
Abstract
In this paper, an object detector is proposed based on a convolution/subsampling feature map and a two-level cascade classifier. First, a convolution/subsampling operation alleviates illumination, rotation and noise variances. Then, two classifiers are concatenated to check a large number of windows using a coarse-to-fine strategy. Since the sub-sampled feature map with enhanced pixels was fed into the coarse-level classifier, the checked windows were drastically reduced to a quarter of the original image. A few remaining windows showing detailed data were further checked using a fine-level classifier.
In addition to improving the detection process, the proposed mechanism also sped up the training process. Some features generated from the prototypes within the small window were selected and trained to obtain the coarse-level classifier. Moreover, a feature ranking algorithm reduced the large feature pool to a small set, thus speeding up the training process without losing detection performance. The contribution of this paper is twofold: first, the coarse-to-fine scheme shortens both the training and detection processes. Second, the feature ranking algorithm reduces training time. Finally, some experimental results were achieved for evaluation. From the results, the proposed method was shown to outperform the rapidly performing Adaboost, as well as forward feature selection methods.
1. Introduction
Object detection has received significant attention due to a large number of requirements in the computer vision field. For robot systems, robust and real-time object detection is a first and critical step for object recognition. A significant success rate, especially in face detection and license plate detection, has been achieved using various algorithms such as principle component analysis (PCA)[1], artificial neural networks (ANNs)[2, 3] and support vector machines (SVMs)[4, 5], among others. Generally, a window-based object detection process consists of four stages: pyramid image construction, window sliding, window verification and post-processing. First, pyramid images are constructed as the result of various object sizes. An original image is scaled to various smaller images on a scale of 1.25 in order to fit the object located within a window. Since an object can appear at any location, a window slides through all pyramid images. Next, a classifier is designed to check whether the window contains an object or not. Finally, postprocessing methods and/or operations or fusing algorithms are applied to determine exact object locations and sizes.
The first challenge for object detection is that objects have to be detected in real time. The detector has to check a large number of windows to complete this process in real time. Decreasing the number of windows and reducing the checking time per window are two strategies for improving efficiency. The second challenge is that the training process for the detector has to be completed as soon as possible. For example, a large number of weights are trained in ANN, while many feature candidates are checked in Adaboost-based algorithms.
ANNs are widely used in face detection. In Rowley's method [6], two independent MLPs (multiple layer perceptrons) are constructed using a bootstrapping training strategy. Each window has to be checked twice to determine if it contains a face or not. In Han's method [8], morphology-based preprocessing removes most backgrounds to speed up the detection process. In addition to the traditional MLP methods, a convolutional neural network (CNN) proposed by LeCun et al. [15] has been successfully used in handwritten character recognition (HCR) [16] and face detection [7, 18].
Three basic components, local receptive fields, shared weights and spatial subsampling are used for feature extraction. Feature maps are robust to rotation, scaling, shifting, pixel distortion and illumination variations. Additional applications, i.e., document analysis [17], face pose estimation [19], facial expression recognition [20], face recognition [21], generic object categorization [22] and hand tracking [23] have been developed. In Viola [9], a face detector based on the Adaboost algorithm is proposed. Asymmetric cascade classifiers and integral image-based features rapidly filter out background regions. Moreover, many variants of Adaboost algorithm have been proposed for improvement. The FloatBoost algorithm [12] was designed to solve the monotonic problem on sequential Adaboost training for multi-view face detection. Forward feature selection (FFS) [13] reduces the training time of feature selection using a pre-computing strategy. The LDA plus FFS algorithm [14] enhances classification ability. The designed face detectors with high performance in [12–14] are all robust in terms of face variations.
Although the Adaboost-based algorithm has been successfully applied for face detection, many researchers have applied various other features for face detection. Jeong et al. [24] successfully applied semi-local structure patterns in face detection. Gunasekar et al. [25] proposed qualHOG features for face detection on distorted images. The Adaboost-based feature selection algorithm proposed by Jun et al. [26] selects local gradient patterns, binary histograms of oriented gradient patterns and hybridization for improving face detection performance. Face detection is also a critical step in other applications. For example, the performance of face recognition was dramatically affected by the results of face detection [27]. The first step of facial expression recognition or facial feature tracking was also the application of successful face detection [28].
In addition to face detection, license plate detection (LPD) is an important application in object detection, particularly for intelligent transportation systems (ITS). Wang and Lee [29] propose a cascade framework based on the Adaboost algorithm for license plate detection. The feature pool is composed of original Haar-like features, as well as skewed Haar-like features. Zhou et al. [31] present a plate detection algorithm using SIFT features. According to the invariant merit of SIFT features, variation among view angles, scales and illumination can be remedied. Giannoukos et al. [32] propose an LPD algorithm by analysing the contexts of the sliding window. The performance of LPD was improved in this case because only regions of interested were scanned. Wang et al. [33] present a discrete wavelet transform in which LP features are found and verified from the HL sub-band. Horizontal lines are checked to determine the LP location in sub-band LH. Li et al. [34] presented a component-based license plate detection algorithm that decomposed license plates into several candidate regions of digital characters. These candidates were then verified by a constructed conditional random field model. Al-Ghaili et al. [35] presented a fast vertical edge detection algorithm for locate license plates. Additionally, they pointed out LP detection as the first step in LP recognition, traffic data collection, crime prevention and ITS.
The CNN and Adaboost methodologies have been integrated in this study. A brief review of these two methods is given below. The CNN-based object detector uses several convolutional/subsampling feature maps and a multilayer perceptron for feature extractors and face classifiers, respectively. According to results obtained by Garcia [7], although CNN can extract features to alleviate the variations of rotation, scaling, shifting, distortion and illumination, its extensive architecture renders implementation and training difficult. Additionally, CNN detection speed is also slow. The convolutional and subsampling operations in CNN not only alleviate variations among facial images, but also condense the pixel information within a checked window. This approach was adopted in Rowley [6] and Han [8], in which one complex pre-processing step extracts facial features for detection. In our approach, multiple feature maps in convolutional and subsampling layers were reduced to one simple map only.
An Adaboost-based detector in the method applied by Viola [10] detects facial regions in real time using several cascade strong-classifiers composed of thousands of weak classifiers. Asymmetric cascade classifiers and integral image-based features quickly filter out background regions. However, significant training time is needed for selecting 38 cascade strong-classifiers from hundreds of thousands of block-based features within a window of 24 by 24 pixels.
In this study, a two-level cascade detector, as shown in Fig. 1, was used based on a simple feature map and a coarse-to-fine strategy. According to our experience, image enhancement improves detection performance and shortens the training process. Window pixels were convoluted and subsampled by the trained coefficients for enhancement. The detector was composed of a coarse-level classifier and a fine-level classifier. Small windows with enhanced pixels were verified by the coarse-level classifier, while large windows with detailed data were verified by the fine-level classifier. The coarse-level and fine-level classifiers were composed of eight and 12 cascade strong-classifiers, respectively. The coarse-level classifier applied only a small number of features and filtered out most backgrounds using the map with condensed data at layer S. The fine-level classifier rechecked the remaining windows using the original data in fine resolution. The main function of the fine-level classifier was to reduce false alarms (FAs) while retaining high detection rates (DRs). In the detection process, pyramid-based localization techniques were proposed for fusing the candidates and identifying the objects' regions. In order to detect objects of various sizes, an input image was repeatedly sub-sampled by a factor of 1.25 and a set of pyramid sub-images was generated at various scales. The windows in each sub-image were verified by the trained detector. Finally, a clustering-based fusing method was performed to determine object location.
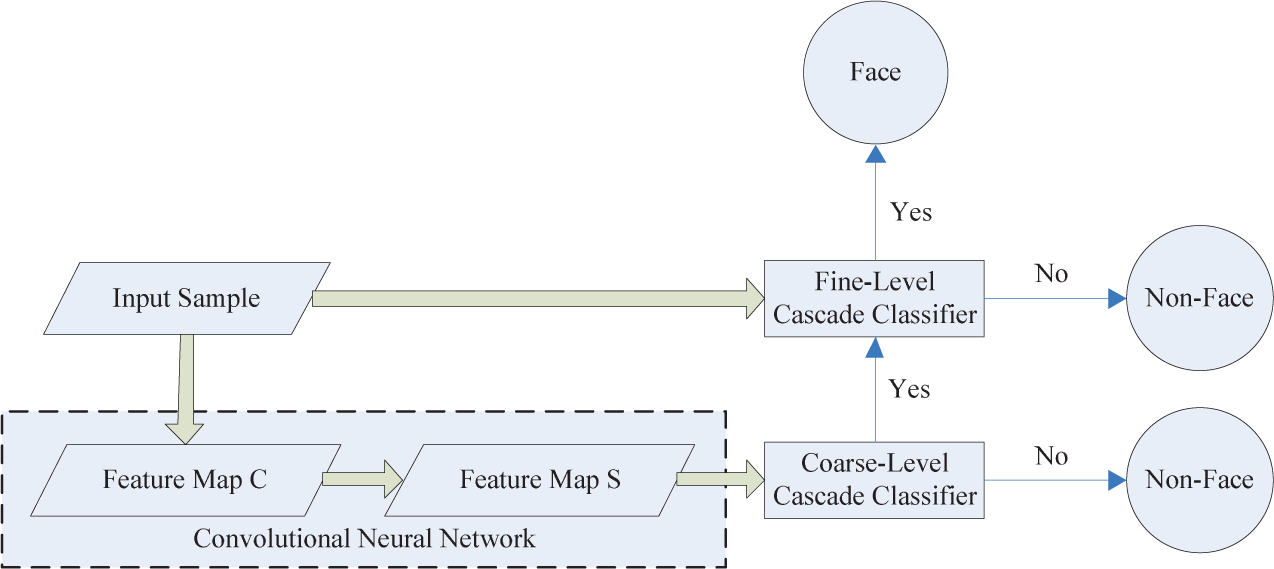
The proposed system architecture
The rest of this paper is organized as follows: the mechanism for feature extraction using convolutional and subsampling operations is presented in section 2. A single feature map was constructed and the weights were trained. Two-level cascaded classifiers and the coarse-to-fine strategy are described in section 3. In addition, a small feature set was pre-generated by ranking the features in order to speed up the training process and is also presented in this section. The experiments conducted for showing the feasibility and efficiency of the proposed method is given in section 4. Finally, concluding remarks are provided in section 5.
2. Single Convolution-Subsampling Feature Map
Using the architecture of CNN, convolutional and subsampling operations were performed for feature extraction without any preprocessing. In Garcia [7], feature maps were responsible for extracting and fusing a set of appropriate features. The input plane received window pixels at a size of 32 by 36 pixels in order to be classified as either face or nonface. Successive convolutional and subsampling operations were performed on the feature maps from layers C1 to S2. Layers C1, S1, C2 and S2 were composed of four, four, fourteen and fourteen feature maps, respectively. Consider a window of pixels w and h as shown in Fig. 2(a), e.g., a widow of 24 by 24 pixels for face detection in this study. A single feature map with convolutional layer C and a subsampling layer S was constructed for feature extraction. Edge features such as two eyes, two eyebrows, the nose and the mouth, were enhanced for reinforcing discrimination abilities. Additionally, these weights were in each layer trained by examples. The corresponding feature extraction for license plate detection is shown in Fig. 2(b). Edge features were also enhanced with convolution and subsampling operations.

CNN with a single feature map for (a) human face detection; (b) plate detection
At layer C, the values in the feature map were convoluted from the original window by the trained weights as follows:

Here, ten trained weights wC(i, j), i, j = 0, 1, 2 and a bias bC were the shared coefficients in the convolution operation. Next, a subsampling operation was completed for size reduction between layers C and S. Each element at layer S received a 2 by 2 neighbouring field from layer C as shown below:
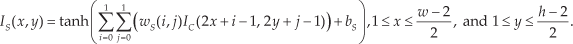
The elements at layer S were generated from the non-overlapping receptive fields of 2 by 2 at layer C. Four weights and one bias were also trained between layers C and S. The window size wS by hS at layer S (11 by 11 for face and 27 by 7 for LP) was a quarter of that at layer C (22 by 22 for face and 54 by 14 for LP). The convolution-subsampling mechanism was designed to simultaneously enhance the texture features and reduce the window size using the trained weights. The windows of a new feature map, a quarter of the original image in size, were verified by a cascade classifier to filter out most background regions. In practical systems, the checked windows were extended to the detected images during the detection process. The convolutions and subsampling operations were first performed on all the images by using the trained weights. Furthermore, the sliding windows were checked by the designed two-level classifier following the feature extraction step. In order to train the face detector, 5000 facial images (positive samples 1 ) and 5000 non-facial images (negative samples) were collected. In the training phase, facial images with various sizes were collected from web sites. Face-only images without any hair or backgrounds were cropped and normalized to a size of 24 by 24. In addition, negative samples of the same size were randomly collected from the natural scene images without any face samples among them. Several facial and non-facial images, respectively, are given in the first and third rows in Fig. 3(a). The correspondingly convoluted images are also shown in the second and fourth rows. The edge features on two eyes, two eyebrows, the nose and the mouth were all enhanced; 8721 plate images and 8721 non-plate images were manually collected for training the LP detector. LP images were scaled to a size of 56 by 16, as shown in Fig. 3(b). Similarly, LP and non-LP images are shown in rows one and three. Their corresponding convoluted images are shown in the second and fourth rows in Fig. 3(b).

Training samples for (a) face detection; (b) plate detection
Fig. 3 shows the training of facial/non-facial patterns. The images tabulated in the first and third rows represent facial and non-facial images, respectively. Their correspondingly convoluted images are shown in the second and fourth rows. As can be seen, the edge features on two eyes, two eyebrows, the nose and the mouth were all enhanced. As such, there were no objects in the scene images. The shared weights in layers C and S were trained by these 10 000 samples, a process described below.
In order to train the weights, a CNN (see Fig. 2) was constructed by layers C and S, as well as by a classic MLP fully connected to layer S within a supervised classification. The objective values of training samples were assigned, e.g., 1 for positive samples and −1 for negative samples. Moreover, a hyperbolic tangent function was used as an activation function at both layers C and S. Fifteen trainable parameters at layers C and S, 3×3+1 weights for convolutions and 2×2+1 weights for subsampling operations performed the feature extraction in the proposed method.
3. Two-level Classifier
Although CNN can simultaneously train feature maps and classifiers [7], the large architecture of CNN made it difficult to implement this and also decreased detection performance. To accelerate the detection process, the CNN was simplified to a single convoluting-subsampling feature map and a two-level classifier was trained for window checking using a coarse-to-fine strategy. In the detection scheme, original images were first convoluted and sub-sampled. The wS by hS windows were verified using the convoluted data throughout the entire image in the coarse-level stage. Owing to the condensed information in the feature map, a quarter of the original windows were checked by the coarse-level classifier. Most non-face/non-plate backgrounds were filtered out quickly. A small amount of remaining face/plate-like wS by hS windows was further verified using the original image data in the fine-level stage.
In this section, the cascade classifier was introduced based on FFS algorithms. To speed up the training process, features in a huge pool were evaluated by a ranking algorithm. A new and small feature pool was generated by selecting features with high discriminating abilities. Most redundant features were not checked in each loop of the FFS algorithm.
3.1 Adaboost and the Forward Feature Selection (FFS) Algorithm
In Viola [10], a well-known algorithm based on the Adaboost algorithm [11] was proposed for building a detector employing cascading numerous classifiers. In addition to facial detection, it was also trained for license plate detection [29] and pedestrian detection [30]. During the training process, all samples were equally weighted. Features with smaller weighted errors were iteratively selected from a feature pool. The selected features formed a strong classifier and the stronger classifiers were cascaded for constructing a detector. However, significant training time was needed for assembling the detector.
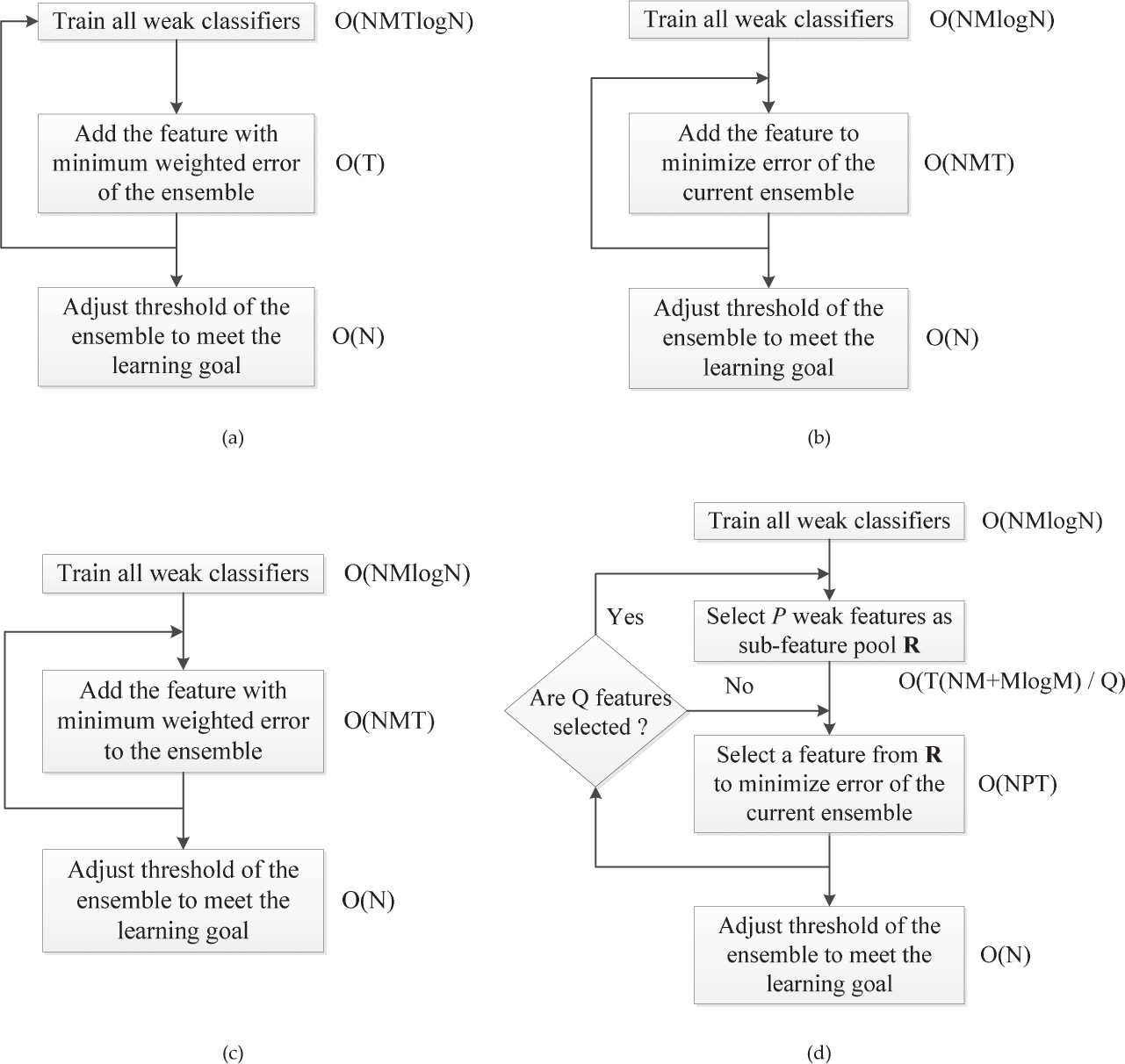
To alleviate the time-consuming problem in the Adaboost-based classifier, Wu et al. [13] propose an FFS scheme for decreasing training time. The pre-computing strategy significantly speeds up the training process in the FFS algorithm [13]. In addition, only 3% of memory usage as that of the fast Adaboost algorithm was required, because each entry in table V had a binary value and required one bit. All operations were performed by direct memory access rather than slow disk access. Considering that N training samples of M features in a pool, the flowcharts of naive Adaboost implementation and the FFS algorithm are given in Fig. 4(a) and 4(b), respectively. By comparing these two algorithms, blocking of the ‘train all weaker classifiers' in FFS was removed from the loops in Adaboost. Due to the complexity in this block, O(NM logN) was needed to update the sample weights for the new decision function of a weaker classifier. The complexity of the FFS algorithm was O(NMT + NM logN), while that of the naive implementation of the Adaboost algorithm was O(T + NMT logN) when T features were selected, i.e., T loops approximated 6000 for an entire classifier. Moreover, an improved naive Adaboost implementation called fast Adaboost implementation was modified by Wu et al. [13], as shown in Fig. 4(c). Similarly, blocking the ‘train all weaker classifiers' function was moved from the loops in the naive Adaboost implementation. The complexity of the FFS and fast Adaboost implementation were both O(NMT + NM logN).
3.2 Feature Ranking
When the window was large, the feature pool, i.e., the possible feature number M, was large, too. For example, when the size was increased from 11 by 11 to 24 by 24, the possible features were rapidly increased from 6556 to 143 900 by using five prototypes, as shown in Fig. 5. Similarly, when the window size of LPD was increased from 27 by 7 to 56 by 16, the number of possible features was increased from 41 887 to 77 365 using the prototypes, as shown in Fig. 10. As already noted, the sliding window size was reduced to 11 by 11 at layer S to decrease the number of features. To alleviate this problem in the context of the fine-level classifier, a feature ranking algorithm was used to reduce the large feature pool to a smaller set by ranking the discriminating power of features. It was not necessary to check the redundant features with low discriminating powers during the iterations.

Feature prototypes for facial detection
A pre-selection strategy was adopted in the feature ranking algorithm. This was a trade-off for shortening the training process to contain only a few features or to maintain the generality of the original feature pool. The goal of the proposed ranking algorithm was to decrease features to a small set without losing the generality of the feature pool. The pre-selection strategy is presented below.
First, all features in the original pool were ranked according to their weighted errors, e.g., the mis-classification error of each weaker classifier. Second, the features with the lowest P errors were chosen to generate a small feature set
During detection, candidates of various sizes were obtained when the detector with multi-scale windows was moved over the original image. A post-process was then performed to project all candidates of various scales to the original scale for fusing the overlapped regions. For face detection, post-processing was the same as that in [13]. The candidate regions were further checked using the vertical and horizontal gradients in order to remove any false alarms in LP detection.
4. Experimental Results
In this section, some experimental results are discussed to indicate the feasibility of the proposed method in object detection, e.g., in facial and license plate detection.
The algorithms were implemented using C programming language and conducted on a PC-based machine with an Intel-based CPU, 3.4GHz and 11G RAM. In order to show the efficiency of the proposed method, two state-of-the-art algorithms, the FFS [13] and fast Adaboost algorithm [13] were conducted in the same workspace.
4.1 Facial Detection
In face detection, the 24 by 24 windows were checked by the trained detector. A benchmark testing dataset ‘CMU +MIT' 2 was composed of 130 images with 507 facial images for evaluation. In the training phase, 6556 and 16 233 features, respectively, were generated for training both coarse- and fine-level classifiers using five feature prototypes, as shown in Fig. 5. In the detection process, an input image was processed by the convolution and subsampling operations. A sliding window was checked in terms of whether it contained a face or not. If it did, the window had to satisfy both the coarse-level and fine-level tests. The sub-sampled FM and the source image were inputted into the coarse-level and fine-level classifiers to decrease the number of checked windows. Since the features in FM were enhanced, only eight stages with 392 features were used in the coarse-level classifier. Most non-facial background regions were filtered out. Following on, only a few windows remained for locating the exact number of faces via 12 stages with 1650 features. Various scales with an increasing rate 1.25 were applied to detect objects of various sizes. Some detected results for the dataset ‘CMU+MIT’ are shown in Fig. 6(a). All detected faces were drawn within the bounding boxes. Here, the definition of a correctly detected face is identified in [13]. Moreover, missed faces and false alarms are shown in Fig. 6(b). The mis-detected faces occurred in the following contexts: small sizes, dark-faces, profiles, wearing sunglasses. In the final three cases, faces could be detected by proper image training.

Detection results for dataset ‘CMU+MIT’
The performance of detection was highly dependent on various performance indices: detection rates, false alarms, detection time, feature numbers and training time. Two state-of-the-art cascade face detection algorithms based on Harr-like features, FFS and fast Adaboost, were trained by programs available on the Internet 3 . Since the detection rates contradicted the number of false alarms, the cascade classifier with more stages delivered a lower detection rate and slower detection speed. The detection rate of a classifier should be higher than 90% for a practical system. Thus, the detection results with the condition “while detection rate is higher than 90 per cent and false alarms are less than 100” were chosen for comparison.
The face detectors with 2042, 3132 and 3932 features were trained using the proposed methods, that is, the FFS and fast Adaboost algorithms. Best detection rates and false alarms are tabulated in Table 1. In the empirical tests, various errors that occurred in facial detection can be summarized as follows: 1) mis-detected faces: due to the lack of diversity in training samples, some faces such as those wearing sunglasses, profiles, rotations and obstructed faces will be missed; 2) false alarms: we found that “eyes” were the most important features of faces. Therefore, we were able to observe that these false alarms occurred in the presence of “eye-like” features. Furthermore, the ROC curves of the detection rates versus the false alarms are given in Fig. 7. Table 1 and Fig. 7 show that the proposed algorithm slightly outperformed other algorithms.
The performance of the proposed method, FFS and fast Adaboost algorithms for face detection

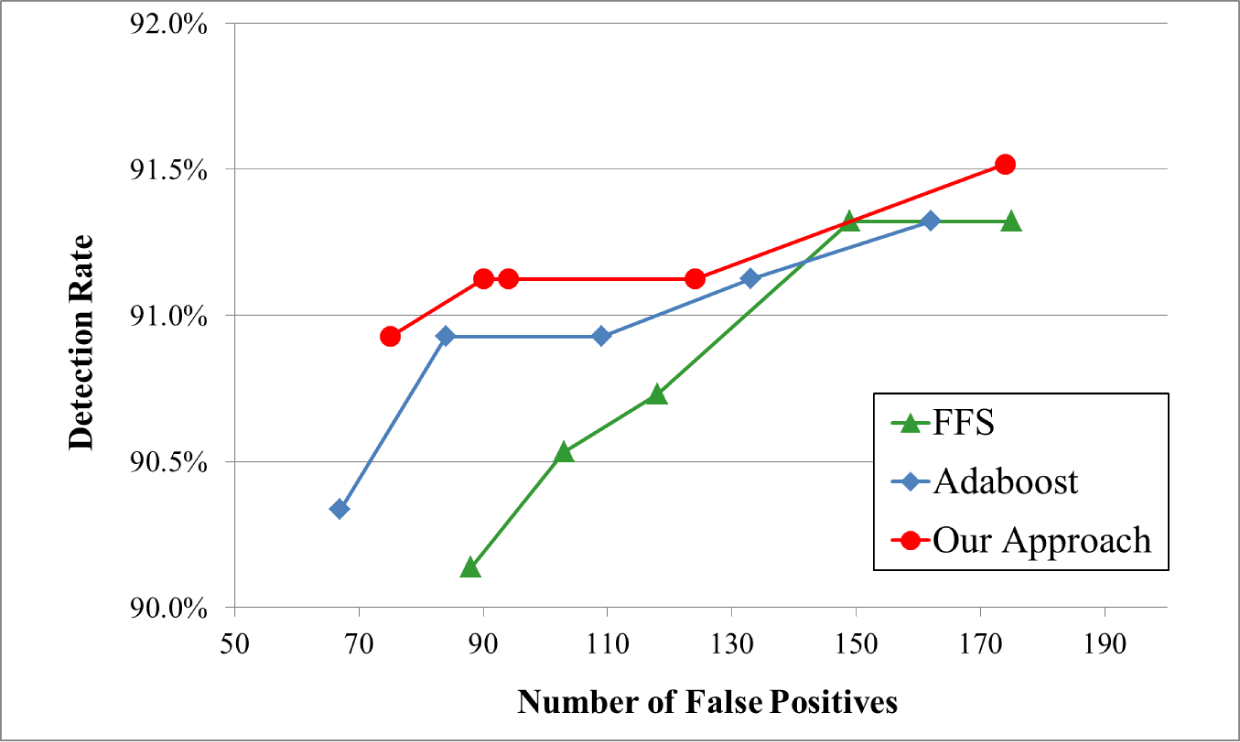
The ROC curves for the detection rates and the number of false alarms for three algorithms using the ‘CMU+MIT’ database
Next, detection time was analysed. One thousand (1000) testing images at 320 × 240 were collected for evaluating detection efficiency. For a fair comparison, all algorithms were run on the same machine. In addition, pyramid images were constructed for a fair comparison with the FFS algorithm, as per Wu's source codes. The FFS algorithm with 3132 features and the fast Adaboost algorithm with 3932 features achieved detection rates of 11.6 frames/seconds (f/s) and 9.8 f/s, respectively. Both detection rates were less than 15 f/s. According to the coarse-to-fine strategy and some trained features, a detection rate of 20.4 f/s was achieved by using the proposed mechanism. The statistical rates of filtered windows in the first eight stages are illustrated in Fig. 8 to indicate filtering power of algorithms FFS, Adaboost, and ours. Due to the different scales, the total number of checked windows for the proposed method, FFS and fast Adaboost algorithms were 18 436 485, 73 621 281 and 73 621 281, respectively. Shown in Fig. 8(a), the verified number of windows in the proposed method was significantly less than in the other two algorithms during the first eight stages. Moreover, the filtering rate was defined as the ratio of filtered windows over the total number of checked windows in each stage. Since the proposed method filtered out more than 70% of the checked windows in the first stage (See Fig. 8(b)), the checking time was rapidly reduced and detection speed was significantly increased, even though lowered filter rates were achieved in later stages. The performances for the three algorithms are summarized in Table 1.
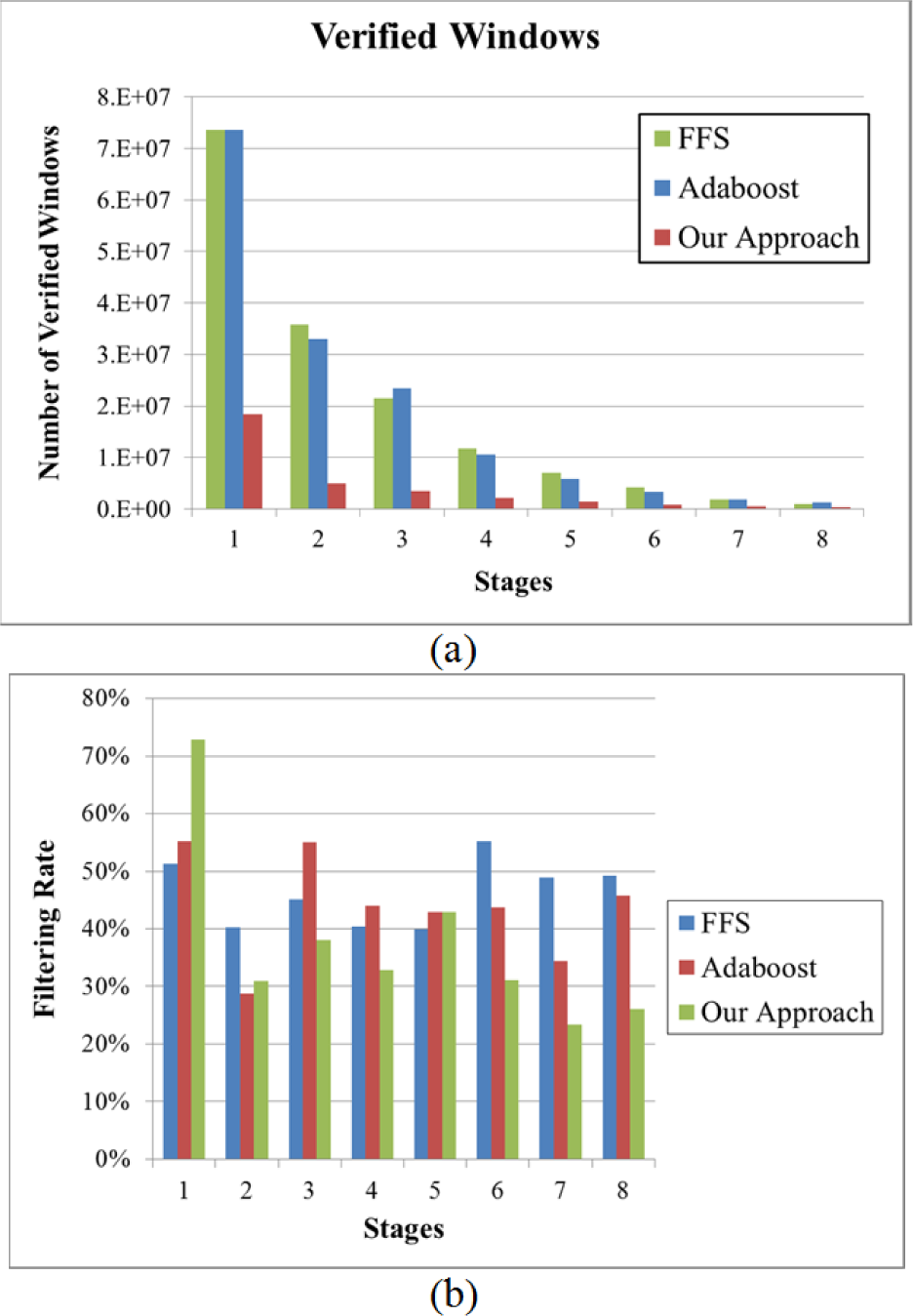
Comparisons for three algorithms in the first eight stages: (a) verified windows; (b) filtering rates
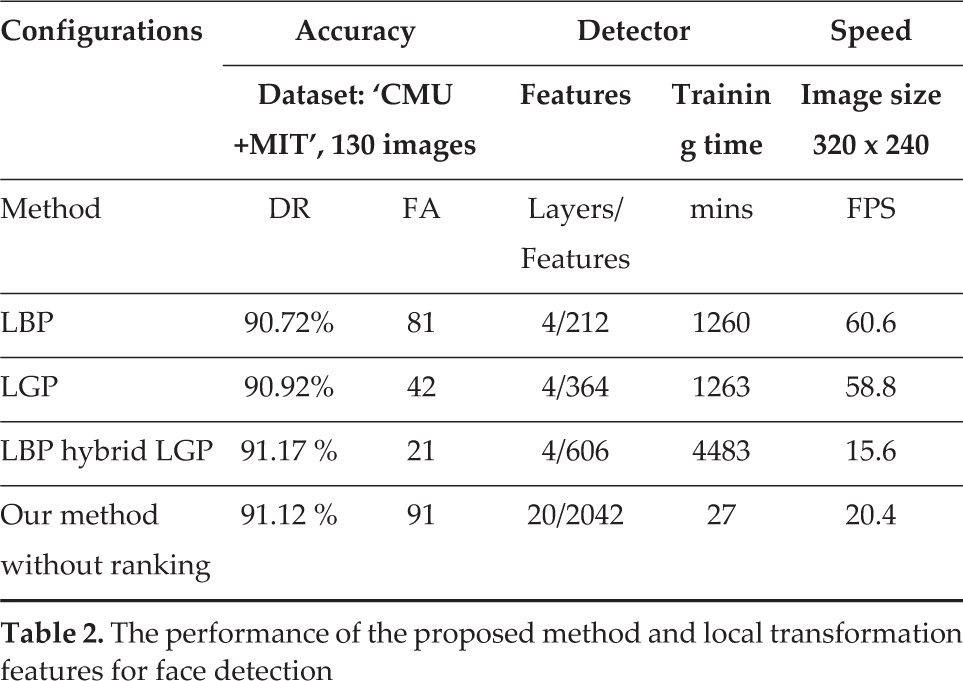
Furthermore, the efficiency of the coarse-level classifier is also given in Table 1. The results in Table 1 and Fig. 8 show that most of the checked windows were filtered out by the coarse-level classifier and a reasonable detection rate could be preserved by the fine-level classifier. Moreover, in order to show the effectiveness and robustness of the proposed method, three cascade face detection algorithms based on local transform features, LBP, LGP and LBP hybrid LGP [36], were trained. The best detection rates and false alarms have been tabulated in Table 2. According to this table, the methods with local transform features slightly outperformed the proposed method. However, the training time of the proposed method was 46.6, 46.6 and 166 times shorter than those of LBP, LGP and LBP hybrid LGP methods. This indicates that the proposed method is extremely practical.
The performance of the proposed method and local transformation features for face detection
Finally, the efficiency of the training process was analysed. For a fair comparison of training times, the pool of Haar-like features used in Wu et al. [13] was adopted for training these three cascade classifiers 4 . The convolution-subsampling pre-processing, the coarse-level classifier and the fine-level classifier were trained in 3, 3 and 21 minutes, respectively. The training times of the proposed method, FFS and fast Adaboost algorithms were 27, 37 and 85 minutes, respectively. Although the proposed method achieved a shorter training time, the efficiency of its feature ranking was not apparent, because the feature pool was very small (16233 Haar-like features were included in this experiment). In a later experiment, training time was sufficiently improved when the feature pool for LPD was large.
4.2 License Plate Detection
The results for car plate detection are given in this subsection. The efficiency of the proposed feature ranking scheme in the training phase, when the pool of Haar-like features was large, is given. The proposed method, FFS and fast Adaboost algorithms were evaluated using a license plate dataset; 6498 vehicle images were collected from surveillance systems installed on urban roads, at toll stations and at a parking lot in a basement. The captured image sizes were 320 by 240. Since drivers switch on car headlights in a basement, the LP areas were frequently dark in the captured images. On the other hand, for images captured on roads, weather conditions and cluttered backgrounds increased image complexity. When images were captured at toll stations, capturing time at night impacted on image quality. The training set was composed of 8721 positive manually selected plate images from the Internet and 8721 negative, randomly generated samples from scene images, whose sizes were normalized to 56 by 16.
Capturing scenes were located on urban roads. The feature prototypes used in the training phase were the same as those used in Wang and Lee [29], as shown in Fig. 9. Furthermore, 41 880 and 77 365 features, respectively, were generated for the training of both coarse- and fine-level classifiers. The dataset was tested by the trained detector under three testing conditions. The correctly detected results, the mis-detected LPs and the false alarms are displayed in Figs. 10 and 11, respectively. All detected LPs are identified by drawing in the bounding boxes. Most of mis-detected LPs occurred at skewed, polluted, obscure or overexposed LPs, as shown in Fig. 11(c). Furthermore, in order to evaluate the robustness of proposed method on LP detection, the presence of noise due to the weather conditions (e.g., rain and snow) was adopted. Due to the lack of benchmark datasets for these conditions, several testing samples were collected from the Internet to serve as reference. The LPD results for rainy and snowy days are shown in Fig. 12 and Fig. 13, respectively. In Fig. 12(a), all detected LPs for rainy days are identified via drawing in the bounding boxes. Meanwhile, mis-detected LPs are presented due to invisible LPs, as shown in Fig. 12(b). Fig. 13 demonstrates the detected results for snowy days. Similarly, all detected LPs are identified by the bounding boxes, as shown in Fig. 13(a). The mis-detected LPs for snowy days also occurred in the case of invisible characters for LPs, as shown in Fig. 13(b).
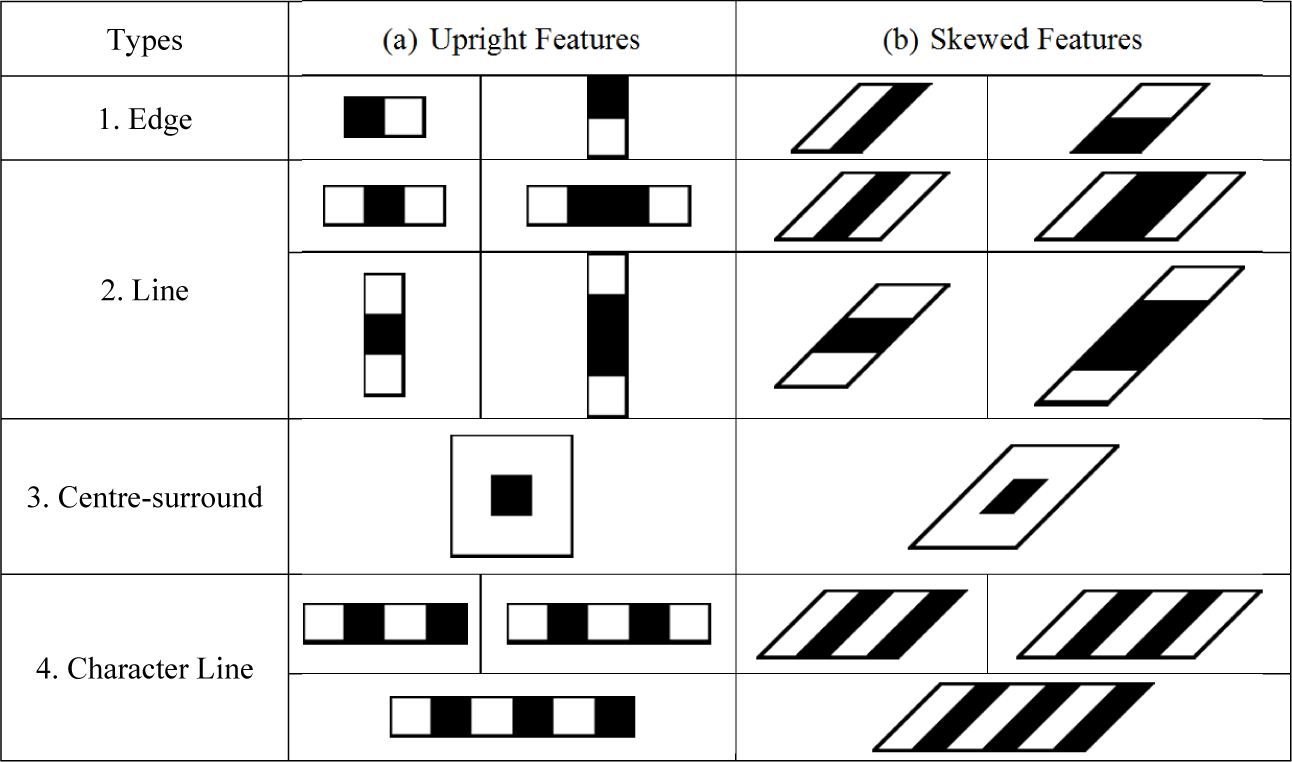
Feature prototypes of upright and skewed Haar-like features for LPD [29]

Correctly detected results. Images grabbed from cameras (a) in a parking lot in a basement; (b) on urban roads; (c) at toll stations

Mis-detected results and false alarms. Images grabbed from cameras (a) in a parking lot in a basement; (b) on urban roads; (c) at toll stations

Detection results for license plates on a rainy day

Detection results for license plates on a snowy day
In order to show the efficiency of the feature ranking scheme, detection rates and the training times for fast Adaboost, FFS and the proposed method were analysed for various parameters P and Q, as shown in Figs. 14 and 15. Fig. 14 shows that the ROC curves for detection rates vs. false alarms in various parameters P and Q were very similar for all three algorithms. The generality of the feature pool was retained when a small feature set was chosen. Further evaluation results of different training times for the three algorithms are shown in Fig. 15. The training times of the processes within the loops of various parameters were calculated for the three algorithms as shown in Fig. 15. On average, training time without feature ranking was 10.4,9.3 and 9.4 times that of feature ranking. However, the total training time without feature ranking was 2.65, 1.5 and 1.83 times that of feature ranking, i.e., all blocks in the algorithms were included. The total training time was not exceptional, because the block “train all weaker classifiers” used a significant amount of time to complete. Moreover, the ROC curves of the detection rates vs. the number of false alarms for the three algorithms in the LPD database are shown in Fig. 16. The performances for the compared algorithms in terms of LP detection are tabulated in Table 3. According to our experience, the DRs contradicted the FAs each other. DRs are reported in Table 3 for comparisons under the condition “the FAs are less than 1600”. In addition, the configurations for the trained detectors are also shown in this table. According to the coarse-to-fine strategy, the detection frame rate of the proposed method was higher than the fast Adaboost method even though the layer numbers and feature sizes were larger. This table also shows that the detection speed of the proposed method was faster than for the other two methods.
The performance of the proposed method, FFS and fast Adaboost algorithms for LPD


ROC curves for the detection rates versus the number of false alarms for various parameters P and Q on LPD

Training time for the cascade classifiers with feature ranking and one without feature ranking

ROC curves for the detection rate versus the number of false alarms for three algorithms with better results regarding LPD
In summary, the proposed method using feature ranking improved both the detection and training processes for LP.
4.3 Discussion
From the experimental results of this study, the proposed mechanism can efficiently improve both detection and training processes for LP as summarized in the following.
5. Conclusions
In this study, a coarse-to-fine cascade classifier was designed to detect facial or LP objects. In the two-level classifier, small windows with enhanced pixels were verified by the coarse-level classifier and large windows with detailed data were further verified by the fine-level classifier. A small feature map with enhanced pixels (i.e., 1/4 of the original image size) was trained by the convolution and subsampling operations. Using this mechanism, most background windows were filtered out by the coarse-level classifier and a few surviving foreground windows were further verified by the fine-level classifier. On the other hand, the feature pool was also reduced to speed up the training process using the following two strategies: (1) Some features were generated from the prototypes with a small window at the coarse level and (2) a small feature set was generated from the ranking algorithm at the fine level. The experiments were conducted to show the feasibility and effectiveness of the proposed method. In future, this two-level mechanism will be extended to detect more complex objects such as text characters, cars and pedestrians.
Footnotes
6. Acknowledgements
This research was supported by the National Science Council under grant no. NSC 100-2221-E-239-035 and NSC 101-2221-E-239-034.
4
The features used in the training of a fine-level classifier were the same as those used in Wu's program, i.e., 16 233 features. However, the feature number used in the training of a coarse-level classifier was 6556, due to the smaller window size.