
Abstract
This paper concentrates on improving a text-based human-machine interface integrated into a robotic wheelchair. Since word prediction is one of the most common methods used in such systems, the goal of this work is to improve the results using this specific module. For this, an exponential interpolation language model (LM) is considered. First, a model based on partial differential equations is proposed; with the appropriate initial conditions, we are able to design a interpolation language model that merges a word-based n-gram language model and a part-of-speech-based language model. Improvements in keystroke saving (KSS) and perplexity (PP) over the word-based n-gram language model and two other traditional interpolation models are obtained, considering two different task domains and three different languages. The proposed interpolation model also provides additional improvements over the hit rate (HR) parameter.
1. Introduction
One of the major faculties that most people with severe disabilities lose is the ability to speak. The ability to participate in complex communication enables the exchange of ideas and concepts, as well as helping in social integration. Once this connection between the mind and the outside world is broken, frustration, loneliness and a lack of confidence will inevitably be felt.
Besides speech problems, these people may have other disabilities that affect their motor skills. This can make the communication process slow and challenging, often requiring the use of specialized keyboards or other input devices.
One alternative for people with disabilities is the use of augmentative and alternative communication (AAC) devices within the human-machine interface (HMI) field. According to [1], ACC refers to the use of methods or devices to supplement the communication skills of a person with disabilities, and can be a dedicated device and/or a computing solution with simple output sound messages, or more complex systems, using techniques such as eye tracking and brain signals [2, 3]. In this context, the use of word prediction systems (WPS) in the communication process, such as automatic speech recognition (ASR) [4, 5], becomes essential.
Formally, WPSs were developed as a communication aid method, in order to increase message composition rate for people with severe motor and speech disabilities [6, 7]. Nowadays, text prediction methods – if adequately integrated within user interface – can benefit anyone trying to produce text messages or commands [8]. Generally, “word prediction” refers to those systems that guess which letters, words, or phrases are likely to follow a given segment of a text [9]. In [10] and [11], the WPS is considered an important element within the context of natural language processing (NLP), whereby the correct word is predicted given a particular context. In all these cases, the main goal of these systems is to improve the keystrokes saved (KSS) value, which is the percentage of keystrokes that the user saves by using WPS, while ensuring a good quality of produced text. Thus, this work focuses on the improvement of this aspect in order to achieve a better performance in a text-based user interface located within a robotic wheelchair. To do this, a WPS is considered. The robotic wheelchair. To do this, a WPS is considered. The WPS, throughly described in [12], aims to enable people to interact with other people, using a written language in a natural way. Figure 1 shows the general architecture of the HMI with a text-based model incorporated.
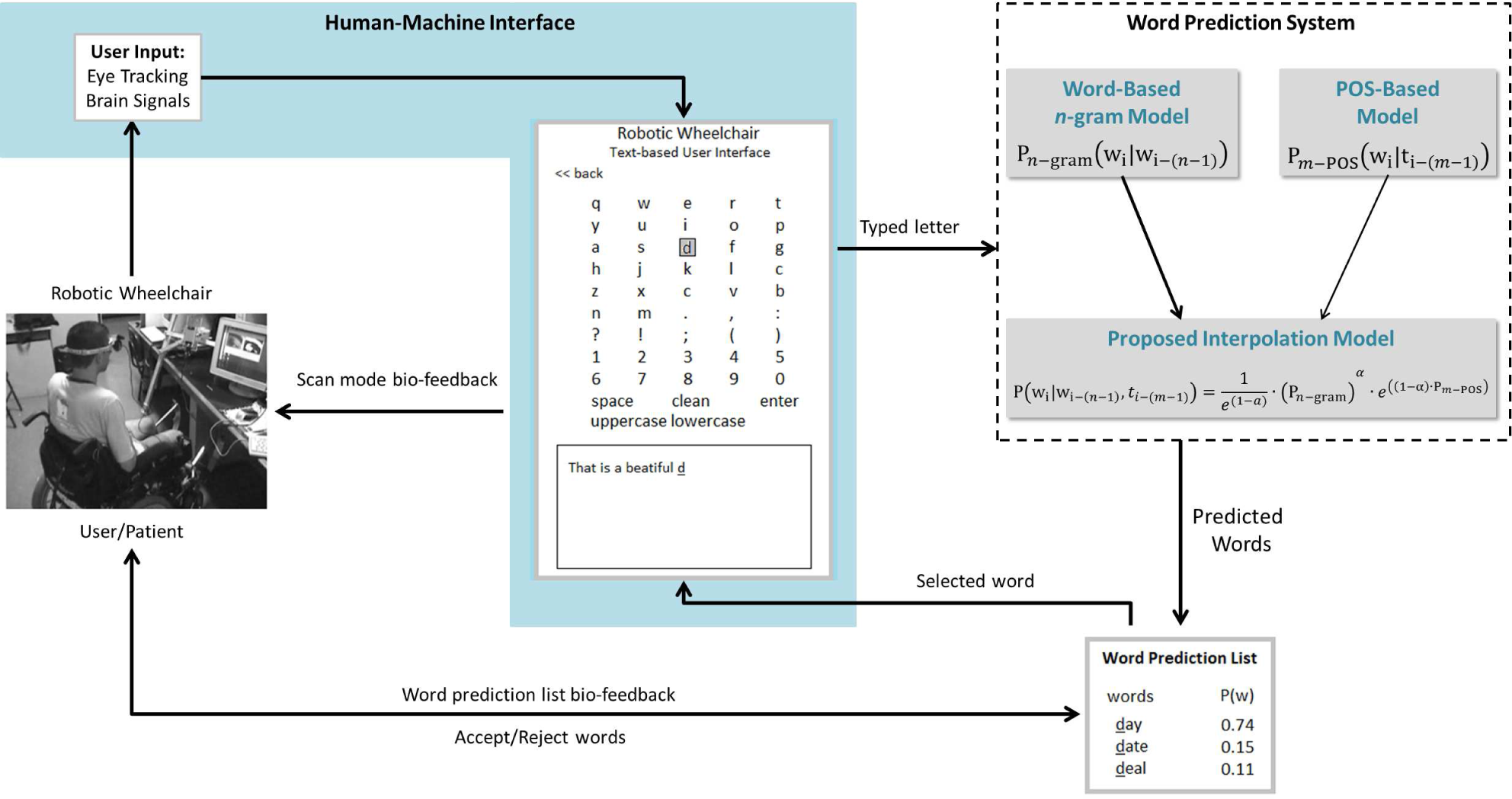
General architecture of the HMI with a text-based user interface within a robotic wheelchair
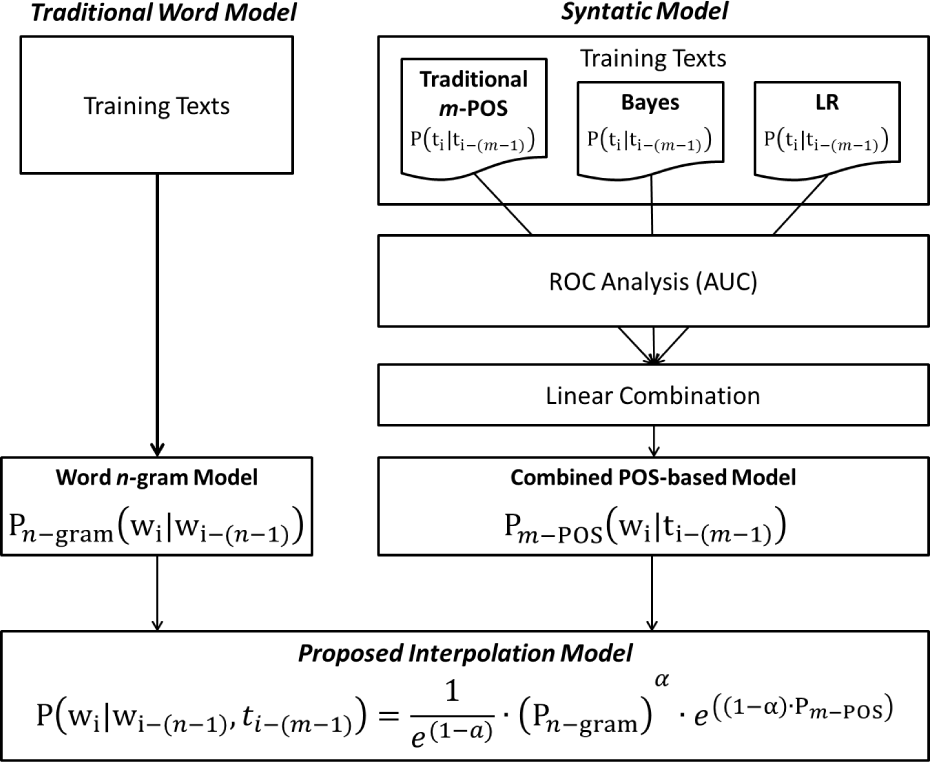
General overview of the proposed methodology
The proposed system shown in Figure 1, as with the work developed by [2] and [13] to control a robotic wheelchair, uses myoelectrical eye blinks, iris-tracking and a brain- computer interface to choose letters in a personal digital assistant (PDA). The PDA provides a graphic interface containing possible letters and actions. Once a specific letter has been selected using a scan mode, the WPS displays a number of possible words. Thus the user only has to accept – or reject – the suggested words. This kind of interface decreases the effort of the user when writing the text, delegating the writing effort to the WPS.
Since the WPS plays a fundamental role in the proposed system, improvements should be made in this direction. In this regard, we are proposing an interpolation language model (LM), based on the exponential combination of a word-based n-gram language model and a part-of-speech-based (POS) language model. To corroborate the methodology, results obtained by the proposed interpolation model were compared with the linear and geometric interpolations tested in three different languages: English, Portuguese and Spanish.
The rest of the paper is organized as follows: Section 2 presents a brief overview of the HMI within the robotic wheelchair; Section 3 gives a general overview of the word-based model and the POS-based model, as well as introducing our proposed interpolation method for combining these language models; Section 4 reports the outcomes of the experimental evaluations conducted using a WPS in English, Portugese and Spanish; and finally, Section 5 gives conclusions and outlines for future research.
2. Overview of the HMI System
The main objective of the HMI is for the user/patient to be capable of writing a text by means of his/her biological signals. In this work, the robotic wheelchair – developed at the Federal University of Espírito Santo (Brazil) – is able to use different HMIs, such as eye tracking, brain signals and sip-and-puff. All these HMIs involve acquisition systems, which include the amplification, filtering, digitization, recording and processing of the different kinds of signals provided by the wheelchair user [3]. The signals are recorded and classified, sending the identified command to a PDA. This PDA can be used to control the robotic wheelchair or, as in our case, write a text. Once a valid command is identified, a voice player confirms the option chosen, providing feedback to the user, as well as allowing communication with the people around.
3. Language Models to Word Prediction
There are several WPSs that have been and are being developed using distinct methods for different languages [9, 14]. Traditionally, these systems have been based on statistical n-gram language modelling. Recently, more sophisticated language models have been developed in order to improve the performance of these traditional language models [15]. In many cases, these language models explore and capture separately specific phenomena of natural language. Here, a question naturally arises regarding how to build more powerful and complex language models, capable of integrating all language components (such as syntactic, semantic and morphological structures).
To answer this question, the most efficient method would be to combine them in some optimal sense [16]. A simple method that can combine a broad range of models is that of linear interpolation (Equation 1), which takes into account a weighted sum of the probabilities given by the component language models. Normally, it is used to add a part-of-speech (POS) cache-component to a word-based n-gram model [17], taking into account the semantic structure of the language [18], or both POS and semantic structures [19]. Nonetheless, according to [20], even if the perplexity of the linear combined model is minimized, this type of methodology does not guarantee optimal use of the different information sources. This way, [21] proposes a method based on the latent maximum entropy principle, which extends the basic principle of maximum entropy proposed in [22], incorporating a hidden dependence structure. Distinct from linear interpolation, this approach generates probabilistic models capable of capturing all the information from the different sources, but with computational limitations in the estimation of the model parameters. In order to improve this, [21] has also proposed a methodology based on directed Markov random fields, first developed in [23]. With this model, the authors were able to combine a word trigram model, a probabilistic model based on context-free grammar, and a probabilistic model based on latent semantic analysis.

As can be seen, the above-mentioned language models reach a high level of mathematical (and computational) complexity, despite the efforts exerted to minimize it. Such models are widely used in applications such as automatic speech recognition (ASR) and machine translations (MT). However, when dealing with word prediction, it is recognized that the syntactic structure of the language plays a key role – in many cases, a primary one – in the composition of the language model. According to [24], the problem of word prediction in English and similar languages can be seen as a combination of two problems: the prediction of function words on the one hand, and content words on the other. Function words are the words used to make sentences grammatically correct. Pronouns, determiners, prepositions, and auxiliary verbs are examples of function words. Content words are words such as nouns, most verbs, adjectives, and adverbs, which refer to some object, action, or other non-linguistic meaning. In [24], it has also been shown that the performance of word prediction systems is mainly correlated with the ability to predict very common words, i.e., function words. In this context, word-based n-gram models are very effective. To predict content words, topic-based or POS-based language models can be used.
Thus, this work is motivated by the assumption that n-gram models could be more effective in WPSs, performing in combination with POS-based language models, and therefore proposes a novel exponential approach, based theoretically on partial differential equations as a way of combining them. As in many natural processes, once the differential equations that characterize a particular system have been determined, it is possible to extract relevant information about them. Figure 1 gives a general overview of the proposed methodology.
3.1 Word-Based Language Model
In word prediction, a statistical language model tries to predict the next word based on the history of previously used words. This idea of word prediction is formalized by probabilistic models called n-gram models, which in turn predict the next word from the n-1 previous words. In its simplest version, the unigram model only considers the absolute frequency of the word. When using this model, at each moment the most frequent words that begin with the written letters of the word in progress are predicted. By considering the sequence of words, or the probability that each word will follow the previous words, there arises bigram, trigram,…, n-gram models. In other words, suppose a sentence in which the sequence of words given so far is

where wi-n-1 are the n – 1 previous words and cwi is the current word prefix typed by the user. In this case, the bigram model (n =2) is given by

This equation can be simplified, since the sum of all the bigrams beginning with the wn-1 must be equal to the count of the word unigram. Therefore,

which can be easily extended to the n-gram model, or

where F (wi-(n−1)… wi) and F (wi- (n−1) … wi−1) are the frequencies of the nth and (n – 1) th previous word sequences, respectively.
According to [25], some of the disadvantages of the word-based n-gram language model include its large number of parameters and its high dependence on the discourse domain, since it measures perplexity on a set of different texts belonging to (or outside of) the linguistic domain of the training corpus. As described by [25], a solution for overcoming the data sparseness problem and reducing the dependence on the discourse domain might consist of grouping words together into equivalence word classes (or POS in our case), instead of those of individual words. In this context, before detailing the POS-based language model itself, it is necessary to (briefly) describe the technique used to determine the POS tagset employed in this paper.
3.2 POS-Based Language Model
As shown in [26], the use of certain major POSs (noun, verb, adjective, etc) – along with inflections like gender (masculine, feminine, neuter), number (singular, plural, neuter) and person (1st, 2nd, 3rd, 1st/3rd) – can generate accurate POS-based word predictors with a relatively low-speed list of predicted words. Thus, an initial POS tagset was first derived by selecting the most functional POS tags corresponding to English, Spanish and Portuguese. Even though relatively low numbers of POS tags were chosen, this work also used the methodology developed in [27] to further reduce the number of POS tags in Spanish and Portuguese. Table 1 shows the POS tagset and the morphological analyser used for each language.
POS tagset for Portuguese, Spanish and English

As in [27], a syntactic predictor has access to the following sequence of words and POS tags to predict the current word:
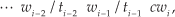
where ti-2 and ti−1 are the POS tags of the previous words wi-2 and wi−1, respectively, and cwi is the current word prefix typed by the user. The algorithm predicts words starting with cwi.
According to [1], there are different methods for incorporating the statistical POS tag information into the word predictor. As in [31], the m-POS predictor (with m = 2) was here estimated by
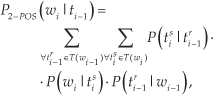
where tsi is the sth tag for wi, which varies from 1 to | T (wi) |; T (wi) is the set of all possible POS tags that may be assigned to the word wi; P (tsi | tri−1) is the bigram POS tag probability (the probability of tsi being t r i−1 the tag of the previous word); P (wi | tsi) is the conditional probability of the word wi given tsi as its POS tag; and P (t r i−1 | wi−1) is the conditional probability of the previous word wi−1 to be tagged with its rth tag t r i−1.
This method can be extended to include in the prediction as many previous words as desired. The current system considers a maximum of two previous words in the prediction (3 – POS model), or

There is an important difference concerning the POS-based language model used within this paper and the ones used in works like [1]. The difference lies in the calculation of the POS tag probabilities P (tsi | t r i−1) and P (tsi | tir-1 t p i-2). Traditionally, these probabilities have been calculated using the frequencies of the previous word classes, or
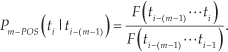
In this work, a traditional statistical POS-based language model (Equation 7), a logistic regression (LR) POS-based language model and a naive Bayes (NB) POS-based language model [32] using the area under the ROC curve (AUC) are combined.
The ROC curve 1 is a technique for visualizing, organizing and selecting classifiers based on their performance. According to [34], in order to compare classifiers, it is possible to reduce the ROC performance to a single scalar value representing the expected performance. A common method is to calculate the AUC, which has an important statistical property: the AUC of a classifier is equivalent to the probability that the classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance [35].
The AUC is usually estimated in the same way as the error rate. To classify the accuracy of a classifier using this measure, the following equivalence is adopted:
90% to 100%: excellent;
80% to 90%: very good;
70% to 80%: good;
60% to 70%: fair;
50% to 60%: poor;
<50%: fail.
In this way, a classifier that obtains an AUC of 86%, for example, will be considered a very good classifier, with a score of β = 0.86. In the same way, if a classifier obtains an AUC of less than 50%, it will fail and the score will be approximated to β = 0.
ROC analysis and the AUC are commonly employed in two-class problems; with more than two classes, as in our case, the situation becomes much more complex [33]. For handling this problem, different AUCs were calculated, one for each POS tag, using the one-against-all method. Thus, for a set of | T (wi) | POS tags, one can have β(.) =[β1,β2, … β|T (wi)|] and the combined m-POS language model given by
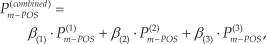
where (1) represents the traditional statistical POS-based language model, (2) represents the LR POS-based language model, and (3) represents the NB POS-based language model.
3.3 Proposed Method
3.3.1 Mathematical Formulation
Before presenting the interpolation model proposed in this paper, the work presented in [36], which uses a model based on geometric interpolation (Equation 9), is discussed in detail, to better explain the relationship between the independent models and the mathematical model merging them.
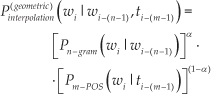
Mathematical models seek to quantitatively and qualitatively explain natural phenomena, and usually employ differential equations to describe the dynamic evolution of systems [37]. By solving such equations, it is possible to extract relevant information about such systems and possibly to predict their behaviour.
The main challenge involved in modelling using differential equations is that of formulating the equations describing the problem from a set of limited information about the general behaviour of the system. However, since a possible solution to the proposed modelling problem (Equation (9)) is available, it is possible to analyse, based on a number of assumptions, the opposite way, and thus determine the differential equations that represent our language model problem.
Considering that the overall goal of the interpolation model is to integrate the benefits of each language model. and assuming language modelling to be a natural system problem, it is possible to treat this problem as the solution of a partial differential equation, i.e.,
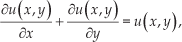
where u (x, y) is the interpolation model, and x and y are the independent variables, representing the word-based n-gram and POS-based language models, respectively.
By analysing (9), it is possible to see that this equation is not a particular solution of (10), but a particular solution of another partial differential equation, namely

To solve (3.3.1), it is possible to use the technique of separation of variables, which reduces the partial differential equation to several ordinary differential equations [37]. In this case, it is assumed that a solution can be expressed as the product of two unknown functions, where each one is only a function of the respective independent variable. This assumption seems very reasonable, after a study considering each language model as an independent problem. Thus, it is possible to have


Dividing (11) by XY, it follows that
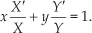
Since X is only a function of the variable x and Y of y, each term in (12) should be constant and equal to α (known as the separation constant[37]), or

which is implied by two ordinary equations, namely

and

where γ1 and γ2 are two constants.
Finally, substituting (14) and (15) into (3.3.1), one obtains

where γ = γ1 · γ2 is also a constant.
Applying the condition u(1,1) = 1 to (16), it follows that

and the solution will be

which is the same as the geometric interpolation presented in 9.
Even when presenting satisfactory results to word prediction, as can be seen in Section 4, the interpolation model based on geometric interpolation has some negative characteristics that occur when, for example, any independent language model has a zero (or very low) probability, causing the interpolation model to present a zero probability output.
In such a context, considering that word-based n-gram models play a fundamental role in predictive modelling systems and can be improved by their combination with a POS-based language model, we here propose a modified partial differential equation, given by

The modelling performed in (3.3.1) seeks to create a natural exponential function to interpolate the word-based n-gram model and the POS-based language model. This methodology, common in the modelling of natural processes (radioactive decay and population decay, among others), reduces the negative characteristics presented by the interpolation model based on geometric interpolation.
In a similar way to the geometric interpolation modelling, the new interpolation model can be found by solving (3.3.1), the solution of which is

Again, applying the condition u(1,1) = 1 to (19), one has

and, finally,

Rewriting (21) in terms of the language models, it follows that

where α can be empirically obtained.
It is worth noting that (22) has a form that is similar to the conventional maximum entropy model first developed in [22]. In the latter, the authors confront two of the essential tasks of statistical modelling: to determine a set of statistics that captures the behaviour of a random process, and to combine these facts into an accurate model of the process – a model capable of predicting the future process output. In attempting to solve this problem, the proposed methodology, based on differential equations, addresses the problem of building interpolation models and thus opens the way for the use of different mathematical tools to construct and analyse natural language comprehension.
4. Experimental Framework
The tests and subsequent analyses needed to confirm the assumptions made are presented in this section. Firstly, to construct possible comparisons between the methodology adopted here and the existing state-of-the-art methodology, it was necessary to select appropriate training and test sets, as well as proper procedures for testing each methodology.
The text set used for training and testing is one of the key aspects of the evaluation step, since it may significantly influence the results. Thus, texts from newspapers and text transcripts from spoken language were chosen to compose the test set. Texts from newspapers were adopted because they employ a language directed at a great number of readers, providing a reasonable contextual diversity in terms of vocabulary and grammatical constructions. Text transcripts from spoken language were adopted, in turn, because they are more spontaneous, less rigid, and cover daily communication in general.
The evaluation procedures for the word prediction were conducted using automatic methods, whereby all language models were incorporated into a WPS for the experiments, a common approach in these types of systems.
It is also important to consider that any changes in the configuration parameters of the experiment (language, test and training texts, WP interface system, etc.) can lead to significant variations in the results. This variability makes it very difficult to compare the results presented here with others already established (in [31], the main factors that can affect the prediction results of a given system are exposed and discussed).
4.1 Word Prediction Engine
In order to evaluate our method, the PredWin software was used. This software was first developed for Spanish by [31] and was adapted here for Portuguese and English. This system has some important blocks, such as the following:
As in [31], it is also important to highlight certain system parameters that will affect the word prediction process:
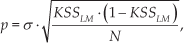
where p is the confidence interval, KS SLM is the keystrokes saved by each language model, N is the total number of keystroke needed to write the text without word prediction, and σ is a constant parameter that depends on the confidence interval, usually set to 1.96 (or 95% of confidence). Thus, the KSS in the experiment is within the range
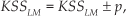
and it will be considered significantly better (with respect to the baseline) if the results are better, and moreover, if the confidence intervals do not overlap.
Number of words in each general dictionary

Number of words used in the training set for each language model

4.2 Training Set
The training sets used to train the language models and to generate the dictionaries for each language here addressed (Portuguese, Spanish and English) are shown in Table 3.
4.3 Validation Set
The validation sets used to find the coefficients α needed to combine the language models (n-gram and m-POS) are shown in Table 4, with Table 5 showing the values of α used in the WPS, after considering the best results achieved when analysing the KSS parameter.
Number of words in the validation sets used to find the best α values

Optimized values of α for each interpolation model considering 1 and 5 words in the prediction list

4.4 Test Set
For the test sets, it is important to use texts that were not used in the training or validation sets. Therefore, for Portuguese, texts were chosen from the journalistic corpus TeMário [48], as well as the “Português Falado” corpus [49], which contains transcript texts from audio recordings of the language spoken in Brazil. To compose the test set for Spanish, the Europarl corpus [50] was used, which contains transcript texts from speeches in the European Parliament, along with texts from the HC corpus [51], consisting of newspaper articles from different sources. Finally, for English, the test set was extracted from the Brown corpus [52] and the Uppsala Student English corpus [53], consisting of newspaper articles and transcript texts, respectively. Table 6 shows the domain, number of words and keystrokes needed (without word prediction) to write the texts in each test set.
Domain and number of words used in the test set

It is important to mention that about 3% of the words in each test set were not categorized. For the moment, particular attention has been paid to the known words, at the expense of the unknown words. This was treated as a separate problem and smoothing techniques were used to avoid null probabilities for any unseen events in the test set.
4.5 Performance Measures
The WPS was evaluated according to four different criteria: keystrokes saved (KSS), hit rate (HR), words predicted (WP) and perplexity (PP).
The KSS refers to the percentage of keystrokes that the user saves when using the word prediction system. It is calculated by comparing two measures: the total number of keystrokes needed to type the text (KT) without the help of word prediction, and the effective number of keystrokes needed when using word prediction (KE). Hence,

The higher the KSS value, the better the system performance.
The HR is defined as the percentage of instances in which the suggestion list contains the correct word before any letters of the following word have been entered. In other words, it is the relation between the number of times that a word is guessed without any letters being known and the total number of words in the test text. Again, a higher HR means a better performance.
The PP can be defined as the average number of potential choices/words after a given string of words [38]. Therefore, the lower the PP value, the better the language model.
4.6 Results
In order to evaluate the WPS with different interpolation models, the experiments have been conducted with the texts shown in Table 3. The results are presented in Table 7, considering the word-based n-gram model as a baseline. The relative improvements were also evaluated and the results are presented in Table 8, along with the test of significance for each model.
Word prediction results for the different interpolation models, with one and five words in the prediction lists

Test of significance and relative improvement for the results shown in Table 7

4.7 Discussion
From Table 7, it can be noted that all the interpolation models show improvements with respect to the number of KSS, compared to the word-based n-gram model. These results are in agreement with [54] and support one of the assumptions made in this work: that the problem of word prediction can be solved by finding linguistically relevant factors, and that one efficient method is the combination of a POS-based and word-based language models. In some cases, especially when the results obtained from language models with fine suggested words are considered, the impact of the POS model on the improvement in KSS (i.e., even with the decrease in the number of words predicted) can be clearly seen.
It is also important to note, from Table 7, that the proposed interpolation model shows the best results in all parameters related to word prediction (WP, HR and KSS) when only one word is considered in the prediction list. However, when considering fine words in the prediction list, the word-based n-gram models present, in all languages, the best results for the WP parameter. These results clearly show the importance of word-based n-gram models in the prediction of function words – consisting mainly of pronouns, determiners, preposition and auxiliary verbs – and words with a lower number of letters, as opposed to content words: normally nouns, verbs, adjectives and adverbs.
When the PP values in Table 7 are analysed, the proposed interpolation model also shows the best results for both one and five words in the prediction list. When five suggested words were considered, the model achieved a 20.69%, 25.92% and 13.85% relative reduction for Spanish, Portuguese and English, respectively. With one word in the prediction list, the proposed model reached 7.21%, 17.14% and 7.76% relative reduction in the PP. This measure was consistent for almost all models, i.e., it can also be noted from Table 6 that the PP obtained by the geometric model for the English and Spanish languages is higher than the value obtained by the word-based n-gram model, even with higher values of KSS. Such inconsistencies have been already presented and discussed in other works, such as [38].
As Table 8 shows, the relative improvements in English using the proposed interpolation model (1.66% and 0.57% for one and five words in the prediction list) are lower than those obtained for the other languages. These results illustrate the statement that English is grammatically poor when compared to Portuguese and Spanish, and are consistent with the work in [39]. Using a linear combination (with α =0.8) to combine a word bigram model with a POS-based model considering two previous POSs – trained using 81 million words and 5.8 million categorized words, respectively – [39] has presented a total of 53.14% KSS against the 52.90% KSS obtained by the word bigram model itself, when considering five words in the prediction list, a test set of 951, 932 words and a POS tagset with 79 classes.
It is also worth analysing, using Table 8, the relative improvements obtained by each interpolation model, considering the number of words in the prediction list. In this case, it can be seen that increasing the number of suggested words reduces the relative improvement of each model, yet it also increases the total number of KSS. In addition, it should be noted that some of the results for English, excluding the results obtained by the proposed model, were not significant. A possible solution to this could be to increase the number of words in the test set.
The empirically optimized values for the coefficient α in Table 5 also deserve discussion. It can be observed that the values found for the linear and geometric interpolation model were almost equal to 0.9 (the linear model showed a value of 0.8 in Table 5 for Spanish with five suggested words). These results are consistent with [38] and [36]. However, when analysing the values of α obtained by the proposed model, this parameter showed different values for each language and domain analysed, which means that the proposed model could be more susceptible to the relationship between the word-based n-gram model and the POS-based model. This characteristic is quite interesting and points the way forward in the search for the optimal method to determine the separation coefficient α.
Finally, even though real users were not used in the test set, the results show good prospects for the application of the proposed system within the text-based user interface in the robotic wheelchair. Besides presenting better results in the KSS parameters, the proposed method was able to improve the percentage of instances in which correct words appear in the suggestion list before any letter has been entered (HR), a parameter that is directly related to avoiding extraneous effort on the part of the user when generating the HMI signals. Moreover, the PP results show that the proposed interpolation LM is a better predictor than the state-of-the-art interpolation models.
5. Conclusion
The goal of this work was to explore text-based human-machine interactions by considering a word prediction system installed in a robotic wheelchair. Since the word prediction system plays a fundamental role in improving the writing of text, this work proposed an exponential interpolation model, which combines a traditional word-based n-gram language model with a POS-based language model. We addressed this problem by first finding a differential partial equation to represent the modelling of the language, which would then be used to derive the interpolation model.
The proposed methodology was evaluated for two different domains (journalistic and spoken texts) and three different languages (Portuguese, Spanish and English). The results reported in this paper show improvements in the KSS, HR and PP parameters, with both one and five words in the prediction lists.
Future efforts could concentrate on testing the proposed model with real users in the robotic wheelchair. Moreover, we could improve the proposed differential partial equation by adding more information through a semantics-based model, as part of the search for a more sophisticated language model. Finally, we also plan to test our current interpolation language model on another task: that of automatic language recognition.