
Abstract
This paper presents a novel approach to discovering motor primitives in a hierarchical database of example trajectories. An initial set of example trajectories is obtained by human demonstration. The trajectories are clustered and organized in a binary tree-like hierarchical structure, from which transition graphs at different levels of granularity are constructed. A novel procedure for searching in this hierarchical structure is presented. It can exploit the interdependencies between movements and can discover new series of partial paths. From these partial paths, complete new movements are generated by encoding them as dynamic movement primitives. In this way, the number of example trajectories that must be acquired with the assistance of a human teacher can be reduced. By combining the results of the hierarchical search with statistical generalization techniques, a complete representation of new, not directly demonstrated, movement primitives can be generated.
Introduction
In contrast to robot manipulators used in industry, autonomous robots working in domestic environments are not expected to repeat the same task with the same movements over and over again. Since the tasks and related conditions change constantly, manually programming the movements for every variant of a given task is not feasible. One of the most successful and widely used approaches to the acquisition of new sensorimotor behaviours is learning by imitation (or programming by demonstration) [1, 4, 23]. In such systems, initial movements are acquired by observing a human demonstrating a task. The demonstration is often captured using magnetic or optical marker-based systems. Such an approach has been utilized to replicate hard-to-program movements, such as dancing [26, 20, 19]. Research on markerless, vision-based systems for human tracking has also become a thriving area [18] and has seen a lot of success with the advent of low-cost RGB-D cameras [24]. Alternatively, a human can physically guide the robot to perform the desired movement via kinaesthetic teaching [7], which has the advantage that the captured movement is already adapted to the robot's kinematics and dynamics.
An aspect of research on imitation learning focuses on learning from a single demonstration, such as, for example, in the case of dynamic movement primitives (DMPs) [8]. Hidden Markov models [9] are another popular representation for the encoding of movement primitives. Multiple demonstrations have been used, for example, by Forte et al. [6], where a set of example trajectories was generalized with local regression methods to synthesize a trajectory that solves the task in a new situation within the trajectory training space. For this approach to work, the trajectories must transition smoothly between each other as a function of the parameters describing the task. Multiple demonstrations were also encoded with Gaussian mixture models [2, 10]. Alternatively, reinforcement learning was applied to generalize motor primitives for new situations by Kober et al. [12]. The need to acquire numerous demonstrations in order to generalize example trajectories for new situations is one of the major stumbling blocks in the practical application of imitation learning systems.
Compared to the work in the computer graphics community - which has always assumed that a large database of diverse motion data is available for the generation of computer animations - the number of example movements considered in robot programming by demonstration research has usually been much more limited, and the example trajectories have been less diverse. The work of Kulić et al. [15, 14] is a notable exception. They used hidden Markov models for incremental learning and the hierarchical organization of motion primitives, but they do not focus on discovering new movements in these data. In contrast, the computer graphics community has shown that, by exploiting the structured nature of motion capture data - which is made evident in motion graphs - smooth transitions between interconnected body movements can be found [21]. Motion graphs were proposed to encapsulate connections in the available motion capture data. They were applied by Kovar et al. [13] to generate different styles of locomotion along arbitrary paths. Their graph search algorithm was able to find nodes which represent possible transitions between parts of the captured movements. Motion graphs and interpolation techniques were combined by Safonova and Hodgins [22] in order to increase the number of paths through a graph. While the motion graph literature is vast, our work is most closely related to the approach of Yamane et al. [27], who used binary trees to organize the data and the resulting transition graphs in order to generate human body locomotion on a desired path. Sidenbladh et al. [25] also use a binary tree structure for the efficient sampling of human poses.
This paper proposes an approach that uses the concept of motion graphs, binary trees and a hierarchical search to generate new movements that were not directly demonstrated by the teacher. In this way, the number of human demonstrations needed to synthesize new movements can be reduced. New example trajectories are generated through a graph search, which can be used by statistical generalization [6] to create new movement primitives for arbitrary configurations.
Initial demonstrated example movements are organized in a hierarchical graph-like structure. State vectors, encoding demonstrated movements, are clustered using the k -means algorithm [16], as it was shown to be most efficient for our approach. The results of clustering are used to construct a binary tree, which represents the captured data at different levels of granularity. Every level of the binary tree is associated with a transition graph that describes transitions between the nodes at that level. The nodes contain state vectors from all example trajectories. The database is used to find new connections between nodes and thus new movements. If the path at the desired level does not exist, a top-down hierarchical database search is employed in order to find optimal partial paths. Dynamic movement primitives are used to combine them into smooth and continuous trajectories from the given start and end state vectors at the desired level of granularity. Statistical methods [6] are then utilized to generalize the newly discovered sets of trajectories and to create a complete representation of a newly discovered movement primitive.
While other works relating to motion graphs synthesize new movements through a graph search and/or interpolation, we employ a hierarchical partial paths search, which enables us to synthesize new movements by finding partial paths at lower levels of granularity. With this, we generate movements at desired levels of granularity while avoiding big parts of movements stemming from interpolation, which would reduce the similarities to demonstrated movements and in turn reduce the needed precision for, inter alia, manipulation tasks.
The rest of the paper is organized as follows. In Section 2, we present the process of constructing the database. The next section is divided into three parts; Subsection 3.1 deals with path searches in transition graphs, Subsection 3.2 with hierarchical searches of partial paths, and Subsection 3.3 with time evolution and DMPs. Section 4 presents the statistical generalization of the newly discovered sets of movement trajectories. The experimental evaluation of our approach is given in Section 5, while the discussion and conclusion are given in Section 6.
Generation of a hierarchical database of example movements
The example trajectories can be acquired either in the task or in the joint space. For the purpose of building the database, we concatenate the acquired trajectories in a sample motion matrix,

where

where pji and

where the j -th joint angle and its velocity at time ti are denoted by qji and
Once example trajectories are stored and arranged in a sample matrix, they can be utilized to build a binary tree. The complete sample data matrix
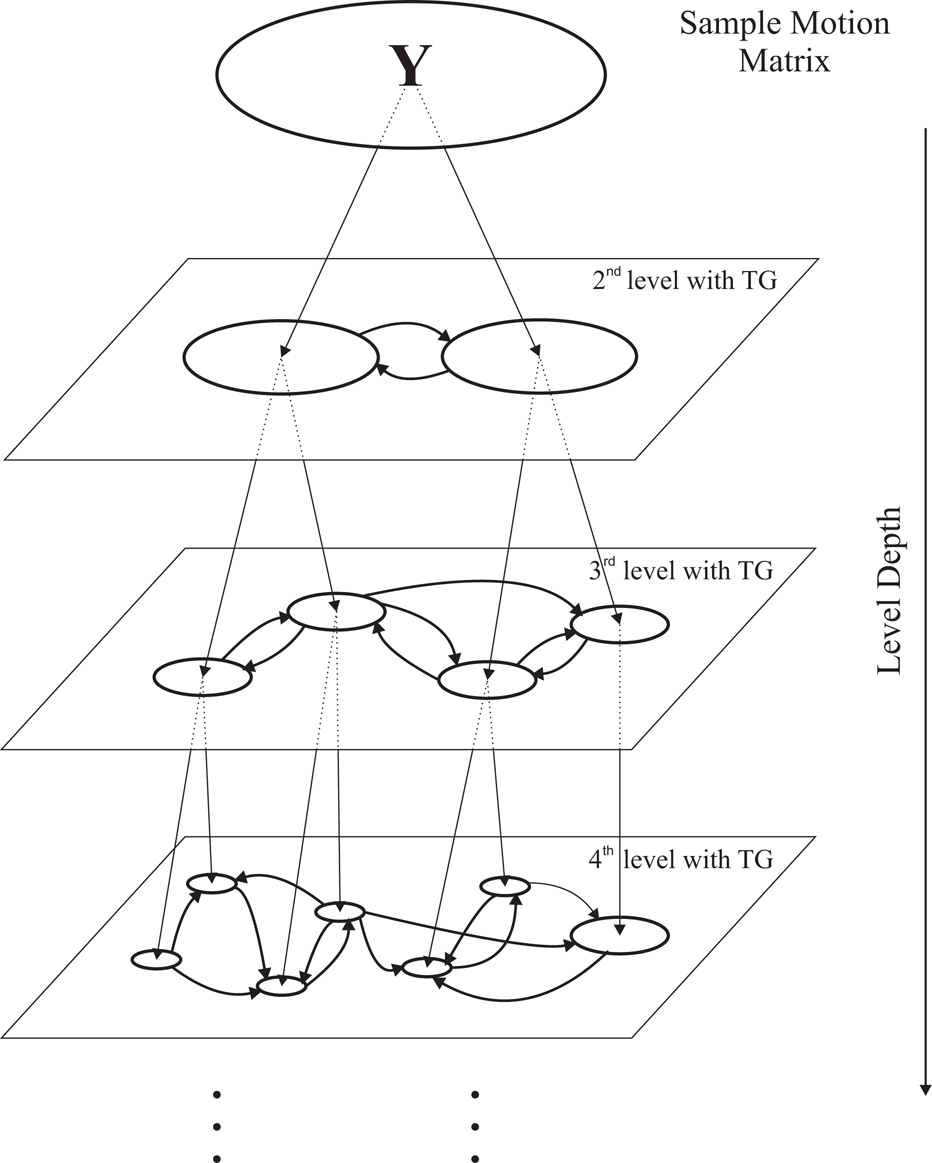
Generation of the hierarchical movement database with binary tree and transition graphs. The figure shows the structure of our database. The sample motion matrix
A criterion based on the variability of the data contained in the node is used do decide when to stop splitting the tree nodes. We define the mean distance dv of node v as

where nv denotes the number of state vectors clustered at node v. The Euclidean distance d(
At each depth level of the binary tree, we build a transition graph that represents all the transitions between the nodes at the current depth (see Fig. 1). The edge weights in the transition graph represent the probability of transition from one node to another. The transition probability from node vk to node vl is estimated by

where n vk denotes the number of state vectors clustered at node vk and mkl denotes the number of transitions observed in all the trajectories of the original data, i.e., all the state vectors clustered in node vk that have a successor in node vl.
To accelerate processing we compute the mean xv of the position components of all the state vectors yvi associated with node v. Only if the node contains exactly one final configuration on an example trajectory do we store this final configuration instead of the position mean of all the state vectors. In this way, we ensure that the movements generated by the graph search end in the same end points as the original movements. By combining several trajectories in the same node, we lose the time component. We will explain later on in Section 3.3 that the time duration tv of each node v is estimated through a ratio of the number of state vectors associated with node v and the number of original example trajectories passing through it.
Given the binary tree, the means of the state vectors
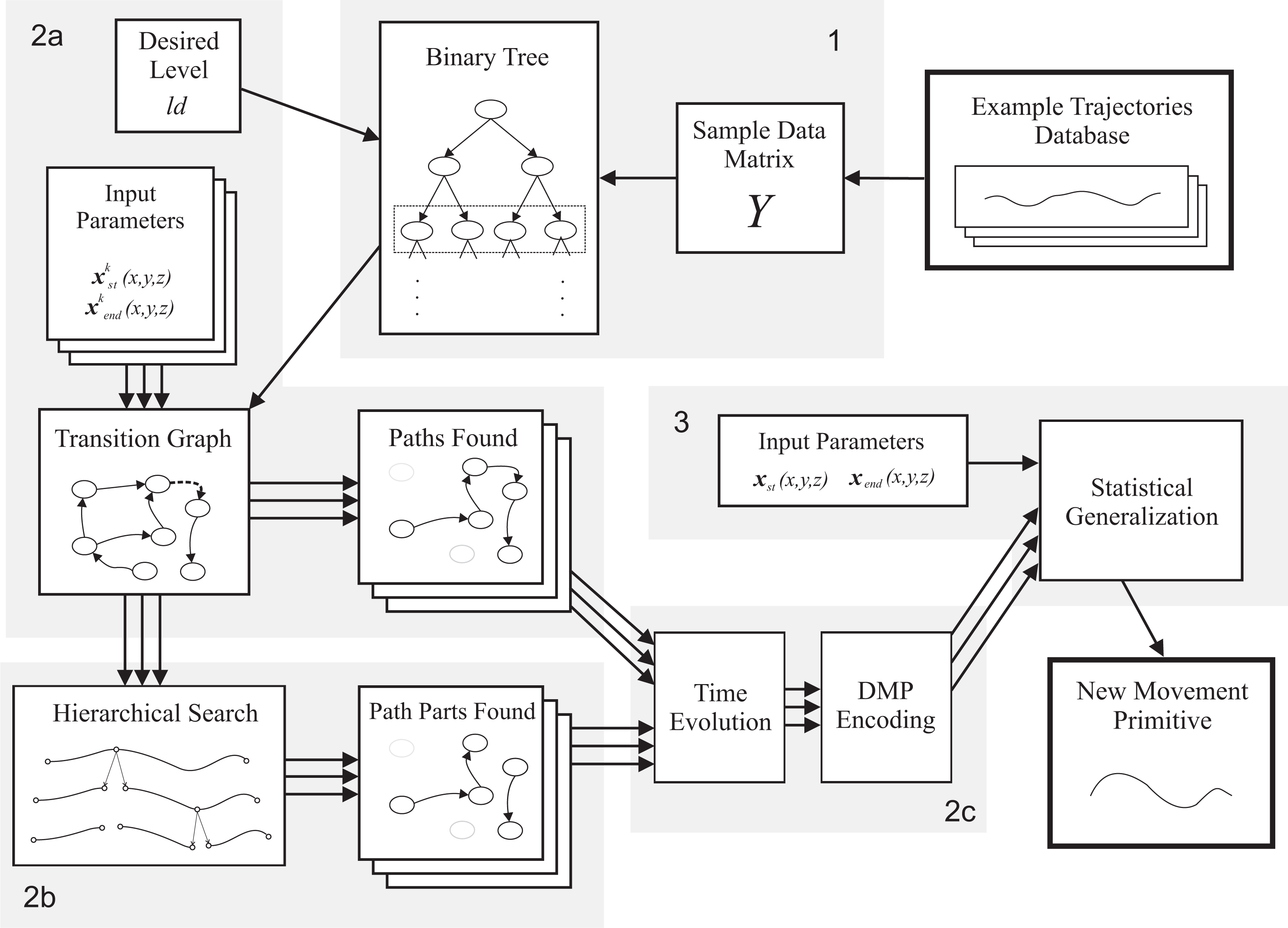
A block diagram presenting the proposed approach.
We start the process of discovering new discrete movement primitives (i.e., point-to-point movements such as reaching or grasping) by selecting the desired start and end points
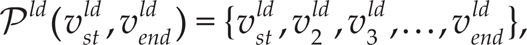
connecting start and end nodes in the transition graph at level ld. If this is not the case, we need to find partial paths connecting the nodes (Tine 2 in Alg. 1 and Fig. 2), using the proposed hierarchical search.
If the desired start and end nodes are not connected in the transition graph - which can happen especially if the start and end points do not belong to the same trajectory - at the desired level, we take advantage of the hierarchical structure of the binary tree to find partial paths that would connect them (Alg. 2 and Fig. 2, subpart 2b). First, we find the deepest level at which the transition graph has a connection between the nodes v st l and v end l that are associated with the desired start and end points xst and xend. Such a level always exists because there is only one node at the top level. This is done by moving up the levels and using the A* search algorithm until a path Pl is found (Alg. 2, Lines 1–5). However, this higher level does not have the desired granularity. To achieve proper granularity, we need to move down to the desired depth ld. Since the desired path does not exist at the deeper levels, we need to find a series of partial paths {p P i ld } which connects the desired start and end nodes v st ld and v end ld at the desired level ld.
The hierarchical search for partial paths is outlined by a simple example in Fig. 3 and by pseudo-code in Alg. 2, Lines 7–20. The search is started by taking the path Pl at the lowest level l at which such a path exists. This means that, at the beginning, there is only one partial path. We then start moving down the levels, l = l + 1, and find all the child nodes of the border nodes of each partial path. We then apply A* to find a connecting path, i.e., the paths between successive border nodes (Alg. 2, Line 12). If the direct connecting path at this level does not exist, then the nodes that broke the connection must be found. These are used to construct partial paths between the desired nodes (Alg. 2, repeat loop starting at Line 11). Once a series of partial paths that can be used to connect the start and end nodes at this level (i.e., v st l and v end l ) has been found, we select the shortest connection between these two nodes (Alg. 2, Line 19 and Fig. 3). We continue moving down the levels and searching for partial paths until we reach the desired level l=ld. At this point, the discovered path connecting the desired start and end nodes is represented by a series of partial paths,

which can be translated into a sequence of nodes
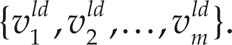

Hierarchical search of partial paths (see Alg. 2) illustrated by a simple example. After the path Pld (v st ld , v end ld ) was not found at the desired level of the database ld, the lowest level ld − 4, where a connecting path exists, was found. We then moved one level down to find connection at level ld − 3. As the direct connecting path at this level Pld−3(v st ld−3, v end ld−3) did not exist, we searched for a node that broke the connection. A* search was used in order to find the two partial paths. One connecting the start node v st ld−3 and one of the break node's children and the other connecting the other break node's child with the end node v end ld−3. We then move down another level to ld − 2 starting with the two partial paths. No new break points occurred at this level. When moving down one more level to ld − 1, it was not possible to connect the descending border nodes of the right partial path. New partial paths had to be found instead, so moving to the desired level ld resulted in three partial paths. The bottom of the figure shows DMP-based interpolation of partial paths into a smooth and continuous trajectory.

Hierarchical search for partial paths Find Partial Paths
New example trajectories are defined by the positional means
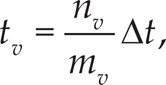
where 1/Δt is the sampling frequency, nv denotes the number of state vectors clustered in node v, and mv the number of trajectories passing through node v. The discovered trajectories can now be written as a sequence

where

We encode each dimension of the discovered trajectory {(


The linear part of Eqs. (12) – (13) ensures that y converges to the desired final configuration, denoted by “g”. The nonlinear part f(s) modifies the shape of a given movement and is defined by a linear combination of radial basis functions,
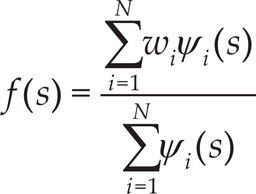

where ѱ i defines the basis functions, with centres at ci and widths of hi > 0. As seen in Eq. (14), f (s) is not directly time dependent. Instead, the phase variable s defined in Eq. (16), with an initial value s(0) = 1, is used

The phase is common across all the DOFs or dimensions. By specifying the time evolution through the phase, it becomes easier to stop the clock in the case of external perturbations which cause the robot to deviate from the desired trajectory. It can be shown that - given the properly defined constants K, D, τ, α s > 0 - the above system is guaranteed to converge on the desired final configuration g.
Eq. (12) – (13) can be rewritten as a second-order system,
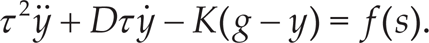
By substituting y with the corresponding component of

where the goal value g is specified by the corresponding component of

we can write a system of linear equations

where

with ѱ i and si set according to (15) and (16).
By solving the above system, we gain the appropriate DMP weights w and thus learn the target function (18). By transforming (10) into a DMP, we ensure that combined partial paths result in a smooth and continuous trajectory and thus prepare the newly discovered movements for execution on a robot. The gaps between successive partial paths can be successfully bridged by DMPs, as shown below in Fig. 9.

Our experimental setup. It consists of two Kuka lightweight robot arms, three fingered Barrett hand, two mounted cameras, and a shelving unit. The shelving unit consisted of six compartments, i. e. goal areas. The starting area on the table, where the object was put before each execution, is marked with blue lines.

Vision error. Different positions across the starting area were determined by robot's forward kinematics and at the same time estimated by stereo vision. Blue dots represent positions obtained by forward kinematics, whereas the connected red dots represent the same object position as estimated by vision. Note that the z axis is scaled for better visibility. On the average the systematic vision error was 0.85 cm.
Through a hierarchical graph search and DMP-based interpolation, we can connect the start and end configurations even if they do not belong to the same demonstrated movement. In this way, we can significantly increase the number of initial example movements {Mk), where the example movements are defined as in (10).

Evaluation of clustering algorithms. Top graph shows Davies-Bouldin index values for each database level and each algorithm. Lower values represent better clusters. Similarly, the bottom graph shows Dunn index values, but with Dunn index, higher values represent better clusters.
But even if a large set of movements {
Given the DMP representation and trajectory data expanded by the graph search {
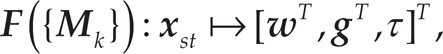
where
We evaluated our approach in an experiment where a robot had to learn how to pick an object positioned anywhere in the starting area and put it on a desired shelf. The starting area was 62 cm by 76 cm in size. There were three levels of shelves and each of them was further divided into two parts. Each goal area could be reached through a 30 cm by 30 cm opening. Unless stated otherwise, data in Cartesian space were used, i.e., all the state vectors included in the hierarchical database are defined in Cartesian space (2). Two Kuka lightweight robot arms were used for the experiment: one for holding the stereo camera system used for vision and one for executing the task. Objects were grasped using a three-finger Barrett hand. They were easy to grasp and detect, as these issues are not the main subject of our research. The experimental setup can be seen in Fig. 4.

Demonstration of reaching movements by kinesthetic guiding of the Kuka lightweight robot arm. From each of the six areas in the starting zone, 5 movements were demonstrated to a unique shelving unit part. The object was held with the Barrett hand and its starting position was estimated by stereo vision. The object did not collide with the shelving unit during the demonstration.
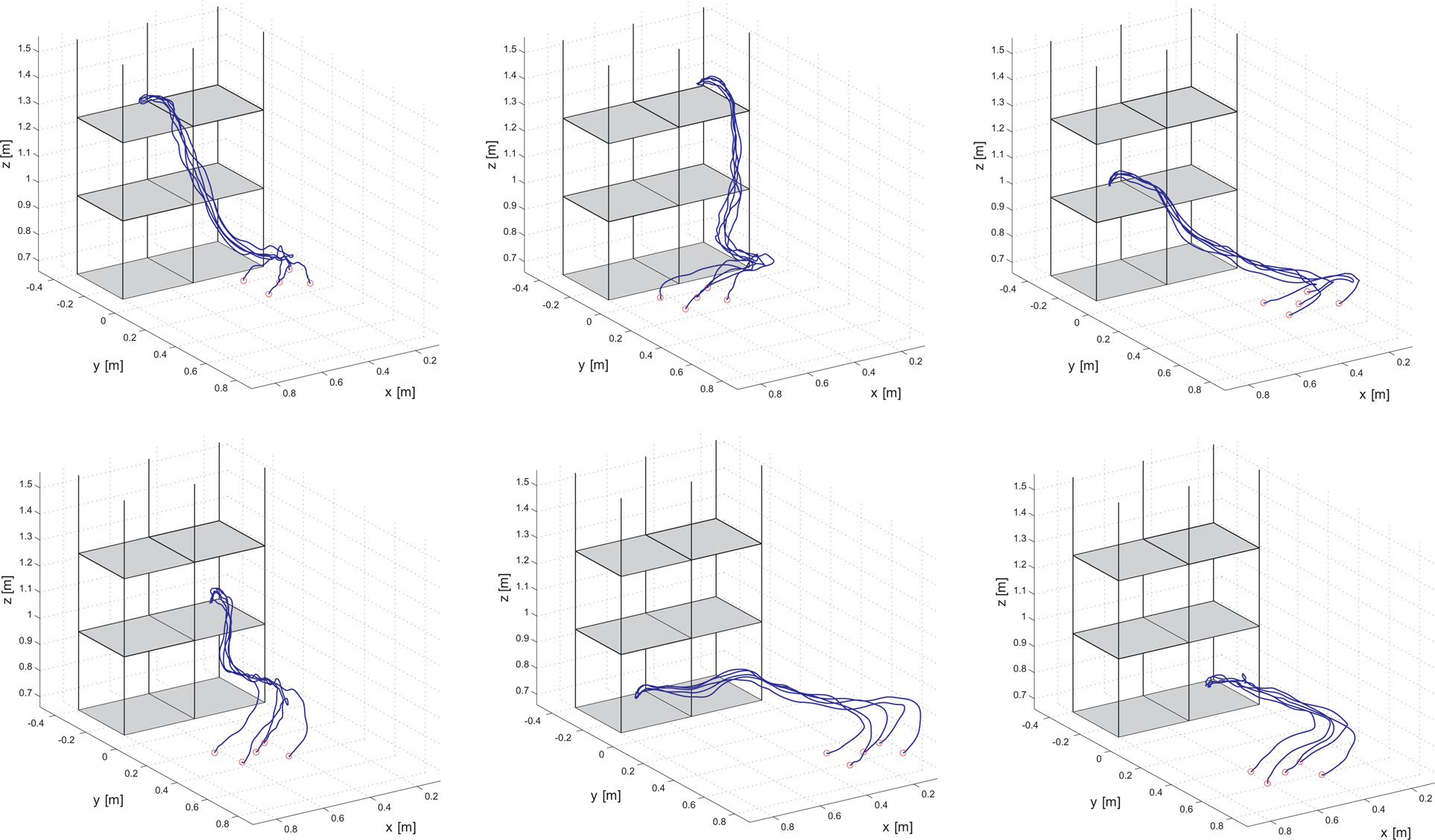
Captured movements for the example database. The goal areas, i. e. the shelving unit is shown in black and gray. The trajectories of captured movements are shown in blue. The trajectory starting points are marked with red circles. From each of the six areas in the starting zone, 5 movements were captured to a unique shelving unit part. Altogether 30 movements were demonstrated and captured.
As stated before, the starting object positions were estimated by stereo vision. Some noise and errors are to be expected with such estimation despite accurate camera calibration. By comparison of the positions obtained by the robot's forward kinematics and stereo vision, we estimated the systematic vision error to be 0.85 cm. These positions, which roughly cover the starting area, can be seen in Fig. 5. The systematic vision error can in part be learned by Gaussian process regression, which is used for generalization. Since stereo vision is used to estimate the object's starting position in training and when generating new movements, the vision error is corrected by Gaussian process regression.
Clustering algorithm evaluation
Before building the binary tree database, we needed to select a clustering algorithm. We compared three popular and widely-used approaches by building our database from the captured movements, as explained in Section 2, and then evaluating clusters at each level. Two metrics were used, both of which were internal evaluating schemes. We evaluated the clusters by calculating Dunn [5] and Davies-Bouldin (DB) indices [3] at each level of the binary tree build by each of the three algorithms: k -means, PCA with the minimum-error thresholding technique, and expectation-maximization (EM) clustering [17]. The evaluation results are shown in Fig. 6. The top graph shows the DB index values for each database level and algorithm. Lower DB index values represent better clusters, as they define smaller distances between values in clusters and larger distances between cluster centres. It can be seen in the graph that k -means outperforms PCA and EM clustering with lower values at the important (i.e., lower) levels. The bottom graph shows the Dunn index values, again, for each level and algorithm. In this case, higher index values represent better clusters. We can see that EM performs just slightly better than k -means in the lower levels, but in our opinion it does not justify a much higher computational cost and poorer DB scores.
Properties of the constructed database

Properties of the constructed database
The first step in building the database was the acquisition of example trajectories for the sample motion data matrix.

Using DMPs for interpolation and combining partial paths. Top three figures show three dimensions of a newly synthesized movement. The bottom three figures enlarge the transition part from one partial path to another. Grey circles represent mean state vectors

Newly generated trajectories. The goal areas i. e. the shelving units, are shown in black and gray. The new trajectories are shown in blue, while its starting points are marked with red circles. Each series now covers all of the starting area for each goal area.
The demonstrated trajectories were obtained by kinaesthetically guiding the robot arm, as seen in Fig. 7. For each of the six goal areas, we captured a series of five movements that roughly covered one-sixth of the starting area − 30 movements altogether. These captured movements are shown in Fig. 8. For each movement, the object's starting position was estimated by stereo vision and saved together with the trajectory data. With the selected k -means clustering algorithm, we constructed the database using the 30 example trajectories. The hierarchical database included transition graphs at different levels of granularity, as explained in Section 2. The resulting database consisted of 20 levels with 4,133 nodes at the deepest level.
The goal of the next step was to discover six new series of reaching movements, one for each shelf. In contrast to the training trajectory data, which covered only one-sixth of the starting zone for each shelving unit - the newly discovered series covered the entire starting zone. Each new series consisted of 30 movements, which were associated with the input parameters
Statistical generalization
Although the example trajectories now cover the entire starting zone, it is highly unlikely that the object would be located precisely at one of the 30 starting positions. Because of this, we use statistical methods to generalize newly found trajectories and compute a movement for every starting position of our object. Some example trajectories obtained by the statistical generalization of one of the new series of trajectories can be seen in Fig. 11 and Fig. 12.

New trajectories obtained by statistical generalization. Trajectories used for generalization are in black, whereas the synthesized trajectories are shown as red dashed lines. Starting points are marked with circles. The newly generated trajectories are adapted to the new starting positions.

New trajectories obtained by statistical generalization. Trajectories used for generalization are in black, whereas the synthesized trajectories are shown as red dashed lines. Note that the generalized trajectories are similar to the original ones.
With the generalization of newly found series of shelf-placing movements, our robot was able to pick the object from any position in the starting area and place it at any of the six goal positions on the shelving unit with a smooth motion while avoiding collisions with the shelf, as can be seen in video (http://tinyurl.com/VideoAppendix-HDb). One of these new placing movements can also be seen in Fig. 13. All the movements avoid collision with the shelf because the demonstrated trajectories avoid such collisions. This property is preserved by the graph search, the hierarchical search and the statistical generalization, which result in trajectories that are similar to the parts of the demonstrated trajectories.

Execution of a new movement. The movement with such a combination of start and goal position was not contained in the training data. Even if the object is positioned at a random spot inside the starting area, the robot can successfully place it to any of the 6 desired shelving unit parts.
The main experiment synthesized new movement primitives using data in Cartesian space (2). This means that clustering, a partial path search, DMP interpolation and statistical generalization were done in Cartesian space. This subsection of the evaluation focuses on synthesizing new primitives from data in the robot's joint space instead. The same human demonstrations for the same pick-and-place task were used. However, while the approach for synthesizing new primitives remained the same, the state vectors were now defined in the robot's joint space (3). Once the sample motion data was built, a hierarchical database with transition graphs was constructed. The database consisted of 21 levels with 3,464 nodes at the deepest level. The proposed approach managed to find all the new trajectories using this database, i.e., the same number of trajectories as in the main experiment, connecting all the start positions with all the racks. A comparison of an example new trajectory synthesized using Cartesian space data with a trajectory synthesized with the joint space data is shown in
Figs. 14 and 15. While some discrepancies can be noted between the majority of the new trajectories, the new trajectories retain the needed shape to execute a given task.
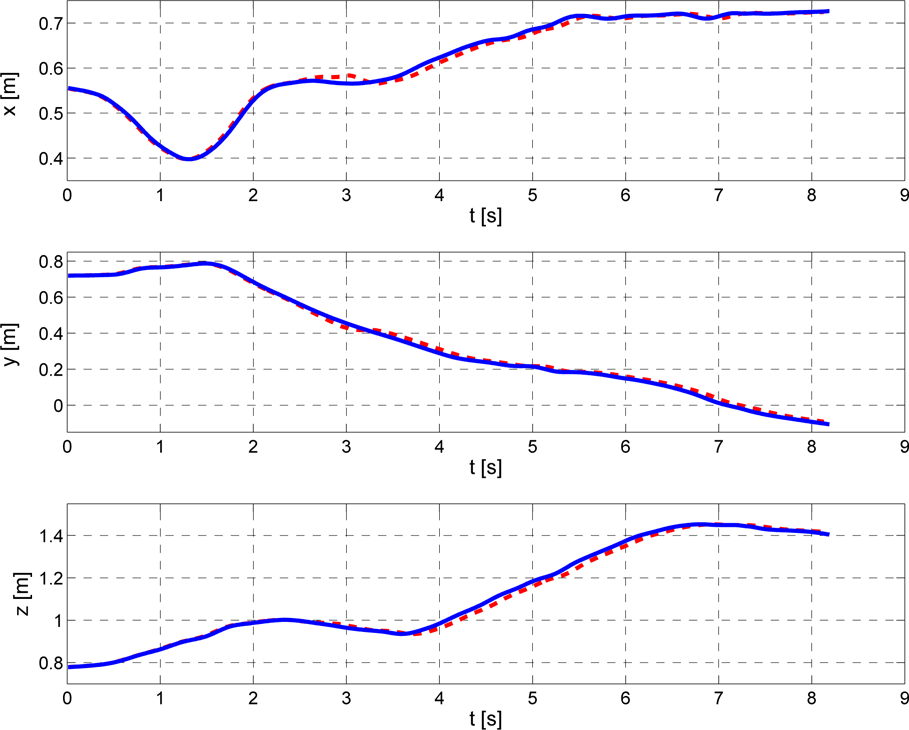
An example of a newly generated trajectory synthesized using joint space data for each of the three dimensions. The figure shows two trajectories. A new trajectory generated using joint space data and then transformed to Cartesian space is denoted with a dashed red line, while a trajectory gained in the previous experiment, using Cartesian space data, is denoted with a blue line. While the trajectories are mainly identical, there are some minor discrepancies.
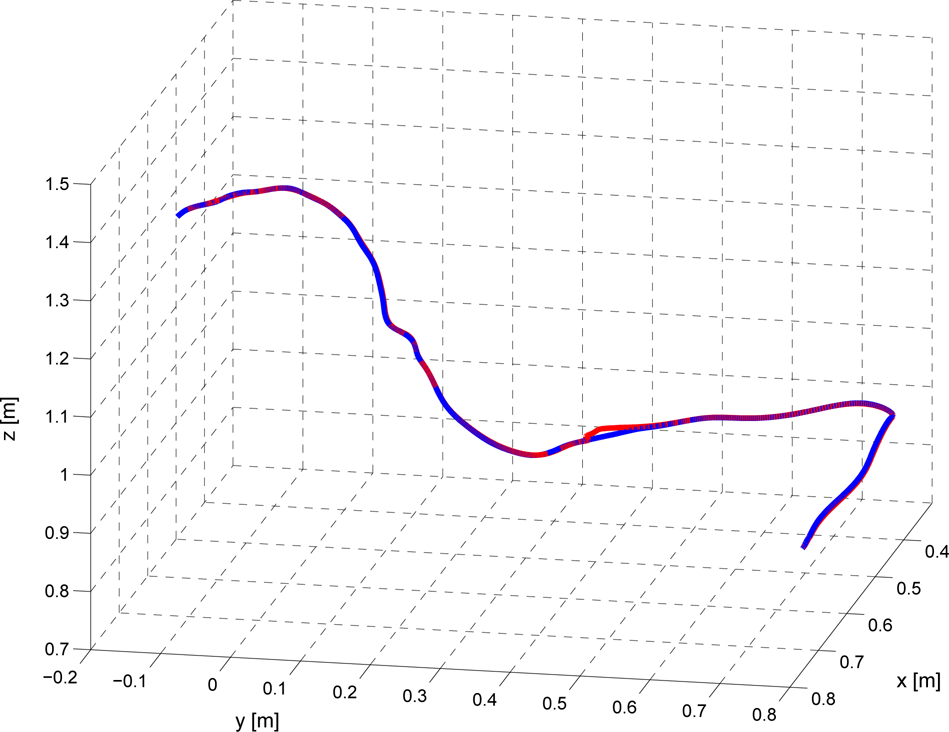
An example of a newly generated trajectory synthesized using joint space data in 3 dimensions. The figure shows two trajectories. A new trajectory generated using joint space data and then transformed to Cartesian space is denoted with a red line, while a trajectory gained in the previous experiment, using Cartesian space data, is denoted with a blue line. While the trajectories are mainly identical, there are some minor discrepancies.
The experimental results showed that it is possible to discover new movement primitives in a database of example demonstrated movements. Unlike many other approaches in imitation learning, it is assumed that the training database consists of different types of movements. They are combined by exploiting the interconnections between the movements using graph search technologies. This search process generates new movements that are not part of the initial training database. A novel hierarchical graph search procedure was developed, which starts at the highest level where the direct connection between the desired start and end robot configurations exists, and progresses through the transition graph levels, finally producing a series of partial paths connecting the two nodes at the desired level of granularity. These partial paths are combined using DMP-based interpolation. The interpolation procedure ensures that the newly generated trajectories are smooth. In this way, connections are generated between desired configurations, even if they do not belong to the same example component at the desired level of granularity. The proposed approach reduces the burden of demonstrating many trajectories while preserving the needed precision, shape and smoothness of movement. This was shown by evaluating the hierarchical search, where 30 demonstrated reaching movements were expanded to 180 new reaching movements, each of them retaining the shape of movement and precision needed for successfully executing the task. While this task could be accomplished by motion planning algorithms, we believe that it shows the applicability of our approach by extensively expanding the initial database through a combination of different parts of movements, and thus reducing the burden of multiple demonstrations usually needed for programming by demonstration. By merging the results of the hierarchical search with statistical generalization, a complete representation of a new movement primitive could be constructed.
In our evaluation, the data are acquired through kinaesthetic guidance by a human demonstrating a pick-and-place task. As the task is defined in Cartesian space, the human will automatically devote more attention to the robot's end-effector in Cartesian space than to the pose of the robot. This is one of the reasons Cartesian space data was used throughout the main experiment. In order to show the robustness of the proposed approach, an additional experiment using joint space data from the same demonstrations was performed. While no extra attention was paid to the robot's pose during the kinaesthetic guidance, the joint trajectories still shared sufficiently similar parts so as to make synthesis and interpolation viable.
While the prosed approach for the synthesis of new movement primitives is related to the work of Yamane et al. [27], some fundamental disparities need to be noted. While they proposed clustering the state vectors from the example trajectories using principal component analysis (PCA) and a minimum-error thresholding technique [11], this paper evaluates various clustering approaches and proposes clustering the data with the k -means algorithm [16], as it is shown to be more efficient. Note that, unlike Yamane et al., whose interest was primarily in full-body movements, this paper focus on arm trajectories and manipulation tasks, which often require finer precision. The criterion for stopping further clustering is therefore based on the variability of the data in clusters rather than solely on the number of nodes, which enables higher precision. It mainly needs to be emphasized that, in contrast to Yamane et al., we do not assume connections between the desired start and end nodes at the desired level. Instead, a novel approach of a hierarchical database search is used to find optimal partial paths.
Future work will involve the evaluation of our approach on larger databases consisting of more diverse movements. With the increasing size of the database, we might encounter greater computational costs, but the research performed by the computer animation community has shown that such databases can be processed in a reasonable time. The implementation of an optimized code in a faster programming language would also reduce computational times. The database could also be expanded with additional data, e.g., information about objects involved in the action. It could be extended to generate human-robot cooperative movements [28]. Forces and torques arising during manipulation actions could also be encoded in the database and used for compliant movement generation.
Footnotes
Multimedia Appendix
8.
The research leading to these results has received funding from the European Community's Seventh Framework Programme FP7/2007-2013 (Specific Programme Cooperation, Theme 3, Information and Communication Technologies) under grant agreement no. 270273, Xperience.