
Abstract
With the rapid growth of computing powers and recent advances in deep learning, we have witnessed impressive demonstrations of novel robot capabilities in research settings. Nonetheless, these learning systems exhibit brittle generalization and require excessive training data for practical tasks. To harness the capabilities of state-of-the-art robot learning models while embracing their imperfections, we present Sirius, a principled framework for humans and robots to collaborate through a division of work. In this framework, partially autonomous robots are tasked with handling a major portion of decision-making where they work reliably; meanwhile, human operators monitor the process and intervene in challenging situations. Such a human–robot team ensures safe deployments in complex tasks. Further, we introduce a new learning algorithm to improve the policy’s performance on the data collected from the task executions. The core idea is re-weighing training samples with approximated human trust and optimizing the policies with weighted behavioral cloning. We evaluate Sirius in simulation and on real hardware, showing that Sirius consistently outperforms baselines over a collection of contact-rich manipulation tasks, achieving an 8% boost in simulation and 27% on real hardware than the state-of-the-art methods in policy success rate, with twice faster convergence and 85% memory size reduction. Videos and more details are available at https://ut-austin-rpl.github.io/sirius/.
1. Introduction
Recent years have witnessed great strides in deep learning techniques for robotics. In contrast to the traditional form of robot automation, which heavily relies on human engineering, these data-driven approaches show great promise in building robot autonomy that is difficult to design manually. While learning-powered robotics systems have achieved impressive demonstrations in research settings (Andrychowicz et al., 2018; Kalashnikov et al., 2018; Lee et al., 2020), the state-of-the-art robot learning algorithms still fall short of generalization and robustness for widespread deployment in real-world tasks. The dichotomy between rapid research progress and the absence of real-world application stems from the lack of performance guarantees in today’s learning systems, especially when using black-box neural networks. It remains opaque to the potential practitioners of these learning systems: how often they fail, in what circumstances the failures occur, and how they can be continually enhanced to address them.
To harness the power of modern robot learning algorithms while embracing their imperfections, a burgeoning body of research has investigated new mechanisms to enable effective human–robot collaborations. Specifically, shared autonomy methods (Javdani et al., 2015; Reddy et al., 2018) aim at combining human input and semi-autonomous robot control to achieve a common task goal. These methods typically use a pre-built robot controller rather than seeking to improve robot autonomy over time. Meanwhile, recent advances in interactive imitation learning (Celemin et al., 2022; Kelly et al., 2019; Mandlekar et al., 2020c; Ross et al., 2011) have aimed to learn policies from human feedback in the learning loop. Although these learning algorithms can improve the overall efficacy of autonomous policies, these policies still fail to meet the performance requirements for real-world deployment.
This work aims at developing a human-in-the-loop learning framework for human–robot collaboration and continual policy learning in deployed environments. We expect our framework to satisfy two key requirements: (1) it ensures task execution to be consistently successful through human–robot teaming, and (2) it allows the learning models to improve continually, such that human workload is reduced as the level of robot autonomy increases. To build such a framework, this idea of robot learning on the job resembles the Continuous Integration, Continuous Deployment (CI/CD) principles in software engineering (Shahin et al., 2017). Realizing this idea for learning-based manipulation invites fundamental challenges.
The foremost challenge is developing the infrastructure for human–robot collaborative manipulation. We develop a system that allows a human operator to monitor and intervene the robot’s policy execution (see Figure 1). The human can take over control when necessary and handle challenging situations to ensure safe and reliable task execution. Meanwhile, human interventions implicitly reveal the task structure and the level of human trust in the robot. As recent work (Hoque et al., 2021; Kelly et al., 2019; Mandlekar et al., 2020c) indicates, human interventions inform when the human lacks trust in the robot, where the risk-sensitive task states are, and how to traverse these states. We can thus take advantage of the occurrences of human interventions during deployments as informative signals for policy learning. Overview of Sirius, our human-in-the-loop learning and deployment framework. Sirius enables a human and a robot to collaborate on manipulation tasks through shared control. The human monitors the robot’s autonomous execution and intervenes to provide corrections through teleoperation. Data from deployments will be used by our algorithm to improve the robot’s policy in consecutive rounds of policy learning.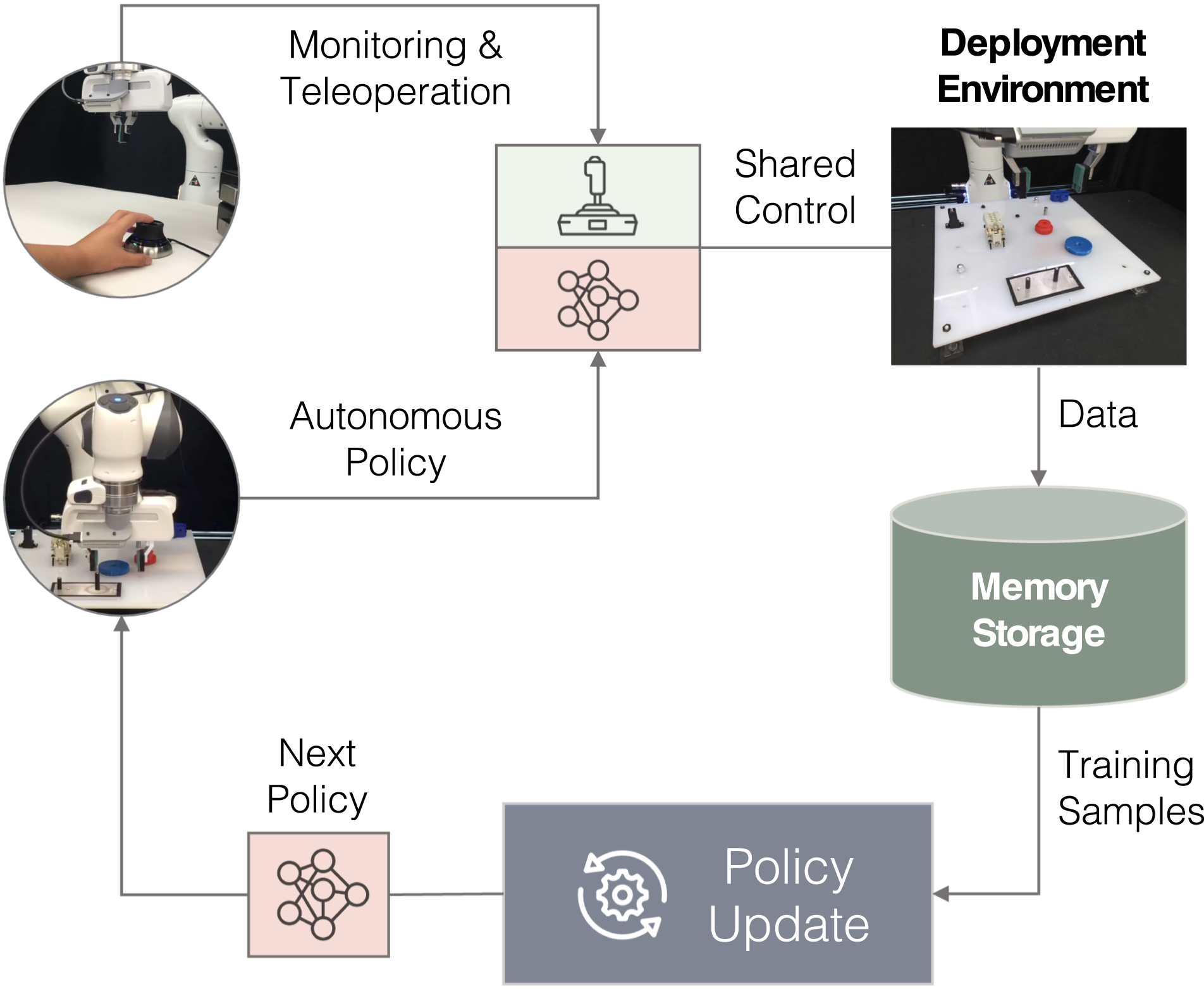
The subsequent challenge is updating policies on an ever-growing dataset of shifting distributions. As our framework runs over time, the policy would adapt its behaviors through learning, and the human would adjust their intervention patterns accordingly. Deployment data from human–robot teams can be multimodal and suboptimal. Learning from such deployment data requires us to selectively use them for policy updates. We want the robot to learn from good behaviors to reinforce them and also to recover from mistakes and deal with novel situations. At the same time, we want to prevent the robot from copying bad actions that would lead to failure. Our key insight is that we can assess the importance of varying training data based on human interventions for policy learning.
To this end, we develop a simple yet effective learning algorithm that uses the occurrences of human intervention to re-weigh training data. We consider the robot rollouts right before an intervention as “low-quality” (as the human believes the robot is about to fail) and both human demonstrations and interventions as “high-quality” for policy training. We label training samples with different weights and train policies on these samples using weighted behavioral cloning, the state-of-the-art algorithm for imitation learning (Sasaki and Yamashina, 2021; Xu et al., 2022; Zolna et al., 2020) and offline reinforcement learning (Kostrikov et al., 2021; Nair et al., 2021; Wang et al., 2020). This supervised learning algorithm lends itself to the efficiency and stability of policy optimization on our large-scale and growing dataset.
Furthermore, deploying our system in long-term missions leads to two practical considerations: (1) it incurs a heavy burden of memory storage to store all past experiences over a long duration, and (2) a large number of similar experiences may inundate the small subset of truly valuable data for policy training. We thus examine different memory management strategies, aiming at adaptively adding and removing data samples from the memory storage of fixed size. Our results show that even with 15% of the full memory size, we can retain the same level of performance or achieve even better performance than keeping all data, and moreover enables three times faster convergence for rapid model updates between consecutive rounds.
We name our framework Sirius, the star symbolizing our human–robot team with its binary star system. We evaluate Sirius in two simulated and two real-world tasks requiring contact-rich manipulation with precise motor skills. Compared to the state-of-the-art methods of learning from offline data (Kostrikov et al., 2021; Mandlekar et al., 2021; Nair et al., 2021) and interactive imitation learning (Mandlekar et al., 2020c), Sirius achieves higher policy performance and reduced human workload. Sirius reports an 8% boost in policy performance in simulation and 27% on real hardware over the state-of-the-art methods.
2. Related work
2.1. Human-in-the-loop learning
A human-in-the-loop learning agent utilizes interactive human feedback signals to improve its performance (Cruz and Igarashi, 2020; Cui et al., 2021; Zhang et al., 2019). Human feedback can serve as a rich source of supervision, as humans often have a priori domain information and can interactively guide the agent with respect to its learning progress. Many forms of human feedback exist, such as interventions (Kelly et al., 2019; Mandlekar et al., 2020c; Spencer et al., 2020), preferences (Bıyık et al., 2022; Christiano et al., 2017; Lee et al., 2021; Wang et al., 2022), rankings (Brown et al., 2019), scalar-valued feedback (MacGlashan et al., 2017; Warnell et al., 2018), and human gaze (Zhang et al., 2020). These feedback forms can be integrated into the learning loop through learning techniques such as policy shaping (Griffith et al., 2013; Knox and Stone, 2009) and reward modeling (Daniel et al., 2014; Leike et al., 2018), enabling model updates from asynchronous policy iteration loops (Chisari et al., 2021).
Within the context of robot manipulation, one approach is to incorporate human interventions in imitation learning algorithms (Dass et al., 2022; Kelly et al., 2019; Mandlekar et al., 2020c; Spencer et al., 2020). Another approach is to employ deep reinforcement learning algorithms with learned rewards, either from preferences (Lee et al., 2021; Wang et al., 2022) or reward sketching (Cabi et al., 2020). While these methods have demonstrated higher performance compared to those without humans in the loop, they require a large amount of supervision from humans and also fail to incorporate human control feedback in deployment into the learning loop again to improve model performance. In contrast, we specifically consider the above scenarios which are critical to real-world robotic systems.
2.2. Shared autonomy
Human-robot collaborative control is often necessary for real-world tasks when we do not have full robot autonomy while full human teleoperation control is burdensome. In shared autonomy (Dragan and Srinivasa, 2013; Gopinath et al., 2017; Javdani et al., 2015; Reddy et al., 2018), the control of a system is shared by a human and a robot to accomplish a common goal (Tan et al., 2021). The existing literature on shared autonomy focuses on efficient collaborative control from human intent prediction (Dragan and Srinivasa, 2012; Muelling et al., 2011; Perez-D’Arpino and Shah, 2015). However, they do not attempt to learn from human intervention feedback, so there is no policy improvement. We examine a context similar to that of shared autonomy where a human is involved during the actual deployment of the robot system; however, we also put human control in the feedback loop and use them to improve the learning itself.
2.3. Learning from offline data
An alternative to the human-in-the-loop paradigm is to learn from fixed robot datasets via imitation learning (Florence et al., 2021; Mandlekar et al., 2020b; Pomerleau, 1989; Zhang et al., 2018) or offline reinforcement learning (offline RL) (Fujimoto et al., 2019; Kidambi et al., 2020; Kostrikov et al., 2021; Kumar et al., 2020; Levine et al., 2020; Mandlekar et al., 2020a; Yu et al., 2020, 2021). Offline RL algorithms, particularly, have demonstrated promise when trained on large diverse datasets with suboptimal behaviors (Ajay et al., 2021; Kumar et al., 2022; Singh et al., 2020). Among a number of different methods, advantage-weighed regression methods (Kostrikov et al., 2021; Nair et al., 2021; Wang et al., 2020) have recently emerged as a popular approach to offline RL. These methods use a weighted behavior cloning objective to learn the policy, using learned advantage estimates as the weight. In this work, we also use weighted behavior cloning; however, we explicitly leverage human intervention signals from our online human-in-the-loop setting to obtain weights rather than using task rewards to learn advantage-based weights. We show that this leads to superior empirical performance for our manipulation tasks.
3. Background and overview
3.1. Problem formulation
We formulate a robot manipulation task as a Markov Decision Process
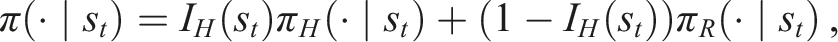
3.2. Weighted behavioral cloning methods
We aim to learn a robot policy π
R
with the deployment data to enhance robot autonomy and reduce human costs in human–robot collaboration. Weighted Behavioral Cloning (BC) has recently become one promising approach to learning policies from multimodal and suboptimal data. In standard BC methods, we train a model to mimic the action for each state in the dataset. The objective is to learn a policy π
R
parameterized by θ that maximizes the log-likelihood of actions a conditioned on the states s:
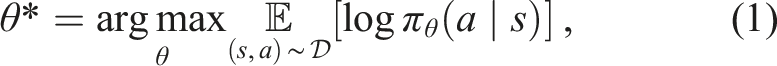
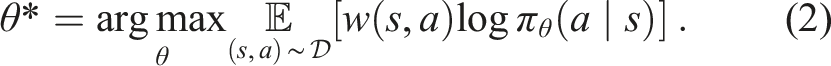
The weighted BC framework lays the foundation of several state-of-the-art methods for offline reinforcement learning (RL) (Kostrikov et al., 2021; Nair et al., 2021; Wang et al., 2020). Different weight assignments differentiate high-quality samples from low-quality ones, such that the algorithm prioritizes high-quality samples for learning. In particular, advantage-based offline RL algorithms calculate weights as w(s, a) = f(Q π (s, a)), where f(⋅) is a non-negative scalar function related to the learned advantage estimates A π (s, a). High-advantage samples indicate that their actions likely contribute to higher future returns and, therefore, should be weighted more. Through the sample-weighting scheme, these methods filter out low-advantage samples and focus on learning from the higher-quality ones in the dataset. Nonetheless, effectively learning value estimates can be challenging in practice, especially when the dataset does not cover a sufficiently wide distribution of states and actions—a challenge highlighted by prior work (Fu et al., 2020; Gulcehre et al., 2020). In the deployment setting, the data only constitute successful trajectories that complete the task eventually. Empirically, we find in Section 5 that the nature of our deployment data makes today’s offline RL methods struggle to learn values.
In contrast to the value learning framework, some prior works (Chisari et al., 2021; Gandhi et al., 2022a; Mandlekar et al., 2020c) have developed weighted BC approaches that are specialized for the human-in-the-loop setting. In particular, Mandlekar et al., 2020c proposes Intervention-weighted Regression (IWR) which designs weights based on whether a sample is a human intervention. Inspired by these prior works, we introduce a simple yet practical weighting scheme that harnesses the unique properties of deployment data to learn performant agents. We elaborate on our weighting scheme in the following section.
4. Sirius: Human-in-the-loop learning and deployment
We present Sirius, our human-in-the-loop framework that learns and deploys continually improving policies from human and robot deployment data. First, we define the human-in-the-loop deployment setting and give an overview of our system design. Next, we describe our weighting scheme, which can learn effective policies from mixed, multi-modal data throughout deployment. Finally, we introduce memory management strategies that reduce the computational complexities of policy learning and improve the efficiency of the system.
4.1. Human-in-the-loop deployment framework
Our human-in-the-loop system aims to constantly learn from the deployment experience and human corrective feedback so as to obtain a high-performing robot policy and reduce human workload over time. It consists of two components that happen simultaneously: Robot Deployment and Policy Update. In Robot Deployment (top thread in Figure 2), the robot performs task executions with human monitoring; in Policy Update (bottom thread), the system improves the policy with the deployment data for the next round of task execution. Illustration of the workflow in Sirius. Robot deployment and policy update co-occur in two parallel threads. Deployment data are passed to policy training, while a newly trained policy is deployed to the target environment for task execution.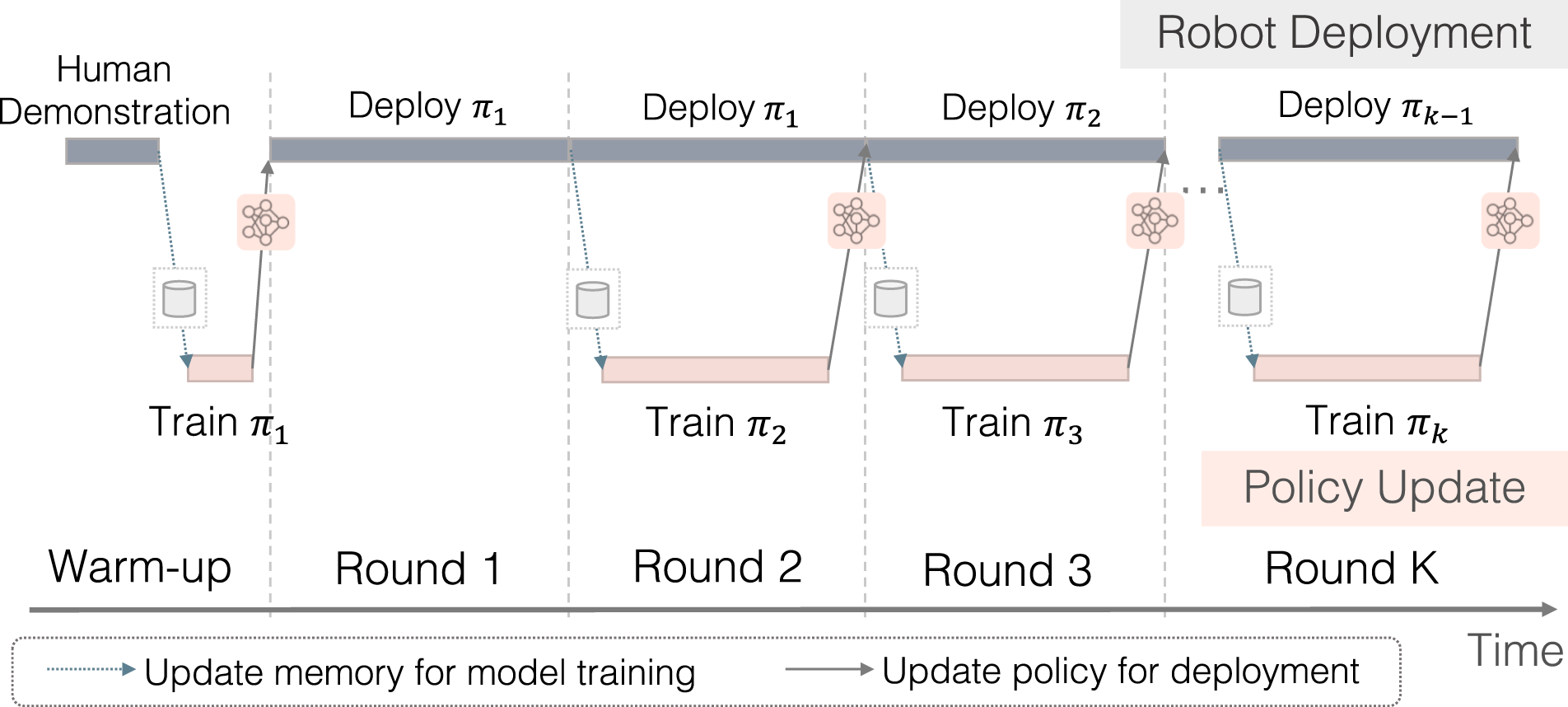
The system starts with an initial policy in the warm-up phase, where we bootstrap a robot policy π1 trained on a small number of human demonstrations. Initially, the memory buffer comprises a set of human demonstration trajectories
Upon training the initial policy π1, we deploy the robot to perform the task, and in the process, we collect a set of trajectories to improve the policy. A human operator who continuously monitors the robot’s execution will intervene based on whether the robot has performed or will perform suboptimal behaviors. Note that we adapt human-gated control (Kelly et al., 2019) rather than robot-gated control (Hoque et al., 2021) to guarantee task execution success and trustworthiness of the system for real-world deployment. Through this process, we obtain a new dataset
In subsequent rounds, we deploy the robot to collect new data while simultaneously updating the policy. We define “Round” as the interval for policy update and deployment: It consists of the completion of training for one policy, and at the same time, the collection of one set of deployment data. In Round i, we train policy π
i
using all previously collected data. Maintaining the previous rounds of collected data allows us to retain a diverse coverage of the state distribution, which has the potential benefit of regularizing the policy and keeping the policy robust (Hoque et al., 2021; Mandlekar et al., 2018). Meanwhile, the robot is continuously being deployed using the current latest policy πi−1, and gathered deployment data
Our system aggregates data from deployment environments over long-term deployments. This presents a unique set of challenges: first, the generated data comes from mixed distributions consisting of robot policy actions, human interventions, and human demonstrations; also, the system produces data that is constantly growing in size, imposing memory burden and computational inefficiency for learning algorithms. We address these challenges in the following sections.
4.2. Human-in-the-loop policy learning

Our first intuition is that human intervention samples are highly important samples and should be prioritized in learning. Human-operated samples are expensive to obtain and should be optimized in general, but human intervention occurs in situations where the robot is unable to complete the task and requires help. These are risk-sensitive task states, so data in these regions are highly valuable. Therefore, these state-action pairs should be ranked high by the weighting function, and we should upweight the human intervention samples such that these samples will positively influence learning more.
Moreover, we should not only make use of what human samples to use, but also when the human samples take place. We make the critical observation that when the robot operates autonomously, it usually performs reasonable behaviors. But when it demands interventions, it is when the robot has made mistakes or has performed suboptimal behaviors. Therefore, human interventions implicitly signify human value judgment of the robot behavior—the samples before human interventions are less desirable and of lower quality. We aim to minimize their impact on learning.
With these insights, we devise a weighting scheme according to intervention-guided data class types. Recall that each sample (s, a, r, c) in our dataset contains a data class type c, indicating whether the sample denotes a human demonstration action, robot action, or human intervention action. To incorporate the timing of human interventions, we distinguish and penalize the samples taken prior to each human intervention. We define the segment preceding each human intervention as a separate class, pre-intervention ( Overview of our human-in-the-loop learning model. We maintain an ever-growing database of diverse experiences spanning four categories: human demonstrations, autonomous robot data, human interventions, and transitions preceding interventions which we call pre-interventions. We set weights according to these four categories, with a high weight given to interventions over other categories. We use these weighted samples to continually learn vision-based manipulation policies during deployment.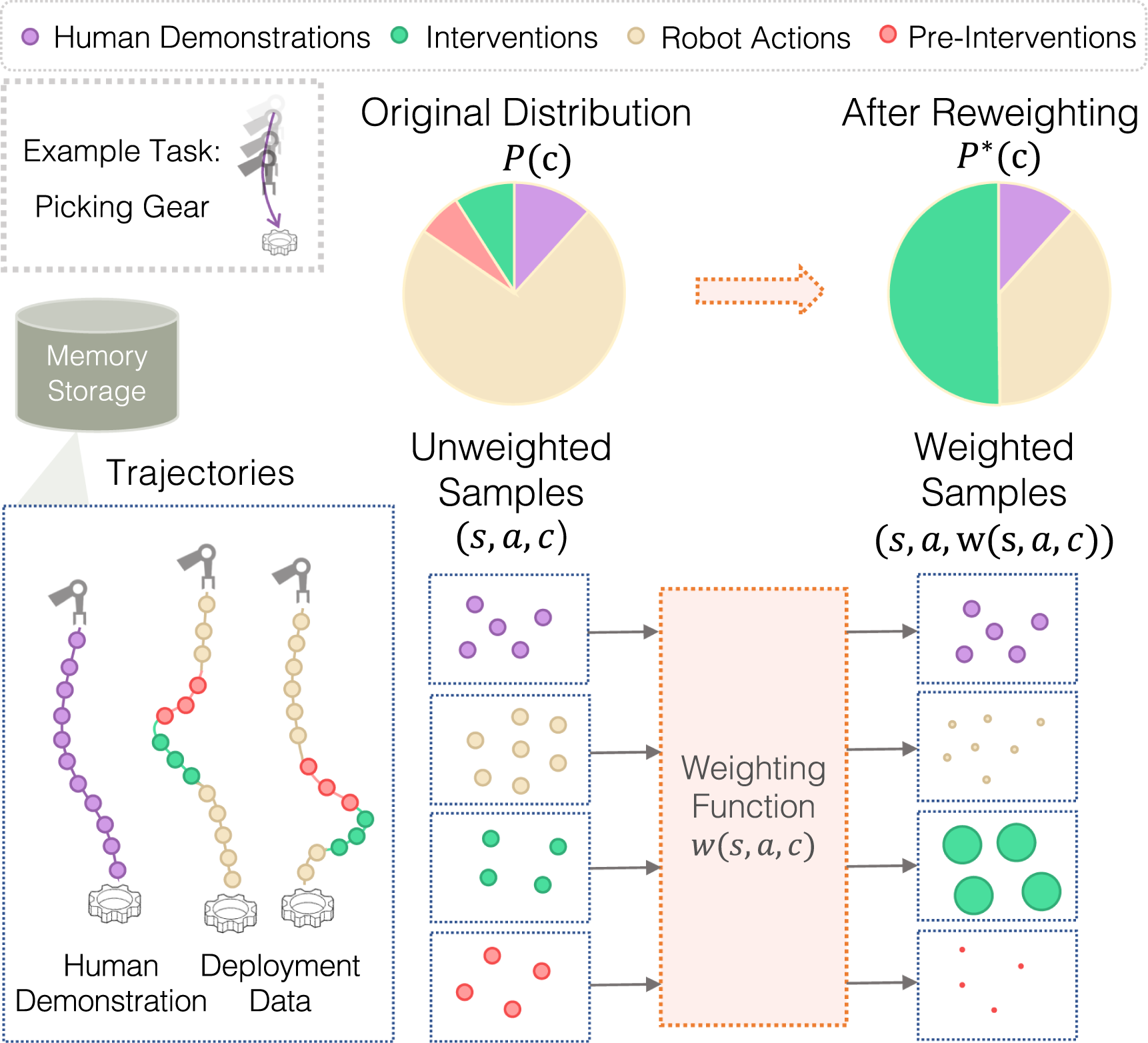
We derive the weight for each individual sample according to its corresponding class type c. Suppose the dataset 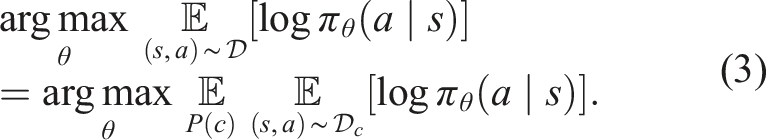
4.3. Memory management
As the deployment continues and the dataset increases, large data slows down training convergence and takes up excessive memory space. We hypothesize that forgetting (routinely discarding samples from memory) helps prioritize important and useful experiences for learning, speeding up convergence and even further improving policy. Moreover, the right kind of forgetting matters, since we want to preserve the data that is most beneficial to learning. Therefore, we would like to investigate the following question—with limited data storage and a never-ending deployment data flow, how do we absorb the most useful data and preserve more valuable information for learning?
We assume that we have a fixed-size memory buffer that replaces existing samples with new ones when full. We consider five strategies for managing the memory buffer of deployment data. Each strategy tests out a different hypothesis listed below:
(Preserving the most human intervened trajectories keeps the most valuable human and critical state examples, which helps learning the most).
(Successful, unintervened robot trajectories yield higher quality data for learning compared to those that require intervention).
(More recent data from a higher performing policy are higher quality data for learning).
(Initial data from a worse performing policy have greater state coverage and data diversity for learning).
(Uniformly selecting trajectories can yield a balanced mix of diverse samples, aiding in the learning process).
With the intervention-guided weighting scheme for policy update and memory management strategies, we present the overall workflow of human-in-the-loop learning in deployment in Algorithm 1.
4.4. Implementation details
For the robot policy (see Figure 4), we adopt BC-RNN (Mandlekar et al., 2021), the state-of-the-art behavioral cloning algorithm, as our model backbone. We use ResNet-18 encoders (He et al., 2016) to encode third person and eye-in-hand images (Mandlekar et al., 2020b, 2021). We concatenate image features with robot proprioceptive state as input to the policy. The network outputs a Gaussian Mixture Model (GMM) distribution over actions. GMM is used to handle the multimodality of human actions: GMM generates different modes and creates a probability distribution of the different modes the actions can take, and therefore is more flexible and effective than deterministic actions, or a single gaussian distribution of actions (Chernova and Veloso, 2007; Mandlekar et al., 2021). Policy architecture. Our vision-based policy uses BC-RNN as our policy backbone. Our inputs are workspace camera image and eye-in-hand camera image, as well as robot proprioceptive states.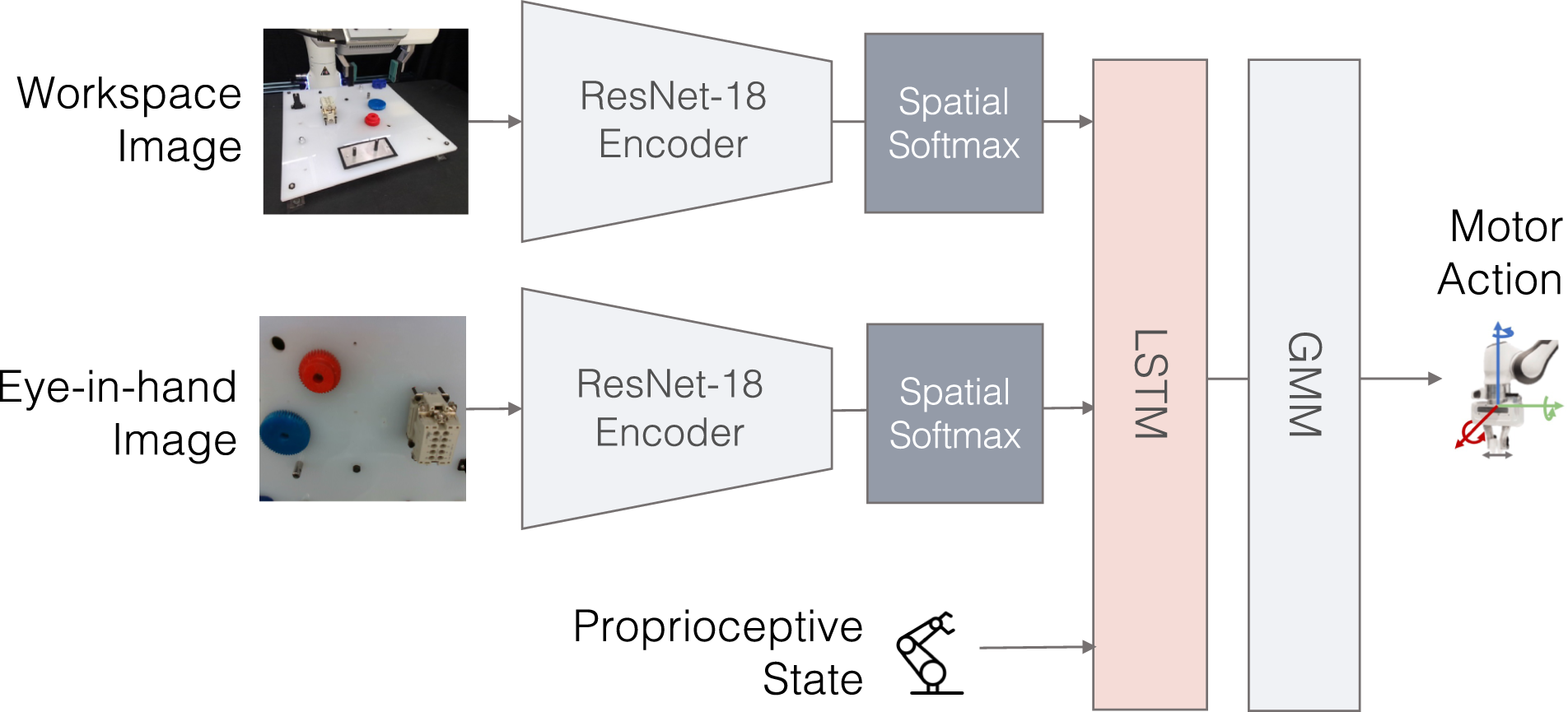
For our intervention-guided weighting scheme, we set
We set a segment of length ℓ before each human intervention as the class
5. Experiments
In our experiments, we seek to answer the following research questions: (1) How effective is Sirius in improving autonomous robot policy performance over time? (2) Can this system reduce human workload over time? (3) How do the individual design choices in our learning algorithm affect overall performance? and (4) Which memory management strategy is most effective for learning with constrained memory storage?
5.1. Human-robot teaming
We illustrate the actual human–robot teaming process during human-in-the-loop deployment in Figure 5. The robot executes a task (e.g., gear insertion) by default while a human supervises the execution. In this gear insertion scenario, the expected robot behavior is to pick up the gear and insert it down the gear shaft. When the human detects undesirable robot behavior (e.g., gear getting stuck), the human intervenes by taking over control of the robot. The human directly passes in action commands to perform the desired behavior. When the human judges that the robot can continue the task, the human passes control back to the robot. Human–robot teaming. Left: The robot executes the task by default while a human supervises the execution. Right: When the human detects undesirable robot behavior, the human intervenes.
To enable effective shared human control of the robot, we seek a teleoperation interface that (1) enables humans to control the robot effectively and intuitively and (2) switches between robot and human control immediately once the human decides to intervene or pass the control back to the robot. To this end, we employ SpaceMouse 1 control. The human operator controls a 6-DoF SpaceMouse and passes the position and orientation of the SpaceMouse as action commands. The user can pause when monitoring the computer screen by pressing a button, exert control until the robot is back to an acceptable state, and pass the control back to the robot by stopping the motion on the SpaceMouse.
5.2. Tasks
We design a set of simulated and real-world tasks that resemble common industrial tasks in manufacturing and logistics. We consider long-horizon tasks that require precise contact-rich manipulation, necessitating human guidance. For all tasks, we use a Franka Emika Panda robot arm equipped with a parallel jaw gripper. Both the agent and human control the robot in task space. We use a SpaceMouse as the human interface device to intervene.
We systematically evaluate the performance of our method and baselines in the robosuite simulator (Zhu et al., 2020). We choose the two most challenging contact-rich manipulation tasks in the robomimic benchmark (Mandlekar et al., 2021):
5.2.1. Nut Assembly
The robot picks up a square nut from the table and inserts the nut into a column.
5.2.2. Tool Hang
The robot picks up a hook piece and inserts it into a very small hole, then hangs a wrench on the hook. As noted in robomimic (Mandlekar et al., 2021), this is a difficult task requiring precise and dexterous control.
In the real world, we design two tasks representative of industrial assembly and food packaging applications:
5.2.3. Gear insertion
The robot picks up two gears on the NIST board and inserts each of them onto the gear shafts.
5.2.4. Coffee pod packing
The robot opens a drawer, places a coffee pod into the pod holder, and closes the drawer.
5.3. Baselines
We compare our method with the state-of-the-art human-in-the-loop learning method for robot manipulation, Intervention Weighted Regression (IWR) (Mandlekar et al., 2020c). Furthermore, to ablate the impacts of algorithms versus data distributions, we compare the state-of-the-art imitation learning algorithm BC-RNN (Mandlekar et al., 2021) and offline RL algorithm Implicit Q-Learning (IQL) (Kostrikov et al., 2021). We run these two latter baselines on the deployment data generated by our method for a fair comparison.
Common hyperparameters.

BC backbone hyperparameters.

For IQL (Kostrikov et al., 2021), we reimplemented the method in our robomimic-based codebase to keep the policy backbone and common architecture the same across all methods. Our implementation is based on the publicly available PyTorch implementation of IQL. 2
IQL hyperparameters.
5.4. Evaluation protocol
To provide a fair comparison with existing human-in-the-loop methods, we follow the round update protocol established by prior work (Kelly et al., 2019; Mandlekar et al., 2020c): three rounds of policy learning and deployment, where each round of deployment runs until the number of intervention samples reaches one third of the initial human demonstration samples. The motivation for this protocol is to ensure that the total amount of intervention data across all rounds matches the demonstration data, allowing us to evaluate the ability to learn from the same amount of human interventions across different human-in-the-loop baselines. We benchmark human-in-the-loop deployment systems in two aspects: (1) Policy Performance. Our human–robot team achieves a reliable task success of 100%. Here we evaluate the success rate of the autonomous policy after each round of model update; and (2) Human Workload. We measure human workload as the percentage of intervention in the trajectories in each round. While we acknowledge that human workload is a complex domain that can benefit from qualitative metrics such as the NASA-TLX (Task Load Index) (Hart and Staveland, 1988), our current evaluation follows the convention of prior human-in-the-loop literature by focusing on quantitative measures (Hoque et al., 2021, 2022; Li et al., 2022). A comprehensive study using these advanced methodologies could be done in future research. We perform rigorous evaluations of policy performance as follows: • Simulation experiments: We evaluate the success rate of each method across three seeds. For each seed, we evaluate the success rate at a set of regularly spaced training checkpoints and record the average over the top three performing checkpoints to avoid outliers. For each checkpoint, we evaluate whether the agent successfully completed the task over 100 trials. • Real-world experiments: We evaluate each method for one seed due to the high time cost for real robot evaluation. Since real robot evaluations are subject to noise and variation across checkpoints, we first perform an initial evaluation of different checkpoints (5 checkpoints) for each method, evaluating each of them for a small number of trials (5 trials). For the checkpoint that gives the best initial quantitative behavior, we perform 32 trials and report the success rate over them.
5.5. Experiment results
5.5.1. Quantitative results
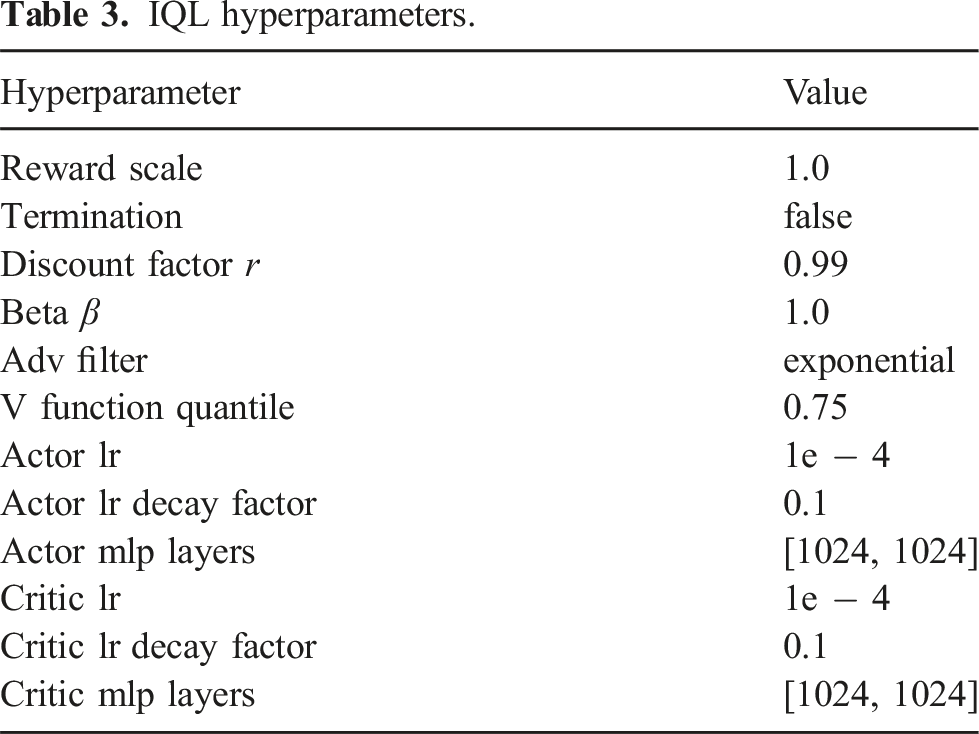
We show in Figure 6 that our method significantly outperforms the baselines on our evaluation tasks. Our method consistently outperforms IWR over the rounds. We attribute this difference to our fine-grained weighting scheme, enabling the method to better differentiate high-quality and suboptimal samples. This advantage over IWR cascades across the rounds, as we obtain a better policy, which in turn yields better deployment data. Quantitative evaluations. We compare our method with human-in-the-loop learning, imitation learning, and offline reinforcement learning baselines. Our results in simulated and real-world tasks show steady performance improvements of the autonomous policies over rounds. Our model reports the highest performance in all four tasks after three rounds of deployments and policy updates. Solid line: human-in-the-loop; dashed line: offline learning on data from our method.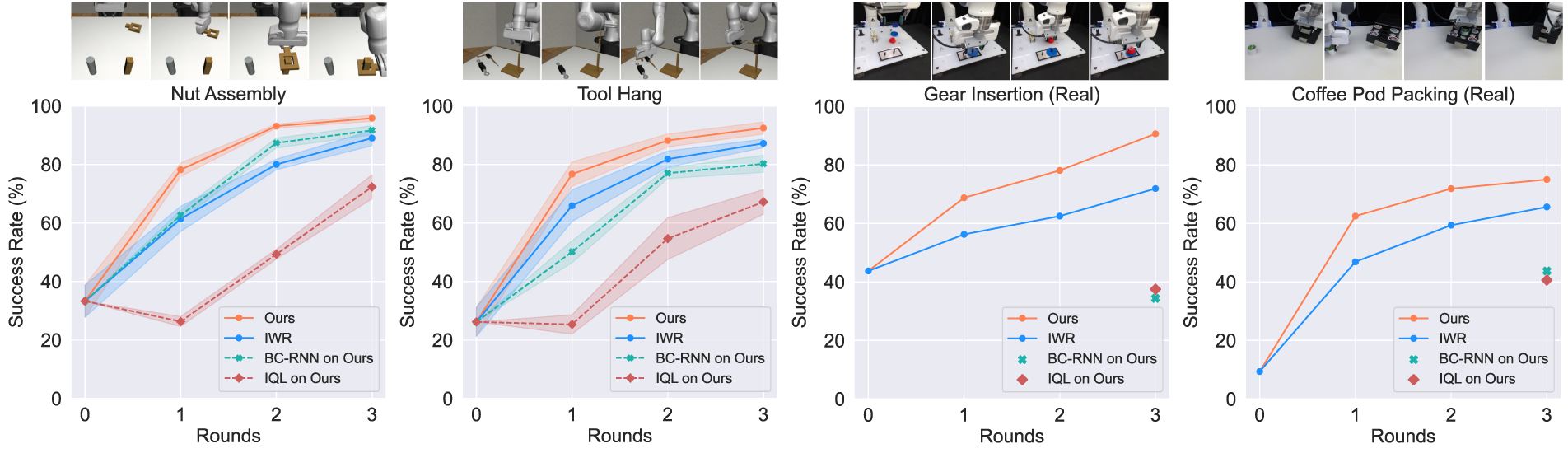
We also show that our method significantly outperforms the BC-RNN and IQL baselines under the same dataset distribution. This highlights the importance of our weighting scheme — BC-RNN performs poorly due to copying the suboptimal behaviors in the dataset, while IQL fails to learn values as weights that yield effective policy performance.
5.5.2. Ablation studies
We perform an ablation study to examine the contribution of each component in our weighting scheme in Figure 7 (Right). We study how removing each class, that is, treating each class as the robot action class (and thus removing the special weight for that class), affects the policy performance: • remove demo class: not preserving the true ratio of • remove intv class: not upweighting the • remove preintv class: not downweighting the (Left) Ablation on intervention ratio weight. We show how policy performance first increase then decrease as
We run each ablated version of our method on Round 1 data for the simulation tasks. We choose Round 1 data for this study because they are generated from the initial BC-RNN policy rather than biased toward data generated from our method. As shown in Figure 7 (Right), removing any class weight hurts the policy performance. This shows the effectiveness of our fine-grained weighting scheme, where each class contributes differently to the learning of the deployment data.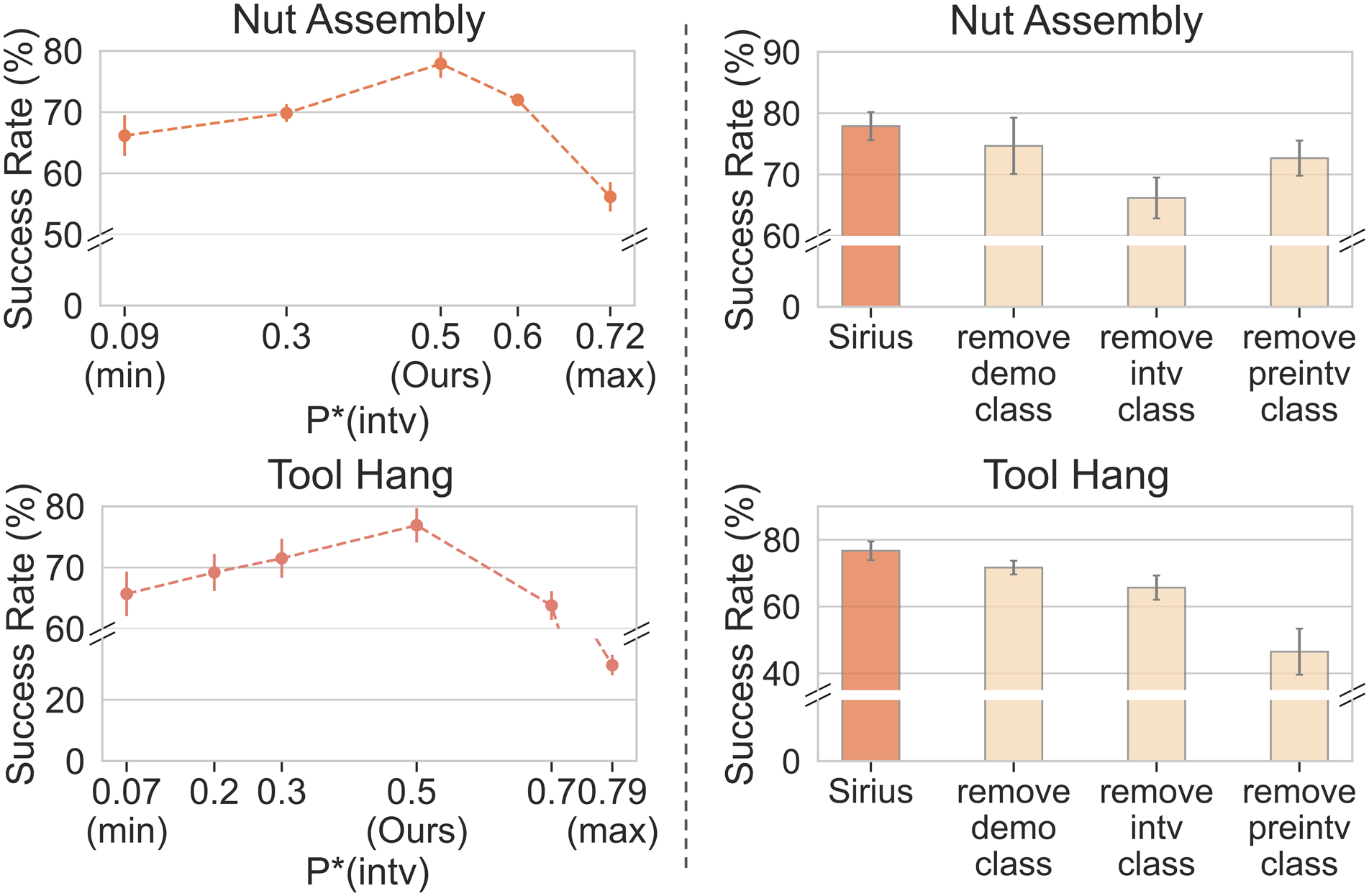
We also conduct an in-depth study on the influence of human intervention reweighting ratio
5.5.3. Analysis on memory management
We compare the effectiveness of Memory Management strategies in Section 4.3 at deployment. Figure 8 shows the result of memory size reduction on the two simulation tasks in Round 3, where the Nut Assembly accumulated 3000 + trajectories and the Tool Hang task 1600 + trajectories. By capping our memory buffer size at 500 trajectories, we manage to reduce memory size to a much small proportion of the original dataset size (15% for Nut Assembly and 30% for Tool Hang). Ablation on memory management strategies. We study the five different strategies introduced in Section 4.3. LFI (discarding least frequently intervened trajectories) matches and even yields better performance over keeping all data samples (Base) while taking much less memory storage.
Among all of the strategies, LFI (discarding least frequently intervened trajectories) is the only strategy that matches and even yields better performance over keeping all data samples (Base). In addition to minimizing storage requirements, LFI also improves learning efficiency. Under LFI, the policy converged twice as fast as Base for both tasks (where we define convergence as the number of epochs to reach 90% success rate). The faster convergence speed, in turn, yields faster model iterations in real-world deployments.
There are a number of potential explanations for the superior performance of LFI. First, note that among all of the strategies, LFI preserves the largest number of human intervention samples. This suggests that human interventions have high intrinsic value to our learning algorithm, as they help to ensure robust policy execution under suboptimal scenarios. Another perspective is that LFI preserves the more frequently intervened trajectories, which exhibit wider state coverage and a diverse array of events. This facilitates the trained policies to operate effectively under rare and unexpected scenarios. MFI (discarding most intervened trajectories) has the opposite effect, favoring trajectories that require less human supervision and often exhibit less diverse behaviors. The results on FIFO and FILO suggest that managing samples according to deployment time is not the most effective strategy, as valuable training data can be collected all throughout the deployment of the system. Finally, the naïve Uniform strategy is ineffective as it does not incorporate any distinguishing characteristics of samples to manage the memory.
5.5.4. Human workload reduction
Lastly, we highlight the effectiveness of our method in reducing human workload. In Figure 9, we plot the human intervention sample ratio for every round, that is, the percentage of intervention samples in all samples per round. We compare the results for the HITL methods, Ours and IWR. We see that the human intervention ratio decreases over rounds for both methods, as policy performance increases over time. Furthermore, we see that this reduction in human workload is greater for our method compared to IWR. Human intervention sample ratio. We evaluate the human intervention sample ratio for the four tasks. The human intervention sample ratio decreases over deployment round updates. Our methods have a larger reduction in human intervention ratio as compared with IWR.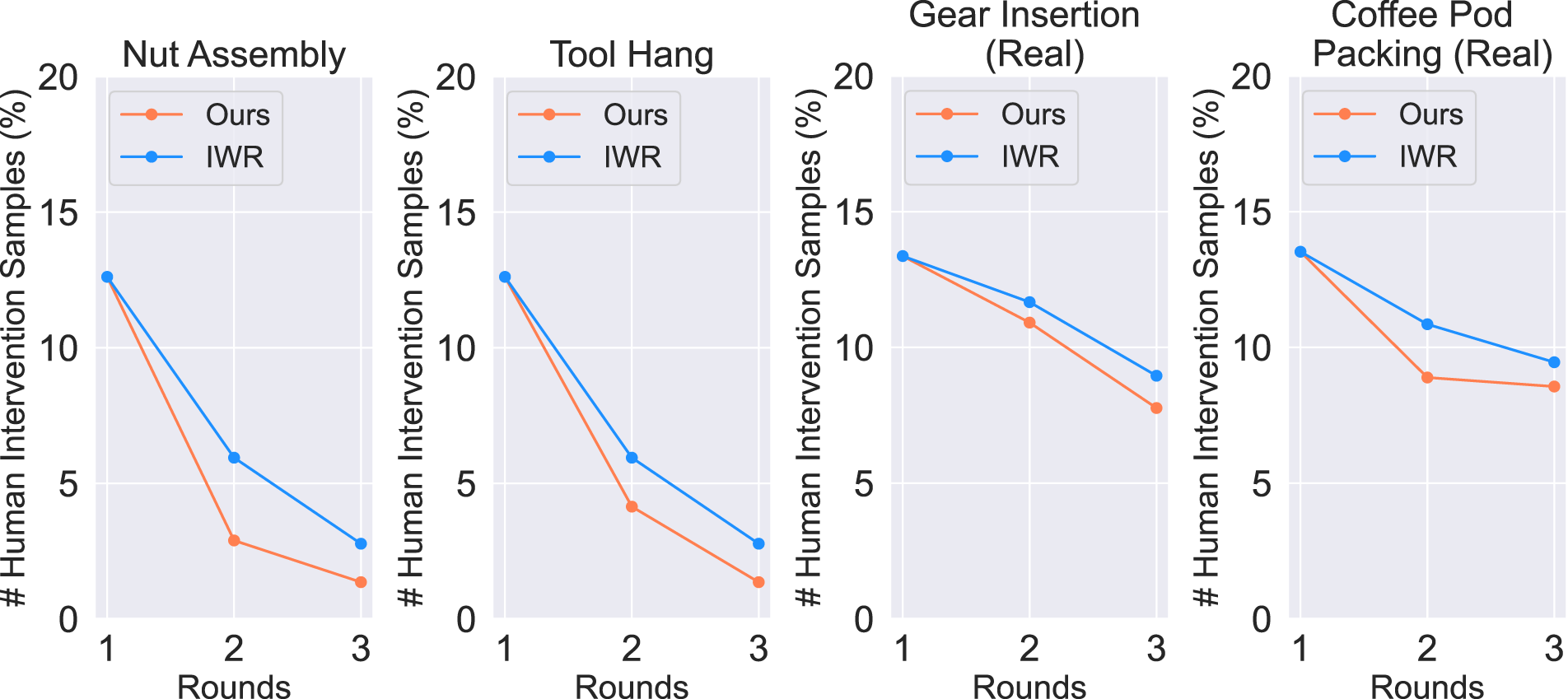
Qualitatively, we visualize how the division of work of the human–robot team evolves in Figure 10. For the Gear Insertion task, we do 10 trials of task execution in sequence for our method in Round 0 and Round 3, respectively, and record the time duration for human intervention needed during the deployment. Comparing Round 0 and Round 3, the policy in Round 3 needs very little human intervention, and the intervention duration is also much shorter. This serves as a qualitative illustration of the changing human–robot dynamics within our framework, visualizing the changing nature of human-in-the-loop deployment. Human intervention distribution. The two color bars represent the time duration over 10 consecutive trajectories and whether each step is autonomous robot action (yellow) or human intervention (green). In Round 1, much human intervention is needed to handle difficult situations. In Round 3, the policy needs very little human intervention, and the robot can run autonomously most of the time.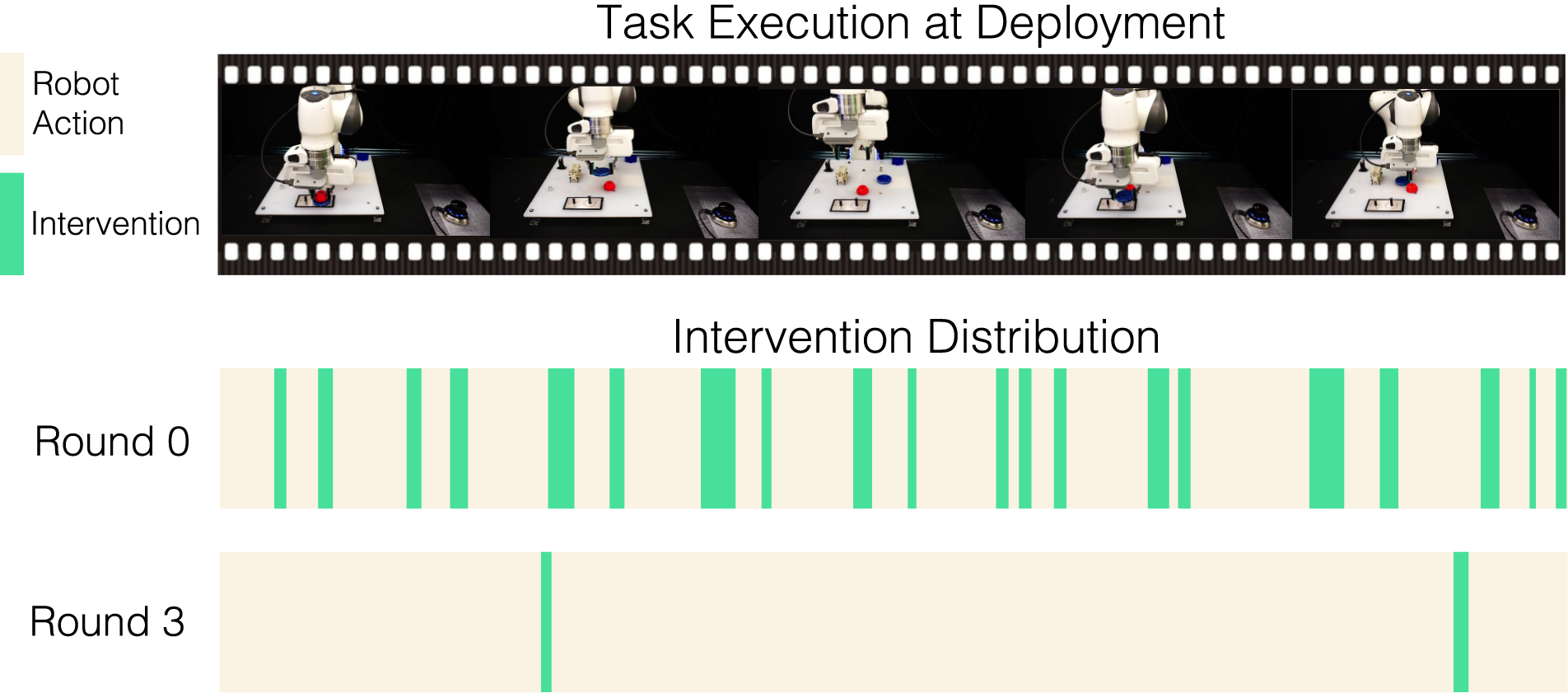
6. Multi-human Sirius
Real-world deployment scenarios often require multiple human operators to manage a fleet of robots. Different humans vary in their skills, familiarity with the system, and level of risk tolerance, which could potentially influence the intervention behavior. To address this variability, we study Sirius’s human-in-the-loop deployment in the multi-human setting. To this end, we conducted a comprehensive human study involving 12 participants, who engaged in both human demonstrations and intervention data collection under the Sirius framework. The research goal is to analyze the distribution and characteristics of multi-human data, and to assess its impact on the learning algorithm’s performance in diverse multi-human real-world scenarios.
6.1. Participants and Procedures
For our user studies, we selected a diverse group of 12 university students, aiming to encompass a range of experiences and backgrounds. This group included 8 males and 4 females, aged 19-26 years, with an average age of 23.3. Half of the participants were PhD students, and 7 out of the 12 worked in robotics-related fields. To ensure a broad representation of skill levels, only 4 of the 12 participants had prior experience in teleoperating robots. We adhered to the IRB protocol approved by the university for all our human studies.
We asked each participant to perform 50 human demonstrations and 150 intervention rollouts in the simulated Nut Assembly environment. Each participant was informed about the task goal and practiced teleoperation for around 10 min before starting the actual experiment, regardless of their prior teleoperation background.
6.2. Learning from initial human demonstrations
To better understand the multi-human intervention in Sirius, we analyze human demonstrations without robot interaction. This approach allows us to observe how different levels of operator expertise influence the behavioral learning process. In this section, we seek to answer the following research questions: • How does the different individual human expertise affect the policy performance for learning from demonstrations? • How does data diversity (in terms of human operator skill expertise) affect policy performance?
6.2.1. Experiment results
First, we present the multi-human data quality distribution, measured by the policy performance of learning from each person's human demonstration dataset (50 trajectories). We show the distribution of policy success rate in Figure 11. We see that this group has a large variance in demonstration performance, with a maximum success rate of 42.9% and minimum success rate of 14.0%. The considerable variation in performance highlights the need for human-in-the-loop algorithms to be robust, effectively accommodating a diverse array of human behaviors and decision-making patterns. Learning from single-human demonstration. There are large variations in policy performance when the dataset is the demonstrations from a single human source.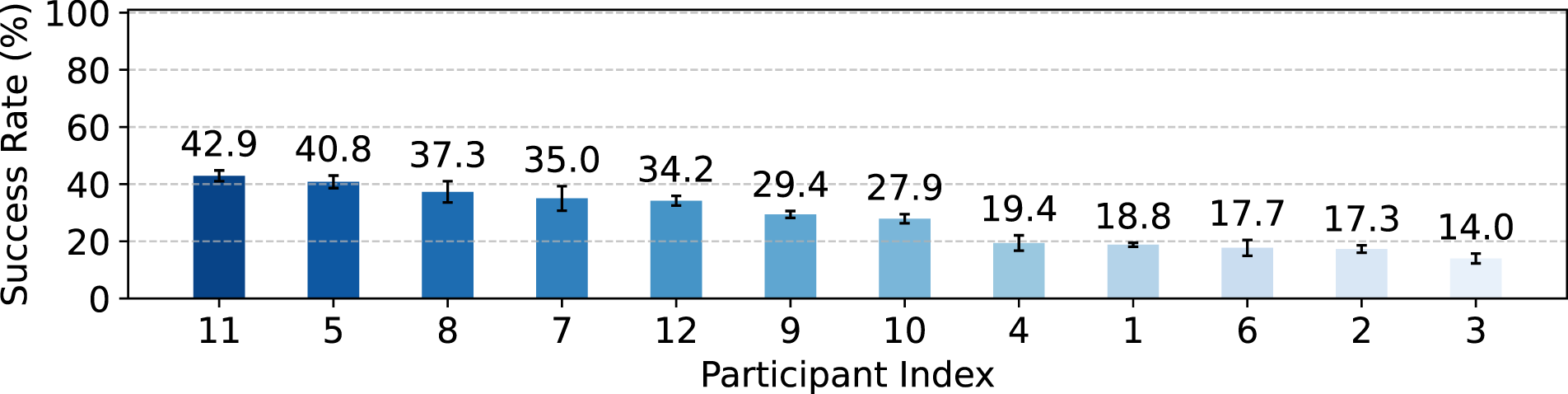
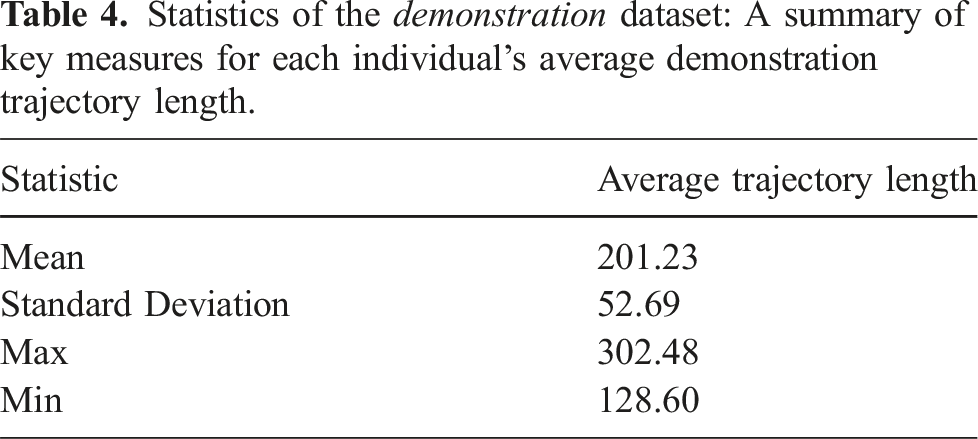
Statistics of the demonstration dataset: A summary of key measures for each individual’s average demonstration trajectory length.
We also show results of performing behavioral cloning on the mixed multi-human dataset. We show results of using 50, 200, 400, and 600 demonstrations (sampling around 8%, 33%, 67%, and 100% trajectories from each human dataset, respectively) in Figure 12. First, we demonstrate that the multi-human dataset is effective for BC, with the learning performance progressively improving as the volume of data increases. Additionally, for the case with 50 demonstrations, we observe that the mixed dataset yields a moderate policy performance in success rate (29.2%) when compared to the performance of policies trained on each individual’s demonstrations (shown in Figure 11). Learning from a mixed quality dataset is worse than learning from the highest quality dataset from the most skilled human operator, which could potentially be attributed to two factors. Firstly, although the heterogeneity offers more diverse approaches and strategies for task completion, potentially enhancing generalization, the diversity of the data leads to multimodality, which has been known to hurt BC performance (Gandhi et al., 2022b; Shafiullah et al., 2022). Second, a more diverse dataset also incorporates demonstrations of lower quality. These suboptimal demonstrations potentially add noise and introduce less effective strategies into the learning process. Policy performance from the mixed multi-human demonstration dataset (Round 0), across different dataset sizes.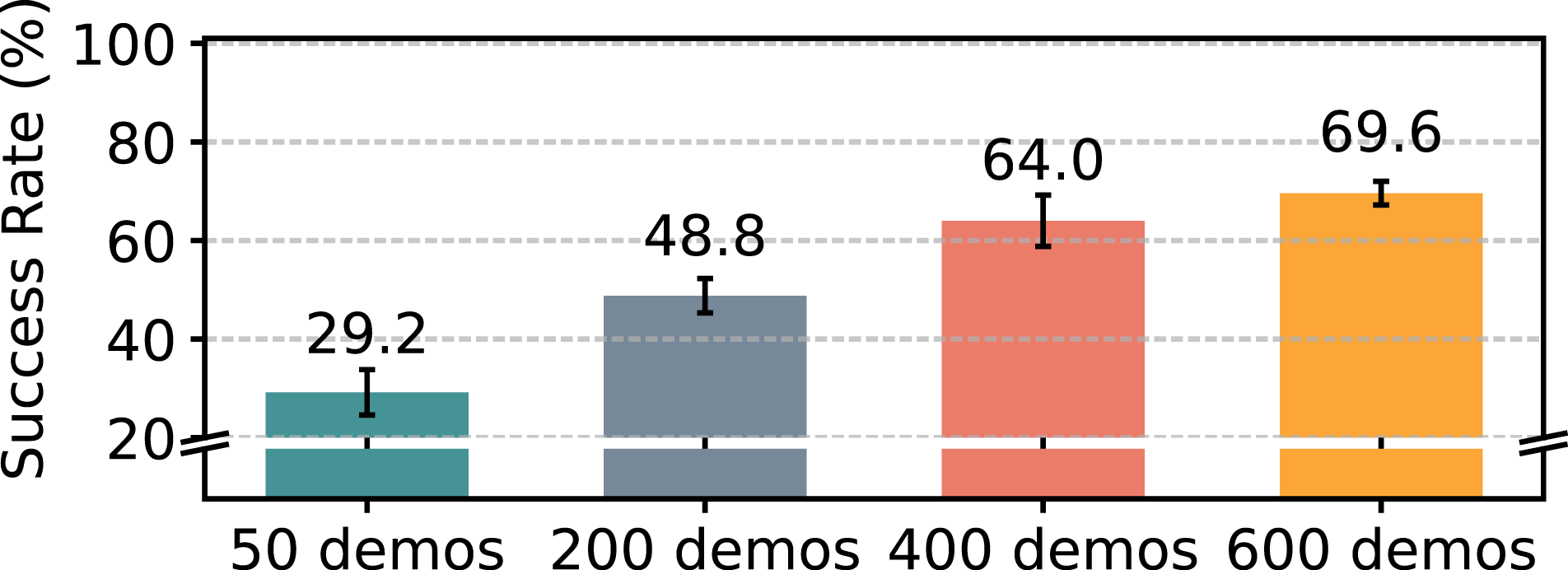
6.3. Human-in-the-loop deployment
This section evaluates the multi-human Sirius setting where multiple humans interact with robots, providing interventions. We seek to answer the following research questions: • Is the Sirius deployment framework and learning algorithm still effective for a multi-human setting? • How does different individual human expertise affect the policy performance for human-in-the-loop deployment? • How does data diversity (in terms of human operator skill expertise) affect policy performance?
6.3.1. Experiment results
We combine the demonstration data from Round 0 and intervention data from Round 1 as the multi-human Sirius dataset. We run three algorithms: Sirius, IWR, and BC-RNN on the multi-human dataset to evaluate the Sirius algorithm’s effectiveness. Figure 13 shows the policy performance at Round 1 of deployment, where Sirius outperforms the other two baselines. The results suggest that Sirius is well-suited to multi-human settings, where the data is more diverse and appears less prone to overfitting to a single human operator. As we hypothesized, Sirius performs better because of its intervention-based reweighting scheme. This approach allows us to capture the common principles of human–robot interaction, independent of the variability in specific human behaviors. By leveraging this scheme, Sirius can generalize better across different human operators, making it robust in more diverse and realistic multi-human environments. Sirius outperforms BC-RNN and IWR baselines for the multi-human deployment dataset over one round (Round 0 + Round 1).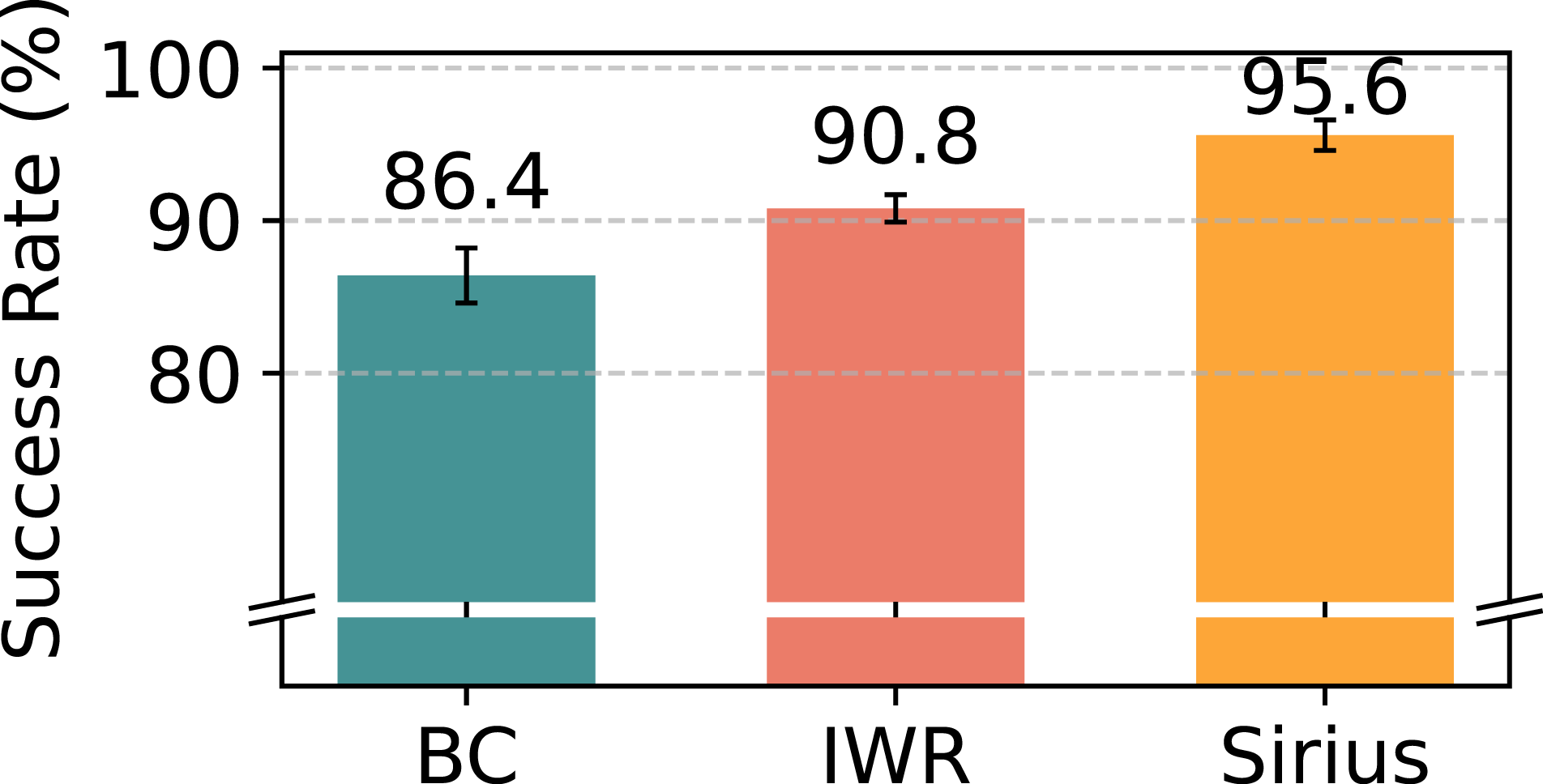
6.3.2. Influence of varied human expertise on learning from interventions
Does individual human operators' skill level and experience play a critical role in the policy learning process when it involves human interventions? This inquiry seeks to understand how the distinct abilities of each operator affect the performance of collaborative human–robot learning systems. To study this problem, we evaluate the policy performance of learning from each individual intervention dataset from Round 0 + Round 1 (50 demonstration trajectories + 150 intervention trajectories), each run from a single human operator. Figure 14 shows the variance in policy performance for each single human operator, with a maximum success rate of 72.7% and a minimum success rate of 44.8%, showing that the difference in individual skills contributes significantly to policy learning. We also show the statistics of the intervention dataset in Table 5. In contrast to the demonstration trajectories, the intervention trajectories exhibit a lower mean and smaller standard deviation. This difference is likely due to the presence of a robot policy that handles the majority of tasks, with human variation primarily occurring in the decision of when and how long to intervene. Learning from single-human intervention. There are large variations in policy performance when the dataset is one round of deployment data from a single human source. Statistics of the Intervention dataset: A summary of key measures for each individual’s average intervention rollout trajectory length, intervention ratio, average intervention length, and average number of interventions per trajectory.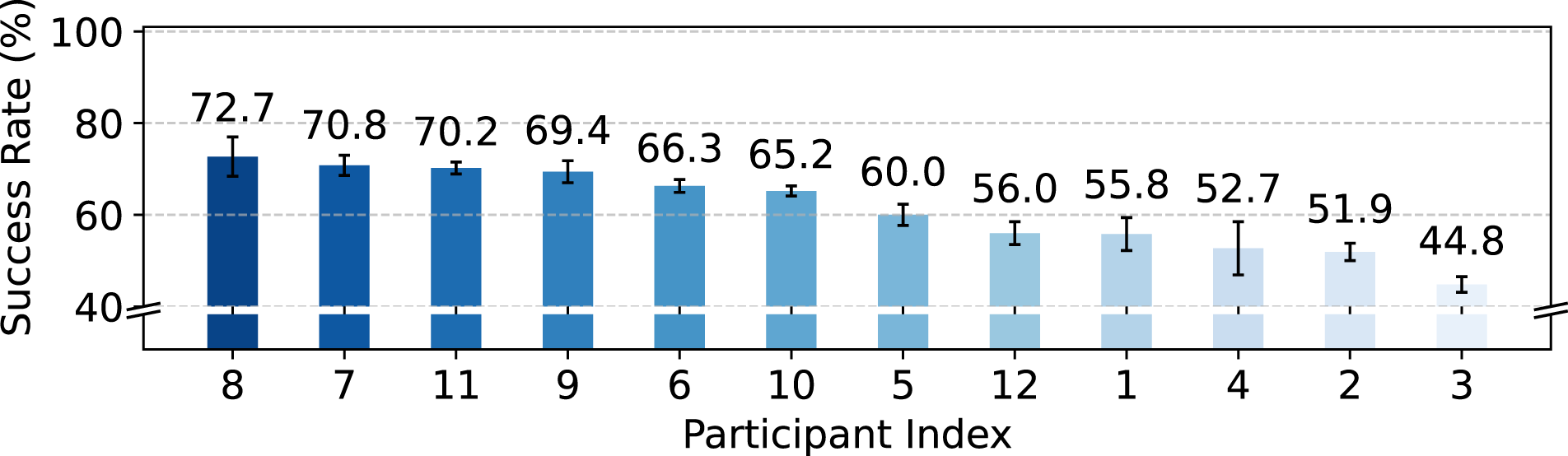
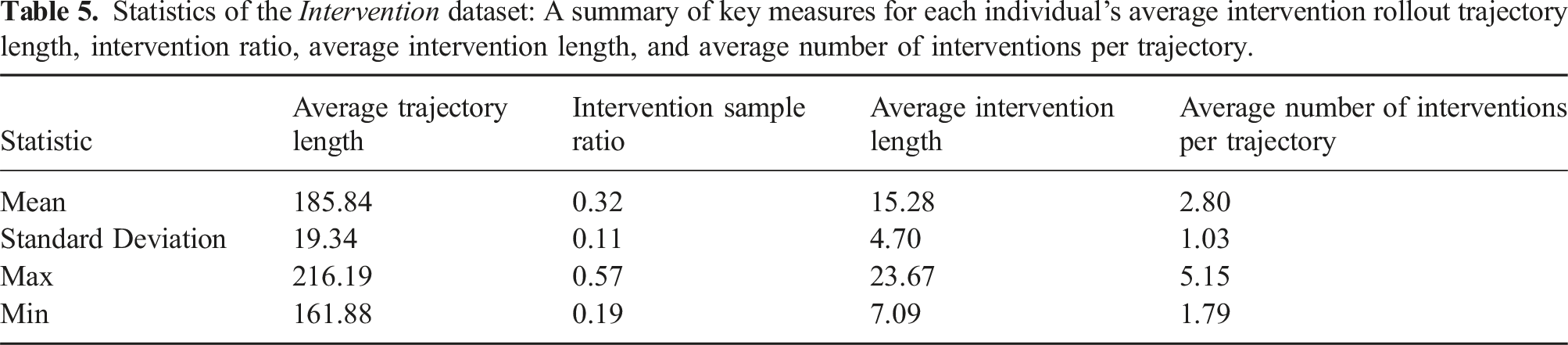
Additionally, we utilize the Intervention Sample Ratio in Section 5 to measure the fraction of timesteps completed by humans compared to the total number of timesteps. This metric shows the various extent of human involvement in the process. We also define and include two other key metrics: the Average Intervention Length and the Average Number of Interventions per Trajectory. The Average Intervention Length quantifies the average duration of each human intervention, showing how long humans typically engage in the task during an intervention before giving control back to the robot. Meanwhile, the Average Number of Interventions per Trajectory indicates how frequently humans intervene in a single trajectory. As shown in Table 5, the considerable variability in the three metrics highlights that different individuals exhibit unique intervention patterns, both in frequency and duration.
6.3.3. Impact of Data Diversity on Policy Performance
This study aims to determine if policy learning outcomes significantly vary between a dataset sourced from a larger, more diverse pool of individuals and a dataset sourced from fewer individuals and thus more consistent. Participants are divided into three sub-groups based on their individual policy performance, creating three sub-groups of datasets: Best, Medium, and Worse. Additionally, we create another more diverse dataset by collecting samples from every participant. We ensure that the combined number of trajectories matches those in the three sub-groups of datasets. We compare the policy performance of learning from this more diverse dataset with the three homogeneous sub-groups. Figure 15 illustrates that when utilizing the most diverse dataset (Max Diversity), there is a noticeable decline in policy performance compared to the results achieved with the best consistent group (Best). Nonetheless, the enhancement in data diversity does not lead to performance dropping below that of the Worse group. This result indicates that the quality of individual datasets plays a more crucial role than diversity alone in determining overall effectiveness. Impact of data diversity on policy performance. We compare the performance of the most diverse sampled dataset against the three more homogeneous subgroups with 33.3% of the data.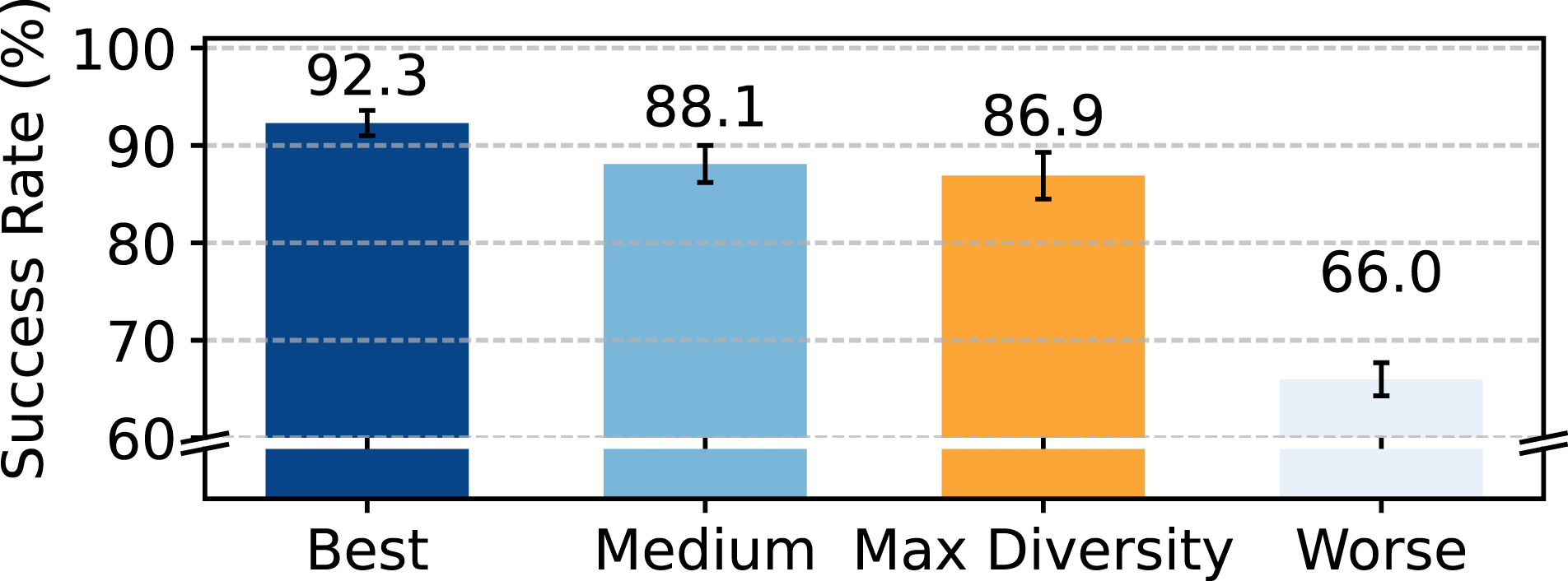
7. Conclusion
We introduce Sirius, a framework for human-in-the-loop robot manipulation and learning at deployment that both guarantees reliable task execution and also improves autonomous policy performance over time. We utilize the properties and assumptions of human–robot collaboration to develop an intervention-based weighted behavioral cloning method for effectively using deployment data. We also design a practical system that trains and deploys new models continuously under memory constraints. For future work, we would like to improve the flexibility and adaptability of the human–robot shared autonomy, including more intuitive control interfaces and faster policy learning from human feedback. Another direction for future research is to alleviate the human cognitive burden of monitoring and teleoperating the system. To ensure trustworthy execution, our current system still requires humans to constantly monitor the robot. Developing deployment monitoring mechanism would allow the system to automatically detect robot errors without constant human supervision. Lastly, to study human workload reduction, we employed a simple measurement method based on the intervention percentage. Conducting qualitative human studies to measure human mental workload would provide deeper insights.
Footnotes
Acknowledgements
We thank Ajay Mandlekar for having multiple insightful discussions, and for sharing well-designed simulation task environments and codebases during the development of the project. We thank Yifeng Zhu for valuable advice and system infrastructure development for real robot experiments. We would like to thank Tian Gao, Jake Grigsby, Zhenyu Jiang, Ajay Mandlekar, Braham Snyder, and Yifeng Zhu for providing helpful feedback for this manuscript.
Declaration of conflicting interests
The author(s) declared the following potential conflicts of interest with respect to the research, authorship, and/or publication of this article: Yuke Zhu holds a part-time research scientist at NVIDIA Research, where he works on relevant robotics research and products. The research presented in this article was conducted independently of his professional activities at NVIDIA. The author(s) affirm that no financial support or direct influence from NVIDIA Corporation was received in connection with this research.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: We acknowledge the support of the National Science Foundation (grant numbers 1955523, 2145283, and 2318065); the Office of Naval Research (grant number N00014-22-1-2204); and Amazon.