal interview and in other years as a telephone interview or a web-based questionnaire (e.g., NEPS, the SOEP, TwinLife). In this overview, we focus on the mode(s) of the Big Five assessment (see Table 2). The Big Five were commonly assessed in the form of a personal interview (with an interviewer reading out each question and coding the answer; e.g., PASS, SHARE, NEPS Starting Cohort 6). In other surveys, Big Five questionnaires were self-administered (without an interviewer present; e.g., the GESIS Panel, TwinLife, GIP).
Further Research Potential
Besides the analysis of associations between the Big Five and various outcome variables, associations among partners/household members, and potential longitudinal effects or methodological differences among instruments, samples, and modes, the data sets also have further research potential.
Paradata
For most of the selected survey programs, some form of paradata (i.e., data describing the data collection process) are provided. These may include the assessment date, the assessment duration, regional information, information about the assessment itself (where it took place, if others were present, etc.), or information about the interviewer (i.e., the person conducting the interview and recording the answers; e.g., SHARE). Such paradata can be used for both methodological (e.g., Cheng et al., 2020) and substantive analyses (allowing, e.g., analyses of the effects of weather on personality self-reports; see Rammstedt et al., 2015).
Regional information in particular allows survey data to be merged with geodata—for example, on pollution, regional wealth, or regional political orientation—which offers wide analytical potential (e.g., Ebert et al., 2022; for a general overview, see Bluemke et al., 2017).
International Survey Programs
Although most of the survey programs included in Table 1 are national surveys conducted in Germany only, some (e.g., SHARE, the International Social Survey Programme [ISSP], the WVS, the International Social Justice Project [ISJP]) are part of international comparative survey programs. In these cases, cross-nationally comparative analyses for the Big Five are possible (e.g., Levinsky et al., 2019; Rammstedt et al., 2013; Schmitt et al., 2008).
Replication and Integrative Data Analysis
Beyond their individual value as data sources, the selected survey programs offer unprecedented analytical potential when combined to answer a specific research question. Researchers can fruitfully combine multiple data sources in different ways. For example, they can conduct independent tests of the same hypothesis in multiple data sets to ascertain whether the results replicate across studies and are robust to variations in study design, measures, sample composition, and other survey characteristics. In some cases, it may even be possible to use meta-analytical techniques to combine results obtained in separate samples. This will contribute to building a more robust and replicable body of evidence in personality psychology. Additionally, for some research questions, researchers might want to pool and harmonize several data sources in order to use them for an integrative data analysis (see Curran & Hussong, 2009; Curran et al., 2008). Among other advantages, this may be a useful way of increasing statistical power or improving the coverage of certain sociodemographic subgroups or geographical units. Such a mega-analysis was for example conducted based on ten panel studies (also including the SOEP) to investigate the prospective associations of the Big Five with several life outcomes (Beck & Jackson, 2022).
Conclusion
The present paper aimed to provide personality researchers with an overview of data-sets from large-scale surveys in Germany that include measures of the Big Five. By that we aimed to increase the awareness and interest of psychologists—usually trained in primary data assessment and usage—in reusing these available high-quality datasets as they provide a broad research potential and clear methodological advantages compared to the typically used small-scale selective samples. This potential includes, on the one hand, substantive issues, such as concurrent associations between the Big Five and a broad variety of outcome variables (e.g., Denissen et al., 2018) or personality change over time and across cohorts. Also of interest from a personality psychology point of view are associations between the Big Five and the additional psychological constructs assessed (e.g., intelligence; see, e.g., Rammstedt et al., 2016), or similarities between personality self-ratings of target persons and their partners (see, e.g., Rammstedt & Schupp, 2008) or (other) household members.
On the other hand, the available longitudinal data allow researchers to predict outcomes based on previously assessed personality structure (e.g., COVID-19-related attitudes and behavior; Rammstedt et al., 2021) in order to investigate personality change based on repeated Big Five assessments (Lucas & Donnellan, 2011; Roemer et al., n.d.; Specht et al., 2011) and to draw stronger causal inferences (e.g., Anger et al., 2017; Sander et al., 2021).
Linked paradata in particular allow researchers to answer innovative research questions related to regional personality differences (e.g., Ebert et al., 2022; Obschonka et al., 2019) or differences in self-ratings depending on situation effects, for example, interviewer characteristics (e.g., Brunton‐Smith et al., 2017).
And finally, methodological questions, such as the effects of different assessment modes (e.g., Lang et al. 2011), acquiescence (e.g., Rammstedt et al., 2010), or response formats, can be answered by combining data from different studies.
Besides all the mentioned potentials and benefits of these high-quality large-scale data, such studies also suffer some drawbacks. For example, the included (personality) scales are usually only short scale measures with their limitations with regard to reliability and validity. In addition, per definition using secondary data does only allow to use the included constructs and their measures, which could undermine the fit for specific research questions. Also, the level of detail in the documentation of the survey programs varies. Finally, inflated error rates may occur when researchers use the same data to answer similar questions, or dependencies among research papers that may appear as presenting distinct evidence but are in fact based on the same data, or shared sampling bias and overfitting (for recent overviews, see, e.g., Mroczek et al., 2022; Thompson et al., 2020).
In this paper, we have tried to provide as comprehensive and complete an overview of the available surveys as possible. Because our search procedure was subjective in some regards, and was based partly on hearsay, we may have overlooked other available studies that would have met our criteria. To enable missed studies to be added, we have made our overview tables available in an OSF project (see Supplementary Materials), and any OSF user can post comments suggesting further surveys for inclusion.
As mentioned above, we restricted our overview to surveys conducted in Germany and focusing on the general adult population or on adult subpopulations. We are convinced that there is a similar need for a comparable overview of survey programs focusing, for example, on children and adolescents, or of survey programs conducted in countries other than Germany. For example, in addition to the two adult cohorts covered by the NEPS data sets included in this overview, NEPS provides additional data on the personality traits of primary and secondary school students. These data lend themselves to research on personality development and trait–outcome relationships, such as links between personality and achievement (e.g., N. D. Brandt et al., 2020; Lechner et al., 2017; Roemer et al., 2022).
In sum, with our paper we hope to inspire researchers to make more use of these valuable data sets, and to avail themselves of these data's potential to answer important research questions.
Footnotes
Acknowledgments
We would like to thank the following experts of the included surveys for reviewing our survey descriptions: Cordula Artelt, Beatrice van Berk, Michael Blohm, Barbara Felderer, Tobias Gummer, Monika Jungbauer-Gans, Kseniya Kizilova, Leo Panreck, David Richter, Joss Rossmann, Frank Spinath, Harald Schoen, Mark Trappmann, Bernd Weiss.
Data Availability
Supplementary Materials
The Supplementary Materials contain a more detailed table with information on the different datasets (see Roemer et al., 2022).
The authors have no funding to report.
The authors have declared that no competing interests exist.